
Abstract
An essential feature of the linear logistic test model (LLTM) is that item difficulties are explained using item design properties. By taking advantage of this explanatory aspect of the LLTM, in a mixture extension of the LLTM, the meaning of latent classes is specified by how item properties affect item difficulties within each class. To improve the interpretations of latent classes, this article presents a mixture generalization of the random weights linear logistic test model (RWLLTM). In detail, the present study considers individual differences in their multidimensional aspects, a general propensity (random intercept) and random coefficients of the item properties, as well as the differences among the fixed coefficients of the item properties. As an empirical illustration, data on verbal aggression were analyzed by comparing applications of the one- and two-class LLTM and RWLLTM. Results suggested that the two-class RWLLTM yielded better agreement with the empirical data than the other models. Moreover, relations between two random effects explained differences between the two classes detected by the mixture RWLLTM. Evidence from a simulation study indicated that the Bayesian estimation used in the present study appeared to recover the parameters in the mixture RWLLTM fairly well.
Keywords
Introduction
Mixture item response models have been developed to represent the possibility that students may not be sampled from a homogeneous population, as assumed in conventional item response theory (IRT), but rather, a mixture of multiple latent subpopulations or classes. In mixture item response models, the unobserved heterogeneity of populations is investigated using latent class analysis, and observed responses within each class are modeled using IRT models. Applications of mixture item response models in educational and psychological contexts have attempted to enhance our understanding of the differences between examinees in different classes. For example, latent classes differ in their use of strategies for test items (e.g., Bolt, Cohen, & Wollack, 2001; Mislevy & Verhelst, 1990; Rost, 1990), developmental stages in task solution (e.g., Draney, Wilson, Gluck, & Spiel, 2008; Wilson, 1989), and individual differences in the presence of test speededness (e.g., Bolt, Cohen, & Wollack, 2002; De Boeck, Cho, & Wilson, 2011; Meyer, 2010).
The distinguishing features of mixture item response models are that (a) students from distinct populations are qualitatively differentiated (De Boeck, Wilson, & Acton, 2005) and (b) each person’s population membership is unknown; instead, it is a latent variable. Thus, in mixture item response models, it is very important to find discrete characteristics that define each latent class of examinees. For example, Mislevy and Verhelst (1990) developed the idea of the mixture LLTM (MixLLTM) by coupling the concept of the linear logistic test model (LLTM; Fischer, 1973) and the mixture item response model framework, more specifically by relating characteristics of each class to known features of items. In the LLTM, items are built based on item design properties using psychological and cognitive theory, or other features of the items, and then the item difficulties are explained using the design properties. As such, the LLTM is referred to as an explanatory item response model with respect to items (De Boeck & Wilson, 2004). In the MixLLTM, each class is differentiated by the way in which item properties affect item difficulties, and these differences define the meaning of latent classes.
In addition, the random weights LLTM (RWLLTM; Rijmen & De Boeck, 2002), an extension of the LLTM, allows individual differences in the extent to which the item properties determine the item difficulties. In contrast to the LLTM, which assumes that the effects of the item features are constant for all persons, in the RWLLTM, each person can have different effects of the item properties on the item difficulties through random coefficients. In this regard, the RWLLTM captures more information about the examinees than the LLTM does. Therefore, it is interesting and potentially beneficial to formulate and investigate a mixture extension of the RWLLTM (MixRWLLTM), which can take advantage of the item explanatory aspect of the LLTM and also incorporate individual differences detected by the RWLLTM to define characteristics of latent classes. Specifically, the MixRWLLTM can be employed to identify latent classes that differ in multidimensional aspects, that is, differences in a general latent trait and specific latent dimensions defined by item design features. The primary objective of the present study is to investigate the use of the MixRWLLTM to distinguish a subpopulation of examinees as well as to improve interpretations of differences among latent classes.
To this end, this article is organized as follows. First, the LLTM and the RWLLTM are briefly reviewed, and the MixLLTM is described. Based on these approaches, the MixRWLLTM, which is of major interest in the present study, is presented with respect to model specifications. Following that, we describe an estimation algorithm for the MixRWLLTM using the Markov chain Monte Carlo (MCMC) approach implemented in WinBUGS 1.4.3 (Lunn, Thomas, Best, & Spiegelhalter, 2000) for parameter estimation of the proposed models. Then, in order to show how the MixRWLLTM can be applied to an empirical example, the results of the analysis of a verbal aggression data set are presented. Finally, a simulation is conducted to assess parameter recovery and correct identification of class membership of the MixRWLLTM.
