
Abstract
The coronavirus disease 2019 (COVID-19) pandemic has wreaked havoc globally. Beyond the pandemic, the long-term effects of the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) virus in multiple organ systems are yet to be deciphered. This calls for continued systems science research. Moreover, the host response to SARS-CoV-2 varies person-to-person and gives rise to different degrees of morbidity and mortality. Mass spectrometry (MS) has been a proven asset in studies of the SARS-CoV-2 from an omics systems science lens. To strengthen the proteomics research dedicated to COVID-19, we introduce here a web-based portal, CoVProt. The portal is work in progress and aims for a comprehensive curation of MS-based proteomics data of COVID-19 clinical samples for deep proteomic investigations, data visualization, and easy data accessibility for life sciences innovations and planetary health research community. Currently, CoVProt contains information on 2725 different proteins and 37,125 different peptides from six data sets covering a total of 202 clinical samples. Moreover, all pertinent data sets extracted from the literature have been reanalyzed using a common analysis pipeline developed by combining multiple tools. Going forward, we anticipate that the CoVProt portal will also provide access to the clinical parameters of the patients. The CoVProt (v1.0) portal addresses an existing significant gap to study COVID-19 host proteomics, which, to the best of our knowledge, is the first effort in this direction. We believe that CoVProt is poised to make contributions as a community resource for proteomic applications and aims to broadly support clinical studies to facilitate the discovery of COVID-19 biomarkers and therapeutics with translational potential.
Introduction
The coronavirus disease 2019
Advances in multiomics technologies, such as genomics, transcriptomics, and proteomics, have greatly facilitated deciphering COVID-19 pathology and SARS-CoV-2 biology (Aggarwal et al., 2021; Uddin et al., 2020; Wang et al., 2021; Zhang and Holmes, 2020). Mass spectrometry (MS)-based proteomics has played an immense role in discerning the host–pathogen interactions and resolving the varied molecular perturbations pertaining to this novel infectious agent (Aggarwal et al., 2021; Amiri-Dashatan et al., 2022; Mukherjee et al., 2021).
A huge number of proteomics analyses of a variety of clinical isolates such as serum (D'Alessandro et al., 2020; Filbin et al., 2021; Geyer et al., 2021; Hou et al., 2020; Shu et al., 2020; Suvarna et al., 2021a; Suvarna et al., 2021b; Vanderboom et al., 2021; Zhang et al., 2022), oro- and nasopharyngeal swab (Ayass et al., 2022; Bankar et al., 2021; Mun et al., 2021; Rivera et al., 2020), semen (Ghosh et al., 2022; Parikh et al., 2021), bronchoalveolar lavage fluid (BALF) (Zeng et al., 2021), urine (Bi et al., 2022; Chavan et al., 2021; Li et al., 2020; Liu et al., 2022), among others, from patients with varying degrees of disease severity has led to the accumulation of an enormous wealth of clinical data.
These data have accelerated the development of diagnostic, prognostic, and therapeutic strategies to tackle the pandemic. However, such data are currently scattered across the literature in the form of isolated studies, limiting the scientific understanding of the proteins across different specimens and clinical samples.
A portal holding proteomic data sets from different studies on a common platform would enhance the knowledge of the protein behavior across different samples and specimens. The expression profile of the proteins and associated information could be explored further for biomarker-related studies. To date, to the best of our knowledge, such efforts are lacking to develop a platform for the MS-based studies of COVID-19 host proteomics.
In this study, we report, for the first time, the development of the COVID-19 Proteomics data portal (CoVProt), a novel platform to make MS-based clinical proteomics data accessible to the scientific and medical community. The portal is a work in progress, and enables easy, rapid, and user-friendly search of a protein of interest and visualization of its expression profile in the form of bar graphs across different data sets of varying sample types.
Materials and Methods
Data curation and analysis
An in-depth literature survey and data mining were conducted to collect the MS-based studies focused on COVID-19. Furthermore, an extensive literature review was done based on data availability, data set format, patient groups, and type of approach used for MS analysis. For the current version of the CoVProt, we included the studies for which data were acquired using data-dependent acquisition (Table 1). All patients' data sets and clinical parameters in the corresponding studies were downloaded.
Research Articles Uploaded on the Portal
Tested positive for COVID-19.
Tested negative for COVID-19.
BALF, bronchoalveolar lavage fluid; COVID-19, coronavirus disease 2019.
