
Abstract
Genetic algorithm (GA) is often used to solve the optimization model of groundwater pollution source identification. However, GA is prone to premature convergence and fall into local optimum. Thus, homotopy algorithm and GA are used in combination to improve the disadvantage. Then hybrid homotopy-genetic algorithm (HGA) was applied to solve the optimization model. A 0–1 mixed integer nonlinear optimization model (0–1MINLP) based on kriging surrogate model was used to simultaneously identify hydraulic conductivity, location, and release history of pollution sources. The results showed that the 0–1MINLP based on a kriging surrogate model could simultaneously identify the hydraulic conductivity and information of pollution sources, while maintaining a certain level of precision and reducing calculation load. The combination of homotopy algorithm and GA can improve the shortcomings of GA that is easy to fall into premature convergence. The identification results obtained by the HGA were closer to the true values of the pollution source characteristics compared with GA.
Introduction
Groundwater is located underground, and thus groundwater pollution is generally characterized by concealment and a delay before its discovery. As a consequence, there is a poor understanding of the status of groundwater pollution sources, including the number, location, and release history of groundwater pollution sources in aquifers, which can hinder the design of groundwater pollution remediation schemes, risk assessments, and determining liability for pollution (Snodgrass and Kitanidis, 1997; Lapworth et al., 2012). Therefore, investigating the identification for groundwater pollution is particularly important.
Groundwater pollution source identification (GPSI) is based on measured groundwater pollution values as well as auxiliary information obtained from field investigations and professional experience. Solving numerical simulation models of groundwater pollution using various mathematical methods can identify relevant information about the groundwater pollution sources in aquifers, including the number, location, and release history (the release history refers to the release intensity of contaminants in each period) (Sun et al., 2006).
Effective GPSI can provide the basic conditions for the rational formulation of a groundwater pollution remediation plan, pollution risk assessments, and determining the liability for pollution. Thus, it has important theoretical significance and possible practical applications (Bagtzoglou and Atmadja, 2005).
The problem of GPSI was formulated in the 1980s. Gorelick et al. (1983) identified the location and release intensity of groundwater pollution sources by using least squares regression and linear programming. Mahar and Datta (2000) proposed a identification method for GPSI based on a nonlinear optimization model, and they studied the effects of the relative locations of observations on the identification accuracy. Mahinthakumar and Sayeed (2005) applied a genetic algorithm-local search (GA-LS) method to identify the location and release intensity of groundwater pollution sources. Their results showed that the identification results obtained using the GA-LS method were better than those produced with a single GA method or a local search method. Sun et al. (2006) used a constrained robust least squares method to identify the release history for pollution sources. Singh and Datta (2007) used an artificial neural network model to identify the release intensity of groundwater pollution sources and the missing concentration data for pollutants. Mirghani et al. (2009) used a parallel evolutionary search strategy to solve the simulation optimization model for a groundwater pollution source and identified the location and initial release intensity of the pollution source. Ayvaz (2010) embedded the MODFLOW and MT3DMS simulation models in an optimization model, and then used the heuristic harmony search algorithm to solve the optimization model to identify the number, location, and release history of pollution sources. Tamer Ayvaz (2016) used a combination of a GA and generalized simplified gradient algorithm to identify the location and release intensity of groundwater pollution source.
GA is a heuristic search method and is often used to solve the optimization model of GPSI. However, the GA is affected by the risk of premature convergence (An et al., 2009; Guo and Zhou, 2009). Therefore, it is important to improve the problem of GA in terms of premature convergence and fall into local optimum. The GA needs to initialize the population at the beginning of the iteration. The initialization methods of the population include random method and fixed value setting method. Using random methods to generate initial population cannot control the quality of initial population. The selection of the initial population for the GA will affect the identified result of the optimization problem. If the initial population is far from the true value, the algorithm is affected by the risk of premature convergence and the real pollution source information is not obtained. Thus, combining the homotopy algorithm with the GA and applying the homotopy method to generate the initial population (fixed value setting method) for the GA through path tracking can make the initial population more appropriate. Thus, combining the homotopy algorithm with GA can improve the disadvantages of premature convergence (fall into local optimum) for GA.
The simulation optimization method is used to perform GCSI in this study. A 0–1MINLP was established to simultaneously identify the hydraulic conductivity, location, and release history of pollution sources. The surrogate model of the simulation model was linked to 0–1MINLP to reduce the calculation load and time required when solving the optimization model while ensuring the inversion accuracy (Xing et al., 2019). The homotopy-genetic algorithm
Methodology
In this study, the hydraulic conductivity, location and release history of pollution sources were identified based on simulation-optimization method.
