
Abstract
Background:
ChatGPT, an artificial intelligence (AI) chatbot, is the fastest growing consumer application in history. Given recent trends identifying increasing patient use of Internet sources for self-education, we seek to evaluate the quality of ChatGPT-generated responses for patient education on thyroid nodules.
Methods:
ChatGPT was queried 4 times with 30 identical questions. Queries differed by initial chatbot prompting: no prompting, patient-friendly prompting, 8th-grade level prompting, and prompting for references. Answers were scored on a hierarchical score: incorrect, partially correct, correct, or correct with references. Proportions of responses at incremental score thresholds were compared by prompt type using chi-squared analysis. Flesch–Kincaid grade level was calculated for each answer. The relationship between prompt type and grade level was assessed using analysis of variance. References provided within ChatGPT answers were totaled and analyzed for veracity.
Results:
Across all prompts (n = 120 questions), 83 answers (69.2%) were at least correct. Proportions of responses that were at least partially correct (p = 0.795) and correct (p = 0.402) did not differ by prompt; responses that were correct with references did (p < 0.0001). Responses from 8th-grade level prompting were the lowest mean grade level (13.43 ± 2.86) and were significantly lower than no prompting (14.97 ± 2.01, p = 0.01) and prompting for references (16.43 ± 2.05, p < 0.0001). Prompting for references generated 80/80 (100%) of referenced medical publications within answers. Seventy references (87.5%) were legitimate citations, and 58/80 (72.5%) provided accurately reported information from the referenced publication.
Conclusion:
ChatGPT overall provides appropriate answers to most questions on thyroid nodules regardless of prompting. Despite targeted prompting strategies, ChatGPT reliably generates responses corresponding to grade levels well-above accepted recommendations for presenting medical information to patients. Significant rates of AI hallucination may preclude clinicians from recommending the current version of ChatGPT as an educational tool for patients at this time.
Introduction
Thyroid nodules are a relatively common finding with a reported prevalence of 2–65% in adult patients depending on the population and method of detection. 1 These lesions are typically asymptomatic and benign; however, ∼5–15% of nodules are malignant. 2,3 Exclusion of thyroid malignancy secondary to nodular disease is greatly important, especially in patients that are female, of older age, have prior radiation exposure, and have iodine deficiency. 1 Workup of thyroid nodules most often includes ultrasound imaging, but may also involve fine-needle aspiration biopsy and molecular testing. 2 Thyroid cancers, most of which are differentiated thyroid carcinomas, are relatively treatable depending on the stage and type of tumor. Thus, prompt diagnosis and initiation of treatment greatly reduces mortality and improves prognosis. 4
Given the high prevalence and potential for malignancy of thyroid nodules, adequate patient education on this topic is paramount. Of the many resources available to patients for medical information, the internet is often one of the most utilized. A recent multiyear study of the Health Information National Trends Survey (HINTS) including upwards of 18,000 survey responses demonstrated that 68.9% of adults used the internet as their first source of health-related information. 5 Prior studies of educational materials pertaining to thyroid nodules available to patients have shown that current resources include inadequacies and are often written above recommended patient reading levels. 6,7 Therefore, resources for thyroid nodule education have capacity for improvement to better involve patients in their health care decision-making.
A rapidly emerging large language model (LLM) utilizing artificial intelligence (AI) called ChatGPT represents a potential avenue for patient education in health care. 8 The popularity of this tool is immense, as website visits have been estimated at >1.8 billion as of June 2023. As a patient education modality, ChatGPT has been able to provide acceptable responses pertaining to cardiovascular disease prevention and postoperative instructions following different pediatric otolaryngologic procedures. 9,10 Other health care-related topics of current ChatGPT research have centered around the chatbot's ability to provide high-quality and empathetic responses to prompted patient questions, and its performance on US Medical Licensing Exam (USMLE), neurosurgery boards, and radiology boards-style questions. 11 –14 Collectively, the current literature demonstrates potential uses of ChatGPT in patient education, medical education, and research, but further work is required to optimize its benefit. The goal of this study is to determine the utility of ChatGPT as an educational resource for patients on thyroid nodules.
