
Abstract
Abstract
Prediction of groundwater level in a basin is of immense importance for the management of groundwater resources, especially in coastal regions where the water table fluctuations are to be limited to avoid sea water intrusion. Lack of strong predictive tools, or perhaps the lack of experienced users of those tools, may contribute to problems in data interpretation and failure to reach consensus about the need for key water management actions. Therefore, it is extremely important to comprehend the spatiotemporal variations of the water level for the management of groundwater in the coastal areas. In this article, a hybrid, artificial neural network-geostatistics methodology is presented for spatiotemporal prediction of groundwater levels. The proposed model contains two separated stages. At the first stage, an artificial neural network is trained for each piezometer for time-series modeling of the water level, so that the model can predict the groundwater level the next month. At the second stage, predicted values of water levels at different piezometers are imposed to a calibrated geostatistics model in order to estimate groundwater level at any desired point in the plain. This methodology is applied for the Shabestar plain, which adjoins to Urmieh Lake as a coastal aquifer in East Azerbaijan Province, Iran. The most appropriate set of input variables to the model are selected through a combination of domain knowledge and available data series. Results suggest that the feed-forward neural network trained with Levenberg-Marquardt algorithm for temporal and Kriging scheme for spatial modeling are good choices for predicting groundwater levels in the coastal aquifer.
Introduction
The consequences of aquifer depletion can lead to local water rationing, excessive reductions in yields, drying of wells, producing erratic groundwater quality changes, changes in flow patterns of groundwater, which, in turn, results in the poorer inflow water quality, and sea water intrusion in coastal areas. The water levels if forecasted well in advance may help the administrators to better plan the groundwater utilization. Also, for an overall development of the basin, a continuous forecast of the groundwater level is required to effectively use any simulation model for water management. In developing countries, water management planning usually proceeds through the use of one or more computer simulation models. These models, which may be very simple or highly complex, are based on observed data or theoretical principles, stochastically or deterministically driven, and provide a framework for decision making that is endorsed by the community of water users and water regulators. Sometimes, a model is valued not so much for its accuracy of representation as for its utility in building social consensus.
Groundwater systems possess features such as complexity, nonlinearity, being multi-scale and random, all governed by natural and/or anthropogenic factors, which complicate the dynamic predictions. Therefore, many hydrological models have been developed to simulate this complex process. Models based on their involvement of physical characteristics generally fall into three main categories: black box models, conceptual models, and physical-based models (Nourani and Mano, 2007). The conceptual and physical-based models are the main tools for predicting hydrological variables and understanding the physical processes that are taking place in a system. In these models, the internal physical processes are modeled in a simplified way. Even if not applying the exact differential laws of conservation, conceptual models attempt to describe large-scale behavior of hydrological processes in a basin. However, these models require a large quantity of good quality data, sophisticated programs for calibration using rigorous optimization techniques, and a detailed understanding of the underlying physical process. Due to the recognized limitations of these models and the growing need to properly manage overdeveloped groundwater systems, significant researches have been devoted to improve their predictive capabilities. Despite large investments in time and resources, prediction accuracy attainable with numerical flow models has not satisfactorily improved for many types of groundwater management problems. Studies on groundwater levels reveal spatiotemporal information on aquifers and auriferous systems and help us take appropriate measures. For management of groundwater resources, traditional numerical methods, with specific boundary conditions, are able to depict the complex structures of aquifers including complicated prediction of groundwater levels. However, the vast and accurate data required to run a numerical model are difficult to obtain owing to spatial variations and the unavailability of previous hydrogeology surveys. As a result, numerical methods have been restricted in their use in remote, sparsely monitored areas. If sufficient data are not available and accurate predictions are more important than understanding the actual physics of the situation, black-box models remain a good alternative method and can provide useful predictions without the costly calibration time (Daliakopoulos et al., 2005).
In recent years, artificial neural network (ANN) as a black-box model has been widely used for forecasting in many areas of science and engineering. ANNs are proved to be effective in modeling virtually any nonlinear function to an arbitrary degree of accuracy. The main advantage of this approach over traditional methods is that the method does not require the complex nature of the underlying process under consideration to be explicitly described in mathematical form. This makes ANNs attractive tools for modeling water-table fluctuations.
The development of ANNs began approximately 70 years ago (McCulloch and Pitts, 1943), inspired by a desire to understand the human brain and emulate its behavior. Although the idea of ANNs was proposed by McCulloch and Pitts, the development of these techniques has experienced a renaissance only in the last decades due to Hopfield's effort (Hopfield, 1982) in iterative auto-associable neural networks. A tremendous growth in the interest of this computational mechanism has occurred since Rumelhart and McClelland. (1986) rediscovered a mathematically rigorous theoretical framework for neural networks, that is, back propagation algorithm. Consequently, ANNs have found applications in many engineering problems.
Since the early 1990s, ANNs have been successfully used in environmental and hydrology-related areas such as rainfall-runoff modeling, stream flow forecasting, groundwater modeling, water quality, water management policy, precipitation forecasting, and reservoir operations (ASCE, 2000a, 2000b). Also, ANN models have been used for rainfall-runoff modeling (Tayfur and Singh, 2006), precipitation forecasting, and water-quality modeling (Govindaraju and Ramachandra, 2000). In the water level modeling context, Tayfur et al. (2005) presented an ANN model to predict water levels in piezometers placed in the body of an earthfill dam in Poland considering upstream and downstream water levels of the dam as input data. Neural networks have also been applied with success to temporal prediction of groundwater level (Coulibaly et al., 2001a). Two researches have been carried out into forecasting floods in a karestic media (Beaudeau et al., 2001), determining aquifer outflow influential parameters, and simulating aquifer outflow in a fissured chalky media (Lallahem and Mania, 2003). ANNs have been successfully used for identifying the temporal data necessary to calculate groundwater level in only one piezometer (Lallahem et al., 2005). ANNs were also employed to solve complex groundwater problems and for predicting transient water level in a multilayer groundwater system under variable pumping states and climate conditions (Coppola et al., 2003). Coppola et al. (2005) developed an ANN model for accurately predicting potentiometric surface elevations in alluvial aquifers. Relationships among lake levels, rainfall, evapotranspiration, and groundwater levels were determined by Dogan et al. (2008) using ANN-based models. Nourani et al. (2008) employed the ANN approach for time-space modeling of groundwater level in an urbanized basin.
