
Abstract
Introduction:
We aimed to develop machine learning (ML) algorithms for the automated prediction of postoperative ureteroscopy outcomes for pediatric kidney stones based on preoperative characteristics.
Materials and Methods:
Data from pediatric patients who underwent ureteroscopy for stone treatment by a single experienced surgeon, between 2010 and 2023 in Southampton General Hospital, were retrospectively collected. Fifteen ML classification algorithms were used to investigate correlations between preoperative characteristics and postoperative outcomes: primary stone-free status (SFS, defined as stone fragments <2 mm at the end of the procedure confirmed endoscopically and no evidence of stone fragments >2 mm at Xray kidney-ureters-bladder (XR KUB) or ultrasound kidney-ureters-bladder (US KUB) at 3 months follow-up) and complications. For the task of complication and stone status, an ensemble model was made out of Bagging classifier, Extra Trees classifier, and linear discriminant analysis. Also, a multitask neural network was constructed for the simultaneous prediction of all postoperative characteristics. Finally, explainable artificial intelligence techniques were used to explain the prediction made by the best models.
Results:
The ensemble model produced the highest accuracy (90%) in predicting SFS, finding correlation with overall stone size (−0.205), presence of multiple stones (−0.127), and preoperative stenting (−0.102). Complications were predicted by Synthetic Minority Oversampling Technique (SMOTE) oversampled dataset (93.3% accuracy) with relation to preoperative positive urine culture (−0.060) a1nd SFS (0.003). Training ML for the multitask model, accuracies of 83.3% and 80% were respectively reached.
Conclusion:
ML has a great potential of assisting health care research, with possibilities to investigate dataset at a higher level. With the aid of this intelligent tool, urologists can implement their practice and develop new strategies for outcome prediction and patient counseling and informed shared decision-making. Our model reached an excellent accuracy in predicting SFS and complications in the pediatric population, leading the way to the validation of patient-specific predictive tools.
Introduction
Kidney stone disease is an important condition in the pediatric population, with an estimated prevalence in the European population of around 2%, with 10% of all urolithiasis cases diagnosed among children. 1 The prevalence is thought to be increasing, mainly owing to its association with comorbidities such as diabetes, obesity, and hypertension. 2 There is a high risk of recurrence that can affect more than a quarter of patients with urinary stones in the first 5 years since diagnosis. This makes the burden of urolithiasis in the pediatric population of importance worldwide. 3 With rising interest addressed to prevention and medical optimization of patients affected by this condition, surgical treatment remains of primary importance. 4
The European Association of Urology guidelines include different procedures as first-line treatments for different type of stones. 5 Shockwave lithotripsy and flexible ureteroscopy with laser lithotripsy (fURSL) represent the gold standard for stones smaller than 2 cm, whereas percutaneous nephrolithotomy (PCNL) is to be considered for larger calculi. Evidence is increasing for the role of ureteroscopy lasertripsy (URSL) for higher stone burdens. As innovation in technology has improved, the quality of the instruments has improved leading to shorter operative times and faster laser lithotripsy. 6
Different preoperative and intraoperative features have been addressed as potential risk factors for development of postoperative complications in addition to failure of achieving stone-free status (SFS) in a single procedure. 7 First, the size, location, shape, and hardness of the calculus could represent a limitation to the retrograde surgery and hence correlate with postoperative events. Another well-known risk factor is the presence of a preoperative positive urine culture. 8 Even with this knowledge, there is a lack of certainty about the exact correlation between preoperative and postoperative features, which thwart the creation of efficient predictive tools for post-fURSL events.
In recent years, the integration of machine learning (ML) in health care has garnered significant attention, offering unprecedented opportunities to enhance patient care and outcomes. 9 One notable area of application is the use of ML as a predictive tool for postoperative outcomes. 10 The ability to forecast postoperative complications, recovery trajectories, and overall patient well-being represents a paradigm shift in surgical health care. 11 With this study, we aim to develop ML algorithms for the automated prediction of postoperative ureteroscopy outcomes, for pediatric kidney stones, based on preoperative characteristics.
Materials and Methods
Data collection
Data from pediatric patients who underwent fURSL for stone treatment performed or supervised by a single experienced surgeon, between 2010 and 2023 in a tertiary pediatric endourology center, were retrospectively collected. Data were fully anonymized, and parental and/or patient consent was standardly obtained before the procedure in all cases. This pediatric kidney database comprises 150 records, recording preoperative (age, gender, anatomical variabilities, comorbidities, stone size, stone burden [cumulative stone size], number and location, positivity of urine culture, presence of preoperative urinary drainage), intraoperative (length of procedure, type of anesthesia, use of ureteral access sheath [UAS], insertion of a postoperative ureteral stent), and postoperative characteristics (length of hospitalization, postoperative complications, stone composition, and SFS at follow-up).
SFS was defined as stone fragments <2 mm at the end of the procedure confirmed endoscopically and no evidence of stone fragments >2 mm at US KUB and/or KUBXR at 3 months follow-up. Followed by an US, a clinic follow-up was done at 4 months.
Eight preoperative datasets were labeled as input: age, gender, preoperative urine culture urine, anatomical variants, stone location, presence of multiple stones, total stone size, and presence of preoperative urinary drainage (stent or nephrostomy). Inputs were used to predict outputs, defined as four intra- or postoperative characteristics: use of UAS, insertion of postoperative stent, complications, and SFS.
Data preprocessing and analysis
The proposed workflow comprises data cleaning and preprocessing. A statistical analysis of the data was performed. Then multiple ML algorithms were trained on the individual tasks. In addition, a multitask artificial neural network (ANN) was trained on all the tasks collectively. Finally, explainable artificial intelligence (AI) techniques were used to provide explanations for the predictions made by these algorithms.
