
Abstract
The objective was to identify individuals with undiagnosed prediabetes from administrative data using adaptive techniques. The data source was a national Medicare Advantage Prescription Drug (MAPD) plan administrative data set. A retrospective, cross-sectional study developed and evaluated data adaptive logistic regression, decision tree, neural network, and ensemble predictive models for metabolic syndrome and prediabetes using 3 mutually exclusive cohorts (N = 279,903). The misclassification rate (MCR), average squared error (ASE), c-statistics, sensitivity (SN), and false positive (FP) rates were compared to select the final predictive models. MAPD individuals with continuous enrollment from 2013 to 2014 were included. Metabolic syndrome and prediabetes were defined using clinical guidelines, diagnosis, and laboratory data. A total of 512 variables identified through subject matter expertise in addition to utilizing all data available were evaluated for the modeling. The ensemble model demonstrated better discrimination (c-statistics, MCR, and ASE of 0.83, 0.24, and 0.16, respectively), high SN, and low FP rate in predicting metabolic syndrome than the individual data adaptive modeling techniques. Logistic regression demonstrated better discrimination (c-statistics, MCR, and ASE of 0.67, 0.13, and 0.11 respectively), high SN, and low FP rate in predicting prediabetes than the other adaptive modeling techniques or ensemble methods. The scored data predicted prediabetes in 44% of the MAPD population, which is comparable to 2005–2006 National Health and Nutrition Examination Survey prediabetes rates of 41%. The logistic regression model demonstrated good performance in predicting undiagnosed prediabetes in MAPD individuals.
Introduction
T
Based on fasting glucose or glycosylated hemoglobin (HbA1c) levels, an additional 86 million Americans aged 20 years or older were diagnosed with prediabetes in 2012 and 51% of those individuals were aged 65 years or older. 1 Recent clinical practice guidelines from the American Diabetes Association (ADA) identify individuals with prediabetes based on laboratory criteria including an impaired fasting glucose (IFG) of 100–125 mg/dl, impaired glucose tolerance (IGT) of 140–199 mg/dl, or HbA1c 5.7%-6.4%. 3 According to the National Health and Nutrition Examination Survey from 2005–2006, 45.6% of elderly individuals with diabetes had undiagnosed diabetes while 40.8% of this population had prediabetes. 4 Disease onset and progression may be delayed through lifestyle or pharmacological interventions if individuals at higher risk of developing diabetes during the prediabetic period can be identified. 5 –7
Identifying individuals at risk for prediabetes is a challenge and is a potential barrier to implementing timely effective interventions. According to the Centers for Disease Control and Prevention, only 4.7% to 10.6% of individuals with prediabetes had been informed of this condition by their health care professionals. 8 Several public health initiatives for diabetes screening have failed; mainly attributed to low turnout, cost associated with screening a large number of individuals, and barriers to accessing care that provides guidance or appropriate referrals. 9
Metabolic syndrome (MS), an indicator of prediabetes, is widely defined among practice guidelines. A constellation of cardiometabolic conditions, MS includes elevated waist circumference/central obesity, dyslipidemia, hypertension, and impaired fasting glucose. 10,11 The National Cholesterol Education Program Third Adult Treatment Panel (NCEP ATP III) defines MS as the presence of at least 3 of the aforementioned abnormalities. The prevalence of MS in adults has been estimated to be 22% to 34% using the NCEP ATP III definition. 12,13 Although IFG ≥100 mg/dl is one of the contributing factors to MS and can be a single indicator of prediabetes, its absence does not eliminate the risk of prediabetes if other components of MS are present; however, this has not been adequately explored and quantified, further complicating timely identification of patients for lifestyle or pharmacological interventions.
