
Abstract
For educators seeking to differentiate instruction, cognitive ability tests sampling multiple content domains, including verbal, quantitative, and nonverbal reasoning, provide superior information about student strengths and weaknesses compared with unidimensional reasoning measures. However, these ability tests have not been fully evaluated with respect to fairness and validity for English-language learners (ELL). In particular, reliability is an important aspect of validity that has not been sufficiently evaluated. In this study, multivariate generalizability methodologies were used to explore the differential reliability of the Cognitive Abilities Test across ELL and non-ELL students in two schools with large Hispanic populations. Results suggest that verbal and quantitative reasoning skills are measured less precisely for ELL students than for non-ELL students. However, the composite score of the three batteries showed strong reliability in both groups. We conclude that multidimensional tests provide reliable information about the academic strengths of ELL and non-ELL students, though further research is needed.
Ability tests play an important role in helping teachers provide differentiated instruction to students (e.g., Lohman & Hagen, 2001b; Reschly & Hosp, 2004). However, they are often criticized for not providing fair and valid assessments of students who are English-language learners (ELL), because the strong language demands of the verbal components of many ability tests do not permit ELL students to fully engage in the task and demonstrate their abilities (Ford, Grantham, & Whiting, 2008). Similar charges have been made with respect to achievement tests, particularly mathematics tests where the language demands are seen as extraneous to the construct of interest (Abedi & Lord, 2001; Li & Brennan, 2007).
Validity research exploring the utility of such tests for ELL students is imperative given the rapidly increasing population of such students in the U.S. school system (American Federation of Teachers, 2004; Harris, Rapp, Martinez, & Plucker, 2007). There is also continued interest in creating talent development programs that better serve culturally and linguistically diverse students (Callahan, 2005; Ford et al., 2008; Harris et al., 2007). Developing such programs requires adopting assessments that provide valid and useful information about the abilities of these students. Previous research has explored aspects of predictive and construct validity of tests when used with culturally and linguistically diverse populations (Keith, 1999; Kvist & Gustafsson, 2008; Lohman, Korb, & Lakin, 2008). The purpose of this study was to explore a less commonly considered aspect of fairness: differences in measurement precision between ELL and non-ELL students. In particular, we investigated the precision of a test measuring reasoning in verbal, quantitative, and nonverbal/figural content domains for a sample of Hispanic ELL students compared with a sample of primarily White and Hispanic non-ELL students.
The Benefits of Multidimensional Tests
Researchers of cognitive abilities have recognized that tests with varied content are better indicators of ability than unidimensional measures (Floyd, Shands, Rafael, Bergeron, & McGrew, 2009; Süß & Beauducel, 2005). In particular, researchers have demonstrated that multidimensional reasoning tests have greater construct representation because they sample more aspects of what it means to reason well (Carroll, 1993). For example, although figure analogies are excellent measures of general reasoning skills, they require the examinee to manipulate figures and shapes. These figural reasoning skills do not necessarily translate into effective reasoning with words or numbers. Thus, a test consisting only of figural analogies taps into only one element of what it means to reason well. A test measuring multiple, broad content domains, such as verbal, quantitative, and nonverbal symbol systems, would better represent the construct of reasoning than a test of nonverbal reasoning alone.
In an educational context, multidimensional tests are also more useful and valid because they better align with the criterion of interest—academic success. Research has confirmed that ability tests sampling a range of school-relevant reasoning abilities (particularly in language and math) are important in predicting future academic achievement, because those tests are more reflective of the criterion of interest—future achievement across a variety of academic domains (Gustafsson & Balke, 1993; Wilhelm, 2005). Importantly, other research has indicated that the types of specific reasoning abilities that are important to academic success are the same for the largest U.S. ethnic groups (Keith, 1999).
From a teacher’s viewpoint, multidimensional ability tests might also provide more helpful information for how the teacher might differentiate instruction, because the multiple scores reported by these tests provide a richer description of the cognitive strengths and weaknesses that can form aptitudes for learning in the classroom (Snow, 1992). Scores on multidimensional tests such as the Cognitive Abilities Test (CogAT; Lohman & Hagen, 2001a) provide at least two pieces of useful information. One is the level of ability the student demonstrates across batteries. Level of ability (or elevation) provides teachers with a useful guide for providing instruction at a pace and level of complexity appropriate to a student’s skill (Cronbach & Gleser, 1953). The second useful piece of information is the shape of the profile, which reveals the relative strengths and weaknesses for each student, which the teacher can then use to adapt instruction (Lohman & Hagen, 2001b). The profiles provided by the CogAT have been found to provide reliable and useful information about student abilities (Lohman, Gambrell, & Lakin, 2008).
Current Practice in Assessing ELL Students
English language learners are students who enter U.S. schools with limited English proficiency and who are acquiring English while also continuing to learn academic content, usually instructed in English. Because ELL students acquire English at different paces and because new ELL students enter schools each year, this group of students is highly variable in terms of their current proficiency and academic knowledge. Because of these students’ variable English proficiency, current practice in assessing the cognitive abilities of ELL students often advocates the use of nonverbal assessments (Lewis, 2001; Pierce et al., 2007; Powers & Barkan, 1986). Nonverbal tests are preferred because they reduce the language load of the test, which is expected to increase fairness for ELL students. However, the ELL student population varies greatly in their English proficiency, with some nearing full proficiency. And development of English proficiency is itself an important academic outcome for ELL students. Therefore, measuring a broader range of cognitive abilities may be desirable. The nonverbal tests most frequently used yield single indicators of general ability that lend themselves only to general instructional modifications (Lohman, 2005). Such tests provide limited information on how teachers might adapt instruction to strengths and weaknesses, particularly with respect to verbal domains.
