
Abstract
Multidimensional item response theory (MIRT) models use data from individual item responses to estimate multiple latent traits of interest, making them useful in educational and psychological measurement, among other areas. When MIRT models are applied in practice, it is not uncommon to see that some items are designed to measure all latent traits while other items may only measure one or two traits. In order to facilitate a clear expression of which items measure which traits and formulate such relationships as a math function in MIRT models, we applied the concept of the Q-matrix commonly used in diagnostic classification models to MIRT models. In this study, we introduced how to incorporate a Q-matrix into an existing MIRT model, and demonstrated benefits of the proposed hybrid model through two simulation studies and an applied study. In addition, we showed the relative ease in modeling educational and psychological data through a Bayesian approach via the NUTS algorithm.
Keywords
Introduction
In social science research, assessments are developed to measure individuals’ latent traits. To analyze responses from assessment data, item response theory (IRT) models have evolved as a mainstream class of psychometric models since the 1970s (Lord & Novick, 1968).
Many current assessments developed under the IRT framework are unidimensional because multidimensional assessments require longer test lengths and larger examinee sample sizes. For example, an assessment can be designed to measure students’ math ability in education or self-esteem in the area of psychology as a unidimensional trait. Although unidimensional IRT models are commonly used, the assumption of trait unidimensionality is often difficult to meet in practice (e.g., Ackerman, 1994, 1996; Reckase, 1985). For example, correctly answering math items may also require reading skills to understand the item stems, and items measuring self-esteem may produce data that are confounded with relevant traits such as achievement or happiness. Ultimately, dimensionality is never a “black or white” question as no test data can be truly unidimensional (Liu, Huggins-Manley, & Bulut, 2018; Thissen, 2016).
When unidimensionality is violated or when a test is specifically designed to measure more than one trait, multidimensional IRT (MIRT) models can be used to model the complex interactions between an individual’s multiple abilities and items representing multiple constructs (Reckase, 2009). MIRT models are promising in education because teachers and students are often interested in obtaining scores on subscales, and they are also useful in psychology because personality assessments are often intended to measure more than one correlated trait.
Despite the advantages of MIRT models, their uses in practice are somewhat limited because the number of parameters in MIRT models is much larger than unidimensional IRT models (e.g., Drasgow & Parsons, 1983). As a result, MIRT models require long test lengths and large sample sizes for a reliable estimate of parameters and latent traits on multiple continua (e.g., Haberman & Sinharay, 2010; Maydeu-Olivares, 2001; Templin & Bradshaw, 2013).
More recently, a newer class of multidimensional models called diagnostic classification models (DCM; e.g., Rupp, Templin, & Henson, 2010) has become popular in psychometrics. Instead of locating examinees on multiple continua, DCMs classify examinees into groups based on their possession/nonpossession of certain traits. DCMs can achieve higher reliability than MIRT models for a given test length, all else being equal, mainly because of three unique features. First, the latent traits in DCMs are categorical so that the estimates of those traits have a smaller range, resulting in higher reliability (e.g., Templin & Bradshaw, 2013). Second, DCM reliability is commonly defined at the categorical level (Templin & Bradshaw, 2013), which results in higher coefficients as compared to those for continuous scores. We should note that categorical latent traits are less commonly seen than continuous latent traits in psychometrics. As discussed in Liu, Qian, Luo, and Woo (2017), the definition of reliability varies across IRT and DCM scoring approaches, but the overall concept of partitioning the total variance into true and error holds across different definitions. In DCMs, the use of categorical variables (e.g., 0 and 1) minimizes error, thus leading to higher reliability. Third, DCMs incorporate a prespecified relationship between items and latent traits (i.e., which items measure which traits). As a result, if an item is not designed to measure a particular trait, the associated parameters are not freely estimated. This relationship can be captured in an item by trait incidence matrix commonly known as a Q-matrix (Tatsuoka, 1983).
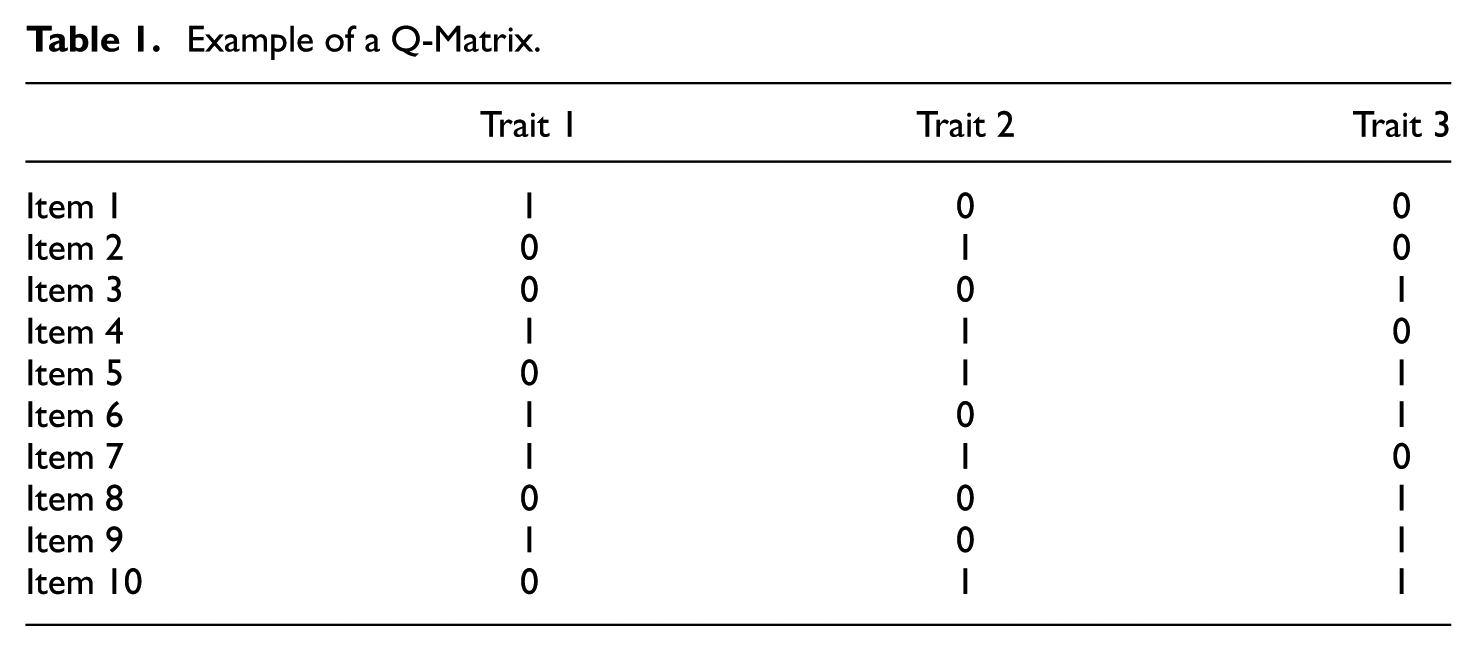
A Q-matrix is represented by a binary matrix that defines the relationship between items and latent traits (or skills in the cognitive context).
Table 1 is an example Q-matrix for dichotomous traits, although polytomous traits are also possible. In a dichotomous Q-matrix, an entry equals 1 if an item measures the trait and 0 otherwise. For example, Items 1 and 2 in Table 1 measure Traits 1 and 2, respectively. Using the Q-matrix in DCMs not only limits the number of parameters that need to be estimated and thus allows for smaller sample sizes and shorter test lengths, but also accurately reflects the item and test design considerations. Although the Q-matrix has such advantages, its use has largely been limited to research and application in DCMs.
