
Abstract
To quantify heredity's effects on the burden of illness in the Medicare population, this study linked information between participants in a research twin registry to a comprehensive set of Medicare claims. To calculate disease categories, the authors used the Centers for Medicare & Medicaid Services Hierarchical Conditions Categories (HCC) model that was developed to risk adjust Medicare's capitation payments to private health care plans based on the health expenditure risk of their enrollees. Using the Medicare database, 2 sets of unrelated but demographically matched control pairs (MCPs) were generated, one specific for the monozygotic twin population and the second specific for the dizygotic twin population. The concordance and correlation rates of the 70 HCC categories for the 2 twin populations, in comparison to their corresponding MCP, was then calculated using Medicare claims data from 1991 through 2011. When indicated, HCCs for which there was a statistically significant difference between the twin and corresponding MCP control group were analyzed by calculating concordance and correlation rates of the International Classification of Diseases, Ninth Revision codes that compose the HCC. Findings reveal that monozygotic twins share 6.5% more HCC disease categories than their MCP while dizygotic twins share 3.8% more HCC disease categories than their MCP. Atrial fibrillation is a highly heritable disease category, a finding consistent with prior literature describing the heritability of the cardiac arrhythmias. These findings are consistent with qualitative assessments of heredity's role found in previous models of population health, and provide both novel methods and quantitative evidence to support future model development. (Population Health Management 2015;18:383–391)
Introduction
T
This analysis had 2 major goals. The first goal was to determine the feasibility and utility of using Medicare administrative data to conduct twin studies. This would build on prior studies that have used Medicare claims data to calculate the disease associations that enable the construction of disease networks,
1
as well as the integration of claims data with disease-gene associations and information on cellular interactions so as to better inform relationships between cellular networks and disease phenotypes.
2
Studies also have found that the pattern of disease combinations in the Medicare population is highly complex, consisting of a minimum of 1 million to 2 million unique combinations of disease categories.
3,4
The second goal focused on the role heredity may play in the distribution of clinically significant diseases in the Medicare population, as well as measures of disease burden such as health care system expenditures and longevity (see this article's online Twin Longevity Study Supplement Analysis, available in the online article at
In prior models of population health, the role of heredity has been assessed qualitatively. For example, Blum qualitatively ranked heredity as the least significant of the 4 variables considered (the remaining 3 in ascending order of significance were behavior, health care services, and the environment). 5 By quantifying heredity's effects, the relative contribution of social, cultural, economic, and environmental factors on the health care system can be better understood as a component of the variation when constructing approaches for measurement of burden of illness. Moreover, this study's methods of linking twin registries and claims databases could be a useful tool for population health researchers seeking to account for the role of heredity in their studies.
To accomplish these goals, a novel twin study design was developed that exploits an inherent advantage of the national Medicare data set, specifically the ability to construct unrelated but demographically matched control pairs (MCPs) from the general population. MCPs control for disease differences between the MZ and DZ twin sets that are related to demographic factors (eg, sex, age, race, geography), but without appropriate controls, might be falsely attributed to heredity. By providing for 2 independent comparisons, MZ versus the MZ-MCP and DZ versus DZ-MCP, shared observations are more likely to be true positives than a single MZ versus DZ comparison. Also, MCPs do not share either the degree of genetic identity (50% between MZ and DZ twins) or the family environments that are present in both the MZ and DZ twin populations. Thus, comparisons between MCPs and their corresponding twin population also should be more sensitive to the effects of heredity than twin methodologies that detect correlations based solely on the 50% increase in genetic identity when comparing MZ twins to DZ twins.
Finally, it should be noted that Medicare data sets are currently unrivaled with regard to the size of the population, length of data available, and geographic coverage (eg, national coverage of more than 30 million beneficiaries per year for more than 20 years). Their utility will grow over time as they will span multiple generations of beneficiaries, potentially contributing to family studies, and for many older individuals may be the sole source of readily available data.
Methods
Institutional Review Board and human research protection
This study was approved by the Institutional Review Boards at Virginia Commonwealth University and Acumen LLC.