Data were initially cleaned, removing blank spaces and irrelevant characters. Then, data were preprocessed, with preoperative characteristics imputed with the mode values, since categorical in nature. Correlation, the variance inflation factor (VIF), and logistic regression analysis were carried out on all the four tasks for statistical analysis.
ML algorithms
Fifteen ML algorithms were trained using the processed data for all the four tasks. The ML algorithms used are logistic regression, support vector machine (SVM), decision tree, random forest, linear discriminant analysis (LDA), quadratic discriminant analysis, Extra Trees classifier, AdaBoost, Gradient Boosting, XGBoost (Extreme Gradient Boosting), CatBoost classifier, Naïve Bayes, K-Nearest Neighbor, and Bagging classifier. These classification algorithms were trained on all eight input characteristics to predict each of the four output characteristics (UAS, postoperative stent, complications, and SFS) individually.
Multitask network
ML multitasking is one of the algorithms that makes multiple predictions at the same time. In this study, a multitask ANN was constructed to predict all the postoperative characteristics at the same time (Fig. 1). The network comprises shared layers for feature extraction, followed by task-dependent layers. The ANN has an input layer with 8 neurons, followed by a common hidden dense layer of 128 neurons of rectified linear unit activation function. Then the network branches into four dense output layers of one neuron with sigmoid activation function, each for one postoperative characteristic.
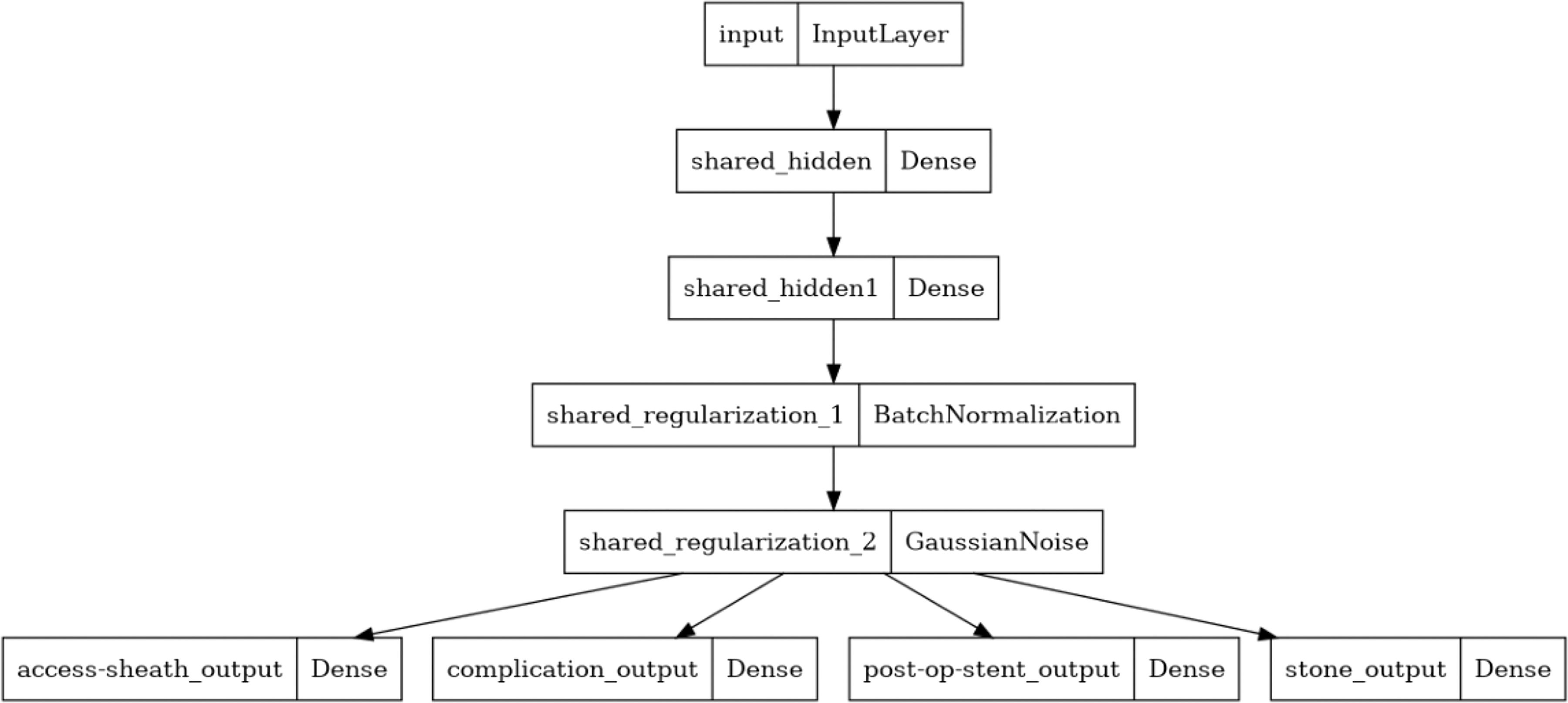
Multitask network constructed for outcomes prediction.
Evaluation metrics
The confusion matrix and the classification report are the primary metrics for evaluating the performance of ML algorithms. The confusion matrix comprises of true positive, true negative, false positive, and false negative values. The metrics derived from the confusion matrix are the accuracy, precision, recall, and F1 score. The classification report has the precision and recall values for each class of the task.
