
Abstract
Approaches to determining direction of dependence in nonexperimental data are based on the relation between higher-than second-order moments on one side and correlation and regression models on the other. These approaches have experienced rapid development and are being applied in contexts such as research on partner violence, attention deficit hyperactivity disorder, and currency exchange rates. In this article, we propose using these methods in the context of latent variables analysis. Specifically, we propose creating component or factor scores and relating the component score or factor score variables to each other by using methods for the determination of direction of dependence. Empirical examples use data from the development of aggression in adolescence. In the discussion, issues concerning the establishment of causal relation in empirical research are addressed.
In nonexperimental research, the direction of dependence, also called the direction of effects, is not always obvious. For example, Dodge and Rousson (2001) asked which of the world currencies affects others to increase or decrease in value. Nigg et al. (2008) asked whether an increased blood lead content is the cause for attention deficit hyperactivity disorder or whether attention deficit hyperactivity disorder has the effect that children expose themselves more often to lead-tainted objects. von Eye and DeShon (2012) asked whether intimate partner violence has the effect that the victims turn depressive or whether depressive individuals are more likely to become victims of intimate partner violence.
In the context of methods of analysis of manifest variables, there have been approaches to statistically identify the directional dependence that are based on third- and fourth-order moments of the observed variables (e.g., Dodge & Rousson, 2001; Dodge & Yadegari, 2010; Sungur, 2005; von Eye & DeShon, 2008, 2012). The idea that carries these methods is discussed in the context of a valid linear regression model. The idea is that the distribution of an observed dependent variable, Y, is a convolution of the distribution of an independent variable, X, that can be nonnormally distributed, and the normally distributed residual. Because this residual is added to X, the distribution of the dependent variable, Y, is necessarily closer to a normal than the distribution of Y without the effect of X. Measures of skewness and kurtosis can be employed to compare the skewnesses of X and Y, or of Y with and without the presence of X.
Two additional approaches to the analysis of directional dependence have been discussed, both in the context of an analysis of manifest variables. First, the direction of dependence perspective has been extended based on the third moments of linear regression residuals (Wiedermann, Hagmann, Kossmeier, & von Eye, 2013). Second, models of copula regression have been proposed to determine direction of dependence. Recent copula regression approaches use asymmetric models that allow one to also consider variable interactions (Kim & Kim, 2013).
In the context of methods of analysis of latent variables approaches to the analysis of direction dependence are scarce. The issue is either discussed in the context of causality, as, for example, by Sobel who states (1996) that the interpretation of SEM parameters as effects does “not generally hold, even if the model is correctly specified and a causal theory is given” (p. 376), or in the context of causal foundations of structural equation modeling (see, e.g., Pearl, 2012). One reason for this state of affairs is that most structural equation models use moments of first and second, but not higher order.
In the only approach to analyzing directional dependence in latent variables that is known to the authors, Shimizu and Kano (2008) proposed including higher order moment structures. The authors assume nonnormal distributions of exogenous variables. This approach can be viewed as parallel to the one proposed by Dodge and collaborators for manifest variables. The use of higher order moments is not new in structural equation modeling. It has been proposed, for example, in the context of asymptotically distribution-free, generalized least squares estimation (Bentler, 1983; Browne, 1982, 1984) and in the context of analysis of interaction effects (e.g., Jöreskog & Yang, 1996). The use of higher order moments in the context of directional dependence is unique to the work by Shimizu and Kano (2008).
In the present article, we build on these approaches and propose methods for the analysis of the direction of dependence in contexts of latent variable analysis and structural modeling. Specifically, we propose using standard latent variable models, and we propose relating latent variables from these models to each other using methods proposed for the determination of direction of dependence for manifest variables.
This article is structured as follows. First, we review an approach to determining direction of dependence in manifest variables. This review consists of two parts. In the first, we focus on correlation methods, in the second, we focus on regression methods. Second, we apply these methods to component scores from principal component analysis (PCA). Third, we apply these methods to factor scores from structural modeling.
Direction of Dependence in Manifest Variables
For the considerations in this section, we use observed, manifest variables that are nonnormal. This is typically the case in observed, specifically psychometric data. Micceri (1989) found that not one of the 400 psychometric data sets that he examined can be shown to be drawn from a normal population. Nonnormal variables have skewness or kurtosis that deviate from expectation. This characteristic will be used throughout this article. In addition to being assumed to be nonnormal, the variables discussed here are viewed in a linear regression context. Let two variables under study be X and Y. The two regression equations that can be estimated to predict these two variables from each other are

and

where the subscripts indicate the dependent variable. The parameters β0 refer to the model intercepts, the β1 refer to the slope parameters, and the

where the numerator shows the covariance of X with Y, and the denominator shows the standard deviations of X and Y. Using information from regression, the correlation between X and Y can also be expressed as
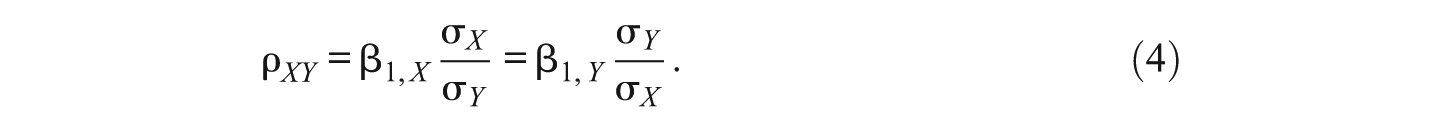
However, as was shown formally by Dodge and Rousson (2001), Muddapur (2003), and by Sungur (2005), the correlation ρ XY also has an asymmetric property if one considers the skewness of the two variables, X and Y. Specifically, the authors show that

where γ X and γ Y are the skewness coefficients of X and Y, respectively. This relation holds if γ Y > 0 and γ X > γ Y , which reflects the asymmetric property of ρ XY . Similarly, Dodge and Yadegari (2010) show that

where κ X and κ Y are the kurtosis coefficients of X and Y. As for skewness, the relation of the two kurtosis measures holds if κ X > 0 and if κ X > κ Y .
Let X be hypothesized to be the explanatory variable and Y the response variable. Let both be observed in a nonexperimental study. To determine whether there is support for this hypothesis, the statistic
When hypotheses about directional dependence are tested, five implications of this relationship between γ X and γ Y are of importance (von Eye & DeShon, 2012):
Let
The cube of the correlation coefficient can be interpreted as the percentage of skewness that is left after a linear model was applied to describe the relationship between X and Y.
If the ratio of the two skewness scores lies outside [−1; +1], the cube of the correlation suggests that Y, not X, is the explanatory variable.
If X is perfectly symmetric as is the case in normal or in uniform distributions, directional dependence cannot be determined by using the methods discussed here.
Above and beyond what is generally known about Pearson’s correlation coefficient, ρ XY , it does, in the context of linear modeling and when variables are not bivariate normal, possess asymmetric properties.
Direction Dependence Based on Linear Regression Residuals
Recently, the directional dependence perspective has been used as a starting point to investigate properties of residuals of competing linear regression models (Wiedermann et al., 2013). Again, consider the two linear regression equations

