
Abstract
Abstract
Research into the seasonality of mood has long been stymied by a lack of data, in part due to the prohibitive cost of traditional data collection and the tendency for data to be highly localized. Recent work using social media data has evinced the utility of psycholinguistic features in tracking mood and mental illness, but Twitter data, which are nonanonymous and short-form by design, have almost exclusively been the subject of analysis. In this article, we present a novel corpus within this field of study, comments from the social network Reddit, which does not suffer from these potential limitations. We find that although there are no notable changes in mood in the entire population over the course of a year, a small cohort is acutely sensitive to changes in the relative day length (i.e., the relative photoperiod). Our findings corroborate the phase shift hypothesis, which is the prevailing theory for the seasonality of mood. We also demonstrate the viability of the Reddit comments corpus for studies in mood and, more broadly, mental health.
Introduction
R
The prevalence of SAD varies wildly, but is generally greater at more extreme latitudes, 7 ostensibly because of more pronounced seasonal differences. In Canada, 2–6 percent of the population experience SAD and 15 percent experience S-SAD. 6 In the United Kingdom, 2 percent experience SAD and 20 percent S-SAD. 6 The prevailing theory in SAD research is the phase shift hypothesis, which contends that a disruption in the circadian rhythm, triggered by a change in the day length (i.e., the photoperiod), is responsible for the disorder. 8 Because other climatic variables that change seasonally (e.g., temperature, precipitation) might confound the phase shift effect, we restrict our analysis of seasonality to photoperiod, the causal variable.
Research in this field has long been stymied by a lack of data. The existing data also tend to be highly localized. This is partly due to traditional methods of data collection, which can be costly, laborious, and reliant on subjects to report symptoms long after experiencing them. Social media, which readily and cheaply offers reams of data, is thus becoming an appealing source, especially since mental health conditions have been found to present significantly in language use.9,10 Still, much of the work that has leveraged social media has been limited to Twitter,11,12 which is neither anonymous nor long-form by design. Anonymity has been found to reduce inhibition when discussing mental health online, 13 and Twitter's limit of 140 characters per tweet prevents users from discussing matters at length.
We circumvent these issues by collecting a novel corpus, specifically comments from the social network Reddit. Although mental health discourse on Reddit has been studied briefly, 13 the moods of its users have not. Reddit is an anonymous platform by design, on which users can make long-form comments (up to 40,000 characters) in topic-specific forums called subreddits. The anonymity offered by Reddit has already been found effective at facilitating more open dialogue regarding mental health. 13 In this article, we track the comments made by Reddit users over their entire comment history, across all subreddits, for variations in psycholinguistic features across a multiyear period.
Much of the work that has used social media for psychology research involves building models that can diagnose users with mental illness; Coppersmith et al. 14 sought self-diagnoses of post-traumatic stress disorder on Twitter as a source of labeled data, and de Choudhury et al. 11 enlisted the help of Amazon Mechanical Turkers. Given the unreliability of self-diagnoses of SAD and SADs high comorbidity with other conditions, 15 we do not attempt to build a model or make “armchair diagnoses” of SAD in this article. Instead, we aim to show the viability of Reddit as a corpus for studying mood and analyze how photoperiod affects mood in the general population at a global scale.
Following Coppersmith et al. 16 and Golder and Macy, 17 we use Linguistic Inquiry and Word Count (LIWC), a validated psychometric tool, for tracking psycholinguistic changes in users' comments after its typical preprocessing of the text. Although LIWC is in some ways a rudimentary tool, for instance, it does not distinguish between multiple word senses, it is widely used in this field of research10,11,16,17 and has successfully been used by many to track various psychological disorders 16 and seasonal changes in mood. 17 It has even been used to create a reliable predictor of depression using social media data. 11 After tracking changes in the entire Reddit population, we use Gaussian mixture models (GMMs) to cluster users based on similar responses of mood to changes in daylight. We then use hypothesis testing to find the dimensions along which these clusters of users differ. The key contributions of this article are thus the novelty of the Reddit corpus within this domain of research and the breadth of its psycholinguistic analysis.
Data
Only a subset of the complete dataset of 1.7 billion Reddit comments spanning 8 years (October 2007–May 2015) can be used, as the majority of users cannot be matched to a specific geographic location. The location is needed to estimate the historical photoperiod to the second, using PyEphem, 18 by subtracting the sunrise time from the sunset time for each day. Although no explicit geographic information is available, Reddit does have city-specific subreddits, such as/r/nyc, in which users may post and comment. Users may subscribe to subreddits, but these subscription lists are not public. Instead, we match users to their city of residence based on how exclusively and frequently they comment in a particular city's subreddit, while introducing criteria to mitigate the noise engendered by the activity of nonresidents (e.g., tourists).
