
Abstract
Objective:
To evaluate and compare the quality and comprehensibility of answers produced by five distinct artificial intelligence (AI) chatbots—GPT-4, Claude, Mistral, Google PaLM, and Grok—in response to the most frequently searched questions about kidney stones (KS).
Materials and Methods:
Google Trends facilitated the identification of pertinent terms related to KS. Each AI chatbot was provided with a unique sequence of 25 commonly searched phrases as input. The responses were assessed using DISCERN, the Patient Education Materials Assessment Tool for Printable Materials (PEMAT-P), the Flesch–Kincaid Grade Level (FKGL), and the Flesch–Kincaid Reading Ease (FKRE) criteria.
Results:
The three most frequently searched terms were “stone in kidney,” “kidney stone pain,” and “kidney pain.” Nepal, India, and Trinidad and Tobago were the countries that performed the most searches in KS. None of the AI chatbots attained the requisite level of comprehensibility. Grok demonstrated the highest FKRE (55.6 ± 7.1) and lowest FKGL (10.0 ± 1.1) ratings (p = 0.001), whereas Claude outperformed the other chatbots in its DISCERN scores (47.6 ± 1.2) (p = 0.001). PEMAT-P understandability was the lowest in GPT-4 (53.2 ± 2.0), and actionability was the highest in Claude (61.8 ± 3.5) (p = 0.001).
Conclusion:
GPT-4 had the most complex language structure of the five chatbots, making it the most difficult to read and comprehend, whereas Grok was the simplest. Claude had the best KS text quality. Chatbot technology can improve healthcare material and make it easier to grasp.
Introduction
Kidney stone (KS) disease, known as nephrolithiasis or urolithiasis, is an ancient medical condition. It ranks as the third most prevalent urological condition, behind urinary system infections and prostate-related disorders. 1 The prevalence of KS is increasing globally, with an estimated 1%–15% of persons experiencing it at some point. This rise is perhaps because of changes in dietary habits and the effects of global warming. 2 The prevalence rates of nephrolithiasis vary widely, at 7%–13% in North America, 5%–9% in Europe, and 1%–5% in Asia. 3 Given that it is such a common disease worldwide, people are increasingly using the internet to learn more about it. Chatbots and other digital technologies have the potential to revolutionize how information about symptoms and therapy for KS is accessed. By providing a means of support that does not require direct human involvement, these advancements can impact the diagnosis and treatment of the condition.
Artificial intelligence (AI), which refers to computer systems capable of carrying out activities that typically need human intellect, 4 has gained significant prominence in contemporary medicine and the medical domain. Research has shown an increasing utilization of AI-powered chatbots, which are changing how individuals interact with technology by adopting a more friendly and interactive approach, resulting in improved user satisfaction. AI-powered chatbots have the potential to be helpful in multiple areas of healthcare, including customer support and symptom assessment. They can assist users in determining whether they should seek medical attention from a healthcare professional. However, when obtaining health information online, there are challenges and concerns, as AI is not always accurate, reliable, or easy for patients to read and understand. Furthermore, individuals with limited knowledge of medical terminology may need help assessing the credibility and authenticity of the information they encounter. ChatGPT, the most well-known AI chatbot, has over 175 million users and is emerging as a popular online information source. 5 It can provide precise and complete responses to medical inquiries. But is this the best and enough?
Nowadays, AI chatbots developed by different companies are rapidly increasing in use. In a study comparing different AI chatbots, we obtained different results regarding the readability, understandability, and quality of content. 6 The aim of this study was to evaluate and compare the quality and ease of understanding of information generated by five different AI chatbots with respect to the most frequently searched topics related to KS.
Materials and Methods
On April 10, 2024, the Urology Department of Tekirdag Namik Kemal University conducted a study involving no procedures on living beings or human data, meaning that obtaining ethical committee approval was unnecessary. Similarly, there was no need for an Institutional Review Board number or an informed consent form for the same reason. No patient data were used since this study does not pertain to clinical research. To prevent bias, personal browser data were deleted before conducting the searches. Google Trends was used to identify the most commonly searched phrases related to KS, collected from global searches between 2004 and April 10, 2024. The top 25 most frequently searched phrases were compiled, covering diverse topics. Three phrases were excluded from the study because of their irrelevance: “back pain,” “kidney infection,” and “bladder stone.” Geographical regions were categorized and recorded using subregions.
