
Abstract
We bring together recent discussions on data capitalism and biocapitalization by studying value flows in consumer genomics firms—an industry at the intersection between health care and technology realms. Consumer genomics companies market genomic testing services to consumers as a source of fun, altruism, belonging and knowledge. But by maintaining a multisided or platform business model, these firms also engage in digital capitalism, creating financial profit from data brokerage. This is a precarious balance to strike: If these companies’ business models consist of assetizing the pool of genomic data that they assemble, then part of their work has to revolve around obscuring to consumers any uncertainties that would potentially impinge on these processes of assemblage. We reflect on the nature of these practices and the market relationships that enable them, and we relate this reflection to debates around alternative market arrangements that would potentially mitigate the extractive tendencies of these and other digital health firms.
In July 2018, a number of consumer genomics companies—including the industry’s leaders Ancestry.com and 23andMe—signed up to a new data privacy protocol, which had been developed in conjunction with the data activist organization Future of Privacy Forum (FPF) (Romm & Hartwell, 2018). These best practices include provisions for express and fully consented sharing of genomic data with third-party organizations (FPF, 2018). While focusing attention on the firms’ privacy practices, the guidelines remain surprisingly silent of the fact that the commercial “sharing” or sale of genomic data is an intrinsic part of these firms’ business models. Questions of data privacy in consumer genomics are inseparable from questions of data ownership and the profits arising thereof, yet the former has received vastly more research and public attention than the latter.
In this article, we broaden recent discussions on data or platform capitalism as practiced by data-driven technology firms such as Google or Facebook (Langley & Leyshon, 2017; West, 2019) by considering health care as a realm that is becoming increasingly entangled with data capitalist business models. As Atkinson, Glasner, and Lock (2009, p. 5) point out, the bioeconomy “generates a different form of value to that found in the wider economy,” namely value that always entangles economic with social and public concerns. But where and to whom does this economic value accumulate if it goes digital? What are the market arrangements and business models that enable economic value to flow in these so-called digital health industries, and are there any alternatives to the current models?
By locating our inquiry in the consumer genomics industry, we study an industry that has been embroiled in controversies from its earliest days—in Cole and Banerjee’s (2013, p. 555) words, it is “morally contentious.” Social science commentators have raised questions around the mantle of democratization of health insights and clinical research that the consumer genomics industry likes to cover itself with (Prainsack, 2014; Regalado, 2017; Tutton & Prainsack, 2011). The industry has also encountered enduring skepticism from clinicians around the provision of worrying and even misleading information to consumers without the benefit of professional medical support (Rockwell, 2017). Despite these criticisms, judging by the industry’s growth rates (Deloitte 2015), consumer genomics companies seem to have been successful at portraying genomic information as a font of empowerment, belonging, and knowledge to consumers (Turrini & Prainsack, 2016).
While alert to these ethical debates, in this article we focus on the processes through which consumer genomic information is turned into assets, which allows these firms to operate on several markets at the same time—consumer, data licensing, venture capital, and intellectual property markets. Following Birch (2017, p. 463), we define assets as “resources that generate recurring earnings.” We contend that for consumer genomics firms’ business models to work, there is a precarious balance to strike: If these companies aim to assetize the pool of genomic information that they assemble, then part of their work has to revolve around assuring an uninterrupted flow of data that can be turned into assets. We claim that this is done through three interlinked processes: of first accumulating consumer data; second, maintaining and augmenting it; and third, obscuring to consumers any uncertainties that would potentially impinge on the first two processes. In tracing the value flows in this industry, we thus examine the practices that these companies engage in with regard to assetizing genomic information. More broadly, we argue that the move to assetization presents a major conceptual shift for firms that operate in the health care realm. Conceptually, we combine theories of biocapital and data capitalism to analytically grasp and critique these processes of assetization.
While our argument is conceptually driven, we draw on several empirical sources to inform our analysis: We examine genomic firms’ business models and market relationships through an analysis of their marketing collateral and websites, and we support this analysis through documents published either by the firms themselves or by technology journalists and analysts. We complement these documentary sources through eight interviews with industry insiders. Our investigation remains on the producer side. We study how consumer genomics firms “act in markets to affect what is valued and how it is valued” (Aspers & Beckert, 2011, p. 23), not how this value is perceived and realized by the consumer. Though we focus predominantly on economic value flows, we fully acknowledge that there are various values at play in these markets—ethical, social, and individual. Yet, as Rose and Novas (2005) point out, these are often conflated with or even turned into “marketable assets” themselves. Comparing our findings with extant research, we discuss the “inevitability” of the private accumulation of economic value from consumer genomic data, to which our title refers, 1 and we point to debates around alternative market arrangements in consumer genomics and the broader bioeconomy. With this reflection, we contribute to discussions on valuation and assetization practices at the intersection of individual, health care, and commercial realms (Dussauge, Helgesson, & Lee, 2015; Poitras & Meredith, 2009). We also add to an emerging literature scrutinizing the intersection of digital technology and health care practices in so-called digital health industries (Fiore-Gartland & Neff, 2016; Geiger & Gross, 2017; Saukko, 2018). Most fundamentally, our argument speaks to Birch’s (2017) question of what gets valued and how this is done in the bioeconomy.
Our article proceeds as follows. The next section introduces three strands of literature around “capitalisms”—bio-, data-, and platform—bringing insights from the practices researchers have identified in data and platform capitalist firms into debates around biocapitalization. After briefly presenting our analytical approach, we use these conceptual foundations to first analyze the four value flows we have identified as constituent parts of a typical consumer genomic business model. We then explore 15 direct-to-consumer genomic testing firms’ marketing strategies to establish how these firms endeavor to create and maintain the “tidal flow” of data that underlies these value flows. Our Discussion summarizes our analysis before moving to build a research agenda for future research, centering on debates around conceiving alternative market mechanisms in the consumer genomics and related digital health industries.
From Biocapital to Biocapitalization: Theories of Bio-Value
Conceptually, our article brings together two strands of research that have not yet frequently met: the long-established notion of biocapital (Helmreich, 2008; Sunder Rajan, 2006) and the more recent research on data capitalism and the market relationships through which it expresses itself (Langley & Leyshon, 2017; West, 2019). This section will briefly review work in each area before considering the various entanglements between biocapital(ization) and data capitalism.
Theories of biocapital were the first to address the question of how economic value is extracted from lively or bodily material (molecules, genomic materials, tissues, stem cells, or reproductive organs)—or, in Nikolas Rose’s (2001) famous words, from “life itself.” These theories gained momentum with the ascent of the biotech industry in the late 1990s and early 2000s, with prominent exponents including Catherine Waldby (2002), Nikolas Rose (2001, 2008), Kaushik Sunder Rajan (2006), and Stefan Helmreich (2008). Early conceptualizations of biocapital were heavily influenced by Marxist thinking and broadly focused on the commoditization of vital materials (Helmreich, 2008). Franklin and Lock (2003, p. 8), for instance, define biocapital as a wealth that depends on extraction through “mobilizing the . . . agency of specific body parts.” Mitchell and Waldby (2010, p. 336) similarly see biovalue created through “the yield of both vitality and profitability produced by the biotechnical reformulation of living processes.” Weberian thinking represents a second anchoring point for critical analyses of biocapital (Helmreich 2008). Both Rose and Sunder Rajan diagnose the advent of a new “somatic ethic” (Rose, 2008, p. 36) where concerns about bodily functions and health have been individualized and productive capitalist citizens have been made complicit in the creation and extraction of bio-value.