In spite of promise ability of the ANNs in temporal and time-series prediction, they could not find notable application for the spatial modeling of the environmental processes. Instead, powerful interpolating tools of geostatistics are extremely used for unbiased estimation of the spatial variables at a given point. Geostatistics has made rapid advances in recent years since it was first developed by Matheron (1963). Recently, the term “geostatistics” has been used more generally to describe all applications of statistics in hydrogeology in which the attributes is a random field in space. The heterogeneity of the subsurface is often difficult to adequately characterize for use in deterministic models; therefore, geostatistical techniques are often used to generate estimates of parameters in deterministic mathematical models where parameters are random variables in space. For groundwater flow problems, attributes such as water levels are sampled at a limited number of sites, whereas values at un-sampled sites are usually needed for analysis. Geostatistical techniques such as Kriging and Cokriging can be applied to estimate the values of attributes at un-sampled sites (Ma et al., 1999). For examples, various forms of geostatistical tools have been used to map potentiometric surfaces from water level data alone (Delhomme, 1978; Aboufirassi and Marino, 1983; Neuman and Jacobsen, 1984). A comprehensive review of the applications of geostatistics to hydrogeology can be found in the ASCE Task Committee report (ASCE, 1990a, 1990b). Also, a few applications of the geostatistics tools in groundwater level predictions can be found in the literature (e.g., Ma et al., 1999; Finke et al., 2004; Barca and Passarella, 2008).
According to the inherent capability of ANNs in temporal forecasting and geostatistics tools in spatial estimating, a hybrid ANN-geostatistic (ANNG) black-box model is proposed in this paper, and its potential for spatiotemporal prediction of groundwater level in a coastal aquifer located in Iran is evaluated.
The combination of an ANN model with other mathematical tools, such as wavelet transform and fuzzy logic, have been already utilized for accurate prediction of hydrological time series (e.g., Alvisi et al., 2006; Nourani et al., 2009a, 2009b; Rajaee et al., 2009). However, in the current research, the proposed hybrid model is developed in order to estimate time-space modeling of the groundwater level.
The Urmieh Lake (study area) as a second salty lake in the world has created huge environmental, hydrological, ecological, economical, and agricultural challenges for scientists, because it is going to be dried due to some climatic and engineering problems; and the presented research may be also considered as a practical study so that researchers and engineers may use the presented new hybrid model to predict the space-time variation of the groundwater level around the lack or investigate the effect of the lake's depth reduction on the region's wells.
Study Area and Data
The data used in this paper are from the Shabestar plain (Fig. 1), which is located in northwest Iran at Azerbaijan Province (between 45° 26′ and 46° 2′ north latitude and 38° 3′ and 38° 23′ east longitude). The plain area is 1300 km2 and its main channel is Daryanchai, which discharges to Urmieh Lake. The headwaters of the river are situated in the Misho Mountain. Plain elevation is varying from 1278 m to 3135 m above sea level, and its longest waterway is 15 km in length.
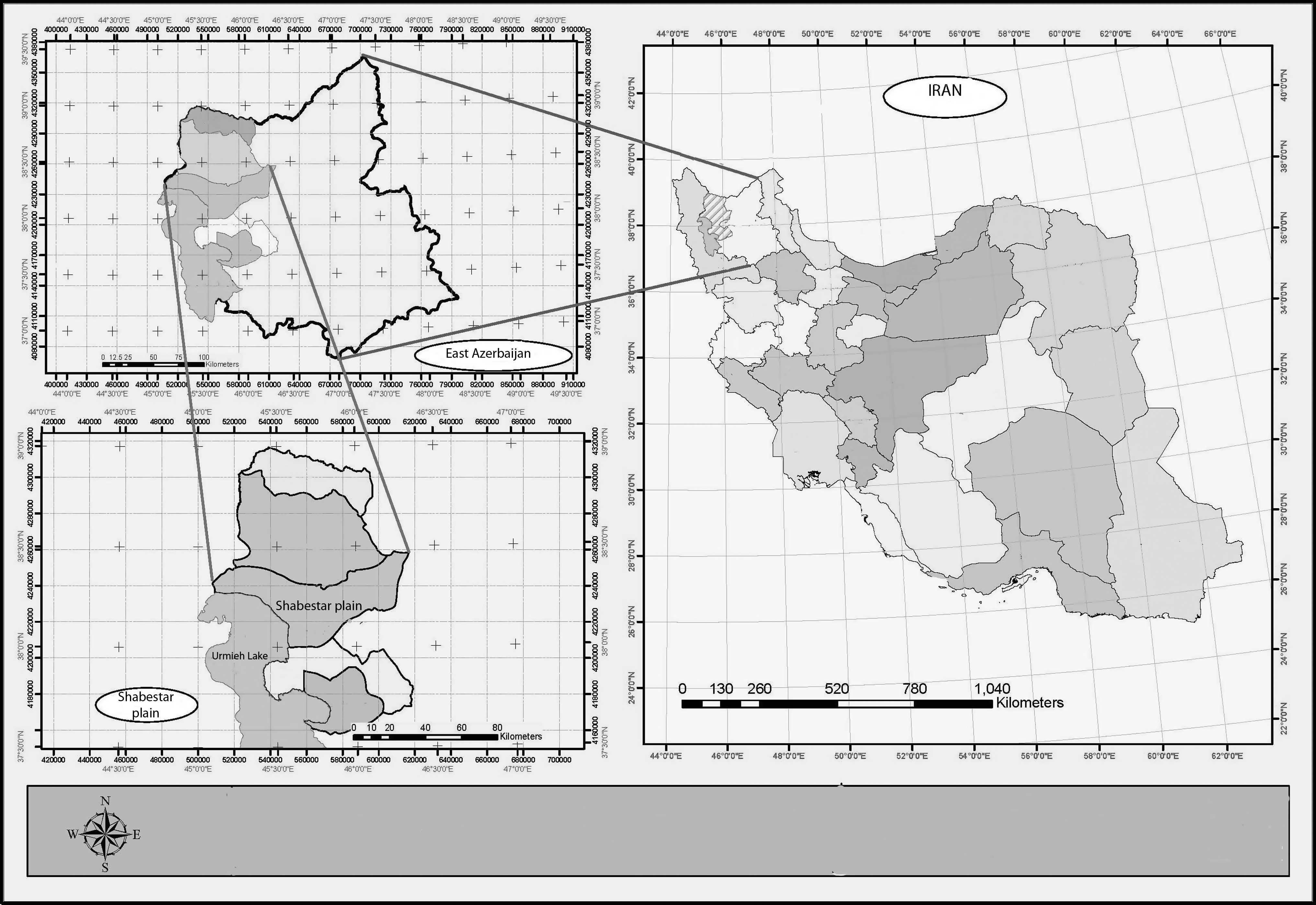
Study area.
The main daily temperature varies from −19°C in January up to 42°C in July, with a yearly average of 11°C; and the average annual rainfall is about 250 mm.
Urmieh Lake, located in northwestern Iran, is an oligotrophic lake of thalassohaline origin, the20th largest, and the second hyper saline lake in the world, with a total surface area between 4750 and 6100 km2 and a maximum depth of 16 m at an altitude of 1250 m. The lake is divided into north and south parts separated by a causeway, in which a 1500 m gap provides little exchange of water between the two parts. Due to drought and increased demands for agricultural water in the lake's basin, the salinity of the lake has risen to more than 300g/L during recent years, and large areas of the lake bed have been desiccated. The possible causes of rising salinity are likely to be surface flow diversions, groundwater extractions, and unsuitable climate condition.