The search phrases were systematically inputted into five AI chatbots: GPT-4 (https://openai.com/gpt-4/), Claude-3 (https://claude.ai/), Grok (https://grok.x.ai/), Mistral Large (https://mistral.ai/), and Google PaLM 2 (https://ai.google/palm2/). The initial sequence of searches was preserved, and each query was handled on its own web page to guarantee segregation and enhance the analytical process. To provide a clear differentiation, separate accounts were created for engaging with each AI chatbot. Prior to commencing the searches, all browser data were completely deleted. The chatbot replies were saved for further assessment of their quality and readability.
To assess the accuracy and reliability of the healthcare information provided by each chatbot, two established tools were employed: DISCERN 7 and the November 2020 edition of the Patient Education Materials Assessment Tool for Printable Materials (PEMAT-P). 8 DISCERN is a validated tool designed to help information providers, and patients evaluate the quality of written material on treatment options. The questionnaire seeks to foster the development of dependable and scientifically substantiated health information for consumers by setting standards and serving as a reference for authors. The test has 15 questions and enables evaluation on a scale of 1 to 5. The PEMAT-P applies to both printed and digital products. Understandability pertains to the ease with which individuals from various backgrounds and levels of health literacy can comprehend, analyze, and articulate the main message conveyed in materials. Actionability pertains to the simplicity with which customers can discern the necessary course of action based on the information provided. The PEMAT-P consists of 24 items. Fifteen items use a 2-point agreement scale, where 0 means disagree and 1 means agree, and nine items use a 3-point agreement scale, where 0 means disagree, 1 means agree, and 3 means not applicable. The greater the score, the more comprehensible or practicable the content. M.F.Ş., E.C.T, and Ç.D, who are very experienced and informed about urolithiasis, performed the assessment processes for PEMAT-P and DISCERN, whereas C.M.Y. was contacted in cases of contradictions. The AI chatbot replies were compiled from the referenced sources. The evaluators were blinded to which specific AI chatbot was being used, and the level of agreement among the evaluators was 96%.
The AI chatbots’ information was evaluated for readability using Flesch–Kincaid Grade Level (FKGL) and Reading Ease (FKRE) scores. Both score calculations involve total word, sentence, and syllable counts. 9 A lower score on the FKGL indicates better comprehension, whereas a higher score suggests sophisticated and complex language. A higher FKRE score indicates better readability and a lower score suggests more complexity.
Statistical analysis was performed using SPSS version 29.0 (IBM, New York, USA). The normality of the data was evaluated using the Shapiro–Wilk test. Continuous data were examined using minimum, maximum, mean value, and standard deviation, whereas categorical data were expressed using frequency. The Kruskal–Wallis test was used to assess differences and means between groups. A significance level of 0.05 was used, leading to a confidence interval of 95%.
Results
The three most frequently searched terms were “stone in kidney,” “kidney stone pain,” and “kidney pain.” Three terms—“back pain,” “kidney infection,” and “bladder stone”—were removed because they were irrelevant to the main topic (Table 1).
Presents the Google Trends Statistics for the Top 25 Phrases Searched Worldwide for Kidney Stone from 2004 to 2024
The level of interest in KS differed between countries, as shown in Figure 1. Nepal, India, and Trinidad and Tobago were the top three countries with the most search interest in KS, with search interest scores of 100, 81, and 80, respectively.