A standard analysis pipeline using Maxquant (v.2.0.1.0) (Tyanova et al., 2016a), Perseus (v.1.6.15.0) (Tyanova et al., 2016b), and Peptide uniqueness checker (Schaeffer et al., 2017) was developed for the reanalysis of the collected data sets (Fig. 1). For this, raw data were acquired for each data set and reanalyzed using MaxQuant against a UniProt-reviewed protein database. MaxQuant output files were further processed in Perseus for data normalization and missing value imputation. Parameters used for MaxQuant and Perseus analysis are shown in Table 2.
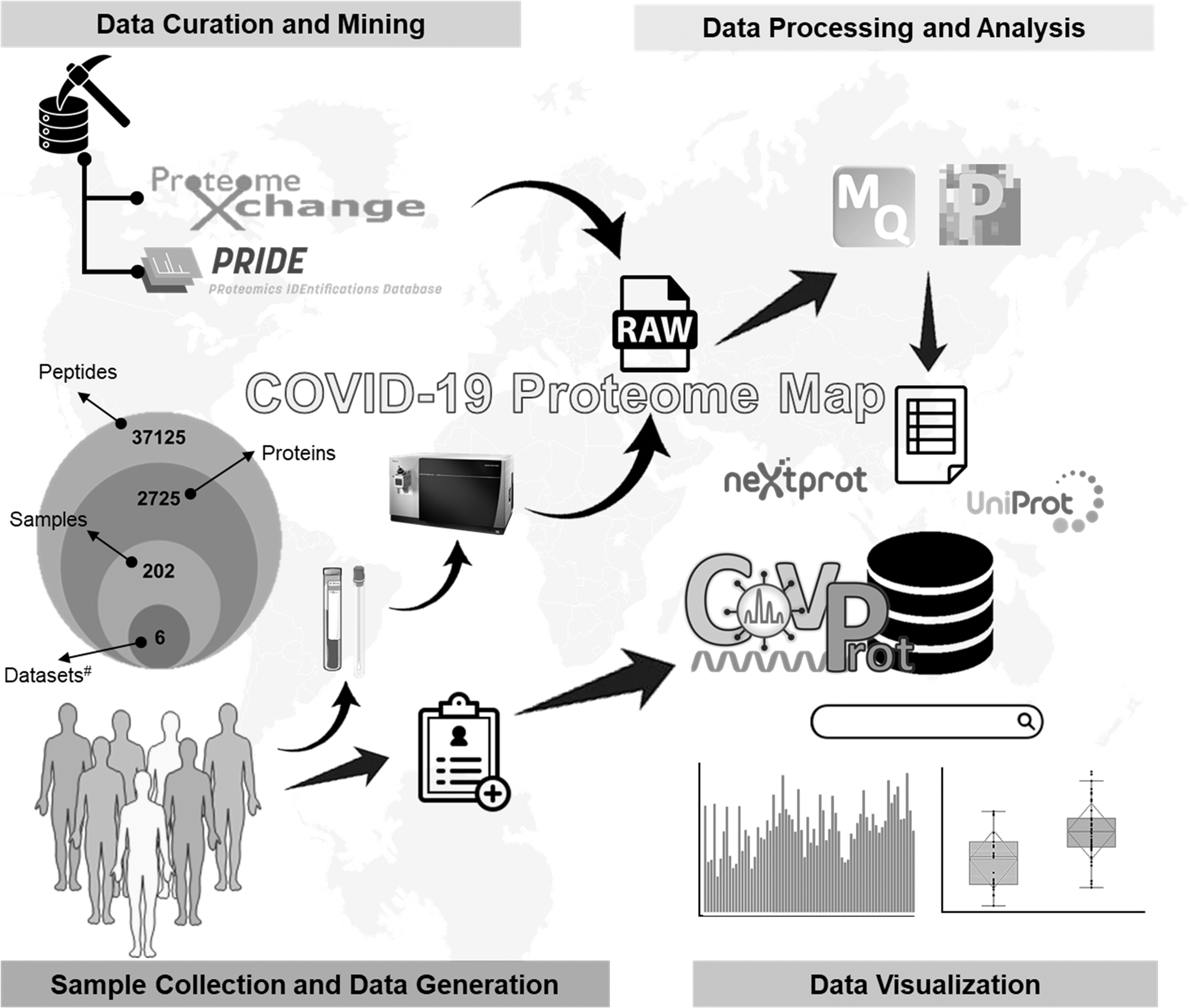
Schematic workflow adopted to develop CovProt. Data mining and data curation were done to select the data sets. Raw data were downloaded from PRIDE or Proteome Exchange. Reanalysis of the collected data was performed using a combination of tools that included MaxQuant, PRIDE, and Peptide uniqueness checker. Reanalyzed data sets were uploaded on the portal and data visualization of the results was done in the form of box plots and bar plots. In total, six data sets were used for the development of the portal at this time that comprised 2725 proteins and 37,125 peptides.
