
Abstract
Cultural consensus theory (CCT) is a data aggregation technique with many applications in the social and behavioral sciences. We describe the intuition and theory behind a set of CCT models for continuous type data using maximum likelihood inference methodology. We describe how bias parameters can be incorporated into these models. We introduce two extensions to the basic model in order to account for item rating easiness/difficulty. The first extension is a multiplicative model and the second is an additive model. We show how the multiplicative model is related to the Rasch model. We describe several maximum-likelihood estimation procedures for the models and discuss issues of model fit and identifiability. We describe how the CCT models could be used to give alternative consensus-based measures of reliability. We demonstrate the utility of both the basic and extended models on a set of essay rating data and give ideas for future research.
Introduction
The problem of analyzing ratings from multiple raters is an established problem in psychometrics and in educational testing research. Consider a simple educational scenario, where n students write an essay and are graded on the content of the essay. Grading for essays is not an exact science, so to increase reliability, each essay is graded by multiple raters. Research in this area has traditionally concentrated on measuring the reliability of the ratings; see, for example, Raykov and Marcoulides (2011, pp. 147-181).
In this article, we take a slightly different approach. We consider each rater to have some underlying latent competency, which is an inverse measure of the rater’s error variance. The aggregate rating for an item is not calculated as a simple average of the scores of the multiple raters, but as a weighted average, where each score is weighted by the rater’s competency. The primary advantage of this approach is that the effect of inconsistent/poor quality raters can be minimized when calculating the aggregate score, which is calculated endogenously by the model. Thus, the overall reliability of the score is increased. The models described in this article come under the banner of cultural consensus theory (CCT). CCT is a technique with roots in scientific anthropology and was created to help aggregate and define cultural concepts using the idea of a common culture. In statistical terms, CCT is a method for information pooling or data aggregation. The original application for CCT was the analysis of folk medical beliefs (Romney, Weller, & Batchelder, 1986), which used simple dichotomous CCT (Batchelder & Romney, 1986; Batchelder & Romney, 1988). Modern reviews of CCT include Batchelder and Anders (2012) and Oravecz, Anders, and Batchelder (2013).
In this article, we examine and extend the continuous response CCT model introduced in Batchelder and Romney (1989). Given a set of user ratings, a competency parameter is calculated for each user and a competency weighted consensus aggregate rating is calculated for each item. An extension of the model allows for bias parameters to be calculated for each user. The authors describe a fixed point optimization procedure for the model. The basic model is built on several axioms. The axioms include common truth (Axiom 1), random error (Axiom 2), local independence (Axiom 3), and inhomogeneous variance (Axiom 4). Axiom 2 can be adapted to account for additive bias and multiplicative bias. Full technical details of the basic model and axioms are described in the appendix. This description follows the treatment of Batchelder and Romney (1989).
In the subsequent sections of this article, we describe several extensions to the Batchelder and Romney (1989) model. We describe two methods for modeling the rating easiness/difficulty for individual items. We describe the advantages and disadvantages of different approaches to optimizing both the original and the extended models. We show how the continuous CCT models described in this article can be used to produce competency adjusted reliability metrics. We describe a methodology for ensuring the identifiability of model parameters. We illustrate the usefulness of both the basic model and the model extensions using an illustrative grading application and then give suggestions for future work.
Cultural Consensus Analysis and Item Easiness/Difficulty
In rating/grading tasks, some items may be harder to rate than other items. The traditional method of modeling item difficulty in exam scoring models is the Rasch model (see Fischer & Molenaar, 1995). Given multiple items, multiple subjects, and simple dichotomous data, fitting the Rasch model gives both subject score and item difficulty parameters. A version of the Rasch model for continuous data is given in Müller (1987). A CCT model incorporating item difficulty has been developed for dichotomous CCT (Batchelder & Romney, 1988; Karabatsos & Batchelder, 2003), where item difficulty is conceptualized in a similar manner to the Rasch model. Overall, the underlying Rasch principle of calculating both the aggregate item difficulty and the average subject score within a single procedure provides a parsimonious representation for a range of problems. In a standard examination setting, the items are actual “questions” and the subjects are exam takers. In an essay evaluation setting, the items are the student’s essays and the subjects are the exam raters. The idea of item difficulty can be expanded to a general rating setting, where each item is assigned both an item score and an item difficulty and each rater is assigned a competency.