Example of a Q-Matrix.
The purpose of this study is to formulate the item–trait relationship in current MIRT models, incorporating information from experts or previous knowledge through a Q-matrix. Thus, a new formulation of MIRT models is defined in order to alleviate parameter estimation and provide a new interpretation of MIRT modeling.
We want to stress that researchers and practitioners have previously restricted the item–trait relationship when implementing MIRT models, and we are not in any way proposing new models. Instead, the study aims to explore the utility of the Q-matrix in MIRT models and propose a way to clearly express the item–trait relationship as a function in MIRT models. In this way, we add flexibility to the existing MIRT models and practitioners can tailor their models to a specific test through the Q-matrix specification.
To present and evaluate the idea of incorporating Q-matrices in MIRT models, we first formulate the multidimensional two-parameter logistic model with a Q-matrix (M2PL-Q model). Then, we report the results of two simulation studies. The first simulation study examined the parameter recovery of the M2PL-Q, and the second simulation study examined some impacts of using the correct Q-matrix as compared to using an item–trait fully crossed model and a bifactor model. Next, we report on an applied study that examined the performance of the M2PL-Q with real data. A discussion and conclusion are provided at the end.
The M2PL-Q Model
We consider a test designed to evaluate
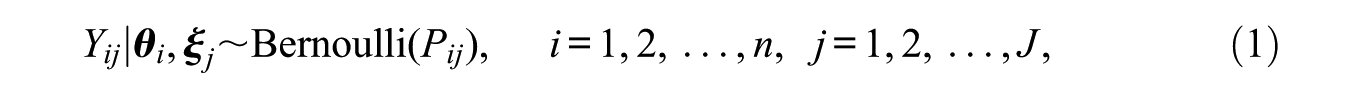
where
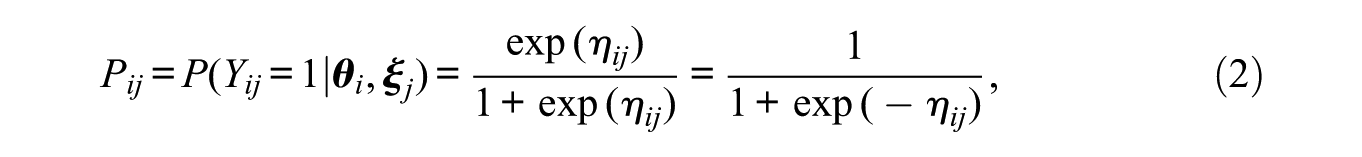
where
In order to present the multidimensional two-parameter logistic model with a Q-matrix (M2PL-Q model), we define the new latent linear predictor
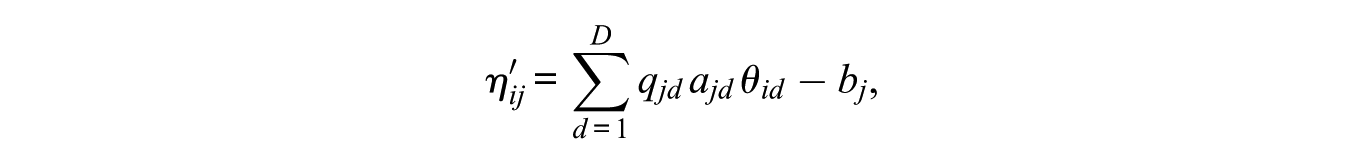
where
The probability of individual
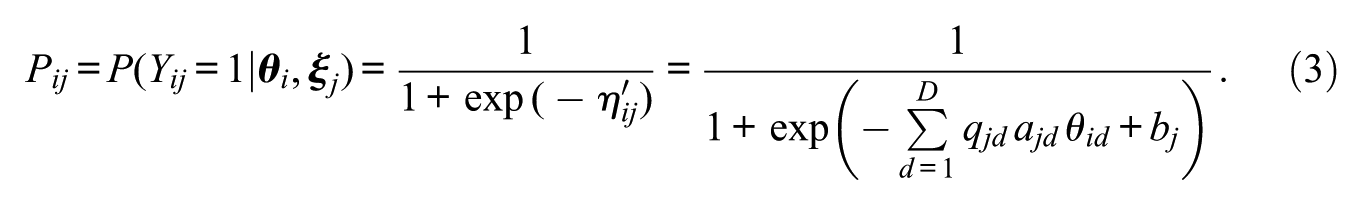
Note that the M2PL-Q model is a generalization of other models. When we use the matrix full-Q, which is composed only of elements equal to 1, we obtain the M2PL model (described in Equation 2), which we call the M2PL-Q full model. In the same way, the bifactor 2PL model (Gibbons & Hedeker, 1992), which is characterized by considering a global latent trait and at least two other specific traits, can also be obtained from the M2PL-Q model. For this, it is enough to define a convenient Q-matrix, such that the first column, which corresponds to the global latent trait, is formed only by elements equal to 1, in order to allow all items to evaluate it; and the other columns, corresponding to the specific latent traits, are defined containing only one element equal to 1 per line, so that each item evaluates one, and only one, specific latent trait. We call a Q-matrix under these conditions a bifac-Q and the M2PL-Q model with the bifac-Q matrix is referred to as M2PL-Q bifac. In addition, when considering other particular cases where the Q-matrix is customized by experts (matrix custom-Q), we refer to a M2PL-Q custom model.
We present an example of the full-Q, bifac-Q, and custom-Q matrices for
To obtain similar interpretations of the parameters from a one-dimensional IRT model, Reckase (2009) and Fragoso and Cúri (2013) suggest calculating the multidimensional parameters of each item. For the M2PL-Q, the discriminating power of the jth item is given by
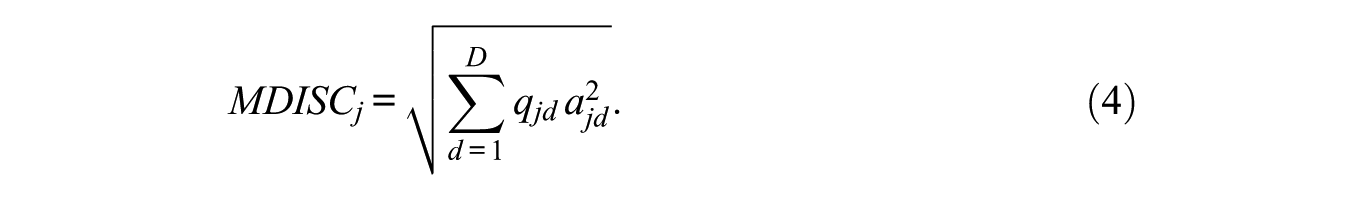
This measure encompasses only the discrimination parameters associated with the dimensions that each item measures and provides for each item an omnibus discrimination for all latent traits evaluated. Also, the multidimensional difficulty of the M2PL-Q, denoted by

Bayesian Estimation
In this article, we propose using Bayesian estimation with Markov chain Monte Carlo (MCMC) algorithms to estimate the parameters of the M2PL-Q model. We define its likelihood and the prior distributions of its parameters. We also describe the No-U-Turn Sampler (NUTS) method, some model comparison criteria, and the posterior predictive distribution.
Likelihood
Let

where
Prior and Posterior Distributions
The specification of the prior distributions for the parameters of the model is an important procedure in the Bayesian analysis, since the posterior distributions of the parameters are influenced by both the sample and the prior distribution. This influence is due to the fact that the posterior distributions are defined as being proportional to the product of the likelihood described in Equation 6 and the prior distributions of the model parameters.