we obtain
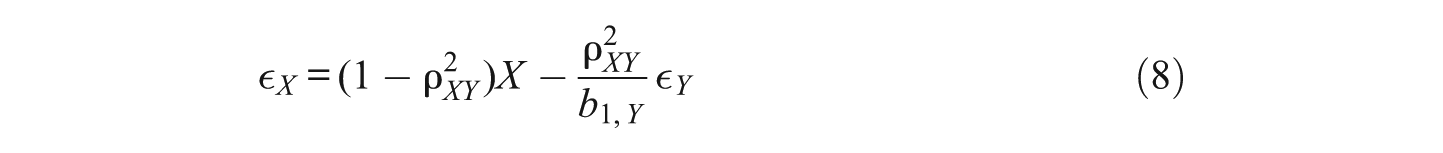
for the residual term
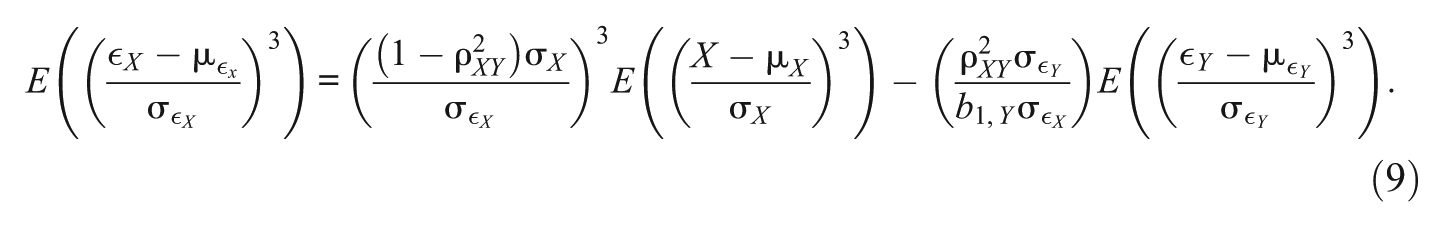
Assuming symmetrically distributed residuals for the true regression model, that is,

we arrive at the following three implications:
The skewness of X and the skewness of
If the remaining terms in the above equation are fixed, the skewness of
If the remaining terms are fixed, the skewness of
In particular, from implication (2) we can conclude that the skewness of residuals can be used for decisions on the direction of effects. That is, for the correctly specified regression model, we would assume that the null hypothesis of symmetric residuals can be retained. Conversely, for the misspecified model, we would expect the null hypothesis of symmetry be rejected.
Decision Rule. When
Direction Dependence in Latent Variables Contexts
When latent variables or structural models are specified, the situation can be quite similar to the one encountered for manifest variables. It is not always clear which of the latent variables, for example, principal components or factors, has the response variables as indicators and which has the explanatory variables as indicators. Therefore, a method such as the one described in section “Direction of Dependence in Manifest Variables” can be useful in the analysis of latent variables as well. In the following sections, we discuss such a method. We begin with a description of the data situation in latent variables analysis.
Component Scores
In this section, we discuss the case of principal components analysis (PCA). We first provide a brief review of those elements of PCA that we need for the calculation of component scores. The presentation follows that by Bartholomew and Knott (1999; cf. Hershberger, 2005).
Let Σ be a p×p variance–covariance matrix, Λ a p×q matrix of coefficients (loadings), and Ψ a p×p diagonal matrix of variances. Then, for q = p, the representation

is possible, because Σ is symmetric. Σ can also be expressed as

where Θ is a diagonal matrix. The elements of Θ are the eigenvalues of Σ, and A is an orthogonal matrix whose column vectors are the eigenvectors of Σ. The first equation for Σ, above, follows if Λ = AΘ1/2 and Ψ = 0 (under the second of these conditions, PCA and principal factor analysis are equivalent).
Now, let y be the q latent variables, and let x be the p observed variables, conditionally distributed as

where µ is a vector of constants (means, intercepts). Given that Λ = AΘ1/2, the conditional distribution of x can be expressed as a linear combination of independent variables,

The variables

are the well-known principal components. It is standard procedure to choose the first principal component such that the explained portion of variance of x is maximized. The second principal component maximizes the explained portion of the remaining variance while being uncorrelated with the first component, and so on.
Component scores, F, indicate the coordinates of individual cases in the space of principal components. They are straightforwardly calculated as

The distribution of component scores depends on a number of factors, including sample size and the underlying data generation process. Component scores and factor scores are not necessarily normally distributed (for illustrations, see, e.g., Steinley & McDonald, 2007). The following considerations are based on component scores that are not normally distributed.
Component Scores and Directional Dependence
As was discussed above, third- and fourth-order moments (skewness and kurtosis) can be used to examine distributional characteristics of data. Third- and fourth-order moments are central moments (for an overview, see Walwyn, 2005). Let F be the random component score variable and k a natural number. Then, the kth central moment, aka kth order moment, is

that is, the expectation of F minus a constant c, raised to the power of k. Usually, the mean is used for c. In the present context, the second, third, and fourth moments are of interest. The first moment is the sum of deviations from the mean. The second moment is the variance of F. The third moment, the skewness of F, is

and the fourth moment, the kurtosis of F, is

Definition and computational aspects of central moments are covered in many textbooks (e.g., Hogg & Tanis, 1993; see also D’Agostino & Pearson, 1973).
Karl Pearson (1895) proposed that skewness and kurtosis can be used to determine whether a variable is normally distributed. Based on this proposition, two lines of research have evolved. The first involves deriving tests of (multi)normality (see, e.g., D’Agostino, 1971; D’Agostino, Belanger, & D’Agostino, 1990; D’Agostino & Pearson, 1973; Mardia, 1970, 1980; von Eye & Gardiner, 2004). The second line of research concerns the determination of direction of effects (see, e.g., Dodge & Rousson, 2000, 2001; Muddapur, 2003; Shimizu, Hoyer, Hyvärinen, & Kerminen, 2006; Shimizu & Kano, 2006; Sungur, 2005, von Eye & DeShon, 2008, 2012; Wiedermann et al., 2013).
In the following paragraphs, we review, discuss, and build on the second of these lines of work. We begin by deriving the equation
Let FY be the component score variable for the principal component that is hypothesized to take the role of the dependent variable and FX the component score variable for the principal component variable that is hypothesized to be explanatory. Then, the correlation between these two variables is