Some existing nonverbal tests do acknowledge the important role that multiple-item formats play in sampling a wider range of cognitive processes, including the Comprehensive Test of Nonverbal Intelligence (cTONI; Hammill, Pearson, & Widerholdt, 1996) and Universal Nonverbal Intelligence Test (UNIT; Bracken & McCallum, 1998). Multiple-format nonverbal tests arguably increase the construct coverage over single-format nonverbal tests and cancel out irrelevant task-specific sources of variance (McCallum, Bracken, & Wasserman, 2001). However, as long as the tests do not tap into the ability to reason with language and mathematical symbols, they will always underrepresent the construct of interest to educators (Ortiz & Ochoa, 2005) and fail to provide useful information for differentiating instruction (Lohman, 2005, 2009).
The limitations of nonverbal tests are revealed in predictive validity studies. Strong relationships between ability and achievement test scores are an important component to an ability test’s validity argument, as having strong cognitive reasoning skills should correlate with academic accomplishment in the long term (Thorndike, 1982). However, whereas verbal and quantitative measures have strong predictive validity for academic outcomes, nonverbal tests have sometimes yielded disappointingly low predictive validities. For example, Borghese (2009) found that the UNIT full-scale scores correlated .51 with math achievement, but only .28 with reading as measured by the Stanford Achievement Test (SAT-10), 1 which is much lower than what is typically observed for verbal tests (about .80; Lakin & Lohman, 2011). Likewise, Jones (2006) found correlations below .10 between UNIT scores in first grade and reading achievement on the Texas Assessment of Knowledge and Skills in third grade for both ELL and non-ELL students.
Even when the nonverbal tests perform well, they are rarely more effective at predicting academic success than multidimensional tests with language and math components, even among ELL students. Although Lakin and Lohman (2009) found moderate relationships between the Nonverbal Battery of the CogAT and the Arizona Instrument to Measure Standards achievement test in reading and math (r = .41 and .57, respectively), the relationships for the Verbal and Quantitative Batteries were significantly stronger: r = .60 between Verbal and Reading scores and .68 between Quantitative and Mathematics scores in their sample of Hispanic ELL students. Such research suggests that the field of psychological assessment underestimates the viability and value of assessing cognitive abilities in ELL students beyond figural/nonverbal reasoning.
Lakin and Lohman (2009) concluded that verbal and quantitative reasoning tests could provide valuable information about the abilities of ELL students, and they also cautioned that the tests showed some undesirable psychometric properties, including substantial range restriction in the battery scores of ELL students. This range restriction accounted for a large part of the lower predictive validity for ELL students compared with non-ELL students, but the reason for the narrowed range of scores was unclear. One potential explanation for the range restriction is that the items are more difficult for ELL students due to their language load. A mismatch of item difficulty may also affect the precision with which the construct is measured for ELL students (Thorndike, 1982).
Other researchers concerned with the assessment of ELL students have called for greater attention to measurement precision as a contributor of test bias. Young (2009) called attention to the dearth of validity research focusing on the assessment of ELL students, especially evaluations of test reliability. Solano-Flores and Li (2006) called for more research incorporating generalizability theory analyses to explore the role of language on achievement tests. Differences in reliability are an often overlooked, but potentially important, contributor of bias because unreliability can depress other aspects of validity, including predictive validity.
To investigate the reliability and sources of error for multidimensional test scores for ELL students, this study addressed the following questions:
Are measures of verbal, quantitative, and nonverbal ability equally reliable for ELL and non-ELL students?
What does a generalizability-like coefficient indicate about the probable reliability of examinee profiles? Is the probable reliability of a randomly selected ELL student profile different from that of a randomly selected non-ELL student profile?
What is the impact of manipulating domain sampling attributes on measurement precision? That is, if the table of specifications were altered so all 152 items came from just one content domain (verbal, quantitative, or nonverbal), what would be the effect on measurement error?
Method
CogAT Form 6 (Lohman & Hagen, 2001a) was administered to a sample of 145 ELL and 236 non-ELL students in third and fourth grade. Students receiving any kind of ELL services were classified as ELL by the school. In this district, ELL services are determined on the basis of number of years in the school and performance on the Stanford English Language Proficiency test (Harcourt Educational Assessment, 2003). The data for this study were collected as part of Project Bright Horizons, a study developed by a team of researchers and school administrators (described in more detail in Lohman, Korb, et al., 2008). Two schools in a Southwestern school district in the United States participated in the study. The district has a large population of Hispanic students: 50% of the non-ELL students and 95% of the ELL students were Hispanic.
The district also has a large proportion of students receiving free or reduced-price lunch: 95% of the Hispanic students, 91% of students from other minority groups, and 53% of the White students were eligible. Additional demographic information is provided in Table 1.
Breakdown of Sample by Demographic Category

Note. ELL = English-language learners.
Measures Used
The CogAT is a measure of cognitive abilities comprising Verbal, Quantitative, and Nonverbal Batteries. 2 Each battery consists of three unique item formats. The Verbal Battery uses verbal analogies, verbal classification, and sentence completion item formats. The Quantitative Battery consists of number series, equation building, and quantitative relations tasks. Finally, the Nonverbal Battery consists of figure analogies, figure classification, and paper folding tasks. The CogAT shows strong convergent and discriminant validity with other measures of abilities (Lohman & Hagen, 2002).
CogAT was designed to measure general fluid reasoning (Gf) by tapping into reasoning abilities in verbal, quantitative, and nonverbal/figural symbol systems (Lohman & Hagen, 2002). These symbol systems correspond to the three CogAT batteries, which were chosen because they are important psychologically and instructionally (Carroll, 1993). Users are encouraged to rely on individual battery scores (verbal, quantitative, or nonverbal) rather than the composite score to make criterion-referenced instructional decisions, such as gifted and talented identification, as each battery provides unique information about a student’s aptitude for success in different academic domains. For differentiating instruction, users are encouraged to use the detailed profiles of battery scores provided, which specify level, shape, and scatter of scores—as these profiles align with specific instructional recommendations (Lohman & Hagen, 2001b).
