
Abstract
Abstract
Objective:
Automating conversation analysis in the natural clinical setting is essential to scale serious illness communication research to samples that are large enough for traditional epidemiological studies. Our objective is to automate the identification of pauses in conversations because these are important linguistic targets for evaluating dynamics of speaker involvement and turn-taking, listening and human connection, or distraction and disengagement.
Design:
We used 354 audio recordings of serious illness conversations from the multisite Palliative Care Communication Research Initiative cohort study.
Setting/Subjects:
Hospitalized people with advanced cancer seen by the palliative care team.
Measurements:
We developed a Random Forest machine learning (ML) algorithm to detect Conversational Pauses of two seconds or longer. We triple-coded 261 minutes of audio with human coders to establish a gold standard for evaluating ML performance characteristics.
Results:
ML automatically identified Conversational Pauses with a sensitivity of 90.5 and a specificity of 94.5.
Conclusions:
ML is a valid method for automatically identifying Conversational Pauses in the natural acoustic setting of inpatient serious illness conversations.
Introduction
Improving clinician–patient communication in serious illness is a priority for twenty-first century healthcare. 1 However, traditional approaches to measuring communication in the natural clinical setting are cumbersome, expensive, resource intensive, and cannot be done in real time. 2 Clinical conversations in serious illness are complex, dynamic, and relational phenomena that exist in a variety of clinical contexts. Understanding the quality of such conversations, therefore, requires an “ecological” approach to analyzing them3–5 capable of evaluating complex interactions between the conversation content and the contexts in which they occur. Machine learning (ML) holds great promise for automating elements of conversation measurement for use in large sample epidemiological studies required to evaluate complex interactions. 2
We focus here on an important linguistic measure of conversational process and dynamics—the Conversational Pause.6–13 We define Conversational Pauses as moments when no participant in the target conversation being recorded is speaking or otherwise audibly attempting to claim the speaking floor. 13 Linguists, sociologists, anthropologists, psychologists, medical scientists, and others have long endorsed the empirical value of Conversational Pauses in the study of clinical conversations.6–10,13–20 For example, the acoustic features of Conversational Pauses can potentially help researchers distinguish moments of listening, engagement, and human connection from moments of disengagement, awkwardness, and distraction, and lend insights into dynamics of professional politeness, turn-taking, etiquette, and power dynamics in often terrifying clinical settings.6–15,17–19 However, the capacity to automate the measurement of Conversational Pauses has not yet been confirmed for use in natural clinical settings.
Methods
Overview
This is a cross-sectional study of audio recordings of palliative care consultations involving 231 patients and 54 palliative care clinicians in the multisite Palliative Care Communication Research Initiative (PCCRI). 21 Human coders identified Conversational Pauses that were subsequently used to train a ML algorithm to automate their identification.
Participants and setting
The parent cohort study took place at two academic medical centers with well-established palliative care services: The University of Rochester Medical Center in New York and the University of California San Francisco Medical Center. Hospitalized adult patients were eligible for the study if they spoke English, were diagnosed with advanced cancer, and were referred for inpatient palliative care consultation. All clinician members (i.e., physicians, nurses, nurse practitioners, physician assistants, social workers, and chaplains) of the palliative care teams were eligible.
With informed consent, research staff placed digital handheld recorders in the hospital room immediately before palliative care consultation. All participants were shown how to turn off the recorder and informed that they could do so (or request it to be turned off) at any time if they wished to (this never happened). The recorders had built-in omnidirectional microphones and were placed within three feet of the patient, usually on rolling bedside tables. Occasionally, staff placed the microphones further away (e.g., four to five feet) when the rooms were crowded or the microphones were otherwise deemed intrusive by research staff.
The study focused on initial consultation with the palliative care team. Sometimes, however, these initial conversations are cut short due to clinical demands (e.g., transport to CT scan) or by the patient's preference to wait for a loved one to arrive, usually later that same day. Therefore, the study protocol allowed for up to three recorded conversations per patient for situations that required multiple visits for an “initial” consultation conversation. The PCCRI dataset is fully described elsewhere 21 and contains 363 conversations involving 231 patients and 54 palliative care (PC) clinicians. We excluded nine conversations (from six patients) having sufficiently low audio quality (n = 8) or nonverbal methods of communicating (n = 1) that some speakers in the target conversation could not be heard well enough to know whether a pause was happening. This analysis includes the remaining 354 conversations from 225 patients comprising 9770 minutes of audio data.