Explainability
Network interpretability and explainability has become important with increasing awareness and demand, especially in crucial applicative sectors such as health care. This technique is used in cases where the predictive algorithms are complex and not understandable, such as ANN, which are often considered as black boxes. There are some techniques that can be implemented on the predictions made by the models by highlighting the important features along with their contribution to the output. In this work, the tree explainer, feature importance, and Shapley Additive exPlanations (SHAP) plots were used to provide explanations to the model predictions.
Results
Cohort demographic
In total, 146 patients were included in this analysis. Mean age was 9.78 ± 4.52 years, with a range from 2 to 16 years. Seventy-four patients were males (50.68%) and 72 females (49.32%). They presented with normal anatomy in 115 cases (78.77%) and with anatomical variants in 31 (21.23%; these included presence of ureteral stricture or pelvic junction obstruction, megaureter, horseshoe kidney, duplex system, or transplanted kidney). Only nine patients were known to have metabolic abnormalities at the time of the procedure: four had cystinuria and five had hypercalciuria. At preoperative imaging, 112 (76.71%) patients had a single stone and 34 (23.29%) had multiple calculi. The mean stone size was 11.6 ± 6.7 mm. Eighty-four children (57.53%) did not require preoperative urinary drainage, whereas 58 (39.72%) had a stent and 4 (2.74%) had nephrostomy insertions before the procedure.
An access sheath was used in 48 (32.88%) of the cases, and a postoperative ureteral stent was left in 69 patients (47.26%). In total, 135 (92.47%) children did not experience any complications; 5 (3.4%) reported postoperative pain, 5 (3.4%) developed postoperative urinary tract infections (UTI), and 1 patient (0.68%) required readmission for sepsis. The average follow-up time was planned at 3–4 months after the procedure, revealing a primary SFS in 105 cases (71.92%), with 36 (24.66%) children showing fragments larger than 2 mm and 5 patients still awaiting follow-up at the time of the analysis. Table 1 summaries the patient demographics and clinical and procedural factors.
Demographic Characteristics of Patients Included in the Analysis
UTI = urinary tract infection.
Prediction of use of access sheath
Statistical analysis
Different input features were correlated to the use of an access sheath. Out of them, the highest correlation was found not only for total stone size (burden) (0.323), age of the patient (0.310), presence of multiple stone (0.229), and stone location (0.259) but also for the absence of postoperative complication (0.305). The effect of SFS was irrelevant (0.058).
The VIF was used to observe the multicollinearity in the input features. This was done as a general analysis for all the four dependent task vectors. All the output vectors have a high VIF indicating that they have a good correlation between the other feature vectors. The preoperative urine and multiple stones have moderate VIF indicating slight chances for multicollinearity (correlation between input features).
Logistic regression was used to quantify the relationship between the input features and the output predictors. The absence of preoperative stent and the presence of anatomical variants showed negative impact on the access sheath use (−0.370 and −0.024, respectively), whereas the others had a positive impact, with age (1.744) and total stone burden (1.130) having strong impact.
