
Abstract
Learning disabilities affect the ability of children to learn, despite their having normal intelligence. Assistive tools can highly increase functional capabilities of children with learning disorders such as writing, reading, or listening. In this article, we describe a text-to-audiovisual synthesizer that can serve as an assistive tool for such children. The system automatically converts an input text to audiovisual speech, providing synchronization of the head, eye, and lip movements of the three-dimensional face model with appropriate facial expressions and word flow of the text. The proposed system can enhance speech perception and help children having learning deficits to improve their chances of success.
Introduction
Learning disabilities are professionally diagnosed learning difficulties with reading, writing, spelling, reasoning, or math that are the result of a presumed central nervous system dysfunction.
1
Children with learning disabilities have normal intelligence but a problem in one or more areas of learning. Learning disabilities can cause a person to have trouble in reading, writing, listening, speaking, reasoning, and doing math as well as building social relationships. Most common learning disabilities include the following
2,3
: • Dyslexia, causing difficulty in understanding written words • Dysgraphia, which interferes with writing • Auditory and visual processing disorders, which cause difficulty in understanding language, despite normal hearing and vision • Nonverbal learning disabilities, causing problems in recognizing and translating nonverbal cues, such as facial expressions or tone of voice, into meaningful information
The emotion of speech is not only affected by the words it uses, but also by the way the speech is said. 4,5 The vocal nonverbal component is more efficient than the verbal content for communicating information about the speaker's state or attitude. 6 To realize a more efficient and pleasant human–computer communication, vocal cues should be included in the synthetic speech, especially for robots in social situations. 4,5
The following specific features of speech may contribute to convey emotional information
4,5,7
: • Pitch and duration play an important role in speech emotion. In particular, the interaction of pitch with loudness and with the grammatical features of the text seems to be critical. In some conditions, pitch and duration are sufficient to distinguish among neutral speech, joy, boredom, anger, sadness, fear, and indignation. • Loudness alone may not be important, but the correct synthesis of loudness can help to deliver emotional information. Spectral energy distribution and spectral structure can carry much of the affective information. • Voice quality is also significant in showing the affective information.
As many as 1 out of every 5 people in the United States has a learning disability. Almost 3 million children, 6–21 years old, have some form of a learning disability and receive special education in school. 8 Compared with 53% of students in the general population, only 13% of students with learning disabilities attend a 4-year postsecondary school program within 2 years of leaving high school. 9 Children with learning differences grow up to be adults with learning differences. In the adulthood, 48% of those are out of the workforce or unemployed. 1
Children having learning difficulties often rely on other individuals such as parents, siblings, friends, and teachers for help. Over-reliance on other people may cause slow transition into adulthood. Moreover, because such children require others to solve a problem rather than themselves, it may lower their self-esteem. They also struggle a loss of hope for future success. To provide an assistive tool for such children, we developed a text-to-audiovisual speech synthesizer system that converts any source of given text to the three-dimensional (3D) facial animation talking the text. There have been numerous investigations that have shown the importance of visual information in speech communication. 10,11 Adding a visual channel into speech communication, our tool can improve the speech intelligibility and speech perception by hearers, which may help children having writing, reading or listening difficulties.
In this article, we describe our text-to-audiovisual speech synthesizer system generating lip, head, and eye movements with emotional expressions corresponding to speech. We demonstrate the use of the system by implementing two applications: (1) a Web interface that creates facial animation with a specified pitch and speed value from free text, a text file, or an Internet site and (2) an animation pad that speaks text files and, at the same time, highlights the words currently spoken aloud.
Facial Animation
Key Frame-Based Animation
In key frame-based animation, the face motion is obtained by interpolating the key frames for different emotions and visemes (mouth shape) over time to obtain the face shapes between key frames. A key frame is a deformed version of a face shape. Each viseme corresponds to a phoneme, which is the smallest part of a spoken word. Phonemes are dependents on the spoken language. English has 40 different phonemes. 12 In mapping the phoneme sequence with the visemes, visemes are located on the starting utterance frames for each phoneme. Although most phonemes correspond to a single key frame, some require a linear combination of two or more key frames. 13 Interpolation of key frames using a function (linear or cubic) produces the smooth final animation.
Mpeg-4 Animation
MPEG-4 is an International Organization for Standardization standard developed by Moving Picture Experts Group (MPEG) in 1999. 14,15 The standard defines numerous tools for representing rich multimedia content. According to MPEG-4 facial animation specification, 84 feature points are specified on the human face. Facial animation parameters are used for defining animation parameters as well as animating faces of different sizes and proportions. Figure 1 shows the set of feature points. The facial animation is controlled by 68 facial animation parameters driving the animation on the feature points.
