
Abstract
This article reproduces correspondence between Georg Rasch of The University of Copenhagen and Benjamin Wright of The University of Chicago in the period from January 1966 to July 1967. This correspondence reveals their struggle to operationalize a unidimensional measurement model with sufficient statistics for responses in a set of ordered categories. The article then explains the original approach taken by Rasch, Wright, and Andersen, and then how, from a different tack originating in 1961 and culminating in 1978, three distinct stages of development led to the current relatively simple and elegant form of the model. The article shows that over this period of almost two decades, the demand for sufficiency of a unidimensional parameter of the object of measurement, which enabled the separation of this parameter from the parameter of the instrument, drove the theoretical development of the model.
Keywords
In his article “The Function of Measurement in Modern Physical Science,”Kuhn (1961) argues that, contrary to the common understanding that scientific theories are derived from measurements, measurements are themselves derived from scientific theories. He summarizes this position as follows:
In textbooks the numbers that result from measurements usually appear as the archetypes of the ‘irreducible and stubborn facts’ to which the scientist must, by struggle, make his theories conform. But in scientific practice, as seen through the journal literature, the scientist often seems rather to be struggling with facts, trying to force them to conformity with a theory he does not doubt. Quantitative facts cease to seem simply the ‘given’. They must be fought for and with, and in this fight the theory with which they are to be compared proves the most potent weapon. Often scientists cannot get numbers that compare well with theory until they know what numbers they should be making nature yield (p. 193).
Because it is presented in text books and is programmed in software, we now take for granted the polytomous Rasch model (PRM) for ordered categories, both the rating scale and partial credit parameterizations. Therefore, the suggestion that, in the development of this model, there is an analogy to struggling with facts and having a theory as a potent weapon might come somewhat as a surprise.
Below are excerpts of correspondence between Georg Rasch and Ben Wright sharing their struggles to implement the model in the late 1960s. The correspondence refers to Erling Andersen, then a PhD student with Rasch, and subsequently his successor as Professor of Statistics as applied to the Social Sciences at The University of Copenhagen. The excerpts are from letters that deal with other matters, which are not included here. The letters were typed with a typewriter of course, and to retain the feel for the correspondence, I have retained the few typographical errors. Although Rasch’s first name was “Georg,” in this correspondence he signed “George”; Wright also sometimes addressed him as “George.” Following the excerpts, which give insights into their reasoning, inevitably not readily evident in text books, I summarize the approach taken by Rasch, Wright, and Andersen, and how their work was the basis for the final form of the model.
By 1960, and based on the requirement of invariant comparisons, Rasch had developed a measurement theory (Rasch, 1960, 1961) from which he explained and formulated models for measurement, whether in the physical or social sciences. He summarized this theory, which required the separation of object and instrument parameters, in Rasch (1977). To separate these parameters, any probabilistic model for measurement was required to have sufficient statistics. As shown below, the development of the PRM was a struggle, and in its development the requirement of statistical sufficiency proved the potent weapon—it made explicit the kind of model the measurement theory had to yield.
Georg Rasch and Ben Wright Correspondence
Dear Ben 19th January, 1966 The item analysis for more than two categories does seem to present considerable technical difficulties in spite of Erlings [sic] optimism when he was leaving. If I interpret your remarks on it correctly you are going to try an a priori assumption of one -dimensionality of the parameters. In some cases it may be a way out and in principle it could be generalized as assuming r = 2, etc. I am very anxious to know how it works, not least whether and how you get cheated when actually r = 2, while working on assumption that r = 1. Simulations may be illustrative. Your sincerely, George. Dear George: November 16, 1966 Erlings [sic] just spent two days with us here in Chicago and we did some good work together. Our topic was the case where a number of categories for an answer are more than two. After seeing the general maximum likelihood solution to this problem and realizing the difficulty in computing the more complicated symmetric functions involved, we concentrated on the more typical case, where the researcher expects of the categories to be ordered and is really only in doubt about whether the hypothesis of ordering fits the data and second what the weights opositions [sic] in order are. Solving this problem seems the simpler and we came to a possible solution requiring more less [sic?] computing than the general case. This is where we are at now. Our plan is to get together again in a few months to try to create a computer program for doing the work and to test it out on some data. We hope to complete all this by next summer, and anticipate a third conference with Erling perhaps in July. Sincerely, Benjamin D. Wright. Dear George: January 25, 1967 Our second preoccupation continues to be how to deal with the case of more than two categories. We too decided that it was unrealistic to work on the hypothesis of one dimension underlying the various categories. Erling’s full treatment of the problem is unmanageable even on a giant computer when there are more than five or six items. It is fantastic how the number of calculations and storage space necessary mount, as the number of items goes up to say, twenty, and the number of categories goes up to say, six. A little elementary arithmetic convinced us that we would never be able to solve any problems of that size with the algorithm Erling proposed. As an alternative, we are sampling terms from the symmetric functions involved, and estimating the symmetric functions in this way. In principle, some of those symmetric functions had billions of terms in them, asking us to sample several thousands of terms at random [to] [sic] approximate the symmetric function in this way and make another round in the iteration of the item parameters. Of course we do not know whether this will work, but we like the idea and would benefit very much from your opinion of it. Sincerely, Benjamin D. Wright. Dear Ben, 9th February, 1967 A couple of years ago we considered the possibility of utilizing the analogue to Chapt. X.3 for m > 2. At that time we abandoned the idea as impractical. Recently I have reconsidered it and I think there is a point we missed by [sic] then. Of course the number of cases where category g in items i meets category Yours truly, George Dear Georg: March 14, 1967 The news is better than good. It is marvellous. We are having surprisingly good success with the M > 2 model. The pair-wise algorithm that you reminded us about is marvellously quick and surprisingly efficient. It will certainly serve as a most excellent starting point for any iterations to meet the maximum likelihood criterion. Maybe in some case the pair-wise approach will be as good as maximum likelihood approach unless one is willing to spend quite a bit of computer time improving the estimates. Summing up our current work: We have coded and tested two different programs for estimating the parameters in the We also have a principal component routine for factoring rectangular matrices so that when a matrix of estimated item category parameters is obtained, we can factor it into item and category component (sic) and evaluate its rank. The first fastest and surprisingly accurate algorithm is the pair-wise approach. In this algorithm we cross tabulate the category responses for each of items, take the log of the ratio of symmetric cells, and average these logs over categories and items. The resulting average when normalised so that all margins means are zero, forms a very good estimate of the generating parameters. Our second algorithm uses the maximum likelihood equation for the M > 2 case but instead of computing the symmetric function recursively, we compute them for each score vector sampling of its term rather than compute the whole function. This method is quite a bit slower than the pair-wise method, taking perhaps ten times longer for the same size problem. It depends a lot on how large a sample of the terms we take. Sincerely, Benjamin D Wright Dear Georg: July 6, 1967 Our interest in this has been increased because computing symmetric functions for the multinomial case where M > 2 has turned out to be quite difficult. The recursive methods so far devised accumulate sizeable round off errors so that there is a definite limit on how far the estimation iterations can go. We have a practical working program for getting estimates in the multinomial case, but it produces rather coarse estimates because of this accumulation of round off error.
This correspondence was given to the author here by Ben Wright some time in 1977, and there is no more on the model in this correspondence. There is a letter dated July 17, 1967 with no reference to the model. Wright did write a paper with Dorothy Vogt (Vogt and Wright, n.d.) which must have been written in the late 1960s, showing estimation equations along the lines captured in the above excerpts. It had no example. It seems the paper was never published and in my studies as a student with Wright (October 1971 to September 1973), the polytomous model did not come up.
The Approach Taken by Georg Rasch, Ben Wright, and Erling Andersen
In the summary below, the notation that is now more familiar than that used by Rasch is shown. The response vector for a dichotomous response is simply