Specifically, we limit our pool of users to those that (i) have only ever commented in one city-specific subreddit and (ii) who have made, in that subreddit, at least 11 comments. This threshold is chosen because it is at the 80th percentile in the distribution of the number of comments in city-specific subreddits made by users meeting criterion (i) above. Selecting too high a threshold (e.g., 25 comments, the 90th percentile) would select for users who are exceptionally active on Reddit. A threshold of 11 yields a large set of 100,045 users in 106 cities across the world. These users' comment histories, across all subreddits, constitute the final dataset.
The majority of users come from the United States (57.20 percent), Canada (20.37 percent), the United Kingdom (5.03 percent), and Australia (10.85 percent); the remaining 6.54 percent are distributed across the remaining 25 countries. Even in the United States, many are from smaller cities such as Anchorage, Alaska (0.16 percent). Although the age and sex of these users cannot be ascertained, on Reddit overall, there are only slightly more males (54 percent) than females (46 percent). 19 Save age (the age of Redditors skews younger 20 ), our dataset appears representative of the broader population.
Methodology
We choose to track 49 LIWC features that capture aspects of mood or behavior, namely the LIWC categories of affect words, social words, cognitive processes, perpetual processes, biological processes, core drives and needs, time orientation, relativity, personal concerns, and summary variables. All except the four summary variables, analytical thinking, clout, authenticity, and emotional tone, are measured as percentages of words in a given text, after preprocessing. 9 For instance, if a Reddit comment has a “posemo” (positive emotion) score of 4.2, 4.2 percent of the words in the comment have positive affect, according to LIWC. The summary variables result from more complex algorithms and are standardized.
We first plot the summary variables against language proficiency, the percentage of words in the comment that are in the built-in LIWC dictionary. We find that the two—analytical thinking (r = −0.301) and authenticity (r = 0.223)—are mildly Spearman-correlated with proficiency, ostensibly because language proficiency affects the manner in which users express themselves. Following Golder and Macy, 17 we add a “proficiency threshold” (85 percent), which is the percentage of words in the comment that must be in English. This subsequently reduces these correlations to acceptable levels—analytical thinking (r = −0.155) and authenticity (r = 0.02). This is at the sentence level, not the user level, hence preventing multilingual users from being excluded for making non-English comments.
Since users have varying baseline values, before tracking population-level changes, it is necessary to mean center the data with respect to each user. This makes data from different users more comparable in scale, emphasizing, in Golder and Macy's parlance, within-individual changes over between-individual changes. 17
Tracking population-level changes
To detect psycholinguistic changes in the entire population, we plot each mean-centered feature against the photoperiod (in seconds) on the day of the comment's writing. If the population, as a whole, experienced some seasonal mood shift, a moderately strong correlation with the photoperiod would be expected. Like Golder and Macy, 17 we also plot each mean-centered feature against the relative amount of daylight (i.e., the marginal change in the photoperiod from the previous day), since, according to the phase shift hypothesis, it is the change in daylight that triggers changes in mood. 8 For brevity, the relative amount of daylight is referred to as relative photoperiod hereafter. Bonferroni correction is applied to decrease the chance of there randomly being a significant relationship: because we study 98 relationships—49 LIWC features with two types of photoperiod—for a correlation to be significant at the 5 percent level, its p value must be less than 0.00051 ( = 0.05/98). Similar conditions apply for alpha values of 0.01 and 0.001.
Clustering individuals based on response similarity
We then cluster individuals based on similar changes in mood in response to changes in photoperiod. To do this, we first construct a 98-dimension “sensitivity vector” for each individual, where each feature is the average change, across all the user's comments, in one of the 49 mean-centered LIWC features due to a unit increase in either the absolute or relative photoperiod. The average change (i.e., the sensitivity) is the regression coefficient from the univariate regression of the mean-centered feature against absolute or relative photoperiod.
