
Abstract
Background:
Appendicitis is an inflammatory condition that requires timely and effective intervention. Despite being one of the most common surgically treated diseases, the condition is difficult to diagnose because of atypical presentations. Ultrasound and computed tomography (CT) imaging improve the sensitivity and specificity of diagnoses, yet these tools bear the drawbacks of high operator dependency and radiation exposure, respectively. However, new artificial intelligence tools (such as machine learning) may be able to address these shortcomings.
Methods:
We conducted a state-of-the-art review to delineate the various use cases of emerging machine learning algorithms for diagnosing and managing appendicitis in recent literature. The query (“Appendectomy” OR “Appendicitis”) AND (“Machine Learning” OR “Artificial Intelligence”) was searched across three databases for publications ranging from 2012 to 2022. Upon filtering for duplicates and based on our predefined inclusion criteria, 39 relevant studies were identified.
Results:
The algorithms used in these studies performed with an average accuracy of 86% (18/39), a sensitivity of 81% (16/39), a specificity of 75% (16/39), and area under the receiver operating characteristic curves (AUROCs) of 0.82 (15/39) where reported. Based on accuracy alone, the optimal model was logistic regression in 18% of studies, an artificial neural network in 15%, a random forest in 13%, and a support vector machine in 10%.
Conclusions:
The identified studies suggest that machine learning may provide a novel solution for diagnosing appendicitis and preparing for patient-specific post-operative complications. However, further studies are warranted to assess the feasibility and advisability of implementing machine learning-based tools in clinical practice.
Appendicitis is one of the most common surgically treated diseases, with more than 300,000 appendectomies being performed in the United States annually. 1 Despite the prevalence of appendicitis in children and adults, appendicitis (especially acute complicated appendicitis) is difficult to diagnose. Diagnoses of appendicitis are missed in 3.8% to 15.0% of children and in 5.9% to 23.5% of adults during emergency department visits; the incidence of negative appendectomy is also notably 15% to 39% in the United States.2,3 Although white blood cell, C-reactive protein, and bilirubin levels are informative, no specific biomarker has been identified for acute appendicitis. Diagnosis of appendicitis thus currently relies on clinical scoring systems such as the Alvarado Score to stratify patients by risk of perforation. 4
However, atypical presentations and poor predictive value of laboratory tests complicate diagnoses and decisions for surgical intervention. Using ultrasound and computed tomography (CT) scans does enhance the accuracy of appendicitis diagnosis, but each imaging method bears their own unique drawbacks. Ultrasound is highly operator-dependent in its implementation and radiologic interpretation, whereas also being less sensitive in its predictions. Past consensus studies estimate ultrasound sensitivity at 55%: because of its low sensitivity, ultrasound can yield false negatives and cannot rule out equivocal or negative cases of appendicitis. 5 On the other hand, CT provides better sensitivity and specificity, but it is a high-cost approach that involves radiation exposure. It would thus be prudent to develop a framework for selective use of CT scans, especially for equivocal cases of appendicitis. Furthermore, low-resource settings such as in lower middle-income countries face profound challenges with securing universal access to imaging. 6 Subsequent health disparities are further exacerbated by challenges with post-surgical decision-making; systematic tools for predicting potential complications are also limited. The need to address these concerns of healthcare quality and equity warrants the development of new diagnostic and prognostic tools for appendicitis.
Machine learning, an emergent computational approach in healthcare, may have the potential to improve diagnostic sensitivity and specificity for appendicitis beyond current clinical tools. This artificial intelligence approach uses historical data to train a model that captures existing patterns in data to make informed predictions. Contrary to traditional statistical methods, machine learning (ML) models are scalable and equipped to analyze large, complex datasets in a high-throughput fashion. 7 Machine learning models have already been applied in other surgical specialties such as vascular surgery, neurosurgery, plastic surgery, and orthopedic surgery. 8 The systematic review by Senders et al. 9 of ML applications for neurosurgical diagnosis, pre-surgical planning, and outcome prediction especially claimed that artificial intelligence methods can outcompete “natural intelligence” (clinical expertise) in most performance metrics. Of note, beyond solely contributing to diagnostic classifications in the aforementioned surgical disciplines, ML algorithms have also been trained to predict various post-operative variables such as surgical site infections, patient survival, and even pain/satisfaction ratings. Machine learning is thus starting to be used at various stages of peri-operative management for surgically treated diseases. The aim of our review is to catalog the recent use of such novel machine learning algorithms in the context of appendicitis diagnosis and management.
