
Abstract

Dear Editor:
The Ohio Supercomputer Center (OSC) has supported data-intensive science projects in the physical sciences [e.g., ALICE—A Large Ion Collider Experiment (http://www.osc.edu/press/releases/2010/supercollider.shtml)] and the environmental sciences [e.g., ASR—Arctic System Reanalysis (http://www.osc.edu/press/releases/2007/bromwich.shtml)]. In biomedical sciences, OSC is actively supporting data-intensive biomedical research groups located at the Comprehensive Cancer Center (CCC) at The Ohio State University's Medical Center as well as those at the Research Institute at Nationwide Children's Hospital (RINCH). These organizations contain a number of core facilities, common laboratories providing analysis to a collection of research and clinical groups. Currently, OSC is engaged with the following core facilities at the CCC:
Small Animal Imaging Shared Resource (SAISR)
Microscopy Shared Resource (MSR)
Biomedical Informatics Shared Resource (BISR)
Comparative Pathology and Mouse Phenotyping Shared Resource (CPMPSR)
For example, the MSR offers services that range from routine microscopy to leading edge, live animal, multiphoton microscopy. The SAISR supports a variety of in vivo small animal imaging modalities as a noninvasive tool for studying morphological, biochemical, or genetic perturbations in small animal models of cancer. The SAISR generates multidimensional data from various microimaging modalities including microCT, microMRI, nuclear (microPET microSPECT), ultrasound, and optical. Despite the variety of instruments and data types employed in the biomedical research community, common workflow, data storage, processing, and distribution requirements exist across these cores. Common solutions developed at OSC point to a number of research opportunities for the national cyberinfrastructure community.
Remote Instrumentation Services
Biomedical research is conducted by researchers and clinicians and can be encapsulated by different workflow patterns (Saltz et al., 2008). It is important to understand these patterns to illustrate the challenges posed by data-intensive biomedical science. The first pattern we have encountered is called single mode analysis. This pattern occurs when a researcher interacts with a core facility to generate sets of single mode data such as image, genomic, cellular, or spectral data. The pattern has the following activities:
Administration—facility scheduling and sample management at the beginning of the experiment; invoicing and billing at the end. For example, the SAISR is investigating MIMI (Szymanski et al., 2007) for these functions.
Acquisition—creation of the raw data set. For example, obtaining an image set from a microCT.
Raw Processing—largely automated processing of raw data. For example, image cropping, artifact removal, filtering, segmentation, and feature detection for images.
Analysis—creation of rich data (e.g., spatial or temporal morphological data) from processed data.
Classification—annotation of rich data with semantic information.
Distribution—dissemination of semantic information and selected rich information either locally in a laboratory information management system (LIMS) or nationally through repositories like BIRN or caBIG.
Single-mode analysis can be repeatedly performed on different samples or with different instruments as part of a single study. A second important pattern is integrative mode analysis (Kurc et al., 2009), in which a researcher correlates and integrates multimodal data (likely generated and managed by different core facilities). This pattern begins with the researcher making a set of semantic queries to retrieve data of different modalities from common repositories such as the individual core facilities' LIMS. Second, the data is correlated and integrated using specialized tools such as geWorkbench (Floratos et al., 2010) for genomic data.
Infrastructure
Core facilities at the CCC and RINCH are generating ever-increasing amounts of data. They need large-scale storage, HPC processing to reduce analysis time, visualization, and data distribution services. These services largely lie outside their capabilities, funding, and resources. OSC supports these facilities through a program called Remote Instrumentation Services (RIS). RIS provides production services for large-scale data import, HPC-based raw data processing, and remote visualization (Fig. 1).
