
Abstract
Objective:
The goal of the study was to develop and validate a prediction model for cesarean delivery after labor induction that included factors known before the start of induction, unlike prior studies that focused on characteristics at the time of induction.
Materials and Methods:
Using 17,370 term labor inductions without documented medical indications occurring at 14 U.S. hospitals, 2007–2012, we created and evaluated a model predicting cesarean delivery. We assessed model calibration and discrimination, and we used bootstrapping for internal validation. We externally validated the model by using 2122 labor inductions from a hospital not included in the development cohort.
Results:
The model contained eight variables—gestational age, maternal race, parity, maternal age, obesity, fibroids, excessive fetal growth, and history of herpes—and was well calibrated with good risk stratification at the extremes of predicted probability. The model had an area under the curve (AUC) for the receiver operating characteristic curve of 0.82 (95% confidence interval 0.81–0.83), and it performed well on internal validation. The AUC in the external validation cohort was 0.82.
Conclusion:
This prediction model can help providers estimate a woman's risk of cesarean delivery when planning a labor induction.
Introduction
The risk of intrapartum cesarean delivery is a common concern for induced labors. When deciding on the method for an interventional delivery, the choice between labor induction and pre-labor cesarean delivery involves weighing the desire for a vaginal delivery against the aversion for an attempted vaginal delivery ending in emergency cesarean delivery. An understanding of each woman's risk for cesarean delivery after labor induction would be highly valuable for supporting individual counseling and patient
Risk factors for cesarean delivery after induction of labor include primiparity, hypertension, diabetes, obesity, and older age. 1,2 Less cervical dilatation, 1,3 –8 longer cervical length, 9 –12 or the need for cervical ripening 13 at the time of induction have also been associated with cesarean delivery. Fewer studies have assessed the extent to which risk of cesarean delivery can be accurately predicted at the individual level, as opposed to modeling associations. 14 In addition, prediction models have largely focused on clinical variables at the time of presentation for induction; such as cervical ripeness. 15 –20 Models that require information collected in labor are less helpful to health care providers and patients when making the decision about whether or not to schedule on induction days to weeks in advance, as the cervical status at the start of labor induction would be unknown at that time.
In this analysis, we sought to develop, internally validate, and externally validate multivariable prediction models for labor induction resulting in cesarean delivery, focusing on conditions that were known at the time that the induction was being considered (i.e., before the start of labor induction). These models are useful, because they provide information about an individual's likelihood of cesarean delivery after a labor induction irrespective of details from the ultimate course of labor and delivery that cannot be known until the start of the labor induction.
Materials and Methods
We studied linked maternal and newborn records from the National Perinatal Information Center/Quality Analytic Services, for patients discharged between January 1, 2007 and December 31, 2012. The National Perinatal Information Center comprises member hospitals throughout the United States that submit administrative discharge data supplemented by information abstracted from the medical record, such as gestational age.
Methods to construct the analytic dataset have been previously described. 21 Briefly, starting with 50 National Perinatal Information Center hospitals and more than 1.3 million deliveries, maternal and newborn records were linked within hospital and year. After restricting to records with 34–42 completed weeks' gestation (i.e., 34 weeks, 0 days to 42 weeks, 6 days), we further limited the sample to 14 hospitals that reported valid parity data. Parity was categorized as primipara (no previous live or still births) or multipara (at least one previous live or still birth). We excluded stillbirths and records with conditions that are commonly accepted contraindications for labor induction or vaginal delivery, including pregnancies with multi-fetal gestations, placenta previa, cephalopelvic disproportion, non-vertex presentation, prior cesarean delivery, and uterine abnormalities. 22
Analyses were restricted to women who underwent labor induction, which was identified by ICD-9 procedure codes 73.1, 73.01, and 73.4. Cesarean delivery was identified through the All Patient Refined Diagnosis Related Group code 540, which is based on the ICD-9 procedure codes 74.0, 74.1, 74.2, 74.4, and 74.99. 23 Inductions were classified as medically indicated if there was evidence of at least one condition of The Joint Commission list of medical indications possibly justifying early delivery, and as without having a documented medical indication otherwise. 24
Recognizing that the decision process for labor inductions may differ based on whether the induction is planned without medical necessity or considered for emergent situations, we developed separate prediction models for: (1) term inductions (37–42 completed weeks' gestation) with no documented medical indication and (2) medically indicated inductions at term and all preterm inductions (34–36 completed weeks' gestation). We focused our analyses primarily on the term inductions with no documented medical indication, because the ability to predict likelihood of cesarean delivery would carry more weight when there is no clear need for immediate interventional delivery and thus more flexible timing for the induction.
