
Abstract
The Foodborne Diseases Active Surveillance Network (FoodNet) is currently using a negative binomial (NB) regression model to estimate temporal changes in the incidence of Campylobacter infection. FoodNet active surveillance in 483 counties collected data on 40,212 Campylobacter cases between years 2004 and 2011. We explored models that disaggregated these data to allow us to account for demographic, geographic, and seasonal factors when examining changes in incidence of Campylobacter infection. We hypothesized that modeling structural zeros and including demographic variables would increase the fit of FoodNet's Campylobacter incidence regression models. Five different models were compared: NB without demographic covariates, NB with demographic covariates, hurdle NB with covariates in the count component only, hurdle NB with covariates in both zero and count components, and zero-inflated NB with covariates in the count component only. Of the models evaluated, the nonzero-augmented NB model with demographic variables provided the best fit. Results suggest that even though zero inflation was not present at this level, individualizing the level of aggregation and using different model structures and predictors per site might be required to correctly distinguish between structural and observational zeros and account for risk factors that vary geographically.
Introduction
T
The FoodNet model is used on data aggregated by year and FoodNet site to account for the growth of surveillance area from 5 sites in 1996 to 10 sites in 2004, and adjust for site to site variation in incidence. This level of aggregation limits our ability to explore variations in incidence for smaller geographic areas or units of time, or demographic features of individual cases, such as patients' age and sex, all factors that have been shown to describe unique characteristics of Campylobacter epidemiology (Samuel et al., 2004; Ailes et al., 2008). Exploration of changes in incidence over time associated with specific subgroups may contribute to hypotheses regarding geographically or time-varying sources of Campylobacter infection. However, disaggregating data can cause an increase in the proportion of case counts in each subgroup that is zero, because the total population in each group is decreased.
Zero-augmented models consist of two separate model components: one for modeling case counts (using a NB distribution) and one for modeling the proportion of zeros (using a binomial distribution). The zero-inflated and hurdle models differ in whether their count model component can yield a count of zero. Zero-inflated models assume zeros can be either structural or true observational zeros, and therefore zeros are estimated by both binary and count components and have an additional mixing parameter not present in hurdle models. Hurdle models assume that all zeros are structural zeros and therefore only model the binary component and use conditionally specified versions of the NB distribution, which are truncated to begin at a count of one (Mullahy, 1986; Desjardins, 2013).
Consequently, zero-augmented models, hurdle and zero inflated, may be useful to model Campylobacter case counts in FoodNet where the high proportion of observed zero counts may be attributed to factors that make it impossible to observe a case (structural zeros) as well as factors associated with the sampling (observational zeros) (Ridout et al., 1998; Hu et al., 2011). We hypothesized that factors such as diagnostic testing performance or population immunity may contribute to the presence of structural zeros and the size of the surveillance population contributes to observational zeros.
We examined zero-augmented modifications (zero inflated and hurdle) of the regression model used by FoodNet to estimate changes over time and added predictors to account for additional sources of variation in incidence. We hypothesized that modeling structural zeros and including demographic variables would increase the fit of FoodNet's Campylobacter incidence regression models. Our objectives were to explore modeling incidence at a finer geographic level, evaluate the effect of covariates that vary geographically, and examine the characteristics of zero counts in Campylobacter surveillance data.
Materials and Methods
Dataset preparation
Data were available for 48,088 cases of Campylobacter infection ascertained between 2004 and 2011 in the FoodNet surveillance system. The county, state, month, and year in which the Campylobacter cases were diagnosed and the age and sex of the patient were used for the analysis. Sixty-six cases with missing age or sex information were excluded.
Case patients were classified by age group [Age_Group: less than 5 (1), 5–17 (2), 18–24 (3), 25–44 (4), 45–64 (5), and 65+ (6) years of age] using categories used in previous FoodNet publications and that represent different life stages: preschool age, school age, college age, younger working age, older working age, and retirement age (Ailes et al., 2008). Month of diagnosis was used to make a season variable (Season), which grouped the months into high (High) and low (Low) seasons with each season including six consecutive months with the highest or lowest case counts, respectively. The high season included May to October and the low season included November to April. The patients' sex remained a binary variable (Sex) with two levels: Male and Female.