or
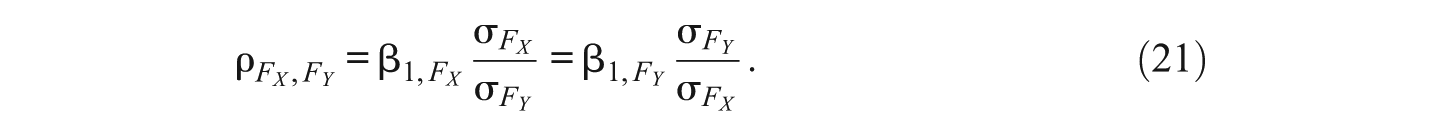
The linear relationship between these two variables is
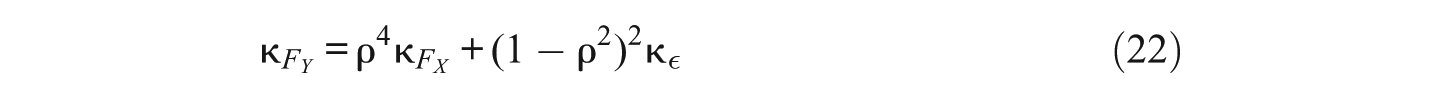
(from here on, we again omit the subscripts of
The kurtosis coefficients of FY, FX, and the residual
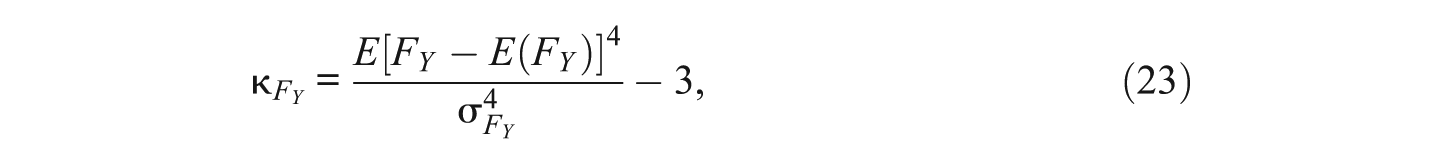
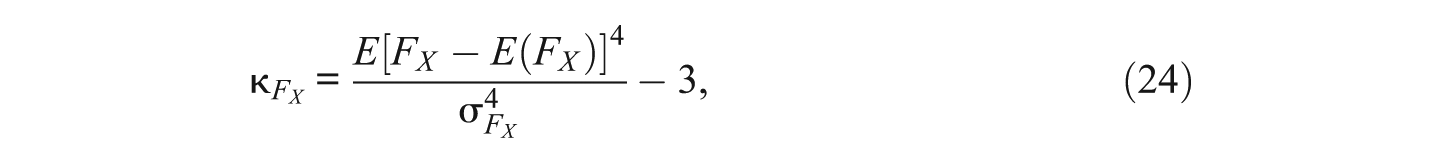
and
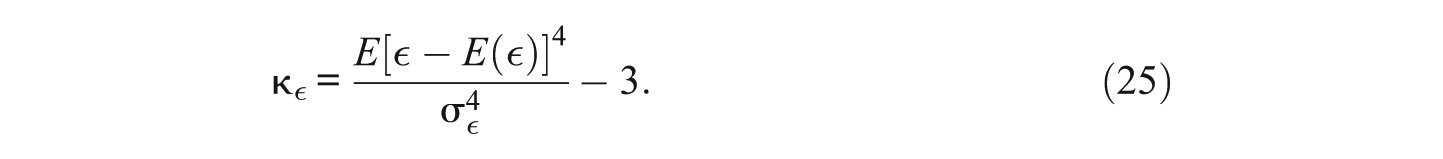
Based on the equations for the linear relationship between FY and FX and the correlation between FY and FX, we obtain

From (26), we obtain

Equation (27) can also be derived as follows (Dodge & Yadegari, 2010, derive this for manifest variables). Because FX is independent of

Under expectation, we can rewrite the expression FY−E(FY) as

In the next step, we divide Equation (29) by
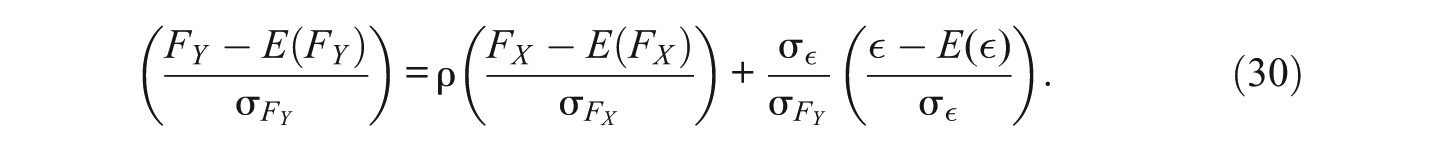
Raising (30) to the fourth power yields

where according to Dodge and Yadegari (2010), C = 4!(2!(4 − 2)!). After simplification and using (28) again, we obtain
In a similar way, we can derive the relationship between ρ and skewness that was originally derived, for manifest variables, by Dodge and Rousson (2000). Specifically, we now raise the expression in (30) to the third power and obtain

From using (28) again, we obtain
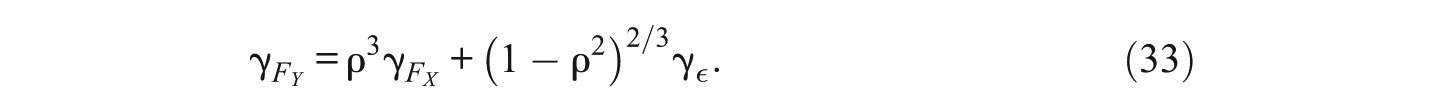
If the residual is normally distributed,
In applications in which researchers aim to determine whether FX or FY is the explanatory variable, both skewness measures must be unequal to zero.
Interpretation. As is well known, the square of the correlation coefficient indicates the portion of variance shared by two variables, in the present case FX and FY. Accordingly, ρ3 indicates the portion of skewness of FY that can be explained by FX, and ρ4 indicates the portion of kurtosis of FY that is explained by FX.
Decision rules. In parallel to the decision guidelines proposed by von Eye and DeShon (2008), we suggest the following decision rules based on the skewness of two nonnormal component score variables, FX and FY:
If
If
If
Two approaches are available for statistical inference on
Component Scores and Properties of the Regression Residuals
As was discussed in section “Direction Dependence Based on Linear Regression Residuals,” indicators of the skewness of linear regression residuals can be used to evaluate the direction of effects. Again, let

