
Abstract
Objective:
To evaluate the performance of computer vision models for automated kidney stone segmentation during flexible ureteroscopy and laser lithotripsy.
Materials and Methods:
We collected 20 ureteroscopy videos of intrarenal kidney stone treatment and extracted frames (N = 578) from these videos. We manually annotated kidney stones on each frame. Eighty percent of the data were used to train three standard computer vision models (U-Net, U-Net++, and DenseNet) for automatic stone segmentation during flexible ureteroscopy. The remaining data (20%) were used to compare performance of the three models after optimization through Dice coefficients and binary cross entropy. We identified the highest performing model and evaluated automatic segmentation performance during ureteroscopy for both stone localization and treatment using a separate set of endoscopic videos. We evaluated performance of the pixel-based analysis using area under the receiver operating characteristic curve (AUC-ROC), accuracy, sensitivity, and positive predictive value both in previously recorded videos and in real time.
Results:
A computer vision model (U-Net++) was evaluated, trained, and optimized for kidney stone segmentation during ureteroscopy using 20 surgical videos (mean video duration of 22 seconds, standard deviation ±13 seconds). The model showed good performance for stone localization with both digital ureteroscopes (AUC-ROC: 0.98) and fiberoptic ureteroscopes (AUC-ROC: 0.93). Furthermore, the model was able to accurately segment stones and stone fragments <270 μm in diameter during laser fragmentation (AUC-ROC: 0.87) and dusting (AUC-ROC: 0.77). The model automatically annotated videos intraoperatively in three cases and could do so in real time at 30 frames per second (FPS).
Conclusion:
Computer vision models demonstrate strong performance for automatic stone segmentation during ureteroscopy. Automatically annotating new videos at 30 FPS demonstrate the feasibility of real-time application during surgery, which could facilitate tracking tools for stone treatment.
Introduction
Ureteroscopy for treatment of urinary calculi has been utilized since the development of the pulsed lasers in the 1980s. 1 In addition to the advances in energy delivery for lithotripsy, improvements in observation and the transition to flexible ureteroscopes have promoted the wide adoption of retrograde intrarenal surgery. However, the depth perception and field of view of ureteroscopes are still limited. 2 In addition, intraoperative blood and debris may hamper observation and tracking of stone fragments, leading to increased operating time and residual stone fragments. 3,4 Although image quality has improved with digital computer chip detectors, further improving stone localization and tracking could improve operative efficiency and stone-free rates.
Computer vision, a field within machine learning that focuses on the automatic interpretation of visual data, could be used to enhance endoscopic observation during ureteroscopy. By using a specifically annotated set of visual data (i.e., training), a deep learning-based computer vision model can be built to automatically identify specific targets. Deep learning (a subset of machine learning) creates a nonlinear neural network model that can perform repeated tasks with subsequent iterative improvement of the outcome. Within urology, these techniques have demonstrated accurate prediction of stone composition from CT imaging or direct visual analysis. 5,6 Likewise, computer vision methods could be leveraged during endoscopic stone surgery to automatically track stones and stone fragments during treatment.
We sought to develop a computer vision model to automatically segment and track kidney stones from endoscopic video feeds during flexible ureteroscopic stone treatment.
Materials and Methods
Cohort
After approval from the institutional review board, we obtained endoscopic surgical videos from 20 patients who had undergone flexible ureteroscopy and holmium laser lithotripsy for kidney stone disease by two surgeons from January to June 2021. All patients were at least 18 years old and had radiographic evidence of renal stones with indications for ureteroscopic treatment. A flexible digital ureteroscope (Karl Storz Flex Xc) was used for each case. Preoperative imaging characteristics of all stones, as well as their postoperative compositions, were recorded.
Model training and selection
Individual video frames were extracted from the surgical videos at 20 frames per second (FPS) and cropped. The frames were evaluated to have low noise/interference and standard resolution was obtained from Karl Storz Flex Xc digital ureteroscopes (1920 × 1080 pixels). Each frame was then annotated by two endourologists (Cohen's Kappa agreement of 0.80 based on pixel annotation) to identify kidney stones and generate a “ground truth” data set for model training and evaluation (Makesense.ai, San Francisco, CA, USA). 7 Eighty percent of the data were used for model training, with 10% used for validation (i.e., hyperparameter tuning), and 10% reserved for eventual model testing.
