
Abstract
Over the past 3 decades, the diversity of ethnic, religious, and political backgrounds worldwide, particularly in countries of the Middle East and North Africa (MENA), has led to an increase in the number of intercountry conflicts and terrorist attacks, sometimes involving chemical and biological agents. This warrants moving toward a collaborative approach to strengthening preparedness in the region. In disaster medicine, artificial intelligence techniques have been increasingly utilized to allow a thorough analysis by revealing unseen patterns. In this study, the authors used text mining and machine learning techniques to analyze open-ended feedback from multidisciplinary experts in disaster medicine regarding the MENA region's preparedness for chemical, biological, radiological, and nuclear (CBRN) risks. Open-ended feedback from 29 international experts in disaster medicine, selected based on their organizational roles and contributions to the academic field, was collected using a modified interview method between October and December 2022. Machine learning clustering algorithms, natural language processing, and sentiment analysis were used to analyze the data gathered using R language accessed through the RStudio environment. Findings revealed negative and fearful sentiments about a lack of accessibility to preparedness information, as well as positive sentiments toward CBRN preparedness concepts raised by the modified interview method. The artificial intelligence analysis techniques revealed a common consensus among experts about the importance of having accessible and effective plans and improved health sector preparedness in MENA, especially for potential chemical and biological incidents. Findings from this study can inform policymakers in the region to converge their efforts to build collaborative initiatives to strengthen CBRN preparedness capabilities in the healthcare sector.
Introduction
The risk of chemical, biological, radiological, and nuclear (CBRN) incidents has increased worldwide over the last 30 years. 1 Previous studies have indicated the tentative role of terrorist groups in weaponizing CBRN agents worldwide.2,3 For example, the Aum Shinrikyo group released sarin in a metro subway in Japan in 1995, resulting in more than 600 casualties suffering from acute neurogenic and respiratory symptoms. 4 In the Middle East and North Africa (MENA) region, terrorist groups have attempted to weaponize biological agents such as anthrax, ricin, and cyanide for use in metropolitan cities.3,5 Furthermore, CBRN incidents pose significant risks to the health sector and can lead to widespread public health emergencies if not adequately managed. CBRN incident planning is crucial for governments and the healthcare sector. Once an incident occurs, it has devastating consequences, including injury, illness, death, and widespread panic. Hence, effective preparedness involves identifying potential risks and vulnerabilities, developing preparedness and response strategies and protocols, and coordinating emergency services with other stakeholders to ensure a swift and effective response. Therefore, due to cross-border risks, collaboration across the MENA health sector is crucial to ensure appropriate assessment readiness for managing overwhelming numbers of victims with acute clinical presentations. Similar to other global experiences, such as in Europe,6,7 engaging MENA experts in expressing their opinions about MENA international cooperation through interviews can be a helpful measure to enhance perspectives on building a collaborative approach for CBRN threat health sector readiness.
Artificial intelligence (AI) is a broad and evolving science widely used in medicine for educational purposes, clinical diagnoses, therapeutic decisionmaking, and innovative health research. It stimulates cognizable human functions and provides a detailed problem-solving view. 8 Text mining (TM) is an AI technique that utilizes natural language processing and sentiment analysis techniques to extract meaningful insights by processing unstructured text data into a numeric form, exploring in-depth relationships between variables, and uncovering valuable insights and patterns in data that might be missed with manual analysis alone. 9 At the Spiez Convergence biological arms control conference in 2021, researchers put AI, usually used to search for helpful drugs, into a “bad actor” mode to show how easily it could be abused. 10 It took less than 6 hours for drug-developing AI to invent 40,000 potentially lethal molecules. All the researchers had to tweak their approach to seek out, rather than weed out, toxicity. The AI created thousands of new substances, some similar to the venomous agent X, the most potent nerve agent ever developed. 11 Studies in healthcare have used TM and machine learning (ML) to explore public health information from patients' free-text feedback, which has rarely been fully exploited while valuable information may be hidden.12,13 Other disaster preparedness and resilience studies have used TM for mental health research by analyzing sentiments beyond social media posts during unusual emergencies. 14 Another study used TM to process newspaper articles about the emotional impact of the COVID-19 pandemic on the community. 15 Overall, TM uses different approaches to help mitigate risks by building verbal input-based textual dictionaries that facilitate sentiment polarity assessment and ML algorithm modeling, enabling automated sentiment identification. 16
Expert feedback is considered an invaluable source of information that contributes to determining robust service delivery improvements in system problem-solving measures.17,18 Hence, using TM techniques could help produce an in-depth, objective analysis of experts' free-text feedback regarding the perspectives of MENA countries' coordination and preparedness for CBRN threats, considering the variability of political and geographical challenges and health system readiness levels across the region.
The MENA countries account for 6% of the global population. 19 They are strategically located between Asia, Africa, and Europe, which increases their risk of exposure to disasters, including deliberate and accidental CBRN incidents. The MENA region, particularly the Gulf Cooperation Council, is a global economic power with an important petroleum product hub. Over the past 20 years, the region has witnessed multiple conflicts involving chemical weapons, 20 significantly increasing the risk of exposure to CBRN incidents. Few studies have explored MENA experts' opinions on disaster preparedness levels in the region.21-23 To our knowledge, no previous study has used AI algorithms to explore experts' opinions concerning the MENA healthcare system's readiness to respond to CBRN incidents.