Methods
A state-of-the-art review was conducted based upon systematic assessment of relevant articles found in PubMed, Web of Science, and Embase published from January 1, 2012, to January 1, 2022. State-of-the-art reviews are narrative reviews that seek to catalog the current state of a field as well as identify present challenges that warrant future investigation; this approach seemed most suitable given the rapidly evolving nature of our topic. 10 Search terms included the following: “Appendectomy” OR “Appendicitis” and “Machine Learning” OR “Artificial Intelligence.” Boolean operators were used to connect related keywords appropriately. Only studies including an application of at least one machine learning algorithm implemented on a separable appendicitis-specific dataset were considered. All studies attempting to predict appendicitis diagnoses were required to use pathology as a gold standard. Studies with pediatric or adult cases were indiscriminately accepted. Our review protocol was registered with Open Science Framework (osf.io/4u7gq).
Results
We initially identified 150 articles through our search of PubMed (n = 37), Web of Science (n = 43), and Embase (n = 70). There were 84 articles remaining after duplicates were removed. Furthermore, we excluded 26 studies that did not implement a ML algorithm and 19 studies that did not analyze an independent appendicitis/appendectomy dataset. For example, several results in our query contained data concatenated for different emergency general surgery procedures. No results were excluded on the basis of using pathology as a gold standard for diagnosis; all diagnostic prediction studies satisfied this guideline. The final state-of-the-art review included 39 studies (Fig. 1).
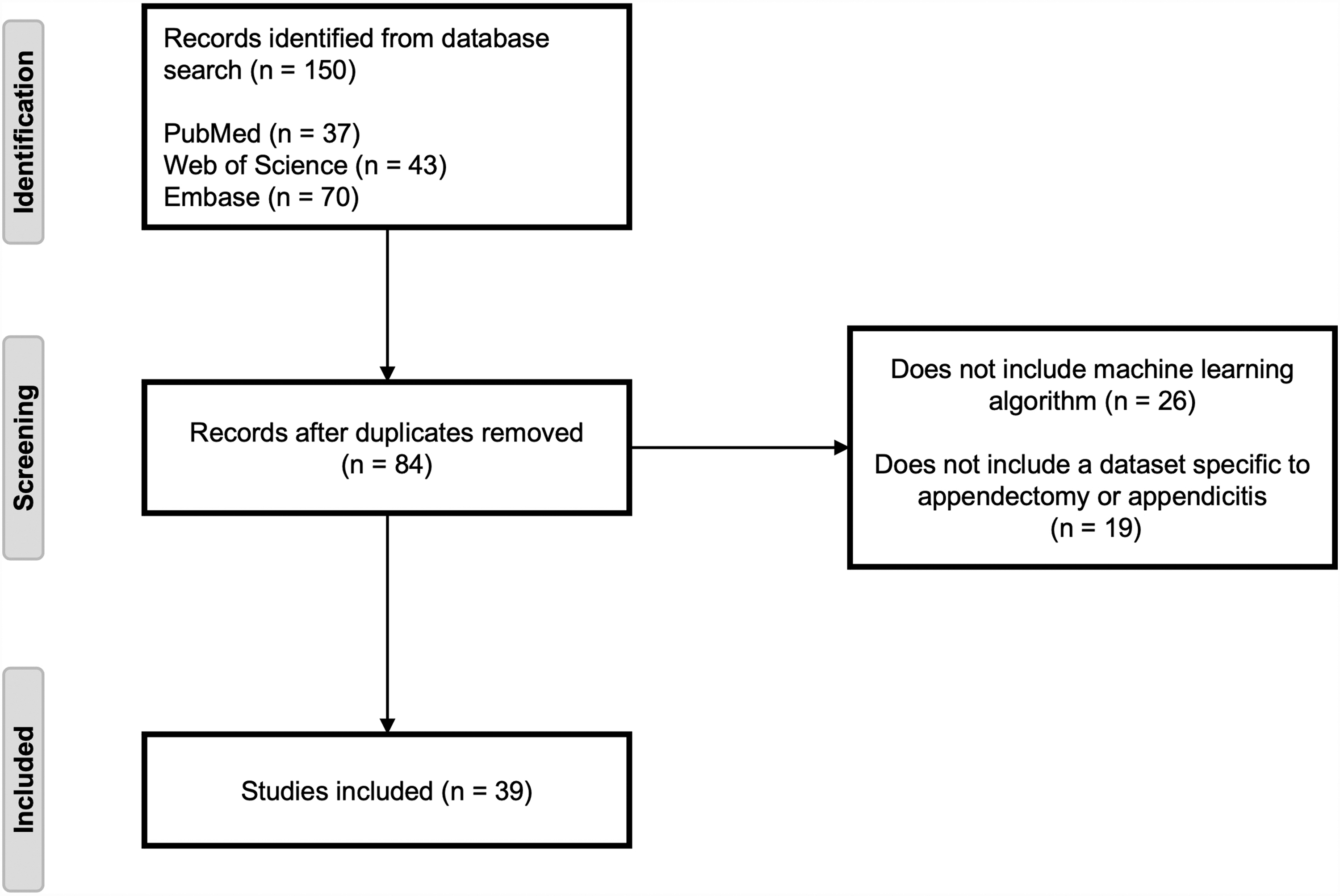
Preferred Reporting Items for Systematic reviews and Meta-Analyses for Protocols (PRISMA) flow diagram for our state-of-the art review. After relevant screening based on inclusion criteria listed in Methods, 39 studies remained.
Study characteristics
The 39 identified studies utilized an average sample size of 16,426 patients in their data: 24 studies included <1,000 patients, six studies included 1,000 to 10,000 patients, and nine studies included 10,000+ patients. With the exception of three prospective single-center studies automating post-operative pain assessments, all other studies were retrospective. Of the 36 retrospective studies, 26 included single-center data and 10 included multicenter data.
Algorithm specifications and applications