To optimize and select a high performing model, we compared three different architectures of established baseline deep learning computer vision models. The primary baseline utilized was a U-Net model, which we compared with a U-Net++ and DenseNet model. 8 –10 Training was a standard iterative pipeline (i.e., forward propagation and loss computation, followed by back propagation with frequent validation checks). Standard hyperparameter searches were performed and compared to evaluate the best conditions for each model (i.e., learning rate, batch size, number of epochs, and the scaling factor).
Figure 1 shows workflow for model training and testing. We compared the different architectures throughout training using the Dice similarity coefficient (a standard metric of geometric overlap between a model's segmentation and the ground truth), as well as the binary cross entropy (BCE) loss function (a measure of uncertainty between model prediction) (Supplementary Appendix SA1 and SA2). 11,12
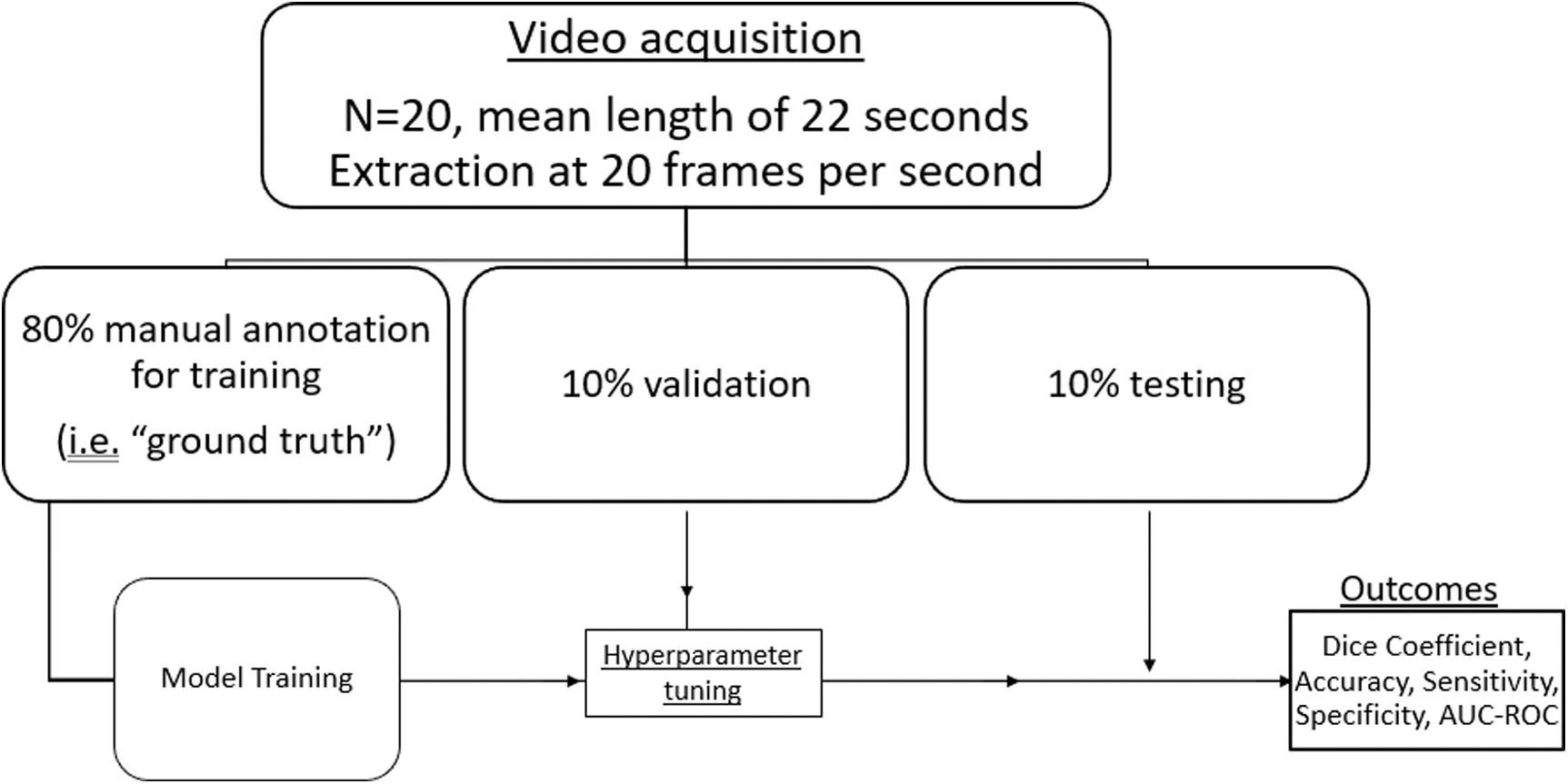
Workflow for model training and evaluation.
