
Abstract
We argue word embedding models are a useful tool for the study of culture using a historical analysis of shared understandings of social class as an empirical case. Word embeddings represent semantic relations between words as relationships between vectors in a high-dimensional space, specifying a relational model of meaning consistent with contemporary theories of culture. Dimensions induced by word differences (rich – poor) in these spaces correspond to dimensions of cultural meaning, and the projection of words onto these dimensions reflects widely shared associations, which we validate with surveys. Analyzing text from millions of books published over 100 years, we show that the markers of class continuously shifted amidst the economic transformations of the twentieth century, yet the basic cultural dimensions of class remained remarkably stable. The notable exception is education, which became tightly linked to affluence independent of its association with cultivated taste.
People classify objects along myriad axes of meaning to interpret the social world. In addition to core social categories such as gender and race, a diverse array of cultural dimensions—fair/unfair, beautiful/ugly, new/old—play key roles in patterning interactions and structuring institutions. Although dominant theories of culture posit such a multidimensional matrix of meanings, empirical investigations commonly limit their attention to one or two facets due to the analytic and methodological difficulties associated with incorporating higher dimensionality.
Social class, a central sociological construct, is itself a complex and multidimensional attribution. Stratification scholars commonly treat class as a composite of several distinct factors, including affluence, education, and occupation, as well as status and cultivated taste. Decades of social science research has produced extensive knowledge of how these various socioeconomic dimensions are materially and causally interrelated (Chan and Goldthorpe 2007; DiMaggio 1982; Hout 2012). Yet the multiple dimensions of class are not only attributes used by analysts to articulate an individual’s economic standing; they also serve as axes of cultural distinction actors deploy in daily life. People, groups, and everyday objects carry cultural associations of affluence, education, cultivation, and status, which together comprise profiles of classed meaning (Bourdieu 1984; Warner, Meeker, and Eells 1949). These profiles are evoked when individuals make decisions regarding what to purchase, where to spend the evening, how to present themselves, and who to befriend. Stratification scholars have developed strong conceptions of the material relations between the multiple dimensions of class, but understanding how the meanings of these dimensions relate to one another and co-evolve over time remains underspecified.
In this article, we apply an emerging computational approach—neural-network word embedding models—to analyze the cultural dimensions of social class and their evolution over the twentieth century. Word embedding algorithms input large collections of digitized text and output a high-dimensional vector-space model 1 in which each unique word is represented as a vector in the space (Mikolov, Yih, and Zweig 2013; Pennington, Socher, and Manning 2014). This means each word appearing in the analyzed documents is ascribed a set of coordinates that fix its location in a geometric space in relation to every other word. Words are positioned in this space based on their surrounding “context” words in the text, such that words sharing many contexts are positioned near one another, and words that inhabit different linguistic contexts are located farther apart. Previous work with word embeddings in computational linguistics shows that words frequently sharing contexts, and thus located nearby in the vector space, tend to share similar meanings.
We provide new evidence that the dimensions of word embedding vector space models closely correspond to meaningful “cultural dimensions,” such as rich-poor, moral-immoral, and masculine-feminine. We show that a word vector’s position on these dimensions reflects the word’s respective cultural associations. For example, projecting occupation names on an “affluence dimension,” we find that traditionally well-compensated occupations, such as banker and lawyer, are positioned at one end of the dimension, and poorly paid occupations, such as nanny and carpenter, lie at the other. This occurs because with each discursive context that “banker” shares with wealthy words like “affluent,” “moneyed,” and “rich,” it is nudged toward the rich pole of the affluence dimension, and each time “nanny” shares a context with terms like “needy,” “destitute,” and “poor,” it is nudged toward the poor pole.
After empirically validating word embeddings’ ability to capture widely shared cultural associations, we apply this method to the question of how collective understandings of social class evolved in the United States over the course of the twentieth century. To gain new leverage on this question, we train word embedding models on text from millions of books published over the entire twentieth century digitized in the Google Ngram corpus. We then identify dimensions in these models corresponding to five cultural dimensions of class described by classical and contemporary sociological theory as well as two other cultural dimensions frequently invoked in association with class: affluence, employment, status, education, cultivation, morality, and gender. 2
Comparing texts from each decade of the twentieth century, we discover that the cultural dimensions of class comprise a complex yet remarkably stable semantic structure. We find that affluence and status serve as cultural mediators between a cluster of education, cultivation, and morality on one hand and associations of employment and ownership on the other. This persistent and intransitive structure requires high dimensionality to represent without distortion. Furthermore, we find that the cultural markers signifying positions within this robust structure are in continual flux, with terms distinguishing high and low class shifting over the decades, following steady patterns of cultural circulation and turnover.
Multidimensionality of Class
Social class, the systematic and hierarchical distinction between persons and groups in social standing, has long been recognized to operate along multiple distinct dimensions. Affluence is often treated as a core aspect of class, with income commonly serving as a proxy for socioeconomic status. This is not an arbitrary selection; money is quickly and easily convertible into many forms of capital, power, and influence, making it a particularly salient element of class (Simmel [1900] 2004).
Nevertheless, scholars long have argued that the economics of class cannot be reduced to affluence alone. Analysts in the Marxist tradition foreground socio-structural position and relation to capital as the basis of social class instead (Gramsci 1992; Marx [1867] 2004; Wright 1979). From this perspective, it is not the accumulation of wealth, but rather one’s position as an owner or worker, that determines a shared interest with respect to politics, culture, and social life (Marx and Engels 1970). In addition to occupational position and wealth, social scientists frequently include education as a third element of socioeconomic status. Education became particularly central to the study of class after World War II, when the expansion of mass schooling and the demands of a changing labor market turned education into a critical axis of social division (Fischer and Hout 2006).
Theorists have also noted that a full conception of social class requires accounting for its symbolic manifestations. In an early articulation of this distinction, Weber (1978) contrasted economic class with status (Stand), which operates via social honor and prestige. Because status refers to actors’ ability to make a credible claim of esteem rather than their power in a market, it need not always coincide with affluence (Chan and Goldthorpe 2007). Recent research confirms the empirical relevance of this theoretical distinction, finding that status shapes associational networks independently of economic factors, and individuals commonly distinguish prestige from earnings in their subjective evaluations of occupational social standing (Chan and Goldthorpe 2004; Freeland and Hoey 2018).
Another line of research establishes how cultivated tastes serve as a crucial marker of class distinct from individual or collective status. Veblen ([1899] 1912) and Elias (1978) articulated this connection between cultivation and class early in the twentieth century, and Bourdieu (1984) recentered this association at century’s end with the concept of cultural capital. Numerous studies show how actors parlay cultural capital into economic gains (DiMaggio and Mohr 1985), but Bourdieu’s (1984) original conception draws a more complex connection between cultivated taste and affluence, with cultural elites such as artists and intellectuals comprising their own high-status social groups that stand in opposition to the economic elite.
The cultural associations of class are entwined with many diverse dimensions of social classification. For example, a growing literature on valuation and moralized markets outlines how socioeconomic attributions are shaped by moral classifications (Fourcade and Healy 2007; Zelizer 1979). This scholarship details how moral distinctions become mapped onto socioeconomic positions (Svallfors 2006) and how moral sentiments shape economic valuation (Fourcade 2011). In this vein, Lamont (1992, 2000) illustrates how middle- and working-class Americans deploy moral and socioeconomic distinctions in tandem when forming judgments about their neighbors, their friends, and themselves. Classed associations similarly interact with understandings of gender. Feminist scholars have shown how gender permeates class in the labor process (Hochschild 2012; Salzinger 2003), consumption patterns (Cohen 2003; Illouz 1997; Mears 2010), and the macro system of economic stratification (Cha and Weeden 2014; Gilman 1999; Ridgeway 2011). Arising from historical processes that differentially distribute power and prestige by gender, classed meanings are frequently also gendered meanings (Veblen [1899] 1912).
Together, contemporary and classical work paint class as a complex construct with many facets at once connected yet analytically and culturally distinct. The precise ways these cultural dimensions of class relate to one another, however, and how these interrelations have evolved over time, remain open empirical questions.
Social Class in the Twentieth Century
The twentieth century was a period of dramatic class transformation in the United States and beyond. Large organizations came to dominate the Western world’s industrial and economic landscape, mass education heightened the importance of formal credentials for occupational attainment, and the gender composition of the workforce shifted radically as women entered historically male jobs and the incidence of divorce spiked (Collins 1979; Fischer and Hout 2006). Nevertheless, it is unclear whether the system of class-based meanings used by lay actors underwent parallel transformations. Despite voluminous scholarship focused on how shared understandings of class operate on the micro-level in particular times and places (e.g., Bourgois 2003; Khan 2010; Willis 1977), macro-historical analyses of the dimensions of meaning undergirding class remain rare.
Commentators offer competing narratives about the cultural trajectory of class in the twentieth century. Some characterize the twentieth century as the eclipse of social-structural positions by identities and lifestyles. According to this line of inquiry, noneconomic identifiers, such as gender, race, education, and consumption patterns, form the new backbone of political organization and group solidarity (Clark 2018; Hunter 1992; Pakulski and Waters 1996). This literature coincides with the popularization of cultural capital in anglophone sociology, which stresses the rising importance of symbolic attributions in determining class (DiMaggio and Mohr 1985).
Other scholars argue against the “death of class” narrative, claiming that occupation and position in class structure continue to play key roles in determining wealth and shaping collective identity (Weeden and Grusky 2005; Wright 2000). Yet most research on the durable importance of occupational position and control of capital focuses on their relations to observable life chances and is not directly concerned with the cultural matrix of class. It remains unclear whether sociology’s increasing attention to identity and lifestyle in transforming social class reflects concurrent trends in how class is understood in public discourse.
A third possibility is that symbolic factors like cultivation and status have always been central to how class is collectively understood. For instance, Accominotti, Kahn, and Storer’s (2018) analysis of New York Philharmonic attendance recounts how cultivated taste developed into a currency of cultural capital among a middle-class intelligentsia in the nineteenth century. Moreover, classical accounts of status and cultivation suggest these symbolic components have been structuring class since at least the end of the Industrial Revolution (Elias 1978; Veblen [1899] 1912; Weber 1978).
These considerations suggest the possibility that collective understandings of class are founded on a durable system of meanings resilient to large-scale economic transformations. Empirical investigation into whether class’s cultural components remained stable over the twentieth century has been stymied by methodological difficulties associated with macro-cultural analysis. Following a line of successful inquiry (Bearman and Stovel 2000; Franzosi 2004; Mohr, Wagner-Pacifici, and Breiger 2015), we propose formal text analysis as a promising avenue for recovering widely-shared understandings of class from historical populations no longer available for direct observation.
Formal Text Analysis in the Study of Culture
Cultural scholars from sociology, anthropology, and socio-linguistics have commonly theorized that a group’s language reflects its cultural system (Lévi-Strauss 1963; Whorf 1956). Following this insight, text has served as a key source of data for scholars investigating cultural categories and meaning structures. Text is particularly well-suited to historical-cultural analysis, as it is often the most semantically-rich record a group leaves behind. In sociology, analysis of text has historically been dominated by qualitative approaches, the two most common being interpretivist close-reading and systematic qualitative coding.
Interpretive text analysis, in which the researcher draws insights from a holistic deep reading, has produced great advances in sociological understandings of culture, but it suffers from clear limitations in reproducibility (Ricoeur 1981). Qualitative coding, in which the researcher selects a number of themes and systematically tracks their deployment in text (Glaser and Strauss 1967), can be more reproducible than a singular close reading, but it suffers from low inter-coder reliability when themes are complex or subtle. Because these dominant techniques are not easily replicable and rely on the analyst’s intuition and finesse, the study of culture in sociology has largely remained a “virtuoso affair” (DiMaggio 1997). Furthermore, both interpretive text analysis and qualitative coding are limited by the pace of human reading, so neither are well suited for the analysis of very large corpora or entire socio-cultural domains.