for the residual term

If we insert the third centralized moments, we obtain
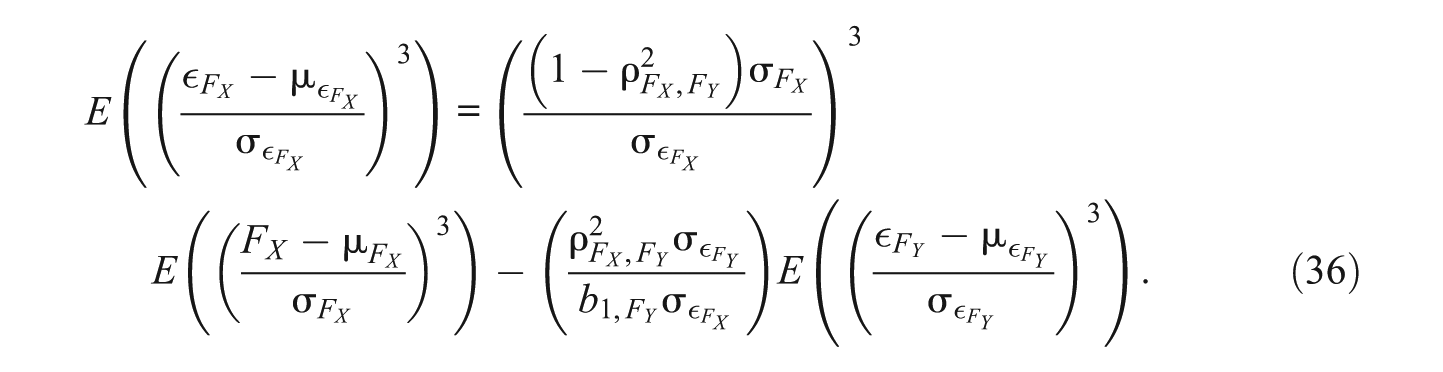
If we further assume that the residuals of the true linear regression model are symmetrically distributed, that is,
The skewness of the component score
Assuming that the remaining terms are fixed, the skewness of
Assuming that the remaining terms are fixed, the skewness of
Decision rules. In parallel to the decision guidelines discussed above, the component score
Data Example
For the following example, we use data from a study on the development of aggression in adolescents (Finkelstein, von Eye, & Preece, 1994). In this study, 38 boys and 76 girls in the United Kingdom responded to an aggression questionnaire in 1983, 1985, and 1987. The average age at 1983 was 11 years. Two of the dimensions of aggression examined in this study were Verbal Aggression Against Adults (VAAA) and Physical Aggression Against Peers (PAAP). In the present example, we first perform two principal component analyses. The first uses the three measures of VAAA from 1983, 1985, and 1987. The second uses the three measures of PAAP from the same years. We ask whether verbal aggression allows one to predict physical aggression or vice versa.
To answer this question, we first create the component scores of the principal components of VAAA and PAAP. For these scores, we calculate skewness and kurtosis and, then, make a decision about direction of effect following the guidelines proposed above. All analyses were performed with SYSTAT 12 and the R statistical environment.
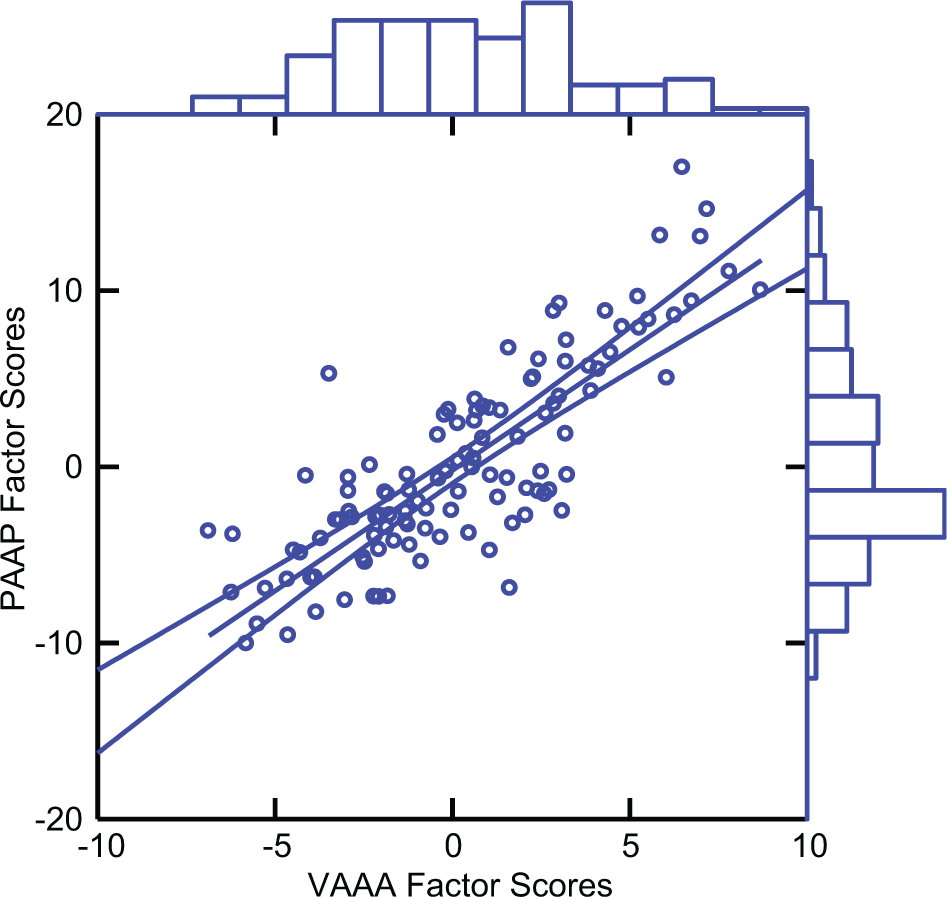
The scatterplot of the component scores for VAAA and the component scores for PAAP is depicted in Figure 1. The univariate distributions appear on the margins of the plot.
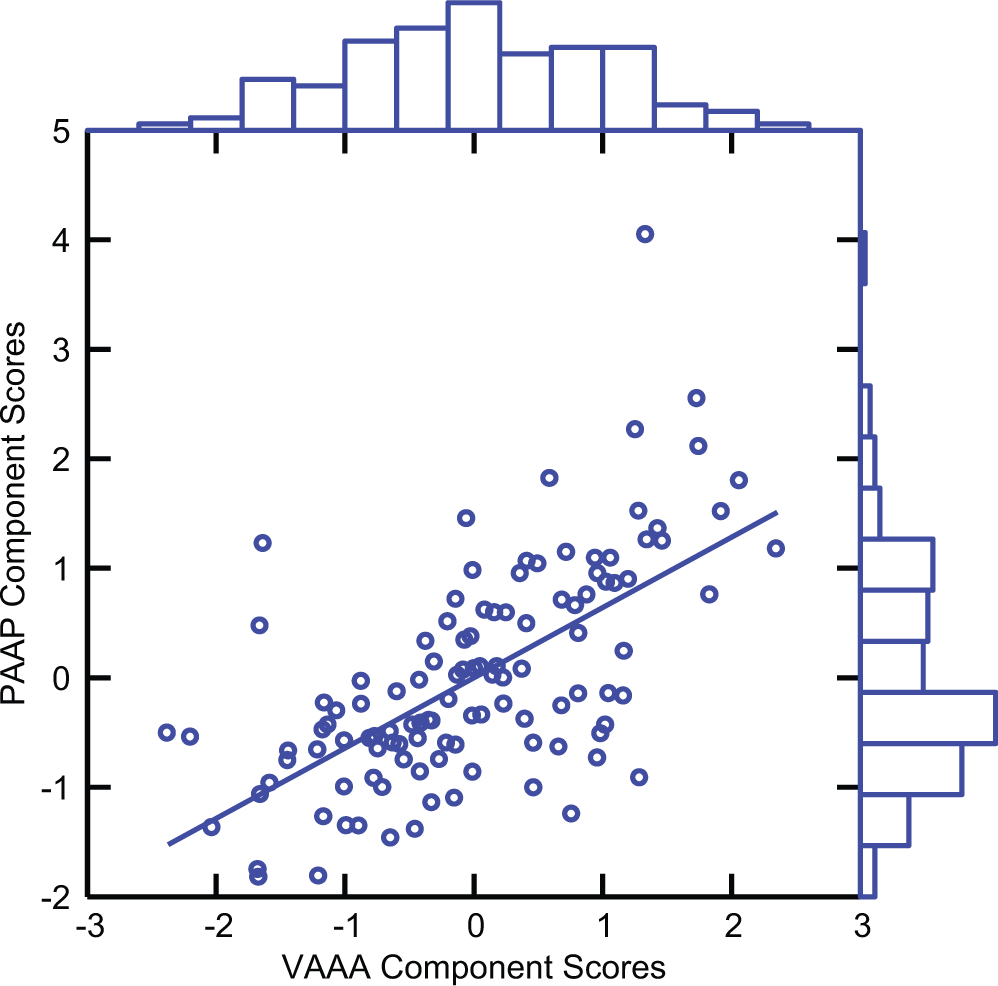
Distributions and scatterplot of component scores of Verbal Aggression Against Adults (VAAA) and Physical Aggression Against Peers (PAAP).
The univariate distributions in Figure 1 suggest that the distribution of the component scores of VAAA is closer to a normal distribution than the distribution of the component scores of PAAP. Table 1 quantifies this impression.
Descriptive Statistics of Component Scores of Verbal Aggression Against Adults (VAAA) and Physical Aggression Against Peers (PAAP).
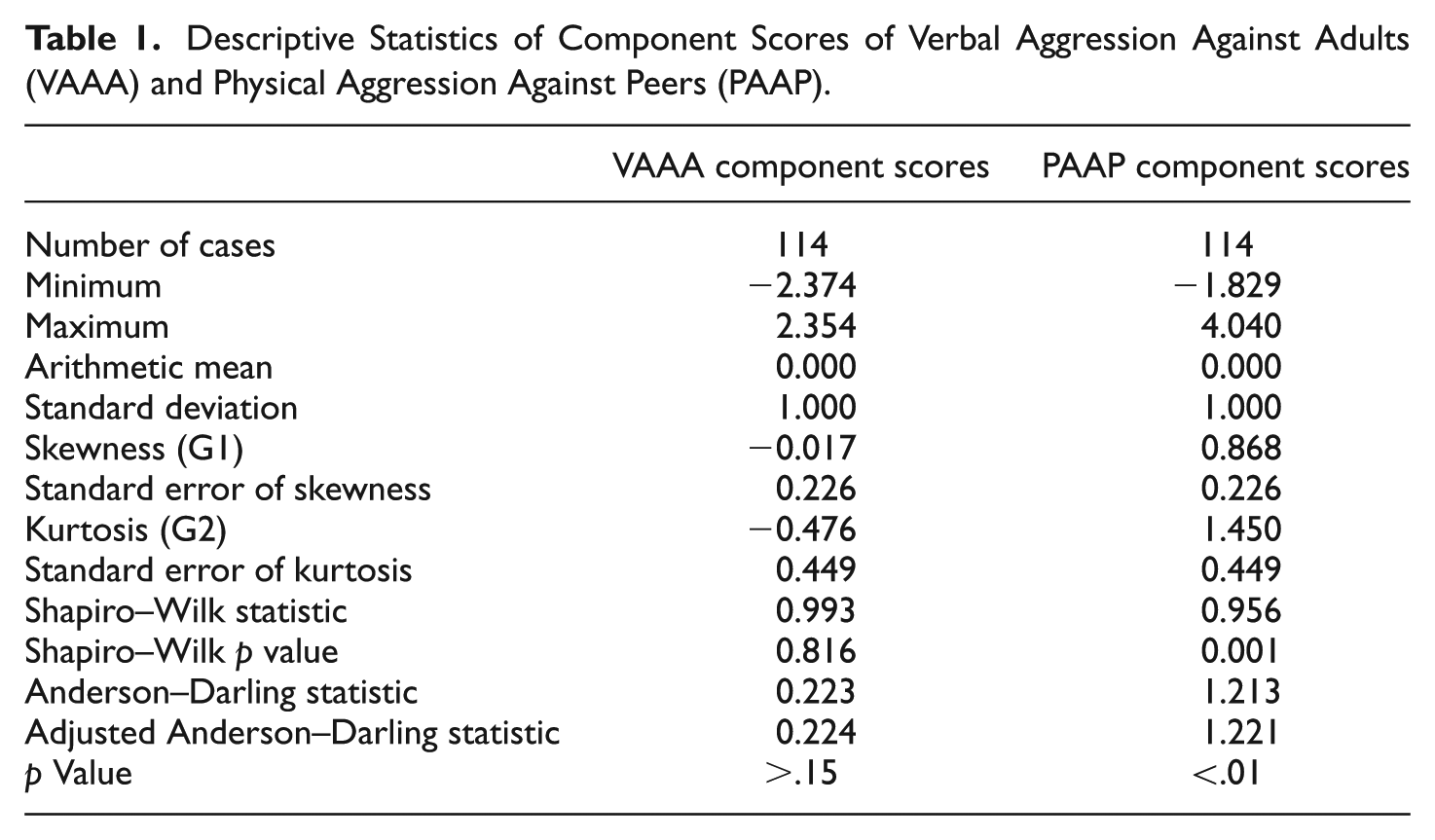
The results in Table 1 suggest that neither skewness nor kurtosis of the component scores of VAAA is excessive. In addition, neither the Shapiro–Wilk statistic nor the Anderson–Darling statistic suggests that the component scores of VAAA deviate significantly from normality. In contrast, all measures suggest that the component scores of PAAP are non-normally distributed.