Definition of conversational pauses
We define the “target conversation” as that involving the people gathered for the palliative care consultation visit (e.g., patient, family, and clinicians). We define a Conversational Pause as any event of two seconds or longer when no participant in the target conversation is speaking or attempting to claim the speaking floor (e.g., “um,” “uh-huh”). Other nonspeech sounds in the target conversations (e.g., light sighs or seemingly involuntary sounds such as a soft cry, cough, or heavy breathing) are not considered interruptions in Conversational Pauses. Other environmental conversations, including televisions, clinicians in the hallway, a neighboring patient/family in a shared room, and other similar contexts, are not considered part of the target conversation.
Acoustic features for ML
We extracted 17 audio features commonly used in automated audio event detection for speech recognition or emotion detection. 22 These include 13 Mel Frequency Cepstral Coefficients,23,24 which are transformations of an audio signal that approximate the way sound is perceived by the human ear. In addition, we computed zero-crossing rate, 25 energy, 26 energy entropy, 26 and spectral entropy.26,27 These 17 audio features were initially computed for 50 ms time intervals (with 25 ms overlap) and subsequently aggregated for 0.5-second nonoverlapping intervals using five common statistical aggregators (mean, median, standard deviation, minimum, and maximum). This yielded 85 audio features for each 0.5-second interval.
Creation of the training dataset
A human coder first identified 239 Conversational Pauses and 936 segments of conversational speech, each of duration 1.8–2.3 seconds, in 60 randomly selected conversations with a variety of voice types and amid a variety of background noise settings. The human coders used audio editing software to listen to the audio clips while simultaneously viewing the amplitude of the audio signal. Durations of Conversational Pauses were determined by clicking the mouse on the start and end times of each Conversational Pause on the amplitude graph. The 1175 segment dataset included roughly four times more speech events than Conversational Pause events, because we sought to include speech samples that spanned the wide variety of voices in this study. Two additional human coders independently labeled each event as either speech or Conversational Pause, and we defined the event as a Conversational Pause only when all three human coders were in agreement. We subsequently divided each of the 1175 training segments into 0.5-second intervals for training the ML algorithm, described as follows.
ML for identification of conversational pauses
We implemented an ML classifier to identify Conversational Pauses using a two-step process. In step 1, the classifier labeled each nonoverlapping 0.5-second interval as either containing speech or not. In step 2, we identified contiguous intervals totaling two seconds or longer that had been labeled (in step 1) as not containing speech and defined these to be Conversational Pauses.
For step 1, we initially experimented with several types of supervised ML classifiers, including Support Vector Machines, 28 Counterpropagation Neural Networks, 29 and Random Forests. 30 We also experimented with using either the raw audio feature vectors or their principal components 31 as training data. We evaluated each method using 10-fold cross-validation. Ultimately, we observed the best performance (average cross-validation accuracy of 0.98), using Random Forests with 50 decision trees, trained on the raw audio feature vectors. Training a final Random Forest on all 1175 training samples required 2.2 seconds on a 3.2 GHz Intel Core i5 processor.
For step 2, the final trained Random Forest was used to predict whether each 0.5-second interval contained speech or not for all 354 recorded conversations. Conversational Pauses were identified as occurring whenever there were four or more consecutive 0.5-second intervals not containing speech (i.e., that totaled two seconds or longer). We settled on a two-second minimum cutoff because with shorter pauses, it was challenging for human coders to distinguish between normal transitions between speakers and actual pauses in the conversation. We considered a longer pause threshold but observed substantial decrease in prevalence for each 0.5 increment beyond two seconds (Fig. 1).
