
Abstract
Social media continues to be an ever-present part of people’s lives. One of the largest social media websites, Reddit has more than 430 million unique visitors monthly. What is unknown to scholars is how gifted education fits into this modern form of communication. In our research, we examined how gifted education is discussed over Reddit using text mining in combination with sentiment analysis. In addition, our research conditioned sentiment on variables such as self-disclosure, interest, and controversy. We found that, overall, discussion of giftedness was neutral in terms of sentiment and used common language across subreddits. We also found that the language used and distribution of sentiment were similar between self-disclosures and non-self-disclosures.
Social media has become a vital part of cultures worldwide, permeating daily life and influencing how, when, and why people interact. Its users share different types of media and information to engage with others around the globe, encourage civic participation, and highlight issues that might otherwise pass largely unnoticed by the global community. Social media is accessible to anyone with an internet connection; users can interact instantaneously to share their beliefs, ideas, news, and experiences without being restricted by networks or locations. The popularity of some types of social media may be region-specific, but others enjoy relatively consistent popularity around the globe. The most current data suggest that 72% of adults in the United States use at least one social media site (Auxier & Anderson, 2021). These interactions have increased public access to content previously buried beneath paywalls and other barriers, such that knowledge can spread through a population with ease.
Tapping into this wealth of knowledge has become an area of great interest in social science research, as social media platforms serve as potential sources of vast and varied digital data (McCay-Peet & Quan-Haase, 2017). Ruths and Pfeffer (2014) argued that the fusion of computational power and the volume of social media data has created a new area of research that draws on interdisciplinary perspectives and tools “at unprecedented scale” (p. 1063). Moreover, Ladd et al. (2020) asserted that “measures drawn from social media can capture people’s attitudes, emotions, and interests on topics typically studied using large surveys, as well as behaviors and reactions typically captured using observations” (p. 5). The use of social media platforms as data sources has emerged as a promising tool for ascertaining public opinion on social policy (Ceron & Negri, 2016; O’Connor et al., 2010) and examining social interactions regarding topics like education (Carpenter et al., 2018; Staudt Willet & Carpenter, 2020) and public health (Park & Conway, 2017). Other social media research considers potential harms of these online communities through work on misinformation spread (Anspach & Carlson, 2020) and cyberbullying (Craig et al., 2020). Social science researchers recognize the rich potential in social media analysis and education researchers can use the wealth of social media data to better understand stakeholders’ concerns and interests.
In educational research, investigations of what people discuss on social media platforms, and how they discuss it, have lent critical insight into the methods by which individuals solicit social support, seek information, and develop opinions on educational systems (Relucio & Palaoag, 2018), teacher quality (Chang-Kredl & Colannino, 2017), and the implementation of curriculum policies (Y. Wang & Fikis, 2019). One yet unexplored area of focus is how social media users engage in discussions regarding giftedness and gifted education. Researchers of gifted education have emphasized the importance of examining the assumptions and ideals of giftedness held by educational stakeholders and have positioned these beliefs as central to “implementing gifted education to maximize learning” (Dixson et al., 2020, p. 25). Recent literature urges educational stakeholders and policy makers to rethink traditional conceptions of giftedness and reframe the purpose of gifted programs (Dixson et al., 2020; Ottwein, 2020), and highlights the potential systemic benefits toward equity and inclusion when these shifts in mindset occur across all levels of a school district (Mun et al., 2021). The notion that beliefs of giftedness are central to maximizing the equity and efficacy of gifted programming underscores the need to better understand the beliefs of giftedness held by educators as well as the public.