Methods
This investigation was exempt from Institutional Board Review at Thomas Jefferson University. ChatGPT (April 2, 2023, version) was queried four times with an identical set of 30 sequential questions pertaining to patient education on thyroid nodules. Each of the four 30-question queries generated a unique question-and-answer thread on GPT-3.5. Currently two versions of ChatGPT exist: GPT-3.5 and GPT-4. GPT-3.5 was chosen for analysis because it is the most widely used and is free to the public. Each thread differed by how ChatGPT was prompted before asking the first question: no prompting, patient-friendly prompting, 8th grade-level prompting, and prompting for references (Table 1, prompt numbers 1–4). Eighth-grade prompting was chosen because National Institutes of Health (NIH) recommends that patient educational materials be written at or below the eighth-grade level. 15
ChatGPT Prompt Names and Prompt Provided
“Prompts” were placed immediately before the first question posed to ChatGPT. Each prompt was only entered once.
Questions were divided into the following four categories: epidemiology (1–5), diagnosis (6–15), prognosis (16–20), and management (21–30). Given that ChatGPT's answers build upon prior questions-and-answers within the same thread, each thread posed questions in an identical order to minimize chatbot response variability. This research methodology largely mirrors prior work from our group investigating the utility of AI-generated responses for patient education on obstructive sleep apnea (OSA). 16
Answers were reviewed and graded based on medical accuracy and clinical appropriateness using a four-part hierarchical scale: incorrect, partially correct, correct, or correct with a reference (“correct+”). Partially correct answers were subdivided based on their reason for the grade: too vague, or incomplete. Responses were independently assessed by two otolaryngology resident physicians. In the setting of a grade discrepancy, a third author decided on the most appropriate grade. Grades were then approved by an experienced thyroid and parathyroid head-and-neck-attending surgeon. Response accuracy was guided by preexisting published literature or guidelines. Specifically, queries related to diagnosis and management were graded based on the most recent American Thyroid Association guidelines and statements. Queries related to epidemiology and prognosis were graded based on recently published literature related to their respective topics.
For each answer, the number of words, sentences, and syllables were collected to generate a Flesch–Kincaid (FK) grade-level score. The FK grade level is intended to correspond to the estimated US academic grade level of presented text-based information (e.g., 7 is middle school level, 10 is high school level, and 14 is collegiate level). 17 The total number of publications and corresponding publication years for each reference provided by ChatGPT was recorded. Each reference was further investigated in a two-part sequence: (1) verification of the reference is real (e.g., has a DOI, is findable online), and (2) verification of ChatGPT is citing correct information from the corresponding reference (e.g., statistics or conclusions drawn are correct).
ChatGPT (September 25, 2023 version) was further queried using the 8th-grade level prompting and two additional sequential grade-level prompting strategies: 6th-grade-level prompting and 4th-grade-level prompting (Table 1, prompt numbers 3, 5–6). These additional prompting strategies were chosen specifically to assess the chatbot's ability to sequentially lower its response grade level and were only used to calculate FK grade-level scores.
Analysis of graded responses were performed to assess whether initial chatbot prompting influenced scoring outcomes. Using a two-sided chi-squared analysis, proportions of responses either satisfying or not satisfying the following test thresholds were compared by prompt type: (1) at least partially correct, (2) at least correct, or (3) correct+. Tests were performed with alpha at 0.05 with post hoc Bonferroni correction applied to subset each possible paired comparison. One-way match analysis of variance (ANOVA) tests were performed to assess the relationship between prompt type to word count and FK grade level. IBM SPSS Version 28.0.1.0 was used to conduct statistical analyses with p-value <0.05 to indicate statistical significance.
Results
A summative representation of ChatGPT response grading is displayed in Figure 1. Across all prompt types (n = 120 questions), scoring frequencies were: 3 (2.5%) incorrect, 34 (28.3%) partially correct, 57 (47.5%) correct, and 26 (21.7%) correct with reference (“correct+”). Within the 57 partially correct answers, 26 (76.5%) were deemed incomplete, and 8 (23.5%) were deemed “too vague.” Eighty-three (69.2%) answers were at least correct (i.e., correct or correct+). On chi-squared analysis, proportions of responses that were at least partially correct (p = 0.795) or correct (p = 0.402) did not differ significantly by prompt type (Table 2). Proportions of responses that were correct+ (p < 0.0001) did differ significantly by prompt type. Within the chi-squared test using a correct+ threshold, prompting for references yielded a significantly higher proportion of correct+ responses than that of the other prompt types (p < 0.05) on Bonferroni post hoc analysis after adjusting significance thresholds based on the number of unique comparisons.
