
Abstract
The prevalence of human trafficking has remained as elusive as the method of producing its estimation is contested. There are significant variations in the way prevalence estimation is produced, with some methods garnering more attention than others. To complicate the issue further, the hidden nature of human trafficking makes it difficult to apply conventional probability-based sampling strategies, without which for reference purposes one cannot easily assess the merits of alternative estimation techniques. This special issue represents the most recent development and applications of one particular method, the multiple systems estimation (MSE) method. Although we remain biased towards primary data for prevalence estimation, MSE represents a cost-effective alternative for the purposes of advocacy, policymaking, and victim services.
Keywords
Introduction
A group of applied methodologists and statisticians gathered in Edinburgh in 2019 and engaged in a 2-day lively debate on ways to improve prevalence estimations using varied techniques in triangulating existing records, or the multiple systems estimation (MSE). The products of the 2-day conference, seven articles in total, are presented here in this special issue. These papers represent the most current development in the application of MSE in different settings and suggestions on how to improve the prevalence estimation of human trafficking with existing records. In all circumstances, the authors offer candid views on the strengths of the MSE techniques as well as suggestions for further improvement.
Background
Since the passing of the United Nations Convention against Trafficking in Persons (or the Palermo Convention) 2 decades ago, the anti-human trafficking movement, led by the West with a frequent focus on sex trafficking, has spread around the world. The Palermo Convention established the legal definition of human trafficking, and most countries have now ratified the Palermo Convention and established legal and structural mechanisms to combat human trafficking. Anti-trafficking activism has also attracted tremendous attention as well as resources from both government agencies and civil societies. According to a study by researchers at the United Nations University, between 2000 and 2013, 30 donor countries committed more than $4 billion in efforts against human trafficking, with the US being the largest funding source accounting for about 60% of the global total (Gleason & Cockayne, 2019).
Despite the worldwide attention and global anti-trafficking efforts, much confusion remains about the extent and severity of the problem globally or locally. For instance, in a literature review of 94 articles, Okech et al. (2018) found much of the current trafficking research lacks a clear conceptualization and definition on trafficking, as well as evidence-informed empirical research to inform programs, practice, and policy. Varied estimations have been circulated, so much so that researchers are questioning the veracity of the claims made by a few sources of information that have come to fuel the global movement against human trafficking (see Weitzer, 2011, 2014; Zhang, 2009, 2012). For instance, Fedina (2015) conducted a systematic review of trafficking research literature on prevalence and found that the vast majority of published books use existing data that were not rigorously produced. Fedina sounded the alarm that continued use of such unsubstantiated data may be misleading and even detrimental to the anti-trafficking movement. Weitzer (2014, p. 9) listed specific examples of a few notable macro-level prevalence estimations that seem to make little sense and with limited empirical data. These critics question the empirical foundation of some of the common claims that have been widely circulated about human trafficking: (1) the number of trafficking victims worldwide is huge, (2) the magnitude of trafficking is steadily growing worldwide, (3) human trafficking is the second or third largest organized criminal enterprise after illegal drug and weapons trading. These researchers are calling for greater attention and emphasis on gathering primary data to support policymaking and to guide law enforcement and intervention efforts.
Despite the dissenting voices that challenge the appropriateness and methodological rigors of the various prevalence estimation methods, there are political and moral imperatives to produce such estimations. To inform policy makers and victim support groups, as well as law enforcement agencies, many researchers have moved forward to doing just that—estimating the size of the dark figure. The importance of producing reliable estimates is self-evident, but the reality is often replete with complications and challenges that have long been noted by the research community (De Cock, 2007; Gozdziak & Collett, 2005; International Labor Organization [ILO], 2011; Laczko & Gozdziak, 2005; Laczko & Gramegna, 2003; Tyldum & Brunovskis, 2005; Zhang, 2009).
Estimating Hard-to-Reach Populations
Most of the challenges that confront the prevalence estimation of human trafficking can be summarized into two categories: (1) counting rules (i.e., what to count as human trafficking activities) and (2) estimation strategies (i.e., data collection and calculation methods used to estimate the size of the victim population or the scope of the problem).
