
Abstract
Test tampering, especially on tests for educational accountability, is an unfortunate reality, necessitating that the state (or its testing vendor) perform data forensic analyses, such as erasure analyses, to look for signs of possible malfeasance. Few statistical approaches exist for detecting fraudulent erasures, and those that do largely do not lend themselves to making probabilistic statements about the likelihood of the observations. In this article, a new erasure detection index, EDI, is developed, which uses item response theory to compare the number of observed wrong-to-right erasures to the number expected due to chance, conditional on the examinee’s ability-level and number of erased items. A simulation study is presented to evaluate the Type I error rate and power of EDI under various types of fraudulent and benign erasures. Results show that EDI with a correction for continuity yields Type I error rates that are less than or equal to nominal levels for every condition studied, and has high power to detect even small amounts of tampering among the students for whom tampering is most likely.
The cheating scandal in the Atlanta Public Schools (see Kingston, 2013) brought the issue of test tampering into the national spotlight. Although Atlanta was not the first instance in which teachers were found to have engaged in changing students’ answers after tests were complete (Asimov & Wallack, 2007; McGraw & Woo, 1988), it has demonstrated the severity of the problem like no previous cheating scandal, and has sent a clear signal to districts and states that they should be actively looking for signs of teacher/administrator tampering.
Test tampering is most commonly associated with paper-based testing, where educators may change student answers after the tests are complete. It is for this reason that both Smarter Balanced and PARCC assessments will be predominantly computer-based, and many other educational accountability programs are moving toward computer-based tests. However, lack of computer capacity is causing the transition from paper-to-computer delivery to happen slowly for many states (Camara, personal communication, September 19, 2014). Accountability programs such as ACT, Iowa Assessments, and the New York Regents exam are all largely or exclusively paper-based and are anticipating continuing with that platform as the primary mode of delivery for the foreseeable future.
However, depending on the administrative conditions, test tampering may also be possible in the computer-based testing environment. Tests that are administered with scheduled breaks after which students can resume the test are also susceptible to tampering by educators, as are any tests for which students are instructed not to submit their answers immediately on finishing.
Detection of test tampering is usually approached from one of two angles. The first of these is with models that focus on detecting unusually large gains (Skorupski & Egan, 2012; Wollack & Maynes, 2011). Within the school context, approaches looking at gains detect not only tampering, but also illegal coaching. One of the inherent challenges in approaches focused on gains is that the goal of education is to produce learning gains. Therefore, distinguishing between gains due to learning and gains due to cheating becomes critical. Unusual gains that are achieved through test tampering are often accompanied by large numbers of erasures, particularly wrong-to-right erasures (WTR). Therefore, the second approach to detecting test tampering is through analyzing secondary light marks on answer sheets that are indicative of erasures. There are multiple reasons that an individual student may produce many erasures, but an unusually high number of erasures or WTR erasures for an entire class is very difficult to attribute to anything other than test tampering. For this reason, erasure analysis is often regarded as a useful approach for detecting test tampering.
Erasure detection is a very new science. Existing approaches to detection have overwhelmingly been empirical, creating a distribution of the observed number of erasures (or perhaps WTR erasures) or developing a statistical model that fits empirical data well. An examinee or a group is identified as anomalous if they fall in the upper tail of the distribution or produce a number of WTR erasures that are a predetermined number of standard deviations above the mean (Bishop, Liassou, Bulut, Seo, & Bishop, 2011; Maynes, 2013; Primoli, Liassou, Bishop, & Nhouyvanisvong, 2011). Such empirical approaches have been executed successfully in other forms of cheating detection, such as answer copying or similarity (Allen, 2012; Hanson, Harris, & Brennan, 1987). However, in answer copying contexts, it is customary to build the baseline empirical sampling distribution by pairing students from different testing centers for whom copying was impossible. Consequently, the baseline distribution represents a null distribution. In the erasure context, however, no clear mechanism exists to develop a distribution based on null cases only; hence, the methodologies create sampling distributions that may be, to some extent, contaminated by fraudulent erasures. As a result, it is not possible using these methodologies to have a clear understanding of the error rates (Type I or Type II) associated with the statistical findings. Similarly, empirical approaches, such as have been done, do not allow for accurate probabilistic statements of the likelihood of the result, and produce sample-dependent estimates of the extremity of results.
van der Linden and Jeon (2012) modeled erasure behavior by assuming that all final answers were reached through a two-stage process in which, in Stage 1, every item (i = 1, . . ., n) is answered, and in Stage 2, every item is revisited and the answer is either changed (producing an erasure) or retained (not producing an erasure). Using item response theory, and assuming that examinee j’s θj (j = 1, . . ., N) remains constant throughout the test, item parameters for a two-parameter model are fit to the N× 2n data set, allowing the initial and final items to be separately calibrated. van der Linden and Jeon derived the models for the four conditional probabilities of final responses (e.g., final answers are correct or incorrect conditioned on the initial answers being correct or incorrect). The probability of a final correct answer conditional on an incorrect initial response follows as the probability of a WTR erasure. Using this model, the van der Linden and Jeon approach uses the generalized binomial to derive, for each individual, the exact probability distribution of the number of WTR erasures conditional on the specific set of items that were initially answered incorrectly. Under this approach, examinees with observed WTR scores that are sufficiently improbable are flagged as anomalous.
In this study, we adopt an approach similar to that of van der Linden and Jeon in that we use item response theory to model erasure data, and subsequently develop an index that evaluates the number of WTR erasures against the number expected under the model. This model is evaluated through simulation, as well as analytically, and data on the Type I error rate and power are provided. We conclude with some thoughts about the implications for practitioners.
Development of a New Erasure Detection Index
As mentioned previously, erased items are not indicative of tampering; however, tampered questions will result in erasures. Consequently, the validity of responses to erased items should be approached with some suspicion, particularly if there are many such items on an exam. Furthermore, if trait estimation for examinee j includes tampered items,
The assumption in cases of test tampering is that answers will be changed from incorrect to correct, thereby producing an artificially high number correct score. Hence, our interest is in comparing the observed number correct score across erased items to the expected number correct score across those same items.
The observed score on erased items,
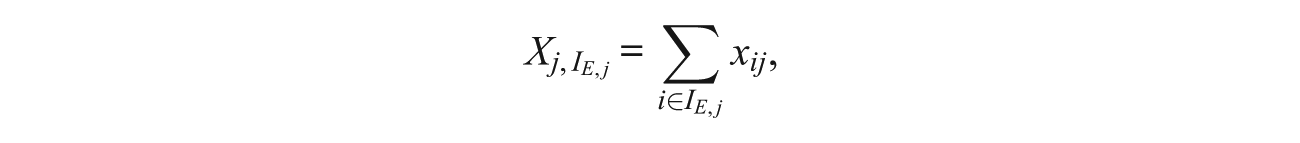
where xij is the right/wrong score for examinee j on item i. This quantity has been shown to follow a generalized binomial distribution (van der Linden & Jeon, 2012; van der Linden & Sotaridona, 2006). However, for purposes of this study,
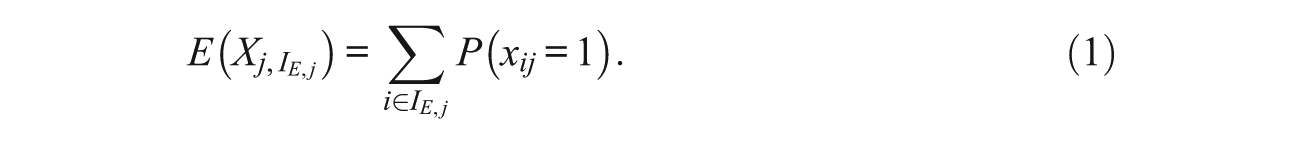
Any item response model appropriate for the data may be used to estimate P(xij = 1).