Candidate predictors considered for the models included the patient characteristics of maternal age, maternal race (Black, Chinese, Filipino, Hispanic, American Indian, Other Asian, White, other, and unknown), parity (nulliparous or multiparous), and gestational age at delivery (as a proxy for gestational age at induction) in completed weeks. All other candidate predictors were based on ICD-9 codes from the mother's delivery hospitalization.
We selected these candidate predictors based on a list of the 100 most common ICD-9 diagnosis codes in the original study sample. We excluded ICD-9 codes for conditions diagnosed after delivery or potentially occurring after the onset of labor, conditions arising close to the onset of labor that would not be helpful when scheduling an induction, and those related to maternal age or parity, as these were already characterized by individual variables. Otherwise, conditions that would be known at the time an induction is scheduled were considered for the final model equally, without prioritizing based on biological plausibility. In prediction modeling, any characteristic that can improve prediction of the outcome can be included in the model, regardless of the causal relationship of the characteristic with the outcome.
We combined ICD-9 codes for related conditions as follows: Hypertensive disorders included chronic hypertension, gestational hypertension, and chronic hypertension affecting pregnancy; preeclampsia included mild, severe, and superimposed types, as well as eclampsia; pre-gestational diabetes was based on the presence of any ICD-9 codes indicating chronic insulin use, pre-gestational diabetes affecting pregnancy, type 1 diabetes, or type 2 diabetes; obesity included three individual codes indicating obesity; and known or suspected fetal abnormality included chromosomal abnormalities, central nervous system abnormalities, other abnormalities, or fetal damage. In addition, we combined hypothyroidism with thyroid dysfunction, two ICD-9 codes for tobacco use, maternal congenital and non-congenital cardiovascular disease, and fibroids with uterine leiomyoma.
In total, there were 47 variables considered for the medically indicated induction prediction model. For term inductions with no documented medical indication, we did not consider high station (ICD-9 code for failure of head to enter pelvic brim at term) or 16 other variables that defined inclusion in the medically indicated group when developing the prediction model, resulting in a total of 30 candidate predictors (Table 1).
Descriptive Statistics of Candidate Predictor Variables and Specifications of the Final Multivariable Prediction Model
The sample includes N = 17,370 women with labor induced at term without a documented medical indication for delivery, of whom n = 1282 had a cesarean delivery.
p-Values for chi-square test except maternal age, which is from a t-test.
Hospital is not a candidate predictor but was examined in sensitivity analyses.
AUC, area under the curve; CI, confidence interval; SD, standard deviation.
With preliminary data suggesting more than 1200 cesarean delivery outcome events among inductions without a documented medical indication, we were confident in the ability to fit a logistic regression model with 46 covariates, as there were considerably more than the minimally suggested 10 outcome events per covariate. 25 By design, there were no missing data. As mentioned earlier, records were required to have valid maternal age, gestational age, and parity data to be included in the dataset. Records with missing maternal race data were categorized as unknown. All variables based on ICD-9 codes were dichotomized as present or absent based on the administrative record.
We evaluated the association of each candidate predictor variable with cesarean delivery by using univariable logistic regression. The maternal age variable was continuous, and all other variables were categorical. Model selection was informed by the area under the curve (AUC) for the receiver operating characteristic (ROC) curve and associated p-values. To obtain parsimonious models, which have a greater utility at the point of care, we performed forward stepwise selection with p-value for entry of 0.90 and p-value for remaining in the model of 0.10 and calculated the difference in the AUC on inclusion of each additional variable. We selected the best model as the model for which the addition of any subsequent variables increased the AUC by less than 0.0025. We assessed whether maternal age should be modeled with a log or square term and also whether a maternal age
In the final models, we assessed model calibration, risk stratification capacity, and classification accuracy. 26 –28 Model calibration was assessed visually by plotting the number of observed versus expected cesarean delivery outcomes by decile of predicted probability, and by the Hosmer-Lemeshow goodness-of-fit statistical test. Stratification capacity was assessed by examining the extent to which the model's predictions separated the study population into clinically distinct risk groups.