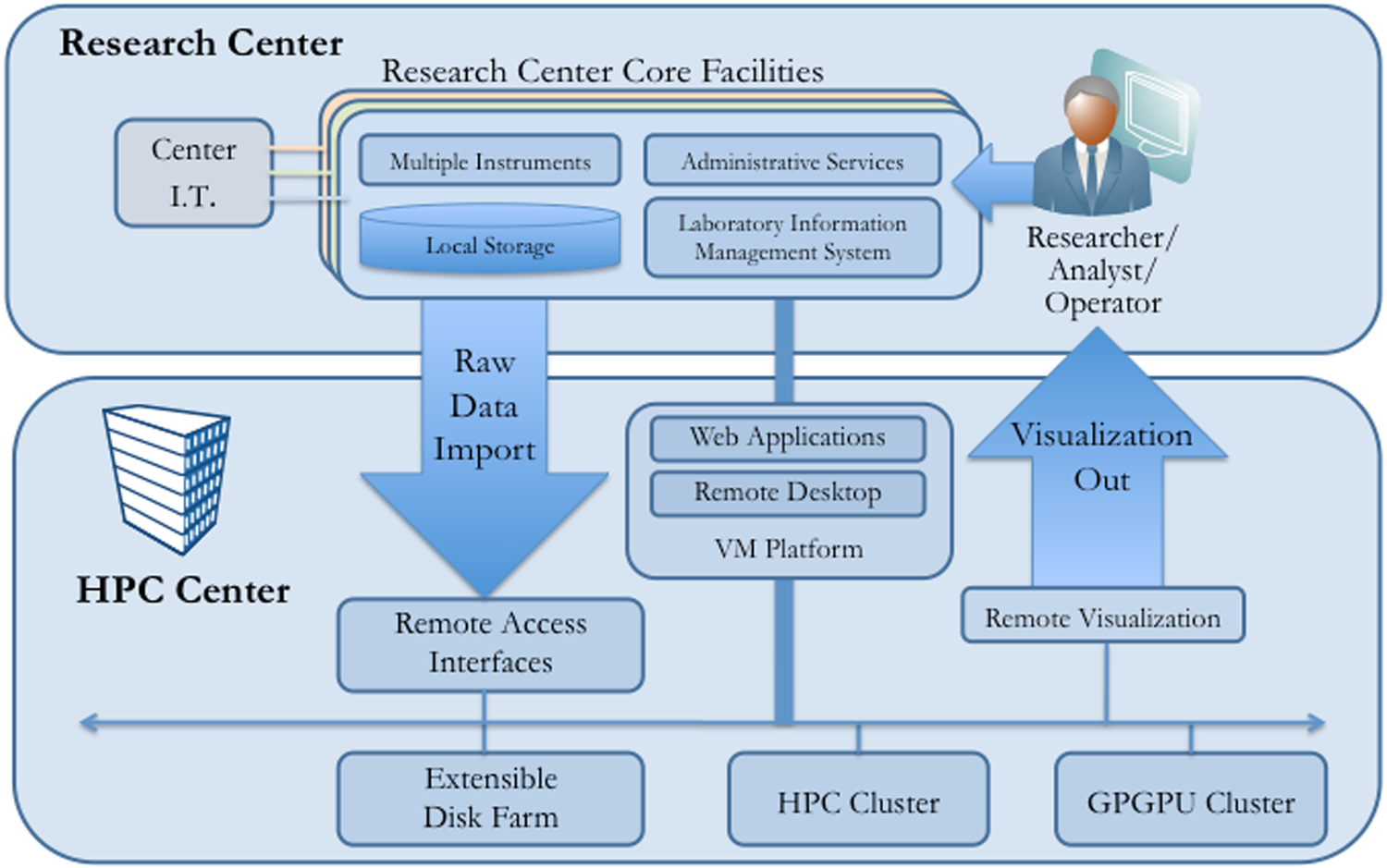
Remote Instrumentation Services can be used by CORE facilities for large-scale storage, processing, visualization, and data distribution services.
We have developed a data import service that automatically transfers acquired data from the individual core facilities to the Extensible Disk Farm at OSC. The service allows core facilities to schedule and track data transfers and alerts OSC support staff in the event of transfer failures or errors. GridFTP is used for data transport. In addition, hosting facilities are provided in a virtual machine environment to support Web applications and remote desktop applications required for data inspection and manipulation.
Gaps, Challenges and Opportunities
Multiple gaps exist in meeting the storage and processing requirements posed by the biomedical sciences community. The RIS data import service has allowed core facilities to move large quantities of data to OSC. Our current large-scale data processing solution consists of staging raw data to a parallel file system (PVFS) and running HPC cluster jobs on multiple nodes. For example, gene-sequencing jobs from a core facility use 128 nodes. An alternative architecture for such processing is the sharding model in which loosely coupled nodes, each with its own local storage, are managed and programmed using methods like MapReduce or Dryad. Sharded environments can be locally built using software like Hadoop. We believe sharded environments for data-intensive computing could become a standing service at HPC centers, as leasing sharded solutions from a vendor like Amazon EC2 is inefficient (due to the data transfer time between the HPC Center and the vendor) and prohibitively expensive (primarily due to the per-byte data transfer costs). Opportunities exist for the research and development of bioscience data processing solutions using these sharded programming models. In addition, a notable opportunity exists for automatic data migration among file systems (e.g., NFS, PVFS, and Hadoop FS) and integration with hierarchical storage management (HSM) for long-term data.
Visual analysis is an important component of modern biomedical science. However, with the increasing size of data, it is suboptimal and inefficient to transfer processed data sets to end users. Existing remote desktop technologies such as VMware View Manager™ do not have the ability to virtualize the GPU and such are not a good solution for GPU-accelerated visualization applications. We have tested a system that uses VNC and VirtualGL to remotely access visualization applications that use CUDA and OpenGL to provide interactive manipulation of large datasets over the network with acceptable latency. We are currently developing a system to improve remote user experience, accessibility, and ease of use for this remote visualization application using GPU-enabled systems in a HPC cluster environment. Furthermore, we are investigating the integration of hand-held and tablet devices into this system to achieve more ubiquitous visualization.
Footnotes
Author Disclosure Statement
The authors declare that no conflicting financial interests exist.