The most common use case of ML algorithms overall was for predicting appendicitis diagnosis (n = 28; Table 1). There were 27 diagnostic studies that used supervised learning methods (three of which applied deep learning to supervised learning tasks) and one study that used unsupervised learning. Other common applications of ML included predicting various post-operative outcomes (n = 11; Table 2) such as pain rating, development of sepsis, length of hospital stay, and 30-day mortality. For post-operative studies, there were 10 studies that used supervised learning methods (two of which applied deep learning to supervised learning tasks) and one study that used unsupervised learning.
Characteristics of Diagnostic Prediction Studies (n = 28)
ML = machine learning; SL = supervised learning; uSL = unsupervised learning; SVM = support vector machine; LR = logistic regression; RF = random forest; GLM = generalized linear model; GBM = generalized boosted regression model; NN = neural network; ANN = artificial neural network; CNN = convolutional neural network; KNN = k-nearest neighbors; CRP = C-reactive protein; WBC = white blood cell; HER = electronic health record; AUC = area under the curve.
Optimal models listed only on the basis of accuracy (or AUC if accuracy is not reported).
Characteristics of Post-Operative Outcome Prediction Studies (n = 11)
ML = machine learning; ICU = intensive care unit; LOS = length of stay; WBC = white blood cell; RMSE = root mean squared error; AUC = area under the curve; SL = supervised learning; uSL = unsupervised learning; SVM = support vector machine; LR = logistic regression; RF = random forest; GLM = generalized linear model; NN = neural network; ANN = artificial neural network; CNN = convolutional neural network; KNN = k-nearest neighbors.
Optimal models listed only on the basis of accuracy (or AUC, if accuracy is not reported).
Of the 28 diagnostic studies, 17 developed an algorithm for differentiating individuals with appendicitis from those without and 11 developed an algorithm for differentiating between complicated and uncomplicated appendicitis. Studies for diagnostic prediction mostly used laboratory characteristics such as C-reactive protein and white blood cell (WBC) counts as well as imaging findings such as >6 mm appendiceal diameter as features for training their ML models. Studies primarily used combinations of laboratory data (n = 14), imaging findings (n = 9), and symptoms/clinical features uncovered by physical examinations (n = 5). One study used genomic data exclusively to identify genes that were differentially expressed between complicated and uncomplicated appendicitis cases for subsequent diagnostic predictions. Another study analogously examined proteomic signatures in urine alone in their algorithm to predict acute appendicitis. Other unique features used for predictive modeling of diagnosis across the various studies included demographic data, vitals, text extracts from clinical records, and raw imaging data for automatic processing.
