
Abstract
For computerized adaptive tests (CATs) to work well, they must have an item pool with sufficient numbers of good quality items. Many researchers have pointed out that, in developing item pools for CATs, not only is the item pool size important but also the distribution of item parameters and practical considerations such as content distribution and item exposure issues. Yet, there is little research on how to design item pools to have those desirable features. The research reported in this article provided step-by-step hands-on guidance on the item pool design process by applying the bin-and-union method to design item pools for a large-scale licensure CAT employing complex adaptive testing algorithm with variable test length, a decision based on stopping rule, content balancing, and exposure control. The design process involved extensive simulations to identify several alternative item pool designs and evaluate their performance against a series of criteria. The design output included the desired item pool size and item parameter distribution. The results indicate that the mechanism used to identify the desirable item pool features functions well and that two recommended item pool designs would support satisfactory performance of the operational testing program.
Item pool quality has been acknowledged to play a critical role in the measurement accuracy and efficiency of computerized adaptive tests (CATs; e.g., Flaugher, 2000; Jensema, 1977; McBride & Wise, 1976; Reckase, 1976, 2003; van der Linden, Ariel, & Veldkamp, 2006; Veldkamp & van der Linden, 2000; Xing & Hambleton, 2004). However, despite the fact that the CAT research emerged during the late 1960s, it was not until the early 2000s that researchers started to attend to the problem of item pool design for the CATs. Unlike the problem of item pool assembly, in which an item pool is assembled from an available master pool according to the desired specifications, an item pool design effort focuses on developing an item pool blueprint in which the distribution of numbers of items with all possible combinations of the relevant statistical and nonstatistical attributes of the items are described (van der Linden et al., 2006). In other words, item pool design is distinct from item pool assembly because at the time of the design no items are available. An item pool design effort is tasked to identify the item features that can support the functioning of the target CAT program. As item development can be very costly and an item pool cannot be infinite in size, item pool size becomes another important issue that an item pool design effort needs to address.
In van der Linden et al. (2006), an optimal item pool is defined as one
consist(ing) of a maximal number of combinations of items that (a) meet all content specifications for the test and (b) are most informative at a series of ability levels reflecting the shape of the distribution of the ability estimates for a population of examinees. (p. 82)
This definition clearly spells out several factors that an item pool design effort is expected to attend to and these factors can be further categorized into two aspects: technical and nontechnical. The technical aspects mainly deal with different components that constitute adaptive test algorithms, for example, item selection algorithm, exposure control procedure, termination procedure, and item overlap restriction. The nontechnical aspects deal with such issues as target examinee population or test purpose. As each adaptive testing program is unique in a way that it has its own target examinee population and test purpose and operates on its own test algorithms, we would expect the item pool designs for different CATs to be different. For example, it is reasonable to speculate that, other things being equal, a longer adaptive test may require a larger item pool than a shorter one. A CAT that aims at measuring the examinees’ abilities equally well over the full range of abilities will likely require an item pool with design features different from a CAT that aims at differentiating a group of examinees in a gifted program from each other. In other words, in order for the item pool design to reflect the intended test and examinees characteristics, it needs to be tied up to the technical aspects of the testing programs, the target examinee population, and specific test purposes.
So far, there are two lines of approach that have been used to design item pools for CATs: the mathematical programming approach, represented by the shadow-test approach (STA; Veldkamp & van der Linden, 2000), and the heuristic approach, represented by the bin-and-union method proposed by Reckase (2003). Implementation of the former relies on specialized knowledge of linear programming and software, such as CPLEX and LINDO, to implement binary linear integer programming to construct a shadow test.
In contrast, the bin-and-union approach is straightforward and requires no specialized software. To apply the bin-and-union approach, a set of “bins” are defined on the ability scale used for reporting results of the CAT and for calibrating the items. These bins, with a specified width on the ability scale, are used to tally the number of administered items needed for that range of the scale. Items in each bin are treated as equivalent to each other in use and bins are mutually exclusive to each other. To design an item pool, the task is first divided into a series of smaller design problems related to nonstatistical attributes, such as content strands. Then, the full adaptive algorithm of the target test is simulated to determine the desirable item parameter features that are needed to support the efficient estimation of examinee abilities. An examinee is randomly sampled from the expected population and administered the target CAT with items that have the features exactly needed by the item selection procedure. All the required items are assumed available.
Different IRT models and item selection rules will have different definitions of the desirable item features. In the case of a CAT based on the Rasch model using maximum information item selection, the desirable features of an item has difficulty parameter (denoted as b thereafter) exactly equal to the current ability estimate. These optimal items are assumed available and sorted into the prespecified “bins” according to their b values as they are administered. The result is a tally of the number of items needed in each range of the ability scale for the CAT for one person. The same procedure is then repeated for subsequent examinees. Because items selected for one person can be used for another one, the required item pool is the union of the item sets that are administered for each examinee. It can be anticipated that the number of the items that needs to be added after each examinee would diminish with increase in the number of sampled examinees, and the pool size should asymptote to some value that will satisfy the requirements of all sampled examinees. Thus, the end-product of above procedures includes item pool size, item difficulty distribution, and items’ other nonstatistical properties.
For most CAT programs, exposure control and content-balancing procedures are two important and indispensable components that need to be considered. These procedures support test security and provide supportive evidence for content validity. Content-balancing also helps make different administrations of the CAT comparable. However, these two procedures have the consequence of complicating the implementation of adaptive testing. As mimicking the adaptive algorithm of the target adaptive test constitutes an important part of item pool design process, the presence of both exposure control and content-balancing procedures in the target CAT introduces additional complexities to item pool design efforts. In Reckase (2003), the application of the bin-and-union method to identify the desirable item pool features is limited to a fixed-length adaptive test with a simple design considering no exposure control and content balancing procedures. Reckase (2010) sketched an example of item pool design for a CAT that considers exposure control and content balancing. Sufficient details and procedures needed for the practitioners to design operational item pools, however, were not provided. In addition, how different design factors such as the choice of different bin widths interact with the target adaptive algorithms to influence item pool designs was barely studied.
To fill in this gap, this study was conducted with the primary purpose to provide step-by-step, hands-on guidance on the item pool design process by applying the bin-and-union method (Reckase, 2003) to design item pools for a large-scale licensure CAT. The focus was on how the complex adaptive algorithm of the target test, including variable test length, content balancing, and exposure control procedures, were captured in the design process and how they interacted with other design factors, in particular, bin width, in the design process. In addition, information was provided about the evaluation of alternative pool designs and the trade-offs among different pool size, test security, and accuracy of test results that needed to be considered when evaluating alternative pool designs.
Provided below is a brief illustration on how the bin-and-union method works.
Suppose two examinees have taken a computerized adaptive test and their true abilities were −.0953 and .0264, respectively. A simulation of a CAT procedure using these two true abilities and the CAT algorithm described in the CAT Model section indicates that the first examinee was administered 250 items whereas the second one was administered 115 items. In each case, the next item selected for administration had a Rasch b-parameter exactly equal to the current estimate of ability. This was the same as selecting items that give maximum Fisher information at the current ability estimate. The difficulties of items selected for these two examinees were distributed as shown in Figure 1A and B. These distributions used a bin width of .4 on the ability scale to tally the number of items required in each bin.