Classification accuracy, or discrimination, was evaluated based on the AUC, which is also known as the c statistic, and by calculating likelihood ratios across the ranges of tenths of predicted probability to assess how many times as likely women with cesarean delivery are to have a predicted probability in a given range than women without cesarean delivery. 29 Categories with likelihood ratios <0.1 or >10.0 were considered to be informative [strong evidence for the absence (<0.1) or presence (>10.0) of cesarean delivery], those with likelihood ratios 0.1 to 0.2 or 5.0 to 10.0 were considered to be moderately informative, and those with likelihood ratios 0.2 to 5.0 were considered to be non-informative. 30
We determined an “optimal” cutoff of the predicted probabilities using the Youden Index, which maximizes the vertical distance from the line of equality to the ROC curve, valuing sensitivity and specificity equally to minimize the total number of misclassified results. 31 Using this cutoff, we calculated sensitivity, specificity, positive predictive value, and negative predictive value.
There is concern that prediction models perform better in the sample from which they were developed than in a new population, because variables are chosen to obtain an optimal model in the sample and, consequently, overfitting is possible. 32 Internal validation of the same sample used to create the prediction model can be used to assess the potential for overfitting and estimate the model's performance in a new sample. 28
Internal validation was assessed through bootstrapping of the forward stepwise selection logistic regression model starting with 50 candidate predictors. We used 200 iterations of random sampling with replacement, repeated the forward stepwise selection process, chose the most discriminating model for that iteration based on incremental improvement in AUC, and recorded its AUC value. 33 Confidence intervals (CIs) for the baseline model AUC were calculated based on the 2.5th and 97.5th percentiles of the bootstrapped AUC values. Bias or optimism was calculated as the average of the differences in AUC between each bootstrap model's AUC and the AUC of the original prediction model. 28
We evaluated whether the predictive ability of the models differed by hospital characteristics. The 14 hospitals were dichotomized as large or small based on total number of births per year. Hospitals were identified as teaching or non-teaching based on the presence of an obstetrics and gynecology residency program. We calculated predicted probabilities for each subgroup and obtained AUC estimates.
A second step in the validation process, external validation, involves testing prediction models in observations not used to develop the original model. Using discharge data linked to birth certificate data from a single hospital not in the original cohort, we studied 55,830 deliveries occurring during 2004–2012. Labor induction, cesarean delivery, and parity were identified from birth certificate information; all other conditions were determined based on ICD-9 codes as described earlier.
Applying the same exclusions as in the original cohort, we restricted the sample to 39,921 singleton liveborn deliveries between 34 and 42 weeks' gestation and without prior cesarean delivery, placenta previa, cephalopelvic disproportion, nonvertex presentation, or uterine abnormalities. Using the developed prediction equations, we calculated the predicted probability of cesarean delivery for each labor induction in the validation cohort. Then, we assessed the calibration capacity, risk stratification, and discrimination of the models in the external validation cohort.
Data analyses were conducted by using SAS version 9.3 (SAS Institute, Cary, NC) and Microsoft Excel 2010. We used an SAS macro to calculate the AUC for the hospital characteristic analyses. 34 The study was approved by the Women & Infants Hospital Institutional Review Board (Project 13-0039), which is the research oversight committee for the National Perinatal Information Center, and determined exempt from further review by the Brown University Institutional Review Board (No. 1401000978).