All tests on the CogAT begin with directions that are read aloud by the teacher and also presented as text to the students. In this study, directions were read in Spanish when teachers found it to be more appropriate for their students. However, all three sections of the Verbal Battery and one section of the Quantitative Battery require some reading in English. On the Verbal Battery, students must read either individual words (verbal classification and verbal analogies) or short sentences (sentence completion). On the quantitative relations section of the Quantitative Battery, students read individual words (e.g., foot or gallon). The other Quantitative Battery sections and all the Nonverbal Battery tests do not require reading.
CogAT Form 6 tests have substantial overlap (around 80%) across grade levels. For each section of a battery, this means that only 3 to 5 items are unique to each level of the test. The overlap is systematic: at each level, the easiest 3 to 5 items are dropped from the beginning of each section and new, more difficult items are added at the end. Therefore, the third- and fourth-grade students in this study took 152 common test items across the three batteries. To simplify the model in this study, only these overlapping items were used in the analyses. At the battery level, the common items included 52 verbal items, 48 quantitative items, and 52 nonverbal items. The data for the other 38 nonoverlapping items at each level were discarded. 3
Data Analysis
This study used the framework of generalizability theory (G-theory), which essentially marries classical test theory with factorial analysis of variance (ANOVA) methods to decompose observed scores into their constituent parts: universe-score variance (which is akin to true-score variance), variance due to the facets of the design (which are similar conditions of the measurement procedure in which the investigator is interested), and error. Generalizability studies (G-studies) specify a universe of admissible observations, which identifies the conditions of measurement in which the researcher is interested. For example, if students were tested on a sample of items, which were then scored by raters, the researcher might be interested in knowing how much variability in student performance was attributable to the specific items represented on the test (the items facet), to the raters scoring the tasks (raters facet), and to the interaction of these two facets. G-studies use factorial ANOVA approaches to estimate variance components corresponding to the facets of the design, facilitating comparisons of the relative importance of various sources of error. Decision studies (studies), on the other hand, define a universe of generalization, which characterizes what constitutes a replication of the measurement procedure. D-studies permit estimation of variance components necessary for supporting decisions about a given measurement procedure, such as the minimum number of prompts, raters, or other facets needed to achieve certain levels of reliability. Univariate G-theory has been extended to accommodate multivariate designs, in which each person is assumed to have multiple universe scores—one score corresponding to each of several, correlated domains (Brennan, 2001b).
In this study, we performed multivariate G- and D-studies. For each of these analyses, we used the fully crossed p• × i◦ “table of specifications” design, in which each battery (verbal, quantitative, and nonverbal) featured a unique, nonoverlapping set of items. 4 In this design, we treated both persons and items as random in the universe of generalization. As in the achievement domain, items on ability tests represent merely a sample from the universe of possible items. Thus, in making inferences about examinee ability, it is necessary to generalize beyond the specific items represented on a given instantiation of the test to encompass all the possible items that could have been represented. In the p• × i◦ design, all persons respond to all items, and items are nested within three levels of the fixed facet (i.e., the three batteries of the test). The closed circle corresponding to the persons facet represents the fact that persons are crossed with all levels of the fixed facet. The open circle corresponding to the items facet represents the fact that items are nested within levels. We treat the three batteries of the CogAT as fixed because they do not change across subsequent revisions, even though the items themselves are replaced every 8 to 10 years. Note that this design entails estimation of covariance components corresponding to the linked facets (i.e., those with closed circles). Thus, in this case, we estimate only the covariance between universe scores on the various levels of the fixed facet (i.e., scores on the separate batteries), since different items appear on each battery.
We performed multivariate G- and D-studies on the combined group of students as well as separately for each language group (ELL and non-ELL). However, results from the global analysis of the total group were almost identical to results for the non-ELL group of students, so we report only separate group-level results in the current article. The purpose for conducting separate analyses—one each with the separate language groups—was to contrast results obtained from the different modeling approaches. Brennan (2001b) recommends using this general strategy when the objects of measurement are stratified according to some characteristic. 5 Furthermore, Li and Brennan (2007) point out that reliability estimates computed on the total group of students may misrepresent the reliability of a measure for a specific subgroup of students, because the different facets of the measurement procedure can contribute in different ways to the variability of student performance. Thus, performing separate analyses for each group permits a comparison of the relative contribution of each facet across groups.
We performed D-studies to estimate how many more verbal, quantitative, and nonverbal items would be needed to obtain estimates of ELL ability that were comparable in reliability with those from non-ELL examinees and to explore the effect of manipulating domain sampling attributes on error. In addition, because one of the recommended uses of the CogAT is to support instructional differentiation based on a student’s profile, we explored the error associated with examinee profiles and pairwise difference scores. We conducted all analyses in mGENOVA using raw scores as input (Brennan, 2001a).
Results
Table 2 reports basic distribution information in the raw-score metric, including effect sizes in Cohen’s d metric and variance ratios (the ratio of variance for non-ELL students to variance for ELL students) for all three batteries. As can be seen by examining the values for Cohen’s d, non-ELL examinees outperformed the ELL examinees on all three batteries, although as expected, the Verbal Battery exhibited the most dramatic difference. Variance ratios indicated significantly narrower score distributions for the ELL students on the Quantitative and Verbal Batteries. A value of 1.97 for the Quantitative Battery indicates that non-ELL students were 97% more variable than ELL students (Feingold, 1992).
