
Abstract
Introduction
More than half of Americans 25–29 years of age now live in households with mobile phones but no traditional landline telephone according to a December 2010 report on phone use by the U.S. National Center for Health Statistics at the Centers for Disease Control and Prevention. 1 The same study also found that the younger children are, the more likely they are to live in homes that only have wireless phones, suggesting that younger parents are becoming increasingly reliant on mobile phones even as they adjust from being single to a more settled family lifestyle. 2
Although the mobile phone has been widely used for several decades, smartphones are a more recent advance. The latest generation of smartphones is increasingly viewed as hand-held computers rather than as phones, because of their powerful on-board computing capability, capacious memories, large screens, and open operating systems that encourage development of applications (apps). 3
According to a recent video report by Mobile Future, 4 there has been a massive increase in the numbers of consumer smartphone apps downloaded over the past 2 years, with figures going up from 300 million apps downloaded in 2009 to 5 billion in 2010. Kailas et al. 5 stated that there are already in excess of 7,000 documented cases of smartphone health apps. The potential for the creation of simple and easy-to-download apps for smartphones has created a vibrant emerging healthcare industry.
Android™ (Google™, Mountain View, CA) has a large community of developers writing apps that extend the functionality of the devices. Developers write primarily in a customized version of Java. 6 Apps can be downloaded from third-party sites or through online stores such as Google Play (formerly Android Market), the app store run by Google. In October 2011, there were more than 500,000 apps available for Android, 7 and the estimated number of apps downloaded from the Android Market as of December 2011 exceeded 10 billion. 8 The operating system itself is installed on 130 million total devices. 9 The Android platform has also grown to become a favorite among mobile developers.
The goal of this study was to design an intelligent app on Android smartphone for colorectal cancer (CRC) screening. The app would provide three models with different parameter complexity of the diagnosis of colorectal adenomatous polyp based on some prediction rules mined from a clinical dataset. It will reduce overhead costs and examination duration for CRC candidates or patients. In addition, this application also delivers some useful information about medical service referral on customer-oriented services when a user is diagnosed as a high-risk patient. To the best of our knowledge, there has been no previous app for CRC screening on a smartphone platform.
Background
It is clear that the potential for mobile communication to transform healthcare and clinical intervention in the community is tremendous. Significant economic benefits have also been reported where mobile communication is used in the provision of remote healthcare advice and telemedicine. 10 Extensive reviews 11 –16 of the use of mobile phones and hand-held computing devices in health and clinical practice can be found, notably in the collection and collation of data for healthcare research, and as used in support of medical and healthcare education and clinical practice in the community.
In the area of mobile diagnostics using mobile phone technologies, there have been several recent developments. For example, Kaplan 17 has highlighted the successful use of mobile phones to support telemedicine and remote healthcare in developing nations. Martinez et al. 18 used camera phones and paper-based microfluidic devices in real-time off-site medical diagnosis. Jin et al. 19 have developed a system to record electrocardiograms via a cellphone. Tan and Masek 20 have developed a system to interface with Doppler devices for fetal ultrasound assessment. Black et al. 21 have created a low-cost pulse oximeter attached to a cellphone to try to distinguish pneumonia from other febrile illnesses. Chen et al. 22 have developed an intelligent heart sound diagnostics capability on a cellphone based on the use of the audio channel to determine heart rate and heart rate variability.
CRC is an important health problem in Western countries and also in Asia. CRC is nowadays a leading cause of cancer death throughout the world. It is also the third leading cause of cancer death in both sexes in Taiwan. 23 In 2009, the age-adjusted CRC incidence in the United States was 61.2 cases per 100,000 population among men and 44.8 per 100,000 population among women. 23 According to the well-known adenoma-to-carcinoma sequence, the majority of CRC develops from colorectal adenomatous polyps through a series of genetic and epigenetic alterations. 24 Adenomatous polyps may take at least 10 years to undergo malignant transformation. In addition, early cancer usually needs several years to progress to the invasive stage. This concept provides the rationale for screening and prevention of CRC. The prevalence of adenoma among the average-risk population varied in previous literature reports. A recent meta-analysis found that the prevalence of adenoma and CRC was 30.2% and 0.3%, respectively. 25 A very recent study in Austria found that the prevalence of adenoma and CRC was 19.7% and 1.1%, respectively. Male gender was significantly associated with a higher prevalence of adenoma (24.9% versus 14.8%) and CRC (1.5% versus 0.7%). 26 Among healthy asymptomatic patients older than 50 years of age, screening colonoscopy should detect adenoma in 25% of men and 15% of women. Accumulating evidence supports the proposal that early detection and removal of colorectal adenomas could reduce the mortality and incidence of CRC. 27 Therefore, CRC is a good candidate for screening, and several modalities are recommended, including the fecal occult blood test (FOBT), flexible sigmoidoscopy, and colonoscopy. 28 The FOBT is the mostly widely used screening method for CRC. Current guidelines suggest an annual FOBT test in asymptomatic adults 50 years of age and older. 28 Many potential risk factors have been investigated previously, including age, sex, family history, smoking, high-fat diet, inflammatory bowel disease, diabetes mellitus, post-cholecystectomy, and overweight. 29 –32
Data mining analysis is the process of selecting and exploring large amounts of data, without setting the hypothesis, in order to discover unknown patterns or relationships. In recent years, data mining technologies have matured and become more popular, providing a useful tool to analyze, classify, and predict the large amounts of data gathered from various fields. Early detection of medical problems is important to increase the chance of successful treatment. Such detection is often formulated as a binary classification problem. Various classification methods have been developed for the detection of a potential medical problem. 33
Subjects and Methods
Data Source
We prospectively enrolled patients who had undergone diagnostic colonoscopy in the endoscopy unit of a 1,312-bed academic urban tertiary-care referral center because of clinical symptoms or screening for colon lesion between August 2009 and August 2010.
