
Abstract
An accurate prognostic model is extremely important in severe traumatic brain injury (TBI) for both patient management and research. Clinical prediction models must be validated both internally and externally before they are considered widely applicable. Our aim is to independently externally validate two prediction models, one developed by the Corticosteroid Randomization After Significant Head injury (CRASH) trial investigators, and the other from the International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury (IMPACT) group. We used a cohort of 300 patients with severe TBI (Glasgow Coma Score [GCS] ≤8) consecutively admitted to the National Neuroscience Institute (NNI), Singapore, between February 2006 and December 2009. The CRASH models (base and CT) predict 14 day mortality and 6 month unfavorable outcome. The IMPACT models (core, extended, and laboratory) estimate 6 month mortality and unfavorable outcome. Validation was based on measures of discrimination and calibration. Discrimination was assessed using the area under the receiving operating characteristic curve (AUC), and calibration was assessed using the Hosmer–Lemeshow (H-L) goodness-of-fit test and Cox calibration regression analysis. In the NNI database, the overall observed 14 day mortality was 47.7%, and the observed 6 month unfavorable outcome was 71.0%. The CRASH base model and all three IMPACT models gave an underestimate of the observed values in our cohort when used to predict outcome. Using the CRASH CT model, the predicted 14 day mortality of 46.6% approximated the observed outcome, whereas the predicted 6 month unfavorable outcome was an overestimate at 74.8%. Overall, both the CRASH and IMPACT models showed good discrimination, with AUCs ranging from 0.80 to 0.89, and good overall calibration. We conclude that both the CRASH and IMPACT models satisfactorily predicted outcome in our patients with severe TBI.
Introduction
S
Two important prediction models, the Corticosteroid Randomization After Significant Head injury (CRASH) and International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury (IMPACT) models, have recently been published, and they have enormous potential for use in clinical practice and research. 4,5 They were based on large numbers of patients, and were cross-validated with each other. A good prognostic model, if robust enough, may be used in populations different from those from which it was derived. As with any scientific hypothesis, the more diverse the settings in which the system is tested and found accurate, the more likely it will be generalizable to an untested setting. 6 Continued development, refinement, and validation of prognostic models in TBI are advocated. 7,8
Our aim is to independently externally validate these two prediction models using our cohort of patients, a consecutive series of 300 patients with severe TBI admitted to a single neurosurgical intensive care unit in a Singapore hospital. Only patients with severe TBI (GCS ≤8) were selected, because it is this group of patients who would most benefit from an accurate prognostic model.
Methods
Study population
Prospective data were collected from a consecutive series of 300 patients with severe TBI (GCS of ≤8) admitted between February 2006 and December 2009 to a single neurosurgical intensive care unit in the National Neuroscience Institute (NNI), Singapore. The NNI database comprises patient demographics (age, sex, and race), various etiologies of brain injury (road traffic accidents, falls, assaults, and others), severity of injury (GCS, pupillary reactivity, and other major extracranial injury), brain CT characteristics and physiologic data such as hypoxia, hypotension, blood results, and glucose levels. Data were prospectively collected for both admission characteristics prior to any surgical intervention and outcome at 14 days and 6 months. Additional radiological information that was necessary to calculate the CRASH and IMPACT prognostic models, as will be described, were retrospectively obtained. The NNI data were complete for all the predictors required to calculate the CRASH and IMPACT models, except for missing blood glucose levels in 36 patients (12%). When the glucose level was not available, data from these patients were excluded from the IMPACT laboratory model to predict outcome.
CRASH prediction model
The CRASH prognostic model was developed using patients from the CRASH trial, which included 10,008 adults with TBI, who had a GCS score of ≤14, and who were within 8 h of injury. 4,9 There were two defined outcomes for each of the models: one was mortality at 14 days, and the other was unfavorable outcome at 6 months, defined by the authors based on the Glasgow Outcome Scale (GOS) as severe disability, vegetative state, or death. It was developed for two separate sets of patients; namely, those from high-income countries and those from low/middle-income countries. It had two types of models: the basic model, which had four predictors – age, GCS, pupil reactivity, and the presence of major extracranial injury – and the CT model, which added on results of CT derived from the first CT scan performed post-injury. The selected CT criteria included petechial hemorrhages, obliteration of the third ventricle or basal cisterns, subarachnoid bleed, midline shift, and unevacuated hematoma.