Model performance evaluation
After identifying the highest performing model, we evaluated segmentation performance during initial kidney stone localization and laser treatment of stones. Specifically, we used separate sets of endoscopic surgical videos (three videos each) to evaluate segmentation performance during four tasks: (1) digital ureteroscope stone localization, (2) fiberoptic ureteroscope stone localization, (3) laser stone fragmentation (0.8 J and 8 Hz), or (4) laser stone dusting (0.3 J and 30 Hz). Individual video frames were again extracted from each surgical video at 20 FPS and cropped.
A total of 57 frames were manually annotated to evaluate segmentation during digital ureteroscope localization, whereas 45 frames were annotated to evaluate fiberoptic ureteroscope stone localization, laser stone fragmentation, and laser stone dusting, separately. Model performance was compared with manual stone annotation for each task. In addition, model performance was evaluated during three live surgical cases.
A subanalysis was performed on 10 frames to compare model performance during treatment of stones based on size of fragments. Threshold for comparison of stone fragments was based on the diameter of the laser fiber tip (272 μm). Five frames containing fragments smaller than the laser fiber were compared with five frames larger than this cutoff.
Evaluation metrics
Primary outcomes included the average area under the receiver operating characteristic curve (AUC-ROC), sensitivity, positive predictive value, and accuracy of a pixel-based stone segmentation across all annotated frames for each task with the computer vision model (Supplementary Appendix SA3). In addition, we evaluated whether the model maintained performance when processing frames at 30 FPS (i.e., in real time) and displayed predicted stone annotations through a heatmap with pixel-based probabilities of stone segmentation. All analysis was done using
Results
Postoperative stone analysis revealed that a variety of stone types were used during model training with a predominance of calcium stones (75%). Most stones were identified in the renal pelvis (55%). Stone characteristics are reported in Table 1. Average surgical video time was 22 seconds (standard deviation ±13) with a total of 578 frames extracted and annotated for initial model training. In comparison of the models in the validation data set, U-Net++ achieved highest Dice coefficient (0.84), followed by U-Net (0.83) and DenseNet (0.59). Similarly, U-Net++ had the lowest (best) BCE loss among models, whereas DenseNet had the highest (Supplementary Appendixes SA1 and SA2). Thus, the U-Net++ model was used for further testing.
Stone Characteristics in Training Data Set
The model performed best during stone localization. Specifically, mean AUC-ROCs for stone localization with a digital and flexible ureteroscope were 0.98 and 0.93, respectively (Fig. 2). For the laser treatment of stones, the model performed better for segmentation during fragmentation (AUC-ROC: 0.87) than during dusting (AUC-ROC: 0.77; Fig. 3). In addition, the model was able to accurately annotate new videos at 30 FPS and was evaluated in the operating room during three cases, showing maintained performance.
