
Abstract
Aim:
This study assesses the reliability of artificial intelligence (AI) large language models (LLMs) in identifying relevant literature comparing inguinal hernia repair techniques.
Material and Methods:
We used LLM chatbots (Bing Chat AI, ChatGPT versions 3.5 and 4.0, and Gemini) to find comparative studies and randomized controlled trials on inguinal hernia repair techniques. The results were then compared with existing systematic reviews (SRs) and meta-analyses and checked for the authenticity of listed articles.
Results:
LLMs screened 22 studies from 2006 to 2023 across eight journals, while the SRs encompassed a total of 42 studies. Through thorough external validation, 63.6% of the studies (14 out of 22), including 10 identified through Chat GPT 4.0 and 6 via Bing AI (with an overlap of 2 studies between them), were confirmed to be authentic. Conversely, 36.3% (8 out of 22) were revealed as fabrications by Google Gemini (Bard), with two (25.0%) of these fabrications mistakenly linked to valid DOIs. Four (25.6%) of the 14 real studies were acknowledged in the SRs, which represents 18.1% of all LLM-generated studies. LLMs missed a total of 38 (90.5%) of the studies included in the previous SRs, while 10 real studies were found by the LLMs but were not included in the previous SRs. Between those 10 studies, 6 were reviews, and 1 was published after the SRs, leaving a total of three comparative studies missed by the reviews.
Conclusions:
This study reveals the mixed reliability of AI language models in scientific searches. Emphasizing a cautious application of AI in academia and the importance of continuous evaluation of AI tools in scientific investigations.
Introduction
The application of artificial intelligence (AI) in medical research is a subject of increasing debate, characterized by its transformative potential across various domains such as data collection, analysis, and article writing.1–3 The advent of AI technologies, particularly large language models (LLMs), heralds significant advances in the efficiency and capabilities of medical research, yet it also raises critical ethical and practical concerns. 4 While LLMs like ChatGPT are capable of responding to complex queries with high efficiency, their integration into sensitive fields such as medicine must be navigated with caution due to potential inaccuracies and the ethical implications of their use in health care settings. 5
LLMs are increasingly used to generate, correct, evaluate, and analyze text through sophisticated natural language processing (NLP) techniques. These models, which learn from vast corpora of digitized text, have demonstrated a remarkable ability to perform language-related tasks that are critical in medical research, such as literature synthesis and hypothesis generation.6–9 However, the reliance on generative AI for sourcing medical literature is contentious, primarily due to concerns over the models’ tendency to produce fabricated or noncredible findings, a significant risk when the stakes involve human health and clinical outcomes.10,11
Given these concerns, we aimed to critically assess the reliability of literature references provided by LLMs, focusing on recent systematic reviews (SRs) and meta-analyses that compared open, laparoscopic, and robotic techniques in inguinal hernia repair. By contrasting these AI-sourced references to those cited in traditional academic research and considering the recent insights provided by Fleming et al. (2023), 12 our goal is to ascertain the credibility and potential biases of AI-driven tools in medical research contexts. This study seeks to provide empirical evidence on the efficacy and reliability of LLMs, potentially guiding future integrations of generative AI in medical research.2–9
Methods
Bing Chat AI, ChatGPT 4.0 (OpenAI, San Francisco, California, April 2023 version), ChatGPT 3.5 (OpenAI, San Francisco, California, January 2022 version), and Google Gemini were instructed to identify observational comparative studies and randomized controlled trials (RCTs) comparing open, laparoscopic, and robotic repair techniques indexed on PubMed, Embase, and Scopus. The LLMs were then instructed to calculate the total number of results generated from each database and present a comprehensive list of references derived from the search query. Comparative studies and RCTs were sought both simultaneously and independently. Results were tabulated for reference, verified with the results of the prior systematic review and meta-analyses, and confirmed online for validity. Two authors (J.P.G.K. and C.A.B.S.) thoroughly extracted relevant studies from the compared articles, and a third person (D.L.L.) reviewed the extracted studies for accuracy and completeness. A Venn diagram was generated using the Bioinformatics and Evolutionary Genomics Venn diagram tool to display the results of the analysis. 13 Complete text inputs and results can be viewed in Supplementary Appendix. LLMs were not used in the writing or editing of the main content of this article.