Therefore, this study used TM, including natural language processing and sentiment analysis, as well as ML techniques to analyze open-ended multidisciplinary disaster medicine experts' opinions and emotions concerning MENA countries' joint efforts and preparedness for potential CBRN incidents.
Methods
Study Design and Setting
This was a qualitative cross-sectional study of open-ended responses to a modified interview method for multidisciplinary experts through an online link generated by the Phonic application from October to December 2022. Phonic allowed participants to respond to open-ended questions using recorded audio responses or free text according to their preference. Audio or textual responses were saved automatically within the application and were accessible only to the first author. International experts, selected according to their organizational roles and contributions to the scholars, were sent an invitation email explaining the study objectives and procedures. All participants were required to sign a research consent form on Phonic to access the survey questions. The questions were written in English and French (see Supplemental files, www.liebertpub.com/doi/suppl/10.1089/hs.2023.0093). Both languages are used most in MENA from high school until postgraduate education levels and in the region's national and international scientific events, making them the most suitable for communicating scientific evidence.24,25 Transcripts translated into English were provided by the Phonic application and double-checked by bilingual coauthors to ensure accuracy. By the end of the study period, responses were downloaded in a CSV (comma-separated values) format file. The modified interview method included 37 questions: 12 general questions (including 5 demographic questions), 7 questions about national practices and policies, 6 questions regarding international cooperation, 7 questions on hospital preparedness, and 5 questions about mass gatherings. Questions about mass gatherings were included because MENA countries frequently organize mass-gathering events, such as the Hajj in Mecca in the Kingdom of Saudi Arabia, religious events in Karbala and Arbaeen in Iraq, Christian pilgrimages in Jerusalem, Jewish pilgrimages in Djerba in Tunisia, 26 sporting events (eg, the recent International Federation of Association Football World Cup in 2022 and the approaching basketball World Cup in 2027 in Qatar), as well as African, Arabic, and Asian championship leagues and other festivals.27-29
Participants
We used purposeful sampling to identify information-rich individuals corresponding to the study objective for selection. 30 Based on these criteria, we sent invitation emails describing the study objectives to 92 CBRN experts (76 English-speaking and 16 French-speaking) from different MENA countries, including Egypt, Iran, Kuwait, Morocco, Oman, Qatar, Saudi Arabia, Tunisia, Turkey, and the United Arab Emirates, who were interested in the MENA region. Study participants included experts with at least 1 master's degree and expertise in CBRN, toxicology, emergency and disaster medicine, or health sciences. Their expertise was defined through their organizational roles and contributions to the academic field. To ensure a meticulous selection, candidates were identified from the authors' global professional networks, with prioritization given to those who met the inclusion criteria and were affiliated with national and international governmental and nongovernmental organizations, such as MENA ministries of health and interior, the World Health Organization (WHO), and other United Nations agencies. The research consent form, refresher leaflet, and Phonic user guidelines, prepared in French and English, were attached to the email.
Data Analysis
Data analyses were performed using R language accessed through the RStudio environment. The code generated in R for data cleaning and analysis is presented in the Supplemental files (www.liebertpub.com/doi/suppl/10.1089/hs.2023.0093).
Data Cleaning
Data cleaning is essential for rendering raw data suitable for descriptive, TM, and ML analyses. Code was created in RStudio through the following steps: (1) special characters such as “/”, “@”, and “|” were replaced with spaces; (2) all spaces between words were removed; (3) all dataset words were converted into lowercase words; (4) stop words, such as “the”, “a”, “is”, “at”, and “on”, which are frequently used in the spoken language but were insignificant for the analysis, were removed; finally, (5) numbers and punctuation were removed.
Natural Language Processing and Sentiment Analysis
First, we performed a word count, followed by the creation of a “word cloud.” This enabled easy visualization of the most common words in the text according to size. The larger the word size on the word cloud, the more frequently the word was mentioned in interviews. The word cloud oriented us to the key themes that experts showed interest in.
Subsequently, the correlation coefficient was calculated for the top 6 repeated words, with the remaining words in the text using the function “findAssocs()”. This helped provide insights into the context in which these words were mentioned. We then performed sentiment analysis by calculating the sentiment scores of the participants using the “get_sentiment()” and “get_nrc_sentiment ()” functions. Several packages in R calculate sentiment scores and determine their ranges differently. In this study, the Syuzhet package was used. 31 It works well with other popular text analysis packages in R, such as “tm” and “tidytext”, making it easy to incorporate sentiment analysis into a broader TM workflow, allowing multiple sentiment extraction methods.31,32 Upon examining the first vector score, the sentiment scores ranged from -0.5 (representing the most negative) to 10.3 (representing the most positive). A summary of the descriptive statistics of the sentiment scores and the Shewhart control chart were used to observe score variation among the participants. A Pareto chart was used to observe the overall sentiment score according to the participants' nationalities.