A trained nurse interviewed these subjects for eligibility and invited them to participate on the examination day. Subjects were excluded if (1) they were unable to answer questions from the investigator, (2) data from the chart were incomplete, (3) there was a failure to achieve complete colonoscopy without a diagnosis, (4) there had been poor colon preparation (semisolid or solid stool at colonoscopy), or (5) there was colorectal carcinoma with an incomplete check of the total colon.
Before a colonoscopy, patient characteristics and medical history were obtained from charts and interview. In total, 20 variables made up the patient's demographic data (age, sex, body height, body weight, and body mass index), reasons for colonoscopy (bloody stool, abdominal pain, constipation, bowel habit change, anemia, tenesmus, positive FOBT, colon polyp history, family history of CRC, or elevation in carcinoembryonic antigen level), and patient's habits (smoking, drinking, betel nut chewing, or tea or coffee consumption).
Colonoscopy was performed by one of three experienced endoscopists (with a minimum experience of 2,000 colonoscopies) with a colonoscope device (model CF-H260AZI; Olympus Optical Co., Ltd., Tokyo, Japan). The scope was passed to the cecum. Complete colonoscopy examination was defined when the scope reached the cecum and was documented by photography. The detected lesions and procedural variables were recorded, including size, morphology, location, biopsy, or polypectomy. Removed polyps were examined by a pathologist who was unaware of clinical history or endoscopic finding. The pathology results were divided into adenomatous neoplasm (included adenoma, dysplasia, and adenocarcinoma) or not (included hyperplastic polyp or others).
After being approved by the Institutional Review Board, the study was completely de-identified to all subjects, and all subjects signed written informed consent before participation. This study initially collected 343 subjects' records. Finally, 225 records were used in the following analysis by using data processing techniques to exclude missing data and outliers.
System Architecture
The system architecture (shown in Fig. 1) is proposed by the combination of five modules, including the Android smartphone app, the data analysis server, the medical information service servers, the physiological signals measurements, and the multiple physiological signals gateway. 34 The analysis server extracts the decision rules from a clinical dataset by using a data mining approach for app programming, and the users can directly retrieve the related medical treatments and services information from some Web servers by smartphones with Wi-Fi or third-generation wireless communication technology. The connection between the Android smartphone and the data analysis server is adopted in an offline manner. The new version of the intelligent app will be automatically updated to the user's smartphone if the decision rules are renewed from the data analysis server. The dashed box in Figure 1 represents the optional facilities of the proposed system.
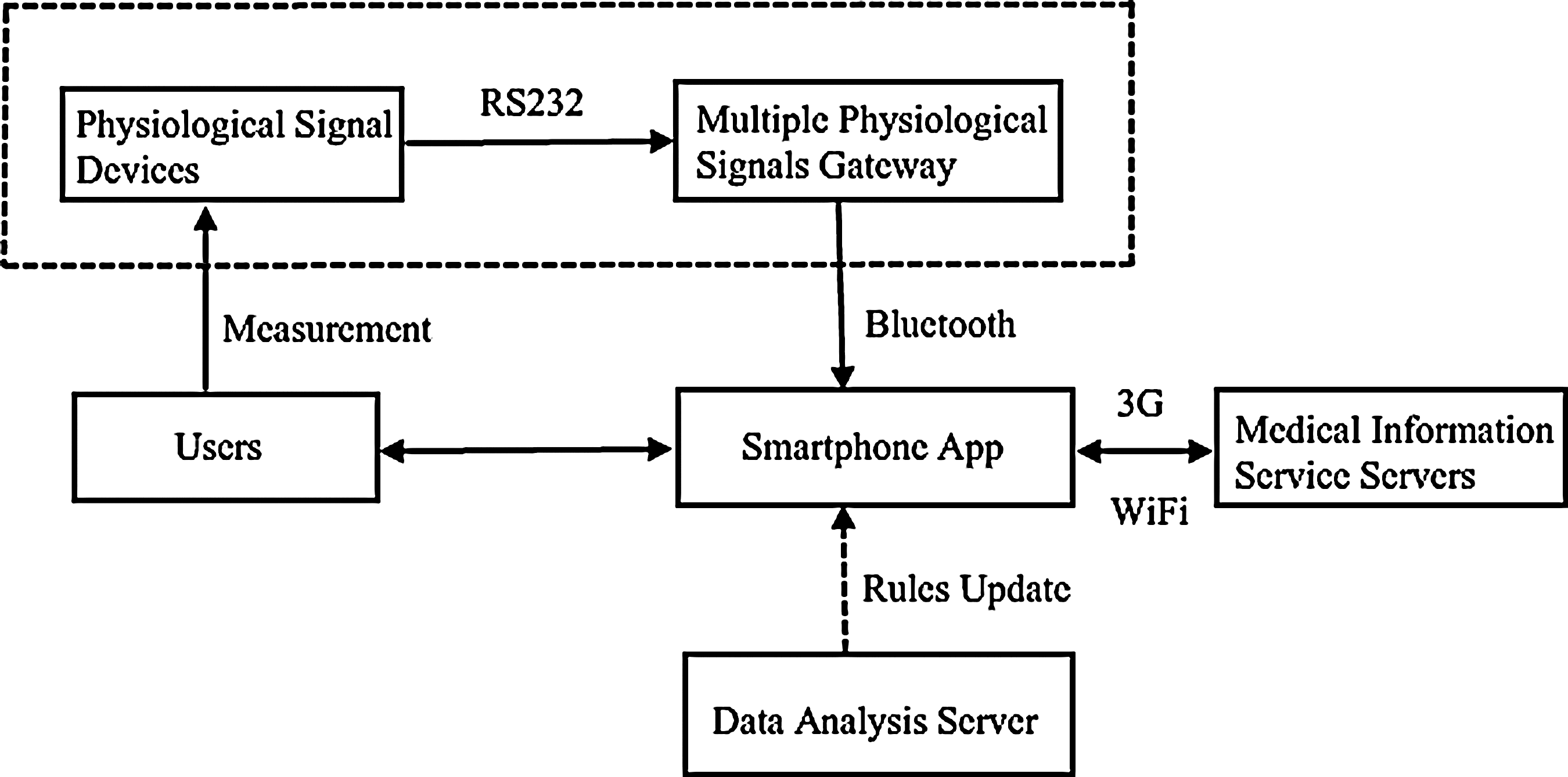
System architecture. 3G, third generation.
In this prototype system, users can directly input their personal characteristics (such as sex, age, body weight, and body height) to the Android smartphone through the app interface. Users also can use the multiple physiological signals gateway to transmit the user's body weight value to the Android smartphone from the physiological measuring device by using Bluetooth® (Bluetooth SIG, Kirkland, WA) communication.
Decision Tree Algorithms