ML analysis
Logistic regression, Naïve Bayes, and SVM produced the highest validation accuracy, with logistic regression producing the highest precision and recall. The confusion matrices and classification reports of the top three ML algorithms in the validation set are available among the supplementary materials (Supplementary Fig. S1).
An ensemble hard voting model was developed using these three top performing ML algorithms, and it produced an increase of 6% in validation accuracy and 3% and 8% in validation precision and recall, respectively. Supplementary Figure S2 represents the performance of the ensemble model on the training and validation sets and the confusion matrices and classification reports for the ensemble model on the training and validation sets.
Explainable AI analysis
Feature importance and SHAP techniques were used for explainable results on prediction of intraoperative use of access sheath (Fig. 2). For the prediction of access sheath, age is considered as the most important feature followed by total stone burden and multiple stone. According to the SHAP beeswarm, it is observable that for total stone burden, location, and age, lower values have less importance and higher values have higher importance. However, for pre-op urine and sex, the condition is opposite (high importance for low values).
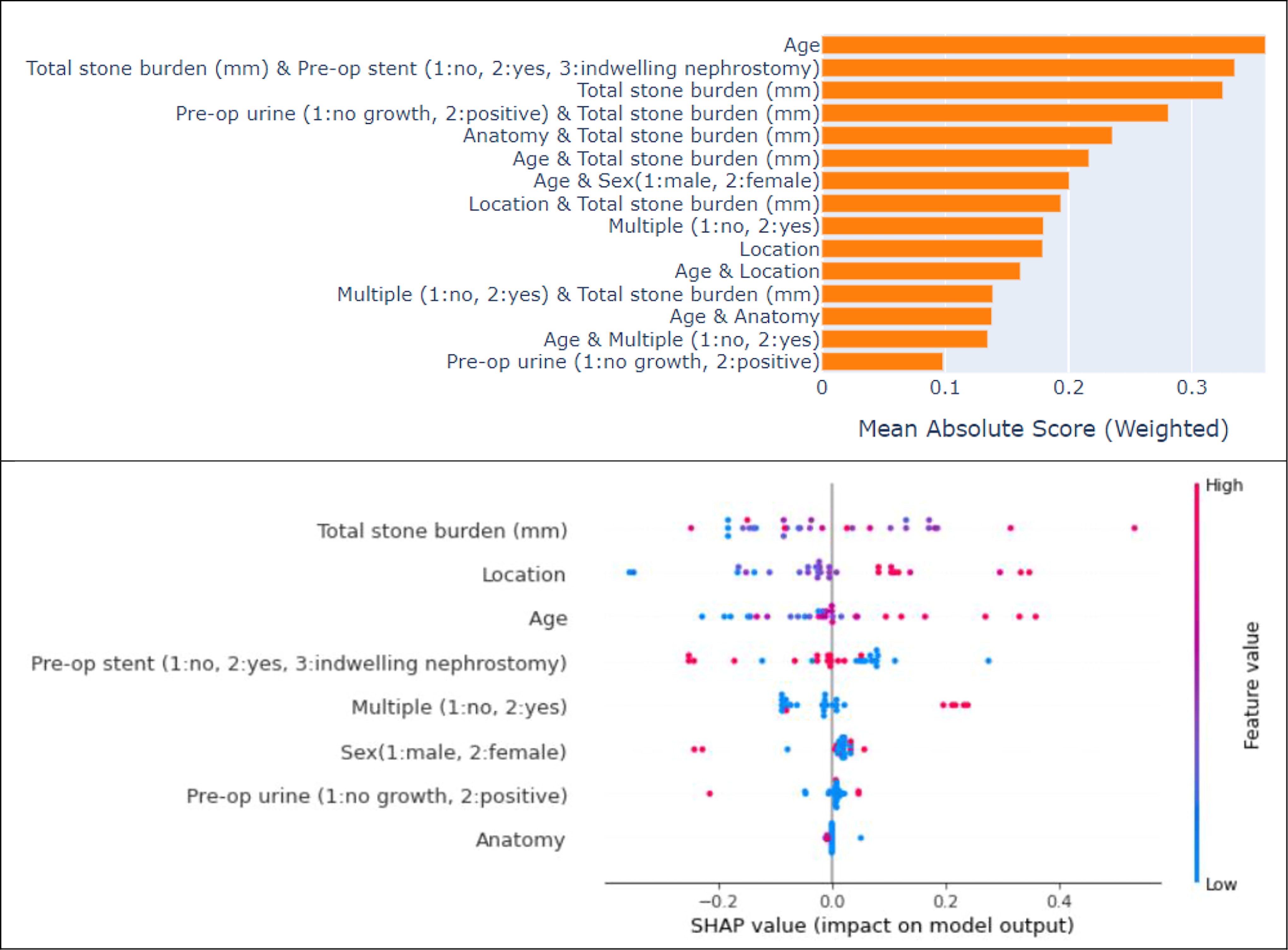
Explainable AI analysis for prediction of access sheath. The upper figure explains the importance of each feature with respect to the target class. In the lower figure, the SHAP beeswarm chart depicts the distribution of the SHAP values for each feature. AI = artificial intelligence.
Prediction of insertion of ureteral stent
Statistical analysis
The correlation analysis was done to qualitatively identify the relationship of the input features with that of the target for the need of stent post operation. The total stone burden had the highest correlation of 0.33, followed by equal correlation of location and multiple stones and a negative correlation of preoperative urine.
At logistic regression, the features showing negative impact on the decision to leave a postoperative stent were the absence of anatomical variants (−0.011), the absence of a preoperative drainage (−0.314), and a negative preoperative urine culture (−0.608). The rest of the inputs showed positive impacts on the decision, with total stone burden as the only characteristic having strong impact (1.673). The decision to leave a postoperative ureteral stent was related to higher stone burden (0.337) at correlation analysis and mildly to the absence of complications (0.207).
ML analysis
Decision tree, Bagging classifier, and CatBoost classifier produced the highest validation accuracy, but all were overfitting. Decision tree had the highest validation precision and recall. The confusion matrices and classification reports of the top three ML algorithms in the validation set are available among supplementary materials (Supplementary Fig. S3 and Fig. S4).
Explainable AI analysis
Feature importance and SHAP were used to produce explainable results on prediction of postoperative stent insertion (Fig. 3).
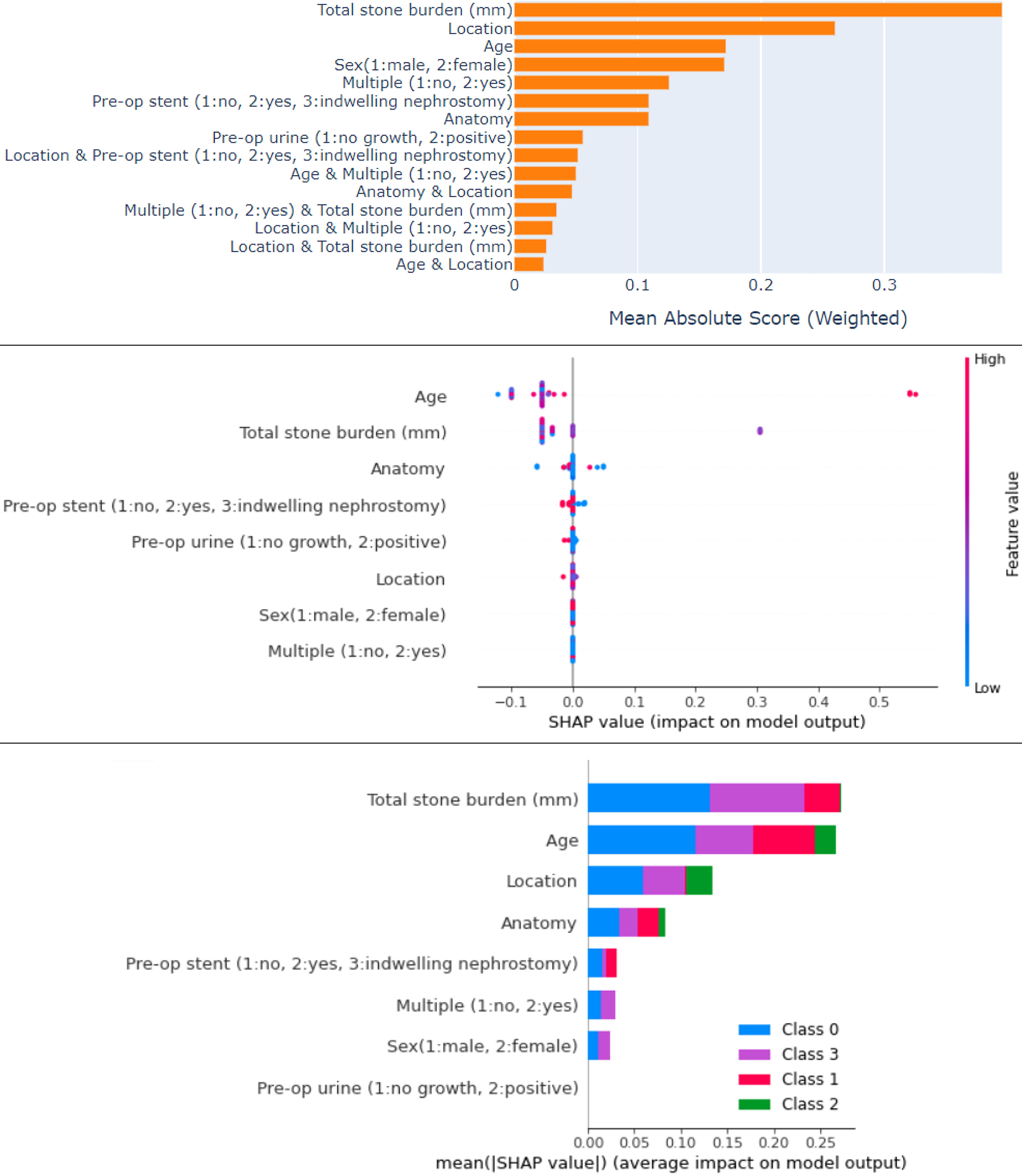