Limitations of qualitative textual analysis have motivated scholars of culture in the social sciences and humanities to develop an array of formal and quantitative methods of text analysis (Evans and Aceves 2016). Two such methods that have gained popularity in recent years are semantic network analysis and topic modeling. Semantic networks are typically constructed by treating words as nodes in a network and textual co-occurrences as links (Carley 1994; Hoffman et al. 2017; Kaufer and Carley 1993; Lee and Martin 2015). Examining structural characteristics of a semantic network, such as central words or words that bridge semantic or cultural holes, can provide insight into the relationship between individual words and the overall conceptual structure undergirding a text (Corman et al. 2002; Pachucki and Breiger 2010; Vilhena et al. 2014).
Alternatively, topic modeling is a more recent approach that uses a well-formed probability model to enable inductive discovery of “topics” structuring a corpus, each learned as a sparse distribution over words that tend to co-occur in text (Blei, Ng, and Jordan 2003; Mohr and Bogdanov 2013). Topic modeling can detect polysemy by tracing words that exist in multiple topics, and heteroglossia, the multiple voices of a single text, by inducing the mixture of distinct topics across documents (Blei 2012; DiMaggio, Nag, and Blei 2013).
Both methods can generate important insights into the cultural system that produced a text, but there remain many sociologically important questions for which these methods are poorly suited. When corpora grow sufficiently large, standard semantic network analysis metrics fail to distinguish between concepts that are close or distant by considering topological information alone. 3 Topic modeling sorts words into a predetermined number of clusters, or topics, based on co-occurrence in text, and such discrete clusters do not capture continuous relationships between words.
As such, both networks and topic models are ill-suited for representing the multifarious associations and cultural valances that characterize all words in a corpus. Questions regarding how masculine or feminine, good or bad, high- or low-class a given object is within a cultural system remain difficult to answer using existing formal methods for text analysis. Furthermore, investigation into the relations between cultural dimensions, such as how closely a culture’s rich/poor distinction relates to its masculine/feminine dimension, is beyond the scope of prior approaches.
Word Embedding Models and Complex Semantic Relationships
Recent work in natural language processing has made great strides by representing relationships between words in a corpus not as networks or topical clusters but as vectors in a dense, continuous, high-dimensional space (Joulin et al. 2016; Mikolov, Yih, et al. 2013; Pennington et al. 2014). These vector space models, known collectively as word embeddings, have attracted widespread interest among computer scientists and computational linguists due to their ability to capture and represent complex semantic relations.
In a word embedding model, each word is represented as a vector in shared vector space. Words sharing similar contexts within the text will be positioned nearby in the space, whereas words that appear only in distinct and disconnected contexts will be positioned farther apart. Figure 1 schematically illustrates the structure of the descriptive problem that word embeddings attempt to solve: how to represent all words from a corpus within the k-dimensional space that best preserves distances between n words across m semantic contexts. The solution, which we illustrate in subsequent figures, is an n-by-k matrix of values, where k « m, bolded here where k = 3.
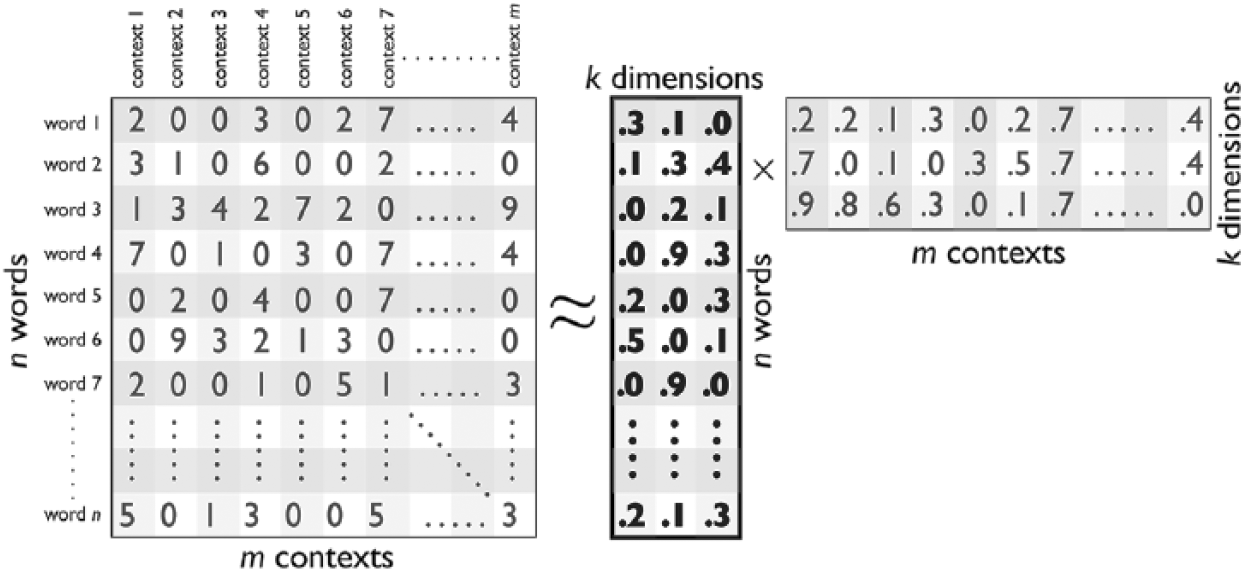
Schematic Illustration of the Descriptive Problem Neural Word Embeddings Solve—How to Represent All Words from a Corpus within a k-Dimensional Space That Best Preserves Distances between Words in Their Local Contexts
An early approach to word embeddings, Latent Semantic Analysis (LSA), used singular-value decomposition (SVD) to factorize this word-context matrix when contexts were large—entire documents containing hundreds, thousands, or tens of thousands of words. The first singular value explained the most variation in the original n-by-m word-context matrix, the second component the second most, and so on, such that k was typically trimmed when the marginal kth singular value explained arbitrarily little variation in the matrix.
From efficiency considerations, SVD placed strict upper limits on the number of documents and lower limits on the size of semantic contexts they could factorize. Neural word embeddings use heuristic optimization of a neural network with at least one “hidden-layer” of k internal, dependent variables. This enables factorization of much larger word-context matrices constructed from vast numbers of documents containing many distinct words (large n) but very local word contexts (large m). 4
In these models, k « m, but substantial natural language corpora require k ≥ 300 to minimize the error of word-context matrix reconstruction (Mikolov, Yih, et al. 2013). Note that because the optimal distance between two vectors is a function of shared context rather than strict co-occurrence, words need not co-occur for their vectors to be positioned close together. If “doctor” and “lawyer” both appear near the word “work” or “office,” then the vectors for “doctor” and “lawyer” would be located near each other in the embedding, even if they never appear together in text.
Distance between words in an embedding space is typically assessed using “cosine similarity,” the cosine of the angle between two word vectors. This is preferred to the Euclidean (straight-line) distance due to properties of high-dimensional spaces that violate intuitions formed in two or three dimensions. For example, as the dimensionality of a hypersphere grows, its volume shrinks relative to its surface area as more of that volume resides near the surface. 5 We normalize all word vectors (Levy, Goldberg, and Dagan 2015) such that they lie on the surface of a hypersphere of the same dimensionality as the space.
Word2vec, the most widely used word embedding algorithm and the primary approach we apply in the following analyses, uses a shallow, two-layered neural network architecture that optimizes the prediction of words based on shared context with other words. 6 Because words are located together in the embedding model if they appear in similar local contexts in the corpus, abutting words in the vector space tend to share similar meanings.
A word’s nearest neighbors are often either its synonyms or syntactic variants. A word’s broader neighborhood in the embedding space is typically populated by a host of terms with related meanings. Therefore, a great deal of semantic and cultural information is available simply by examining the word vectors that surround a word of interest. Kulkarni and colleagues (2015) have used word embedding models in this way to trace shifts in the meaning of the word “gay” over the course of the twentieth century, from a location in the vector space beside “cheerful” and “frolicsome” to one near “lesbian” and “bisexual.” Hamilton, Leskovec, and Jurafsky (2016) similarly used word embedding models to investigate how a word’s rate of semantic change, measured as change in the word’s overall position in space, depends on its frequency and polysemy, finding that words occurring with high frequency change meaning more slowly and polysemous words change more rapidly.
Past work with word embedding models also shows that semantically meaningful relations can be found between words not directly proximate in the space. Word2vec initially attracted a great deal of attention by virtue of its intriguing ability to solve analogy problems by applying simple linear algebra to word vectors (Mikolov, Chen, et al. 2013). For example, the analogy “man is to woman as king is to _____” can be solved with a model trained on a large body of text by performing the arithmetic operation with the word vectors
Cultural Dimensions of Word Embeddings
In this article, we present a novel method for applying word embedding models to the sociological analysis of culture. We show that derived dimensions of word embedding vector spaces correspond closely to “cultural dimensions,” such as affluence, gender, and status, which individuals use in everyday life to classify agents and objects in the world. By discovering and examining these culturally meaningful dimensions in a word embedding, analysts can reveal individual words’ associations on those dimensions and determine how these dimensions are positioned relative to one another in that space.
For instance, an analyst can use a word embedding model to determine whether “opera” is considered more affluent than “jazz” by projecting the word vectors corresponding to “opera” and “jazz” onto the dimension of the space corresponding to affluence. Similarly, the researcher can determine if “jazz” is more masculine or feminine than “opera” by projecting these words onto the dimension corresponding to gender in the same space. This dimensional approach emphasizes that semantic meaning is contained not only in the distance between two word vectors but also in the direction of that distance.
The technique we present for discovery of cultural dimensions in a word embedding vector space builds on logic for solving analogies with word embeddings. One interpretation for why
An approximation of the affluence dimension is captured not only by (
The process we propose for identifying cultural associations with word embeddings is diagrammed in Figure 2. To identify the cultural valence of a word, we calculate the orthogonal projection of the word vector onto the cultural dimension of interest. Because vectors are normalized, the projection of a word vector onto a “cultural dimension” vector is equivalent to the cosine of the angle between the two vectors. For instance, to determine the affluence association for the word “tennis,” we project
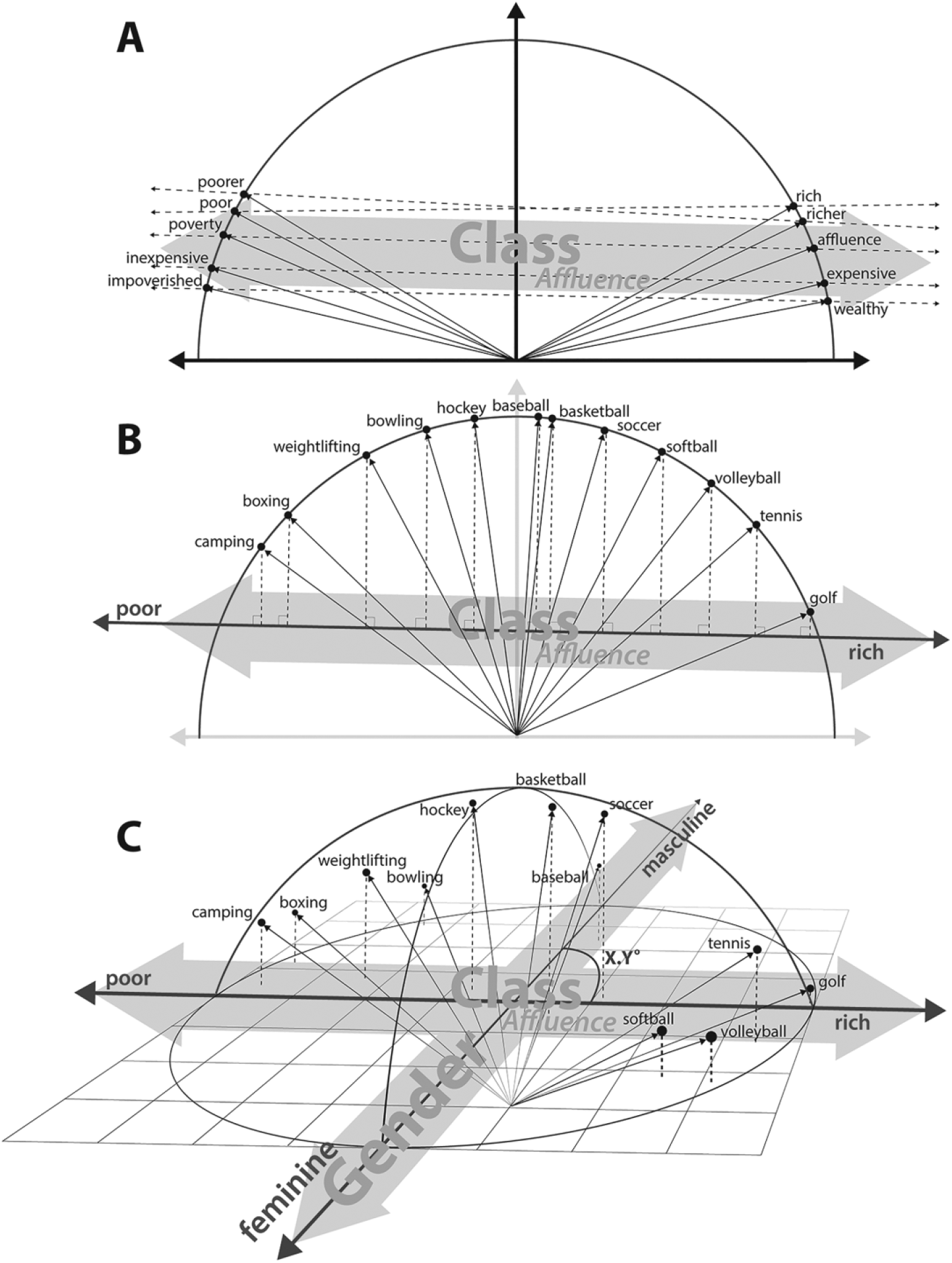
Conceptual Diagram of (A) the Construction of a Cultural Dimension; (B) the Projection of Words onto That Dimension; and (C) the Simultaneous Projection of Words onto Multiple Dimensions
Panel A of Figure 2 shows the construction of an affluence dimension by averaging the differences of several related antonym pairs. Panel B depicts how, by projecting the names of several sports onto the affluence dimension, we find that “boxing” and “camping” project onto the poor side of the dimension, “baseball” and “basketball” are nearly orthogonal to affluence, indicating no strong class association, and “golf,” “tennis,” and “volleyball” all project rich. Panel C shows how this process can be repeated for another dimension, in this example gender, and how words may be simultaneously positioned along multiple cultural dimensions. The angle between these dimensions can be calculated to capture the similarity between axes of cultural meaning, and it can be evaluated at multiple time points to trace shifts in categorical relations. Induced dimensions like affluence or gender will be approximately orthogonal if those dimensions are semantically and contextually unrelated. 11 When the angle between dimensions deviates from 90 degrees, it suggests a meaningful relationship between them, as we will demonstrate.
