
Abstract
Abstract
Paying attention to the rising popularity of virtual assistants (VAs) that offer unique user experiences through voice-centered interaction, this study examined the effects of modality, device, and task differences on perceived human likeness of, and attitudes toward, voice-activated VAs. To do so, a 2 (modality: voice vs. text) × 2 (device: mobile vs. laptop) × 2 (task type: hedonic vs. utilitarian) mixed factorial experimental design was employed. Findings suggest that voice (vs. text) interaction leads to more positive attitudes toward the VA system mediated by heightened perceived human likeness of the VA, but only with utilitarian (vs. hedonic) tasks. Interestingly, laptop (vs. mobile phone) interaction also enhanced perceived human likeness of the VA. This study offers theoretical and practical implications for VA research by exploring the combinational effects of modality, device, and task differences on user perceptions through human-like interactions.
Introduction
Thanks to the increasing adoption of digital assistants in various contexts (e.g., shopping, 1 entertainment, 2 and public service 3 ), virtual assistants (VAs) are expected to lead a market of $12 billion by 2024. 4 In particular, major tech companies are heavily investing in the development of VAs primarily designed to facilitate voice interactions between users and the systems (e.g., Amazon Alexa, Apple Siri, Google Assistant, Microsoft Cortana). However, audio is not the only modality that such systems embrace to interact with users; many of the current VAs also offer type-in features. Taking into consideration the increasing prevalence of such voice-activated VA systems in individual households, and the various modality options that they offer, we explored whether auditory (vs. textual) recognition and responses from Vas, indeed, offer distinctive and more intimate user experiences. Specifically, we predict that voice (vs. text) interaction will induce more positive evaluations through enhancing perceived human likeness of the VAs. The possible moderating effects of device and task differences are also explored.
Modality effects and the role of human likeness in VA interactions
VA research in speech has tended to focus on how certain characteristics embedded in the virtual agent's voice (e.g., emotional tone, 5 vocal pitch, 6 naturalness of voice 7 ), usually coupled with the virtually embodied agent's facial cues (e.g., smiling vs. neutral facial expressions6,8), can enhance human-like perceptions of VAs. In reality, major VAs on the market are capable of delivering human-like impressions to users through simply one type of assigned synthetic voice even without signaling particular anthropomorphic physical cues (e.g., facial expression). Nevertheless, the limited voice variation and/or disembodiment do not seem to stop users from developing emotional attachment to VAs. We believe that one attribute that renders the interaction with voice-activated VAs more natural and seamless is the use of voice itself.
According to the computer are social actors (CASA) paradigm, 9 individuals show a tendency to apply human social rules to computers that project certain human communication attributes. Among many cues that can lead users to respond to non-lifelike artifacts as they would to human counterparts, “the presence of voice is a(nother) strong trigger for anthropomorphic perception”. 10 (p204) Extending CASA to the context of voice-activated VAs, we can expect that the presence of voice will be influential enough for users to feel more connected to the VA. Especially as voices from VAs increasingly emulate human speech, the incorporation of speech interaction in and of itself may have considerable impact on how people perceive and respond to virtual beings, 11 perhaps more so than earlier.
Nonetheless, only a handful of studies in VA research have focused on exploring the effects of the presence (vs. absence) of voice. Among the few that directly compared modality difference (voice vs. text), on the one hand, Berry et al. 12 found that when health messages were offered in text (vs. through voice from the virtual agent), the messages were perceived as easier to understand. On the other hand, Moorthy and Vu 13 found that users felt more comfortable using voice-activated VAs such as Siri over keyboard search in private (vs. public) locations and for nonprivate (vs. private) information entry. However, in both studies, participants did not directly interact with the virtual agent in the text conditions (e.g., searched mobile web, read a word document). Considering that VAs such as Cortana and Siri incorporate both audio and textual interaction, a more thorough comparative testing between voice and text effects from the same VA source is needed.
