
Abstract
A polymerase chain reaction (PCR)–mass spectroscopy assay was developed to identify non-O157 Shiga toxin–producing Escherichia coli (STEC) with Plex-ID biosensor system, a platform identifying short PCR amplicons by specific base compositions. This assay simultaneously amplifies five fragments of two housekeeping genes, two subunits of stx2 gene, and four other virulence genes of STEC. A total of 164 well-characterized STEC isolates were examined with the assay to build a DNA base composition database. Another panel of 108 diverse STEC isolates was tested with the established database to evaluate the assay's identification capability. Among the 108 isolates, the assay specificity was 100% for three (stx1, eae, and aggA) out of five tested virulence genes, but 99% for stx2 and 96% for hlyA, respectively. Main stx1/stx2 subtypes and multiple alleles of stx1/stx2 could be differentiated. The assay successfully identified several clinically significant serotypes, including O91:H14, O103:H25, O145:H28/NM, O113:H21, and O104:H4. Meanwhile, it was able to group isolates with different levels of pathogenic potential. The results suggest that this high-throughput method may be useful in clinical and regulatory laboratories for STEC identification, particularly strains with increased pathogenic potential.
Introduction
N
Identification and characterization of STEC isolates during foodborne outbreak investigations can help establish the link between clinical isolates and those from food or environmental samples, therefore outlining the possible source. Polymerase chain reaction (PCR) coupled to electrospray ionization mass spectrometry (PCR-MS) is a novel technique for microbial detection and identification (Ecker et al., 2008). This technology uses mass spectrometry–derived base composition obtained from PCR amplicons of targeted genome fragments to identify microorganisms. The method is demonstrated to be fast and effective, with high-throughput detection capability (Ecker et al., 2008). To date, it has been successfully applied to clinical microbial characterization (Lamson et al., 2006; Sharma et al., 2011). It can potentially be very useful in other fields, including food safety.
Previously, we developed a 96-well Plex-ID foodborne pathogen assay (FBP) to identify Salmonella, Shigella, E. coli, and Listeria using eight pairs of primers, of which six pairs targeted mutS and mdh genes in Gram-negative enteric bacteria, and the other two were specific for L. monocytogenes (Pierce et al., 2012). The second version of FBP (Foodborne Bacteria v2) was developed in the present study by replacing primers irrelevant to E. coli with those that target major STEC virulence factors, including stx1, stx2, eae, hlyA, and aggA. The aim of this study was to (1) build an extensive database for STEC using a panel of well-characterized isolates with diverse genetic background, and (2) assess the identification abilities of the new assay.
Materials and Methods
Bacterial isolates
A collection of 272 well-characterized STEC isolates including 99 from humans, 103 from animals, and 70 from food were used, of which 10 were outbreak strains. In addition to our collection (Xia et al., 2010; Ju et al., 2012), these isolates were kindly provided by the Center for Veterinary Medicine of the U.S. Food and Drug Administration (FDA), U.S. Center for Disease Control and Prevention, and the STEC center at Michigan State University. Serotypes were initially determined by conventional serotyping and confirmed by molecular methods (Machado et al., 2000; Ju et al., 2012), whereas virulence genes were identified using molecular methods described previously (Beutin et al., 2007; Zheng et al., 2008; Xia et al., 2010). Since Shigella produce Shiga toxin, and share high homology with E. coli, 56 Shigella (12 S. flexneri, 17 S. dysenteriae, 8 S. sonnei, and 19 S. boydii) from FDA were also included in the study.
Foodborne Bacteria v2 plate design
The layout of Foodborne Bacteria v2 plate (Abbott Molecular, Abbott Park, IL) is shown in Figure 1. The wells from rows A to E included primer pairs targeting mutS and mdh, and the wells in the last three rows contained primer pairs targeting virulence genes: stx1A (stx1 A subunit) and stx2B (stx2 B subunit) in row F, stx2A (stx2 A subunit) and EHEC hlyA in row G, and eae and aggA in row H. The 11 sets of forward/reverse primer sequences and the target gene segments are listed in Table 1. The Foodborne Bacteria v2 plate was preloaded with 0.2 mM deoxynucleoside triphosphates, 0.5 μM PCR primers, 1 U of Immolase DNA polymerase in PCR buffer, and 100 copies of calibrant in each well.