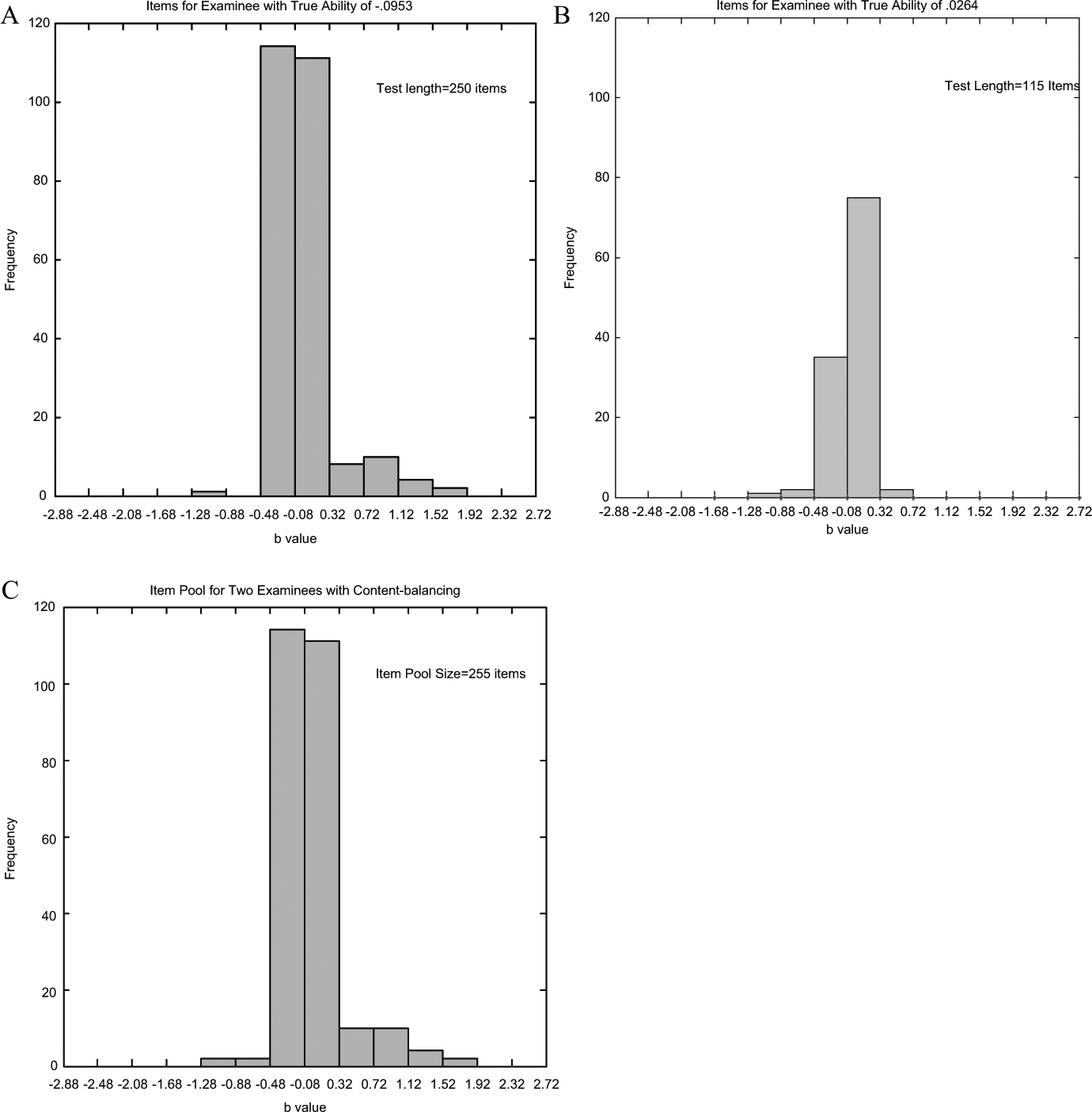
Item distributions for two examinees with true abilities of −.0953 and .0264, respectively, and the item pool constructed for these two examinees.
Inspection of the two distributions shows that the items selected for these two examinees have a lot in common since a large number of items were in the bins from −.48 to −.08 and from −.08 to .32 on the ability scale. This means the second examinee could use the items that have been selected for the first examinee. Therefore, rather than needing 365 items, that is, the sum of the number needed for each examinee, the pool needed for these two examinees required only 255 items. This number was the count of the items in the union of the two sets. Figure 1C displays the full item pool built up for these two examinees. When a third examinee was selected, the set of items required for that examinee could be determined. The union of that set and the set for Examinees 1 and 2 combined could be determined. That gave the number of items for the three examinees. That process can be continued until the number of items needed no longer increases. Figure 2 illustrates how the required item pool increases in size as the number of examinees increases. For the example given here, the item pool size reached an asymptote at 1,086 items.
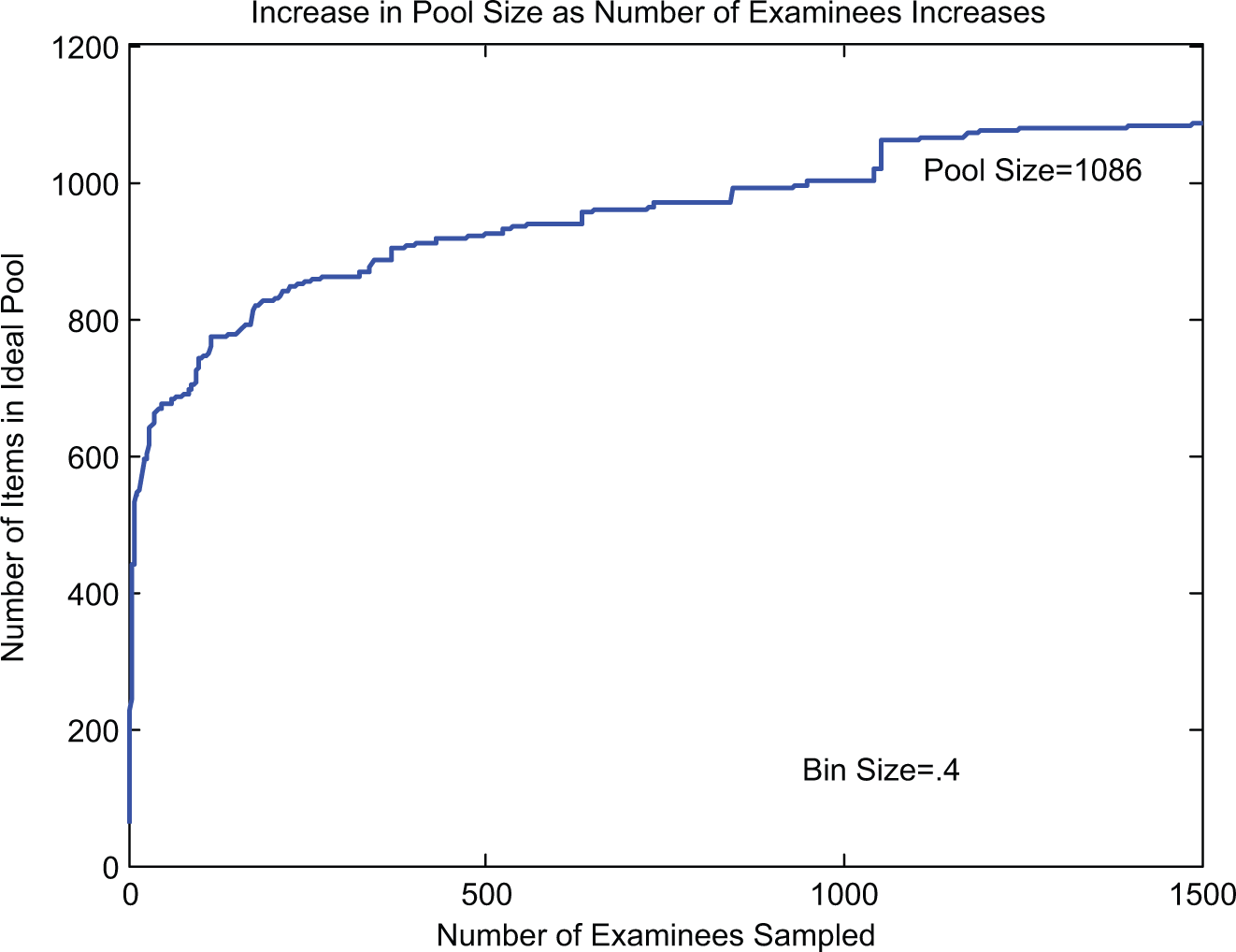
Increase in required pool size as number of examinees increases.
Method and Procedure
CAT Model
The CAT model used for the analyses reported here mimicked that used in a large-scale high-stakes licensure CAT program. The Rasch model was used as the basis for the CAT. Maximum information item selection procedure was used to choose the item that maximizes the obtained psychometric information about the examinee’s location on the ability scale. A mixture of Bayesian and maximum likelihood estimation was used for ability estimation. The Bayesian estimation procedure (Owen, 1975) was used at the beginning of the test with a prior having a specified mean and variance. When both correct and incorrect responses were available, the estimation procedure switched to maximum likelihood estimation. The item selection mechanism involved content-balancing and a randomesque exposure control procedure (Kingsbury & Zara, 1989). This exposure control procedure randomly selected an item for administration from a set of 15 items with difficulty parameters closest to the current ability estimate. The minimum test length was 60 items. When the 95% of the confidence interval around the candidate’s current ability estimate no longer included the cut score of −.28, the test stopped and a pass/fail decision was made. When the confidence interval of ability estimate included the cut score, the procedure continued administering items with the same content constraints and exposure control until the ability estimate had a 95% confidence interval that did not include the cut score, or a maximum test length of 250 items was reached. This was a very complex adaptive testing algorithm with variable test length, a decision-based stopping rule, content balancing, and exposure control.
Choice of Bin Width
The selection of the bin width is arbitrary, but generally can be guided by such analyses as how much information that items can provide or how precise the final ability estimates are expected to be. In general, the more precise the final ability estimates are expected to be, the narrower the bin width needs to be. Figure 3 shows the information function for the Rasch model. Analysis of the characteristics of the information function can be used to decide on the bin width. In this example, the information function has been scaled so that the x-axis is the distance between item difficulty parameter and examinee ability and the y-axis is the proportion of the maximum item information. The curve shows how much reduction in information occurs when an item is selected that does not exactly match the ability estimate. For example, the figure shows that if the item difficulty is .4 logit away from ability estimate, then there is an approximately 4% reduction in information from the maximum item information. If a .4 bin width were used, the worst case of item selection from items in the bin compared with a perfect match to the ability estimate would be a 4% reduction in information. The wider the bin width, the more reduction from the maximum item information, but with a possibly smaller the item pool size.