In order to develop a simple, reliable, and accurate app in this study, the detection rules were first extracted at the data analysis server from a clinical dataset by a data mining approach with decision tree algorithms, and then these rules was confirmed by hepatogastroenterology medical experts.
Large amounts of data have been gathered routinely in the course of day-to-day management in medicine and the delivery of health services. For mining useful information and helpful knowledge from these large databases, an important research area has been developed called data mining. 35
Data mining is the process of extracting hidden knowledge from large volumes of raw data. It can also be defined as the process of extracting hidden predictive information from large databases. Data mining is more intuitive, allowing for increased insight beyond data warehousing. An implementation of data mining in an organization will serve as a guide to uncovering inherent trends and tendencies in historical information. It will also allow for statistical predictions, groupings, and classifications of data. Most hospitals collect, refine, and deduce massive medical data. Data mining techniques can be implemented rapidly on existing software and hardware platforms to enhance the value of existing information resources and can be integrated with new products and systems as they become part of the system. Some value results can be extracted by using data mining tools to deliver answers to many different types of predictive questions. 36 There are many tasks associated with data mining, such as classification, clustering, regression, and association rule mining.
Decision trees are powerful and popular methods for classification and prediction. In medical applications, both the accuracy of a prediction and the ability to explain the reason for a decision are equally crucial. The attractiveness of decision trees is due to the fact that, in contrast to neural networks and support vector machines, decision trees are able to generate understandable rules. Rules can readily be expressed so that humans can easily understand them, and they can be used directly in applications. Decision trees also can provide a clear indication of which fields are most important for prediction or classification.
The goal of decision tree learning is to create a model that predicts the value of a target variable based on several input variables. The decision tree is a classifier in the form of a tree structure, where each node is either a decision node or a leaf node. Each decision node specifies some test to be carried out on a single attribute-value, with one branch and subtree for each possible outcome of the test. Each leaf represents a value of the target variable given the values of the input variables represented by the path from the root to the leaf. A decision tree can be used to classify an example by starting at the root of the tree and moving through it until a leaf node, which provides the classification of the instance.
Most algorithms that have been developed for constructing decision trees usually work top-down by choosing a variable at each step that is the next best variable to use in splitting the set of items. 37 The best attribute is defined by how well the variable splits the set into homogeneous subsets that have the same value of the target variable. Different algorithms use different formulas for measuring the best attribute. A tree can be constructed by splitting the training set into subsets based on the best attribute. This process is repeated on each derived subset in a recursive manner called recursive partitioning. The recursion is completed when the subset at a node all has the same value of the target variable or when splitting no longer adds value to the predictions.
