
Abstract
Despite numerous calls for improvement, the US biosurveillance enterprise remains a patchwork of uncoordinated systems that fail to take advantage of the rapid progress in information processing, communication, and analytics made in the past decade. By synthesizing components from the extensive biosurveillance literature, we propose a conceptual framework for a national biosurveillance architecture and provide suggestions for implementation. The framework differs from the current federal biosurveillance development pathway in that it is not focused on systems useful for “situational awareness” but is instead focused on the long-term goal of having true warning capabilities. Therefore, a guiding design objective is the ability to digitally detect emerging threats that span jurisdictional boundaries, because attempting to solve the most challenging biosurveillance problem first provides the strongest foundation to meet simpler surveillance objectives. Core components of the vision are: (1) a whole-of-government approach to support currently disparate federal surveillance efforts that have a common data need, including those for food safety, vaccine and medical product safety, and infectious disease surveillance; (2) an information architecture that enables secure national access to electronic health records, yet does not require that data be sent to a centralized location for surveillance analysis; (3) an inference architecture that leverages advances in “big data” analytics and learning inference engines—a significant departure from the statistical process control paradigm that underpins nearly all current syndromic surveillance systems; and (4) an organizational architecture with a governance model aimed at establishing national biosurveillance as a critical part of the US national infrastructure. Although it will take many years to implement, and a national campaign of education and debate to acquire public buy-in for such a comprehensive system, the potential benefits warrant increased consideration by the US government.
The authors propose a conceptual framework for a national biosurveillance architecture and provide suggestions for implementation. The framework is focused on the long-term goal of having true warning capabilities. Therefore, a guiding design objective is the ability to digitally detect emerging threats that span jurisdictional boundaries, because attempting to solve the most challenging biosurveillance problem first provides the strongest foundation to meet simpler surveillance objectives. Core components of the vision are: (1) a whole-of-government approach to support currently disparate federal surveillance efforts that have a common data need; (2) an information architecture that enables secure national access to electronic health records; (3) an inference architecture that leverages advances in “big data” analytics and learning inference engines; and (4) an organizational architecture with a governance model aimed at establishing national biosurveillance as a critical part of the US national infrastructure.
T
Electronic surveillance systems for reportable diseases have seen appreciable progress over the past 2 decades, and systems specifically devoted to a number of infectious diseases integrate reporting across local, state, and national jurisdictional levels.10-12 However, the collection of reportable disease data is not currently automated, and reporting is generally acknowledged to be incomplete. Moreover, the capability of these systems to provide early warning of epidemics of new variants of highly communicable viral diseases such as influenza is also limited, although the utility of such systems for situational awareness, once outbreaks are detected, is generally accepted. 13 Similarly, systems for detecting adverse events associated with vaccines or other types of medical products still rely on reporting by clinicians or other anecdotal sources to initiate more rigorous statistical studies. 14
National security considerations also highlight the need to develop a system that can more effectively provide warning of outbreaks of new and emerging threats to human health. While past biosurveillance programs had in mind competently executed large-scale attacks with classical biowarfare agents, historical scenarios suggest that terrorist use of such weapons is more likely to be characterized by numerous attempts with limited success, resulting in small numbers of casualties distributed over time and location.15-17 In contrast to an immediately obvious mass casualty scenario, one sees instead a gradual unfolding and belated recognition of events. Recognition of outbreaks whose etiology is unknown, unfamiliar, easily misdiagnosed, or that are widely distributed in time and location still primarily relies on the astute clinician and the coincidental presentation of several patients at a single hospital or clinic.
The modest demonstrated benefits to public health surveillance that have accrued from the investment of considerable public resources in automated systems over the past decade have led to questions about the appropriate strategy to guide any future investments.
18
One analysis of the national system has observed that “[c]urrently, there are more than 300 separate disease surveillance efforts operated on the federal, state, and local levels,”19(pp307-308) and “there is no complete inventory of all government disease surveillance programs and no overarching federal strategy.”19(p306) It is generally recognized that a key to controlling the high costs associated with developing and maintaining a national system is to take advantage of the strong commonality among computational and information technology needs of the various biosurveillance applications, thus simplifying and consolidating current systems for syndromic and reportable disease surveillance, vaccine adverse events, and medical product safety. Ultimately, a successful national biosurveillance architecture must address several interrelated shortcomings of the present US surveillance system by:
• Improving the warning capability of automated surveillance; • Producing a useful information product to assist epidemiologic investigations at the local, state, tribal, and territorial levels; • Providing clinicians with tools that help them recognize clusters of cases with unusual symptomology; • Speeding the rate of adoption; • Lowering the costs associated with adoption and maintenance; and • Consolidating automated systems and those that rely on clinician or public health officer reporting to produce a unified system for syndromic and reportable disease surveillance, adverse event detection, and health product safety.