For the specification of prior joint distributions of the parameters of the M2PL-Q model, it is assumed that there is an independent prior structure, such that
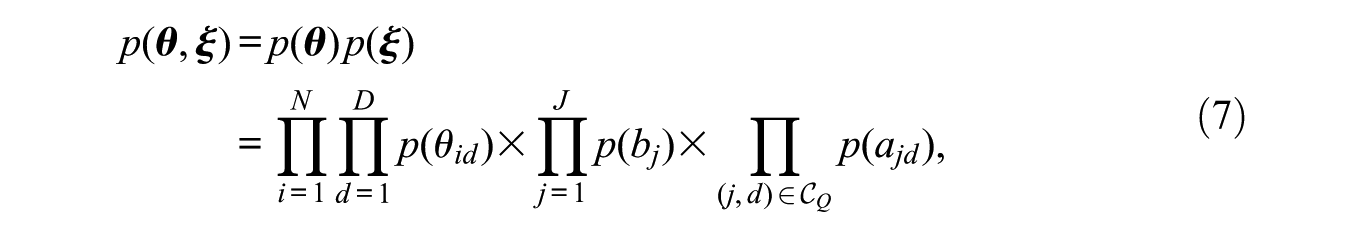
where
Based on Curtis (2010), Bazán, Branco, and Bolfarine (2006), and Béguin and Glas (2001), we define the prior distributions for the parameters
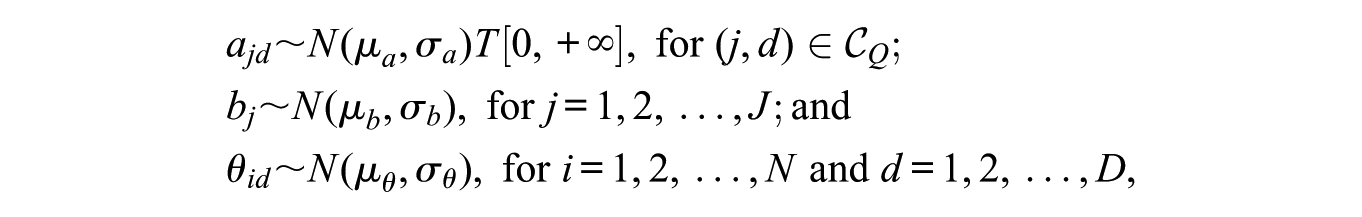
where
According to Béguin and Glas (2001), Fragoso and Cúri (2013), and Reckase (2009), to guarantee the identity of the M2PL model it is sufficient to set
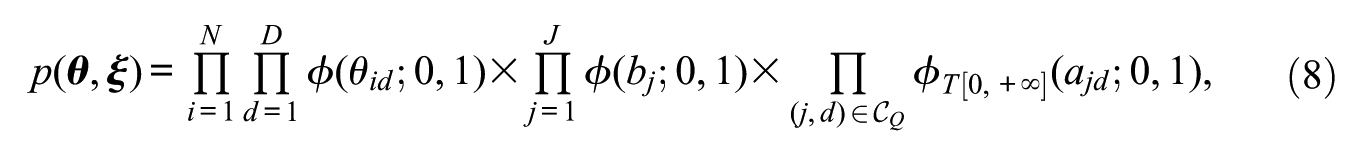
where
The posterior distribution of the parameters of the M2PL-Q model, denoted by
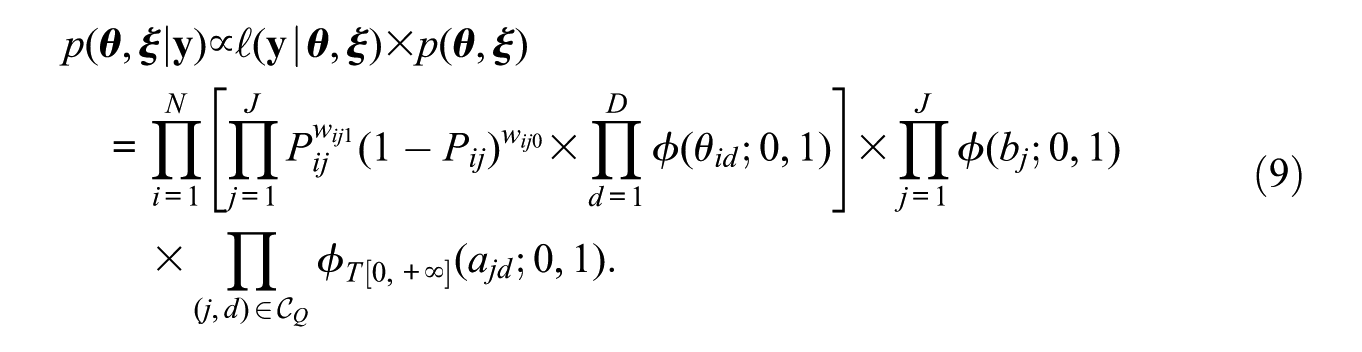
Since the posterior distribution given by Equation 9 has an intractable form, we use MCMC algorithms to obtain samples from it. Specifically, we chose to use an MCMC method called the No-U-Turn Sampler via Stan software (Carpenter et al., 2017), briefly described below.
NUTS Algorithm and Stan Software
The NUTS algorithm is an MCMC method developed by Hoffman and Gelman (2014) from the Hamiltonian Monte Carlo method (HMC) in order to construct a Markov chain more efficiently than other widely known MCMC methods used in Bayesian inference, such as Metropolis Hastings (Hastings 1970; Metropolis, Rosenbluth, Rosenbluth, Teller, & Teller, 1953) and Gibbs sampling (Gelfand & Smith, 1990; Geman & Geman, 1984). These methods use a probability distribution to construct a Markov chain and require a very large number of iterations. In contrast to Metropolis-Hastings and Gibbs sampling, HMC and consequently NUTS use Hamiltonian dynamics instead of a probability distribution to construct a Markov chain, making the simulation converge more quickly to the target distribution with low autocorrelation. The explanation of the NUTS algorithm can be found in Hoffman and Gelman (2014) and da Silva, de Oliveira, von Davier, and Bazán (2018).
In this article, we use NUTS via Stan software, a free and easy-to-use software, because it allows the user to write the statistical model similarly to BUGS software (Lunn, Thomas, Best, & Spiegelhalter, 2000) and JAGS software (Plummer, 2003), and it reproduces the C++ language model, compiles the code, executes the code, and produces an MCMC sample. We use Stan in the R software, through the RStan package (Stan Development Team, 2017).
Simulation Studies
In this section, we conducted two simulation studies using the M2PL-Q full, M2PL-Q bifac and M2PL-Q custom models. In the first study, we evaluated the parameter recovery of these three models using the NUTS algorithm in order to check the accuracy of the estimates of the parameters for the three Q-matrices considered. In the second study, we simulated a dataset using the M2PL-Q custom model, fitted the three models to this dataset and compared the estimates to the true values of the parameters, aiming to investigate the impact of the misspecified Q-matrix on the parameter estimates.
In both studies, we designed the Q-matrices to mirror a particular case taken from the data used in the application of this work and presented in the appendix. Specifically, the custom-Q was built for a 28-item English language test measuring three latent traits. Descriptions of this Q-matrix can be found in Buck and Tatsuoka (1998), Henson and Templin (2007), and Templin and Hoffman (2013). Similarly, for the full-Q and bifac-Q, we also fixed the number of items to
Recovery of the Parameters
The values of discrimination and difficulty parameters were generated from a uniform distribution such that
Based on Azevedo et al. (2011), we considered the sample size N as 500 and 1,000. Then, we simulated 10 replicate matrices of responses for each Q-matrix and we fit these replicas using 10,000 iterations in the NUTS algorithm, the first half being burn-in. This number is sufficient for the chains to converge using the NUTS algorithm. This was checked using the Gelman and Rubin diagnostic (Gelman & Rubin, 1992).