Homotopy algorithm
Many studies have considered the existence and effective solutions of nonlinear equations, but these methods have an inevitable shortcoming because whether they can search for the optimal solution of the optimization problem has a certain relationship with the choice of the initial population. If the appropriate initial population is not selected at the beginning of the iteration process, the optimal solution may not be obtained (Puangdownreong et al., 2004; Bei, 2014). However, for most nonlinear equations, it is difficult to find appropriate initial population, which can make it difficult or impossible to solve the nonlinear problem. The homotopy algorithm is a method for obtaining the solutions of nonlinear equations, and it has previously been applied to topology problems in the field of algebra. Due to the complexity of the nonlinear system, the traditional solution method often has difficulty obtaining the exact solutions for the equations that need to be solved. Thus, a system of equations is constructed, which are simple to solve. The path track is finally obtained by solving these simple equations. Finding a solution for the system of equations is the basic idea of the homotopy algorithm (Garrigues and Ghaoui, 2008). This method imposes no strict limit on the initial population and it requires a small amount of calculations. This simple algorithm has a high success rate (Watson and Wang, 1981). The principle of the homotopy algorithm is as follows:
where
Genetic algorithm
GA is an optimization method for random global search, which mimics the evolutionary mechanism of biological evolution in nature (Zwickl, 2008). In this algorithm, a new population is generated that is more adaptable to the environment than the previous group by applying random genetic operators such as selection, crossover, and mutation to an arbitrarily selected initial population (Guo et al., 2018). After evolution for several generations, the new population gradually evolves into better areas of the search space. Finally, the population converges until it is the best adapted to the environment and this individual is the optimal solution to the problem. The principle of GA is detailed in Guo et al. (2018) article. The GA is simply explained as follows.