The correlation between the two component score variables is r = 0.642. The ratio of the two skewness measures is, therefore, r3 = 0.265, suggesting that 26.5% of the skewness of the component scores of VAAA is left unexplained by the skewness of PAAP. The ratio of the two kurtosis measures is r4 = 0.170, suggesting that 17% of the kurtosis of the component scores of VAAA is left unexplained by the kurtosis of PAAP. Using the above decision rules, we, therefore, conclude that the direction of effect goes from PAAP to VAAA.
To support this conclusion, we compared the skewness and kurtosis of the latent variables VAAA and PAAP by using the three test procedures mentioned above, that is, the skewness and kurtosis tests proposed by D’Agostino (1971), Anscombe and Glynn (1983), a nonparametric bootstrap procedure based on the differences in skewness and kurtosis proposed by Pornprasertmanit and Little (2012), and the three resampling tests proposed by Wiedermann et al. (2013) to evaluate residuals of competing regression models. Table 2 displays the results of these tests.
Comparing the Skewness and Kurtosis of the Latent Variables VAAA and PAAP.
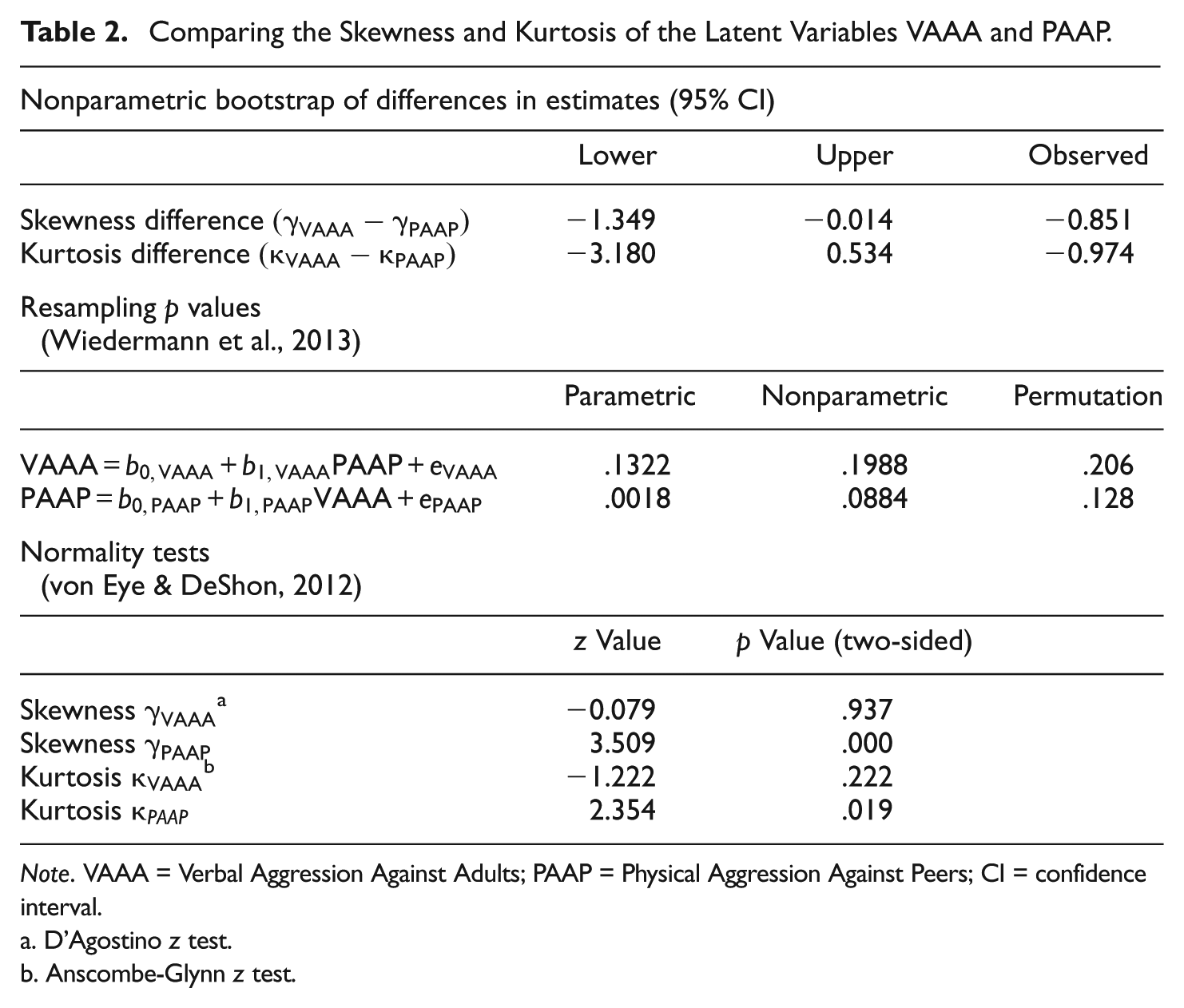
Note. VAAA = Verbal Aggression Against Adults; PAAP = Physical Aggression Against Peers; CI = confidence interval.
D’Agostino z test.
Anscombe-Glynn z test.
The test results shown in Table 2 can be interpreted as in support of the decision that VAAA is the outcome variable and PAAP is the explanatory variable. The only exception to this interpretation is the kurtosis difference κVAAA−κPAAP. This difference is nonsignificant. In all other cases, VAAA deviates less from normality than PAAP.
Latent Variable Scores in Structural Equation Models
In this section, we first review methods of estimation latent variable scores other than component scores. We discuss direction of effects in the context of structural modeling, and then apply the methods described in the last section in the context of latent variables analysis. For latent variable models other than PCA, a number of models have been discussed.
To describe the methods of estimation, we use the following notation (see Bartholomew & Knott, 1999; Jöreskog, Sörbom, & Yang-Wallentin, 2006; Lastowicka & Thamodaran, 1991).
X = n×p matrix of p standardized variables, observed on n cases, with (1/(n− 1))X′X = R, the correlation matrix of the p variables
F = an n×r matrix of standardized scores of r latent variables, for example, common factors, with r < p and (1/(n− 1))F′F = Φ, the correlation matrix of the r latent variables
S = an n×p matrix of standardized scores on p unique, independent latent variables (one such variable per observed variable) such that 1/(n− 1))S′S = I. These latent variables are independent of the latent variables in F, that is, (1/(n− 1))SF′ is a p×r null matrix
B = a p×r matrix of weights of the latent variables in F
U = a p×p diagonal matrix of weights of the latent variables in S
The model that we consider is