We propose two methods of incorporating variable item difficulty/easiness into the standard consensus model. Both these methods split the measure of competency into rater competency and item easiness. We use “easiness” rather than “difficulty,” as easiness is consistent with competency when modeling the error variance.
Method 1: Multiplicative Scaling Factor Model
Let
Given the scaling factor
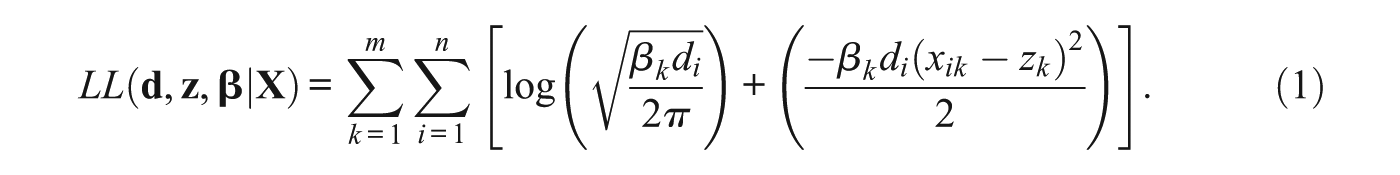
This multiplicative model can be connected to the Rasch model. The precision for i and k can be defined as the inverse of the variance, so that the precision is

As

If the difficulty parameter qk is replaced with the negative of an “easiness” parameter ek, then equating Equation (3) with Equation (2) gives
Method 2: Additive Scaling Factor Model
Additive models have been used to decompose and examine rater effects. For example, de Gruijter (1984) gives an additive model for examining rater effects for overlapping raters. Raymond and Viswesvaran (1993) give a range of least squares fitting techniques for additive rater models. The additive scaling factor model follows in this tradition. If it is assumed that the error variance is proportional to both the inverse of the sum of the user competency and the item easiness, Axiom 4 can be rewritten as follows:
The log-likelihood function for the additive scaling factor model is given in Equation (4). Bias corrected versions of the model can be created by adding bias to the
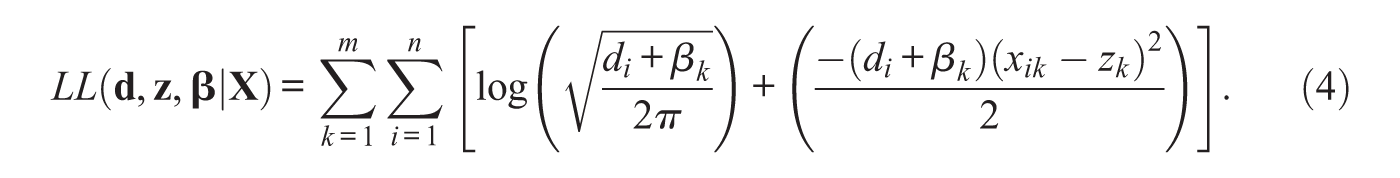
Model Fitting and Optimization
Each of the models described in this article can be fit by maximizing its log-likelihood function using continuous optimization. We have expanded the basic methodology in Batchelder and Romney (1989) and have created a flexible set of optimization routines that can deal both with constrained and unconstrained models. In particular, we have extended existing work by developing a methodology for examining and dealing with model identifiability in continuous CCT models.
We have created a software library in MATLAB (France, 2013) for both the basic continuous CCT model and the two item easiness extensions. Three optimization methods are implemented in the software. These are (a) fixed point optimization, (b) gradient-free optimization, and (c) first-order gradient optimization. The fixed point optimization procedure is implemented in previous work on continuous CCT (Batchelder & Romney, 1989). The gradient-based optimization and derivative-free optimization algorithms are standard nonlinear optimization techniques implemented by MATLAB and are described in Bazaraa, Sherali, and Shetty (2006). The fixed point optimization procedure, where each parameter vector (e.g.,
Implementation Issues
In initial experiments, all three optimization methods converged to good solutions. In cases with only a few raters, one rater may become dominant and that rater’s competency will go toward infinity. A similar problem can occur for item easiness values. The problem of dominant competency and item easiness values can be mitigated by setting bounds on the allowed competency and item easiness parameters. Empirical work in France and Batchelder (2013) shows that as the number of items increases, the chance of dominant competencies decreases. Based on empirical experiments on generated data (France & Batchelder, 2013), a competency bound of around di = 5 gives good results, though the exact optimal value may be dependent on the data set, so some tuning may be necessary.