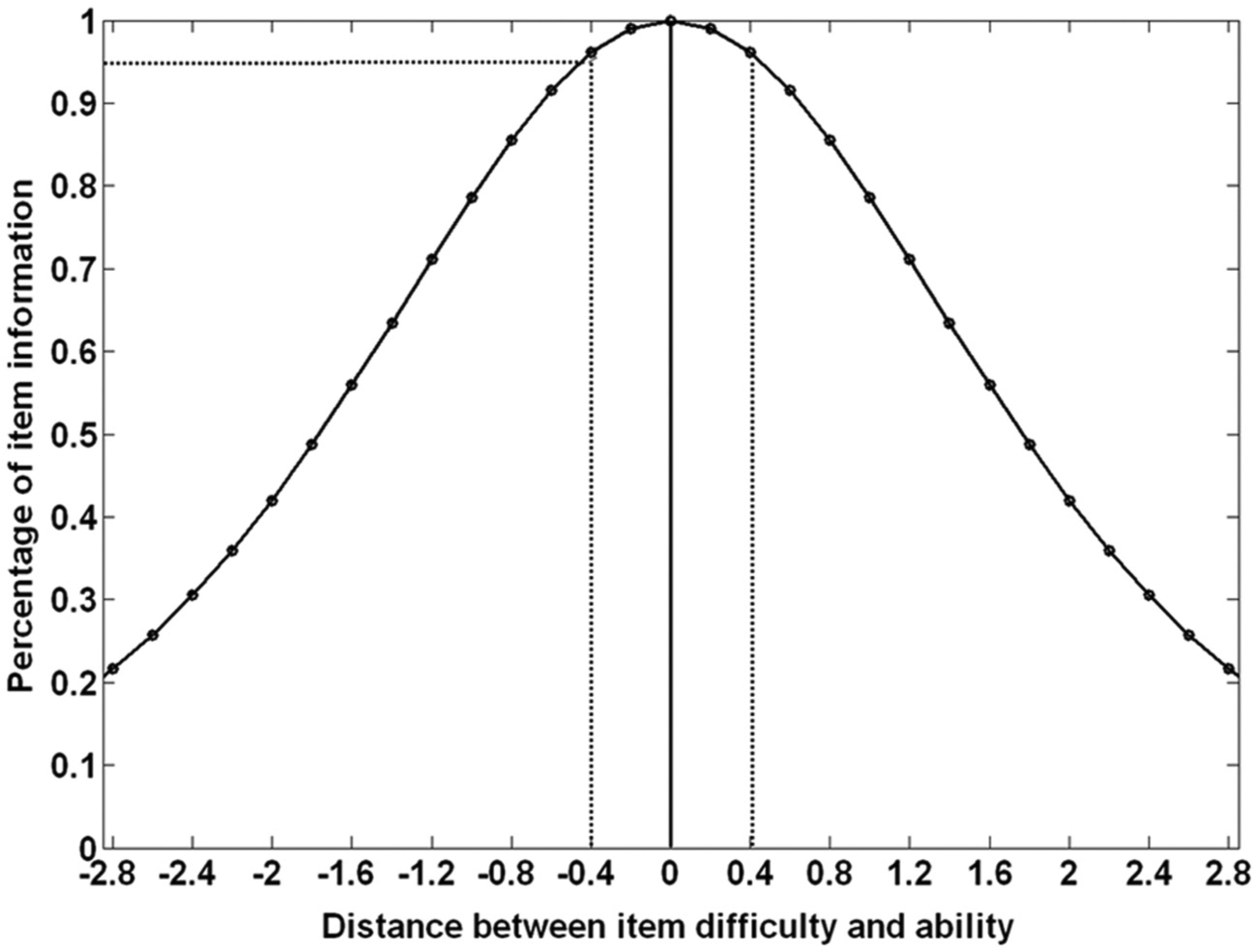
Percentage of maximum item information conditional on the distance between item difficulty and ability.
Simulation Procedure
This study was carried out in two major phases. In the first phase, the characteristics of several item pool designs were identified and item pools were constructed according to these designs. In the second phase, the performance of these candidate item pools was evaluated against a series of criteria. Two candidate item pools were recommended for practical use, and their performance was compared with that of a retired operational item pool.
Phase I
To identify the characteristics of the item pools, the adaptive algorithm described in the CAT Model section was simulated with the assumption that every item that was requested by the item selection rule was available for administration. This assumption allowed the methodology to identify the item pool features for the test. As the target test used the Rasch model and maximum item information item selection, the desirable feature of an item should have its b value equaling the current ability estimate. To determine the items needed for the item pool, 3,000 examinees were randomly sampled from the expected examinee ability population and each was administered the CAT. The expected examinee ability distribution was obtained from historic data and the technical report of the target CAT program. For each examinee, all items administered in each content strand in the test were allocated to the “bins” on the ability scale based on their b values. Three sets of bin sizes, .4, .8, and varied bin-widths with narrower bins (i.e., .4) near the cut score and wider bins (i.e., .8) at the extremes of ability—were used to tally items so that the item pool size could be determined.
To examine how the exposure control procedure affected the pool size, for each bin size, two pools were considered—one with the exposure control procedure and one without. The effect of excluding the items with the extreme b values was also investigated by developing two item pools that were exactly the same, except that the items with the extreme values were removed from one pool. Consequently, a total number of seven item pool designs were developed. Fifteen replications were conducted for each design. This number was considered adequate because we kept track of the item pool size from each replication and did not observe much difference in item pool size estimates for the replications. Table 1 describes the item pools designed in Phase I.
Item Pools Designed in This Study.
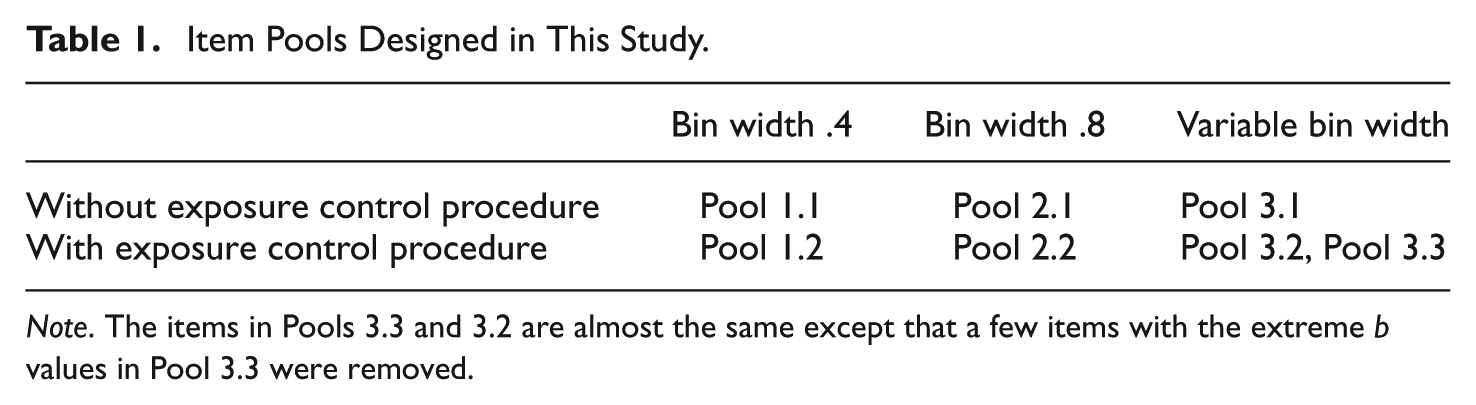
Note. The items in Pools 3.3 and 3.2 are almost the same except that a few items with the extreme b values in Pool 3.3 were removed.
Once the desired characteristics of the item pool for this test were identified, seven simulated candidate item pools were constructed by creating item records with content strand identification and Rasch difficulty parameters that matched the designs. As mentioned earlier, the design features for each item pool included item pool size and item difficulty distribution across different content strands.
Phase II
The evaluation was carried out in two steps by using overall and conditional samples, respectively. The first step simulated a fixed sample of 10,000 simulees randomly drawn from the same ability distribution used in Phase I and administered the CAT using each of the seven candidate item pools. The second step was focused on two item pool designs that were found to function the best in the previous step. Specifically, for these two recommended item pool designs, their performance was compared with that of a retired operational item pool by simulating examinee samples with ability points equally spaced over the range between −3 and 3 at an interval of .5. The statistics conditional on each ability point included standard error, bias, mean square error, and classification accuracy level.
Evaluation Criteria
The following criteria were used to evaluate the performance of the seven item pool designs.
Average test length.
Classification accuracy of the ability estimates for both overall and conditional samples.