Study participants and data sets
The Mid-Atlantic Twin Registry (MATR) provided the identification and zygosity information for the twins used in this analysis. Investigators seeking access to the twin data used in this study may do so by contacting MATR. 6
The data sets used in this study consist of all Centers for Medicare & Medicaid Services (CMS) Medicare Part A and Part B claims data from 1991 through 2011. Part A claims include all hospital inpatient services. Part B claims include outpatient facility services such as those provided in hospital outpatient departments, rural health clinics, and renal dialysis facilities, as well as services rendered in physicians' offices, and other ancillary services such as independent clinical laboratories, ambulance providers, and freestanding ambulatory surgical centers. Investigators seeking to access Medicare claims data may do so by contacting Research Data Assistance Center (ResDAC). 7
Matching MATR twin pairs with Medicare enrollment data
Twin identification data were received from the MATR. A weighted linking strategy was used to assign an individual twin to his or her Medicare enrollment and utilization data. The data included names of individuals, their social security numbers (SSNs), current addresses, sex, and dates of birth (day, month and year). A summary of the matching criteria are presented in Table 1. To be accepted, a link had to score 15 or more points. Only individuals with a single qualifying match and whose age was at least 65 years as of January 1, 2010, were included in the study. Individuals whose original reason for enrollment was the end-stage renal disease entitlement were excluded from the study cohort as these individuals have highly skewed cost, complicating subsequent comparisons. However, beneficiaries who later developed end-stage renal disease were kept in the study. After the MATR twin record to Medicare beneficiary enrollment matching was complete, MATR provided additional data to indicate which individuals were twin pairs and their corresponding zygosity. The data were then moved to a de-identified database dedicated to this project.
The variables used to link the twins from the Mid-Atlantic Twin Registry (MATR) to the Medicare claims database are listed along with their weight and, when applicable, penalty values. The linkage needed to equal or exceed a value of 15 to be included in the study.
Criteria for MCPs
MCPs were constructed for each MZ and DZ pair based on matching the following demographic information as reported in the Medicare enrollment database: sex, year of birth, race, current county of residence, and original reason for Medicare entitlement. Isolated twin pairs for whom no matching control pair could be found were dropped from further analysis. The data were then moved to a de-identified database dedicated to this project.
Construction of the both deceased subset
To extend the analysis to a complete end point at which both twins are deceased, a subset of twin and control pairs was constructed in which both members of the pair were deceased by December 31, 2011—the both deceased subset (BDS).
Disease category model
The research team used the CMS Hierarchical Conditions Categories (HCC) model that was developed in 2004 to risk adjust Medicare's capitation payments to private health care plans based on the health expenditure risk of their enrollees. 8 This model hierarchically aggregates approximately 3000 International Classification of Diseases, Ninth Revision (ICD-9) codes, most associated with increased expenditure over a prospective 12-month period, into 70 HCCs (the reader should be aware that the HCCs are not numbered consecutively and many HCCs are assigned labels greater than 70). The team determined the set of HCCs associated with each beneficiary by uniquely mapping each ICD-9 code in his or her claims history to the corresponding HCC. This calculation was done for the hospital inpatient, hospital outpatient, and physician office/ancillary service settings. Each beneficiary's set of HCCs also was uniquely consolidated across the hospital inpatient, hospital outpatient, and physician office settings into an All-Setting HCC (All-HCC) category for further analysis.
Calculation of total and shared HCC burden
The total number and number of shared HCCs across all 70 HCCs were calculated for the MZ, DZ, and both MCP samples to yield the proportion of shared HCCs in each cohort. This proportion was calculated, within a sample, by summing the total number of disease concordant pairs across all 70 HCCs and multiplying by 2. Next this value was divided by the total number of HCCs in the specific sample to give a proportion of shared HCCs. Subsequently, the proportions were tested for pairwise statistically significant differences using a 2-sample, 2-tailed proportion test (z test).
A bootstrapping methodology was used to construct confidence intervals for the proportion of shared HCCs. Specifically, the data for each twin or control set was resampled 1000 times, with each resampling being equivalent in size to the original set and produced by random sampling with replacement. Each of the 1000 resamples consisted of the twin pair linked to its corresponding MCP. The percentage of shared HCCs was computed for each of the resamples. From this set of proportions, the values corresponding to the lower bound 2.5th percentile and upper bound (UB) 97.5th percentile were used to construct the 95% confidence interval for each set's shared HCC proportion.