Campylobacter cases were grouped into one of 24 possible subgroups per county and year arising from the total combinations of 6 age groups, 2 seasons, and 2 sex categories (6 × 2 × 2). Eight years of surveillance for each of 486 counties with 24 subgroups each generated 93,312 subgroups (8 × 486 × 24). Population estimates by year, state, county, age, sex, and race were provided under a collaborative arrangement with the U.S. Census Bureau (U.S. Census Bureau, 2011). The population data were used to calculate county level incidence by dividing the number of cases by the total population of each subgroup per county.
The distribution and basic statistics of case counts and incidence were examined for all subgroups. The annual observed incidences per county were divided into four quartiles. The quartiles were used to construct choropleth maps where counties were shaded by incidence quartile using qGIS version 1.8.0 (QGIS Development Team, 2013). Because California counties were the only surveillance area in FoodNet without any subgroup case counts of zero, all data from these three counties (information on 7810 case patients) were removed from model analyses. The final dataset had 40,212 observations and 92,736 case count subgroups.
Model building and comparison
The data were evaluated for overdispersion by comparing the overall mean and variance of case counts for each subgroup (McCullagh and Nelder, 1989). Models of Campylobacter case counts in each subgroup were built using R version 3.1.2 and its MASS, stats, and pscl libraries (R Core Team, 2013). An NB distribution was assumed for the outcome variable in all the models. A histogram of case counts with an NB-fitted curve overlay was produced. The reference groups selected for State, Age Group, and Sex were those that represented the largest proportion of the population: Georgia, 25–44 years old, and Male, respectively. For Year and Season, the earliest year (2004), and the low season (November–April) were used as reference groups.
The first model was an NB that included Year and State as nominal categorical predictors. Season, Age_Group, and Sex were added as categorical predictors to produce the next model (
The zero-augmented and nonzero-augmented models were estimated by a maximum likelihood algorithm. The Akaike information criterion, Bayesian information criterion (BIC), and −2 log-likelihood were computed for comparison. The BIC-corrected Vuong test was used to compare the fit of nonnested models, and the likelihood ratio test was used to compare the fit of nested models (Vuong, 1989). The zero component intercepts in the zero-augmented models were evaluated as a large negative coefficient value does not support the idea of zero inflation in the data (Erdman et al., 2008; Schwadel and Falci, 2012).
Model assessment was done by evaluating the mean absolute error using leave-one-out-cross-validation (Kuhn and Johnson, 2013). The difference between the predicted and observed zero case counts was compared for all models. Quantile-Quantile plot and residual histogram for the best fitting model were inspected for normally distributed errors. The source code of all analysis steps is available by request.
Results
Descriptive statistics
On average, 5027 (±SD 300) cases of Campylobacter infection were reported to FoodNet each year between 2004 and 2011 (Range: 4751 in 2004 to 5636 in 2011). The majority (63.0% ± 0.9%) was reported during the high season (May–October). The average annual incidence (all reported per 100,000 persons) for all sites combined was 11.8 (±0.5) and ranged between 11.3 in 2008 and 12.8 in 2011. The average state incidence was 13.4 (±5.0) and varied from state to state (Range: 6.8 in Georgia to 19.5 in California). The average age group incidence was 14.2 (±5.7) and was highest for children aged less than 5 years (25.4) and lowest among persons aged 5–17 years (9.0). Males had higher rates than females (14.6 vs. 11.5).
To provide a visual representation of geographic variation in incidence among counties, quartiles of annual county-level incidence were mapped for Minnesota, Georgia, New Mexico, and Oregon as examples (Fig. 1). The average annual incidence per county was 12.8 (±10.0) per 100,000. The wide standard deviation was a function of county incidence variation among and within states illustrated in Figure 1.