Precision of ability estimation. Overall bias, mean square error (MSE), and correlation coefficients between estimated and true person abilities were computed using Equations (1) to (3). At each conditional ability point, conditional bias, mean square error, and classification accuracy were also computed.


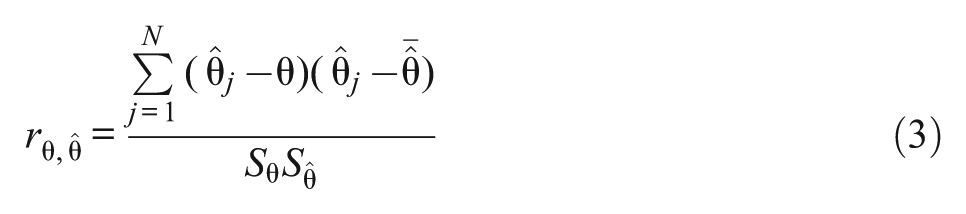
where
Test security. Percentage of overexposed items and item overlap rate were used as two test security indices and computed as described below.
Item usage. Percentage of underexposed items, as described below, was used to depict item usage.
Percentage of overexposed items
The exposure rate of an item is defined as the ratio of the observed frequency of item administrations divided by the total number of the examinees. A moderate level of item exposure rate is generally desired. A high exposure rate for an item implies an increased risk of the items being known by the prospective examinees, potentially threatening test security. A commonly used cutoff value to evaluate whether an item is overexposed is .2 (see, e.g., Eignor, Stocking, Way, & Steffen, 1993; Hau & Chang, 2001). This rate means that a test item is administered to 20% of the examinees. When this rate is used, this is the maximum exposure that is allowed for an item.
Item overlap rate
Item overlap rate (sometimes called test overlap rate) is defined as the number of common items encountered by two randomly selected examinees divided by the test length in the test. The following equation is used to calculate the average item overlap:

where T is the total number of items shared by
Percentage of underexposed items
Low item exposure rate means an item is rarely used. An item pool with too many items with very low exposure rate indicates the underutilization of the pool. In this study, an item with an exposure rate lower than .02 is considered underexposed. Note when evaluating the performance of the item pool in this study, this criterion was not given the same weight as other criteria for the reason that the target test is high-stakes in nature.
Results
Results From Phase I
Due to page limits, the distributions of all candidate item pools cannot be presented. As an illustrative example, the target item distributions of four representative content strands for Pool 2.2 developed with a bin width of .8 are presented in Figure 4. Note the differences in these subcontent pool sizes were due to the fact that the target percentages of items from each content strand were set differently in the target exam.
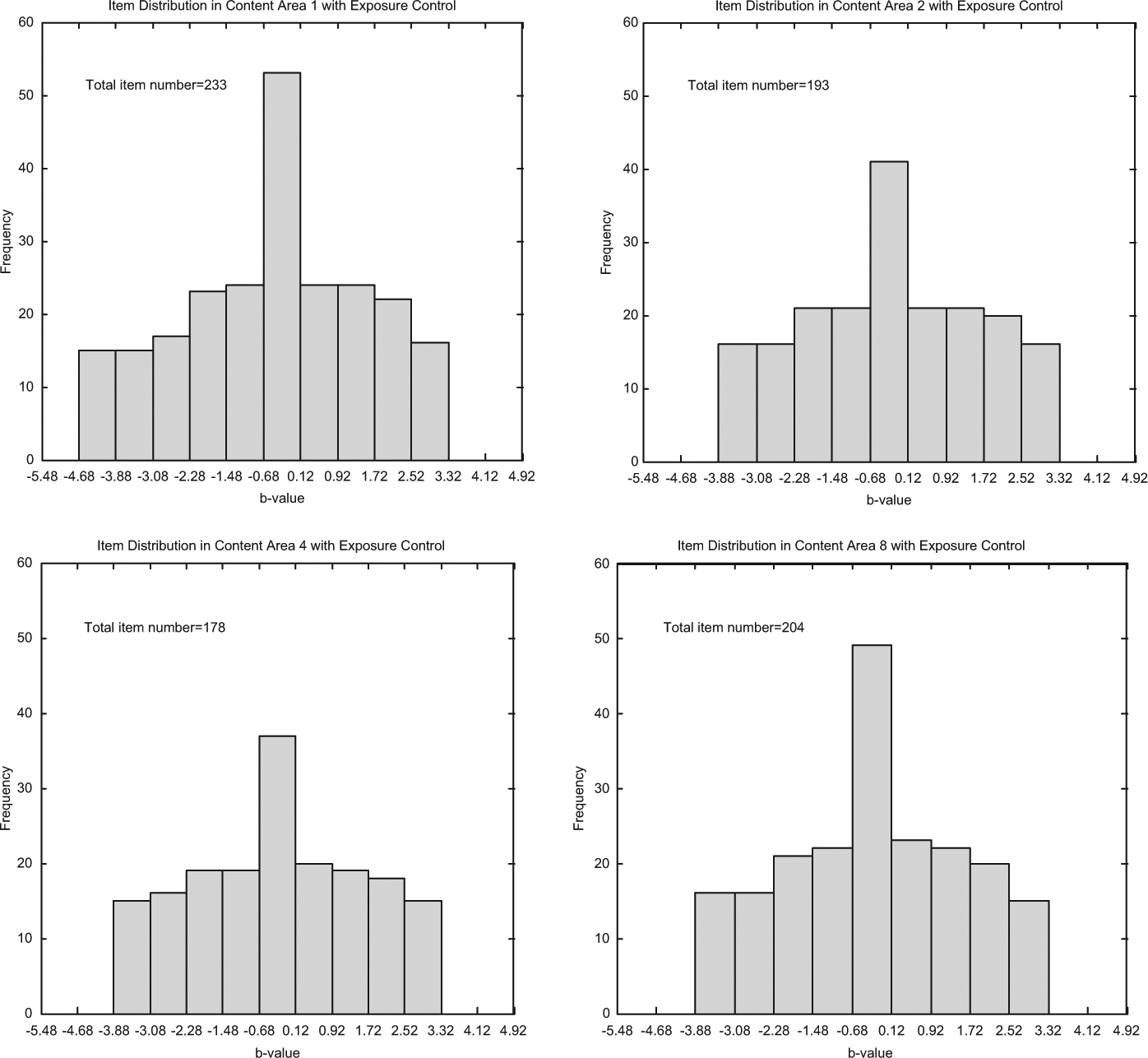
Item difficulty distributions for four representative content strands for Pool 2.2.
As Figure 4 indicates, the target item distributions share some similarities across all content strands. This was true when other bin widths, including .4 and variable bin-widths, were used as well. These similarities included the following (a) the item distributions were far from a normal distribution, but were slightly negatively skewed with a peak centering on the middle category of b values near the cut score on the ability scale; (b) the number of items decreased in the bins farther away from the cut score; and (c) all item pools had a wide coverage of item difficulty and sufficient depth at points along the ability scale to support the exposure control procedure.
The effect of the item exposure control procedure on the item pool size is illustrated in Figure 5, which depicts the target item distributions of Pools 1.1 (without exposure control) and 1.2 (with exposure control). Obviously, the number of items increased substantially when the item exposure control procedure was implemented. Recall that the item exposure control procedure in the target exam involved randomly selecting one out a set of 15 items with difficulty parameters closest to the current ability estimate. This means each bin in each content strand needed 14 more items than the bins obtained when no exposure control procedure was implemented. Even for those sets of items at the tails of the scale and seldom used in the exam, at least 15 items were needed to enable the exposure control procedure to function well and still select items that were appropriate for the current ability estimate.