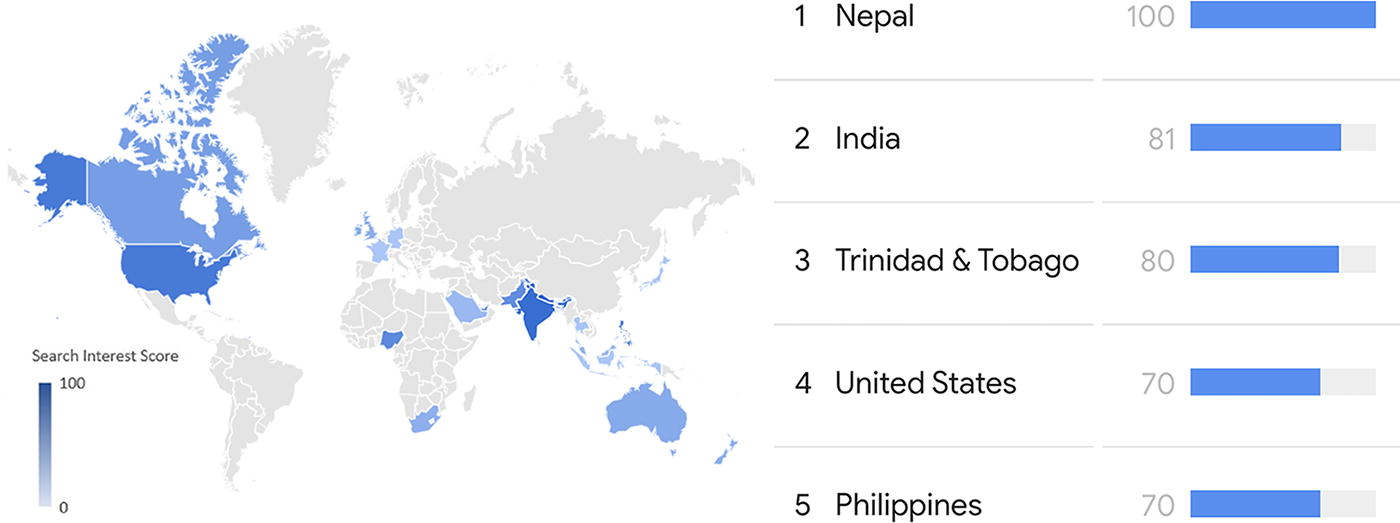
Google Trends data showing worldwide search interest in KS by region from 2004 to 2024, excluding locations with low search volumes. KS = kidney stone.
The study’s findings revealed a significant difference (p = 0.001) in the FKRE ratings among the chatbots. The application of the Bonferroni correction further underscored the importance of these differences, showing a statistically significant variance in the FKRE scores between ChatGPT and Google PaLM, ChatGPT and Grok, Claude-3 and Grok, and Mistral and Grok. Notably, GPT-4 scored the lowest, whereas Grok emerged with the highest score (p = 0.001), emphasizing the substantial variations in performance.
According to the research findings, there were also significant differences (p = 0.001) in the chatbots’ FKGL scores. After implementing the Bonferroni correction for the pairwise comparison of FKGL scores, differences were identified between Grok and Mistral, Grok and Claude, and Grok and GPT-4. Grok scored the lowest, whereas GPT-4 scored the highest (p = 0.001).
There were also significant differences in the chatbots’ PEMAT-P scores (p = 0.001). Upon analyzing the PEMAT-P scores for understandability using the Bonferroni correction, Google PaLM had significantly higher scores than the other chatbots. Claude’s score was the highest for the actionability component, and Google PaLM’s was the lowest.
The chatbots displayed significant differences in their DISCERN scores (p = 0.001). Google PaLM and Grok had the lowest scores, and Claude had the highest (Table 2).
The FKRE, FKGL, PEMAT-P, and DISCERN Scores of the Five Different Chatbots
Difference is between ChatGPT and Google PaLM, ChatGPT and Grok, Claude-3 and Grok, and Mistral and Grok.
Difference is between Grok and Mistral, Grok and Claude, and Grok and GPT-4.
Differences are between Google PaLM and others.
Differences between Google PaLM and Mistral, Google PaLM and Claude, and Grok and Claude.
Differences are between Google PaLM and Mistral, Google PaLM and GPT-4, Google PaLM and Claude, Grok and Mistral, Grok and GPT-4, and Grok and Claude.
FKGL = Flesch–Kincaid Grade Level; FKRE = Flesch–Kincaid Reading Ease; IQR = interquartile range; PEMAT-P = Patient Education Materials Assessment Tool for Printable Materials; SD = standard deviation.
