
Abstract
Introduction:
The da Vinci Skills Simulator (DVSS) is an effective platform for robotic skills training. Novel training methods using expert gaze patterns to guide trainees have demonstrated superiority to traditional instruction. Portable head-mounted eye-trackers (HMET) offer the opportunity for eye tracking technology to enhance surgical robotic simulation training.
Objective:
To evaluate if training guided by expert gaze patterns can improve trainee performance over standard movement training techniques during robotic simulation.
Methods:
Medical students were recruited and randomized into gaze training (GT, n = 9) and movement training (MT, n = 8) groups. First, the participants reviewed an instructional video, with the GT group emulating expert gaze patterns and the MT group (n = 8) standard movement-based instruction. Training consisted of 10 repetitions of “Suture Sponge 3” on the DVSS while wearing HMET; the first three repetitions were followed by group-appropriate video coaching (gaze vs movement feedback), while the remaining repetitions were without feedback. Finally, two multitasking repetitions with a secondary bell-counting task were completed. Primary outcomes included DVSS scores during training and multitasking. Secondary outcomes included metrics collected from the HMET (gaze patterns and gaze entropy).
Results:
Total score, efficiency, and penalties improved significantly over the training in both groups; the GT group achieved higher scores on every attempt. Total scores in the GT group were higher than the MT group postvideo review (20.3 ± 21.8 vs 3.0 ± 6.2, p = 0.047), after coaching repetitions (61.8 ± 18.8 vs 30.1 ± 26.2, p = 0.01), and at the last training attempt (73.0 ± 16.5 vs 63.1 ± 17.4, p = 0.247). During multitasking, the GT group maintained higher total scores (75 ± 10.1 vs 63.3 ± 15.3, p = 0.01), efficiency (86.3 ± 7.4 vs 77.4 ± 11.2, p = 0.009), and superior secondary task performance (error: 6.3% ± 0.06 vs 10.7% ± 0.11, p = 0.20). Gaze entropy (cognitive-load indicator) and gaze pattern analysis showed similar trends.
Conclusion:
Gaze-augmented training leads to more efficient movements through adoption of expert gaze patterns that withstand additional stressors.
Introduction
Simulation-based training (SBT) has become a standard component of modern surgical education, yet effective implementation of evidence-based training programs remains challenging within an increasingly demanding training environment. 1 –4 Several reports have validated virtual reality (VR) simulators as effective training platforms for robotic surgical education. 5 As a result of this overwhelming evidence, SBT research has shifted from determining effective simulators toward clarifying features that can effectively expedite the learning curve for surgical trainees. 1,6,7
Eye tracking is the process of measuring either the point-of-gaze (where one is looking) or the motion of an eye relative to the head. Contemporary research in other fields (e.g., aviation, sports) has revealed that gaze training interventions support the development of robust motor skills. 8 Newly developed portable head-mounted eye-trackers (HMET) require minimal setup thus permitting their application within multiple aspects of health care education. 9 Infrared cameras are used to track the eye position and produce high-quality quantitative data for analysis of eye movements and pupil behavior. 10 Thus far, eye tracking has primarily been utilized to provide objective measurement of surgical skill, eliminating the need for subjective expert evaluations. 11 Studies have demonstrated differences in gaze patterns between expert and novice surgeons in simulated environments. 12 Furthermore, displaying an expert's point-of-gaze to the novice (gaze-augmented training) during laparoscopic simulation tasks has shown to be an effective tool in enhancing surgical training compared with the traditional movement-based training during laparoscopic simulation tasks. 13,14
This study aims to evaluate the impact of gaze-augmented training for robotic surgical training using the VR-based da Vinci Skills Simulator (DVSS; Intuitive Surgical, Sunnyvale, CA) in comparison with traditional movement-based training in robotic-surgery-naive participants.
Methods
Study design
Medical students without prior robotic experience were recruited through a school-wide email. Twenty-four respondents were selected to complete a DVSS orientation and HMET system (Pupil Labs, Berlin, DE) fit. Six respondents failed to calibrate accurately with the HMET system. The remaining 18 participants were scheduled to complete five phases: pretraining evaluation, prelearning, video coaching, proficiency, and stress test (Fig. 1).