The appropriate standard error for
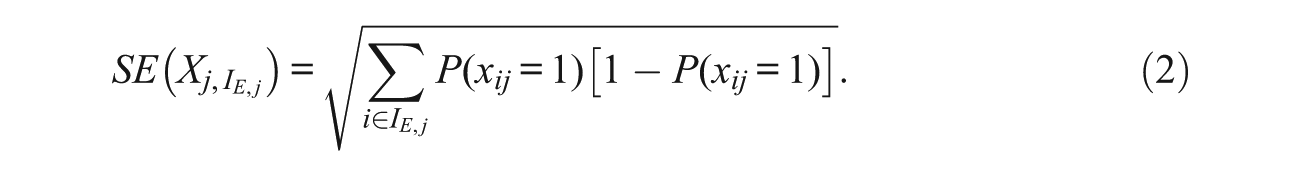
The erasure detection index (EDI) used to determine whether the number of WTR erasures exceeds that expected due to chance is
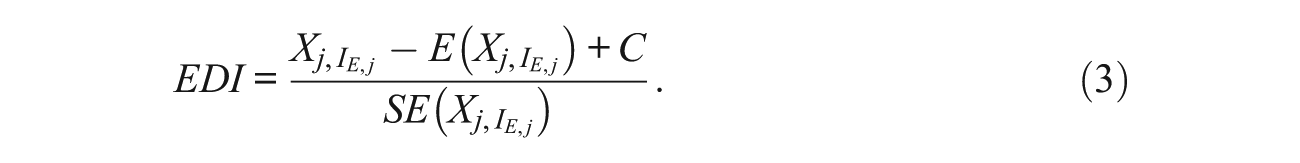
Previous research has found that indexes of this structure (e.g., the ω statistic for answer copying detection [Wollack, 1997]) have somewhat inflated false positive rates for low ability examinees when tests are short (van der Linden & Sotaridona, 2006). Because the number of erased items is likely to be a subset of all items, it is expected that, even in cases where tampering occurred, the maximum value of
Simulating Erasures
Two different types of erasures were simulated—benign erasures, in which examinees legitimately erased and changed their answers on reconsideration of the item choices, and fraudulent erasures, in which a test administrator (e.g., teacher, proctor, principal, etc.) erased and changed students’ answers after the test was over. The data set analyzed was simulated to simultaneously include both types of erasures, including some students whose item response vectors consisted of a combination of benign and fraudulent erasures, so as to be consistent with the situation in practice, when all types of erasures may be embedded in a data set.
As a first step in the simulation, responses were generated for 250,000 examinees on a 50-item 5-alternative multiple-choice test using the nominal response model (NRM; Bock, 1972). The distribution of examinee ability was assumed to be normal (e.g., θ ~ N(0, 1)). NRM item parameter estimates from an English language usage test administered to nearly 25,000 college freshmen were treated as the generating parameters.
Next, benign erasures were simulated. According to the research, erasures on state accountability exams are not common. Primoli et al. (2011) conducted a comprehensive study of erasure rates in which they analyzed 3 years’ worth of data from 45 tests in eight subject areas in nine grades as part of four different state testing programs. On average, they found the distribution of erasures to be heavily positively skewed. Examinees produced erasures on approximately 2% of the items. Mroch, Lu, Huang, and Harris (2012) found erasures to be even less prevalent, thereby supporting the assertion that erasures of any sort are generally uncommon.
In this study, three different types of benign erasures were simulated. Random erasures refer to situations in which a student either accidently bubbles in the wrong answer on the answer sheet, identifies it immediately, and changes it to the intended answer, or the case in which a student initially answers an item one way, but on reconsideration, changes that answer. Misalignment erasures (sometimes called shift errors) refer to situations in which a student accidently bubbles in the answer to item i in the space on the answer sheet reserved for item i+1 (or i−1), and continues to mark answers for a string of consecutive items in the wrong fields. The erasure comes about when the student finally realizes the mistake, erases the answers to the misaligned items, and marks those same answers again, this time in the correct fields on the answer sheet. String-end erasures refer to the situation in which students find that they are running out of time, so randomly fill in answers to the remaining questions to make sure that no questions are left unanswered. As time permits, the students return to the questions and answer them on merit, erasing and changing the answers, if necessary.
In this study, each simulee was simulated to have Yj benign erasures. Because misalignment and string-end erasures both would be very rare occurrences, these types of erasures were each simulated for 1,000 students. To facilitate studying the performance of EDI for examinees of different ability levels, examinees were sorted into quintile groups based on θ. For each condition, 200 students within each quintile group were randomly selected to produce misalignment erasures, and another 200 were simulated to produce string-end erasures. The remaining 248,000 students were simulated to have random erasures.
For simulees selected for random erasures, Yj was generated from a binomial distribution with p = .02 and N = 50 (the number of items). Consequently, on average, examinees had one random erasure and nearly three-quarters of the examinees were simulated to have zero or one benign, random erasure. Under this model, only 6 in 100,000 examinees would have 7 or more random erasures. A graph of the expected benign random erasure distribution is shown in Figure 1.

Binomial distribution with N = 50 and p = .02 used to simulate the number of benign random erasures per examinee.
After finding the number of random erasures per examinee, for each examinee, Yj random numbers from U[1,50] were drawn, without replacement, to identify the specific items on which student j produced a random erasure. For each erased item for person j, a second response was generated using the NRM, conditional on the response being different than the original answer. These new responses were taken to be the examinees’ initial responses which were subsequently erased. The originally simulated answers (which allowed simulees to choose any of the response options) were taken as the final answers.
If indicator function Iijν = 0 when ν equals the final response by person j to item i, initial responses were generated based on probabilities from the conditional NRM shown below
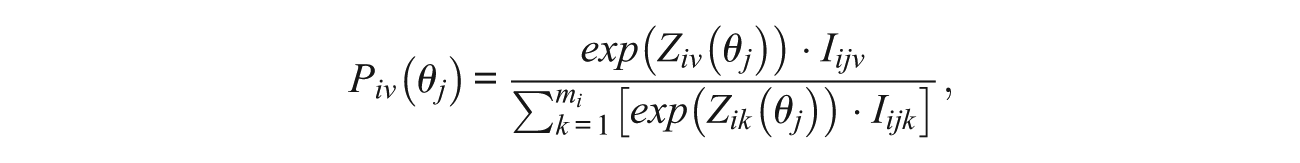
where mi denotes the number of alternatives for item i, and Ziν(θj) = ζiν+λiνθj, with ζiν and λiν being the NRM slope and intercept parameters, respectively, for alternative ν of item i.
Misalignment issues, if undetected for a long time, will produce a rather large number of erasures. Here, we use a binomial distribution with N = 50 and p = .25 to identify the number of misaligned items for simulee j, Mj. Note that Mj provides an upper bound for Yj, because not all alignment errors will result in erasures. This distribution for Mj, shown in Figure 2, produces rather long sequences of misaligned items. On average, examinees in this condition misalign 12.5 items, and approximately 80% of examinees produce between 9 and 16 misalignments. To identify the location of the first misaligned item, we randomly generated a number from a U[1, 50 −Mj+1]. For each misaligned item, we compared the response indicated for item in position i with the response indicated for item i− 1. If they were different, the response to item i− 1 was taken as the erased response for item i. If the responses to the two items were the same, this suggests that the correctly marked item happened to be marked the same way as the misaligned item, so it would not be identified as an erasure.