The 11 studies leveraging post-operative data assessed several types of surgical outcomes: length of stay (n = 3), post-operative pain (n = 3), sepsis development (n = 2), 30-day mortality (n = 1), financial cost (n = 1), and racial/ethnic disparities (n = 1). Studies assessing postoperative outcomes primarily used patient demographics (n = 8), facial expression data (n = 3), and hospital characteristics (n = 2) as parameters for machine learning models. Facial expression data was only used in the three studies that attempted to predict pain ratings following laparoscopic appendectomy.
Model performances
On average, the algorithms across all chosen studies yielded an accuracy of 85.5% (range, 51%–96%), a sensitivity of 81.1% (range, 57.3%–100%), a specificity of 74.9% (range, 17.5%–97.5%), and an area under the receiver operating characteristic curve (AUROC) of 0.815 (range, 0.619–0.976) where reported. Diagnostic study algorithms performed with an average accuracy of 84.7% (range, 51%–96%), a sensitivity of 81.3% (range, 57.3%–98%), specificity of 72.4% (range, 17.5%–97.5%), and an area under the curve (AUC) of 0.825 (range, 0.619–0.976). Post-operative study algorithms performed with an average accuracy of 89.6% (range, 88%–90.9%), sensitivity of 80.7% (range, 64.7%–100%), specificity of 82.7% (range, 64.5%–96.3%), and AUC of 0.774 (range, 0.707–0.89). Accuracy was reported in 18 of 39 studies, sensitivity in 16 of 39 studies, specificity in 16 o 39 studies, and AUROC in 15 of 39 studies. Certain studies reported alternative performance metrics such as an F-score (n = 2), precision/recall (n = 1), or a Brier score (n = 1). Each of the three studies that compared their highest-performing algorithm to the Alvarado Score reported that their ML-based method demonstrated greater accuracy than the Alvarado scoring system.
Based on accuracy alone, across all use cases, logistic regression was the optimal model in seven studies, an artificial neural network in six studies, a random forest in five studies, and a support vector machine in four studies. The highest performing models in the remaining studies used various ensemble algorithms or otherwise unique techniques.
Three of the 39 overall studies used varying methods of learning optimization, including parameter optimization (n = 2) to find the best training weights for each input feature and hyperparameter tuning (n = 4) to optimize certain variables inherent to each algorithm type. All four studies with hyperparameter tuning used k-fold cross-validation followed by grid search as a part of their optimization strategy. One study notably used both grasshopper optimization to find the best training parameters and opposition-based learning to search for the best algorithm hyperparameters.
Discussion
To analyze the potential applicability of machine learning methods for appendicitis, we have reviewed the current literature to understand better the successes and challenges faced in developing such algorithms among the studies that met criteria for inclusion.
Feature selection
Feature selection is a seminal challenge in developing predictive models. Choosing too few input features generally results in suboptimal model performance (lower accuracy), whereas the inclusion of too many input features may result in overfitting of the training dataset. The prominent inclusion of measures of CRP levels and WBC counts as diagnostic algorithm features mirrors the contributions of leukocytosis and left shift of WBC count (neutrophilia) to the Alvarado Score. Use of the >6 mm maximal outer diameter rule in imaging findings to conclude acute inflammation also recapitulates established diagnostic guidelines. 11 However, several studies opted to also include additional demographic variables (age, gender, etc.), vital signs, and unique data modalities to achieve notable model performance.
For example, to address the high operator dependency and potential for interpretive error inherent to ultrasound, Kim et al. 12 created a tool for automated segmentation to extract appendiceal features from raw ultrasound images instead of relying on clinical records of imaging findings. Noguchi et al. 13 developed an analogous tool for CT scan results to assess appendiceal diameter, wall enhancement, and peri-appendiceal fat stranding among other hallmarks of appendicitis. The appreciable model performance of the two studies, Resimann et al. 14 and Zhao et al., 15 that exclusively used genomic or urinary proteomic data suggests that incorporating additional data types into algorithms may further optimize accuracy. Whereas input features seemed to be generally chosen based on the consensus of clinical experts or prior literature, some studies such as Xia et al. 16 and Iliou et al. 17 used computational methods such as random forests to select the most informative features and reduce redundancy. A combination of both manual and computational vetting may be a useful strategy for isolating the most important features for future algorithms that could integrate diverse data types.
