
Abstract
Abstract
This article presents the application of feed-forward multilayer perceptron (MP) networks to forecast hourly nitrogen oxides levels 24 h in advance. Input data were meteorological variables, average hourly traffic, and nitrogen oxides hourly levels. The introduction of four periodic components (sine and cosine terms for the daily and weekly cycles) was analyzed to improve the models' prediction powers. Data were measured during 3 years at monitoring stations in Valencia (Spain) in two locations with high traffic density. The models' evaluation criteria were mean absolute error, root mean square error (RMSE), mean absolute percentage error, and correlation coefficient between observations and predictions. Comparisons of MP-based models proved that insertion of four additional seasonal input variables improved the ability of obtaining more accurate predictions, which emphasizes the importance of taking into account seasonal character of nitrogen oxides. When using seasonal components as predictors, root mean square error improves from 20.29 to 19.35 when predicting nitrogen dioxide and from 45.07 to 42.37 when forecasting nitric oxides if the model includes seasonal components at one study location. At the other location, RMSE changes from 23.76 to 23.05 when predicting nitrogen dioxide and from 33.94 to 33.10 for other pollutant's forecasts. Neural networks did not require very exhaustive information about air pollutants, reaction mechanisms, meteorological parameters, or traffic characteristics, and they had the ability of allowing nonlinear and complex relationships between very different predictor variables in an urban environment.
Introduction
A
Tools to predict pollution levels can be used in different ways. Deterministic and statistical models have been developed for the purpose of forecasting. Deterministic models are not appropriate as prognostic models in coastal zones (Rye, 1995). They are more suitable for extensive areas such as whole regions and large cities. One of the causes of the uncertainty of deterministic models is the lack of sufficient data, as they require precise data from the emission and transportation of pollutants (deriving from traffic) and meteorological conditions. As the complexity of a problem increases, the theoretical understanding decreases due to ill-defined interactions between systems, and statistical approaches are required.
Statistical models are able to establish a relationship between input variables (predictors) and output variables, without detailing the causes and effects of the formation of pollutants. Autoregressive statistical models are often used to analyze the seasonality, trend, and autocorrelation of pollutant variability (Prada-Sanchez et al., 2000; Box et al., 2008), but they are limited by their weakness when modeling nonlinear temporal variations.
Classification and regression trees have also been applied to study the pollutant variability (Ryan, 1995; Gardner and Dorling, 2000). The possible presence of chaotic dynamics in pollutant concentrations allows modeling of nonlinear time series (Kocak et al., 2000). Donnelly et al. (2015) applied a nonparametric kernel regression model to forecast nitrogen dioxide concentrations 48 h in advance, using temporal variations and correlations with meteorology. The model had low computational resources and gave the index of agreement values between 0.74 and 0.94.
During the last two decades, the use of artificial neural networks and, in particular, the application of multilayer perceptron (MP) models have been developed to forecast pollutant concentrations (Gardner and Dorling, 1998). Neural networks have been shown to be effective alternatives to more traditional statistical techniques (Shalkoff, 1992). The neural network models can be trained to approximate virtually any smooth measurable function (Hornik et al., 1989). Unlike other statistical techniques, they make no prior assumptions concerning the data distribution. They can model highly nonlinear functions and can be trained to accurately generalize when presented with new unseen data (Bishop, 1995).
These features of neural networks make them an attractive alternative to developing numerical models and also when choosing between statistical approaches. Ibarra-Berastegi et al. (2008) focused on the prediction of hourly levels up to 8 h ahead for five pollutants at six locations in the area of Bilbao (Spain) using MP. The best performance of these models at the different sensors in the area was obtained for the prediction of nitrogen dioxide (NO2) 1 h ahead (correlation coefficient between observations and predictions=0.9), and the worse results were observed for the prediction of ozone 8 h ahead.
