
Abstract
Background:
A surgeon's skill in the operating room has been shown to correlate with a patient's clinical outcome. The prompt accurate assessment of surgical skill remains a challenge, in part, because expert faculty reviewers are often unavailable. By harnessing the power of large readily available crowds through the Internet, rapid, accurate, and low-cost assessments may be achieved. We hypothesized that assessments provided by crowd workers highly correlate with expert surgeons' assessments.
Materials and Methods:
A group of 49 surgeons from two hospitals performed two dry-laboratory robotic surgical skill assessment tasks. The performance of these tasks was video recorded and posted online for evaluation using Amazon Mechanical Turk. The surgical tasks in each video were graded by (n=30) varying crowd workers and (n=3) experts using a modified global evaluative assessment of Robotic Skills (GEARS) grading tool, and the mean scores were compared using Cronbach's alpha statistic.
Results:
GEARS evaluations from the crowd were obtained for each video and task and compared with the GEARS ratings from the expert surgeons. The crowd-based performance scores agreed with the performance assessments by experts with a Cronbach's alpha of 0.84 and 0.92 for the two tasks, respectively.
Conclusion:
The assessment of surgical skill by crowd workers resulted in a high degree of agreement with the scores provided by expert surgeons in the evaluation of basic robotic surgical dry-laboratory tasks. Crowd responses cost less and were much faster to acquire. This study provides evidence that crowds may provide an adjunctive method for rapidly providing feedback of skills to training and practicing surgeons.
Introduction
I
There are a variety of surgical performance evaluation tools, including basic measures (path length, time, economy of motion, mistakes, and errors), structured human assessments (objective structured assessment of technical skill [OSATS], global evaluative assessment of robotic surgery [GEARS], and others), and algorithmic assessment using machine learning algorithms such as hidden Markov models. 4 –8 Global rating scales are popular because of their relative accessibility and ease of use. OSATS and GEARS scores, provided by expert surgeons and experienced observers, have been shown to correlate with surgeon seniority and cases performed and are often used to assess videos of surgical performances and dry-laboratory tasks, increasing the objectivity of the review. 5,9 These are the only assessment tools that have been shown to correlate directly to patient outcomes. 3 However, they are time-consuming and expensive given that only senior surgeons are trusted to assign scores. This challenge is compounded by the reality that to support the anticipated U.S. population by 2030, we will need 100,000 newly trained surgeons, which will cost up to $37 billion to train. 10 The following study is an attempt to facilitate the accurate, cost-effective, and rapid objective quantification of technical skill.
During medical school and residency, physicians in training are required to pass the United States Medical Licensure Exam (USMLE). The USMLE is primarily a cognitive test of the subject's knowledge of medicine and its provision. A clinical skills portion of the examination tests subjects' ability to interact with test patients, but no procedural skills are examined beyond ability to perform a standard physical examination. Few surgical boards require any sort of technical skill qualifications—the fundamentals of laparoscopic surgery (FLS) through the American Board of Surgery is one exception. However, such tests have been shown to be biased heavily toward task time with little assessment of elements of surgery such as tissue handling, bimanual dexterity, and efficiency. 11,12 The final qualification to perform surgery in a U.S. hospital is hospital surgical privileges. These can be procedure and system specific. Each hospital establishes its own rules, but typically surgeons must apply for privileges and then perform a number of procedures under the supervision of a surgeon with privileges. This requirement is time-consuming and imprecise, given the variable nature of surgical performance and the subjectivity of the reviewers.
Crowdsourcing is the practice of asking large groups of people to perform cognitive or judgment tasks in fields in which they are not trained. 13 Enabled by the Internet, crowdsourcing has been used to solve protein folding problems, to offer medical diagnoses, and has been preliminarily used to assess robotic surgery skill in a dry-laboratory setting. 14 –18 Crowdsourcing platforms such as Amazon Mechanical Turk (AMT; Amazon, Inc., Seattle WA) provide a web interface for the crowd to work on tasks presented by researchers, businesses, and others (known as requesters). The crowd members are known as workers or Turkers and consist of anyone around the globe, age 18 or older, and having access to a computer with an Internet connection. They include people working for fun, for supplemental income, and for full-time employment. Some members of the crowd even have experience working in healthcare. The workers are paid a small commission, on the order of $.05 to $50 for tasks ranging in length from 1 minute to a few hours and including such tasks as classifying items, transcribing audio or video, or any other task the requesters offer. The AMT marketplace can easily be adapted to request new types of tasks.