We construct a GMM with k components and a convergence threshold of 0.001, then fit the model to the newly constructed vectors, and partition the users depending on which component assigns a higher posterior probability to their sensitivity vector. Each component in the GMM is a 98-dimensional Gaussian distribution that corresponds to one of the k groups; given the feature vector for a user, the distribution that assigns the highest probability to the vector represents the group to which the user most likely belongs. We determine the value of k—the number of components—using the Dirichlet Process, testing up to k = 25. For the concentration parameter α, values 0.1, 1, 10, and 100 were tested. All permutations of α and k found that the optimal number of clusters is 2. Although k-means clustering has been used similarly in the past, 21 we use GMM-based “soft” clustering since k-means tend toward equal-sized clusters, and it is not known, a priori, whether the clusters are of similar sizes.
Using hypothesis testing, we then find the dimensions of the sensitivity vector along which the two groups differ significantly. Welch's t test (two-tailed) is used so as not to assume that the two groups have an equal population variance. The Student's t test (two-tailed) is used to determine whether the mean of a feature across all users in the same group is nonzero. Bonferroni correction is applied in both instances.
Results and Discussion
Population-level changes
Overall, the Reddit population's mood is not tied to the photoperiod. As detailed in Table 1, none of the 49 LIWC features have any notable correlation with the photoperiod (absolute or relative) over the entire population; no correlation was greater than 0.0054 in magnitude. This is consistent with some previous findings,1,2 including one with Twitter as a corpus. 17
The correlation of each mean-centered LIWC feature with the absolute and relative photoperiod across all comments by all users. The SD of the mean-centered feature is also provided. The mean of each mean-centered feature across all comments is 0, which is why it is not provided. *Denotes significance at the 5 percent level, **at the 1 percent level, and ***at the 0.1 percent level.
LIWC, Linguistic Inquiry and Word Count; SD, standard deviation.
However, deeper analysis reveals several interesting patterns. Let the total sensitivity of a user be the magnitude of their sensitivity vector. The distribution of total sensitivity across all users has a high degree of positive skew. However, the distribution of the logged total sensitivity of all users, plotted in Figure 1, is approximately Gaussian, although it still retains some positive skew. There is also a small group of highly insensitive users, with a logged total sensitivity near −40. It should be noted that while users with a similar total sensitivity have a similar acuity of response to changes in photoperiod, the manner in which they respond is not necessarily similar.

The distribution of the logged total sensitivity for all users. A user's logged total sensitivity is the natural log of the magnitude of their sensitivity vector.
Differences between clusters
Clustering users based on similar changes in mood in response to changes in photoperiod yields two distinct clusters. The first cluster comprises 468 users (0.468 percent of the population) that are exceptionally sensitive to the photoperiod; the magnitudes of their sensitivity vectors are exceptionally high, as seen in Figure 2. The second cluster comprises the remaining users, who are insensitive to such changes. Henceforth, we refer to the clusters as sensitive and insensitive, respectively. Sensitive users have a total sensitivity that is on average 171.96 times larger compared with insensitive users, t(467) = 46.82, p < 0.001.

The logged total sensitivity of insensitive and sensitive users. A few outliers, with logged total sensitivity below −30, are excluded. A Gaussian mixture model with two components, one representing each group, determines the designation of a user as “sensitive” or “insensitive.”
Because each of the 98 features in the sensitivity vector is the average change in one of the original 49 LIWC categories with respect to either relative or absolute photoperiod, they are hereafter referred to as X-REL or X-ABS, where X is an LIWC category. X-RELS, for example, is the mean of some relative photoperiod feature X across the entire sensitive cohort; X-ABSI is the equivalent for the insensitive cohort.
Let the total relative sensitivity (TRS) be the magnitude of a sensitivity vector calculated only using the X-REL features; total absolute sensitivity (TAS) using only the X-ABS features. In Figures 3 and 4, distributions of the logged TRS and TAS are graphed for sensitive and insensitive users. Sensitive users are significantly more sensitive to changes in relative than absolute photoperiod—TRS is on average 21.53 times higher than TAS, t(574) = –41.77, p < 0.001. Insensitive users are also significantly more sensitive to relative photoperiod—for them, TRS is on average 31.97 times higher than TAS, t(103,670) = –41.77, p < 0.001. This is expected, given that the phase shift hypothesis ascribes seasonal changes in mood to changes in the relative—not the absolute—amount of daylight.

The logged TAS and logged TRS of all sensitive users. A user's TAS is the magnitude of their sensitivity vector, where the magnitude is calculated with the X-ABS elements of the vector (i.e., those with respect to the absolute photoperiod). A user's TRS is the magnitude of their sensitivity vector, where the magnitude is calculated with the X-REL elements of the vector (i.e., those with respect to the relative photoperiod). TAS, total absolute sensitivity; TRS, total relative sensitivity.