where
The generalization that Rasch first made in the case of more than two ordered categories was to specify the response vector of
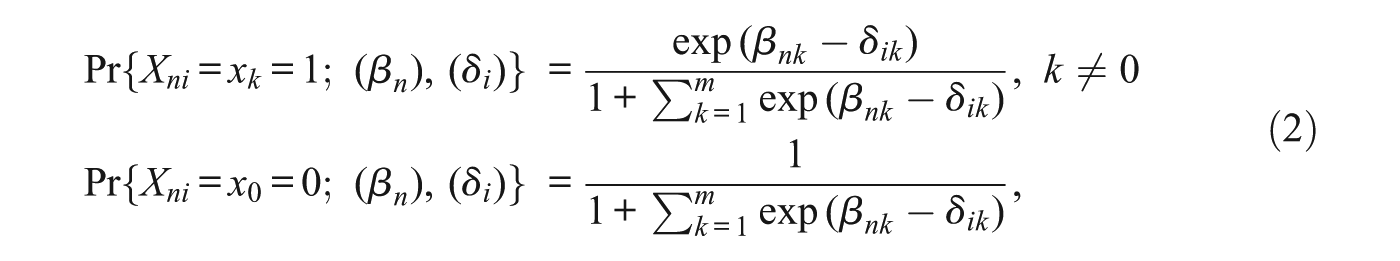
where
Vector Sufficiency and the Polytomous Rasch Model
Taking complete data in the sense that every person responded to every item
In his work with polytomous items, Rasch took the categories to be the same in each item, there being
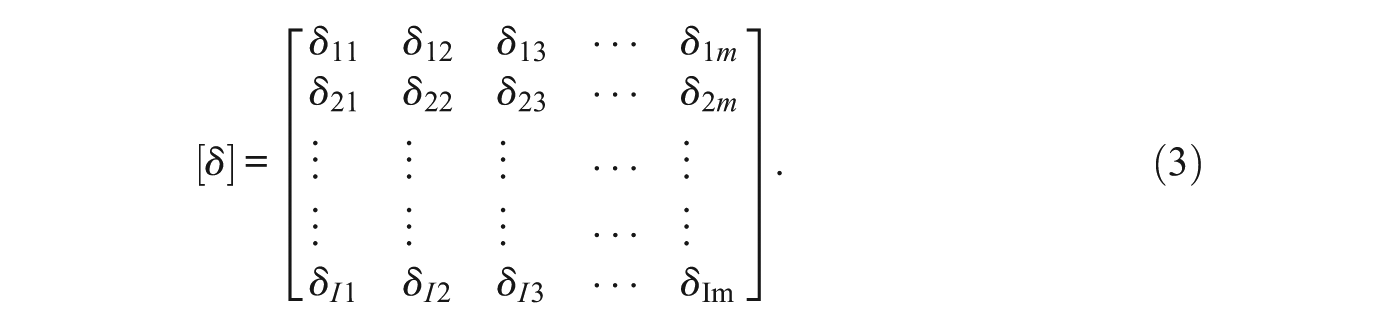
Rasch and Wright, with Andersen, worked on estimating this matrix, and their correspondence focuses on the various issues that arise from that. As is evident from their correspondence, there are many complications in this approach and the most successful algorithm involved pairwise conditioning, taking two items at a time.
Having estimated the matrix of item parameters, and on the assumption that the categories in some sense are of increasing intensity on a single dimension or variable, and that the item parameters are on this dimension, Rasch proposed that this multiparameter matrix be decomposed into the unidimensional form

