
Abstract
In light of the rapid development of human society, there has been a notable surge in waste production, which has resulted in environmental pollution and degradation. This is a pervasive issue that requires attention. To address the environmental problems caused by waste generation and advance the development of recyclable domestic waste detection, this article proposes waste classification as a solution. Traditional waste sorting methods have proven to be inefficient and prone to errors, hence the need for a more effective approach. A multiobjective recyclable domestic waste detection and classification method based on improved You Only Look Once v5s (YOLOv5s) is proposed in this study. In this study, the network structure is enhanced through the implementation of the Bidirectional Pyramid Network (BiFPN). The coordinate attention mechanism is then incorporated to elevate the accuracy of the model. Additionally, the loss function is refined by adopting the Efficient Intersection Over Union Loss (EIOU_Loss) metric to further optimize network performance. Finally, the introduction of the Ghost convolution module reduces parameter count and significantly improves the real-time detection speed. The waste dataset named Multi-classified Recyclable Domestic Trash Identification Dataset (MULTI-TRASH), which is composed of machine shooting, web crawler, and artificial photography, is used for verification due to its good generalization and representativeness. The mean Average Precision at a threshold of 0.5 (mAP@0.5) value of 94.8% is achieved by the improved model, which is a 30.72% reduction in the number of parameters and a 1.2% improvement in the mAP@0.5 value compared with YOLOv5s. The effectiveness of the proposed algorithm is proved by a comparison with other target detection algorithms. This study aims to provide technical references for the development of a recyclable domestic waste detection system.
Introduction
With the improvement of people's living standards and the continuous expansion of urbanization and industrialization, an increasing amount of waste is being produced, leading to waste management becoming a pressing issue in modern times (Chen et al., 2020). Effective waste management and recycling can minimize waste generation, reduce harmful impacts on the environment, and achieve a circular economy of resources (Sarc et al., 2019). Therefore, recycling, sorting, and reusing waste provides a feasible and cost-effective solution to overcome the current resource and environmental crisis.
With the rapid development of target detection technology, from the initial machine learning methods to the gradual evolution into deep learning algorithms, this technology has gradually matured and found good application and widespread use in many fields. Automatic classification has important significance for quickly and accurately sorting items. The transition from traditional manual classification to utilizing machine learning and deep learning for automatic classification has greatly improved work efficiency. However, the technology for automatic classification also has some deficiencies and requires further improvements to the accuracy and robustness of the algorithms. This chapter presents the research work of scholars in the area of image recognition and waste datasets.
A good waste dataset is crucial and can effectively improve the recognition performance of model algorithms. Zhang et al. (2022a) developed a multi-label waste classification model based on YOLO-WASTE (a Multi-label Waste Classification model) transfer learning and created a dataset of multi-label waste images, each containing multiple waste types. Mao et al. (2022) proposed a Taiwan Recycled Waste Database (TRWD), which they developed and compared against TrashNet Dataset (Yang and Thung, 2016), a traditional waste database. The results showed that the performance benefits of using TRWD were much greater than using TrashNet Dataset. Vo et al. (2019) created the VN-trash (Trash from Vietnam) dataset and improved the ResNext model for trash classification. By applying the VN-trash dataset to the model, they demonstrated that it achieved good recognition accuracy. Therefore, this article uses deep learning to classify waste images.
Since each graph contains only one type of waste, the dataset does not address real-life needs. Most of the currently used waste datasets consist of only one kind of waste image per image, which cannot meet practical needs. Therefore, to meet the practical needs, this study constructs a multitarget waste dataset.
Deep learning is an important technical tool for image recognition, and deep learning is used in a wide range of applications, such as image diagnosis and recognition in medicine (Esteva et al., 2017), detection of white grape varieties and yields in agronomy (Sozzi et al., 2022), and face recognition (Ding and Tao, 2018). Convolutional neural networks (CNN) have now become a popular research object in the field of image recognition. CNN is based on a wide range of raw data and obtains feature descriptions through continuous learning to better represent image information. Based on this, deep learning is used to accomplish image classification mostly based on CNN (Simon and Rodner, 2015). Deep learning is also widely applied in waste image recognition. Mao et al. (2021) used the optimized CNN for waste classification. Optimization using genetic algorithm has improved the accuracy of waste classification with good results. Rad et al. (2017) proposed a computer application based on waste on street and sidewalk images and used CNN to classify waste.