Unsupervised Machine Learning
Supervised and unsupervised ML can be used to analyze open-ended responses. Supervised ML is primarily used for sentiment analysis because it is labeled and known. This study used unsupervised ML to explore unlabeled text data and identify any existing similarities provided by the participants. Cluster analysis was conducted to explore the textual data, 33 with fewer clusters indicating better consensus in opinions. ML is widely used to explore data through open-ended text responses. 34 Hierarchical and k-means algorithms were used in this study, and a dendrogram plot was used to identify the clusters in both algorithms. 33 The silhouette coefficient, which ranges between -1 and 1, was used to assess model accuracy. A value between 0 and 1 indicates good clustering—the closer the value is to 1, the better. A model with a high silhouette coefficient is preferred. 33 A principal component analysis was conducted to identify participants' clusters.
Ethical Board Approval
This study was approved by the ethical review board of the Faculty of Medicine, “Ibn Eljazzar” of Sousse in Tunisia (CEFMS 110/2022) and by the Hamad Medical Corporation's Medical Research Centre Institutional Review Board Committee in Qatar (MRC-01-22-258).
Results
Demographic Data
Thirty-five participants agreed to participate in the study. After conducting interviews with 29 participants, we achieved data saturation; hence, further data collection was stopped. The mean age of the participants was 34.37 years (SD 8.01 years). Table 1 and Figure 1 present the demographic characteristics of the study participants.
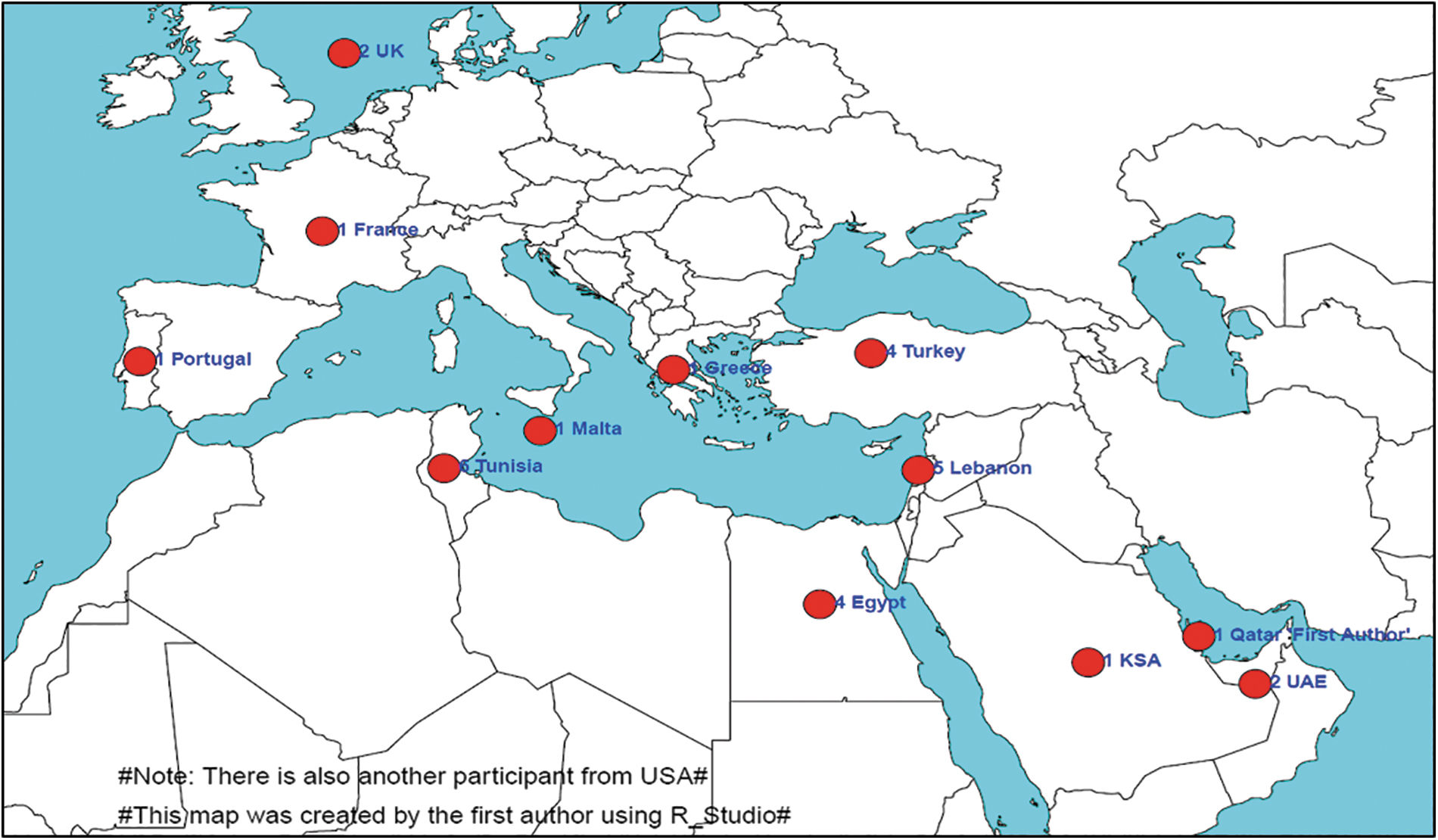
The geographic distribution of participants according to their country of residence. Abbreviation: KSA, Kingdom of Saudi Arabia; UAE, United Arab Emirates; UK, United Kingdom; USA, United States of America.
Participant Demographic Information
Abbreviations: CBRN, chemical, biological, radiological, and nuclear; Max, maximum; MIM, modified interview method; Min, minimum; Qu, quartile; SD, standard deviation.
