
Abstract
Digital health, an emerging scientific domain, attracts increasing attention as artificial intelligence and relevant software proliferate. Pharmacogenomics (PGx) is a core component of precision/personalized medicine driven by the overarching motto “the right drug, for the right patient, at the right dose, and the right time.” PGx takes into consideration patients’ genomic variations influencing drug efficacy and side effects. Despite its potentials for individually tailored therapeutics and improved clinical outcomes, adoption of PGx in clinical practice remains slow. We suggest that e-health tools such as clinical decision support systems (CDSSs) can help accelerate the PGx, precision/personalized medicine, and digital health emergence in everyday clinical practice worldwide. Herein, we present a systematic review that examines and maps the PGx-CDSSs used in clinical practice, including their salient features in both technical and clinical dimensions. Using Preferred Reporting Items for Systematic Reviews and Meta-Analysis guidelines and research of the literature, 29 relevant journal articles were included in total, and 19 PGx-CDSSs were identified. In addition, we observed 10 technical components developed mostly as part of research initiatives, 7 of which could potentially facilitate future PGx-CDSSs implementation worldwide. Most of these initiatives are deployed in the United States, indicating a noticeable lack of, and the veritable need for, similar efforts globally, including Europe.
Introduction
Digital health is an emerging frontier of clinical practice that was, in part, a catalyzed attendant to the unprecedented planetary health challenges of the COVID-19 pandemic. Digital health offers several veritable prospects such as providing clinical pharmacy and medical and public health services remotely and without interruption, both in rural and metropolitan districts and multiple time zones. Digital health is the field of knowledge and practice associated with the development and use of digital technologies to improve health (World Health Organization, 2024).
Digital health can be situated within the digital transformation of planetary health and the current efforts for precision/personalized medicine. In this context, pharmacogenomics (PGx) is a core component of precision/personalized medicine and is driven by the motto the right drug, for the right patient, at the right dose, and the right time. Personalized medicine aims to optimize health care for the individual patients with use of predictive biomarkers to improve outcomes and prevent adverse effects (Sadee et al., 2023). Patient-to-patient genetic/genomic variations along with environmental and ecological determinants of drug efficacy and side effects are key considerations of PGx. Moreover, according to the National Human Genome Research Institute (NHGRI), PGx is a component of genomic medicine so as to tailor the selection of drugs used for their treatment, aiming to provide a more individualized (and precise) approach (National Human Genome Research Institute, 2024). The importance of PGx is demonstrated by its inclusion in clinical trials as a valuable tool for enhancing our understanding of the effectiveness and safety of new drugs (Nogueiras-Álvarez, 2023).
To integrate PGx into everyday clinical practice, one of the digital health approaches pursued is the use of e-health tools, such as Clinical Decision Support Systems (CDSSs). CDSSs are used to support health care professionals (HCPs) in their complex decision-making processes via the provision of data analytics or alerts/warnings. When available, CDSSs are typically integrated into everyday operational software systems used by HCPs such as electronic health care records (EHRs) (Dramburg et al., 2020; Kashani, 2016; Matui et al., 2014; Sunjaya et al., 2022; Sutton et al., 2020).
CDSSs for pharmacogenomics (PGx-CDSSs) are specialized tools designed to aid HCPs in making personalized medication decisions by utilizing an individual’s genetic information. The clinical utility of adopting PGx guidelines with the implementation of PGx-CDSSs has been demonstrated in the past (Shah et al., 2021). Depending on the way of interaction with the end-user, PGx-CDSSs (but also CDSSs in general) can be categorized as active, which is typically rule-based and requires the system to be the active agent, that is, the system interrupts the e-prescription process via an alert/warning. In contrast, passive PGx-CDSSs provide information or further interpretation with no interruption, only for users who take the initiative to access them. In other words, the user is the active agent, and the system is passive. Of note, when combined, hybrid PGx-CDSSs can successfully support the clinicians’ decision-making process (Wake et al., 2022).
Regarding the moment of decision and the execution of genetic testing in conjunction with the operation of a PGx-CDSS, there are the following two main approaches: a point-of-care approach in which genotyping for specific variants(s) is undertaken at the time of drug prescription, and a preemptive approach in which multiple genetic variants are tested in an individual patient and the information archived for later use (Roden et al., 2018). Referring to the type of gene test, there are also main categories depending on the number of genes (single gene vs. panel), genome area (partial vs. whole), the sequencing technology that was utilized, among others (Haidar et al., 2022). The alerts in such a system can be categorized as either pretest or post-test, depending on the timing of the genetic testing. Pretest alerts warn the HCPs that genetic tests should be run (if the patient’s genetic profile is not already available) before the respective drug is prescribed to ensure optimum results. Post-test drug alerts come up when the patient’s genetic profile is already available and it seems that some variations might be related to potential adverse drug reactions (ADRs).
When designing PGx-CDSSs, the utilization of reliable PGx guidelines and attendant sources is essential to ensure their accuracy and effectiveness. Many evidence-based pharmacogenetic guidelines with clear recommendations are available for clinical decision-making by HCPs, patients, and other stakeholders (Abdullah-Koolmees et al., 2021). The development of PGx clinical guidelines and recommendations has been supported by working groups such as the international Clinical Pharmacogenetics Implementation Consortium (CPIC) (Clinical Pharmacogenetics Implementation Consortium, 2024), the Dutch Pharmacogenetics Working Group (DPWG) (Dutch Pharmacogenetics Working Group, 2024), and deployment of relevant data sources such as the Pharmacogenomics Knowledge Base (PharmGKB) (Pharmacogenomics Knowledge Base, 2024). The existing scientific evidence has driven several worldwide regulatory agencies, in particular, the United States Food and Drug Administration (US FDA) (United States Food and Drug Administration, 2024) or the Pharmacogenomics Working Party of the European Medicine Agency (EMA) (European Medicine Agency, 2024) to support the reimbursement of specific genetic tests before administering drugs with existing PGx guidelines (Alshabeeb et al., 2022).
However, despite its promising potentials for individually tailored therapeutics and improved clinical outcomes, adoption of PGx in clinical practice remains slow (Koufaki et al., 2021). Hence, the rationale of the present systematic review (SR) was, in part, the current knowledge gap on the ways in which digital health has supported the implementation of PGx. Specifically, this SR aims to outline the PGx-CDSSs that have been used in clinical practice and identify potential research gaps for future research work. In addition, this SR comprehensively maps the distinctive PGx-CDSS salient features, in both technical and clinical dimensions, as well as the relevant technical components that have been typically developed as part of research initiatives and are not yet mature enough to be widely adopted, but nonetheless could facilitate further PGx-CDSS development.
Materials and Methods
The methodology of the SR was based on the Preferred Reporting Items for Systematic Reviews and Meta-Analysis 2020 statement (PRISMA 2020) (Page et al., 2021). The PRISMA 2020 27-item checklist and the PRISMA 2020 abstract checklist are available in Part A of the Supplementary Data S1. The research question was defined as What are the distinctive features of PGx-CDSS used in clinical practice? Subsequently, technical, functional, and general mapping criteria were set (Fig. 1).