Descriptive Statistics (Raw Scores)
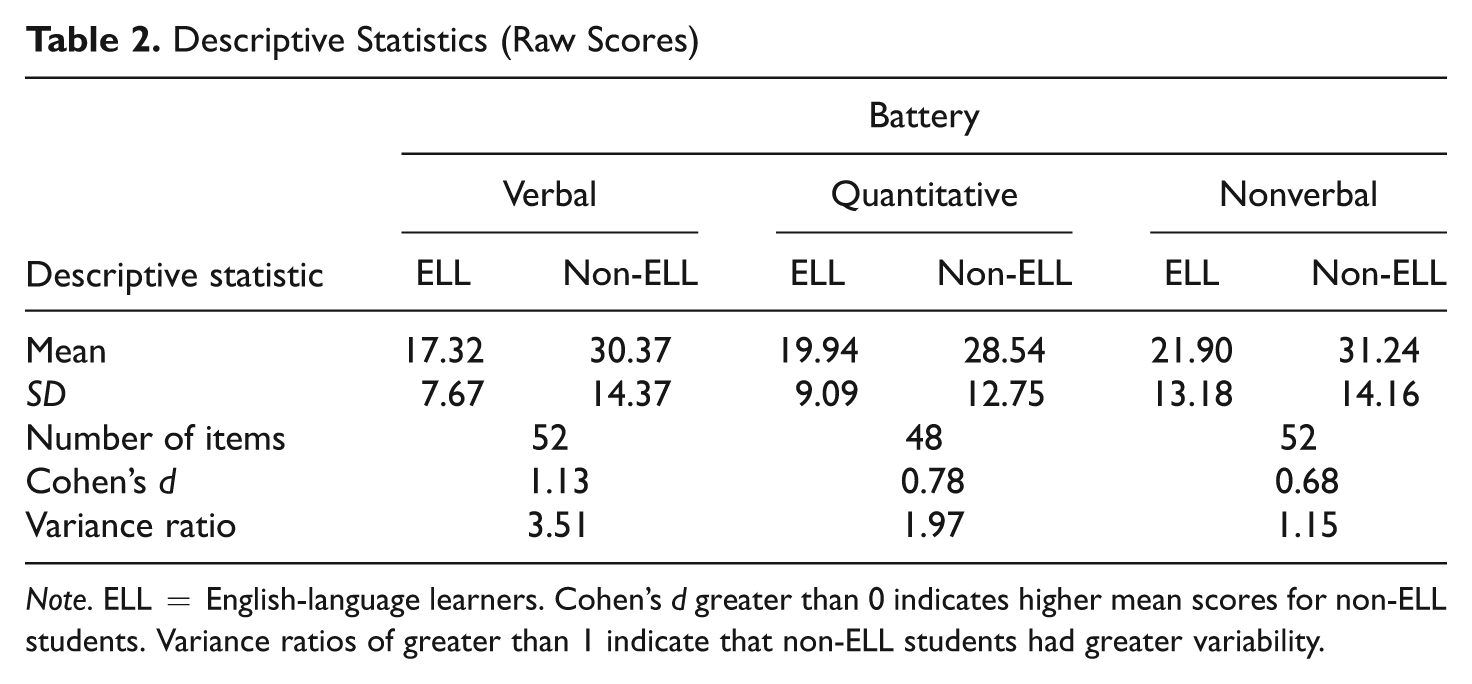
Note. ELL = English-language learners. Cohen’s d greater than 0 indicates higher mean scores for non-ELL students. Variance ratios of greater than 1 indicate that non-ELL students had greater variability.
Table 3 reports estimated G-study variance and covariance components for the p• × i◦ design for ELL and non-ELL students separately. It should be noted that these results represent item scores for single persons, in contrast to the results presented in Table 2, which were expressed as total scores. Examining first the results for the non-ELL group, the magnitude of estimated disattenuated correlations 6 among universe scores from the various batteries (reported in italics in the upper diagonals in the first block) suggests the test is measuring related, though distinct, constructs. The single largest variance component across all three batteries is clearly the persons by items interaction, which alone accounts for around 65% of the total variance in scores. Conceptually, this result suggests that most of the variance in scores is due to the fact that students perform differentially well on different items. The second largest variance component is the person effect (around 30%), which indicates that individual differences in the underlying construct contribute strongly to test performance. The distribution of variance components across the three batteries is remarkably similar, which suggests that the relative contribution of each facet to performance on batteries measuring verbal, quantitative, and nonverbal reasoning skills is essentially the same.
G-Study Estimated Variance/Covariance Components

Note. ELL = English-language learners. Estimated disattenuated correlations are reported in italics in the upper diagonals. Estimated covariances are reported in the lower diagonals. Numbers in parentheses represent the percentage of the total variance attributable to that variance component.
In contrast, results for ELL students differ in several ways from the non-ELL results. First, estimated disattenuated correlations indicate that the relationships between performance on the Verbal Battery and performance on the other two batteries were noticeably weaker for ELL students than they were for non-ELL students. Whereas the correlations for non-ELL students were around .65 among all the batteries, for ELL students, the correlations with the Verbal Battery were around .45 for quantitative and nonverbal. On the other hand, the correlation between quantitative and nonverbal reasoning was equally strong for ELL and non-ELL students. Together, these results suggest there is less overlap among estimates of verbal, nonverbal, and quantitative abilities for ELL students than for non-ELL students.
Second, the relative magnitudes of the variance components (reported in parentheses) are quite different across the three batteries for ELL students. In particular, for ELL students, the Nonverbal Battery showed much more variance attributable to persons and less variance attributable to the person–item interaction compared with the other two batteries. In contrast, for non-ELL students, the distribution of variance components across the three batteries was relatively similar. Finally, the absolute magnitudes of the variance components differed for ELL students versus non-ELL students. In particular, the pi component, representing the interaction between persons and items as well as all unmeasured sources of variance, was uniformly larger for ELL students than for non-ELL students. This latter result suggests that language status does matter with respect to measurement precision for Verbal and Quantitative Batteries.
Table 4 reports the estimated D-study universe score and error matrices for the p• × i◦ design for the same analyses. Turning first to the error matrices, both relative and absolute errors were larger for ELL students than for non-ELL students. Accordingly, when we analyzed ELL students separately, we obtained somewhat lower reliability estimates, particularly for the Verbal and Quantitative Batteries. When we combined the three individual battery scores to form a composite, reliability estimates were high (in the mid .90 range) even for ELL students.