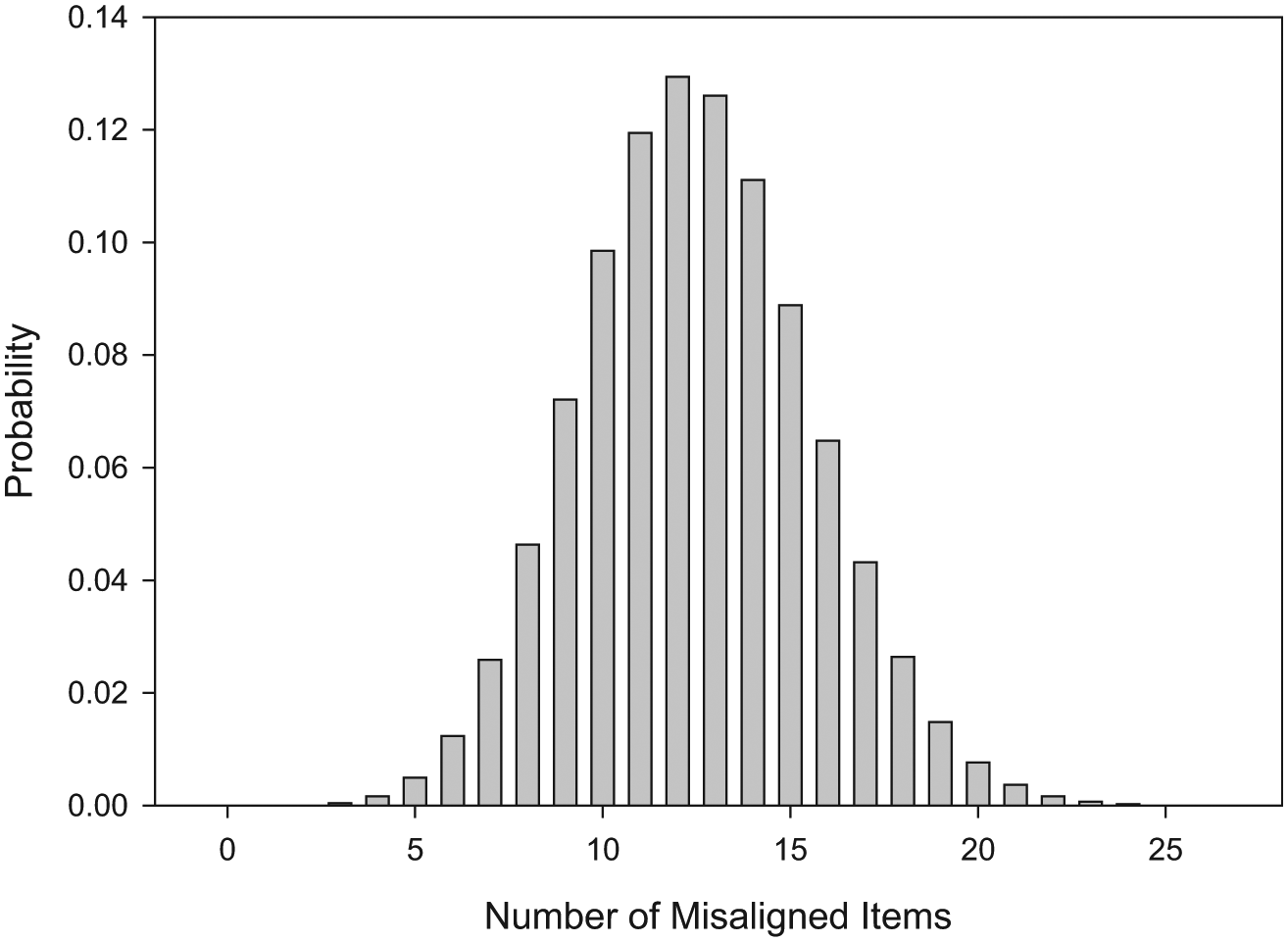
Binomial distribution with N = 50 and p = .25 used to simulate the number of misaligned items.
String-end erasures, like misalignments, have potential to involve long strings of items. In the interest of consistency with the misaligned examinees, string-end erasures were simulated by generating a randomly guessed initial response for the last 12 items on the exam (Items 39-50) such that the probability of selecting each alternative was equal to 0.2. In cases where the randomly selected alternative matches the answer from the final data, the item would not be detected as an erasure.
Fraudulent erasures were simulated on top of the benign erasures, so that simulees with fraudulent erasures likely had benign erasures too. Within each quintile group, a total of 1,000 examinees were randomly selected to be victims of tampering. Two different types of fraudulent erasures were simulated: fixed and variable tampering. In the fixed tampering conditions, a fixed number of items were erased and changed to be correct. Because correctly answered questions would not likely be erased (and even if they were, they would be replaced by bubbling in the same circle), only items that were answered incorrectly originally were candidates to be erased and changed. For each examinee, the incorrectly answered items were all equally likely to be erased and changed to correct. The fixed tampering condition had three levels: 5 items, 10 items, and 15 items. Given the test lengths, it is understood that examinees in the higher quintile groups may not have had enough incorrectly answered items to allow for changing as many items as was required for the condition. In this case, all incorrectly answered items were changed to be correct.
In the variable tampering condition, we simulated a situation in which an administrator changed just enough items to help a student get from not proficient to proficient. Because some simulees are farther from the proficiency cutoff than others, this resulted in different numbers of items being erased for each person. According to Hull (2008), the average percentage of students proficient in math across the United States is approximately 55%. Under the assumption of an underlying normal ability distribution, the 55th percentile corresponds to a θ = −0.126. Given the test characteristic curve associated with the generating item parameters in this study, a θ = −0.126 corresponded to a true score of 26.66. Because 26.66 was not a possible raw score, for purposes of this study, we define as proficient any examinees with scores of 26 or higher.
As in the previous simulation, 1,000 simulees within each quintile group were randomly selected as tampered examinees. Because only students below the 45th percentile were eligible to be selected, no simulees in quintiles 4 or 5, and only the lowest scoring simulees from quintile 3 were selected. The number of erased items per simulee was based not on their number correct score, but on their true score, as it seems more likely to these authors that teachers/administrators would decide which examinees’ responses to change based on their familiarity with the students’ abilities than based on their actual test scores. Consequently, true scores, rounded down to the nearest whole number, were found for each erasure victim. Because teachers/administrators are unlikely to know the exact cutoff and would probably build in a small cushion, we took the difference between the examinees’ rounded true scores and 27—one more than the proficiency cutoff—as the number of WTR erasures for each examinee.
After data were simulated,
EDI values were computed for all examinees in all conditions, both with and without continuity correction. In cases for which continuity correction was applied, EDI was calculated with C from (3) equal to −½. C was set to zero when continuity correction was not applied.
Evaluative Measures
For each quintile group within each simulated type of benign erasure, the Type I error rate of EDI was evaluated at seven different α levels, ranging from .00001 to .05, by dividing the number of examinees for whom tampering was not simulated, but who produced statistically significant EDI values, by the total number of nontampered examinees. For purposes of the Type I error study, all Type I error data were collapsed across the different fraudulent erasure conditions, resulting in very nearly one million nonfraudulent examinees on which to base Type I error results. Power was calculated separately at each of the seven α levels for each quintile group within each of the four different fraudulent erasure conditions. Power was computed as the number of tampering victims detected divided by the number simulated in each category.