Explainable AI analysis for prediction of stent insertion. The upper figure explains the importance of each feature with respect to the target class. The SHAP Beeswarm chart (middle figure) depicts the distribution of the SHAP values for each feature. The lower plot explains the importance of each feature with respect to the target class.
The SHAP beeswarm chart depicts the distribution of the SHAP values for each feature. It is observable that for age, lower values have less importance, and higher values have higher importance. However, for total stone burden, the condition is opposite (high importance for low values). Other features do not have that much significant importance. The SHAP bar chart shows the importance of each feature for each class of the output. We can observe the majority of feature contributions for normal, followed by ureteral catheter, pain, and UTI. For the prediction of postoperative stent insertion, the total stone burden is considered as the most important feature followed by location and age.
Prediction of complications
Statistical analysis
The presence of postoperative complication showed the highest correlation with the total stone burden (0.311), the presence of multiple calculi (0.212), and the decision not to leave a stent (0.207). It was not clearly related to the positivity of preoperative urine culture (−0.060).
At logistic regression, male gender (0.161), a negative preoperative urine culture (0.250), and the absence of preoperative drainage had positive impact on the absence of postoperative complication, whereas the others had a negative impact, and all were weak in nature. The strongest impact on the development of postoperative UTI was, as expected, the presence of a positive urine culture (0.847), whereas postoperative pain was negatively correlated to the presence of a preoperative drainage (−0.909).
ML analysis
Bagging classifier and LDA produced the highest validation accuracy of 87%, but the precision and recall values are less. The Bagging classifier algorithm is overfitting (large gap between training and testing), whereas the LDA algorithm has trained well. The confusion matrices and classification reports of the top three ML algorithms in the validation set are available among supplementary materials (Supplementary Fig. S5).
An ensemble hard voting model was developed using these three top performing ML algorithms and trained with the oversampled dataset with a strategy of 125 samples per class. After applying the SMOTE oversampling technique, the precision and recall values of the testing set have increased to 70%, and the validation accuracy also boosted to 93%.
Table 2 represents the performance of the ensemble model on the training and validation sets. The confusion matrices and classification reports for the ensemble model on the training and validation sets are available among supplementary materials (Supplementary Fig. S6).
Performance of the Ensemble Model on the Training and Validation Sets for Prediction of Complications
Explainable AI analysis
Bagging classifier and LDA produced the highest validation accuracy of 87%, but the precision and recall values were less. The Bagging classifier algorithm was overfitting (large gap between training and testing), whereas the LDA algorithm had trained well.
AI was also used to produce explainable results on prediction of postoperative complications (Fig. 4).