The first category of problems deals with the operationalization of international or country-specific legal frameworks into measures or survey instruments. This is no easy task because there are few agreements on how to translate a legal framework into specific items. Throw in additional measures of risk/protective factors associated with victimization and profiles of the victims, the neatly packaged legal codes quickly become messy. Those of us who have worked on primary data collection over the years would agree that one major obstacle in obtaining valid estimates of human trafficking is the general lack of consistent and uniform measures that researchers can use for data collection purposes (Zhang, 2012). Many studies have reported prevalence estimates of labor trafficking, in which researchers all claimed to adhere to the legal framework of the ILO Convention, the United National’s Palermo Convention, or the U.S. Trafficking Victims Protection Act (TVPA). Comparative analysis is all but impossible because of the inconsistencies in the operationalization of the legal frameworks, that is, the actual translation of legal concepts into specific measures. This situation is akin to public health researchers applying varied diagnostic criteria to a disease under investigation. One can only imagine the difficulty in producing macro-level prevalence estimations under such a circumstance. Whether it is called human trafficking, forced labor, modern slavery, or some other terms, global knowledge and progress will be difficult to measure if we cannot agree on the commonalities of these human experiences. In the past decade, the research community has made much progress on measurement issues. One such example is the publication by ILO (2018) of guidelines concerning the measurement of forced labor, representing a significant step in moving the field towards greater standardizations in measures as well as analytical strategies. There are continuing efforts led by such agencies as the ILO and US State Department to improve the standardization in measuring various forms of human trafficking in a global context.
The second category of the challenges deals with data collection and subsequent estimation strategies. To a great extent, how we estimate the extent of any social problem is often determined by the form and quality of data we can afford to collect. Human trafficking can be estimated with two data sources: (1) cases already known to the authorities and social service agencies, or reported in the news media, in which case records of some sort exist for secondary data analysis, and (2) primary data collection, in which various sampling strategies are applied to generate estimates. Much of our current knowledge on the scale of human trafficking reflects findings based on existing records, prime examples of which include the estimates produced by the International Labor Organization (ILO, 2012) and the Global Report on Trafficking in Persons issued by the United Nations Office on Drugs and Crime (UNODC, 2016).
Prevalence Estimation through Primary Data
Few doubt the merits of collecting first-hand data (i.e., primary data) to estimate the prevalence of human trafficking. Because of the perpetual challenge of funding, most prevalence studies have thus far been limited in scale and location, which prompted doubts on the feasibility of estimating human trafficking activities at a macro-level. For instance, Weitzer (2014, pp. 13, 14) listed specific examples of a few notable macro-level estimates gone awry.
The GSI Model of Extrapolation
Since global surveys of human trafficking are prohibitively expensive and logistically impractical, some methods of extrapolation (or generalization) have been developed, in which local and regional data points are collected to produce global estimates. An extrapolation or scale-up scheme must be developed to generalize what is known to estimate the unknown. As additional local and regional data become available, such a conjecture strategy should improve over time.
The most prominent extrapolation example is the Global Slavery Index (GSI) 1 , produced by Walk Free, an anti-slavery organization based in Australia, 2 which employs the Gallup World Poll to strategically collect respondent data across multiple countries. An extrapolation methodology using hierarchical Bayes models was developed to take into account respondent-level survey data and country-level predictors from the current GSI vulnerability model in order to estimate the prevalence of modern day slavery beyond the current sample of 48 countries. The country-level vulnerability scores are used in the multilevel models to improve predictions for countries where no survey data exists. This approach is based upon the belief that countries with similar socio-economic and political conditions will likely share similar levels of slavery. Furthermore, GSI’s vulnerability model has gone through several iterations and reviews since its first appearance in 2014. Based on human security and crime prevention theories, the vulnerability model consists of 23 variables grouped into five dimensions; (1) Governance Issues, (2) Lack of Basic Needs, (3) Inequality, (4) Disenfranchised Groups, and (5) Effects of Conflict. Similar estimation efforts are routinely employed by demographers who must study population trends and shifts between censuses. Extrapolation strategies are also frequently used in public health to estimate the prevalence of diseases. Such an extrapolation scheme is an excellent alternative when national surveys are unavailable or impractical to obtain.