Coding: Before the GA performs the search, the solution to the actual problem is converted into binary data called code.
Generating the initial population: The evolution algebra counter and maximum evolution algebra are set, and M individuals are randomly generated as the initial population P(0).
Fitness evaluation test: The fitness function is defined according to the specific practical problem and the fitness is calculated for each of the individuals in the group P(t).
Evolution: The selection operator, crossover operator, and mutation operator are applied to the group. The group P(t) is selected, crossed, and mutated to obtain the next generation P(t + 1).
Termination condition judgment: If
Kriging method
The kriging method is an interpolation method proposed by the Georges Matheron. The kriging method was applied to establish a surrogate model in recent years (Hemker et al., 2008; Coetzee et al., 2012; Guo et al., 2018). The principle of kriging method was as follows:
where
where R is the spatial correlation function matrix, θ denotes the correlation parameter, n denotes the number of dimensions in the set of design variables,
Based on the input and output data for the n known sample points, the output value corresponding to any point x in the predicted feasible domain is:
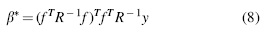
where r(x) is the correlation vector of the point x and n sampling points  is the matrix
is the matrix
The variance estimate value
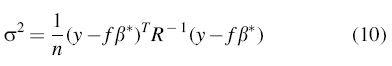
The surrogate model can be established by solving the nonlinear unconstrained optimization problem defined above. After obtaining the undetermined parameters
Method application