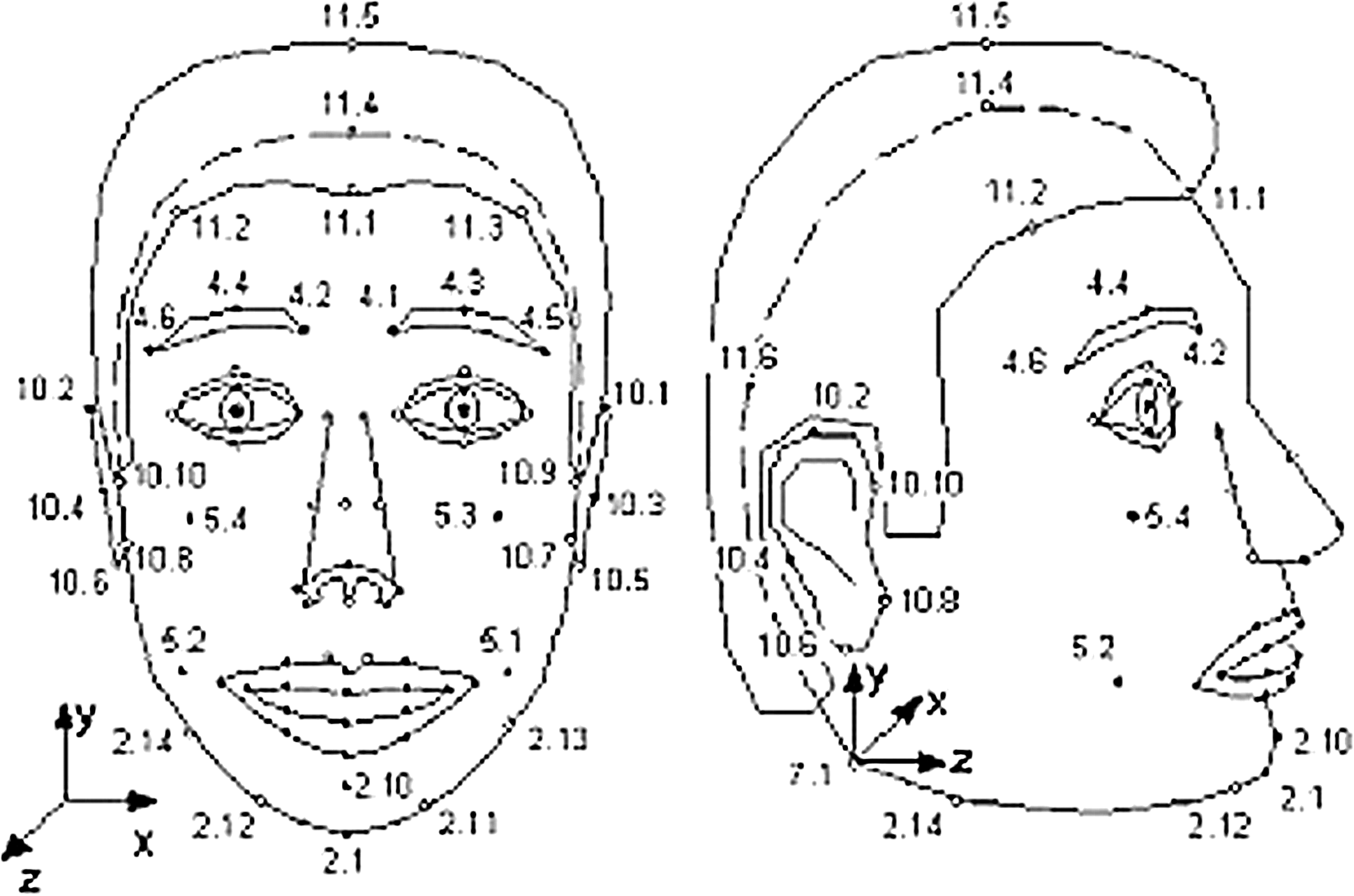
Moving Picture Experts Group-4 feature points.15
System Overview
An overview of the system is shown in Figure 2. The system has three components: speech processing, visual processing, and speech-visual synchronization.