Fluctuation of Urmieh Lake water levels has tremendous environmental impacts, especially on the adjoining groundwater resources. About 4.4 million people live in the Urmieh Lake basin, whose irrigation economy is strongly dependent on existing surface and groundwater resources in the area. Accordingly, human population growth in the lake's basin has seriously increased the need for agricultural and potable water in recent years, all of which are supplied from surface and groundwater sources in the area. These issues, together with poor weather conditions, have significantly reduced the volume of water entering the lake so that, at present, Urmieh Lake has shrunk significantly and large areas of the former lake bed have been exposed. According to the interaction between the water depth of the lake and groundwater level of the plain, decreasing of the water depth of the lake leads to decrease of groundwater level of the plain and also increase of the groundwater salinity.
In this article, an attempt has been made at utilizing the ANN and geostatistics concepts in order to investigate the effects of the lake's water depth and other hydro-meteorological parameters on the groundwater level via spatiotemporal modeling.
The data utilized in this study were collected over 13 years (from April 1994 to March 2006) with a one-month time interval. Table 1 shows the statistical analysis of the observed groundwater levels of piezometers.
UTM, Universal Transverse Mercator.
The monthly data collected consist of the following categories:
Observed water levels of piezometers located within the Shabestar plain (P1, P2, P3, … , P11 for training and TP1, TP2, and TP3 for cross-validation purposes). Figure 2 shows positions of the piezometers in the study area. Rainfall in Sharafkhaneh station. Average discharge of Daryanchai in Daryan station. Urmieh Lake level, Temperature in Sharafkhaneh station.

Piezometer positions.
Artificial Neural Network
ANNs offer an effective approach for handling large amounts of dynamic, nonlinear, and noisy data, especially when the underlying physical relationships are not fully understood. This makes them well suited to time-series modeling problems of a data-driven nature. In general, the advantages of an ANNs over other statistical and conceptual models can be classified as the following (Nourani et al., 2008):
The application of ANN does not require prior knowledge of the process, because ANNs have black-box properties,
1) ANNs have the inherent property of nonlinearity, as neurons activate a nonlinear filter called an activation function. 2) ANNs can have multiple inputs having different characteristics, which can represent the time-space variability. 3) ANN has been proved to be effective in modeling virtually any nonlinear function to an arbitrary degree of accuracy. The main advantage of this approach over traditional methods is that it does not require the complex nature of the underlying process under consideration to be explicit.
ANN is composed of a number of interconnected simple processing elements called neurons or nodes with the attractive attribute of information processing characteristics such as nonlinearity, parallelism, noise tolerance, learning, and generalization capability. Among the applied neural networks, the feed-forward neural networks (FFNN) with back-propagation (BP) algorithm are the most common used methods in solving various engineering problems (Nourani and Kalantari, 2010).
FFNN technique consists of layers of parallel processing elements called neurons, with each layer being fully connected to the preceding layer by interconnection strengths, or weights. Initial estimated weight values are progressively corrected during a training process that compares predicted outputs with known outputs. Learning of these ANNs is generally accomplished by BP algorithm (Hornik et al., 1989). The objective of the BP algorithm is to find the optimal weights, which would generate an output vector, as close as possible to the target values of the output vector, with the selected accuracy.
The network is determined by architecture of the network, the magnitude of the weights, and the processing element's mode of operation. The neuron is a processing element that takes a number of inputs, weights them, sums them up, adds a bias, and uses the results as the argument for a singular valued function called the transfer function. The transfer function results in the neuron's output. At the start of training, the output of each node tends to be small. Consequently, the derivatives of the transfer function and changes in the connection weights are large with regard to the input. As learning progresses and the network reaches a local minimum in error surface, the node outputs approach stable values. Consequently, the derivatives of the transfer function with regard to input, as well as changes in the connection weights, are small.
The BP neural network is the most widely used ANN in hydrologic modeling and is also used in this study. A typical BP neural network model is a full-connected neural network including input layer, hidden layer, and output layer. Various steps of the BP training procedure are described in Fig. 3.
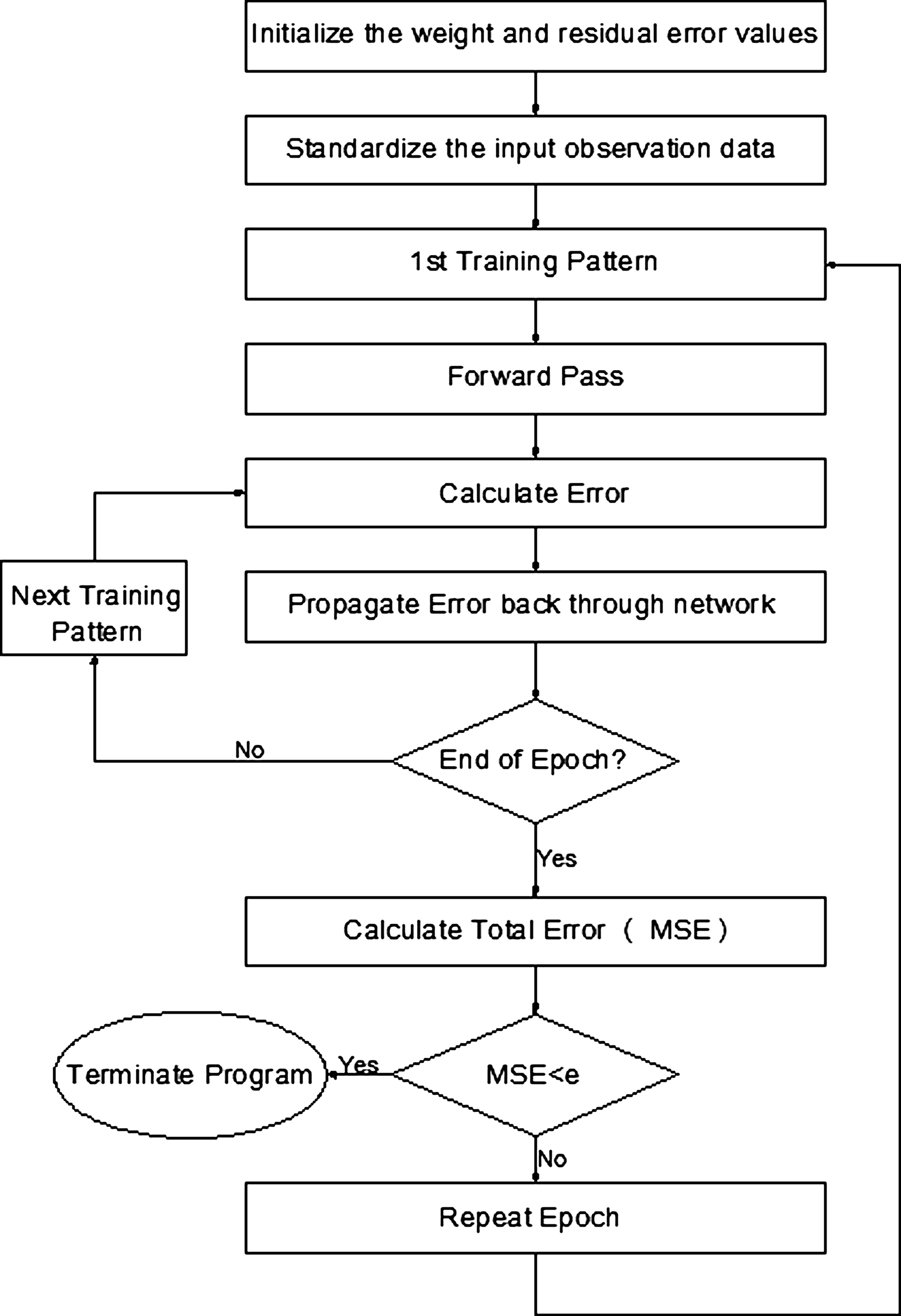
Flowchart of back-propagation algorithm.