The CCT models described in this article can include parameters for item answers, additive biases, multiplicative biases, and item easiness values. Fitting multiple sets of parameters together can lead to a loss of model identifiability. In initial experiments, we found that there is no identifiability problem when fitting the models without bias, that is, the optimal values of
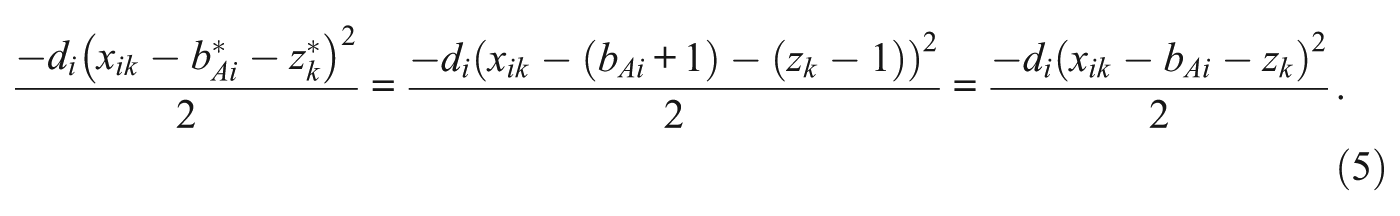
The MATLAB software developed to implement the models in this article contains a set of fix parameters to deal with identifiability issues. In the implemented software, users can specify an input vector with the entries [Fixz, Fixd, FixbA, FixbM], where each entry of the vector can be 0, 1, or −1. Here, 0 indicates no fix, 1 a partial fix (one variable), and −1 a total fix (all variables). The fixed values are set by running a restricted, identified version of the model and then fixing a single value (the one with the maximum partial log-likelihood) or values from this restricted model. Based on initial results, fixing the value of zk for a single item k gives a fully identified model when bias is added to the model. The differences between fixing a single value (a partial fix) and all the variables (a full fix) are both practical and philosophical. A partial fix still fits the full model. For example, for the basic model with additive bias and the fix vector [1, 1, 0, 0], bias is a component of the overall cognitive model and the variable fixes do not alter the overall log-likelihood of the model. A full fix essentially prioritizes the fitting of the subset of variables from the restricted model. For example, given the basic model with additive bias and the fix vector [−1, −1, 0, 0], the values of
Cultural Consensus Theory and Reliability Theory
How does consensus theory fit in with traditional psychometric methods of reliability for multiple raters? There are several methods for calculating reliability for continuous data. We describe one of these methods and discuss how it can be adapted to fit the consensus paradigm and related models. Most methods for calculating agreement use some measure of variance or correlation. Berry and Mielke (1988) extend the kappa measure (Cohen, 1960) to continuous multivariate data and use Euclidean distances to measure differences between scores. Janson and Olson (2001) use squared Euclidean distances rather than standard Euclidean distances. We describe this formulation, as it fits well with the squared Euclidean distance terms in the CCT likelihood functions. The original Janson and Olson (2001) agreement measure allows for each item to have multiple traits. For simplicity, and to fit with the consensus model, we only describe a single trait version of the measure. The expected disagreement De is defined as the average squared Euclidean distance between a rater’s score for one item k and any other rater’s score for any other item. The observed disagreement Do is defined as the average squared Euclidean distance between a rater’s score for one item k and any other rater’s score for the same item.