where
Although the approach of estimating the matrix of item parameters was challenging, Andersen (1972), whose theoretical work in advancing Rasch’s measurement theory is sometimes underestimated, provided and operationalized a set of equations that essentially provided a solution to this problem. However, because the solution was not easy to implement and the results not always easy to understand, it would not have become a standard, practical approach. Andersen himself then took a different tack based on Rasch’s (1961) earlier formulation. His was one of three sequential but distinct stages, each involving struggles to make the model conform to the potent weapon of sufficiency.
Stage 1: A Unidimensional Expression of the Polytomous Rasch Model
Although it was not followed up initially, Rasch (1961) had specialized the multidimensional model of Equation (2) algebraically to a unidimensional form. Thus, rather than maintaining a vector of parameters for each item to the point of estimation, and then reducing the whole matrix of item parameter estimates to a unidimensional form, the vector of parameters for each item was reduced to a unidimensional form algebraically with separate category parameters, and then its consequences studied.
From a sequence of derivations requiring invariance of comparisons of parameters through sufficient statistics, Rasch successively simplified the model of Equation (2) to the form

where
Stage 2: Scalar Sufficiency and the Polytomous Rasch Model
Abandoning the simultaneous estimation of a matrix of item parameters, Andersen (1977) focused on the further consequences of sufficiency for the scalar parameter