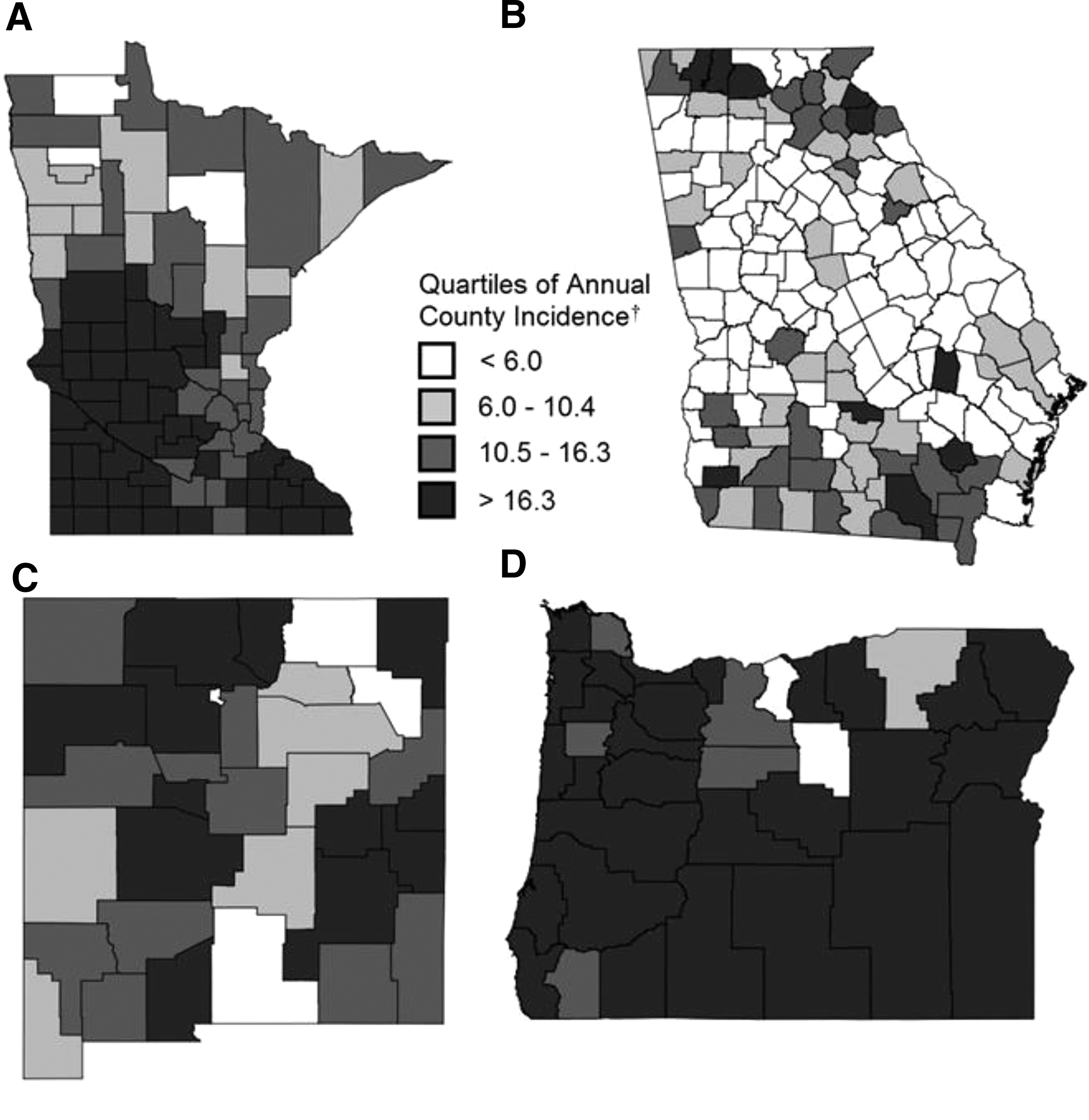
Observed county incidence per 100,000 in
Building models
Variance (1.71) and mean (0.43) of all the Campylobacter counts in the final dataset were calculated. The large variance relative to the mean suggested that the data were overdispersed (Rao and Sumathi, 2011). This was further supported by the NB's estimated overdispersion parameter [log(theta)], which was significantly different from zero with a p-value less than 0.001 (Cameron and Trivedi, 2013). The histogram in Figure 2 shows the case count frequency with a normal NB curve overlay (number of observations = 92,736, mean = 0.434, and theta = 0.213). Out of the 92,736 total subgroups, 78.6% had a zero case count. The curve mirrors the observed values closely and zero inflation is not apparent.

Count frequency of Campylobacter cases in FoodNet (bars) with normal negative binomial curve overlay (number of observations = 92,736, mean = 0.434, and theta = 0.213). Y axis is shown using a square-root scale.