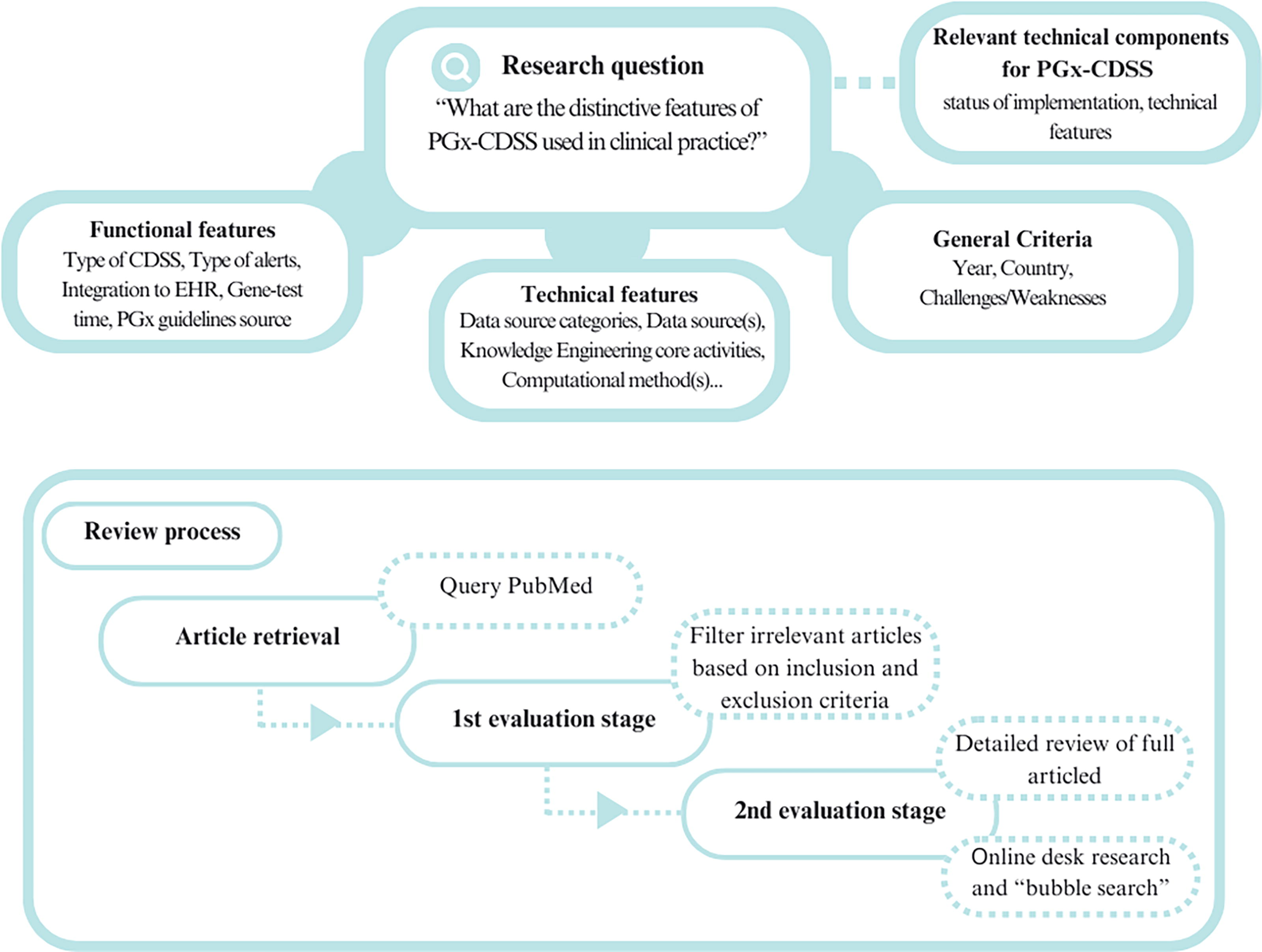
Rationale of the systematic review (SR) methodology. The research question, “What are the distinctive features of PGx-CDSS used in clinical practice?” guided the goal to map the technical and functional characteristics of identified pharmacogenomic clinical decision support systems (PGx-CDSSs) implemented in clinical practice over the last decade. The review process commenced with article retrieval from the PubMed database, followed by the 1st Evaluation Stage, which involved setting the inclusion and exclusion criteria. The 2nd Evaluation Phase encompassed a detailed review of selected full articles, supplemented by online desk research and “bubble” searches for additional information.
The search query was constructed by combining terms related to both PGx and CDSSs (Part B of the Supplementary Data S1). The PubMed database was utilized to conduct the research. Following the retrieval stage, where research and review articles published in the last decade (January 2014—January 2024) in English were gathered, the first evaluation stage was conducted. During this phase, the authors A.F. and P.N. performed the first screening by reading only the title and abstract of the retrieved articles, and doing so independently. Both reviewers have different scientific backgrounds to ensure a comprehensive evaluation. Specific inclusion and exclusion criteria were identified to facilitate the selection process (Table 1). Conflicts between the two authors’ selections were resolved through consensus meetings. Cohen’s kappa metric was used to assess the inter-rater reliability during the selection process of studies. Cohen’s kappa is a statistical measure that evaluates the agreement between two raters who each classify items into mutually exclusive categories (McHugh, 2012). Further details regarding the rationale for using Cohen’s kappa in this SR can be found in Part C of the Supplementary file.
Inclusion and Exclusion Criteria Set for the First Evaluation Stage and Mapping Criteria Established for the Second Evaluation Stage Following the Completion of Full Article Review, Online Desk Research, and Bubble Searches
During the second evaluation phase, both authors conducted a critical review of the full articles to identify and map manually the PGx-CDSSs, along with the technical, functional, and general criteria. Weekly meetings were held between reviewers throughout the review process to discuss and compare their assessments of the included studies. From the final selection of articles, the PGx-CDSSs that were reported to be used in clinical practice as well as relevant technical components for PGx-CDSS implementation were identified and listed to be further investigated via online desk research. More specifically, manual exploratory searches (in the PubMed database and/or relevant websites) were conducted in cases where the resulting articles did not provide sufficient information to complete the mapping of the criteria that were set. In addition, relevant articles were also identified via “bubble search” (i.e., the process of starting from the selected articles and interesting references be reviewed) and mapped. A narrative synthesis of the identified PGx-CDSSs and technical components was conducted to outline their implementation in clinical practice.
Results
Article selection
From the retrieving stage, 489 articles were collected. At the first evaluation stage, 418 were excluded following the inclusion/exclusion criteria that were set. At the second evaluation stage, 71 articles were full-text reviewed, leading to the final selection of 29 articles (Fig. 2). Nineteen articles were selected because they described PGx-CDSS implementation (Bell et al., 2014; Bielinski et al., 2014; Blagec et al., 2022; Blagec et al., 2018; Caraballo et al., 2017; Cecchin et al., 2017; Danahey et al., 2017; Dunnenberger et al., 2015; Hayward et al., 2021; Herr et al., 2015; Hicks et al., 2016b; Klein et al., 2017; Liu et al., 2023; Liu et al., 2021a; Liu et al., 2021b; Nguyen et al., 2022; O’Donnell et al., 2017; Smith et al., 2023; Wick et al., 2023). The other 10 articles described relevant technical components (Caraballo et al., 2020; Hoffman et al., 2016; Kidwai-Khan et al., 2022; Lee et al., 2017; Linan et al., 2015; Miñarro-Giménez et al., 2014; Monnin et al., 2019; Qin et al., 2022; Rooij et al., 2015; Samwald et al., 2015). The inter-rater reliability of the article selection process was assessed using Cohen’s kappa, yielding a kappa value of 0.843, indicating agreement between the reviewers. From the desk research and bubble search, 9 additional interesting articles were identified and utilized for the best understanding and mapping of the identified PGx-CDSSs (Dawes et al., 2016; Goldspiel et al., 2014; Gottesman et al., 2013; Herr et al., 2019; Hoffman et al., 2014; Manzi et al., 2017; Pasternak et al., 2020; Swen et al., 2023; Ubanyionwu et al., 2018). The conducted review identified 19 PGx-CDSSs. A comprehensive description of them is provided in Part D of the Supplementary Data S1. The detailed mapping of the 19 PGx-CDSSs and the 10 technical components is available in Part E of the Supplementary Data S1. A graphical abstract of the following methodology is provided, highlighting also the main findings from the SR (Fig. 3).