Study design, outlining the five phases of the study. SS3 = Suture Sponge 3.
Phase I: pretraining evaluation
Participants completed Peg Board 1 on the DVSS for proficiency. Proficiency was defined as two cumulative attempts with an overall score on the DVSS of ≥90%. Participants were ranked (1–18) based on the number of attempts to reach proficiency and randomized into either a gaze-augmented training (GT) group or motor-training (MT) group. This ensured equal skills in both groups before starting the training sessions. One participant declined to schedule a follow-up session.
Phase II: prelearning
Participants reviewed a prerecorded video of an expert surgeon completing Suture Sponge 3 (SS3) on the DVSS with voiceover highlighting teachable moments that aligned with their training group type. The video footage was identical in both groups with the exception that the expert's gaze marker was available to the GT group (Fig. 2). The GT video narration focused on description and instruction of the expert user's gaze patterns (i.e., point-of-gaze during the task), while the MT narration focused on standard movement-based instruction (i.e., manipulation of instruments and needle) (Supplementary Video S1).

Screenshots from instructional videos:
Phase III: video coaching
After fitting and calibrating the HMET, participants completed three SS3 trials. Each trial was followed by a 15-minute summative feedback session, where video footage captured from the HMET during the simulation session was reviewed with a consistent coach with prior experience coaching robotic VR tasks. 15 Coaching in the GT group characterized gaze performance and the MT group focused exclusively on movement-based coaching.
Phase IV: proficiency
Participants completed seven more SS3 attempts in the same setting without immediate review or feedback, for a total of 10 attempts. Proficiency criteria were based on previous work that characterized attempts to reach proficiency. 15
Phase V: stress test
All participants were familiarized with a secondary task consisting of counting an irregular bell tone. SS3 was then repeated twice while simultaneously completing the secondary task. No coaching was delivered in this phase.
Measurements
The primary outcome of this study was participant performance, measured through the DVSS scorecard generated after each attempt and performance maintenance during the stress test. The overall score consisted of efficiency and penalty metrics: efficiency included time, master workspace, and economy of motion; penalty included number of drops, instrument collisions, excessive force, instruments out of view, and missed targets (Table 1). Secondary task precision was calculated as follows:
Outcomes of Score Card Generated by the da Vinci Skills Simulator at Analysis Points: Baseline (Attempt 1), Coaching (Attempt 3), Proficiency (Attempt 10), and Stress Test (Average of Attempts 11 and 12)

Secondary outcomes included changes in participant gaze patterns and cognitive load measurements (gaze entropy) collected from the HMET system software (Pupil Labs, Berlin, DE) and analyzed in MATLAB (MathWorks, Inc., Natick, MA). Of the 68 recordings, 16 were lost due to errors in the recording software and 10 were removed from analysis due to calibration errors. Gaze entropy, an accepted measure of cognitive load that quantifies the dispersion of gaze over the visual field, was calculated over the entirety of the exercise using Shannon's wave entropy formula. 16 Needle-driving sections of each recording were isolated; instances where participant gaze was locked on the needle entrance point (target locking) and their instruments or needle (instrument locking) were manually marked. Fixations (instances of visual focus with dispersion less than three visual degrees and longer than 300ms) were exported and aligned with the gaze markings. The time fixated on the instrument and target was calculated as a percentage of total fixation time.
Results
Pretraining evaluation
For the Peg-board 1 task, there was no significant difference between both groups in the number of attempts to reach proficiency (GT = 4.6 vs MT = 4.2, p = 0.633) or the mean score of all the participants' attempts (82.5 ± 17.9 vs 85.2 ± 12.8, p = 0.43).
