
Abstract
Background:
Competence in transurethral resection of bladder tumors (TURB) is critical in bladder cancer management and should be ensured before independent practice.
Objective:
To develop an assessment tool for TURB and explore validity evidence in a clinical context.
Design, Setting, and Participants:
From July 2019 to March 2021, a total of 33 volunteer doctors from three hospitals were included after exemption from the regional ethics committee (REG-008-2018). Participants performed two TURB procedures on patients with bladder tumors. A newly developed assessment tool (Objective Structured Assessment for Transurethral Resection of Bladder Tumors Skills, OSATURBS) was used for direct observation assessment (DOA), self-assessment (SA), and blinded video assessment (VA).
Outcome Measurements and Statistical Analysis:
Cronbach's alpha and Pearson's r were calculated for across items internal consistency reliability, inter-rater reliability, and test–retest reliability. Correlation between OSATURBS scores and the operative experience was calculated with Pearson's r and a pass/fail score was established. Differences in assessment scores were explored with paired t-test and independent samples t-test.
Results and Limitations:
The internal consistency reliability across items Cronbach's alpha was 0.94 (n = 260, p < 0.001). Inter-rater reliability was 0.80 (n = 64, p < 0.001). Test–retest correlation was high, r = 0.71 (n = 32, p < 0.001). Relationship with TURB experience was high, r = 0.71 (n = 32, p < 0.001). Pass/fail score was 19 points. DOAs were strongly correlated with video ratings (r = 0.85, p < 0.001) but with a significant social bias with lower scores for inexperienced and higher scores for experienced participants. Participants tended to overestimate their own performances.
Conclusions:
OSATURBS tool for TURB can be used for assessment of surgical proficiency in the clinical setting. DOA and SA are biased, and blinded VA of TURB performances is advised. Clinical Trials NCT03864302.
Introduction
Transurethral resection of bladder tumors (TURB) is challenging to learn. Nonetheless, TURB is considered an easy procedure often performed by resident doctors, and the procedure's importance in bladder cancer (BC) management has been neglected for decades. 1,2 Correct initial surgery, staging, and strategy are essential in BC treatment. Therefore, there is an emerging awareness of the importance of a safe and correctly performed TURB, and several studies have drawn attention to the influence of surgical experience on TURB quality indicators. 3
Inexperienced TURB surgeons have a higher rate of detrusor muscle absence in tumor specimens, higher readmission rates, and higher recurrence rates. 4 –6 Furthermore, studies have identified significant variations in recurrence rates among different European institutes suggesting troublesome differences in surgical skills. 7 Finally, a recent study found that the learning curve in TURB is strikingly long and acceptable surgical and oncologic outcomes are only reached after >100 TURB procedures. 8
Surgical apprenticeship is based on theoretical knowledge, observation in the operation theater, and supervised procedures before the trainee can operate independently. The transfer from one phase to the next is not well defined. Some institutes have training programs, but these are often based on local traditions rather than evidence-based medical education.
Assessment of skills is essential for effective training programs. Identifying proficiency should be based on timely objective assessment with minimal bias. Dedicated assessment tools can help achieve this, but evidence of validity must be explored to ensure that they measure what they are supposed to measure. 9 Unfortunately, relatively few publications on assessment in surgical skills use recommended contemporary frameworks for evidence synthesis, for example, Messick's five sources of validity: construct, response process, internal structure, relation to other variables, and consequences. 10
Different contexts of assessment of surgical skills can be applied: self-assessment (SA), direct observation assessment (DOA), and blinded video assessment (VA).
SA is a reflective process wherein the trainees assess their own performance. The majority of surgical training today depends on SA to some degree. Often, there is no formal assessment of surgical skills, and trainees are left with SA and DOAs from senior doctors. 11
We wanted to develop an objective assessment tool for TURB and explore validity evidence from Messick's five sources of validity in a clinical context.
The aim of our study was to explore whether the novel assessment tool could identify surgical skills proficiency in TURB, and secondary whether VA, DOA, and SA were suiatible for proficiency assessment in TURB.