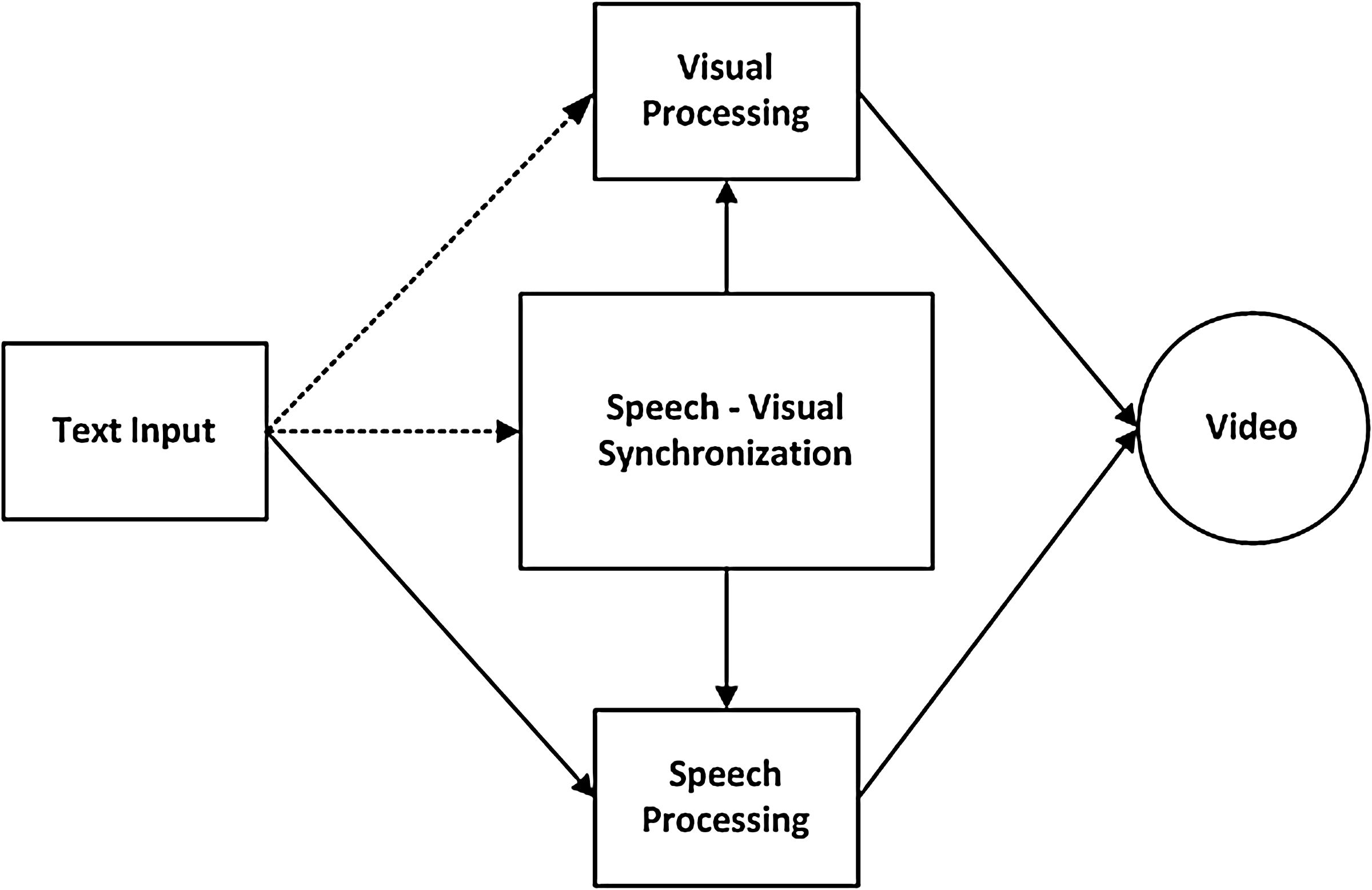
System overview.
Speech processing involves conversion of the textual information into synthetic speech and phonetic data. The input text is converted to speech via a text-to-speech engine by adding a voice. Two commonly used text-to-speech engines are Microsoft Speech API 16 and Java Speech API. 17 They are both publicly and freely available toolkits producing audio and phoneme sequences for a given text input. Our applications are based on Microsoft Speech API to extract speech and phoneme data. Then, phonemes, the smallest part of a spoken word and dependents on the language, and phoneme durations are extracted from the speech.