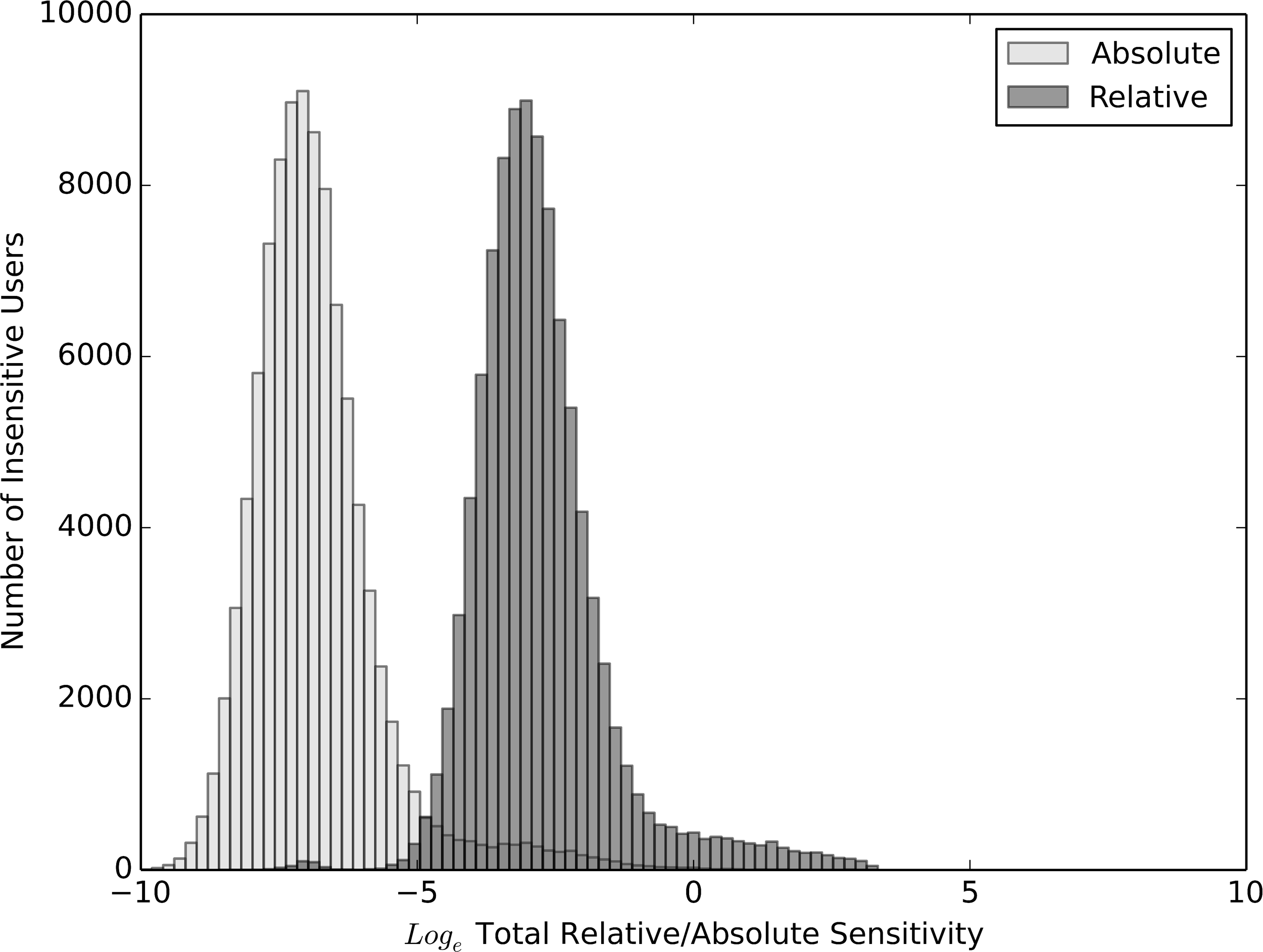
The logged TAS and logged TRS of all insensitive users. A user's TAS is the magnitude of their sensitivity vector, where the magnitude is calculated with the X-ABS elements of the vector (i.e., those with respect to the absolute photoperiod). A user's TRS is the magnitude of their sensitivity vector, where the magnitude is calculated with the X-REL elements of the vector (i.e., those with respect to the relative photoperiod). TAS, total absolute sensitivity; TRS, total relative sensitivity.