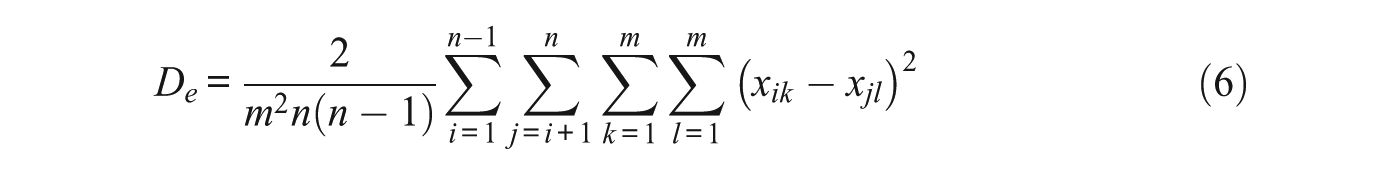
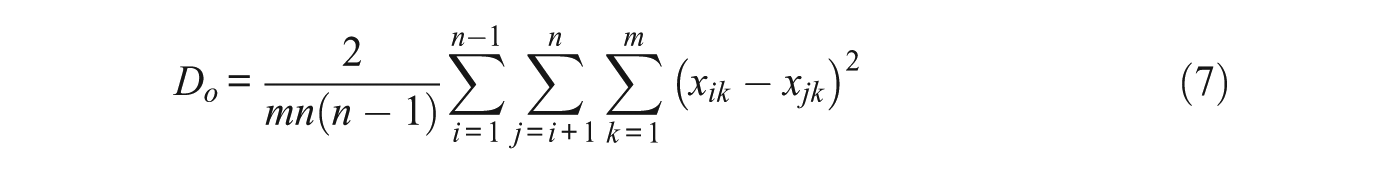
The overall level of agreement between raters is denoted by iota (ι), which is defined in Equation (8) and has a maximum value of 1 when there is no observed disagreement, that is,

The value of ι can be taken as a measure of the reliability of an overall score, based on the agreement between raters.
For a CCT answer key, outlying raters with low agreement contribute less to the overall score than raters with high agreement. This should boost the overall level of agreement of the aggregate score. For each k, calculating the value of
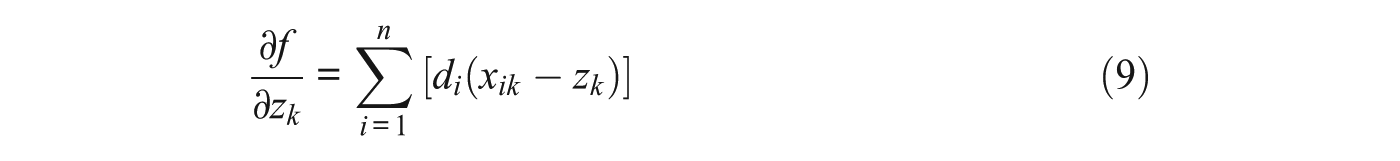
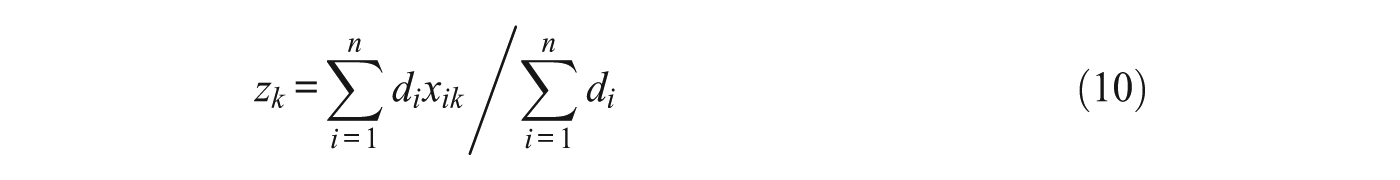
Thus, the contribution to

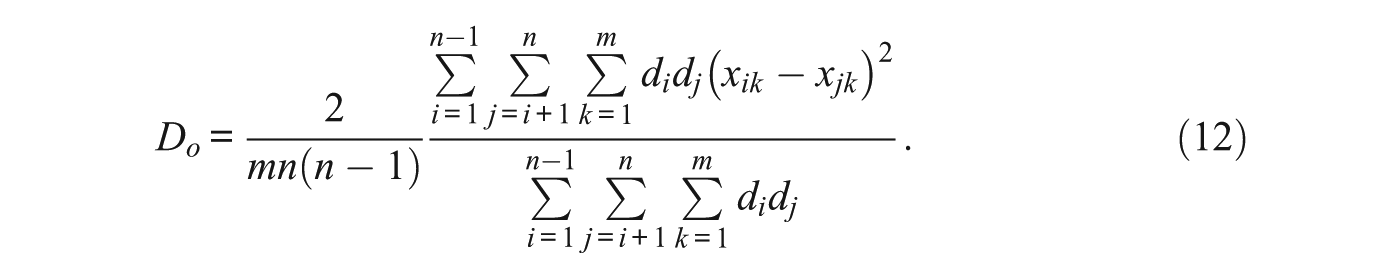
Inaccuracies can occur in correlational measures such as Cohen’s kappa when users have intrinsic biases (Di Eugenio & Glass, 2004). However, scores from bias corrected competency models can account for errors due to bias. In fact, the first derivatives of any model described in this article can be used to provide an adjusted measure of agreement. For example, the value of

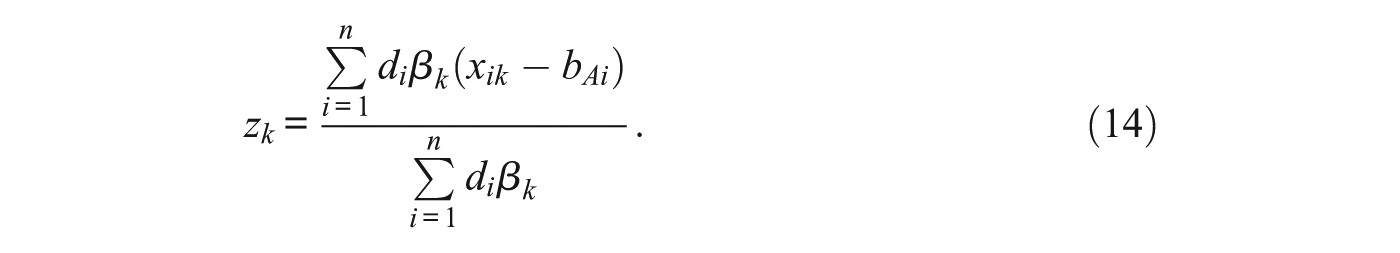
The resulting disagreement values, accounting for competency, item difficulty, and bias are given in Equations (15) and (16):

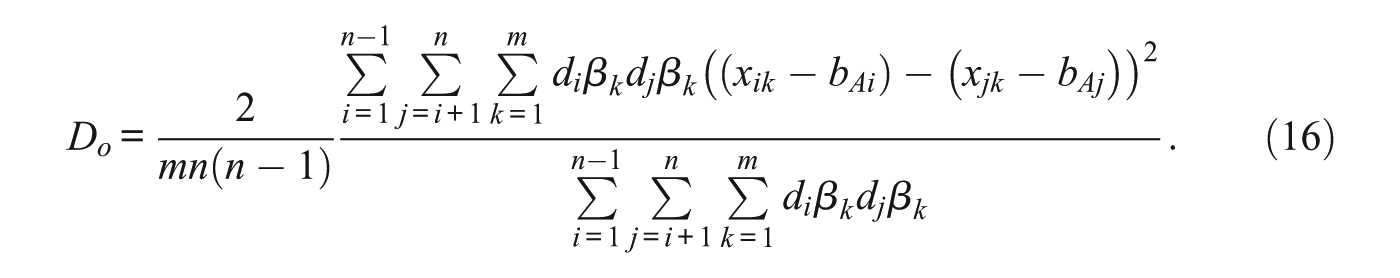
In a practical sense, the agreement measures can be used to calculate the level of “reliability” of the consensus answer key
The metrics described by Berry and Mielke (1988) and Janson and Olson (2001) can be described in terms of the analysis of variance (ANOVA) framework and the sum of squares decomposition of the rater answers. In fact, Barnhart, Haber, and Lin (2007) describe an agreement model that uses a two-way fixed effect model and splits the mean squared dissimilarity (MSD) of
Exam Grading Illustrative Example
Cultural Consensus Theory and Exam Grading
We demonstrate the use of the CCT models described in this article using an illustrative real world example. Though the models can be used with a wide range of rating/estimation data, educational rating/grading data are particularly relevant to CCT. Consider a situation where multiple raters grade a set of essays. To maintain fairness, there should be a high degree of consistency between raters. Traditionally, reliability analysis has been used to analyze the effectiveness of essay graders; see, for example, Braun (1988). However, reliability analysis gives limited information on the relative competency of the individual graders. Some reliability measures, for example, the ι measure described in Janson and Olsson (2001), allow for the weighting of items, but the weighting is a priori. When analyzing essay grading patterns, the items are the individual “essays” and it is difficult and time consuming to guess the easiness/difficulty of the essays. Applying the item easiness CCT models to the data gives a set of grader competencies, a set of competency weighted aggregate essay grades, and a set of item easiness factors. Information measures based on the model log-likelihood, for example, the Akaike information criterion (AIC; Akaike, 1974), or one of the adjusted reliability metrics described in the previous section, can be used to provide an overall aggregate measure of grader reliability.
