
Abstract
In educational assessments and achievement tests, test developers and administrators commonly assume that test-takers attempt all test items with full effort and leave no blank responses with unplanned missing values. However, aberrant response behavior—such as performance decline, dropping out beyond a certain point, and skipping certain items over the course of the test—is inevitable, especially for low-stakes assessments and speeded tests due to low motivation and time limits, respectively. In this study, test-takers are classified as normal or aberrant using a mixture item response theory (IRT) modeling approach, and aberrant response behavior is described and modeled using item response trees (IRTrees). Simulations are conducted to evaluate the efficiency and quality of the new class of mixture IRTree model using WinBUGS with Bayesian estimation. The results show that the parameter recovery is satisfactory for the proposed mixture IRTree model and that treating missing values as ignorable or incorrect and ignoring possible performance decline results in biased estimation. Finally, the applicability of the new model is illustrated by means of an empirical example based on the Program for International Student Assessment.
When cognitive ability or achievement tests are administered, test-takers respond to administered items and are expected to answer all items with maximum effort. The resulting measures are expected to provide inferences about their performance; these inferences in turn inform classroom instruction or enable international or interstate comparisons on large-scale assessments. Within the framework of classical scoring rules, number-correct scoring assumes that a test-taker responds to all items according to his or her ability, and no credit is given when items are omitted (Lord, 1975). However, this may not be the case in practice because test-takers are more likely to adopt different response strategies when they do not know the correct answers or when they are not motivated to answer. The formula scoring that has been proposed for correction of test raw scores defines three different operational processes in item responses: test-takers know the correct answer and endorse it, test-takers are not certain about the answer and omit it, and test-takers randomly guess among the given options (Rowley & Traub, 1977). In several empirical studies, researchers found that employing partial knowledge in item responses or answering items with partial effort plays a crucial role in the formula-scoring model (Bliss, 1980; Crocker & Algina, 1986; Cross & Frary, 1977). Thus, aberrant responses, which are defined as responses to test items that are inconsistent and are expected to threaten test validity (Meijer, 1996), can be introduced by the differing operational processes when administering test items. This study focuses on the aberrant responses of item omission and effort decline.
An information-processing approach that is well documented in cognitive component theory serves as an alternative perspective to identify and measure the distinct steps in problem solving for a cognitive ability test (Sternberg, 1977; Sternberg et al., 2003). Test items are viewed as a cognitive task in which success on the items can be explicitly related to distinct and requisite mental processes in sequence. Encountering questions in an ability test comprises at least four stages (Leighton & Gierl, 2007; Messick, 1989; Newell & Simon, 1972; Snow & Lohman, 1989). First, test-takers must pay attention to the question and comprehend it (i.e., the stage of perception and attention). Second, external stimuli are converted into internal representation (i.e., the representation stage). Third, a problem space is created for test-takers to retrieve their substantive knowledge and compare that knowledge and internal stimuli to search for the answer (i.e., the working-memory-process stage). Finally, test-takers have to evaluate the result and generate the answer (i.e., the generation stage). Sometimes, the information process may not be as ideal as the cognitive component theory assumes because noncognitive characteristics of test-takers, such as test anxiety, test-taking strategies, motivation, and perseverance, can interfere with their mental process and influence their test performance (Khine & Areepattamannil, 2016). When a highly anxious test-taker responds to items in a timed high-stakes test, for example, test anxiety and time pressure may disrupt the attention stage and result in not-reached items, interfere with the representation stage and lead to omission of that item, restrict working memory capacity and prevent the test-taker from using cognitive resources as best as he/she can (i.e., performance decline), or harm the strategic use of metacognitive skills (Ashcraft & Krause, 2007; Cassady & Johnson, 2002; Dutke & Stöber, 2001; Eysenck & Calvo, 1992; Peng et al., 2014; Sarason, 1988; Tobias, 1992; Tobias & Everson, 1997).
Item omission and performance decline can also be observed in low-stakes assessments. According to expectancy-value theory (Wigfield & Eccles, 2000), when tests have no consequences, test-takers who place a high value on tests persevere and expend more effort in test-taking than their counterparts who place a lower value on tests (Cole et al., 2008; Peng et al., 2014; Wise & DeMars, 2005). Therefore, a test-taker with low motivation may not persist throughout a test and may drop out after responding to certain items (i.e., not-reached items), may perceive an item and decide to omit it, or may attempt to give an answer but use less effort and seldom use metacognitive strategies (Boekaerts, 1997; Hong et al., 2009; Wise, 2009). Although dropping out, skipping, and performance decline processes can be attributed to different reasons and explained based on diverse theories, it is evident that these aberrant response behaviors are explicitly distinct and should be conceptualized in different fashions.
The assumption that all test-takers attempt all items to the best of their ability and leave no items blank is not realistic in practical testing situations because test-taker motivation may differ from person to person, and time constraints are frequently placed on the item response process. These nuisance factors contaminate the intended-measure ability and threaten test validity and reliability when fitting standard item response theory (IRT) models (Lord, 1980) to data. For example, the National Report Card showed that on average, 12th graders who did not have outstanding performance on the 2005 National Assessment of Educational Progress (NAEP) earned good grades in advanced courses (Grigg et al., 2007). This result can be explained by the low-stakes nature of the NAEP, which did not motivate test-takers to apply their best efforts (Cao & Stokes, 2008). Another example suggests that test-takers are more likely to receive lower scores on end-of-test items (Bolt et al., 2002; Goegebeur et al., 2008; Jin & Wang, 2014; Yamamoto & Everson, 1997) or to leave end-of-test items blank (Lu & Sireci, 2007; Suh et al., 2012) on a low-stakes large-scale educational assessment (e.g., the NAEP) or a timed power test with high-stakes purposes (e.g., a college entrance examination).
Few studies have simultaneously investigated performance decline in answering test items and missing item responses. Unplanned missing data are essentially unavoidable and the percentage of nonresponse data is not trivial in real testing situations. According to the 2006 Program for International Student Assessment (PISA) study, an average of 10% of the items were skipped and 4% were not reached (OECD, 2009). The missingness mechanism during testing should be considered and distinguished from performance decline on answering test items due to both speededness and low motivation. The tendency to reduce effort in responding to items and the tendency to omit responses are quite different processes constituting the patterns of examinees’ aberrant response behavior. In addition, omitted and not-reached items are mutually exclusive categories, and different processing models should be considered (Lord, 1980). This study integrates different item response models for aberrant response behavior. Additionally, it interprets different cognitively operational processes in test-taking using an IRTree-based approach and extends the tree-based model to classify different aberrant response classes using mixture distributions, which potentially sheds new light on data analysis methods and serves as the major contribution of this study. Using the developed model to fit the data collected from a large-scale assessment or high-stakes test, rather than employing a restricted model that is limited to some specific response behaviors, can facilitate the test validity and scoring inferences of test-takers.
The purpose of this study is to provide a new IRT model for modeling responses with gradual effort decline, skipped items, and not-reached items. This article is organized as follows. First, existing approaches to addressing nonignorable missing responses and performance decline are briefly overviewed. Second, the IRTree-based approach (De Boeck & Partchev, 2012) is extended to simultaneously account for response data with performance decline and nonignorable omissions by developing a mixture IRTree model that combines a mixture IRT model for different response behavior classes and an IRTree model to describe aberrant response behavior. Then, a series of simulations is conducted to assess the efficiency of the proposed model with respect to the parameter recovery using Bayesian estimation. These simulations also demonstrate how treating missing data inappropriately affects item and person parameter estimation. Following the simulations, empirical data from the PISA 2015 reading assessment are presented to illustrate the applications and implications of the mixture IRTree model. Finally, this article closes by drawing conclusions for the new model and making suggestions for future research.