D-Study Estimated Universe-Score and Error Variance Matrices
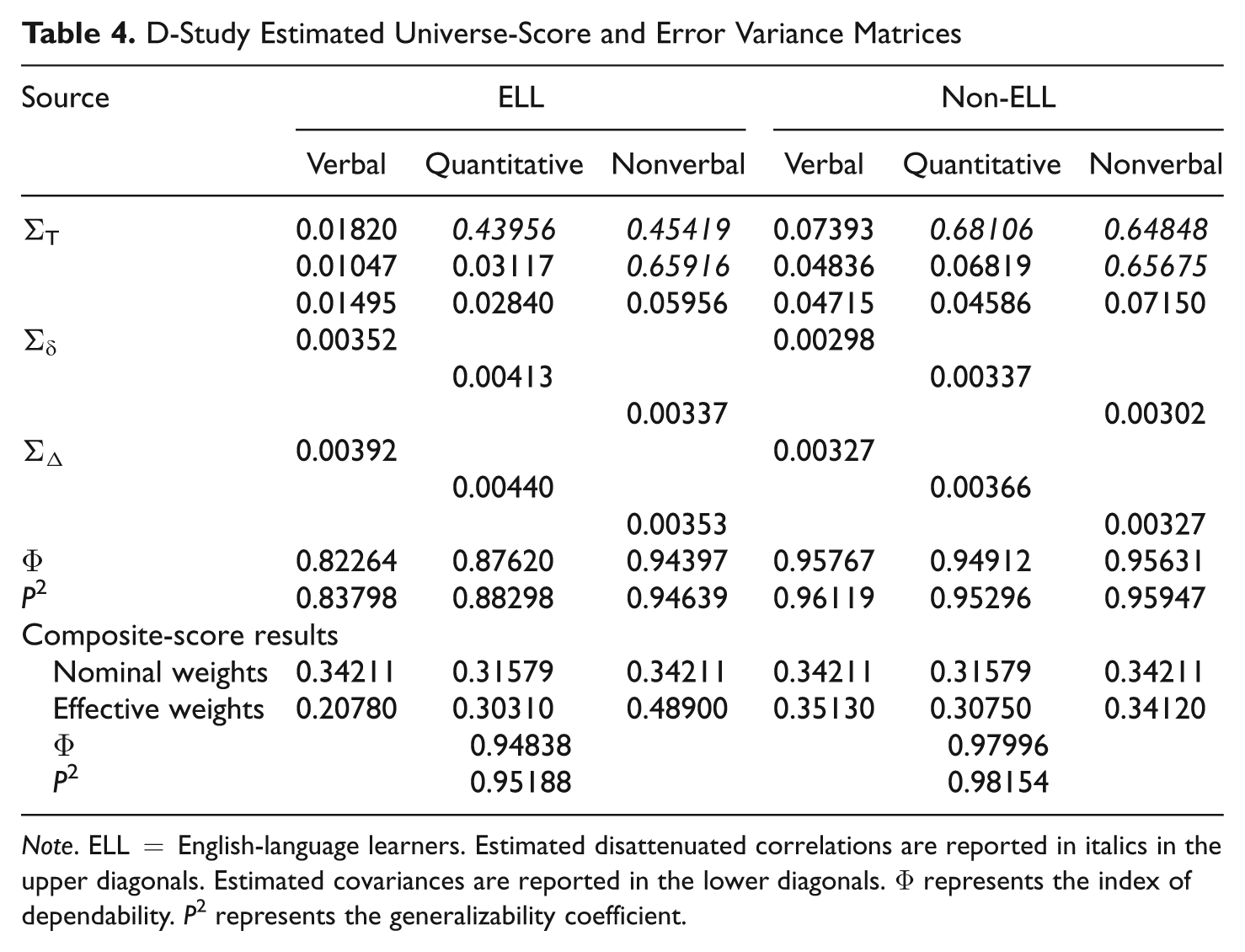
Note. ELL = English-language learners. Estimated disattenuated correlations are reported in italics in the upper diagonals. Estimated covariances are reported in the lower diagonals. Φ represents the index of dependability. P2 represents the generalizability coefficient.
One can also compare nominal and effective weights across groups. Whereas nominal weights are proportional to the number of items in each battery, effective weights are proportional to the contribution each battery makes to composite universe-score variance. Thus, an observed disparity between nominal and effective weights suggests whether certain levels of the fixed facet are contributing more to composite universe-score variance than would be expected given test length. Comparing the relative size of the nominal and effective weights within each of the two groups, one can see that they are quite different. Unlike non-ELL students, for whom nominal and effective weights were comparable across the three batteries, effective weights within the ELL group suggest that almost half of the universe score variance for ELL students is attributable to their performance on the Nonverbal Battery alone.
Figure 1 displays the results of additional D-studies, which investigated the number of verbal and quantitative items necessary to obtain reliability estimates for ELL students that would equal those for non-ELL students. In particular, Figure 1 illustrates how many more verbal and quantitative items ELL students would have to respond to in order to obtain reliability estimates of .96 and .95, respectively, for verbal and quantitative scores. These analyses suggest that ELL students would need to respond to more than twice as many quantitative and more than three times as many verbal items (of similar quality) in order to obtain comparable estimates of reliability. Although increasing the length of these batteries is not a practical solution to the problem of lower reliability of verbal and quantitative scores for ELL students, these results communicate the magnitude of the disparities in estimated reliability coefficients for ELL and non-ELL students.