As seen in Table 2, along no dimension in the sensitivity vector are the two groups significantly different. However, as noted above, sensitive users have a significantly higher total sensitivity than insensitive users. In concert, these two results imply that sensitive users have little in common. They do not respond to changes in photoperiod in a similar manner; rather, they are distinct from insensitive users only because of the extreme acuity of their sensitivity. This is depicted in Figure 5, wherein sensitive and insensitive users are plotted along the axes of posemo-REL and negemo-REL. Although insensitive users are far greater in number, they are concentrated near the origin (0, 0), while the sensitive group is far more diffuse, tending to have more extreme values of posemo-REL and negemo-REL. Despite the difference in sparseness, the two groups are distributed similarly about the origin, which is why there exists no significant difference between posemo-RELs and posemo-RELI and between negemo-RELs and negemo-RELI. Because the total sensitivity captures only the magnitude of sensitivity and not its direction, it captures the difference in sparseness across the two groups.
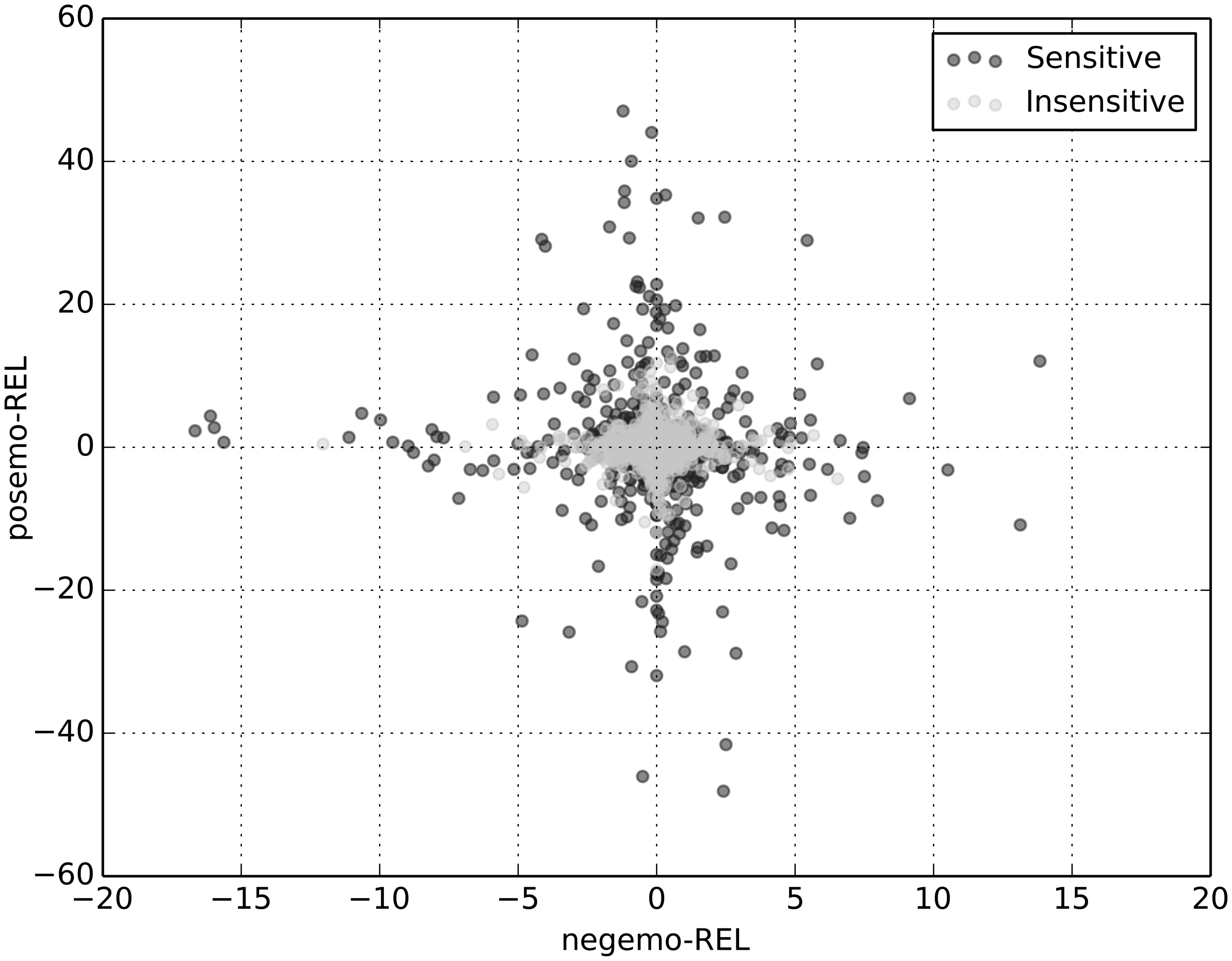
Changes in positive (posemo) and negative (negemo) emotion associated with changes in relative photoperiod, for both sensitive and insensitive users. The change is the regression coefficient when the values of posemo and negemo for a user, across all their comments, are regressed against the relative photoperiod.