Contribution of heredity to specific HCCs and diseases
For each of the 4 groups and across all 70 HCCs, correlation coefficients (CC) measuring HCC concordance were calculated and confidence intervals were constructed through the bootstrapping procedure described for the proportion of shared HCCs (the same set of 1000 replicates underlies both calculations). It was required that both the MZ-CC and DZ-CC exceed the UB 97.5% confidence interval of the corresponding MCP group's CC, and that there were at least 10 concordant twin pairs (ie, any combination of concordant MZ twins and/or DZ twins) for preliminary hereditary status designation. HCCs meeting these criteria were subjected to subanalysis at the condition category and ICD-9 code levels to further characterize the nature of the disease association.
Calculation of average monthly expenditure difference
To determine if expenditures of twin pairs were of greater similarity in comparison to the corresponding MCP, the research team elected to use the average monthly expenditure difference (MED). The MED was chosen, instead of absolute expenditures, because pair members may differ in the extent they used the Medicare Advantage (capitated payment-based managed care) as opposed to fee-for-service (FFS) coverage. The MED for each beneficiary was calculated by summing Medicare Part A and Part B claims expenditures from enrollment into Medicare through December 31, 2011. To calculate the average monthly expenditure, this sum was then divided by the months each individual was enrolled in FFS Medicare. The MED for each pair was then calculated as the absolute value in dollars of the difference between the pair members' average monthly expenditure. Finally, the pairs were ordered from least to greatest MED and the cumulative distribution functions were plotted for comparison. Because the distribution of health care expenditures is skewed toward a minority of high-cost patients, the 2-sample Kolmogorov–Smirnov test was used to determine if differences in expenditures between the groups were significant.
Oversampled MCP
It is important to note that there is a body of research documenting geographic variation in Medicare expenditures and care patterns. 9 Based on these findings, the research team favors matching at the county level for the construction of control sets. In investigations of expenditures, to narrow the confidence range, the team found it useful to construct a larger oversampled MCP of 30 control pairs for every MZ or DZ twin pair. To do this it was necessary to relax the geographic criteria to matching at the state level. All data were then moved to a de-identified database dedicated to this project.
Results
Matching of MATR twins to the Medicare enrollment database and construction of the MCP
MATR data contained 3248 records of twins aged 65 years and older. Of these, 2969 records could be matched to single unique enrollments in the Medicare FFS administrative data and were used for further analysis. Of these, 2329 (78.44%) were exact SSN matches (only 9 exact SSN number matches were dropped from the study because of scores lower than 15). Additionally, 202 matches (6.83%) lacked an SSN but matched exactly on all other fields, 122 matches (4.11%) were discrepant for SSN but matched identically on all other fields, and 166 matches (5.59%) lacked an SSN but matched identically on last name, first name, sex, and full date of birth. These patterns account for 95% of the matches. The research team estimates that the overall accuracy of linking a MATR record to a Medicare beneficiary is 90% or greater. In interpreting these results it is useful to note that research in electronic privacy has determined that individuals become uniquely identifiable with relatively few data elements. For example: sex, full date of birth, and zip code has been reported to uniquely identify 87.1% of the population of the United States. 10 Based on these matches, it was possible to assign 2604 of these individuals to complete twin pairs; ultimately, it was possible to further match 399 pairs of MZ twins and 378 pairs of same sex DZ twins to an MCP. Table 2 illustrates the overall similarity between the twin and control groups' demographic data including survival, and extent of utilization of Medicare Part C (managed care plans). Further analysis indicated that in all 4 populations, Medicare Part C utilization was limited and most beneficiaries who used it did so for 5 years or less.
DZ, dizygotic twin group; DZ-MCP, dizygotic matched control pair group; HCC, Hierarchical Conditions Categories; MZ, monozygotic twin group; MZ-MCP, monozygotic matched control pair group; SD, standard deviation.
Construction of BDS
When followed for survival until December 31, 2011, a total of 75 MZ pairs, 84 MZ-MCP pairs, 90 DZ pairs, and 91 DZ-MCP were detected in which both members were deceased.