Our technique for identifying cultural dimensions is closely related to recent work using word embedding models to detect bias 12 in texts. Caliskan, Bryson, and Narayanan (2017) show that a word’s position relative to gendered or racialized labels in a word embedding model is strongly associated with that word’s associations measured by Implicit Association Tests (IAT) capturing unconscious bias (Greenwald, McGhee, and Schwartz 1998). They use this evidence to argue that word embedding models reveal negative racial and gender stereotypes implicit in texts. Bolukbasi and colleagues (2016) deploy a related approach to neutralize such biased associations in text.
Our work builds on these studies in several ways. First, we show that word position within the embedding model correlates not only with the unconscious associations but also with widely shared, conscious associations measured by surveys. Second, we argue that the method presented here detects not only hidden biases but a vast array of cultural valances. Many associations we find here are indeed biased: “criminal” is consistently found to be more “poor” than “rich,” and “scientist” more “masculine” than “feminine.” Word embeddings include harmful stereotypes, however, only because they accurately reflect cultural systems that are themselves rife with such stereotypes. Thus, it is rarely in cultural analysts’ interest to “de-bias” a word embedding model as Bolukbasi and colleagues (2016) propose. Rather, it is by interrogating these biases, as well as the neutral cultural associations present in the models, that analysts can cultivate an understanding of the multifaceted word meanings and cultural categories deployed in text.
Garg and colleagues (2018) begin to move in this direction by using word embeddings to study change in gender and ethnic stereotypes over time. By examining change in stereotypes, they recognize them as more than simply distortions of the semantic system, but rather meaningful characteristics that reflect the culture in which texts were produced. Their analysis, however, like Bolukbasi and colleagues (2016) and Caliskan and colleagues (2017), remains couched in the analysis of bias rather than cultural categories in general. Our approach builds on these studies by interpreting the dimensions of embedding models as representative of meaningful cultural categories rather than simply biases, distortions, or deficits in the semantic system. We then use these dimensions as tools to illuminate complex cultural relations associated with class in a given social context, across contexts, and over time. More broadly, this article is the first to specifically demonstrate the utility of word embedding models for sociological and cultural inquiry.
Word Embeddings and Cultural Theory
Word embedding models at once align and contend with dominant theories of culture in a number of significant ways. First, word embedding models are fundamentally relational in how they represent meaning. “Posh” only has meaning in that it is positioned near “wealth” but closer to “style,” near “fashion” but closer to “rich,” and distant from “plain” and “cheap.” At the same time, “wealth,” “style,” “fashion,” “plain,” and “cheap” themselves achieve meaning through their position relative to “posh” and other words in the space.
This purely relational approach to modeling meaning parallels a diverse body of cultural theorizing, including the structuralist models of meaning developed by Saussure (1916), which posit that individual signifiers are arbitrary and acquire meaning only through placement in a complex system of signification. The fundamental insight that meaning is not immanent within words and phrases but rather coheres within a broader cultural system is inherent in any word embedding analysis. This theoretical congruence makes word embeddings an effective tool for advancing empirical research within relational frameworks popular among contemporary theorists of culture (DiMaggio 2011; Emirbayer 1997; Mische 2011).
Meaning and Dimensionality
Dominant theories of culture often conceptualize meaning in terms of semantic dimensions. Considering objects’ multiple, cross-cutting valences along dimensions such as good/bad, rich/poor, and masculine/feminine not only resonates with structuralist thought (Douglas 1966; Lévi-Strauss 1963), but it is central to contemporary intersectionality, affect control, and field theories. Inducing labeled cultural dimensions from word embeddings thus makes it possible to operationalize and engage with these prominent theoretical traditions using large-scale text. Distances between terms can also be fruitfully analyzed without imposing labeled semantic dimensions onto the space. Word embeddings may therefore be applied to “non-dimensional” theories of meaning, such as those based on cognitive prototypes or family resemblances (Rosch and Mervis 1975; Tversky and Gati 1978).
The ability of word embedding models to simultaneously locate objects on multiple cultural dimensions, including race, gender, class, and many others, makes them a powerful tool for studies of intersectionality. The fundamental insight of the intersectionality literature is that cultural categories, particularly those of identity, cannot be isolated and understood independently (Crenshaw 1991; McCall 2005). Rather, analysts must always consider ways in which the meanings of cultural categories change as they overlap and intersect one another. Interrogation of the intersection of cultural categories becomes empirically tractable through word embedding models.
For example, comparing words that project high on both affluence and masculinity to those that project high on affluence and femininity will reveal how markers of class differ across gender lines within the cultural world in which the texts were produced. The theory that identity is defined by numerous cross-cutting and overlapping categories is itself predicated on a “high-dimensional” model of culture similar to that modeled by Euclidean word embeddings. Indeed, the empirical success of word embedding models to represent cultural dimensions promotes a radical view of intersectional identity, modeled not as a low-dimensional matrix, but rather a high-dimensional array composed of hundreds or thousands of interacting cultural associations.
Our use of word embeddings also shares much in common with Osgood’s semantic differential method, which similarly rates words along cultural dimensions. In the semantic differential method, respondents are asked in an interview to place words on culturally meaningful spectra: for example, “Is ‘dictator’ closer to ‘smooth’ or ‘rough?’” (Osgood, Suci, and Tannenbaum 1957). A key finding from this method is that much of the variance across all dimensions tested can be explained by just three core factors: evaluation (good versus bad), potency (powerful versus weak), and activity (lively versus torpid). Osgood’s insight matured within sociology into Heise’s (1979, 1987) affect control theory, which posits that individuals interpret events and plot courses of action by accounting for culturally based affective meanings, operationalized as the position of words on evaluation, potency, and activity (EPA) dimensions (see also Schröder, Hoey, and Rogers 2016).
Osgood and colleagues’ (1957) work has at times been used to argue for the low dimensionality of meaning systems, but this interpretation overlooks key findings of the semantic differential research program. When Osgood and colleagues (1957) had respondents rate words on a set of semantic dimensions purposely selected to be unrelated in meaning, they found the EPA dimensions captured a relatively small portion of the total variance. Motivated by such results, Osgood (1969) concluded that the semantic differential only effectively captures the “affective” components of objects’ meanings while systematically missing more denotative elements. The recent discovery that word embedding models require upward of 200 dimensions to successfully recover complex semantic relationships suggests that although three dimensions may be able to coarsely bin concepts and predict approximate human responses, higher dimensionality enables fine-grained classification along a rich set of distinctions particularly useful for sociologists, who are often concerned with subtle nuances of meaning between specific dimensions, such as gender, status, and education.
Word embedding models also operationalize and extend key elements of Bourdieu’s field theory. Bourdieusian cultural fields offer a model of how individuals, objects, and positions in social structure are located relative to one another in structurally homologous “social spaces,” with relations between entities described in terms of “distances” (Bourdieu 1989). Bourdieu (1984) frequently represented these social spaces geometrically using the method of correspondence analysis (Greenacre 2017), rendering distances between entities and meaningful dimensions of the field visible by placing them in a two-dimensional plane. By overlaying the space of economic relations with the homologous space of cultural relations, Bourdieu underscores how social class operates at once materially and symbolically.
The vector-space models produced by word embeddings similarly position objects relative to one another in a shared space based on cultural similarity. By leveraging the wealth of information contained in a large corpus, however, word embeddings are able to position words in a semantically-rich, high-dimensional space that need not be reduced to low dimensionality for interpretation. Indeed, the low-dimensional projection of correspondence analysis operationalizes a theory of cultural capital that is itself low-dimensional: social actors struggle to obtain and maintain dominant positions within a cultural field through a single currency of cultural capital and a single dimension of status-distinguishing tastes and preferences (Bourdieu 1984). 13 In this vein, Lamont (1992) criticizes Bourdieu’s approach for overemphasizing distinctions based on aesthetic cultivation such as common/rare while neglecting moral distinctions such as honest/dishonest or fair/unfair.
By preserving higher dimensionality in a cultural space, word embeddings can facilitate the development and testing of high-dimensional theories for how actors acquire and exploit varied cultural capitals along multiple dimensions of distinction. Moreover, identifying cultural dimensions using antonym pairs does not require interpreting orthogonal dimensions like correspondence analysis, but instead allows analysts to examine relations between correlated but distinct semantic dimensions. The high dimensionality of word embeddings thus leaves room for complex interrelations between multiple axes of cultural distinction and opens the relationship between these axes as grounds for empirical investigation.
Data and Methods
Our investigation relies on multiple data sources, 14 first for validation of our method and second for examination of historical trends in the cultural dimensions of class. To determine the ecological validity of our general approach, we compare results from word embedding models to human-rated cultural associations assessed by surveys, both contemporary and historical. Having established the validity of our method, we train word embedding models on Google Ngrams text from books published over the span of the twentieth century, and we use these models to interrogate broadly shared understandings of social class.
Surveys of Cultural Association
To establish a basis of comparison between human-reported associations and associations represented in word embedding models, we fielded a survey of cultural associations to 398 respondents on Amazon Mechanical Turk. The survey was fielded in 2016 and 2017 and was open only to Mechanical Turk users located in the United States. Although our sample cannot be said to be representative of the general U.S. population, responses to basic demographic questions indicate wide diversity in age, gender, and racial composition (Levay, Freese, and Druckman 2016). To improve representativeness, we apply post-stratification weights to the sample, weighting on race (white, black, or other), education (bachelor’s degree or less), and sex (male or female). The results presented here include post-stratification weighting, but unweighted models produce substantively similar findings. This survey and the weighting procedures are detailed in Appendix Part B.