We considered some appropriate statistics to evaluate the parameter recovery of the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models. The square root of the mean square error (RMSE) is the first statistic, given by
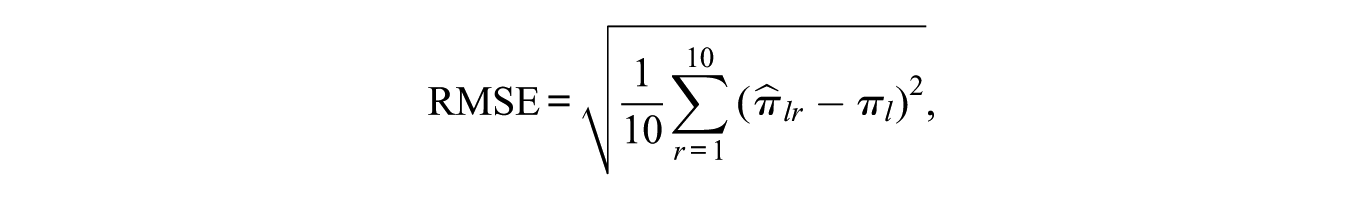
where

where
Table 2 shows the RMSE values for the items’ parameter estimates for the two scenarios constructed from the different sample sizes considered in each model. We also present in Table 2 the average correlations between
Average RMSE Values and Average Correlations for the Parameters of the Items and the Average Execution Time, in Seconds.
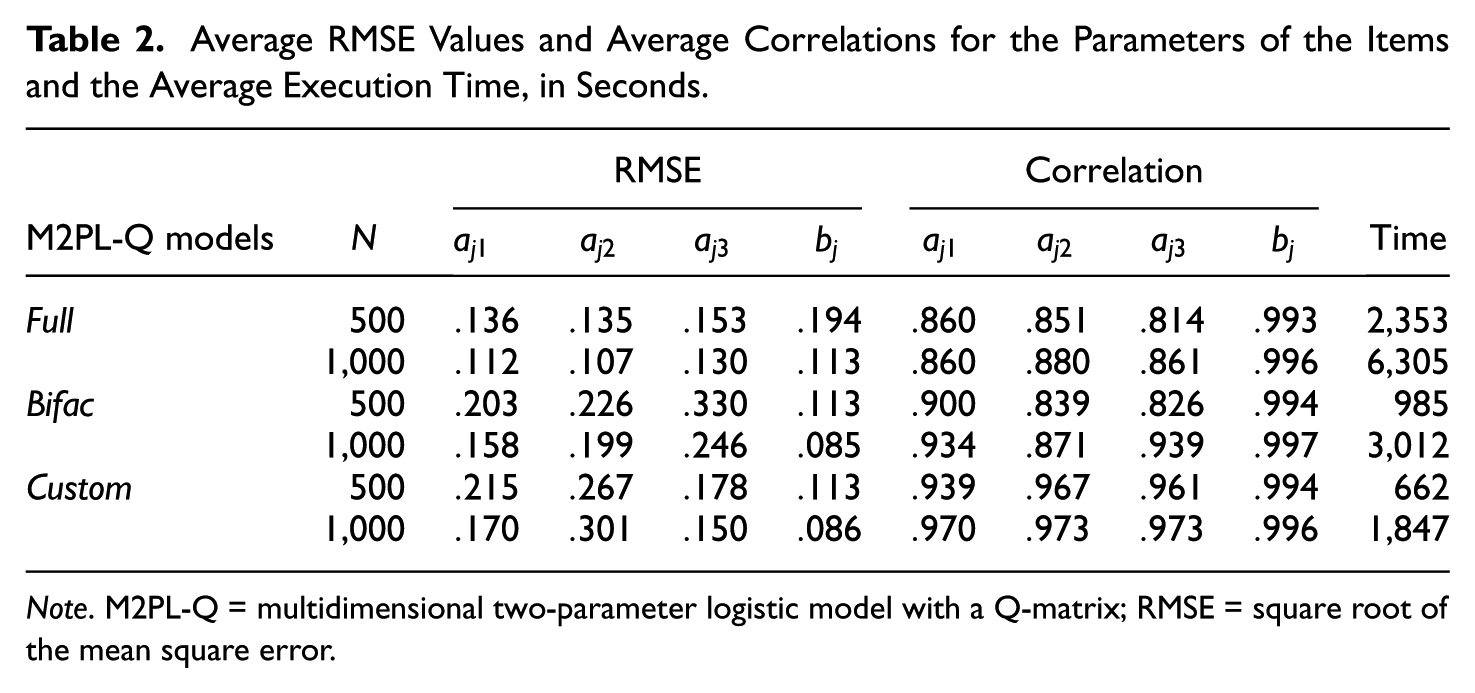
Note. M2PL-Q = multidimensional two-parameter logistic model with a Q-matrix; RMSE = square root of the mean square error.
We can visualize that by increasing the N value from 500 to 1,000, the RMSE values for the parameters decreased in almost all cases, except for the parameter
The AVRB values are presented in boxplot format in Figure 1. The first graph refers to the M2PL-Q full model, the second refers to the M2PL-Q bifac model, and the third refers to M2PL-Q custom model. In each graph, there are four boxplots referring to the items’ parameter estimates for the two sample sizes considered.
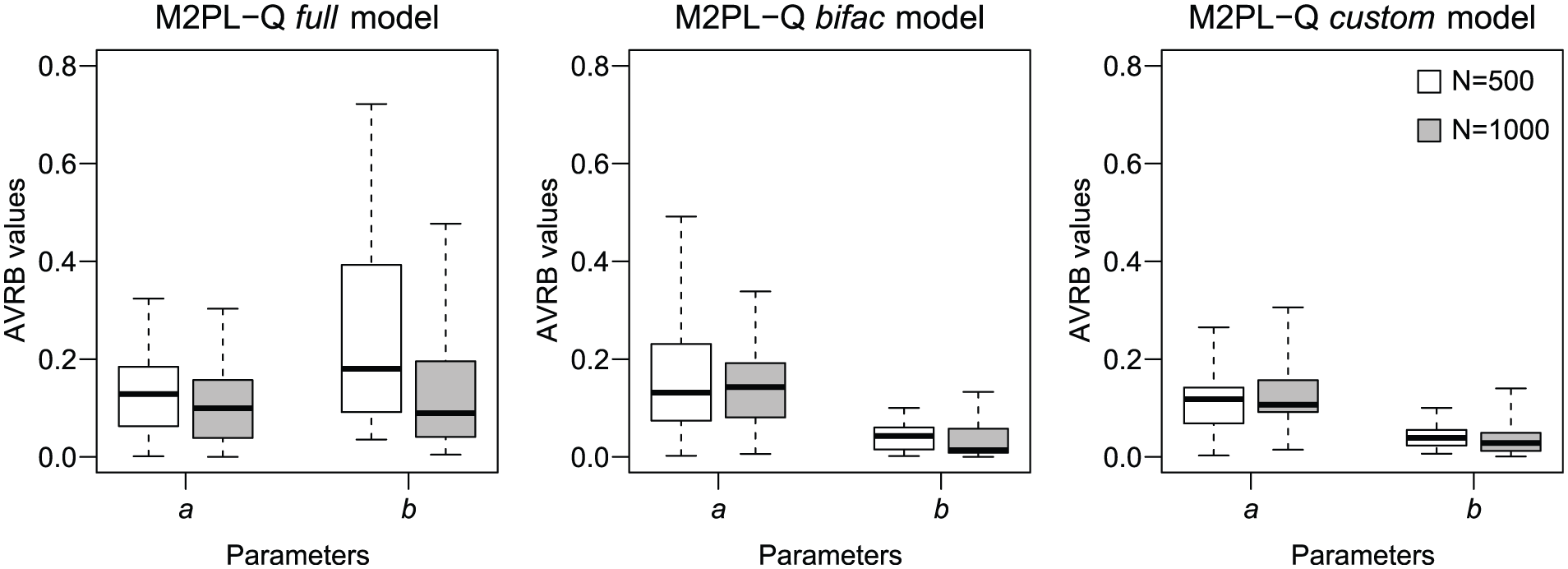
The AVRB values of the discrimination, difficulty, and individual parameters for the three models considered in this simulation study.