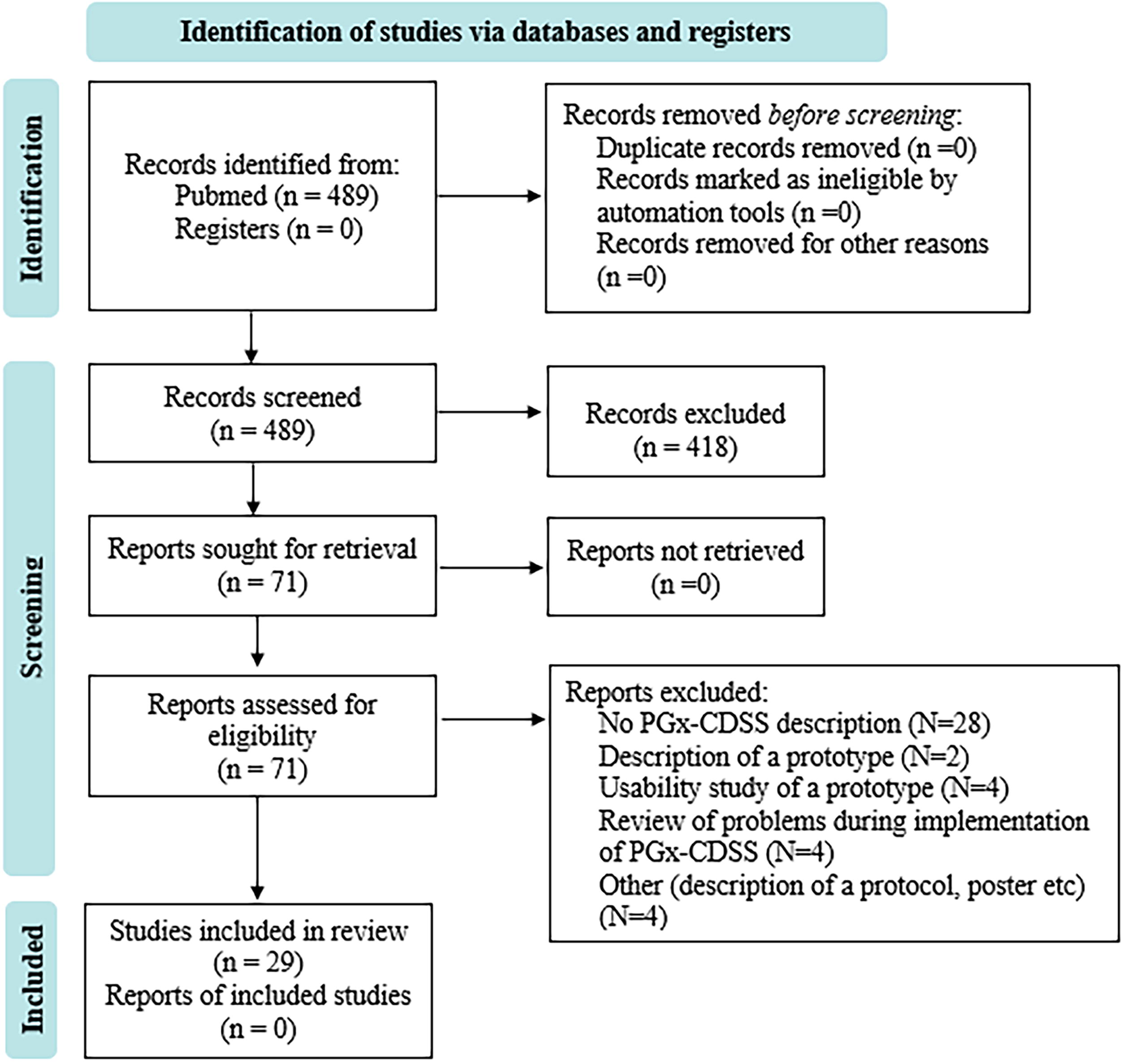
The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram in the context of the current systematic review (SR).
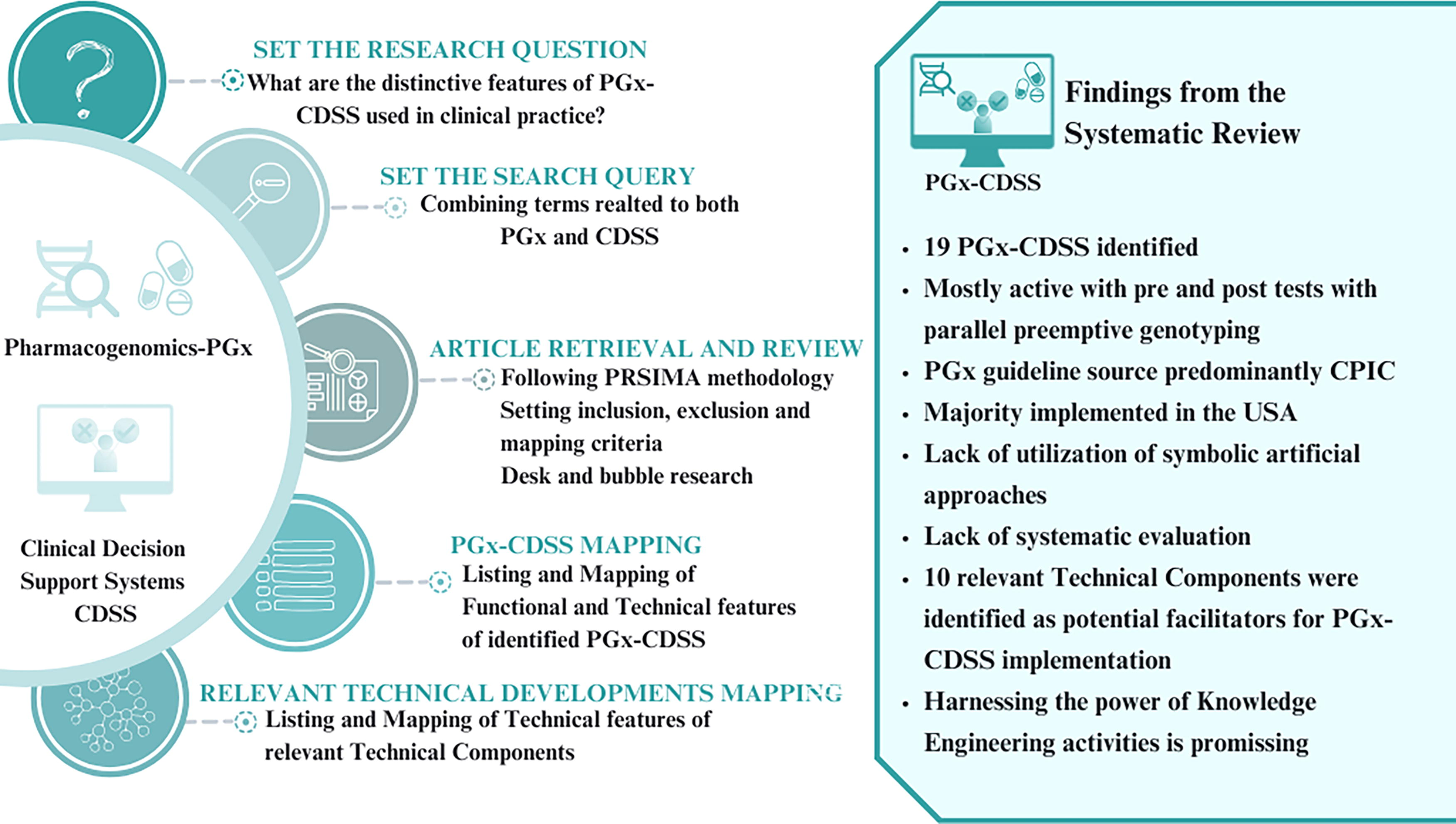
Figure 3 serves as a graphical abstract, illustrating the following methodology and the key findings of the study: the systematic review (SR) process, the identification and mapping of functional, technical, and general features of pharmacogenomic clinical decision support systems (PGx-CDSSs), and the exploration of relevant technical components. The findings reveal distinctive characteristics of 19 identified PGx-CDSSs, their predominant use in the United States, reliance on preemptive genotyping and CPIC guidelines, and potential facilitating technical developments. The study used Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) methodology and involved a comprehensive review process to contribute insights to the field of PGx-CDSS implementation.
Synthesized findings of identified PGx-CDSSs
The 19 identified PGx-CDSSs are depicted in Table 2. In order of appearance, the following PGx-CDSSs, defined by the name of the clinic where they were applied, are listed: Vanderbilt University Medical Center (Blagec et al., 2018; Caraballo et al., 2017; Dunnenberger et al., 2015; Herr et al., 2015; Klein et al., 2017; Liu et al., 2023; Liu et al., 2021b; Liu et al., 2021a; Smith et al., 2023), St. Jude (Bell et al., 2014; Blagec et al., 2018; Caraballo et al., 2017; Dunnenberger et al., 2015; Hoffman et al., 2014; Klein et al., 2017; Nguyen et al., 2022; Smith et al., 2023), University of Florida and Shands Hospital (Blagec et al., 2018; Caraballo et al., 2017; Dunnenberger et al., 2015; Klein et al., 2017; Smith et al., 2023), Mayo clinic following the RIGHT protocol (Bielinski et al., 2014; Blagec et al., 2018; Caraballo et al., 2017; Dunnenberger et al., 2015; Herr et al., 2019; Herr et al., 2015; Klein et al., 2017; Smith et al., 2023), Boston Children’s Hospital (Herr et al., 2015; Manzi et al., 2017; Smith et al., 2023), University of Chicago (Blagec et al., 2018; Caraballo et al., 2017; Danahey et al., 2017; Klein et al., 2017; O’Donnell et al., 2017; Smith et al., 2023), National Institutes of Health Clinical Center (NIH CC) (Goldspiel et al., 2014; Smith et al., 2023), Mount Sinai Medical Center (Blagec et al., 2018; Caraballo et al., 2017; Dunnenberger et al., 2015; Gottesman et al., 2013; Herr et al., 2019, 2015; Klein et al., 2017; Smith et al., 2023), Cincinnati Children’s Hospital Medical Center (Herr et al., 2019, 2015; Smith et al., 2023), Marshfield (Herr et al., 2015; Klein et al., 2017; Smith et al., 2023), Geisinger (Herr et al., 2015), Group Health (Herr et al., 2015), Northwestern Clinic (Herr et al., 2019, 2015; Smith et al., 2023), Mayo Clinic (Smith et al., 2023; Ubanyionwu et al., 2018), University of British Columbia (Dawes et al., 2016; Hayward et al., 2021; Herr et al., 2015; Smith et al., 2023), Cleveland Clinic (Blagec et al., 2018; Caraballo et al., 2017; Hicks et al., 2016b), The Ubiquitous project (U-PGx) (Blagec et al., 2022, 2018; Cecchin et al., 2017; Hayward et al., 2021; Swen et al., 2023), University of Michigan (Pasternak et al., 2020; Smith et al., 2023), and Christ Hospital Health Network (Wick et al., 2023).