De Cock (2007) reviewed several strategies to assess the extent of trafficking activities, including national surveys to estimate prevalence, establishment-based surveys to target the specific labor sector, qualitative studies to seek in-depth knowledge of the nature of trafficking victimization, and a national database to gather all cases that came to the attention of police or service organizations. Although rare, there have been some studies using the traditional survey methods. Most of these efforts were focused on specific labor sectors and at regional scales around the world. The best example was probably the survey conducted by the Gandhi Peace Foundation and National Labor Institute in the late 1970s, which drew a random sample of 1,000 villages in 10 Indian states where peasants were widely known to be attached to the landowners (Sarma, 1981). The study estimated that there were 2.6 million bonded laborers in India. Another example was a study in Cambodia, in which the researchers used geographic mapping techniques and informant-interviewers to estimate the population of sex trafficking victims in the country (Steinfatt & Baker, 2011), applying an innovative field method to map out all sex work venues. More recently, Zhang et al. applied two conventional sampling techniques (i.e., household-based sampling and time-location sampling) to estimate the scale of bonded labor and the worst forms of child labor in the Indian state of Bihar (Zhang, Dank, Vincent, Narayanan, & Balasubramaniam, 2019; Zhang, Dank, Vincent, Narayanan, & Bharadwaj, 2019). While slow, these large scale prevalence estimation studies have appeared here and there, depending on the interest of funding agencies as well as committed resources.
Respondent-Driven Sampling
For most trafficking victims there are no sampling frames suitable for conventional probability-based sampling strategies. In recent years, researchers have been developing and applying various techniques in hopes of developing parametric estimates of the “hidden” population. Heckathorn (1997, 2002) developed a network-based method called respondent-driven sampling (RDS) that purports to eliminate the biases inherent in traditional snowball sampling techniques. The RDS approach relies on a Markov process to achieve diversity and equilibrium (the point at which successive samples/waves no longer mirror initial samples) through several waves of recruitment. This method modifies the traditional snowball sampling design through two basic changes: (1) it employs a dual-incentive system whereby subjects are rewarded for both participation and for recruiting others into the study; (2) by using referral coupons, subjects do not have to identify referrals to a researcher and the resulting anonymity encourages participation (Heckathorn, 1997).
By confining the recruitment opportunities through a structured process, diversity is ensured and thus can be empirically verified. Volunteerism is minimized, as a dual-incentive system is believed to encourage both participation and recruitment. Such a recruitment procedure prevents researchers from deliberately seeking out particular subjects. “Masking” is minimized since researchers are not pointed in the direction of group members, but rather, recruited by group members themselves. Homophily is also minimized since recruitment is limited to three subjects per participant, and equilibrium can be achieved through a relatively small number of waves. Finally, RDS minimizes biases that may be introduced by those with larger personal networks. The RDS method has been successfully used in many studies on hard-to-reach populations (Abdul-Quader et al., 2006; Heckathorn, 1997, 2002; Robinson et al., 2006; Zhang et al., 2014). In the field of human trafficking research, RDS has continued to receive attention from empirical researchers. For instance, Gupta et al. (2011) applied the RDS method in 2006 in the coastal state of Andhra Pradesh, India and recruited a total of 812 female sex workers on their experiences in sex trade. The study found that about 20% of these respondents would meet the UN definition of sex trafficking. Female sex workers who were trafficked were more likely than non-trafficked sex workers to experience violence and worked more days per week.
Vincent Link Tracing Sampling
More recently Canadian statistician Kyle Vincent devised a sampling strategy, the Vincent Link-Tracing Sampling (VLTS, named after its principal developer) that retains the features of conventional probability sampling with traditional RDS recruitment process (Vincent & Thompson, 2017). Briefly, VLTS draws on any existing sampling frames (comprehensive or partial) to develop a large initial sample. The initial sample can be based on conventional sampling designs such as simple random sampling, stratified random sampling, or systematic sampling that are based on available, albeit imperfect, sampling frames, and then individuals are recruited for two to three waves from personal networks of the respondents in the initial sample or seeds. These networks are further explored to identify overlaps between individual from different networks. In other words, upon the selection of the initial sample, one can develop referrals or nominations where social networks can be mapped to identify overlaps, thus adaptively building up the final sample. A Rao-Blackwell inference strategy outlined by Vincent and Thompson (2017) and Vincent (2019) can incorporate additional respondents selected through link-tracing into the inference procedure to allow estimation of population parameters.