Layout of the Foodborne Bacteria v2 plate. This plate was designed for characterization of Shiga toxin–producing Escherichia coli (STEC) and Salmonella. Only STEC strains were tested in this study. Numbers in the wells represent primer ID. The genes they targeted are listed on the left and also in Table 1. Some wells have multiple primer pairs targeting multiple gene segments. Each plate can accommodate 12 isolates, one isolate per column.
PCR-MS
DNA template was extracted using the boiling method. Briefly, pure bacterial colonies grown overnight on freshly prepared LB agar were suspended in 500 μL of sterile water. The bacterial suspension was heated at 100°C for 10 min in a dry heating block, and centrifuged at 10,000×g for 5 min. A portion (10 μL) of DNA supernatant was distributed into each well of the Foodborne Bacteria v2 plate for PCR assay (Eppendorf, Hauppauge, NY). The PCR conditions were as described previously (Pierce et al., 2012). After amplification, the plate was loaded onto the Plex-ID system (Abbott Molecular) to determine the base composition of amplicons.
Data analysis
To build up the base composition database for target genes, 164 STEC isolates (59 from humans, 57 from animals, and 48 from food) with different serotypes and virulence gene profiles were characterized using the Foodborne Bacteria v2 plate, and the PCR amplicon data were analyzed and sorted. The isolates were differentiated based on base composition patterns of the PCR amplicons. The assay for STEC characterization was validated using an additional panel of 108 STEC isolates (40 from humans, 46 from animals and 22 from food) with known serotypes and virulence factors. The serotypes and virulence genes identified by PCR-MS were compared to those tested by conventional and molecular serotyping methods (Machado et al., 2000; Beutin et al., 2007; Zheng et al., 2008; Xia et al., 2010; Ju et al., 2012).
Results
Analysis of virulence factors
The base compositions of virulence genes of the 164 STEC isolates are summarized in Table 2. Three base compositions for Shiga toxin 1 A subunit were observed among STEC isolates carrying subtype stx1a, stx1c, and stx1a+stx1c, respectively (Table 2). STEC carrying stx2b, stx2e, and stx2g were separated from each other and from those carrying other stx2 subtypes based on the base composition of Shiga toxin 2 B subunit. Although stx2a was not differentiated from stx2c and stx2dact, these three subtypes were separated from other stx2 subtypes. Additionally, multiple alleles of stx2 genes could be differentiated; for instance, all isolates that harbored stx2a+stx2dact had two different base compositions of stx2B or stx2A. All 85 eae-positive isolates had the same base composition of eae. Four O104:H4 strains linked to the German outbreak in 2011 exhibited base compositions of aggA, whereas the aggA-negative isolates did not. Four types of base compositions were obtained among 98 hlyA-positive isolates (Table 2).
Number of isolates used to build the database for each virulence gene/subtype.
The base compositions for virulence genes/subtypes from column 1, and they were obtained from the 164 STEC isolates in the database.
Identification of the virulence factors using 108 STEC isolates. Numbers before parentheses represent number of isolates carrying respective virulence gene/subtypes in Column 2 by previous molecular methods. Numbers in parentheses represent the actual number of isolates that obtained the base compositions in Column 3, respectively.
One stx2a/2c/2dact was not amplified and thus not identified by PCR-MS.
Base compositions of stx2B.
Base compositions of stx2A.
Two hlyA were not amplified by PCR-MS and thus were false negatives.
The PCR-MS detected hlyA in the two isolates, which were negative for hlyA by previous methods, and thus were false positives.