Results
Through the utilization of LLMs, generative AI yielded a total of 22 possibly relevant scientific studies citations. These citations encompassed a complete bibliographic dataset, including authorship details, article titles, publication dates, volume and issue numbers, page ranges, and PubMed identifiers (PMIDs). The scope of these generated studies spanned from 2006 to 2023, with publications in journals noted for their high impact factors and distinct influence in the field. 14
An in-depth analysis of these findings highlights that only 4 out of the 22 studies (18.2%) generated citations were previously recognized in recent SRs and meta-analyses.15–17 Moreover, the authenticity of these 22 generated studies underwent a rigorous external validation process. This investigation revealed that the majority (14/22, 63.6%) were genuine publications, as depicted in Figure 1, while the remaining studies (8/22, 36.3%) were identified as fabrications, all of which were uncovered through Google Gemini. Significantly, two out of the eight fabricated studies (25.0%) were erroneously linked to legitimate digital object identifiers (DOIs) that, upon examination, were associated with publications unrelated to the search query, detailed in Table 1.
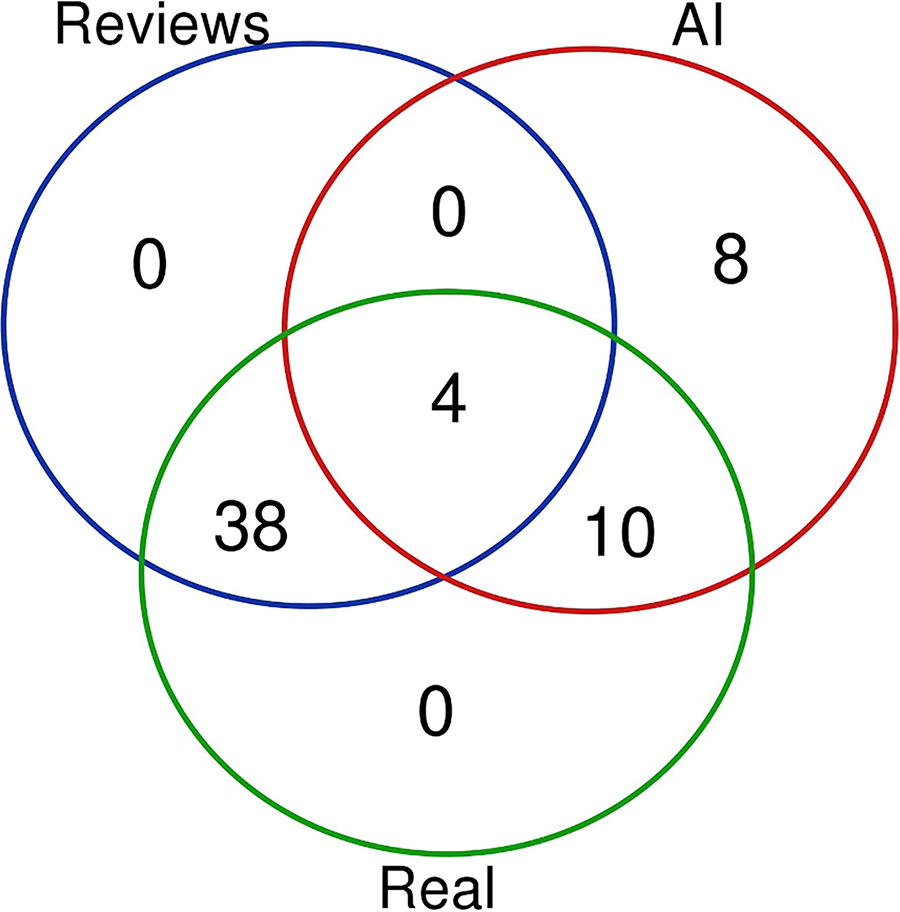
Venn diagram comparing results of a query for studies comparing open, laparoscopic, and robotic interventions for inguinal hernia repair via multiple artificial large language model chatbots (blue), previous published systematic reviews, and meta-analyses (red), and identified real studies (green).
Large Language Model Performance Compared with Articles from Systematic Reviews
Bing AI generated six potentially relevant citations, two of which overlapped with those identified by ChatGPT. ChatGPT, in turn, produced 10 potentially relevant citations. In contrast, Google Gemini generated eight citations; however, all of these were subsequently determined to be fabricated, as previously discussed.
LLMs missed 38 out of the 42 studies (90.5%) included in previous SRs, indicating that generative AI overlooked more than 90% of the studies covered by the SRs. However, the LLMs did identify 10 genuine studies that were not included in the previous SRs. Between those 10 studies, 6 were designed as SRs, and 1 was published after the SRs, leaving a total of three comparative studies missed by the reviews. Adding the 42 studies included in the SRs and the 3 comparative studies identified only by the LLMs, we got a total of 45 studies that would accomplish the SRs inclusion criteria, representing a missing of 6.7% (3/45) of the eligible studies by the published SRs.