Ultimately, VLTS uses all available resources, in the form of auxiliary information based on knowledge of the study population, to obtain as representative a sample as possible early on in the study. As a result, one need not obtain a large number of additional waves, in contrast to conventional RDS, before unbiased estimation strategies can be applied. This strategy allows for more sophisticated network analyses and efficient population size calculations through mark-recapture techniques. The development of VLTS was inspired by the works from the likes of Thompson and Seber (1996) and Frank and Snijders (1994), who studied unevenly distributed populations like endangered species or highly clustered hidden drug-using populations. The method exploits the ability of observing adjacent (neighboring) units of sampled individuals once a unit of high-interest has been found. Estimation of the size of a hard-to-reach population with an adaptive sampling design has received some attention in the literature. Felix-Medina and Thompson (2004) later developed a method based on the assumption that recruitment can be accomplished through the availability of a partial sampling frame for the hidden population and that referrals are made in a predictable fashion.
Network Scale-Up Method
Another method that has gained much attention in recent years on prevalence estimation of hard-to-find populations is the network scale up method (NSUM), as detailed in Salganik et al. (2011). The first serious application of this method in estimating unknown population was by a team of anthropologists, mathematicians, and social network analysts who were attempting to estimate the number of deaths from the large earthquake in Mexico in the fall of 1985. The method rests on the assumption that people’s social networks (i.e., the set of people that you know) are on average representative of the general population in which you live (Bernard et al., 1991; Killworth et al., 1990). For example, if a sample of respondents reported knowing 300 people each on average as the size of their personal network, and on average they reported that two from their personal network died from the earthquake. Then we can assume approximately 2/300th of the general population may have died from the earthquake. Since there is census-level information or known population characteristics about the city, we can apply this method to estimate population sizes of particular interests.
The NSUM can be attached to any probability based sampling procedures because it requires only a set of uniquely designed questions to elicit response on their knowledge of (1) people within their own personal network with particular characteristics (i.e., victims of forced labor), (2) estimations of some known sub populations as references. There are several approaches to estimating personal network sizes, including summation and known population estimators (Maltiel et al., 2015), and more generalized NSUM (G-NSUM) models (Feehan & Salganik, 2016). Essentially respondents will be asked a series of “how many X do you know” questions, where X corresponds to several subpopulations of known and unknown size. Known groups correspond to reference groups where the size and scope has been measured, such as people in the United States who have diabetes; unknown groups correspond to the target population of interest (e.g., sex workers). One will need to adjust for differences between these reference groups and those hidden populations as well as respondents’ views concerning the hidden population being estimated. Because NSUM does not ask respondents to identify any individuals with particular characteristics (including themselves), it is believed to be able to improve honesty in the response. Because NSUM items can be attached to a regular social survey, significant cost-savings can be achieved by searching for “hidden” populations.
Estimating Prevalence Using Existing Records
Despite the wide variations in the current prevalence estimations of human trafficking, there is little disagreement that official crime statistics represent the tip of the iceberg, under which lies a large “dark figure,” a criminology parlance referring to the gap between crimes that are reported and crimes unknown to the authorities. In recent years, MSE has gained much attention in the human trafficking research community because of its attractive features in prevalence estimations.