In the survey, respondents were asked to rate 59 different items on scales representing association along class, race, and gender lines. All questions followed the format, “On a scale from 0 to 100, with 0 representing very working class and 100 representing very upper class, how would you rate a steak?” For measuring race and gender associations, the survey posed similarly worded questions, replacing “working class” and “upper class” with “white” and “African American,” or “feminine” and “masculine,” respectively. A full list of items asked on the survey is available in Appendix Table B1. Words were selected in seven topical domains: occupations, foods, clothing, vehicles, music genres, sports, and first names. A diverse array of topical domains were chosen to test the capacity of word embedding models to detect cultural associations across very different subjects. Specific terms were selected within each topical domain to ensure high variance across dimensions. 15 We calculate the weighted mean of responses for each item, and we use these means as our estimates of a general cultural association. The end product is thus a rating between 0 and 100 on a class dimension, a race dimension, and a gender dimension for each of the 59 words listed in Table B1. Measurement of broadly shared cultural associations with a Mechanical Turk survey is likely to suffer from bias and measurement error, but these weaknesses should only attenuate the correspondence between the surveyed associations and those recovered from word embedding models. Therefore, the associations presented here between survey and word embedding models can be interpreted as conservative estimates.
For historical validation, we draw on a similar dataset collected in the 1950s by semantic differential researchers. To produce a standard set of word scores for social psychologists to use across studies, Jenkins, Russell, and Suci (1958) had 30 college students rate 360 common terms on 20 semantic dimensions, such as hard-soft and good-bad, and published a table reporting the average rating for every word on each semantic dimension. We use these average scores as measures of self-reported cultural associations from the 1950s, enabling us to at once test a broader range of semantic dimensions and validate word embeddings for historical analysis. We exclude 11 terms from the analysis either because they are two-word phrases (e.g., “neurotic man”) or they did not appear frequently enough in the Google Ngrams text to be rendered in the vector space (e.g., “briny”), resulting in a total of 349 words used in the analysis, each scored on 20 semantic dimensions.
Word Embedding Data
We analyze several word embedding models trained on multiple textual archives. The majority of our analyses utilize embedding models trained on publicly-available Google Ngram texts. The Google Ngram corpus, the product of a massive project in text digitization across thousands of the world’s libraries, distills text from 6 percent of all books ever published (Lin et al. 2012; Michel et al. 2011). Any sequence of five words that occurs more than 40 times over the entirety of the scanned texts appears in the collection of 5-grams, along with the number of times it occurred each year. Because word embeddings require local context to determine the meaning of words, we limit our analysis to the collection of 5-grams, and we exclude data on the occurrence of 4-grams, 3-grams, 2-grams, and single words. 16 All characters were converted to lowercase in preprocessing to increase the frequency of rare words. Although the Google Ngrams corpus does not represent one single, identifiable voice, it includes a vast number of documents spanning a variety of genres, including novels, government documents, academic texts, and technical reports, making it sensitive to subtle associations that appear diffusely in general discourse. Google Ngrams are poorly suited for identifying subcultural or contextually-specific meanings, but they are able to successfully capture pervasive and widely-shared meanings that characterize terms across contexts.
The Google Ngram corpus is a uniquely powerful source of textual data, but it suffers from various weaknesses. Google Ngrams have been subject to criticism because the composition of the corpus in a given year may not be representative of total literary output (Pechenick, Danforth, and Dodds 2015). We also recognize that authors whose books and periodicals appear in Google Ngrams are by no means a culturally representative sample of the U.S. general public. Instead, we must limit our generalizations to a relatively elite, “literary public”; a group whose cultural framework of class is consequential given its wide dissemination but possibly different from more marginalized populations underrepresented in the corpus. Word embedding models require very large collections of text to reproduce accurate semantic relationships, and Google Ngrams provide the largest and most extensive sampling of historical English texts. Furthermore, our contemporary and historical validations suggest Google Ngrams over the twentieth century are able to produce cultural associations that mirror human reports on numerous diverse semantic dimensions. We therefore proceed with Google Ngrams as our primary source of historical text and reflect on limitations of our analyses in the discussion.
We train word embedding models on Google Ngrams texts for both the historical analysis of class and contemporary validations. The Google Ngrams corpus contains metadata specifying the year of publication for each string of text, making it possible to trace semantic changes over time. We divide the corpus by decade, training separate models on texts from 1900 to 1909, 1910 to 1919, and so on through 1990 to 1999, resulting in 10 independently constructed word embedding models. By comparing these models side-by-side, we are able to trace macro-cultural trends over this 100-year period. Only words that appear at least 25 times are rendered in the model for a given decade, thus excluding words mentioned too rarely to be accurately placed.
For contemporary validation, we train an embedding model on Google Ngrams of publications dating from 2000 through 2012. We use this range of years because Google Ngrams do not include publications more recent than 2012, and this duration is similar to those used in our historical analyses. For additional validation, we compare the performance of the Google Ngrams embedding to two widely used, pre-trained embeddings: one trained on contemporary Google News text with word2vec and one trained on a broad scraping of website text from the Common Crawl with GloVe. These alternative embeddings are discussed in greater detail in Appendix Part A.
For validation with the 1950s semantic differential survey data, we use the same embedding model trained on 1950 to 1959 Google Ngrams that we use in our historical analysis. We train all word embeddings with word2vec skipgram architecture with 300 dimensions, following standards that prior research found to be effective in solving analogy tasks (Mikolov, Chen, et al. 2013). We also test the validity of our approach across different corpora and word embedding algorithms, including large samples of twenty-first-century news and webpages, which we detail in Appendix Part A.
We identify a diverse set of cultural dimensions in our embedding models for validation and for historical analysis. For contemporary validation, we construct cultural dimensions corresponding to three core sociological axes of classification: affluence, gender, and race (black/white). For historical validation, we construct 20 cultural dimensions corresponding to those measured by Jenkins and colleagues (1958). Finally, for our historical analysis of collective understandings of class, we construct cultural dimensions corresponding to those identified in the literature as being constitutive of, or deeply intertwined with, social class. For these analyses, we again construct dimensions for affluence and gender, and we add dimensions of education, employment (owner/worker), status, cultivation, and morality.
Measuring Cultural Dimensions
To identify cultural dimensions in word embedding models, we average numerous pairs of antonym words. Cultural dimensions are calculated by simply taking the mean of all word pair differences that approximate agiven dimension,
We bound our estimates with 90 percent confidence intervals constructed through a nonparametric subsampling approach. This method involves splitting the corpus into 20 non-overlapping subsamples, independently constructing embedding models on these 20 subcorpora, and calculating the desired estimates on all 20 embedding models. The variance between these estimates is then used to quantify how sensitive the estimates are to particular usages in the text. If a word is used infrequently and appears in several very different contexts, it will produce a wider error bound than a word used frequently in consistent contexts. Technical details regarding our calculation of these confidence intervals is available in Appendix Part C.
To assemble effective lists of antonym terms, we used five thesauri: three contemporary (Bartlett’s Roget’s Thesaurus 1996; Oxford Thesaurus 1992; Webster’s Collegiate Thesaurus 1976) and two historical (Roget 1912; Smith 1903). Drawing words from historical thesauri ensures our list of terms is robust for the early and more recent decades of the twentieth century. Indeed, certain terms only appear in the early decades of the century (e.g., “luxuriant” and “penurious”) and others only appear at the end (e.g., “privileged” and “underprivileged”). Antonym pairs that do not appear in a given decade’s embedding are excluded from calculation of the average cultural dimension. As a result, the terms that comprise a cultural dimension shift as the terms used in discourse to designate the cultural dimension themselves shift.
Some cultural dimensions are characterized by a much larger set of words in the English language than others, leading to substantial differences in the number of antonym pairs included for each. Furthermore, selection of antonym pairs requires some discretion on the part of the analyst, because thesauri often contain a wide range of loosely synonymous terms inappropriate for the given analysis. We present supplemental analyses suggesting that cultural dimensions constructed from fewer antonym pairs may be less robust, but results do not differ substantially between those constructed from 10 pairs and those trained on 40. We further find that the exact ways words are paired (e.g.,
We contextualize our cultural analysis of class by comparing associations held in the general public to those expressed in sociological literature. To produce clear grounds for formal comparison, we compute word embedding models trained on a corpus of all sociology articles published in the twentieth century in the JSTOR collection. The class-based associations we find in this corpus generally accord with widely recognized disciplinary trends (see Appendix Part H).
Results
Validation of Cultural Dimensions
We validate the ability of word embedding models to reflect widely shared cultural associations by calculating the Pearson’s correlation between a word’s mean rating on a given survey scale and the word’s projection on the corresponding cultural dimension in an embedding model. Correlations are calculated using the 59 terms listed in Appendix Table B1. We compare the validation results from the Google Ngrams embedding to two widely-used, pre-trained embedding models to illuminate the strengths and weaknesses of Google Ngrams compared with other corpora. Results are presented in Table 1.
Pearson Correlations between Survey Estimates and Word Embedding Estimates for Gender, Class, and Race Associations
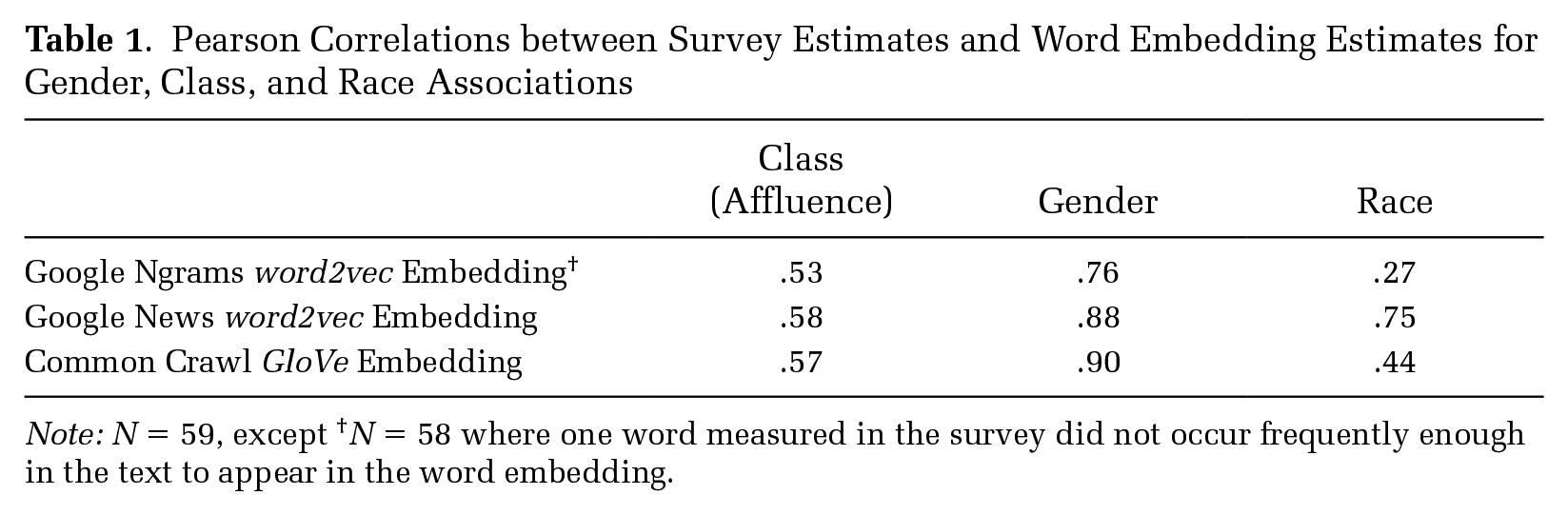
Note: N = 59, except †N = 58 where one word measured in the survey did not occur frequently enough in the text to appear in the word embedding.
The first column of Table 1 presents correlations between survey responses and word vector projections for class. We see that association for the Google Ngrams embedding is .53, and correlations with the two alternative embeddings are .57 and .58 (details in Appendix Part A). The second column displays the correlation between gendered associations in survey response and projection on the embedding’s gender dimension. For gender associations, the Google Ngrams embedding correlates with surveyed ratings at .76, and alternative embeddings correlate at .88 and .90. These correlations attest to how well a gender dimension elicited from the word embedding model corresponds to contemporary individuals’ understandings of masculinity and femininity. The third column shows correlations between word embedding projections and survey ratings for racial associations. The Google Ngrams corpus does relatively poorly in this test, correlating at only .27 with survey response. Other embeddings range widely from .42 to .75.