Parameters Used for Reanalysis of the Data Sets
Perseus output files were further annotated in a common format for all the data sets and uploaded to the developed portal in association with the peptide uniqueness information. Peptides acquired from the analysis were checked for uniqueness using an online tool Peptide uniqueness checker implemented in neXtProt, which classifies the peptides as unique, pseudo unique, nonunique, and identical sequences. Most of the peptides were categorized in the unique group (Supplementary Table S1).
Database implementation
The portal was developed using Django, which is a free and open-source python-based web framework, selected for its scalability and model-view-template architecture. The front end was entirely designed using Bootstrap and customized cascading style sheets (CSS) and JavaScript components, which makes it a mobile-friendly user interface. Bootstrap is also an open-source framework that provides CSS and JavaScript libraries for scalable templates, optimal with variable screen sizes. PostgreSQL database management system is highly dynamic and scalable, which was specifically used for its capability to efficiently handle structured data.
The visualizations displayed in the portal are made using Plotly. The visualizations are dynamically generated each time a user sends a query to the database. Autocomplete methods have been implemented to easily navigate the user toward the required data for the query. The user can access the entire data hosted in the database and download it or access it online through the PRIDE Database. The portal was also designed to fetch and display data from popular external public databases according to the user query. These data, along with various visualization tools and resources, are made available publicly for the first time on CoVProt (https://covprot.org).
Database features
Data visualization
Data visualization on this site includes bar plots and box plots that were dynamically generated using Plotly (“Plotly: Low-Code Data App Development,” n.d. 2015) on the backend. Bar plots represent the variation of protein log-transformed label free quantification (LFQ) intensities among different patient samples while hovering on the columns will exhibit patient demographics and sample data. The data have been normalized to enable easy comparison between different sample types and proteins. Besides, box plots show the variation of the protein LFQ intensities among disease and control groups (SARS-CoV-2 infected patients vs. healthy patients).
Moreover, the user will be able to obtain the mean, median, and standard deviation values for each sample by scrolling on the dots present within the box plots. The portal has been linked to popular public proteomic databases such as neXtProt (Zahn-Zabal et al., 2020) and UniProt (The UniProt Consortium, 2021) and it displays specific protein data for easy reference of the protein characteristics.
Search capability