How MSE Works
The basic logic of MSE is fairly straightforward, as it is an extension of the classic mark-recapture estimation technique. When one human trafficking victim appears in one agency’s list, it is considered “marked,” and if the same individual shows up in another list, it is considered a “recapture.” The number of individuals who are marked on one list (or sample) is used to estimate the population size, based on the principle that the proportion marked in the second sample approximately equals the proportion of marked individuals in the population as a whole, as shown in the following classic Lincoln-Petersen estimator (Petersen, 1896),
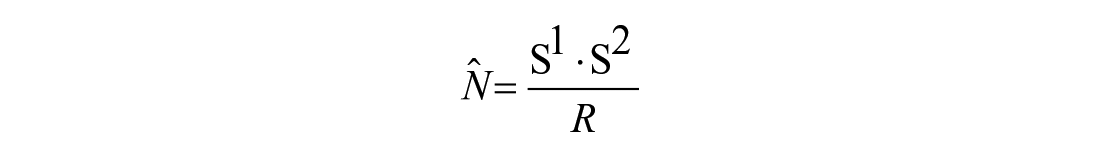
where S1 is the number marked and released into the population (i.e., the size of the first sample), S2 is the size of the second sample, R is the number recaptured in the second sample, and
However, mark-recapture methods, typically used for estimating wildlife populations, face different sets of challenges when applied to human populations. For example, the recruitment patterns of human populations can be radically different from wildlife populations, for instance in the form of “self-selection.” One cannot assume the same level of independence or “by chance” for human beings who come to the attention of the authorities or service providers. There may also be a diverse set of administrative lists that the researchers must face in the mark-recapture analysis, and the records captured for these lists are typically collected through many different mechanisms (like police records, hospital records, and site sampling of victim service providers) with little or no consistency in data keeping. Furthermore, researchers must make allowances for human movements to and from the target population over the course of the study, and take into consideration varied situations of the capture occasions and heterogeneity effects corresponding to the population of interest. Sophisticated mark-recapture models therefore are usually required to obtain meaningful estimates. With the arrival of mark-recapture software, statisticians are able to carry out sophisticated analyses with increased ease these days. 3
MSE has received increased attention from the research community. Among the most prominent examples is the global estimation of forced labor conducted by the ILO, which put the total number of victims at around 20.9 million in the world, with the vast majority being exploited by individual employers or private enterprises (ILO, 2012). Essentially, the ILO sampling method relied on the use of two separate and independent teams of research assistants to build an independent database of all reported cases of forced labor each team could find in order to exploit the principle of mark-recapture. The idea is that if one team searches and finds all reported cases of forced labor, these reports will represent a sample of identified forced labor incidents. If both teams capture the same reported cases, they will represent the overlap between the two “independent” samples. Following this logic, the basic mark-recapture model assumes a binomial probability distribution of the sample cases. Therefore, a trafficking report is either “captured” or “not captured” with respective probabilities p and 1−p. The values of p are the same for all reports but may differ between the teams, say p = p1 for team 1 and p = p2 for team 2.
Despite this significant undertaking, the ILO acknowledges the limitations of using existing victim reports and calls for increased efforts in primary data collection through national or regional surveys. However, at that time, primary data systematically collected from around the world was not available to generate global estimates. This global estimation proves that it is possible and a statistically sound exercise to take advantage of existing records that often represent some of the worst cases in human trafficking violations. Moreover, the ILO method can be enhanced. For instance, one could explore multiple recaptures where, for instance, four teams of research assistants are assigned to look for reported trafficking cases with each team representing an independent sampling occasion.
Advantages of MSE
There are several advantages in the use of MSE. First of all, MSE is probably the least expensive method to produce prevalence estimation of forced labor. Using existing records, this method can come up with statistically sound figures by taking advantages of the overlaps among different agency data systems. The statistical principle behind the estimation technique is simple yet elegant. In the absence of other more rigorous data collection methods, MSE is an efficient and cost-effective way to obtain some indication on the scope of the problem.
The use of MSE in estimating human trafficking and other forms of human trafficking is on the rise, although most of which occurs outside the U.S. Silverman (2014) was among the early adopters of MSE to produce human trafficking estimation. Using the records of 2,744 potential victims of human trafficking in the official records to identify the overlaps between different registries that came to the attention of the authorities or social service agencies. Silverman (2014) estimated that the “dark figure” or cases unknown to the authorities were between 10,000 and 13,000 potential victims in the UK in 2013. Bales et al. (2015) applied mark-recapture type strategies, referred to as multiple systems estimation (MSE), to lists/records of human trafficking victims to estimate the prevalence in the UK. Cruyff et al. (2017) applied MSE techniques that incorporate covariate information to estimate the prevalence of human trafficking in the Netherlands. Lyneham et al. (2019) applied MSE to estimate the number of human trafficking victims in Australia in 2015 to 2016 and 2016 to 2017, and put the number between 1,300 and 1,900 or approximately four undetected victims for every victim detected. Most recently, Farrell et al. (2019) completed perhaps the first empirical application of MSE using administrative records inside the U.S., citing incomplete and missing records as the most serious challenge in producing robust MSE estimations.