Existing Approaches to Addressing Omitted Responses
According to Rubin’s (1976) taxonomy, missing-data mechanisms derived from missing completely at random (MCAR) and missing at random (MAR) do not pose a problem if they are ignored. However, if the missing pattern is missing not at random (MNAR), for example, when systematic patterns of missingness are due to nuisance factors (e.g., time limits or test-takers’ motivation), ignoring nonignorable missing responses leads to biased parameter estimates (Little & Rubin, 1987). Therefore, approaches must be considered with respect to their appropriateness for nonignorable missing patterns. The literature has proposed at least three approaches for handling nonignorable missing data: substituting incorrect answers, ignoring nonresponses, and using model-based approaches. The first two approaches depend on specific assumptions that may not be met in real testing situations and are more likely to result in biased estimation and incorrect inferences (Holman & Glas, 2005; Köhler et al., 2017; Pohl et al., 2014). Furthermore, the processes underlying skipped items and not-reached items should be differentiated; therefore, the model-based approaches are thought of as a better way to deal with nonresponses than previous methods.
A variety of model-based approaches for nonignorable missing data have been proposed by relating test-takers’ proficiency—determined from observed data responses—with their missing-data patterns (e.g., Glas & Pimentel, 2008; Glas et al., 2015; Holman & Glas, 2005; Okumura, 2014; Pohl et al., 2014; Rose et al., 2010; Rose et al., 2017). Among these models, IRTree-based approaches are used and extended in this study because they not only provide separate latent trait models for different cognitively operational processes (i.e., the proficiency and omission processes) but also supply a framework for interpreting different omission processes (i.e., the skipping and drop-out processes).
The use of a tree structure to represent sequential response processes controlled by different latent traits and measurement models (e.g., unidimensional IRT models) for different subprocesses that lead to the observed responses is advantageous because it allows clear-cut interpretation of sequential cognitive operations as test-takers respond to test items (De Boeck & Partchev, 2012). This structure has been widely applied in the field of cognitive psychometrics. To account for nonignorable missing responses due to MNAR, Debeer et al. (2017) propose several plausible IRTree models to decompose the cognitive processes test-takers may exhibit when taking a low-stakes or speeded test. Among these hypothetical models, the item-selection model performs well in parameter estimation using simulated data, and its ability to handle the nonignorable MNAR effect is supported by empirical data analysis. Therefore, this study adopts the item-selection model to model omitted responses and extends it to account for test-takers’ performance decline as a result of effort reduction. Readers who are interested in the original tree-based and item-selection models for not-reached and skipped items as well as the structural representation for the proposed models can refer to the study of Debeer et al. (see Figure 1 in Debeer et al., 2017, p. 337).
Existing Approaches to Addressing Performance Decline
The other aberrant response behavior that occurs when test-takers perceive an item and attempt to answer it is performance decline, which is most salient near the end of a test (van Barneveld, 2007; Wise, 1996). For test-takers with low motivation, it is reasonable to assume that the effort put into answering items is not as high as that of their motivated counterparts. In the most extreme cases, examinees with low motivation are assumed to switch from thoughtfully seeking answers based on their ability to randomly guessing answers after responding to some items. Cao and Stokes (2008) propose the IRT threshold guessing model, which incorporates an item location parameter to specify a threshold individually for each examinee in a two-parameter logistic model (2PLM). In this model, classes with low motivation answer questions up to a certain item (i.e., the examinee-specific item location threshold) and guess the remainder of test items due to loss of motivation. However, the assumption that test-takers suddenly switch from the attentive stage to the random guessing stage may be too stringent to satisfy the practical testing demand because examinees with little or no motivation are more likely to expend decreasing effort as the test progresses and to have a decreased probability of correct responses over the course of the test. A gradual decrease in the probability of correct responses to test items is thus considered to provide a more realistic view of unmotivated-examinee response behavior, which is characterized by the IRT continuous guessing model (Cao & Stokes, 2008) and the mixture IRT models for performance decline (Jin & Wang, 2014) in the literature.
The aberrant response behavior found in low-stakes tests for unmotivated test-takers can also be observed on items toward the end of a speeded test due to limited test administration time. Ignoring the possible local item dependency due to this limited time can cause biased item parameter estimation and incorrect inferences about examinees’ abilities (Bolt et al., 2002; Douglas et al., 1998; Goegebeur et al., 2008; Oshima, 1994). Notably, in speeded tests, test-takers under time constraints are affected by the “speeded effect.” They accelerate in response to the time constraint, changing their performance on items (Evans & Reilly, 1972), and such speeded behavior is often observed in timed power or high-stakes tests (Jin & Wang, 2014). As in the IRT threshold guessing model for unmotivated-examinee behavior, the HYBRID model (Yamamoto & Everson, 1997) assumes that speeded test-takers switch from a problem-solving process (i.e., a 2PLM) to a random guessing process after the examinees pass their speededness points. This sudden switch to random guessing behavior expressed in the HYBRID model remains controversial. An alternative model using the mixture Rasch model to identify nonspeeded and speeded classes was developed to constrain the item difficulty parameters of end-of test items for a speeded class as higher than those for a nonspeeded class (Bolt et al., 2002). However, a prespecified item location threshold where all speeded examinees switch to the speeded process makes this approach unfeasible and impractical because different examinees in a speeded class may feel speeded pressure at different item locations.
Instead of specifying a fixed location threshold and assuming random guessing after responding to a certain number of items, Goegebeur et al. (2008) proposed a speeded IRT model with a gradual process change that incorporates an examinee-specific threshold parameter and an examinee-specific change rate parameter into the three-parameter logistics model (3PLM). In this modeling approach, examinees are assumed to answer items with full effort from the beginning (with the probability of correct response following the 3PLM), and once they feel that there is insufficient time to answer the remaining items (i.e., passing through the item location threshold), they reduce their response efforts according to different change rates and may become completely random guessers near the end of the test. Although the model defined by Goegebeur et al. serves as the most general model to control for speededness effects due to test time limits (Suh et al., 2012), three types of random-effect parameters (i.e., ability, threshold, and change rate) are not linked linearly, making parameter estimation and model extension difficult in practical applications (Jin & Wang, 2014).
The literature has documented that aberrant response behavior occurs in examinees taking both low-stakes and speeded tests and has acknowledged a gradual change in the item-solution process, rather than a sudden switch from concentrated effort to guessing. However, in addition to reducing effort and randomly guessing when answering items, examinees may choose to omit some item responses entirely, and missing responses can be considered an indicator of speededness (Mroch & Bolt, 2006) or motivation loss (Cao & Stokes, 2008) in a test.
Suh et al. (2012) conducted a series of simulations to generate missing responses under the speeded IRT model of Goegebeur et al. (2008) and evaluated the effects on parameter estimation of different methods of scoring missing responses. Several limitations in that study deserve further attention. First, the speeded items (i.e., the items beyond a fixed threshold location) were assumed to be likely skipped; however, test-takers may experience different levels of speededness, and the chance of omitting items does not necessarily depend on the occurrence of performance decline. That is, test-takers may first determine whether to answer an item and then determine how much effort they want to expend if they decide to answer. Second, Suh et al. did not differentiate between skipped and not-reached responses. The literature has indicated that the two types of omitted responses involve different processes and are associated with various sources. Finally, the generated and fitting models in the simulations Suh et al. created were not consistent, so the relationship between the missing responses and the speeded behavior was not completely clear.