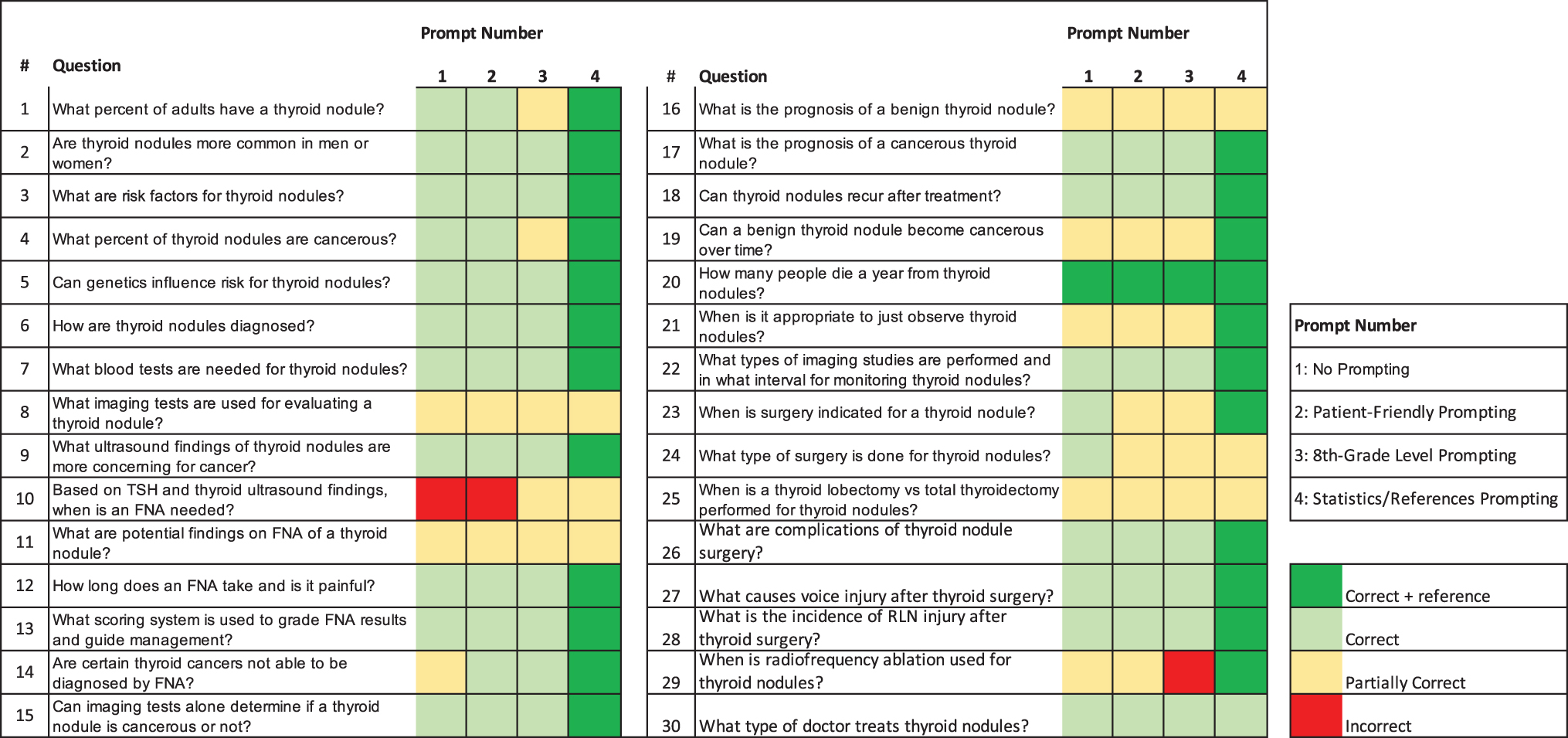
Colormap representation of graded ChatGPT responses by prompt type.
Chi-Squared Tests by Prompt Type and Varying Thresholds of Response Grade
Frequency is presented as a fraction of the total number (n = 30) of questions from a given form number.