Methods
Review of the LLTM and RWLLTM
As discussed above, the LLTM is designed to help explain how item design features influence responses on tests with a prior item structure. Suppose that there are K item properties. Under the LLTM, the probability that person p gives the correct response on item i is written as
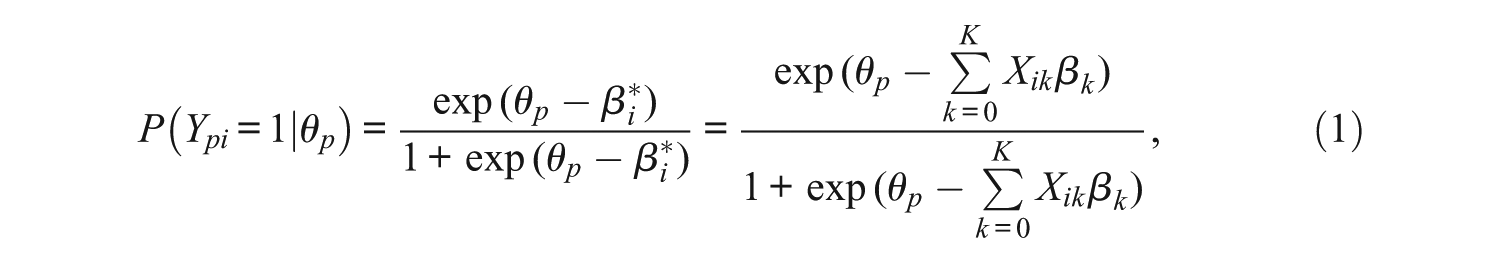
where θp is the latent ability of person p that follows an underlying population distribution (e.g., a normal distribution with mean zero and a constant variance) and
The LLTM has the advantage of parsimony: item difficulties are explained in terms of item features and there are usually fewer item features than items. However, the assumption that item properties explain the item difficulty perfectly and that the effects of the item features are constant for all persons might be unrealistic and strict in many circumstances. The RWLLTM
1
relaxes the assumption of invariant effects of item properties by incorporating person-specific random coefficients. In detail, in the RWLLTM, person-specific random coefficients Θ
pK′
are assumed for a subset of K item properties, K′ of which coefficients are assumed to vary among persons. Therefore, Xis (s∈K′) is the element of the submatrix of the full design matrix associated with random coefficients (or random slopes) θps (s∈K′). For instance, if the random coefficients are assumed for the first and second item properties among four item properties, K′ corresponds to {1, 2}, Xis is the element of the matrix consisting of the second and third columns of the full design matrix
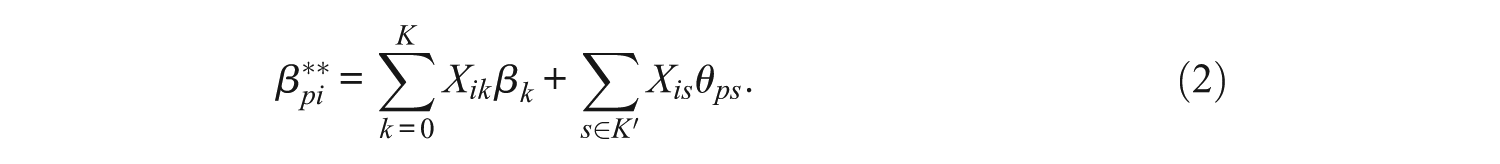
Alternatively, given that Θ pK′ are the person-specific random effects, in the RWLLTM, the person ability is a multidimensional parameter, Θ p = (θp0, Θ pK′ ′)′, a vector of the random intercept θp0 and random coefficients θps (s∈K′). Thus, the required ability for person p to respond to item i is formulated as

where Zis is the value of the I× (S+1) matrix that appends a constant vector of 1 with the length of I for the random intercept θp0 and submatrix of the design matrix
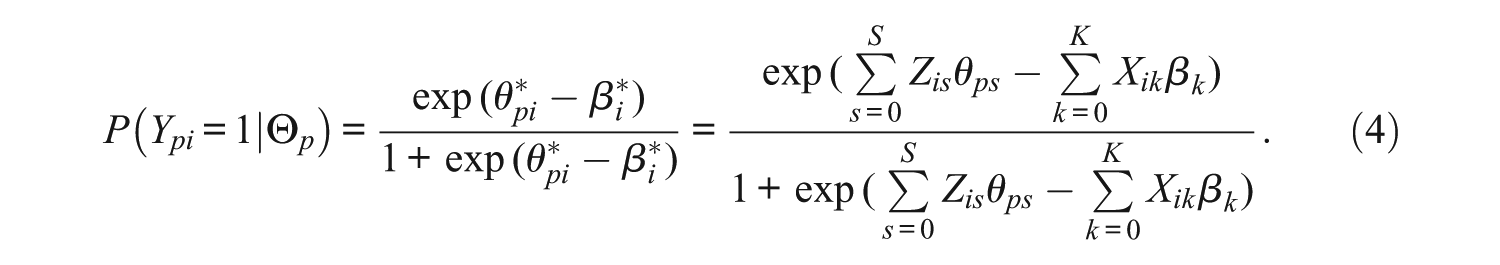
In fact, as noted by Rijmen and De Boeck (2002), the model framework Equation 4 is a special case of an earlier model, the multidimensional random coefficients multinomial logit model (MRCMLM; Adams, Wilson, & Wang, 1997), in which
Mixture Extensions of the LLTM and RWLLTM
The rationale for formulation of the MixLLTM is to combine the heterogeneous population from the mixture item response models and the decomposition of the item difficulties in the LLTM. In the mixture Rasch model (Rost, 1990), within each latent class, the Rasch model is assumed with class-specific person ability and class-specific item difficulty parameters. Similarly, in the MixLLTM, the LLTM is assumed to hold within each latent class. The conditional probability of the MixLLTM that person p endorses item i under the condition that this person belongs to latent class g is
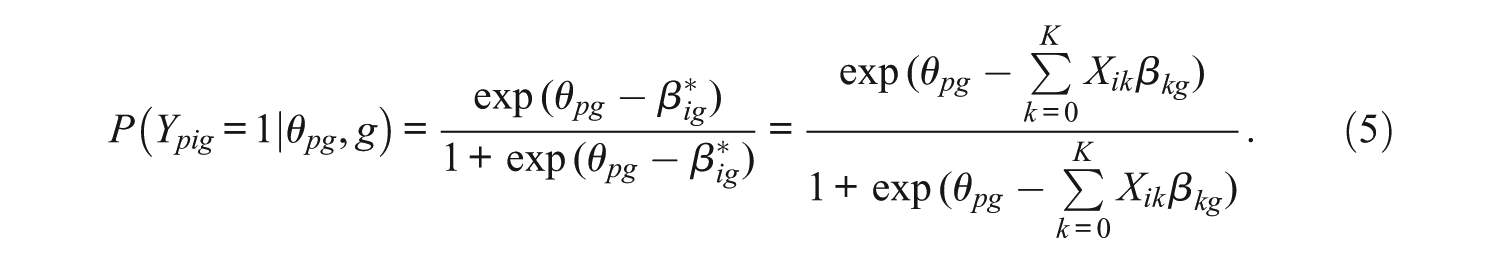