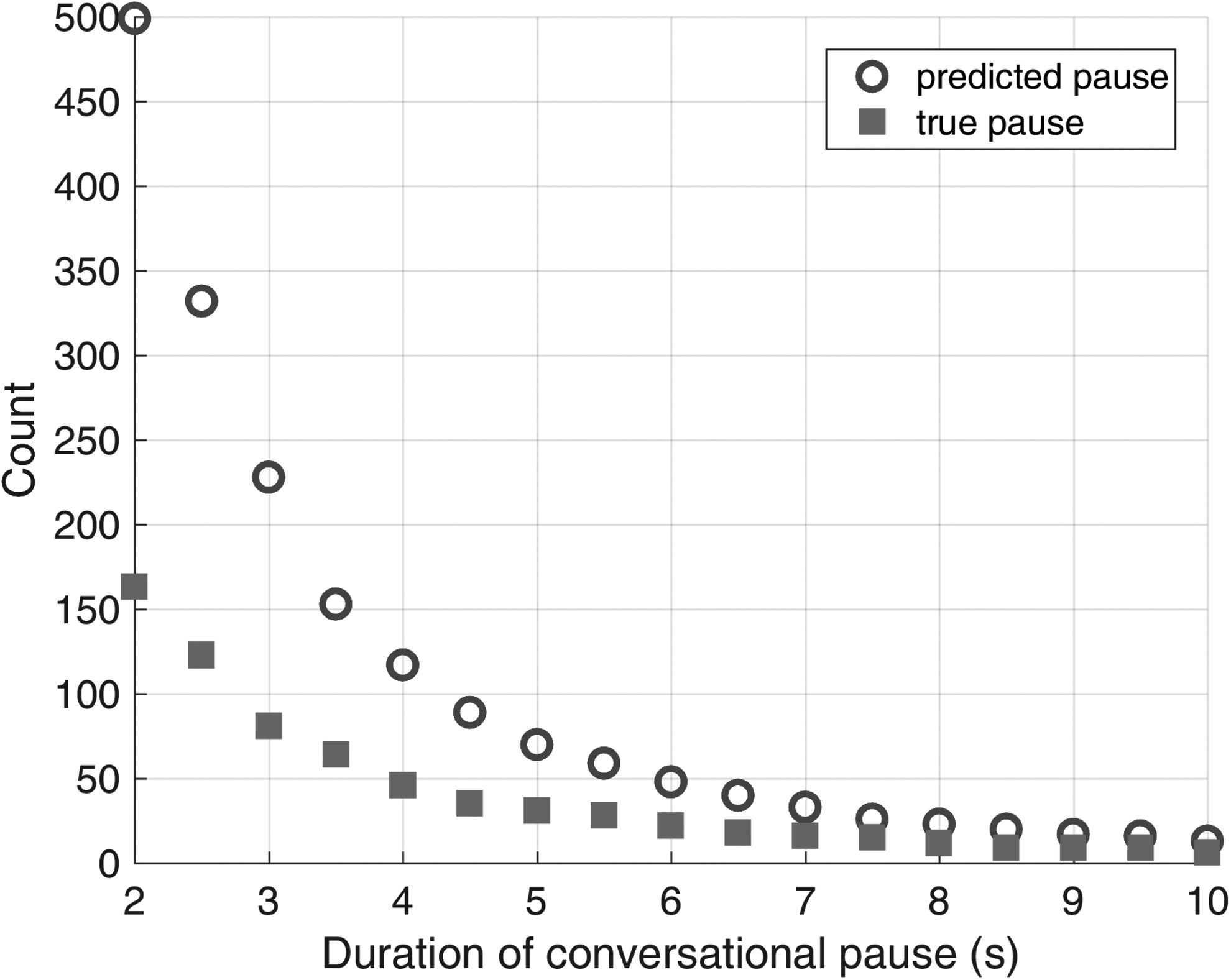
Frequency of predicted and actual Conversational Pauses by duration of pause.
Creation of the testing dataset
We tested the ML classifier on six full-length palliative care consultations (in nine recorded conversations) not used as part of the training data, totaling 260.5 minutes of audio. Three trained human coders manually and independently identified all Conversational Pauses in these recordings. If all three coders identified overlapping Conversational Pauses, we considered this to be one true Conversational Pause, even if the start and end times did not align exactly. We designated the start time of a true Conversational Pause to be the earliest human-coded start time and the stop time to be the latest. The median length of the true Conversational Pauses was 2.5 seconds, so we define true speech events as segments of length 2.5 seconds that contained speech (note that some speech segments contained pauses that were less than two seconds long). The resulting testing set comprised 163 true Conversational Pauses and 6012 true speech events. If the ML classifier predicted a two-second or longer pause that overlapped a true Conversational Pause, we considered it as correctly predicted.
We report several standard performance metrics of the ML classifier and the three human coders in predicting these true Conversational Pauses. We also timed each human coder and the ML classifier on a 10-minute segment of a recorded conversation, then multiplied this by 6 to estimate the number of minutes required per each hour of audio analysis.
Results
The ML classifier achieved 94.4% accuracy and 94.5% specificity in predicting Conversational Pauses (Table 1). Importantly, the ML classifier achieves 90.8% sensitivity (Table 1), only missing 15 of the true Conversational Pauses (Table 2). We found no apparent temporal pattern to the misclassification of Conversational Pauses, relative to the time course of a recording (Fig. 2). The ML classifier exhibited only ∼30% positive predictive value (PPV), misclassifying 349 events containing some speech as Conversational Pauses (Table 2). The discordance in frequency between predicted and actual Pauses decreased the longer pause threshold (Fig. 1). Although individual human coders had about 5% higher overall prediction accuracy and 30%–50% higher PPV, the ML classifier was two orders of magnitude faster than the human coders (Table 1).