This model proposes that the p observed variables can be explained as a function of r+p latent variables. There is an extensive body of literature on the problem of indeterminacy of latent variable scores. This literature will not be reviewed here (see, e.g., Bartholomew & Knott, 1999; McDonald & Burr, 1967). Instead, we now present four of the better known methods of estimation of latent variable scores (Hershberger, 2005; Lastowicka & Thamodaran, 1991).
Least squares estimation (Horst, 1965). This method estimates F such that the trace Tr(Y S S′U) is minimized as

Bartlett’s (1937) method takes into account the differences in the variances of the unique latent variables. The residuals are minimized weighted by the reciprocals of the standard deviations of the unique latent variables. The following estimates result:

Thurstone’s (1935) method assumes regression weights, M. Using these weights, latent variable scores can be estimated from the observed variables via

An OLS solution for M′ is R−1 times the correlations between the observed and the latent variables. Because the correlations between the observed variables and the latent variable scores are BΦ, Thurstone’s factor scores can be estimated by

Anderson and Rubin’s (1956) method represents an improvement over Bartlett’s (1937) method. Bartlett’s method yields correlated latent variable scores even when the latent variables are theoretically orthogonal. The matrix of correlations among Anderson–Rubin estimates is always an identity matrix. The estimates are

The following are three desirable characteristics of latent variable scores (McDonald & Burr, 1967). First, latent variable scores should be highly correlated with their corresponding theoretical factors. This characteristic has been called the validity of latent variable scores. Second, when the latent variables are orthogonal, the scores from different latent variables should be uncorrelated also. In turn, when the latent variables are correlated, the correlations among scores from different latent variables should be close to the correlations among the corresponding latent variables. Estimates with these characteristics are called univocal. Third, the variances of the estimates should be the same as the variances of the corresponding latent variables.
For the following considerations, we opt for Anderson and Rubin’s (1956) method. The main reason for this is that we need to be in a situation in which lack of correlation translates in lack of directional dependency. Anderson and Rubin’s (1956) method is implemented in a number of software packages, for example in LISREL (Jöreskog et al., 2006).
The examination of directional dependence of latent variables in a structural model proceeds in a fashion parallel to the procedures used for manifest variables or principal components. Consider two latent variables, X and Y, on the y-side of a model that are not connected by way of a covariance or a path. That is, β YX = β XY = ψ XY = 0. The skewness of the FAR is
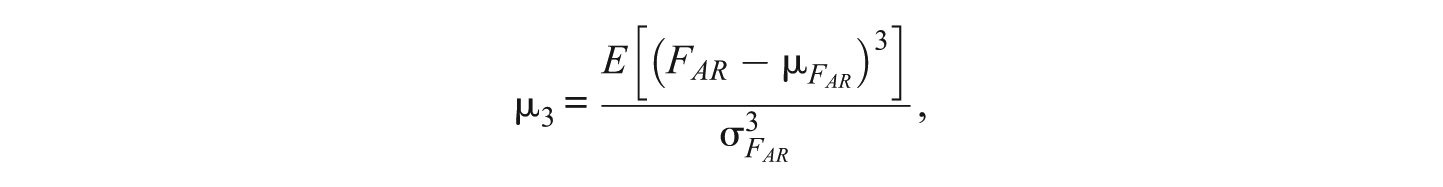
and the kurtosis of the FAR is
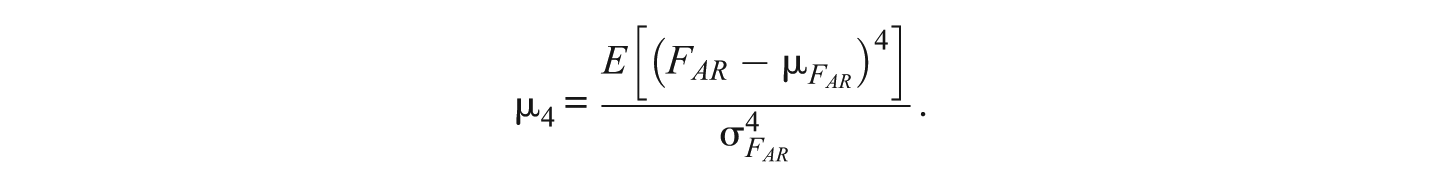
Now, let
Using these relationships, we derive conclusions about the direction of dependence between the latent variables X and Y. Specifically, if the direction of effect goes from X to Y, the following two predictions hold true:
Alternatively, decisions concerning the direction of effects can be made based on distributional properties of residuals of the two competing regression models
Data Example
For the following illustration, we use the same data as for the first example. Using the measures of Verbal Aggression Against Adults from 1983, 1985, and 1987 and the measures of Physical Aggression Against Peers, also from 1983, 1985, and 1987, we create a two-factor ML solution using LISREL 8.8 (the SIMPLIS command file for this model is reproduced in Appendix A). We label the two factors VAAA (for verbal aggression against adults) and PAAP (for physical aggression against peers).
We now proceed as follows. First, we calculate skewness and kurtosis of the factor scores of the two latent variables VAAA and PAAP, and then make a decision about direction of effect using the guidelines proposed above. The analyses of the factor scores were performed using SYSTAT 12. Second, we separately estimate the two competing regression models
The scatterplot of the factor scores for the VAAA and the PAAP factors are depicted in Figure 2. The univariate distributions appear on the margins of the plot.
Distributions and scatterplot of factor scores of Verbal Aggression Against Adults (VAAA) and Physical Aggression Against Peers (PAAP).
The univariate distributions in the margins of Figure 2 suggest the same interpretation as the distributions in Figure 1. The distribution of the factor scores of VAAA is closer to a normal distribution than the distribution of the factor scores of PAAP. Table 3 quantifies this impression.
Descriptive Statistics of the Factor Scores of Verbal Aggression Against Adults (VAAA) and Physical Aggression Against Peers (PAAP).