Results
Because this methodology estimates θ using only a subset of items, it is first necessary to demonstrate that this approach does not introduce bias into the θ estimation, and that θ can be estimated with sufficient precision. Using all examinees for whom tampering was not simulated, we estimated the bias and root mean square error (RMSE) on θ as follows:
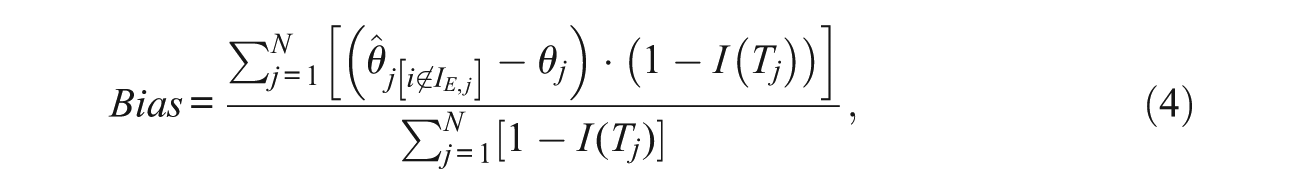
and
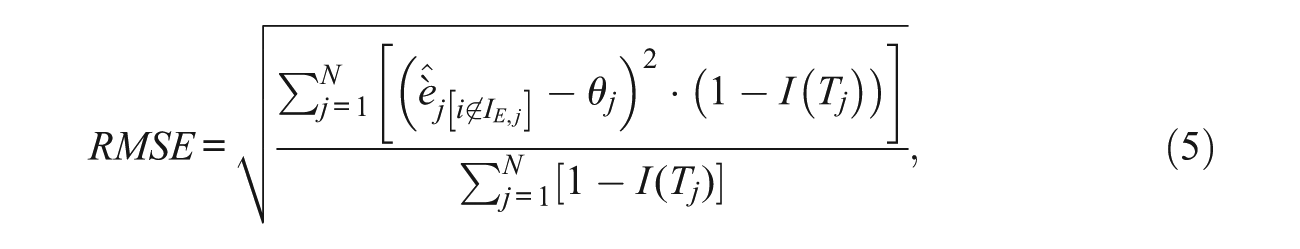
where I(Tj) is an indicator function which equals 1 when the responses for examinee j were tampered, and 0 otherwise. The results are shown in Table 1. Results for the 0 erasures condition serves as a baseline against which to compare the results from the other conditions.
Person Parameter Biases and Root Mean Square Errors.
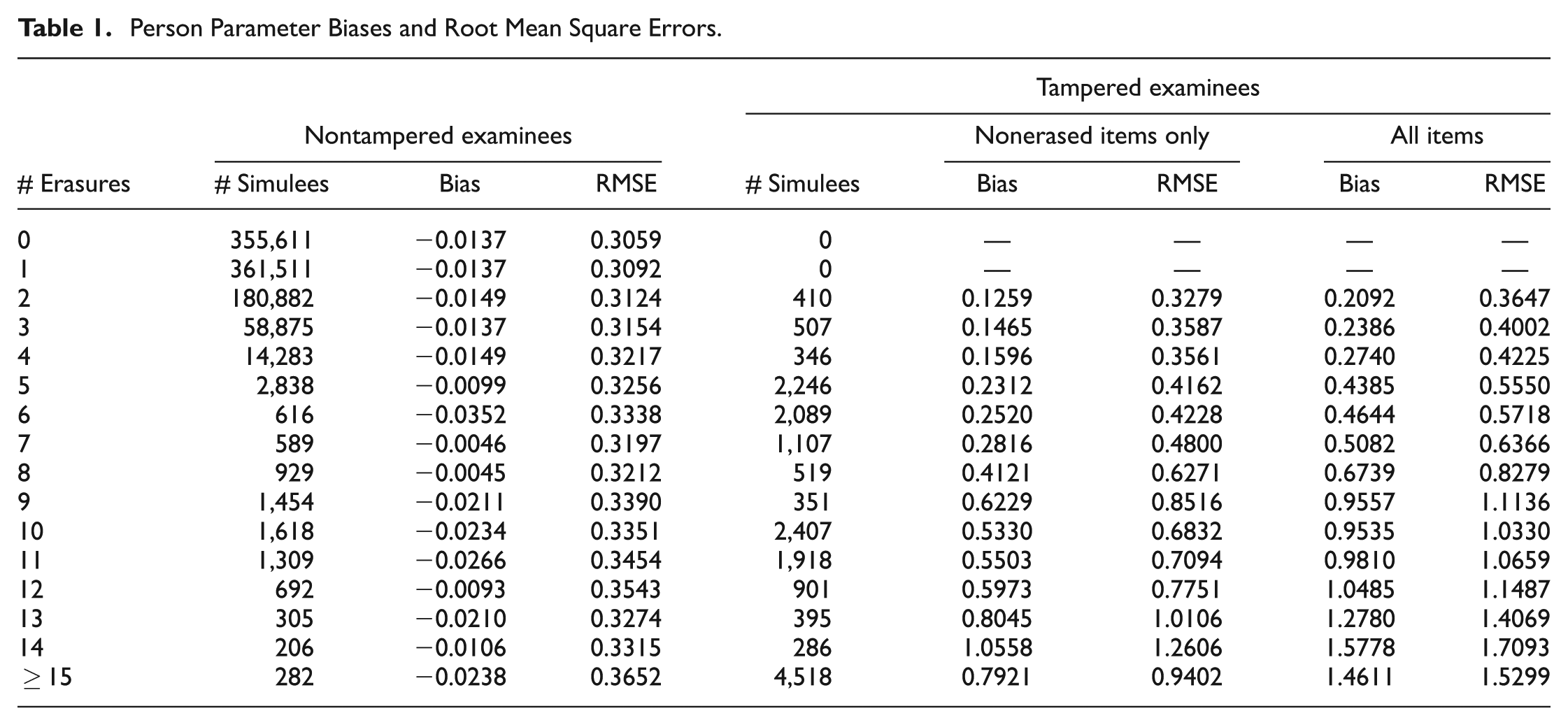
As expected, biases are negligible, even for simulees with as many as 15 benign erasures. Because θ is estimated from fewer and fewer items as the number of erasures continues, it was expected that the standard error of estimation would increase slightly. The expected pattern is observed in the RMSEs, which increase as the number of erasures increases. However, even when θ is estimated from 35 or fewer items, the estimate is only slightly more variable than when all 50 items were used.
For comparison’s sake, the biases and RMSEs are also shown in Table 1 for tampered examinees. With tampered examinees, because the items which are excluded from the estimation are overwhelmingly items that were answered incorrectly by the examinee, systematically removing them and estimating θ across the remaining items (which are more likely to be answered correctly) should result in estimates that are positively biased (i.e., larger than they should be). However, it was anticipated that the amount of positive bias resulting from including the tampered responses would be even larger, thereby providing the justification to estimate θ using only nonerased items.
Table 1 shows the biases and RMSEs for tampered examinees separately based on only the nonerased items and all items as a function of the number of erasures (not all of which were as a result of tampering). The bias and RMSE based on all items were found by replacing
As expected, θ estimates for tampered examinees include noticeable amounts of positive bias, and both bias and RMSE increase sharply as the number of erasures increase. However, it is also clear that excluding all erased items from the estimation process substantially reduces the bias and RMSEs. Biases are reduced by 33% to 47% and RMSEs are reduced between 10% and 39% when only unerased items are used for estimating θ.
To examine the effect of this purification technique for examinees of different ability levels, biases and RMSEs are broken down by quintile group in Table 2. Because of some small sample sizes in particular Number of Erasures × Quintile subgroups, for purposes of Table 2, the number of erasures are collapsed into six groups.
Person Parameter Biases and Root Mean Square Errors by Quintile Group.