List of the 19 Identified PGx-CDSSs
Clinic Name: name of the clinic where the PGx-CDSS is implemented. Project/Protocol Name: name of the project or the followed protocol. Year: year of the start of implementation. Country: the country where the clinic is located. N/S: not stated; information could not be found. N/A: not applicable.
The majority of the identified PGx-CDSSs were implemented in the context of two significant initiatives, the Electronic Medical Records and Genomics, eMERGE network, which stands as one of the leading global efforts to evolve genetic medicine, and the Implementing GeNomics In pracTicE (IGNITE) Pragmatic Clinical Trials Network, which is a National Institutes of Health (NIH)-funded network, dedicated to supporting the implementation of genomics in health care. The eMERGE network is an NHGRI-funded consortium tasked with developing methods and best practices for the utilization of the EHR as a tool for genomic research. Through its funding cycles, eMERGE has made a significant impact on the medical health profession. Throughout the various projects funded by this network over time, the integration of PGx-CDSSs has often been explored [Mayo clinic (The RIGHT protocol) (Bielinski et al., 2014), Mount Sinai Medical Center (The CLIMPERGE PGx program) (Dunnenberger et al., 2015), St. Jude (The PG4KDS protocol) (Dunnenberger et al., 2015), Cincinnati Children’s Hospital Medical Center, Marshfield, Geisinger (Herr et al., 2015)]. In addition, the IGNITE aims to demonstrate how genomic information can be used to guide medical decisions and improve patient outcomes. IGNITE primarily focuses on implementing genomic medicine into various health care settings. In some IGNITE projects PGx-CDSSs have been developed and evaluated such as the Vanderbilt University Medical Center (PREDICT) (Liu et al., 2021b).
During the qualitative analysis, two PGx-CDSSs (Geisinger and Group Health) were excluded from this process, as no additional information was available beyond their mention in the respective reviews; therefore, we deemed it appropriate to exclude them from the subsequent qualitative representation of the collected information. Thus, with a total of 17 identified PGx-CDSSs, it appears that the majority of PGx-CDSSs applied in clinical practice are of the active CDSS type, integrated into the EHR, implementing clinical studies/protocols for preemptive genotyping with pre- and postalerts (Fig. 4).

Distribution of CDSS types, gene-test timing, alert types, and integration in EHR in identified PGx-CDSSs. The diagram illustrates the distribution of different types of clinical decision support systems (CDSSs), gene-test timing, alert types, and integration status into electronic health records (EHRs) among the identified pharmacogenomic clinical decision support systems (PGx-CDSSs). Categories include active, passive, active/passive, preemptive, point of care, preemptive/point of care, pretest, post-test, pre- and post-test, integration to EHR (Yes, No, Yes/No), and instances where specific information was not stated (N/S).
In addition, we observed a high level of confidence demonstrated by the scientific personnel designing the PGx-CDSS in adhering to the clinical guidelines of the CPIC and the FDA (Fig. 5). The acknowledgment of using clinical guidelines by the FDA does not come as a surprise, aligning with the evident prevalence of PGx-CDSS implementation in the United States. During the years 2012–2014, there was funding from the eMERGE II PGx aiming, among others goals, the development of technical and regulatory solutions to integrate PGx information into the EHR in a useable manner (Fig. 6) (eMERGE, 2024).

Distribution of pharmacogenomic (PGx) guideline sources in identified pharmacogenomic clinical decision support systems (PGx-CDSSs). The diagram presents the distribution of PGx guideline sources among the identified PGx-CDSSs. Sources include the Clinical Pharmacogenetics Implementation Consortium (CPIC), the U.S. Food and Drug Administration (FDA), PharmGKB, Dutch Pharmacogenetics Working Group (DPWG), and instances where specific information was not stated (N/S).
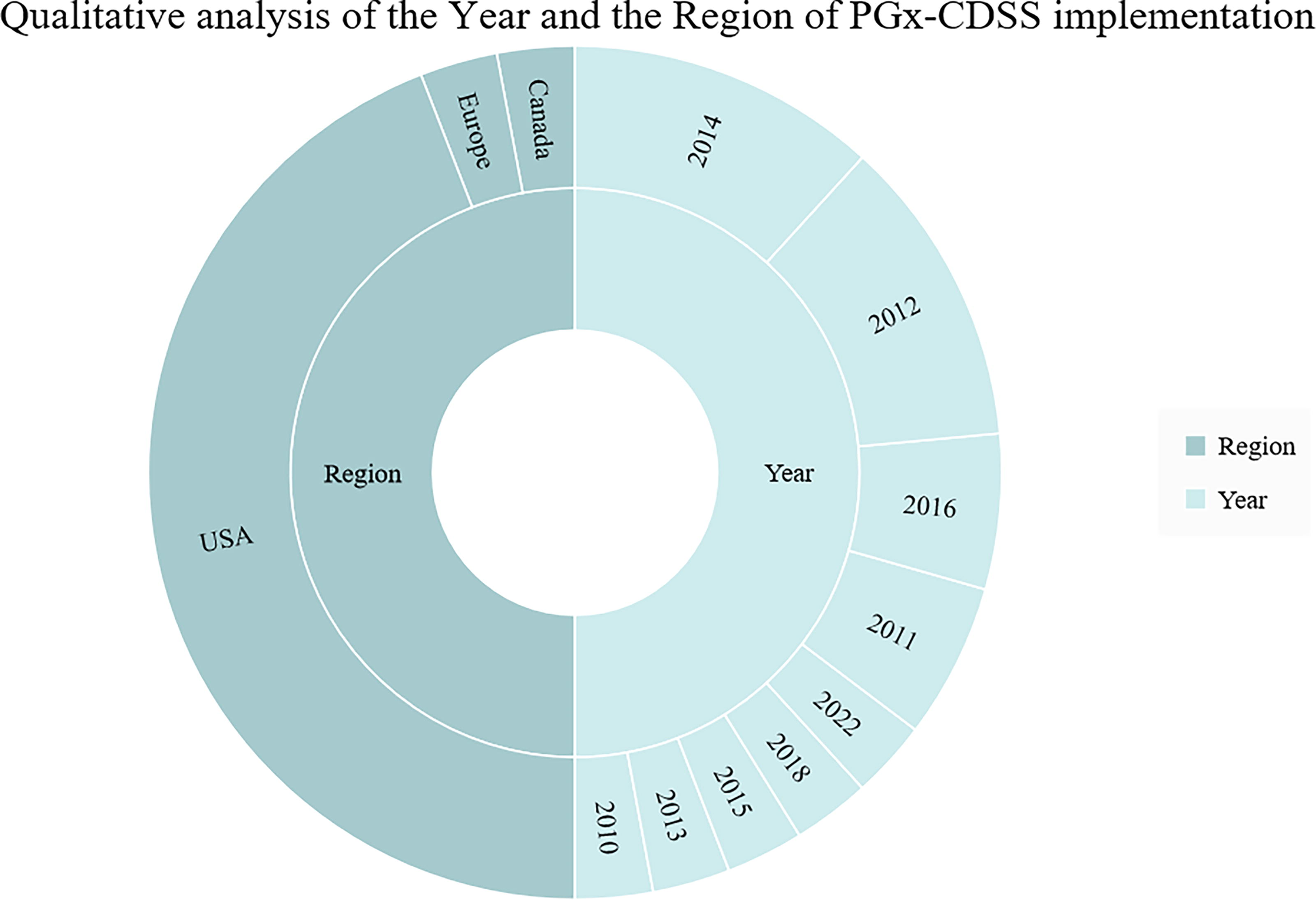
Distribution of identified pharmacogenomic clinical decision support systems (PGx-CDSSs) over the years and countries. The diagram illustrates the yearly distribution of identified PGx-CDSS instances, along with the corresponding countries of implementation. The majority of systems were implemented in the United States, with varying numbers across different years, and a few instances in Canada and Europe during the specified time frame.