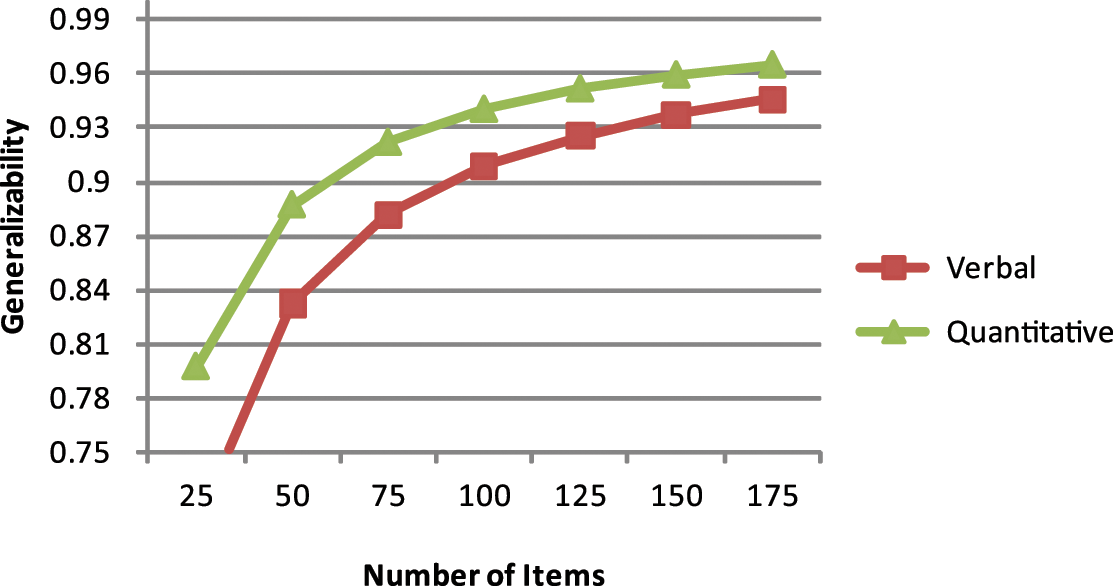
Number of items and generalizability for English-language learner students
A reasonable question to ask is whether taking all 152 items from the battery that is the most reliable for ELL students (the Nonverbal Battery) would improve measurement precision relative to the composite score formed from all three batteries. This is not a trivial question, given the suggestion in the literature that single- and multiple-format nonverbal measures of reasoning abilities are the best representations of ELL student ability (Pierce et al., 2007). Holding the overall test length constant (keeping the same number of total items on the test), but sampling exclusively from the nonverbal reasoning domain, provides a rigorous test of this hypothesis. Results from a D-study in which the nominal weights implied by the universe of generalization were held constant but the estimation weights were manipulated so that all 152 items were drawn from the nonverbal test alone provided interesting results. Specifically, administering a unidimensional test of 152 nonverbal items to ELL students would result in an estimate of mean squared relative error (which provides an index of the amount of error involved in using the observed mean on the Nonverbal Battery alone as an estimate of composite universe score variance) that is nearly 15 times larger than relative error variance of the multidimensional composite. Thus, to the extent that verbal, nonverbal, and quantitative ability are all part of the construct of reasoning, using nonverbal measures alone diminishes both reliability and validity. That is, using only nonverbal measures both underrepresents the construct and reduces the precision of estimated ability. Accordingly, administering all three batteries yields more precise estimates of examinee ability than administering a long version of even the battery that is most reliable for ELL students.
Because one of the recommended uses of the CogAT is instructional adaptation based on examinee ability profiles across the three batteries, we investigated the amount of error associated with profiles. Table 5 reports estimated profile variances, including observed-score profile variability Vx, universe-score profile variability, Vµ, and both relative and absolute error variability (Vδ and VΔ, respectively). These variance components are similar to those estimated for individual battery scores in the context of a D-study, except that they represent a decomposition of the observed variability of profiles formed by scores on the three batteries. 7 The bottom row of Table 5 reports estimates of G, which is the proportion of variance in the profile of observed scores that is explained by the variance in the profile of universe scores. In other words, G represents a type of generalizability coefficient for the profile of battery scores for a randomly selected person from each group (Brennan, 2001b). This index provides some indication of the probable reliability of an individual examinee profile. For example, for the typical native English speaker, 88% of the variance in observed mean scores on the three batteries is attributable to variance in universe scores. Similarly, for the typical ELL, around 85% of the variance in observed mean scores is attributable to variance in universe scores. Thus, whereas results from individual subtest scores were differentially reliable for ELL versus non-ELL students, the score profiles of a randomly selected student from each group would likely be similarly reliable.
Expected Within-Object-of-Measurement Variability
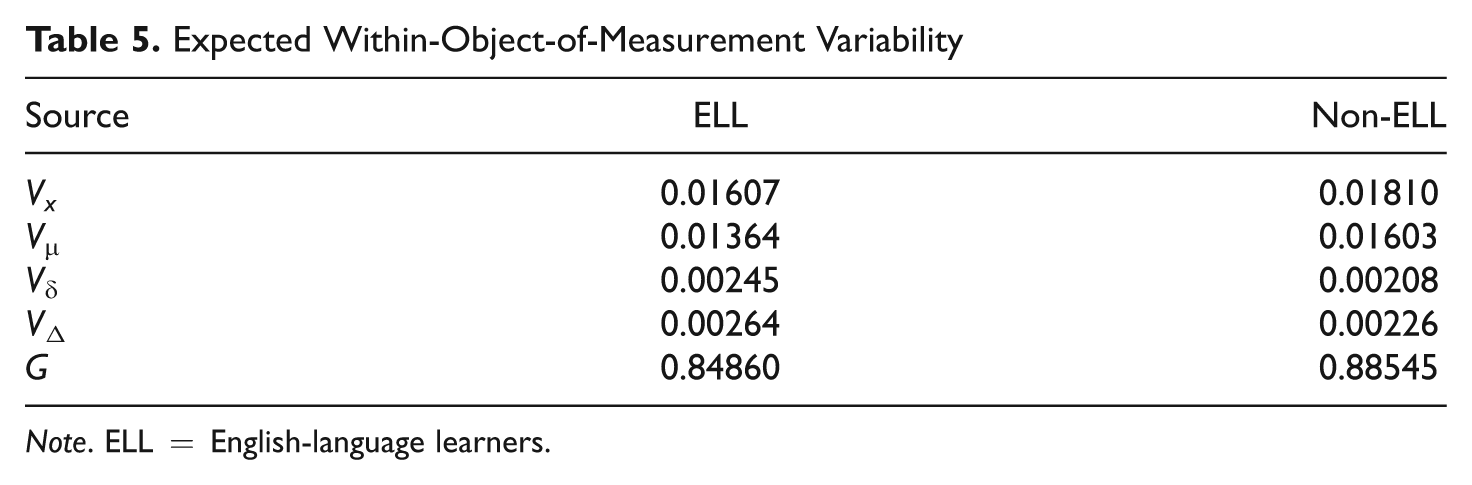
Note. ELL = English-language learners.