For nontampered examinees, Table 2 shows that that θ estimates include small degrees of positive bias for the lowest scoring examinees and positive bias for the highest scoring examinees. This bias at the extremes of the θ distribution is likely attributable to shrinkage toward a mean θ of zero, as is customary with default MAP estimates in MULTILOG (Thissen & Orlando, 2001). There does not appear to be a noteworthy relationship between the number of benign erasures and the shrinkage effect.
For tampered examinees, however, Table 2 shows that bias and RMSE are reduced for all quintile groups when θ is estimated using only nonerased items; however, the largest reductions are for the examinees in the lower quintile groups. Collapsed across all examinees, the average percentage reduction in bias is 60%, 50%, 43%, 33%, and 32% for Quintiles 1, 2, 3, 4, and 5, respectively. Similarly, RMSEs were reduced, on average, by 49%, 35%, 26%, 25%, and 23% for Quintiles 1 through 5, respectively.
Taken together, these results suggest that excluding erased items from the estimation of θ serves to partially neutralize the effect of tampering and improves the quality of estimation, while its effects on nontampered examinees are negligible, even if the number of erasures is high. The effects of this purification approach are most pronounced for low-ability examinees, which are precisely the examinees for whom tampering is most likely. Consequently, this approach was used throughout this study to estimate θ.
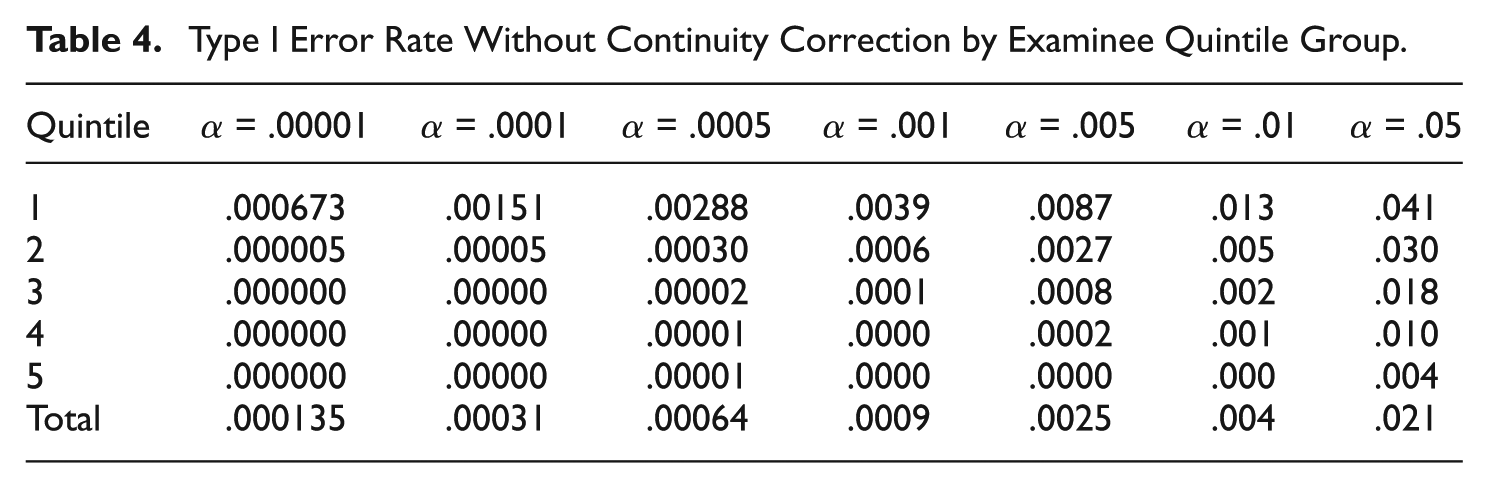
Type I error results are provided when continuity correction is not used for each of the five quintile groups within each benign erasure condition in Table 3, and collapsed across benign erasure conditions in Table 4. From the bottom row of Table 4, one can see that collapsed across erasure type and quintile groups, the overall Type I error rate is well controlled, except for the very smallest α levels. However, the bodies of Tables 3 and 4 both show significant degrees of α inflation in several conditions. In particular, Type I error rates exceed nominal levels as α levels decrease, for lower quintile groups. This is particularly true in misalignment and string-end conditions. Given that, in practice, test tampering is most likely to occur with lower ability examinees and that data forensic techniques are typically applied with conservative α levels, the results of Tables 3 and 4 are troubling.
Type I Error Rate Without Continuity Correction by Benign Erasure Type and Examinee Quintile Group.

Type I Error Rate Without Continuity Correction by Examinee Quintile Group.
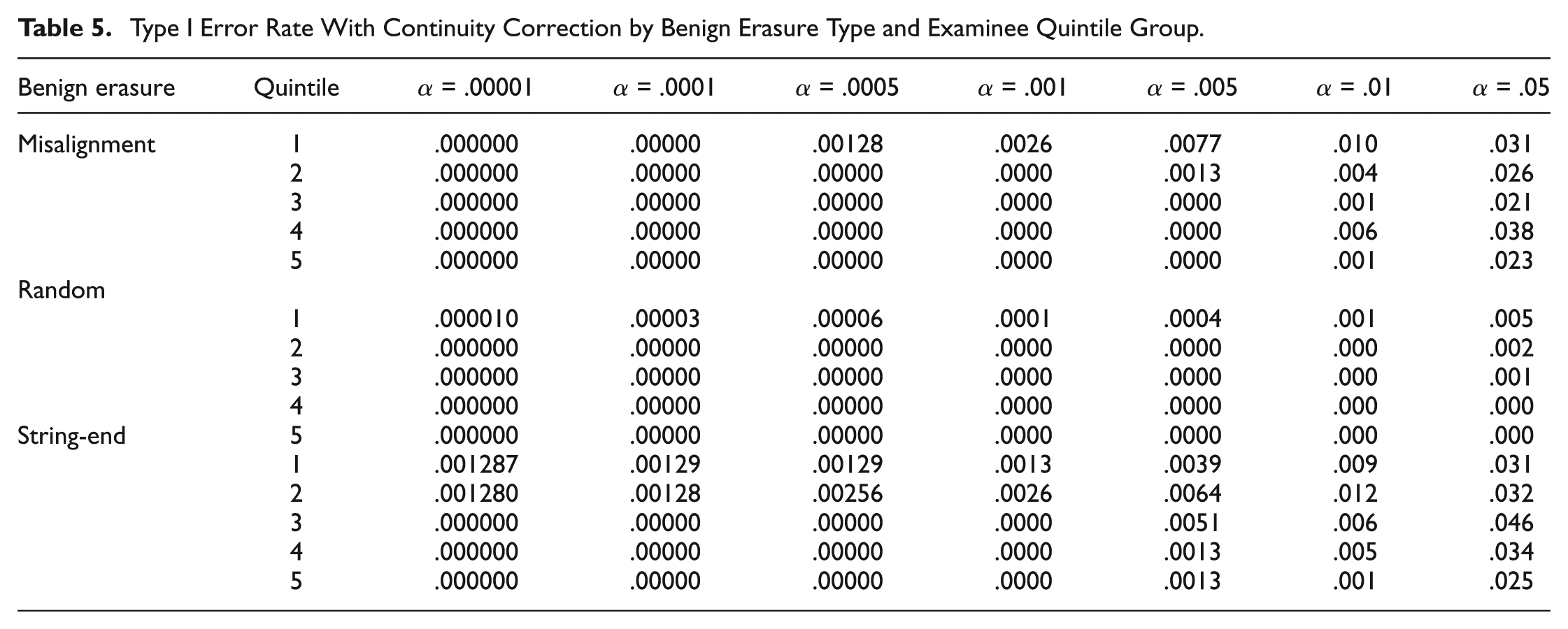
The same data are provided in Tables 5 and 6 when continuity correction is applied. Inspection of Table 5 shows that the false positive rate is well-controlled, if not quite conservative, in nearly all conditions. The few conditions in which there is apparent inflation—for quintiles 1 and 2 at the smallest α levels in the string-end condition—are likely a product of the fact that insufficient string-end erasures were simulated to allow accurate estimation of such small α levels. In fact, the inflated error rates are attributable to a very small number of detected simulees (just 1 in the case of the α = .00001 and .0001 conditions). Because error rates were lowest for the random erasure conditions, when the Type I error rates are collapsed across the three types of erasures, error rates are quite conservative in all conditions.