Health care providers and researchers have been working for years to design robust testing paradigms and instruments to identify individuals with prediabetes. In clinical settings, HbA1c and 1-hour plasma glucose levels were found to be important predictors of type 2 diabetes. 14 Additionally, the Finnish diabetes risk score, based on medical history and health behavior, demonstrated the ability to identify individuals at high risk of this disease. 15 Using a different approach, Gray et al 16 developed a logistic regression model to predict undiagnosed IFG and type 2 diabetes through evaluation of medical history, sociodemographics, behavioral factors, anthropometric information such as weight, height, waist circumference, and IFG data from 2 primary health care centers. Interestingly, another approach to this testing paradigm was put forth in a separate study based on a Chinese population, which used 12 self-reported risk factors such as demographic characteristics, family diabetes history, anthropometric measurements, and lifestyle risk factors, to compare logistic regression, neural network, and decision tree models in terms of accuracy, sensitivity, and specificity for predicting diabetes or prediabetes. 17
A review of the literature suggests that more than 145 risk models for type 2 diabetes have been developed over the past decade. 18 These models have not been introduced in daily clinical practice. Barriers to employing these models are attributed mainly to the inability to obtain necessary clinical, laboratory, and patient-reported information such as anthropometrics, lifestyle-related information, socioeconomics, family history, smoking, and/or laboratory data. 18,19 The challenge of obtaining this information without direct patient contact or invasive resource-intensive laboratory tests makes currently available models potentially insufficient to meet the larger general public health need. These data are potentially obtainable through administrative claims which provides a wealth of longitudinal information regarding a patient's clinical characteristics (diagnoses, procedures, laboratory values, health care utilization, and costs), along with sociodemographics.
Data mining is the process of selecting, exploring, and modeling large amounts of multidimensional data, such as health care claims data, to identify unknown patterns or relationships. Mining administrative data may reduce the need for patient contact in this context and thus the need for patient-reported information and laboratory data. These data can be de-identified and used to build predictive models that can be used to assist in population health management strategies.
While the goal of predictive modeling is to accurately predict potential cases opposed to hypothesis testing; variable selection is based on the strength of the association between the terms and the response variable. Although independent variables in linear inferential regression models lend themselves to interpretation, independent variables for predictive models using high dimensional data are subject to covariate effects, and interpretation of the independent variables is not intended, as each variable is in the presence of the other and, when combined, may explain sufficient variance in relationship to the dependent variable. Variables that explain a sufficient proportion of the variance in the data are retained. Though it can be diminished through dimensionality reduction, multicollinearity is not an issue in predictive modeling as it does not affect a model's predictive ability. 20 Using complex and predicted variables as terms in a predictive model does not threaten the validity or predictive power of a validated predictive model, the issue that threatens this type of model's success is overfitting. That is, bias is significantly reduced and prediction in the training data is extremely accurate; however, accuracy is lost in the new, untrained data, and generality of the model to potential new cases is lost. The best predictive models consistently and accurately predict potential cases in new data samples regardless of the complexity of their terms. 20
Several data adaptive techniques have been developed in recent years. 17,21,22 In medical research, data adaptive techniques have been used to explore unknown factors and build predictive models. 23 –25 However, existing literature suggests that very few studies have explored data adaptive techniques in order to construct predictive models for prediabetes using administrative data. Furthermore, data adaptive ensemble methods that construct a model by combining the predictions from multiple analytic techniques (eg, decision tree, neural network, regression) help improve performance in comparison to a single predictive model. 26
The purpose of this study was to develop a data adaptive predictive model to identify individuals who were at high risk for diabetes during the prediabetic period. MS can be an indicator of prediabetes, but some of the constellation components are sparsely available in administrative claims data (ie, laboratory values, biometrics); therefore, this study aimed to develop and validate (1) an MS scoring algorithm to be evaluated for inclusion in (2) a prediabetes scoring algorithm for predicting prediabetes based on administrative claims data using data adaptive techniques. The rational for the 2-stage approach was to ensure that each patient had a predicted probability for MS, a constellation of conditions prognostic for prediabetes, which was then considered for inclusion in the final prediabetes predictive model. 27
Methods
Data source
This retrospective, observational, cross-sectional study utilized administrative claims data from patients with a Medicare Advantage Prescription Drug (MAPD) health plan offered by Humana, a health and well-being company that predominately serves people in the southern and midwestern United States through Medicare Advantage, stand-alone prescription drug, and commercial health plan offerings. The study cohort was developed utilizing enrollment, medical, pharmacy, and laboratory data from the de-identified Humana research database from January 1, 2013, to December 31, 2014. The study was approved by an independent Institutional Review Board.