He further showed that only if
Clearly, this condition for combining categories was not obvious in advance. Indeed, Jansen and Roskam (1986) considered this property so counterintuitive that it rendered the model unsuitable for the analysis of ordered categorical data! Nevertheless, driven by the requirement of sufficiency, it was an insightful derivation by Andersen, one which proved critical. Although he derived the constraint of Equation (6) for the scoring function
Stage 3: A Response Process That Is Characterized by the Polytomous Rasch Model
That third stage, beginning independently of Equation (2) but with a focus on it and Equation (5), was to hypothesize a latent dichotomous response process at each of the
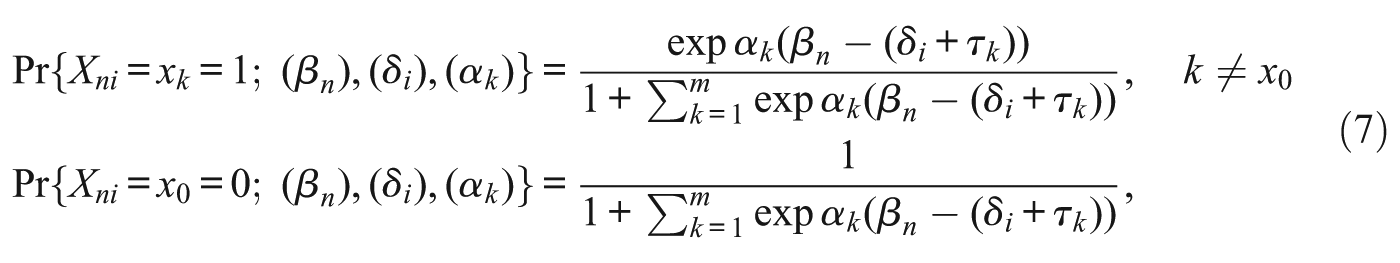
Then to account for the ordering of the categories, the
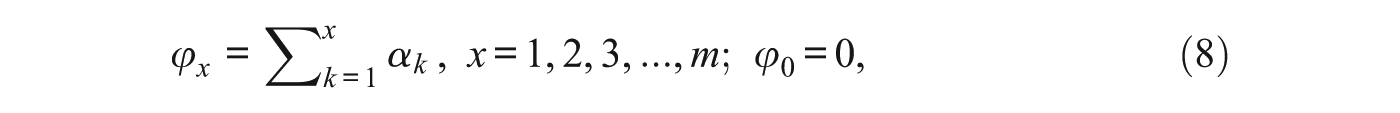
where

Equation (9) clearly met Andersen’s condition in Equation (6)—the thresholds needed to have equal discrimination, in the same way that dichotomous items must have equal discrimination, to provide scalar sufficiency. Equation (8), which can be expressed in the recursive form
In addition, after specifying

which gives the simplified form of Equation (5) with
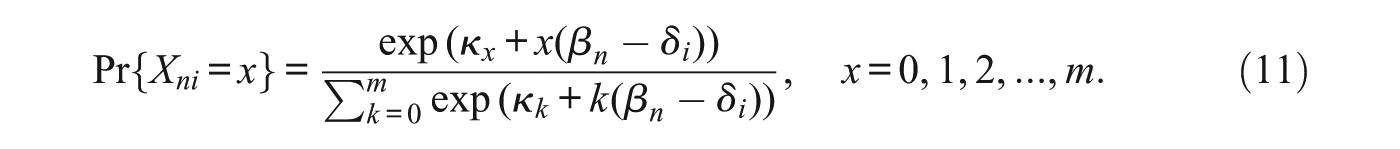
Because many rating scales have the same categories across items, this is referred to as a rating scale parameterization. If the thresholds are allowed to vary in number and value among items, then the model takes the form equivalent to

where
Thus rather than being estimated, the scoring function
Finally, the category coefficients
Reflections on the Role of Rasch’s Measurement Theory and the Demand for Sufficiency
It is difficult to imagine that the recursive relationships in Equations (8) and (10), which involve the familiar concepts of thresholds (points of equal probability between two adjacent categories), and discrimination at these thresholds, could have been identified simply by deducing algebraically the consequences of sufficiency from Equation (2) or even Equation (5). Thus, it is not surprising to read about the struggles Georg Rasch and Ben Wright, with the help of Erling Andersen, had with their initial approach to the model. However, their work in operationalizing a model for ordered categories which revealed complications, and the theoretical work which tried to get around these complications, was necessary to set up the equations that had to be satisfied for sufficiency to hold. Then when the category coefficients and scoring function were identified with the model of Equation (5), and the latter explained the conditions formulated by Andersen, it meant the model of Equation (11), where
It is relevant to note that the articles Rasch (1961), Andersen (1977), and Andrich (1978), were entirely theoretical, had no examples meaning that the model was not derived to account for any data set, and focused on the response of one person to one polytomous item. It is also salutary to note, in this day of outcomes, publication demands of academics, and so on, that the publications described above spanned some 18 years. Thus, work over more than 18 years initially gave rise to just these three, theoretical, publications. The publications and applications they have generated since have been in the thousands.
From 1978 (a decade after the last piece of correspondence between Ben Wright and Georg Rasch on the model), Ben Wright again became interested in this model in the form of Equations (11) and (12), and introduced it to his many students. On seeing an application of the simple form of the model in the contingency table context (Andrich, 1979) in the journal Biometrics, of which Rasch was a founding member, Rasch seemed beguiled and showed great interest. Unfortunately, Rasch died in 1980 and could neither fully appreciate how his measurement theory led to the final, elegant form of the model, nor witness its many applications.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.