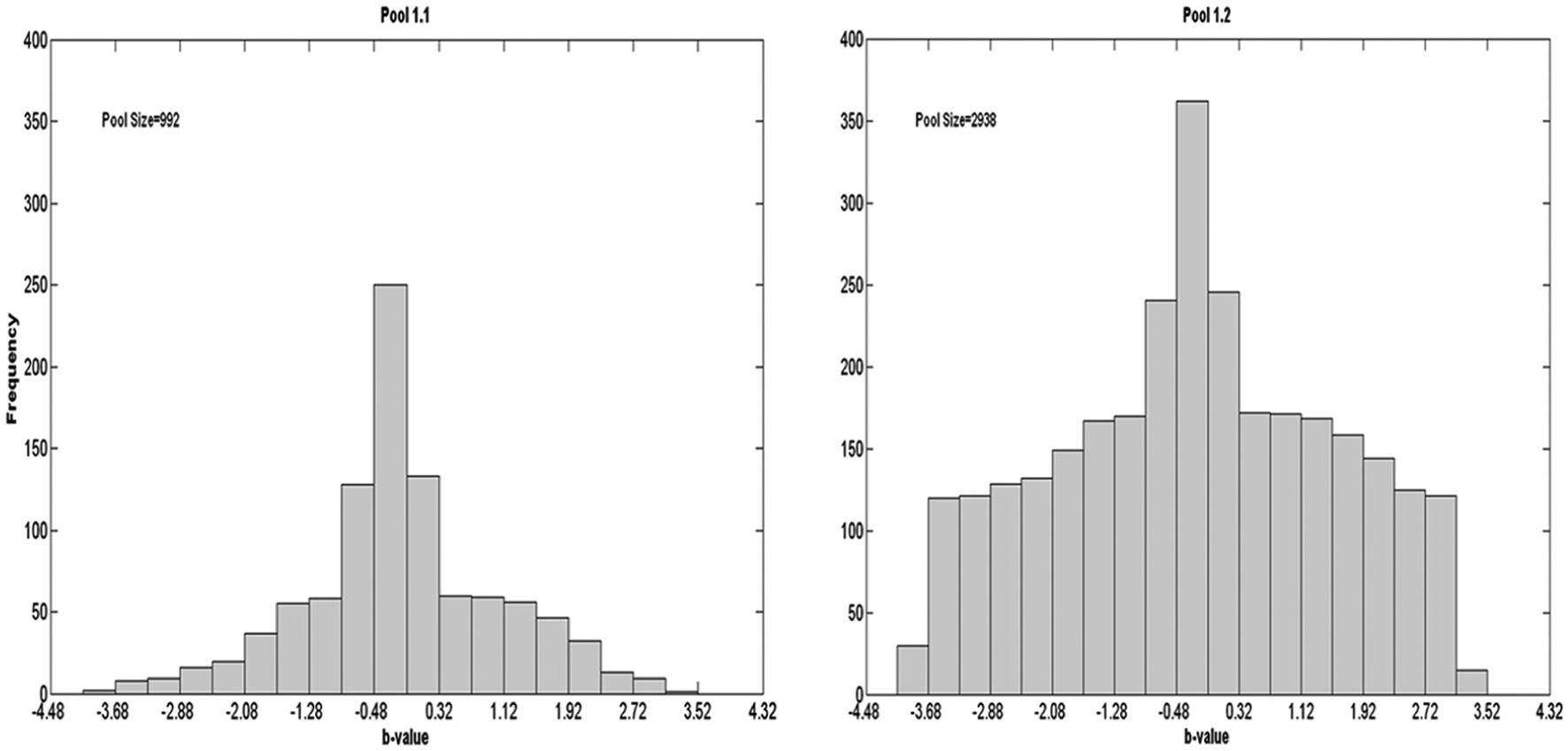
Item distributions of Pools 1.1 and 1.2.
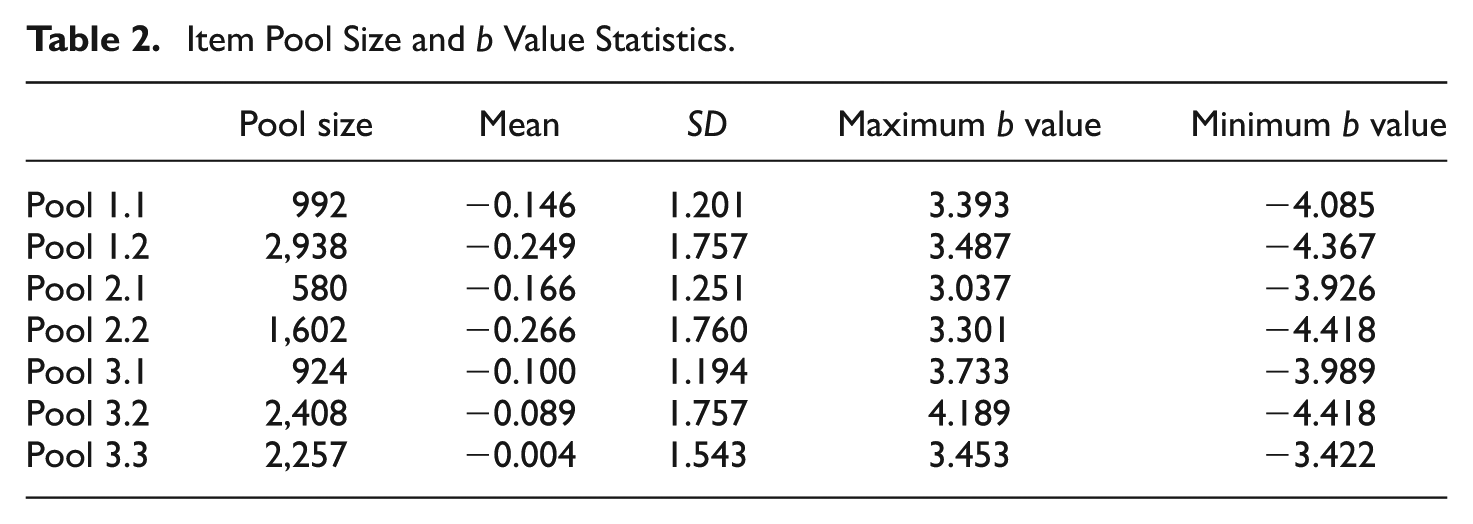
Table 2 presents the descriptive statistics for these seven candidate item pools. From this table, we can see that the pool size varies for different pool designs and this variation was the result of the bin size utilized to develop the pool designs and the use of exposure control procedure by the target test. Other things being equal, the pools designed with a smaller bin width tended to be larger. Likewise, other things being equal, the pools designed with the consideration of the exposure control procedure tended to be larger. The pool designs without the exposure control procedure had higher average b values and lower standard deviations than the pool designs with the exposure control procedure. This can be attributed to adding additional 14 items to each bin in each content strand to respond to the needs of the exposure control procedure.
Item Pool Size and b Value Statistics.
Results From Phase II
Evaluating the seven item pool designs
Table 3 presents an overview of the evaluation results for the seven item pool designs. In this table, we can see that the average test length yielded by the different pool designs was slightly different; and Pool 2.2 tended to yield the shortest average test length. The percentage of the classification accuracy did not vary much across these pool designs. The pool designs with the exposure control procedure, in comparison with the pool designs without the exposure control procedure, tended to yield a slightly more accurate pass–fail decision. Regarding ability recovery accuracy, the ability estimates from all pool designs exhibited slightly positive but negligible bias. MSE from all pool designs were comparable with each other, along with correlation between the true and the estimated abilities. All pool designs, except Pool 2.1, gave reasonable item overlap rates, considering that the average test length yielded by all pool designs was approximately 110. The percentage of overexposed items dramatically dropped as a result of the increase in pool size. For example, Pools 1.2, 3.2, and 3.3 did not have any overexposed items. The item pool designs with the exposure control procedure, however, yielded a higher rate of underexposed items than those without the exposure control procedure. A further look revealed that, in all seven item pool designs, items with b values beyond the range of approximately −1.6 to 1.5 tended to be underexposed. In addition, the item exposure distributions for individual content strands slightly varied across the pool designs developed with the different bin widths. For each item pool design, the item exposure rate distribution for each content strand shared a very similar pattern.
Summary Statistics of the Performance of the Seven Designed Item Pools.
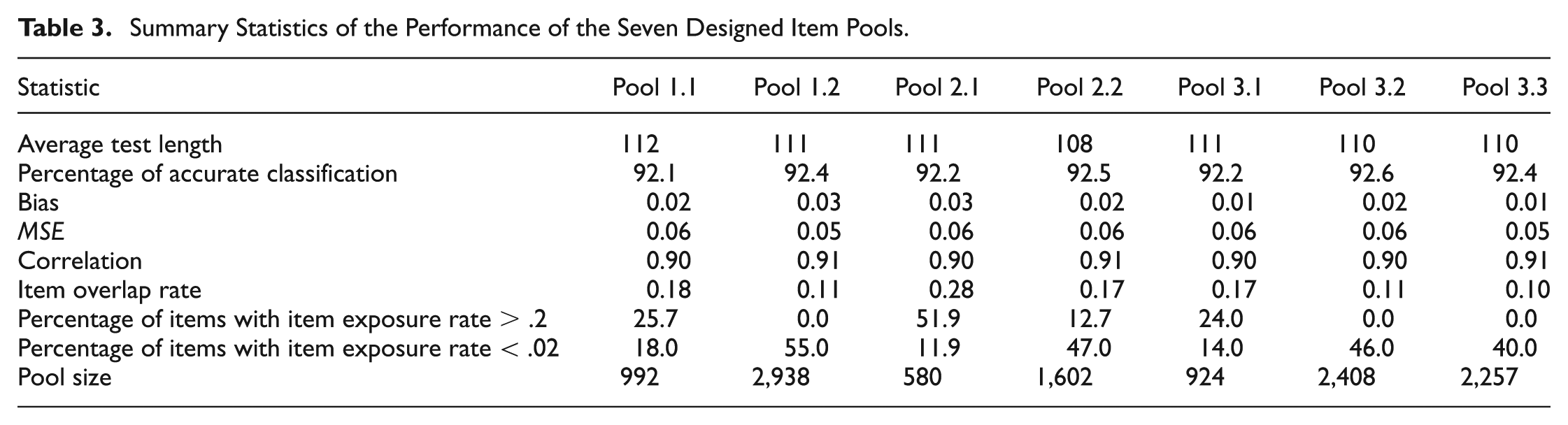
In summary, the above results suggest that Pool 2.2 and Pool 3.3 were the most desirable item pool designs based on the combination of pool size, test security, and measurement accuracy, although neither of them were the best on all the desired features. Pool 2.2, compared with Pool 3.3, needed 655 fewer items and yielded a shorter average test length. However, Pool 2.2 produced a higher item overlap rate than Pool 3.3, and 12.7% of the items in Pool 2.2 were overexposed, whereas Pool 3.3 did not have any overexposed items. Therefore, for Pools 2.2 and 3.3, there existed a trade-off between the pool size (or the cost-effectiveness of pool development) and test security, given comparable measurement accuracy levels. The selection of either one of these two pool designs could depend on the priority given to different features of the test. These two item pool designs were recommended for practical use; and their performance was compared with that of a retired operational item pool.