Baseline (attempt 1)
After reviewing the expert training video that aligned with their training group, the GT group achieved significantly higher total DVSS score compared with the MT group (20.3 ± 21.8 vs 3.0 ± 6.2, p = 0.047). The GT group also had nonsignificantly higher efficiency scores (45.5 ± 30.5 vs 23.9 ± 22.1, p = 0.119), significantly smaller master workspace range (7.8 ± 1.7 vs 9.9 ± 1.7 cm, p = 0.029), and significantly lower total penalty scores (−42.3 ± 17.6 vs −67.4 ± 28.0, p = 0.04) (Table 1).
Postvideo coaching (attempt 3)
While the GT group started from a significantly higher baseline, by the third attempt, overall scores increased by 41.6 points (p < 0.01) compared with a 27.1-point gain in the MT group (p = 0.012). This represented the greatest improvements seen throughout the entire training session (Table 1).
Proficiency (attempt 10)
Although nonsignificant, the GT group achieved a mean overall score of 9.9 points greater than the MT group (73.0 ± 16.5 vs 63.1 ± 17.4, p = 0.247). This difference was largely due to the nonsignificantly higher efficiency scores (85.9 ± 12.7 vs 75.8 ± 8.4, p = 0.075) and significantly smaller economy of motion (395.6 ± 68 vs 319.5 ± 62, p = 0.029). Penalties were nearly equivalent between both groups (−12.9 ± 7.0 vs −12.7 ± 10.6) (Table 1).
Stress test (attempts 11 and 12)
During the stress test, the GT group maintained a significantly higher total score (75.0 vs 63.3.4 ± 11.3, p = 0.01), efficiency (86.3 ± 7.4 vs 77.4 ± 11.2, p = 0.009), economy of motion (335.2 ± 48 vs 394.6 ± 65 cm, p = 0.004), and lower master workspace range (6.6 ± 0.8 vs 8.1 ± 2.2 cm, p = 0.009) than the MT group. Time to completion was not significantly different (300.6 ± 69 vs 321.9 ± 75 seconds, p = 0.40) (Table 1). Although not significant, fewer errors in the secondary counting task were