Nowakowski and Pamula (2020) used Region-based Convolutional Neural Networks (R-CNN) to identify and classify e-waste, and the selected wastes were identified and classified correctly at more than 90%. However, existing techniques have limitations (Adedeji and Wang, 2019; Carrera et al., 2022; Khan et al., 2022), including small sample sizes lacking realism, unfocused perspectives, and inability to generalize from single images. To address these issues, this article constructs a large-scale recyclable waste image dataset and proposes an object detection method based on You Only Look Once v5 (YOLOv5) for effective identification and classification of different waste types. YOLOv5 is a CNN architecture characterized by high accuracy, speed, and simplicity despite its high data requirements, making it well suited for waste identification and classification in this study. The constructed dataset will be used to train and optimize the YOLOv5 model for waste detection and classification.
Existing waste sorting methods face challenges. This study proposes a multiobjective approach using deep learning for automated detection and classification of recyclable domestic waste. We hypothesize that the YOLOv5 algorithm along with improved schemes and a new automated-annotated waste dataset can achieve fast and accurate recyclable waste image detection and classification. In collecting the dataset, we assume adequate uniform illumination, coverage of common waste types, multiangle images, no occlusion or clutter, and sufficient samples. This study aims to provide a practical solution for waste sorting and recycling, advancing waste management.
The main contributions to this work are as follows:
Constructing a new waste image dataset using automated labeling. Improving accuracy through enhancements to the residual network, loss function, and attention mechanism. Employing the Bidirectional Pyramid Network (BiFPN) to optimize feature fusion. Adding a lightweight network to reduce parameters and increase operation speed.
Materials and Methods
Study design and domestic waste dataset
For TrashNet Dataset, a small recyclable waste dataset, although put into the algorithm can achieve good accuracy, but still many shortcomings: (1) the number of data is not sufficient; (2) there is only one waste type for a single image; (3) the image background is too single to meet the actual application. Therefore, this study addresses the shortcomings of TrashNet Dataset. In this article, a multilabeled waste image dataset named Multi-classified Recyclable Domestic Trash Identification Dataset (MULTI-TRASH) is constructed using machine shooting, web crawlers, and mobile photography. Since many places have specialized recycling sites for waste fabrics, such as some old fabrics, this thesis no longer considers waste fabrics as such waste. This dataset was divided into four classes: paper, plastic, glass, and metal.
The web crawler pictures were obtained using PyCharm software (developed by JetBrains, a Czech company) on the web. Each picture was assigned to a single category. To showcase multiple categories in a single picture, a random stitching technique was employed using PyCharm software, where pictures were combined into a 2 × 2 or 3 × 3 grid. To enhance the variety of images, a total of 3,156 photos were stitched together, resulting in an image resolution of 512 × 512.
To recreate a realistic trash can environment, a simple experimental platform was designed to minimize the interference of external light sources on the waste sorting machine's camera. The platform consisted of a camera positioned above the trash can, two lights situated below, and a conveyor belt at the base. For this study, the MV-GE200GC-T GigE color industrial camera from the Chinese manufacturer Mindvision was selected. The image capturing uses LabVIEW software (developed by National Instruments). This camera features a resolution of 1,600 × 1,200 and a frame rate of 60 frames per second (FPS). As for the supplementary lighting system, a versatile strip light source, specifically the MaiDot BL5R-812-W type LED light, was employed. The conveyor belt was set to operate at a speed of 0.5 m/s.
To increase the diversity of the data, mobile photography was chosen in different regions and different backgrounds. Data augmentation operations were performed on the dataset constructed using machine shooting and mobile photography in this article. This includes adding steps such as rotation, flip, and brightness overlay on each other to minimize network overfitting, improve the robustness of the model, and increase the generalization ability of the training model.
The above three types of picture data are enhanced with a total of 10,542 pictures, because the number of datasets is too large, manual labeling needs to consume a lot of time, so this time the automatic labeling method is used. Three kinds of sampling datasets are carried out separately, using Labellmg (an annotation tool) each labeled 800 pictures, the typed labels are placed into YOLOv5 for training to get the training model, and then the remaining photos will be automatically labeled by machine, and the labeling results will be checked manually, and the wrong images will be picked out and relabeled. The specific operation flow of the procedure is shown in Fig. 1. Seventy percent of each of the three types of images are for training and the remaining 30% are for testing.