Calculation of total and shared HCC burden
This study finds that both MZ and DZ twin pairs share significantly (P<0.001) more HCCs than their corresponding MCPs (Table 3). For example, using the All-HCC category, MZ twin pairs shared 26.3% of their HCCs as compared to 19.8% shared HCCs for their MZ-MCP controls (a 6.5% absolute increase and a 33% relative increase). As expected, the DZ twin pairs show a reduced level of similarity with 25.6% shared in the All-HCC category as compared to 21.8% in their DZ-MCP (a 3.8% absolute increase and a 17% relative increase). Although these findings are consistent with greater disease similarity among the MZ twins, it should be noted that the 0.7% increase in shared HCCs when comparing the MZ twin pairs directly to the DZ twin pairs did not reach significance. To address the possibility that the role of heredity may be more apparent at the end of life, a subcalculation of shared HCCs was performed with the BDS (Table 4). This analysis demonstrates a general increase in the level of shared HCCs across both twin and both MCP groups, as well as an overall reduction in statistical significance in comparisons between twin and MCP groups (consistent with the smaller sample size of the BDS). However, the magnitude of increased sharing of HCCs by twin pairs versus their corresponding MCP is similar to the original calculations (eg, MZ twins shared 5.8% more HCCs when compared to the MZ-MCP).
DZ, dizygotic twin group; DZ-MCP, dizygotic matched control pair group; HCC, Hierarchical Conditions Categories; MZ, monozygotic twin group; MZ-MCP, monozygotic matched control pair group.
BDS, both deceased subset; DZ, dizygotic twin group BDS; DZ-MCP, dizygotic matched control pair group BDS; HCC, Hierarchical Conditions Categories; MZ, monozygotic twin group BDS; MZ-MCP, monozygotic matched control pair group BDS.
Although only 1 HCC achieved statistical significance for increased disease concordance between twins (see the following section) the increase in shared HCCs was broadly distributed across the 70 HCCs for both the MZ and DZ populations. When comparing the MZ to MZ-MCP, there are 31 HCCs in which there are more MZ than MZ-MCP concordant pairs (summing to 294 shared HCCs), versus 12 HCCs (summing to 52 shared HCCs) in which MZ-MCP concordant pairs outnumbered the MZ group. For the DZ versus DZ-MCP comparison, there are 26 HCCs in which there are more DZ than DZ-MCP concordant pairs (summing to 210 shared HCCs) versus 11 HCCs (summing to 70 shared HCCs) in which the DZ-MCP concordant pairs outnumber the DZ group.
Contribution of heredity to specific HCCs and diseases
The only HCC that met the study criteria was HCC-92 “Specific Heart Arrhythmias.” For HCC-92 in the MZ population there were 230 individual twins and 55 concordant pairs, and the MZ-CC=0.268, compared with the MZ-MCP's UB of 0.230. Corresponding data for the DZ twins were 244 individual twins and 61 concordant pairs, with the DZ-CC=0.264, compared with the DZ-MCP's UB of 0.226. Because HCC-92 consists of a set of ICD-9 codes that include both ventricular and atrial arrhythmias, a subanalysis was performed to further characterize these findings. This analysis revealed that the large majority of the correlation is associated with ICD-9 code 427.3, Atrial Fibrillation and Flutter (AF). Specifically, for ICD-9 427.3 in the MZ population there were 190 individual twins and 41 concordant pairs, MZ-CC=0.254, compared with the MZ-MCP's UB of 0.248. Corresponding data for the DZ twins were 205 individual twins and 46 concordant pairs, DZ-CC=0.379 that narrowly missed exceeding the DZ-MCP's UB of 0.389. Alternatively, when ICD-9 code 427.3 was dropped from the analysis of HCC-92, the MZ-CC fell to 0.162 (134 affected individuals with 20 concordant pairs) compared to the MZ-MCP's UB of 0.250. Correspondingly, the DZ-CC fell to 0.110 (139 individuals with 19 concordant pairs) compared to the DZ-MCP's UB of 0.247. The research team interprets these findings as supporting a role for heredity in cardiac arrhythmias with the bulk of the correlation resulting from AF.