seen in the GT group (percent error: 6.3% ± 0.06% vs 10.7% ± 0.11%, p = 0.20) (Fig. 3) where 16.7% (3 of 18) attempts in the GT group were error free compared with 6.25% (1 out of 16) in the MT group. Despite the introduction of the stress test, the GT group had greater increases in score from proficiency performance over the MT group (1.9 vs 0.2).
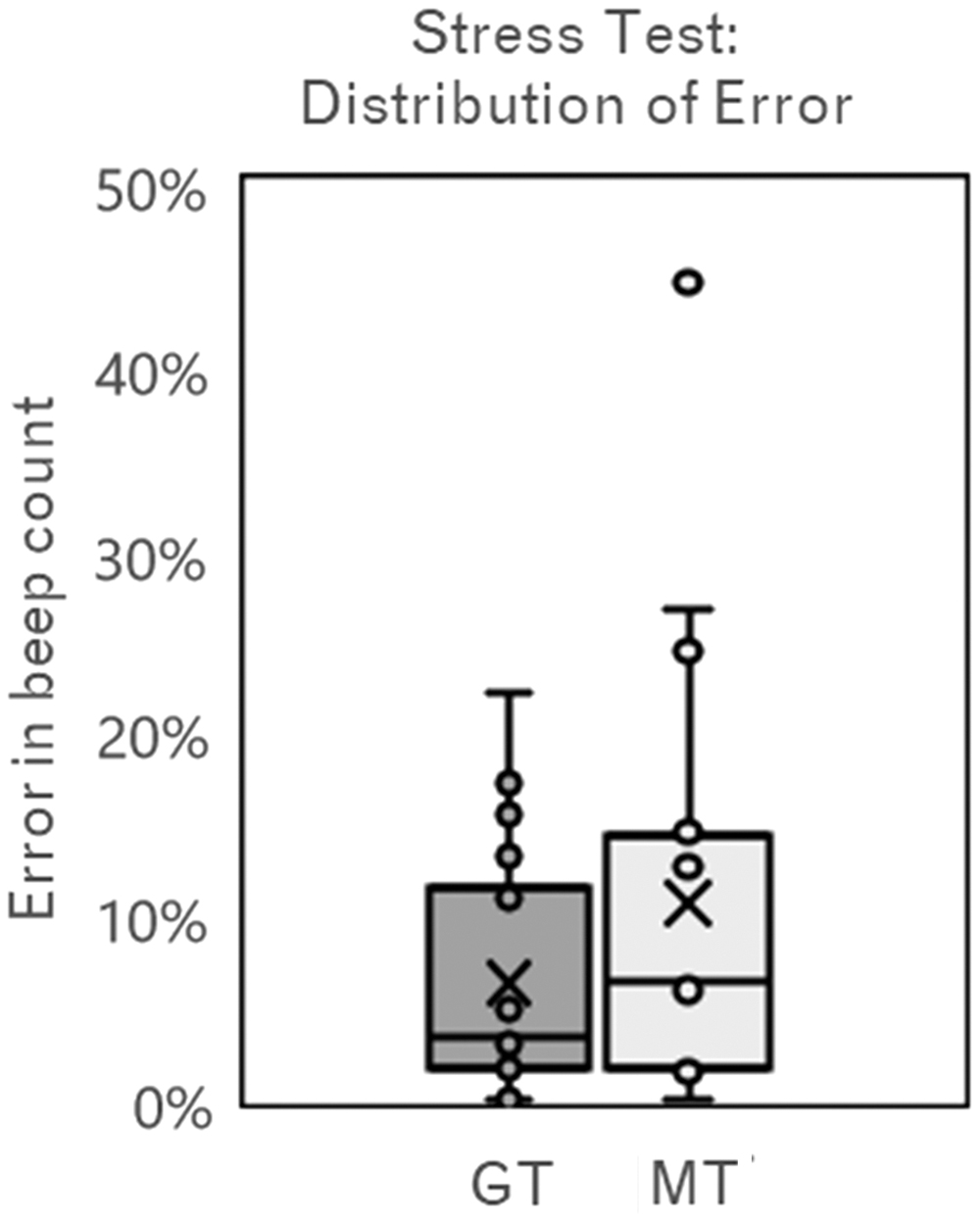
Box and whisker plot displaying distribution of error in secondary beep task during stress test (attempts 11 and 12). Error was calculated as a percent deviation from the correct total for the GT group and MT group where “X” represents the mean, lines represent quartile range, and endpoints define range. GT = gaze training; MT = movement training.
Over the course of the training, both groups' total score, efficiency, and penalties improved significantly between the 1st and 10th attempt. In addition, compared with their pretraining evaluation rankings, GT group participant ranks increased an average of 1.2, while those in the MT group dropped an average of 3.5 when reranked according to their performance at proficiency.
At baseline, a nonsignificant difference in percentage of total fixation time fixated on the target existed between groups (78.2% ± 7.3% vs 66.6% ± 11.8%, p = 0.15). However, the GT group consistently spent a significantly higher percentage of total fixation time fixated on the target compared with the MT group at proficiency (92.0% ± 5.1% vs 62.3% ± 4.4%, p < 0.01) and stress test (89.7% ± 8.1% vs 75.7% ± 7.2%, p = 0.04) (Fig. 5a). Gaze entropy was highest in both groups at baseline (GT = 103,600 bits vs MT = 95,500 bits) and lowest at proficiency (GT = 46,000 bits vs MT = 55,400 bits). During the stress test phase, gaze entropy remained constant in the GT group (+1200) and decreased in the MT group (−13,000) (Fig. 5b).