There are several reasons why it is timely to consider a new national biosurveillance architecture as a means of achieving these goals. The goals of enhancing and integrating biosurveillance have been called out in a presidential policy directive as elements of national policy. 20 It is important to note that early detection of highly distributed outbreaks and other public health events of national significance are an implicit goal of that policy. Also, “meaningful use” legislation has opened the window to a potentially powerful new source of data for national public health surveillance by providing financial incentives for adoption of certified electronic medical record (EMR) technology. 21 One form of “meaningful use” is a capability to provide patient information to public health agencies for surveillance purposes. Finally, recent technological advances made in other industries could and ought to provide potential ideas for improving disease surveillance. For example, the credit industry automatically mines massive transaction data sets to discover patterns that signify fraudulent activity and notifies cardholders and fraud investigators in real time. 22 Smart grid concepts detect anomalous changes in power demand and respond by notifying consumers while coordinating myriad energy producers to fill evolving needs. 23 Sophisticated search software allows users to query enormous collections of heterogeneous data to find similar events, objects, or documents. 24
A Whole-of-Government Approach
The biosurveillance enterprise spans many mission areas, including infectious disease surveillance, vaccine and medical product safety, environmental hazard regulation, and disaster response. While many agencies have established ad hoc surveillance programs to service these missions, cost considerations alone decisively favor choosing an automated biosurveillance architecture that can underpin all elements of the national surveillance enterprise, enabling truly national surveillance and integrating seamlessly with state, local, and federal responsibilities in the public health and national security arenas (Figure 1).

A hierarchal view of the biosurveillance enterprise showing the central role of a national automated biosurveillance system. The flow of surveillance data goes from bottom to top. ED = emergency department; EHR = electronic health record; BDS = biological detection system; OTC = over the counter; LE = law enforcement.
In the US federal system, the states have the authority to respond to acute public health threats, and they often delegate these responsibilities to local jurisdictions. Thus, the primary function of an automated surveillance infrastructure is to serve state and local public health authorities by bringing potential threats to their attention, assisting them with the decision to direct public health resources in further investigation, and to provide information that makes performing those investigations easier. In addition to this primary function, the national surveillance system must facilitate 6 core federal-level agency responsibilities: detect and monitor foreign (external) threats to US civilian health and assess and communicate those risks to federal and state officials; detect and monitor health threats to US military forces; identify multistate outbreaks and health events and provide support to states when requested; support states in disasters and emergencies; identify and attribute Title 18 events (chemical, biological, radiological, nuclear, and explosive incidents); and fulfill treaty obligations (eg, International Health Regulations [IHR]).
Since responsibilities for these functions fall on several different agencies, a national system should be conceived as a whole-of-government enterprise, rather than an asset of federal public health officials. Unlike the authorities assigned to public health agencies, disease outbreaks generally do not follow jurisdictional boundaries; jurisdictional issues should not interfere with the ability of the surveillance system to recognize multistate outbreaks or exposure incidents. In effect, the event should largely define the appropriate jurisdiction, and an effective biosurveillance system would exhibit secure, continuous, 2-way information flow with no latency across jurisdictional boundaries, to enable detection of previously difficult-to-detect events that span public health jurisdictions.
The experience of public health authorities with infectious disease surveillance suggests that the development of a successful national system should follow 4 principles:
1. Each citizen is the primary “owner” of his/her medical data. The patient must be permitted to restrict access to personal health records, except in those situations governed by extant laws. This may mean providing an opportunity to “opt out” of some surveillance activities. 2. Data remain where they are collected and are not sent to a centralized location for surveillance analysis. This architecture emphasizes secure data access over “data sharing.” State and local jurisdictions approach data-sharing agreements with caution, and recent documents suggest that there is no clear path to universal EMR data sharing without more liberal data-sharing agreements.
25
Differing data-sharing agreement details among state and local entities make it more difficult to detect cross-jurisdictional outbreaks. In a distributed architecture, temporary accumulations of data for analysis must be erased once the analysis operation is complete. In addition, some analytical operations can, and should, be performed on encrypted data.26,27 Systematic use of data suppression algorithms would reduce the number of uninformative, and hence unnecessary, data transfers.
28
Any personal identifying information must be stored and transmitted in an encrypted form that can be accessed only by a public health officer for investigation purposes. The categories of information used by the system should be available for public scrutiny. 3. The functionality of the national surveillance system must be restricted to surveillance alone. It should be strictly conceived as operational infrastructure, not a tool for research. Firm legal grounds for surveillance exist in most jurisdictions, and historically the general public has supported public health surveillance for threats of disease or chemical exposure. Much of the suspicion regarding biosurveillance can be traced to the perception of carte blanche access for less obviously critical applications such as research.