By harnessing the power of the crowd, certain domains of surgical skills assessment may no longer exclusively require the time and energy of experienced surgeons. We hypothesize that crowd-sourced surgical skills assessment can provide performance feedback rapidly, accurately, and inexpensively. If this can be demonstrated as true, it may enable an expansion of standardized objective surgery skills curricula, assist in certification processes, and provide formative feedback to trainees.
Materials and Methods
To test whether crowds could discriminate surgical skill levels, the crowd-sourced assessment of technical skill (C-SATS) method was applied to a large group of surgeons' task videos (Fig. 1). Our previous work established a three-domain subset (depth perception, bimanual dexterity, and efficiency) of the grading categories validated by Goh and colleagues in their GEARS grading tool. 5,16,17 This modification worked well in previous studies and adaptation of such tools is common in the literature. 3,16,17

Video of a surgeon performing fundamentals of laparoscopic surgery intracorporeal suturing task using the da Vinci surgical robot.
The institutional review board approval was granted (UW IRB# 35096) to recruit surgeon subjects to perform two dry-laboratory surgical tasks, robotic rocking pegboard and robotic intracorporeal suturing (adapted from the FLS—suturing task), on the da Vinci surgical robot (Intuitive Surgical, Sunnyvale, CA). 19,20 The tasks are described in Lendvay and colleagues and were chosen because they are either (A) a widely used test of basic technical surgical skill (the FLS suturing task) or (B) a challenging task that demands advanced surgical abilities beyond that of early trainees (the rocking pegboard task). Furthermore, thanks to the analysis presented by Lendvay and colleagues, this set of task videos was known to span a spectrum of performance from novice to expert, thus facilitating a comparison of surgeon assessment to crowd assessment across a range of performance levels. The videos of the tasks include the da Vinci endoscope video feed view from the beginning to the end of the task. 19 Videos of a total of 49 surgeons of skill levels ranging from novice to expert, based on surgical case volume were analyzed for both suturing and rocking pegboard tasks in this study. Each of the videos was scored using the modified GEARS tool by three experienced surgeon graders. The same tasks were subsequently scored using C-SATS. This allowed a comparison between the crowd scores and the surgeon scores.
We created a grading website for the surgeon assessors and the crowd to use to provide their evaluation. Performance videos were shown alongside the three grading domains, each with a free text response field. The crowd website featured additional screening questions to ensure response quality, known as attention check questions. This included a discrimination question wherein the crowd worker had to identify the better of two side-by-side robotic FLS block transfer tasks of a poor performance and a good performance. Then, the worker had to correctly respond to an attention question ensuring that the worker was not just clicking responses for remuneration. From these qualification questions, we excluded those workers who answered either or both incorrectly from the final analysis. All crowd workers were remunerated, irrespective of whether they provided valid qualified responses. AMT users (requesters) create human intelligence tasks known as HITs, which take the form of web pages serving tasks to crowd workers. We used the AMT web interface to create a series of HITs that served our grading website using an iframe (inline frame) HTML element. Each HIT showed the workers our grading website, including the attention questions, a video performance, and the three-domain subset of the GEARS grading tool. We requested 30 crowd responses for each of the 49 rocking pegboard and 49 suturing task videos. Using the standard deviation of responses from Chen and colleagues, we calculated that we would need 30 responses/videos from the crowd in order for the 95% confidence interval of each video to be±1 point on the C-SATS scale. 16
Table 1 describes the HIT parameters, including the pay per tasks completed. AMT manages the assignment of HITs to workers so that the 30 responses collected per performance were from unique workers. Since some of the workers answered the screening questions incorrectly, the work from these workers was rejected and the HIT relaunched for other workers to complete. This allowed us to assure that we collected at least 30 valid responses per performance. The scores assigned by the crowd were averaged to determine an overall crowd score for each video.
HIT=human intelligence tasks.