Limitations of MSE
Although MSE has its inherent advantages as discussed above, the method is not without its drawbacks. The biggest one is the way existing sources of data were created in the first place. As with most prevalence estimation methods, MSE-based findings should be treated as tentative at best, because, as Silverman (2014) put it, the modeling assumptions cannot be easily verified and the data sources also have limitations. One obvious limitation is the officially identified victims registered either by government or community agencies represent a very small fraction of the potential population, which in turn also limit the subsequent estimations.
There are multiple challenges in constructing the lists that enable the varied MSE estimation strategies discussed in this special issue. Existing records compiled by government or community agencies rely on the willingness of survivors or victims to divulge personal experiences. For two primary reasons, trafficking records are not easy to collect. First, victims or survivors are often reluctant to report their experiences for fears of repercussion or embarrassment, inadequate assurance of personal safety, possible abuse by law enforcement representatives, a general lack of trust among victims or survivors, or inadequate training and tools of law enforcement to identify trafficking victims. As mentioned earlier, inconsistencies in record keeping also make official lists difficult to compare. These challenges in record collection and compilation combine to threaten the validity of MSE estimations.
Further, sex trafficking and labor trafficking, while overlapping occasionally under special circumstances, mostly occur in very different labor sectors and therefore demand different investigation entities and service providers. The varied service needs and victimization experiences thus create additional layers of complexities in data tracking and recording, which may introduce further complications to subsequent data pooling for MSE estimations.
There are other limitations with the MSE estimation approach. First, mark-recapture methods rely on independent samples from a “hidden” population that is impossible or impractical to enumerate, such as draining a pond to count all the fish. In other words, it is difficult to establish the probabilities or control for “self-selection” bias among victims who come to the attention of the authorities. For instance, in a study of forced labor by Owens et al. (2014), of all the victims identified in 122 labor trafficking cases, none were rescued by the authorities or the social service providers while they were in the middle of their abuse. They found their ways to reach these service providers who later identified them as victims of trafficking, months after they had left the abusive work environment. In other words, the odds of being “captured” as an independent sample, a requisite in mark-recapture analysis, are never easy to establish in existing official records.
Second, publicly available records, such as those used by the ILO in its global estimation, are mostly accessible via some publicly available venues, especially the internet. If all teams of research assistants under the ILO study are doing their utmost due diligence, theoretically they should find all known cases of trafficking reported in the media, government reports, or agency reports. Therefore it is fair to say that trafficking cases uncovered by all teams of research assistants could be identical and the overlap should be 100%, or close to it. If the overlaps between two “independent” samples are perfectly matched, the mark-recapture method becomes pointless.
Third, there will inherently be some dependence within lists, that is, that the probability of one “source” being captured can easily influence another “source” being captured on the same sampling occasion (i.e., by the same research team). For example, a magazine may report two or more cases of trafficking victims being rescued in a major city. Evidently, if one case is captured then it is very likely that the other case will also be captured. This violates one of the basic assumptions in mark-recapture, that is, that capture probabilities between individuals are independent within sampling occasions.
There are, however, ways to mitigate these problems. For instance, one can avoid sampling with dependence within sampling occasions by recording only the first captured case that the team encounters, stopping, and then starting from scratch to find a new captured case. Also, one can possibly use the original approach to come up with a semi-exhaustive set of captured cases, randomly permuting them and then taking the final sample to be every kth captured case in the permuted list. One can also repeat the mark-recapture inference procedure by re-permuting and evaluating the estimator over these lists, each based on the kth entry. This strategy helps to reduce the effect of dependence; consider the analogous effect of autocorrelation and considering only every kth entry to remove dependence. With the arrival of mark-recapture software, statisticians can now carry out sophisticated analyses with ease. 4
Applying and Improving MSE
Following the overview article, Durgana and Van Dijk begin this special issue laying out several MSE estimation strategies to make the best use of government-held trafficking statistics to generate the prevalence estimation of human trafficking. Upon a review of the applications of MSE in eight countries, Davina and Van Dijk assess the suitability of existing databases on trafficking victims for MSE as well as the different likelihoods of various categories of trafficking victims to be detected by the authorities and/or NGOs. The article concludes with a discussion of the limitations of MSE and its prospects for further development, especially among the most developed nations.