There were eight models altogether, and all models showed excellent discrimination with area under the receiver operating characteristic curve (AUC) >0.80. However, only six out of eight models had good calibration when evaluated with the Hosmer–Lemeshow (H-L) test. The CRASH models were externally validated in the IMPACT data set of 8509 patients with moderate and severe TBI from 11 studies conducted only in high-income countries, and also did not include the variables “major extracranial injury” and “petechial hemorrhages,” as these were not available in the validation sample. The external validation revealed lower discrimination than the original data, with AUC of 0.77 for both the basic and CT models. The calibration was excellent for the CT model but poorer for the base model without CT data.
IMPACT prediction model
The IMPACT prognostic model was developed based on the IMPACT data set of 8509 patients with moderate to severe TBI (GCS ≤12) and ≥14 years of age, using data from eight randomized controlled trials and three observational studies conducted between 1984 and 1997. 5,10 The end-point of prognostic analysis for the IMPACT model was 6 month mortality and unfavorable outcome based on the GOS as severe disability, vegetative state, or death. It has three prognostic models. The first is the core model, which includes age, motor score component from the GCS, and pupillary reactivity. Second, there is the extended model, which includes predictors from the core model, plus information on secondary insults of hypoxia and hypotension, and also includes CT characteristics using the Marshall CT classification, traumatic subarachnoid hematoma (SAH), and epidural hematoma. 11 Finally, there is the laboratory model, which includes predictors from the extended model, plus information on glucose and hemoglobin.
The IMPACT models performed reasonably well. Within the IMPACT data, evaluation in the three observational studies showed AUCs of >0.80, but in the randomized control trials they showed lower AUCs (range, 0.66–0.82). The external validation showed better discriminatory ability of the extended model (AUCs of 0.801 and 0.796) compared with the core model (AUCs of 0.776 and 0.780) for predicting mortality and unfavorable outcome. Calibration was better for the patients from high-income countries, with near-perfect calibration for the extended model predicting mortality and for the core model predicting unfavorable outcome.
Statistical analysis
Validation was based on measures of discrimination and calibration as recommended for validation of prognostic models. 8 Discrimination was assessed using the AUC and 95% confidence interval (CI). An AUC ≤0.5 is considered to represent a nondiscriminative model, whereas an AUC ≥0.8 is considered to represent adequate discriminative ability by the model. Calibration was assessed using the H-L goodness-of-fit test, which tests the null hypothesis that the model's estimates fit the observed data. This test divides subjects into deciles based on predicted probabilities, and then computes a χ2 from observed and expected frequencies. A p value is then calculated from the χ2 distribution, to test the fit of the logistical model. If the p value of H-L goodness-of-fit test is >0.05, we fail to reject the null hypothesis that there is no difference, implying that the model's estimates fit the observed data at an acceptable level. Calibration in this study was also assessed with a Cox calibration analysis using a logistical regression model to obtain two derivatives: the slope and the intercept. The slope, as a coefficient of the logit of predicted probability, reflects the degree of variation in predictions. In an ideal model, the slope is equal to 1. The intercept, as a measure of overall calibration, indicates whether the predictions are systematically too low or too high, and this should ideally be zero. 12 All the analyses were done on the NNI database using the Stata statistical software. (Release 11, StataCorp LP, USA).
Results
Study population
In the NNI study population (Table 1), the mean and median age of the patients were 53 years and 54 years, respectively. The NNI database only included patients with severe TBI with GCS ≤8, with median of 5. Approximately half of these patients (47.3%) had a motor component score ≤4, and pupils were either unreactive or there was only one reactive pupil in 32.4%. Major extracranial injury also occurred in 34.2% of the NNI study population. There were no patients in the NNI database classified under Marshalls' CT Classification V, as all patients had data collected on admission, and hence prior to any surgery. Of the NNI study population, 9.3% had hypoxia, 15% had hypotension, and the median glucose and hemoglobin levels on admission were 8.5 and 13.4, respectively.