Exploratory Data With Natural Language Processing and Sentiment Analysis
The word cloud in Figure 2A demonstrates the most repeated words used by participants as represented by their size; the bigger the word cloud, the more that word was repeated. The scatter plot in Figure 2B shows the top 50 words mentioned by participants. The 4 primary prominent stem words were “plan” (n=54), “plans” (n=50), “training” (n=46), and “disaster” (n=38).
(A) Participants' word cloud based on their responses to the questions; (B) scatter plot of the top 40 words mentioned by participants.
Table 2 presents the correlation coefficients for the 5 primary words mentioned by the participants. First, “plan/plans” is highly correlated with words like “country,” “needed,” and “international,” among others. Participants mentioned a lack of available and accessible plans, which could cause challenges when managing CBRN emergencies. The word “training” was highly correlated with words like “incident,” “full,” and “preparedness.” Participants mentioned that frequent training sessions to explain the health outcomes of failure in managing a CBRN threat helped ensure adequate preparedness. The word “disaster” was highly correlated with “specialized,” “council,” and “activity.” The participants agreed that committees or councils at the hospital and national levels must ensure readiness plans for each type of disaster according to a country's identified risks. Furthermore, “CBRN” was unsurprisingly mainly correlated with “chemical” and “biological.” According to the participants, these were the most common threats in the wider category of CBRN.
Correlation Coefficients of 6 Prominent Words in the Top 10
Abbreviations: CBRN, chemical, biological, radiological, and nuclear; Coeff, coefficient.
The participants' sentiment scores were calculated using “get_nrc_sentiment ()” of the Syzhut package in R. They were then plotted in the Shewhart chart in Figure 3A using the “qcc” package. The scores varied between -4.4 and 15, and 25 with a mean of 3.11 (SD 5.22). The higher the score, the more positive the sentiment expressed by participants. The Shewhart chart in Figure 3A indicates that the variation in sentiment