Through the qualitative analysis of the technical criteria, it became evident that the predominant data sources used are in the category of “Genetics and Biochemical databases” (i.e., CPIC, single-nucleotide polymorphism database (dbSNP), Pharmacogenomics Global Research Network (PGRN) Data, PharmGKB), “EHRs” (mostly referring to proprietary data sources), and “bibliographic databases” (i.e., PubMed/Medline). Concerning the “Knowledge Engineering Core Activities” criterion, which encompasses the fundamental processes involved in creating, organizing, and managing knowledge within a system, it appears that the majority followed the pattern of knowledge integration and knowledge representation. This approach signifies that these systems combined information from various sources, such as PGx-guidelines databases, EHRs, and bibliographic databases, into a unified and comprehensive user interface. The integrated knowledge was integrated within already deployed software systems in a way that facilitated effective processing and utilization. Referring to the used “computational methods,” the use of rule-based inferencing approaches is the identified predominant approach. Rule-based inferencing is a form of computational reasoning where logical rules are applied to produce alerts/warnings to support HCP-informed decision-making. Sometimes, the term is also interchangeably used with the term “symbolic artificial intelligence” where explicit knowledge structures (e.g., ontologies and/or rule-bases) are used to deduce new “hints” or alerts/warnings based on advanced mathematic-based reasoning processes. However, it should be noted that there were no articles found implying the use of such symbolic reasoning approaches. Concerning “reference terminologies” (standardized sets of terms and concepts used in a particular domain), the available information is limited, primarily depicting the use of SNOMED CT, a widely used clinical health care terminology (Fig. 7).
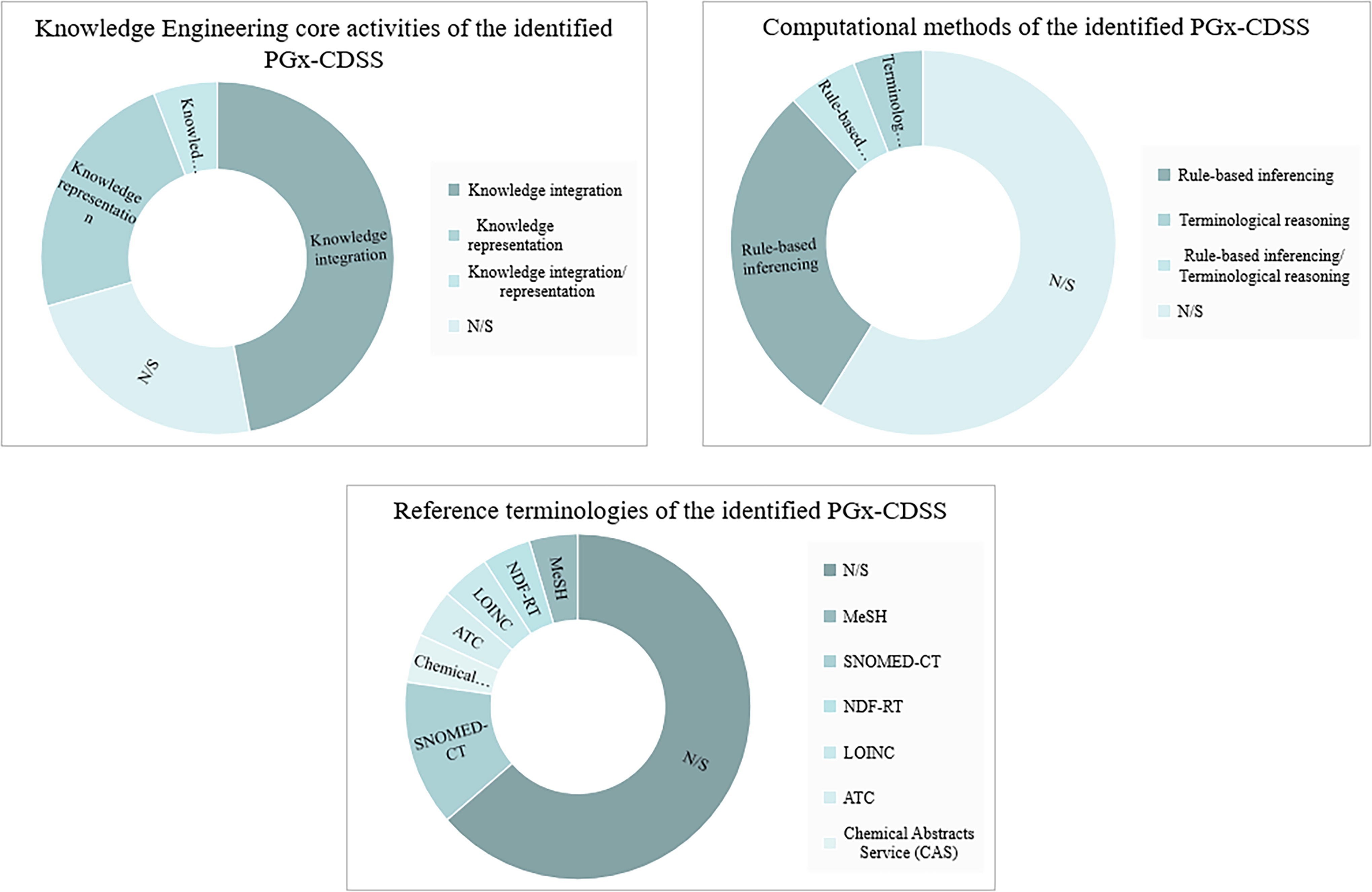
Distribution of Knowledge Engineering Core Activities, computational methods, and reference terminologies in identified PGx-CDSSs. The diagram illustrates the frequencies of different Knowledge Engineering Core Activities, computational methods, and reference terminologies found in the identified pharmacogenomic clinical decision support systems (PGx-CDSSs). Knowledge integration, knowledge representation, and their combination are represented in the Knowledge Engineering category. Rule-based inferencing and terminological reasoning are highlighted in the Computational Methods category. Various reference terminologies such as SNOMED-CT, MeSH, NDF-RT, LOINC, ATC, and CAS are depicted in the Reference Terminologies category. “N/S” denotes instances where specific information was not stated.
Regarding “knowledge representation formalism” (the method used to represent information in a structured way within a system), relevant information is typically missing. Information is only available for the Vanderbilt University Medical Center, which utilizes a relational approach (Liu et al., 2021b), and the University of Chicago, which uses a frame-based ontology and a relational approach (Danahey et al., 2017).
During the review, some challenges/weaknesses of the mapped PGx-CDSSs were also identified. More specifically, the lack of relevant training emphasizing on the use of PGx information to support clinical decision-making is identified as a crucial challenge. Along these lines, the lack of wide adoption of PGx rules and the lack of relevant resources were also reported. Regarding technical issues, notable observations include technical integration challenges (e.g., linking with commercial EHR systems), the lack of systematic evaluation or evaluation on a very narrow scope, unavailability of the used knowledge representation model implying also a failure to adhere to a knowledge representation standard, and substantial reliance on manual processing. As most of the presented systems are rule-based, the lack of use of advanced technical approaches to support automatic “reasoning” (e.g., the use of formal description logic (DL) semantics) should also be noted (Fig. 8).