Materials and Methods
First, a combined overall assessment tool was drafted by the principal researcher (S.H.B.). To ensure content, the overall assessment tool was based on the design of the Objective Structured Assessment of Technical Skills (OSATS) tool, 12 and on existing recommendations from the BC expert panel of the European Association of Urology (EAU), recommendations from the British Urology Society on Direct Observation of Procedural Skills (DOPS), the Danish Bladder cancer group (DABLACA), and a previous report by De Vries et al. (Supplementary Appendix SA1). 13
The combined overall assessment tool was discussed and refined at an expert meeting. Experts included three urologists with surgical expertise in TURB (N.A., R.B.H., and C.D.), one expert in assessment of procedural skills (L.K.), and one with experience in both (S.H.B.). Only items with expert agreement were included in the final assessment tool, the Objective Structured Assessment for Transurethral Resection of Bladder Tumors Skills (OSATURBS; Supplementary Appendix SA2). OSATURBS consists of nine items each with three anchors on a Likert scale from 1 to 5, where anchor 1 was unskilled, anchor 3 was acceptable skills, and anchor 5 was excellent skills.
Next, dedicated raters were appointed. Three direct raters performed DOA (P.S.K., M.G.M., and S.H.B.), and two blinded video raters (J.L.V. and T.N.) rated all videos individually. All raters were specialists in urology, members of the Danish and European Urology Societies, had comprehensive insight into guidelines on BC, and had performed >100 TURBs. To enhance Response Process of the ratings, all raters recieved rater training. 14,15 This included a standardized rater education template with descriptions of common rater errors (halo, leniency, central tendency, and restriction of range), the potential effects of rater errors, and how to avoid them. 14
Furthermore, the template included the assessment tool OSATURBS and instructions with short examples of each item, and each anchor in the 5-point Likert scale was explained. In addition, a video tutorial of TURB performances at different skill levels was used for Rater Error Training, Performance Dimension Training, Frame-of-Reference Training, and Behavioural Observation Training. 16
Afterward, invitations were sent to doctors at three departments of urology, Denmark. All participants were volunteers and gave informed written consent before inclusion. The participants had variant experience with TURB ranging from novices at the beginning of their surgical training to specialist urologists with great experience in the procedure. Three locations in Denmark recruited participants: (1) department of urology, Aarhus University Hospital, Aarhus, Denmark; (2) department of urology, Rigshospitalet, Copenhagen, Denmark; and (3) department of urology, Zealand University Hospital, Roskilde, Denmark. After inclusion, participant demographics were collected, and the participants were given quarantine from performing TURB outside the project.
Eligible patients were identified. Inclusion criteria were
exophytic tumors ≤3 cm and
primary TURBs
or
recurrent bladder tumors or repeated TURBs and
informed patient consent.
Exclusion criteria were
Indications for TURB other than exophytic bladder tumors.
Participants performed two TURBs on patients. One of the direct raters was present at all TURB procedures, ensuring patient safety, supervision if needed, video recordings, and OSATURBS DOA (Fig. 1). Immediately after each procedure, the participant performed an OSATURBS SA. The MediCapture® USB300 Specs High Definition (HD) video recorder was used for video recording.
Participant performing TURB with guidance. TURB = transurethral resection of bladder tumors. Color images are available online.
Finally, both video raters assessed all TURB videos independently (Fig. 2). The video raters were blinded to the identity of the participants. An interval of 30 days from the recording date to VA was used to diminish recall bias. Videos were assessed in random order and anonymized regarding participant TURB experience, and the first or second TURB procedure. Study data were collected and managed using REDCap (Research Electronic Data Capture) electronic data capture tools hosted by the Capital Region of Denmark.
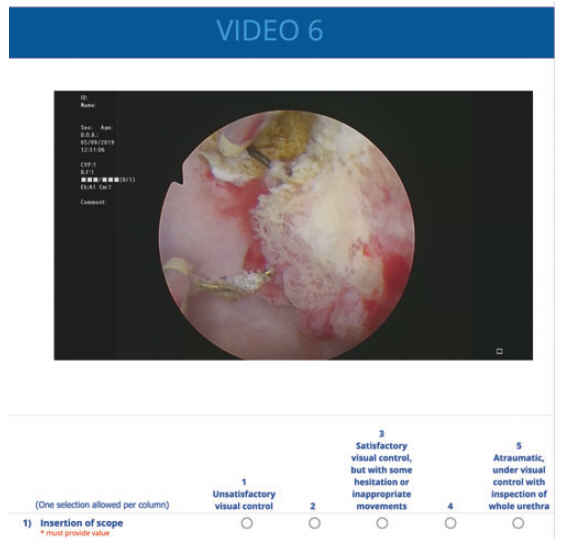
An example of the online video and rating platform. Raters had the opportunity to fast forward and revise the video until all items in the OSATURBS were completed. OSATURBS = Objective Structured Assessment of TURB Skills. Color images available online.
Statistical analysis and outcome measures
All OSATURBS scores were recorded from 1–5 to 0–4. The VA was overruled and changed to 0 for items where the direct rater had noted: “performed by supervisor.”