scores between participants was within the control limits with no significant difference, except for 3 participants (Figure 3B) from Greece, the United Kingdom, and Portugal. They had high scores, likely reflecting positive thinking due to their experience in the field. For example, a participant from Greece with the highest sentiment score had over 35 years of experience as a military physician, had experience in CBRN preparedness and response at hospital emergency departments since 2001, was involved in the 2004 Olympic Games CBRN preparedness efforts, and was an international CBRN instructor working together with the Organisation for the Prohibition of Chemical Weapons to train the Olympic CBRN Response Unit of Army General Hospital of Athens. This participant's high sentiment score is reflected in the Pareto chart in Figure 3C, which shows sentiment score distribution by nationality. The data were categorized as follows: positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust. Figure 3D shows the sentiment scores classified according to the sentiment type and distribution.
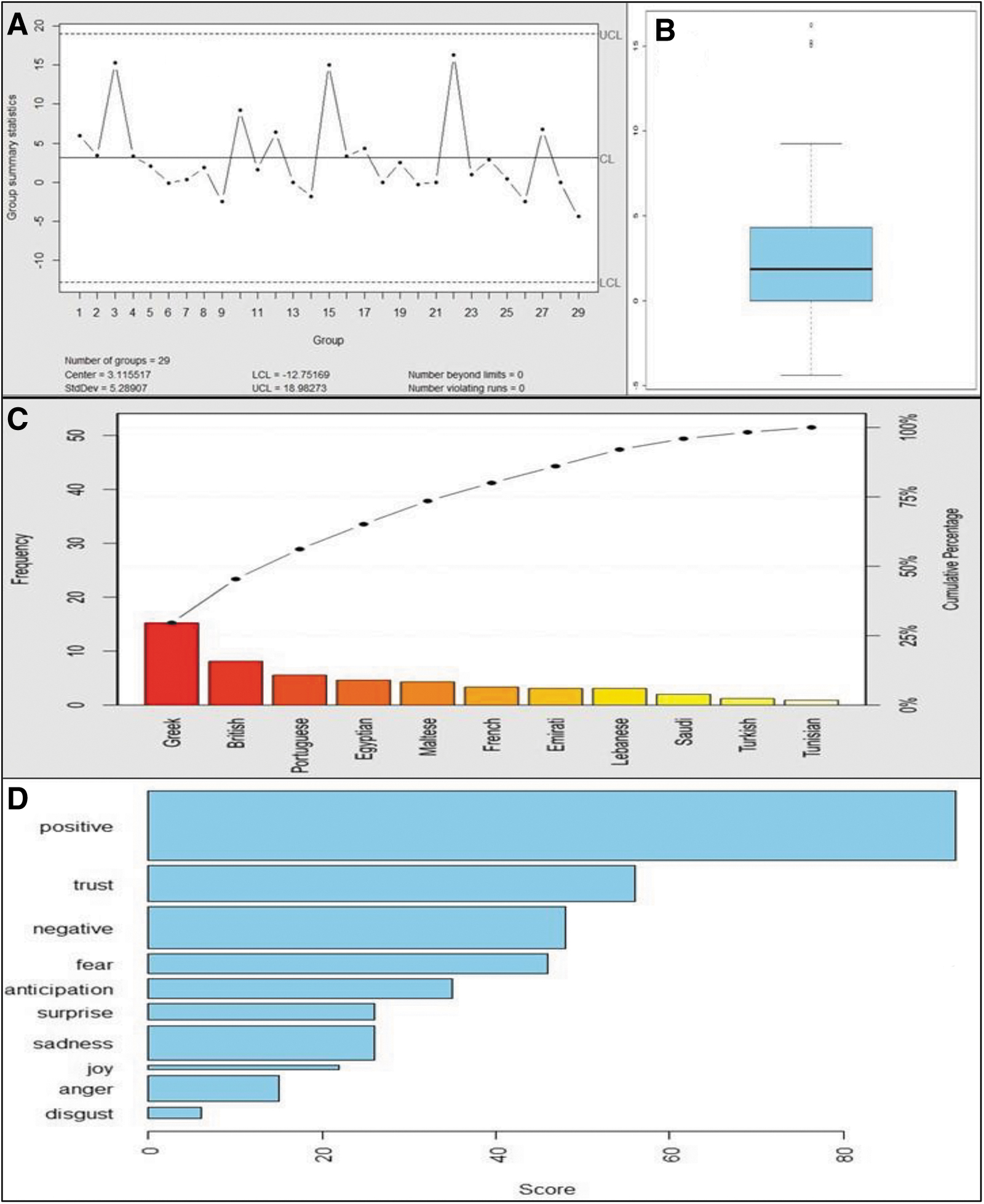
(A) Shewhart control chart of participants' sentiments scores; (B) boxplot chart of participants' sentiments scores; (C) Pareto chart of participants' sentiment scores by nationality; (D) participants' sentiments identified during the modified interview. Abbreviations: SD, standard deviation; UCL, upper control limit; LCL, lower control limit.
In Figure 4, the coordinated parallel plot allows for the visualization of multivariate data in a multidimensional manner. The correlation between emotions and text was calculated using the “COR ()” function. The resulting correlation matrix was used to create a heatmap using “ggplot2” and “reshape2” packages. Finally, the parallel coordinate plot and heatmap displayed the combined chart using the “plot_grid()” function of the “cowplot” package. The parallel coordinate plot shows the distribution and relationships between different emotional variables.
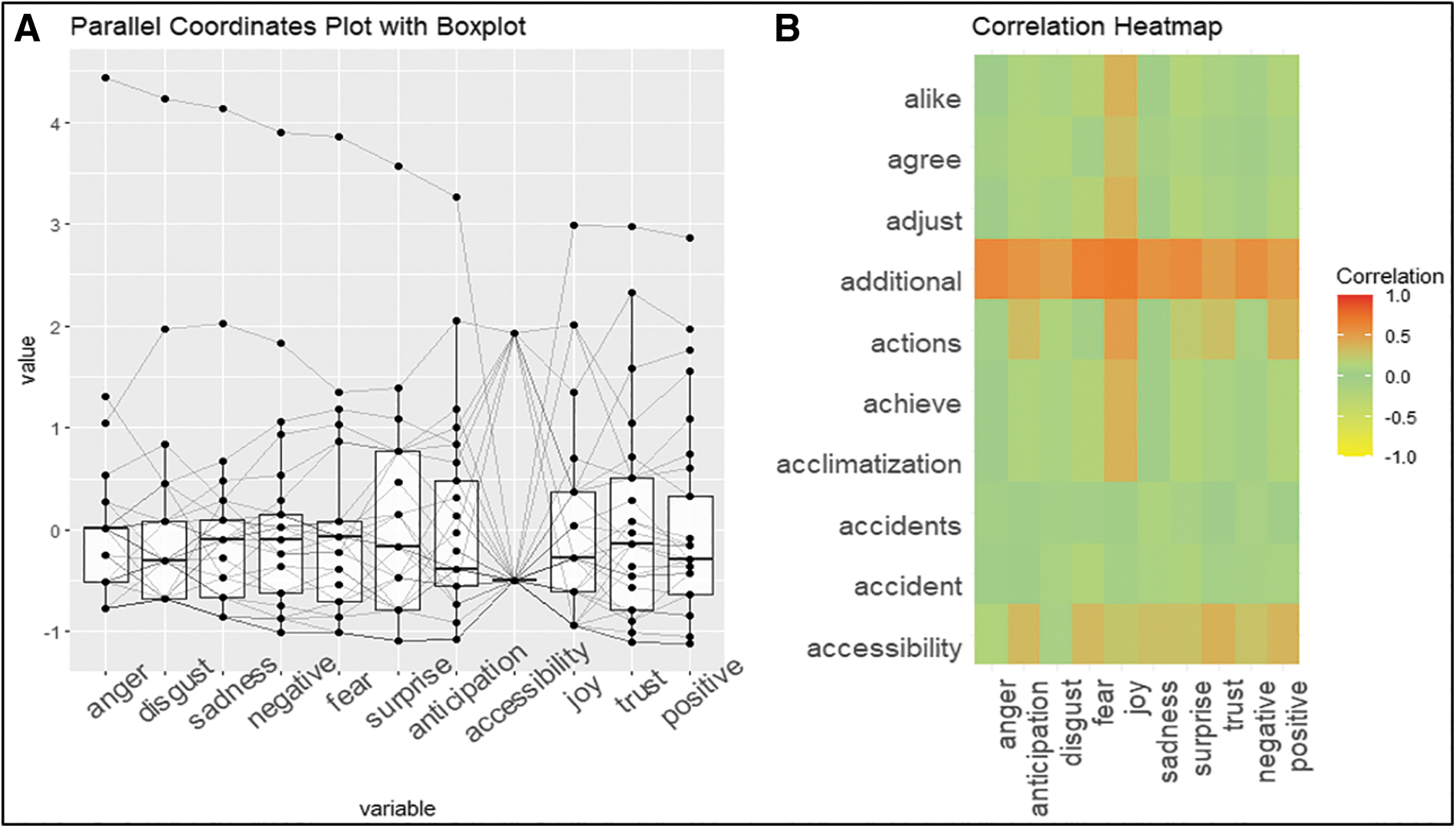
(A) Parallel coordinates plot with boxplots of participants' emotions; (B) correlation heatmap between emotions and words.