Caselli et al. (2009) compared the MP and multivariate regression models to predict critical pollution events. The regression models gave less accurate results mostly for 1 day forecasting and failed when fitting spiked high values of pollutant concentrations. Arhami et al. (2013) investigated the combination of artificial neural networks and Monte Carlo simulations to quantify model uncertainty when predicting several pollutants at two urban sampling locations of a developing country. They used meteorological parameters and seasonal components as predictors and validated the models with simulated data. They concluded that this methodology allowed selecting input variables and models' architecture in their study area. The best mean square errors obtained were 18.7 for nitrogen dioxide predictions and 27.5 for nitric oxides.
Elangasinghe et al. (2014) developed an artificial neural network model for predicting nitrogen dioxide concentrations at a site near a major highway in Auckland, New Zealand. They compared models with different inputs (meteorological parameters, hour, day, and month). Their study revealed that carefully choosing of inputs can give more reliable nitrogen dioxide forecasts, but the authors indicated that the inclusion of emission rates might improve the methodology. The artificial neural network model outperformed a linear regression model based on the same input parameters.
The objective of this study is to investigate, for the first time, the capability of the MP method to forecast NO2 and nitric oxide (NO) concentrations in the Valencia urban area (Spain). The primary goal of the work is to predict concentrations 24 h ahead at two different locations. This forecasting period of 24 h has been selected for practical regulatory reasons; shorter time forecasts are of minimal value for air quality management purposes.
NO2 and NO are relevant air pollutants in Valencia (European Communities, 2007). They are mainly a consequence of motor vehicle emissions, and industrial pollution plays a smaller part (Ballester et al., 2005). Tenias et al. (1998) reported a significant connection between a 10 μg/m3 increase in the NO2 level and the relative risk of asthma emergency visits in Valencia. Daily levels of NO2 in this city are also associated with cardiovascular admissions (Ballester et al., 2001; Ballester et al., 2006).
This pollutant is a precursor of other secondary pollutants that are related to photochemical smog and acid rain. Ambient air NO2 is, in large part, originated by the oxidation of NO. The link between climate and these pollutants plays an important role on their variability and has to be taken into account when selecting optimal pollutant reduction strategies to avoid exceeding emission directives. In this article, several MP models are designed and compared to establish the most efficient performer as a forecasting tool using meteorological and traffic variables, pollutant concentrations, and seasonal components as predictors.
Materials and Methods
Study area and database
The study area is located in Valencia (Spain). This city has around 1 million inhabitants, mediterranean climatology, and structure. An air pollution network managed by the local government since 1995, measures pollution variables in its urban area. The traffic network of the local municipality measures the number of vehicles circulating every hour at locations close to the pollution monitoring sites. The data used in this work were hourly observations from the air pollution and traffic networks.
The study considers two monitoring stations: Pista Silla and Viveros. Figure 1 presents the map of the study monitoring sites' location. These two stations were selected because several high-pollution episodes were registered to them during the period 2002–2005. The limit value of NO2 for the protection of human health in a calendar year (averaging period) was exceeded at Pista Silla in 2003–2005. At this site, the highest annual NO2 mean was observed in 2003.
Map of study monitoring sites' locations.
Mass concentrations of nitrogen oxides are determined using the chemiluminescence method. Pollutant concentrations are expressed in μg/m3. The volumes are standardized at a temperature of 293°K and a pressure of 101.3 kPa. The air pollution monitoring site at Pista Silla also measures wind speed (WS, m/s), wind direction (WD, degrees), temperature (T, °C), solar radiation (SR, W/m2), relative humidity (RH, %), and pressure (P, mbar). At Viveros location, WS, WD, T, and SR observations were provided by the National Institute of Meteorology, which manages a meteorological station close to the air pollution station.
The Pista Silla station is in a roadside site located a few meters from a motorway, and Viveros is in an avenue close to the city's center. The distance between them is 2.6 km. Traffic density is high at both sites. The matrix of data (hourly measurements) had 18,339 entries for Pista Silla (years 2003–2005) and 16,221 for Viveros (years 2002–2004), after eliminating rows with missing values. Table 1 shows averages, coefficients of variation, maximum values of pollutants, and meteorological and traffic variables for both stations, during the study period.