BP algorithms use input vectors and corresponding target vectors to train ANN. The standard BP algorithm is a gradient descent algorithm, in which the network weights are changed along the negative of the gradient of the performance function. There are a number of variations in the basic BP algorithm that is based on other optimization techniques such as conjugate gradient and Newton methods (Hornik et al., 1989).
For properly trained BP networks, a new input leads to an output similar to the correct output. This ANN property enables training of a network on a representatives set of input/target pairs and achieves sound forecasting results. A clear, systematic document about the BP algorithm and the methods for designing the BP model are given by Basheer and Hajmeer (2000) and Jiang et al. (2008). Some researchers claim that networks with a single hidden layer can approximate any continuous function to a desired accuracy and are enough for most forecasting problems (Hornik et al., 1989).
In this study, at first step by using a three-layer neural network via a sensitivity analysis, the effective data sets are chosen. All input values are standardized to a specific range separately after data division. Input and output variables are preprocessed by scaling them between zero and one to eliminate their dimensions and to ensure that all variables receive equal attention during training of the models. Finally, the training and testing data sets are selected, and the network is trained.
The Levenberg-Marquardt (LM) method is a modification of the classic Newton algorithm for finding an optimum solution to a minimization problem. LM has large computational and memory requirement and, thus, it can only be used in small networks (Maier and Dandy, 1998). It is faster and less easily trapped in local minima than other optimization algorithms (Toth et al., 2000; Coulibaly et al., 2001a, 2001b, 2001c).
In this article, among the many training methods, the LM training algorithm was selected, considering its fast convergence ability (Sahoo et al., 2005). Also, a Tangent Sigmoid transfer function was used for hidden layer and a linear transfer function for the output layer according to Qu et al. (2004). The numbers of hidden layer nodes and training epochs are determined using trial and error in the test scenarios.
Geostatistics
Since detailed information about geostatistics and geostatistical techniques such as Kriging can be found in the scientific literature (e.g., Isaaks and Srivastava, 1989), only a brief description of the Kriging method, which is employed in this research, is provided.
Kriging technique is a spatial interpolation estimator Z(x0) used to find the best linear unbiased estimator of a second-order stationary random field with an unknown constant mean:
Where Z(x0) is Kriging estimate at location x0; Z(x i ) is sampled value at x i ; λ i is weighting factor for Z(x i ); and i = 1, … , n in which n denotes to the numbers of samples. The estimation error can be written as
Where Z(x0) is unknown true value at x0; and R(x0) is estimation error. For an unbiased estimator, the mean of the estimates must be equal to the true mean, therefore (Ma et al., 1999):
Where E is expected value and then:
The best linear unbiased estimator must have minimum variance of estimation error. The minimization of the estimation error variance under the constraint of unbiasedness leads to a set of simultaneous linear algebraic equations for the weighting factors as follows (Ma et al., 1999):
Where Var is the abbreviation of variance function. The weighting factors λ i can be determined by solving a nonlinear optimization problem involving the minimization of the foregoing function subject to the constraint in (4) by using the Lagrange multiplier μ as
The necessary conditions for optimal λ i and μ values involve setting the first derivative of equation (6) to zero; therefore, the system of simultaneous linear algebraic equations for λ i and μ can be expressed in matrix form as (Ma et al., 1999):
The Variogram γ can be derived from sampled data as follows:
The presence of a spatial structure where observations close to each other are more alike than those that are far apart (spatial autocorrelation) is a prerequisite to the application of geostatistics. The experimental Variogram measures the average degree of dissimilarity between un-sampled values and a nearby data value and, thus, can depict autocorrelation at various distances. The value of the experimental Variogram for a separation distance of h (referred to as the lag) is half the average squared difference between the value at Z(x i ) and the value at Z(xi+h) as (Ma et al., 1999):
Where n is the number of data pairs within a given class of distance and direction. If the values of Z(x i ) and Z(xi+h) are auto correlated, the results of equation (8) will be small, relative to an uncorrelated pair of points. From analysis of the experimented Variogram, a suitable model (e.g., spherical, exponential) is then fitted, usually by weighted least squares; and the parameters (e.g., range, nugget and sill) are then used in the Kriging procedure (Isaaks and Srivastava, 1989).
Proposed Hybrid Model and Results
By combining the ANN capability in modeling complicated and nonlinear systems and geostatistical ability in linear estimation with low estimation error, a hybrid model of spatiotemporal groundwater level forecasting in a coastal aquifer has been proposed in this article that uses both the mentioned models in a unique framework. Figure 4 shows the proposed model scheme.