Comparing the two recommended item pools with the operational item pool
Table 4 summarizes the performance of the Operational Pool (OP) compared with that of Pool 2.2 and Pool 3.3. Compared with Pools 2.2 and 3.3, the OP yielded slightly longer tests on average and a slightly lower classification accuracy rate. There was less concern over test security for the OP than for Pools 2.2, as the OP had an 8.5% item overlap rate and zero overexposed items. The OP witnessed better item usage than Pool 2.2 and Pool 3.3 with a lower percentage of underexposed items. Table 4 also indicates that correlation with true abilities, estimation bias, and MSE are not substantially different across all three item pools.
Summary Statistics of the Item Pool Performance of OP, Pool 2.2, and Pool 3.3.
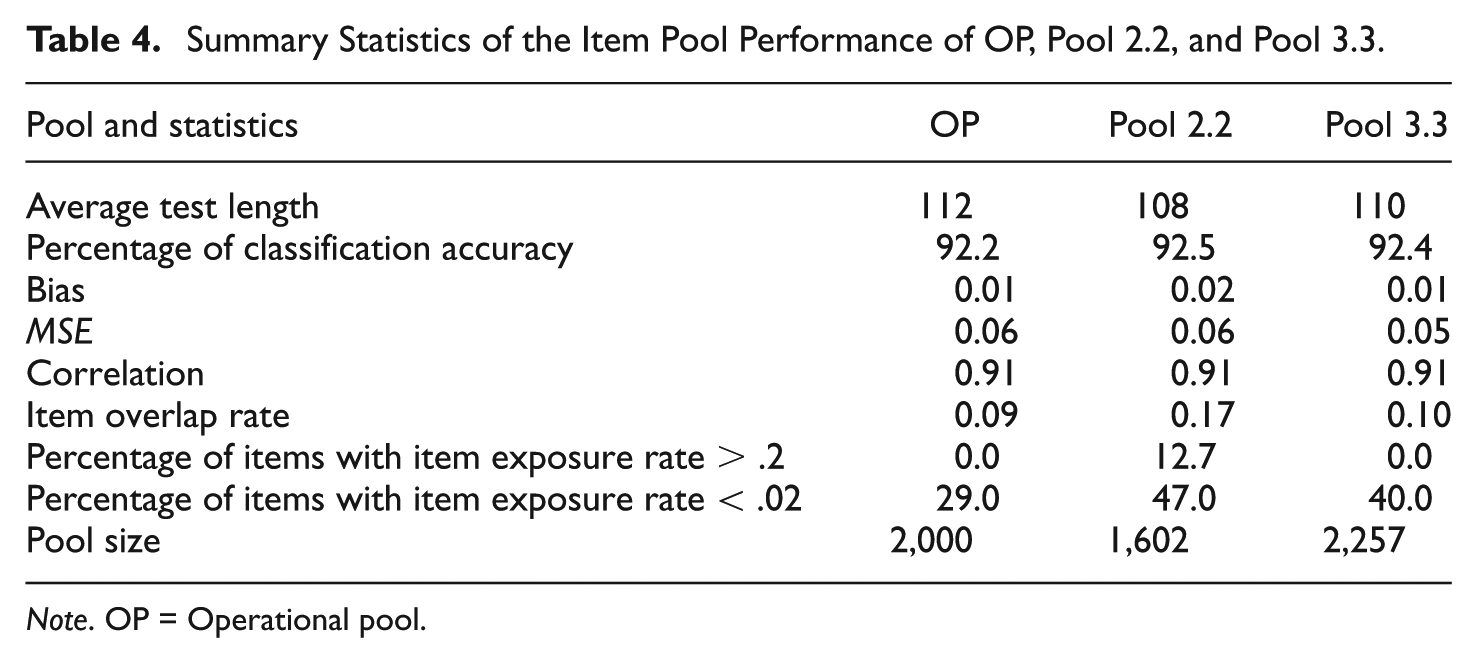
Note. OP = Operational pool.
Results regarding ability recovery accuracy conditional on each ability point provided more information about the performance between the OP and two item pool designs. Figure 6 presents the plots of the conditional MSEs. Unlike Pool 2.2 and Pool 3.3, the OP produced higher conditional MSEs, in particular, beyond −2 and 1.5. The reason was that the OP had fewer items appropriate for administration for these extreme ability levels. This reason also explained why the average test length for the OP came out to be slightly longer than that for Pool 2.2 and Pool 3.3, given how the termination rule works in the target exam.
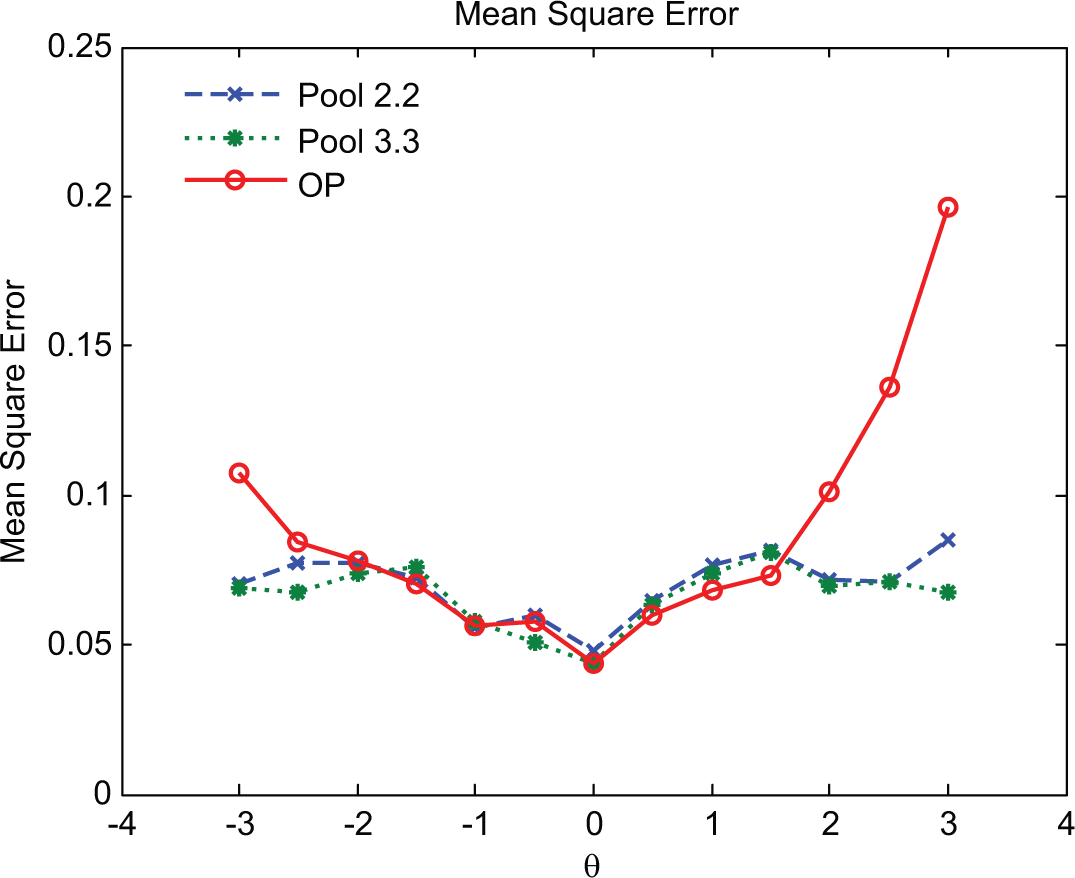
Conditional MSEs for Pool 2.2, Pool 3.3, and operational pool (OP).