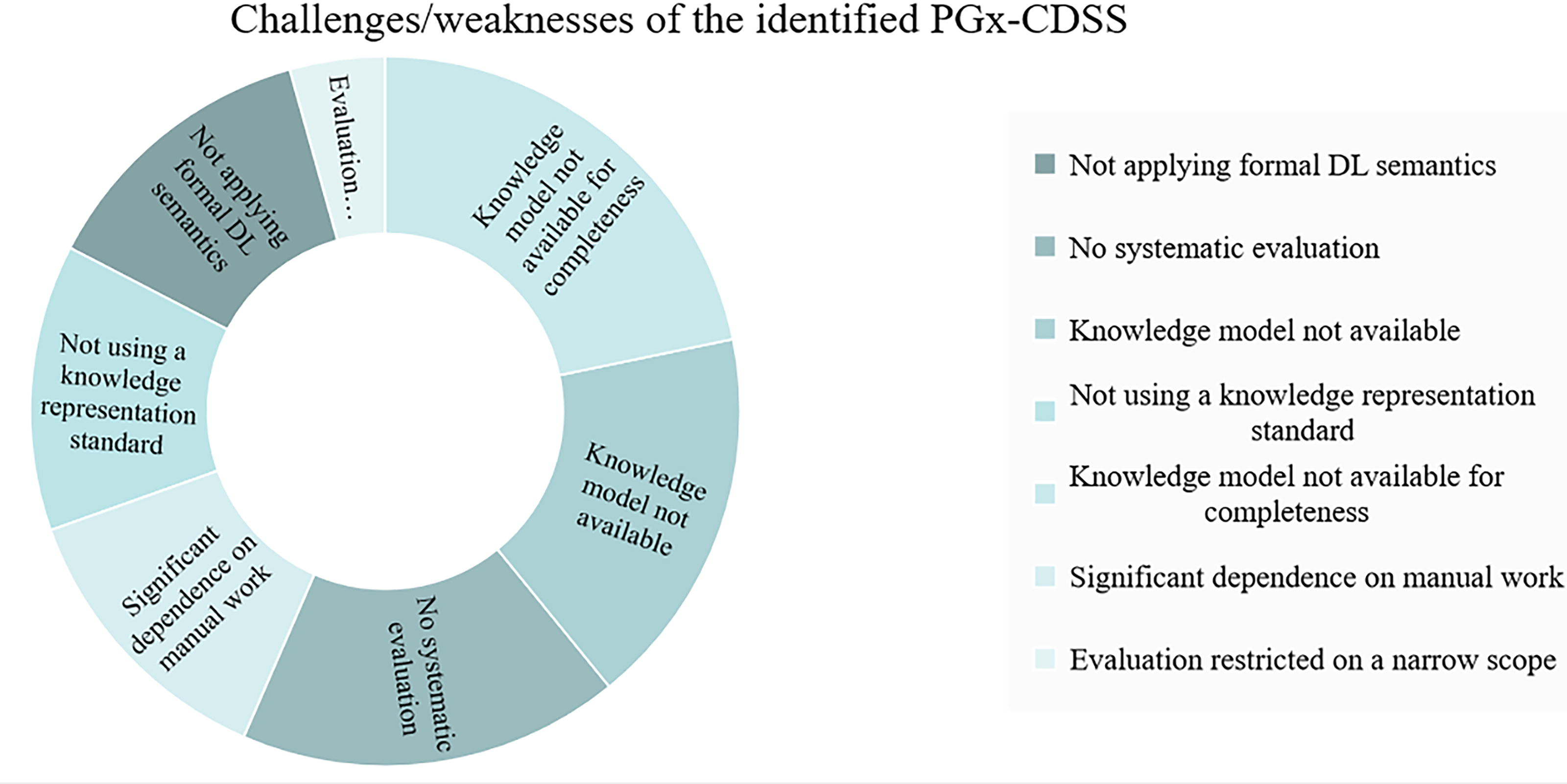
Identified challenges and weaknesses in mapped pharmacogenomic clinical decision support systems (PGx-CDSSs). The challenges include issues such as the nonapplication of formal description logic (DL) semantics, lack of systematic evaluation, unavailability of knowledge models, failure to use a knowledge representation standard, knowledge model absence for completeness, significant dependence on manual work, and evaluations restricted to a narrow scope.
Among the PGx-CDSSs, the implementation at the Vanderbilt University Medical Center should be noted as it appears to have continued its application in clinical practice (Liu et al., 2021a). To this end, the implementation of St. Jude has also produced a recent publication (Nguyen et al., 2022). In addition, the Christ Hospital Health Network appears to have implemented the most recent PGx-CDSS, with a unique aspect being its trial in primary care clinics (Wick et al., 2023). Finally, in Europe, the only systematic and evaluated effort for implementing PGx-CDSSs in clinical practice seems to be through the U-PGx Horizon 2020 project. Their approach to integrating PGx-CDSSs into clinical practice across diverse health care systems makes it particularly intriguing (Blagec et al., 2018).
Synthesized findings of relevant technical components for PGx-CDSS implementation
During the review of PGx-CDSSs implemented in clinical practice, 10 relevant technical components for PGx-CDSS implementation were also identified: medicine safety code (MSC) (Miñarro-Giménez et al., 2014), structured knowledge representations for shareable CDS rules from PGx guidelines (Linan et al., 2015), fast and frugal approach to formalize the decision-making process (Rooij et al., 2015), principles/guidelines from CPIC in a machine-readable form (Hoffman et al., 2016), a knowledge-based system aiming to provide intelligent assistance for pharmacogenomic evidence assessment (Lee et al., 2017), PGxO and PGxLOD ontologies (Monnin et al., 2019), genomic indicator (Gen-Ind) operational model (Caraballo et al., 2020), Pharmacogenomics Clinical Translation Platform (PCTP) (Qin et al., 2022), genomic clinical decision support (Genomic CDS) ontology (Samwald et al., 2015), and pharmacogenomic-driven decision-support prototype with machine learning (Kidwai-Khan et al., 2022). These developments were studied and mapped against the already outlined technical criteria. In addition, we investigated whether they have been implemented or not (Table 3).
Overview of Relevant Technical Components for PGx-CDSS Implementation
This table summarizes various relevant technical components for PGx-CDSS implementation, including their names, publication years, identification of implementation during the review, and the respective countries of origin.
Out of the 10 identified components, the MSC has been practically applied within the U-PGx project, addressing challenges such as the absence of EHRs. Moreover, the technical workgroup of CPIC, which published clinical PGx guidelines in a machine-readable format, was leveraged by PGx-CDSS designers. In addition, at the Mayo Clinic, the Gen-Ind tool was developed and implemented to support the functionality of PGx-CDSS, overcoming the limited readiness of commercial EHRs to implement PGx guidelines. Table 4 presents the functional importance of the identified components.
Comprehensive Overview of Relevant Technical Components for PGx-CDSS Implementation and Their Concepts with Significance
This table provides a detailed summary of relevant technical components for PGx-CDSSs, accompanied by their corresponding descriptions highlighting key concepts and their significance in the field of PGx-CDSS implementation.
Regarding the data sources that have been utilized for the development of the technical components, the conclusions align with those of PGx-CDSS, that is, use of “Genetics and Biochemical databases,” “Bibliographic databases” and “Drug information databases” (CPIC, dbSNP, PGRN Data, PharmGKB, DrugBank), and “electronic health records,” namely proprietary closed data sources. “Core Knowledge Engineering Activities” encompass representation, integration, and extraction, while “Computational methods” include ontology reasoning, rule-based inferencing, and data mining. “Reference terminologies” range from LOINC, NDF-RT, Rx-Norm, SNOMED-CT, UMLS, ATC, MeSH, NCIt, and PROV-O, to PharmCAT. “Knowledge representation” activities utilize OWL, XML, HL7 vMR, Health eDecisions (HeD), and RDF formats. These insights shed light on the diverse strategies applied in crafting relevant technical components to augment the implementation of PGx-CDSS in clinical settings (Fig. 9).