Internal structure was explored by three indices of reliability: Internal consistency reliability was explored across items and reported by Cronbach's alpha. Inter-rater reliability was explored with intraclass correlation coefficients (ICCs), consistency definition and absolute agreement definition, and single measures and average measures. Test–retest reliability between first and second performance was explored with Pearson's correlation. Relation to other variables was explored between TURB experience and total OSATURBS score, reported as Pearson's r.
A pass–fail score was established using the contrasting groups' standard setting method exploring consequences of the test. 17 Average scores correlations of DOA, SA, and VAs were explored with Pearson's r and differences explored with paired sample t-test. To evaluate bias in the DOA, differences between DOA and VAs were explored with independent t-test of delta-values for two different TURB experience levels, <10 TURBs and >10 TURBs, respectively. p-values <0.05 were considered statistically significant.
SPSS was used for statistical analysis (IBM Corp. IBM SPSS Statistics for Windows, Version 22.0. IBM Corp., Armonk, NY, USA).
The ethics committee of the Zealand Region deemed this study to be exempt (REG-008-2018).
Results
Data were collected from June 2019 to March 2021 and included 33 doctors from three university hospitals in Denmark. Participants ranged from first postgraduate year to urologist specialists (Table 1). Two participants had only one video recording because of technical issues. In total, 260 assessments based on 66 procedures and 64 videos were included in the analysis.
Participant Demographics
IQR = interquartile range; PGY = postgraduate year; TURB = transurethral resection of bladder tumors.
Validity evidence
Internal consistency reliability across items was good with a Cronbach's alpha = 0.94 (n = 260). Inter-rater reliability (Fig. 3) between the two video raters was high with a single measure ICC = 0.80 (n = 64, p < 0.001). Average measures ICC was 0.89 for both absolute agreement definition and consistency definition, indicating superior reliability without a hawk–dove effect. Test–retest correlation between procedures was high (Fig. 4), with a Pearson's r = 0.71 (p < 0.001). Relationship with TURB experience was also high with a Pearson's r = 0.71 (Fig. 5).

Inter-rater reliability, level of agreement between the two video raters (n = 64).
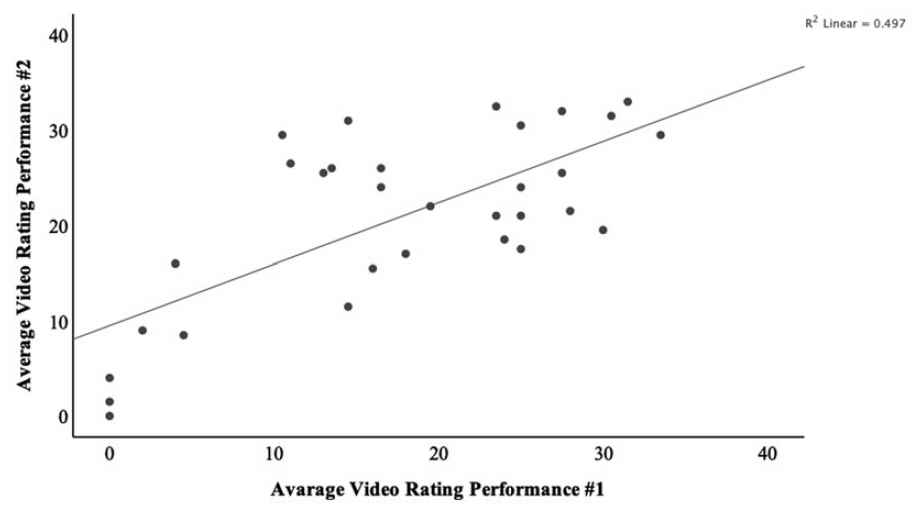
Test–retest, the correlation between average video ratings for procedure 1 and procedure 2 (n = 31).

OSATURBS scores relationship with TURB experience (n = 33). Color images are available online.
Contrasting groups' standard setting comparing the novice and experienced groups established a pass/fail score of 19 points (Fig. 6). The pass/fail score had a theoretical false-negative and false-positive of 6.8% and 20.1%, respectively. The pass/fail score's observed effect was that no experienced doctors failed the test (false-negative rate 0%), and four novice doctors passed the test (false-positive rate 27.3%).