NO2 and NO, nitrogen dioxide and nitric oxide are expressed in μg/m3; WS, wind speed in m/s; WD, wind direction in degrees; T, temperature in °C; SR, solar radiation in W/m2; RH, relative humidity in%; P, pressure in mbar; NV, number of vehicles circulating every hour; CV, coefficient of variation.
Factors mainly contributing to NO2 and NO concentrations are connected with the source activity (e.g., traffic) and periodic variations in nature (e.g., photochemical reactions in the atmosphere). Periodic components are expected in the time series at the week level and in the form of daily variations. Figure 2 represents the average diurnal cycle of NO2 and NO levels at Pista Silla during the study period. The average weekly cycle at the same station for the two pollutants can be seen in Figure 3. The average traffic strength is also plotted in these diagrams with another scale on the right side. There are differences between hours, with concentration peaks associated with a high traffic density. The daily and weekly variations of the two pollutants depend on the average daily and weekly traffic variations. The same cyclical patterns were observed at the Viveros station.

Average diurnal cycles at Pista Silla station.
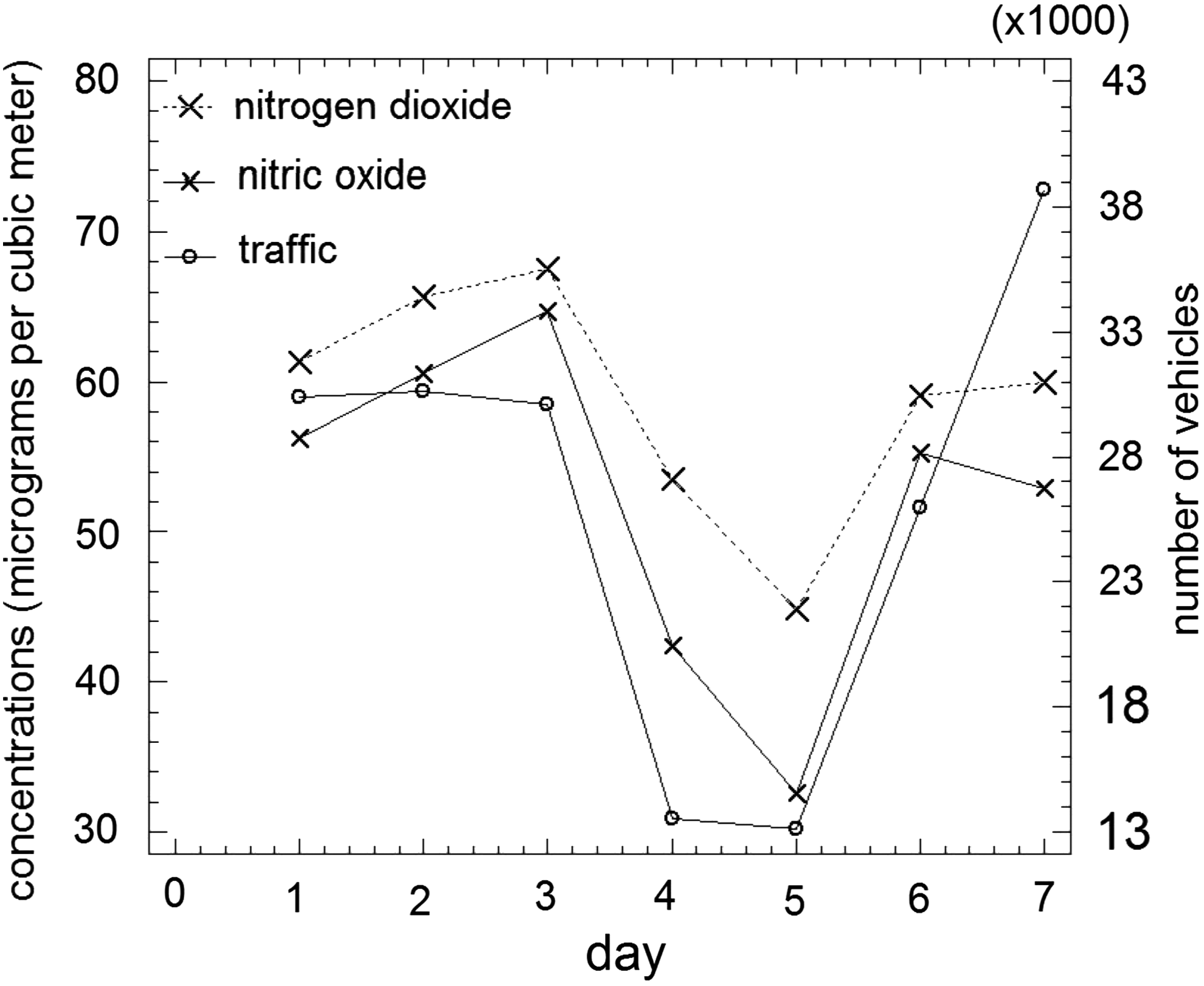
Average weekly cycles at Pista Silla station.