In particular, we focus on how such modality difference could affect user perception by affording more human-like interactions. As CASA suggests, if individuals tend to apply social rules when they are interacting with computers, positive evaluation toward machines may come from the heightened resemblance of human–computer interaction to interpersonal communication. Sundar14,15 also noted how audio modality can promote perceived realism of the interaction between users and digital media. Empirical evidence suggests that certain voice manipulations of virtual agents could imbue a “sense that other intelligent beings co-exist and interact with you, even if those beings are non-human and only seem intelligent”.16(pp289–290) Such socialness evoked during interaction with virtual beings was identified as an important factor to increase the levels of attraction toward robots. 17 Focused on the power of presence of voice, this study extends how modality can alter user perception, especially by promoting a sense of socialness in the interaction between the user and VA. In particular, we argue that the emission of voice (vs. text) itself could have strong impact on perceived human likeness of VAs, in turn increasing positive attitudes toward them.
Device effects in VA interactions
In addition to modality, device options (e.g., mobile phone, laptop, smart home devices) should also be accounted for when it comes to discussing user interactions with VAs. For example, mobile devices are typically perceived as being more accessible, portable, and newer; whereas computers tend to be rated as more faithful and stable. 18 In addition, users reported higher preference for mobile devices, even though they performed better on a web-based task on computers. 19 These findings indicate that users' perceptions of different devices could also play a role in their assessments of VA systems. Further, it is possible that the use of different devices could interact with different modalities of information presentation. For example, Elting et al. 20 found that the combination of picture and speech (vs. picture + speech + text) was the most effective in enhancing recall, but only when participants viewed content via a personal digital assistant (PDA) (vs. a computer or TV). The authors explained that multiple modalities competing to be processed through limited sensory channels can increase cognitive load,21,22 and handling a smaller device can further lead users to become more sensitive to the allocation of cognitive resources in processing different modality outputs. 20 In addition, the difference in screen size between devices could also exert a disparate impact on users' sensory experiences. 15 Relevant to this point, past research has documented that larger screens on TV 23 and mobile devices 24 expand sensory stimulation, which can be pronounced in certain modality interactions. However, not many studies attempted to test the combinational effects of device and modality,20,25,26 especially with non-VA systems. With rising adoption of VA systems through mobile media, the effect of sensory richness, which could vary as a function of device, comes into question. In this study, we compared the effects of using mobile phones versus laptops for VA interaction. Due to the paucity of relevant research, a research question is suggested instead of a directional hypothesis:
Task difference in VA interactions
Users' input and output preferences also depend on other factors such as context, efficiency, and the hedonic quality of the system. 27 For instance, when conversing with a system, the ratio of questions and nonquestions a user adopts depends on factors, including the topic or context (e.g., informational vs. entertainment use). 28 This suggests that interactions with a VA can vary based on the types of topic used in the interaction, which is important to consider since these systems are now capable of answering complex questions. 29 The latest generation of voice-recognizing VAs are even capable of throwing funny jokes to users, in addition to offering factual information. Considering the wide range of functions and types of questions that VAs can process, the effects of task difference in VA interaction deserve further investigation:
Methods
This study employed a 2 (modality: voice vs. text) × 2 (device: mobile vs. laptop) × 2 (task type: hedonic vs. utilitarian) mixed factorial experimental design, with modality and device serving as between-subjects factors, and task type serving as a within-subjects factor. In addition, Microsoft Cortana 30 was adopted for this study, due to its inherent characteristics that allow interactions via both voice and text input, as well as both mobile and laptop devices.
Participants and procedures
Eigty-two undergraduates (NMen = 12; MAge = 19.71, SDAge = 0.87) were recruited from a communication course for extra credits at a northeastern university in the United States in April 2017. Sample size was set to allow at least 20 participants per cell for each of the 2 × 2 between-subjects groups, and the a priori G*Power 31 analysis for a repeated-measure analysis of variance (ANOVA) with a within-between interaction also informed that the required sample size was 72 for medium effect size (f = 0.25) with 98 percent power. The overall procedure of this study was approved by the institutional review board of the authors' university. After consent, two participants at a time were randomly assigned to one of the four conditions (mobile voice, N = 21; mobile text, N = 22; laptop voice, N = 20; laptop text, N = 21), and they were instructed on how to use Cortana accordant with their assigned modality and device conditions. Afterward, they were asked to interact with Cortana involving two different types of task sets (i.e., hedonic vs. utilitarian) for five minutes each with randomized order. For each task type, a list of various questions or statements was given to users to interact with Cortana. Participants were allowed to choose any questions or statements of their preferences within the allotted time. As the final step, participants completed an online questionnaire to evaluate their interactions.