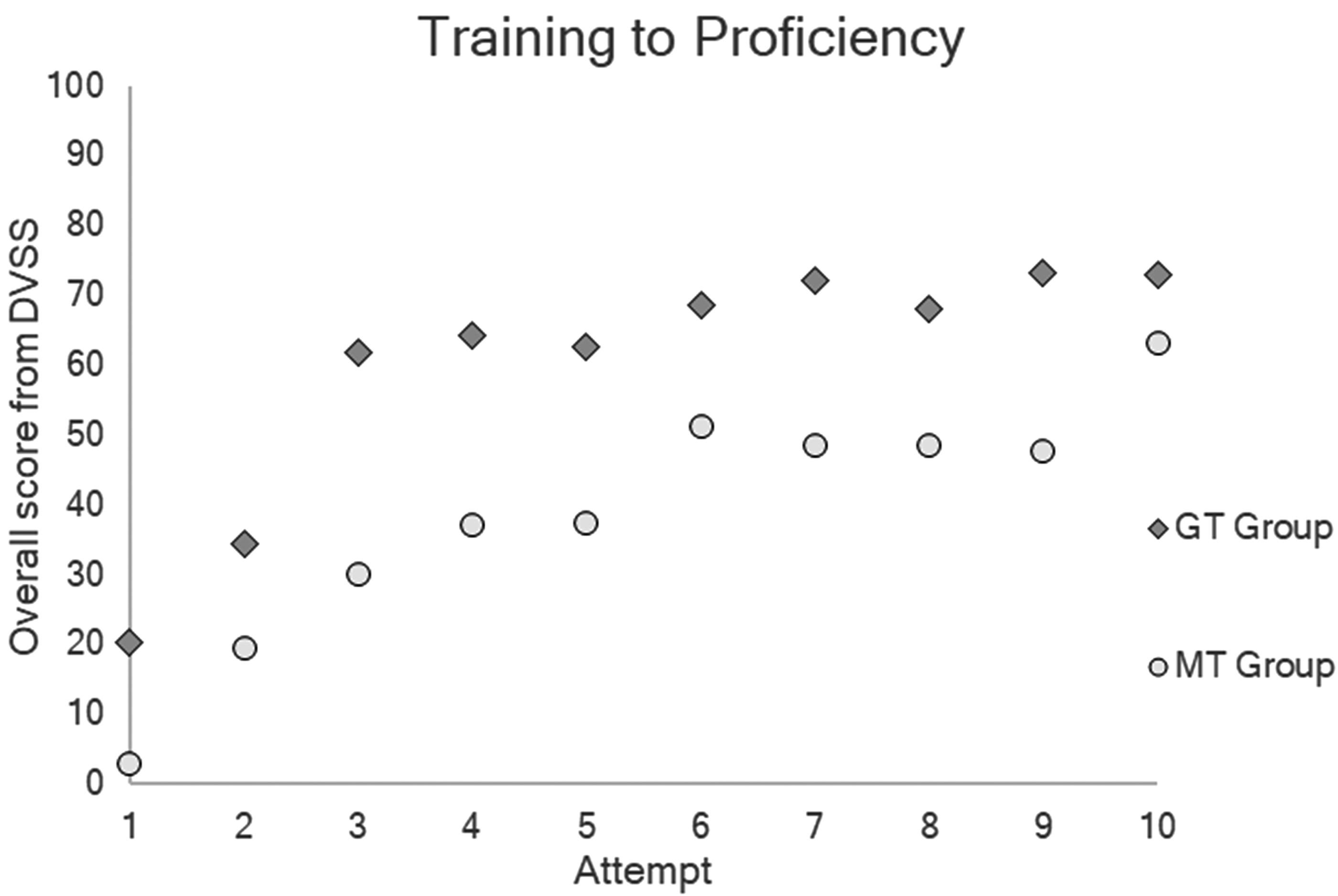
Average total score achieved by GT group (circles) and MT group (diamonds) over the 10 Suture Sponge 3 attempts completed on the da Vinci surgical simulator while training to proficiency. DVSS = da Vinci Skills Simulator.