The parallel plot and heatmap in Figure 4 show the relationship between emotions and words or phrases mentioned in the open-ended text data related to CBRN preparedness in the MENA region. The parallel coordinate plot shows the relationships between each emotion within the text, whereas the heatmap shows the correlation between these variables and the text data of the words. The combination of these 2 plots assessed the relationship between the emotions and language used in the dataset. In Figure 4A, the emotions of “sadness,” “negative,” and “fear” have higher medians, as shown by the boxplots, meaning they were the emotions with higher values in the text data. The parallel plot shows how different emotions are related and the frequencies of words or phrases. Each line in the parallel plot represents a different emotion, and the vertical lines connecting the lines represent the values of each variable, that is, the frequency of the corresponding word or phrase.
Furthermore, these emotions, except “disgust” and “sadness,” converge in the word “accessibility,” indicating that they were mainly associated with it. In contrast, the emotions of “positive,” “trust,” and “joy” diverge from the word “accessibility,” which suggests that there was no association. This is also confirmed by the heatmap in Figure 4B, which shows the correlation between emotions and words. The closer the coefficient is to 1, the stronger the correlation.
In the heatmap in Figure 4B, each row represents a different emotion, and each column represents a different word or phrase. The color of each cell represents the frequency of the corresponding word or phrase in the text data associated with the corresponding emotion; darker colors indicate a higher frequency.
Clustering Analysis
First, the 2-cluster method was utilized for the k-means algorithm as determined by the silhouette coefficient (s=0.57), which ranges between -1 and 1. A value close to 1 indicates good clustering. A silhouette plot was used to determine the distances between the resulting clusters. This helps assess whether a cluster has a high degree of compatibility within its designated cluster and demonstrates low compatibility with neighboring clusters. The dendrogram in Figures 5A and 5B show the clusters according to color. Figures 5C and 5D show that the silhouette coefficient is 0.34, indicating the efficiency of the selected clustering in providing well-structured data.

(A) Dendrogram of k-means clustering algorithm; (B) dendrogram of hierarchical clustering algorithm; (C) cluster silhouette plot for k-means algorithm; (D) cluster silhouette plot for hierarchical algorithm.
Principal component analysis was conducted to determine principal components 1 (PC1) and 2 (PC2), as shown in Figure 6, which depicts the distribution of data points depending on their values. The texts in each cluster tend to cluster together, establishing different groupings. Each point represents a participant's response, and the colors of the points determine the clusters.
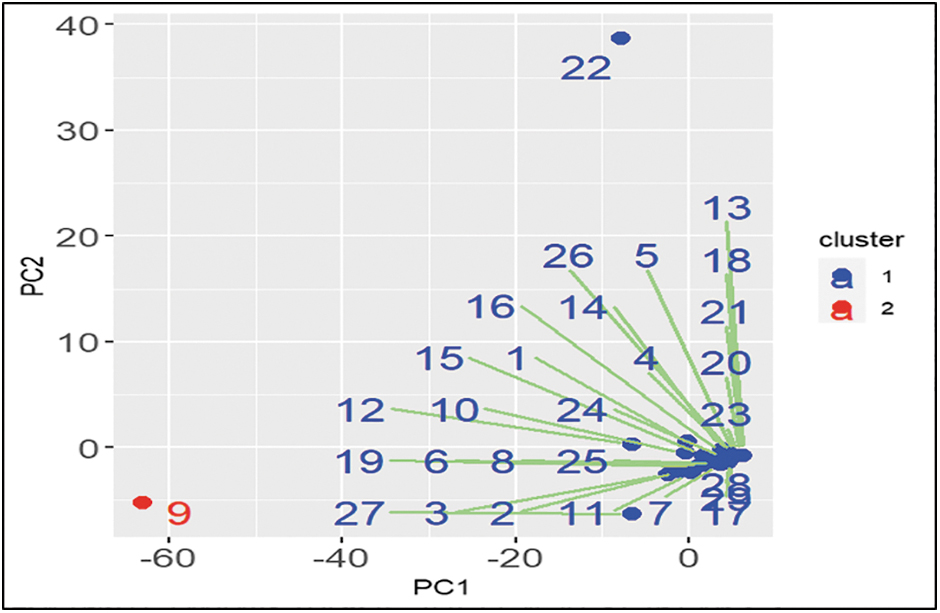
Participants' clustering. Principal component analysis plot for principal components 1 (PC1) and 2 (PC2). Each data point represents a participant's response and the colors indicate clusters.