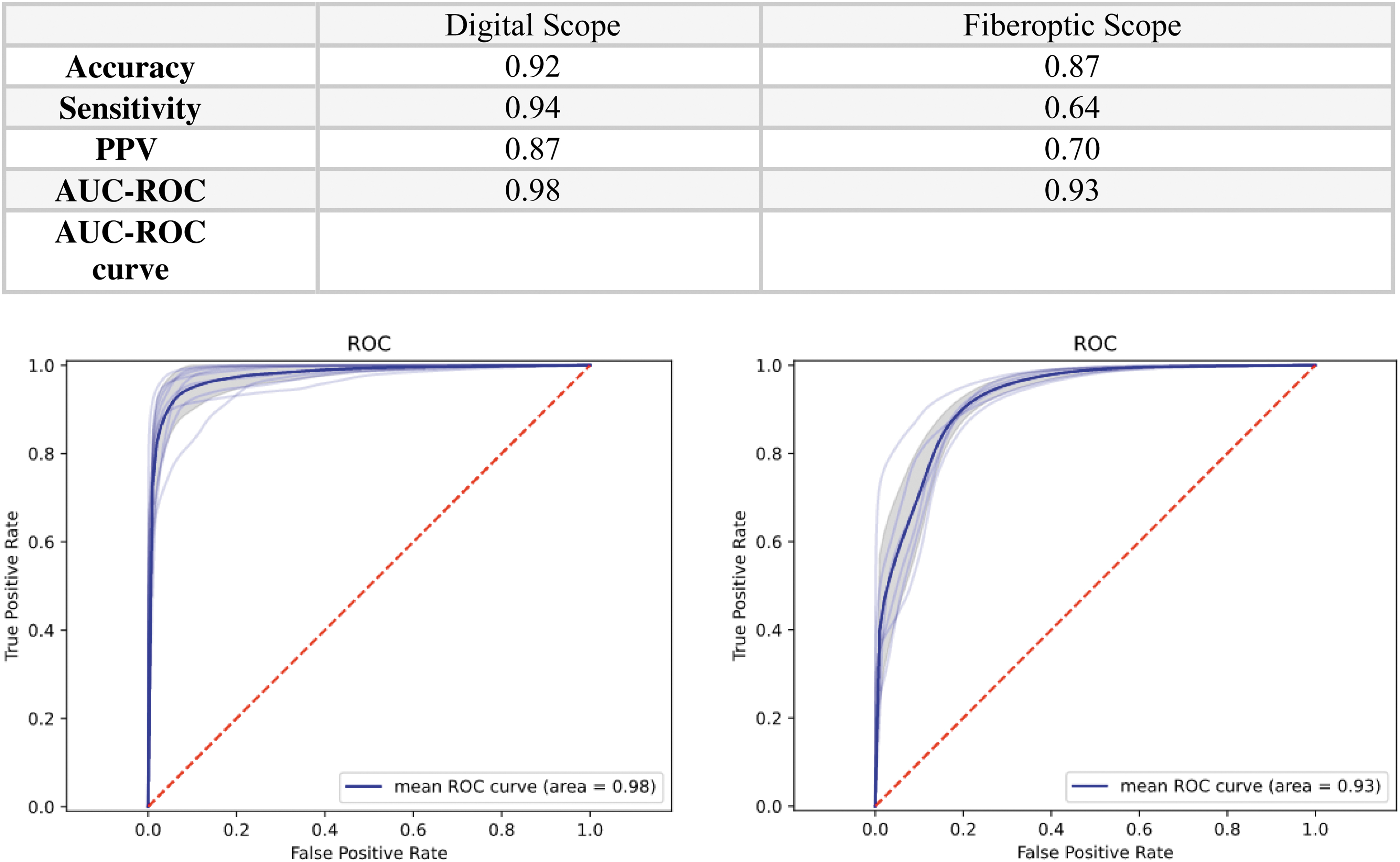
Summary of statistics for the U-Net++ model during stone localization. Values include total pixel evaluation of the model compared with the manually annotated frames (57 frames for digital scope localization and 45 frames for fiberoptic scope localization). *Mean AUC-ROC from the average of all annotated frames. AUC-ROC, area under the receiver operating characteristic curve. Color graphics are available online.