The New Model
In this section, the IRTree-based framework is employed to simultaneously include nonignorable missing data and describe test-takers’ gradual reduction in effort when responding to test items. Because omitting items and carelessly responding may coexist in test-taking (van Barneveld, 2007; Wise, 1996), the two types of behavior can be used as indicators of aberrant latent classes. It is hypothesized that test-takers work on items with full effort and do not provide any blank responses at the beginning of a test. If test-takers give their best performance throughout the test, they are considered to be part of the normal class. However, test-takers may not give their best effort to answer all items and are likely to exhibit some aberrant response behavior as the test progresses. Once test-takers lack motivation or feel time pressure after completing a certain test item, they arguably switch from normal response behavior to aberrant response behavior for the remaining test items. Therefore, a sequential process of aberrant response behavior can be assumed to govern test-takers’ responses to items beyond a certain item location, and three subprocesses (or internal nodes) can be used to represent the subsequences.
Figure 1 visualizes this study’s hypothesized mixture IRTree model that is used to represent the sequential choice process for modeling dropping out, skipping, and effort decline. First, a test-taker may either evaluate the stakes of failing the examination or consider whether he/she has sufficient motivation to take the test. If he/she decides to give his/her best performance throughout the test, the responses to all items are assumed to follow the 3PLM model and not to exhibit any aberrant behavior. Otherwise, the test-taker begins to respond to items in the sequence of item order and may work on items early in the test with full effort, switching to aberrant responses for items near the end of the test. Suppose test-taker i decides to switch from normal response behavior to aberrant response behavior beyond item k. The responses to
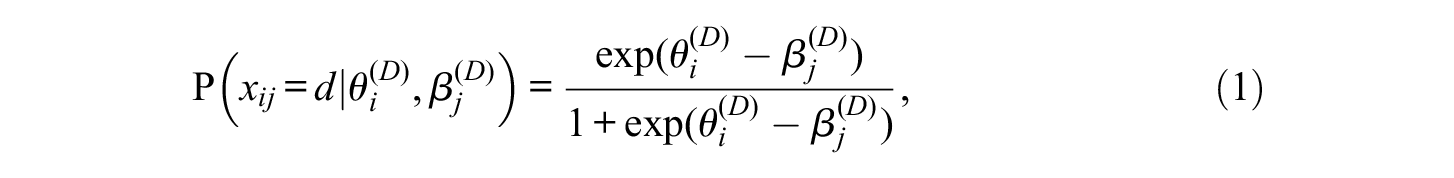
where
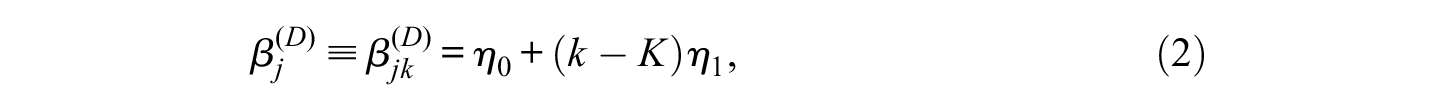
where
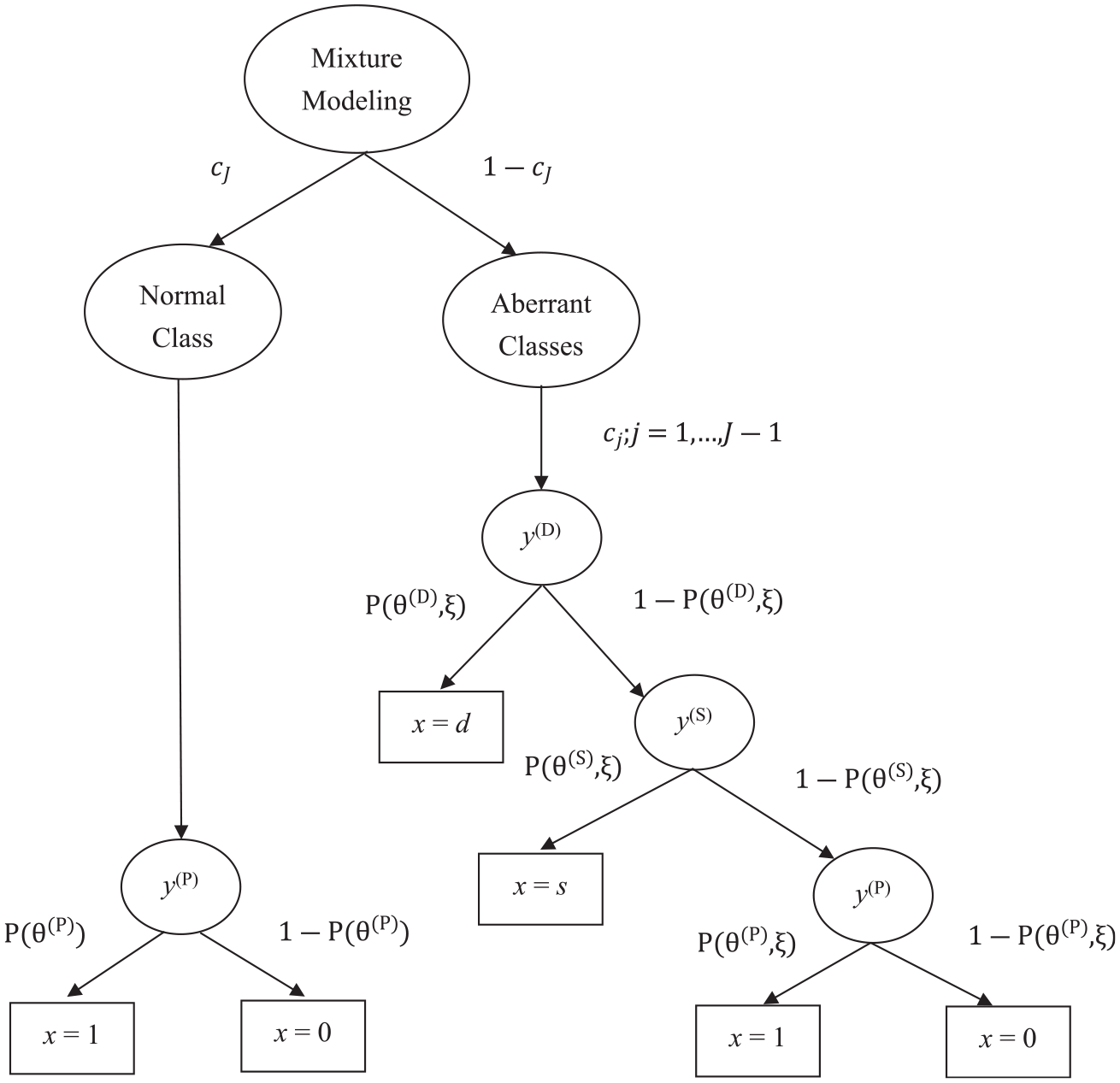
Graphical representation of the mixture IRTree-based model for performance decline and nonignorable missing data.