Discussion
After our first study comparing five chatbots’ responses to questions about erectile dysfunction, 6 including ChatGPT, in this study, we evaluated and compared the readability and quality of five different chatbots. This research revealed that the replies provided by the AI chatbots in response to KS inquiries did not meet the criteria for readability. Different chatbots stood out with different features. Although GPT-4’s readability was somewhat worse than the other chatbots, Grok was the easiest to read. Claude had acceptable quality with minor imperfections, whereas Grok exhibited significant quality problems. This study is the first attempt to evaluate, analyze, and compare KS data provided by these AI chatbots.
Nowadays, many patients attend urology clinics with KS, and the most common symptom in this patient group is renal colic. In our study, three of the five most frequently searched keywords were related to the pain of KS: “kidney stone pain,” “kidney pain,” and “kidney stone symptoms.” Studies indicate that the primary symptom of KS is pain, which may be experienced as intense loin or flank pain, perineal discomfort, or colicky pain. 10 This pain is commonly accompanied by urinary symptoms, such as frequent urination, painful urination, and hematuria. 11 Patients use Google Trends to seek information on KS illness, including symptoms, diagnosis, etiology, infections, treatment alternatives, and particular surgical interventions. 12 They also use chatbots to obtain information about KS. Chatbots can assist in patient education and postprocedure care. However, their usage may sometimes be constrained at times because of practical challenges, such as misplaced instructions or activation difficulties.
Although the prevalence of KS varies across different regions worldwide, it is more common in some endemic regions. Nepal, India, and Trinidad and Tobago were the countries with the most search interest in KS. Regions with a high incidence of KS are the United States, the British Isles, Scandinavian and Mediterranean countries, and the Far East and Central European countries. The term “stone belt” was defined for the endemic regions of KS, starting in Central America in the west and including Eastern Europe and the Balkan countries. It extends from northwest Africa to southeast Asia. It ends in northern Australia, including countries such as India, Indonesia, the Philippines, and Thailand. 13 KS prevalence in India is 12%, 14 and in Trinidad and Tobago, it was recently reported as 17%. 15 These data suggest that KS is prevalent in these areas and that patients in these regions use the internet to obtain information about their diseases and symptoms. Complex internet health information may propagate misinformation, endangering individual health. According to the present study, AI chatbots on KS obtained data beyond the National Institute of Health’s college reading level. Our investigation indicated that GPT-4 required extensive knowledge. With the greatest FKRE and lowest FKGL scores, Grok is more understandable but still needs extensive study. According to Şahin et al., 6 Bard was the simplest to comprehend, whereas ChatGPT needed advanced expertise. These results emphasize AI chatbots’ need to give correct and precise KS information. We think new chatbots should be more straightforward. Human involvement may improve AI chatbot readability. Using algorithms, human monitoring, and current literature, produced information may be reorganized to meet readability standards.
The popularity of accessing health-related information online, mainly using technologies such as AI chatbots, is increasing. However, we maintain the belief that, in its present condition, it cannot substitute the need for a comprehensive medical assessment, physical examination, and consultation with a healthcare professional. Although internet sources may give valuable insights, they need more individualized and comprehensive evaluation, which is necessary for accurate diagnosis and treatment. Developing a physical doctor–patient connection is crucial for tailored therapy that considers individual aspects that cannot be captured entirely by digital interactions alone. Furthermore, it is essential to consider the social background of patients and their families while providing medical advice. Thus, although AI chatbots may provide valuable insights on KS and other health subjects, seeing them as a supplemental tool rather than a replacement for expert medical advice and treatment is crucial.
Health information should be customized to suit the specific geographical, ethnic, and cultural conditions of patients’ living environments. When we look at the regions most frequently searched in our study, we see a distribution across very different geographies. KS is not distributed in a specific region of the world but are widespread and scattered. Chatbots face a significant obstacle because their capacity to adapt information to these various elements is limited. Culturally sensitive AI systems are needed in healthcare services, and this emphasizes the importance of creating chatbots that can effectively meet the different needs of various patient groups. With new chatbots created within different ethnic and cultural frameworks, patients can obtain answers according to their cultural life.