As shown in Equation 5, the conditional probability is the same as in the LLTM, but the model contains class-specific ability θpg and class-specific item property coefficient βkg. In addition, the item difficulties become class-specific due to the class-specific coefficients. It is common to assume that the ability (random intercept) follows a normal distribution with class-specific mean and variance, θpg ~ N(μ0g,
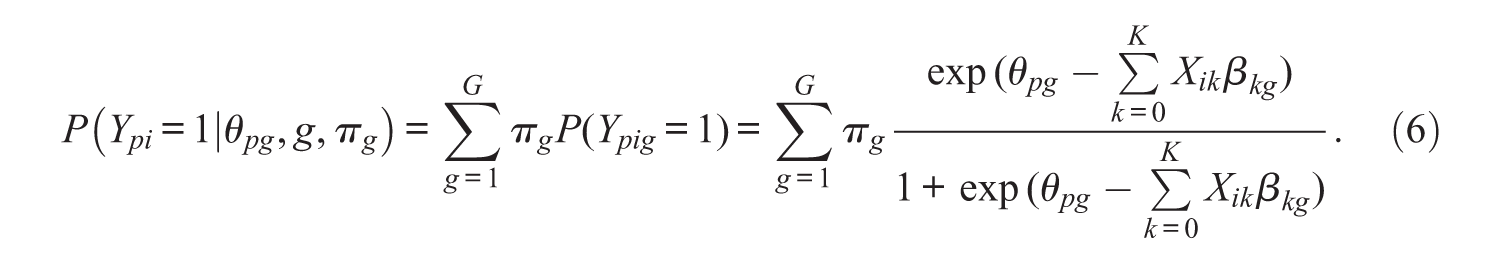
The MixLLTM is capable of identifying distinct classes that depend on a general level of propensity, where each class is defined by class-specific ability distributions and item property parameters. However, it can be assumed that classes are also distinguished by individual differences in the degree to which item properties influence the item difficulty and in the general propensity. This goal can be achieved by extending the RWLLTM into a mixture model. Considering the model framework of the MixLLTM in Equation 6, the marginal probability that person p endorses item i in the MixRWLLTM can be represented by extending the RWLLTM in Equation 4 into a mixture model as
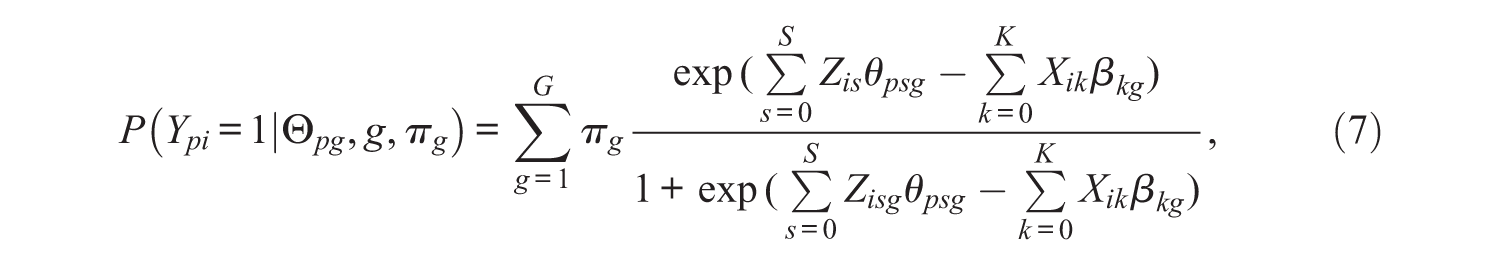
where g and πg represent the class membership and mixing proportions, respectively, as in the MixLLTM. Similar to the MixLLTM, the RWLLTM is assumed for each latent class in the MixRWLLTM. However, unlike the MixLLTM, in each class, as presented in Equation 7, there are multiple random effects: the random intercept θp0g and the random coefficients of item property θpsg, s = 1, . . . , S. In detail, while the random intercept θp0g indicates the general propensity of person p in class g, the random coefficient θpsg represents the degree to which item property s affects the item difficulties of person p in class g. In other words, these are the person- and class-specific variables.
Therefore, in the MixRWLLTM, the classes are characterized by the fixed coefficients of item property βkg and the random effects Θ
pg
= (θp0g, θp1g, . . . , θpSg)′, which follow a multivariate normal distribution with class-specific means and variance-covariance matrix. For example, in the case of incorporating just one random coefficient θp1g in addition to the random intercept θp0g, the

where μ0g and μ1g indicate the class-specific mean of the random intercept and random coefficient, respectively,
We follow the parameterization by Rijmen and De Boeck (2002), in which the fixed effects represent the means of the intercept or the item property difficulties, and the random effects are considered the deviations from these means (the fixed effects). For instance, in the above example, where there is one random coefficient, the difficulty of the first item property corresponds to β1g−θp1g, and β1g and θp1g represent the mean (fixed) difficulty of the first item property and person-specific deviation from the mean difficulty, respectively. In other words, the fixed coefficients βkg, k = 0, 1, . . . , K, indicate the fixed effects or the means of the random effects in latent class g, and hence the means of the random intercept and coefficients are defined as zero by model specifications, such as μ0g = μ1g = 0 in Equation 8.