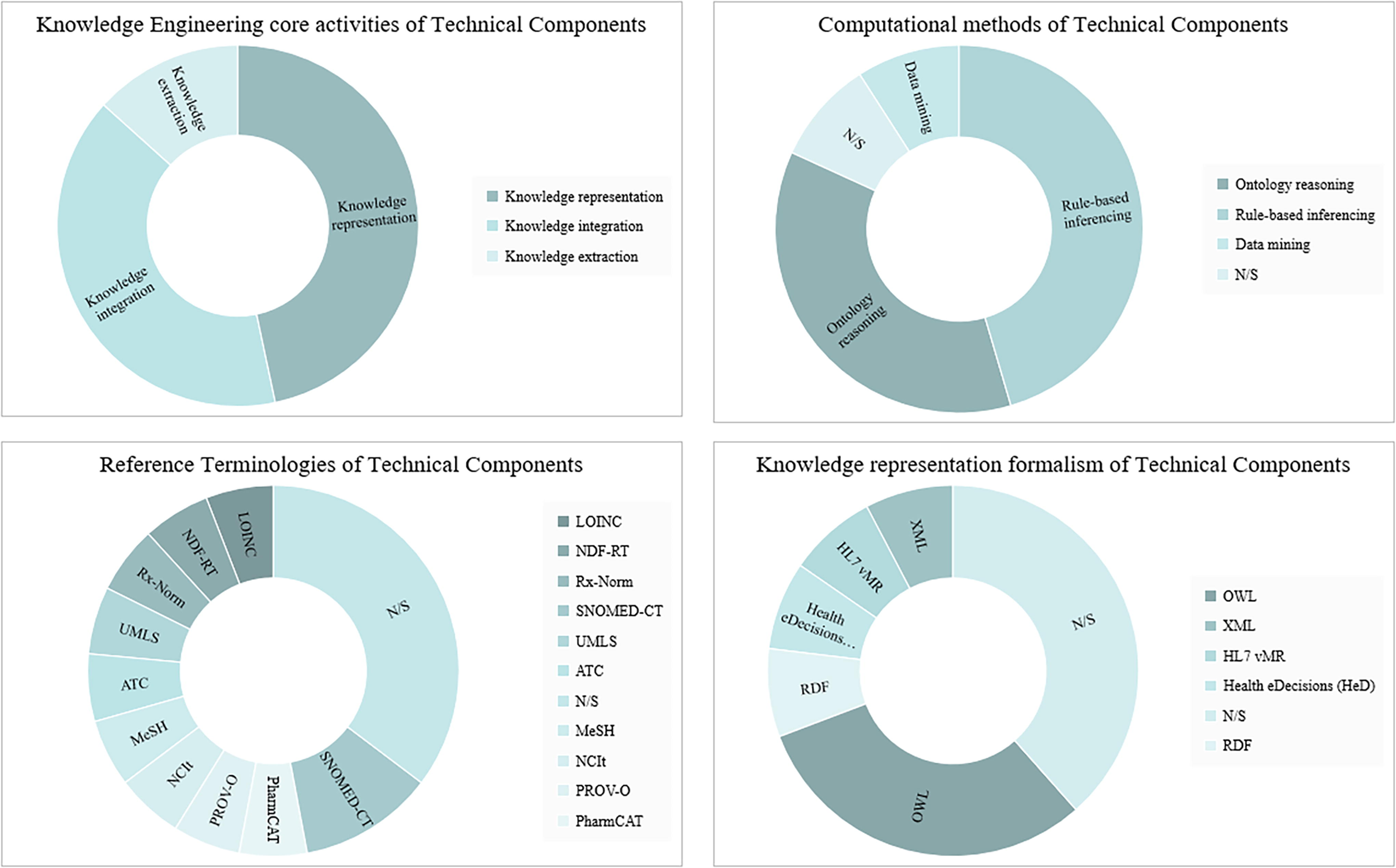
Visualization of the distribution of Knowledge Engineering Core Activities, computational methods, reference terminologies, and knowledge representation formalism in technical components for PGx-CDSS implementation. “N/S” denotes instances where specific information was not stated.
Several challenges/weaknesses of the presented relevant technical components were outlined. A prominent weakness was the absence of systematic evaluation in seven instances, highlighting a gap in the comprehensive assessment of these tools. In addition, the lack of validation for knowledge models in terms of completeness was identified as a significant issue. In certain cases, the knowledge model was entirely unavailable. The reliance on manual work was noted, suggesting a need for increased automation. Other concerns encompassed the lack of adherence to knowledge representation standards, the nonapplication of formal DL semantics, and evaluations conducted solely with simulated data (Fig. 10).
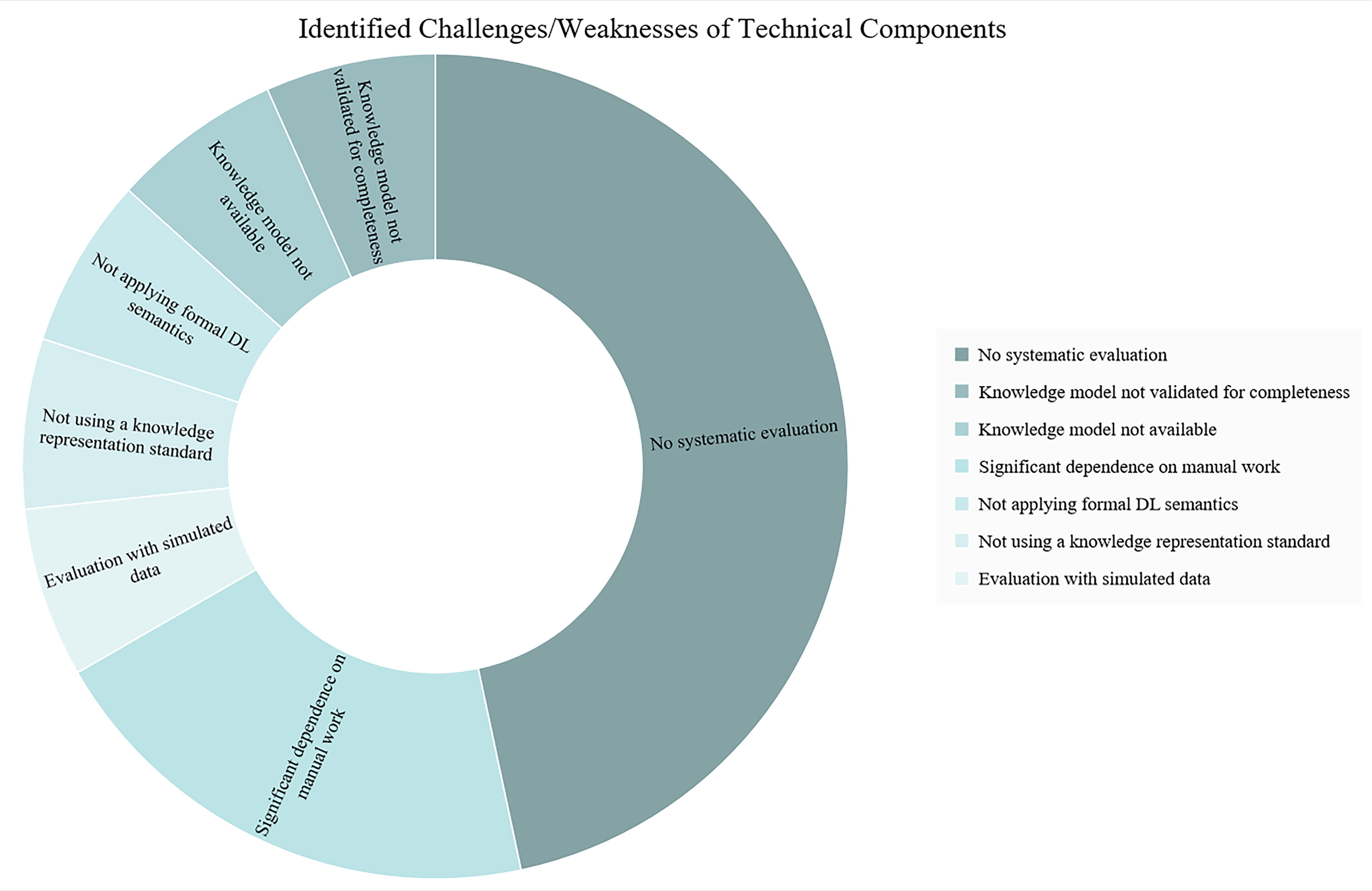
Challenges and weaknesses in technical components for PGx-CDSS implementation. The diagram illustrates challenges and weaknesses identified in relevant technical developments for pharmacogenomic clinical decision support systems (PGx-CDSSs). The data reflect instances of systematic evaluation gaps, incomplete knowledge model validation, unavailability of knowledge models, manual work dependency, nonapplication of formal description logic (DL) semantics, lack of adherence to knowledge representation standards, and evaluations with simulated data.
Discussion
The intersections of digital health with precision/personalized medicine, for example, in the form of e-health tools utilized in the pursuit of PGx clinical practice, are growing and yet remain as understudied fields of scholarship (Lin and Wu, 2022). The present SR aims at this knowledge lacunae and offers new observations, knowledge gaps, and ways forward.
From the qualitative synthesis of the findings, we conclude that the integration of PGx-CDSSs in real-world health care clinical practice is still limited. From the current SR it became evident that there is a significant level of PGx-CDSS implementation activity in the United States. This indicates that the implementation of PGx-CDSS should be investigated in different health care systems, beyond the United States, by exploring factors such as the readiness of the digital ecosystem, user behavior, broader health system requirements, and the context of test reimbursements (Erku et al., 2023; Kabbani et al., 2023). In Europe, the only relevant major initiative was the so-called U-PGx project. However, it is crucial to emphasize that during the article selection stage, notable efforts for applying clinical PGx guidelines in Europe were found, even though PGx-CDSSs were not utilized. One characteristic initiative is developing in Germany, known as the Medical Informatics in Research and Care in University Medicine (MIRACUM) consortium. MIRACUM, funded by eight German university hospitals/medical faculties, envisions medical informatics in translational oncology. Among MIRACUM’s goals is to support precision medicine through PGx-CDSS therapy decisions (Hinderer et al., 2018).