29
4. Strict protocols must be in place for automated notifications. System alerts must be first communicated to the lowest jurisdictional level necessary, consistent with law; a notification is made at a higher level only after all relevant lower levels have been notified. The system must present a common operating picture of a putative event to all levels that are notified. At the federal level, decisions about the significance of a particular alert for a mission that is the responsibility of one agency should not be made by another agency. Thus, formal notification protocols at the federal level should be a matter of prior interagency agreement.
We propose an architecture that uses EMR data at its core to enable inferences beyond those that can be elicited from syndromic and behavioral data alone. To formulate our vision, we have drawn on the extensive body of literature covering policy, organizational, technological, and scientific aspects of biosurveillance. We also interviewed a number of users, data providers, software developers, and other relevant experts to identify the factors underlying the lack of progress toward an integrated national system. We primarily address (1) the flow of information between data sources and analytical elements; (2) how and to whom inferences, alerts, and other results are to be communicated; (3) the way that surveillance data are processed by analytical elements of the system, including how inferences about the possible existence of a public health event are generated; and (4) how measures of confidence are determined. Organizational architecture—which concerns the relationships between the various stakeholders with respect to the development, maintenance, and operation of the system—is addressed cursorily. However, we call attention to the need to regard integrated biosurveillance as an element of national infrastructure with stakeholders in both the public health and other arenas.
The vision we present is a synthesis of ideas that have been discussed or suggested in previous work. It is not intended to be a technical roadmap as much as a compass for further discussion and research. Many of the experts we consulted were dissatisfied with both the technical direction and organizational paradigms of the current national biosurveillance agenda. Our intention is to provide coherent analysis and a framework for debate.
Information Architecture
An information architecture is a framework for the flow of information generated between a constellation of data sources and analytical software modules, as well as how and to whom the information is communicated. A particular problem is resolving privacy, data ownership, and scaling issues and enabling detection of previously difficult-to-detect outbreaks that span public health jurisdictions. We propose a distributed data and computing architecture and some potential models for near-universal EMR access that are compatible with the 4 principles described in the previous section. Figure 2 is a schematic representation of the basic national system architecture for automated surveillance, compared to existing systems. Distinct components within this architecture are: a biosurveillance (BSV) communications grid, EMR data nodes, specialized biosurveillance data nodes, and digital epidemiology nodes.
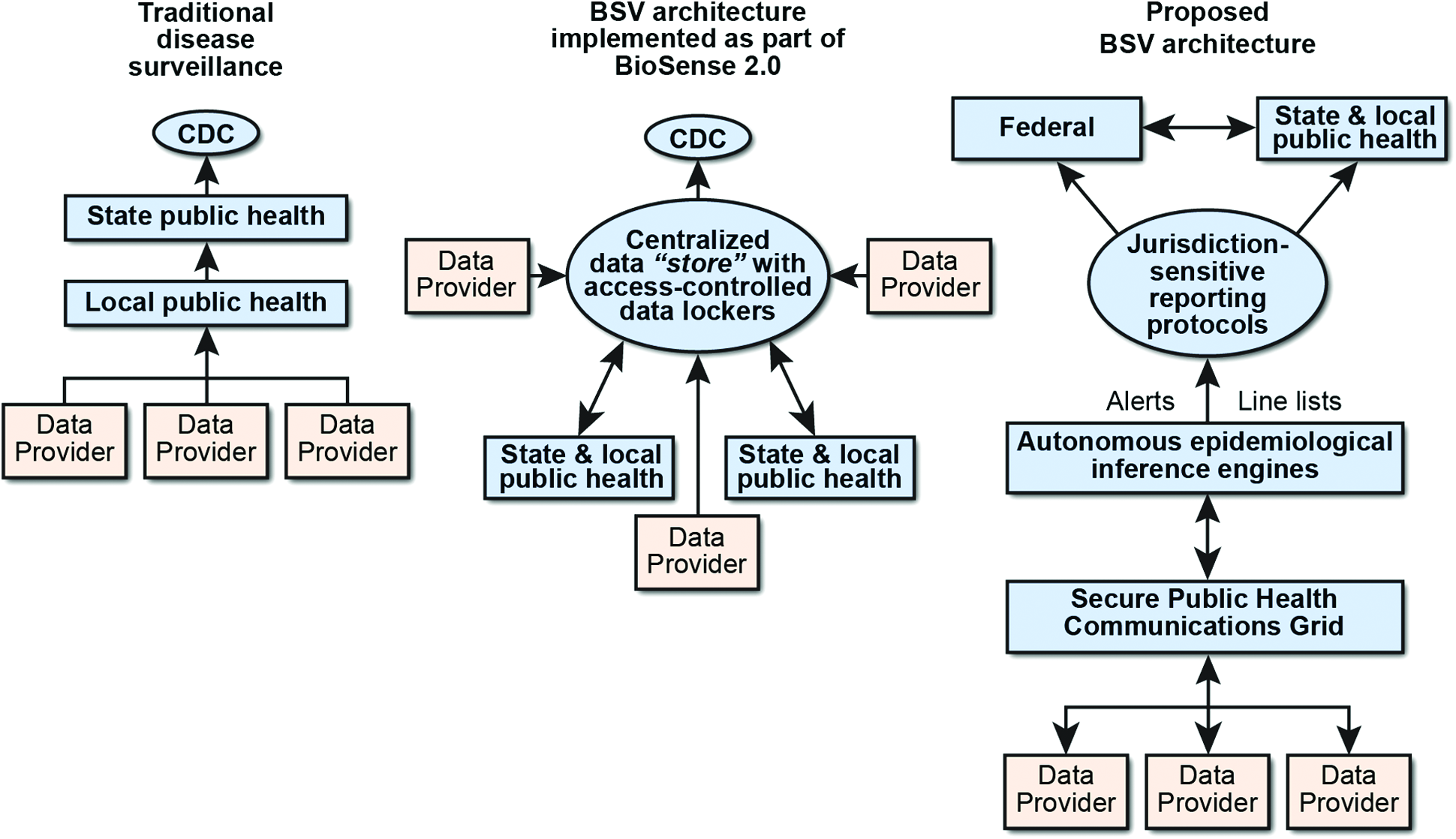
A schematic representation of the basic components of the proposed information architecture, compared to traditional disease surveillance and the National Syndromic Surveillance Program (formerly BioSense).