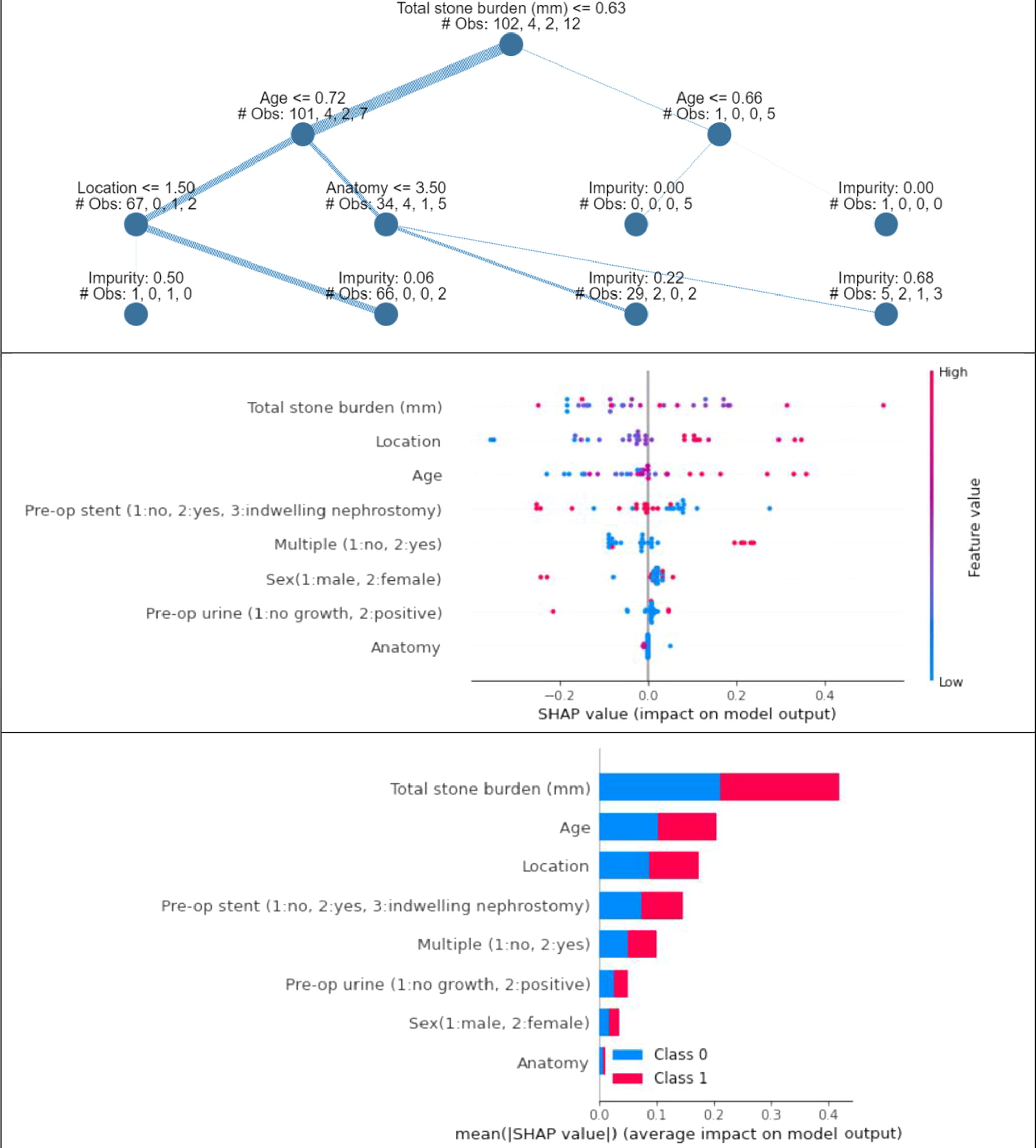
Explainable AI results for prediction of postoperative complications. From the top: explainable tree of prediction; SHAP beeswarm chart; SHAP bar chart.
The explainable tree (top chart in Fig. 4) mentions the ruling system adopted by the trained ML model to predict the output condition. This tree explains the threshold values for each feature used for predicting samples, showing the highest correlation with total stone burden and younger age of the patient, followed by stone location and presence of anatomical variants.
The SHAP beeswarm chart (middle chart in Fig. 4) depicts the distribution of the SHAP values for each feature. It is observable that for total stone burden, location, and age, lower values have less importance and higher values have higher importance. However, for pre-op urine and sex, the condition is opposite (high importance for low values).
The SHAP bar chart (lower chart in Fig. 4) shows the importance of each feature for each class of the output. We can observe that there is equal contribution of each feature for both the classes of output.
Prediction of SFS
Statistical analysis
Total stone burden showed the highest correlation with SFS (−0.205), followed by the presence of anatomical variants (−0.140), multiple stones (−0.127), and preoperative drainage (−0.102). All of these input features had positive correlation.
At logistic regression, SFS was negatively impacted by higher total stone burden (−1.087), presence of multiple stones (−0.312), and preoperative drainage (−0.393). The other features showed weak positive impact of SFS.
The results obtained from the logistic regression allied with that of the correlation analysis, indicating strong positive relation of the postoperative conditions with that of total stone burden primarily.
ML analysis
Random forest and SVM with polynomial kernel got the highest validation accuracy of 80%. However, the precision and recall values for these algorithms were less. In contrast, for CatBoost, the validation accuracy was less, but the precision and recall were high. After applying the SMOTE oversampling technique, the precision and recall values of the testing set increased to 70%, and the validation accuracy also boosted to 93%.
Algorithms were combined to produce an ensemble model: Bagging classifier, Extra Trees classifier, and LDA resulted in the best model. The confusion matrices and classification reports of the top three ML algorithms in the validation set are available among supplementary materials (Supplementary Fig. S7).
This ensemble model, using the three best performing algorithms for prediction of SFS, produced 90% testing accuracy and 98% training accuracy. Table 3 represents the performance of the ensemble model on the training and validation sets. The confusion matrices and classification reports for the ensemble model on the training and validation sets are available among supplementary materials (Supplementary Fig. S8).
Performance of the Ensemble Model on the Training and Validation Sets for Prediction of Stone-Free Status
Explainable AI analysis
AI was also used to produce explainable results on prediction of postoperative characteristics (Fig. 5).