The results in Table 3 show a similar picture as the ones in Table 1. The factors scores of VAAA deviate from normality only randomly. In contrast, with the exception of the kurtosis measure, all measures suggest that the factor scores of PAAP are non-normally distributed.
The correlation between the two-factor score variables is r = 0.828. The ratio of the two skewness measures is, therefore, r3 = 0.568, suggesting that 56.8% of the skewness of the factor scores of VAAA is explained by the skewness of the factor scores of PAAP. The ratio of the two kurtosis measures is r4 = 0.470, suggesting that 47% of the kurtosis of the factor scores of VAAA is explained by the kurtosis of the factor scores of PAAP. Using the above decision rules, we, therefore, conclude, on a descriptive level, that the direction of effect goes from Physical Aggression Against Peers to Verbal Aggression Against Adults. Table 4 shows the results for the nonparametric boostrapping procedure based on the differences of skewness and kurtosis estimates, the resampling p values obtained from the tests based on the skewness of the competing regression residuals, and the test statistics of D’Agostino’s test and the Anscombe–Glynn procedures. The bootstrapping confidence intervals suggest that skewness differences significantly differ from zero; however, there is no significant difference in kurtosis values. Furthermore, although resampling p values for the model
Comparing the Skewness and Kurtosis of the Latent Factor Scores VAAA and PAAP.
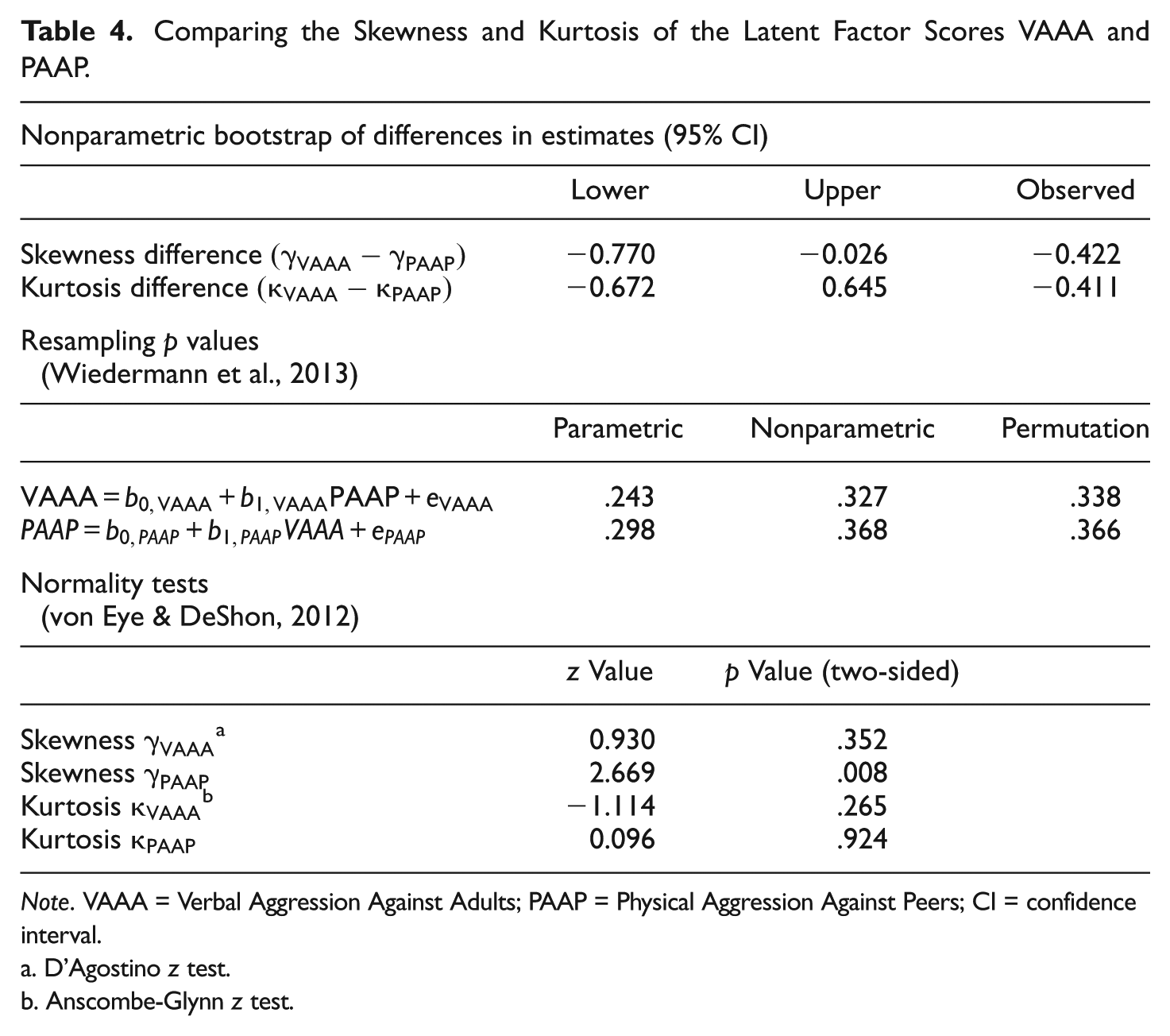
Note. VAAA = Verbal Aggression Against Adults; PAAP = Physical Aggression Against Peers; CI = confidence interval.
D’Agostino z test.
Anscombe-Glynn z test.
In the third analytic step, we regress latent variables of PAAP and VAAA onto each other within a structural model. In a first model, we posit that
The three measures of Physical Aggression against Peers are indicators of a latent variable, PAAP; this latent variable represents the time-invariant element of Physical Aggression against Peers
The three measures of Verbal Aggression against Adults are indicators of a latent variable, VAAA; this latent variable represents the time-invariant element of Verbal Aggression against Adults
PAAP is predictive of VAAA
This model converged, but failed to describe the data well (root mean square error of approximation = .17). Therefore, we introduced a developmental element and allowed the residuals of the first and third measures of PAAP and VAAA, that is, PAAP83 and VAAA83, as well as PAAP87 and VAAA87, to covary. Appendix B displays the LISREL command file for this model. The fit of this model was satisfactory (χ2 = 10.83, df = 6, p = .09; root mean square error of approximation = .08 [.0; .16]; comparative fit index = .98; goodness of fit index = .97). In addition, all estimated loadings were significant, and so was the path from PAAP to VAAA (β21 = 0.77, SE = 0.15, z = 5.27, p < .01). Figure 3 displays model and estimates (standardized scores given).
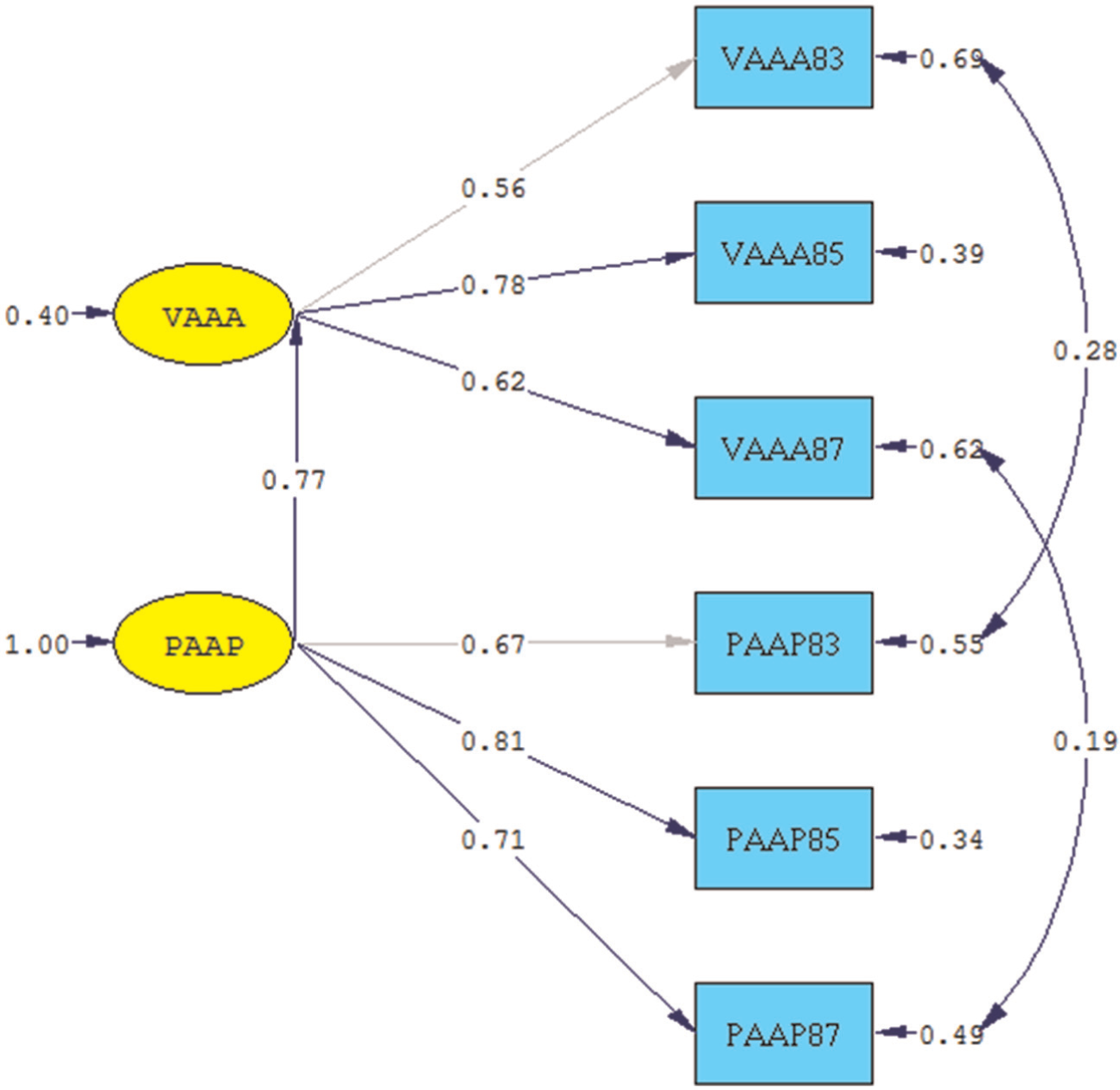
Predicting Verbal Aggression Against Adults (VAAA) from Physical Aggression Against Peers (PAAP).
We now reverse the path in this model so that PAAP is predicted from VAAA. All estimates and model fit (not shown here) are exactly the same. We conclude that structural models as estimated here cannot be used to make decisions about direction of dependence. Only when hypotheses about direction of dependence exist a priori, and when the reverse direction is illogical or implausible, results from models as the ones estimated here can be used to support or reject these hypotheses.
It is interesting to note that causal inferences are often drawn based on matrix B (Sobel, 1995). Specifically, under regularity conditions on B, the parameter π rs of the reduced form equation