The average change in every mean-centered LIWC feature X with respect to either absolute photoperiod (X-ABS) or relative photoperiod (X-REL). X-RELS is the mean of X-REL across all sensitive users; X-RELI is the mean of X-REL across all insensitive users. X-ABSS and X-ABSI are analogous means for X-ABS. None of the X-ABS or X-REL features are significantly different than 0, as determined by two-tailed Student's t tests. Neither are the differences across them significant, as determined by two-tailed Welch's t tests.
Also evident in Table 2 is the fact that none of the individual X-REL and X-ABS values are significantly different than 0 for either group. Although posemo-RELs being 0.13 and negemo-RELS being 0.1463 may give the impression that a marginal increase in relative photoperiod is associated with a marginally more positive mood among sensitive users, neither value, both of which are means across all sensitive users, is significantly different than 0, as determined by a two-tailed Student's t test. The presence of sensitive users whose mood degrades acutely with increases in relative photoperiod balances out the presence of sensitive users whose mood is lifted.
Although it may be possible to partition the sensitive users into smaller subgroups and make diagnoses of Winter SAD, Summer SAD, and S-SAD depending on the nature of their sensitivity to changes in photoperiod, for reasons stated earlier in the article, we make no such attempt to do so. The prevalence of SAD in the United States, United Kingdom, and Canada (2–6 percent),6,7 from which most users in our dataset originate, is also higher than the proportion of users that are sensitive (0.468 percent). However, the data collection method outlined in Data section also selects against inactive users, and given that inactivity is a depressive symptom, 6 seasonally depressed individuals may be underrepresented in our dataset.
It should also be noted that our analysis does not imply causality in itself, which is why we take care to note that increases in absolute and relative photoperiod may be associated with various mood changes, although not necessarily the cause of them. Causality between relative photoperiod and mood, however, is posited in the widely accepted phase shift hypothesis, 8 and our findings appear to be in accord with that theory.
Conclusion
This work shows that Reddit can be a viable alternative to traditional data sources (and Twitter) for the study of mood and, more broadly, mental health, given appropriate data filtering heuristics.
Unsurprisingly, there is no relationship between photoperiod and the overall Reddit population's mood; however, there is a small cohort that is acutely sensitive to changes in the relative photoperiod. However, these sensitive users have little in common other than the acuity of their sensitivity; an increase in the relative photoperiod is significantly associated with a strong overall change in mood in all of them, but the exact dimensions along which mood changes vary greatly across sensitive users. Thus a marginal increase in the relative photoperiod does not significantly change the value of any particular LIWC feature more for sensitive users than it does for insensitive users. As expected from the phase shift hypothesis, changes in absolute photoperiod did not spur as much change.
Although these sensitive users displayed characteristics of the various types of SAD, we make no attempt to diagnose them, although with a proper validation set, constructed using more direct or traditional methods, it may be possible to do so. The actual exposure of Reddit users to sunlight is assumed to be typical; examining further confounds is the subject of future work. LIWC, although popular, is also a fairly simplistic tool with sometimes unclear implications for user behavior.
Previous works that have found certain language features to be a reliable predictor of depression11,22 have proposed clinical applications such as an early warning system that monitors depressive patients' social media feeds. Even though we do not attempt to diagnose Reddit users in this article, our results still suggest that such clinical applications would not be nearly as effective for SAD, since the proportion of users that exhibit extreme change in language use is much smaller than the proportion of the population suffering from the disorder. In this way, we have identified a major limitation to studying mental health conditions using social media data, a field of study that has heretofore focused mostly on depression.
Studies done on Twitter regarding the prevalence of depression and other mental illnesses can be replicated using the Reddit corpus, but features unique to Reddit also open up new lines of research. One such possible line of research is the degree to which a user's language depends on the subreddit in which they are posting, for instance, do individuals use more emotional language in smaller subreddits, where users may be more familiar with one another? Although this article evinces the utility of the Reddit corpus, more complex approaches will be needed to maximize its potential to the scientific and healthcare communities.
Footnotes
Author Disclosure Statement
No competing financial interests exist.