The Microsoft® (Redmond, WA) Decision Trees (MSDT) 38,39 algorithm was developed in the Microsoft SQL server 2005 for classification and regression tasks. The MSDT algorithm mainly uses an interesting score or Shannon's entropy in tree splitting and has support for analyzing discrete and continuous valued attributes. However, like the Chi-Square Automatic Interaction Detector algorithm, it does not have any pruning step but presents a parameter named “complexity penalty” for controlling tree growth. Both multiway and binary-splitting capabilities are provided in MSDT. Furthermore, MSDT has also automatic feature selection and dimension reduction, which are not available in other data mining packages. Bozkir and Sezer 39 reported that MSDT gives a better prediction than the Chi-Square Automatic Interaction Detector and Classification and Regression Tree algorithms because multisplitting decision tree approaches are more suitable than binary-splitting techniques and because multiway splitting decision tree models are clearly more explainable. Therefore, the MSDT algorithm is used in the present study.
A decision tree graph can be converted into a number of If–Then rules. In this study, support factor, confidence factor, and odds factor are also provided to measure the performance of each rule. The support factor measures the coverage of a rule, which is the ratio of the number of instances covered by the rule to the total number of instances. The confidence factor measures the accuracy of a rule. The “odds” of an event is the fraction of the probability that the event will happen to the probability that it will not happen. For a rule “If X then Y” and a training set of N instances, the support factor and confidence factor are defined as
Results
This study used the Eclipse Java development tools to develop the intelligent Android app using a total of five decision rules extracted from the MSDT algorithm for prediction of high-risk groups of patients with colorectal adenomatous polyp.
Descriptive Statistics
Quantitative data were summarized and are presented as mean±standard deviation values. Continuous variables were compared using Student's t test for normal data and abnormal data. Categorical variables were compared using Chi-square χ2 test for different patient groups. A value of p<0.05 indicates statistical significance.
There are 20 attributes in the original dataset. Five noninvasive features were extracted by feature selection, and their definition and basic descriptive statistics are shown in Table 1. There are 97 patients (43.1%) with colon adenoma (abnormal) and the remaining 128 patients (56.9%) without colon adenoma (normal). The prevalence rate of colon adenoma in participants aged 50–79 years is 36.89% in this study. From the result of the significance test between the normal and colon adenoma groups in Table 1, one can find that four noninvasive features (age, weight, body mass index, and sex) pass the significance test with p<0.01. In addition, the feature of height passes the significance test with p<0.05.
Descriptive Statistics of Normal and Colon Adenoma Cases
α=0.05, bα=0.01.
Data are number (%).
BMI, body mass index; SD, standard deviation.
The records of all patients used in this study were divided into two datasets: the training dataset and the validation dataset. There were no significant differences in the clinical backgrounds between these two groups as shown in Table 2. The training dataset is used for learning the colon adenoma pattern and then generating the decision rules, and the validation dataset, which was not used to develop the model, was used to validate the results. The training set contained 150 instances (66.7% of the total records) with respect to the ratio with and without colon cancers that were randomly selected. The remaining 75 (33.3% of the total records) were retained as the validation dataset. In validation instances, the numbers of patients' records classified as “normal” and “abnormal” were 45 and 32, respectively.
Descriptive Statistics of Five Noninvasive Features
Data are mean±standard deviation values or number (%) as indicated.
BMI, body mass index.
Prediction Models
Based on the different complexity levels of parameters, three decision tree models were built in this study. The first model is just to input two parameters (sex and age) into the simple model, which has an overall accuracy of 75.1%. We denoted this as the “simple model” in this study. Figure 2 shows the decision tree graph of this simple model. The second model is the intermediate model: two users' features (body weight and age) gave an overall accuracy of 85.8%. The corresponding decision tree of the intermediate model is shown in Figure 3. The third model used four parameters (age, sex, body weight and body height) in the model, which had an overall accuracy of 88.0% as demonstrated in Figure 4. We considered this as the “best model” in the study.