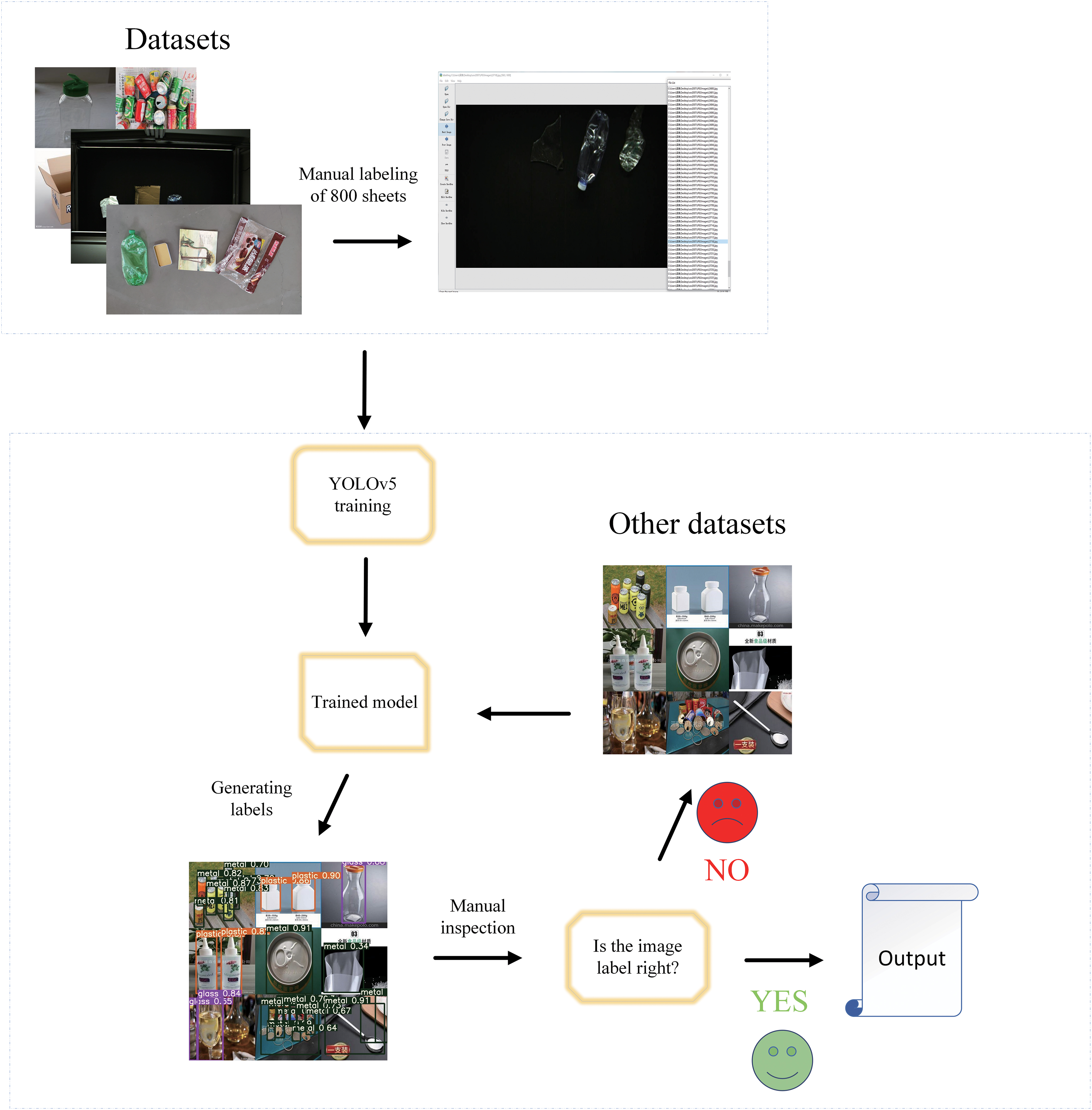
Flowchart of automatic labeling.