Three experienced surgeons (field: urology, experience: 150–500 da Vinci cases, 6–7 years using da Vinci) were recruited to serve as experts. One grader served as both a subject in the study and as an expert grader. A period of 2 years had passed between when this individual's original task performances were recorded and when the grading for this study occurred. The graders were blinded to the identity of the subjects they graded (seeing only the endoscope view of a uniform task field, see Fig. 1), and the subject who also graded was not made aware that their own task video was among those they assessed. Before grading the main corpus of data, the three graders completed 10 practice surveys for tasks from the proficiency phase of the study (initial agreement was computed to be 0.76). Then, a teleconference was held to compare their scores and rewatch the videos from the surveys completed.
Finally, the experts independently graded the 49 suturing and 49 rocking pegboard videos. The scores provided by the experts were averaged, providing an expert score for each video. For each video performance, we thus had two scores intended to measure surgeon skill level and Cronbach's alpha was used to measure the internal consistency of the two assessment tools in measuring the same latent skill quantity.
To provide additional insight into general trends in the accuracy of crowd-derived performance scores related to performance levels, that is, to answer the question “does the crowd score poor performances as accurately as excellent performances?” three additional performances from each task were each presented to 150 workers. The selected tasks were at the 10th, 50th, and 90th percentile level within the range of performances according to the expert surgeon-derived assessment score. This allowed us to analyze the performance quality-dependent bias of the crowd.
Results
Subject demographics
The 49 subjects ranged in age from 27 to 58 with a mean of 35. Subspecialties represented included 55.1% urology, 24.5% general surgery, and 20.4% obstetrics and gynecology. The subjects were in postgraduate year (PGY) 1, 2, or 3 (30.6%) or PGY 4, 5, or 6 (20.4%). The remaining subjects were faculty surgeons (49.0%). 36.7% of the subjects had completed at least 10 cases on the surgical robot as a primary surgeon.
Crowd response characteristics
We launched the rocking pegboard task first and paid $0.25 per completed HIT. Based on the response speed being for this task assessment run, we increased the remuneration for the crowd workers to $0.50/survey for the subsequent suturing task. We observed a much faster completion and higher yield (screening questions answered correctly out of total responses). The response completion time and yield can be seen in Table 1. We also observed variability in responder location, which may have been payment driven (Fig. 2 and Supplementary Fig. S1, Supplementary Data available at
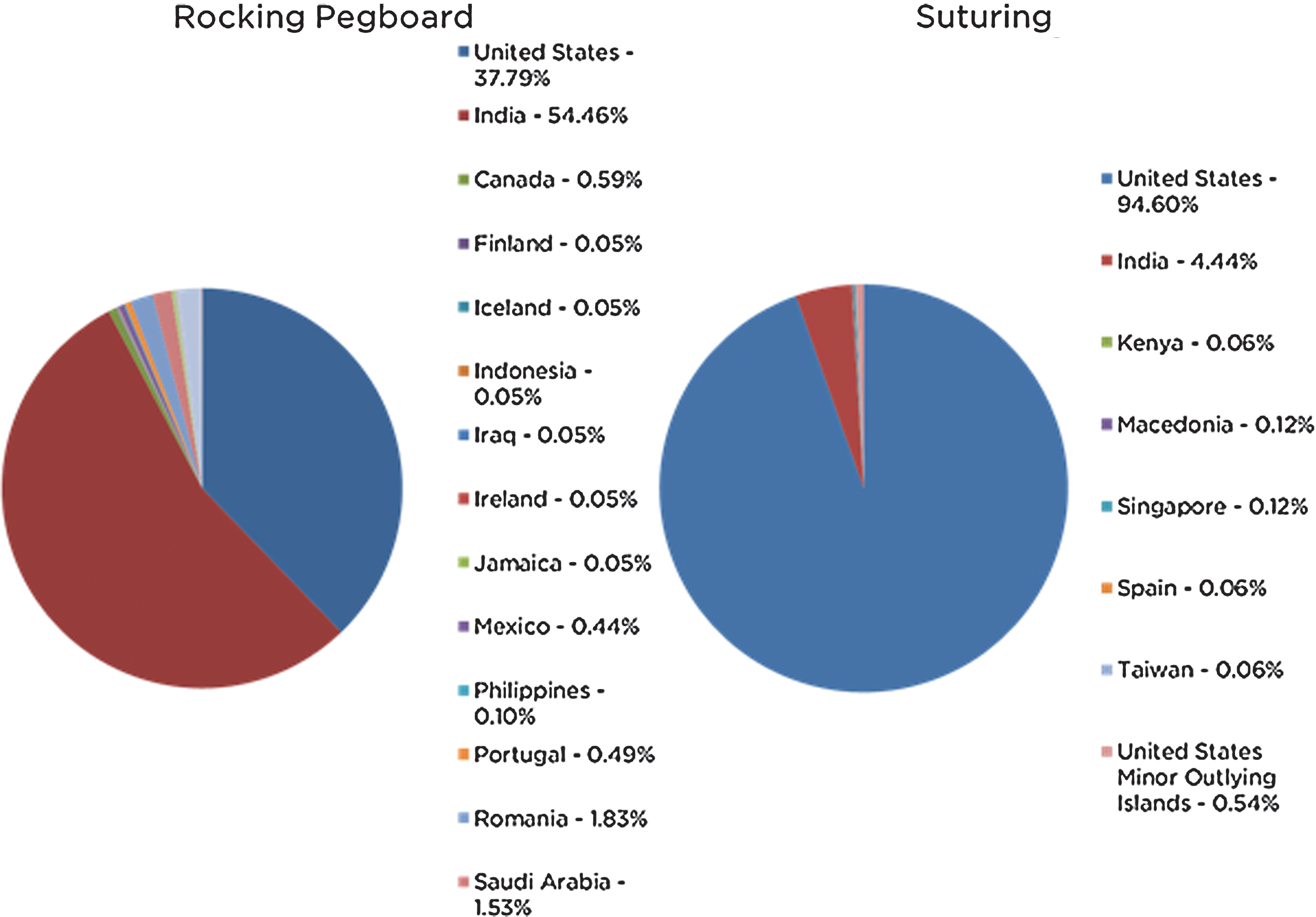
Crowd worker self-reported location.
Validating C-SATSs