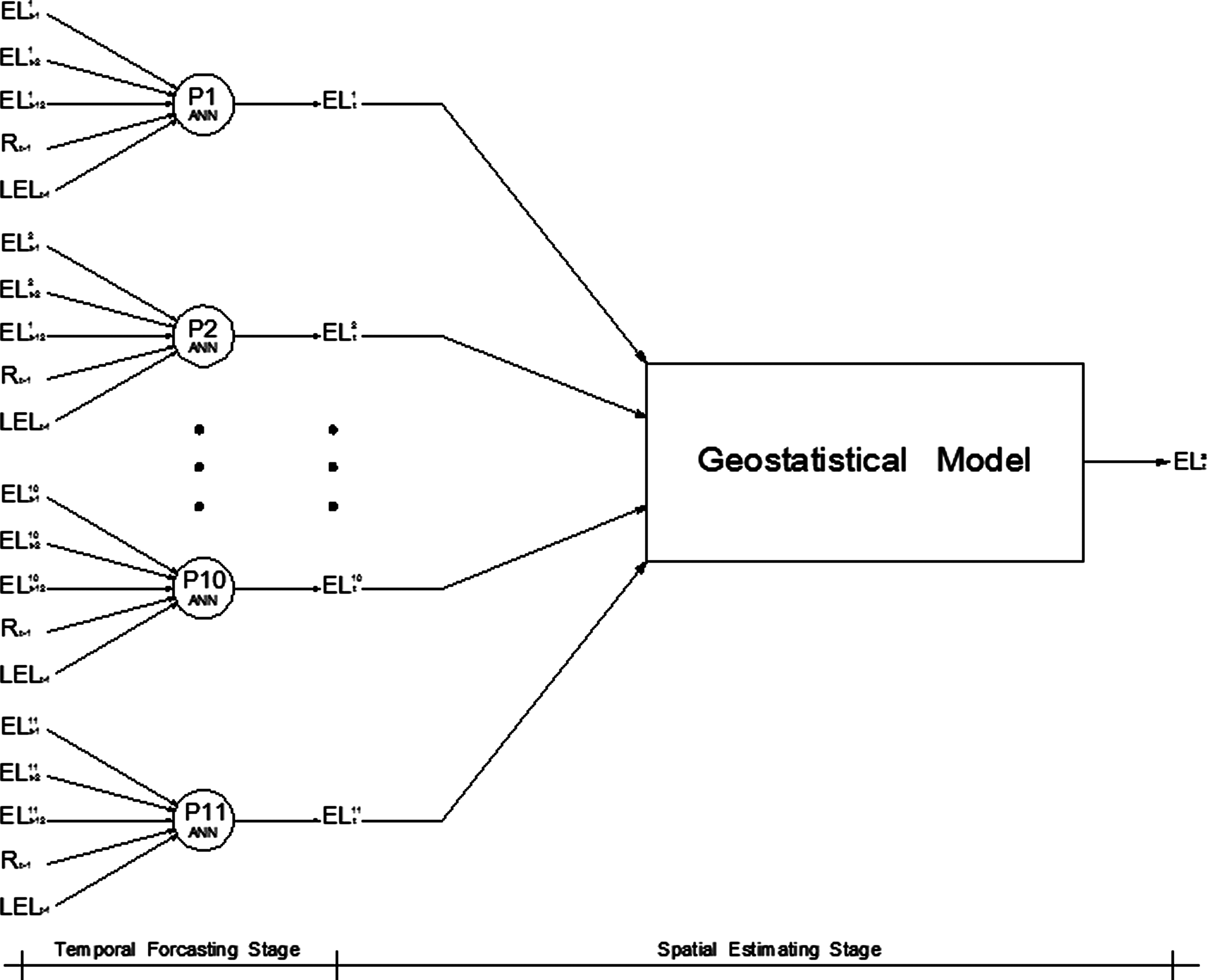
Diagram of proposed hybrid model.
The proposed model contains two separated stages. At the first stage, an ANN is trained for each piezometer (P1, P2, … , P11) for time series modeling of the water level. The model predicts the next month's groundwater level of the piezometer based on quantity of present month rainfall in study area (Rt-1), Urmieh Lake water surface level at that month (LELt-1), and groundwater levels in present, first, and twelfth previous months (ELt-1,ELt-2,ELt-12) in order to handle the seasonality of the process as well as the autoregressive characteristics. A sensitivity analysis was employed to select the mentioned input parameters from all the available data, as will be discussed in the next section.
At the second stage, the predicted values of water levels at different piezometers are imposed to a calibrated geostatistics model in order to estimate groundwater level at any desired point in the plain. Finally, as a cross-validation process, the proposed spatiotemporal model is evaluated by the data of piezometers TP1,TP2, and TP3, which do not contribute in the calibration step of the model. The details and results of the stages are presented in the following sections.
Temporal forecasting stage
In order to ensure good generalization ability by an ANN model, some empirical relationships between the number of training samples and the number of connection weights have been suggested in the literature. However, network geometry is generally highly problem dependent, and these guidelines do not ensure optimal network geometry, where optimality is defined as the smallest network that adequately captures the relationships in the training data (principle of parsimony). In addition, there is quite a high variability in the number of input and hidden nodes suggested by the various rules. Although research is being conducted in this direction by the scientists working in ANNs, it may be noted that traditionally, optimal network geometries have been found by trial and error (Maier and Dandy, 2000). Consequently, in the current application, the number of hidden neurons in the network, which is responsible for capturing the dynamic and complex relationship between various input and output variables, was identified by several trials. Also, this trial-and-error procedure with domain knowledge was explored for general guidance in the number of inputs selected.
The trial-and-error procedure initially started with two hidden neurons, and the number of hidden neurons was increased up to fifty with a step size of one in each trial. For each set of input and hidden neurons, the network was trained in batch mode to minimize the mean square error at the output layer. In order to check any over-fitting during training, a validation was performed by keeping track of the efficiency of the fitted model. The training was stopped when there was no significant improvement in the efficiency. The parsimonious structure that resulted in minimum root mean squared error (RMSE) (equation 9) and maximum efficiency coefficient (equation 10) during training as well as testing was selected as the final form of the ANN model for each piezometer.
The variables are scaled to a limit between zero and one as the activation function warrants. The total available data were divided into two sets, calibration and validation sets. In the training step, the models were trained using data of ten years (1994–2003) and then validated on the rest of the data (2004–2006).
The RMSE and coefficient of efficiency (CE) were used to assess the effectiveness of each model and its ability to make precise predictions. The RMSE is calculated by
Where yi and
Where
CE, coefficient of efficiency; RMSE, root mean squared error.
Spatial estimation stage
Kriging is a geostatistical technique for estimating attribute values at a point, over an area, or within a volume. It is often used to interpolate grid node value in mapping and contouring application. In theory, no other interpolation process can produce better estimates (being unbiased, with minimum error), though the effectiveness of the technique actually depends on accurately modeling the Variogram.
The accuracy of Kriging estimate is driven by the use of Variogram models to express autocorrelation relationship between control points in the data set. Kriging also produces a variance estimate for its interpolation values.
The difference between Ordinary Kriging (OK) and Universal Kriging variants residing in the model is the presence or absence of trend (Goovaerts, 1999). The main reason for using the OK model instead of Universal Kriging in the current research is the possibility of removing the bedrock elevation trend in spatial stage of modeling. Similar methodology was also conducted and reported by Yang et al. (2007); Ma et al. (1999); Cay and Uyan (2009). Also, as mentioned by Ta'any et al. (2009), this type of Kriging (i.e., Ordinary) can be used in the presence or absence of spatial trend after some modifications.
The Variogram measures dissimilarity, or increasing variance between points (decreasing correlation), as a function of distance. In addition to helping us assess how values at different location vary over distance, the Variogram provide a way to study the influence of other factors that may affect whether the spatial correlation varies only with distance (the isotropic case) or with direction and distance (the anisotropic case).Variogram map provides a visual picture of semivariance in every compass direction. If there is anisotropy, this allows one to easily find the appropriate principal axis for defining the anisotropic Variogram model. In this map, the surface (z-axis) is semivariance, and the x and y axes are separation distances in E-W and N-S directions, respectively. The center of the map corresponds to the origin of the Variogram γ(h) = 0 for every direction.