The algorithm principle of YOLOv5
In general, CNN consists of an input and output layer and a hidden layer, where the hidden layer consists of a convolutional layer, a pooling layer, and a fully connected layer. CNN is directly used to implement the whole detection process, combining the two stages of candidate regions and object recognition into one, using predefined candidate regions (not the Anchor used by Faster R-CNN), dividing the image into S × S grids, each allowing to predict two boundaries. Redmon and Farhadi (2018), Redmon and Farhadi (2017), and Redmon et al. (2016) proposed a target detection algorithm (V1–V3). Bochkovskiy et al. (2020) proposed YOLOV4. Compared with R-CNN series target detection networks, YOLO can increase the speed of target detection while maintaining the same accuracy. After previous generations of iterations, the algorithm has now reached the fifth generation. Among them, YOLOv5 proposes a multiscale prediction method that can simultaneously detect targets with different-size image features. As a result, YOLOv5 can be well coordinated in accuracy and operation speed.
Yun et al. (2019) utilized Mosaic data augmentation, employing a regularization strategy to train strong classifiers with localizable features, using CutMix data augmentation as a reference. Stitch four images together by randomly resizing, cutting and randomly lining them up. Mosaic Data enrich the dataset, increase the number of targets, and reduce costs.
YOLOv5 network model consists of Input, Backbone, Neck, and Prediction. Backbone is mainly composed of Convolution (Conv) module, Cross Stage Partial Network (C3), and Spatial Pyramid Pooling with Factorized Convolution (SPPF) modules. YOLOv5 encapsulates three functions in Conv module: including convolution (Conv2d), Batch Normalization and activation functions, while using autopad(k, p) to achieve the effect of padding. YOLOv5-6.0 uses Sigmoid-weighted Linear Unit as the activation function, replacing Leaky Rectified Linear Unit in older versions. The C3 module is used in YOLOv5-6.0, replacing the earlier Bottleneck Convolutional Stem and Parallelism (BottleneckCSP) module. C3 module replaces the earlier BottleneckCSP module. The SPPF module uses multiple small-sized pooling kernels in cascade instead of a single large-sized pooling kernel in the SPP module, thus further improving the operation speed. At the same time retains the original function of fusing the feature maps of different sensory domains.
YOLOv5's Neck is similar to YOLOv4 in that it borrows ideas from Feature Pyramid Network (FPN) and Path Aggregation Network (PANet). The idea of FPN is to enhance multiscale semantic representation by transferring deep semantic information to shallow layers. However, the location information in the shallow layer cannot affect the deep features. At the same time, the top-level information flow in FPN needs to be passed down through the Backbone network (Backbone) layer by layer, which is relatively computationally intensive due to the relatively large number of layers, while PANet effectively solves these problems. PANet introduces a bottom-up path based on the FPN. Top-down (Top-down) feature fusion is followed by bottom-up (Bottom-up) feature fusion, so that the location information of the bottom layer can also be transferred to the deep layer, thus enhancing the multiscale localization capability. At the same time, the number of feature maps to be traversed for bottom-up feature transfer in PANet is greatly reduced compared with FPN, which makes it easier to transfer bottom-up location information to the top layer.
The prediction module includes regression loss function and Non-Maximum Suppression (NMS). The weighted NMS method is used for postprocessing to eliminate redundancy. Complete Intersection over Union Loss (CIOU_Loss) is used to measure the degree of disparity between the prediction box and the true box.
Improvement of the YOLOv5
To achieving more accurate and fast identification of recyclable domestic waste, a YOLOv5-based recyclable domestic waste detection network model is proposed in this article. The structure of the modified model network is shown in Fig. 2. The main modifications include the use of an attention mechanism, BiFPN for bidirectional pyramid networks and an improved loss function, and finally, a lightweight network is added to speed up detection.