If the test-taker does not completely forsake the test, the second process determines whether item
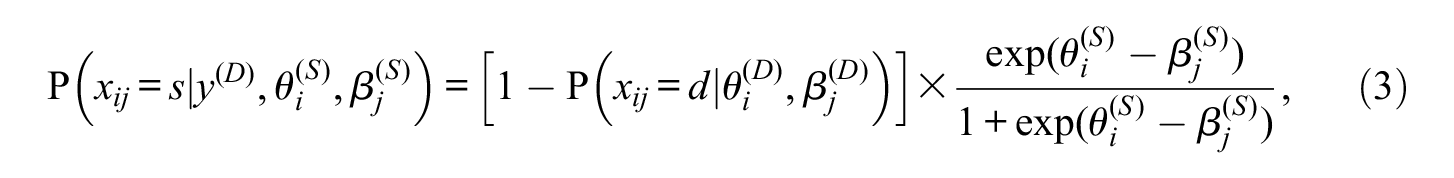
where
When test-taker i decides to respond, leaving no blank responses but exerting only partial effort on items due to personal or environmental factors (e.g., motivation and testing time), the third process of performance decline comes into effect. Consistent with previous findings (e.g., Cao & Stokes, 2008; Goegebeur et al. 2008), we assume that the probability of correct answers gradually decreases with regard to item location and that a linear decrement function of effort with respect to item location can be embedded in the 3PLM.
Because examinees can be classified into a normal response class or multiple aberrant response classes (depending on the switching points), J latent classes should be identified in the mixture IRTree model. Test-takers who always maintain full effort until the last item, J, are classified into the normal class, and others who switch from normal to aberrant behavior at different item locations are classified into one of
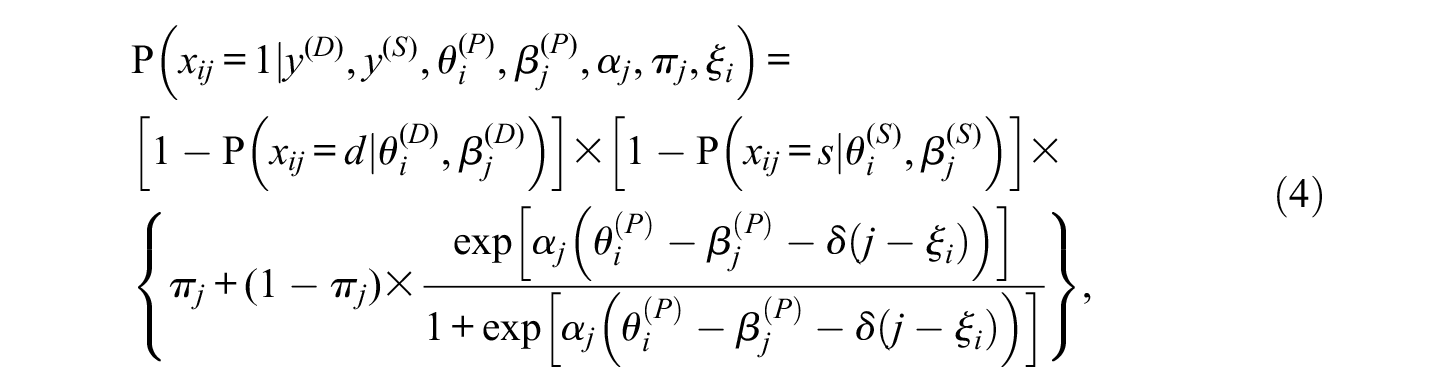
and the probability of an incorrect response to the same item is

where

where
The mixture proportion vector of

The other probabilities used to represent a test-taker switching to aberrant response behavior at different item locations are denoted as
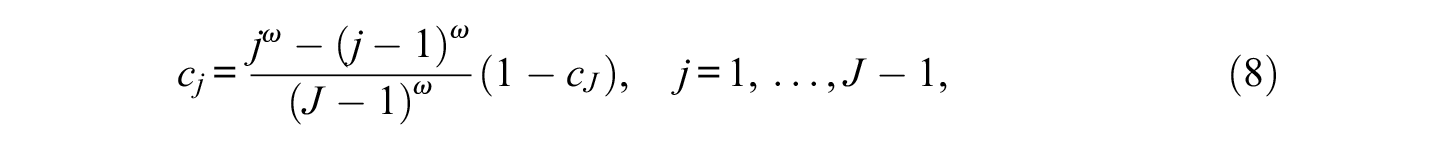
where
As noted by Debeer et al. (2017), an IRTree-based model not only is a purely mathematical formulation for response probabilities of outcome variables but also is capable of representing a “belief” that researchers have about the cognitive processes that underlie an item response. Therefore, the proposed mixture IRTree model in this study may not be universally appropriate for all situations, but we believe it is theoretically more appealing than other possible sequential operational processes. Even so, the IRTree approach is flexible in the sense that where appropriate, researchers can develop customized IRTrees based on substantive knowledge, and the proposed mixture IRTree model for missing data and performance decline can be easily revised to satisfy practical testing demands (Jeon & De Boeck, 2016).
A consistent item order that a linear test commonly uses is assumed for all test-takers in this study. However, test-takers may not respond to items in the sequence of the item order and may go back to review their answers and make changes at any time, unless the test is computerized. We adopt this assumption for several reasons. First, it is acknowledged that test-takers can decide the item response order and prioritize the response sequence. Although the item orders in a test differ between test-takers, item-position effects can be induced, and item characteristics can shift depending on the placement of items and the item order administered to test-takers (Debeer & Janssen, 2013). It is evident that item-position effects can be moderated by test-takers’ effort, motivation, and value attributed to the test (Qian, 2014; Weirich et al., 2017). The following simulations include rotated block and random ordering designs to demonstrate the impacts of position effects on parameter estimation when test-takers are allowed to respond to items in a different order sequence. Second, although item review and answer changes are commonly observed in linear testing designs, test-takers with low motivation may not use the item-review strategy to improve their scores due to the nature of low-stakes tests, and a highly anxious test-taker may not have enough time to change his/her answers due to time pressure in a speeded test. To maintain the scope of this study, the phenomenon of item review is not considered for modeling aberrant response behavior. In addition, the 2015 PISA reading assessment used for empirical demonstration in the following section was administered in computer-based testing situations. The proposed mixture IRTree model is justified to fit the data because both item ordering and item review are restricted in computerized testing.
Method
Simulation Design
A series of simulations with several manipulated factors were conducted to assess the efficiency of the mixture IRTree model for nonignorable missing responses and performance decline. The data were generated according to the proposed mixture IRTree model, with an MNAR missing mechanism and the assumption that some test-takers exert less effort on items as the test proceeds. For the first simulation study, three major independent variables were manipulated: (a) sample size (1,000 and 2,000 examinees), (b) test length (20 and 40 items), and (c) item ordering (one item order and multiple item orders; see below for more detail). The mixing proportion was set to 40% (
When examinees entered the problem-solving process, the 3PLM was used to generate the responses to test items. For the normal response class, the item discrimination parameters were randomly sampled from a uniform distribution between 0.50 and 1.50; the pseudo-guessing parameters were set to 0.20 for all items; and the item difficulty parameters were generated from a joint distribution with the skipping threshold parameters described above. Note that a common pseudo-guessing parameter was estimated across all items because this parameter is too uncertain to estimate precisely, and such a constraint is not uncommon in real testing situations (van der Linden et al., 2010). For the aberrant response classes, the generated parameters relative to the 3PLM were set to the same values as in the normal response class, and decrement parameter
To meet the demands of practical testing situations, such as the large-scale assessments mentioned above, two types of item orders were considered in the simulation design. When one item order was used, all test-takers’ items were ordered in the same way. On the other hand, when multiple item orders were used, four equally sized blocks were rotated to produce four item orders (i.e., four booklets), and each booklet was randomly administered to 250 and 500 examinees in the scenarios with sample sizes of 1,000 and 2,000, respectively. We referred to the rotated block design adopted by Debeer et al. (2017), and the resulting four item orders are listed in Table 1. The item order within each block was fixed: only the order of the item blocks themselves was changed.