is usually interpreted as a standard regression parameter: the effect of a one-unit change in Xir, that is, the rth element of Xi, on Yis, that is, the sth element of Ys. In Equation (43),
Similarly, the stability of a model is a sufficient condition for convergence. It is also estimated based on B. Specifically, it is defined as the largest eigenvalue of B′B which must be less than one for convergence. With respect to our discussion of direction dependence, we note that models of the form estimated in the present data example do not allow one to distinguish between direction of effect based on model stability. The models estimated for both direction of effect hypotheses come with largest eigenvalues of B′B of 0.597. We conclude that even when competing models converge properly and fit, conclusions concerning direction of effect require theory and the methods discussed in this article.
Discussion
The application of methods for the determination of directional dependence is most important in the context of observational research. In this context, manipulation of independent variables, randomization of potential confounders, repetition of observation, or unbiased selection of participants are often impossible. Still, researchers entertain hypotheses about directional dependence even when data are collected in observational studies and in natural settings. Here, the methods discussed in this article are most useful.
However, it can be risqué to base decisions about direction of effects solely on the results of the procedures proposed here.
Therefore, researchers can do worse than considering guidelines such as the ones proposed by Hill (1965; cf. Cox & Wermuth, 2001; Lynd-Stevenson, 2007). According to these guidelines, a dependency is more likely to be causal if
Researchers have developed an a priori explanation of the processes under study.
Researchers have derived such an explanation based on the results of a study. Here, the methods proposed in this article can play an important role. It should be noted, however, that a priori explanations typically carry more weight than ex post explanations.
The studied effect is large; the reason for this part of the guidelines is that, if an effect is large, it becomes less likely that alternative explanations surface by way of unmeasured confounding variables.
If the hypothesized dependency is characterized by a process that involves the same type of relationship as involved in the statistical analysis. In the current context, relationships are examined in the context of a linear, regression-type model. Therefore, conclusions drawn from applications of the methods presented in this article are more convincing if researchers can make plausible that the processes under study can validly be depicted using linear models.
If the same effect, that is, the same conclusion about directional dependence is also found in independent studies which, preferably, are of different design and involve different methods of data collection (see also Lynd-Stevenson, 2007).
If variable relationships can be considered internally and externally valid.
If the dependence is the result of an intervention. This last element of the guideline may be of lesser importance in observational studies. Intervention in natural settings cannot always be performed as cleanly as a lab experiment (Spiel et al., 2008).
If these conditions are fulfilled, dependence can be considered more likely to be causal. The methods developed here add a statistical tool to the decision process. Dependence can be considered directed, which is one of the bases of causal dependence, if the skewness scores and the kurtosis scores of the latent putative explanatory and outcome variables are related as discussed in this article.
The present study focused on the theoretical underpinnings of direction of dependence methods in the context of latent variable modeling and illustrated an application of this methodology using two empirical examples. It is up to future studies to evaluate the Type I error robustness and power behavior of the discussed tests under various scenarios using intensive Monte Carlo simulation experiments.
Footnotes
Appendix A
Appendix B
Acknowledgements
The authors are indebted to J. J. McArdle and Ingo Nader for encouraging and helpful comments on earlier drafts of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.