NNI, National Neuroscience Institute; TBI, traumatic brain injury; CRASH, Corticosteroid Randomization After Significant Head injury; IMPACT, International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury.
CRASH and IMPACT prognostic models' performance
All 300 patients in this data set were followed up for 14 day mortality, 6 month mortality, and 6 month unfavorable outcome. The observed outcomes in the NNI population showed that there was a 14 day mortality of 47.7%, a 6 month mortality of 54.0%, and a 6 month unfavorable outcome of 71.0%. Looking at Table 2, the CRASH base model predicted 14 day mortality to be 38.1% and unfavorable outcome at 6 months to be 67.6%, which were both lower than the observed outcomes of 47.7% and 71.0%, respectively in the NNI study population. The CRASH CT model predicted 14 day mortality to be 46.6%, which was close to the observed 14 day mortality of 47.7% in the NNI population. The CRASH CT model had predicted unfavorable outcome at 6 months of 74.8%, which was higher than the observed value of 71.0% in the NNI population. The three IMPACT models (core, extended, and laboratory), underpredicted 6 month mortality (range from 40.5% to 44.2%) compared with the observed 6 month mortality of 54% in the NNI population, whereas predicted 6 month unfavorable outcome (range from 54.4% to 57.8%) was also underpredicted compared with the observed 71%. Out of the three IMPACT models, the extended model, which includes CT data, gave the closest estimates of the observed findings, with predicted 6 month mortality of 44.2% and predicted 6 month unfavorable outcome of 57.8%.
CRASH, Corticosteroid Randomization After Significant Head injury; IMPACT, International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury; NNI, National Neuroscience Institute; AUC, area under the receiving operating characteristic curve.
All the CRASH and IMPACT models performed well with AUCs ranging from 0.80 to 0.89. The CRASH CT model and IMPACT extended model were chosen as a comparison, as these models were the closest equivalent models with the addition of radiological data. In comparison of the AUCs of the CRASH CT model with the IMPACT extended model in predicting 14 day mortality and 6 month mortality respectively, the CRASH CT model performed better than the IMPACT extended model (Fig. 1A). This is congruent to the abovementioned observation that the CRASH CT model accurately predicted 14 day mortality in the NNI population. Both the CRASH CT model and IMPACT extended model performed similarly when used to predict 6 month unfavorable outcome (Fig. 1B).