The Order of Item Blocks for the Four Booklets in the Simulation Study.
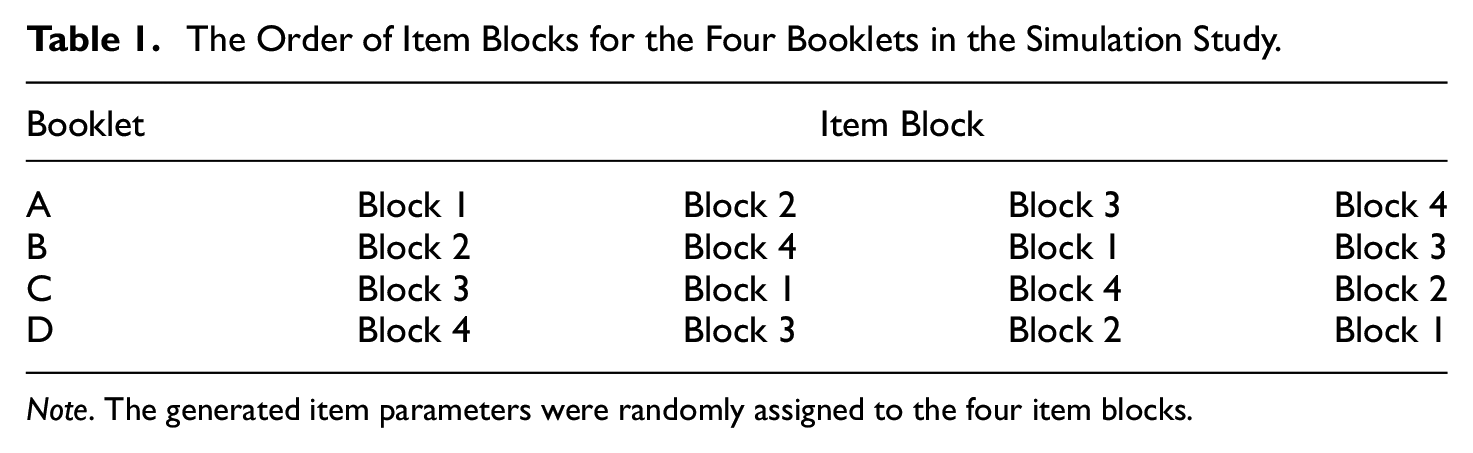
Note. The generated item parameters were randomly assigned to the four item blocks.
Although it is evident that the proportion of aberrant response behavior is not trivial in low-stakes or timed power tests (e.g., Cao & Stokes, 2008), a large proportion of aberrant response behavior among test-takers may not be realistic in practical settings. Therefore, a second simulation study was conducted to increase the mixing proportion of the normal response class to 80% (
Analysis
Bayesian estimation via the Markov chain Monte Carlo (MCMC) method was used to calibrate the model parameters via the freeware WinBUGS (Spiegelhalter et al., 2003). It was necessary to specify priors for the model parameters to produce the joint posterior distributions of the parameters in the Bayesian estimation. A normal prior distribution, with a mean of 0 and a variance of 4, was used for the item difficulty, skipping threshold, and
After screening the convergence diagnostic using the multivariate potential scale reduction factor (Brooks & Gelman, 1998) with three parallel chains for several simulated data sets across simulation conditions, it was determined that 15,000 iterations, with the first 5,000 iterations treated as the burn-in period, were sufficient to provide stable parameter estimates. After that point, no label switching was observed within a single MCMC chain or between multiple MCMC chains. The same prior settings and iteration numbers used in the simulation study were applied to the following empirical data analysis. Although not presented, the WinBUGS commands for the proposed mixture IRTree model are available on request. The bias and root mean square error (RMSE) were computed to assess the recovery of the structural parameters, and the RMSE of the person parameter estimates was used to evaluate the person parameter recovery. It was expected that the parameters in the mixture IRTree model could be recovered satisfactorily, that large samples and long tests would increase the estimation precision, and that mistakenly treating data as MNAR would result in biased estimation.
Results
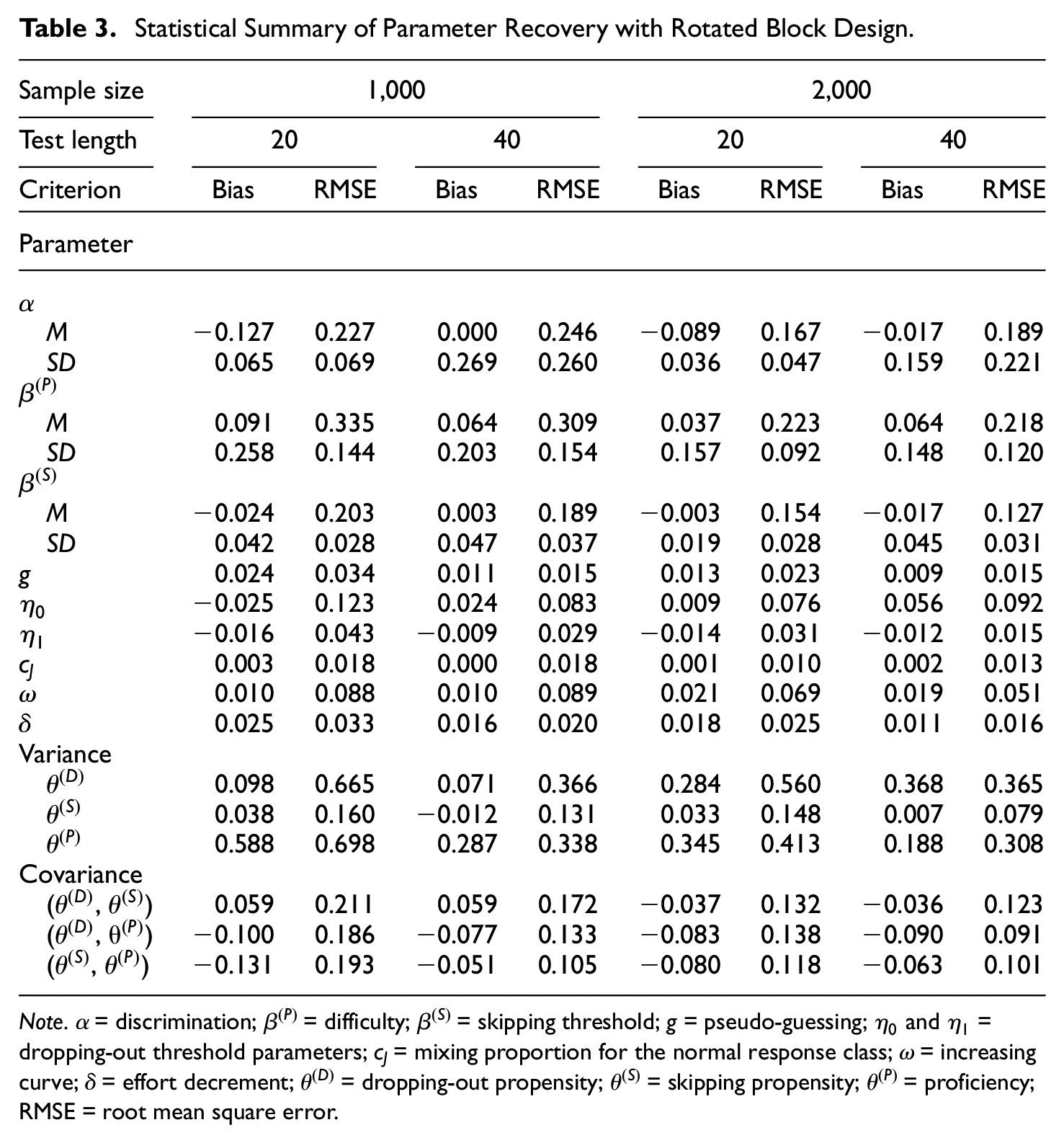
Tables 2 and 3 summarize the results of computing the bias and RMSE to assess the quality of model parameter estimation when the item order was either fixed or rotated. Because numerous item parameters were estimated and space constraints should be considered, the mean and standard deviation of the bias and RMSE across parameters are reported for the item parameters (i.e.,
Statistical Summary of Parameter Recovery with Fixed Item Order Design.