In the Netherlands, we identified some more PGx-CDSSs (from review articles or introduction sections) where detailed information was not available or they were not discussed as stand-alone papers. For instance, at Leiden University Medical Center, a preemptive dihydropyrimidine dehydrogenase (DPYD) genotyping program was implemented (Blagec et al., 2018; Smith et al., 2023). In addition, an active CDSS (adverse drug event alerting system, ADEAS) was connected to several other hospital information systems, including a database that contains PGx dosing guidelines authored by the DPWG was used to alert pharmacists when a patient is at risk of an ADR event (Blagec et al., 2018). In Netherlands seems to be a broader effort to leverage PGx clinical guidelines in the G-standard system, which utilizes multiple health care infrastructures. The G-standaard refers to the database used in the Netherlands for managing and exchanging information about pharmaceuticals. It serves as a standard reference database containing comprehensive information about drugs, including their composition, dosage forms, indications, interactions, and pricing. Another notable effort, referring to Europe, that was identified during the review and is worth mentioning was the development of the FARMAPRICE prototype (Roncato et al., 2019). This initiative was developed in Italy, in 2017, as an active PGx-CDSS prototype integrated with PGx guidelines (following PharmGKB) and patient genetic information in a web service platform, with the function of post- and pretest alert (Roncato et al., 2019).
It is also important to note the significant dissemination of PGx expected due to the utilization of next-generation sequencing (NGS) technology in gene sequencing. The advent of NGS will accelerate the clinical applications of PGx through a series of reliable, cost-effective opportunities. Data collection and interpretation will benefit from the interplay of consortia and information technologies. Regulatory bodies will lead the way toward assay validation and accreditation, considering the difficulties of PGx study replication (Giannopoulou et al., 2019). It seems crucial to establish a functional workflow to manage the vast volume of generated data (Giannopoulou et al., 2019). Furthermore, with the advent of NGS and the discovery of tens of thousands of rare genotypes with unknown functions, a new necessity arises. The utilization of machine learning (ML) methods and the mapping of these uncharacterized genotypes with EHR data can be highly beneficial in identifying significant correlations. In the review of Zhou et al., various approaches are described (Zhou et al., 2022).
In addition, it was noteworthy that in many PGx-CDSS prototypes, usability studies were conducted to measure the acceptance of the proposed applications. Regarding participant selection, some studies chose physicians (Nguyen et al., 2019; Roncato et al., 2019), some physicians and pharmacists (Melton et al., 2016), while some chose nurses (Baker and Dodson, 2021; Dodson and Layman, 2022). Overby C. et al. tried to find if the physicians’ characteristics can influence PGx-CDSS acceptance (Overby et al., 2015). These articles could be utilized in the participatory design of PGx-CDSSs under development, facilitating their maximum acceptance.
Another factor to consider during the design of PGx-CDSS is the possibility of phenoconversion for which we did not identify any specific reference during the SR. In some cases, there is a mismatch between the patient’s genotype-predicted phenotype and their actual phenotype. This phenomenon is called phenoconversion and may be the result of drug–drug interactions (or other factors that could influence the activity of metabolic enzymes) or some renal/liver dysfunction, etc. (Mostafa et al., 2022). In the same context, specific conditions such as marrow transplantation must be taken into account (Massmann et al., 2022). An interesting approach was also that of Socco et al., where the change of administrative is reviewed to overcome PGx barriers (Socco et al., 2022).
From the qualitative synthesis of the findings regarding the technical features of the PGx-CDSS, a significant research gap was identified during this SR. Specifically, the utilization of knowledge engineering approaches is limited. Although interesting technical components were identified, their utilization was also restricted. We did not find the use DL. DL is a mathematical logic typically used to support automatic reasoning upon well-defined knowledge structures represented in “machine-understandable” formats. To harness the power of DL, a basic requirement is that the knowledge be in a machine-understandable format. In our case, two research gaps are identified: the absence of PGx reference terminologies and the translation of PGx knowledge into machine-understandable formats. The translation of PGx knowledge into machine-understandable formats, such as knowledge graphs or ontologies using the corresponding programming languages Resource Description Framework (RDF) or Web Ontology Language (OWL), requires the building of reference terminologies. These Semantic Web approaches make it possible to interlink various knowledge sources, enhancing PGx-CDSS development and PGx knowledge in general by exploring new associations. It should be noted that the systematic evaluation and validation processes are of paramount importance. These processes do not only include technical steps (e.g., software unit tests, regression tests) but they should rather emphasize the overall user experience (e.g., overalerting, interruptions during clinical practice) and relevant clinical endpoints (e.g., improvement regarding specific health outcomes) to validate the overall positive impact of these systems in the provided health care services.
Comparing the current SR to similar works reveals analogous findings. However, this SR extends the focus to technical aspects and explores knowledge engineering approaches that could facilitate PGx implementation and PGx-CDSS. More precisely, two similar works were identified. Hinderer et al. provide an overview of the designs of user–system interactions in recently developed PGx-CDSS, primarily prototypes, aiming to compare user–system interaction designs (Hinderer et al., 2017). They concluded that actual implementation in clinical practice is very restricted and that the majority of articles describe prototypes of pharmacogenomic CDSSs rather than evaluating them. In addition, Smith et al. conducted a recent scoping review focused on PGx-CDSSs with available metrics (Smith et al., 2023). Similar results are presented, referring to the functional mapping criteria (indicating that the prevalence of identified PGx-CDSSs is active with post-test alerts) used in this SR, but without reference to technical aspects. Moreover, it is noteworthy that several reviews have been identified focusing on the problems encountered during PGx or PGx-CDSS implementation in clinical practice from a more comprehensive point of view (Bright et al., 2020; Carter et al., 2022; Giri et al., 2019; Hicks et al., 2016a; Khelifi et al., 2017). These issues include the limited acceptance of PGx by health care professionals, the need for basic and clinical research to drive further developments in evidence-based medicine, and the integration into daily clinical workflows, which introduces new challenges requiring innovative solutions, particularly related to EHRs. In addition, advancements in PGx testing and result reporting highlight the critical need for increased standardization in these areas across laboratories. It is strongly believed that harnessing semantics could facilitate the mitigation of some of these technical challenges.
Referring to the limitations of the present SR, it should be noted that only the PubMed database was utilized. Therefore, a recommendation for future systematic reviews would be to include broader database searches. In addition, extending the PRISMA methodology and relevant guidelines through desk research and bubble searches introduces a risk of bias in the selection of articles. Moreover, limiting inclusion to studies published in English only may exclude relevant research published in other languages and from different geographical areas, such as Asia or China, where surprisingly no implementations of PGx-CDSS were noted. Dependence on the expertise of the reviewers and authors involved in study selection, data extraction, and synthesis could introduce bias based on their interpretations or perspectives.
Conclusions
The current SR reveals the limited implementation of PGx-CDSSs in clinical practice. It appears that in the United States, initiatives such as eMERGE and IGNITE have accelerated the implementation of active PGx-CDSSs integrated into the EHR, utilizing pre- or post (with the parallel application of preemptive genotyping protocols)-test alerts, relying on and trusting the CPIC guidelines. In Europe, the only notable attempt at PGx-CDSS implementation is the U-PGx. Mapping of the technical features indicates a research gap regarding the utilization of ML developments. Simultaneously, the publication of relevant technical components, which by leveraging Knowledge Engineering core activities, can significantly contribute to improving the PGx-CDSS implementation. Further development of PGx knowledge reference terminologies and research into how Semantic web approaches could accelerate the implementation of PGx-CDSS and enhance PGx knowledge in general show promising potential.
Footnotes
Acknowledgments
During the period of synthesis of this SR, A.F. and P.N. were employed at INAB|CERTH. The authors gratefully acknowledge their support. INAB|CERTH had no role in the design of this systematic review and did not have any role during its execution, analyses, interpretation of the data, or decision to submit results.
Authors’ Contributions
A.F.: conceptualization (support), data curation (equal), methodology (equal), visualization (equal), writing—original draft (equal), and writing—review and editing (equal). E.M.: conceptualization (supporting), data curation (supporting), methodology (supporting), supervision (supporting), visualization (supporting), writing—original draft (supporting), and writing—review and editing (supporting). P.N.: conceptualization (lead), data curation (equal), methodology (equal), supervision (lead), visualization (equal), writing—original draft (equal), and writing—review and editing (equal). All authors drafted and revised the article, approved the final version of the article, and take public responsibility for all aspects of the present work.
Author Disclosure Statement
All authors declare that have no competing financial interests.
Funding Information
The authors did not receive operating grants from any organization for the submitted work. No funding was received to assist with the preparation of this article.
Abbreviations Used
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.