Results
In a final eligible sample of 166,559 mother
Term labor induction without a documented medical indication model
Descriptive statistics of the candidate predictor variables with probability of cesarean delivery and odds ratios (ORs) and c statistics (AUC) for the univariable associations of each predictor with cesarean delivery are shown in Table 1 for inductions without a documented medical indication. The most parsimonious predictive model from multivariable regression had 8 predictors (gestational age, maternal race, parity, maternal age, obesity, fibroids, excessive fetal growth, and history of herpes) and AUC = 0.82 (Table 1). Model fit and predictive ability were not improved with the inclusion of other forms of the maternal age variable or a maternal age
The most discriminating model suggested that there was a slightly higher risk of cesarean delivery with labor induction with increasing maternal age. Excessive fetal growth, obesity, and history of herpes increased the risk of cesarean delivery (ORs 2.9–3.7), and fibroids substantially increased risk (OR 5.2). Parity was the strongest individual predictor, with primiparae having more than 14 times increased odds of cesarean after induction compared with multiparae. Non-Hispanic African Americans had 1.4-fold higher odds of cesarean delivery compared with Non-Hispanic Whites; the odds in all other maternal race groups did not differ significantly from Non-Hispanic Whites. The odds of cesarean delivery increased with increasing gestational age. Compared with 39 weeks, the risk of cesarean delivery after labor induction was higher at 40 weeks, but it was not significantly different at other term weeks (Table 1).
The coefficients in Table 1 can be combined with a given woman's characteristics to estimate her individualized risk score, and they can then be converted to a predicted probability as (e risk score)/(1 + (e risk score)). For example, for a woman who is 34 years old, of Chinese ancestry, with one prior live birth via vaginal delivery, without excessive fetal growth, obesity, fibroids, or history of herpes, and planning an induction at 40 weeks' gestation, the risk score would be calculated as −3.128 + 0.3232 (1) + 0.3862 (1) + 0.0486 (34) – 2.7068 (1) = −3.473, with a corresponding predicted probability of 0.03 on a scale from 0 to 1.
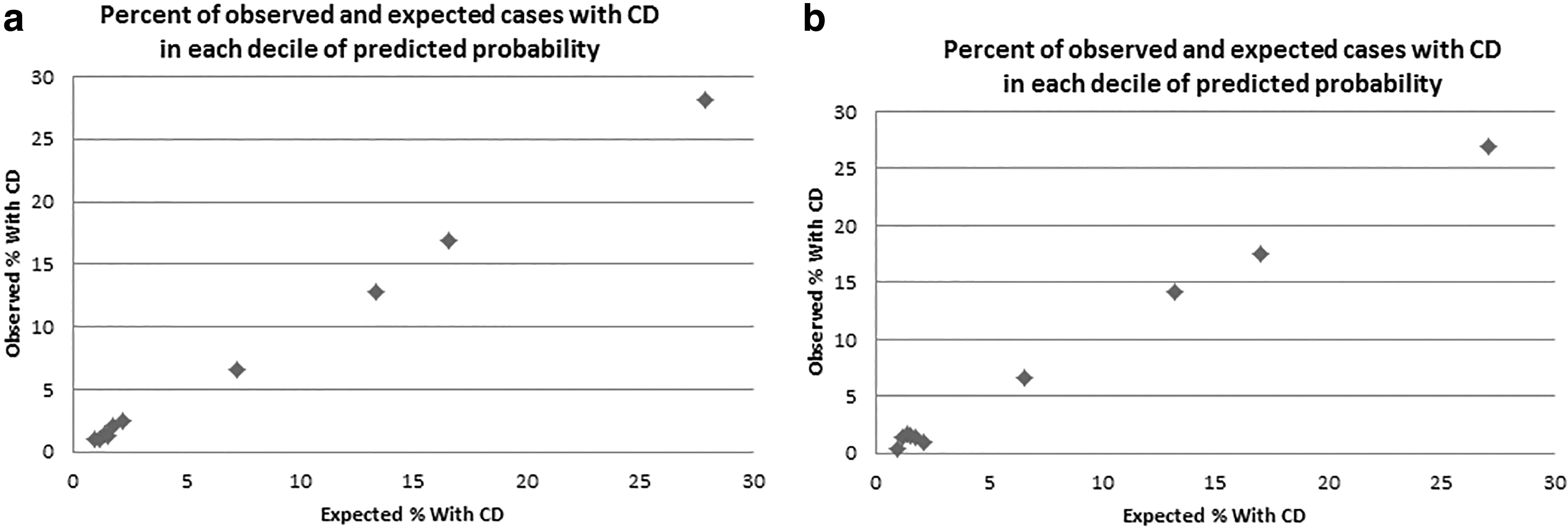
The Hosmer-Lemeshow goodness-of-fit test had a p-value of 0.702, suggesting optimal goodness of fit and the calibration plot of observed versus expected outcomes by decile of predicted probability displayed a generally linear line along the 45° axis with high linear correlation (Fig. 1a). Risk stratification showed that most women had low levels of risk, which was expected based on the mean risk of cesarean delivery of 7.4%. Sixty-seven percent of women had predicted probabilities less than 0.1% and 1.5% had predicted probabilities greater than or equal to 0.4 (Table 2). We collapsed the ranges 0.7–1.0 due to small numbers. According to the calculated likelihood ratios, the predictive probability ranges of 0.4–0.5, 0.5–0.6, 0.6–0.7, and 0.7–1.0 were very informative; the range 0.3–0.4 was moderately informative; and the ranges 0.0–0.1, 0.1–0.2, and 0.2–0.3 were non-informative.