There are many possible explanations for the Google Ngrams’ relatively poor performance in picking up racial associations. The subject matter of news articles and general internet postings may be imbued with more racial associations than the Ngrams corpus, which contains significant non-fiction, including technical reports and scientific publications without narrative content that could invoke ambient, contemporary racial associations within that embedding model’s projections. Additionally, as noted earlier, the Google Ngrams text were reduced to lowercase in preprocessing, which decreased the available number of antonym word pairs for constructing the race dimension from seven to five, possibly resulting in decreased accuracy of the dimension. This poses pronounced difficulties for analyses of race, given that the semantic dimension black-white will likely capture a host of associations related to color but unrelated to race. Because of these difficulties in recovering racial associations from the Ngram corpus, we refrain from analyses of race in our subsequent analyses of class associations over time.
Figure 3 plots the correspondence between word embedding models and our survey of cultural associations. The figure reveals how several music genres—jazz, rap, opera, punk, techno, hip hop, and bluegrass—are arrayed on the cultural dimensions of class and race by survey response and the word embedding trained on Google News, with the average survey rating of a word depicted in black and the projection in gray. Comparing survey ratings to word embedding projections, we see striking similarity in the relative positions of words. In both methods, opera holds the association of being both high class and white. Techno, punk, and bluegrass are similarly white but of distinctly lower class than opera. On the right end of the panel, jazz is associated with both African Americans and high class, whereas hip hop and rap tend toward the working class. Projecting words simultaneously into multiple dimensions, it is clear how word embeddings can be used to examine intersectionality by revealing how class markers vary across racial lines.
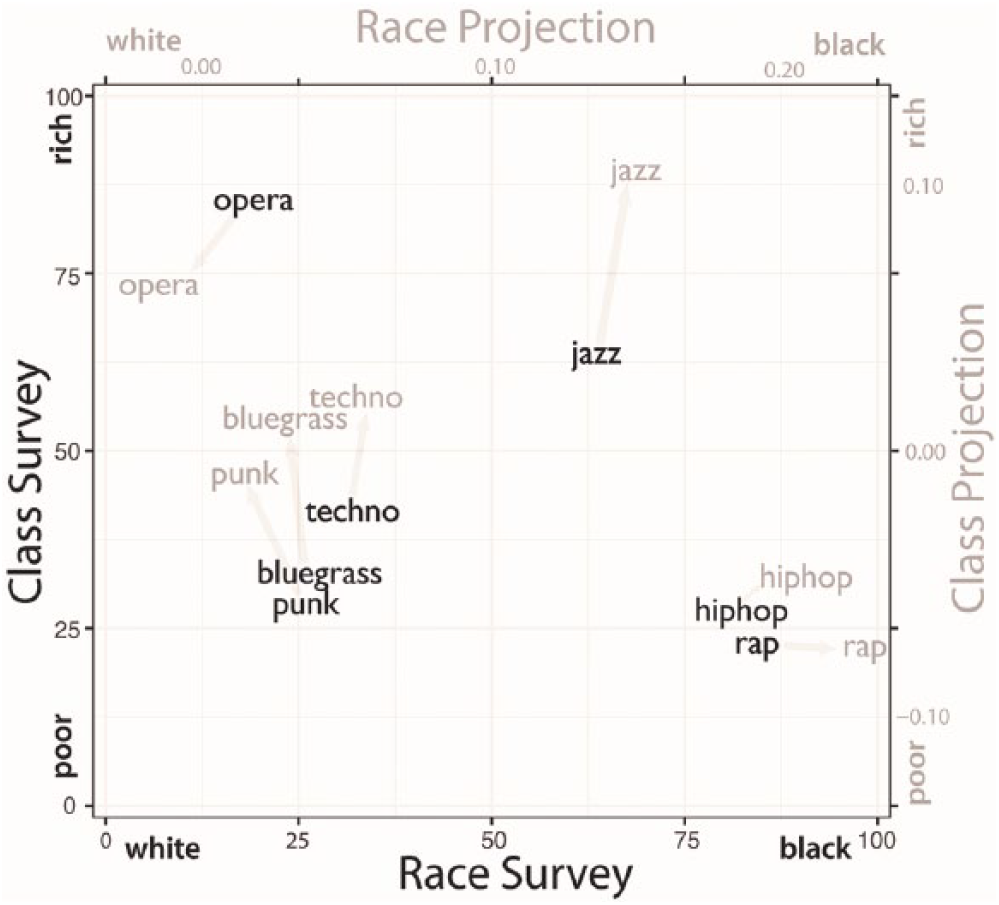
Projection of Music Genres onto Race and Class Dimensions of the Google News Word Embedding (Gray) and Average Survey Ratings for Race and Class Associations (Black)
We next validate results from an embedding trained on 1950s Google Ngrams text on data from a semantic differential survey fielded in 1958 (Jenkins et al. 1958). This validation assesses the ability of Google Ngrams embeddings to capture historical associations and their capacity to reflect a wide variety of semantic dimensions beyond core sociological categories. We take the same set of 349 words and 20 cultural dimensions measured by Jenkins and colleagues and produce a corresponding embedding-derived dataset by projecting the respective word vectors onto corresponding cultural dimensions from the embedding model. The sets of antonym pairs used to construct these cultural dimensions in the embedding are listed in Appendix Table D2.
Figure 4 depicts Pearson correlations between word embedding projections and human ratings for 20 semantic dimensions. We find a statistically significant (p < .01), positive association between human-rated associations and embedding projection on all dimensions. Many correlations are impressively high; correlations on six dimensions exceed .60, including kind-cruel, good-bad, beautiful-ugly, and true-false. We see more modest correlations on other dimensions, but we also find that lower correlations generally correspond to lower variance in average human ratings on those dimensions. This means dimensions with many strongly-rated words on both ends of the spectrum are more successfully captured by word embedding models. For example, subjects tended to rate most words near the middle on the rounded-angular dimension, suggesting they do not register strong associations. Unsurprisingly, these subtle and potentially more noisy associations are more difficult to capture from text. We engage semantic differential theory more deeply with supplemental analyses in Appendix Part G, showing that subspaces of word embeddings can reproduce the dimension reduction typical of semantic differential analysis, but the full spaces cannot be represented in lower dimensionality without considerable loss of information.
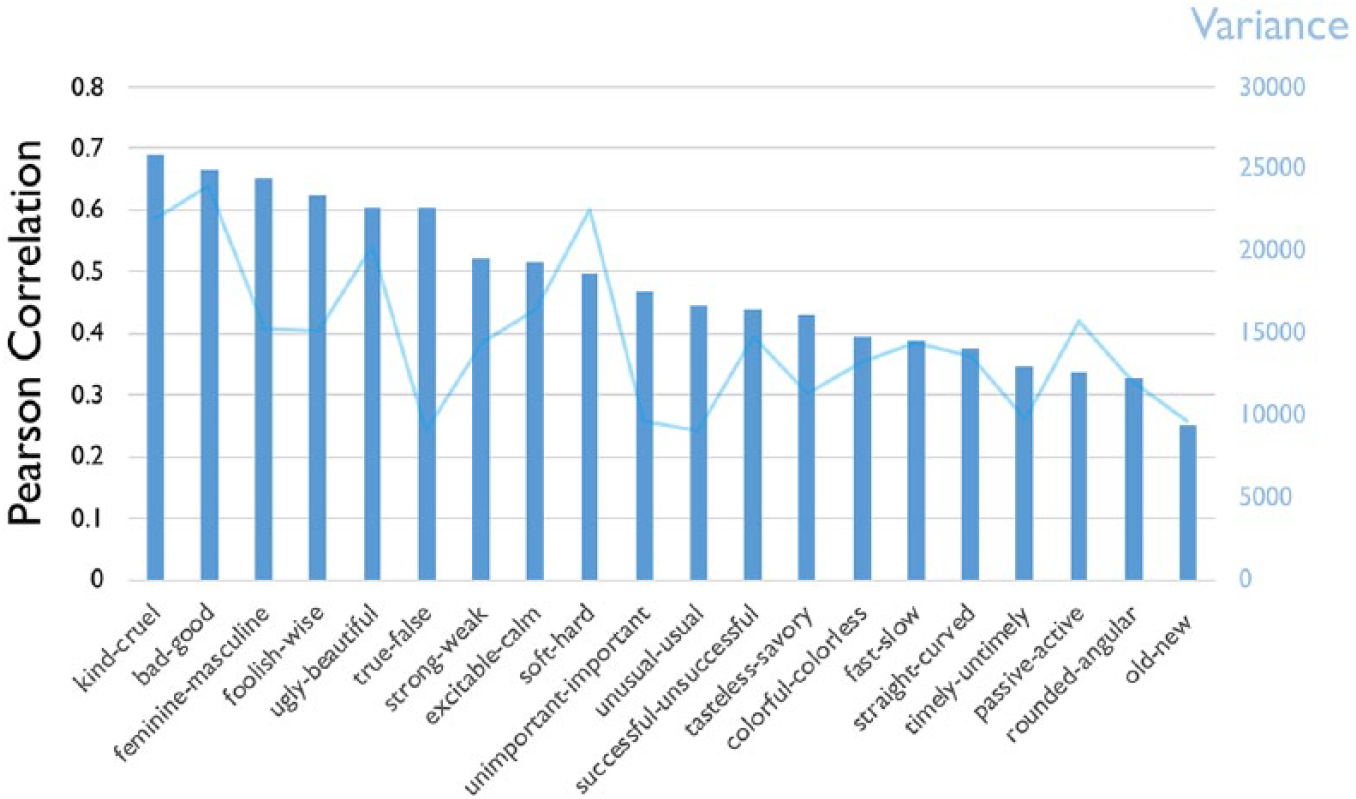
Correlations between Word Embedding Projections and Human-Rated Associations on 20 Semantic Dimensions, Alongside Variance of Average Human-Ratings on Those Dimensions; 1950 to 1959 Google Ngrams Corpus
Meanings of Class across the Twentieth Century
Having validated word embeddings’ capacity to capture meaning along many semantic dimensions, we apply this method to unpack multiple dimensions of class and explore their interrelation in the United States over the twentieth century. Specifically, we seek to discover how shared understandings of social class evolved during a period of dramatic economic transformation and which class components remained stable in spite of these developments. We analyze five dimensions of class identified prominently in sociological theory: affluence, employment (owner/worker), status, education, and cultivation. 18 For additional comparison, we also construct dimensions for two categories that theorists have noted as deeply intertwined with class: morality (Lamont 1992; Lerner and Miller 1978; Skeggs 1997) and gender (Reay 1998; Veblen [1899] 1912).
First, we focus on the cultural dimension of affluence, the ubiquitous class marker that anchors modern understandings of socioeconomic inequality (Piketty 2014). We begin by investigating how affluence has changed its relations to the other components of class. To accomplish this, we calculate the angle between each class dimension and the other six dimensions of interest, and then we explore how these angles shift over the course of the twentieth century. 19 Figure 5 displays the angle, measured in cosine similarity, between the affluence dimension and each of our other six cultural dimensions: employment, status, cultivation, education, morality, and gender. We observe general stability in the relations between affluence and other cultural dimensions, with a few key exceptions. Interestingly, the dimensions most parallel to affluence at the start of the twentieth century are cultivation and status. These are closely followed by morality, gender, and education, respectively. Affluence notably manifests the most modest association with employment position.