Biosurveillance Communications Grid
A biosurveillance communications grid is a system of standardized communications protocols that permits secure 2-way communication among the component nodes of the system. Several initiatives to establish such communication and terminology standards for health data already exist, such as the Centers for Disease Control's (CDC's) Standards and Interoperability Enterprise 30 and Kaiser's Convergent Medical Terminology Program. 31
Electronic Medical Record Data Nodes
EMR data records, including emergency department, urgent care, clinical, laboratory, and other diagnostic data, form a primary set of data sources. All queries to and reporting from these nodes must go through secure limited-access interfaces supporting query authentication protocols. As mentioned, hospitals, clinics, and physicians act as data holders in trust to the actual owners—the patients.
Digital Epidemiology Nodes
Digital epidemiology nodes are a set of autonomous inference engines that continually query data nodes on the grid and weigh available evidence to assemble and test hypotheses about potential outbreaks. These software modules assemble tentative line lists of cases, perform model building, and evaluate uncertainty levels. As autonomous software agents, they perform analysis and query generation and have the ability to learn automatically and continuously during system operation. Such data processing nodes can be specialized to detect particular types of epidemiologic events and may be distributed as needed for speed and computational efficiency. Individual digital epidemiology nodes may be customized to service particular public health missions, including the detection of unknown and emerging threats. Various types of digital epidemiology nodes and their connection through the biosurveillance communications grid are illustrated in Figure 3. Note that the term federal in this figure is meant to encompass all stakeholder agencies, not just CDC. Ideally, agencies whose missions are supported by a particular digital epidemiology node would fund its development and maintenance but work to a common set of standards for data processing software and communication protocols and use a common subroutine “library.”
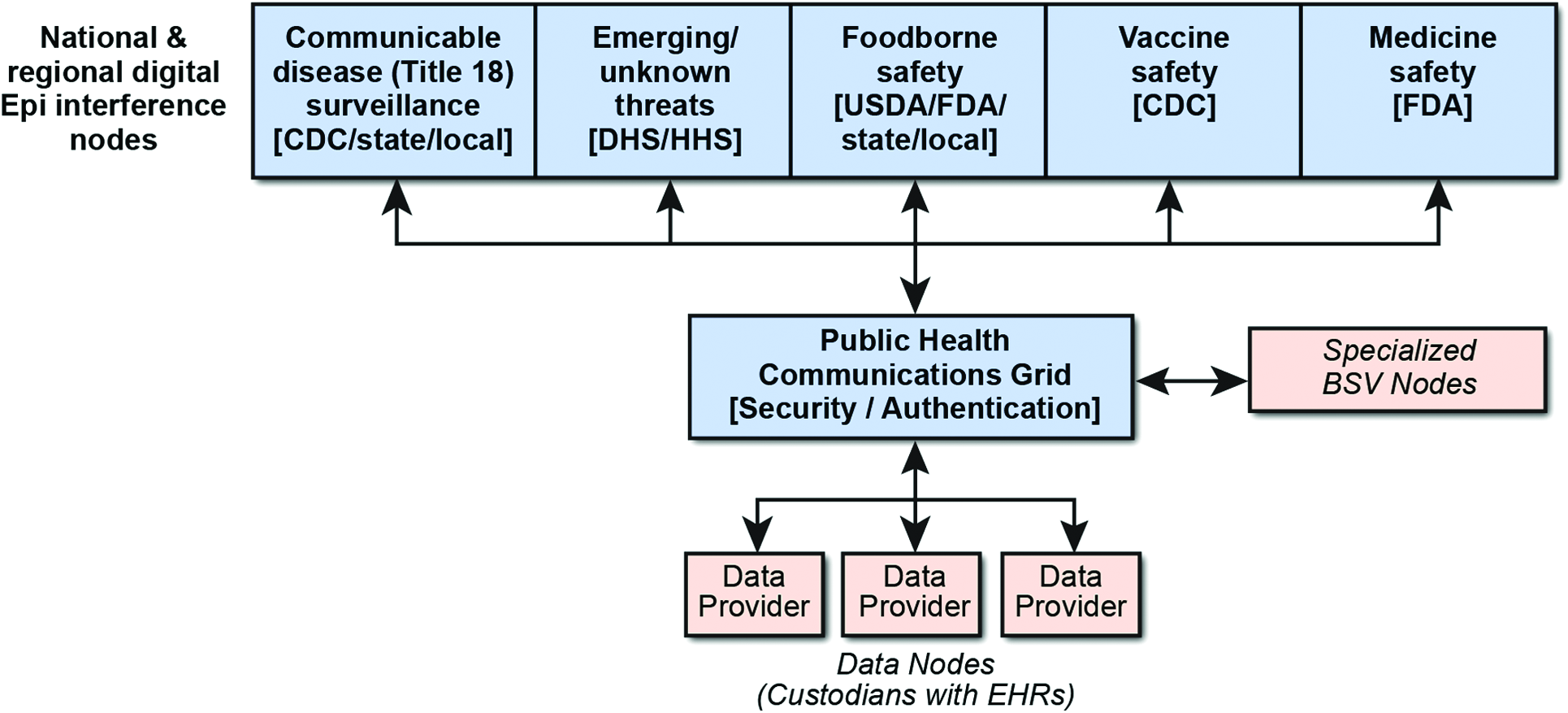
Tailored digital epidemiology nodes that service particular mission areas.
Specialized Biosurveillance Nodes
Specialized nodes are a large set of quasi-independent and highly specialized biosurveillance nodes that monitor the environment, news media, social media, web queries, and over-the-counter pharmacy sales.32-34 As systems that provide early but nonspecific indicators of an outbreak—such as Google Flu Trends, 35 HealthMap, 36 and others 37 —mature, they will provide valuable inputs into the inference engines used for national surveillance.
Achieving Universal EMR Data Access