Note.
Statistical Summary of Parameter Recovery with Rotated Block Design.
Note.
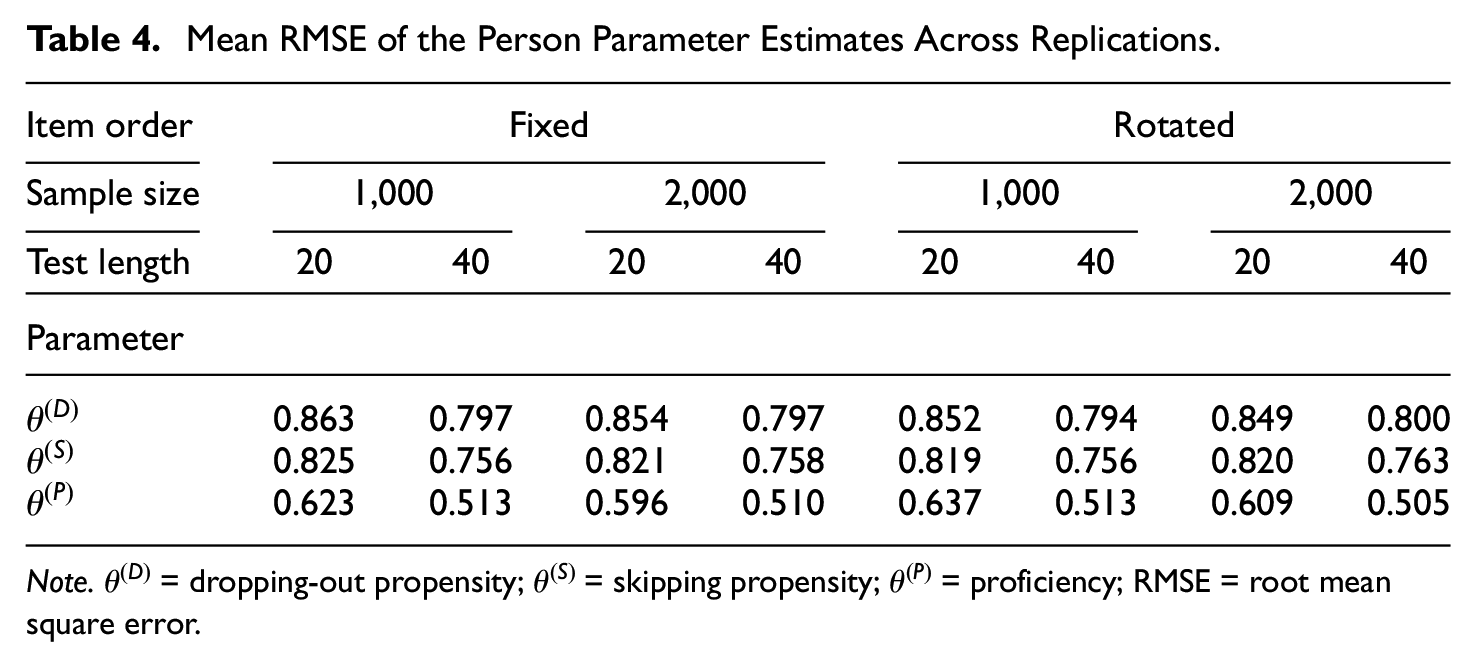
The three person parameters representing the dropping-out propensity, skipping propensity, and substantive proficiency were also estimated, and the mean RMSE values for the three estimates across simulation replications are presented in Table 4. A long test length was associated with a more precise estimation of the person parameters, and sample size had a trivial impact on the person parameter estimation. In addition, because the percentage of missing responses was not substantial in the simulation design, as expected, the dropping-out and skipping propensities were not estimated as precisely as the target latent trait (i.e., proficiency). Additionally, no difference was observed in the person parameter recovery between the fixed and rotated item order designs.
Mean RMSE of the Person Parameter Estimates Across Replications.
Note.
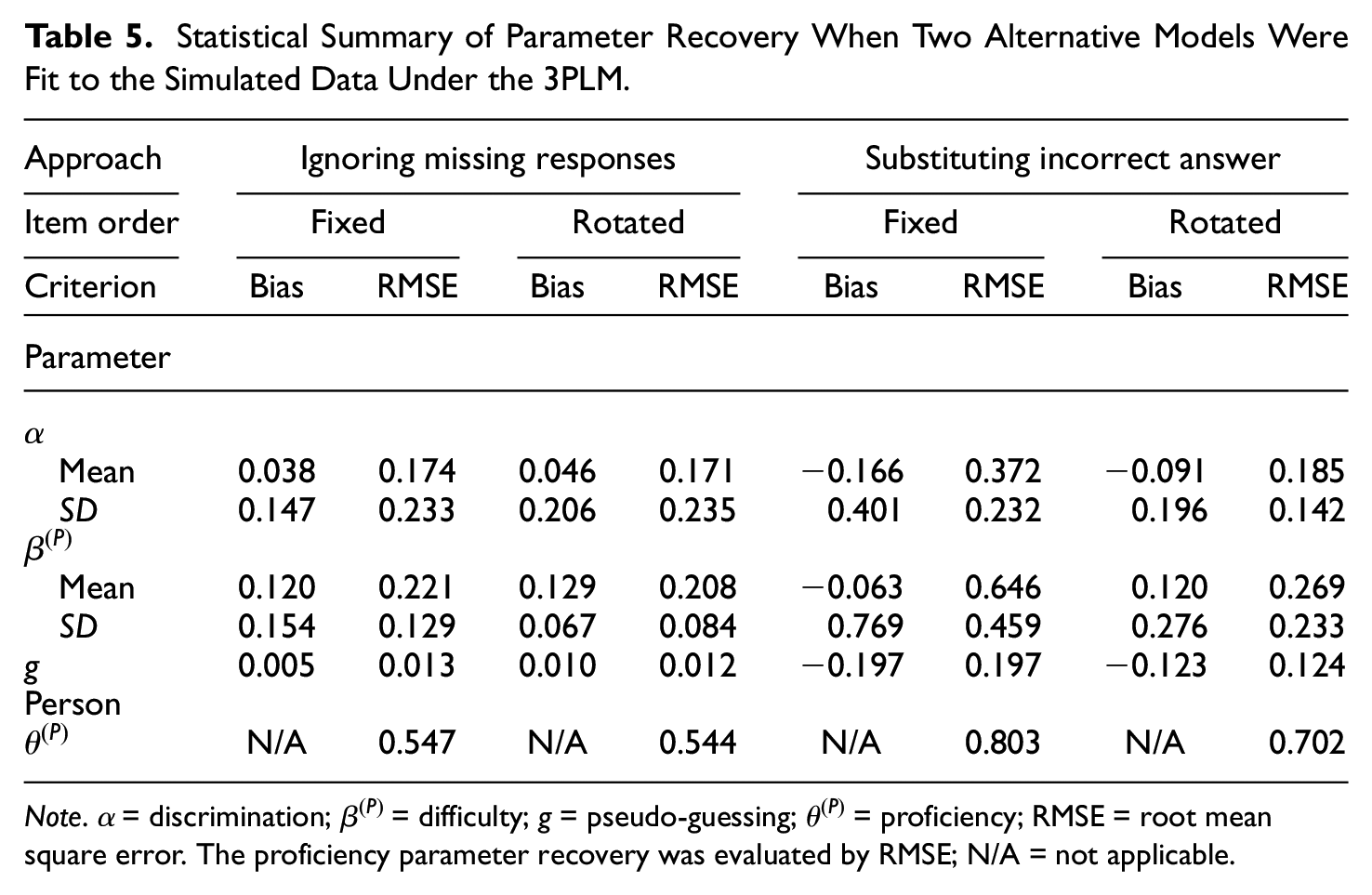
Treating missing data as nonresponses or incorrect responses is common in practical testing analyses and large-scale assessments. In addition to item omission, test-takers who exhibit low motivation or fatigue are often assumed to exert as much effort on responding to items as their full-effort counterparts in real-life data analysis. To investigate the consequences of ignoring MNAR patterns, mistakenly imputing incorrect answers for MNAR data, and treating all test-takers as full-effort ones, the traditional 3PLM was used to fit the simulated data in which missing responses were regarded as MAR or replaced by incorrect responses. The condition with a long test (i.e., 40 items) and a large sample (i.e., 2,000 persons) provided a comparison between different approaches to addressing missing data. For most estimators, as shown in Table 5, the parameters were recovered more poorly than were the parameters estimated by the data-generating model (see Tables 2 and 3), regardless of the model structural and person proficiency parameters being estimated. Furthermore, the parameter estimation was worse when the missing responses were substituted by incorrect answers than when the missingness was treated as MAR. In addition, the fixed block design resulted in more biased parameter estimation than did the rotated block design, especially for the incorrect answer substitution approach. Although not shown, the same conclusions could be drawn when the comparison was conducted in the small-sample and short-test conditions.
Statistical Summary of Parameter Recovery When Two Alternative Models Were Fit to the Simulated Data Under the 3PLM.
Note.
Note that the difference in the RMSE values of the proficiency estimates between the two approaches treating missingness as MNAR and MAR was small such that the missing data appeared to be ignored. This finding was consistent with previous studies because our simulation produced mild magnitudes of nonignorable missing responses (Köhler et al., 2017; Pohl et al., 2012; Rose et al., 2010). As the number of nonignorable missing values becomes large, it is reasonably expected that traditional IRT models cannot serve as appropriately fitting models for data analysis due to biased parameter estimation (Glas & Pimentel, 2008; Holman & Glas, 2005). A small difference in ability estimates between different approaches may have a significant impact on scoring inferences of test-takers (e.g., Huang, 2014), and the assumption of ignorability should be evaluated regardless of the item-nonresponse sizes (Rose et al., 2017); thus, the proposed mixture IRTree model is recommended for use to provide more precise proficiency estimates even though the proportion of missing responses is not substantial.