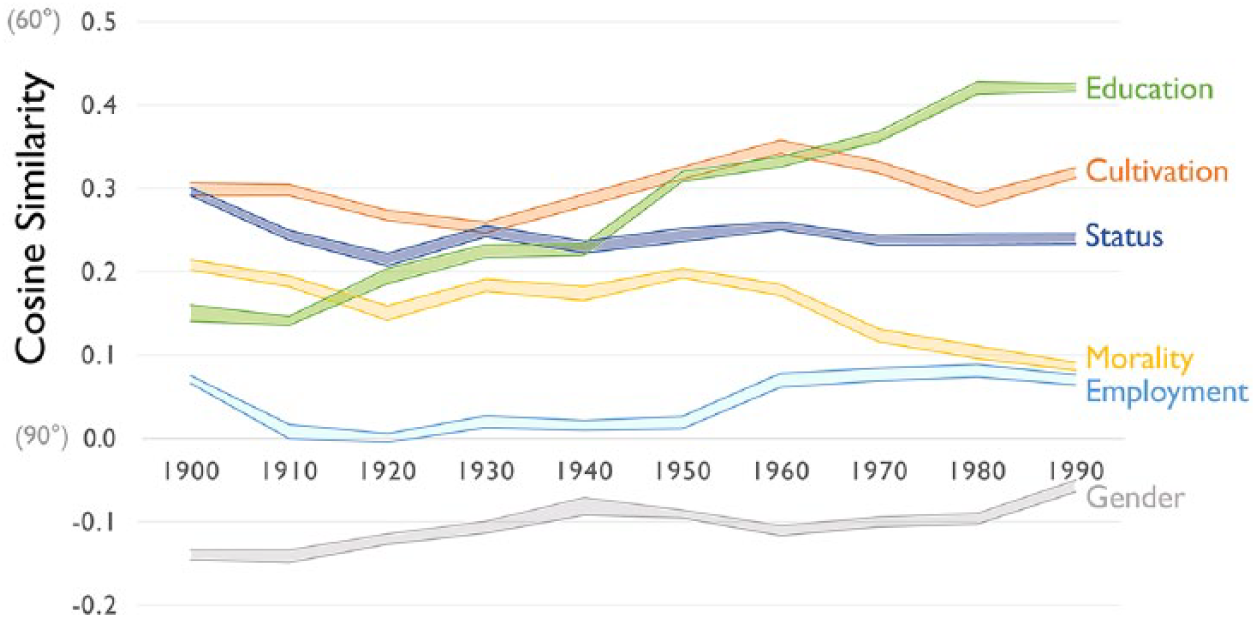
Cosine Similarity between the Affluence Dimension and Six Other Cultural Dimensions of Class by Decade; 1900 to 1999 Google Ngrams Corpus
It is illuminating to consider places where popular cultural associations run counter to understandings of class expressed within sociology. For example, gender’s association with affluence is weakly negative within general discourse, implying an association between affluence and femininity. This finding runs contrary to the sociological expectation that masculinity would be associated with affluence, given that men in the United States earn greater income and control more wealth than women. Such disjunctions between sociological and conventional understandings of class can be verified by comparing results from embeddings trained on Google Ngrams to those trained on sociological literature. We provide this empirical comparison in Appendix Part H.
The popular association of femininity with affluence in general discourse is less surprising when affluence is considered from a historical perspective. Veblen ([1899] 1912) documented how wives and daughters were frequently used as vessels for men’s “vicarious consumption,” and how women’s distance from toil in the workplace served as a marker of class in affluent society. Similarly, Zelizer (1989) notes that women’s money in the early twentieth century was commonly considered “pin money,” earmarked for extravagant and indulgent purchases, whereas men’s money was reserved for mundane necessities. Projections in historical Google Ngram embeddings reinforce this interpretation. Among the 10 nouns most highly projecting on the affluence dimension in the first decade of the twentieth century are “fragrance,” “perfume,” “jewels,” and “gems,” all of which project strongly feminine, suggesting that upper-class women were cultural mannequins for the display of wealth.
Employment position, either as a worker or owner, is similarly prominent in sociological understandings of wealth accumulation in the late twentieth century, yet its relationship with affluence in general discourse is weak. Across the entire century, the employment association is dwarfed by affluence’s relationship with the symbolic factors of cultivation and status. Again, although these findings do not align with how sociologists conceive of social class, they accord with certain key theories of class representation. Bourdieu’s concept of “misrecognition” and Marx’s earlier concept of fetishism both describe how relations of production undergirding systems of economic stratification are obscured while the outward trappings of class, displayed through consumption patterns, remain visible and culturally salient. This perspective also anticipates the tight association between affluence and cultivated tastes in popular discourse throughout the twentieth century.
Most cultural dimensions of class remain remarkably stable over the century, yet we observe a striking change in the relationship between dimensions of affluence and education. Although their association is only weakly positive at the dawn of the twentieth century, it surpasses all other dimensions by the century’s close, suggesting that education and affluence became increasingly synonymous. It is possible, however, that this relationship is mediated by notions of cultivation. Cultural capital scholars have long argued that education reproduces patterns of economic stratification by providing students with cultural knowledge and dispositions that exert signaling effects in the market (Collins 1979; Lamont and Lareau 1988; Lareau and Weininger 2003). In embedding terms, this would imply that words with strong, positive educational valence only have an association with affluence insofar as they also project strongly on cultivation. To determine the extent to which education’s semantic connection to affluence is mediated by cultivation, we use regression to model their relationship and parse the geometry of this cultural space. OLS regression estimates the expected slope along one dimension of the vector space while holding others fixed. Given that non-independence is inherent to word embedding models, we do not intend the quasi-experimental interpretation of regression common in sociological analysis. 20
Figure 6 presents results from OLS regressions of cultivation and education projections predicting affluence projections. Interestingly, when adjusting for cultivation, projection on the education dimension actually exhibits a weakly negative association with affluence in the first half of the twentieth century. In other words, for two words with the same cultivation projection, the word with a greater education projection would have a lower expected affluence projection, suggesting education’s cultural association with affluence was a byproduct of its association with cultivation, sophistication, and refinement. Indeed, at the beginning of the twentieth century, education at times implied a necessity to participate in the world of work rather than living comfortably on rentier income (Veblen [1899] 1912).
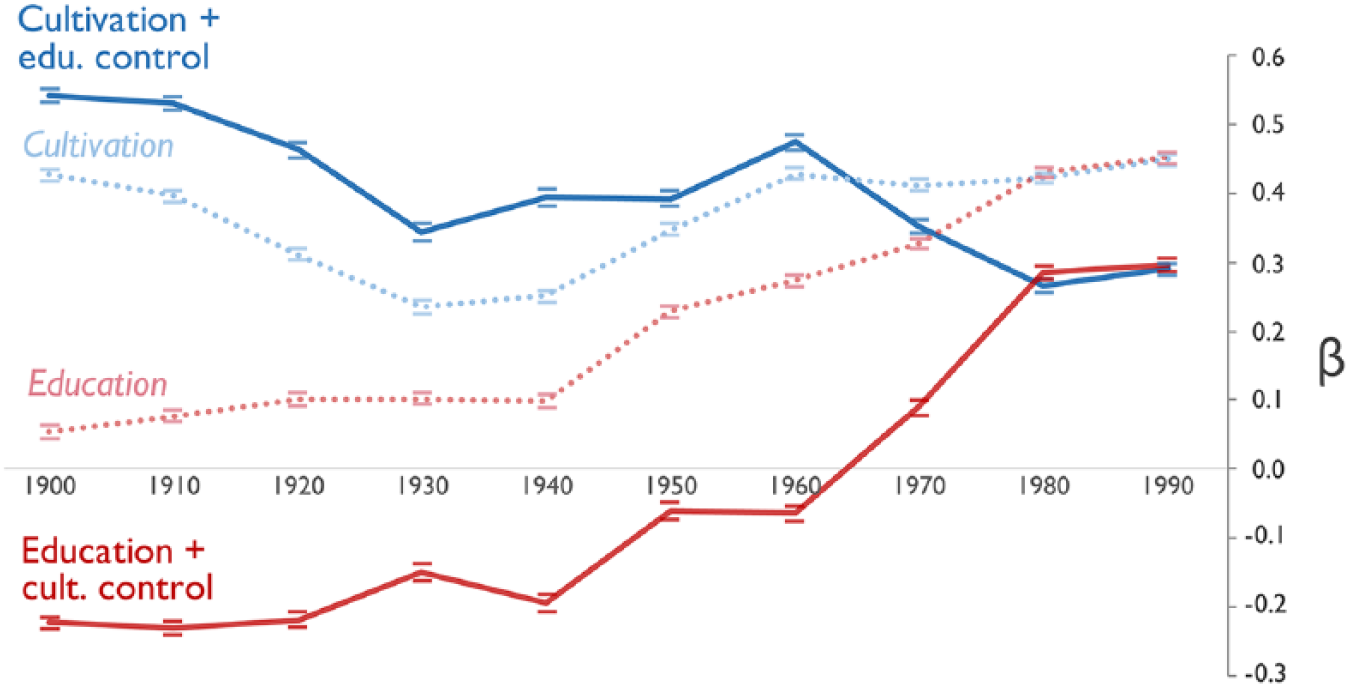
Standardized Coefficients from OLS Regression Models in Which Word Projections on Cultivation and Education Dimensions Predict Projection on the Affluence Dimension; 1900 to 1999 Google Ngrams Corpus
This relationship transforms over the course of the century. By the 1990s, education projections strongly associate with affluence, independent of cultivation. This finding suggests that by the end of the twentieth century, education represents a marginally distinct cultural marker of affluence, no longer redundant with cultivation. Education’s cultural association with affluence was mediated by cultivation at the beginning of the twentieth century, but meanings associated with education and affluence intertwined as education became increasingly essential for socioeconomic attainment.
This finding is ironic when considered against concurrent trends in sociological theories of class. With the rise of cultural capital theory, critical scholars suggested that education influences income by bestowing forms of cultural distinction rather than by providing practical knowledge and skills (see Appendix Part H). Yet, at the moment sociologists came to see education as operating via cultivation, the opposite occurred in public perception, where education became imbued with independent connotations of affluence as its demand among elite, well-paid occupations rose (see Appendix Part I).
In Figure 7, we broaden our focus away from affluence to comprehensively view relations between the multiple dimensions of class, displaying each dimension’s angles with all others. In spite of the rapid and encompassing economic transformations of the twentieth century, we find that relations between the cultural dimensions of class remain remarkably constant. Most dimensions that begin close together remain close, and those orthogonal retain their independence. The rank ordering of most angles is preserved for 100 years. Examining which cultural dimensions are correlated and which are independent, we see that cultivation, morality, and education are consistently close together, moderately related to status and affluence, and almost orthogonal to employment position. In fact, employment shows an association with morality in the opposite direction, with bosses carrying an odious cultural valence relative to workers. Despite its negative relationship with morality, however, employment shares modest but positive associations with affluence and status.