In visual processing, a synthetic 3D face model with a mesh and a texture map as well as numerous facial poses is created from a single image. This is determined from the face modeling tool FaceGen. 18 Figure 3 shows a 3D face model we created. The viseme expressions we used in our applications are exported from the FaceGen tool, which contain 16 speech-related mouth shapes and 1 mouth-closed neutral expression. A viseme is a face shape visually representing the speech sound based on one or more phonemes. There are also different tools using different set of visemes. 19,20
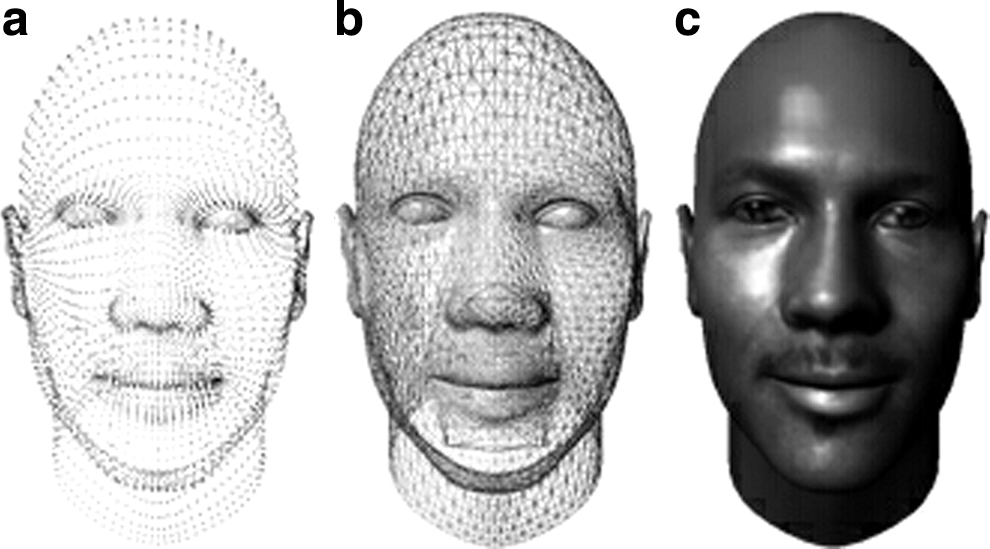
Three-dimensional face model:
Speech-visual synchronization includes mapping of the phoneme sequence with the facial poses by effectively grouping all the possible phonemes to a viseme set. For each phoneme, facial poses are placed on the starting utterance frames. The final face motion is obtained by key frame interpolation 21,22 of those poses over time.
The generation of facial animation is illustrated in Figure 4.

Generation of facial animation. 3D, three-dimensional.
Applications
The first application is a Web interface so that facial animation from a text input can be automatically created. Figure 5 shows the general interface of the Web environment. To make the 3D model speak words and phrases, the user can type the text into the text field and click the “Speak Free Text” button. The interface also provides an easy way to speak whole documents by submitting a text file without the need for copying and pasting large blocks of text. It is also possible to speak a Web page by entering its address into the input box. The speed and pitch attributes can be controlled by the user. Once new speed and pitch values are specified on sliders, the animation updates instantly. Finally, the animation is rendered in the rendering panel so that 3D model speaks the input.
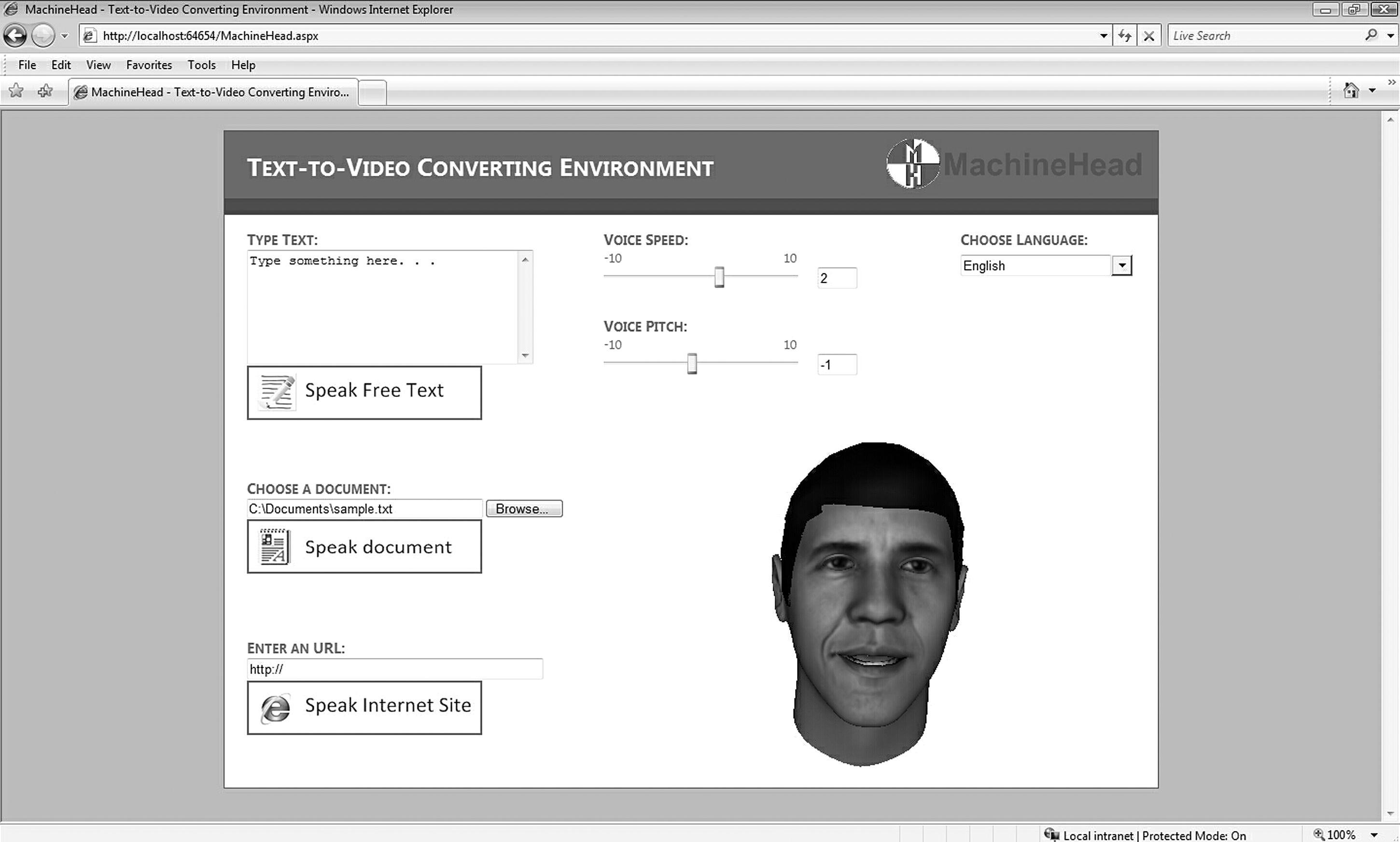
Interface of the Web environment.
The second application is the animation pad (Fig. 6), which speaks text files while highlighting the words currently spoken aloud. The written text can be reviewed by the user by reading it on the screen and, at the same time, seeing the face model speaking the words. Visual communication can help users to catch writing errors that might not have been noticed by reading it.