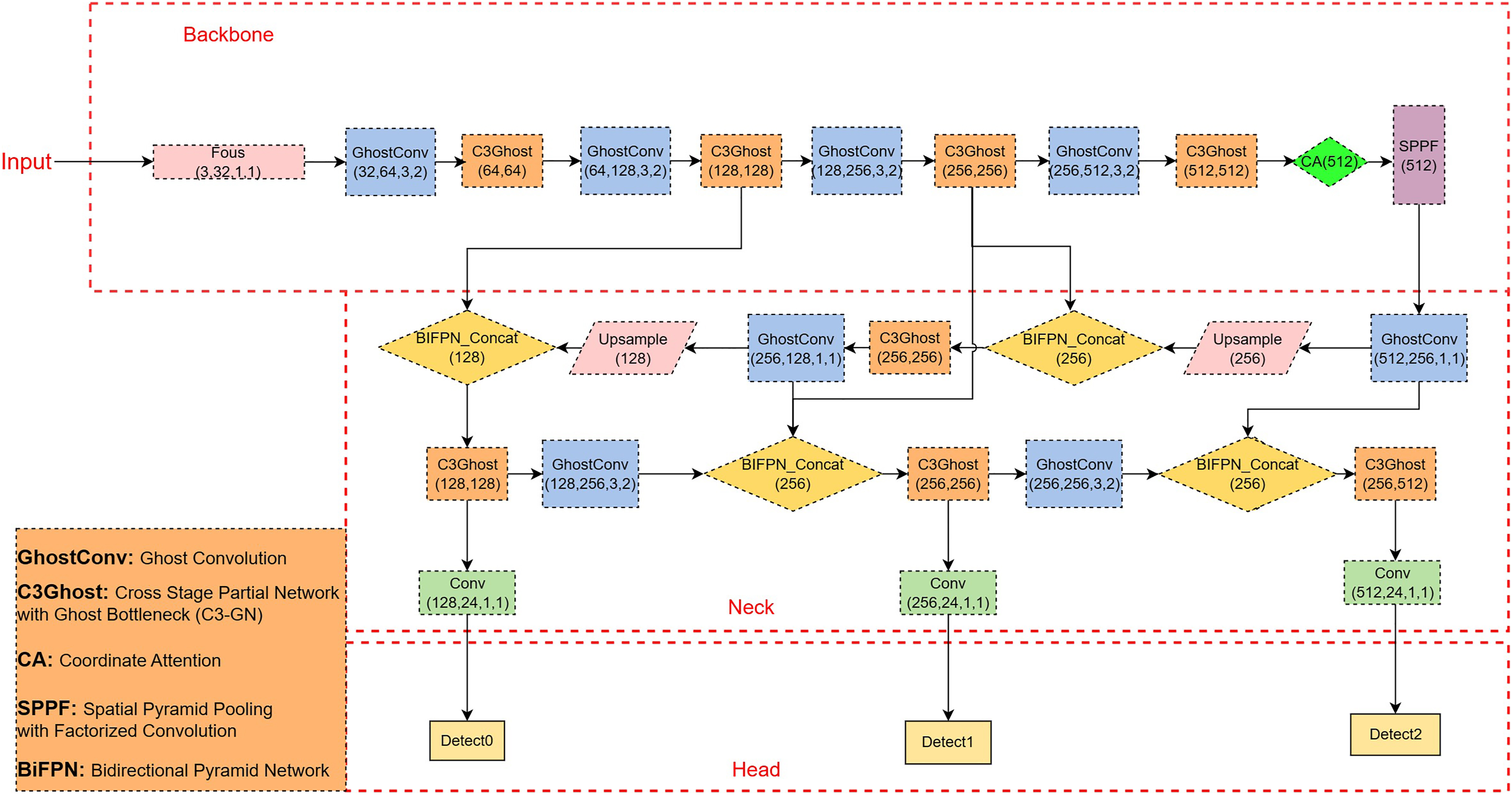
The architecture of the improved network.
Bidirectional FPN
Among the networks of the first YOLOv5, a top-down pathway is established in the traditional FPN for feature fusion, but accuracy cannot be achieved due to the limitation of one-way information flow. In this article, BiFPN in the network replaces PANet to improve detection at different scales. Based on the repeated two-way cross-scale connectivity and feature fusion mechanism, the weights of BiFPN are proposed (Tan et al., 2020). In BiFPN, learnable weights are used to determine the significance of various input features and dynamically adjust the proportion of each scale. This allows the network to effectively fuse these features for improved feature fusion when working with different sizes.
Attention mechanism module selection
To select a more effective attention mechanism, this article compares three attention mechanism modules: squeeze and excitation (SE), convolutional block attention module (CBAM), and coordinate attention (CA). The attention mechanism of SE considers only channel-to-channel information (Hu et al., 2019). The CBAM attention mechanism implements both channel and spatial attention mechanisms, but the convolution can only extract local relationships and cannot extract long-distance relationships (Woo et al., 2018). The CA mechanism can encode both horizontal and vertical position. The CA mechanism can encode both horizontal and vertical location information into channel attention, enabling mobile networks to focus on a large range of location information without excessive computation (Hou et al., 2021).
The different attention mechanisms are shown in Table 1. As can be seen from the table, CA mechanism is more computationally intensive than the SE attention mechanism in terms of network detection. However, the CA mechanism has the largest improvement in accuracy compared with this dataset. Therefore, the CA mechanism is chosen in this article.