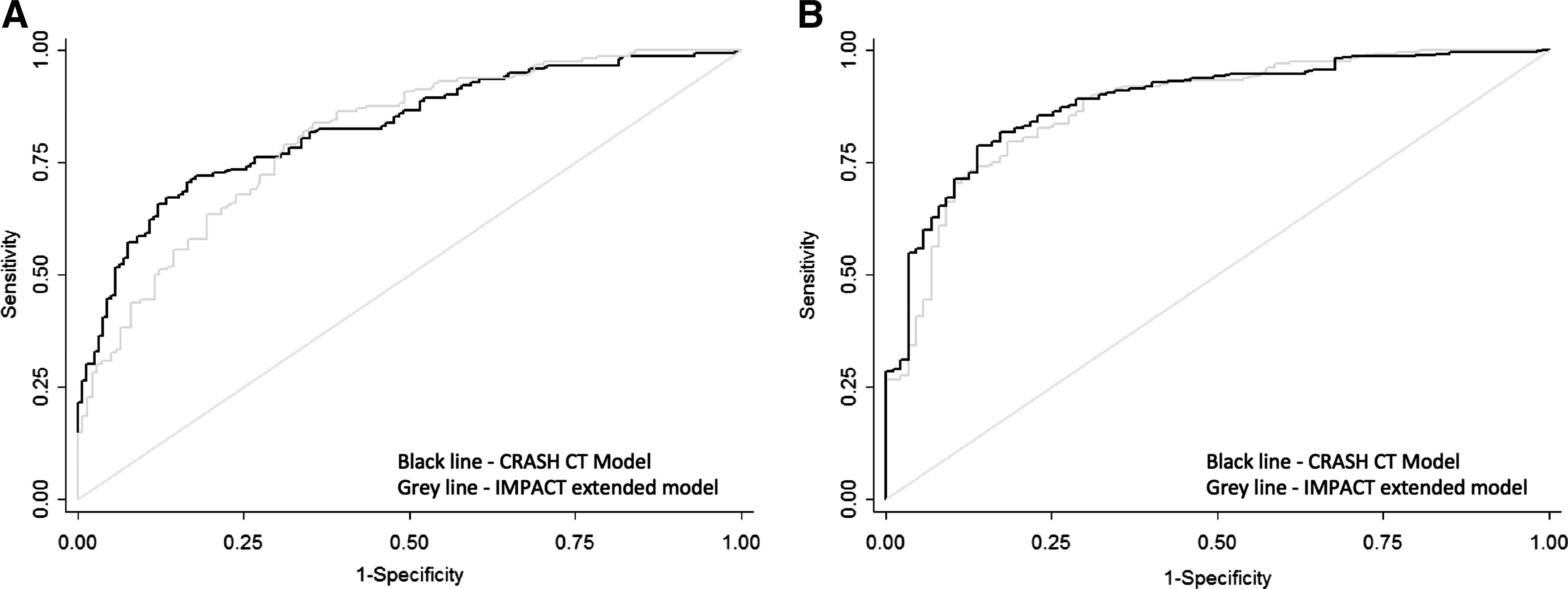
Comparison of the areas under the receiver operating characteristic curve (AUCs) of the Corticosteroid Randomization After Significant Head injury (CRASH) CT model and International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury (IMPACT) extended model in
The H-L goodness-of-fit test showed that both the CRASH and IMPACT models calibrated well when predicting 14 day mortality, 6 month mortality, and 6 month unfavorable outcome (all p values >0.05). Figure 2A–D shows how the CRASH CT model and the IMPACT extended model performed in predicting outcomes in the NNI population. The CRASH CT model performed well in predicting 14 day mortality in the NNI population (Fig. 2A). The same model more accurately predicts unfavorable outcome at 6 months only if the expected outcome is severe disability or a vegetative state (Fig. 2B). The IMPACT extended model is shown to underpredict 6 month mortality and 6 month unfavorable outcome when used in the NNI population (Fig. 2C and D).

Calibration plots of the
The slopes of the Cox calibration regression analysis, as depicted in Table 2, were close to 1 (range, 0.85–1.17) when predicting mortality in both the CRASH and IMPACT models, indicating a strong agreement between observed and predicted events. When used to predict unfavorable outcome, the slopes ranged from 1.12 to 1.58. The Cox calibration regression analysis also showed that both the CRASH and IMPACT models underestimated outcomes in the validation sample, as the intercept was greater than 0 in all (range, 0.03–2.39), consistent with our other findings.
Table 3 shows the comparison of the performances of the CRASH and IMPACT models in predicting 6 month unfavorable outcome. There was no statistically significant difference when the CRASH CT model was compared with the IMPACT extended model (p=0.55).
p values compare AUCs of the modeled data.
CRASH, Corticosteroid Randomization After Significant Head injury; IMPACT, International Mission for Prognosis and Analysis of Clinical Trials in Traumatic Brain Injury; NNI, National Neuroscience Institute; AUC, area under the receiving operating characteristic curve.