We used data from an essay scoring data set, “The Hewlett Foundation: automated essay scoring” (Kaggle, Inc., 2012) data set. The data set contains sets of student essays for several different essay prompts. Each essay set contains the source essays and scores for each essay given by two expert graders. We take data from an essay set, which has the following prompt:
We all understand the benefits of laughter. For example, someone once said, “Laughter is the shortest distance between two people.” Many other people believe that laughter is an important part of any relationship. Tell a true story in which laughter was one element or part.
A grading rubric is associated with the essay set. The essay grading rubric contains six different attributes: “Ideas and Content,”“Organization,”“Voice,”“Word Choice,”“Sentence Fluency,” and “Conventions.” Each essay is to be graded on an integer scale from 1 to 6 for each of the attributes. We chose 50 essays from the essay set. The essays were not chosen completely randomly. We ordered the essays into deciles by quality, using the scores given by the two expert graders. We then randomly selected 5 essays from each of the 10 deciles. This ensured that there was a good range of essay quality in the experimental data set. We brought in 12 student graders. The students were compensated for their time. The student graders were undergraduate juniors or seniors at the University of Wisconsin–Milwaukee. Each grader was given the training materials for the essay, which contained a detailed description of the grading rubric and four example graded essays. The students were tasked with reading each essay and grading it on each of the six attributes described in the grading rubric. The students were given 30 minutes to view the training material and a minimum of 120 minutes and a maximum of 150 minutes to grade the 50 essays (2.4-3 minutes per essay). The time per essay was chosen based on the standard time given to ETS exam graders. The minimum time was to ensure that students did not rush through the essay grading process without thought.
Results
The resulting data set from the experiment contains ratings for the 2 expert raters and the 12 student raters for each of the 50 chosen essays. The rubric guide recommends calculating an overall essay score by summing the constituent attribute scores for each essay. We took two approaches to calculating the overall essay scores. For the first approach, we summed all the attribute scores. As per classical test theory (Raykov & Marcoulides, 2011, pp. 115-136), we assumed that the overall additive scale corresponds to a continuous scale with even intervals between item values. For the second approach, we did not make any initial measurement assumptions regarding the attribute scores. Instead, we used multiple correspondence analysis (Greenacre & Blasius, 2006) to map the data onto a continuous scale. Multiple correspondence analysis creates chi-squared distances between data points from a table of associations between categorical variables. A singular value decomposition can then be used to map the data points to a continuous dimension. The resulting correspondence analysis scores had a Pearson correlation of .9783 with the additive scores, which suggests that the additive classical test theory model holds for the data.
The single culture CCT models described in this article are based on the assumption that the raters belong to a single culture. Given that in the example, graders are grading from a single rubric, one may be able to make the assumption of a single culture, but this is not a given as raters may interpret a single rubric in multiple ways. Fortunately, most CCT models have the property that the interrater correlations across items exhibit an approximate one-factor structure as exhibited by Spearman’s law of tetrads, for example, Batchelder and Romney (1988), Batchelder and Anders (2012). One way of verifying that informants have a single culture is to perform a factor analysis on the interrater correlations and then examine the eigenvalues for evidence of a one-factor structure (e.g., Anders & Batchelder, 2012). For both the additive scores and the correspondence analysis scores, we calculated correlations between the 14 raters and performed a minimum residual factor analysis using the fa() function from the “psych” library in R (Revelle, 2013). The eigenvalues for the additive scores were [λ1 = 11.41, λ2 = 0.62, λ3 = 0.35, λ4 = 0.31] and the eigenvalues for the correspondence analysis scores were [λ1 = 11.60, λ2 = 0.57, λ3 = 0.33, λ4 = 0.27]. For both solutions, the first factor accounted for more than 99% of the solution variance. This strongly suggests a one-factor solution, supporting the single culture assumption of the models.
We ran each of the three models (the basic model and the two-item easiness models), setting a maximum competency and item easiness of 5, to ensure that no rater’s precision was completely dominant over the other raters’ precisions. We ran each model with no bias, additive bias (+), multiplicative bias (×), and simultaneous fitting of both additive and multiplicative bias (+×).