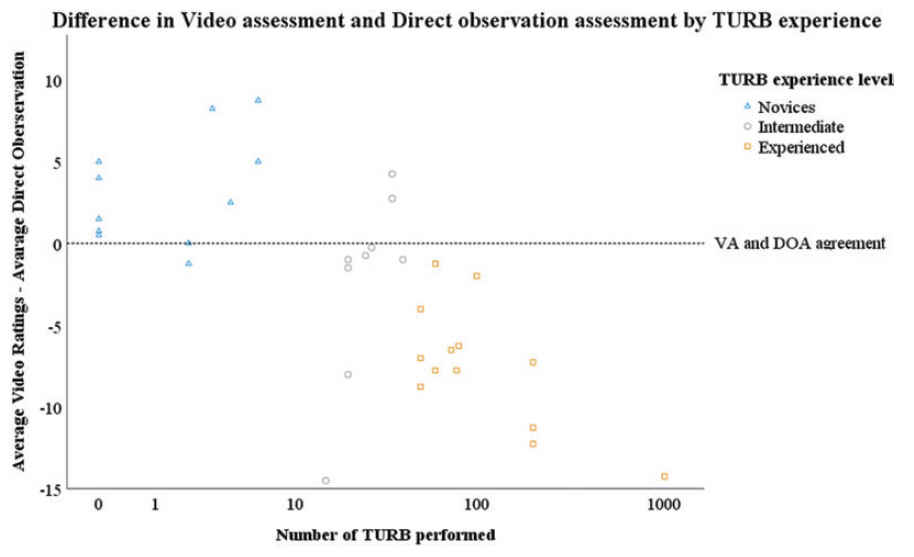
Rater bias, the difference between the DOA score and average video scores stratified by TURB experience. The horizontal line marks DOA and VA agreement. Above the line, VA ratings are higher, below the line, the VA ratings are lower than the DOAs. DOA = direct observation assessment; VA = video assessment. Color images are available online.
Direct observation assessments
DOAs were strongly correlated with video ratings (r = 0.85, p < 0.001), but the direct ratings were significantly higher, on average 2.4 points higher (95% confidence interval [CI]: [0.28–4.63], p = 0.028). The independent samples t-test exploring the differences between DOA and VA showed a significant anchoring bias for inexperienced and experienced participants. The DOAs were lower for novices and higher for intermediates and experienced compared with VAs, mean difference −3.2 points (p < 0.001) and mean difference +5.3 points (p < 0.001), respectively (Fig. 7).
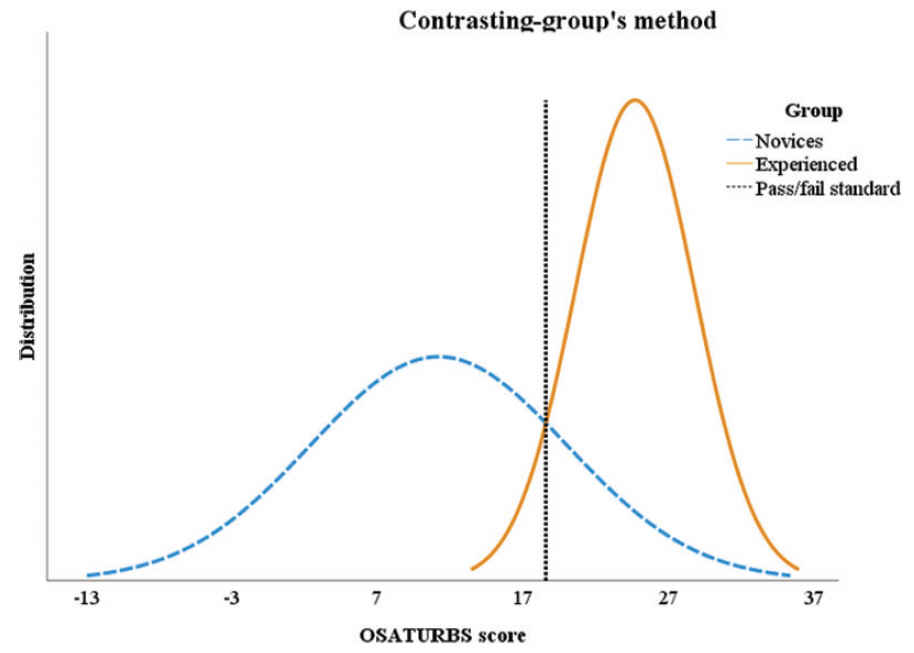
Contrasting groups, between novices and experienced. Dotted line, intercept between the group's normal distributions is the pass/fail standard. Novices have performed <10 TURBs, representing true negatives, or those we expect to fail the test. Experienced have performed >50 TURBs, representing the participants we expect to pass our test or the test's true positives. Color images are available online.