Manipulated conditions
First, for the device manipulation, participants were randomly assigned to interact with Cortana by using either a mobile phone or a laptop. We used two Android mobile phones (i.e., Nexus 6) with the Cortana application installed, and three laptops operated by the Windows 10 system that had Cortana preinstalled by default. Second, for the modality manipulation, participants were randomly assigned and instructed to interact with Cortana by using either voice or text input. To note, output modality mirrored the input modality, in that text input resulted in text output, and audio input prompted an audio response (accompanied by text and/or image search results). Third, for task manipulation, two different types of task sheets were prepared. The hedonic task sheet included a list of 30 questions/statements, and the utilitarian task sheet, a list of 26 (Table 1).
List of Questions and Statements for Hedonic and Utilitarian Tasks
Measured variables
Perceived human likeness
We adapted eight items from the Humanness Index 32 (e.g., Artificial-Natural, Inanimate-Living) and nine items from previous social presence scales16,33 (e.g., “There was a sense of sociability during the interaction,” “While I was using Cortana, I felt as if someone was talking to me”; 1 = strongly disagree, 7 = strongly agree), all measured on a seven-point Likert scale. Social presence was integrated to the scale since it is considered a major factor that contributes to human likeness of technology. 34 In addition, although the humanness scale can represent the static human-like impression of the technology, we believed that the items in the social presence scale can capture the humanness in the dynamic interaction between the user and VA. The humanness and social presence scales were highly correlated (rhedonic = 0.81, p < 0.001; rutilitarian = 0.80, p < 0.001), and results of the reliability test also indicated that the scale was reliable for both task conditions (αhedonic = 0.95, Mhedonic = 4.52, SDhedonic = 1.13; αutilitarian = 0.95, Mutilitarian = 3.61, SDutilitarian = 1.23).
Attitudes toward the VA system
Attitudes were measured with 21 items adapted from past research (e.g., useful, high quality, appealing).35,36 Participants reported how they felt about their interaction with Cortana, with higher ratings indicating more positive attitudes (Hedonic, α = 0.96, M = 5.00, standard deviation [SD] = 1.06; Utilitarian, α = 0.95, M = 5.06, SD = 0.98).
Control variables
Gender and participants' prior experiences with VAs were included as control variables. The levels of prior experiences were measured based on a seven-point interval scale (1 = never heard of it, 7 = use it all the time) for both Cortana (M = 1.43, SD = 0.71) and other VAs (e.g., Apple Siri, Amazon Alexa; M = 4.07, SD = 1.35).
Results
To test the first hypothesis and explore research questions, a series of 2 (modality: voice vs. text) × 2 (device: mobile vs. laptop) × 2 (task type: hedonic vs. utilitarian) mixed-model repeated-measures ANOVA were run. In consideration of the female-dominant sample, when gender was controlled in the model, women tended to report higher levels of perceived human likeness of the VA compared with men [F(1, 77) = 9.15, p = 0.003, partial η
2
= 0.11; MFemale = 4.20, SEFemale = 0.10; MMale = 3.34, SEMale = 0.26]. For the main analyses, first, we examined the effects of modality (i.e., voice vs. text) on perceived human likeness of the VA (
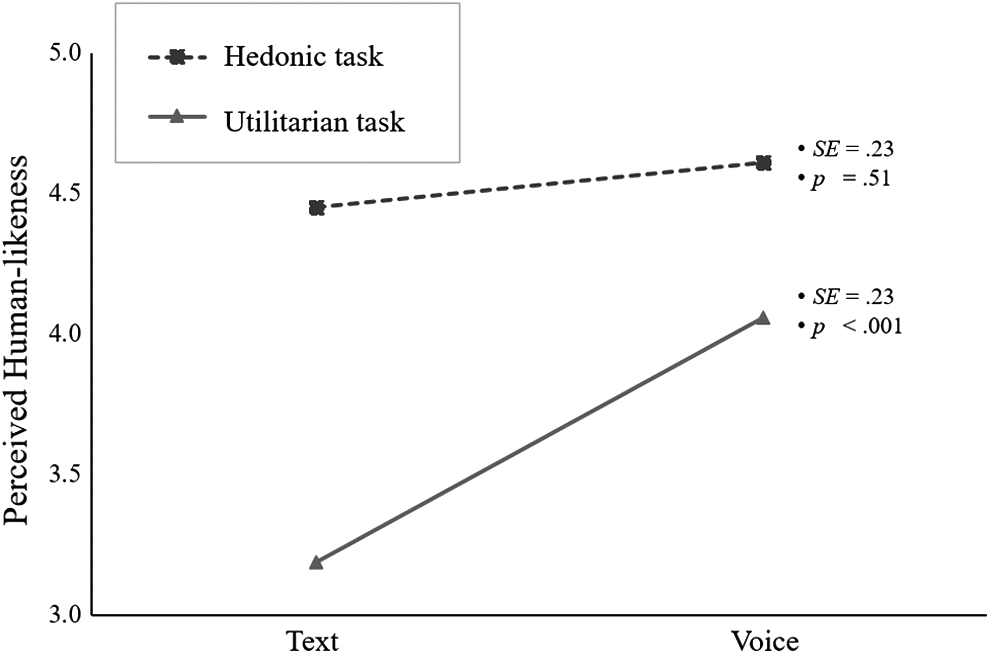
Interaction between modality and task type on perceived human likeness.