Multilayer perceptrons
The MP models used in this work were composed of three layers of neurons: the input layer, the hidden layer, and the output layer. The models were compared with different number I of predictors Xi or neurons in the input layer. The predictors were pollutant concentrations, meteorological parameters, traffic variables, or seasonal components (sine and cosine terms for the daily and weekly cycles). The models' output Y was the prediction of NO2 or NO concentrations 24 h in advance; therefore, the number of neurons in the output layer was equal to 1. Table 2 shows the models that were analyzed. The number of neurons H in the hidden layer was determined by experimentation, training the neural networks with values of H from 5 to 30. Greater values of H did not give a better performance.
MP, multilayer perceptron.
The MP networks were trained with two backpropagation algorithms: the scaled conjugate gradient (SCG) algorithm and the Levenberg–Marquardt (LM) algorithm. It has been proved that both algorithms converge faster and perform better than other backpropagation algorithms (Moller, 1993). The output Yo can be expressed as follows:
where o denotes the elements of the output layer and h indicates the elements of the hidden layer.
In this work, the linear transfer function has been applied for fo. fh is the transfer function of neuron j of the hidden layer. The most widely used fh are the hyperbolic transfer function (tansig) and the logarithmic sigmoid function (logsig):
Figure 4 shows an MP model with I neurons in the input layer, H neurons in the hidden layer, and one neuron in the output layer.

Multilayer perceptron (MP) model.
Overtraining does occur when the MP memorizes the patterns introduced to it and it is not capable of identifying new situations. The early stopping technique can be used to avoid this problem (Sarle, 1995). In this technique, the available database is separated into three subsets: the training set, the validation set, and the test set. The training set is used to update the network weights and biases. During the training, the validation set is used to guarantee the generalization capability of the model, and training should stop before the error on the validation set begins to rise. The test set is a new set used to check the generalization of the MP. In this work, the models were trained on data from the first year. Data from the second year were used as the validation set, and observations from the third year are the test data set. The computations were performed with the Neural Network Toolbox of MATLAB.
Evaluation criteria
Four statistical parameters were obtained to compare the performance of the MP models with the test dataset. They are the most used indices to assess the quality of an estimator (Willmott et al., 1985; Gomez-Sanchis et al., 2006). The correlation coefficient r between the forecasted values Yf and the observations Y quantifies the global description of the model. We computed the root mean square error (RMSE):
where n is the number of observations in the test data set. The mean absolute error (MAE) also measures how close forecasts are to observations:
An expression of accuracy of predictions as a percentage can be computed with the mean absolute percentage error (MAPE):
Results and Discussion
The best performance indices results at the Pista Silla station are shown in Table 3. It contains the best results obtained with the models MP1–MP4 [output (NO2)t+24] and the models MP5–MP8 (output NOt+24). The table indicates the backpropagation algorithm, the transfer function, and the number of neurons in the hidden layer. The comparison of the results indicates that the most accurate predictions of (NO2)t+24 at Pista Silla were obtained with the LM algorithm. The MP2 model using the tansig transfer function and this algorithm gives good values of the four evaluation criteria when the number of neurons in the hidden layer is nh=14. The values of these indices show that the obtained model is a good estimator. The predictors are meteorological parameters, traffic, seasonal components, and (NO2)t concentrations.