Where much focus of this early work remains on how biomaterial is rendered as biocapital, two writers stand out through their interest in the processes that help transform the former into the latter. In his study of deCODE Genetics, the private company that in the late 1990s was tasked with sequencing over half of the Icelandic population, Fortun (2001) shifts concerns to the processes of speculation that make the future an important source of value for biotech companies. In his view, “Biotech and genomic stocks are some of the best exemplars of what are called ‘story stocks’ on Wall Street: stocks whose value . . . is contingent upon the kind of narrative that can be spun around them” (p. 143). Similarly, leaning on late Marxist thought, Sunder Rajan (2006) distinguishes between capital that is dependent on the commodity (industrial capital) and speculative capital that is dependent on monetary circulation (commercial capital). Related to the latter, speculative capitalism focuses on future profit rather than the present exchange.
This research starts to shift our perspective from capital toward capitalization and from commoditization to assetization, two terms that have come to the fore in more recent conceptualizations of bio-value and that are often seen as interlinked: “in order to capitalize on something, it must be either considered an asset, or turned into one (Muniesa et al., 2017, p. 12). An asset can be owned and cashed in; first and foremost, however, it represents an investment that is productive of a future revenue stream (Birch, 2017; Ouma, 2020). An assetization lens allows to study the social and material processes through which the future-casting of value enables economic value flows in the present (Birch & Tyfield, 2013; Ouma, 2020). Timmons and Vezyridis (2017), for instance, demonstrate how the transformation of waste tissue into economically valuable biospecimens in a U.K. National Health Service biobank not only reconfigures prevailing logics but also redefines stakeholder relationships and roles in the long term. Their study also shows the multiple overlaps between moral, social, community, and economic value in the formation and circulation of bio-assets.
Assetization in Data Capitalism
Before we explore assetization practices in the consumer genomics industry, we take two small conceptual detours into contemporary data capitalism and the market relationships through which it manifests. Our reason for these brief detours is threefold; for one, data capitalist firms are masters at assetization by turning consumer data into recurrent value flows (Park & Skoric, 2017). Two, as life science firms increasingly turn to trading information rather than handling lively materials such as tissues or molecules, the dividing line between data capitalist and biomedical firms is becoming porous (Birch, 2017; Birch & Tyfield, 2013). And three, such information trading frequently coincides with a platform business model, a sociotechnical market arrangement where proprietary digital hubs put themselves at the center of multiple value flows and actors (Langley & Leyshon, 2017; MacKenzie, 2017).
West (2019, p. 20) defines data capitalism as a system “in which the commoditization of our data enables an asymmetric redistribution of power that is weighted toward the actors who have access and the capability to make sense of information.” She considers three pervasive features of data capitalism: information asymmetry, selective transparency, and ownership uncertainties. Information asymmetries point toward the large discrepancies of the all-knowing data accumulator (Google in her case) and the consumer who is known through their data traces. Selective transparency highlights the discrepancy between a rhetoric of consumer power and a business model that keeps its algorithms and data collection apparatus strictly secret. Ownership uncertainties underline the contrast between a “free” service and the enclosure of individual information for private gain (Mittelstadt & Floridi, 2016). By centering on the twin issues of power and accumulation across these three processes, West’s data capitalism displays strong parallels with Zuboff’s (2015) surveillance capitalism. For West, however, “data capitalism is not just about surveillance. It is about how the market imbues data with new kinds of informational power and capitalizes upon it while rendering this power invisible . . .” (p. 22). For our purposes, it is important to note that all three of these mechanisms—information asymmetry, selective transparency and ownership uncertainties—point toward an active and in fact highly strategic management of the value flows created by data capitalist firms.
Data capitalism’s logic of accumulation raises important questions over the process through which individual data become an asset—namely in and through its accumulation with other data points (MacKenzie, 2017). Recent reports that the data analytics firm Cambridge Analytica has purportedly bought tens of thousands of user records from Facebook to influence voters in the U.S. Presidential elections and the U.K. Brexit referendum (Cadwalladr & Graham-Harrison, 2018) are a pointer to the potential pernicious power of such “big data.” In the health care realm, Vezyridis and Timmons’ (2017) analysis of the NHS’s care data experiment highlights that even public actors may engage in data capitalist practices of assetizing large datasets—and in the course may confound two very different types of value: “NHS datasets do not hold only one (monetary) value, but a range of other scientific, social and ethical values” (p. 7, original emphasis).
Value Flows in Platform Capitalism
What are the specific exchange relationships that support the assetization practices of data capitalists? Many firms in this space operate through a multisided business model—otherwise known as a platform model. Typically, these firms have (at least) two sets of customers: those who act as sellers and those who act as buyers. By positioning themselves between different sets of customers, a platform firm channels and controls the flows of value across these exchanges, thus capitalizing on various information asymmetries (Srnicek, 2017). Network effects are central to this business model—as MacKenzie (2017) highlights, platform markets’ valuation practices dominantly revolve around matters of size and growth, thus further exacerbating the data capitalist logic of accumulation.
In this context, one additional value flow becomes important. Private firms always operate in a financial market as well as in their main (buyer-seller) market. In the case of data-driven platform firms, the primary financial market is often venture capital driven. By encouraging a mode of scaling quickly, this financing model further feeds into the data capitalist’s logic of accumulation (Langley & Leyshon, 2017). By replacing debt with equity finance, it also encourages the future-casting of economic value (Birch, 2017). In fact, the complicated investment flows that often allow venture capital-backed companies to sustain multiyear losses hide a world in which businesses never quite reveal where the real value is anticipated to come from (Srnicek, 2017). The investor’s gaze, as Muniesa and colleagues (2017) put it, turns entire businesses into an asset and equates them with their potential to generate a future stream of revenue—revenue, to be sure, accumulated to the ultimate benefit of said investor. Thus, “the problem with capitalism . . . [may not be] the fact that things are valued in terms of capital, but rather the unequal distribution thereof” (Muniesa et al., 2017, p. 133).
To summarize our conceptual foundations, we draw on three bodies of work around “capitalisms” to explore the assetization practices of consumer genomics firms: biocapitalization, data capitalism and platform capitalism. The first one points toward the intricate relationships between living matter and how economic value is extracted from it. The second one raises issues of information asymmetry, selective transparency, and power distribution, which highlights questions of where and how this value accumulates, while the third allows us to consider value flows in the broader context of multiple market relationships—or the question of value for whom. In all three arenas, conceptual debate has recently moved toward a processual focus, which speaks to our central concern to understand assetization as a practical and strategically managed endeavor.
Analytical Approach
Our analysis presented below relies on two main sources of material: extant gray literature, academic and journalistic accounts of the consumer-facing genomic testing industry (henceforth called direct-to-consumer or DTC companies), and a detailed analysis of the business models and marketing strategies of 15 prominent consumer-facing genomics firms (Mesko, 2017; see Table 1 for a listing of these companies). For the former, we utilized multiple search strings around “consumer genomics” and “consumer genetics” on Web of Science and Nexis UK, as well as extensive Internet searches for articles not featured in either database. For the latter, we reviewed the firms’ marketing collateral and press releases and examined their YouTube video channels. We also downloaded all available documents from these firms’ websites on their terms and conditions (T&Cs), privacy statements, and informed consent documents (see Supplemental Appendix for details). We accessed publicly available information on the companies’ financing through external portals such as Crunchbase.com.