Self-assessments
SA had a moderate correlation with video ratings (r = 0.67, p < 0.001), with an insignificant difference of 1.4 higher points for SAs (95% CI: [−1.3 to 4.07], p = 0.30). Both inexperienced and experienced participants rated own performance higher than the video raters, which was not statistically significant, 1.5 points (p = 0.96) and 1.4 points (p = 0.97), respectively.
Discussion
In this study, we developed an assessment tool for TURB and established validity evidence including a pass/fail score. To our knowledge, OSATURBS is the first assessment tool with validity evidence for TURB in a clinical context.
George Miller described in 1990 a framework for clinical assessment. 18 The Miller pyramid has four assessment levels: the base is knowledge, the second is competence, the third is performance, and finally the vertex is action.
Previously, we have developed a simulator-based test in TURB to test Miller's third step, the “show how.” 19 The TURBEST test ensures TURB skills in a patient-free environment on a virtual reality TURB simulator. The test is competence based and consists exclusively of simulator metrics including an established pass/fail standard. Trainees are allowed unlimited repetitions, get immediate feedback, and continue until they pass the test.
OSATURBS is designed to test the highest level of Miller's pyramid. Assessment of performance in clinical practice, “the Does” level. 19 We chose to design a new procedure specific tool, based on the same design of the general OSATS tool. Numerous surgical assessment tools exist, but the majority have not been thoroughly tested for evidence of validity in the proposed context. 20 Our findings suggest that one video rater assessing two performances can provide a reliable and valid assessment of TURB proficiency.
We included DOA in our study, as direct observations are ubiquitous in the surgical apprenticeship. Without evidence of validity, our assessment of the trainee will be disposed to several threats. 21 DOA has been described as a chain of events with several links: observation, interpretation, and judgment. All links are at risk of several biases such as anchoring bias (bases the entire assessment on an initial opinion of the trainee), bandwagon bias (other members of faculty's opinion are adopted), visceral bias (judgments based on emotions rather than data), and comparative bias (first performance affects assessments of the following procedures). 21 –23 In conclusion, DOA is essential in surgical skills training but is dependent on rater training and context. 24
We trained all raters and used an assessment tool with defined objectives. That being the case, we still found that the direct ratings were notably higher in the experienced group and lower in the novice group than the ratings by the video raters. Konge and coworkers found that trainees scored 10% lower scores when the raters knew their identity. 25 This finding and our results are important as they underline the limitations of DOAs, and the need to use other assessment technics in evaluations of clinical performances.
VAs are not exposed to social biases as they are blinded for the identity of the trainee, but video rating is a demanding task, as it is different from doctors' daily practice. Nevertheless, VA is less time consuming than DOA and can be assessed by multiple raters improving rater reliability. 26 Video raters still need thorough training as other biases beside interpersonal bias still are a threat to the assessment. Dagnaes-Hansen et al. explored VA in flexible cystoscopy and found high inter-rater reliability between two video raters, but also a hawk–dove effect between raters. 27 Such bias could be minimized by frame-of-reference rater training.
We found that the participants generally tended (not significant) to rate their own performance higher than the video raters did. This is congruent with the existing body of evidence that SA is not suitable for skills assessment. 28 Nonetheless, SA is a useful tool as it enlightens how the participants interpret their own performance. Identifying the participant's perspective makes it possible to construct a desirable difficulty and give targeted praise. Thus, the SA should not be used for summative assessment such as certification but as an educational tool for formative assessment. 28
Several limitations should be considered when interpreting our findings. The pass/fail score resulted in high false positives. This might be explained by variation in case complexity regardless of the inclusion criteria 29 ; the trainees who passed might have had two easy cases because of selection bias. Another explanation could be participant related. Participants were stratified based on previous quantitative TURB experience. Quantitative experience is not necessarily proportional to skills.
Furthermore, at the beginning of their learning curve, surgeons will tend to use a systematic approach that is recognizable and makes the video rating easier and the rater might, therefore, give a higher score. We acknowledge that the video raters have limited information on several important aspects of the procedure, and they have no background information about the patient. This lack of information could potentially influence their ratings both negatively and positively.
Future research should determine the effects of a mastery learning training program. 30 We propose that such a program should use simulation-based training until progression to defined learning objectives, 19 followed by supervised procedures with performance-guided feedback until proficiency level is reached when assessed by video-based assessment.
Conclusion
This prospective study of surgeons performing TURB on patients showed that a novel TURB assessment tool possesses validity evidence for content, internal structure, response process, relation to other variables, and consequences in the clinical setting. Our findings suggest that DOA is not suitable for objective assessments, and we propose introducing blinded video assessments for surgical skill proficiency identification in TURB.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received.
Supplementary Material
Supplementary Appendix SA1
Supplementary Appendix SA2