Type I Error Rate With Continuity Correction by Benign Erasure Type and Examinee Quintile Group.
Type I Error Rate With Continuity Correction by Examinee Quintile Group.
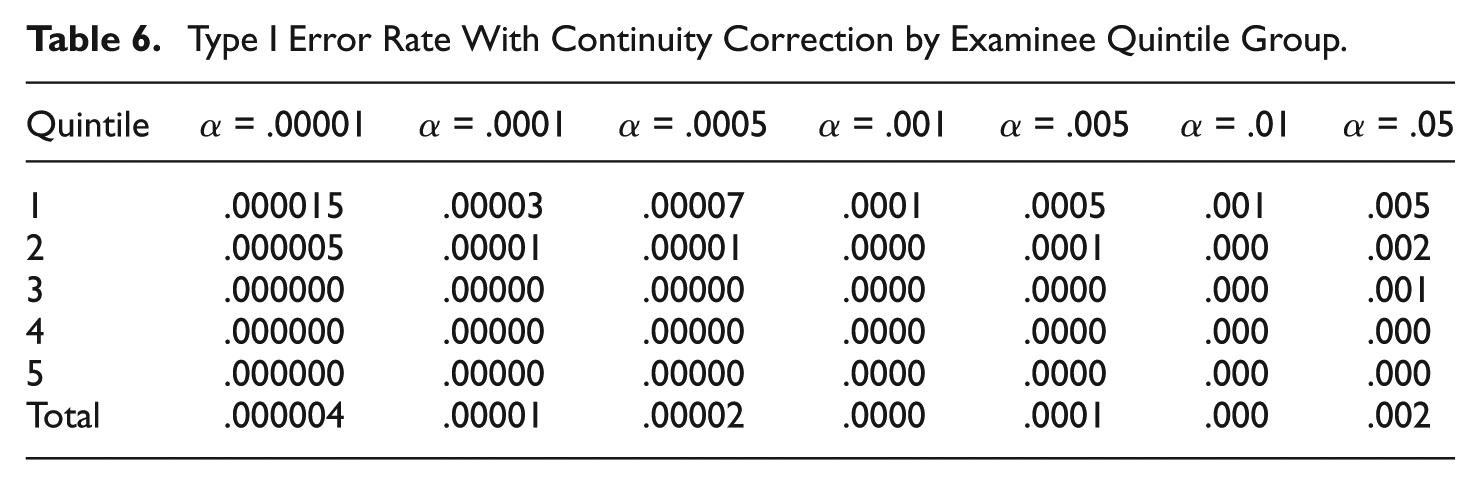
The power of EDI without continuity correction is shown in Tables 7, and with continuity correction in Table 8. Note that power data are only provided for those conditions for which the Type I error rate was not liberal. Power without the continuity correction is, not surprisingly, noticeably higher. However, even when the correction is applied, the power of EDI is quite high to detect small amounts of tampering among first quintile simulees. By the time 10 WTR erasures are observed, detection rates are very strong, even at small α levels. When the correction is not applied, the power is outstanding, detecting nearly every first quintile student when α = .01 or higher, even when only 5 items are erased. The power among first quintile students without the correction cannot be evaluated at most α levels because the Type I error rates are inflated. At higher α levels, the power without continuity correction remains excellent into the second, and even third quintile groups; however, beginning around α = .001, power drops off considerably for the higher quintile groups. From Table 8, one can see that power drops off considerably for second quintile students at smaller α levels when continuity correction is applied, but detection rates are still very strong at higher α levels and when 10 or more erasures are observed. Power continues to decrease into and beyond the third quintile. Detection rates are still reasonable for third quintile students at the highest α levels provided 10 to 15 items are changed. However, detection rates are unimpressive all around for the fifth quintile simulees. This is likely attributable to the fact that examinees in this category were high achieving, and in many cases, their raw scores were sufficiently close to 50 (the maximum) that it was not possible to change as many as 10 or 15 items from incorrect to correct. Consequently, those examinees did not experience the full effect of the condition in which they were placed. Fortunately, the lower power in the upper quintiles presents little practical difficulty, because administrators are much less likely to tamper with the answer sheets of top students.
Power Without Continuity Correction.
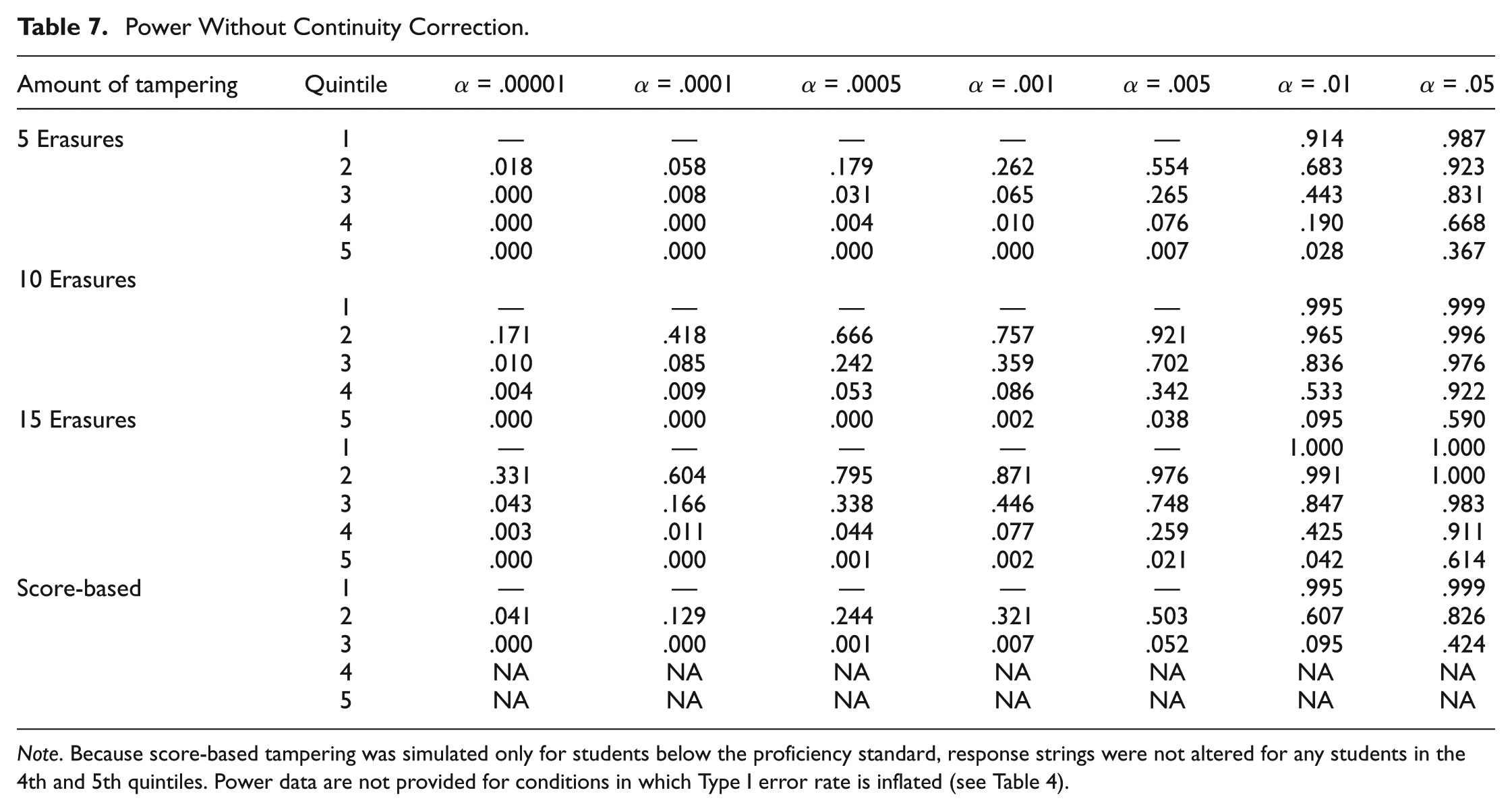
Note. Because score-based tampering was simulated only for students below the proficiency standard, response strings were not altered for any students in the 4th and 5th quintiles. Power data are not provided for conditions in which Type I error rate is inflated (see Table 4).