Site overview
The study considered two hypothetical cases. The advantage of a hypothetical case is that it does not require much time to study the complex conditions in the actual problem, thereby decreasing the time needed to identify and verify the simulation model. Moreover, it is possible to test the identified results.
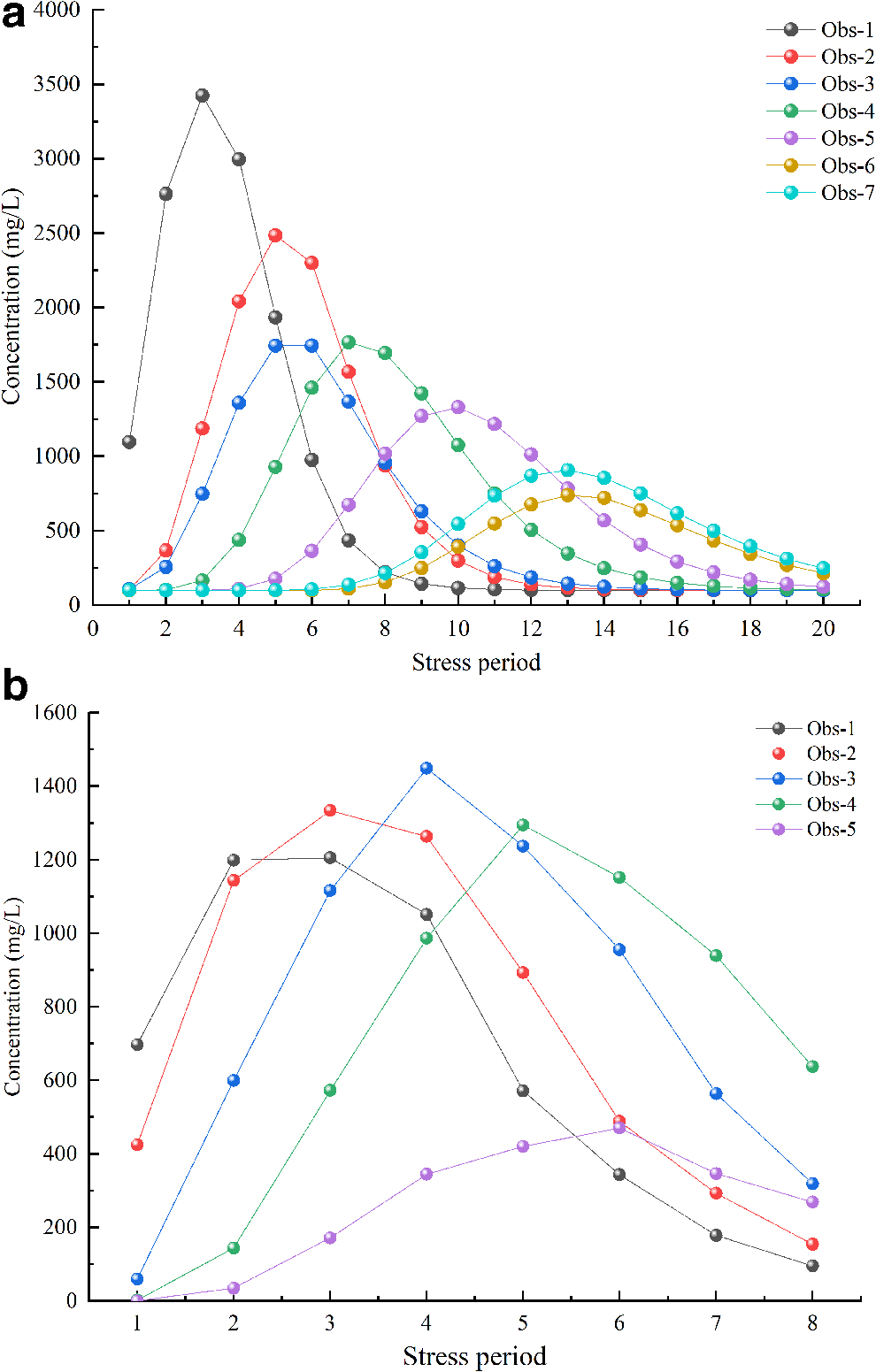
Case 1 is a situation that many scholars have used (shown in Fig. 1a), which involves irregular geometry, inhomogeneous media, and transient flow (Ayvaz, 2010; Xing et al., 2019). Case 2 is a two-dimensional heterogeneous isotropic phreatic aquifer model with an irregular boundary. Three parameter partitions were defined (shown in Fig. 1b). The movement in the phreatic aquifer was transient flow. The vertical direction of the study area received uniform recharge of atmospheric rainfall with a recharge amount of 680 mm/a. Four pollution sources were present in the study area. The total simulation time for pollutant transport was 16 months and divided into eight stress periods (the computational time intervals for a MODFLOW simulation are called “stress periods”). Each stress period contained 2 months. Pollutant was released from the source within 8 months of the first four stress periods. Five observation wells were located in the study area.
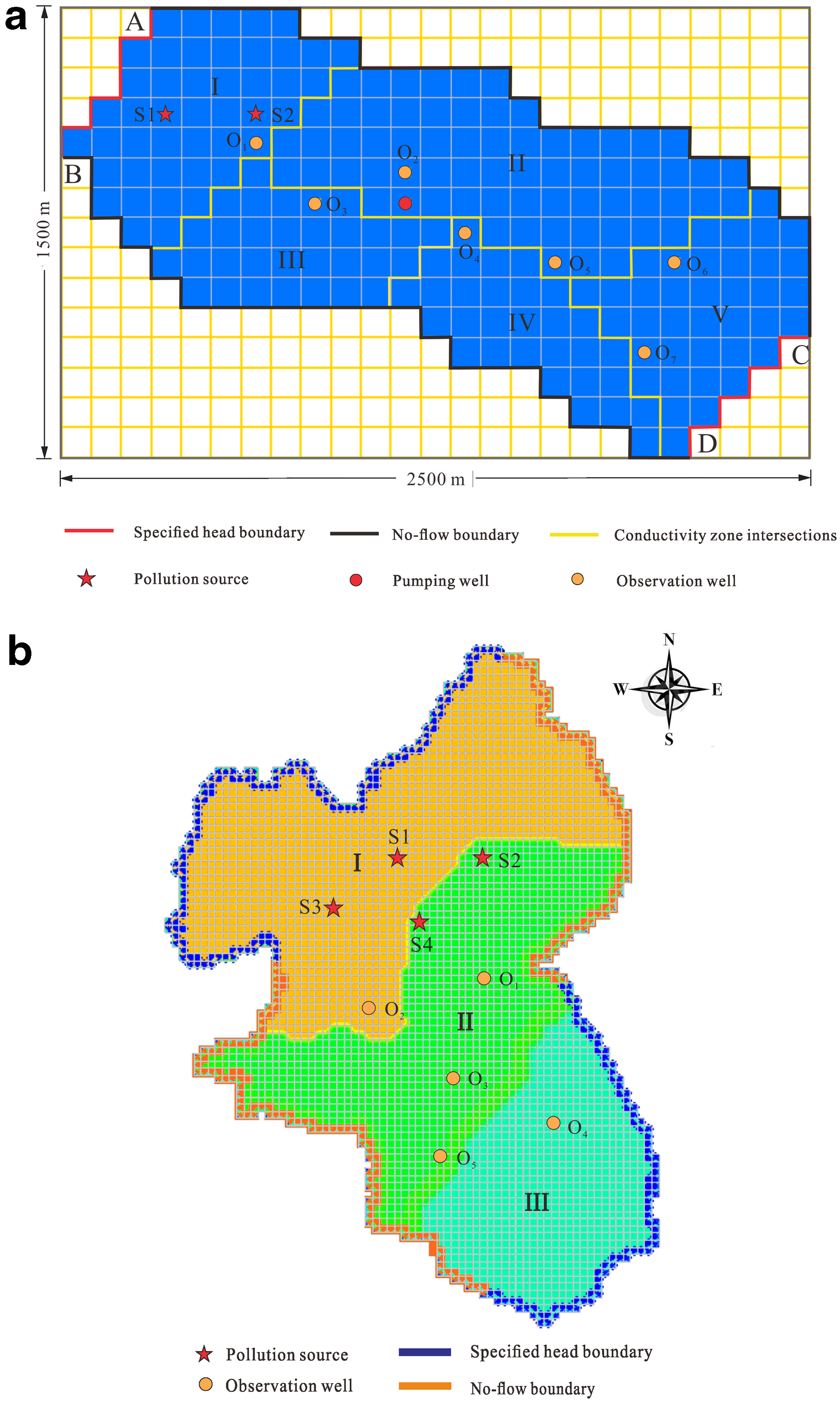
The boundary conditions and other related parameters for the two cases are listed in Tables 1 and 2, respectively. The initial concentration of the pollutants and the release intensities of the sources in for two cases are shown in Tables 3 and 4, respectively.
Aquifer Parameters for Case 1
Aquifer Parameters for Case 2
Pollution Source Release Intensities in the Four Release Periods for Case 1
Pollution Source Release Intensities in the Four Release Periods for Case 2
The application of the identification method is shown in Fig. 2.
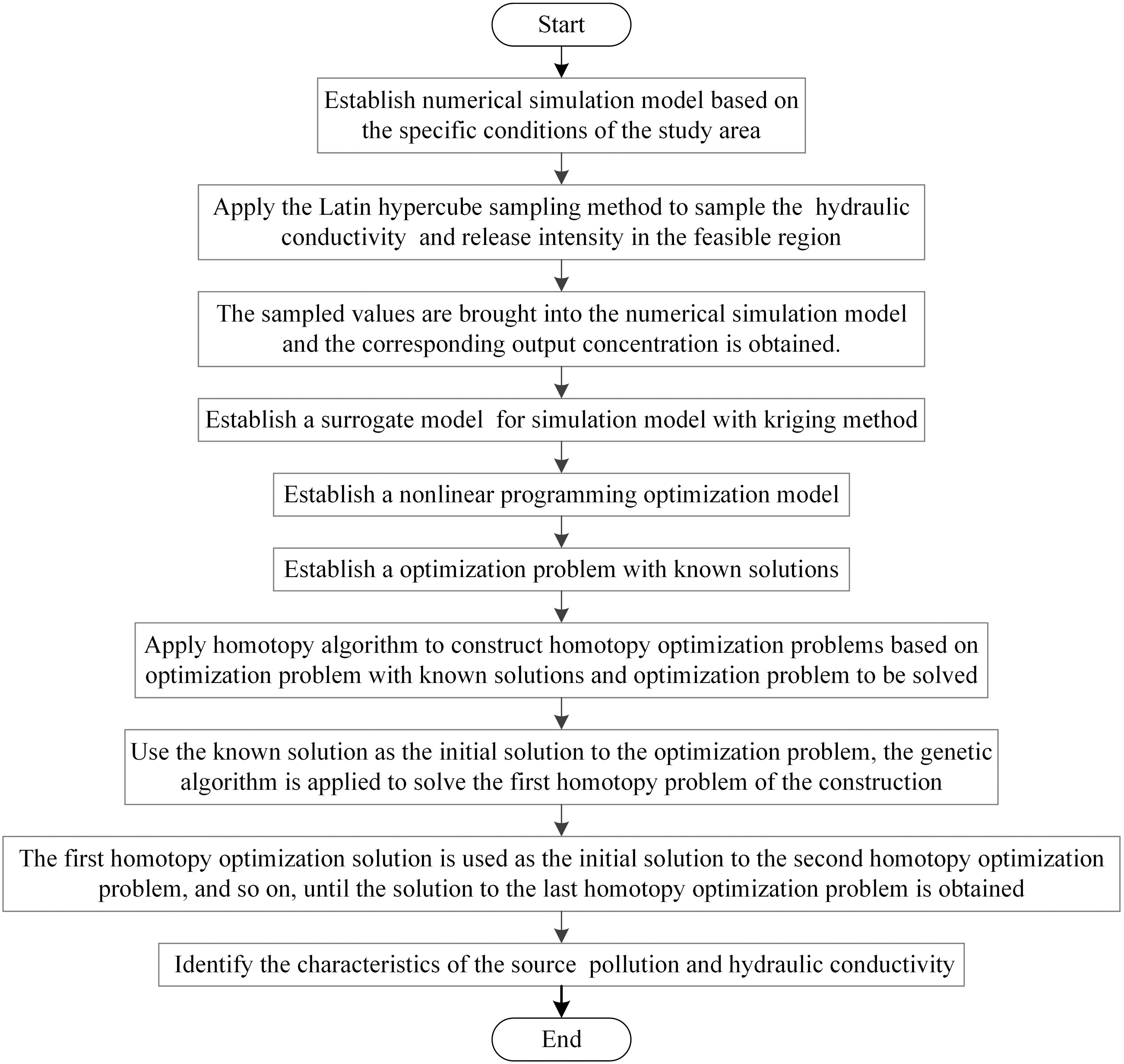
Application of the proposed method to the case study.