In the assay validation study with 108 STEC isolates, the overall specificity was 100% for identifying stx1, eae, and aggA, 99% (107/108) for stx2, and 96% (104/108) for hlyA (Table 2). In comparison, the PCR-MS results were in agreement with those obtained by other molecular testing methods for stx1 subtypes (stx1a and stx1c) and stx2 subtypes (stx2a/2c/2dact, stx2b, stx2e, and stx2g), with a single exception that the sequence of one strain carrying stx2a/2c/2dact was not amplified and thus failed in identification by PCR-MS. A similar agreement between PCR-MS and previous testing methods was also found in one isolate carrying multiple alleles of stx1 subtype (stx1a+stx1c) and two isolates carrying stx2 subtype (stx2a+stx2dact). However, when PCR-MS was applied for hlyA gene identification, two previously positive isolates were tested negative by PCR-MS, and two negative isolates were reported positive (Table 2).
Differentiation of STEC isolates in the database
The Foodborne Bacteria v2 plate showed significant improvement over the previous FBP assay in discriminating STEC (Fig. 2). Based on the FBP assay, the 164 isolates were grouped to 24 base composition patterns, some of which were unique to serotypes O91:H14, O103:H25, O113:H21, O145:H28/NM, and O15:H27. In contrast, the new plate further classified the above 24 patterns into 81 new ones, due to additional information from the new virulence factor amplicon targets (Fig. 2). All O26:H11/NM, O111:H11/H8/NM, and O103:H11 belonged to patterns 1a–1e, all O45:H2/NM and O103:H2/NM to patterns 2a–2d, and O121:H19/NM to patterns 3a–3d. Isolates showing these patterns all had eae, and could be separated from eae-negative ones, like those belonging to patterns 1f–1r, 2e–2i, and 3e–3g, respectively. As the prevalence of eae was high in human and animal isolates but low in food isolates, most human (49/59) and animal isolates (38/57) belonged to eae-positive patterns (1a–1e, 1o, 2a–2d, 3a–3d, 4, 7, and 9), whereas only one food isolate (1/48) belonged to the same pattern group. Strains that caused severe diseases and outbreaks belonged to base composition patterns 1a, 1c, 1o, 2a, 2c, 3a, 3c, 4a, 4b, 4e, 13b, and 13c. It is noteworthy that pattern 1o was unique by including four O104:H4 German outbreak strains with both stx2a and aggA. Furthermore, isolates within a specific serotype could be further divided into several subgroups; for instance, isolates within serotypes O26:H11, O111:H11, O103:H2, O45:H2, O121:H19, and O128:H2 showed different base composition patterns, revealing difference in virulence potential of these subgroups.