At stage two of the current modeling, which deals with spatial prediction of groundwater level, estimated groundwater level of the next month at the location of each piezometer was first corrected via bedrock elevation at the same location due to termination of existing trends (see Fig. 5). Afterward, the Variogram map of the study area was plotted using the temporally averaged values of the groundwater levels at different piezometers.
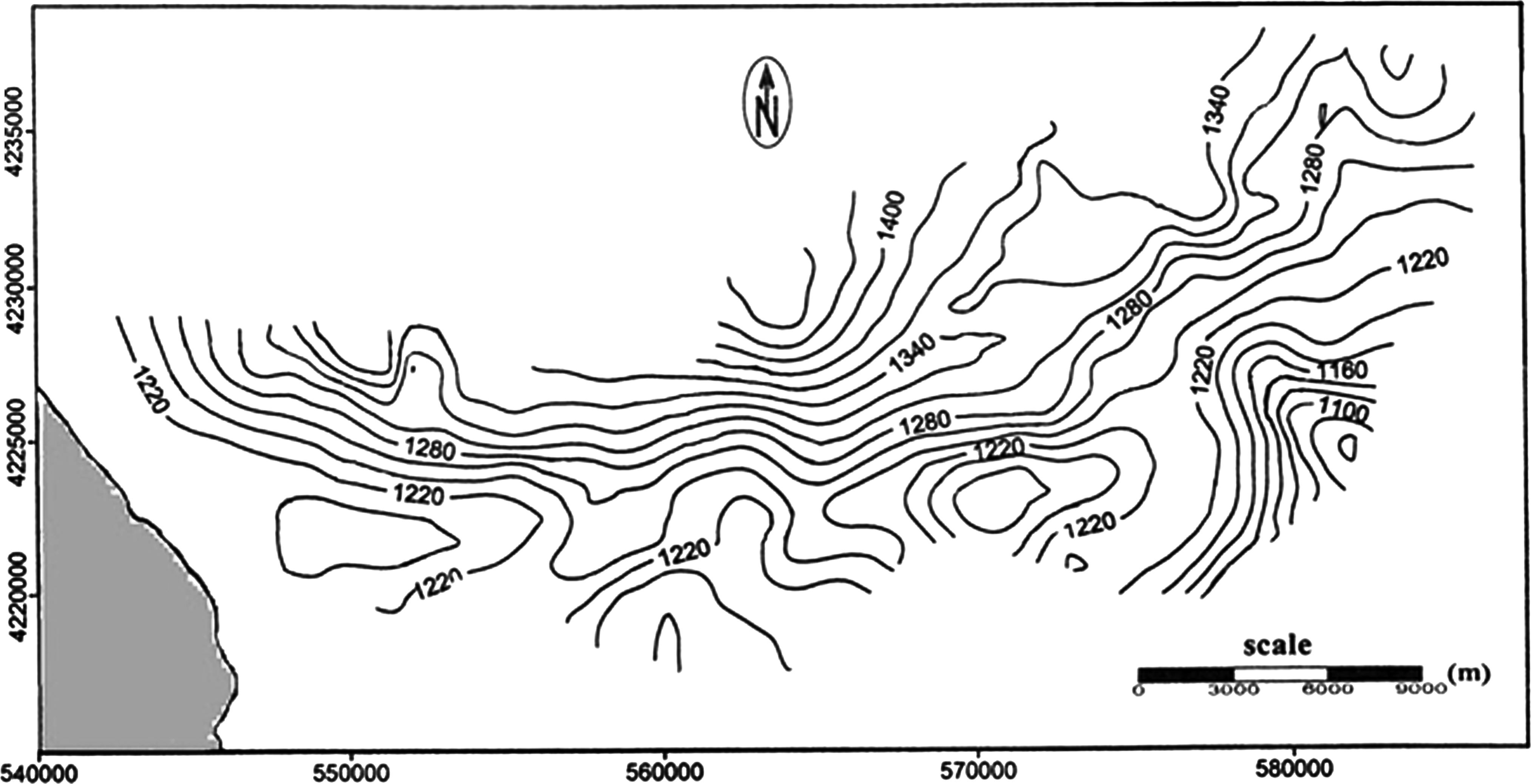
Bedrock elevations in study area (units in meters).
Figure 6 shows that the isotropic spatial modeling of the groundwater levels could be taken in use.
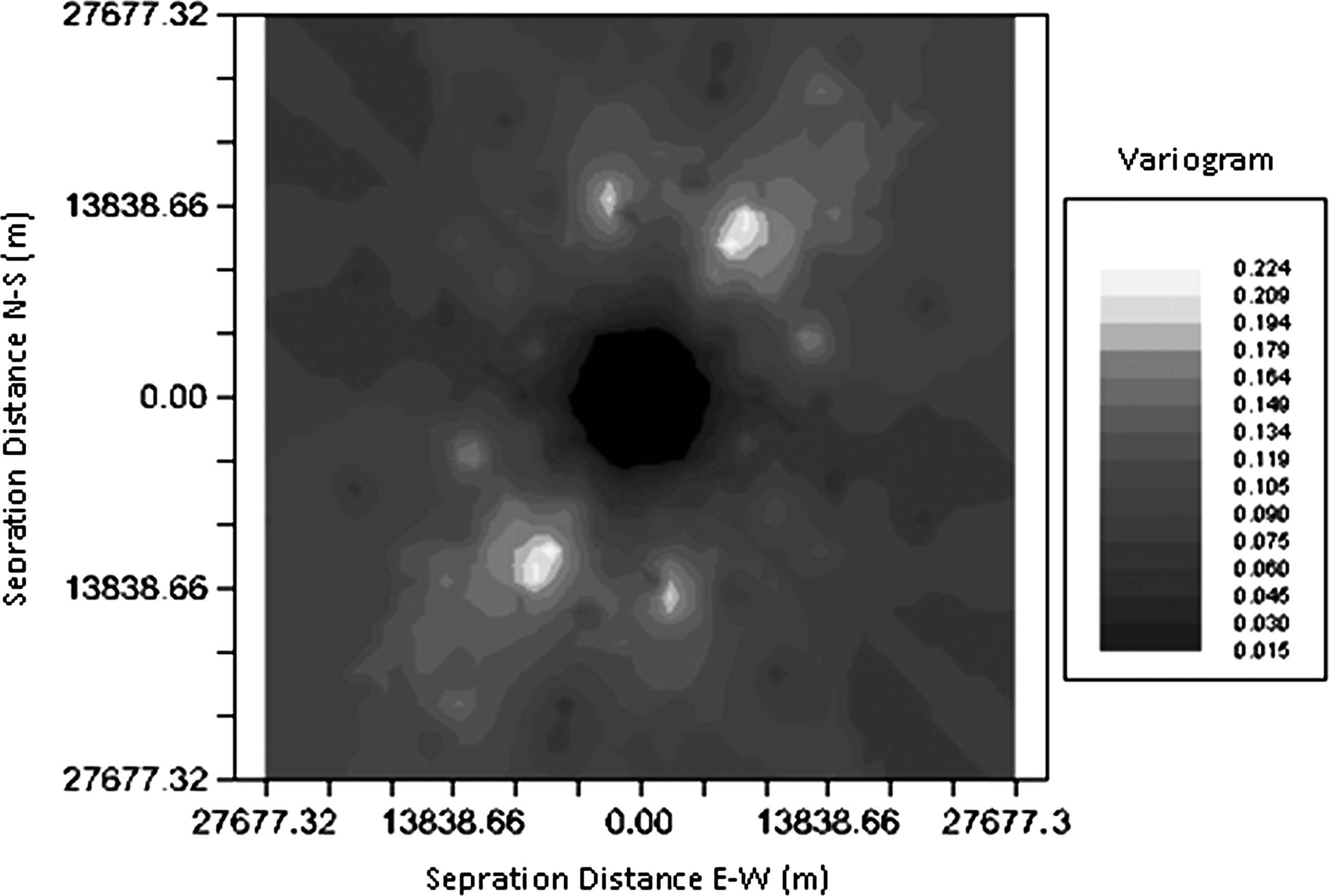
Variogram map (units in meters).