The results for the basic model are given in Table 1 and the results for the item easiness models (multiplicative and additive) are given in Table 2. The model name, the number of parameters, the data preprocessing method (additive or correspondence analysis [CA]), the optimal log-likelihood value (LL*), the AIC value associated with the optimal log-likelihood (2 × No. Parameters -2 × LL*), the minimum and maximum values of the answer, the competency, and the item easiness parameters are given for each model. The bias type (+, ×, or +×) is appended after the model name. The AIC value can be used as a general measure of model fit, relative to the number of parameters. Using the AIC rather than the log-likelihood helps protect against overfitting when testing and comparing models. In addition, the proportion of user competencies and item easiness parameters that take the maximum value of 5 is given as “PMax.” The value of PMax can be considered to be a quality criterion for the solution, with solutions with low values of PMax considered to be good quality. The rationale here is that if too many users have the maximum competency or too many items have the maximum item easiness then this will hinder the interpretability of the solution.
Results for Simple Model.

Note. AIC = Akaike information criterion; CA, correspondence analysis; Param = number of parameters; PMax = proportion of user competencies and item easiness parameters that take the maximum value of 5; LL* = optimal log-likelihood.
Results for Item Easiness Models.

Note. AIC = Akaike information criterion; CA, correspondence analysis; IE, item easiness; Param = number of parameters; PMax = proportion of user competencies and item easiness parameters that take the maximum value of 5; LL = log-likelihood.
The results for the basic models are given in Table 1. For the basic model, adding bias significantly decreased the AIC. For both score types, adding additive bias decreased the AIC by more than adding multiplicative bias and simultaneously adding additive and multiplicative bias decreased the AIC further. The additive scores gave a slightly better fit than the scores calculated with correspondence analysis. All four basic models gave PMax values of 0.
The results for the item easiness models are given in Table 2. For both score types, for the models without bias, the multiplicative item easiness model gave the lowest AIC and had a single item with maximum competency. For both score types, the additive and multiplicative scaling factor item easiness models gave a score of PMax = 0 when bias was added. As per the basic model, adding bias reduced the AIC. The multiplicative item easiness model with both additive and multiplicative bias had the lowest AIC for both additive and correspondence analysis scores.
As an illustrative example, we give scatterplot representations of the parameters for one of the models, the multiplicative item easiness model with multiplicative bias. In the first scatter plot, Figure 1, competency is plotted against bias. The two expert graders are indicated with an “E” and the student graders are indicated with an “S.” One can see that one of the expert graders has a much stronger competence than all the other graders. The second expert grader is part of a cluster of graders with slightly above average bias and competency. Among students, there is a wide variety of biases and competencies. In the second scatter plot, Figure 2, for each item k, the item (essay) easiness βk is plotted against the answer key (essay) score zk. As the values of βk are multiplicative, they are mostly clustered around 1. There is a correlation of −0.3471 (p = .0135) between essay easiness values and essay score values. In particular, there is a cluster of essays with high scores and low item easiness values. This suggests that for this essay prompt, it was harder to evaluate essays with minor errors than essays with major errors. One essay has the maximum item easiness parameter of 5. The content of the essay in its entirety is “I don’t like computers.” Every rater graded the essay as 1 out of 6 on every attribute, leading to zero item error and thus an item easiness parameter which theoretically could go to infinity without affecting the likelihood function. The essay with the lowest easiness value contains musings by a student on social acceptance in a group of peers in a foreign country. The inventiveness and use of the English language in the essay is of a high level, obviously higher than that of most of the other essays. However, the narrative is somewhat fractured and happenstance and the essay is a little shorter than some of the other essays. One can see why this essay was hard to evaluate. Given these two examples, and examining other essays with either high or low easiness values, the item easiness parameters seem to possess face validity.

Plot of multiplicative bias versus competency (d).

Scatter plot of item easiness versus score.
Thus far, we have discussed the meaning of the different output parameters for CCT and how these parameters are fit from the initial ratings data. There are several ways that the parameters could be used to help inform decisions in essay grading applications. Consider a situation where graders are tested on a set of example evaluation essays or exam questions. Each grader can be assigned a competency. These competencies could be used to select graders from a pool of potential graders or to help assign graders to exams. Rather than assigning a fixed number of graders to an essay, the number of graders assigned could be selected based on the competencies of the graders. For example, one essay could be assigned to two high competency graders while another could be assigned to three lower competency graders. When calculating aggregate scores, scores could be calculated using the competencies gained from the example evaluation essays. In the case of the item easiness parameters, it is important to note that in the context of essay rating, “easiness” refers to the ease of grading an answer to a specific essay rather than the overall ease of grading for a certain essay prompt. In an actual test environment, the item easiness parameter could be used as a measure of answer score accuracy. If an essay has a low “easiness parameter” then additional graders could be assigned. For example, in the data set described in this section, if the “I don’t like computers” essay gained the same minimum score from all the initial raters then the “easiness” parameter would be high and additional raters would not be required. If the “exchange student” essay gained several conflicting ratings and a low “easiness” parameter then additional raters could be added to improve accuracy.