Performance Comparison of Different Attention Mechanisms
mAP@0.5: mean Average Precision at a threshold of 0.5. mAP@0.5:0.95: the mean Average Precision at various thresholds ranging from 0.5 to 0.95. FLOPs (G): Floating Point Operations per Second, measured in billions of operations (GigaFLOPs).
CA, coordinate attention; CBAM, convolutional block attention module; SE, squeeze and excitation.
Improvement of loss function
YOLOv5 has three loss functions: confidence loss
Confidence loss is the calculation of the confidence level of the network that can be defined as:
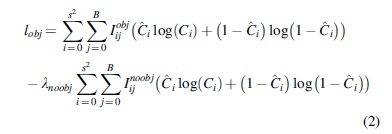
Classification loss is the calculation of a correct or incorrect anchor frame and correspondence can be defined as:
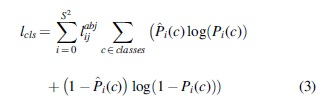
YOLOv5 uses the loss function of Bounding box made by CIOU_Loss, and the specific formula of CIOU_Loss is shown in (4)–(6):
where A and B are the true and predicted boxes, c is the distance between the diagonals of the smallest rectangular box, which contains two frames.
CIOU_Loss is considered the boundary box regression of overlapping area, centroid distance, and aspect ratio. However, in its formula v reflects only the difference in aspect ratio, so it sometimes hinders the effective optimization of the model (Zheng et al., 2022).
Therefore, this article uses the Efficient Intersection Over Union Loss (EIOU_Loss) as the regression loss function. It can be indicated as:
This loss function is given in the above equation in order from left to right as: overlap loss, center distance loss, and width–height loss. Where
The operation of lightweight
To achieve high accuracy, it is necessary for CNN to utilize a large number of parameters and meet the required conditions. Thus, it contains a large amount of redundant information in the feature map. Lightweight models, such as MoblieNetv3 (Howard et al., 2019) and ShuffleNetv2 (Ma et al., 2018), reduce the amount of floating-point computation, but the redundant feature maps generated by convolution are not effectively handled. To solve the accuracy and fast recognition problem of recyclable waste classification, the deep separable convolution GhostConv convolution module is used instead of the original normal convolutional layer. This is a way to implement a lightweight neural network that can be ported to some mobile devices with relatively low computational power, while ensuring the interpretability of the algorithm (Han et al., 2020). The aim is to reduce the number of network model parameters and Floating-Point Operations (FLOPs).
Normal convolution uses a large number of convolutions to generate feature maps for more comprehensive feature extraction, but a large number of convolution kernels and channels generates redundant information, leading to a larger computational effort. In contrast, the Ghost convolution divides the ordinary convolution into two parts, first using less convolution to generate a portion of the feature map, and then using less costly linear operations to efficiently generate the Ghost feature map. Suppose the number of convolution kernels is n, the size of the input feature map is
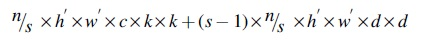
Where  base features need to be output in Ghost convolution to complete the removal of redundancy.
base features need to be output in Ghost convolution to complete the removal of redundancy.
The ratio of FLOPs for normal convolution and lightweight operation is as:
From the above equation, it can be seen that the FLOPs of ordinary convolution are s times higher than those of the lightweight operation, which indicates that the Ghost module can reduce a large amount of computation during feature extraction.
The indicators of evaluation
In this article, the modified model is evaluated against other models in terms of Precision, completion rate, mean Average Precision (mAP), number of floating-point calculations (FLOPs), number of parameters (Params) (Molchanov et al., 2017), and size of occupied storage space (MB). Among them, the precision P, recall R, and mAP formulas are shown in (9)–(11).
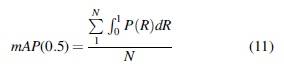
TP and FP denote the number of correct and incorrect waste detected by the improved model in this article, correspondingly. FN is the number of detected waste that is not detected by the model. mAP@0.5 is the average AP of all categories when IOU is 0.5.