In the three models considered, the AVRB values are considered small. In general, the increase in the number of individuals does not appear to have influenced the AVRB values considerably.
Parameter Estimates of M2PL-Q Model for Misspecified Q-Matrices The M2PL-Q Model
In this study, we compared the estimated and true values of the discrimination, difficulty, and individuals’ parameters for the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models. We used the same parameter values generated in the previous study to simulate a response matrix from the M2PL-Q custom model, to which the three models were fit. These three models were defined using the full-Q, bifac-Q, and custom-Q matrices, as specified in Section. Each of these matrices has a concept behind it, considering test characteristics and latent traits of interest. Primarily, this is taken into consideration by content experts.
Discrimination Parameters
The four graphs presented in Figure 2 refer to the estimates of the discrimination parameters of the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models. In addition, the true values of the discrimination parameters used in the simulation of the response matrix from the the M2PL-Q custom model are presented. The first three graphs show the discrimination values associated with Dimensions 1, 2, and 3 corresponding to the M2PL-Q custom model, while the fourth graph shows the values of multidimensional discrimination.

The first three graphs present the true values for each dimension of the discrimination parameters and the estimates of these parameters found from the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models. The last graph presents the multidimensional discrimination calculated from Equation 4 for the true values and for the estimates of the parameters considering the three models.
In general, the estimates of the dimension-specific discrimination parameters of the M2PL-Q custom model were closer to their true values in than were the estimates of those discrimination parameters of the M2PL-Q full and M2PL-Q bifac models, as expected. Considering the fourth graph, the estimates of the multidimensional discriminations were notably closer to their true values than the estimates of dimension-specific discriminations, and estimates of the M2PL-Q custom model were slightly closer to their true values than the estimates of the other two models.
Difficulty Parameters
The four graphs presented in Figure 3 compare the estimates of the difficulty parameters of the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models to their true values. The first three graphs present the true values of the difficulty parameters against their estimates from each of the three models, while the fourth graph presents via boxplots the absolute value distributions of the differences between estimates and true values in each model.
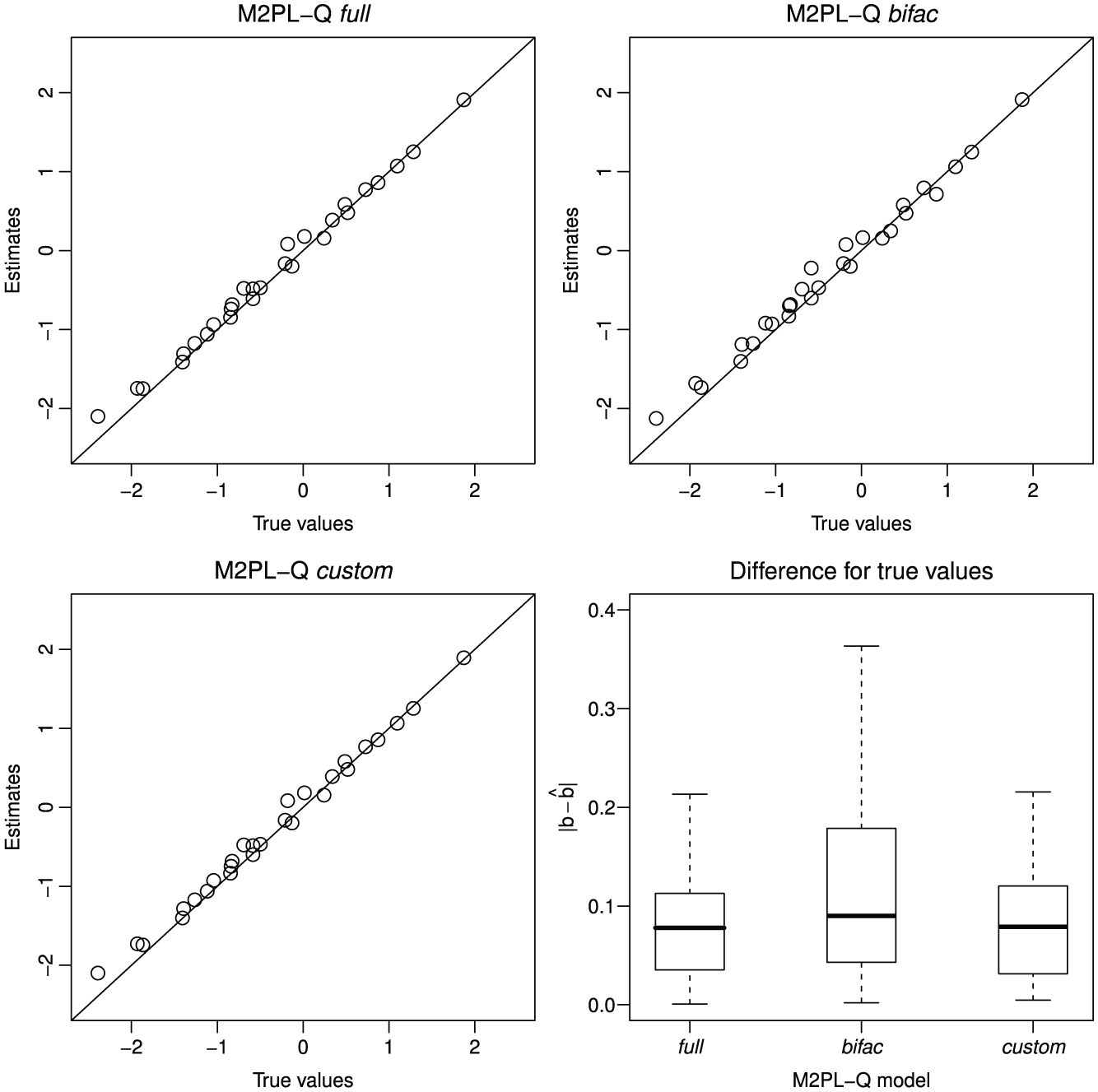
The first three graphs present a comparison between the true values of the difficulty parameters and the estimates of these parameters found from the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models. The last graph presents one boxplot for each model with the differences between true values and estimates of the difficulty parameters.
All difficulty parameters were appropriately estimated using the three models. Although the graphs show that the M2PL-Q bifac model was the worst case, we can still consider those estimates as acceptable.
Individuals’ Parameters
We present in Figure 4 three graphs to compare the estimates of the latent traits to their true values. Each graph refers to a dimension of the individuals’ parameters and contains three boxplots representing the distribution of the absolute values of the difference between estimates and true values.