A subset of category whose column proportions differ significantly from each other at the adjusted 0.05 level on Bonferroni post hoc analysis.
Mean FK grade level by prompt type was 14.97 ± 2.01 (no prompting), 14.05 ± 2.77 (patient-friendly prompting), 13.43 ± 2.86 (8th-grade level prompting), and 16.43 ± 2.05 (prompting for references). There was a significant association between prompt type and FK grade level (p < 0.0001). Specifically, prompting for references led to a significantly higher-grade level than all other prompt types (Fig. 2). Additionally, 8th-grade level prompting led to a significantly lower grade level than no prompting (Fig. 2).
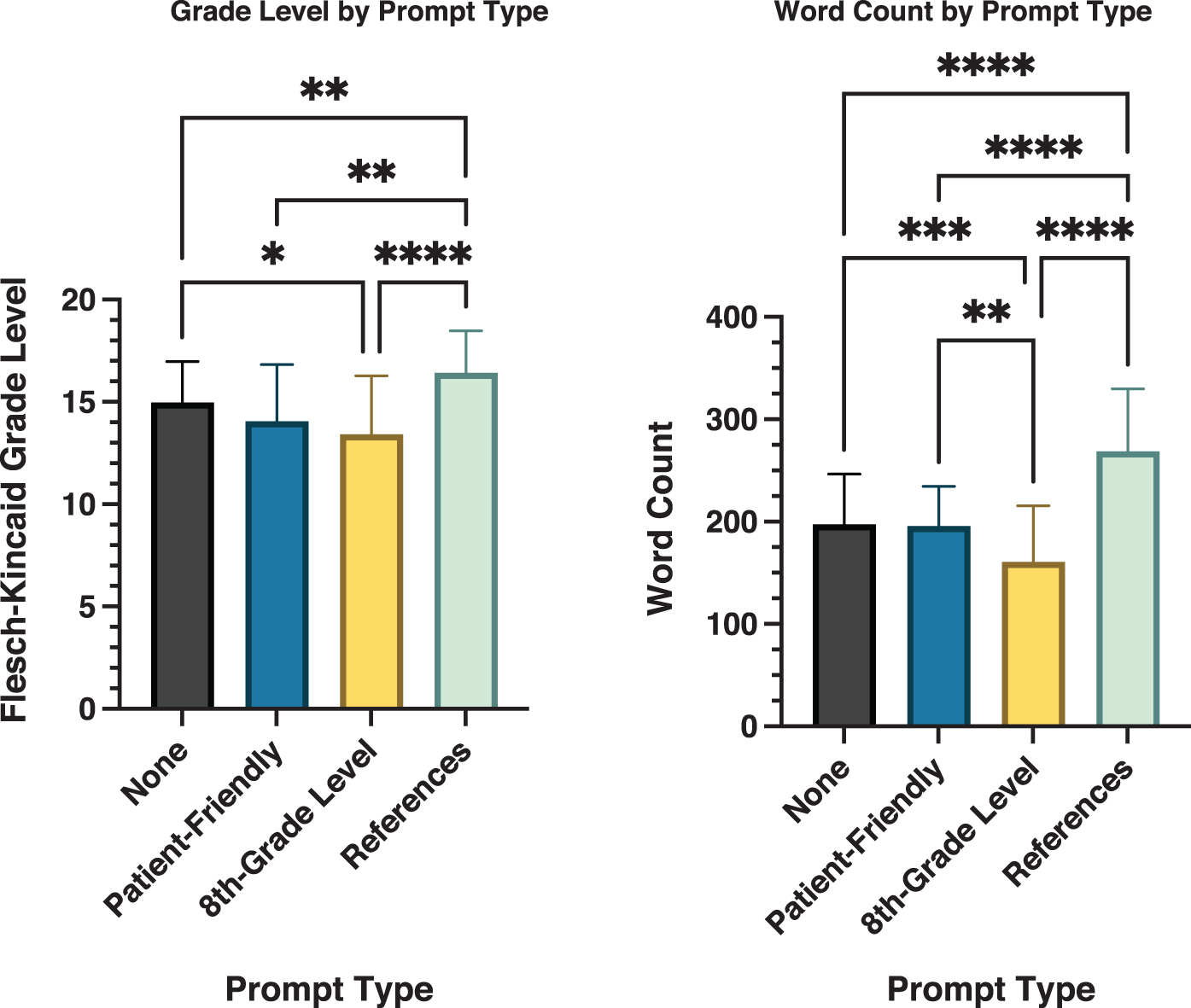
ANOVA assessing prompt type by grade level and word count. *, **, ***, and **** indicate p ≤ 0.05, 0.01, 0.001, and 0.0001, respectively. ANOVA, analysis of variance.