Responses created by AI often include medical language and are mainly composed of information at a rather challenging reading level. AI chatbots lack visual assistance to elucidate complex medical ideas, resulting in low understandability ratings on the PEMAT-P. 16 For PEMAT-P, the higher the score, the more understandable or actionable the material. We found that the average PEMAT-P scores of the chatbots evaluated in our study were relatively low. Among these scores, we concluded that GPT-4, which had the lowest understandability average in correlation with FKRE and FKGL scores, was the most difficult-to-understand chatbot. Regarding actionability, we concluded that Claude gave patients the most comprehensive advice regarding their symptoms or current clinics.
Quality health information improves healthcare delivery’s efficacy, efficiency, and safety. High-quality information boosts patient happiness and engagement. This analysis found that Grok and Google PaLM had substantial DISCERN score issues, whereas GPT-4, Claude, and Mistral had acceptable quality with few faults. In contrast, Cocci et al. 17 found that ChatGPT provided poor urological patient information. AI chatbot system improvements may explain the increase in quality. Since Claude is a more reputable source for health information, Grok and Google PaLM should be used with care. The research by Şahin et al. 6 found that Copilot had the highest DISCERN score and greatest information quality. According to this study, AI chatbot material must be improved. Other techniques include making medical literature and research widely available to boost AI chatbot understanding. This extension may increase their health information reliability. AI models trained with healthcare data characteristics may better provide contextually relevant and medically accurate answers.
The differences between medical literature and chatbot content are evident. The study’s results indicate the necessity of improving the quality of texts produced by various chatbots. There are several methods to achieve this enhancement. For instance, providing chatbots access to medical literature and research could expand their knowledge base, leading to better-informed and reliable responses on health-related subjects. In addition, incorporating specific criteria for prioritizing health information while training AI models like chatbots could significantly improve their capacity to offer contextually relevant and medically accurate answers. 18
There are certain limitations to this study. First, the search was limited to the first 25 keywords, undermining the thoroughness of the results. A more comprehensive process could provide more accurate findings by including more keywords. This excludes explicit inquiries on KS from the general public and healthcare practitioners fluent in their native language, which might result in challenges or an inability to comprehend replies in a foreign language. This situation necessitates the creation of the instrument via international cooperation between AI and medicine. Expanding the use of non-English keywords might enhance the scope of the evaluation, leading to more generally applicable findings. Furthermore, this research specifically assessed the responses of a limited sample size of five AI chatbots. Another limitation is that it needed to be evaluated whether the texts produced by chatbots have the expertise of human professionals. In this study, only the quality and readability of the content were compared with other chatbots, and no comparison was made with real physician opinions. This could be the basis for other studies on this subject. Considering the ever-changing nature of this industry and the growing development of innovative models, future research should include a wider variety of AI chatbots. These studies have the potential to improve the accuracy of these findings.
Conclusion
Of the five chatbots compared, GPT-4 had the most sophisticated linguistic structure, making it the hardest to read and comprehend, while Grok was the easiest to understand. Claude exhibited the highest level of text quality in relation to KS. As chatbot technology develops, we hope that better quality content will develop in healthcare with more straightforward, easy-to-understand content.
Scientific Responsibility Statement
The authors declare that they are responsible for the article’s scientific content, including study design, data collection, analysis and interpretation, writing, some of the main line, or all of the preparation and scientific review of the contents and approval of the final version of the article.
Animal and Human Rights Statement
All procedures performed in this study were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. No animal or human studies were carried out by the authors of this article.
Ethical Statement
No ethical approval was needed because this is not a human study and only online information was used.
Footnotes
Authors’ Contributions
M.F.Ş., E.C.T., and Ç.D.: Conceptualization, investigation, writing—original draft preparation, writing—review and editing, and project administration. S.Ş., R.Ö., and Ç.D.: Conceptualization, investigation, writing—original draft preparation, writing—review and editing, and project administration. M.A. and C.Y.: Conceptualization, supervision, writing—review and editing, and funding acquisition.
Author Disclosure Statement
None of the authors received any type of financial support that could be considered a potential conflict of interest regarding the article or its submission.
Funding Information
No funding was received for this article.