Risk Stratification of Sample
The true positive and false positive rates are calculated with the cutoff as the starting number in the predicted probability range. True positive rate is the same as sensitivity, and false positive rate is the same as 1-specificity.
The AUC for the ROC curve was 0.82 (Fig. 2a). The chosen ideal cutoff corresponding to maximum Youden Index was predicted probability 0.078. Predicting cesarean delivery for women with probabilities at or above 0.078 and predicting no cesarean for women with probabilities below 0.78 resulted in sensitivity 0.85, specificity 0.70, positive predicted value 0.18, and negative predicted value 0.98. Internal validation using bootstrapping of the model selection process resulted in a 95% CI for the AUC of 0.81 to 0.83, with an average bias of 0.0003.

We evaluated effect modification of the prediction model by hospital size and hospital teaching status. We classified large hospitals as those with ≥5000 births per year on average during the study period and small hospitals as those with <5000 births per year. Among 12,290 inductions from seven large hospitals, AUC = 0.82; whereas among 4380 inductions from seven small hospitals, AUC = 0.80. Among 12,548 inductions from eight teaching hospitals, AUC = 0.84; whereas among 4822 inductions from six non-teaching hospitals, AUC = 0.79.
Medically indicated or preterm labor induction model
Results from the medically indicated or preterm labor induction prediction model can be found in Appendix A2. The best model from multivariable regression had seven predictors (maternal race, maternal age, parity, obesity, fibroids, high head at term, and excessive fetal growth) (Table A1) and an AUC of = 0.77, slightly lower than the AUC for the no documented medical indication model (Figure A1, Figure A3). Six of the predictors were the same as the no documented medical indication model, but high head at term was considered and included for this model whereas gestational age and history of herpes were not included.
According to the calculated likelihood ratios, the predictive probability ranges of 0.7–0.8, 0.8–0.9, and 0.9–1.0 were very informative; the range 0.6–0.7 was moderately informative; and the ranges 0.0–0.1, 0.1–0.2, 0.2–0.3, 0.3–0.4, 0.4–0.5, and 0.5–0.6 were non-informative, and so overall this model was less informative than the no documented medical indication model. (Table A2) Predicting cesarean delivery for women with probabilities at or above 0.25 and predicting no cesarean for women with probabilities below 0.25 resulted in sensitivity of 0.76, specificity of 0.62, positive predicted value of 0.38 and negative predicted value of 0.89. Sensitivity, specificity, and positive predictive value were lower in this medically indicated model than the no documented medical indication model, but negative predictive value was higher. Internal validation using bootstrapping of the model selection process resulted in a 95% CI for the AUC of 0.76 to 0.78, with an average bias of 0.0005.
External validation
Among hospitals in the development sample, the cesarean delivery rate was 36% and the labor induction rate was 21%. In the hospital used in the validation sample, the cesarean delivery rate was comparable at 32% and the labor induction rate was comparable at 19%. Among 39,921 eligible deliveries in the validation sample, 9362 (23%) had labor induction. The rate of cesarean delivery after labor induction was similar in the validation and development cohorts (19% and 18%, respectively), so we did not adjust the baseline rates in the prediction model equations before validation.
There were 2122 term inductions without documented medical indication. The AUC in the external validation cohort was 0.82 (95% CI 0.79–0.86), with sensitivity = 87% and specificity = 70% using the same predicted probability cutoff of 0.078 as in the evaluation of the development model (Fig. 2b). Among inductions with predicted probability range 0.0 to 0.1, only 1.5% had a cesarean delivery. More than 90% of women had a predicted probability less than 0.2. Ranges 0.5 to 1.0 were found to be most informative based on the likelihood ratio value (Table 3).