Estimation
Bayesian estimation using MCMC was implemented in the WinBUGS 1.4.3 software (Lunn et al., 2000) to estimate the parameters of the MixRWLLTM and MixLLTM. For this purpose, prior distributions must be specified for all parameters, which include the person-specific ability with class-specific mean and variance, class-specific item property coefficients, group membership, and mixture probabilities. Although each parameter can have a number of different prior distributions, this study limits its scope to the simple and straightforward commonly used ones, such as the conjugate priors. This means that the posterior distribution belongs to the same family as the prior distributions. More specifically, assuming a normal distribution is standard practice for the ability and item parameters, and the conjugate prior for the variance of the normal distribution is the inverse-gamma distribution. It is reasonable to assume that, given the mixture probabilities, each individual’s group membership follows a multinomial distribution, and one of the conjugate priors for the mixture probabilities is the Dirichlet distribution (Cho, Cohen, & Kim, 2013; Cohen & Bolt, 2005; Gelman, Carlin, Stern, & Rubin, 2004).
Consequently, the following prior and hyper-prior distributions were used to estimate the MixLLTM in the present study:
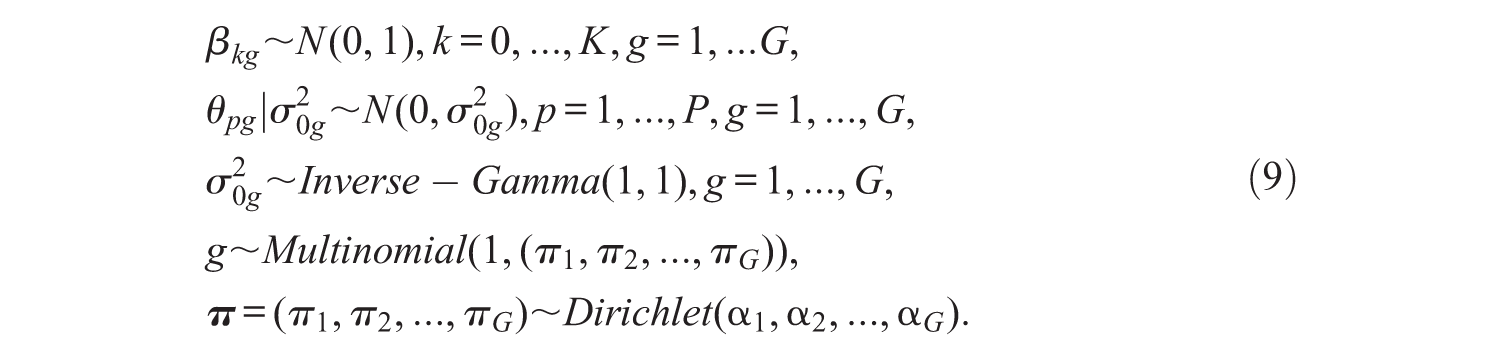
By model specification, the means of the ability distributions were treated as zero for every class. Mildly informative prior distributions for item property coefficients βkg and variance of ability

Considering their distributional assumptions, the only difference between the MixLLTM and MixRWLLTM is the latent ability Θ pg that includes θp0g and θpsg. For this variable, we assumed a multivariate normal distribution with mean zero and a variance-covariance matrix ∑g for each class (as assumed in the RWLLTM). An inverse-Wishart distribution, which is a conjugate prior of the variance and covariance of the multivariate normal distribution, was specified for ∑g (Gelman et al., 2004). Accordingly, the prior and hyper-prior distributions of ability in the MixRWLLTM were as follows:
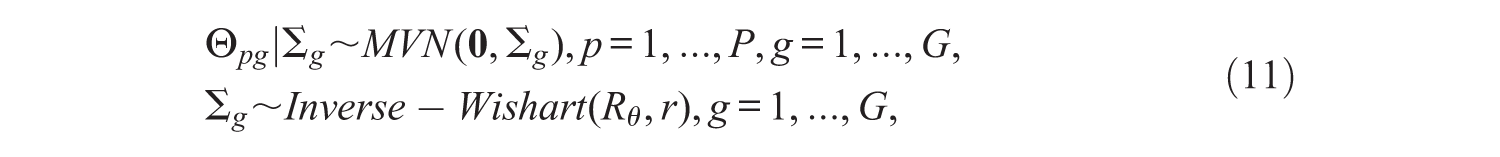
where Rθ and r represent the scale matrix and degree of freedom of the inverse-Wishart distribution. For parameters other than the ability, the same prior distributions as the MixLLTM were assumed. The posterior distribution of the MixRWLLTM is derived from

Empirical Data Study
Data Source
Verbal aggression data (Vansteelandt, 2000), previously analyzed by De Boeck (2008) and by Ip, Smits, and De Boeck (2009), were selected to illustrate how the proposed model can be applied to real data (the data can be downloaded from http://bearcenter.berkeley.edu/EIRM/). A total of 316 individuals, 243 females and 73 males, responded to 24 items that described verbally aggressive reactions in a frustrating situation. Responses were dichotomized as 0 for “no” and 1 for “perhaps” or “yes.”