To contextualize this documentary investigation, we attended several conferences at the intersection of digital and health care realms (Health 2.0, MedX, and HIMSS) and a specialized genomics workshop (Harnessing the Power of Genomics). We further followed key opinion leaders on Twitter and approached eight industry experts with whom we carried out interviews to verify our understanding of the industry and its practices. It is worth pointing out that of the eight experts interviewed, three had undergone direct-to-consumer genomic tests themselves, as has one of the authors.
Our analysis involved repeated individual readings of and collective discussions on all documents and empirical materials through our broad theoretical lens of assetization until we agreed on the processes that we saw emerging from the data. We subsequently compared and contrasted the practices we identified with existing academic insights to arrive at a trustworthy and credible account of how firms assetize genomic data. We presented this account at two academic conferences and at a practitioner workshop, and we used feedback from these sessions to further adjust our interpretations.
Value Flows in the Consumer Genomics Industry
Deloitte (2015) estimates that the global genomics market was worth £8.1 billion in 2015, a figure expected to have doubled by 2020. The genomics industry began in the 1990s when the genotypic information of genetic variants was first provided by medical laboratories (Nishida et al., 2008). By 2003, the human genome was fully sequenced, and soon thereafter the prominent geneticist and entrepreneur Craig Venter became the first human whose full genetic code was sequenced by a private firm, at an estimated cost of US$100 million (Zhang, Chiodini, Badr, & Zhang, 2011). Over time, faster and cheaper sequencing technologies were introduced, dramatically reducing costs and triggering the explosion of commercial genomics firms, which loosely separated into consumer and medical business models (though these lines are increasingly blurring). The former typically offer advice on general health and well-being, ancestry and ethnicity, paternity and family relationships, and personality traits. The latter center on screening for medical conditions, pharmacogenomics reactions, inherited cancer genes, and prenatal or preconception diagnoses.
As mentioned, consumer genomics companies often operate through a platform approach. In this context, Stoeklé, Mamzer-Bruneel, Vogt, and Hervé (2016) analyzed two sides of DTC companies’ business models, namely consumers obtaining over-the-counter genomic tests on one side and pharmaceutical firms, private or public research laboratories buying these data on the other. We identify two further value flows in the typical DTC business model, which we will outline below and illustrate in Figure 1.
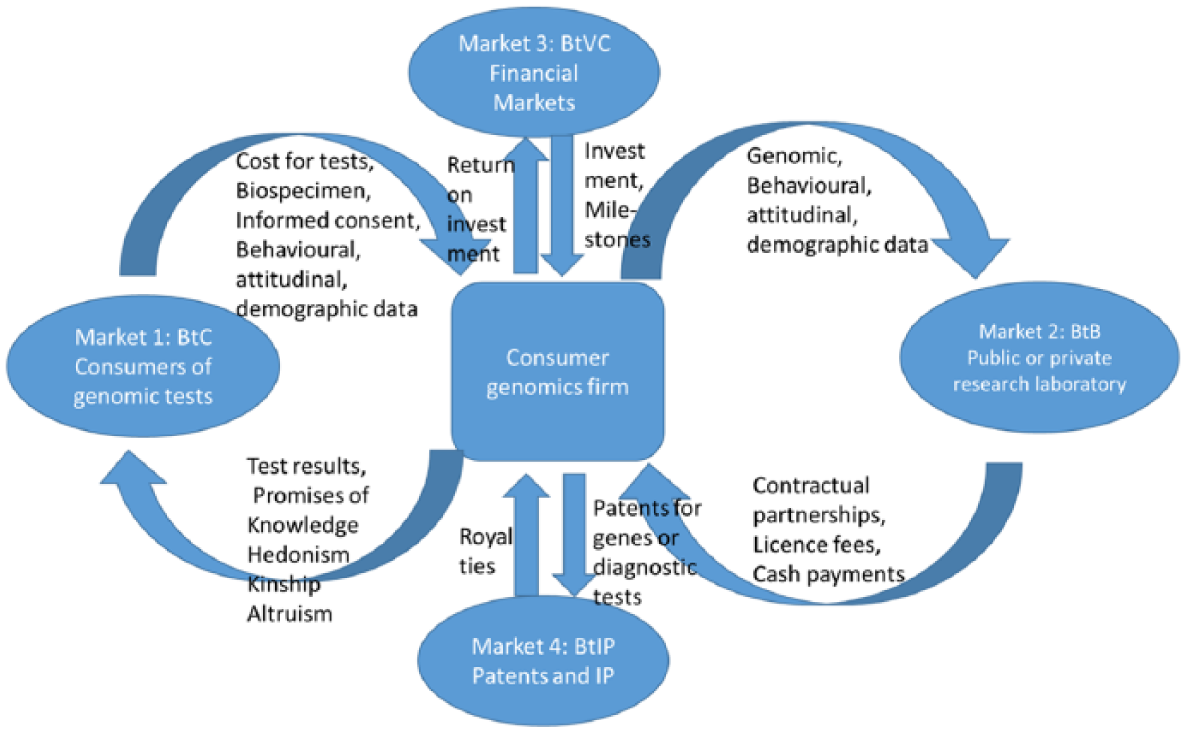
Value flows in the consumer genomics industry.
The first and most obvious value flow, labeled BtC (for “Business to Consumer”) in Figure 1, arises from gathering saliva samples from consumers in return for information such as an individual’s dispositions for medical conditions, tolerance to pharmaceutical products, or issues such as genealogy, ancestry, paternity, relationships, lifestyle, sports, diet, and fitness. DTC companies charge as little as US$99 for single-nucleotide polymorphisms (SNP) genotyping, and some companies now even “speed”-sequence the full human genome for less than US$1,000 (Mesko, 2017). 2 As of spring 2018, an estimated 12 to 15 million individuals in the United States alone have undergone DTC genomics testing. Of these, seven million and three million, respectively, utilized the services of the two leading DTC firms, Ancestry and 23andMe, with both firms enjoying steep increases in sales in 2017 (Regalado, 2017). Among the millions of goods available on the Amazon.com website, the 23andMe gift kit was among the Top 5 sellers on Black Friday 2017 (Koetsier, 2017). 3 To note, while this BtC value flow is on the surface a relatively straightforward commodity trade—money exchanged for a testing service—it provides the basis for the assetization processes taking place across the other three value streams. It is also noteworthy that consumer genomics companies often erect a large smoke screen between this and the other three value flows.
The second value flow illustrated in Figure 1 is a Business to Business (BtB) revenue stream and stems from what the industry typically describes as “sharing” of accumulated data with interested third parties such as research laboratories or pharmaceutical companies (Best, 2015; Stoeklé et al., 2016). These data include consumers’ genomic data as well as behavioral, personal, and attitudinal information, obtained through “enticing and fun, even slightly addictive” consumer surveys (Harris, Wyatt, & Kelly, 2013, p. 241). In the case of 23andMe, of its over five million world-wide customers, the company says, about 80% have agreed to donate their DNA data for research purposes [1]. 4 And this treasure trove of data is ever-growing: “on average, one individual contributes to 200 different research studies” and “to date, the company has collected one billion phenotypic data points” [2]. On the basis of this significant pool of data, the firm regularly announces collaborations with pharmaceutical or biotechnology companies [3] (Zhang, 2018). Genentech, for instance, reportedly paid 23andMe US$60 million for the genome sequences of 3,000 Parkinson’s patients—that is, a rather significant US$20,000 per genomic profile (Mullard, 2015). In financial terms, this single deal was hailed by financial commentators as a firm “finally finding its business plan” (Herper, 2015, n.p.). Likewise, commentators noted on the company’s most recent US$300 million deal with pharmaceutical giant GlaxoSmithKline that “You don’t make that kind of money selling US$99 spit kits” (Zhang, 2018, n.p.). In this value stream, genomic and other personal information are turned into financial assets; capable, that is, of providing recurrent income either through sales or licensing fees.