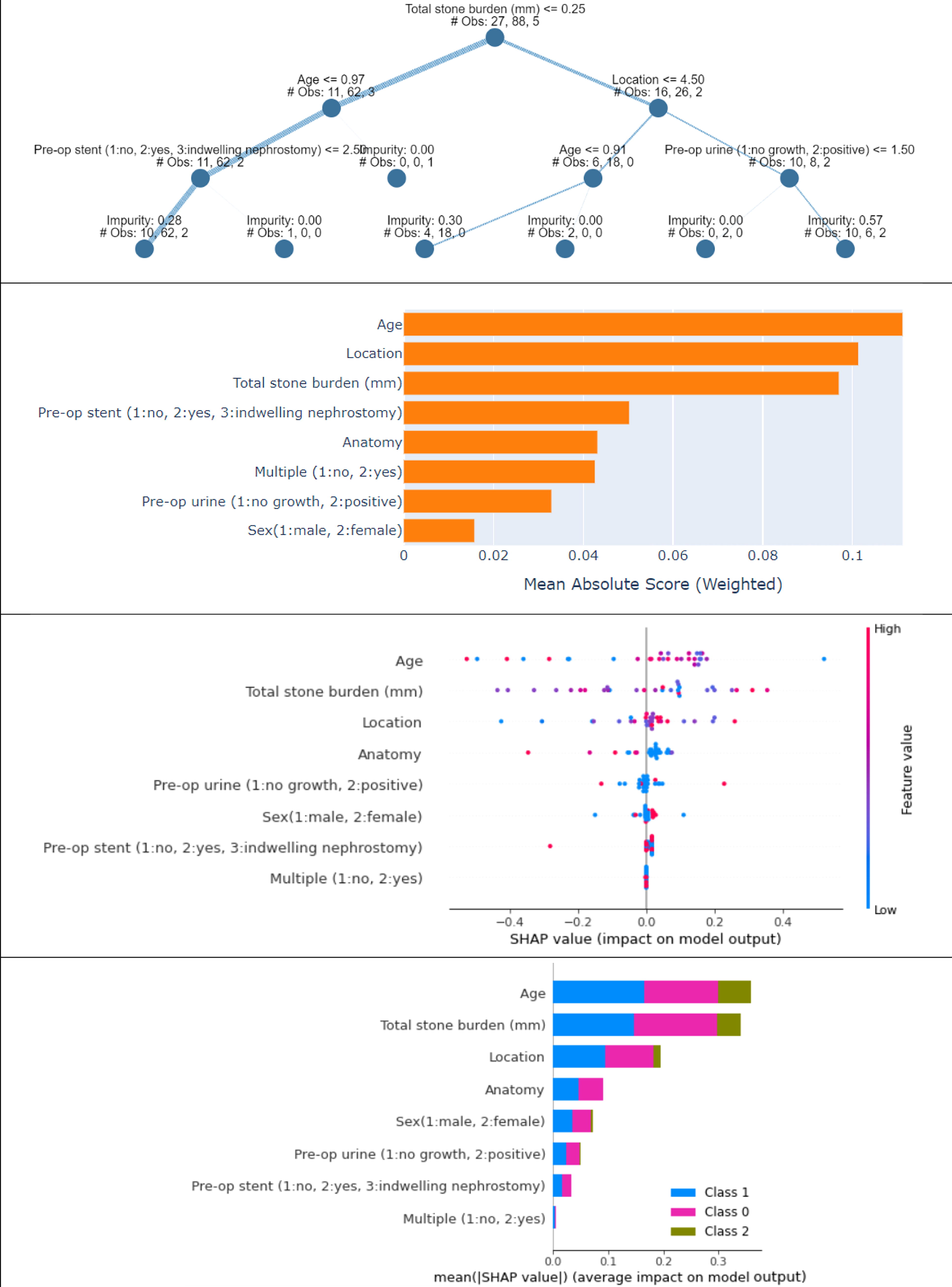
Explainable AI results for prediction of postoperative complications. From the top: explainable tree of prediction; visual chart of the importance of different features on stone-free status; SHAP beeswarm chart; SHAP bar chart.
The explainable tree (top chart in Fig. 5) mentions the ruling system adopted by the trained ML model to predict the output condition. This tree explains the threshold values for each feature used for predicting samples, showing the highest correlation with total stone burden, patient’s age, and location of the stones.
The second plot in Figure 5 explains the importance of each feature with respect to the target class. For the prediction of SFS, age is considered as the most important feature followed by location and total stone burden.
The SHAP beeswarm chart (third chart in Fig. 5) depicts the distribution of the SHAP values for each feature. It is observable that for location and age, lower values have less importance and higher values have higher importance. However, for pre-op urine and anatomy, the condition is opposite (high importance for low values). The SHAP bar chart, in the lower part of Figure 5, shows the importance of each feature for each class of the output.
Multitask model
The developed multitask model was trained on the processed dataset. Table 4 shows the performance results of the multitask models on the training and validation sets.
Performance Results of the Multitask Model on the Training and Testing Set
AUC = area under the curve.
The model produced more than 80% accuracies for stone-free and complication task, respectively, followed by 75% for access sheath and the least of 60% for post-op stent. The model trained well for all the tasks, except in post-op stent that shows overfitting. The precision values for access sheath and post-op stent are <50%, while the others are >80%.
The multitask neural network is tough to train, especially with four branches comprising both binary and multiclass classification tasks. The same is exhibited in the performance plots, indicating fluctuations in precision and recall values, especially for access sheath and complications. Figure 6 represents the area under the curve (AUC) of the trained multitask model. Additional performance plots are available among supplementary materials, alongside the confusion matrix and classification report for the multitask model (Supplementary Figs. S9 and Figs. S10). The confusion matrix and classification report indicate that for the task of complication and stone-free prediction tasks, the precision and recall for minority classes are 0 owing to the issue of class imbalance and less data size. However, it shows high values of precision and recall for majority classes.

AUC of the trained multitask model for outcomes prediction. AUC = area under the curve.