Mean word count per answer by prompt type was 197.4 ± 49.2 (no prompting), 195.7 ± 38.7 (patient-friendly prompting), 160.9 ± 54.7 (8th-grade level prompting), and 268.7 ± 61.2 (prompting for references). There was also a significant association between prompt type and response word count (p < 0.0001). Specifically, 8th-grade level prompting led to a significantly lower response word count than all other prompt types (Fig. 2). Additionally, prompting for references led to a significantly larger response word count than that of no prompting and patient-friendly prompting (Fig. 2).
The secondary analysis used ChatGPT (Sept 25, 2023, version) to assess the chatbot's ability to lower response grade level using only the sequential grade level prompting strategies (Table 1, Prompt Numbers 3, 5–6). Mean FK grade levels were 12.98 ± 2.65 (8th-grade level prompting), 9.80 ± 2.13 (6th-grade level prompting), and 8.65 ± 2.48 (4th-grade level prompting). These grade levels were additionally compared to the original 8th-grade level prompting results (using ChatGPT April 2, 2023, version). There was no significant difference in response grade level between the original 8th-grade level prompting responses (using ChatGPT April 2, 2023, version) and the newer 8th-grade level responses (using ChatGPT September 25, 2023 version) (p = 0.443). However, 4th-grade level prompting led to a significantly lower grade level than 6th-grade level prompting (p < 0.001) and both 8th-grade level prompting strategies (p < 0.0001). Additionally, 6th-grade level prompting led to a significantly lower grade level than both 8th-grade level-prompting strategies (p < 0.0001) (Fig. 3).