Discussion
Undoubtedly, learning from the opinions of academically trained experts in disaster management, particularly CBRN, is crucial for decisionmaking and may help ensure the continuous improvement of preparedness and response plans. While using open-ended questionnaires and interviews may be time-consuming, they allowed us to explore various profound aspects of the study objective. Furthermore, the nature of the unstructured responses enabled participants to express their opinions freely. However, determining whether experts have a consensus involves a complex assessment that can be subjective based on the researcher's interpretation and own views. Hence, in this study, we used TM, including natural language processing and sentiment analysis, as well as ML techniques to convert textual input into numbers using a logical sequence of learning steps of a clustering algorithm and built an explanatory model through a dictionary-based approach to express the sentiments of participants. Using these AI tools, an in-depth analysis of open-ended feedback from the modified interview was performed by transforming the textual data into numeric values and providing an overview of the most frequently used words in the form of a word cloud. The analysis also identified the participants' sentiments, understood their correlation with the textual input, clustered the participants' opinions and emotions according to their responses, and helped determine correlations between the words and sentiments (Figure 4 and Table 2).
Sentiment analysis is considered a powerful tool in the medical field for identifying linguistic quirks of opinions and the emotions behind them. 35 In healthcare, for example, a substantial amount of feedback data are being gathered on the patient experience. However, this information has not been exploited fully or adequately because of the difficulty in determining a pattern of free-text feedback. Sentiment analysis enabled an in-depth exploration of free-text data and an understanding of the emotions behind it, which was similarly utilized in a recent study analyzing patient experience feedback. 36
In this study, although the experts had positive sentiments toward improving intercountry cooperation in the MENA region, fear and sadness were also identified regarding the accessibility of preparedness plans by healthcare staff at the hospital and national level (Figures 3 and 4). Access to a documented contingency plan was also identified as a primary challenge in effectively ensuring readiness to manage biological threats, such as pandemics. 36 Furthermore, a MENA study emphasized that contingency plans must be available to everyone, which would enable frequent testing and evaluation of these plans and guide improvements. 37 Experiences during the severe acute respiratory syndrome pandemic in 2002, the Middle East respiratory syndrome in 2012, and the recent COVID-19 pandemic have highlighted that designing response plans and disseminating them without testing may frustrate healthcare professionals if no prior training is conducted. 38 Testing, adapting, and updating plans is an ongoing process, that occurs during all phases of a disaster management cycle. 39 Another study showed that participants' confidence in responding to CBRN disasters increased with practice. 40 Additionally, the clustering determined by unsupervised ML in Figures 5 and 6 helped to identify that most participants agreed with the elements raised in the modified interview method questions. These questions explored their opinions on a few themes, including CBRN preparedness, international cooperation perspectives within the MENA region, the value of tabletop exercises as a training modality for CBRN, and the role of WHO in leading coordination within the region. In the same context, studies have found that appropriate preparedness can be ensured through adequate planning and training for all healthcare professionals.41-43 Researchers in Saudi Arabia have also recommended implementing disaster management training in medical school undergraduate programs to improve disaster preparedness metrics. 44 Despite that respondents in this study identified negative and fearful feelings about some points, such as accessibility (Figure 4), the experts expressed similar positive sentiments, indicating a consensus on the overall perspectives raised in the interview questions.
Further, the experts mentioned “planning,” “training,” and “coordination,” the first triad within the top 10 words (Figure 2B). A couple of studies have identified effective coordination and appropriate coordinated training as crucial to ensure the appropriate readiness of healthcare professionals for CBRN incidents in hospitals, thereby promoting the development of this concept at the regional level in MENA.43,45 However, experiences in the MENA region during previous reemergent pandemics over the last 2 decades have revealed challenges at various levels. These include challenges in the academic and research settings that varied significantly between MENA countries, which limited initiatives and promoted a culture of not sharing information. 19 Such challenges led to the isolation of MENA academic research sectors and weakened healthcare readiness for all CBRN threats, including reemerging pandemics, by following other countries' newly identified therapeutic guidelines and not leading to any emerging initiatives. A 2020 study 19 in the MENA region identified that despite the availability of healthcare experts in the MENA region and the Gulf Cooperation Council as financial and industrial powers, no published clinical trials were conducted in the region during the 2009 swine flu pandemic, the 2002 SARS outbreak, 2014-2016 Ebola outbreak, or the 2012 Middle East respiratory syndrome outbreak; however, a few clinical trials were conducted related to the COVID-19 pandemic.19,46
The second triad within the top 10 words mentioned by experts was “health,” mass,” and “chemical.” Previous worldwide experiences in Japan, the United Kingdom, and a few MENA countries have taught us that chemical and biological agents are easier to weaponize and utilize in attacks, exhausting health sector countermeasures. 47 The experts also identified the most accessible elements to be weaponized and utilized by terrorist groups in MENA. 48 Their immediate effects lead to the rapid onset of acute respiratory syndrome, which is sometimes fatal. 49 Furthermore, previous studies have identified that healthcare professionals, if not well trained, are easily exposed to the secondary contamination of chemical and biological agents, including viruses, when delivering lifesaving interventions.50,51 This explains the concerns among respondents about the preparedness of healthcare staff for chemical and biological agents. In addition, the frequent mention of the word “mass” indicates that these incidents aim to create the highest number of casualties possible, resulting in mass exposures. A WHO report 52 generated in Beirut in 2019 identified that most MENA countries have not conducted a national risk assessment for hosting large crowds or any focused risk assessment for specific large crowds, despite that the MENA region hosts a number of the world's largest mass-gathering events annually. For example, the Muslim pilgrimage in Mecca and the gatherings in Arbaeen in Iraq are attended annually by worshippers from hundreds of neighboring countries. These events can be targeted by terrorist attacks that use chemical and biological agents and radiological dispersal or emitting devices. Therefore, WHO encouraged the MENA countries to meet frequently, share their best practices, and enhance collaboration for mass-gathering incident preparedness.