Discussion and Future Work
We have introduced a set of CCT models for analyzing rating data. The models take an n user ×m item input matrix
CCT provides a cognitively based aggregation scheme that can correct for different rater biases in the aggregation process. However, when bias parameters are added to the model, model identifiability issues can occur. We implemented a method of fixing certain model parameters. In this method, the fixed values are taken from an optimized model with a fully identified subset of the model parameters. Constraining a single parameter value gives the same optimal solution as the unconstrained solution. Fixing all parameters of a given parameter type essentially introduces a parameter fitting hierarchy. Further analytical and empirical work on analyzing identifiability issues in CCT models could be useful.
CCT models are applicable to a wide range of rating/questionnaire data from the social and behavioral sciences. Applications include anthropological analysis of cultural knowledge (Romney et al., 1986), cross-cultural analysis (Lamm & Keller, 2007), determining ties in a social network (Batchelder, Kumbasar, & Boyd, 1997), analyzing social survey data (Oravecz, Faust, & Batchelder, in press), grammaticality aggregating judgments of sentences in linguistics (Anders & Batchelder, 2013) and aggregating product reviews (France & Batchelder, 2013). In this article, we gave a specific example in the area of education. We demonstrated the utility of CCT models on a set of essay scoring data. CCT models are models of shared culture and shared belief. In this sense, when we used CCT to analyze essay scoring data, we were analyzing the culture of the essay graders. The graders with the highest competency were the graders closest to the center of the culture. In the example given in this article, graders were given a training rubric and a set of graded examples. If implemented properly, exam rubrics can help increase consistency among graders (Moskal & Leydens, 2000). In the context of CCT, the rubrics form the basic cultural knowledge. However, individual graders may stray from the rubric or may interpret the rubric differently than one another. The “culture” of the raters is defined by their actual essay rating behavior and may or may not reflect overall adherence to the grading rubric. For example, there may be a situation where there is a group of experienced essay graders who have previously used an old version of the rubric and a smaller group of new graders who have only ever used the current version of the rubric. If the majority of the raters are still influenced by the old rubric then these raters will be considered more competent than those strictly following the current rubric. In this case, a multiculture (Anders & Batchelder, 2012) or clusterwise (France & Batchelder, 2013) CCT model may be required to split the raters into groups.
In the experiment, we implemented three different models, with four bias variants for each model. We gained parsimonious model information for all the models tested. All three models showed a noticeable improvement in fit as bias parameters were incorporated into the model. However, the results are only for one data set and the differences in the AIC values between the additive and multiplicative models and between the additive and multiplicative biases are small, so the best model may depend on the best interpretation for the task at hand.
The CCT models described in this article assume continuous input data. However, most ratings data are measured on an ordinal scale. The data set analyzed in the experiment had six different traits, each measured on an ordinal scale from 1 to 6. We calculated an overall scale value from the six traits using an additive model, as per classical test theory, and using multiple correspondence analysis. Correspondence analysis is a technique that can be used to approximate a continuous scale from ordinal data. In the case of ordinal data, it is more appropriate to calculate an overall continuous scale using correspondence analysis rather than factor analysis, as correspondence analysis is designed specifically to analyze ordinal and nominal categorical variables. We found that the additive scores were very strongly correlated to the continuous correspondence analysis scores. This suggests that at least in the case of the essay grading, the additive scores can be taken as continuous. In fact, Kennedy, Riquier, and Sharp (1996) examine a range of Likert-type scale ratings data and show that when mapped to a continuous scale using correspondence analysis, the differences between Likert-type category values are almost even, allowing the data to be approximated as continuous. In addition, experiments in Batchelder, Strashney, and Romney (2010), which describes a model where ordinal boundaries are mapped onto a continuous scale, show that a continuous model gives a good approximation to Likert-type scale data.
For future work, explicit modeling of ordinal variables could be incorporated into the CCT optimization routine. The update equations for the fixed point technique for
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The second author gratefully acknowledges support from research grants from the Army Research Office (ARO) and the Oak Ridge Institute for Science and Education (ORISE).