Study subject selection
The study cohort included fully insured MAPD individuals aged 65–89 years as of January 1, 2014 who had continuous enrollment for 2 years, from 2013 to 2014. Calendar year 2013 was considered the baseline period and 2014 was considered the identification period. Patients diagnosed with diabetes, historical pregnancy-related complications, and chronic kidney disease during the baseline or identification period were excluded (see Supplementary Table S1; Supplementary Data are available online at
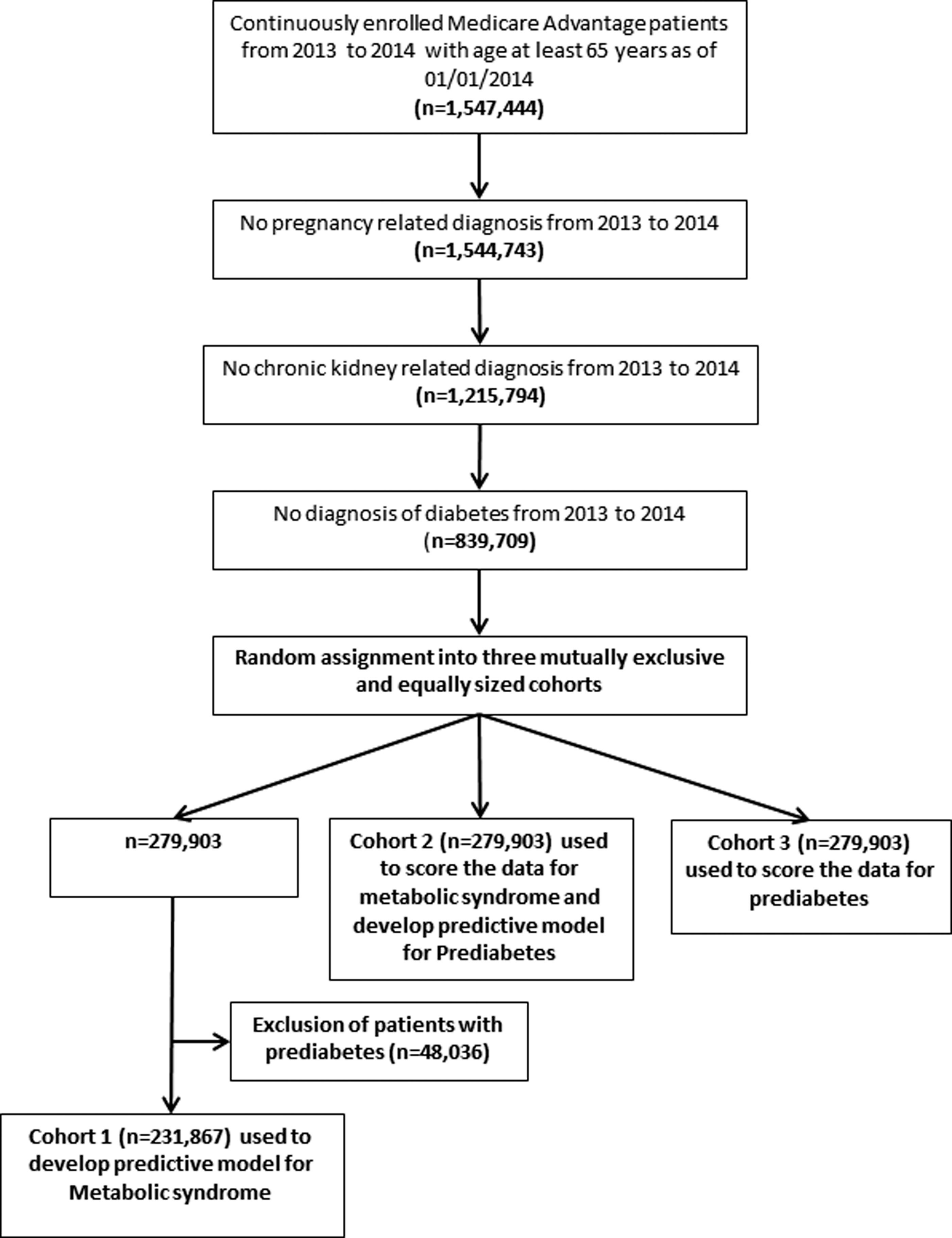
Identification and attrition of eligible individuals and cohort development.