The third value flow, not mapped by Stoeklé and colleagues (2016), is through the financial markets, which we label as Business to VC (BtVC) in our Figure 1. A brief investigation into the funding bases of some of the major DTC firms quickly reveals an industry valued through, and consequently governed by, a large influx of venture capital (see Table 1). This financing context differs from more traditional biotechnology firms, which are often financed through partnerships with larger pharmaceutical firms or public funds due to their lengthy R&D timeframes (Hogarth, 2017). 5 The difference is important, as it builds pressure on DTC companies to focus on their growth rates—currently estimated at 15% year-on-year—even if scientific evidence would caution against some of the veracity claims associated with the testing and analysis methods used (Dickenson, 2013). 6
Case Companies Including Funding History.

Source. Crunchbase.com, July 31, 2017, and company websites. All figures US$.
Note. VC = venture capital.
The financial value of a venture capital-backed technology firm becomes almost entirely future-oriented (Mirowski, 2012). Industry insiders, for instance, predict that “DNA applications across a wide range of categories may be hard to imagine now, but will soon be commonplace.” (Venture capitalist, quoted in Business Wire, 2016, n.p.). As we will further explore below, this financial imaginary of future riches hinges more on the projective value of the data assets these firms control than on current value flows. In communication with the financial community, firms are relatively open as to where their future value stems from—where, in other words, the industry’s assets are located: The long game here is not to make money selling kits, although the kits are essential to get the base level data . . . Once you have the data, [the company] does actually become the Google of personalized health care. (23andMe board member, reported in Murphy, 2014)
Indications of the (promissory) asset that genomics firms as a whole represent to their investors can be seen in the so-called trade sales figures that these firms achieve when they get sold. In 2012, for instance, the pharmaceutical firm Amgen paid US$415 million for the private US-Icelandic firm deCODE Genetics, a company which had filed for bankruptcy in 2009 (Hirschler, 2012). Likewise, pharmaceutical giant Roche purchased pregnancy screening company Ariosa Diagnostic in 2014 for US$625 million [4] (Genomeweb, 2015). As we will discuss below, just how valuable a DTC firm is to potential buyers generally depends on three factors: how large their genomic database is; how “augmented” by other data the database is (for instance, lifestyle and behavioral data); and how “rare” the genomic profiles in the firm’s possession are (generally the rarer, the more valuable).
The fourth—and relatively recent—value flow in DTC business models is related to the use of genomic data by companies themselves for research and development, which we will label “BtIP,” to signal a flow between the DTC business and the market for intellectual property. A handful of the larger DTC firms such as 23andMe have started their own biomedical R&D activities. This represents a clear shift in their strategy by moving downstream from data broker to becoming patent holder for diagnostic or therapeutic tests or insights themselves [5]. We separate this value flow from the second value flow as the nature of the traded asset differs in both flows. Where DTC firms typically sell data in a BtB market, in a BtIP market the firms get involved in creating intellectual property that is subsequently licensed out. In an era where intellectual property is a highly valued intangible asset, this substantially enhances their attractiveness to capital markets (Zeller, 2007), thus creating an important positive feedback loop to the other value streams. While highlighting the need for “big” data, similar to the BtB flow, this value flow also points toward the need for data to be specific to certain target diseases or demographic groups. For instance, the strong relationship 23andMe has fostered with the Parkinson’s community has helped them garner the largest existing Parkinson’s gene pool [6]. Not coincidentally, the first patent the firm took out was one related to Parkinson’s disease [7]. This forefronts questions of enclosure and exclusion at a communal level, to which we will return in our discussion (Lezaun & Montgomery, 2015; Rimmer, 2012).
Assetizing Consumer Genomics
In our analysis of company materials and press coverage, we detected three interrelated sets of strategies through which DTC firms’ business models create assets from consumers’ genomic information: strategies that allow the companies to assemble and accumulate large genomic databases; strategies that help them maintain and augment these databases; and strategies that they pursue to obscure any uncertainties that may jeopardize the first two sets of practices. Figure 2 illustrates these strategies and the subsequent sections discuss them in some detail.
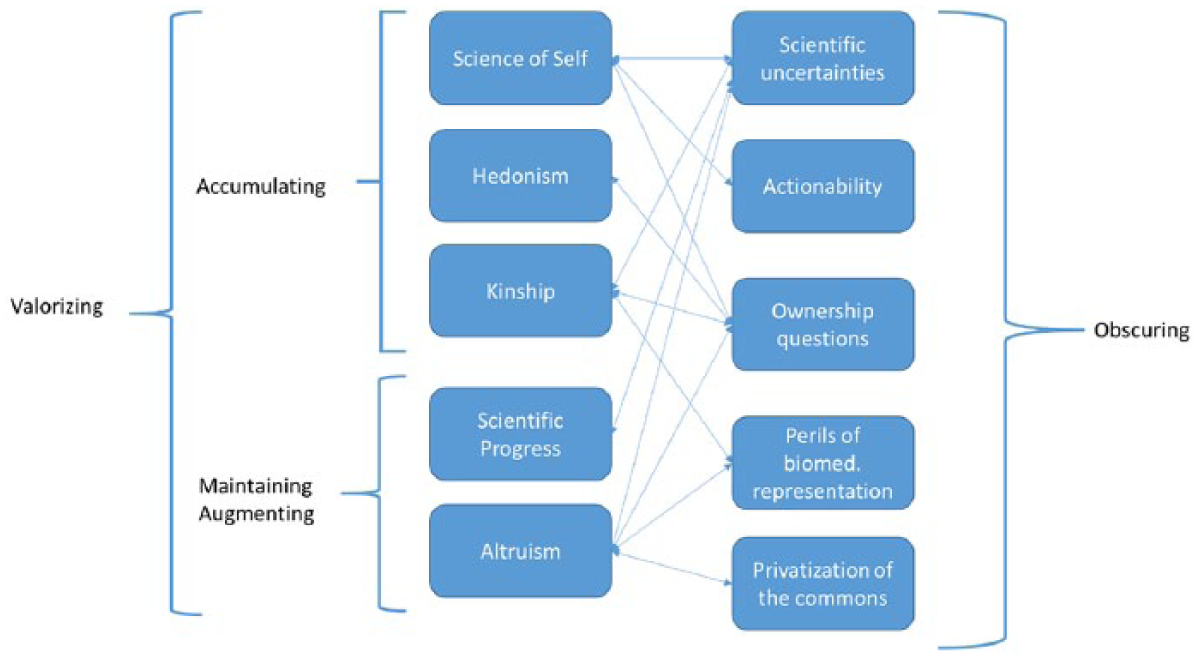
Valorizing and obscuring practices in consumer genomics.