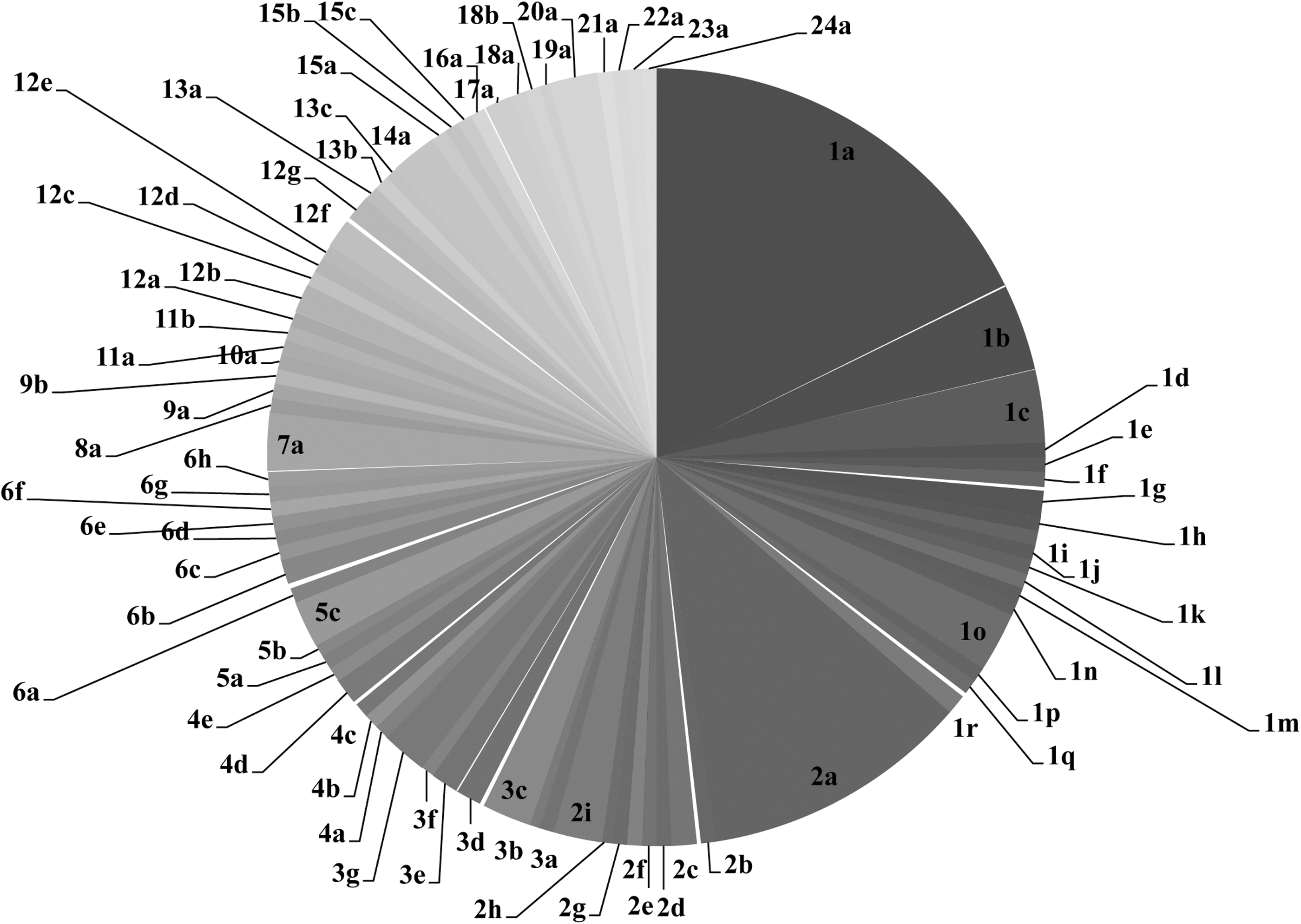
The pie chart results of the 81 base compositions patterns of the 164 non-O157 Shiga toxin–producing Escherichia coli isolates by Foodborne Bacteria v2 plate. The patterns are obtained from the MS profiles of mutS, mdh, stx1A, stx2B, stx2A, hlyA, eae and aggA, and are shown by arabic numbers and letters. The arabic numbers (1–24) correspond to the 24 foodborne pathogen assay (FBP) patterns that are based on the mass spectrometry profiles of mutS and mdh. Among them, each of the following serotypes—O91:H14 (Pattern 5), O103:H25 (Pattern 7), O113:H21 (Pattern 13), O145:H28/NM (Pattern 4), and O15:H27 (Pattern 18)—has its unique FBP pattern. The letters after the arabic numbers represent the subpatterns further divided by the additional virulence factors in the Foodborne Bacteria v2 plate. The area of each pie slice is proportional to the number of isolates within each pattern. The serotypes/serogroups and the number of isolates within each pattern are shown as follows.
Identification of serotypes/serogroups
The capability of PCR-MS assay for STEC serotyping is illustrated in Table 3. All isolates of serotypes O91:H14, O103:H25, O113:H21, O145:H28/NM, and O104:H4 were correctly identified according to its unique PCR-MS signature of each serotype. However, other single base composition patterns may encompass multiple possible serotypes, as observed for isolates belonging to serotypes O26:H11/NM, O111:H11/H8/NM, O103:H11, O45:H2/NM, O103:H2/NM, and O121:H19/NM. All of the tested isolates belonging to serotypes O26:H11/NM, O111:H11/H8/NM, O103:H11, O45:H2/NM, O103:H2/NM, and O121:H19/NM were correctly identified as belonging to their respective serotype groups, though not uniquely. One exception was one O45:H2 isolate; it was misidentified as O128:H16 (pattern 3e) instead of patterns 2a–2d, which included all other O45:H2/NM isolates in the database. One O118:H16 isolate was identified as pattern 3g instead of pattern 1a, which included the other O118:H16 isolate in the database. One isolate of O104:H21, one O55:H7, and five isolates with unknown serotypes had new patterns and thus were not identified by PCR-MS based on the current database.