Table 6 summarizes the parameter recovery for the second and third simulation studies with a sample size of 2,000 and a test length of 40 items. When the proportion of the normal response class increased to 80% and 90%, the parameters relative to the 3PLM were estimated more precisely compared with the condition of the small proportion (i.e., 40%) used in the first simulation study. On the other hand, because the number of test-takers with aberrant response behavior decreased and the information associated with aberrant responses was not sufficient to provide precise estimation, as expected, the structural parameter estimates in the dropping-out and skipping subprocesses became more deteriorated compared with the first simulation study. The same findings for the structural parameter recovery applied to the person parameter recovery, as evidenced by the mean RMSE values of 0.896, 0.868, and 0.488 for the dropping-out propensity, skipping propensity, and substantive proficiency, respectively, in the 80% normal response class condition and 0.925, 0.891, and 0.486 for the three respective person parameters in the 90% normal response class condition.
Statistical Summary of Parameter Recovery for the Second and Third Simulation Studies.

Note.
Regarding the random item order design, as shown on the right-hand side of Table 6, the patterns of the structural parameter recovery were similar to those in the rotated block design. In addition, the person parameter recovery in the third simulation study was found to be comparable to that in the first simulation study, as indicated by the mean RMSE values of 0.794, 0.753, and 0.510 for the dropping-out propensity, skipping propensity, and substantive proficiency, respectively. In summary, increasing the numbers in the normal response class yielded better parameter estimation for the problem-solving process and poor parameter estimation for the aberrant response processes, and different item orders of test-takers had a trivial effect on the parameter recovery when the item-position effects were taken into account.
Empirical Demonstration
As a low-stakes assessment, PISA data were chosen as an empirical example to demonstrate how to apply the proposed mixture IRTree model to real data analysis. In 2015, the main survey in PISA included 66 forms (booklets) to measure reading, mathematics, science, and collaborative problem-solving literacy competencies. Six reading assessment forms were used in our analysis, where six testing clusters were administered in different sequences and the numbers of items in each cluster were 18, 14, 15, 14, 15, and 16. Consequently, the test lengths were 32 for Form 1 (Clusters 1 and 2), 29 for Form 2 (Clusters 2 and 3), 29 for Form 3 (Clusters 3 and 4), 29 for Form 4 (Clusters 4 and 5), 31 for Form 5 (Clusters 5 and 6), and 34 for Form 6 (Clusters 6 and 1). The sample recruited from Taiwan in 2015 to take the six forms consisted of 1,276 students: 7% of the respondents failed to attempt the last item, and 27% omitted at least one response. Detailed information about the assessment design of the 2015 PISA survey is available in the PISA 2015 technical report (OECD, 2017).
Because both selected- and constructed-response items were administered to test-takers in the reading assessment, to fit the proposed model, the polytomous items were dichotomized to convert a full credit response into a correct response and other responses into incorrect answers. Additionally, the one- and two-parameter logistic models were considered as the item response function in the framework of the mixture IRTree model. We were interested in the following questions: (a) Was it necessary to estimate the discrimination parameters? (b) Was the missingness pattern MAR and ignorable? (c) Was it necessary to include an effort decrement parameter to capture the phenomenon of test-taker performance decline as the test proceeded? Therefore, six fitting models were proposed to address these concerns: the mixture two-parameter IRTree model (Model 1), the mixture one-parameter IRTree model (Model 2), the mixture two-parameter IRTree model with zero covariance (MAR assumed; Model 3), the mixture one-parameter IRTree model with zero covariance (MAR assumed; Model 4), the mixture two-parameter IRTree model without performance decline (Model 5), and the mixture one-parameter IRTree model without performance decline (Model 6). The Akaike information criterion (AIC) and the Bayesian information criterion (BIC) were computed to assess the model fit, and smaller values indicated a better fit of the model to the data.