Accumulation Strategies
Just as in other data capitalist business models, the first task to create economic value in the DTC industry is to assemble a large enough database. All other value flows described above hinge on the capacity of the DTC firm to accumulate, grow, and maintain this consumer-sourced data. Bioethicists have previously examined the social consequences of the mass creation of the genomic consumer in some detail (Curnutte & Testa, 2012). We focus in this section on the sales and marketing strategies that genomics companies employ to recruit a large enough community of willing data donors in the first instance. For this to happen, consumer genomics firms have to convince enough consumers that getting a genomic test is “worth it” for the retail price of, say, US$99. In other words, why would an ordinary consumer, shopping, for instance, in a retail pharmacy branch of Boots in the United Kingdom or Walgreens in the United States, decide to pick up a genomic test and throw it into their shopping basket? Or to click on the “order now” box when seeing a Christmas promotion for a testing kit on Amazon [8]? It is this one gesture, multiplied a million-fold, that is the central enabler to activate the three other value flows and to unleash the data tidal wave our title refers to. We identified three major valorization strategies DTC firms employ to persuade potential customers to engage in this gesture, which we will explore in turn: valorizing the science of the self, valorizing hedonism, and valorizing kinship.
Valorizing the Science of the Self
A central task of any DTC company is to convince consumers that there is valuable information “hidden deep” within their DNA, which can be revealed by DTC tests—as the 23andme Christmas advertising 2017 states, giving consumers “the gift of discovery” [9]. Ariosa Diagnostics, for instance, compels women to “demand clarity” and offers “a unique DNA-based method to achieve exceptionally precise results” [10]. Color Genomics, a company analyzing genes for common hereditary cancers, urges customers to “learn your risk for the most common hereditary cancers” [11], while Helix, the self-proclaimed world’s first app store for genomics, encourages customers to “crack your code” [12, 13]. Ubiome, a company that specializes in microbiome screening, tells customers to be a “citizen scientist” by “discover[ing] the bacteria that live in and on your body, and learn how diet and lifestyle factors affect your microbiome” [14].
Regarding the neoliberal assumptions underpinning this notion of a citizen or rather consumerist science, Dupras and Ravitsky (2016) have pointed to the “regime of truth” governing the field of epigenetics, which consists of a blend of molecularization and biomedicalization. Simply put, this twin notion signals a societal belief that if there is something wrong with me, (a) it can be explained through insight into my molecules and (b) it can likely be fixed (see also Clarke, Shim, Mamo, Fosket, & Fishman, 2003; Conrad & Leiter, 2004; Rose, 2008). The marketing communication strategy of DTC companies clearly plays within these two notions. For the largest DTC companies such as 23andMe, an intensive distribution strategy through major pharmacy chains, including CVS and Walgreens in the United States and Boots in the United Kingdom, further serves to normalize this valorization strategy. It also renders picking up a genomic test as an intrinsic part of a regime of the governance of the healthy self.
Valorizing Hedonism
Where health knowledge may not be the sole driver to motivate consumers to undergo testing, firms often engage in a second valorization strategy, which plays to consumers’ sense of hedonism and curiosity. A 23andMe advertisement entitled “Incredible You,” which celebrates individuality, aptly illustrates this strategy [15]. The company has also repeatedly utilized cartoon characters in their advertisements [16]. Helix entices consumers to “discover more about yourself . . . from the profound to the just-for-fun” [17] and dedicates an entire entertainment rubric to “fun” purchases, such as finding out what wines suit one’s DNA profile (Vinome package) or how one’s DNA stacks up against that of the world’s greatest athletes (Startline package).
Prior research has indicated that those availing of the service indeed experience considerable hedonic value from their unearthing of the hidden “incredible you” in the context of an increasingly narcissistic consumer culture (Dickenson, 2013; Harris, Kelly, & Wyatt, 2014; Ruckenstein, 2016; Saukko, 2018; Turrini & Prainsack, 2016). Even some of our expert interviewees admitted to a sense of curiosity and thrill doing these tests, referring to genomic sequencing as an “interesting dinner party conversation” and “a lot of fun [for] only US$100!” This appeal to consumers’ hedonism allows firms to shift perceptions from genomics tests as associated with health and illness toward likening them to experiential consumer goods. This move widens the potential target market for these tests from scientists of the self to just about anyone, regardless of whether or not they are currently concerned with health issues. This strategy is further pushed by mass consumer price promotions, such as the Independent Newspaper Group’s 23andMe discount coupons for 23andMe in September 2018. 7 It may well be that this shift toward testing as a hedonic consumption activity also leads to consumers lowering their guard about privacy concerns.
Valorizing Kinship
A third marketing strategy heavily employed by DTC companies is that of valorizing genetic kinship. The two largest DTC companies, Ancestry and 23andMe, both play heavily on the idea of interconnection. Ancestry.com, for instance, reportedly spent over US$100 million in 2017 alone on advertising this message to their potential target market (Regalado, 2018). Ancestry advertisements depict customers tracing their roots back to faraway geographies or finding unknown distant cousins. As for 23andMe, in one advertisement entitled “Surprisingly Interconnected” [18], the firm’s founder Anne Wojicki is shown saying “If I just look at you, how do I actually know what your background is? You look at me and you probably think I am European. But I actually have a tiny bit of Asian.” These “surprising interconnections” are always mobilized in a liberal discourse. In one YouTube video with this specific title on the Ancestry.com channel, a set of people are asked what their worst imaginable connection to another race would be. Lo and behold, the big revelation shows in each case that the “worst case” was not only true, but it also led to a shedding of tears and prejudices [19]. This appeal to people’s rootedness and connection is apt to awaken deep-seated human needs for belonging. Even renowned cognitive psychologist Steve Pinker found himself “thrilled” when a genomic test indicated Ashkenazi Jewish roots, making him suddenly feel “tangibly connected to two millenniums of history” (Pinker, 2009, n.p.). Where valorization strategies of self-knowledge and hedonism play on an individualizing register, notions of kinship clearly play on a collectivizing one (Rose & Novas, 2005).
Maintaining and Augmenting the Asset
As the previous section argued, the first step in data assetization is to unleash a continuous flood of customer-generated data. Yet the real economic value for consumer genomics companies lies in the continued ability to make these data available to third parties, thus maintaining the asset value of these data. This asset value is further increased through the flexible combination or “augmentation” of DNA data with behavioral or attitudinal data. Thus, ensuring both customer retention and continued engagement, including opt-ins to data reuse and participation in new waves of research, is vital in this business model. We identified two strategies to keep consumers encouraged to share the gift of their genomic insights and other personal data with third parties.
Valorizing Scientific Progress
With new data privacy policies currently coming into effect that regulate an individual’s right to be forgotten, such as the EU-wide General Data Protection Regulation, firms need to prevent consumers from opting their data out of reuse or requesting their deletion. DTC companies utilize the argument of a rapidly evolving genomic science to release new tests over time, which existing consumers can avail of based on their database record. Saukko (2018) argues that this strategy of leading consumers to always-new discoveries adds to the firms’ appeal by creating a sense of flow, not unlike that generated by data capitalist consumer firms such as Facebook. This strategy is most clearly visible in the emergence of platform service providers such as Helix, a “genomics app store” that prides itself on helping consumers to explore their DNA “for decades to come” [20]. Helix stores consumers’ DNA data for retesting in various lifestyle and medical contexts, with new applications emerging frequently and more promised continually. Helix DNA starter kits allow consumers to get their DNA sequenced once and for all, for as little as US$20. For an additional US$29.99, one receives a DNA passport promising “troves of DNA-based insights that grow over time,” including but not limited to traits like ancestry, appearance, and wellness (Saukko, 2018). Within its short existence since 2015, Helix has completed two venture funding rounds that are remarkable even for those used to large Silicon Valley valuations: a Series A funding round of US$100 million and a recent Series B funding round of US$200 million (see Table 1 and crunchbase.com). This financial stream clearly signals the robust confidence of Silicon Valley investors in the future value of such genomics-based platforms that present genomic information to consumers as the gift that keeps on giving.