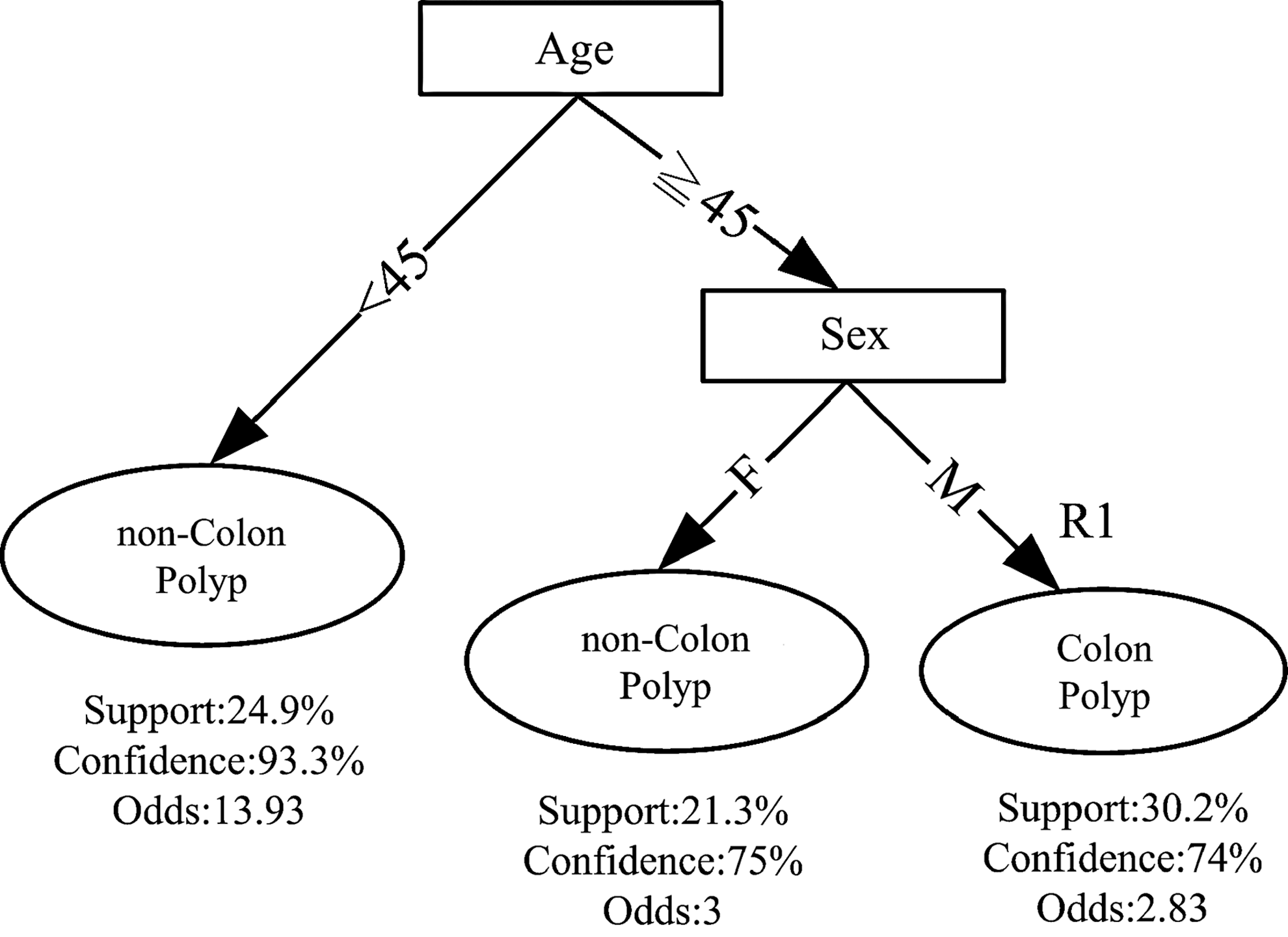
Decision tree of the simple model. F, female; M, male.
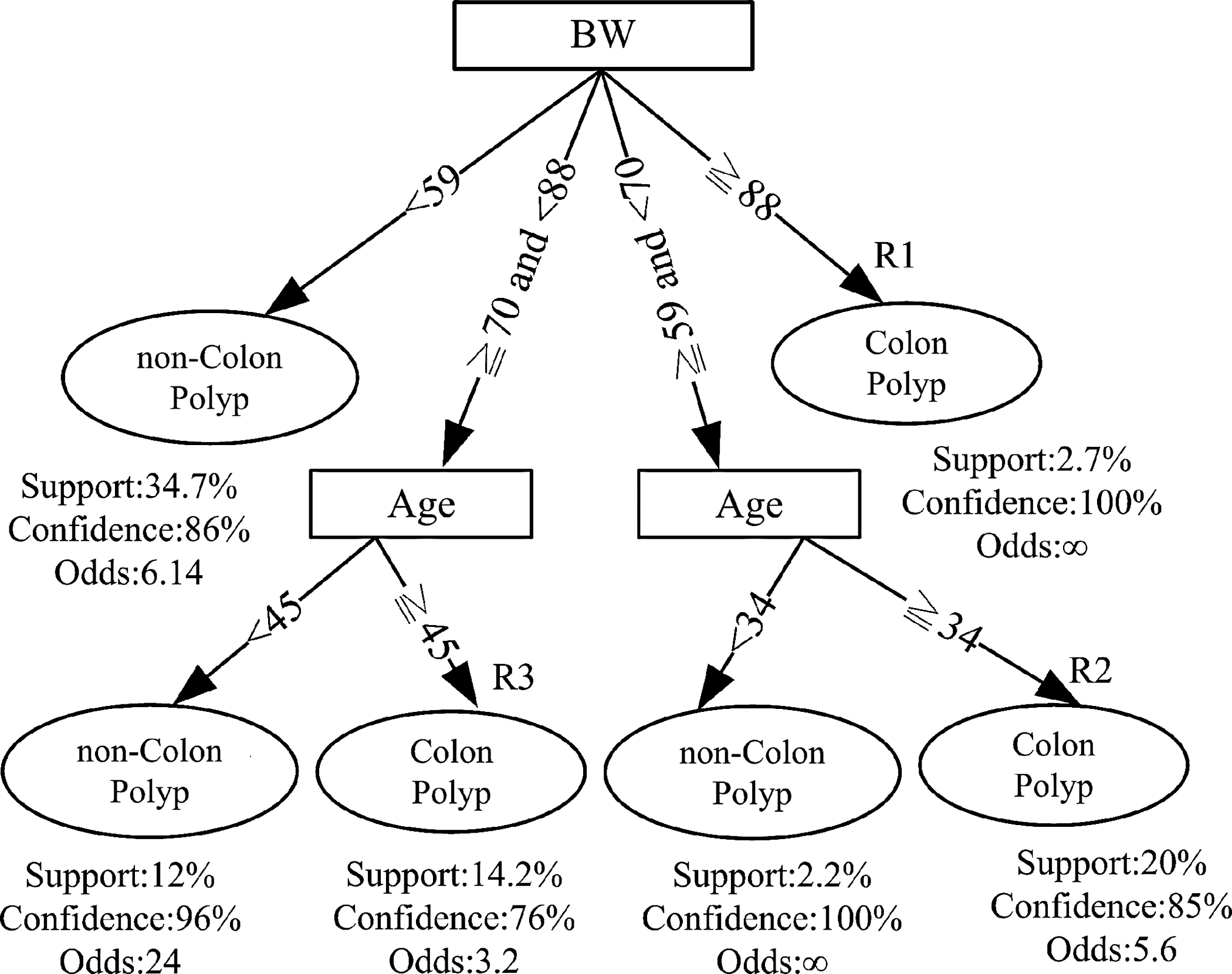
Decision tree of the intermediate model. BW, body weight.