Experimental Design and Results Analysis
The training and testing of the experiments in this artic;e were conducted under the framework of windows 10 and PyTorch. The software environment was python 3.8, CUDA 11.3, and CUDNN 8.2.1, and the computer hardware contained a 12th Gen Intel(R) Core(TM) i5-12400F 2.50 GHz CPU, NVIDIA GeForce RTX 3060 GPU. Considering the experimental hardware conditions, the specific parameters for model training are set as: image size of 640 × 640 pixels, batch size of 16, learning rate of 0.01, and momentum parameter of 0.937.
TrashNet Dataset and MULTI-TRASH Dataset comparison experiment
The realistic situation of waste classification requires multitarget detection, and for TrashNet Dataset, only single target recognition is performed, which cannot adapt to the needs of realistic scenarios, while the data volume is small and the background image is single. In this experiment, the TrashNet dataset and MULTI-TRASH dataset were used to train You Only Look Once v5s (YOLOv5s), respectively, resulting in the TrashNet-trained model and MULTI-TRASH-trained model. As Fig. 3a is a graph from the MULTI-TRASH dataset, the two training models are detected and identified separately for Fig. 3a. The results show that the model trained with TrashNet Dataset tends to recognize fewer objects, and is less effective for multitarget image recognition.

Validation results with TrashNet Dataset and MULTI-TRASH model. MULTI-TRASH, Multi-classified Recyclable Domestic Trash Identification Dataset.
CA mechanism visualization experiments
To represent and to show the advantages of the CA mechanism over the original, the model feature attention heat map is visualized in this article. The three parts of the dataset are compared separately, as shown in Fig. 4a–c are the original, the heat map without the CA mechanism, and the heat map with the CA mechanism, respectively, where the red area indicates the part of the model that needs attention to determine the object type. The red areas with the CA mechanism are more focused on the target object than the areas without the CA mechanism, which also proves that the model with the CA mechanism is not easily affected by the environment and can reflect the subject–object in the image.

Original, without and with attention map visualizations
Ablation experiments
The ablation experiments are divided into two parts: Ghost convolution replacement experiments and improvement of each part of the ablation experiments. ghost convolution replacing the normal convolution will lead to a decrease in accuracy but can effectively reduce the computation and inference speed, so to explore the relationship between the Ghost convolution replacement part and the accuracy, this article uses different positions of the Ghost part of the module for experiments. Figure 5 shows the change of mAP of the convolutional modules at different positions, where YOLOv5s is the original model, YOLOv5s_Ghost all indicates that the ordinary convolutional module C3 is replaced by the Ghost convolutional module, and YOLOv5s_backbone indicates that the ordinary convolutional module C3 on the backbone is replaced by the Ghost convolutional module. YOLOv5s_neck means to replace the normal convolution module C3 on the neck with the Ghost convolution module.

Variation values of convolutional module mAP for different positions. mAP, mean average precision.
Table 2 represents the convolution modules at different locations. From Table 2, it can be seen that Ghost_all decreases 48.73% and 47.48% compared with the original model FLOPs and the number of parameters, respectively, and the number of parameters decreases the most compared with several other replacement modules, but the value of mAP@0.5 decreases slightly. The replacement backbone and neck are both improved by 0.1% compared with the original network accuracy for the former, while the latter is on par with the original network, with FLOPs and number of parameters decreasing by 32.91% and 27.50% for the former, and by 15.82% and 19.99% for the latter. Since the addition of the lightweight network makes the volume of the model reduced to some extent, the FPS of the model obtained by adding Ghost's convolution at different positions is improved compared with the original model.
Convolution Modules at Different Positions
The terms “YOLOv5s,” “YOLOv5s_Ghost,” “YOLOv5s_backbone,” and “YOLOv5s_neck” refer to different versions of the YOLOv5s model, where the Ghost convolution module replaces the ordinary convolution module C3 in specific parts of the architecture.
FPS, frames per second; YOLOv5s, You Only Look Once v5s.
To explore and verify the effect of each part, ablation experiments are used to compare with YOLOv5s, as shown in Table 3. The main network improvements in this article are as follows, respectively: adding Ghost lightweight, adding the CA mechanism, modifying the loss function, and improving the feature fusion network. The accuracy of the original network is 93.6% and the number of parameters is somewhat large at 7020913. To improve the recognition speed, we added the Ghost module. At this point, the accuracy rate decreased by 0.2%, but the amount of parameters decreased by 47.48% and the FPS increased accordingly. To improve the accuracy, we added the CA mechanism module, changed the loss function to EIOU_Loss, and used a two-way pyramid network BiFPN, finally the accuracy improved 1.2%, 30.72% decrease in the number of parameters, and a certain improvement in FPS.