Valorizing Altruism
The industry uses a second strategy to ensure customers’ continued engagement, namely the projection of a participatory research ideal (Harris et al., 2013; Prainsack, 2014; Saukko, 2018; Tutton & Prainsack, 2011). Indeed, slogans referring to a “crowdsourced healthcare revolution” are generously strewn across many DTC companies’ marketing collateral to elicit DNA contributions from the general customer base and/or from specific patient groups. Ancestry, for instance, states that “part of our mission is to advance research related to the study of human genetics, genealogy, anthropology and health” [21], while Color Genomics encourages customers to “give back” by providing their genomic sample for the purpose of “furthering research in under-studied populations” and to “support people in need” [22].
This strategy is often used when DTC firms seek insights into a specific patient community or when they coax existing consumers to fill out behavioral or attitudinal surveys with a view to augmenting extant genomic datasets with highly targeted information for particular data clients. One particular 23andMe advertisement poignantly illustrates this process. Entitled “Give us your hand,” it is narrated by Mohammed Ali’s daughter Lonnie Ali, who is extolling patients diagnosed with Parkinson’s disease to contribute to the company’s Parkinson’s research drive [23]. During our research, 23andme was recruiting consumers for a depression and bipolar study via Twitter, for which they offered free testing kits. The ubiquitous message is that this research is “for you and with you,” and the rhetoric employed leaves little space to question the societal or communal value of the research undertaken. Data provision is thus construed as a “donation” whenever firms seek consumers to opt in to make identifiable data available to third parties or when engaging in commercial research themselves.
Obscuring Uncertainties
West (2019) diagnosed selective transparency and information asymmetry as fundamental features of data capitalist businesses, particularly in relation to the tracking technologies these firms employ. We detected similar processes in the DTC industry. In our case, they were strategically deployed both to keep the tidal wave flowing and to erect a smoke screen between the BtC value flow and the other three flows in Figure 1. These strategies revolve around obscuring (a) scientific uncertainties, (b) the actionability of medical information, (c) ownership questions, (d) the perils of biomedical representations, and (e) the privatization of the genomic commons (see Figure 2).
Obscuring Science Uncertainties
Referring to Abby Lippman’s concept of geneticization, Weiner, Martin, Richards, and Tutton (2017 p. 2) point to genomic discourses’ reductionism, which suggests “that models of health and disease can be reduced to a set of (biological) components and that, in the end, genes determine health.” Many scientific commentators have highlighted that correlations between genomic information and disease status are at best directive rather than absolute, even claiming that consumer genomic test results are essentially “astrology” (Thomas, 2013, n. p.). However, DTC companies typically gloss over any scientific uncertainties associated both with the analysis methods and testing results. 8
On their homepage, 23andme boast that their “Genetic Health Risk and Carrier Status reports meet FDA criteria for being scientifically and clinically valid” [24]. In the frequently asked questions section “how accurate is the test,” Ancestry states AncestryDNA uses advanced scientific techniques to produce your results. We measure and analyze a person’s entire genome at over 700,000 locations. During the testing process, each DNA sample is held to a quality standard of at least a 98% call rate.[25]
In a 2017 version of their “how it works section,” Helix states that “Helix’s world-class laboratory then uses the most advanced technology to read your DNA—all from that one sample (amazing, right?)” [26]. In these statements, and despite early calls for modesty around claims made (Berg & Fryer-Edwards, 2008), any uncertainties surrounding the genomic knowledge gained from DTC tests are verbally obscured behind a language that projects scientific certainty and expertise. One needs to go digging deep into the firms’ terms of service to find hedging statements such as “Future scientific research may change the interpretation of your DNA. In the future, the scientific community may show previous research to be incomplete or inaccurate” [27]. This and similar statements on other firms’ websites betray the fact that many scientific experts keep warning against overreporting on an individual’s health status in a field where scientific insights change rapidly.
Obscuring Questions of Actionability
From a more pragmatic perspective, in their online marketing collateral DTC firms also evade the question of what kinds of medical information are actually useful for individuals to obtain. As genomic and ethics experts have pointed out, many genomic interpretations are not only scientifically uncorroborated, they are also a source of considerable and potentially unjustified anxiety. For example, 77% of people with an unfavorable Alzheimer gene component never go on to develop Alzheimer’s disease, whereas 47% of Alzheimer’s sufferers do not have a genetic mutation (Dickenson, 2013). The National Human Genome Research Institute (2017) admits that The Food and Drug Administration (FDA) has the authority to regulate genomic tests but it has to date only regulated the relatively small number of genomic tests sold to laboratories as kits . . . it does not examine whether the tests performed are clinically meaningful.
Skepticism over the meaning and actionability of the information conveyed is particularly justified in the absence of therapeutic treatments for genetic illnesses such as Parkinson’s or Alzheimer’s. For other hereditary diseases such as Huntington’s, carrier status information leaves would-be parents with the actionable but rather stark choice of avoiding biological parenthood or risking to pass on a deleterious gene. These uncertainties do not get voiced in DTC firms’ online marketing materials. In addition, out of the 15 firms we studied, two thirds do not offer genomic counseling once consumers have received potentially life-changing information—a situation that has not changed much since the industry’s beginnings (Berg & Fryer-Edwards, 2008).
Obscuring the Perils of Biomedical Representations
Related to our last point is the danger that increased genomic self-knowledge may lead to potential ruptures in individuals’ and collectives’ identities even if the information is not about life-threatening carrier genes (Brekke & Sirnes, 2011; Gibbon & Novas, 2007). Analyzing 23andMe’s African Ancestry Project, Merz (2016) outlines how DTC companies capitalize on individuals’ need for a sense of belonging, especially in populations that for historical reasons have seen their roots severed and their ancestry obscured. For these target groups, the promise of a genealogical empowerment is given despite the “sizeable uncertainties” and “highly contestable statistical probability” (Merz, 2016, p. 132) accompanying any indication of a definitive racial ancestry.
The consequences of genomic determinism may also occur at an individual level. The danger here is that we may become who or what our genomic tests tell us we are—for instance, prospective or proto-patients, if they reveal us to be at a higher risk of a disease, or over-anxious soccer moms, if our children are diagnosed with a “soccer gene” on Helix.com. As Pinker (2009) highlights, we may use knowledge of ourselves to analyze the genetic read-out, only to find this knowledge scientifically confirmed. While DTC tests are marketed heavily and distributed broadly, across the 15 companies we studied, we could not find a single warning about the potential psychological consequences of undergoing the testing procedure. On the contrary, as pointed out above, they are unanimously portrayed to enhance rather than threaten consumers’ self-knowledge and self-worth.
Obscuring Ownership Questions
Creating an asset always opens up questions of property rights (Park & Skoric, 2017). Without wishing to delve too deeply into the sizable scholarship around this area, property rights theorists typically distinguish between two types of rights of (self) ownership: control rights and income rights (Christman, 1991). Thus, ownership of one’s DNA should not only include full control over “the right to manage use by others,” but also “the right to the income and capital value” (Honoré, 1961). Yet with information on future use of data buried in lengthy T&Cs and opt-outs often hard to find, issues of data control, ownership, and benefits are often left ambiguous in the DTC industry. Even for specialists, the question of data ownership is impossible to answer. To our question of who owns her genomic data, one of our expert interviewees laughs and responds: I don’t think anyone can tell you that! I mean I have access to the data and have downloaded it. They still have my data, I think that a team of lawyers and judges would not be able to tell you who actually owns it.