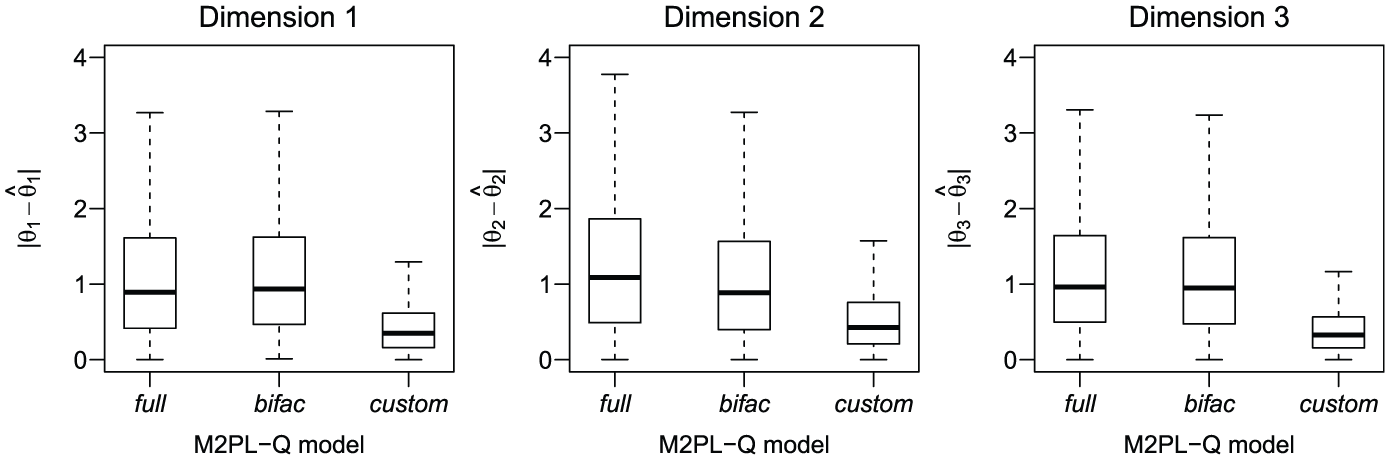
The three graphs present one boxplot for each model with the differences between true values and estimates of the individuals’ parameters.
Considering the three dimensions, the distributions of the absolute values of the differences between estimates and their true values are similar for the M2PL-Q full and M2PL-Q bifac models. However, the absolute values of the differences between estimates and their true values from the M2PL-Q custom model are smaller in the three dimensions, indicating as expected that the M2PL-Q custom model is the most appropriate for the data. To make this clear, we estimated a 95% highest posterior density (HPD) interval for each latent trait from each model and checked how many contained the true value of the corresponding parameter. Table 3 contains the percentage of true values of the individuals’ parameters that were contained in these intervals for each dimension and model.
Percentage of the True Values of the Individuals’ Parameters That Were Within the Estimated 95% HPD Interval in Each Dimension and Model Considered.
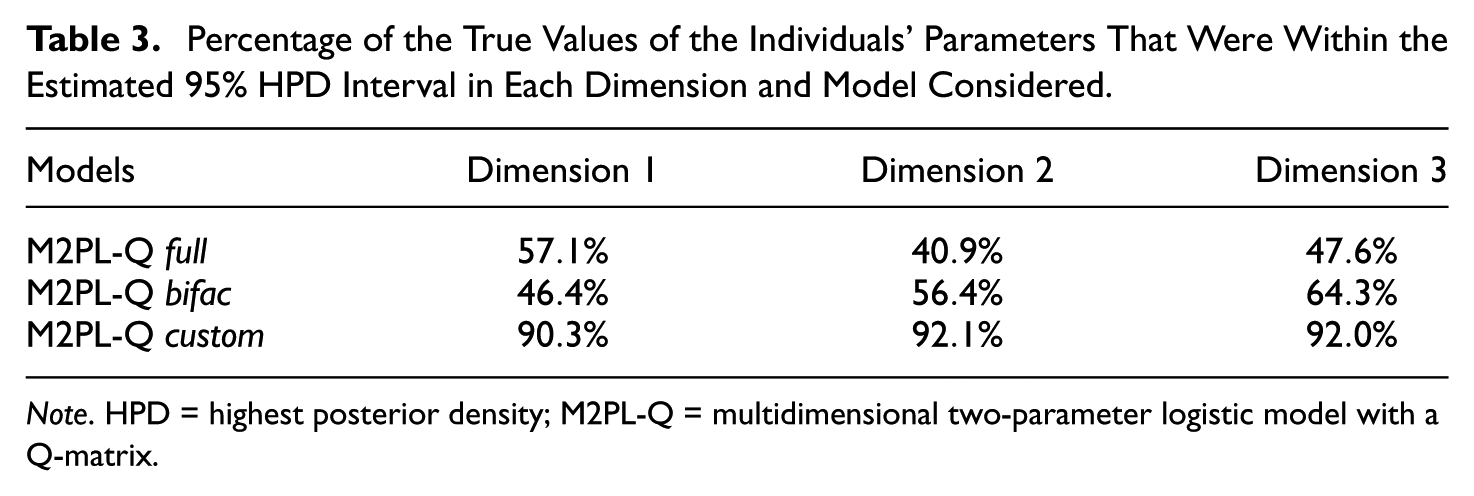
Note. HPD = highest posterior density; M2PL-Q = multidimensional two-parameter logistic model with a Q-matrix.
Considering the individuals’ parameters on Dimension 1, the HPD intervals constructed from the M2PL-Q full model contain 57.1% of their true values. Considering this interpretation for the other percentages presented in Table 3, these values indicate that, among the three models compared, only the M2PL-Q custom model is adequate to estimate latent traits from the simulated data. Again, this result demonstrates expected findings.
Application
In this section, we conducted an application with real data of English proficiency measures in order to illustrate the use of the M2PL-Q model in practical problems.
Description of the Data
We used a dataset with 2,922 individuals who answered 28 items on the Examination for the Certificate of Proficiency in English (ECPE). Written permission to use this dataset was obtained from the Cambridge Michigan Language Assessments (CaMLA). The ECPE is designed to measure the English language skills for nonnative English speakers. The 28 items on the ECPE were designed to measure three skills: “knowledge of (1) morphosyntactic rules, (2) cohesive rules, and (3) lexical rules” (see Templin & Hoffman 2013).
We fit the data to the M2PL-Q model with three different Q-matrices: (1) the oneD-Q matrix, defined as the unit vector
Setting the Fit of the M2PL-Q Model
The 2PL, M2PL-Q custom, and M2PL-Q custom-global models were fit to the data using the NUTS algorithm via Stan software. We used 10,000 iterations, the first half being burn-in and therefore discarded. The convergence of the posterior distributions of the parameters in both models was checked from the Gelman and Rubin Convergence Diagnostic (Gelman & Rubin, 1992).
Main Results
In order to verify which model was most appropriate to the Proficiency in English data, we present in Table 4 the values of three model comparison criteria considered in this study: deviance information criterion (DIC; Spiegelhalter, Best, Carlin, & van der Linden, 2002), widely available information criterion (WAIC; Watanabe, 2010), and leave-one-out cross-validation criterion (known by LOO; Vehtari, Gelman, & Gabry, 2017).
Model Comparison Criteria to M2PL-Q Model Fitted to the Proficiency in English Data.