LM, Levenberg–Marquardt; MAE, mean absolute error; MAPE, mean absolute percentage error; RMSE, root mean square error.
Figure 5 represents predictions with this model corresponding to the first 100 h of the test data set. The period is from 00:00 h on January 1, 2003, to 3:00 h (am) on January 5, 2003. Valencia shows clear seasonal variations, with increasing activity during the coldest months. Nitrogen oxides emissions are higher during times of lower temperatures and also increase with reduced traffic speed, which in Valencia also occurs during winter months when urban locations have a greater density of traffic. The optimal neural network matches actual observations very appropriately and captures the concentrations' peaks and troughs. Figure 6 gives the scatterplot of the data set test predictions versus observations.
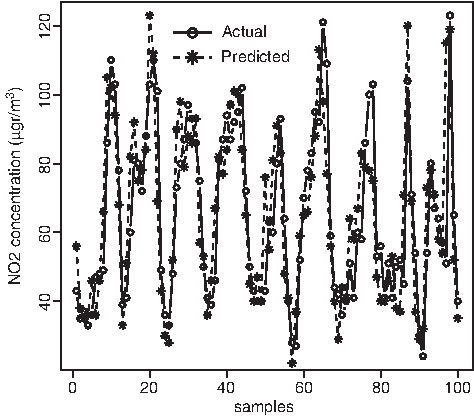
Nitrogen dioxide prediction 24 h in advance in first 100 h of the test data set at Pista Silla. The model is the MP, including (NO2)t, meteorology, traffic, and seasonality as predictors, with 14 neurons in the hidden layer, the tansig transfer function, and the Levenberg–Marquardt (LM) backpropagation algorithm. Correlation coefficient r=0.63 and mean absolute error (MAE)=15.38.

Scatterplot of nitrogen dioxide predictions 24 h in advance versus observations at Pista Silla. The model is the MP, including (NO2)t, meteorology, traffic, and seasonality as predictors, with 14 neurons in the hidden layer, the tansig transfer function, and the LM backpropagation algorithm.
The evaluation of NOt+24 predictions at Pista Silla is also in Table 3. In this case, the LM algorithm also gives most accurate forecasts. The MP6 model with nh=10, this algorithm, and the logsig transfer function provided the best value of the RMSE. In this case, the predictors are meteorology, traffic, seasonality, and NOt concentration. The model MP8 gives better prediction results in terms of MAE and MAPE. This model includes all the potential predictors (Table 2).
The Figure 7 shows actual and predicted values of NOt+24 with this model for the first 100 h of the test data set (from 00:00 h on January 1, 2003, to 3:00 h am on January 5, 2003). The neural model fits the observed values correctly. The accuracy of predictions of these models for the two pollutants can be compared using the two adimensional parameters, MAPE and r. MAPE, which computes this accuracy as a percentage, is better for (NO2)t+24 (MAPE=0.45) than for NOt+24 (MAPE=1.13).
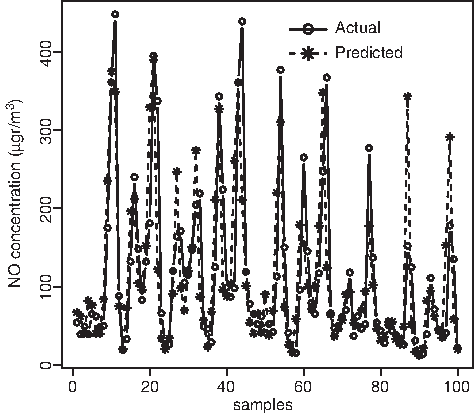
Nitric oxide prediction 24 h in advance in first 100 h of the test data set at Pista Silla. The model is the MP, including NOt, (NO2)t, meteorology, traffic, and seasonality as predictors, with seven neurons in the hidden layer, the logsig transfer function, and the LM backpropagation algorithm. Correlation coefficient r=0.66 and MAE=25.57.