In this example data, the items were developed using four factors that describe a person’s propensity toward verbal aggression. The first design factor reflects the expected tendency that we do not always actually do whatever we want to do. The factor is referred to as the behavior mode, which differentiates between two levels of behavior: wanting to engage in verbal aggression (termed as Want) and actually engaging in verbal aggression (termed as Do). The second design factor is based on the assumption that people display more verbal aggression when others are responsible for discouraging situations. Specifically, this factor, defined as the situation type, contrasts situations in which someone else is to blame (termed as Other-to-blame), such as missing a bus or train because a bus fails to stop, and situations in which the individual is to blame (termed as Self-to-blame) such as a grocery store closing because the person is late. The last two design factors, related to the behavior type, include three levels: Curse, Scold, and Shout. The third and fourth factors are Blaming and Expressing, which deal with the extent to which respondents ascribe blame and express aggression, respectively. Among the three behavior types, cursing and scolding are regarded as blaming and cursing, and shouting as expressive.
For example, the item, “A bus fails to stop for me. I would want to curse” describes factors of want (behavior mode), other-to-blame (situation type), and curse (blaming and expressing). The four design factors are referred to as the item properties, and these item designs enable application of the LLTM and its extended models. The coding scheme for the item properties, which designates the values of the design matrix, is presented in Table 1. In detail, dummy coding was used for the behavior mode and the situation type, in which the want behavior mode and the self-to-blame situation type were the reference categories; and contrast coding was used for the behavior type where the overall mean was the reference category. The item design matrix with the constant item predictor (k = 0) is given in Appendix A.
Coding Scheme for Item Properties in the Verbal Aggression Data.

Analysis
In the present study, an MCMC algorithm as implemented in WinBUGS was used to extend the LLTM and RWLLTM into mixture models using the verbal aggression data. Three chains with different initial values were specified, and in order to check convergence, time-series plots were monitored. Convergence of the three chains was determined using the
Furthermore, for ease of interpretation, one random coefficient for the behavior mode (k = 1), θp1, was assumed in addition to the random intercept, θp0, for the random weights models. Thus, in the RWLLTM and MixRWLLTM, S = 1 and
Given that the four models, LLTM, MixLLTM, RWLLTM, and MixRWLLTM, considered above are not nested a likelihood ratio (LR) test is not appropriate to compare the relative fit of the models. In the present study, Akaike’s (1974) information criterion (AIC) and Schwarz’s (1978) Bayesian information criterion (BIC) indices were reported, and the BIC was used to determine the better fitting model. Li, Cohen, Kim, and Cho (2009) found that the BIC selects the true data-generating model better than the other methods do, including the AIC and the deviance information criterion (DIC; Spiegelhalter, Best, Carlin, & Van Der Linde, 2002) in mixture dichotomous IRT models using Bayesian estimation. In detail, we followed the method suggested by Li et al. (2009) to define the AIC and BIC for MCMC estimation as
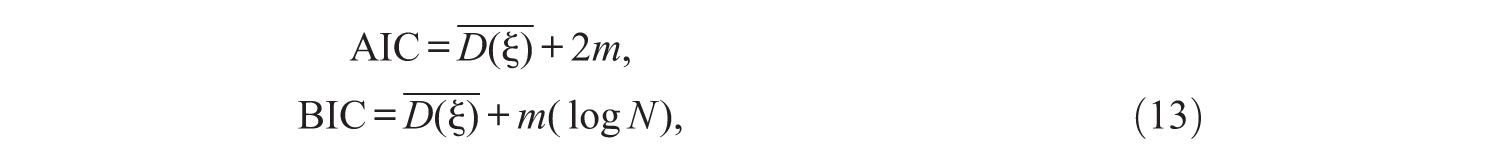
where
Another critical issue in mixture IRT modeling is the label switching problem (Cho et al., 2013; Li et al., 2009). The first type of label switching occurs across iterations within a single MCMC chain, and the second type occurs when the latent classes switch over replications or for different initial values. An occurrence of the first type of label switching results in multiple modes of density for the parameters; thus, the estimated marginal posterior densities were examined in the empirical data analysis in order to detect label switching. In fact, none of the marginal posterior distributions had multiple nodes, which implied that label switching did not occur. The second type of label switching is often observed in simulation studies, as detailed in the simulation study section.
Results
Table 2 summarizes the model fit indices including the AIC and BIC, and the parameter estimates and corresponding standard errors obtained by applying the one-class and two-class LLTM and RWLLTM to the verbal aggression data.
Parameter Estimates and Standard Errors of the One-Class and Two-Class LLTM and RWLLTM.

Note. The values in parentheses indicate the standard errors associated with the parameter estimates.
First of all, comparisons of the estimated AIC and BIC values suggested that the MixRWLLTM fitted better than the other models did. As presented in Table 2, extensions of the LLTM into the RWLLTM and the MixLLTM yielded better fits than the LLTM did, and the MixLLTM explained the verbal aggression data better than the RWLLTM did. In other words, the two-class LLTM assuming subpopulations described the data more correctly than the one-class RWLLTM allowing a random coefficient of the behavior mode. And most importantly, the two-class RWLLTM, assuming heterogeneous populations that differ in the general propensity of verbal aggression and the effects of the behavior mode property, described the data more correctly than the two-class LLTM. For a more detailed discussion, the fixed and random effect estimates of each model are described below.
Under the LLTM, the estimate of the first design factor (
Estimates of Coefficients for the Behavior Type.