Numerical simulation model
The numerical simulation models of the groundwater flow and pollutant transport migration for case 1 and case 2 were established based on the specific conditions in the area. The governing partial differential equation for the transient flow in a two-dimensional aquifer system according to Darcy's law and the water balance principle can be given as follows: (Singh and Datta, 2007):
where Kij is the hydraulic conductivity, H is the hydraulic head, W is the volumetric flux per unit volume, and x are the Cartesian coordinates.
The partial differential equation that describes the transport of a contaminant in a two-dimensional aquifer system established by Fick's law is expressed as follows.
Darcy's law can be used to determine ui in Equation (15):
where
The MODFLOW and MT3DMS toolboxes in GMS software were used to simulate the groundwater flow and contaminant transport processes.
Unlike the actual problem, the hypothetical case contained no actual measured data. Therefore, it was necessary to forward run the pollutant transport simulation model of the cases (input the aquifer parameters and real information of pollution sources into the model) and obtain the pollutant concentration data for the observation wells in each stress period after operation as the measured data for identification. The simulated concentration data were disturbed by artificial noise to simulate the situation where the concentration measurements contained noise (the value of noise intensity is 0.05). Refer to the study of Mahar and Datta (1997; 2000) for the specific method of adding noise in simulated concentration. Figures 3 and 4 show the contaminant plume distributions and obtained pollutant concentration values, respectively.

Kriging surrogate model of the simulation model
During the iterative calculation process conducted to solve the GPSI problem with the 0–1MINLP, it was necessary to call the simulation model hundreds of times, thereby leading to a high computational load and long calculation period. This problem was solved effectively by establishing a surrogate model of the simulation model and linking the surrogate model as an equality constraint to the 0–1MINLP.
A surrogate model of the simulation model was established using the kriging method. The hydraulic conductivity and release intensities for the pollution sources in each release period were used as the input variables to establish the surrogate model and the concentration data for the observation wells were used as the output variables in the surrogate model. First, the Latin hypercube method was used to sample the hydraulic conductivity (the probability distribution of the hydraulic conductivity are shown in Tables 5 and 6) and release intensities for the pollution sources in their feasible regions. In total, 200 groups were sampled. Then, the sampled data were input to the simulation model, and the corresponding output concentration data for the 200 groups were obtained by running the simulation model. One hundred sixty groups of input and output data sets were prepared to train the surrogate model. According to the kriging method, the training code for the kriging surrogate model was written using MATLAB, and then the surrogate model was established by using kriging method.
Probability Distribution and Value Ranges of Hydraulic Conductivity for Case 1
Probability Distribution and Value Ranges of Hydraulic Conductivity for Case 2
After obtaining the trained surrogate model, it is necessary to test the approximation degree of the surrogate model output to the simulation model output. Forty input and output data sets were used to test the accuracy of the surrogate model. The following two indicators were used to test the accuracy of the surrogate model.
The mean relative error (MRE) was calculated as follows.
The coefficient of determination (R2) was calculated as follows.
In these formulae, yi is the output value of the ith sample in the pollution transport simulation model,
Optimization model
After establishing the surrogate model of the simulation model, an optimization model was established for identifying the hydraulic conductivity and characteristics of the groundwater pollution sources by comprehensively applying various mathematical methods, numerical simulation models (using surrogate models instead of simulation models), and limited data measurements to identify groundwater pollution source characteristics.