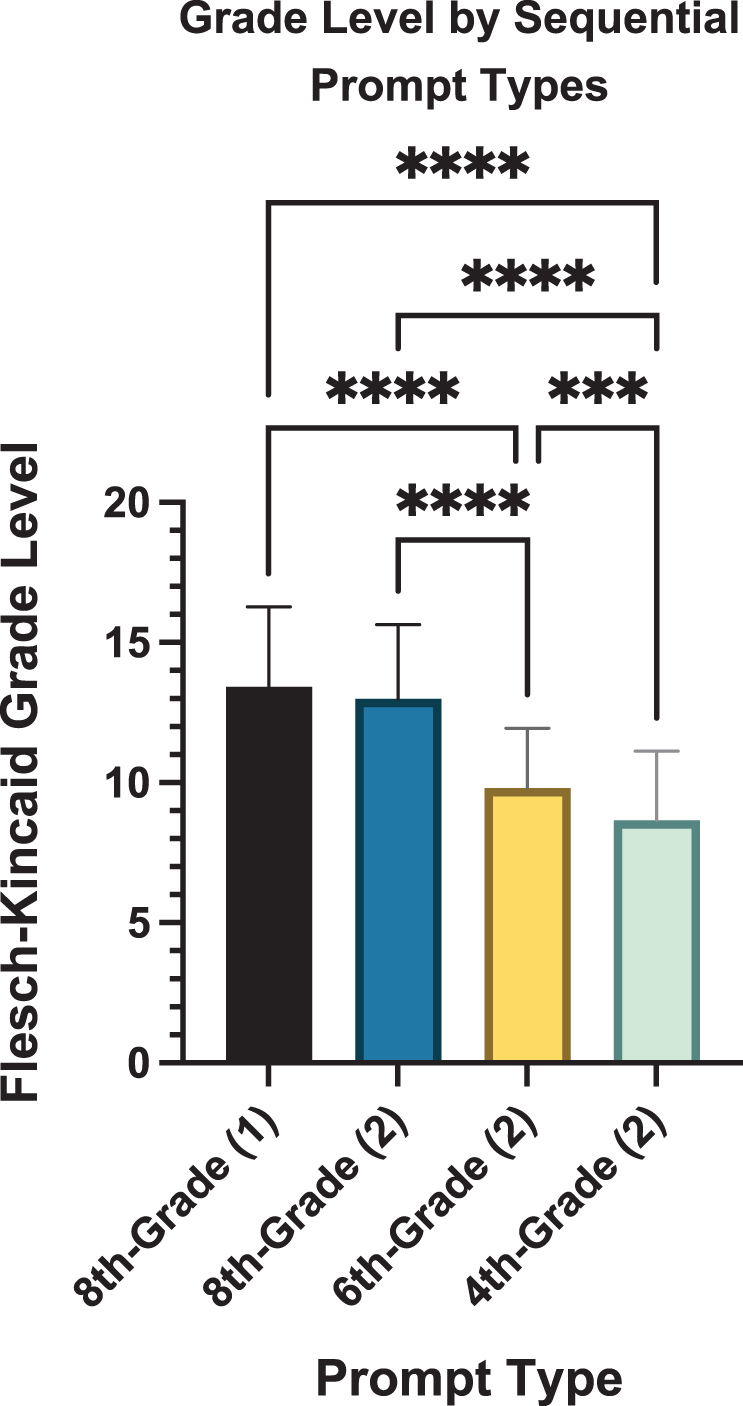
ANOVA assessing grade level by sequential prompt types. For prompt type, (1) indicates use of ChatGPT April 2, 2023 version, and (2) indicates use of ChatGPT September 25, 2023 version. *** and **** indicate p ≤ 0.001 and 0.0001, respectively.
Across all prompts (n = 120 questions), GPT-3.5 provided 84 total references for its answers: 80 (95.2%) from published medical literature, and 4 (4.8%) from academic medical organization websites. The four website citations were specifically to the following question: “How many people die a year from thyroid nodules?” For all four prompting strategies, the chatbot correctly referenced statistics from the American Cancer Society website. All 80 (100%) references from published medical literature came from responses in the prompting for references question-and-answer thread. Median publication year of these references was 2015 (range: 1993–2021) (Fig. 4). Seventy (87.5%) of these references were legitimate citations with an associated DOI and findable online. The remaining 10 (12.5%) references either were unfindable or incorrect. Of the 70 legitimate citations, GPT-3.5 successfully extracted accurately reported information in its responses from 58 (82.9%) of the citations. In 12 (17.1%) of the 70 legitimate citations, GPT-3.5 either incorrectly stated or completed falsified findings from the corresponding citation in its response.
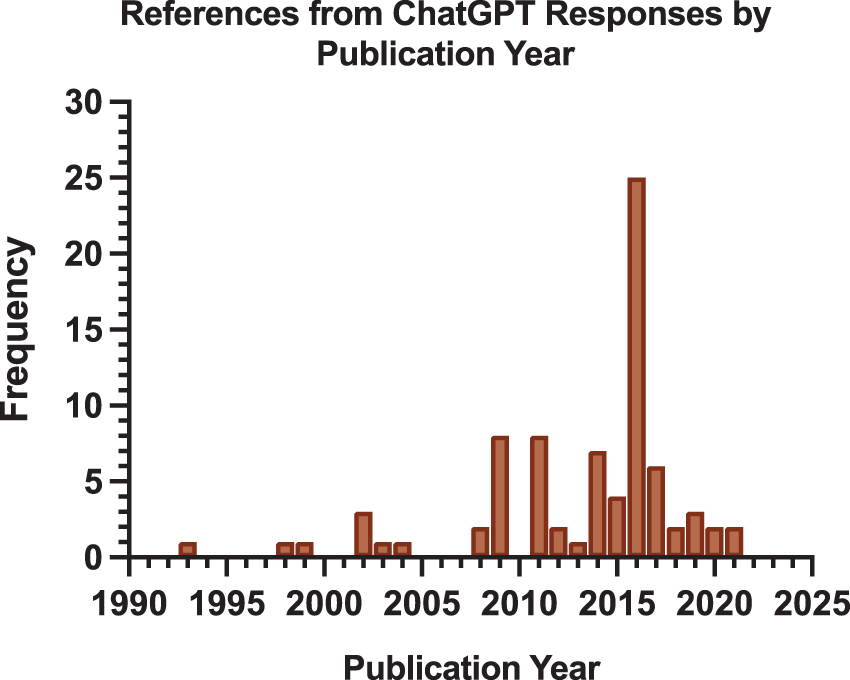
Frequency distribution of references from ChatGPT by publication year. Eighty (n = 80) references from reported published medical literature from ChatGPT responses are included.