Because stroke is a well-known complication of AF, the team also observed that for HCC-96, “Ischemic or Unspecified Stroke,” the MZ twin pairs were significantly more likely than the MZ-MCP to be concordant. Specifically, for HCC-96 there were 129 individual twins and 22 concordant pairs, MZ-CC=0.217, compared with the MZ-MCP's UB of 0.125. However, for HCC-96 the DZ-CC=0.142 did not exceed the corresponding UB for the DZ-MCP=0.191. When beneficiaries with AF were dropped from the analysis of HCC-96, the MZ twins were no longer significantly different from their control group (MZ-CC=0.069 versus the MZ-MCP UB=0.145).
To compare these results to those of a traditional twin study design, the MZ and DZ twin sets were compared at the individual HCC level, using the same 2-sample, 2-tailed proportion z test described earlier. In comparison, the traditional twin study methodology was not significant for either HCC-92 (P=0.64) or HCC-96 (P=0.25); however, it was significant (P<0.025) for both HCC-15, Diabetes with Renal Manifestation, and HCC-71, Polyneuropathy. For HCC-15, in the MZ population there were 58 individual twins and 13 concordant pairs compared to 52 individual twins and 6 concordant twin pairs in the DZ population. For HCC-71, in the MZ population there were 132 individual twins and 25 concordant pairs versus 113 individual twins and 9 concordant twin pairs in the DZ population. It should be noted that in both these cases the MZ versus MZ-MCP comparisons also were significant (for HCC-15 MZ-CC=0.403 versus the MZ-MCP UB=0.157, and for HCC-71 MZ-CC=0.260 versus the MZ-MCP UB=0.098). However, the DZ versus DZ-MCP comparison did not reach significance for either HCC-15 or HCC-71.
Calculation of MED