After excluding patients with known prediabetes, Cohort 1 (N = 231,867) was used to develop a predictive model for MS. Cohort 2 (N = 279,903) was used to score the data to identify predicted MS utilizing the model developed from Cohort 1. Subsequently, Cohort 2 (N = 279,903), which included patients with known prediabetes, was used to develop a predictive model for prediabetes. Cohort 3 (N = 279,903) was used to identify individuals most likely to have undiagnosed prediabetes and to descriptively compare them with individuals less likely to have prediabetes. This approach resembles the methods discussed by Kvancz et al. 27
Primary dependent variables (target variables)
MS was defined as having a diagnosis of MS or at least 2 of the following risk factors obtained from diagnostic and/or laboratory results during the identification period: elevated waist circumference/central obesity, dyslipidemia, hypertension, and impaired fasting blood glucose (see online Supplementary Table S1). 28 The dependent variable (target variable), MS, was a binary categorical variable (0 and 1), where 0 meant normal or no MS identified via claims and 1 indicating the presence of MS.
Prediabetes was defined according to the ADA clinical guideline using diagnosis and laboratory data obtained during the identification period, as patients with either International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) code for prediabetes, or elevated HbA1c, or IFG, or IGT (see online Supplementary Table S1). 29 The dependent variable (target variable), prediabetes, was a binary categorical variable with 2 categories (0 and 1), where 0 meant normal or no prediabetes identified from claims and 1 indicating the presence of prediabetes.
Independent variables (input variables)
The independent variables (input variables) included mainly patient demographics, clinical history, health care utilization, costs, and physician characteristics. Patient demographic characteristics including age, sex, race, geographic region of residence, health plan benefit type, low-income subsidy status, and access to care proxies were obtained from the enrollment file during the baseline period. Baseline clinical characteristics included Deyo-Charlson comorbidity index and clinical conditions based on the Agency for Healthcare Research and Quality (AHRQ) Clinical Classification System Software (CCS) level II, and were identified from ICD-9-CM diagnosis categories. 30 Health care utilization and amount of medical services utilized were derived from Current Procedural Terminology and Healthcare Common Procedure Coding System procedure data based on AHRQ CCS Health Care Cost and Utilization Project (H-CUP). 31 All-cause health care utilization included counts of emergency department (ED) visits, inpatient hospital visits, and outpatient visits, and was measured based on all medical claims and associated place of treatment codes from the baseline period. All-cause health care costs were calculated based on financial data associated with medical and pharmacy claims and adding plan-allowed and patient out-of-pocket costs from the baseline period. Provider characteristics such as provider specialty (primary care physician, internal medicine, endocrinology, other), provider sex, and type of practice (group, solo, other) were obtained from the last provider office visit during the baseline period. A total of 512 independent variables related to patient baseline and provider characteristics were assessed for inclusion in the predictive models (see online Supplementary Table S2). The independent variables were informed by subject matter expertise, and aggregated using a common data grouper (H-CUP) allowing the use of all data available and common to administrative claims.
Analytical plan
Data cleaning, manipulation, and variable creation was performed using SAS Enterprise guide version 7.1 and data adaptive prediction models and subsequent scoring of data was constructed with SAS Enterprise Miner version 14.1 (SAS Institute Inc., Cary, NC). 32 A descriptive analysis was conducted for patient demographic characteristics, provider characteristics, all-cause health care utilization, and access to care proxies using a t test for continuous variables and chi-square test for categorical variables. The data adaptive models that were explored included decision tree, probability decision tree, binary logistic regression, neural network, and ensemble models (a combination of the aforementioned machine learning techniques), and were constructed using training and validation data sets separately for the dependent variables MS and prediabetes.