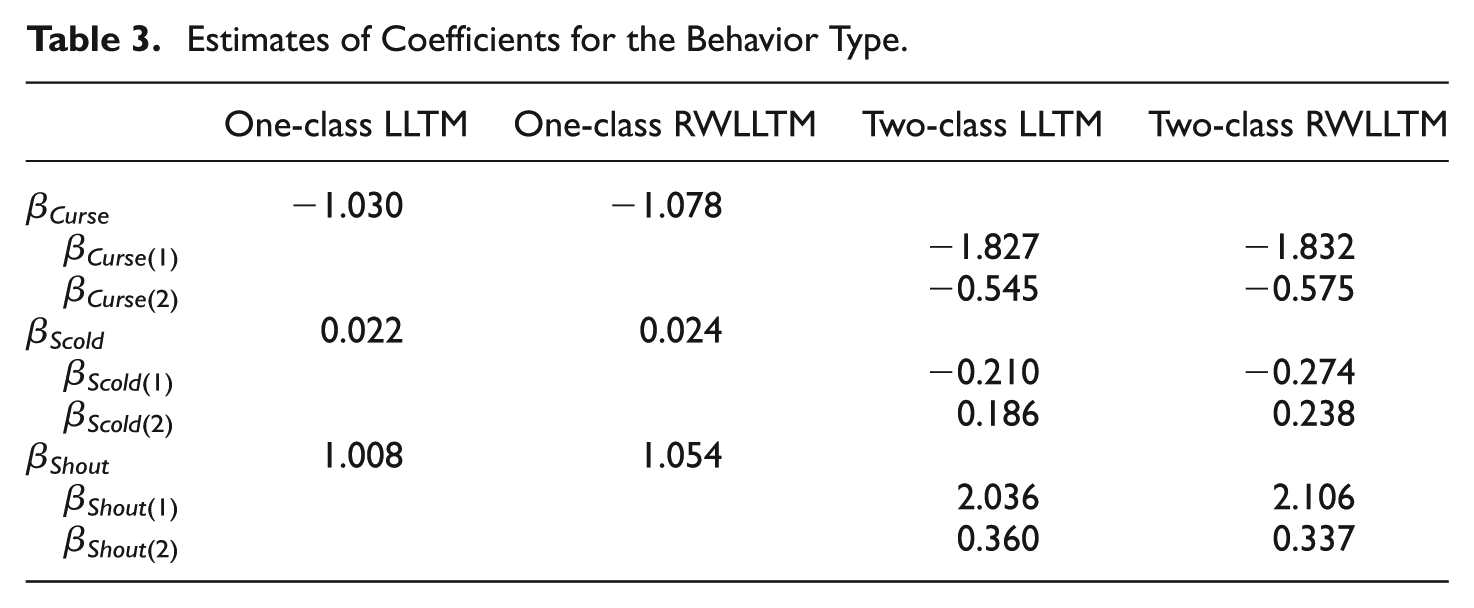
The third column of Table 2 displays the results of extending the LLTM into the RWLLTM. Comparisons of the estimates of the LLTM and the RWLLTM revealed that similar patterns regarding the fixed effect parameters were found, even though absolute magnitude of the estimates was slightly greater in the RWLLTM. In this model, a random coefficient of the behavior mode (θp1) was included to model individual differences in their tendency to display aggression when the behavior mode changed from wanting to do to actually doing. In detail, while the difference between the two behavior modes was assumed to be constant as β1 across all examinees in the LLTM, −θp1 was added to the difference for person p in the RWLLTM. As a result, the variance of the random coefficient
As discussed above, mixture extensions of the LLTM and RWLLTM enable us to take advantage of the explanatory aspects of the LLTM and RWLLTM to define characteristics of latent classes. First, the two-class LLTM produced class proportions of approximately 47.8% in Class 1 and 52.2% in Class 2. In this model, the two classes differed in the fixed effects of the item properties and their general propensity of verbal aggression (random intercept). In general, the patterns of the estimated difficulties of the item properties in each class were similar to those in the LLTM. For instance, in the two classes, the probability of being verbally aggressive decreased when going from wanting to do to actually doing, and they were more likely to be aggressive in other-to-blame situations than in self-to-blame situations. However, in Class 1, the coefficient of the behavior mode was much greater, and the coefficients related to the behavior type were smaller than those in Class 2. In other words, compared to Class 2, the tendency to take action decreased much more in Class 1. The estimated coefficients of the three behavior types in Table 3 implied that the examinees in Class 1 were more likely to curse and scold, and less likely to shout than those in Class 2. The variance estimate of the random intercept in Class 1 (
As in the MixLLTM, two latent classes of almost equal class size (48.2% in Class 1 and 51.8% in Class 2) were detected in the two-class RWLLTM. Compared to the one-class RWLLTM, the MixRWLLTM found two classes that differed in the fixed coefficients related to the behavior type. In Class 1,
More interestingly, the MixRWLLTM found that the two classes did differ in a meaningful way with respect to the random effects. In this model, by introducing a person-specific random effect of the behavior mode, the latent trait was assumed to follow a mixture of two bivariate normal distributions. In Class 1, the estimated variance of the intercept (
Moreover, the estimated correlations between the two random effects delineated the difference between the two classes more clearly. Specifically, the negative correlation in Class 1 meant that people who had a higher propensity toward verbal aggression appeared to have a smaller random coefficient of the behavior mode. Given that the coefficient of the behavior mode for person p, represented as β1−θp1, indicates the difference in the probability of wanting to take verbally aggressive action and of actually doing, this result implied that, as the general propensity of verbal aggression (θp0) increased, the random coefficient (θp1) decreased; thus the difference between wanting and doing increased. However, in Class 2, the general propensity of verbal aggression and the random coefficient of the behavior mode were virtually independent of each other. The estimates of the latent variables related to the general propensity and the coefficient of the behavior mode for each class in the MixRWLLTM are presented in Figure 1.

Diagram of estimated Θ pg by each latent dimension.