Precision Curves of Each Model
BiFPN, Bidirectional Pyramid Network; EIOU, Efficient Intersection Over Union.
Model comparison experiments
To verify the advantages of the improvements in this article, the commonly used monopole detection algorithms: YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x, YOLOv3, YOLOv3 tiny, and Single Shot MultiBox Detector (SSD) models are selected for comparison experiments. The specific results are shown in Table 4. The table shows that the improved algorithm proposed in this article compared with YOLOv5s and YOLOv5x with 1.2% improvement in mAP, and 1% improvement in mAP compared with YOLOv5m and YOLOv5l.
Performance Comparison of Different Detection Algorithms
Compared with the traditional monopole detection SSD algorithm, there is a huge improvement in accuracy by 9.8%, a reduction in model size by 81 MB, an improvement in FPS by 41, and a decrease in the number of parameters by 81.84%. The improved model shows a large improvement in accuracy and PFS compared with YOLOv3 and YOLOv3-tiny. The data in Table 4 are kept only for YOLOv5s, YOLOv3, YOLOv3 tiny, SSD and modified models for analysis by radar plot. The results are shown in Fig. 6. The experiments show that the improved algorithm outperforms other networks in speed and accuracy. It can be used to meet the accuracy and light weight requirements of recyclable domestic waste target detection.

Performance comparison of different detection algorithms.
Discussion
After analyzing the results of the initial experiments presented in this study, several conclusions can be drawn regarding the performance of the different models and techniques employed. First, it was observed from the experimental results that the TrashNet Dataset model is less effective in recognizing multiple objects and may not be suitable for complex image recognition tasks. Second, it was found that the inclusion of the CA mechanism enhances the ability of the model to focus on the target object and reduces the impact of the surrounding environment. This finding highlights the potential benefits of attention mechanisms in improving the accuracy of object detection models. Third, it was demonstrated that the replacement of the regular convolutional module with the Ghost convolutional module in the YOLOv5s model reduces the number of parameters and FLOPs while maintaining a comparable level of accuracy. This suggests that lightweight convolutional modules can be an effective technique for optimizing the efficiency of object detection models.
Lastly, the proposed improved algorithm outperforms other networks in terms of both speed and accuracy. Compared with the conventional SSD algorithm for unipolar detection, the improved model exhibits significant enhancements in accuracy, model size, and FPS.
In conclusion, the initial experimental results of this study suggest that lightweight convolutional modules and attention mechanisms hold promise as techniques for improving the efficiency and accuracy of object detection models. However, further research is needed to fully explore the potential and generalizability of these techniques in different contexts and applications.
Conclusion
This study presents a thorough evaluation of an improved YOLOv5s model for detecting recyclable domestic waste, a crucial task in waste management. The proposed model is compared against two commonly used models, SSD and YOLOv5, and achieves a superior mAP@0.5 value of 94.8% on the experimental dataset.
To better represent the complexity of waste in real-world scenarios, a new waste dataset, MULTI-TRASH, is constructed, addressing the limitations of traditional datasets. The improved model effectively detects multitarget waste images in diverse contexts, making it a valuable tool for practical applications in waste management.
Furthermore, the proposed model adopts a lightweight design with a reduced number of parameters, achieving a real-time detection speed of 70 FPS. This makes it suitable for use in intelligent waste management systems, enabling efficient waste treatment practices that promote sustainability.
In summary, this study demonstrates the potential of deep learning models for accurate and efficient detection of recyclable domestic waste. The proposed model and waste dataset can serve as a foundation for future research in this field, contributing to the development of intelligent waste management systems that enhance the effectiveness and sustainability of waste treatment practices.
Footnotes
Acknowledgment
The authors thank the Jiangsu Beier Machinery Co. for providing equipment and sample support.
Authors' Contributions
Q.W.: Writing—Review and Editing, Validation, and Project administration. T.L.: Data curation, Software, and Writing—Original draft. H.F.: Funding acquisition, and Supervision. Y.W.: Visualization, and Investigation. M.W.: Supervision. D.H.: Supervision.
Data Availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the Qing Lan Project of the Higher Education Institutions of Jiangsu Province and the 2022 Jiangsu Province Science and Technology Program Special Funds (International Science and Technology Cooperation) (BZ2022029).