Compared with the features used in diagnostic algorithms, algorithms for predicting post-operative outcomes levied more diverse modalities of data across studies. This may in part be because of the additional data available in the given time window (both pre-operative and intra-operative variables for post-operative predictions). Although the studies for predicting diagnosis and post-operative outcomes all have similarly well-performing models with accuracies greater than 75%, a reasonable next step would be to standardize input features. Feature standardization may be especially critical given the previously mentioned issue of overfitting. Most of the reviewed studies trained and tested their models on internal datasets within respective hospitals, and thus insights from their algorithms may not be generalizable to distinct datasets. Only the studies by Su et al. 18 and Bunn et al. 19 used nationally validated databases: the National Hospital Ambulatory Medical Care Survey (NHAMCS) and the National Surgical Quality Improvement Program (NSQIP), respectively. However, ambitions for standardizing input features may be limited by access to relevant data. For example, NSQIP, as a clinical database, contains more clinically relevant and longitudinal data whereas NHAMCS, as an administrative database, exclusively provides data about inpatient comorbidities and complications. 20 Equity-based concerns related to data availability also exist: access to imaging is a key limitation in low-resource settings. 21
The utility of demographic data (used in two studies found in this review) in appendicitis diagnosis is also worth further interrogating; current literature seems to find no link between ethnicity and likelihood of diagnosis, but other demographic factors, including male gender and patient age, have identified as independent predictors of positive histology for appendicitis. 22 On the other hand, ethnicity has been associated with post-operative outcomes including hospital length-of-stay. The literature surrounding the impact of age on appendicitis diagnosis is also mixed. Some studies cite that unusual presentations in pediatric appendicitis lead to more frequent misdiagnoses, whereas other epidemiologic analyses suggest no age-related difference in presentation or perforation rates.23,24 Of our 39 selected studies, 11 studies explicitly analyzed pediatric patient cohorts. Several other studies notably either combined pediatric and adult cases in their analysis or did not explicitly specify the age range of the patients included in the study.
Patient socioeconomic status as an input feature is also contentious. Some global studies of appendicitis diagnosis have established that patients from low-income populations bear higher risks for appendicitis as well as higher hospital costs, but the one study we found using socioeconomic status as an input feature concluded variability between hospital policies to be a stronger predictor of inpatient expenditure.25,26 Overall, discrepancies between facilities was found to be a more important factor for post-operative outcome prediction than for appendicitis diagnosis prediction.
Summary of applications
Despite current challenges in systematizing feature selection, the retrieved studies (28 for pre-operative predictions, 11 post-operative predictions) showcase the diverse applications machine learning algorithms may offer at several stages of appendicitis management (Fig. 2). Pre-operative studies for predicting diagnosis and the need for surgical intervention levied several modalities of data from genomic, proteomic (laboratories, and radiomic sources. No study has presently integrated all of these modalities to assess the utility of a composite predictive algorithm. Studies leveraging imaging data notably varied in their use of raw data versus radiological interpretations. For example, Kim et al. 12 and Noguchi et al. 13 developed segmentation algorithms to quantify appendiceal diameters and detect whether they exceeded the pathological threshold, thereby bypassing challenges of ultrasound operator subjectivity. All other diagnostic studies relied on conclusions drawn from radiologist notes. Reporting of algorithmic input features was less detailed for post-operative studies, but these studies more frequently used baseline demographic characteristics when compared to pre-operative studies.

Depiction of use cases for machine learning algorithms in retrieved literature. Machine learning (ML) can use pre-operative data to predict diagnosis and guide surgical decision-making, while also being capable of using pre-operative and intra-operative data to predict post-operative outcomes. (Source: Figure adapted from “Risk Factors of Dementia” by BioRender.com (2022) and retrieved from https://app.biorender.com/biorender-templates).
Performance metrics
Although ML is clearly applicable to appendicitis and surgery at-large, the approach's advisability in specific clinical contexts is still to be determined. Less than half of the 39 reviewed studies reported standard model performance metrics such as accuracy, sensitivity, specificity, and AUROC. This low level of reporting adherence may be expected due to the recent rise of such studies in the last decade, but it also shows the need for standardizing the reporting of machine learning algorithm performance metrics for appendicitis management and beyond.