A classroom teacher using individual student performance profiles to support particular instructional decisions at the student level would need some idea of the amount of error associated with various difference scores. Thus, we conducted an additional series of D-studies investigating the reliability of pairwise differences separately for ELL and non-ELL students. Table 6 reports the generalizability coefficients associated with each difference score. The coefficients are relatively similar and uniformly high across the three battery contrasts for non-ELL students. However, the verbal/quantitative difference score appears to be somewhat less reliable for ELL students. Thus, the inference of a relative strength or weakness between verbal and quantitative reasoning will be less stable for ELL than for non-ELL students.
Reliability of Difference Scores
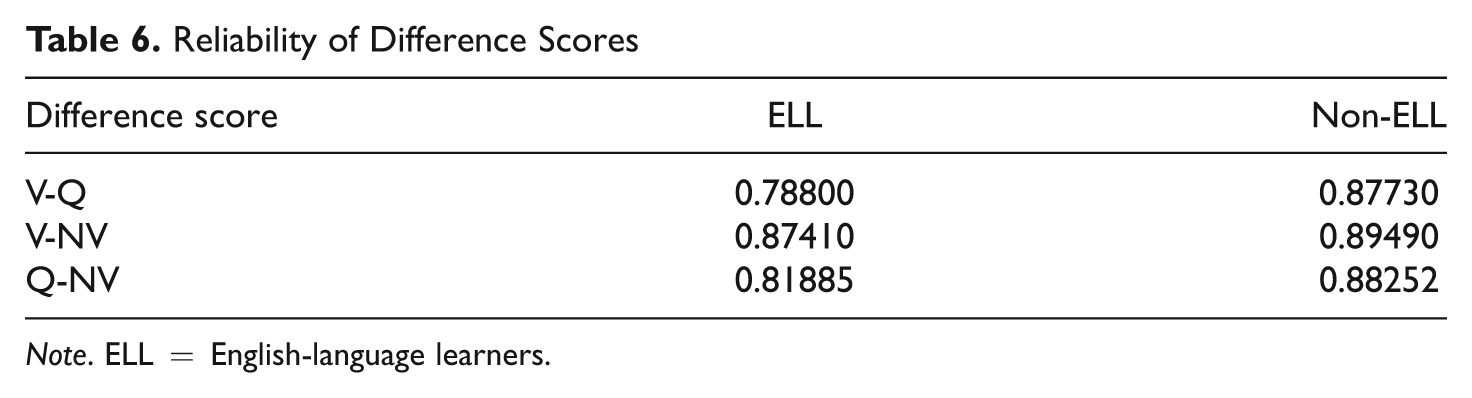
Note. ELL = English-language learners.
Discussion
On a multidimensional measure of abilities comprising verbal, nonverbal, and quantitative reasoning skills, non-ELL students outperformed their ELL peers, with the most dramatic group differences exhibited on the Verbal Battery and smaller differences on the Quantitative and Nonverbal Batteries. ELL student scores, in turn, exhibited range restriction compared with non-ELL student scores. Results from this study shed some light on potential consequences of this range restriction. Specifically, results suggest that verbal and quantitative reasoning skills are measured less precisely for ELL students than they are for non-ELL students. ELL students’ verbal reasoning scores also correlated less strongly with their scores from the Nonverbal and Quantitative Batteries compared with non-ELL students. In addition, the generalizability coefficients for the Verbal and Quantitative Batteries were substantially lower for ELL students than they were for non-ELLs, for whom all three batteries performed uniformly well. In fact, ELL students would need to respond to more than twice as many quantitative items and more than three times as many verbal items in order to achieve comparable reliability to non-ELL students. These results are consistent with Li and Brennan (2007), who also found substantially lower precision for ELL students taking a reading achievement test. They estimated that their reading test would need to double in length to match precision for ELL and non-ELL students. The fact that G- and D-study results differed across the two groups of students in our study suggests that language status does, in fact, matter for measurement precision.
Despite these limitations in the measurement precision for ELL students, results also suggest that the Verbal and Quantitative Batteries of this multidimensional ability test may contribute reliable information about the abilities of these students. Although the Verbal and Quantitative Batteries showed lower reliability than the Nonverbal Battery, the coefficients (.84 and .88) are comparable with the reliabilities of many subtest scores on individually administered ability tests (Lohman, 2009). Moreover, simply administering a much longer version of the Nonverbal Battery to ELL students underrepresents the construct and diminishes measurement precision, to the extent that verbal, nonverbal, and quantitative reasoning all form part of the ability construct. Combining verbal, quantitative, and nonverbal reasoning scores produces composite scores that are almost as reliable for ELL students as they are for non-ELL students. Furthermore, a reliability-like coefficient for individual student profiles was quite similar for both groups of students.
Implications
Researchers of cognitive abilities have long recognized that tests with varied content are better indicators of ability than unidimensional tests. Despite this, researchers concerned with the assessment of culturally and linguistically diverse students tend to prefer nonverbal reasoning tasks for ELL populations, believing they provide the only reliable means of measuring these students’ cognitive abilities. This study found evidence that the concern over the use of verbal and quantitative content is only partially supported. Certainly, the differences in reliability for the Verbal and Quantitative Batteries across language groups warrant further research into developing tests that better measure the full range of reasoning abilities in ELL students. However, this study clearly showed that administering a measure of cognitive abilities that draws on a range of content areas provides superior reliability to a test that consists of only nonverbal items. Indeed, we showed that creating a nonverbal test with the same number of items as the CogAT would not achieve equivalent reliability to a test with verbal, quantitative, and nonverbal items, even for ELL students.