Model results
All variables included in the nonzero-augmented models (NB and
The count components of all models (NB,
Model assessment and comparison
The zero component intercepts in the zero-augmented models had large negative coefficient values, which do not support the idea of zero inflation in the data. This is further supported by the goodness of fit evaluations summarized in Table 1. The likelihood ratio test led to the same results as the Vuong test when applied to nested models. Using the goodness of fit measures, the
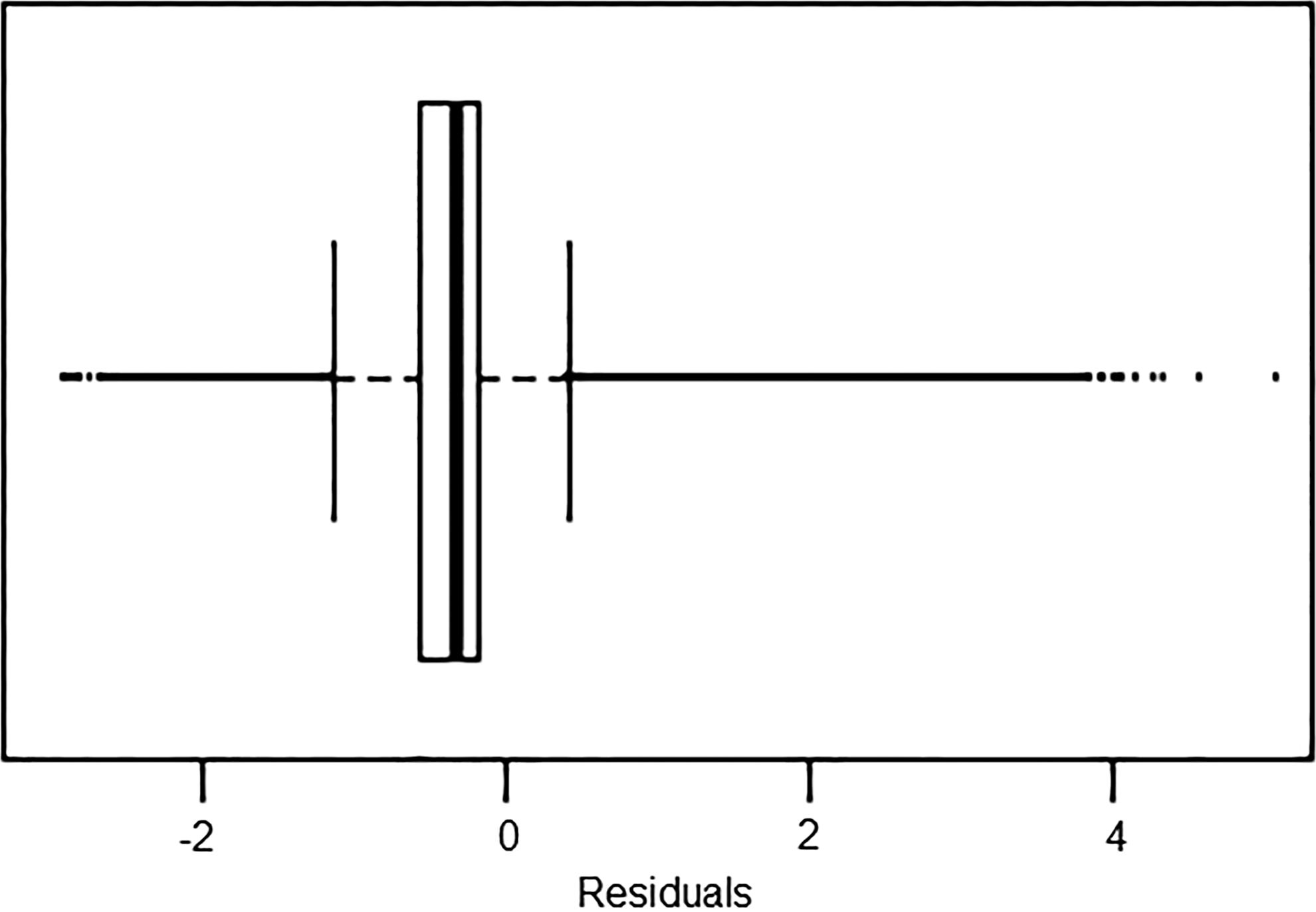
Residual box plot of negative binomial model with demographic covariates (
Models are listed from left to right and top to bottom as their fits improve; *Hurdle NB = Hurdle negative binomial with covariates in the count component only, NB = Negative binomial without demographic covariates, Hurdle NB Full = hurdle negative binomial with covariates in both zero and count components, ZINB = Zero-inflated negative binomial with covariates in the count component only, NB. Plus = Negative binomial with demographic covariates; †Null model; LR = Likelihood ratio test; V (BIC) = Vuong BIC corrected Non-Nested Hypothesis Test-Statistic; *** = p-value less than 2.2e-16 when testing model 1 versus model2 with alpha < 0.05; ‡Number of parameters estimated.