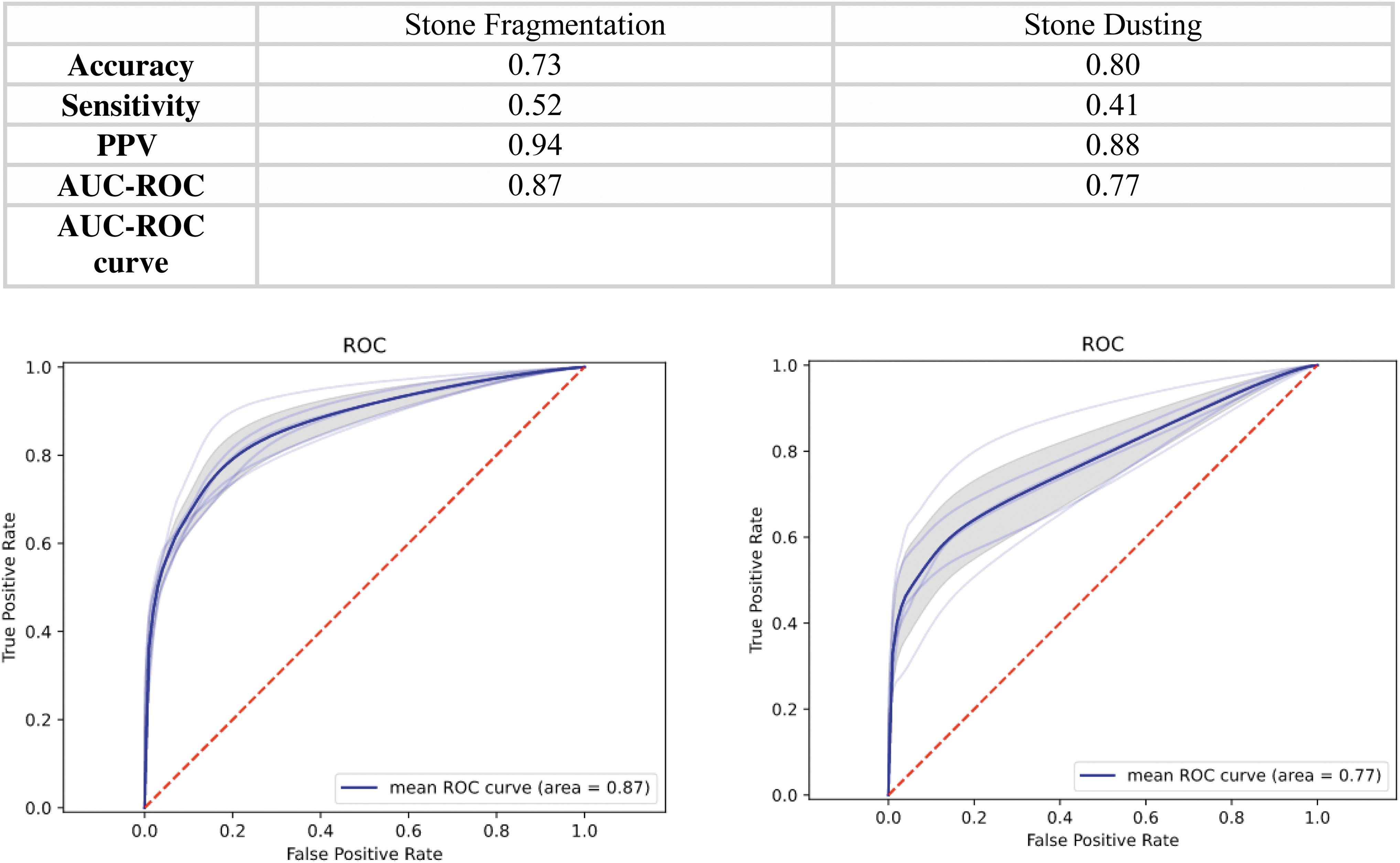
Summary of statistics for the U-Net++ model during laser treatment of stones. Values include total pixel evaluation of the model compared with the manually annotated frames (45 frames for both stone fragmentation and dusting). *Mean AUC-ROC from the average of all annotated frames. Color graphics are available online.
Video reconstruction containing the input, the prediction, and the corresponding heatmap is shown in Figure 4. Stones much <270 μm in diameter (i.e., the size of the laser fiber and consistent with “dust”) were trackable. 13 Subanalysis comparing fragments smaller and larger than this threshold showed the model performed better when stones were larger (AUC-ROC 0.98 vs 0.69).