The expert surgeon technical skill scores were compared to the scores provided by the members of the crowd who answered the screening questions correctly. Figure 3 shows the relationship between the expert surgeon C-SATS scores and the crowd C-SATS scores. We computed the level of agreement between the surgeons as a group and the crowd as a group. The agreement on the rocking pegboard task score was 0.84 and the agreement on the suturing task scored was 0.92, as computed with Cronbach's alpha. The correlation coefficient between surgeon score and crowd score was found to be 0.79 for the rocking pegboard task and 0.86 for the suturing task, indicating that the scores were highly correlated (Table 1).
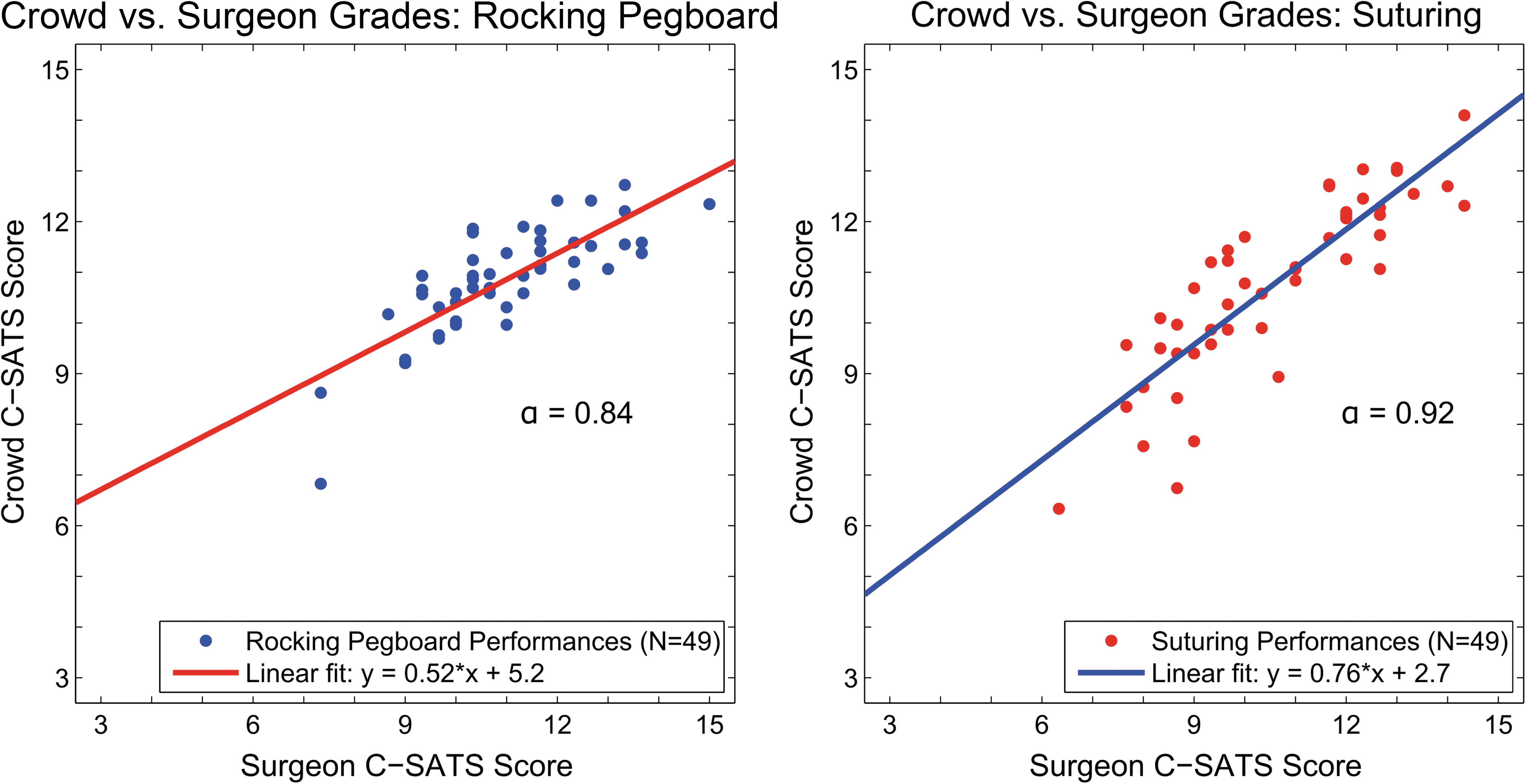
Crowd-surgeon agreement and lines of best fit. Left: Rocking pegboard, cronbach's alpha=0.84; Right: Suturing, cronbach's alpha=0.92. C-SATS=crowd-sourced assessment of technical skills.
To assure validity of the expert scores, the score from the three experts was compared to each other using Cronbach's alpha and computer to be 0.79 and 0.89 for the rocking pegboard and suturing tasks, respectively.
Results from the deep bias analysis, in which three performances from both tasks were presented to 150 members of the crowd, showed similar bias for better rocking pegboard performances as seen above (Fig. 4). While the crowd bias was flat across the suturing performance spectrum, the crowd disagreed with the surgeons for the 90th percentile rocking pegboard performance, scoring nearly two points more critically, meaning the experts rewarded the top 90th percentile performances higher. Understanding this task and performance quality-dependent bias could allow for a correction factor to be applied in future efforts, thus recovering a more accurate estimation of surgeon-equivalent scores from the crowd.