The AIC values were 38,690; 39,260; 39,340; 39,880; 38,840; and 39,260; respectively, for the six fitting models, and the BIC values were 40,190; 40,300; 40,820; 40,900; 40,210; and 40,290. The mixture two-parameter IRTree model (Model 1) had the smallest AIC and BIC values and was therefore selected as the best-fitting model. The descriptive statistics for the best-fitting model were as follows: the estimates were between 0.13 and 2.13 (M = 0.87) for the discrimination parameters, −4.37 and 4.48 (M = −0.89) for the difficulty parameters, −0.57 and 6.39 (M = 3.28) for the skipping thresholds,
Table 7 shows the missing response patterns of selected test-takers and the estimates of proficiency and omission propensity. The selected examples represent some typical response patterns when test-takers did their best or exhibited aberrant response behavior over the course of the six testing forms. Note that test-takers were classified into the normal response class when their switching points were equal to the test length for each testing form and that the information obtained from the variance–covariance matrix contributed to the estimation of omission propensity even though no omissions were observed. The same data set was fit to the 2PLM by treating the missingness mechanism as MAR and assuming that test-takers exert continuous effort. The comparison of the proficiency estimates between the two models was the focus. The estimates calibrated by the mixture two-parameter IRTree model were referred to as the gold standard because aberrant response behavior of test-takers was taken into account. As shown in Table 7, the differences in the proficiency estimates between the two models were most substantial when test-takers had both skipped and not-reached items, followed by when test-takers had only skipped items and when test-takers responded to test items with full effort and left no blank responses. Although the comparisons were illustrated in the low-stakes PISA assessment and the consequences of using the misleading model appeared to be trivial, similar results can be expected, and the impacts are likely to not be trivial for high-stakes assessments when time constraints are imposed and the effect of speededness should be taken into account.
Response Pattern Summary and Person Parameter Estimates for Selected Samples.

Note. 2PLM = two-parameter logistic model; IRTree = item response tree; N/A = not applicable. There were 32, 29, 29, 29, 31, and 34 items in test forms 1 to 6, respectively.
Conclusion
Test developers and administrators commonly assume normal responses of test-takers to test items measuring their performance on a specific domain; however, a variety of nuisance factors in real-life testing situations often violate this assumption. Aberrant response behavior as test-takers encounter items interferes with scoring and causes biased parameter estimation. Among the diverse types of aberrant response behavior, effort reduction and item omission may be the most salient factors for test scoring interpretation and have been investigated and modeled by various methodological approaches for low-stakes or timed power tests (e.g., Cao & Stokes, 2008; Debeer et al., 2017; Jin & Wang, 2014; Pohl et al., 2014; Rose et al., 2017). This study integrates mixture modeling and IRTree-based approaches to simultaneously classify test-takers with normal or aberrant response behavior and to construct the psychological process as aberrant response behavior arises. Few studies have discussed such an integration. In the proposed mixture IRTree model, a mixture sequential choice process is assumed for test-takers’ responses to test items, where normal respondents give their best performance throughout the test and do not leave any blank responses. On the other hand, beyond a certain item location, other respondents may switch to aberrant responses from normal responses due to motivation loss or time limitation pressure and decide whether to drop out, skip, or exert partial effort for the remainder of the test items by the three sequentially interconnected subprocesses. The mixture IRTree model is sufficiently flexible such that any type of IRT model can be used as a function of the subprocess responses. Following the previous approaches for nonignorable missing data and achieving the most generalization, in this study, the 3PLM is used as the item response function for the substantive process, and the 1PLM is used as the item response function for both the dropping-out and skipping processes.
The simulation results showed that the model structural and person parameters can be recovered satisfactorily, and similar to most simulation studies, increasing the sample size and test length results in a more precise estimation of the model and person parameters. Mistakenly treating MNAR missing responses as incorrect or MAR by fitting a standard 3PLM resulted in biased estimation, and incorrect answer substitution was substantial. To simulate practical testing situations, a reasonable proportion of missing responses was generated, in contrast to previous studies using relatively large numbers of missing responses (e.g., Glas & Pimentel, 2008). This may be the main reason that the difference in parameter recovery between the 3PLM and the true data-generating model was not as substantial as the literature has reported. The resulting difference in the precision of test-takers’ proficiency estimation may not have significant consequences in low-stakes tests but should not be neglected in high-stakes assessments. Furthermore, the precision of parameter estimation relative to the dropping-out and skipping processes deteriorated as the proportion of the normal response class increased, and the random item order design had little impact on parameter estimation.
The applicability of the mixture IRTree model was demonstrated using the 2015 PISA reading assessment from the Taiwan data. The results indicate that the missing-data pattern was MNAR and could not be ignored. Moreover, as in the simulation study, reading proficiency was negatively related to the propensities to drop out and to skip. When the data were fit to the 2PLM and test-takers’ normal responses to items were assumed, the biased estimates of test-takers’ reading proficiency were more stringent for the aberrant response classes with omitted responses than for those who attempted all test items. Although the developed mixture IRTree model is extraordinarily interpretable and flexible in the cognitive process of test-takers’ response behavior, we do not exclude other possibilities for alternative cognitive processes, and the conclusions derived from the empirical example may not apply to other countries and assessments. If a more convincible theory or appealing hypothesis arises, the modeling can easily be adjusted and customized by researchers to satisfy their conditions.
When not-reached and skipped items are derived from the MNAR mechanism, test-takers’ propensities to drop out and to skip are treated as threats to test validity and should be considered and included in the data analysis. However, the dropping-out and skipping propensities do not serve merely as nuisance factors. The relationship between missing data and other variables, such as test-takers’ background variables or other measured outcomes, can help us understand how test-takers’ learning environment influences their test-taking behavior. An explanatory IRTree model can be constructed that includes these manifest or latent variables as predictors in the item response function to provide deeper and more significant insight about the latent response processes (De Boeck & Wilson, 2004). For example, two measures obtained from a self-regulation scale or a self-control scale can be used to predict the levels of dropping-out propensity and can be evaluated and compared with respect to the proportion of variability that the external measures can explain. Similarly, item properties (e.g., abstract or concrete) can be introduced into the skipping-process function to predict the item’s skipping threshold parameter. The aberrant response behavior of test-takers may thus be mitigated by providing instructional interventions (e.g., self-regulation training) or by designing items in an appropriate manner.
Future directions for model extensions are provided as follows. First, as noted early in this study, IRTree-based models are merely a mathematical model to reflect the beliefs or assumptions that researchers have about the processes underlying an item response. Based on the rationale and abundant research of previous studies, we adopted the item-selection model proposed by Debeer et al. (2017) for dropping-out and skipped items and extended it to have a discrete latent class structure for different response behaviors. Other plausible IRTrees may be more suitable and applicable in some situations; for example, although the scenario is not theoretically appealing, test-takers may decide whether to skip an item at the beginning and then decide whether to drop out after that item. Diverse IRTrees for interpreting the latent processes that operate in dominating aberrant response behaviors should be explored and investigated. Second, this study focuses on several types of aberrant response behavior and disregards other possibilities. If possible, the mixture IRTree model should be extended to include additional subprocesses that represent other aberrant test-taking response behaviors (e.g., cheating or collusion), which can maximize the generalizability of mixture IRTree models at the price of increased computational burden. Finally, cognitive diagnostic assessments and their corresponding cognitive diagnosis models have recently prevailed in the fields of educational and psychological testing (Rupp et al., 2010). Applying IRTrees to cognitive diagnosis models to investigate test-takers’ aberrant response behavior in cognitive diagnostic assessments is an interesting topic for future study.
Footnotes
Acknowledgements
The author thanks the editor and two anonymous reviewers for their constructive comments on earlier drafts of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Ministry of Science and Technology, Taiwan (No. 108-2410-H-845-011).