Distribution of true and ML-predicted Conversational Pauses over quintiles in the time course of the nine conversations comprising the testing set. ML, machine learning.
Prediction Metrics of the Machine Learning Classifier and Human Coders on the Testing Dataset
Sensitivity for the human coders is not reported since it is 100% by definition (“ground truth” for Conversational Pauses was defined as the consensus of all three human coders).
This includes 1 minute for file input/output and 0.46 minutes for ML prediction on a 3.2 GHz Intel Core i5 processor.
ML, machine learning.
Machine Learning Prediction of Conversational Pauses and Speech Events in the Testing Dataset
We subsequently examined all 15 true Conversational Pauses that the ML classifier had misclassified as speech, both with and without the surrounding context, to better understand the causes of misclassification (Table 3). The ML classifier missed five Conversational Pauses due to synchronization issues, where the nonoverlapping 0.5-second intervals classified by the algorithm did not align exactly with the start and end times of Conversational Pauses that were very close to two seconds in length. In these instances, the ML algorithm identified only three, rather than four, consecutive 0.5-second intervals as not containing speech. Six of the true Conversational Pauses contained speech from background or televised conversations but not from the target conversation. The remaining four Conversational Pauses included sounds such as coughing, audible breathing, or sounds due to movement (e.g., chairs moving or the microphone being bumped).
Predominant Issues Identified in the 15 Conversational Pauses the Machine Learning Algorithm Misclassified as Speech
Discussion
Our results indicate that it is feasible and efficient to automate the detection of Conversational Pauses in audio recordings made in the natural hospital environment using ML. Specifically, we show that the Random Forest classifier predictions achieved >94% accuracy in discriminating between Conversational Pauses and speech events on a previously unseen testing dataset. Conversational Pauses are relatively low-frequency events when compared with total conversation time. Therefore, as done with sequential screening or diagnostic tests, we desire a classifier that minimizes false negatives so that it may function well as a “first pass” in processing recorded conversations. Thus, it is encouraging that the ML classifier detects Conversational Pauses with nearly 91% sensitivity while simultaneously reducing coding time by two orders of magnitude. What remains unknown is whether ML can distinguish between clinically important subtypes of Conversational Pauses. For example, sometimes a Conversational Pause may represent moments of distraction and other times it might represent a skillful use of silence amid expressions of compassion in palliative care conversations. 21 Similarly, pauses might also provide glimpses into the emotional state of the patients (e.g., fear). In our companion article in this issue of JPM, we demonstrate a tandem ML–human coding approach for semiautomating the identification of one clinically important type of silence. In this tandem method, the ML algorithm greatly reduces the conversational search space for human coders to efficiently subclassify clinical subtypes of Conversational Pauses that represent important moments of human connection in serious illness conversations.
In future work, we will seek to improve both sensitivity and specificity by adding Conversational Pauses into the training dataset that include problematic nonspeech sounds such as coughing, labored breathing, and the movement of objects near the microphone. We anticipate using overlapping time windows for the ML classification, rather than the nonoverlapping time windows used here, to eliminate the synchronization issues that may occur on short Conversational Pauses. This would enable greater resolution when identifying the start and end (and, therefore, duration) of predicted Conversational Pauses.
Various voice activity detection (VAD) techniques32–36 have been developed for filtering out the bulk of the nonspeech as a means of improving the efficiency and performance of various speech processing applications, but it is not clear how sensitive these methods are in identifying all nonspeech segments. Furthermore, natural clinical settings such as hospital environments contain significant and unique types of noise37–39 that are not reflected in the typical VAD research literature. In this article, we have demonstrated that an ML approach can reliably detect Conversational Pauses in palliative care conversations, recorded in natural hospital environments, with high accuracy, sensitivity, specificity, and efficiency. Future work will use this method as a first pass for studying the potential association of types and patterns of Conversational Pauses with patient-reported measures of communication quality. Such automated approaches to conversation measurement may facilitate both training and assessment of effective communication in clinical environments.
Footnotes
Acknowledgments
This work was funded, in part, by a Research Scholar Grant from the American Cancer Society (RSG PCSM124655; PI: Robert Gramling). We thank the American Cancer Society and the palliative care clinicians, patients, and families who participated in this work for their dedication to enhancing care for people with serious illness. Additional funds were provided by the Holly & Bob Miller Endowed Chair in Palliative Medicine at the Larner College of Medicine at the University of Vermont and by the College of Engineering & Mathematical Sciences at the University of Vermont. We thank Lindsay Ross, Aidan Ryan, and Michelle Niland for their careful coding of Conversational Pauses.
Author Disclosure Statement
No competing financial interests exist.