The architecture illustrated in Figure 3 relies on access to EMR data at a national scale. A pathway for implementation will be extremely challenging, but lessons can be learned from existing approaches. CDC's BioSense data-sharing model, for example, is based on cloud storage of contributed data in a common data format with specific sharing agreements among BioSense, jurisdictional public health officials, and the data collectors. 38 However, BioSense primarily accesses data that are already available in one of the common data transfer formats—for example, HL7. It does not provide a universal model for accessing EMR data in a query-driven manner at national scale, given the variety of proprietary formats adopted by EMR vendors.
At least 2 other federal health surveillance programs have addressed the EMR access problem. The Sentinel program, 39 administered by the US Food and Drug Administration (FDA), and the CDC's Vaccine Safety Data Link (VSD) 40 utilize cooperative data-sharing models to perform surveillance for medical product safety and vaccine adverse effects, respectively. These programs have assembled consortia of hospital-associated research groups who work under fee-for-service contracts to perform studies of interest to CDC and FDA that use specific data extracted from EMRs and stored in a common format. However, these agreements are sustained by a steady flow of research funding, and participants tend to be larger hospital consortia and university hospitals that perform research as part of a business model. Even so, very extensive coverage of the population is possible, with Sentinel ostensibly covering more than 100 million patients. 41 This particular model works for vaccine and medical product surveillance because, in this case, surveillance consists of specific analysis activities that can be well defined and linked to a known event—the introduction of a new vaccine or other product—and motivated by preliminary evidence of adverse reactions or other harms to health caused by that vaccine or product. It is difficult to see how to reformulate biosurveillance as a research activity in order to fit the national surveillance architecture into this framework.
Two other approaches may provide feasible routes to near-universal access to EMRs. The first is the national adoption of a universal data format for EMRs, based on a common markup language for stored data using metadata-tagged data elements. This approach, based on 2 advisory group studies funded by the White House 42 and the Agency for Healthcare Research and Quality, 43 would neatly solve the problem of heterogeneous EMR formats and make the creation of a query-based software architecture at national scale much simpler. Both the President's Council of Advisors on Science and Technology (PCAST) and the JASONs also advocated an approach to data privacy based on cryptographic key management that is consistent with the distributed architecture described earlier. However, adoption of the PCAST and JASON recommendations is far from certain. For example, discussions with government experts suggest that it is unlikely that this type of standardization will be mandated in future meaningful use directives. Moreover, EMR vendors do not see any short-term market incentive to begin this type of major transition. Thus, a movement toward a common data format is most likely to evolve gradually, if at all, only as different market incentives arise.