Interface of the animation pad.
The face model can show expressions such as joy, surprise, disgust, fear, anger, and sadness during speech. Expressions can be embedded in the input text using XML (Extensible Markup Language) tags (i.e., <joy>, <surprise>, <disgust>, <fear>, <anger>, <sadness>). For instance, the statement <joy>Hello, how are you?<\joy> makes the face verbalize the given text with a happy expression. Figure 7 shows emotion key frames of a model.

Emotion key frames: anger, disgust, joy, fear, surprise, sadness.
Results
We tested our applications with four graduate students at the Department of Computer Science of the University of Arkansas at Little Rock who have dyslexia and three high school students. They all found the applications very useful. In fact, one of the graduate students who was a member in the team at the Microsoft Imagine Cup competition did experience difficulties in memorizing the content from the paper copies for the presentation. With a customized avatar, the text-to-speech engine was put in place for him to use for preparation. The outcome was amazingly positive, and the performance during the presentation was a complete success. In the future, as we enhance the prototype, we plan to test the applications with more people.
In order to give the idea to the readers, some demo prototypes/components of the applications showing the current status of the work are available online at
Discussion
We have presented a text-to-audiovisual speech synthesizer that generates audiovisual speech from a text input. The proposed system produces facial motion of the 3D face model synchronized with the head, eye, and lip movements with emotional expressions corresponding to speech. Our solution can be used as an assistive tool for children having difficulties in reading, writing, or listening and help them to accomplish particular tasks on their own as well as increase their independence.
Footnotes
Acknowledgments
We would like to give special thanks to the members of the Microsoft Imagine Cup team (Albert Moropoulos, Serpil Tokdemir, and Ecehan Bayrak) for their help. Additional appreciation is extended to the individuals who took time to evaluate the system while in development.
Disclosure Statement
No competing financial interests exist.