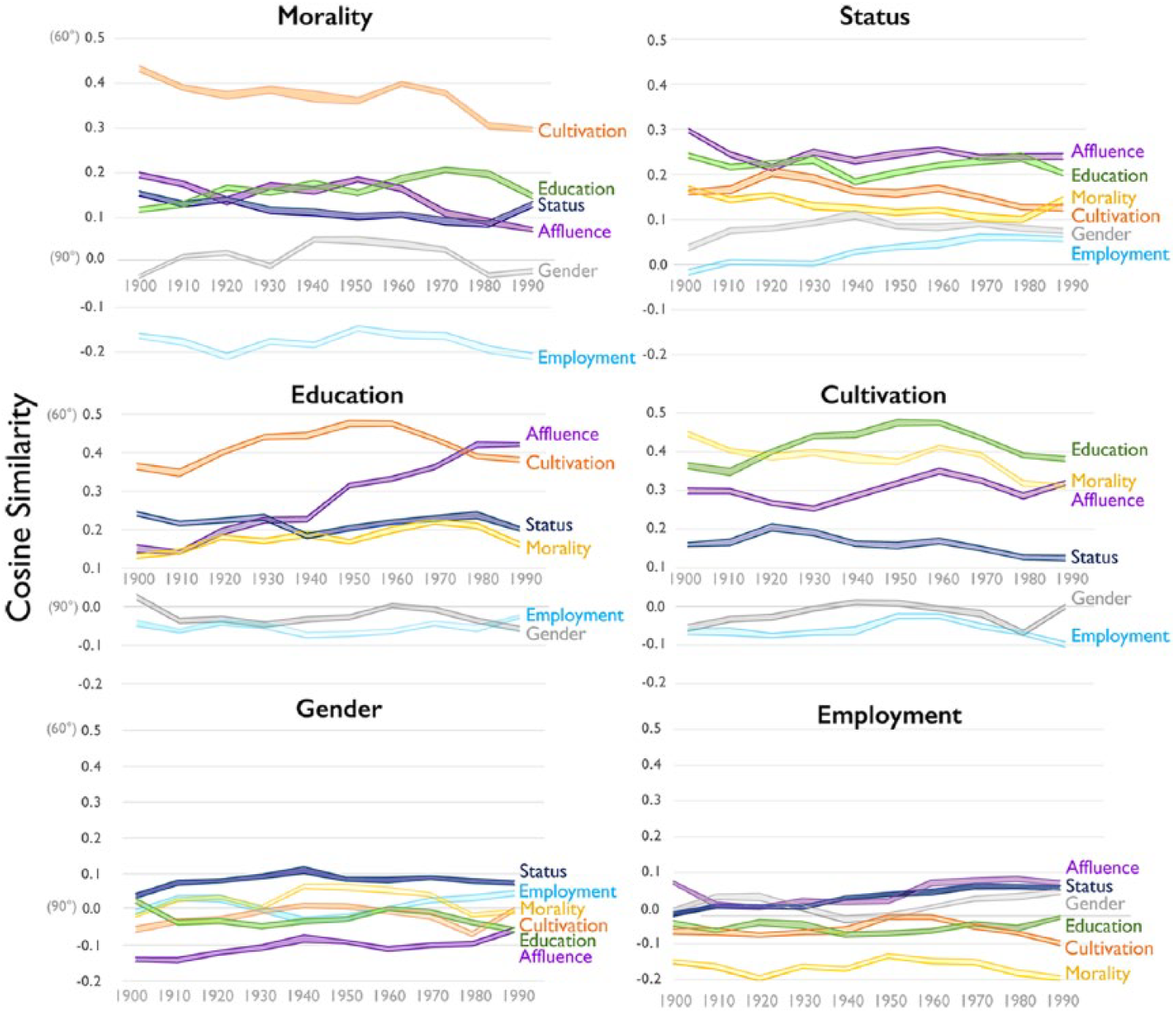
Cosine Similarity between Each Class Dimension and All Others by Decade; 1900 to 1999 Google Ngrams Corpus
Taken together, these results demonstrate a remarkably stable and complex structure among the cultural dimensions of class, with dimensions most closely associated with social distinction—morality, cultivation, and education—clustered on one end, employment position on the other, and status and affluence mediating these otherwise unrelated domains. Observing this structure holistically helps clarify the cultural relationship between these dimensions, which are rarely considered simultaneously. Status and affluence are at once colored by two distinct cultural valances. On one side, they carry connotations of ownership and power. On the other, they are signaled by refinement, virtue, and edification—characteristics with little association to power and industry.
This complex semantic structure requires high dimensionality for representation. In Figure 8, conceptual diagrams illustrate that two dimensions are not enough to reproduce the angles between any three dimensions of class without significant distortion. If the relation between employment and cultivation is held at its measured value of 90°, then it is impossible to keep the angle between cultivation and status at 85.5° while also maintaining that between employment and status at 79.3°. Thus, even when considering cultural categories closely related to class, high dimensionality is necessary to preserve crucial distinctions between meanings.
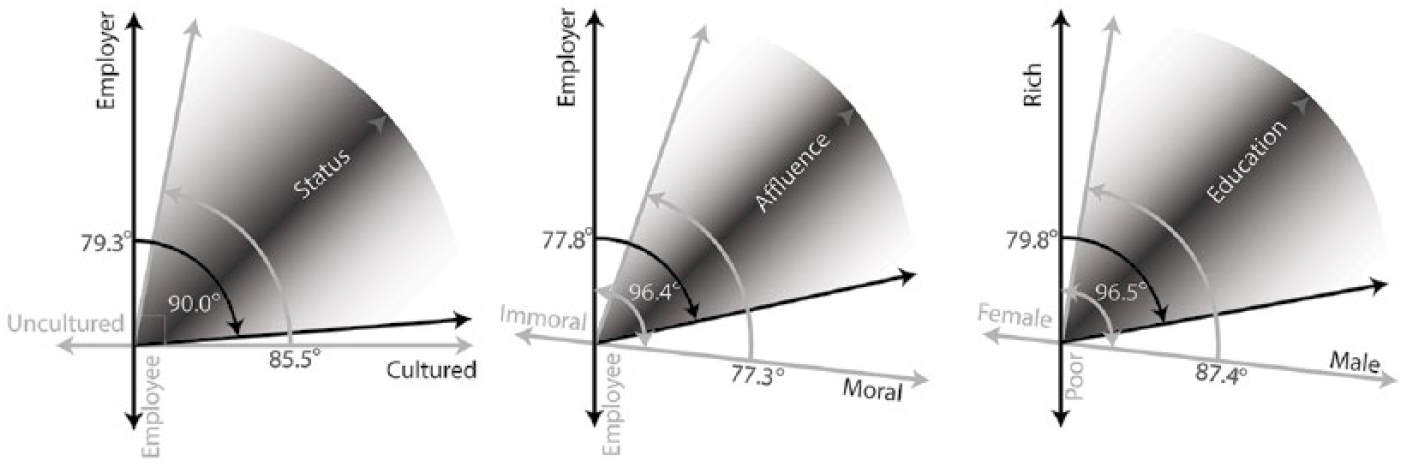
Conceptual Diagram of the Distortions Introduced When Reducing High-Dimensional Embeddings to Two-Dimensions
Finally, we turn from relations between class dimensions to focus on the stability of meanings within dimensions. We operationalize stability as the correlation between words’ projection on a given dimension in one decade and their projection in subsequent decades. Figure 9 displays the stability of projections for the 50,000 most common words on each class dimension. The first line represents the average correlation of word projections in the 1900s with their projections in the 1910s, 1920s, and so on through the 1990s. Similarly, the second line shows the correlation between projections in the 1920s with those in the 1930s, 1940s, and so on. For each decade, a word’s projection is highly correlated with its projection the following decade, in most cases greater than .9. This correlation diminishes by decade, however, such that the correlation between a word’s projection in the 1900s and 1990s falls between .7 and .6. This pattern reveals that beneath the historic stability of class’s dimensional structure, there is continuous flux in how cultural markers are positioned along these spectra.
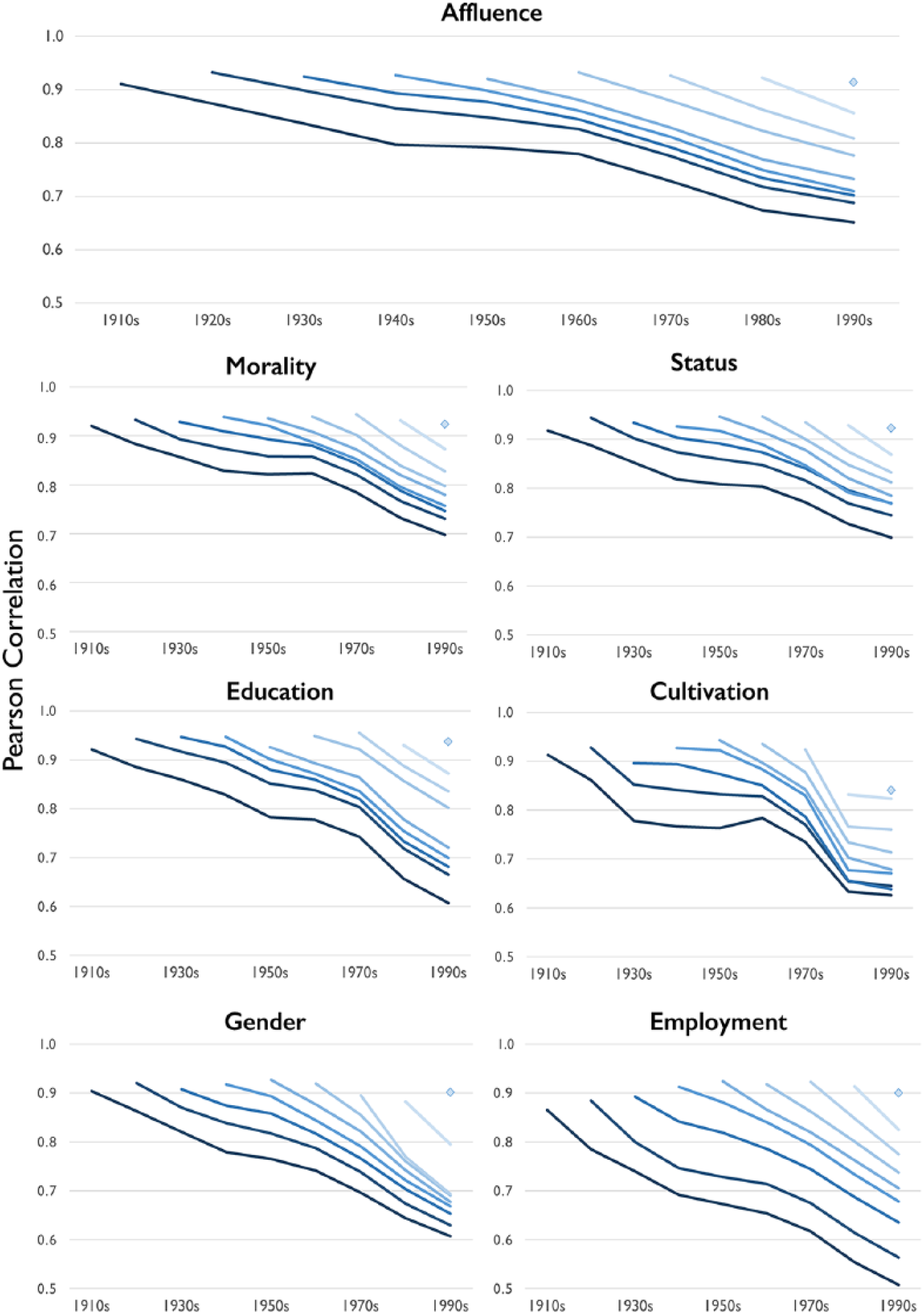
Correlation of 50,000 Most Common Words’ Projection in One Decade with Their Projection in Each Subsequent Decade for Seven Cultural Dimensions of Class; 1900 to 1999 Google Ngrams Corpus
To clarify this process of cultural circulation, we look more closely at how particular words change their projections on the employment dimension over the twentieth century. We select employment because it shows the greatest decline in correlation between the beginning and end of the century in Figure 9. Figure 10 displays the four highest and lowest loading words on the employment dimension in the beginning (1900s to 1910s) and end (1980s to 1990s) of the century, along with exemplary terms that display informative semantic trajectories. The top-left of the figure shows that many terms most strongly associated with the employer position were titles of formal office: “lords,” “governor,” “mayor,” “earl,” “bishop,” and “secretary.” As the century progresses, however, these titles lose ascendency to terms associated with power in an industrial and financialized economy: “promoter,” “speculator,” “rival,” “designer,” and “mogul.”