Figure 7 presents the conditional estimation bias for these three pools. An interesting finding regarding bias was that, for these three pools, the ability points of −.5 and 0 yielded much higher biases than other points and they moved in opposite directions. It should be noted that the magnitudes of the biases for ability points of −.5 and 0 were of no concern, as they were still relatively small (|.08|). Also note both −.5 and 0 were close to the cut score that the target exam adopted to make the pass–fail decision. This result seemed to be related to test length, which was in turn affected by the stopping rule of the test. Additionally, the OP, as a whole, produced higher bias at the extreme abilities than the other two pools. In summary, the OP yielded higher average conditional bias and MSE than Pool 2.2 and Pool 3.3, as Figure 8 indicates. As to the conditional classification accuracy, Figure 9 shows Pool 2.2 tends to yield better conditional classification accuracy than other two pools and all three pools tended to produce the lowest pass–fail decision accuracy for those examinees with true abilities between −.5 and 0.
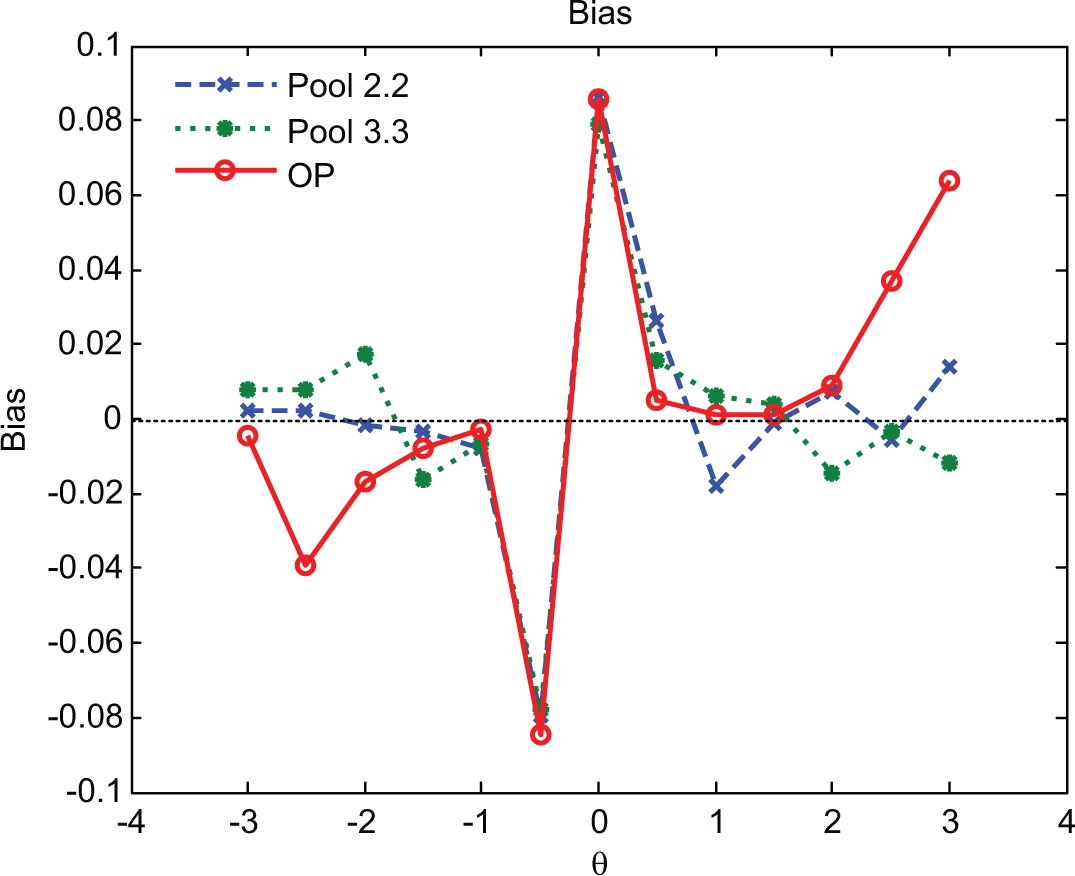
Conditional biases for Pool 2.2, Pool 3.3, and operational pool (OP).
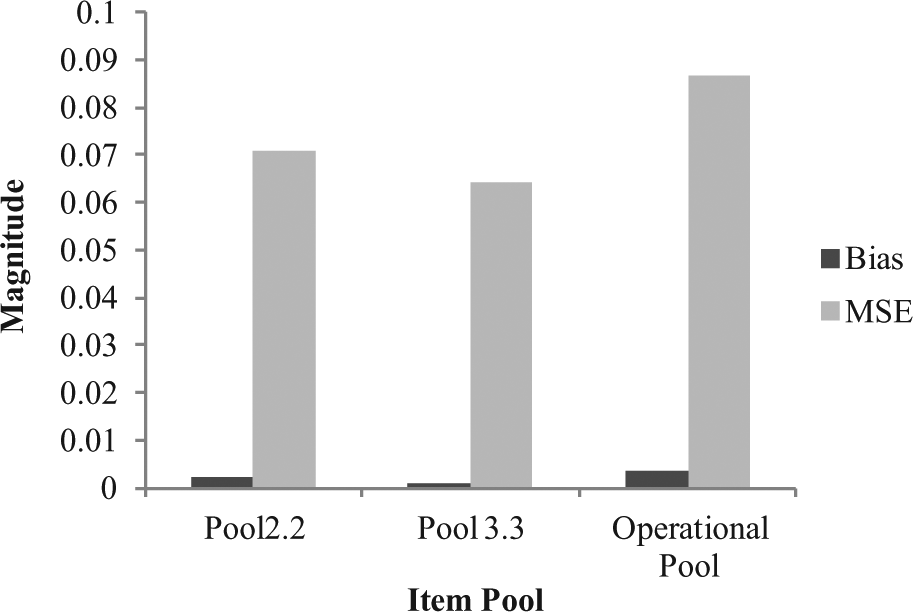
Average conditional bias and MSE.
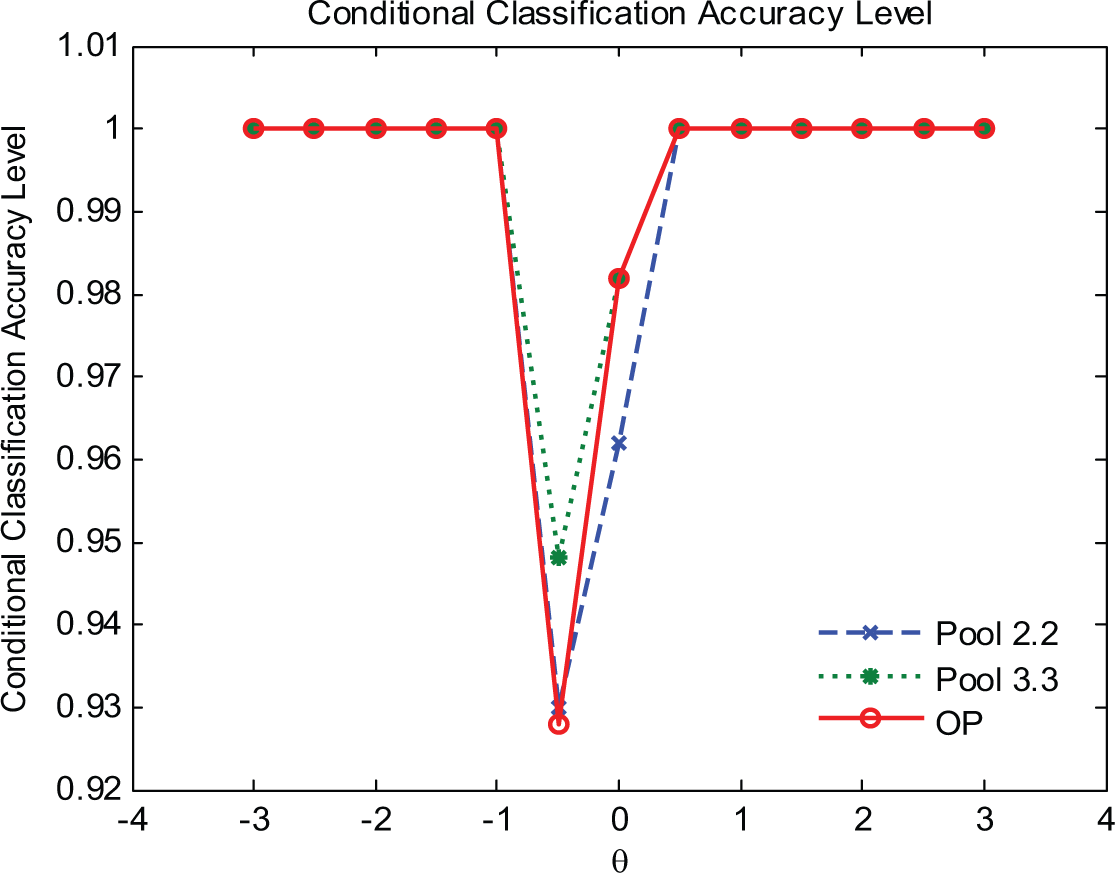
Conditional classification accuracy level for Pool 2.2, Pool 3.3, and operational pool (OP).