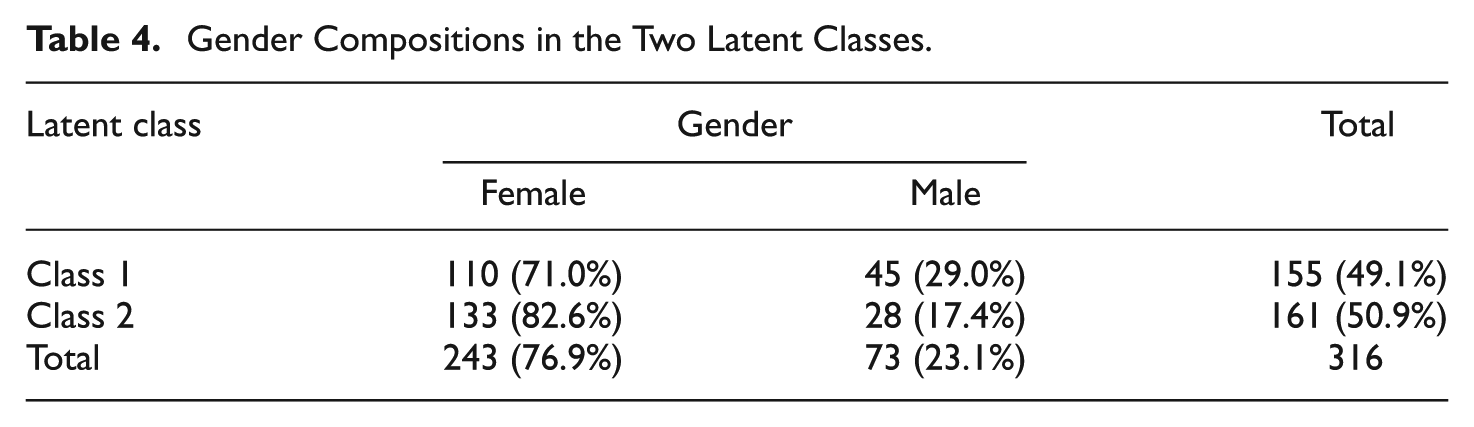
In addition to estimates of the item parameters, the variances of the latent ability distributions, and the mixing proportions, examinees in mixture item response models are also characterized by a parameter that indicates each examinee’s latent group membership g. In the two-class RWLLTM, the estimated mixing proportions classified 155 (110 females and 45 males) examinees into Class 1 and 161 (133 females and 28 males) examinees into Class 2 (see Table 4). In the total sample, the proportions of females and males were 76.9% and 23.1%, respectively, while the proportions in Class 1 were 71% and 29%, respectively, and the proportions in Class 2 were 82.6% and 17.4%. There were more males in Class 1 and more females in Class 2 than in the total sample. The chi-square test of independence indicated that gender was associated with class membership (p < 0.05), although the correlation between gender and class membership was weak (ρ = 0.138).
Gender Compositions in the Two Latent Classes.
Simulation Study
Data Generation
The simulation design followed the empirical example of the verbal aggression data, as described previously. The data were generated from the two-class RWLLTM, in which 1,000 examinees responded to test items designed using the four item properties, as in the empirical application. The simulation design included two test lengths: 24 items and 48 items. In the 24-item condition, the design matrix used for the verbal aggression data was assumed. In the case of the 48-item condition, the elements of the design matrix for the first 24 items were repeated for the last 24 items.
The structure of the verbal aggression data was kept, and the estimates of the two-class RWLLTM, presented in the fifth column of Table 2, were assumed as the true values in the data generation. In other words, two latent classes, with class size parameters

In addition, the two classes depend on the fixed coefficients of the item properties. The R software (R Core Team, 2013) was used to generate the data and 30 replications were made for each condition of the two test lengths.
Analysis
Once the data were generated, the two-class RWLLTM, was applied using the MCMC algorithm. As implemented in the empirical data application, WinBUGS was run using three chains with 10,000 post-burn-in iterations after discarding 10,000 burn-in iterations. Convergence of the three chains was determined by the Gelman and Rubin (1992) method.
The second type of label switching in mixture item response models, which refers to class switching over replications, was observed in the simulation study described here. For example, if label switching has occurred, Class 1 in one replication corresponds to Class 2 in the true model; thus, labels of the parameter estimates and group membership need to be switched, such as from Class 1 to Class 2. Given that we know the true values of the parameters in the simulation study, the detection of label switching is possible by simply comparing the item parameter estimates and estimated group membership with the generating values (Cho et al., 2013; Li et al., 2009). In this simulation study, the covariance of the random effects, of which true value in Class 1 was negative and larger in absolute value than the one in Class 2, was used to detect label switching.
Results
After adjusting for label switching, the bias and root mean square error (RMSE) of the parameters in each class were assessed, and they are reported in Table 5. In general, the estimated biases were not substantial under the two test length conditions. According to the one-sample t-test, none of these bias estimates was significantly different from zero at the 5% level. These results suggested that the estimates of the generating model were approximately unbiased. The RMSEs in the 48-item condition were slightly smaller than those in the 24-item condition.
Bias and RMSE of Parameters in the Simulation Study.

In addition, recovery of group membership was investigated by comparing the estimated latent group membership with the generating one, and the percentage of correct identification was evaluated in each replication. The averages of the percentage of correct identification across 30 replications were 86.69% and 93.8% for the 24- and 48-item conditions, respectively, indicating that recovery of group membership increased as the test length increased.
Discussion and Conclusions
In this study, the MixRWLLTM was developed to find multiple subgroups of examinees and to interpret the meaning of latent classes. The existence of subgroups is identified using latent class analysis or mixture item response modeling; however, the meaning of latent classes can be specified only after estimated class-specific parameters, such as item difficulties and distributions of the latent variables, are interpreted and compared across latent classes. This study showed that the MixRWLLTM can contribute to a better understanding of characteristics of latent classes, by incorporating the explanatory aspect of the LLTM and the individual differences of examinees captured by the RWLLTM.