Discussion
Our study is the first investigating the role of ML in prediction of outcomes of fURSL in pediatric patients affected by kidney stones. We demonstrate how ML algorithms can correctly predict clinical outcomes of fURSL using preoperative characteristics, in particular stone burden and presence of preoperative stents.
A higher overall size of stones is indeed associated with a reduced likelihood of achieving SFS. This aligns with prior results, emphasizing that overall stone size is the most precise measure of stone burden and consequent outcomes. 12 However, the diverse methods used to measure stone volume can yield varying results, and different features of the stone burden, such as number and shape of the stones, are to be kept in mind. Recent advancements in technology, particularly those driven by AI, have revolutionized the medical field. 13 AI encompasses ML algorithms enabling automated recognition and learning from experience and data. In various medical specialties, including urology, ML methods are increasingly prevalent and widely adopted across urological subspecialties. 14
The role of stent insertion pre-ureteroscopy is controversial. Of course, in cases of acute presentation with urosepsis and obstruction, stent insertion cannot be delayed and fURSL must be postponed. 15 But for relative indications such as partial obstruction, when stenting is not mandatory, the decision to stent may affect the subsequent outcomes. 16 Some authors have highlighted how the presence of preoperative stenting can increase the rate of success of fURSL owing to the “passive ureteral dilatation” that reduces the risk of failed ureteroscopy. 17 At the same time, the likelihood to need a postoperative stent is decreased in patients with a preoperative drainage. 18 On the contrary, though, studies have also investigated the relationship between indwelling stents and postoperative complications and found that the risk of UTI post-fURSL is nearly tripled in adult patients with preoperative indwelling stent for longer than 4 months. 19
Our results seem to be in line with the previous literature, reporting on a strong correlation between SFS and stone burden, defined as number and size of calculi. The role of preoperative stents appears to be linked to not only higher SFS but also higher postoperative complications, mainly UTI. In our cohort, the overall rate of complication was low at 7.5%, highlighting the feasibility and safety of fURSL in the pediatric population.
Through this study, we observed how ML algorithms excel in handling complex and multifactorial datasets, making them well suited for predicting postoperative outcomes. 20 By leveraging patient data, including demographic information and preoperative characteristics, ML models can generate personalized risk assessments. These predictive models offer clinicians valuable insights into potential complications, enabling proactive measures to mitigate risks and enhance patient recovery. 21 The integration of ML algorithms into the health care system provides clinicians with decision support tools that can aid in preoperative planning and risk management. Predictive models can assist in identifying high-risk patients, optimizing resource allocation, and tailoring postoperative care plans. 22 Consequently, health care providers can make informed decisions, improving overall patient safety and optimizing health care resources.
Previous studies reporting on the role of ML in kidney stone disease for prediction of outcomes found results aligning with our analysis. Pietropaolo and colleagues ran ML algorithms to predict post-fURSL septic events in 114 patients. 23 Their predictive model achieved an accuracy of 81.3% for postoperative sepsis. Aminsharifi et al. conducted an analysis on the data of 146 adult patients who underwent PCNL to assess the effectiveness of a ML algorithm in predicting outcomes. 24 The program demonstrated an impressive accuracy of up to 95% in predicting the results of PCNL. In a separate study, Blum et al. developed a ML framework aimed at enhancing early identification of clinically significant hydronephrosis resulting from pelvic–ureteral junction obstruction using renogram data. 25 This framework achieved a notable 93% accuracy in predicting the early detection of severe cases that necessitated surgical intervention.
Despite its promise, the application of ML in health care presents challenges, including data privacy concerns, model interpretability, and the potential for algorithmic biases. 26 Striking a balance between the benefits and ethical considerations is crucial to ensure the responsible deployment of predictive tools in postoperative care.
Our study is not free of limitations. Although this is a retrospective study, consecutive patients were included, and this limitation has been partially overcome by the cleaning process of data that removed the incorrectness and missing information. In addition, a single experienced surgeon performed or supervised all procedures, limiting the representativeness of the study. Further prospective controlled trials are required to strengthen our findings, and external validation of our predictive model will further assess the reliability of the ML model. Nevertheless, this study reports on a significant cohort of pediatric patients on a subject that is currently underinvestigated and represents the first such study to produce an automated predictive model for outcomes of fURSL in children. With additional analysis and validation, ML algorithms could also be applied to the development of accurate calculators and nomograms to help treat pediatric urolithiasis.
Conclusion
Ureteroscopy for treatment of urolithiasis in the pediatric population remains a feasible procedure with good outcomes. Risk factors for an incomplete SFS and development of postoperative complications are primarily related to the stone burden, including stone size and location. The role of preoperative stenting is controversial. The presence of a preoperative stent increases the chance of a complete stone clearance but is also associated with increased risk of postoperative complications, especially UTIs. Those characteristics are correctly predicted by our ML model that achieved an accuracy of over 90%. Further external validation of the model is required to confirm its precision in predicting outcomes in the pediatric population.
Footnotes
Authors’ Contributions
C.N.: Data collection and article writing. A.S.: Data analysis and article editing. S.G.: Article editing. N.N.: Article editing. S.G.: Article editing. B.K.S.: Project development, supervision, and article editing.
Author Disclosure Statement
There is no conflict of interest and nothing to disclose.
Funding Information
No funding was received for this work.
Supplementary Material
Supplementary Figure S1
Supplementary Figure S2
Supplementary Figure S3
Supplementary Figure S4
Supplementary Figure S5
Supplementary Figure S6
Supplementary Figure S7
Supplementary Figure S8
Supplementary Figure S9
Supplementary Figure S10
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.