In summary, two simulated item pools—Pools 2.2 and 3.3—yielded comparable measurement precision for examinees at the middle of ability scale but better measurement precision for examinees at the extremes of the ability scale than the OP. The OP and Pool 3.3 supported better test security than Pool 2.2 in terms of a lower item overlap rate and zero percentage of the overexposed items. Additionally, the OP appeared to better utilize the items with a lower number of underexposed items. However, this security came at the cost of 400 more items. Table 5 summarizes the comparison results for these three pools in light of pool size, test security, and measurement precision.
Performance Comparison Among OP, Pool 2.2, and Pool 3.3.
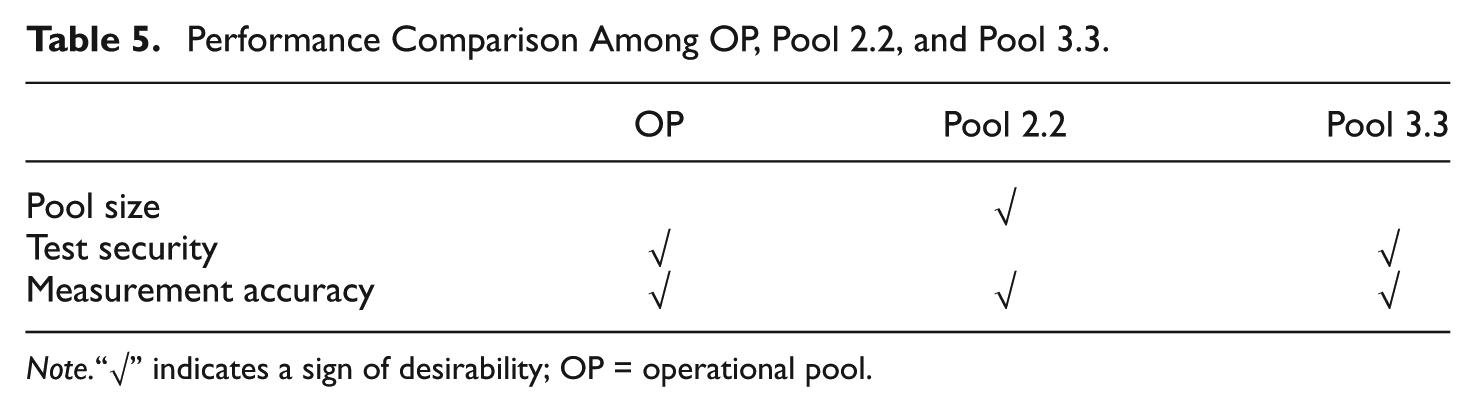
Note.“√” indicates a sign of desirability; OP = operational pool.
Conclusion and Discussion
Item pool development constitutes a fundamental component in constructing a CAT (e.g., Flaugher, 2000; Parshall, Spray, Kalohn, & Davey, 2006, Reckase, 2010; Thompson & Weiss, 2011). Yet, the existing literature provides insufficient guidance to carry out such development. This study was undertaken to improve the level of guidance available to practitioners as they encounter the rigor of item pool development. It has provided step-by-step, hands-on guidance on how to apply the bin-and-union method to item pool design for a real-life CAT program that adopted a very complex adaptive algorithm with variable test length, a decision-based stopping rule, content balancing, and exposure control. The item pool design effort depicted in the article assumed no items at the time of the design and its aim was to develop an item pool blueprint in which the distribution of items with all possible combinations of the relevant statistical and nonstatistical item attributes of the items are described. The step-by-step guidance demonstrated several major components of the design process, typically completed through extensive simulation. These major components included using the observed performance distribution of examinees as the target distribution for the simulation of the CAT, conducting analysis to inform the choice of bin width, identifying the desirable item characteristics and capturing unique needs of the target test such as exposure control and content-balancing methods while simulating the full adaptive algorithm, implementing the bin-and-union method to establish item distribution and pool size associated with different bin widths, as well as evaluating different item pool designs to identify the design suitable for the target CAT. In particular, this study applied the variable bin width in the design process. While Reckase (2003, 2010) has described the basic concepts of the bin-and-union method of item pool design, this article included additional details needed for implementing the procedure. Specifically, information was provided about the evaluation of alternative pool designs, and the trade-offs that needed to be considered among item pool size, exposure control, and accuracy of test results.
To demonstrate how design factors such as the choice of bin width and the target CAT algorithms affected the item pool design features, seven candidate item pool designs were purposefully generated in this study by crossing three bin widths with with/without exposure control procedure. The results indicate that target examinee population, the design features of the target CAT such as content balancing and exposure control, and the design factors such as bin width collectively affect item pool characteristics hence the performance of the CAT. For example, to address the content-balancing requirement that items were selected from the least-represented content strand—a popular method commonly used in most of operational CAT programs—the item pool design task was broken down for each content strand for which the bin-and-union method was applied to identify design features and estimate the size of the mini item pool for each content strand. By this means, each mini item pool wound up having an item count proportional to the target administration percentage. Because the exposure control procedure worked by selecting one of a set of 15 items with difficulty parameters closest to the provisional ability estimate for administration, 14 more items were added to each bin in each content strand to help the test to meet the exposure control requirement. Other things being equal, this treatment has increased the pool size by about threefold. The choice of the bin width used in the design process also played an important role in shaping the item pool design features. As expected, the narrower the bin width was used in the design process, the larger the pool size was. For the target CAT, the item pools developed with .8 bin width were around two thirds as large as those developed with .4 bin width. The use of variable bin width, as this study in particular indicates, appears as a viable alternative particularly for tests with the focus on classifying examinees based on a single cut score. The reason was that the use of narrower bin width around the cut score than that on the extreme could potentially result in more items around the cut score. By and large, the overall results have demonstrated the capacity of the bin-and-union method to design item pools with specifications that could support successful testing applications for the target exam.
As mentioned in the study, simulating full adaptive algorithm in the target CAT consisted of a key part of the design process, and the underlying IRT model and item selection rule, as part of the adaptive algorithm, played a key role in deciding the desirable item features. Clearly, the use of other IRT models such as the two- or three-parameter model rather than the Rasch model implies new methods need to be developed to cope with other IRT models. Fortunately, efforts have been made in this regard, and Gu (2007), He (2010), and He and Reckase (2011) can be referred to with regard to item pool design for CATs using two- or three-parameter IRT model. It should be noted that, even in the case of CATs based on the two- or three-parameter IRT model, the major components of the design process still be kept the same as that for the Rasch model except that different methods are used to identify the desired item features in accordance with the underlying IRT models.
As also mentioned in the study, the shadow-test approach represents another line of approach to design item pools for the CAT. Although the shadow-test approach, which is based on the linear programming method, and the bin-and-union heuristic approach work on different logic, they share certain major common characteristics: (a) both use the similar concept of “bin” to collect items and (b) both require the extensive simulation of the target CAT to identify the desirable item and pool features—both statistical and nonstatistical. It would be interesting to conduct such a comparative study in the future.
Clearly, item pool design features are different depending on the selection of the different design factors. Once different pool designs are evaluated and a particular design is found to function well to the target CAT, it can serve multiple good purposes. Two examples are serving as a template for item pool assembly and providing meaningful guidance to item writing. In practice, two types of item pools are often used in an operational CAT program: master and operational. The master item pool, also known as a “vat” by some researchers (e.g., Way, 1998; Way, Steffen, & Anderson, 1998), stores a large quantity of items. An operational item pool, that is, the one that provides the resources from which operational tests are delivered, is assembled out of such a vat. In practice, to ease the test security concern that arises from the nature of the CAT as a type of continuous testing, operational item banks need to be reassembled or refreshed with new items every now and then. To make sure each resembled or refreshed operational item pool performs well and similarly to the old one, a “model item pool” (Way et al., 1998)—typically an operational item pool that has been demonstrated to function well with the target examinees—is recommended to guide item pool assembly. As item pool design process produces a blueprint describing the desirable features of an item pool, this blueprint can serve as the best possible “model item pool” to guide item pool assembly and help ensure item pools reassembled or refreshed at different time are parallel with each other. This helps ensure the comparability of ability estimates obtained at different time points (Wang & Kolen, 2001). In the case when an existing item bank is available, the gap analysis result, that is, what the existing item pool is missing with reference to the model item pool, can inform where the development efforts of the new items can be focused.
Footnotes
Acknowledgements
The study was completed when the first author was a doctoral student at the Michigan State University. The authors thank the editor, two anonymous reviewers, Dr. Carl Hauser, and Dr. Steve Wise for their valuable comments and suggestions on the earlier version of this paper. The authors also thank National Council of State Board of Nursing for the support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received the following financial support for the research, authorship, and/or publication of this article: The authors received a research funding from the National Council of State Board of Nursing (NCSBN).