The third triad within the top 10 words mentioned by experts was “disaster,” “CBRN,” and “will,” which was the modified interview method question's main interest.
While sentiment analysis inherently captures subjective perceptions, our integration of ML and TM aimed to systematically reduce interpretive biases. 53 This approach strived for a balanced, structured analysis of expert opinions, fostering a reproducible framework for understanding nuanced sentiments in the complex realm of disaster medicine.
Further, in light of our findings, it is imperative to outline potential pathways forward for CBRN preparedness in the MENA region. First, a concerted effort is needed to make preparedness information more accessible to healthcare professionals. This could be achieved by establishing regional knowledge hubs or online platforms dedicated to CBRN preparedness. Such platforms could host webinars, training modules, and best practice guidelines, ensuring that professionals have a 1-stop shop for all their information needs. Second, fostering intercountry collaborations can streamline resource-sharing and knowledge transfer. Countries can collectively enhance their preparedness levels by leveraging strengths and sharing challenges. Last, policymakers must initiate public–private partnerships, bringing in expertise and resources from the private sector and ensuring that preparedness measures are holistic and well rounded. For example, the CBRNE Research and Innovation Conference epitomizes collaborative engagement with an array of professionals ranging from emergency medical services to esteemed academics from institutions like the University of Strasbourg. It offers an interdisciplinary platform and emphasis on cutting-edge topics, from CBRN detection and protection to medical countermeasures and forensic sciences, which resonates with our study's aspirations. 54 Such events underscore the essence of face-to-face dialogues, workshops, and experiential learning, which could be indispensable for replicating and enhancing the outcomes of our research in wider contexts. With these steps, the MENA region can look forward to a more robust, informed, and collaborative approach to CBRN preparedness.
While the MENA region's significance in disaster medicine is paramount, our study collected feedback from leading experts. Despite a 31% (n=29) participation rate, this cohort was sufficient to achieve data saturation, underscoring that quality often prevails over quantity in qualitative research. 55 Although broader participation might have enriched perspectives, the depth of expertise captured was robust. AI analysis techniques enhanced our data's richness, spotlighting core themes and ensuring the relevance and rigor of our findings.
This study has several limitations. First, experts from some MENA countries, such as Iran, Jordan, Kuwait, Morocco, Oman, and Qatar did not accept the invitation to participate. To foster a collaborative approach to CBRN readiness, it is imperative to comprehensively understand each country's unique challenges and strengths within the MENA region. While our study provides crucial insights from the participating countries, we acknowledge the limitation of nonresponses from certain nations. Engaging with these nonresponding countries in future research is vital. Their perspectives will enrich the dialogue and facilitate a more unified and holistic regional strategy, ensuring that collaborative CBRN preparedness efforts are both inclusive and effective. Second, despite using the Phonic application, which helped ensure a smooth process, responding to open-ended questionnaires and participating in interviews was time-consuming for experts who had other responsibilities in their respective states. Third, TM and ML algorithms' performance could improve with an increased amount of text-based feedback. However, finding more disaster medicine experts who fulfilled the inclusion criteria and were willing to participate and help ensure the diversity of information was challenging.
Conclusion
The results of the sentiment analysis showed that the overall sentiment toward the preparedness and response capacity of the health sector in the MENA region was generally positive. However, some experts expressed concerns about various challenges. These insights can be used to identify areas that require improvement and to inform policies that enhance the preparedness and response capacity of the health sector in the MENA region. Moreover, this study demonstrated the potential of natural language processing techniques for analyzing experts' opinions on complex issues related to public health and safety. Such methodologies may be crucial, offering policymakers and stakeholders invaluable insights and enabling judicious decisionmaking in enhancing the MENA region's readiness for CBRN incidents.
Footnotes
Acknowledgments
The authors would like to thank all experts who participated in the study and agreed to be acknowledged, including Craig Campbell, Ayşe Dökmeci, Mohammed Heriza, Henda Chebbi, Amira Jaafar, Sami Souissi, Nelson Olim, Mike Lynch, Ahmed Abdulsaboor, Joelle Khadra, Mohamed Abdelaziz, Ayla Sayın Öztürk, Gamal Eldin Khalifa, Mohammed Heriza, Adham Abulnour, Michael Spiteri, Rabih Asmar, Nelson Olim, and Fadi El Ters. The authors would also like to extend their appreciation to King Saud University, Riyadh, Saudi Arabia, for funding this work through the Researchers Supporting Project (RSPD2023R649). The first author would like to thank Ms. Cyrine Abidi for all the machine learning knowledge she has previously shared, as well as the University of Sfax in Tunisia, especially Prof. Imed Gargouri, for all the data science courses in their institution. The authors thank the reviewers for their constructive feedback that helped improve this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.