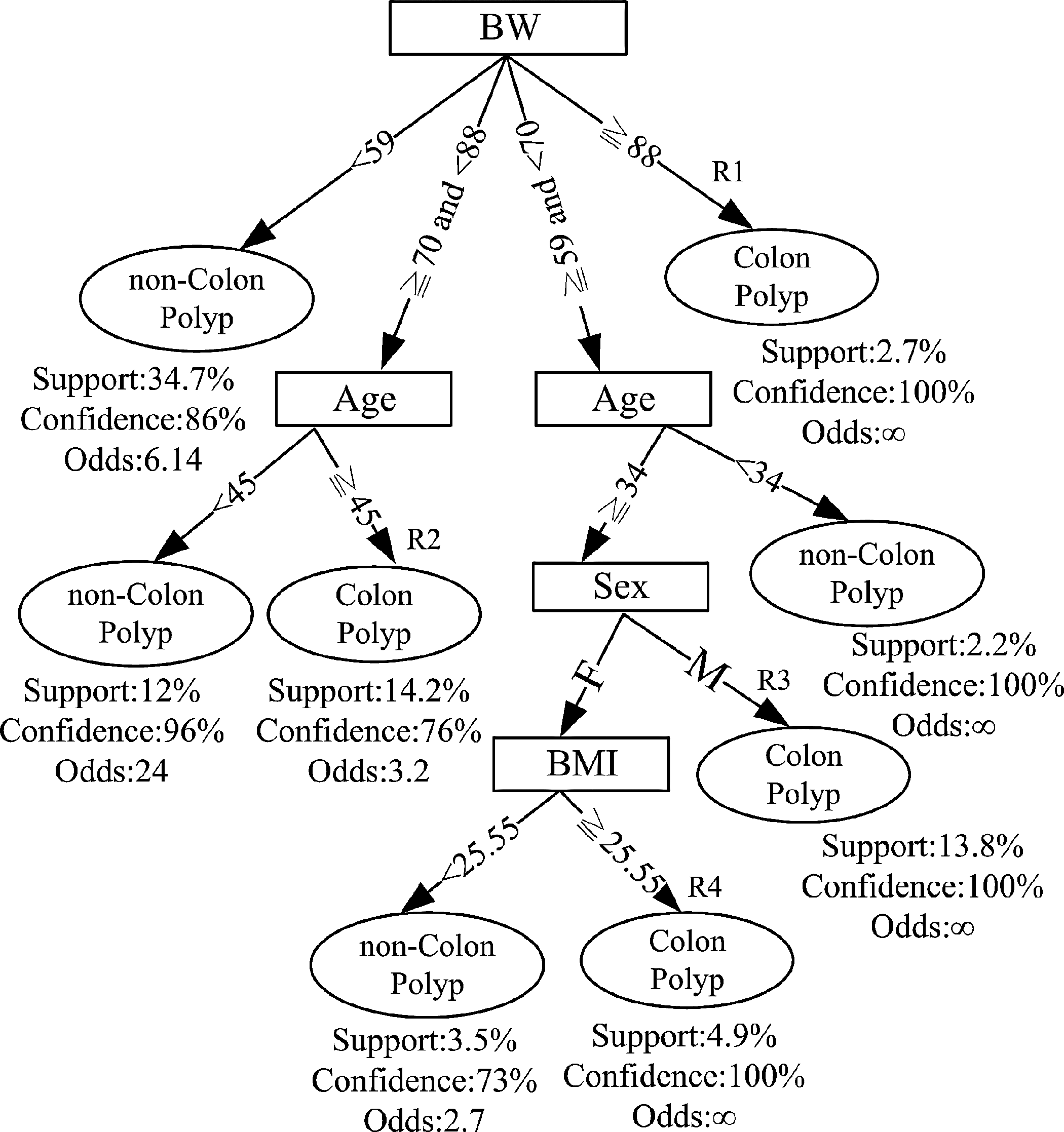
Decision tree of the best model. BMI, body mass index; BW, body weight; F, female; M, male.