Studies most commonly reported accuracy and evidently featured high-performing models, with an average accuracy of 85.5%. However, more focus on accuracy as a primary performance metric seemed to come with tradeoffs in sensitivity and specificity. On the extremes, sensitivity could be as low as 57.3% and specificity as low as 17.5%. Overall averages of sensitivity (81.1%) and specificity (71.4%) were also notably lower than the average accuracy attained across all the studies; this finding was true even among the individual groupings of diagnostic and post-operative studies. The AUROC was also the least commonly reported metric (15/39 studies), despite being a better indicator of predictive model performance at several thresholds. Furthermore, a limited number of articles compared their algorithms to standard scoring systems such as the Alvarado Score or the Appendicitis Inflammatory Response Score. All of the three studies that did conduct a comparison to the Alvarado Score did however outcompete the system in accuracy, sensitivity, and specificity. Nevertheless, the performance metrics cataloged in this study may serve as additional benchmarks for future algorithm developers to improve upon in this nascent field, alongside further comparisons to existing clinical benchmarks like the Alvarado score (see Table 3 for a full list of performance metrics used by the selected studies).
Common Performance Metrics
AUC = area under the curve; AUROC = area under the receiver operating characteristic curves
Limitations
There are certain limitations to the insights gleaned from this study regarding the applicability of ML for appendicitis. First, publication bias ensures that only projects with the most accurate algorithms appear in literature. Especially given the use of parameter and hyperparameter optimization conducted within each study's specific dataset, it is difficult to predict how each study's model would generalize to new datasets. The aforementioned problem of feature standardization, especially complicated by struggles in determining the clinical utility of certain patient features such as patient age, also makes generalizability difficult. Furthermore, data involving real-time implementation of machine learning is limited. Except for the three prospective studies involving the prediction of post-operative pain assessments, no clinical trials or studies implementing machine learning at the bedside were found.
Future considerations
This review has illustrated the need for standardized computational and ML performance reporting frameworks to enable better model comparisons. But given the lack of real-time implementation of ML appendicitis models in clinical settings, it would also be advisable to investigate how patients would tolerate the incorporation of artificial intelligence tools for critical healthcare diagnoses like that of appendicitis. Past studies into patient perception of human-artificial intelligence interactions in health care cite anxieties about communication barriers, regulatory standards, and health privacy. 27 The accuracy and scalability of ML models thus does not undercut the importance of patient-physician interactions: in fact, ML predictions trained on limited datasets may bias physicians and lead to undesirable heuristic shortcuts. 28 At the same time, such drawbacks would have to be weighed against the cost-effective nature of AI-based approaches to diagnosis in low-resource settings.
Conclusions
The identified studies suggest that ML may perform similarly to or better than current clinical predictive tools relevant to diagnosis and post-operative management of appendicitis. However, despite the broad emergence of ML studies in the field of appendicitis treatment, translation to real-world practice remains limited. No formal clinical trial studies using machine learning for appendectomy were found. Further studies will be needed to elucidate the relative performance of such approaches to the Alvarado Score and to assess the feasibility and advisability of implementing ML-based tools in clinical practice.
Footnotes
Acknowledgments
Presented at the Connecticut Chapter of the American College of Surgeons Annual Meeting, Trumbull, Connecticut, October 2022 and the Society of American Gastrointestinal and Endoscopic Surgeons Annual Meeting, Montreal, Canada, March 2023.
Authors' Contributions
Each author has contributed significantly to the review and has contributed in one or more aspects of the study as noted below.
Conceptualization: Bhandarkar, Schneider, Ahuja. Methodology: Bhandarkar, Schneider, Brackett, Ahuja. Formal analysis: Bhandarkar. Investigation: Bhandarkar, Tsutsumi. Resources: Schneider, Brackett, Ahuja. Data curation: Bhandarkar, Brackett. Writing—original draft: Bhandarkar. Writing—review and editing: Bhandarkar, Tsutsumi, Schneider, Ong, Paredes, Brackett, Ahuja. Visualization: Bhandarkar. Supervision: Tsutsumi, Schneider, Ong, Ahuja. Project administration: Schneider, Ahuja.
Funding Information
There were no sources of funding for this work.
Author Disclosure Statement
The authors declare no conflicts of interest.