Table 4 shows the best prediction results of the test data set at the Viveros station. Forecast evaluations of (NO2)t+24 can be seen in the first four rows (models MP1–MP4). Very similar results were obtained with the two transfer functions. The MP2 model gives the best RMSE result as can be seen in the table, when using the SCG algorithm, the tansig transfer function, and with a number of neurons in the hidden layer nh=10. The inputs to the neural network are meteorological variables, traffic, seasonal components, and (NO2)t levels. Predictions of this model in the first 100 h of the test data set are plotted in Figure 8. The period is from 17:00 h on February 25, 2002 (the first complete record), to 21:00 h on February 28, 2002. The value of the MAPE=0.98 indicates that the fit is less accurate than at Pista Silla, where the MAPE results are smaller with the four models (Table 3).
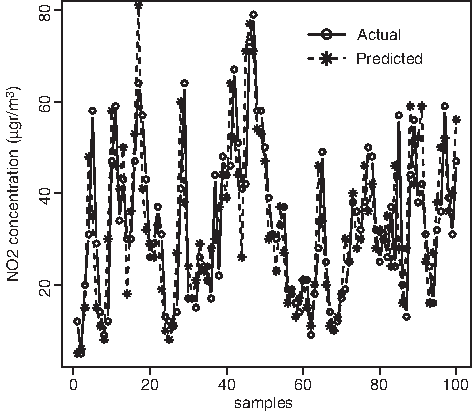
Nitrogen dioxide prediction 24 h in advance in first 100 h of the test data set at Viveros. The model is the MP, including (NO2)t, meteorology, seasonal components, and traffic as predictors, with 10 neurons in the hidden layer, the tansig transfer function, and the Scaled Conjugate Gradient backpropagation algorithm. Correlation coefficient r=0.07 and MAE=18.31.
SCG, scaled conjugate gradient.
The correlation coefficients between (NO2)t+24 observations and predictions are very small in Viveros (Table 4). This indicates that the linear agreement between these two variables is very poor and then the performance of the model MP1–MP4 is worse than at Pista Silla. Figure 5 also shows a closer agreement between observations and forecasts than Figure 8. The model MP4, which includes NOt as a predictor, has a smaller MAPE value.
Evaluation indices for the predictions of NOt+24 at Viveros are also in Table 4. The model that provides the best RMSE of NOt+24 forecasts is the MP8 model at the Viveros station. The transfer function is the tansig, with the LM backpropagation algorithm, and the number of neurons in the hidden layer is nh=10. Figure 9 shows the time series of NOt+24 predictions and actual values in the first 100 h with complete data of the test data set at Viveros (the first 20 h had missing records). Predictions are less accurate than at Pista Silla, where the correlation coefficient resulted for this pollutant r=0.66 and the MAPE is equal to 1.13 with this model. At Viveros, these parameters are r=0.52 and MAPE=3.32.
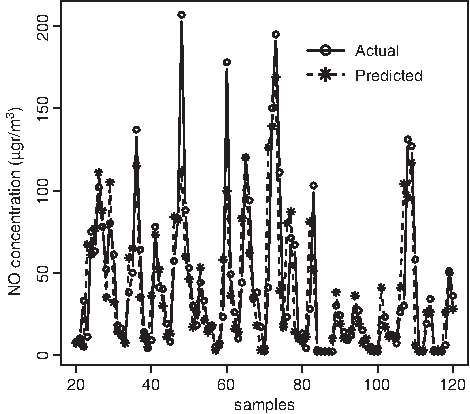
Nitric oxide prediction 24 h in advance in first 100 h with complete records of the test dataset at Viveros. The model is the MP, including NOt, (NO2)t, meteorology, traffic, and seasonality as predictors, with 10 neurons in the hidden layer, the tansig transfer function, and the LM backpropagation algorithm. Correlation coefficient r=0.52 and MAE=19.1.