For instance, in the MixRWLLTM, the fixed class-specific coefficients of the item properties describe how people within each class would respond differently on items related to the item properties. Because the item property coefficients represent the fixed effects, interpretations based on these parameters are assumed to be the same across individuals within the same class, and therefore, describe overall characteristics of latent classes.
Moreover, the MixRWLLTM allows individual differences in the effects of the item features, as in the RWLLTM. Within each class of the MixRWLLTM, each individual has person-specific random effects in the general latent variable the test items intend to measure and in the coefficients of certain item features. Therefore, individual differences in these multidimensional aspects and relations across multiple dimensions can be used to disclose key characteristics of latent classes. Furthermore, given that in the MixLLTM the meaning of latent classes is determined based mainly on the fixed coefficients of the item properties, we expect that the MixRWLLTM provides a more comprehensive understanding of how latent classes are defined and why people across classes respond or behave differently.
The illustrative example, using the verbal aggression data, showed that the MixRWLLTM yielded much better agreement with the data than the LLTM, RWLLTM, and MixLLTM did. Additionally, in order to compare performance of the MixRWLLTM to the mixture Rasch model, the verbal aggression data were also analyzed using the two-class Rasch model. In the mixture Rasch model, the item design features in the verbal aggression data were not considered and the difficulties of the 24 items were estimated for the two classes. The estimated values of the AIC and BIC of the mixture Rasch model supported a better fitting of the MixRWLLTM to the data. 2 In other words, by taking into account the design features of items, the MixRWLLTM provided more correct description of the data.
In addition to improving goodness of fit, the MixRWLLTM revealed an interesting difference across latent classes that was not detected by the other approaches. The MixRWLLTM identified two distinct classes that differed considerably in relations between the general propensity toward verbal aggression and the random effect related to the behavior mode. In general, the results indicated that people in the two classes were reluctant to actually take verbally aggressive action compared to just wanting to do so, based on the class-specific fixed coefficients of the behavior mode. However, in one class, people whose general propensity toward verbal aggression was higher displayed a greater difference between their tendency to want and to actually do; thus, they were more reluctant to take action. In sum, the empirical data study suggested that interpretations of latent classes in the MixRWLLTM can be improved by considering the multidimensional random effects of respondents, and more specifically, by using their general latent trait and person-specific effect of an item feature. In this regard, cognitive theories or features of the items, which direct the instrument development in the LLTM, also enrich interpretations of classes in the mixture extensions of the LLTM.
The simulation study indicated that Bayesian estimation using WinBUGS appeared to recover the parameters and group membership of the MixRWLLTM fairly well. By increasing the number of test items, recovery of group membership of the MixRWLLTM increased.
Overall, the results from the empirical and simulation studies suggested that the MixRWLLTM was able to identify the latent classes of examinees and that the item design properties could play a crucial role in an improved understanding of characteristics of latent classes. There are also some possible extensions of the current model. Here, because the primary goal of the study was to extend the RWLLTM into the mixture model, we limited ourselves to a simple model by classifying examinees into two classes. However, it is possible to introduce more than two latent classes (e.g., Cho et al., 2013; Frederickx, Tuerlinckx, De Boeck, & Magis, 2010). The WinBUGS code given in the Appendix B can be easily generalized to deal with more than two classes. Likewise, more random coefficients of the item properties can be included.
One concern in applications using mixture item response models is that they may not always detect the true latent classes, but yield spurious latent classes; for example, Alexeev, Templin, and Cohen (2011) showed that fitting the mixture Rasch model to data generated by the 2PL model could produce false classes. In a supplementary simulation, to examine whether the classes detected via the MixRWLLTM were spurious or not, we generated data from the one-class RWLLTM, and the one- and two-class RWLLTMs were fitted to the data. Across 15 replications, the estimated BIC values were consistently lower for the one-class RWLLTM, which suggested that spurious classes were not found. However, when the one- and two-class LLTMs were fitted to the data, the two-class LLTM yielded a better fit than the one-class LLTM across all the replications. Consequently, according to these additional simulations, the MixRWLLTM developed in the present study did not produce latent classes when indeed there were none but the MixLLTM did. Thus, when the multidimensional structure of the random effects is not modeled appropriately (i.e., fitting the MixLLTM to the data generated by the RWLLTM), spurious classes can be produced. Even though these simulations have not shown a problem regarding false classes for the MixRWLLTM, further studies should be carried out to investigate the possibility of detecting spurious latent classes in the context of multidimensional IRT models.
In the present study, we have successfully applied the Bayesian approach to estimate the MixRWLLTM, using conjugate and mildly informative prior distributions in order to make the fitting procedures more stable (Bolt et al., 2001, 2002; Cho & Cohen, 2010). However, given that the specification of the prior distributions could have substantial impacts on estimation (Gelman, 2006), it is worth investigating more deeply the use of different prior distributions. In order to examine the sensitivity to the prior distributions, less informative priors on the item property coefficients such as N(0, 10) and N(0, 100) were employed in the empirical data analysis. We found that the use of less informative priors yielded estimates only slightly different from the ones using the mildly informative prior, which suggested that the results of the present study were robust to the specification of the prior distributions.
Finally, the MCMC procedures implemented in WinBUGS required substantial computing time for convergence, which is not uncommon in MCMC estimation. To enhance the practical use of the proposed model, other software that handles multidimensional mixture models for discrete data (e.g., LatentGold; Vermunt & Magidson, 2005) might be considered for future studies.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.