This point, likely the most central for assetization purposes, is also the one where practices between the companies we studied diverge the most. Some DTC firms address questions of ownership and privacy frontally, while others engage in a great deal of obscuring this issue. Futura Genetics, a Vancouver-based company specializing in lifestyle and health care genomic testing, states in the “privacy and security” section of their website: “Your DNA test results are yours and yours alone” [28]. Similarly, MyDNA, an Australian company specializing in medication testing and personalized medicine, explains in its T&Cs: “My reports and genomic data will be treated as my property and will never be disclosed or shared with third parties” [29]. However, it is rare to find this level of transparency. A third of the consumer companies we researched had information about the ownership and transferability of data assets hidden in the small print of their T&Cs, informed consent, or privacy policy (see Table 2).
Small Print about Ownership/Transferability of Data Assets.

Labyrinthine statements around data access, use, and control have led critics to claim that while learning about their ethnic roots and unknown relatives, consumers of Ancestry, for instance, would find themselves handing over the ownership of their DNA perpetually and royalty-free with a world-wide license (Winston, 2017)—though the company has strenuously refuted these claims [30]. According to our analysis of the 15 firms’ privacy statements, it seems that for most companies, the use of identifiable data falls within privacy and consent policies such as the recent one drawn up by the FPF (2018). However, anonymized data seem to automatically lose its associated property rights, as this example demonstrates: If you do not complete a Consent Document or any additional consent agreement with 23andMe, your information will not be used for 23andMe Research. However, your
Two points are noteworthy in this context, especially in light of current data privacy debates. First, even fully anonymized data can be turned into a lucrative investment, so that questions of consent and (economic) benefit should always be discussed in tandem. Second, the term “reasonably” in the statement above indicates a blurring of lines between identifiable and anonymized data, as scientists have repeatedly demonstrated how anonymous genomic data can be reidentified through triangulation (Gymrek, McGuire, Golan, Halperin, & Ehrlich, 2013). We should also recall that the data assets these T&Cs talk about are wide-ranging and may include DNA samples, genomic data, self-reported health and trait data, relational data, and “other data about you,” as well as “other information you voluntarily share with us as we expand our Services, such as biosensor data recorded by mobile phones or activity trackers or health and wellness data collected from other devices.” [32]
In some cases, obscuring tactics around ownership sometimes go hand in hand with explicit denial of any benefits arising from data use. For instance, in its informed consent form, Counsyl Genomics specifically states, If any individuals or corporations benefit financially from studying your genetic material, no compensation will be provided to you or your heirs. [33] (our emphasis)
The issue of compensation raises the possibility that enterprising consumers may understand the value of this genomic asset and seek to self-manage its profit potential Airbnb-style. Among consumers, awareness of DNA’s commercial value seems to be slowly growing, according to this report: Mary O’Connor had long wanted researchers to decipher her genomic code to better understand a deadly heart condition that runs in her family. But the 52-year-old woman balked at providing a saliva or blood sample to researchers because they would neither promise to give her the results nor pay her for her trouble. O’Connor, of Nantucket, Massachusetts, finally submitted her sample in March after a start-up medical company, DNAsimple, gave her US$50 for it—no windfall, but enough to meet the monthly co-payments for three of her medicines. Plus, she’ll get another payment every time a new sample is needed. (Daley & Cranley, 2016, n.p.)
With this so-called biorights movement demanding “cash and control” (Daley & Cranley, 2016) of genomics information, a few firms have started to respond entrepreneurially to this shift in consumer sentiment. Sure Genomics, a personalized genomic testing start-up, charges a premium price of US$2500 for full genomic sequencing and testing. In return, the company promises customers to fully “own, access and examine their own DNA.” In their FAQ section, Sure Genomics states that “Upon request, we will assist our customers with sales transactions.” [34] Of course, such brokerage services would require putting a price tag on an individual’s DNA, something that is typically only considered of value when sold or acquired in bulk. They would also open up the possibility of targeting certain lucrative or high-need segments for the potential sale of their DNA, opening the door to a host of potential social consequences. We will briefly return to this point in our Discussion.
Obscuring the Privatization of the Genomic Commons
The issue of benefit from use explored in the last section plays at an individual as well as at a community level. As mentioned, the potential financial gain accruing to the firm of individuals’ participation in research requests typically remain obscured under the mantle of altruistic contribution to the advancement of future cures. Prainsack (2014) highlights that this participatory picture not only obscures the substantial financial value formed by the crowd, but also the fact that the step from enclosing a collective good into private property is a relatively small one. In 2012, 23andMe caused outrage among patient groups when it became known that it had filed patent applications for the development of a range of genomic tests and treatments, which would limit rather than broaden access to research results based on gene data “donations” (Sterckx & Cockbain, 2014).
As of 2017, it remains impossible even for an analytical eye to ascertain the true purpose of many of 23andMe’s research partnerships from their press releases and other promotional materials. In one recent case where the firm recruited 4,500 women in record-speed for a fertility project under the header of “collaborative science,” the only information indicating the commercial nature of this project is a cosponsorship by a “personalized fertility health company” [35]. In another recent case of a partnership with a pharmaceutical company on pain tolerance, a company spokesperson reportedly “didn’t give much detail on what 23andMe will do with the data, other than to say the results ‘may help develop a more personalized approach to pain medication’” (Mullin, 2017, n.p.). What becomes clear in these formulations is that any notion of citizen science goes hand-in-glove with a heavily financialized business model, where citizen science may quickly lead to the privatization of the genomic commons.
Discussion
When the human genome was first sequenced in the early 2000s, the public imaginary of genomic science was rooted in a better, healthier future for all (Dickenson, 2013). At the same time, commentators started warning against the dangers of a privatized and largely unregulated industry (Berg & Fryer-Edwards, 2008). Our argument in this article is that this rapid privatization and consumerization created an industry that is based on the extraction of economic value from lively matter as much as it is based on the large-scale accumulation and assetization of individuals’ data points. Consumer genomics firms cannot be fully understood or constructively criticized unless we focus on their intersections with data capitalist practices and the heterogeneous market relationships they entertain. While some of their marketing strategies may be regulated through “truth in advertising and promotion standards” (Williams-Jones & Ozdemir, 2008), the fact that these strategies facilitate further and more significant value flows elsewhere in the market calls for a broader analysis of these firms’ market practices.
Our assetization lens complements the current focus on data privacy and other ethical issues related to this industry (Dickenson, 2013; Merz, 2016; Prainsack, 2014) with a broader market perspective, drawing particular attention to the various value flows that DTC firms maintain. We add to the assetization literature by supplementing Birch’s (2017) analysis of investors’ valuation processes in biotechnology, studying the specific strategies through which firms prepare the ground upon which these valuations happen. In relation to recent work on data capitalism (West, 2019), we demonstrate that data capitalist practices of creating information asymmetries and selective transparency have spread far beyond the realms of the consumer Internet giants into industries including health care. As we highlighted, in addition to concerns about individual exploitation common across data capitalist realms (Zuboff, 2015), in health care these processes also obtain a critical societal dimension (see also Vezyridis & Timmons, 2017). We contribute to emerging social sciences commentary on so-called digital health industries by analyzing the valuation strategies at one of the intersections between health care and technology. Finally, our twin focus on the parallel deployment of valorizing and obscuring strategies deepens existing insights into the making of the neoliberal health consumer. Pointing to what in essence look like relatively mundane marketing practices of customer acquisition and retention, our findings may help explain why this industry has by and large evaded public outcry and scrutiny outside academic circles (Finlay, 2017).