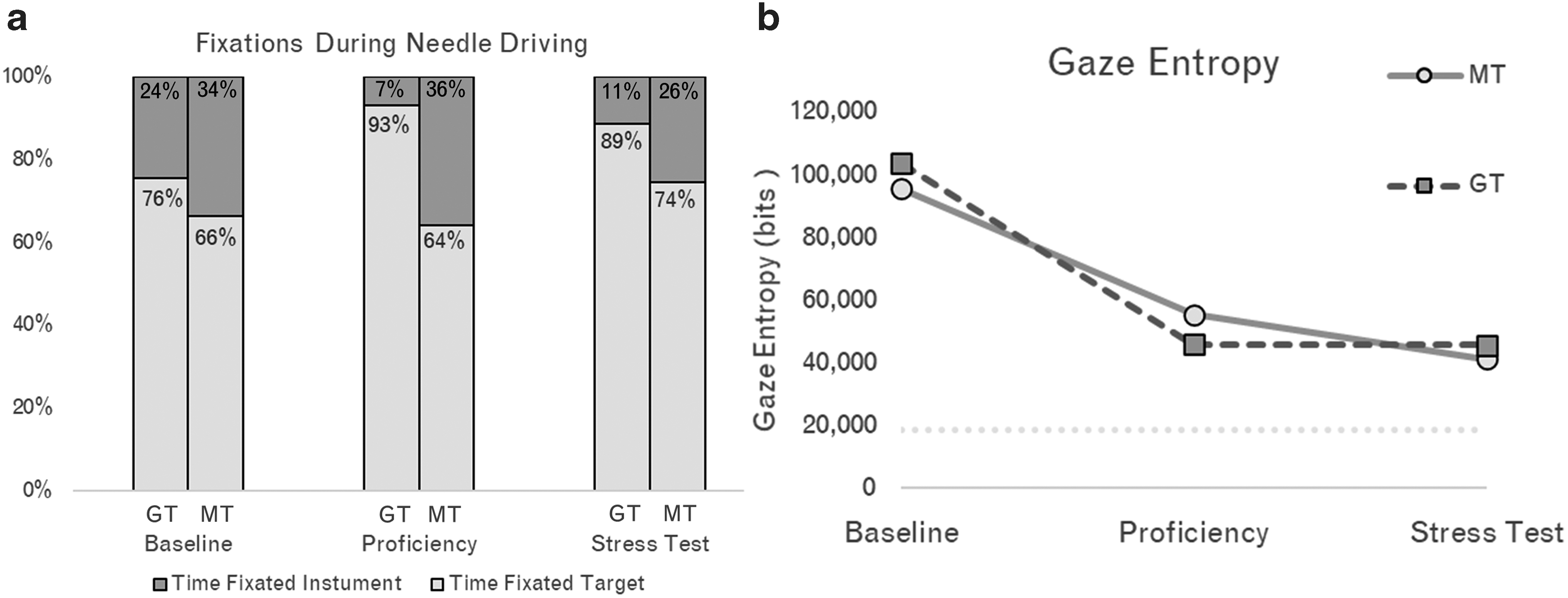
Gaze-related metrics investigated for the GT group and MT group during the preassigned analysis points: Baseline (attempt 1), Proficiency (attempt 10), and Stress Test (average of attempts 11 and 12).
Discussion
The results of our study support the efficacy of GT in enhancing robotic SBT. Participants who underwent GT were able to perform a suturing task more efficiently than those who underwent standard MT. The effectiveness of gaze-augmented feedback was most pronounced early in the training. After the initial instruction during the prelearning phase, the GT group significantly outperformed the MT group in total score (Δ = 17.3 points) and penalties (Δ = 21.6 points). After completion of the video coaching phase, the largest difference between groups in total score (Δ = 31.8 points) and penalties (Δ = 25.3 points) was seen. After seven additional repetitions without feedback, the GT group maintained a mean overall score difference of 9.9 points over the MT group. These differences highlight that gaze feedback during SBT is more effective at the beginning of the learning curve.