External Validation of Model for Term Inductions Without Documented Medical Indication: Risk Stratification of Sample
The true positive and false positive rates are calculated with the cutoff as the starting number in the predicted probability range. True positive rate is the same as sensitivity, and false positive rate is the same as 1-specificity.
There were 7240 preterm or medically indicated inductions. (Appendix 2) The AUC in the external validation cohort using the same predictors was 0.73 (95% CI 0.71–0.74), with sensitivity = 68% and specificity = 65% using the same predicted probability cutoff of 0.250 as in the evaluation of the development model (Table A3, Figure A2, Figure A4).
Conclusions
We developed and validated a model to predict the risk of cesarean delivery after term inductions without documented medical indication (AUC >0.8) based on maternal characteristics, chronic conditions, and pregnancy complications that would be known in the days and weeks leading up to a labor induction. A predicted probability threshold of ≥7.8% had 85% sensitivity and 70% specificity in predicting cesarean delivery. Even with suboptimal prediction for the aggregate of all women, the model appears to be useful at identifying women with very low or very high risk of cesarean delivery.
The proposed prediction model is valuable, because it can be applied when a decision regarding induction is still being considered and has not yet been made, that is, it is not limited to characteristics that only become available during or immediately before labor. Previous models that have incorporated only measures of cervical readiness reported AUC values 0.39–0.72. 3,9 –12 Prediction models that included both measures of cervical readiness and maternal characteristics reported AUC values 0.69–0.83. 16,17,19,20 Our model with AUC of 0.82 has better predictive ability than most previous models and does not require cervical assessment at the time of labor induction. Further, our model was developed from deliveries at 14 hospitals geographically distributed across the United States, so the results should not be influenced by patterns of care specific to a certain hospital or provider.
The eight predictor variables in our model have been shown to have an influence on cesarean delivery risk, either in prior prediction models or in observational epidemiologic studies of cesarean delivery. Primiparity is an established risk factor for cesarean delivery. 2,4,17,20,35 Older maternal age has been found to increase the risk of cesarean delivery after labor induction. 2,3,19,35,36 Though we only had access to an ICD-9 code for obesity, maternal body mass index has been implicated as a risk factor for cesarean delivery after labor induction. 1,3,4,17,19,20,35,37 The finding of increased risk of cesarean delivery after labor induction with increasing gestational age is also in agreement with prior studies. 19,20,36 Excessive fetal growth was a predictor in a prior model. 20 Cesarean deliveries also have been found to be more common among African Americans, 38,39 women with fibroids, 40 and those with herpes simplex virus. 38,41
The cesarean delivery rate in other studies of induced women ranged from 11%–13% 3,7 to 29%–30%. 9,17 The overall rate of cesarean delivery after labor induction in this study when the inductions with and without documented medical indications are combined is 18%. This is comparable to several other studies having rates of 17–22%. 10 –12,15 However, some of our initial exclusion criteria may have eliminated women with the highest risk for cesarean delivery after labor induction.
A limitation of this study is that maternal characteristics were based on discharge diagnoses, which could have issues with misclassification. First, we acknowledge a limitation with administrative data in that the recorded information is dependent on expert clinical opinion, appropriate documentation in the medical record, and institutional coding practices, subject to variation relative to the actual condition of the patient and not methodically assigned. Second, the exact timing of onset of the condition is unknown. We attempted to restrict our list of predictors to those that would be known at the time an induction is being scheduled; however, it is possible that in some women, the conditions considered for the model were not diagnosed until the delivery hospitalization.
Although the potential for confounding by hospital appears to be low, we cannot rule out a small degree of hospital influence on the final model. The minimal overfitting found through the internal validation, which may be the result of inclusion of deliveries at 14 different hospitals, would lead us to expect better success in external validation than a model based on only one population. A strength of this study is the large dataset with more than 1200 outcome events, which enabled the consideration of a large number of predictors. Finally, incorporating ICD-9 codes into our model utilized diagnostic methods already in practice; therefore, implementing our model would not require additional specialized tests to be performed in the course of clinical care to estimate risk. 42
In summary, we developed a model to predict the probability of cesarean delivery after labor induction without documented medical indication at term based on gestational age, maternal race, parity, maternal age, obesity, fibroids, excessive fetal growth, and history of herpes. The model had good stratification and discrimination ability and showed high internal validity. The model also showed good external validity. This prediction model could be used by clinicians to help estimate an individual's risk of cesarean delivery after labor induction in women with term pregnancies without a documented medical indication for delivery.