An alternative strategy is based on strategic public-private partnerships with the EMR industry to provide the necessary software interfaces for EMR access. The feasibility of this approach is based on 2 observations. First, market dominance by a small minority of vendors implies that only a handful of the largest vendors need participate in order to achieve widespread coverage. Recent market information suggests that with only the 4 largest EMR system providers, a system could access more than 70% of patient medical records in the United States. 44 Second, it is reasonable to assume that since each EMR vendor knows the data format for his or her system, a query-handling application programming interface (API) for surveillance would be relatively simple to implement. In fact, many vendors have already developed APIs that permit the extraction and transfer of data elements from EMRs for clinical decision support systems and for transmittal to third parties. With appropriate modification, this provides a straightforward basis for the development of a query-handling API for biosurveillance. Moreover, the industry has begun to consider standardization of clinical decision support APIs, which might obviate concerns about EMR heterogeneity altogether. Even without standardization, access to a significant fraction of US patient records is still feasible with a small number of custom API development contracts.
If EMR providers included such surveillance interface software, it would greatly simplify adoption as an element of a meaningful use–style incentivization program, placing a minimal burden on hospital information technology resources and, to a large extent, making surveillance “invisible” to hospital operations. Therefore, this approach both makes optimal use of industry capabilities and minimizes the compliance burden on healthcare providers.
Inference Architecture
Developing an accurate, automated surveillance system that is most effective for public health officials requires: (1) increasing the specificity of patient data available to the system by accessing electronic medical records; (2) incorporating autonomous feeds from a variety of special biosurveillance nodes; and (3) developing digital epidemiology nodes that use more sophisticated methods than “anomaly detection” to perform epidemiologic inference. The statistical process control paradigm that currently underpins the inferential architecture of nearly all syndromic surveillance systems—for example, CDC's BioSense—is based on the statistical process control (SPC) paradigm, 45 which seeks to identify anomalous deviations from a background level of disease. Statistical process control approaches assume that, in the absence of an outbreak, people with a given syndromically defined ailment encounter the healthcare system at a stable baseline rate with a stable variance. When the observed rate exceeds the expected variance by a preset amount, the event is classified as an anomaly and an alarm is triggered. It is of some interest that the foundations of this paradigm have been questioned even in the context in which it was originally conceived—industrial process control. 46
To understand why the anomaly detection paradigm is not effective for disease warning, it is instructive to consider a situation where it is moderately effective. The credit industry analyzes past transaction data, and banks develop a “user profile” for each cardholder. Criteria for identifying deviations from the norm are “learned” from a body of everyday transaction data that overwhelmingly represents “normal” behavior. Banks also use a cost model to guide responses to the detection of a putative fraudulent event. Asking customers to verify potential false charges is relatively inexpensive, so banks can tolerate a fairly high “false-positive rate.” A charge denied by the cardholder is often too low to be worth the cost of investigating further; canceling the card may also be inconvenient and costly. Therefore, the bank accepts a certain “false-negative rate” and the financial losses this entails; industry experts suggest that a fairly high rate of false negatives is tolerated. 22
Unlike credit card transaction activity, syndromic data arise from a continuous and overlapping sequence of exposure events and outbreaks of diverse type and widely varying degrees of severity in which it is difficult to define a “normal” state. Theory and experiment have shown that, for contagious diseases, surveillance data exhibit heavy-tailed randomness that makes the identification of “typical” statistical behavior problematic.47,48 Moreover, syndromic data for influenzalike respiratory and communicable gastrointestinal illnesses that have been of greatest interest to public health surveillance originate from a complex mixture of multiple etiologies that may be highly correlated due to seasonal effects.49,50 These phenomena contribute to the difficulty in establishing true baseline and variance estimates, weaken the tradeoff between false alarm and true detection probabilities, and thwart the utility of anomaly detection approaches that use syndromic data alone. This is reflected in the poor tradeoff between detection and false alarm rates exhibited by statistical quality control algorithms and the low confidence that even experienced users place in the utility of syndromic surveillance systems for detecting outbreaks.3-7, 50,51
Epidemiologists also effectively employ a cost model that determines their response to indications of a potential outbreak, although this is seldom explicitly discussed. The limited resources available to most public health departments, coupled with the large number of public health issues they are required to deal with, means that they cannot afford to investigate alerts that are likely to be false positives. Some events, though real, are not worth the cost of investigating, so even with a very high statistical confidence associated with the event, an epidemiologist considers other features (eg, size, severity, benefit of intervention, etc) in deciding whether to respond to the alert. 52 Therefore, public health investigators often express a desire for a surveillance system that can provide information that helps them characterize the event: estimates of severity and transmissibility, case mortality ratios, and demographic risk factors.13,53 These parameters help direct resources and predict consequences of intervention decisions. This implies that a useful surveillance system would go beyond simply detecting “anomalies” but could infer—with an explicit level of confidence—the characteristics of the event itself. We refer to this as a model-building paradigm.