AIC, Akaike information criterion; BIC, Bayesian information criterion; MAE, Mean absolute error; NB, negative binomial.
Adding the demographic variables to the nonaugmented models decreased the mean absolute error by 0.0249 (decreased the error). For the zero-augmented
Discussion
The aim of this analysis was to explore different methods to analyze campylobacteriosis case counts ascertained by FoodNet surveillance sites at a finer geographic level, evaluate the effect on incidence of covariates that may vary geographically, and examine the characteristics of zero counts in FoodNet Campylobacter data. The subgroups selected for analysis represented demographic and geographic variables known to influence incidence of Campylobacter infections (Ailes et al., 2008). Although a disproportionate number of observations were zero, zero inflation was not apparent, and the NB model with inclusion of demographic and seasonal variables significantly increased the fit of the model (see Table 1,
Zero-augmented modifications (zero inflated and hurdle) of the regression models were used to examine a possible separation of observational and structural zeros. We anticipated that a significant proportion of zero case counts was observational; differences in county size and population demographics among the FoodNet surveillance sites result in very small subpopulation sizes among counties and a high probability that no cases will be observed among many counties. Our finding that the hurdle models did not fit the data well supports this assumption. Although we hypothesized that several surveillance and epidemiologic factors may contribute to structural zeros in the data, our analysis suggests that zero inflation is not apparent at the level of disaggregation of demographic covariates we studied; this finding is supported by the observation that inclusion of zero-augmentation mixing fractions did not improve the models' fit.
Although zero inflation was not present in the dataset, zero-augmented modeling techniques are likely to be important for future analyses, including modeling of other pathogens under FoodNet surveillance. Our models included only data ascertained by FoodNet active surveillance activities, and it is likely that inclusion of data from sites conducting passive surveillance, as well as data obtained from other sources, such as household income and access to healthcare, would contribute to the presence of structural zeros in the modeled data. The differences in data collection associated with different surveillance systems and data sources would likely result in excess zero case counts where at least a portion (structural zeros) arises from a process different from the positive counts. Although both hurdle and zero-inflated models may be used to model these types of data, it is likely best modeled by a zero-inflated model because the zeros are modeled as a mixture of both observational and structural zeros.
We removed the California observations because there were no zero case counts in any county subgroup, complicating our exploration of models for zero case counts. Removal of the California data eliminated convergence issues and allowed exploration of the effect of zero inflation. Removing the California data decreased the dataset's variance, but overdispersion was still prominent. An NB distribution helped in modeling the overdispersed data; however, there were still case counts that were outside the expected distribution. These case counts may be associated with undetected outbreaks (i.e., clusters of cases originating from a common exposure), which were not excluded from the analysis. Further exploration of these outliers, using compound distributions, would help better characterize them and might yield more information on risk factors of potential outbreaks (Hinde, 1982).
Conclusions
The addition of demographic and seasonal variables when modeling Campylobacter counts accounted for more variability and resulted in improved goodness of fit compared with models that only included a state factor. However, the complexity and variation in the epidemiology of Campylobacter were still not fully addressed, suggesting that differences in surveillance populations among the FoodNet sites or other epidemiological factors vary geographically. For example, the models did not fully account for the incidence variation among counties and states as illustrated in Figure 1. County-level variation associated with differences in county geographic size, population, and other unmeasured factors could result in additional sources of structural zeros in case counts. Although we investigated structural zeros at the state level, the possibility for structural zeros to vary by county was not examined. Potentially, the level of aggregation and count distribution could be adjusted per site to better fit the data and further explore structural zeros. Therefore, future steps should focus on individual sites.
Footnotes
Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.