The sum of squared error between the monitored concentrations in the observation wells and the simulated calculated concentrations in the observation wells were minimized as the objective function. The location (regard as 0–1 integer variable), the hydraulic conductivity and release intensity of the pollution sources (regard as continuous variables) were used as the decision variables in the optimization model. The surrogate model for the simulation model was used as the pollution transport law constraint. A 0–1MINLP was established for identifying the hydraulic conductivity and information of pollution sources:
where
The ill-posedness of the two inverse problems in this study were evaluated by refering to Carrera and Neuman (1986), Draper and Smith (1998), Carrera et al. (2005) and Tarantola (2005), and it was found that the ill-posedness of the two GPSI inverse problems were weak and had little effect on solving the optimization model to obtain the optimal identification results.
Hybrid mixed HGA
The GA is a heuristic search method. However, there is some issues that GA is easy to lead premature convergence and into the plight of local optimum (Li and Tong, 1999; An et al., 2009; Guo and Zhou, 2009). The combination of homotopy algorithm and GA can avoid this shortcoming to a certain extent. The homotopy algorithm constructs a series of homotopy equations using known solution equations and equations to be solved, and then applies the GA to solve the homotopy equations step by step, so as to achieve the goal of “tracking” the solution of the equation to be solved from the known solution equation; therefore avoiding the drawbacks of the heuristic algorithm into local convergence to a certain extent (Abbasbandy et al., 2007; He and Li, 2013). The homotopy algorithm was combined with the GA to improve the disadvantages of its dependence on the initial population selection and preventing it from becoming trapped by a local optimum (premature convergence).
The principle of the combined use of homotopy method and GA is as follows:
Based on the simulation model, an optimization problem Determine the variation form of homotopy parameter
The principle of constructing the homotopy equation is as follows:
where X is the hydraulic conductivity and information of pollution sources,
Take the solution of the optimization problem corresponding to
The path tracking process evolved gradually in the solution process, so the solutions of two optimization problems located adjacent to each other were also very close. Applying the solution of the (i-1)-th optimization problem as the initial solution for the i-th optimization problem ensured that the optimization process evolved gradually, thereby avoiding the premature convergence problem caused by selecting an inappropriate initial population.
By performing the above operations, we can start from the optimization problem with the known solution, and finally obtain the hydraulic conductivity and pollution source information to be identified through path tracking.
Results and Discussion
Accuracy of the surrogate model
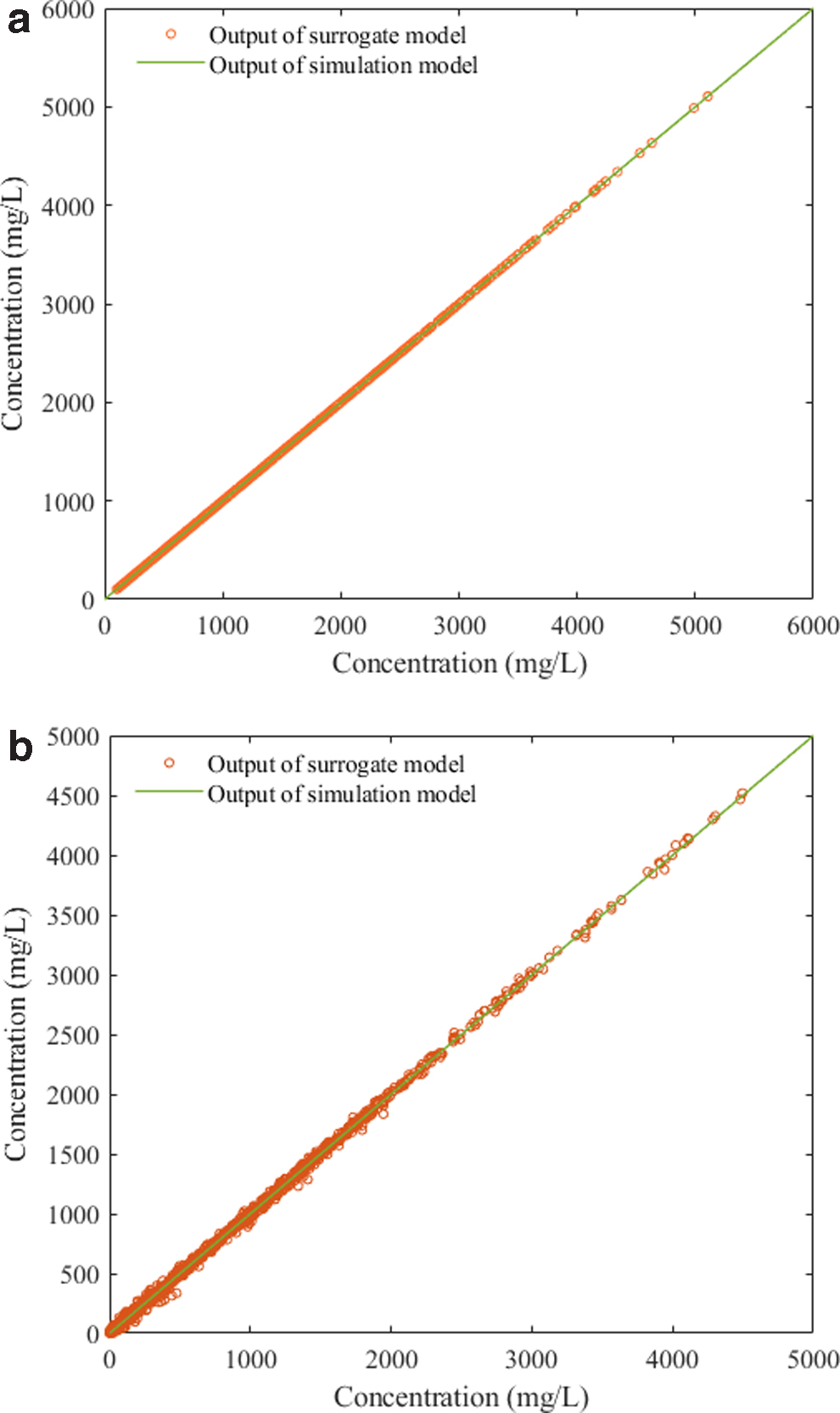
Forty sets of concentration data were obtained by entering 40 sets of hydraulic conductivity and release intensity data into the surrogate model. The fitting diagram for output concentrations of the surrogate model and simulation model are shown in Fig. 5. The accuracy evaluation indexes comprising R2 and MRE for the surrogate model are shown in Tables 7 and 8.