Social Media Use Among Educational Stakeholders
Like many groups, educational stakeholders have leveraged the possibilities of social media to build online communities: Parents, students, and educators use it to share resources and experiences (Ammari et al., 2019; Bouton et al., 2021; Staudt Willet & Carpenter, 2020). Research on how parents utilize social media indicates that platforms like Reddit, Facebook, parenting blogs, and other web-based forums provide parents with channels for garnering parenting information, advice, and social support (Ammari et al., 2014, 2019; Haslam et al., 2017). Ammari et al. (2014, 2019) suggested that the anonymity associated with digital communities may cause parents to perceive less judgment when sharing personal information and that this may encourage both increased self-disclosure of potentially stigmatizing information and subsequent positive feedback from others. Ammari et al.’s (2019) work is supported by additional research from Andalibi et al. (2018) who used a mixed methods approach to find that posts from anonymous, or “throwaway,” accounts were more likely to include self-disclosing posts and self-disclosing responses, plausibly because of a perceived lower risk of judgment. These online spaces often take the shape of digital communities in which parents feel supported and encouraged by the shared experiences of others. In a qualitative study of mothers of gifted children who maintain homeschooling blogs, Jolly and Matthews (2017) found that participants took great satisfaction in the facilitation of community building and the informational exchange that their blogs enabled.
Much like parents, students also use social media for reasons that extend beyond entertainment and social engagement. Recent examinations of how and why undergraduates use social media indicate that they use such platforms to seek information and support from administrative personnel (Amador & Amador, 2014) and to access immediate academic help from peers (Alt, 2017). Additional research has found that social media use may also impact the development of postsecondary goals and increase feelings of academic efficacy. In an analysis of data from Reddit, Jacobs et al. (2020) explored the academic and professional experiences of women in STEM (science, technology, engineering, and math) fields. Their analysis revealed findings like those of previous qualitative studies that suggested that women in STEM programs experience gender-based harassment, barriers to access, and inequitable opportunities for professional success (Jacobs et al., 2020).
Investigations of how teachers use social media have identified multiple ways that educators have leveraged such platforms as tools for seeking support, self-generating professional development, networking (Prestridge, 2019), and promoting student engagement (Dragseth, 2020; Junco et al., 2013). Research on the use of Reddit reveals that teachers use the site for seeking both practical and emotional support regarding topics that may be perceived as too sensitive to discuss with colleagues (Carpenter et al., 2018) and that sites like Reddit may serve as forums for raising “practical and pragmatic concerns that teacher education courses are neglecting” (Staudt Willet & Carpenter, 2020, p. 229).
Social Media and Gifted Education Research
Arguably, gifted education is an area in which the use of social media has been underexplored. Recent literature has investigated how frequently gifted students use social media (Kara et al., 2020), the degree to which social media engagement and peer interactions differ between gifted and nonidentified students (Sureda Garcia et al., 2020), and how parents of gifted students build community networks for social support and informational exchange (Jolly & Matthews, 2017). However, this work has not included social media sentiment analysis. Moreover, this work has not included the attitudes, experiences, or behaviors of teachers and other gifted education practitioners. Sentiment analysis examines the attitudes that people express in discussions; combining sentiment analysis with social media data has the potential to provide insight into current attitudes about giftedness.
Although it is clear that social media is being used by gifted individuals, it is not clear how it is being used, or how different types of posts may evoke different reactions within online discussions of giftedness. Exploring how people use social media to engage with one another in discussions of giftedness may provide insight into how to improve education practice and policy and inform new areas that may be ripe for research. Sentiment analysis may be a way forward for the field because it allows researchers to quantify the emotional context of large amounts of text. One challenge to social media research is the sheer volume of available data and sentiment analysis provides an alternative to more time-consuming and expensive analytical methods. In addition, the current project extends earlier work on how teachers and parents perceive students’ use of social media. For example, Molin et al. (2015) argued that knowing teacher and parent perceptions of how students use social media is critical for understanding how best to serve and support young people with disabilities. These authors recommended further research that explores how individuals self-present in online situations and we seek to fill that gap in the literature.