Finally, PROCESS (Model 4)
37
was employed to test the mediating role of human likeness in the relationship between modality and attitudes toward the VA (

Indirect effects of modality on attitudes toward the VA with hedonic tasks. VA, virtual assistant.

Indirect effects of modality on attitudes toward the VA with utilitarian tasks.
Discussion
Consistent with our main hypothesis, the positive effect of voice interaction on attitudes toward Cortana was mediated by perceptions of human-like characteristics. However, we only found support for the utilitarian task condition; for hedonic tasks, no mediation effects were found. This discrepancy may come from the greater efficiency expected by users for utilitarian (vs. hedonic) tasks, which has been shown to be the case for online shopping. 38 Thus, it is possible that for utilitarian tasks, voice interaction was perceived to be more efficient, compared with typing via keyboards, 39 which led to better evaluations.
Another interesting (and perhaps counterintuitive) finding from our study is that laptops elicited more human-like perceptions toward the VA than mobile phones, regardless of the type of task. One possible explanation stems from expectation violation. Participants in this study were relatively less exposed to Cortana (M = 1.43, SD = 0.71), which is one of the few VAs compatible with laptop systems, compared with other VAs such as Siri and Alexa (M = 4.07, SD = 1.35), which are commonly used through handheld or smart home devices. Therefore, it is possible that users had lower expectations for the anthropomorphic performance of the laptop Cortana, leading to better evaluations. Another explanation can be derived from cognitive overload.21,22 According to Elting et al., 20 people using a mobile device (PDA), compared with desktop or TV, put more effort into handling the device since “fewer resources were available for the task at hand”(p61) in a smaller screen. Thus, participants who interacted with Cortana on a mobile device may have felt higher cognitive overload during the interaction, and therefore gave lower ratings. At last, simply the greater sensory richness that users enjoy from large (vs. small) screens, which resulted in better attitudes toward smart devices by promoting both utilitarian and hedonic qualities of the devices, 40 can also account for these results.
The findings offer both theoretical and practical implications for VA research. Theoretically, the study extends our knowledge on how the interactions among modalities, devices, and task types could impact perceived human likeness of virtual agents and the attitudes toward them. Consistent with Sundar,14,15 our study illustrates how modality as a structural feature in new media technology can cue particular heuristics, including human likeness. This study further shows that modality in VA interactions can function differently contingent on certain task types. Practically speaking, the findings suggest that voice as a modality should be considered a primary option for VA services designed to serve utilitarian tasks. In addition, results support that computers may also be a good venue for incorporating VA systems.
Nonetheless, a few limitations of this study merit note. One limitation was associated with the difference in mobile versus laptop responses. For example, the results given by Cortana were only shown within the dialogue frame of the app on mobile phones. On the other hand, for some questions asked through the laptop, Cortana automatically opened a pop-up web browser and provided the Bing search engine results. In addition, although we did not record how many questions/statements participants got through within the time limit, it seemed that individuals needed longer time to work on a single question/statement with text (vs. voice) input. The conditions just cited add complexity to disentangling the effects of modality and task from those stemming from other factors. Finally, the lab environment interactions with Cortana restricted the generalizability of our study results. Thus, adopting a better controlled environment for experiments and exploring other methodologies to investigate VA effects in more natural settings are recommended for future studies.
Footnotes
Author Disclosure Statement
No competing financial interests exist.