Discussion
In the present study, we assessed the reliability of various LLMs, specifically ChatGPT, Bing Chat AI, and Google Gemini, in generating scientific literature. Our results revealed that while ChatGPT 4.0 and Bing Chat AI aligned well with the predefined search parameters, Google Gemini exhibited a propensity to fabricate citations, falsely attributing them to reputable surgical journals. Notably, ChatGPT 3.5 generated no results, underscoring significant advancements in AI capabilities with its more advanced version, ChatGPT 4.0. This contrast highlights the evolution within AI systems, although it remains crucial to recognize that not all are currently equipped to reliably conduct scientific literature searches. The necessity for meticulous external validation continues to be paramount to prevent the dissemination of false research findings. 18
AI encompasses a range of subdomains, including machine learning, artificial neural networks, NLP, and computer vision.4,18 Despite notable advancements in these areas, our analysis suggests that these technologies do not yet offer uniform reliability in their applications. This variance in readiness necessitates a cautious approach to the utilization of generative AI within scientific research.
Moreover, the integration of generative models such as ChatGPT into medical education reveals both promising applications and inherent challenges, reflecting broader concerns about AI-generated content within the scientific community. As Eysenbach (2023) 19 discusses, while ChatGPT shows substantial potential in enhancing educational tools and methodologies, its tendency to generate fabricated content, such as incorrect citations, presents a significant risk. This propensity to “hallucinate” data highlights a fundamental limitation of current AI technologies, which could mislead learners and researchers, potentially leading to the propagation of erroneous information. Thus, a call for rigorous scrutiny and continuous evaluation of these models is critical, particularly in domains where precision and reliability are paramount. 19
The rapid proliferation of LLMs such as ChatGPT has introduced significant advancements in text generation capabilities, making them invaluable tools in various domains, including public health and medical research. However, as De Angelis et al. (2023) highlight, these models also pose the novel threat of an “AI-driven infodemic” in public health. 20 The ability of LLMs to generate vast amounts of plausible yet potentially misleading or inaccurate content could exacerbate the spread of misinformation on an unprecedented scale. The authors stress the importance of stringent regulatory frameworks and the development of sophisticated detection tools to differentiate between human-generated and AI-produced texts. Such measures are crucial in mitigating the risks associated with the dissemination of false information and ensuring the integrity and credibility of health information communicated to the public. 20
Furthermore, AI chatbots have evolved to simulate human decision-making processes, using algorithms that allow them to interpret data and learn from experiences. 21 The expanding applications and the increasingly nuanced capabilities of AI mark it as a burgeoning tool in the scientific community. Its potential and the implications of its evolving nature warrant continuous observation and analysis. As we advance, it is essential to monitor and evaluate the impact and reliability of AI across diverse scientific domains, anticipating the possibilities it holds for the future. In this context, it is crucial to consider both the achievements and the limitations as outlined by Thirunavukarasu et al. (2023), who caution against the premature application of such models without rigorous validation, especially in high-stakes environments such as patient care and clinical decision-making. 5
Conclusion
Our study evaluated the reliability of generative LLMs in providing scientific literature on inguinal hernia repair techniques, specifically Open, Laparoscopic, and Robotic approaches. While advanced models such as ChatGPT 4.0 and Bing Chat AI demonstrated certain alignment with predefined search parameters, the propensity of Google Gemini to fabricate citations highlights significant inconsistencies across different Generative AI models. This variability highlights the necessity for external validation to prevent the dissemination of false findings. As AI continues to evolve, continuous monitoring, rigorous scrutiny, and the development of sophisticated validation frameworks are essential to ensure the credibility and reliability of AI-generated content in high-stakes scenarios such as health care.
Footnotes
Authors’ Contributions
The authors included each contributed significantly to this research as per the guidelines of the International Committee of Medical Journal Editors (ICMJE). Study design: V.S., J.P.G.K., D.L.L., L.T.C., F.M., and J.M. Data collection and analysis: V.S., J.P.G.K., D.L., C.A.B.S., and A.C.R. Article preparation and editing: V.S., J.P.G.K., D.L., F.M., C.A.B.S., A.C.R., J.M., and L.T.C.
Disclosure Statement
V.S., J.P.G.K., D.L., C.A.B.S., A.C.R., and J.M., disclose no conflict of interest. L.T.C. discloses consulting fees from BD and Medtronic outside the submitted study. F.M. discloses consulting fees from BD, Intuitive, Integra, DeepBlue, Allergan and Medtronic, outside the submitted study.
Funding Information
There was no funding for this project.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.