Polymerase chain reaction coupled to electrospray ionization mass spectrometry identification (PCR-MS ID) is shown by the base composition pattern by Foodborne Bacteria v2 plate. The possible serotype(s) within each pattern are illustrated in the legend for Figure 2. The number of isolates identified to belong to each base composition pattern is shown in parentheses. Bold results indicate that these isolates were identified to the correct serotypes/serotype groups (base composition patterns) by PCR-MS.
These serotypes were uniquely identified due to the unique FBP pattern (based on MS profiles of mutS and mdh) of each serotype.
The serotypes of these 11 STEC isolates were unknown but did not belong to the several common clinically relevant O serogroups listed above. Their virulence gene information was known and therefore they were used mainly for identification of virulence genes/subtypes.
Identification of Shigella isolates
The PCR-MS results for all Shigella isolates indicated that they were not STEC, since they were negative for the virulence factors of STEC. Although PCR-MS identified three stx1a for three S. dysenteriae type 1 isolates, the S. dysenteriae type 1 isolates could be differentiated from STEC by distinct MS profile of mdh and mutS (data not shown). This indicated that the Foodborne Bacteria v2 plate could differentiate Shigella from STEC.
Discussion
Recent advances in PCR-electrospray ionization (ESI) using mass spectrometers have enabled the identification of bacterial species, subspecies, and even genotyping with a high degree of resolution (Sauer and Kliem, 2010). While the previous FBP assay could identify E. coli O157:H7 and its evolutionary precursor O55:H7, based on their unique MS profiles of mutS and mdh (Pierce et al., 2012), the present study focused on non-O157 STECs. Unlike O157:H7, non-O157 STEC strains are highly diverse in genetic content and virulence. Currently, identification of non-O157 STEC, especially the pathogenic non-O157 STEC strains, is challenging. Among the numerous factors that are indicative of virulence, virulence gene and serotype are the two most important indicators. Thus, there is a need for the ability to determine the virulence genes/subtypes and serotypes of non-O157 STEC before more discriminative methods such as pulsed-field gel electrophoresis are applied for accurate typing.
The current plate was able to identify most of the virulence genes of non-O157 STECs successfully. The stx1, eae, and aggA genes were identified 100% of the time. The correct identification for eae has great clinical value, since eae carrying STEC isolates are considered to be highly pathogenic to humans (Werber et al., 2003). One stx2a/2c/2dact was not identified by PCR-MS, and two false negatives (1.8%) and two false positives (1.8%) were observed for the hlyA gene. The false negatives may be due to the failed amplifications of gene targets in PCR-MS, and the false positives for hlyA may result from contamination, or because the primers used in this assay were different from those in previous methods. Detection of virulence genes using this plate has advantages in that it not only detected them, but also determined the subtypes for most of the targeted stx genes, but not for eae, for which primers were designed to target the conserved region. This is significant, since these subtypes play an important role in causing human diseases. Although the assay was not able to discriminate stx2a from stx2c or stx2dact, it successfully identified and differentiated them from other stx2 subtypes. This has important clinical value, because the three stx2 subtypes are often associated with hemorrhagic colitis and hemolytic–uremic syndrome (Eklund et al., 2002; Friedrich et al., 2002; Kallquist et al., 2010). Another advantage of this assay is the successful identification of multiple alleles of stx1 and stx2. PCR/restriction fragment length polymorphism is currently a preferred tool for investigating multiple stx subtypes (Beutin et al., 2007; Gobius et al., 2003), but is time consuming and labor intensive (Beutin et al., 2007). PCR-MS is highly automated, fast, and high throughput, and thus could provide a more accurate, effective, and timely response in outbreaks of foodborne illness.