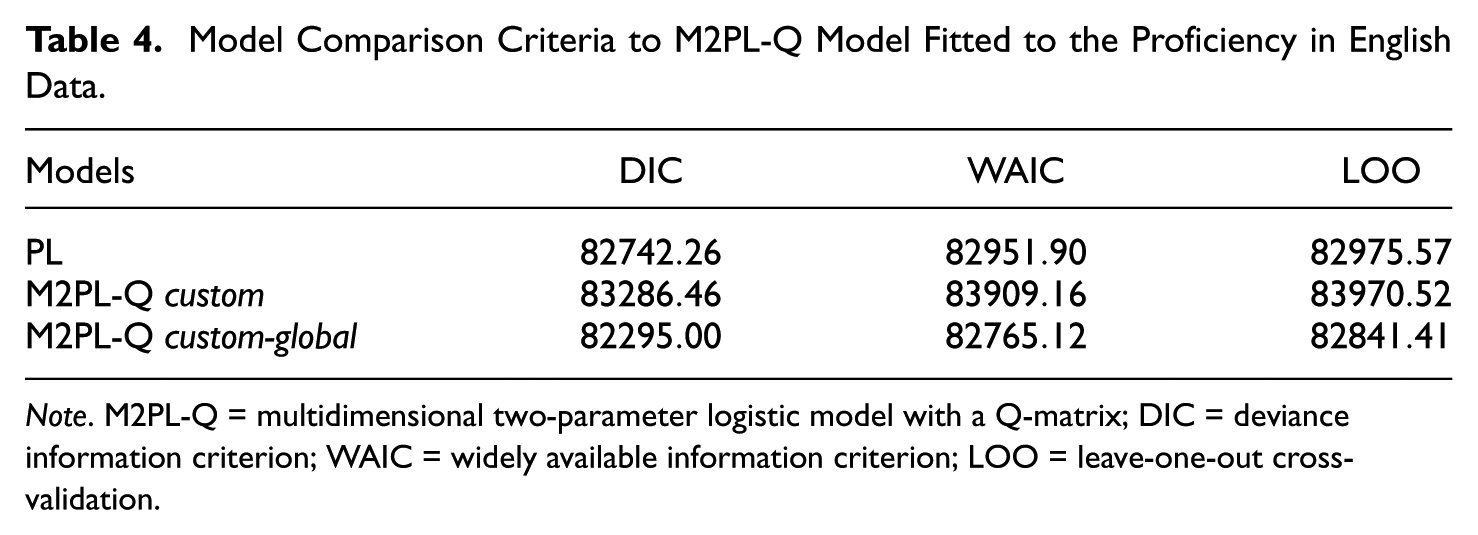
Note. M2PL-Q = multidimensional two-parameter logistic model with a Q-matrix; DIC = deviance information criterion; WAIC = widely available information criterion; LOO = leave-one-out cross-validation.
From the values of the fit indices, we considered the M2PL-Q custom-global model for data analysis. We present in Figure 5 estimates of discrimination parameters, in Figure 6 estimates of difficulty parameters, and in Figure 7 estimates of individual parameters.
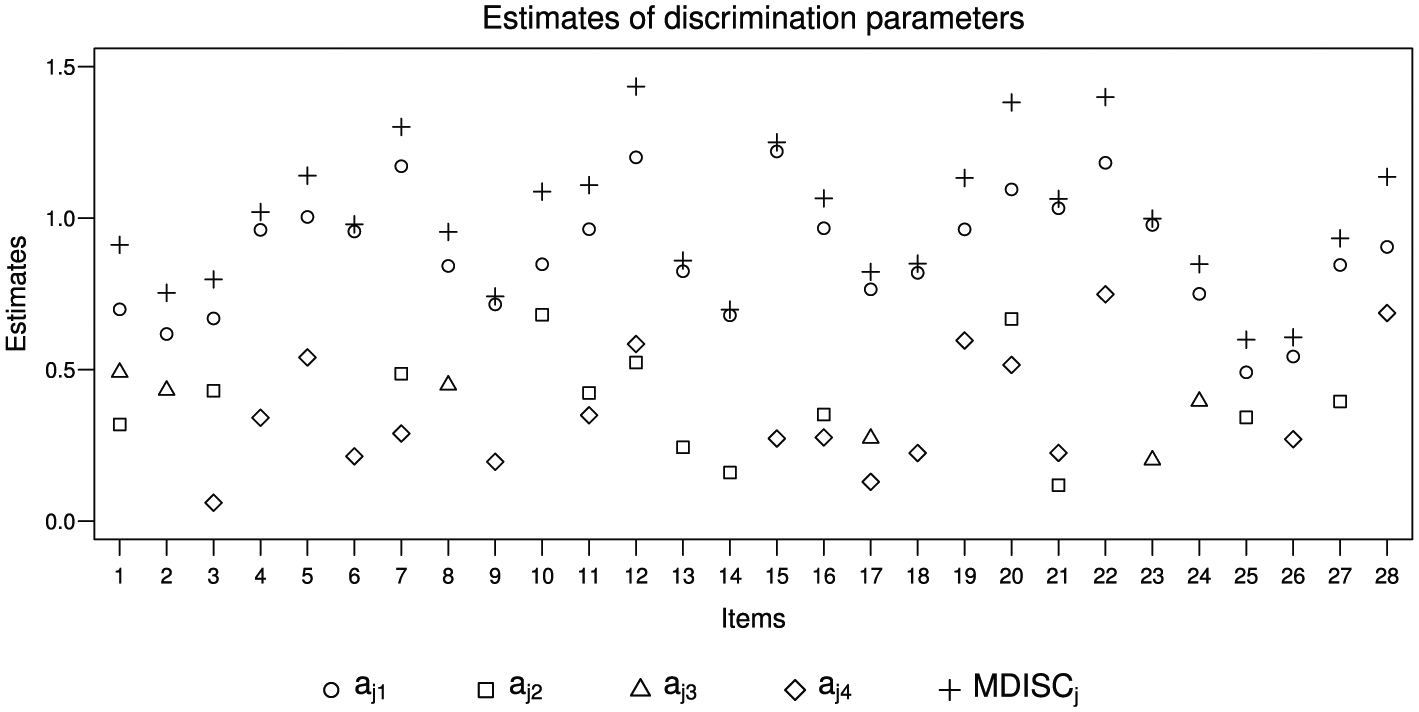
Estimates of global, specific, and multidimensional (MDISC) discrimination’s parameters considering the latent traits evaluated from M2PL-Q custom-global model.