Thereafter, a suitable Variogram model was determined by fitting some well-known Variogram models (i.e., spherical, exponential, and Gaussian) to the experimental Variogram by using weighted least-squares method (Myers, 1982).
The geostatistical model, which leads to the least RMSE, was selected by comparing the observed water-table values with the values estimated by Variogram models.
According to Table 4 the best-fitted model was Gaussian model, and its parameters (i.e., range, nugget, and sill) were then used in the Kriging procedure.
The selected Gaussian model is shown in Fig. 7, which is similar to the exponential model but assuming a gradual rise for the y-intercept. This model is described by the following formula (Goovaerts, 1997):
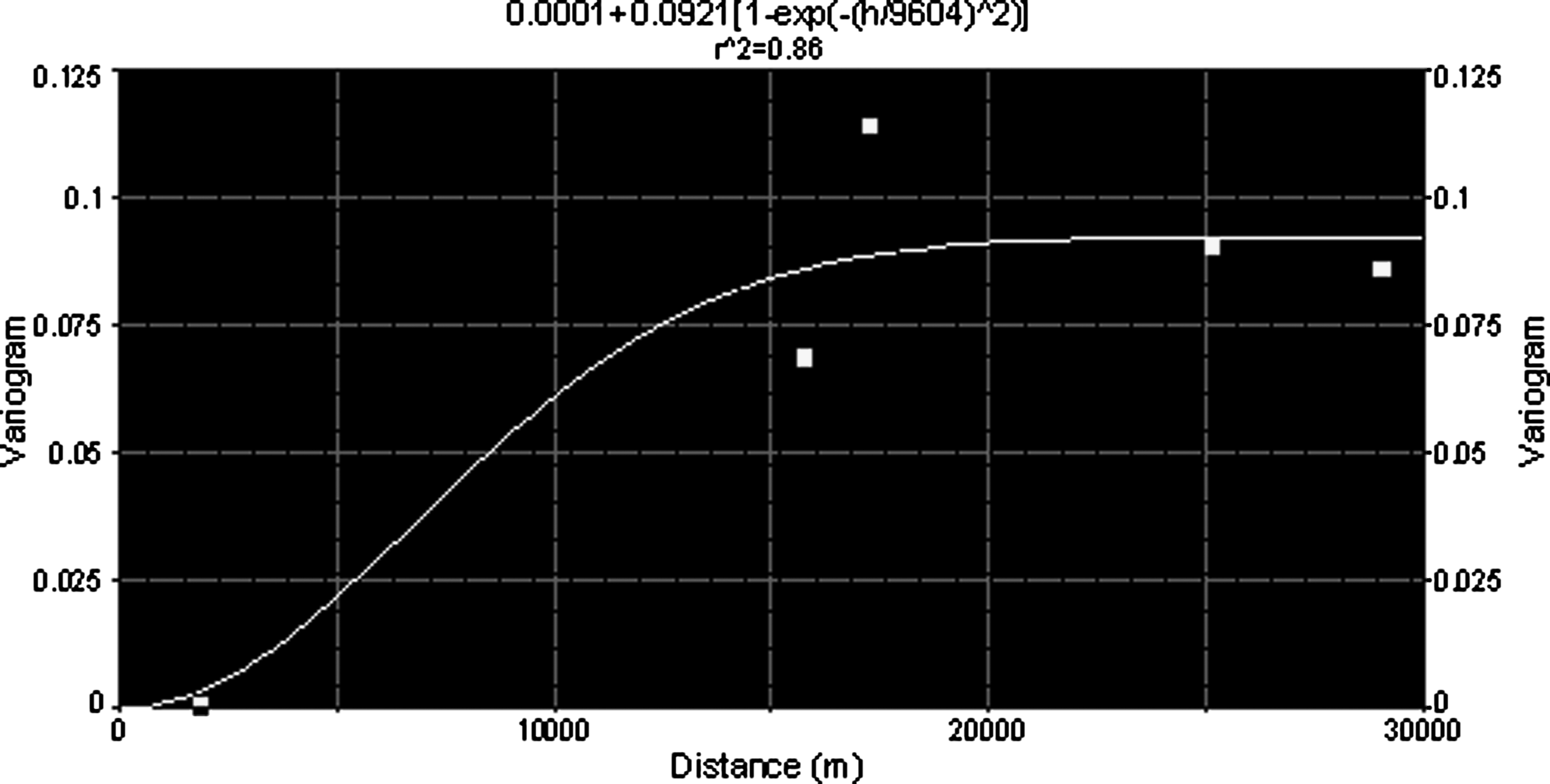
Selected variogram model.
Where: h = lag interval,
C0 = nugget variance ≥0,
C = structural variance ≥C0, and
A0 = range parameter.
The range parameter in this model is simply a constant defined as that point at which 95% of the sill is approached. The range can be estimated as 1.73A0 (1.73 is the square root of 3).
Based on the mentioned Variogram model, spatial groundwater-level estimation of the area has been carried out using Kriging method. The calibrated Kriging method was then verified via a cross-validation technique. Cross validation is a process for checking the compatibility between a set of data, the spatial model, and neighborhood design. In cross validation, each point in the spatial model is individually removed from the model, and then its value is estimated by a covariance model. In this way, it is possible to complete estimated versus actual values. Figure 8 shows the results of cross-validation procedure as a scatter plot, which denotes the reliability of the proposed geostatistical modeling.

Cross-validation results.