Accuracy of the Surrogate Model for Case 1
MRE, mean relative error.
Accuracy of the Surrogate Model for Case 2
Figure 5 clearly shows that the outputs from the surrogate model were very close to the outputs from the simulation model. Tables 7 and 8 show that the MRE values for the observation wells of case 1 were less than 1.5% and the MRE values for the observation wells of case 2 were less than 8.5%. The surrogate model approximated the simulation model very well and the accuracy was also satisfactory. Moreover, the R2 were close to 1, thereby indicating that the accuracy of the surrogate model was very high. Thus, the surrogate model could be applied instead of the simulation model to linked to the 0–1MINLP.
Pollution source identification analysis results
The HGA was used to solve the 0–1MINLP. The homotopy equation was constructed by using the optimization problem for the known solution and the optimization problem for the unknown solution. The homotopy equations obtained by the transformation were transformed into the corresponding optimization problems and the optimization models for each optimization problem were established in turn, before applying the GA to solve each optimization model. The GA toolbox in MATLAB was used to solve the optimization model for each homotopy equation corresponding to the optimization problem. The main parameters of the GA were set as shown in Table 9, the meaning and settings of all the parameters in Table 9 can be found in the optimization toolbox of the MATLAB software.
Parameter Settings for the Genetic Algorithm
The path was tracked from the known solution, so the initial population selection of each optimization model was appropriate, thus, the disadvantage that GA is easy to fall into premature convergence is avoided.
The identification results obtained using the HGA are shown in Tables 10 and 11. As the homotopy parameter
Results Obtained Using the Homotopy-Genetic Algorithm for Case 1
Results Obtained Using the Homotopy-Genetic Algorithm for Case 2
Comparison of HGA and GA
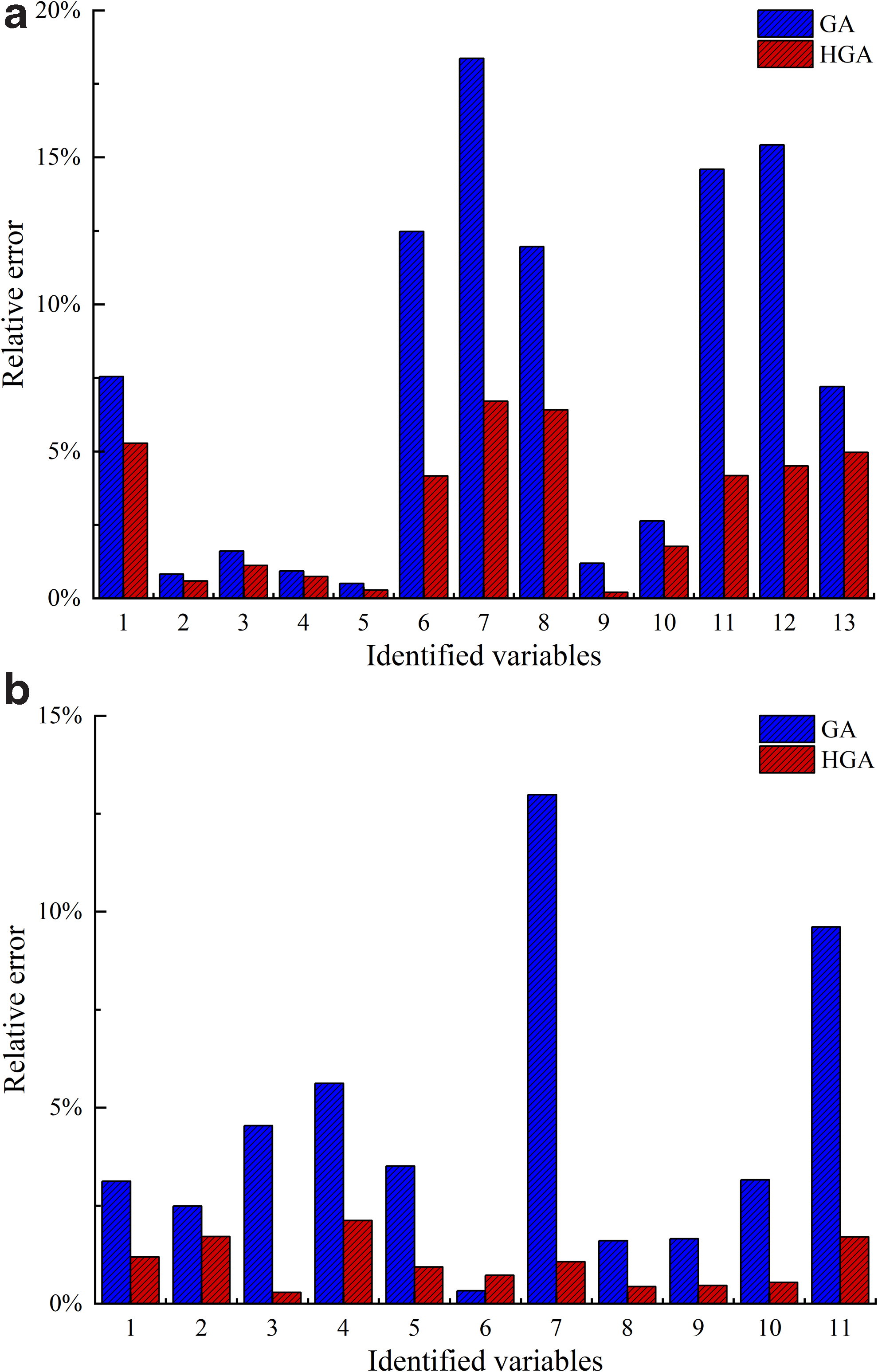
Tables 12 and 13 and Fig. 6 show that the identification results calculated using the HGA were closer to the true values of the pollution sources than those calculated using the GA alone. For case 1, when the GA was used to identify aquifer parameters and groundwater pollution source information, the maximum relative error of the identified results exceeded 17.5%, while the maximum relative error of the identified results obtained using the HGA did not exceed 7.5%. For case 2, the maximum relative errors of the identified results obtained by the HGA and GA exceed 12.5% and 2.5%, respectively. It can be seen from Fig. 6 that for any variable to be identified, the accuracy of the identified results obtained by the HGA is higher than that of the GA.