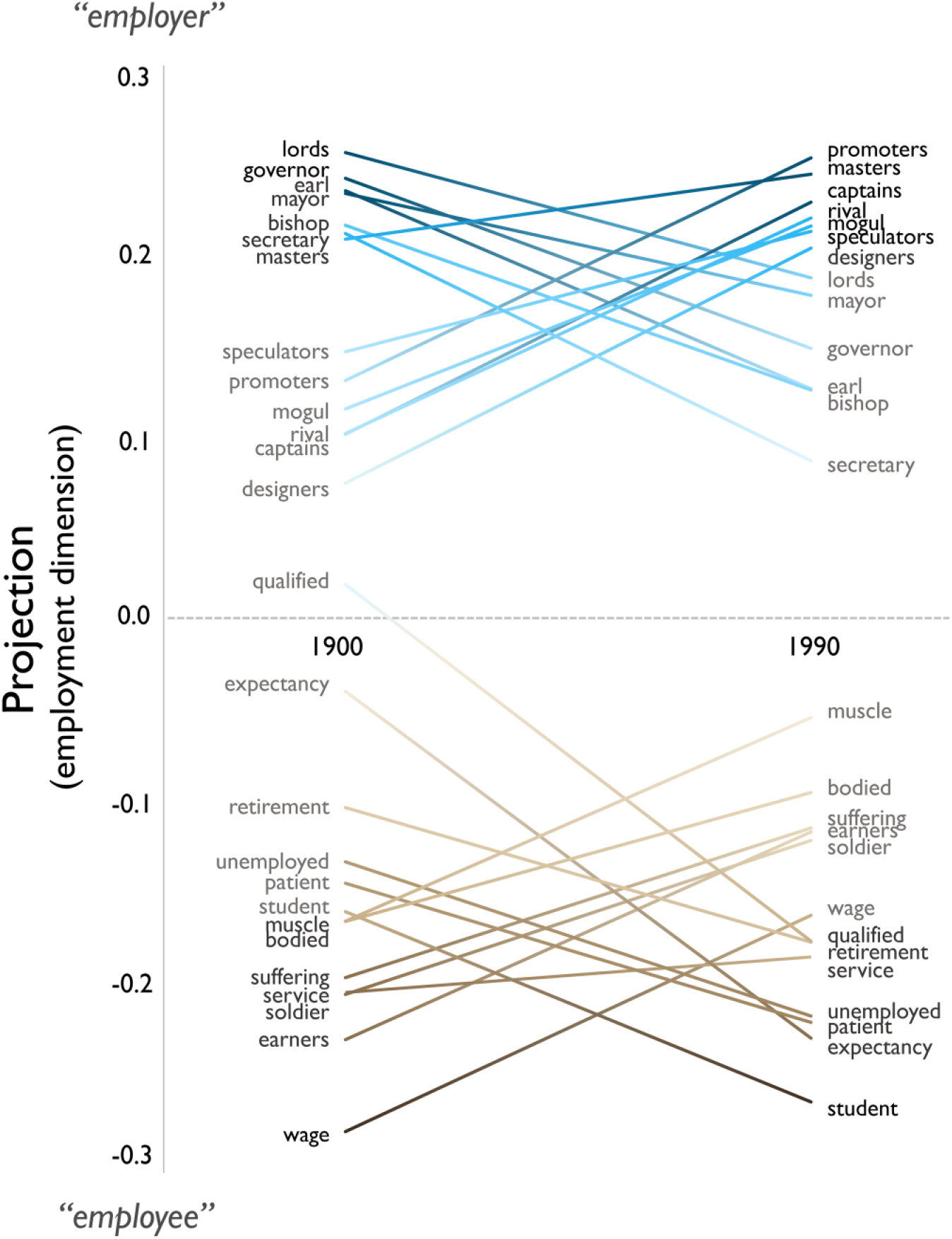
Words That Project High and Low on the Employment Dimension of Word Embedding Models Trained on Texts Published at the Beginning and End of the Twentieth Century; 1900–1919 and 1980–1999 Google Ngrams Corpus
The bottom of Figure 10 shows terms associated with the position of worker or employee. The strongest association at the start of the century is with “wage” and “earners”; this attenuates as a greater share of the U.S. workforce becomes contracted and salaried employees. The words “soldier,” “muscle,” and “bodied” project strongly on the “employee” end of the employment dimension during a period when manual labor comprised a large proportion of the workforce and World War I saw a large share of able-bodied workers enlisted into armed service. These words are displaced over time, with preeminent markers of “employee” at century’s end including “retirement,” “qualified,” and “student.” This suggests an emerging cultural image of the worker as white-collar and middle-class. Widespread perceptions of worker problems also shift with time. “Suffering” ceases to be a strong marker, but “unemployed” becomes prominent.
Other results of this analysis are not so easily interpretable. The words “patient” and “expectancy” are among the strongest negative projections on the ownership dimension at the end of the century, suggesting a powerful “employee” valence for both terms. Imaginative explanations for such findings are always conceivable—perhaps a growing recognition of workers as subject to ailment or injury led to an equivalence between “workers” and “patients.” Yet this style of post hoc interpretivism is vulnerable to misleading conclusions drawn from statistical flukes. These ambiguous findings provide an instructive example of how inductive approaches must be applied cautiously to word embedding analyses.
Discussion
Summary of the Argument and Results
In this article we introduce word embedding models as a productive method for the analysis of cultural categories and associations. By representing the relationship between words as the relationship between vectors in a high-dimensional vector space, word embedding models distill vast collections of text into a singular representation while preserving much of the richness and complexity of their semantic relations. We describe how dimensions of word embedding models correspond closely to “cultural dimensions” such as rich-poor, good-evil, and masculine-feminine, and how the positions of words arrayed on salient cultural dimensions of a word embedding reflect patterns of association and classification within a given cultural system. Furthermore, by calculating angles between cultural dimensions, we are able to investigate relationships between the axes of classification themselves.
After validating our method by comparing multiple word embeddings to contemporary and historical surveys of cultural associations, we apply it to a macro-historical investigation of shared understandings about social class in the United States over the twentieth century. We take up five facets of class and two related cultural dimensions that have been extensively theorized in the past. For each, we identify corresponding dimensions in word embedding models trained on texts produced over the twentieth century. We then measure relations between these class dimensions, bringing to light their dynamics, but also their stability, in the face of economic and industrial transformation. Our findings reveal that the multiple dimensions of class identified in sociological theory comprise a complex yet stable semantic structure that can only be represented faithfully in high dimensionality. We find persistent, close relations between dimensions of cultivation, morality, and education, and these interrelated spectra are nearly orthogonal or negatively associated with cultural conceptions of the classic Marxian owner/worker relation. Nevertheless, both share a connection to status and affluence, which intermediate them, serving as a cultural nexus between the outward trappings of class and the social relations that produce and reproduce class in the modern world.
The relationships between the cultural dimensions of class remain stable over the century, but locations of individual words on those dimensions are in constant flux. Collectively, these findings suggest that many of the basic dimensions through which class is understood were robust against the twentieth century’s tectonic shifts in the organization of economy, industry, and employment. What evolved were symbols used to signify locations in the multidimensional architecture of class.
General Implications of the Study of Culture
The full range of potential applications for word embedding models reaches far beyond the class example presented in this article. Following the general approach piloted here, analysts could use word embedding models to compare the cultural systems represented by literary genres, texts produced by distinct authors, or texts written in different languages (Lev, Klein, and Wolf 2015). A wide array of social collectives, including scientific disciplines, political elites, and contributors to online forums, can be analyzed and compared by training word embedding models on the text they produce. Furthermore, while this article focused on insights produced by identifying, extracting, or comparing “cultural dimensions” from the vector space, we do not maintain this is the only method for utilizing word embedding models to advance social science. Simply calculating the proximity of word vectors can also provide a strong indicator of the similarity or distance between word meanings (Kulkarni et al. 2015).
Word embedding models can further be used to classify and predict which group produced a text, given multiple corpora produced by distinct social groups (Taddy 2015a). Finally, future word embeddings that use hyperbolic or elliptical geometries could be used to systematically capture nonlinear relations in language, such as hierarchy or clustering (Chamberlain, Clough, and Deisenroth 2017; Nickel and Kiela 2017; see Appendix Part A). We argue that a wide range of techniques for productively developing and applying word embedding models to social and cultural inquiry are possible but yet to be developed. Nevertheless, Euclidean word embeddings are conducive to modeling and evaluating intersecting dimensions of culture in a way that maps onto a wide range of cultural theory.
Caveats and Limitations
As well as identifying broad potential, our investigation exposed clear limitations of word embedding models for cultural analysis. First, word embeddings must be trained on very large corpora if the output vector space is to capture subtle and complex associations of interest to culture analysts. Previous studies indicate that analogy tests can only be reliably solved when input text comprises several million words or more (Hill et al. 2014). As a result, groups that do not leave extensive textual records are difficult to study with word embeddings.
Second, the exact algorithmic processes undergirding the training of word embedding models can be highly complex and therefore elude theoretically parsimonious description. Although the word embedding models we present (word2vec and GLoVe) rely on two-layered neural networks with a single hidden layer, state-of-the-art deep-learning models deploy many-layered neural architectures with hundreds of millions of parameters for improved performance on natural language and intelligence tasks like question-answering (e.g., Devlin et al. 2018). Added algorithmic complexity can produce more sensitive and informative models, but it may also diminish the researcher’s understanding of how the model is generated and what distortions it is likely to produce. 21
Moreover, word embeddings are not able to adjudicate the suitability of a given corpus for an investigation. Just as rigorous sampling is crucial in interview-based methods, the ability to make cultural inferences about a given group with word embeddings depends on the sample of text utilized in model training. In our analysis, we opted to use a broad sampling of U.S. texts over time. The magnitude of our corpora enables recovery of subtle and diffuse semantic relations, but it requires combining texts produced by very different groups across vastly different social and cultural contexts. The resulting model captures broadly shared meanings that characterize U.S. culture in a given decade, but it levels the cultural heterogeneity of the individuals and groups that articulated them.
Furthermore, we acknowledge that the voices and worldviews published in books digitized by Google are not a random sample of U.S. culture. Poor and marginalized populations are unlikely to have their discourses published in the books, periodicals, and pamphlets that comprise the Google Ngrams corpus. We therefore must limit our population of inference to the U.S. “literary public” in any given decade. The correspondence between these word embedding findings and surveyed Americans on Mechanical Turk suggests the models’ associations are prevalent in the general public, but identifying exactly where this generalization succeeds and fails falls beyond the scope of this investigation.
A set of texts should not be taken as a pure or complete reflection of the culture that produced it. Authors may strategically emphasize or obscure semantic associations depending on their goals in producing the text (Jakobson 1960). Factors including the genre, purpose, and audience must be considered when utilizing texts for analysis and inference. Moreover, various elements of culture, such as tacit knowledge and embodied practices, are not inscribed in written discourse and therefore remain overlooked by formal models of text such as word embeddings (Lizardo 2017).
Finally, word embeddings cannot identify the cultural dimensions most important for a given semantic system or social process. Analysts can identify the cultural dimensions of the model that explain the most variance, either across the entire semantic space or within a circumscribed vocabulary. But although high explained variance indicates that terms have strong positive and negative valences along the dimension, it reveals little about how these valences are deployed in social life and to what ends. It is possible that subtle cultural associations may be deeply consequential for action, and thus explained variance could be misleading as an indicator of social significance. We argue that selection of cultural dimensions for analysis should be motivated by theoretical considerations, as we ultimately did here with class, rather than emergent and sometimes arbitrary qualities of the embedding space. 22
Concluding Remarks
Despite their limitations, word embedding models can serve as a powerful tool for analysts of culture. Word embedding algorithms require large corpora to create informative models, but the amount of digitized text produced and available to analysts is growing exponentially (Evans and Aceves 2016; Salganik 2017). Although social scientists have widely recognized that these vast archives contain a cache of cultural information with great potential for analysis, scholars have remained limited by the available tools for integrating and analyzing large-scale text. Neural word embeddings present a method for producing rich models of semantic relationships from corpora too large for techniques such as topic modeling or semantic network analysis. When adequate text is available, contemporary word embedding approaches can distill detailed and precise semantic information and relationships with a fidelity that exceeds prior methods and approaches human performance (e.g., Devlin et al. 2018).
Cultural dimensions from word embeddings do not simply provide a means of deriving textual measures compatible with intersectionality, affect control, and field theory. The very success of these models provides suggestive validation for relational approaches to cultural theorizing. Furthermore, by operationalizing a high dimensional model of culture, word embedding models allow researchers to extend and contend with theories of culture in novel ways. Embeddings present a much vaster set of potential axes along which individuals and social groups may compete, cooperate, fracture, or coalesce than low-dimension theories of cultural constraint allow. By simultaneously capturing the multiplicity of associations expressed in language, word embedding models are able to represent a complex geometry of culture, which, like a many-faceted crystal, amplifies the subtle and shifting framings that enable coordinated and spontaneous social action.
Footnotes
Appendix
Acknowledgements
We thank John Levi Martin, Etienne Ollion, and Marion Fourcade for their helpful comments. An earlier version of this paper was presented at the 2017 American Sociological Association Annual Meeting in Montreal, QC.
Editors’ Note
Figure 3, Figure 10 and Table B3 were incorrect in the Online First version. They have now been corrected online and in print, along with two related values in the text.