The plate was able to identify most of the non-O157 serotypes. The unique identification of serotypes O91:H14, O103:H25, O113:H21, and O145:H28/NM is significant, since these serotypes have been previously reported in humans and some have caused severe diseases including bloody diarrhea and hemolytic–uremic syndrome (Paton et al., 1999; Karmali et al., 2003; Rivas et al., 2006; Frank et al., 2011). The plate also successfully identified E. coli O104:H4 strains by recognizing two co-existing virulence factors: the aggA and stx genes. As for the clinically relevant serotypes O26:H11/NM, O111:H11/H8/NM, O103:H11, O45:H2/NM, O103:H2/NM, and O121:H19/NM within the “top six” O serogroups, although it was common to observe more than one serotype listed as a possible identification, reducing the list from thousands down to a few possible serotypes is very useful. That information could easily be used to narrow focus during outbreak investigations. This assay has the potential to significantly reduce the time required to characterize STECs and greatly improve the response time for outbreaks. The misidentification of some serotypes indicates that expanding the current reference database will enhance the potential of this assay to provide accurate serotype information of STEC.
Most existing methods for the identification of pathogenic non-O157 STEC from food are based on primers and probes for specific clinically relevant O serogroups (Fratamico et al., 2011; Lin et al., 2011). Since the O and H antigen gene segments evolve rapidly, newly emerging clinically relevant serotypes might not be readily detected by this approach if the primer regions are different from those in the serotypes that have already been known to cause diseases (Moxon et al., 1994; Sasaki 1994; Pierce et al., 2012). However, the emerging clinically relevant serotypes can be screened out by the current assay, because it uses broad-range primers to target the housekeeping genes that which are present in all E. coli strains. Furthermore, this assay can divide STEC isolates into multiple groups that may have different levels of virulence potential. If unknown isolates were identified to be within the groups that included the outbreak strains or strains that have caused diseases, they may have high pathogenic potential.
Future plates that can include primers targeting extra housekeeping genes, and virulence factors of STEC would improve their discriminatory power and could become very promising if applied to molecular risk assessment of STEC strains, and to facilitate real-time monitoring and outbreak investigation. In addition, the expansion of the current reference library will also help improve the accuracy of calls from the instrument. The database will also facilitate rapid information sharing between clinical microbiology laboratories, public health laboratories, and biodefense agencies. The main drawback of the current PCR-MS is high equipment cost, but this could be reduced over time if large numbers of samples are tested. In addition, this technology continues to evolve, with yearly performance increases and cost reductions.
Conclusions
This work reports that the Foodborne Bacteria v2 plate could uniquely identify some clinically relevant STEC serotypes and most major virulence genes and subtypes. Although several possible serotypes were identified for an isolate, the assay helped to narrow down the isolates to a few possible serotypes. With the expansion of the current database and development of extra target genes in the future, the accuracy of identification will be improved. Furthermore, the method can help identify STEC isolates with pathogenic potential, and is very promising in becoming a tool for molecular risk assesment of STEC. The set of plates developed for identification of general foodborne pathogens (FBP for instance), and for particular pathogens (this Foodborne Bacteria v2 plate) may facilitate foodborne bacterial outbreak investigations. Most importantly, the data could be easily shared between microbiology laboratories around the world. Therefore, the PCR-MS assay is a reproducible, rapid, and high-throughput method for STEC detection and identification, and it is a very promising tool for food safety, clinical diagnosis, and epidemiological studies, among others.
Footnotes
Acknowledgment
This work was supported in part by the U.S. Food and Drug Administration (FDA)/Center for Food Safety and Applied Nutrition (CFSAN) and the FDA Commissioner's Fellowship Program, and by funding from the Joint Institute for Food Safety & Applied Nutrition (JIFSAN) at the University of Maryland.
Disclosure Statement
No competing financial interests exist.