Next the MED of MZ twins was compared to the DZ twins and their corresponding MCPs. Figure 1 shows the MED cumulative distribution functions for the 4 comparisons. Note that the MED curve of the MZ twin pair population is to the left of both the MZ-MCP and DZ twin pair populations (indicating a greater similarity in within MZ twin pair expenditures). However, these trends, as well as an identical analysis with the BDS (data not shown), did not reach statistical significance. To further investigate this trend the MED of MZ twins was compared to the DZ twins and their corresponding oversampled MCPs. Figure 2 shows the MED cumulative distribution functions for the 4 comparisons. The MZ within twin pair MED is now significantly smaller than its oversampled MZ-MCP (P=0.001); similarly the DZ within twin pair MED trends toward significance with the oversampled DZ-pairs MCP (compare the P value of 0.665 in Figure 1 with 0.096 in Figure 2).
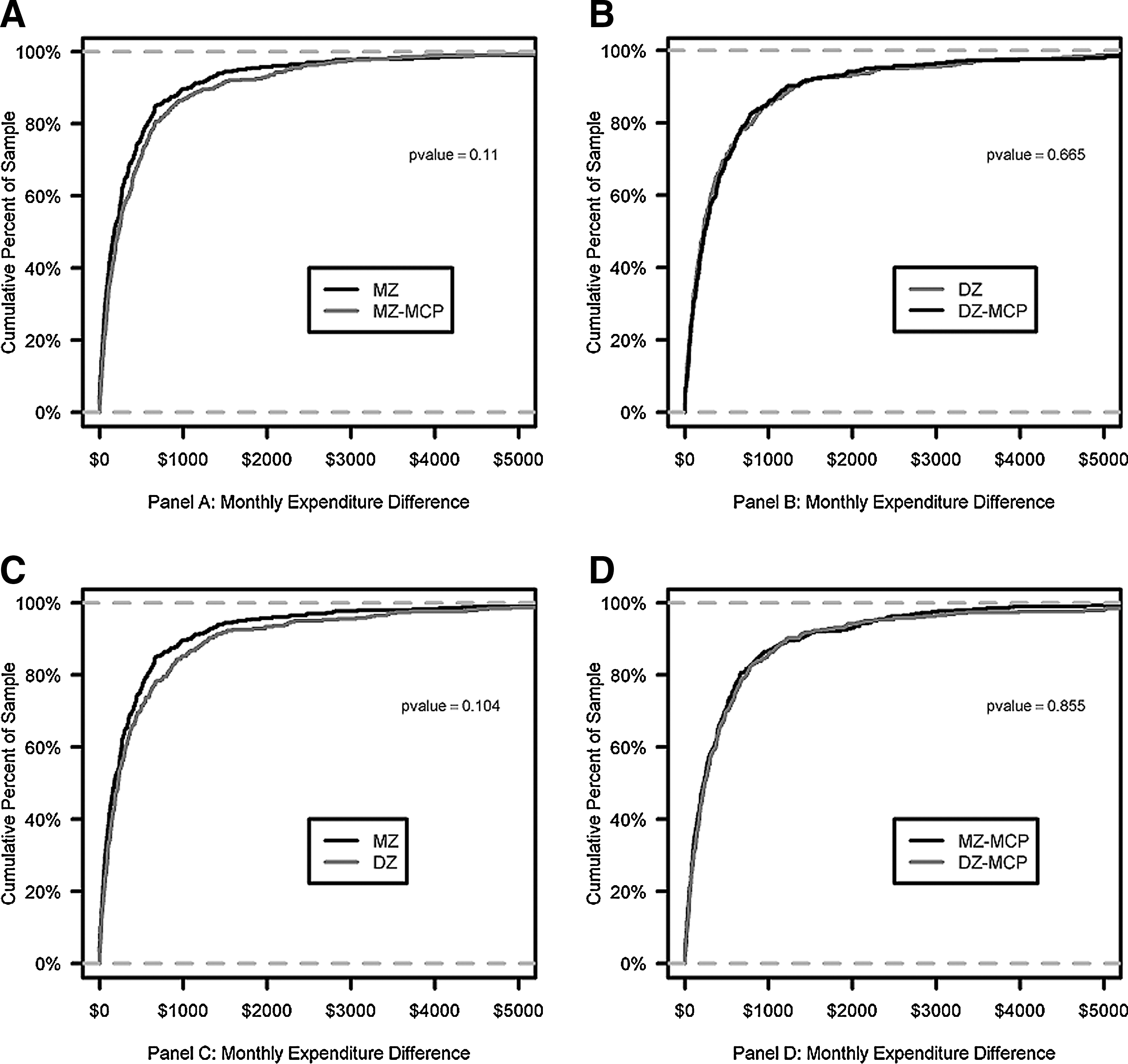
Twin and Control KS-Test Curves of MED.
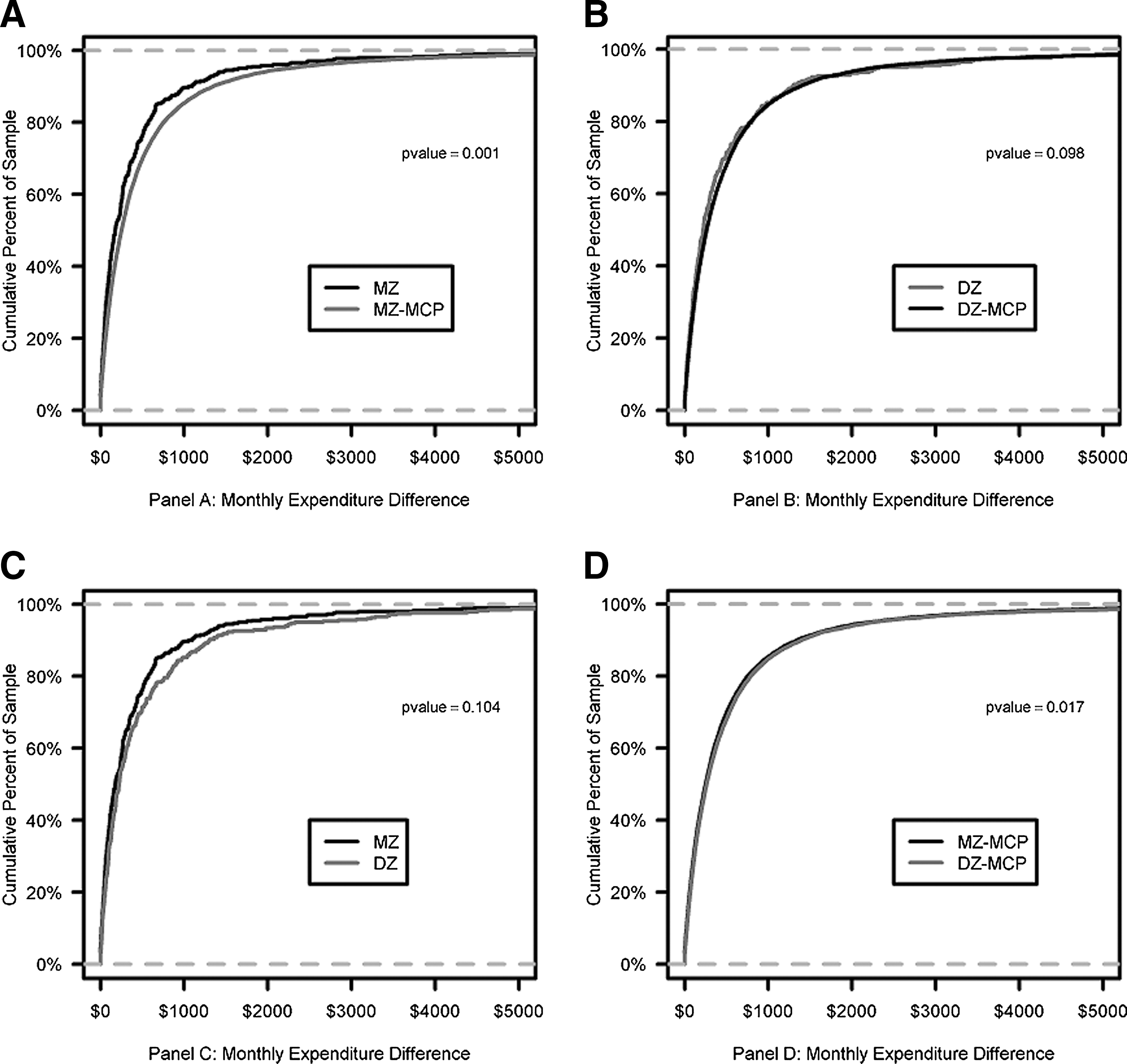
Twin and Oversampled-Control KS-Test Curves of MED.
Discussion
Within the limits of this analysis (to be discussed), the findings indicate that heredity, for individuals older than age 65, accounts for an increased sharing of HCCs. However, the proportion of shared HCCs is relatively small (approximately 6% of HCCs in the case of MZ twin pairs). This finding appears consistent with the ranking of heredity's impact in prior models of population health discussed earlier. However, it will be necessary to design and construct studies that quantitatively rank the remaining variables before this can be confirmed. With modifications, twin study methodologies, including those developed in this paper, may contribute to this goal. For example, MZ twins with discordant levels of education might be compared with MZ twins with similar levels of education, and also with similarly matched control pairs. The results of this study provide further motivation to explore social factors that are more amenable to population health management than would be the case if genetic factors had proved to be dominant.