Statisticians in this issue are offering specific techniques to improve the robustness of MSE-based estimation, particularly when data sources do not overlap in optimal manners. Incomplete lists and few or no overlaps between administrative lists are among the most common challenges to those applying MSE techniques. Far et al. in this issue focus their attention on overcoming problems that arise from list omission and small or no overlaps when combining existing data sources. Cruyff et al. tackle similar problems but with a focus on sparse contingency table of multiple, incomplete population registries and a series of covariates when attempting to find the log-linear model that fits the data. Using a Bayesian framework, they advocate for pairwise associations in the model selection procedure as a strategy to keep the complexity of the models in check. Vincent, Far, and Papthomas in this issue approach the sparse overlap problems by exploiting covariate information to improve estimation in maximum likelihood estimators, model identifiability, and parameter redundancy.
Worthington et al. in this issue discuss how the mark-recapture techniques used in ecological models for estimating highly complex, biologically realistic scenarios such as modeling wildlife population changes through time can enhance techniques used for estimating the prevalence of human trafficking, which have changed little. By comparing and contrasting the similarities and differences, the authors point out key areas where ecological modeling methods can improve MSE in human trafficking research.
Finally, Bird in this issue applies MSE to identify how the escape of one victim may lead to the rescue of others. In her application, she seeks to quantify the density of an escape route which can provide much needed guidance to law enforcement efforts because we assume routes for victims to escape human trafficking are not randomly or arbitrarily distributed. MSE in this case is embedded within the healthcare and other social service agencies that may come in contact with survivors of human trafficking. The authors advocate for national protocols to encourage identified victims to join a research-led cohort where morbidity and mortality can be monitored. In other words, with a few adjustments, records maintained by government and community service agencies can offer significant advantages in identifying and assisting victims of human trafficking based on where they are originated.
Discussion
Despite the many challenges in estimating the prevalence of human trafficking, political necessity makes such estimation necessary so that countries and international organizations can mobilize (or de-mobilize) resources for fighting human trafficking or other gross forms of human rights violations. More importantly, from a scientific point of view, the burden falls upon the research community to answer the question whether human trafficking is a social ill of sizeable and serious proportions that call for large-scale counter measures. Since global surveys of human trafficking are prohibitively expensive and logistically impractical, some methods of extrapolation (or generalization) must be used, in which local and regional data points are gathered to produce global estimates. An extrapolation or scale-up scheme must be developed to generalize what is known to estimate the unknown. As additional local and regional data become available, such a conjecture strategy should improve over time.
This paper reviews a few strategies to produce prevalence estimations of human trafficking and highlights the varied use of MSE with existing sources of data. Whether using MSE for secondary data analysis or collecting data with probability-based or link-tracing sampling, much more attention needs to be paid to how estimates are generated and for what purposes. Critics such as Weitzer (2011) have been alerting the field of the dangers of running a social movement solely on the basis of moral outrage and wild unsubstantiated claims, and urging policymakers and civil societies to seek evidence-based practices and counter measure.
Prevalence estimation is of critical importance to both policy makers because of its influence on advocacy issues and program administrators because of the necessity for baseline measurement. One ought to admit that every estimation strategy has its inherent problems, methodologically or fiscally. Despite these limitations, one thing ought to remain clear is that MSE remains statistically sound and can contribute to the collective body of knowledge on the prevalence estimation of human trafficking. Methods reviewed in this paper have been tried in various forms and fashions around the world with varied successes. Because funding is often at the core of methodological decisions, it behoves the research community to educate the policy makers and advocate for the importance of properly chosen methods for various research questions and occasions. Finally, without reliable information about the scope of the problem, most seeking to influence policy makers must resort to sensational claims and moral appeals, which sooner or later will create a credibility problem and even undermines the moral imperatives of the whole movement.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.