Advanced search functionality allows the required protein data to be searched based on protein ID, UniProt ID, protein name, or gene name. Even if the exact UniProt ID is unknown, users can search for the required protein using a part of the protein name or the gene name and get a list of probable protein IDs and easily navigate to the required data using the autocomplete capability of the portal. These multiple query results are further tabulated and presented as clickable links to analyze and choose from, and the visualizations are generated accordingly (Fig. 2).
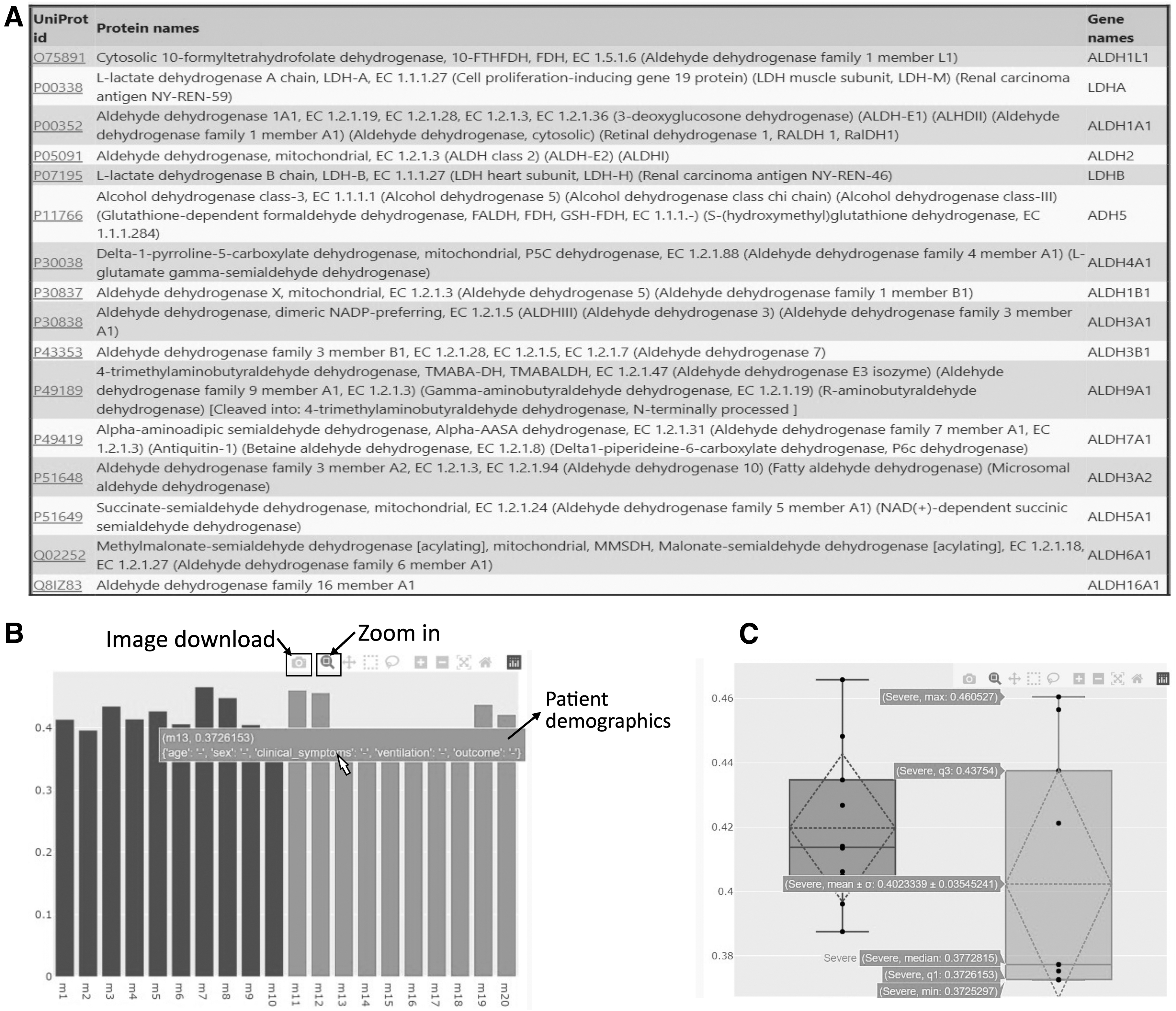
Available raw data
Present data include COVID-19 proteomic LFQ data of swabs, plasma, lung, and bronchoalveolar samples along with clinical information of patients. The protein LFQ intensities are available in the log-transformed form in association with the clinical data of the patients that can be downloaded in comma-separated values format and links to the relevant Pride ID have been provided as well. We have also given access to the patient demographic data from whom the samples are collected and processed to obtain the LFQ intensity data.
This study is supported by IITB Institute Ethics Committee (IEC) proposal no. IITB-IEC/2020/030.
Results and Discussion
From a systems medicine standpoint, the long-term effects of COVID-19 in multiple organ systems are yet to be deciphered. This calls for continued systems science research. Deciphering the role of proteins to investigate the protein biomarkers and therapeutic targets became a major interest since the emergence of COVID-19. MS became a state-of-the-art technique in this regard.
Currently, COVID-19-related proteomics data sets are present either as individual reports on research article servers such as PubMed and medRxiv, or are available as raw data on public repositories such as PRIDE (Martens et al., 2005).
This raises challenges for meta-analysis and comparative studies due to multiple factors such as the large size of data sets, different formats across different publications, different analysis methods, and sometimes limited access to the publication. Moreover, with the advancement in the high-throughput omics technology and the huge amount of data generated as a sequel, data visualization also becomes imperative.
To overcome these challenges, the CovProt database has been developed, which allows the user to investigate the expression data of the protein across different clinical samples and specimens. Statistical results in the form of box plots and bar plots will help the user to relate their findings with the information present on the portal. Furthermore, all the data extracted from different reports were reanalyzed using a common and novel pipeline to facilitate precise and easy comparison of multiple studies across different clinical data sets. Resources such as SARS-CoV-2 PeptideAtlas and CoronaMassKB are also available that provide reanalyzed data sets associated with COVID-19.