For the purpose of the study, Cohort 1 was randomly and equally split into training and validation samples to develop a predictive model for the dependent variable of MS. This model was further used to score Cohort 2. The scored data were used to classify patients with MS with predicted probabilities at a 0.5 cutoff point. Cohort 2 was randomly and equally divided into training and validation samples in order to develop predictive models for the dependent variable prediabetes using the predicted MS along with other independent variables. The final model developed from Cohort 2 was applied to Cohort 3 to score the data and identify individuals most likely to have undiagnosed prediabetes using predicted probabilities at a cutoff point of 0.13 based on the observed proportion of primary outcome of prediabetes. 33
Results
Eligible individuals with an MAPD plan (N = 839,709) were randomly assigned to 3 equally sized, mutually exclusive cohorts (N = 279,903). After excluding MAPD patients with prediabetes from the baseline and identification periods, the remaining Cohort 1 (N = 231,867) had 112,108 (48%) study members diagnosed with MS. Cohort 2 had 37,503 (15%) individuals diagnosed with prediabetes. Table 1 displays the significant difference between those with and without MS in terms of demographics, provider, baseline health care utilization (inpatient, ED, and outpatient visits), and access to care. Deyo-Charlson comorbidity index and the top 10 clinical condition categories based on variable importance factor significantly differed between individuals with and without MS (Table 2). Patients identified with MS had a significantly higher average Deyo-Charlson comorbidity index (0.51 vs. 0.34), and a greater proportion had coronary atherosclerosis and other heart diseases, cardiac dysrhythmias, nutritional, endocrine, and metabolic disorders, thyroid disorders, heart valve disorders, and esophageal disorders (Table 2).
ED, emergency department; HMO, health maintenance organization; MS, metabolic syndrome; PCP, primary care physician; POS, point of service; PPO, preferred provider organization; SD, standard deviation.
MS, metabolic syndrome; SD, standard deviation.
There were significant differences between individuals who had prediabetes and those with no evidence of prediabetes in terms of demographic, provider, access to care-related characteristics, and baseline ED and outpatient visits in Cohort 2 (Table 1). In addition, the Deyo-Charlson comorbidity index and top 10 clinical condition categories were significantly different between individuals with and without prediabetes (Table 2). Patients identified with prediabetes had a significantly higher number of metabolic disorders, predicted MS, essential hypertension, nutritional, endocrine, and metabolic disorders, peripheral and visceral atherosclerosis, and nutritional deficiencies (Table 2).
The model fit and performance statistics for predictive models constructed for MS and prediabetes are displayed in Table 3. In the validation sample, the ensemble model developed by combining the decision tree, probability tree, neural network, and regression models demonstrated the best discrimination (c-statistic, 0.828; misclassification rate, 0.242; and average square error, 0.164), maximized the sensitivity, and lowered the false positive rate of predicting MS (Table 3). The ensemble model developed from Cohort 1 was used to score Cohort 2 data and 123,954 (44%) individuals were classified as having MS with predicted probabilities >0.50. Predicted MS was one of the contributing factors based on variable importance level and Gini coefficient split statistic (Table 2). In the validation sample, the logistic regression model outperformed the decision tree, probability tree, neural network, and ensemble model based on the model fit statistics, and further maximized sensitivity and lowered the false positive rate in comparison to other models while predicting prediabetes (Table 3). Cohort 3 was scored based on the predictive model developed for prediabetes from Cohort 2 and identified 122,849 (43.89%) patients likely to have prediabetes undocumented in administrative claims based on predicted probabilities between 0.13–0.68.
ASE, average square error; FN, false negative; FP, false positive; MCR, misclassification rate.
Indicates final selected model based on fit statistics and model performance.
Table 4 represents the characteristics of Cohort 3 across predicted prediabetes. Notably, the top 10 clinical condition categories were highly prevalent among individuals with predicted prediabetes in comparison to those without predicted prediabetes. The incidence of disorders of lipid metabolism, predicted MS, essential hypertension, peripheral and visceral atherosclerosis, and other nutritional, endocrine, and metabolic disorders were significantly higher among MAPD individuals with predicted prediabetes in comparison to those without predicted prediabetes (P < .0001 for all; Table 4).
ED, emergency department; HMO, health maintenance organization; PCP, primary care physician; POS, point of service; PPO, preferred provider organization; SD, standard deviation.
Discussion
This study developed an MS risk factor scoring algorithm, and subsequently a prediabetes risk scoring algorithm, to identify individuals at high risk for type 2 diabetes during the prediabetic period for patients with an MAPD health plan. As laboratory and biometric data are scarce and often inconsistent within administrative databases, the development of a 2-step approach was used to enhance identification of patients with undiagnosed prediabetes. This study utilized all diagnoses, procedures, sociodemographic, laboratory (when available), and provider characteristics to the full extent while developing predictive models for MS and prediabetes. The ensemble model demonstrated good discrimination, with a c-statistic of 0.83, in order to predict MS in comparison to regression, neural network, and decision tree models. Predicted MS was identified in 44% of individuals in scored data, and was found to be the third most important contributing factor in predicting prediabetes based on variable importance and Gini statistics.