Gaze training as a teaching method was introduced in a randomized-controlled trial involving simulated laparoscopic skills and performance testing. This study recruited laparoscopic-surgery-naive trainees and divided them randomly into groups receiving gaze-guided instruction and feedback (GAZE), standard movement instruction and feedback (MOVE), or no feedback (DISCOVERY). Despite an equal reduction in total path length (∼33%) in all three groups, the GAZE group revealed a performance advantage in terms of completion times (up to 40% improvement) and adoption of expert-like gaze behaviors. 13 This superior performance was attributed to activation of the neural network that integrates visual information with motor commands, thus allowing the motor system to self-organize in a more implicit manner. 17 Another study investigated the potential of teaching trainees to adopt expert gaze strategies by randomizing laparoscopic-surgery-naive trainees into either a discovery-learning (DL) or a GT group. 14 The GT group completed laparoscopic simulation tasks using a novel software designed to highlight key locations on the monitor to guide expert-like gaze strategies, whereas the DL group had a normal view of the monitor. The GT group effectively adopted an expert-like gaze strategy by displaying more target-locking fixations and outperformed the DL group with faster completion times and fewer errors.
Both studies identify that GT individuals exhibit a performance advantage over traditionally trained counterparts by fixating their attention on critical areas to emulate expert-like gaze strategies. 12 –14 Minimally invasive surgery relies heavily on appropriate visual surveillance, correct interpretation of visual information, and effective hand-eye coordination to guide instruments along a safe path toward the intended target. 18 Novices learn mapping rules by switching their point-of-gaze between tool and target, whereas experts utilize a target locking strategy and rarely need to check tool locations. 11,19 This suggests that directing gaze toward a target facilitates the motor system to organize the task more effectively, resulting in implicit acquisition of effective movement patterns. The effectiveness of gaze training was demonstrated by the GT group spending a larger percentage of time fixated on targets rather than their instruments during the needle driving task. This translated to an improvement of the GT group's target to instrument locking ratio in the GT group from baseline to proficiency (∼3:1 to 10:1), while the MT maintained a similar ratio of ∼2:1 throughout the same period.
The improvement of visual scan strategies reduces visual activation and therefore attentional demand on the visual cortex. 20 By manipulating the visual behavior of novices in a way that aligns more closely with that of experts, it is conceivable that novices may bypass the early cognitive phases of visual-motor learning and proceed directly to the associative phase (Fitts and Posner, 1962). 21 To measure cognitive load, we utilized gaze entropy, which is known to increase with increasing task complexity. 16,18 Gaze entropy was highest in both groups at baseline and lowest at proficiency, decreasing 52% in the GT group and 42% in the MT group, indicating decreased mental effort with increased task familiarization.
The performance of proficiency-trained learners has been shown to break down under typical multitasking demands experienced in the operating room. 22 –27 In this study, the GT group maintained a superior economy of motion than the MT group during the stress test. This ability of the GT group to sustain their superior movement patterns during multitasking demands represents the resilience of these implicitly learned motor skills. The nonsignificant differences in error scores among both groups may be explained by the GT group allocating a higher proportion of their mental effort to the secondary task resulting in a higher percentage of correctly counted beeps. Furthermore, the resilience of expert gaze patterns acquired through GT was demonstrated in the maintenance of superior target-locking gaze patterns during the stress test (maintaining the target to instrument ratio reached at proficiency, ∼10:1).
This is the first study that addresses gaze-augmented training within a simulated robotic environment. HMET within the robotic console presented unique technical challenges in this study, especially regarding the calibration essential for accurate gaze projection. During preliminary investigations, the robotic console would often collide with the HMET apparatus, ultimately requiring the need to recalibrate. To address this, a proprietary headrest was constructed to replace the factory-model headrest. Still, a portion of recordings suffered from loss of calibration. Additional limitations include that participants did not reach expert level by the end of proficiency, likely due to the difficulty of the exercise. Overall, this study supports the efficacy of gaze-augmented surgical training compared with movement-based training in a VR robotic suturing task.
Conclusion
The application of HMET offers a unique opportunity to enhance robotic surgery training. Further studies investigating the impact of gaze-augmented training in improving proficiency-based progression, limiting skill decay, reducing expert coaching, and ability to transfer skills acquired at a high-stakes operating room environment are required to optimize the utilization of this technology.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.
Supplementary Material
Supplementary Video S1
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.