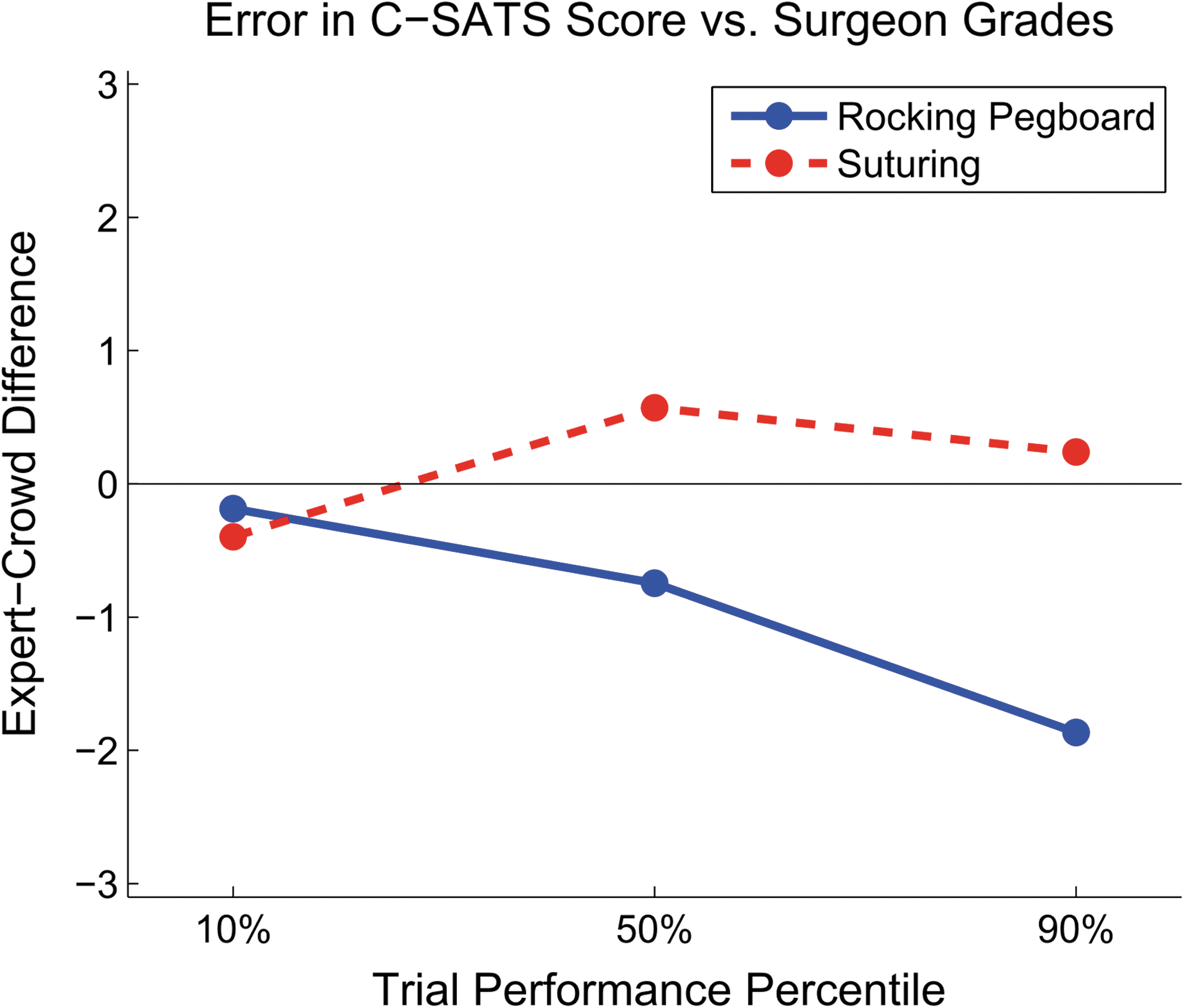
Deep bias analysis shows correlation between surgeon score and crowd score for 3 performances from each of two tasks. The selected tasks were at the 10%, 50%, and 90% of the range of performances according to surgeon-derived C-SATS score. 150 Mechanical Turk workers were recruited to grade the performances, with the aim to determine if the accuracy of the workers is dependent on the quality of the performance.
Cost of crowd assessment vs expert surgeon assessment
The direct cost of paying the crowd in this study can be computed for comparison with the cost of expert surgeon review. For the suturing videos, 30 crowd members each paid $0.50, and factoring in for the 10% overhead paid to AMT, the cost to grade an individual performance comes to $16.50. The surgeons in this study each took approximately 5 to 10 minutes to grade each of the videos in this survey. Given an average annual salary of $340,000 plus 27% for benefits, and a 2000 hour work year, evaluating each video with three surgeons costs between $54.00 and $108.00. 21
Discussion
As shifts in healthcare reimbursement move from fee for service to fee for performance, we as professionals should be inspired to objectively identify and quantify technical skills so that improvement processes can be introduced. C-SATS allows researchers and educators to grade surgical performance videos much faster than is usually possible using structured assessment tools. The technique produces basic technical skill scores that are highly correlated with assessments by trained surgeons, as measured by correlation coefficient and by Cronbach's alpha (Table 1). In most cases, the scores provided by the crowd are within one point of that provided by our group of surgeons. Additional refinement of the application of C-SATS could further improve this agreement. It may be possible to eliminate performance quality bias in the crowd responses. This tool has demonstrated its utility for assessing large sets of data where expert surgeon grading would be impractical or impossible. Furthermore, relative scoring, as opposed to absolute scoring, may be more valuable if educators are to identify performers who may benefit from early remediation or coaching.