Discussion
This investigation assessed the quality of AI-generated responses to questions pertaining to thyroid nodules for patient education. Overall, ChatGPT provided correct answers to 69.2% of posed questions in our study. Importantly, the ability of ChatGPT to produce clinically appropriate answers was not dependent on initial prompting, as the chatbot provided at least correct answers in similar proportions regardless of which of our four prompts was used (p = 0.4024). The capacity to produce accurate answers independent of prompting is reassuring, as many novice ChatGPT users may lack prior knowledge of the tool's ability to generate divergent responses based on contextual questioning.
While prompting did not appear to impact response correctness, it does appear to affect the academic grade level at which information is presented. Our study demonstrated that directing ChatGPT to provide responses at an 8th-grade reading level (NIH-recommended for education materials) elicited answers at a significantly lower grade level than other prompts or without prompting (p < 0.0001). However, such responses corresponded to an estimated U.S. grade level of 13.43 (collegiate level), still significantly above medical organization recommendations for patient education information. 15
Grade level remained similarly elevated on a subsequent analysis using a newer version of GPT-3.5 (September 25, 2023 version) with 8th-grade level prompting at 12.98 (collegiate level), demonstrating the chatbot's continued inability to adequately lower grade level even in the setting of multiple software iterations. Further directing the chatbot to provide references at sequentially lower grade levels (i.e., 6th and 4th grade levels) does sequentially significantly decrease the response grade level; however, even prompting for the 4th-grade reading level still generates responses above recommended levels for patient education.
Prior research investigating patient educational materials on thyroid nodules demonstrates that they are either poor or above the recommended reading levels. 6,7 In a study of freely available content on this topic, Barnes et. al identified 63 separate patient materials for analysis, concluding that the mean reading grade level of such sources was 13 (collegiate level), and that a subset of these sources assessed for quality demonstrated significant informational shortcomings. 7 Separately, Cimbek and Cimbek analyzed online websites (n = 59) that included thyroid nodule information for reading level and patient understandability, finding that the mean reading grade level of reviewed sites was 11.25. 6 Together, our findings suggest that, despite technological advancements in the medium that patient education information is generated and presented, further efforts are required to improve readability for patients.
This absence of effective thyroid nodule educational materials presents a newfound utility for LLMs such as ChatGPT, and our findings suggest that these tools are currently at least somewhat responsive although not entirely precise to specification of outputs. While our investigation does reveal that targeted prompting strategies can influence grade level, future investigations may seek to determine an optimal pre-question chatbot prompt to potentially elicit responses at or below the 8th grade level. Based on our current investigation, medical providers may caution patients that overall chatbot language may be above appropriate levels for patient comprehension.
AI-based models including, but not limited to, ChatGPT have increasingly been used in educating patients on a range of medical and surgical topics. Recent studies have demonstrated efficacy of ChatGPT in educating patients on surgical procedures such as arthroplasty, Mohs surgery, and breast augmentation. 18 –20 Notably, our research group studied the ability of ChatGPT to answer patient education questions pertaining to OSA, concluding that the tool was largely efficacious and similarly generated correct responses regardless of prompt type. 16 As future iterations of ChatGPT (i.e., GPT-4) and other AI-based chatbots (i.e., BingChat, Google Bard) continue to enter the public domain, further investigations by medical professionals are necessary to verify correctness and demonstrate utility to patient education.