The correlation coefficient is better when predicting NOt+24 than (NO2)t+24 at Viveros, but the agreement between actual and predicted values, expressed as a percentage, is better for (NO2)t+24. The MP models might perform worse at Viveros because the nitrogen oxides' temporal variations might depend on other environmental parameters not considered here, such as other meteorology parameters. At the Viveros location, wind speed, wind direction, temperature, and solar radiation observations were used as inputs. At Pista Silla, pressure and relative humidity were also available. Supplementary Tables S1–S6 provide the performance indices for both monitoring sites, and all the MP's parameters.
MP models have the advantages of making no prior assumptions concerning the data distribution. They have also modeled the nonlinear relationships existing between inputs and outputs and have been trained to accurately generalize when presented with new unseen data. They are easy to use and understand compared to other statistical methods. These models can also be applied in other areas with similar air quality problems and meteorological and traffic influences.
Future work will involve their application to forecast other pollutants. However, the MP is a black box learning approach, cannot interpret relationships between inputs and outputs, and cannot deal with uncertainties. There are other linear statistical methods where a greater understanding of the cause and effect can be obtained, but they are not useful in this study, given the highly nonlinear relationships between inputs and outputs. Other approaches such as nonparametric regression models have recently (Donnelly et al., 2015) performed well for air quality prediction in other places. A comparison of MP models with these approaches in the study locations is a promising research area. These models may be a good alternative to the methods used in this work.
Summary
In this work, neural network models and, more particularly, MP models have been developed to forecast nitrogen oxides levels 24 h in advance. This forecasting period was selected because the shorter time forecasts are of minimal value for air quality management purposes. Management of control and public warning strategies for nitrogen oxides levels requires accurate forecasts of the concentration of these pollutants and their dependence on meteorological and traffic variables.
The MP performed better when predicting nitric oxide at the study locations, if the models included daily and weekly seasonal components. These components were introduced with four additional input variables sin (2πh/24), cos (2πh/24), sin (2πd/7), and cos (2πd/7), h=1, 2,…, 24, d=1, 2,…, 7. In one of the monitoring stations (Pista Silla), the best forecast of nitrogen dioxide was obtained when including as input variables, meteorology, traffic, seasonality, and (NO2)t level. At the other site (Viveros), the introduction of seasonality improves the performance of the MP when predicting nitrogen dioxide in terms of the RMSE.
The relative importance of meteorological and vehicle emission variables on surface nitrogen oxides predictions is of great interest to establish the legislative measures that permit to reduce their levels. Models with different architectures have been considered. They have allowed predicting nitrogen oxides concentrations with accuracy. Mechanisms involved in nitrogen oxides concentration are complex and nonlinear. Neural networks do not require very exhaustive information about air pollutants, reaction mechanisms, meteorological parameters, or traffic flow. They also have the advantage of allowing nonlinear relationships between very different inputs or predictor variables.
The application of the models could be extended to forecast the other pollutant's hourly levels in the study area. The predictor variables of this work represent an excellent starting point, but models that consider other inputs should be taken into account for future work. The results support other studies done in other parts of the world using artificial neural network (ANN) techniques (Ibarra-Berastegi et al., 2008, Elangasinghe et al., 2014).
It is the first time that this methodology is applied to the Valencia urban area to predict nitrogen oxides concentrations. If the models were to be used as operational air quality forecast models, forecast traffic data would also be required. This forecast traffic could be obtained by applying ANN using seasonal components as inputs. Forecast traffic values can be used as models' inputs and might improve their performance. A comparison of the models using representative values and forecast traffic data would be useful to evaluate their effects. Future research will also focus on the development of other neural network models for atmospheric pollutant's prediction. Finally, the methodology developed in this study could also be applied in different areas with similar air quality problems and meteorological and traffic influences.
Footnotes
Acknowledgment
The author is indebted to the referees for their constructive comments, which have contributed to improving this article.
Author Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.