Power With Continuity Correction.
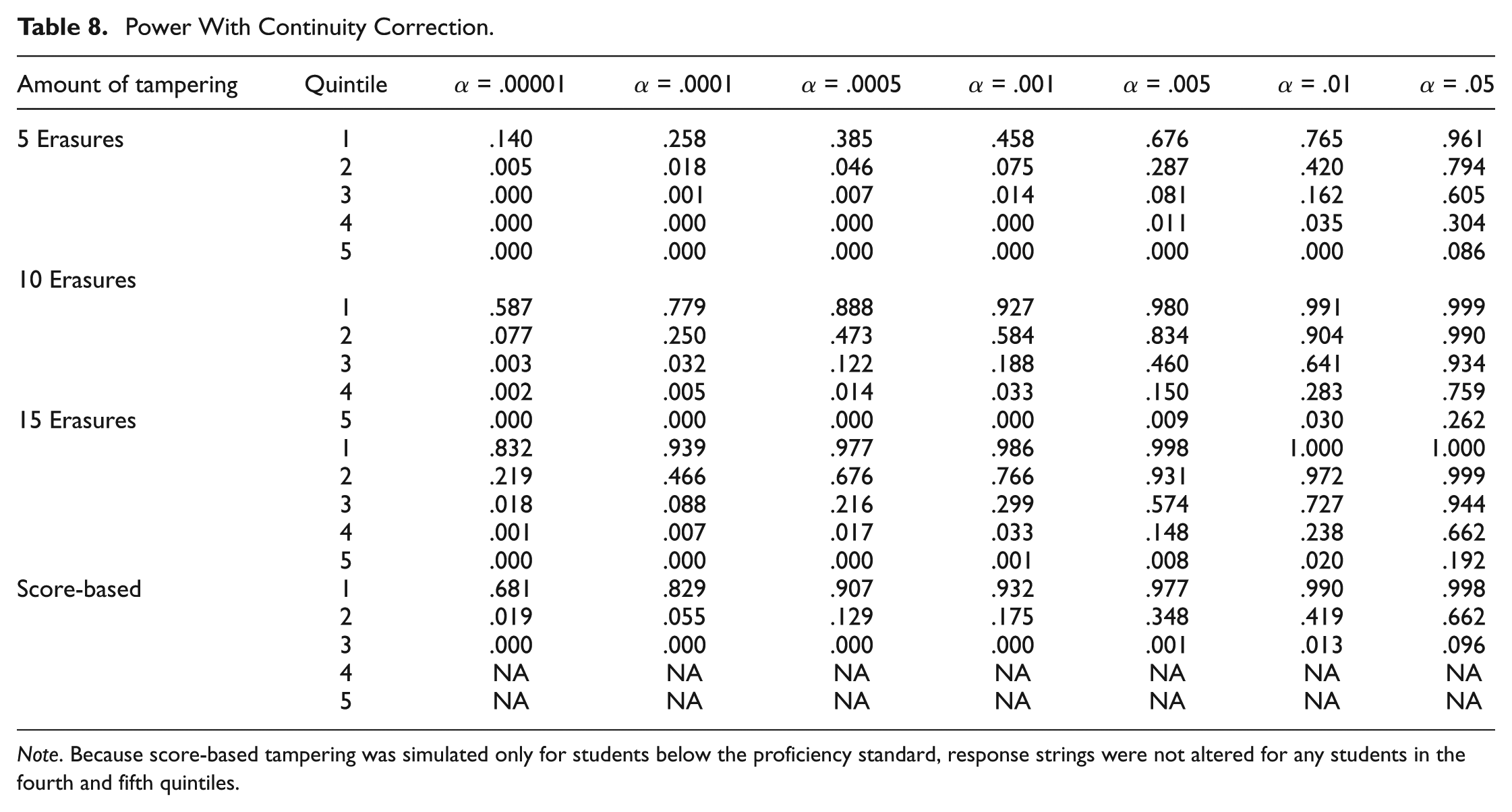
Note. Because score-based tampering was simulated only for students below the proficiency standard, response strings were not altered for any students in the fourth and fifth quintiles.
The score-based condition provides an indication of detection rates in the most egregious of tampering situations in which administrators alter students’ answers just enough to ensure that they will score at the proficient level. The median numbers of erasures were 13 and 5 for students in the first and second quintiles, respectively. Because of where the proficiency cut-score was set, even the weakest of the third quintile simulees were very close to the cut-score. As a result, all third quintile examinees selected were only one raw score point below the cutoff. Because this condition erased enough items to raise scores to one point above the proficiency cutoff, all third quintile students in this condition had only two items erased.
The strong power of EDI can be explained analytically. Computation of EDI involves three components: the number correct score on erased items, the expected number correct score, and the standard error. However, within the test tampering framework, erasures will overwhelmingly be WTR erasures. Given that benign erasures are relatively rare, the number correct score on the erased items,
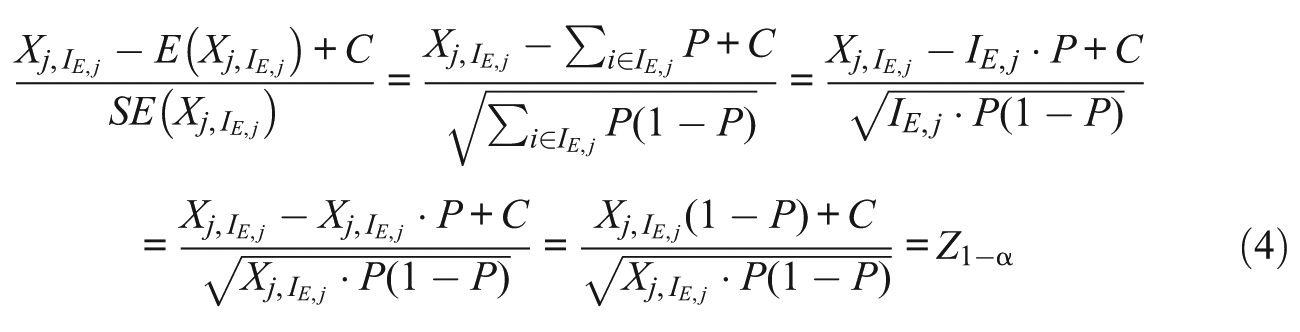
where Z1−α is the value under the normal distribution corresponding to the 100 × (1 −α) percentile.