Identification Results Obtained Using the Homotopy-Genetic Algorithm and Genetic Algorithm for Case 1
GA, genetic algorithm; HGA, homotopy-genetic algorithm.
Identification Results Obtained Using the Homotopy-Genetic Algorithm and Genetic Algorithm for Case 2
This shows that the HGA is an efficient solution for a nonlinear optimization model because it can converge on a large scale and it does not depend on the initial population selected. The HGA has more advantages than the GA when solving the optimization model. The combination of homotopy algorithm and GA can improve the shortcoming of GA that is easy to converge prematurely.
Conclusions
After applying the proposed methods to GPSI, the following conclusions can be made. The combined application of homotopy algorithm and GA improves the shortcomings of GA that is easy to converge prematurely. The homotopy optimization problem is equivalent to a tracker, which evolves from the optimization problem with known solution to the optimization problem with unknown solution. Similarly, the solution evolves gradually as the homotopy optimization problem changes gradually. The solution to the previous homotopy optimization problem can be used as the initial population of the solution for the next homotopy optimization problem, and the solutions of two adjacent homotopy optimization problems are very close. In this way, an appropriate initial solution can be selected for the next homotopy optimization problem, thereby avoiding the problem caused by the dependence on the initial population and becoming trapped by local optimum for GA, so the solution obtained is closer to the true value. The identification results obtained by applying the GA and HGA separately were compared and analyzed. The identification results obtained by the HGA were closer to the true values of the pollution source characteristics, and thus the identified results were more effective.
The kriging surrogate model with high accuracy was linked to the 0–1MINLP instead of the simulation model. The kriging surrogate model could be directly called during the iterative calculations when solving the optimization while reduced a lot of calculation load as well as the time required. The 0–1MINLP based on a kriging surrogate model could simultaneously identify the hydraulic conductivity, location, and release history of pollution sources while maintaining a certain level of precision.
Footnotes
Acknowledgments
Special thanks are given to the journal editors and anonymous reviewers for their valuable comments and suggested revisions.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This study was supported by the National Nature Science Foundation of China (no. 41672232) and Jilin Province Science and Technology Development Project (no. 20170101066JC).