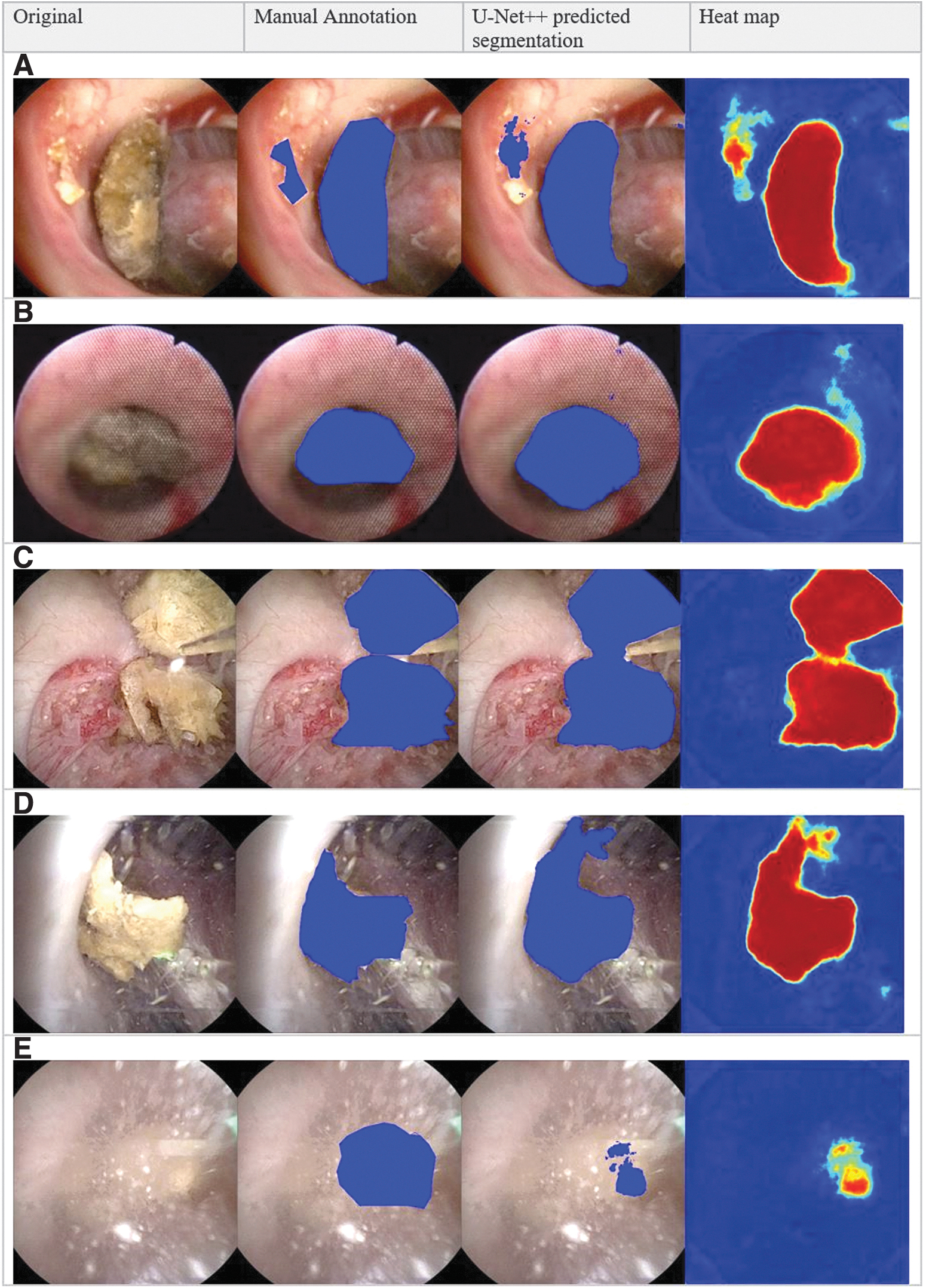
Example of automated segmentation during endoscopic stone surgery for
Discussion
There are several important findings in our study. First, computer vision models can accurately and automatically segment stones during endoscopic stone surgery. Though our model showed good performance during stone localization, stone segmentation was better when using digital than when using fiberoptic ureteroscopes, likely because of the improved image quality. Second, our model showed good segmentation performance during stone treatment with either holmium laser fragmentation or dusting and could track stone fragments much <270 μm in diameter (i.e., stone dust).
Increased debris and stone motion faster than the frame limit (i.e., 30 FPS) likely explain the decreased performance during stone dusting. Third, a preliminary live system was implemented in the operating room to segment and track stone fragments that maintained accuracy in real time.
Despite improvements in endoscopic technology over the past several decades, stone-free rates remain low, leading to subsequent stone events. 14 Though multifactorial, incomplete stone treatment is in part caused by difficulties maintaining visibility and localization of stone fragments during treatment. Furthermore, debris in the urine, blood product, and particles from lithotripsy can increase cognitive workload, impede efficiency, and lead to residual fragments that may require repeat intervention. 15,16 Thus, the development of systems that enhance stone tracking intraoperatively by integrating deep learning technologies can potentially improve outcomes after stone surgery.