For fixed values of
Average Probability of Correct Response Below Which Yields Statistical Significance.
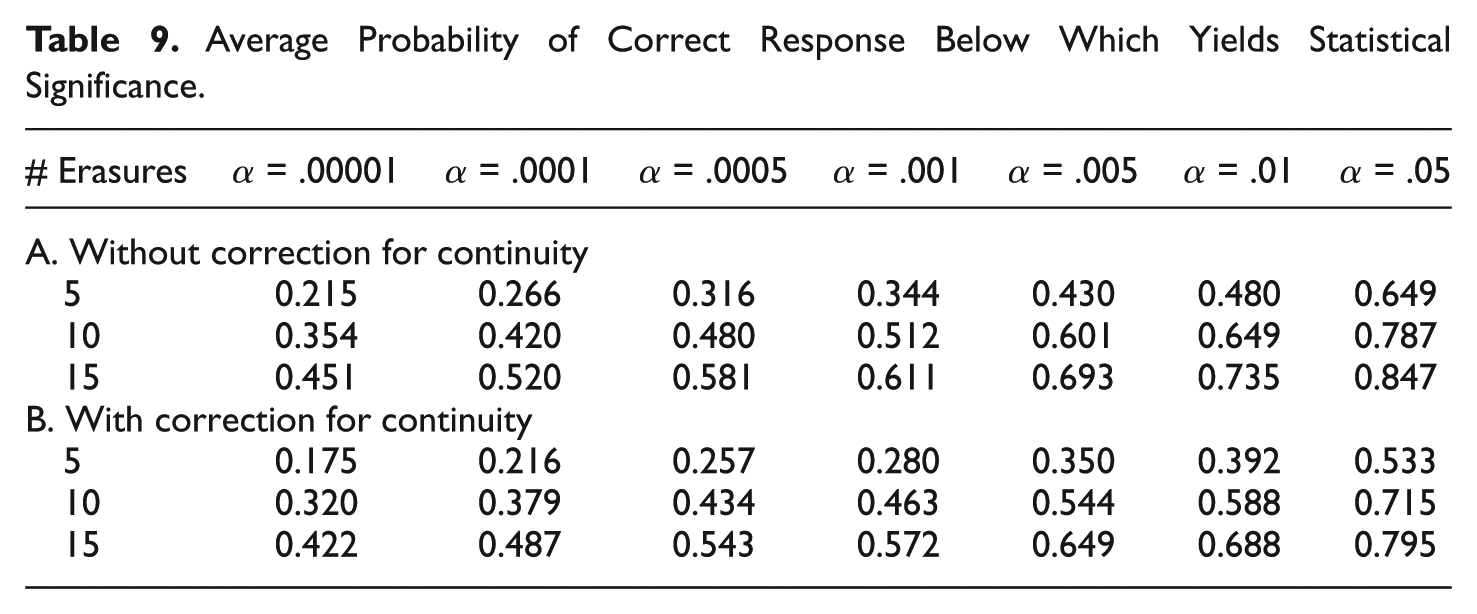
It is worth noting that the assumption of equally difficult items is undoubtedly false. However, of the three components involved in the computation of EDI, varying item difficulties will affect only the standard error. However, for a fixed expected value, the special case in which all items are equally difficult produces the largest standard error, hence the smallest EDI. Therefore, to the extent that the equal difficulty assumption is false, EDI values will be larger, making it even easier to flag students. Therefore, if the average probabilities are equal to the values in Table 9, even if the assumption of equal difficulty is violated, the student is certain to be flagged.
The presence of benign erasures, however, would likely have an impact on the data in Table 9. To the extent that fraudulent erasures are accompanied by some benign erasures that lead to incorrect answers among the erased set, both the expected values and the standard error are likely to increase, making the EDI index less extreme and necessitating items that are harder than reported in Table 9 in order to detect.
Discussion
The EDI index developed here looks to be a very promising tool for detection of test tampering. The results of this study show that the normal approximation approach produced good overall control of the nominal Type I error rate; however, in order to maintain control for the lowest scoring examinees—the ones most likely to be erasure victims—it is necessary to apply a correction for continuity. Even when that correction is applied, the EDI demonstrates strong power to detect test tampering among the lowest achieving students, and respectable power for the second quintile students in the 10- and 15-erasure conditions. In practice, the low power to detect test tampering among high-achieving students is of little consequence, as test tampering is much less likely to occur for high-achieving students. Furthermore, the validity of the test score interpretation is compromised much less with high-ability students than with low-ability students. While ethical reasons suggest that we are still interested in detecting all cheating, even if by high-achieving students, we must recall that in the case of test tampering, it is not the student who is ethically challenged, but the individual who changed the answers. Fortunately, administrators who change answers for high-achieving students likely do similarly for low-achieving students, so other opportunities exist for them to be detected.
One limitation of this study is that, for purposes of demonstrating the efficacy of the model, all analyses were based on item parameters which, by virtue of being parameters, were (a) free from random error and (b) uncontaminated by the effects of tampering. In practice, item parameters will be estimated from the data and to the extent that test tampering existed in the data set, the parameter estimates would be somewhat contaminated. Although this study did not investigate the impact of these sources of error, the effects of both are known. Because the EDI follows the same functional form as the answer copying index, ω (Wollack, 1997), research on the impact of estimating item parameters within the context of data contaminated with varying magnitudes of answer copying generalizes to the present study. Wollack and Cohen (1998) found that replacing item parameters with item parameter estimates partially contaminated by the effects of cheating did not affect the Type I error rates of the ω index. They also found that power was reduced a small amount when sample size was small (e.g., N = 100), but was virtually unchanged for sample sizes of 500. Within the present context of a statewide erasure analysis, sample sizes will always be much larger than 500, so Type I error rate and power are expected to be unaffected. Similarly, the extent of test tampering across an entire state figures to be very small (e.g., a modest proportion of answers for a small proportion of students for a small proportion of teachers within a small proportion of schools). Furthermore, there is no reason to believe that different educators would tamper with the same items (at least across schools). Therefore, the amount of tampering on each question is expected to be minimal. It is not anticipated that realistic amounts of tampering will have any effect on the values of the item parameter estimates.
It is worth noting that the method proposed here is for detection of individuals. However, in practice, testing programs are likely more interested in detecting tampering at the group level than at the individual level. Fortunately, the EDI is easily adapted to a group-level context, and the authors are beginning to study models to aggregate EDI to detect tampering at the class, school, or district level.
Finally, it is likely that EDI would have somewhat better control of the false–positive rate and power if the exact generalized binomial model were used, rather than the normal approximation test used here. van der Linden and Sotaridona (2006) have demonstrated this result with the ω answer copying statistic. However, the normal approximation is computationally much more straightforward, thereby providing an index that is more accessible to school districts that may not have the measurement or programming expertise necessary to derive the compound binomial probabilities. The results of this study suggest that the user-friendly form of the EDI used here has sufficient power and Type I error control that whatever increases in power may be achieved by the exact test are likely offset by the increased complexity which would serve to discourage its use.
As with any data forensic tool, it is important to note that the EDI is a statistical procedure, and false positives will occasionally occur. An accusation of test tampering is very serious, and figures to have negative financial, social, and legal implications on the individuals involved. Therefore, while data forensics should be run routinely to flag potential instances of tampering or other forms of cheating, such statistical procedures should never represent the entirety of the investigation. Whenever suspicious test results are found, it is incumbent on the district/state to conduct a full investigation aimed both at uncovering additional information to support an allegation of misconduct and providing alternative explanations for the anomalous statistical findings. Only after a complete investigation has occurred and alternative explanations have been discounted can one conclude that the findings are indicative of cheating.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.