A Bayes-like Model-Building Approach
The key concept of the model-building paradigm is to mimic at the machine level the process of inference that public health investigators undertake when they investigate an event. An epidemiologist performs certain standard procedures during an investigation: polling local hospitals for similar cases; accumulating additional information from patient interviews and chart review; conducting case-control studies to narrow down possible links between patients who may point to the source of the disease or toxin. In effect, model-building requires the machine to perform these functions automatically, to the extent that is allowed by the information that is available through continuous access to EMR data at a national scale and the integration of information from a variety of nonmedical databases and internet sources. When an alert is generated, it contains rich information that both allows the epidemiologist to evaluate the credibility that a real event has been identified and provides some basic information that is helpful for planning investigation and response. This capability calls for a Bayesian-like approach to machine inference (Figure 4).

Digital epidemiology in a Bayes-like framework. Possible types of public health events are tested against the available data. The prior odds Ω0 of an event are determined by observed population behavior such as internet search frequencies, and external events such as foreign outbreaks. The likelihood of observing patient symptoms, test values, and diagnoses if an event were occurring is compared to the likelihood if it were not. The system estimates the odds that the event is occurring, given the observed data.
Epidemiologic knowledge is used to estimate the likelihood that a certain type of event is occurring, given the stream of incoming information about symptoms, diagnoses, laboratory reports, and other medical data on patients nationwide. In the process, a model of the event is built. The model consists of a list of patients who are most likely to be part of that public health event and some parameters that describe the general features of the event—for example: Is it an acute communicable disease outbreak? A chemical exposure event? Is it geographically distributed? Are the data consistent with a population exposure of short duration or is exposure ongoing? What fraction of presenting cases is severe enough to require hospitalization? Signals from specialized biosurveillance nodes that track population behavior such as internet queries and social media chatter about symptoms or diseases are used to determine the prior likelihoods that certain types of events might be occurring. Similarly, information about external events affects the prior likelihoods just as they influence a physician's level of suspicion about certain diseases. Examples include a heightened vigilance for gastrointestinal disease outbreaks during flooding events or for hemorrhagic fever symptoms during an Ebola outbreak in Africa.
Putative Line Lists for Public Health Epidemiologists
A fundamental piece of information that an epidemiologist requires is a list of patients who have been identified as potentially being linked to an outbreak or other health event—the “line list.” A tentative line list could be assembled over time, first compiled as a list of syndromically linked cases as is currently implemented in the ESSENCE system, for example, 54 and then refined by using additional diagnostic information and laboratory reports contained in inpatient records. The system must determine whether cases represent a common medical condition (a case definition) and whether cases have additional linkages beyond syndromic similarity. In some cases, machine-generated survey queries might be generated to gain additional information from patients who were discharged after an emergency or urgent care visit. A machine-generated line list would be a dynamic object, changing as older cases acquire final diagnoses and new putative cases emerge (Figure 5).

A list of patients nominally associated with a public health event is continuously refined by “learning” from continually updated EMR data.
The ability to establish links between patients electronically will depend on numerous factors. Laboratory identification of a common pathogen is the simplest form of link that is machine accessible, although the evidential strength of this linkage for some commonly encountered pathogens will necessarily depend on the typing resolution of the bacterial assay. Common factors for some patients may be identified through natural language analysis of triage or physicians notes, while access to commercial or government databases might establish common purchase or travel activity. Inferring links between cases at the machine level clearly requires rigorous identity authentication and secure query servicing. Biosurveillance systems with a distributed data architecture and secure query protocols have been built and operated at smaller scale by several groups, and these examples can inform the design of the national system.55-57 In addition, architectural and data analysis concepts from financial, energy, and other smart-system sectors may prove useful.
Public Heath Events Define the Jurisdiction
Detecting geographically distributed outbreaks requires jurisdiction-independent event analysis in which patients are linked across jurisdictional boundaries. For example, visitors at a convention are exposed to a disease in the host city and return to their home states before becoming ill. This type of outbreak may be detected only at the national level, even though the exposure event is strictly within the jurisdiction of the host city health department. In a distributed architecture, the event defines the jurisdiction. Improvements to the system's ability to disentangle syndromic data for influenzalike, respiratory, and gastrointestinal diseases will accrue as new diagnostic technologies that can differentiate infectious agents become less expensive and more widely available. Eventually there will be a need to include data from clinical sequencing technologies, which have the power to identify more unusual or previously unrecognized pathogens. 58
Continuous Feedback and Machine Learning
A final ingredient for improving the performance of an automated biosurveillance system is the systematic incorporation of machine learning techniques to take advantage of the long-term and continuous nature of this activity. Modern machine learning algorithms can be implemented at many levels in the architecture we have described, both for line-list construction and model fitting. The multivariate nature and continuous updating of EMR and other data streams makes this a natural arena for machine learning paradigms based on self-organizing data structures, 59 topological mapping, 60 and Bayesian networks. 61 Moreover, information from field investigations can be incorporated automatically and continuously.