SARS-CoV-2 PeptideAtlas provides information on the SARS-CoV-2 peptides, but without considering the host response, whereas CoronaMassKB is a public platform for sharing analyzed and reanalyzed data related to the corona viruses and not limited to the SARS-CoV-2. However, these portals do not focus on host proteins and their expression profile in response to SARS-CoV-2 infection. The portal developed here aimed to incorporate MS-based studies available in public repositories for the past 2 years. Occasionally, we faced the challenge of different types of methods used to acquire and analyze MS data.
In addition, for some of the articles, raw data were not publicly accessible (Geyer et al., 2021; Maras et al., 2021). For the first version of this portal, we thus restricted the studies acquired through data-dependent acquisition. Currently, data sets and metadata information for six studies have been uploaded. This is work in progress, and the database will be updated continuously in the future. Incorporating more data sets to the portal will improve the probability of protein identification as well as it will help the user to get a more accurate expression profile, based on comparative data of the protein from different studies.
Although there are portals available for MS-based data of brain (Biswas et al., 2021) and human proteomes (Kim et al., 2014) and are proven for their great utility and wide applications, CoVProt is a new and emerging attempt in this direction to accumulate MS-based proteomics data of patients with COVID-19.
Visualization of lactate dehydrogenase using CoVProt
To demonstrate the functionality of the portal, we searched lactate dehydrogenase (LDH), a well-known prognostic marker to predict the disease severity of COVID-19 patients (Henry et al., 2020; Huang et al., 2022; Szarpak et al., 2021) as an illustrative example. LDH is an important enzyme and plays a vital role in cellular respiration. The release of LDH increases when the cell encounters tissue injury or pyroptosis (Yu et al., 2021). An elevated amount of LDH has been observed in COVID-19 patients encountering acute respiratory distress syndrome, myocardial infarction, and hemolysis (Szarpak et al., 2021).
While performing a test search with “lactate dehydrogenase” three search strings appeared (Fig. 2), which display the hyperlinks to
On clicking the tab “patient data,” raw data for the patients were also accessible. Separate tabs provided for each specimen (swab, plasma, lung, BALF, and semen) were used to visualize the expression profile of the LDH across different types of specimens (Fig. 3). Furthermore, the plots for LDH could be downloaded in the .png format using the camera icon.
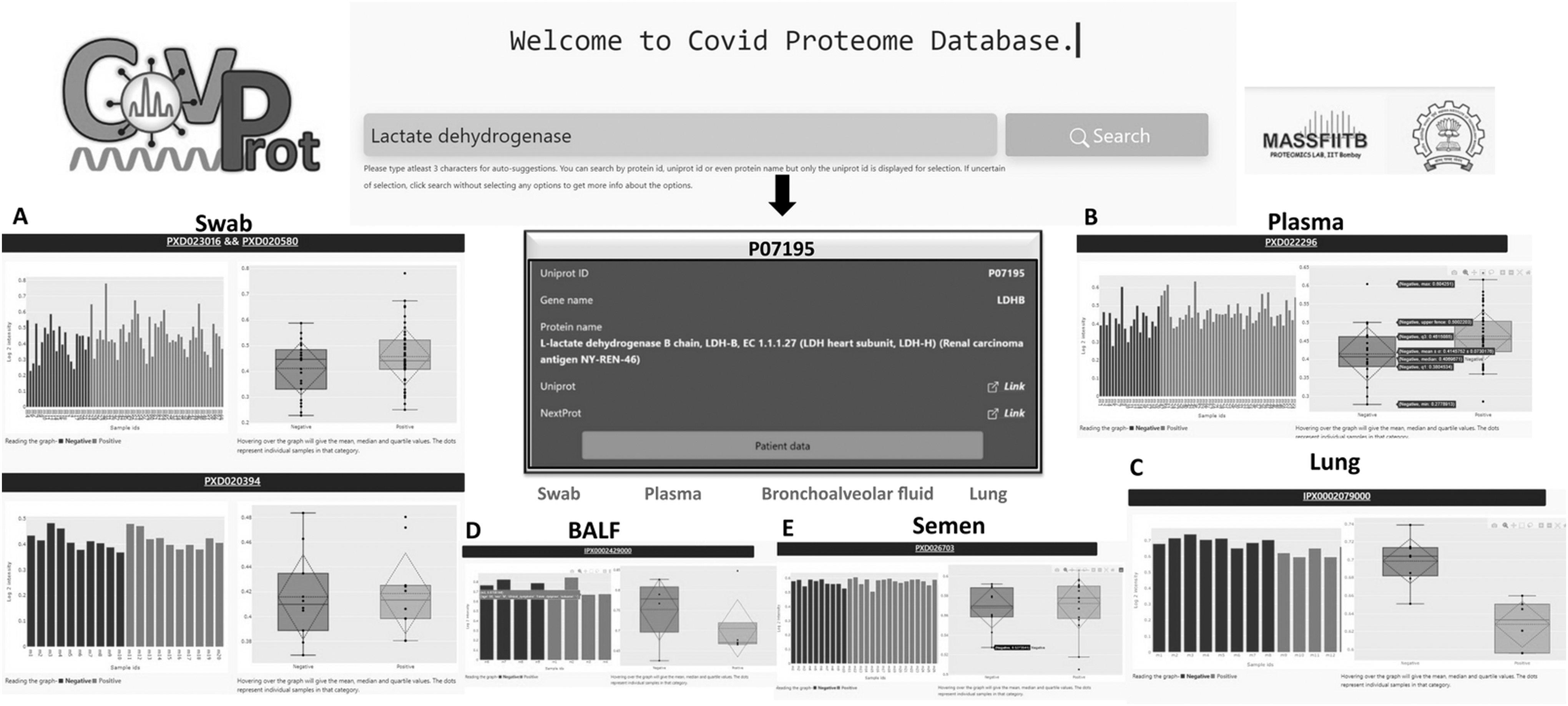
An illustrative example: analysis of COVID-19 marker protein (LDH) using CovProt. LDH (P07195) was given as input to the portal that resulted in the web page showing UniProt ID, gene name, and protein name for “P07195” in addition to the four tabs (swab, plasma, bronchoalveolar fluid, and lung) provided for different specimens.
Data Availability