Prior studies evaluating the utility of computer vision techniques for kidney stone care have demonstrated good performance (accuracy of 91%) in stone composition prediction from preoperative kidney stone imaging, which can be used for preoperative counseling. 6,17 Similarly, Black et al predicted kidney stone composition based on digital photographs of five different types of urinary calculi. The group suggested that this technology could be integrated into endoscopic and laser systems and improve surgical efficiency by modulating laser settings based on stone composition. 5
In this study, we apply computer vision models for stone localization and treatment during ureteroscopy and demonstrate real-time feasibility. We believe that this study could serve as the framework for automated stone tracking tools in the operating room and improve endoscopic stone treatment. Our models can detect fragments much <270 μm in diameter that are typically considered clinically insignificant. Based on this threshold (diameter of the laser fiber), subanalysis showed improved performance with larger fragments. We are currently optimizing and improving our models to incorporate different clinically useful thresholds of size detection.
Though this is an early demonstration of the feasibility of applying computer vision methods for endoscopic surgery, there are many other applications to enhance endoscopic surgery. For example, the technology could be applied to both lower and upper tract urothelial cell carcinoma. It has potential to automatically associate endoscopic surgical technique with surgical outcomes as well as trainee performance. In addition, it could help assess the efficacy of future treatment modalities and novel technologies (lasers, enhanced imaging, etc.). Furthermore, the technology could be integrated with novel robotic ureteroscopes and ultimately facilitate automated treatment of various diseases. 18
Despite the feasibility of automatic kidney stone segmentation demonstrated by our models, other clinical factors that we did not specifically evaluate could decrease performance. For example, scope lighting, motion blur, and significant visual impairment could all affect the models differently. Other considerations including alternative laser settings, fiber types, other instruments, and variable collecting system anatomy could also decrease segmentation accuracy. In addition, there are multiple aspects of the training data that could impact model performance. Important characteristics of training data include volume, quality, and source of frames (i.e., digital vs fiberoptic ureteroscopes). Future study will elucidate how these factors affect our models.
There are several limitations in this study. First, we only used 20 videos to train, validate, and test the model that likely do not diversely represent the intraoperative situations that could be seen during endoscopic stone surgery. For example, most stones were calcium based and in the renal pelvis. A larger training data set may improve model performance and generalizability. Second, digital ureteroscopes were used for training during initial analysis.
This is likely why there is a decrease in performance when segmenting fiberoptic ureteroscope videos, which is given in Supplementary Appendix SA3 (Table B), where stones were incorrectly classified as nonstones in 109 of 304 frames (35.8%). It is possible that if our models were trained with video from fiberoptic ureteroscopes, model performance would improve when using fiberoptic video. With improved observation of digital ureteroscopes and increased use of disposable digital ureteroscopes, a complete analysis based on fiberoptic video was not included.
Another important consideration is that only the best performing model on initial predictive analysis (U-Net++) was used to evaluate performance with digital or fiberoptic video and dusting or fragmentation settings. It is possible that other models may have similar or improved performance with hyperparameter tuning. We used standard holmium laser lithotripsy to evaluate the computer vision model during stone treatment. We defined fragmentation and dusting settings based on standard practices, but the model performance could be impacted by other laser settings, modulations, or laser types.
Further investigation on laser variations and model performance is needed as well as a more robust collection of training data that better incorporate the variations in stone treatment. In addition, we did not assess for stone treatment when using a fiberoptic ureteroscope as many efforts to enhance stone observation involve digital ureteroscopes. Despite these limitations, our study demonstrates the potential of computer vision models to segment and track stones during ureteroscopy. Future optimization of our model in more diverse video data sets will allow for more clinical applicability.
Conclusions
We have evaluated and developed a computer vision model that can segment and track stones in real time. The model performed well during stone localization with both digital and fiberoptic ureteroscopes. Furthermore, the model was able to accurately segment stones during laser fragmentation and dusting. Thus, we show the feasibility of our model to enhance stone tracking during ureteroscopy, which could improve outcomes during endoscopic stone treatment.
Footnotes
Authors' Contributions
S.A.S. contributed to writing—original draft and editing (lead); Z.A.S. was involved in formal analysis (lead); C.F. carried out writing and review (supporting); D.L. was in charge of formal analysis (supporting); I.O. took charge of conceptualization and review (equal); and N.L.K. carried out conceptualization (lead), review, and editing (equal).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.
Supplementary Material
Supplementary Appendix SA1
Supplementary Appendix SA2
Supplementary Appendix SA3
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.