The regression model demonstrated good discrimination with c-statistics of 0.67 and a high sensitivity and low false positive rate in comparison to decision tree, neural network, and ensemble models to predict prediabetes. The predictive model in this study identified approximately 43% with prediabetes in a cohort of MAPD individuals without the diagnosis of diabetes and aged 65–89 years, whereas only 13% were identified based on specific diagnosis and laboratory criteria from the claims data. Clinical condition categories including disorders of lipid metabolism, hypertension, metabolic disorders, nutritional disorders, and deficiencies were highly associated with diabetes and were of increased prevalence in patients predicted to have prediabetes compared with patients not predicted to have prediabetes.
Cowie et al 4 estimated the nationwide prevalence of prediabetes as defined by IFG or IGT to be approximately 40.8% among elderly individuals' aged 65 years and older using National Health and Nutrition Examination Survey data from 2005–2006. The current study identified 44% of MAPD individuals with prediabetes, which is similar to national estimates. Furthermore, Meng et al 17 compared logistic regression, neural network, and decision tree models for predicting diabetes or prediabetes using 12 self-reported risk factors in a Chinese population and evaluated each model for its accuracy, sensitivity, and specificity. They found the decision tree model performed better than other models with a classification accuracy of 77.87%, a sensitivity of 80.68%, and a specificity of 75.13%. However, Meng et al did not construct an ensemble model by combining the different models. Furthermore, the study by Meng et al used only limited self-reported input variables, whereas the current study included 512 input variables in order to predict prediabetes.
This study only included individuals with an MAPD plan, which is a limitation. Unlike original Medicare, individuals enrolled in an MAPD plan may elect to have their entitlement benefit managed by a private health organization. MAPD plans are required to include all the benefits of traditional Medicare with additional value-added benefits (ie, vision, dental, health education, fitness, post-discharge transition planning, enhanced disease management, alternative therapies, transportation). Although this is a limitation to the findings, it is important to note that in 2018 the Centers for Medicare & Medicaid Services expanded their Medicare Diabetes Prevention Program (MDPP) nationally, making the MDPP part of the core benefit, which would have to be offered by any managed care organization (ie, MAPD, or other private fee-for-service providers). The purpose of the MDPP is to prevent the onset of type 2 diabetes through lifestyle management focused on diet and physical exercise with a primary end point of 5% weight loss. 34 For managed care organizations, and from a public health perspective, it is important to identify those individuals who would benefit most from this type of personalized preventive care planning. The current study approach of using a 2-stage adaptive method was taken to improve the accuracy of identifying optimal at-risk individuals.
This study has additional limitations that are common to administrative claims data and attributed to the absence of health behavior-related information, errors in claims coding, scarcity of highly prognostic measures, and the potential influence of unmeasured confounding variables. In addition, laboratory information used to define MS and prediabetes was limited to patients who had this data available.
Conclusions
Ensemble methods and logistic regression models demonstrated good performance in predicting MS and undiagnosed prediabetes, respectively, among individuals with an MAPD plan based on demographic, clinical, and health care utilization information obtained from administrative claims. A 2-step approach ensured that each subject had a metabolic risk factor score, as this constellation of conditions is highly associated with disease progression. This potentially increased the predictive accuracy of identifying individuals most likely to have undiagnosed prediabetes, which is ideal for finding candidates for engagement in a diabetes prevention program.
Footnotes
Author Disclosure Statement
At the time of writing, Dr. Kamble, Ms. Collins, and Mr. Harvey were or are employees of Comprehensive Health Insights Inc., a subsidiary of Humana Inc., which received funding from Novo Nordisk Inc. to conduct this study. Dr. Allen is an employee of Novo Nordisk, Inc., and owns stock in the company. Drs. Kimball and Deluzio, and Mr. Bouchard were employees of Novo Nordisk, Inc. at the time of this study. Dr. Prewitt is an employee of Humana Inc. This research was funded by Novo Nordisk Inc., and conducted as part of the Novo Nordisk-Humana Research Collaboration.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.