This approach is less expensive than the cost of expert surgeons grading performances. Furthermore, it may provide ways to further reduce costs by focusing surgeon resources to areas where their expertise and input are even more crucial. For example, teaching cognitive skills and complex decision-making instead of spending time reviewing large collections of novice and intermediate psychomotor skills to provide the same scores that a crowd can. In addition, there exist online communities of people willing to do similar crowd-sourced work for the advancement of science without getting paid. Due to the ubiquity of the Internet and increased incursion of surgical systems that allow for immediate and possibly automatic upload or real-time streaming of surgical video feeds, wide-scale, low-cost psychomotor skill evaluation may be within reach.
Our work revealed insights into the nature of the crowd and potential issues in its future use. We observed that perhaps because of price sensitivity and because the HIT was launched in the morning in the United States, the majority of responses were from the United States (based on worker self-reporting and IP address analysis), see Figure 2. Based on the predominance of domestic responses for the suturing task, one might suspect the higher yield to be due to the English comprehension capabilities of the workers. Further analysis might indicate that domestic workers produce a higher proportion of valid responses or responses that more closely match those of expert surgeons. We also observed that for the rocking pegboard task, the crowd scored more critically the performances that the surgeons scored at the higher end of the performance spectrum. Further research is warranted to investigate the impact of remuneration, level of experience of the crowd worker, and other factors, such as the range of skill exhibited across sets of performances being assessed, on the overall accuracy of the crowd. Improved understanding of crowd dynamics would allow for tuning to optimize scoring accuracy, speed, and cost.
Conclusion
By a variety of metrics, we have shown evidence that the crowd can provide high-quality performance assessment metrics for the assessment of basic surgical performance. However, there are several limitations to this study. First, this study focused on the dry-laboratory setting and may not generalize to actual human surgery. Further assessment, refinement, and development are needed to see if these strong results hold in the setting of actual surgeries. Second, it is unclear how long a video performance needs to be reviewed to ascertain the full quality of the performance. Does performance quality on subtasks within a surgery correlate to the procedure performance or can a procedure be executed well despite some tasks within it being performed poorly? Unfortunately, these data do not exist for expert review either. Third, this study only examines robotic surgery. For each new setting (laparoscopic surgery, open surgery, other nonsurgical medical tasks), this method of evaluation will need to be validated. Fourth and perhaps most importantly, further study is required to determine the limitations to crowdsourcing to document where it is not applicable. For example, our work is almost strictly limited to evaluation of psychomotor skills in a group of widely varying skills. It is reasonable to assume that a crowd can discriminate such intuitively observable psychomotor skills in such cases. However, it is unlikely that the crowds can evaluate with similar acumen the correct execution or decision-making in complex procedures.
The promise of identifying a convenient deployable tool to maximize surgical performance prompted our team to devise and complete these studies. C-SATS is a novel method to assess surgical performance. It correlates well with the Gold Standard Assessment of performance using expert surgeons. With regard to other methods for analyzing surgical performance, C-SATS compares favorably in terms of convenience, cost, and clinical relevance.
While C-SATS is a promising method for providing cost-efficient, fast, and accurate feedback regarding surgical performance, further work needs to correlate the effects of surgical skill and the performance of a surgeon in the operating room. Predictive validation studies linking C-SATS scores to patient outcomes are desired to demonstrate the ultimate value of this method. The strong evidence we present of C-SATS’ agreement with expert evaluators, speed, and low cost strongly motivates further study.
Footnotes
Acknowledgments
The authors would like to acknowledge Timothy Brand, MD, and Jonathan Harper, MD, for their uncompensated contribution to this work. Author Lee W. White, PhD, had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. The execution of this study was funded, in part, by the Department of Defense Grant W81XWH-09-1-0714 “Virtual Reality Robotic Simulation for Robotic Task Proficiency: A Randomized Prospective Trial of Pre-Operative Warm-up.” Drs. White, Kowalewski, Comstock, and Lendvay are part owners of C-SATS, Inc., a crowd-sourced performance assessment company formed after the completion of this research.
Author Disclosure Statement
No competing financial interests exist.
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.