Two, four, and five decision rules can be generated from Figures 2 –4 for the simple model, intermediate model, and best model, respectively. After three domain experts' review and verification, these decision rules were used to develop the intelligent CRC screening app.
User Scenario
For a sample female user 39 years old, the three models would give the following scenarios: 1. The simple model. Two parameters (age and sex) were input into the simple model of the proposed app. The prediction result showed that she was a non–colon polyp subject. 2. The intermediate model. If she input age and body weight (64 kg) into the intermediate model, the prediction result was that she may be suffering from colon polyp with confidence=85%, odds=5.6, and support=20%. 3. The best model. If she further input her age, sex, body weight (64 kg), and body height (150 cm) together into the best model (shown in Fig. 5), the prediction result tells her that she may be suffering from colon polyp with confidence=100%, odds=∞, and support=4.9% (shown in Fig. 6). The app system suggests medical service referrals as shown in Figure 7.

Best model interface 1.
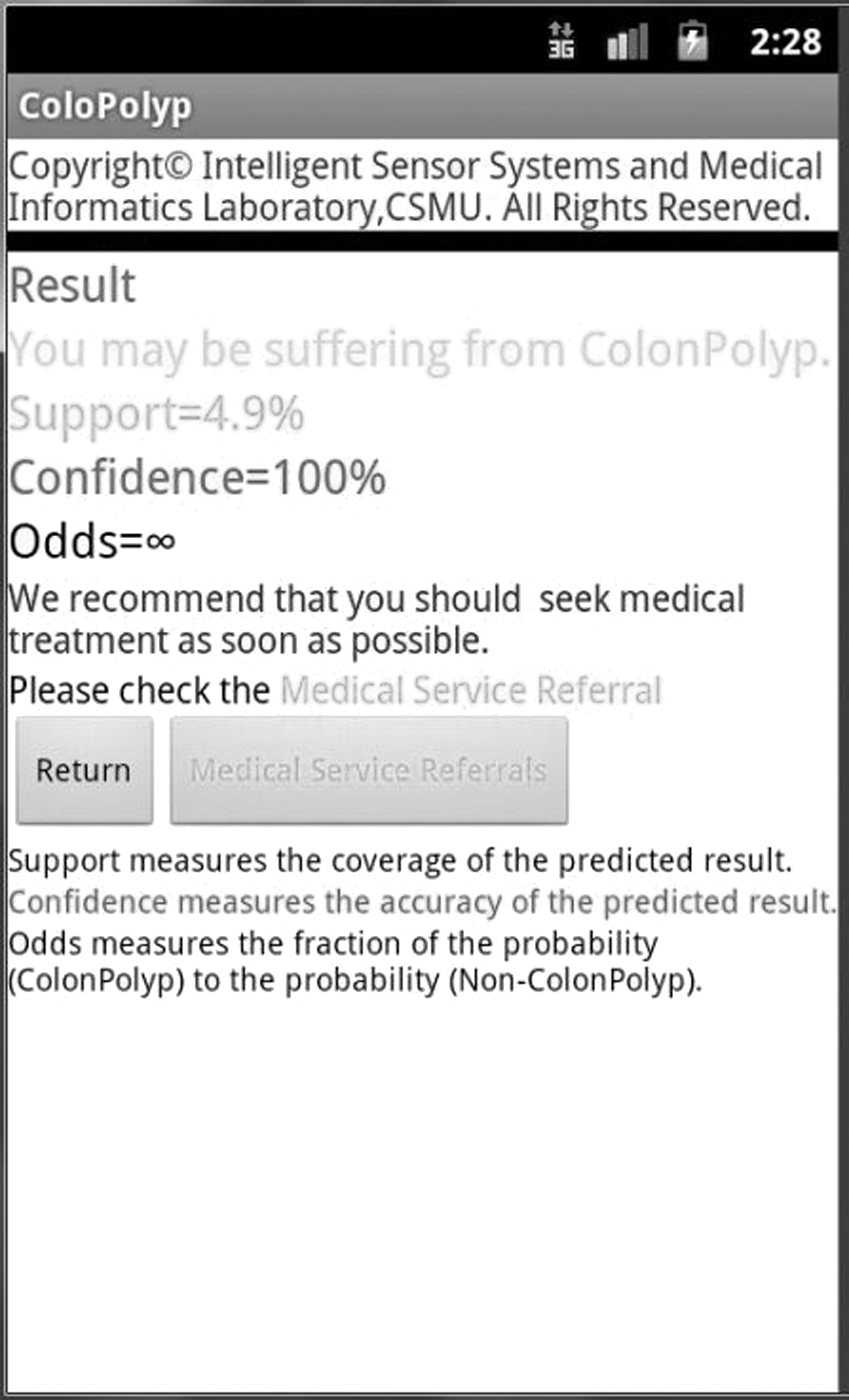
Best model interface 2.

Medical service referrals.
The concept of customer service orientation is that every customer should receive perfect service. In order to perform better customer service, a service provider must first understand what each customer thinks and what he or she wants. When a provider is screening high-risk groups of CRC potential patients, the developed app provides a series of Web link services as shown in Figure 8. The system can link to the hospital network registration system to allow users to directly seek further medical care. Users can also link directly to the associated CRC health education information to obtain more medical knowledge related to CRC. Or, the user can watch or join patient-related associations or a patient's Facebook Web site.