All codes (e.g., Bootstrap and Python) can be accessed at http://github.com/alpharohith/Covprot-data and the web database can be accessed at covprot.org.
Conclusions
From the massive studies available in the literature, it is evident that MS has significantly contributed to unraveling the information regarding COVID-19. CoVProt is a new and emerging resource for previously published host-related MS-based studies of COVID-19 patients. The salient features of this portal include data visualization, easy accessibility of raw data, and availability of clinical information of the patients. The portal is solely dependent on the data available in the public repositories and has used the information submitted from published articles.
The metadata information and raw files have been taken directly and mapped with the information available in the supplementary data and literature. This portal will assist the researchers by providing a platform to gather protein information across different data sets and sample types. This systematic accumulation of curated data offers the promise to provide substantial coverage of host-related proteomics of SARS-CoV-2.
We believe that the accumulating body of information on the portal will help researchers unravel the complex proteomics and omics foundations of coronavirus research and support the studies for future waves of coronavirus infections. For the next version, we plan to include label-based data sets because currently the portal consists of LFQ data sets. Furthermore, we have planned to develop a pipeline to reanalyze and include DIA data sets to this portal in the future.
In all, CoVProt is poised to make veritable contributions as a community resource for proteomic applications, and to support clinical studies to facilitate the discovery of COVID-19 biomarkers and therapeutics with translational potential toward planetary health.
Footnotes
Acknowledgments
The authors want to thank MERCK-COE (DO/2021-MLSP) for their extended support. MASSFIIT (Mass Spectrometry Facility, IIT Bombay) from the Department of Biotechnology (BT/PR13114/INF/22/206/2015) is gratefully acknowledged for MS-based proteomics work.
Authors' Contributions
This study was designed by S.S., S.R., S.B., S.R.K., and H.S.P. including hypothesis and experimental sketch. Programming scripts and codes were generated by D.B, R.K., H.S.P., and H.P. Data collection and data sorting was done by S.R., S.B., and J.P. Data analysis was done by S.R., D.B., S.B., and J.P. Review and writing part of the article was done by S.S., S.R., D.B., S.R.K., H.S.P., D.B., S.B., H.P., and J.P. All authors made significant intellectual contributions to the article.
Author Disclosure Statement
This study was in part supported by a grant from the MERCK-COE (DO/2021–MLSP).
Funding Information
The study was supported through Science and Engineering Research Board (SERB), Department of Science & Technology, Ministry of Science and Technology, Government of India (SB/S1/Covid-2/2020), and a special COVID seed grant (RD/0520-IRCCHC0-006) from IRCC, IIT Bombay to SS. This study was in part supported by a grant from the MERCK-COE (DO/2021-MLSP).
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.