Footnotes
Author Disclosure Statement
D.D.D. has employment and stock ownership in UnitedHealth Group. Otherwise, the authors have no conflicts of interest or financial relationships relative to this article to disclose.
Funding Information
Support for this article was received from the Agency for Health care Research and Quality K01HS025013 (PI: V.A.D.).
Appendix A1. Assessing the Role of Hospital as a Confounder
We evaluated whether hospital was a confounder by comparing the final model with a model containing dummy variables for hospital. This assessed whether there were differences between hospitals in both the prevalence of predictors and the rates of cesarean delivery that could introduce bias to the risk prediction model. In the model without hospital, predicted probabilities were calculated based on all beta coefficients. In the model with hospital, the beta coefficients for the hospital variables were not included in the prediction equation, but the intercept was adjusted so that the mean predicted probabilities matched the mean predicted probabilities in the model without hospital, which is also the rate of cesarean delivery in the non-medically indicated sample (7.4%). This intercept adjustment is necessary to obtain predicted probabilities that are comparable between the two models given that the beta coefficients for hospital are not included in the calculation of predicted probability for the model with hospital. We examined differences in beta coefficients between the two models and also compared the individual predicted probabilities by examining correlations, distributions of the differences, and a scatterplot.
Adding dummy variables for hospital improved model fit; however, hospital did not appear to be a major confounding variable. The differences in beta coefficients for each predictor between the two models ranged from −0.15 to 0.07 with mean 0.00. Predicted probabilities with hospital excluded or included in the model had a correlation coefficient of 0.994. Ninety-nine percent of observations had predicted probabilities with and without hospital within five percentage points of each other, and 87% of observations had probabilities within one percentage point. We used the model without hospital when further evaluating the prediction model.
Appendix A2. Prediction Model Development and Validation Results for Medically Indicated or Preterm Labor Induction
External validation: Risk stratification of sample
| Predicted probability range | No. of women (%) | No. of women with cesarean delivery (%) | No. of women without cesarean delivery (%) | True positive rate (%) | False positive rate (%) | Likelihood ratio (95% CI) |
|---|---|---|---|---|---|---|
| [0.0,0.1) | 2689 (37.1) | 178 (6.6) | 2511 (93.4) | … | … | 0.24 (0.21–0.28) |
| [0.1,0.2) | 568 (7.8) | 97 (17.1) | 471 (82.9) | 89.1 | 55.2 | 0.71 (0.57–0.87) |
| [0.2,0.3) | 2373 (32.8) | 704 (29.7) | 1669 (70.3) | 83.1 | 46.8 | 1.45 (1.35–1.55) |
| [0.3,0.4) | 1196 (16.5) | 442 (37.0) | 754 (63.0) | 40.0 | 17.1 | 2.01 (1.82–2.23) |
| [0.4,0.5) | 241 (3.3) | 96 (39.8) | 145 (60.2) | 12.9 | 3.6 | 2.28 (1.77–2.93) |
| [0.5,0.6) | 66 (0.9) | 34 (51.5) | 32 (48.5) | 7.0 | 1.0 | 3.65 (2.26–5.90) |
| [0.6,0.7) | 39 (0.5) | 29 (74.4) | 10 (25.6) | 5.0 | 0.5 | 9.97 (4.87–20.4) |
| [0.7,0.8) | 36 (0.5) | 22 (61.1) | 14 (38.9) | 3.2 | 0.3 | 5.40 (2.77–10.5) |
| [0.8,1.0] | 32 (0.4) | 30 (93.8) | 2 (6.3) | 1.8 | 0.04 | 51.5 (12.3–215.5) |
The true positive and false positive rates are calculated with the cutoff as the starting number in the predicted probability range. True positive rate is the same as sensitivity, and false positive rate is the same as 1-specificity.