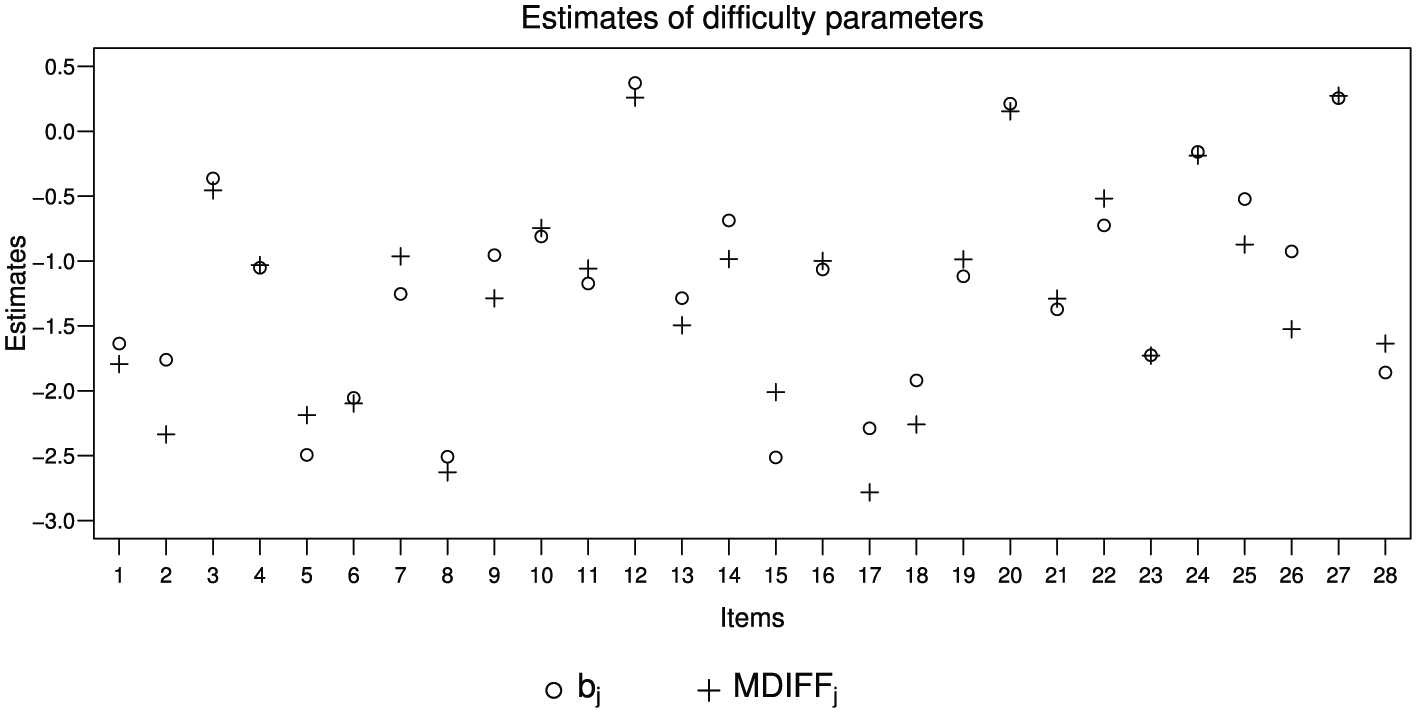
Estimates of difficulty’s parameters and multidimensional difficulty (MDIFF) parameters from M2PL-Q custom-global model.

Summary of estimates of individuals’ parameters.
Estimates of global discrimination parameters were larger than estimates of domain-specific discrimination parameters in all items, indicating that the items better distinguished individuals in terms of the global latent trait than the specific latent traits. Some items had estimates of one of the domain-specific discriminations close to zero, such as Item 3 (
In general, the estimates of the difficulty parameters were small, indicating that the probabilities of individuals scoring correctly on items were high even for those low on the latent traits.
Furthermore, in the one-dimensional 2PL model, the difficulty parameter related to an item corresponds to the value of the latent trait necessary for a .50 probability of correct item response. As in the M2PL-Q model, the difficulty parameters cannot be interpreted in the same way as they are in the one-dimensional 2PL model (Reckase, 2009). However, as in the one-dimensional model,
The mean of the estimates of individuals’ parameters in the four dimensions is close to zero. The standard deviation of the global dimension is higher than in the other dimensions, with a value equal to 0.83. In contrast, the standard deviation of Dimension 2 (Cohesive rules) is the smallest, with a value equal to 0.3.
Conclusions
In this article, we incorporated the Q-matrix into the traditional formulation of the M2PL model and we call it the M2PL-Q. This provides an efficient way of including item specification mathematically, considering expert opinions and prior knowledge available. Also, this M2PL-Q model enables the construction of a link between MIRT models and DCMs. In this section, we summarize the findings of the simulation and applied studies, discuss the properties of the proposed model, and offer future research directions.
The first simulation study, designed to evaluate the recovery of parameters from the M2PL-Q model using different Q-matrices, showed that the estimation method used provides good results for all evaluated cases. As expected, the precision of the estimates improves with increased sample sizes.
The next simulation study was formulated to compare the estimates of the M2PL-Q full, M2PL-Q bifac, and M2PL-Q custom models and the true values of the parameters, considering a simulated dataset from the M2PL-Q custom model. That is, we aimed to investigate the impact of the Q-matrix (mis)specification on the parameter estimates. As we expected, the estimates of the discrimination and individual parameters of the M2PL-Q custom model were closer to their true values than the estimates obtained by the other models. However, the estimates of the difficulty parameters of the M2PL-Q custom model were close to their true values as well as the estimates of the difficulty parameters obtained by the M2PL-Q bifac model and M2PL-Q full model. This indicates that the constraints on the M2PL-Q model do not considerably influence the estimates of the difficulty parameters, although they did considerably affect the estimates of the discrimination and individual parameters.
The application study demonstrated the utility of the proposed model in practice. Here we briefly summarize the steps for practitioners to use the M2PL-Q in operational settings.
Step 1: Specify the item-trait relationship into the Q-matrix.
Step 2: Fit one or more specified M2PL-Q model(s) to the item responses.
Step 3: Evaluate fit indices, dimensionality, and reliability.
Step 4: Examine the discrimination, difficulty and individuals’ parameter estimates.
Step 5: Select models and make changes to the Q-matrix if necessary.
Similar to fitting other psychometric models to item responses, the steps are iterative in nature. After Step 5, one may or may not need to go back to Step 1 in order to specify a new Q-matrix utilizing information from the model-fitting process.
Incorporating the Q-matrix into the composition of IRT models provides some practical benefits. First, relationships between items and latent traits can be specified directly during test development and incorporated into the model through the Q-matrix in a user-friendly manner, which helps education, psychology, or other field experts to easily manipulate these models and insert the restrictions on the relationships between items and latent traits. In addition, these constraints provided by the Q-matrix decrease the number of discrimination parameters of the model, simplify the estimation process, increase the accuracy of latent trait estimates, and considerably shorten the estimation time as compared to a fully unrestricted MIRT (identical to M2PL-Q full). However, we want to point out that the Q-matrix is not a panacea for estimation burdens. The complexity of the Q-matrix, which often is defined by content experts, determines whether the number of parameters can be reduced. Therefore, in practice, greater care is required for the IRT models that incorporate Q-matrices. Information in the literature and empirical support are of great importance for the construction of the Q-matrix. This can be considered a disadvantage of the model proposed in this work.
Future work can be developed in order to extend the proposal of this article. First, other multidimensional IRT models, such as multidimensional 1PL and 3PL models, and models for polytomous items discussed in Reckase (2009), can incorporate the Q-matrix in a similar fashion to the M2PL-Q model proposed in this work. The impact of a Q-matrix specification on these new models can be investigated. Second, incorrect specification of a Q-matrix has been demonstrated to affect parameter estimation, result in poor model fit, and decrease classification accuracy in DCMs (e.g., Gao, Miller, & Liu, 2017; Kunina-Habenicht, Rupp, & Wilhelm, 2012; Liu, 2017; Rupp & Templin, 2008a). Therefore, it would be helpful to explore the effects of Q-matrix specification on the estimation of MIRT model parameters. Third, future research can explore the possibilities of defining a Q-matrix through data validation in MIRT models. Fourth, methods have been proposed about using the item responses to validate the Q-matrix under DCMs (e.g., De La Torre, 2008; De La Torre & Chiu, 2016; Wang et al., 2018). Those methods may shed light on how to recover the true item–trait relationship in MIRT. Fifth, a prior sensitivity study on models that incorporated the Q-matrix is needed when using our proposed estimation method, including cases such as nonnormality of latent traits, as in Azevedo et al. (2011), and asymmetry of link functions, as in Bazán et al. (2006). With the introduction of Q-matrices embedded in MIRT models and the suggestions for future research, we hope this idea will eventually allow for more accurate estimates of individuals’ multiple latent traits through assessments.
Footnotes
Appendix
This appendix presents the Full-Q, Bifac-Q, Custom-Q, and Custom-Global-Q Matrices Used in the Simulation Studies and Application of This Article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was financed in part by the Coordenação de Aperfeioamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. The fourth author was partially supported by the Brazilian agency FAPESP (Grant 2017/15452-5).