Discussion
Our findings showed that both the CRASH and IMPACT models performed adequately when used to predict outcomes in the NNI population. The CRASH CT model was found to be the most accurate among all the models when used to predict 14 day mortality in the population of patients with severe brain injuries presenting to the NNI, Singapore. This was in agreement with the group's own external validation of the CT model in the IMPACT data, which showed nearly perfect calibration. The CRASH CT model predicting unfavorable outcome at 6 months, however, represented an overestimation by 3.8% of the NNI population. The IMPACT models generally underpredicted mortality and unfavorable outcomes in our patients. Out of the three IMPACT models, the model with CT data gave the closest estimate to the observed values, coinciding with the CRASH CT model performing better than the base model, indicating that radiological findings were an important prognostic factor. Overall, both the CRASH and IMPACT models performed well in this external validation exercise, consistent with previous validation studies. 13 –16
Comparing the data sets, there were more patients in the NNI cohort who had major extracranial injury than in the CRASH population, and more patients in the NNI cohort with one or no reactive pupil compared with the CRASH population. This was an expected finding, as the database only included severe TBI with GCS ≤8. We have chosen only to externally validate patients with severe TBI, because it is this group of patients who would most benefit from an accurate prognostic model. We also found that the average age of the NNI population was older than both the CRASH and IMPACT populations. This variation in case mix, as evidenced by the difference in the observed mortality and unfavorable outcomes between the validation series and both the models' developmental data sets, may have an influence on the validation of the risk models. 17 However, in our data set, we found good discrimination and calibration for all the models tested. A limitation of our study is that it is a single center setting, which makes inadequate calibration impossible to distinguish from center level effects. A mitigating factor, however, is that the NNI is the largest center managing TBIs in Singapore, therefore enabling us to have a representative sample of our population.
The authors of the CRASH models attempted to externally validate their models in the cohort of patients of high-income countries from the IMPACT data set, and, reciprocally, Steyerberg et al. also externally validated two out of three IMPACT models, one of which was modified. 4,5 Both of the external validation exercises showed reasonably good results as detailed; however, it is of note that there were several limitations. In the CRASH models' authors' own external validation on the IMPACT data set, the variables “major extracranial injury” and “petechial hemorrhages” were not included, as they were not available in the IMPACT sample. Also, the IMPACT data set did not include mortality at 14 days; therefore, it could only validate models for unfavorable outcome at 6 months. In the IMPACT models' authors' own external validation of the CRASH data set, several factors were not recorded in the CRASH data set: hypoxia, hypotension, extradural hematoma (EDH), glucose, and hemoglobin. Therefore, external validation was only on the core model and a variant of the extended model, in which only the Marshall CT classification and presence of traumatic SAH were added to the core model. Also, not all patients were included, unless they fulfilled criteria of GCS ≤12 and with complete 6 month GOS. Another potential weakness of both the external validations is that both sets of patients were recruited from trial data, which may in itself introduce its own artefacts and biases; hence it is important that both models were also externally validated with a patient population outside of both their data sets. 18 The more numerous and diverse the settings in which the system was tested and found accurate, the more likely it was to be able to generalize to an untested setting. 6 It is also important that prognostic models should be continuously validated externally in order to remain current.
Our cohort of 300 consecutive patients in the NNI, Singapore, represents an unselected population of patients with severe TBI. In this external validation exercise for both CRASH and IMPACT prognostic models, we are an independent group, and have used all their variables as intended and unmodified, confirming the generalizability of these models for outcome prediction in our population.
There are concerns regarding decisions by physicians to limit care early after spontaneous intracerebral hemorrhage in stroke management that may result in self-fulfilling prophecies of poor outcome, because of inaccurate pessimistic prognostication and failure to provide initial aggressive therapy in the severely ill who may have the possibility of a better outcome. 19 Similarly, this may be a potential pitfall in the management of TBI, by assuming a poor prognosis too early and, therefore, possibly withholding optimal treatment. This often includes administering a “do not resuscitate order” which may be a proxy for overall lack of aggressiveness of care that may be critically important in determining patients' outcomes, and has been described as an independent outcome predictor. 20,21 Decisions to limit care early are often predicated on the assumption that treating physicians are able to accurately predict outcome in the specific case at hand; therefore, it is extremely important to have an accurate prognostic model in the management of TBI. The online availability of these two prognostic models makes it likely that they may be increasingly used to predict outcomes in individual patients. However, great caution must be exercised, as these models provide robust probabilistic estimates of outcome in groups of patients, but may not accurately predict outcomes in individuals. 22 Therefore, misuse of the models in this way could result in prediction of death becoming a self-fulfilling prophecy.
Conclusion
We have externally validated the CRASH and IMPACT models using our cohort of patients, and found that both models satisfactorily predicted outcome in our patients with severe TBI, a group of patients who would benefit the most from having an accurate prognostic predictive model.
Footnotes
Author Disclosure Statement
No competing financial interests exist.