While the inferential architecture we propose would have many advantages over systems based on the statistical process control paradigm, it is by no means certain that significant improvement in outbreak detection would be realized for every conceivable event. In some cases, the likelihoods for distinct event models will be very similar—too similar to be distinguishable with “statistical significance.” This is especially true when trying to fit data during the earliest phase of the event, when the number of cases is relatively small. In this sense, each type of event may have a built-in limit for when it can become detectable or can be characterized with a desired degree of precision. In certain cases, this may not be significantly shorter than the time it takes for some astute clinician to discern the event.
Organizational Architecture
In addition to an informational architecture and an inferential architecture, a third component—organizational architecture—is critical for developing a successful automated surveillance system. Unlike the national response framework, which specifies lead agency roles for various types of national emergencies, there is less clarity regarding organizational leadership for the national biosurveillance enterprise. The US Government Accountability Office (GAO) identified 7 federal departments that have key roles and responsibilities for biosurveillance based on agency missions, statutory responsibilities, presidential directives, or programmatic objectives, and it cited a need for a focal entity “with sufficient time, responsibility, authority, and resources to lead the effort” to build “a robust and integrated biosurveillance capability.” 18 Arguably, it has thus far proven difficult to find that focus because no one agency has the technical know-how that spans all of the public health, information technology, and system engineering expertise needed to formulate and execute a sound technical plan for automated surveillance. Regardless, it is easy to see that the organizational architecture for national surveillance must include a dispassionate interagency governing body that can guide the formulation of data standards, oversee the codification of formal notification protocols, define and prioritize research and development needs, regulate the change control process for updating software, and oversee professional development of biosurveillance experts. The governing body must have representation from those agencies that develop and use digital epidemiology modules for specific missions, but it must also have sufficient representation of public health epidemiologists at the state and local levels, because they are primary stakeholders. As the National Syndromic Surveillance Program (formerly BioSense) has demonstrated, appropriate national-level professional organizations such as the Association of State and Territorial Health Officials (ASTHO) can facilitate the participation of members of the “community of practice” for biosurveillence. 62 To the extent that special populations such as active duty military or tribal members are included in surveillance activities, additional stakeholder organizations may also be included.
One of the most critical roles of the governance group will be to ensure that any new analytic modules that are added to the national biosurveillance grid adhere to privacy, information security, and reporting protocol standards. Moreover, this group may also act to oversee and guide the process by which federal-level threat intelligence information is incorporated into digital epidemiology nodes that surveil for new and emerging disease outbreaks. The governance group can also provide key input on national needs to the executive and legislative branches for tailoring future meaningful use objectives or other incentives for improving the availability and scope of electronic medical information.
Conclusion
A national automated surveillance system must first and foremost be a useful tool for the local and state epidemiologists who are the “first responders” to disease outbreaks and other public health events. It is reasonable to expect that a primary function of such a system ought to be early alerting of potential events of public health concern to stimulate more detailed investigations. Syndromic surveillance systems that are now in place do not meet this need and are, in this sense, a technological “dead end” for achieving this goal. Improvement can come only from an architecture that can detect syndromically related cases across jurisdictional boundaries, identify potential linkages among cases, build more “educated” line lists and event models that characterize a putative event, and provide public health practitioners with an assessment of the likelihood that a real event has been revealed. In addition, cost and simplicity suggest that this system be based on an “open” communications grid architecture that permits government agencies access to the information and alerts that they need while leaving medical data where it is collected.
It has been suggested that biosurveillance is a “national public good,” similar in nature to electric power, clean water, and an effective military. 63 However, as a publicly funded enterprise, an integrated, automated biosurveillance system at national scale must be regarded as an element of national infrastructure, requiring a level of analysis, planning, and engineering more akin to other historical infrastructure projects. We have found no perfect analogy among historical national infrastructure projects, but we note that the post–World War II interstate highway system (≈$50B) and the Distant Early Warning radar array (≈$20B) were similar kinds of national security investments. A project of this magnitude calls for an all-of-government consensus on requirements definition, a coherent funding strategy, a more formal trade study, a program of applied research, and well-planned and carefully evaluated pilot projects.
Footnotes
Acknowledgments
Funding for this study was provided by the Department of Homeland Security Science and Technology Directorate. We acknowledge assistance from a number of subject matter experts who graciously lent their time and insight during the production of this document. However, judgments made in this assessment do not necessarily reflect those of contributing subject matter experts or the Department of Homeland Security. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States government or Lawrence Livermore National Security, LLC, and shall not be used for advertising or product endorsement purposes. This work was performed under the auspices of the US Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344.