The market practices we have analyzed beg the question whether the value flows we have identified could be redirected and made to work for either individual, communal, or public benefit rather than commercial gain. While our data do not allow us to answer this important question, in the remainder of this section we will briefly point to debates around alternative market mechanisms centering on fairness and distributive justice. Four such debates in particular may prove relevant in the context of consumer genomics and digital health more broadly. We will discuss these here as an agenda for future research.
Property Rights or Compensation for Individual Benefit
The introduction of individual property rights and/or compensation for use is discussed in both data and biomedical markets. Individualized market-based schemes for valuable bodily material have been thought through in relation to tissue, blood, and marrow bone donations (Hayden, 2018; Truog, Kesselheim, & Joffe, 2012). In data markets, discussions around individual compensation often revolve around the feasibility of de-aggregating data “assets” to the individual level. An individualized compensation scheme for consumer genomic data would come closest to the emerging consumer-centric platforms we alluded to in the last section; in the BtC value flow in Figure 1, money would now flow both ways. However, in parallel to tissue or egg cell markets, such individualized market-based schemes may exploit those consumers who may be dependent on these payments for survival (Waldby, 2008) or those whose data are worth most. There would also be a danger of market-based exchange eclipsing any possibility of communal sharing (Truog et al., 2012). Practically, reinstating individual property rights to genomic data in compensation terms would depend on (a) estimating the prospective value of the agglomerated and de-aggregated asset; (b) individuals exercising these rights, which may only be done by an informed minority; and (c) on the unequivocal attribution of such property rights. This is nontrivial: Genomic data are by essence relational and shared, and the issue of whom they belong to and who should be compensated is bound to quickly lead into cultural and legal impasses (Hayden, 2018; Prainsack, 2017).
Communal Property Rights or Benefits
Debates around trust funds and other benefit sharing schemes move away from the notion of individual gain or compensation toward a community-based perspective on genomic assets and compensation (C. Hayden, 2008; Prainsack, 2017). Early suggestions for genomic trust funds or shareholder schemes, for instance by Winickoff and Neumann (2005), proposed communal handling of property rights and management of donated genomic and informational resources. Benefit sharing means that any test or drug developed on the basis of commercial DNA databases would be available, at no or much reduced costs, to the community that donated the DNA in the first place. It would also likely require that the governance of the communal asset is shared, or that there is at least some communal oversight—similar to community banks or building societies in the financial world. While the notion of communal shareholding is interesting for those groups or communities who share a distinct sense of “biosociality” (Rabinow, 1996), such mechanisms may not be realistic for the large-scale consumer databases accumulated by DTC firms.
Redirecting Value Flows for Societal Benefit
Moving toward fully solidarity-based mechanisms for sharing the economic benefits of genomic assets would lead us into the world of levies and taxes. Taxes in consumer genomics have been discussed as early as the year 2000 when the Ethics Committee of the World Health Organization (WHO) recommended a 1% to 3% levy on net profits, to be used for public health infrastructure (WHO, 2002). Recent calls for a value-added tax system on data brokers and social media platforms have taken a similar slant (Madsbjerg, 2017). These levies could be utilized to address the social determinants of health and alleviate health inequalities (WHO, 2002). Thus, while the asset itself would be owned by the firm, some of the economic value reaped through Figure 1’s value flows would roll back into society. Practical barriers for a tax-based mechanism may parallel those currently seen in data markets where determining firm profits and designating fiscal jurisdictions for them have proven challenging.
Un-assetizing the Data Asset
This last debate revolves around the question of whether the enclosure of genomic data should be prevented in the first place (Baack, 2015; Wilbanks & Topol, 2016). McGowan and colleagues (2017) studied a genomic “bio-hacker” movement, which challenges private and public institutional genomic research processes through a citizen science model of participant-driven genomic research. The movement has as its central ethos the desire to “democratize” the creation and sharing of genomic knowledge. McGowan and colleagues illustrate that though not fully free of the shackles of the data-capitalist market (after all, databases still need to be hosted somewhere), these groups at least attempt to reinstate communal sharing of genomic information and thus preserve its public good character. At the same time, their lack of institutional embeddedness raises questions over the ethical oversight of their activities, including confidentiality, security, and issues of inclusion and exclusion (Rothstein, Wilbanks, & Brothers, 2015). An example of these dangers could be seen in the recent controversy around the use by law enforcement officers of an open source genomic database to catch the so-called “Golden State Killer” (Scudder, Robertson, Kelty, Walsh, & McNevin, 2018). Thus, while radically disrupting the value flows we have identified above, open source genomic databases would need to be governed within tight regulatory bounds. Overly romanticized notions of open access and open source knowledge may also overlook the danger of private companies exploiting these collective efforts at other points of the intellectual property value chain (Lezaun & Montgomery, 2015). As with any of the four debates alluded to in this section, future social science research may help frame this debate conceptually and empirically and evaluate the strengths of the proposed mechanisms vis-à-vis the continuing enclosure of genomic data.
Concluding Remarks
With our analysis of assetization practices in the consumer genomics testing industry, we add to a better understanding of the current intersection between bio- and digital economies. Reflective of neoliberal trends in health care more broadly, these firms’ business models currently create points of no return with regard to the long-term enclosure of the genomic commons. Perhaps more importantly, in a “postgenomic” era where the promissory value of epigenetics lies in combining genomic with contextual and environmental knowledge (Dupras & Ravitsky, 2016; Pickersgill, Niewöhner, Müller, Martin, & Cunningham-Burley, 2013), the intersection that these firms occupy between biomedical and data markets is a unique one. Accordingly, the databases they currently accumulate are unique in the long-term value they hold—but also in the risks they represent when these data are appropriated, assetized as part of a larger pool, put to secondary and often nonconsented uses, and potentially reidentified at any point.
We conclude optimistically by trusting that it is not too late to stem the tide of “inevitability” that this industry conjures up. We call upon social scientists to focus on these health care/data intersections as a new and as of yet barely charted chapter in the medicalization debate, a chapter where the datafication of health can create new identities, power registers, and social divides (Fiore-Gartland & Neff, 2016; Ruckenstein & Schüll, 2017; Saukko, 2018). Within the confines of our study, we were only able to briefly sketch current market practices in one such industry. We hope that future research may help further the debates we referred to around alternative market possibilities, leading to a robust and empirically informed discussion around the ethics and implications of what gets valued and how in the bioeconomy.
Supplemental Material
BAS_18_0090_R2_Appendix_to_Sage – Supplemental material for A Tidal Wave of Inevitable Data?: Assetization in the Consumer Genomics Testing Industry
Supplemental material, BAS_18_0090_R2_Appendix_to_Sage for A Tidal Wave of Inevitable Data?: Assetization in the Consumer Genomics Testing Industry by Susi Geiger and Nicole Gross in Business & Society
Footnotes
Acknowledgements
We thank the Business & Society Associate Editor Dr. Judith Schrempf-Stirling for the expert handling of this article’s revision process and for her and the reviewers’ many constructive comments and observations. We also thank the participants of the 2017 EGOS subtheme 28 “The Politics of Valuation” and the 2016 Macromarketing Conference for their observations and suggestions on earlier versions of this article. Thanks to our interviewees for their time and insights. All interpretations and errors are of course ours.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Susi Geiger has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement No. 771217) while writing this article.
Notes
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.