LLM creators (i.e., OpenAI) have described a tendency for chatbots to produce content that is nonsensical or untruthful in certain situations, termed “AI hallucination.” There are multiple technical reasons for this phenomenon, but AI hallucinations largely occur when LLMs are faced with a prompt that is not well represented in its original training data. 21 While OpenAI suggests that GPT-4 reduces the rate of AI hallucination by up to 40% compared to GPT-3.5, the former is far less likely to be accessed by patients, as it is currently accessed via a limited-use, subscription-based model. 22
In our present study, 12.5% (10/80) of ChatGPT references were either unfindable or incorrect, and of the 70 findable references, 12 (17.1%) either incorrectly or completely falsified stated the findings or conclusions from the referenced publication. The tendency for ChatGPT to falsify references poses a risk to patients attempting to obtain accurate educational information regarding thyroid nodules or other medical topics. These findings suggest that, at this time, GPT-3.5-provided health information should not be the sole source of medical education consumed by patients given clinically unacceptable rates of AI hallucination. As software iterations of ChatGPT become implemented with time and the user base of other AI chatbots (i.e., GPT-4, Google Bard) increase, future investigations into medically acceptable AI hallucination rates may change this recommendation.
The ideal clinical utility of ChatGPT within the existing patient-provider interface has yet to be determined. Given ChatGPT's rapid implementation, care providers may find it inevitable that an increasing subset of patients will use the chatbot for health information, and an honest discussion with patients regarding AI should not be avoided. This investigation's findings may guide clinicians to caution patients seeking information on thyroid nodules via ChatGPT, namely due to its advanced response grade level and defined rate of AI hallucination.
While the authors do suggest that ChatGPT only be used as an educational supplement to provider-based discussion at this time, the chatbot may serve a promising role for thyroid nodule patient education in the peri-clinical appointment period. Patients may query ChatGPT before an initial clinic appointment for a newly diagnosed thyroid nodule, allowing them to come prepared with more targeted and informed questions in the limited time a care provider may have. Following an appointment, patients may use ChatGPT to solidify and/or expand upon topics discussed, perhaps allowing them to generate new questions which may be addressed virtually or at a later clinic date.
In addition to patient education, AI models such as ChatGPT have the potential to impact various aspects of health care including electronic medical record documentation efficiency, health care student and provider education, and medical research. 11 –13,23,24 In an ophthalmic surgery study, Singh et al. demonstrated potential usefulness of ChatGPT in constructing both discharge summaries and operative notes. 23 From a resident/physician educational aspect, several studies have shown that ChatGPT has the capability to adequately complete USMLE, neurosurgery, and radiology board-style examinations while also providing answer rationales, which could feasibly supplement other primary study methods for learners. 11 –13 Lastly, the LLM impact on medical research continues to widen, as models are being explored in reference collection for systematic reviews and as the basis of other primary literature. 24
Our investigation represents a singular subset of AI's potential utility in health care, but given our findings of its inability to correctly follow prompts (i.e., present information at the 8th-grade level) and unknowingly falsify references, rapid implementation ChatGPT as a sole source of medical education poses a safety concern for patients at this time.
The current study is not without certain limitations. ChatGPT was only queried 30 questions on thyroid nodule patient education; patients could theoretically ask an infinite number of questions in a variety of syntactical presentations. Furthermore, as ChatGPT responses are generated in a sequential manner, the order of the questions asked could impact the quality of subsequent responses. To address this, we made a deliberate effort to query ChatGPT using an identical sequence of questions for each thread. However, patients could theoretically ask questions in any such order, and, to our knowledge, no literature exists defining a most likely patient-chatbot conversation scenario which could be used to guide the logical question order. The effect of question reordering on response accuracy is unknown at this time, and future investigations may seek to survey patients to determine the most likely order in which questions should be asked.
Additionally, our response scoring methodology is not validated and only included a single subset of graders. Future investigations may seek to implement a more extensive and eventually validated scoring system across multiple graders across varying aspects of thyroid nodule management. Finally, patient experience and satisfaction with chatbot responses was outside the scope of this current investigation and not assessed.
Footnotes
Authors' Contributions
D.J.C.: conceptualization, methodology, investigation, formal analysis, data curation, writing—original draft, writing—review and editing, visualization, project administration; L.E.E.: conceptualization, methodology, investigation, data curation, formal analysis, writing—original draft, writing—review and editing; E.M.S.: data curation, writing—original draft, writing—review and editing; E.V.M.: conceptualization, methodology, investigation, writing—review and editing; R.A.: data curation, formal analysis, writing—review and editing, visualization; D.R.A.: conceptualization, investigation, writing—review and editing, supervision; E.E.C.: conceptualization, writing—review and editing, supervision.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.