More information services.
Discussion
Logistic regression (LR) is one of the traditional most commonly used statistical methods to identify the risk factors of colorectal adenomatous polyp in previous studies. 40 –42 It could handle both categorical and continuous independent variables and calculate the disease probability. Decision tree analysis is another exploratory technique of data mining and predictive modeling. 36 –39 Using this method, the study results represent a series of rules and identify priorities of these variables by a tree structure. 36 –39 It could generate understandable rules and provide a clear indication of which fields are most important for prediction or classification. Recently, decision tree analysis was used in defining prognostic factors in various diseases such as diabetes mellitus, 43 colorectal carcinoma, 44,45 prostate cancer, 46 liver failure, 47 and chronic hepatitis C treatment. 48 To our knowledge, decision tree analysis has not been used in colorectal adenomatous polyp prediction.
In this study, several proven risk factors of colon polyps were not selected for decision tree analysis, including family history and smoking. Demographic data do not show a statistically significant association between these two risk factors and colon adenomatous polyp in this article. Therefore, family history and smoking were not selected as variables for decision tree analysis.
To compare the performances between our proposed three prediction models and the stepwise backward multivariate LR model, the performance results of these four models are presented in Table 3. The number of features is two, two, four, and four in the simple model, intermediate model, best model, and LR model, respectively. The number of decision rules is two, four, five, and one in the simple model, intermediate model, best model, and LR model, respectively. Based on the results in Table 3, the best model has the highest sensitivity, accuracy, and the area under the receiver operator characteristic curve and the lowest false-positive rate. The accuracy of the best model has a 10.76% higher predictive value than that of the LR model. The false-negative rate of the best model was 7.2% lower than that of the LR model. The false-positive rate of the best model was 13.3% lower than that of the LR model. In addition, the false-negative and false-positive rates have a significant effect in the medical prediction system. Performance analysis results demonstrated that the intermediate and best models had a better performance than the LR model.
Performances of Four Prediction Models
AUC, area under the receiver operator characteristic curve; FNR, false-negative rate; FPR, false-positive rate.
At present, the FOBT is used as a first-line CRC screening tool in many countries. 28,49 Annual or biennial screening with FOBT (guaiac-based or immunochemical) could reduce both CRC and CRC-related mortality. 50 The sensitivity of guaiac-based FOBT is 25–38% for CRC and 16–31% for advanced adenoma. 51 Qualitative immunochemical FOBT provided higher sensitivity for CRC than guaiac-based FOBT. Identification of colorectal adenomas by a quantitative immunochemical FOBT depends on adenoma characteristics, development threshold used, and number of tests performed. There were 11 patients with positive immunochemical FOBT, and 5 subjects were diagnosed with colorectal adenomatous polyp by colonoscopy in this study. The corresponding accuracy is 45.5%. By comparing with the performance result in Table 3, we can see that our proposed application system for colon adenoma screening in this patient group is better than immunochemical FOBT.
Conclusions and Future Work
Smartphones are now widely used over the world and could accomplish the task of information transmission or data processing with a relatively low cost. Also, smartphones are convenient, flexible, and easy to use for most people. It is clear that the potential for mobile communication to transform healthcare and clinical intervention in the community is tremendous. Until now, the Android platform has a large community of developers writing apps that extend the functionality of the smartphones. The possiblity of creating simple and easy-to-download apps for smartphones has created a vibrant emerging healthcare industry. In this sense, it is a good choice to realize efficient low-cost medical care via smartphones. It would be a large accomplishment to use smartphones in medical care, and it will be a milestone to market smartphone-enabled healthcare apps.
Based on medical decision rules from decision tree analysis, an intelligent app on Android smartphones for colon adenoma detection has been developed in this article. The proposed app can provide an easy and efficient way to quickly screen high-risk groups of potential CRC patients. Based on the concept of customer service orientation, the system also provides some medical treatment referrals and Web links to aid users achieve early diagnosis and treatment purposes for sufferers from CRC.
Future directions for our work include the following two points. First, the sample size is small. After patients were divided into different risk groups, some groups contained only several patients. In our analysis, we compared the model building and validation groups. The diagnostic accuracy was similar. However, a larger sample size is needed in a future study. Second, the study subjects were diagnostic-based patients in this article. Rebuilding the model of colorectal adenomatous polyp prediction by another database from the average-risk population is needed in a future study.
Limitations
This study's subjects were diagnostic-based, not population-based, patients. The prevalence rate of colorectal adenomatous polyp in general populations 50–79 years of age is around 19.7–30.2% but was 36.89% in this study, higher than in the average-risk population. Because our study was conducted on patients referred by gastroenterology and hepatology clinics, a bias of performance characteristics will exist if our results are generalized to real populations.
Footnotes
Acknowledgments
This work was partly supported by the National Science Council, Taiwan, Republic of China, under the grant NSC 102-2218-E-040-003.
Disclosure Statement
No competing financial interests exist. This article is not an advertisement for Android smartphones.