At this moment, both stages of the hybrid model have been completed, and the model can be used for spatiotemporal modeling of groundwater level within the Shabestar plain.
Finally, the proposed hybrid model was validated using the verification data set (2004–2006, 3 years) of piezometers TP1, TP2, and TP3, which have been utilized neither for training the ANNs nor for the calibration of the geostatistics model. For this purpose, the forecasted values of the water-level time series at different piezometers (P1, P2, … , and P11) via the trained ANNs models for the verification data set (2003 to 2006) were imposed to the calibrated geostatistical model in order to estimate the water level of piezometers TP1,TP2, and TP3, time step by time step.
The results of the modeling have been presented in Fig. 9, which demonstrates the capability of the proposed time-space hybrid model.
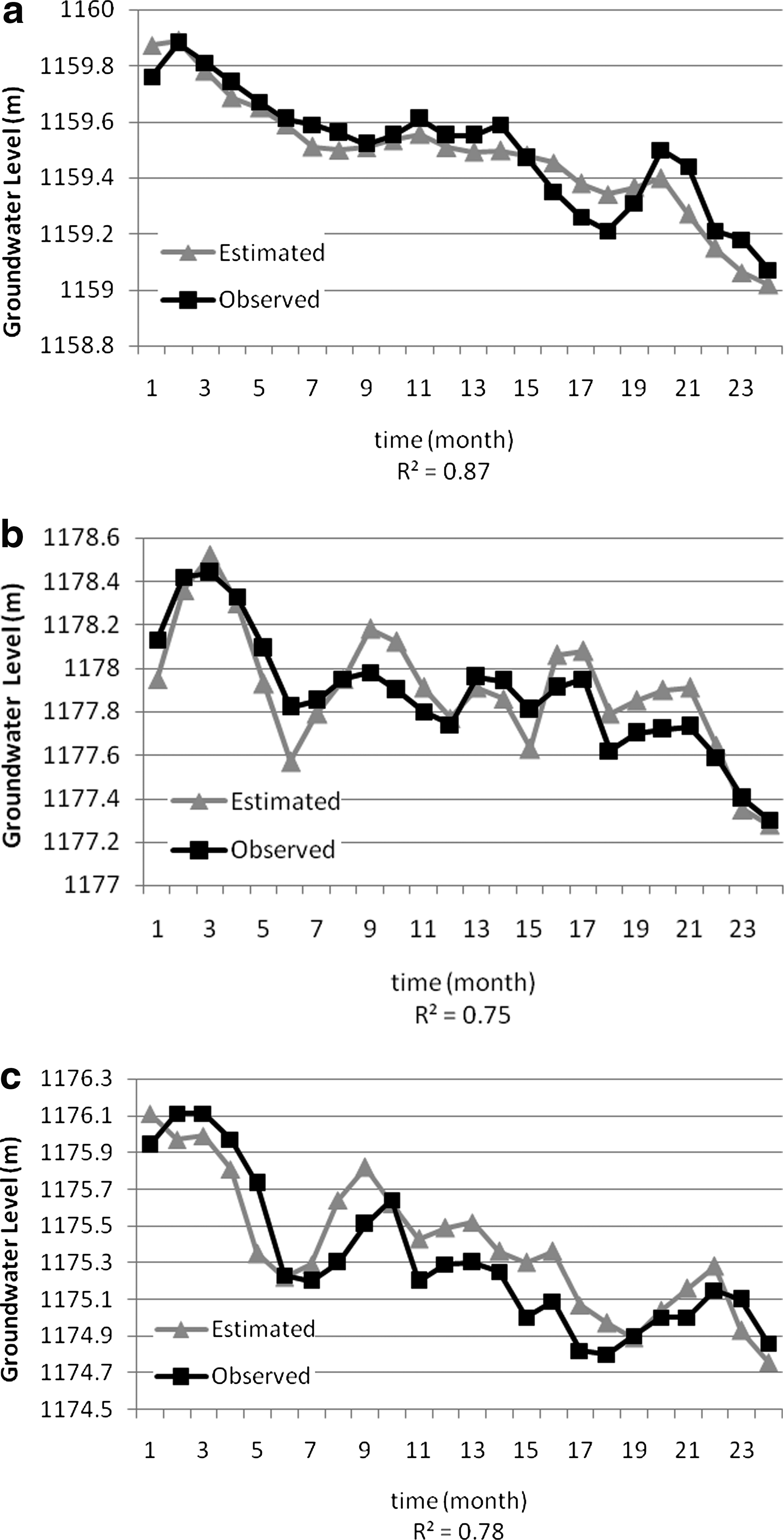
Results of spatiotemporal modeling for piezometers;
According to the obtained results, it can be clearly seen that the model is more capable to estimate the groundwater levels that are close to the lake. Since the water depth of lake is considered as an input variable to the ANNs, the proposed model could simulate the groundwater level of the near region to the lake more accurate than the far points.
Concluding Remarks
There are many hydrological variables that can be viewed as spatiotemporal phenomena. For example, monthly rainfalls or piezometric readings exhibit random aspects both with regard to time and space. The estimation of such variables at unsampled spatial locations or unsampled times requires the adequate thechniques into space-time domain. In this study, according to inherent capability of ANNs in temporal forecasting and geostatistics in spatial estimating, the potential of the proposed hybrid empirical model (ANNG) was evaluated for the purpose of spatiotemporal prediction of groundwater levels in a coastal aquifer in Iran.
Monthly groundwater levels data from eleven piezometers (P1, P2, … P11), rainfall, and lake-water surface elevations in the 13 years are the inputs of multilayer FFNN. Kriging was applied to the outputs from ANN models to estimate groundwater levels in unsampled locations such as coordinates of three selected piezometers (TP1, TP2, and TP3).
This modeling framework is applied for the Shabestar plain, which is located in northwest Iran at Azerbaijan province. The major results of the study are summarized as follows:
The results of the research reported in the article show high efficiency of three-layer BPANN with LM training algorithm for groundwater elevation prediction in the case study for a coastal aquifer.
Due to spatial structure between groundwater levels in adjacent points of the coastal aquifer, application of Kriging with isotrope Gaussian Variogram geostatistical model led to appropriate results.
In general, the results of the case study are satisfactory and demonstrate that the proposed hybrid model (ANNG) is a promising spatiotemporal prediction tool for groundwater modeling and may be also employed to fill the temporally and/or spatially missed data.
In order to complete the current study, it is suggested to extend the presented model for estimation of some qualitative parameters of the groundwater such as salinity via a multivariate geostatistics tool (e.g., Cokriging). Further, the application of wavelet transform or adding some forecasting sub-models for modeling the input hydrologic parameters of the model (e.g., precipitation, lake's water depth … ) (Nourani et al., 2009b) and/or clustering approach, respectively, as spatio temporal data preprocessing techniques, may improve the efficiency of the proposed model.
Footnotes
Author Disclosure Statement
No competing financial interests exist.