There are several sources of biological variation that can account for this finding. For example, MZ twin pairs are known to exhibit copy number variation, 11 as well as epigenetic 12 and metagenomic 13 phenomena that influence an individual's response to his or her environment. These mechanisms may account for significant differences between individual health histories even if they share genomic information and are consistent with the complexity of disease combinations observed in the Medicare population noted earlier.
The heritability of AF has been reviewed. 14 As discussed in detail, genetic contribution to the risk of developing AF has been established through the Framingham Heart Study, 15 family studies, 16 and twin studies. 17 Twin studies also have shown that the co-twin of an AF affected twin has a higher incidence of death. 18 The genetic predisposition to AF has been mapped to numerous ion channel genes. 19 For example, the SCN5A polymorphism H558R has been shown to have an extremely high population frequency of approximately 20% calculated from 1000 genomes (rs1805124). 20
Genetic traits, including ion channels, 21 –23 which are associated with multiple diseases, are an example of pleiotropy, which both complicates the reporting of genetic findings 24 and may lead to an underestimation of the role of heredity when using current disease classification systems.
Note that the trends in MZ twins toward greater similarity in Medicare expenditures do not reach significance with the original MCP. However, there is a significant similarity when using the oversampled MCP. Although the research team methodologically prefers the use of controls matched geographically by county, the team favors the interpretation that the MZ twin pairs' Medicare expenditures are more similar. This will need to be verified by a larger study. The team is not aware of any prior data that might further inform this analysis.