We found that the reliability of composite scores and profiles for ELL and non-ELL students was surprisingly similar. This result provides support for the use of these tests in making instructional decisions, as they provide reliable information about the reasoning skills of students regardless of language status. However, the results of this study do not address larger issues about the validity of the interpretations that can be made from test scores. In fact, given the clear differences in opportunity to learn between ELL and non-ELL students, certain adjustments to the interpretations of scores are warranted for the use of either cut-scores for identification purposes or profiles for differentiating instruction (Lohman, 2006; Weiss, Saklofske, Prifitera, & Holdnack, 2006).
If ability profiles are used, specific instructional implications must be developed for ELL students. Even with the same ability profile, ELL students will differ from non-ELL students in their instructional needs, including pace, structure, and linguistic support (Olsen, 2010). Specific instructional recommendations have been developed for non-ELL students (Lohman & Hagen, 2001b), but a new line of research is needed to develop appropriate ideas for curricular differentiation for ELL students.
Limitations and Future Directions for Research
Several aspects of the study design may limit the extent to which these results generalize to other contexts. First, one cannot assume that the conclusions supported here will apply to other ability tests, even those that conceptualize reasoning abilities as a multidimensional construct. Thus, future studies should investigate whether differences in the precision with which the abilities of ELL and non-ELL students are measured materialize on other multidimensional ability tests. Indeed, we noted that evaluation of reliability coefficients for examinee subgroups (rather than the overall population) may be informative to test developers in a number of contexts who must make decisions about test composition and minimum test length. Second, analyses reported here were based on relatively small samples of ELL and non-ELL students. As such, estimated variance and covariance components are subject to sampling error and should be interpreted cautiously. Third, the ELL sample used in this study consisted almost entirely of Hispanic ELL students. As such, it is possible that the conclusions reached in this study would not apply to non-Hispanic ELL students. Both ELL and non-ELL samples also consisted of large numbers of low SES students, with a slightly greater proportion of ELL students being eligible for free or reduced-price lunch. Thus, future studies should replicate this study using larger and more heterogeneous samples of ELL students and native English speakers. In addition, future studies might consider finer distinctions of ELL categories because language proficiency varies greatly among ELL students and even among non-ELL students, particularly when there are large numbers of former or reclassified ELL students in that group. Fourth, these analyses were based on raw scores while the CogAT only reports scaled scores at the battery level, which are produced by applying a Rasch model scale transformation to raw scores. If the analysis were to be repeated using scaled scores instead of raw scores, it is possible that results would be different, particularly for ELL students, who disproportionately occupy the lower end of the score distribution where scores are most affected by the scale transformation.
One aspect of multidimensional ability tests that might impact measurement precision, but which was not considered in this study, is item format. In the same way that tests measuring varied content and reflecting multiple dimensions of reasoning are better measures of the construct of general reasoning, it is believed that tests using multiple item formats are more representative of the domain than single-format tests (McCallum et al., 2001). Although the measure used in this study includes nine different item formats (three unique item formats within each battery), item format was not included as a facet in the design. Thus, it was not possible to test the hypothesis that varied item formats result in better measurement precision for ELL students relative to single-format tests.
Finally, the developmental effects of grade level could be included in future study designs. The students included in our sample were third- and fourth-grade students, but grade level was not factored into the design. Thus, any potential differences in the reliability of third- and fourth-grade student ability would be partially confounded with differences in language status. Specifically, whereas the distribution of third- and fourth-grade students was 55% and 45%, respectively, for ELL students, this distribution was 40% and 60%, respectively, for non-ELL students. This confounding of grade-level with language status would be problematic, for example, if third-grade reasoning abilities were less reliably estimated than fourth-grade reasoning abilities. Such confounding could yield spurious conclusions of differential reliability for ELL and non-ELL students. However, the fact that other research has found similar disparities in the measurement precision of ELL and non-ELL students lends support to our findings (Li & Brennan, 2007; Solano-Flores & Li, 2006).
The results of this study only support the conclusion that verbal and quantitative ability are measured less precisely for ELL students. Additional research is needed to identify methods of increasing that precision. For instance, while the D-study analysis indicated that twice or three times as many items might be needed, this analysis assumes the test developer is adding items of similar quality. Adding or substituting items of higher quality with respect to measuring the skills of ELL students would increase precision more rapidly. One possibility is creating item formats that are less sensitive to language background while still measuring important reasoning domains. For example, new picture-based verbal item formats are being developed that may tap into verbal reasoning without tying the test items to a particular administration language. 8 Similar research attempting to reduce the language load of mathematics tests is also being conducted extensively in the achievement domain (e.g., Abedi & Lord, 2001).
Conclusion
Multidimensional tests can play an important role in helping teachers adapt instruction appropriately to the range of talents of students in their classroom. However, the interpretation of test scores and the instructional recommendations they offer must be validated for culturally and linguistically diverse students. This study explored the role that language status plays in the precision with which multidimensional ability tests measure the reasoning abilities of ELL and non-ELL students. We concluded that both composite and profile scores may provide reliable information about the abilities of these students when interpreted appropriately. However, this study did not show whether these composite and profile scores have the same instructional implications for ELL and non-ELL students. That is, we have only set the foundation for research on the validity of interpretations made from these tests by showing that they provide acceptable measurement precision. Given the potential for such tests to be used for adaptation of instruction for both ELL and non-ELL students, it is important for additional research to explore the educational value of such applications.
Footnotes
Acknowledgements
We would like to gratefully acknowledge the thoughtful comments provided by Robert Brennan, David Lohman, John Young, Michael Kane, Dan Eignor, and Guillermo Solano-Flores on an earlier draft of this article.
Portions of the research described in this article were completed while both authors were employed by The University of Iowa. Any opinions expressed in this paper are those of the authors and not necessarily of Pearson.
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author(s) received no financial support for the research, authorship, and/or publication of this article.