Perhaps the greatest benefit of Medicare claims data for twin studies is the ability to support the generation of MCPs. The potential advantages of MCPs include a reduction in false positive statistical errors through 2 mechanisms. First, MCPs can control for disease associations related to demographic differences between the MZ and DZ twin pairs that might be falsely attributed to heredity. Secondly, to become significant, the same false positive disease category must occur in both the MZ versus MZ-MCP and DZ versus DZ-MCP comparisons.
This reduction in false positive errors is especially useful when making multiple disease comparisons. When using a UB 97.5% confidence criterion, there is a 2.5% chance that any single HCC may represent a statistical false positive when comparing either the MZ or DZ twin pairs to their corresponding MCP. However, the probability that the same HCC would be falsely positive in both comparisons is 0.0625% or 1 in 1600. Future efforts to improve this approach might include the use of a higher significance threshold when comparing MZ twin pairs (who share 100% genetic identity) to the MZ-MCP than the threshold used in comparing DZ twin pairs (who share 50% genetic identity) to the DZ-MCP. It should also be noted that the MZ versus MZ-MCP comparison might be more sensitive to the role of heredity than the traditional MZ versus DZ comparison. Not only can the MZ-MCP group be more closely matched on demographic factors to the MZ population, but it also lacks both the shared genomic and shared environment components found in the MZ group. In contrast, DZ twins only differ by 50% genetic identity in comparison to MZ twins, and are not explicitly matched for demographic variables. For the same reason, one can also expect that comparisons of MZ and DZ twin pairs to their respective MCPs will be more sensitive to environmental factors than the traditional MZ to DZ comparison.
Additionally, these methods may be integrated with those developed for the MZ to DZ comparison that underlies traditional twin study methodologies (thus further increasing the number of comparisons). This study's findings regarding cardiac arrhythmias, AF, and stroke support the potential utility of this approach. With further development, these methods may expand the frontiers of twin research and contribute to a greater understanding of heredity's effect on population health and disease burden.
There are limitations to this study. The sample is limited in size, predominantly mid-Atlantic in geographic distribution, composed of twin pairs in which both members reached age 65, predominantly white male, and covers diseases that occurred between 1991 and 2011. The data may not account for diseases that present prior to entry into Medicare. Additionally, the use of the HCC model as a disease grouper may result in some relationships being missed. Also, there are limitations to claims data. These are discussed in a recent study that has summarized the advantages and disadvantages of various data sources, including Medicare claims data, and several of the currently available disease grouping systems for conducting health economic and health services research. 25 This study also is limited by the number of twins currently available for analysis through US-based twin registries. Further efforts to recruit twins, including establishing zygosity, should be considered as the total number of MZ and DZ twin pairs represented in Medicare claims data is significantly larger than what is currently available for study.
In conclusion, these results suggest that for those older than 65 years of age, heredity plays a limited role in overall measures of disease burden. This is consistent with a recent analysis of European twin registry data that concluded that MZ twins often have divergent health histories. 26 Thus, the common finding in methodologically different studies is that heredity plays a smaller role than many have anticipated. As this study's authors note, “The general public does not appear to be aware that, despite very similar height and appearance, monozygotic twins in general do not always develop or die from the same maladies.” However, genetic predispositions to diseases that are currently considered unrelated require further investigation. Future twin studies following MCP methodology would be enhanced by greater representation of female and minority participants. Moreover, innovative twin study designs (eg, comparing both disease concordant and discordant twin and control pairs) hold promise to clarify the relative roles of genetics and the environment in mechanisms of disease. 27
Footnotes
Author Disclosure Statement
Drs. Sorace, Millman, Queen, and Kelman, and Mr. M. Rogers, Mr. D. Rogers, Mr. Price, and Mr. Worrall declared no conflicts of interest with respect to the research, authorship, and/or publication of this article.
The authors received the following financial support for this article: This work was supported by contract HHSM-500-2006-00006I between the Department of Health and Human Services and Acumen LLC. The findings and conclusions of this report are those of the authors and do not necessarily represent the views of the Assistant Secretary for Planning and Evaluation, the Centers for Medicare & Medicaid Services, or the Department of Health and Human Services.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.