Sentiment Analysis
In the present study, we employed sentiment analysis to examine the attitudes expressed by people who discuss giftedness and gifted education on Reddit. Sentiment analysis, also referred to as opinion mining, is the process of statistically sorting texts into categories of sentiment or emotion by assigning numeric values (Rani & Kumar, 2017). A statistical algorithm is used to assign sentiment values that are positive, negative, mixed, or neutral. Assigned values range from −1 to 1, where a value of −1 is associated with negative sentiment and a value of 1 is associated with positive sentiment. This is done through matching the words or phrases within a text to prebuilt lexicons (or libraries). These lexicons contain dictionaries of words and phrases but, instead of definitions, they contain associated sentiment values. Using this system of matching words and phrases within a text to their associated sentiments, a calculated sentiment value for a message can be extracted (Rani & Kumar, 2017).
Singh et al. (2020) noted that the current volume (in terms of users and activity) of major social media platforms makes classical techniques for textual analysis untenable. Furthermore, as user base and activity increase, the necessity for computational techniques becomes mandatory (Singh et al., 2020). Sentiment analysis is a modern technique for analyzing large volumes of social media data that are too cumbersome to qualitatively analyze (Yue et al., 2019). For example, in Pak and Paroubek (2010), the authors analyzed 300,000 tweets. In Santos et al. (2018), the authors analyzed 1,938 student reviews. Under ideal circumstances, a team of researchers could individually assess each tweet or student review to extract overall themes. Realistically, extracting any useful information from such large bodies of textual data in a timely manner is not feasible. In social media forums where the corpus of text is ever-expanding, it is impractical to attempt to qualitatively assess an entire corpus.
When conducting a sentiment analysis of a corpus of text, the first step is to determine the level of granularity. Sentiment analysis can be divided into three levels of granularity: document, sentence, and word (Yue et al., 2019). Documents refer to an entire text; in the context of social media, a document can be a tweet, a post on a message board, or a blog post. Researchers conducting a sentiment analysis on documents seek to assign a sentiment to a document. The issue with this approach is that a document can be nuanced. For example, a post on a social media platform might discuss both positive and negative aspects of the same issue. The overall sentiment would be the average across the document and it, in turn, would be unable to capture the nuance of the sentiment within the document. In cases where a researcher wishes to capture varied attitudes within a document, greater granularity is needed. Granularity can be increased to the sentence or word levels. Sentence-level granularity refers to sentiment analysis of sentences and word-level granularity refers to sentiment analysis of individual words within the entire corpus of collected text (Yue et al., 2019). Sarcasm detection is one area in which scholars have made advances using sentiment analysis of sentences (Appel et al., 2016). Previously, the use of sarcasm within online discussion was a barrier to applying sentiment analysis to sentences within a text (Tsur et al., 2010). Researchers interested in conducting a sentiment analysis of words within a text focus on extracting information from the basic units of communication. Furthermore, word-level analysis is the basic component of a sentiment lexicon (Yue et al., 2019). Individual words can provide a researcher with further information, such as demographic characteristics of users. As Yue et al. (2019) pointed out, the level of granularity used in a sentiment analysis should be determined based on the established research questions.
Sentiment Analysis in Education Research
Sentiment analysis is increasingly used to conduct research in education (Balahadia et al., 2016; Rani & Kumar, 2017; Santos et al., 2018). This method is often used by institutions of higher education to holistically analyze large bodies of student reviews. For example, universities regularly collect student evaluations at the conclusion of courses and use them to assess course and educator effectiveness. Using this method, administrators in higher education can analyze student reviews on a large-scale basis. For example, Santos et al. (2018) used text mining scripts to extract 1,938 student reviews for 65 business schools. The authors then used sentiment analysis to extract the associated sentiment from the reviews for each business school and discussed how their research could be used by institutes of higher learning to engage students and modify services. Using a similar technique of text mining in conjunction with sentiment analysis, Rani and Kumar (2017) analyzed student reviews of 25 online university courses conducted over the span of 10 years. The authors analyzed sentiment changes across time and highlighted how sentiment analysis can help administrators and faculty find areas in need of improvement and inform future decisions and actions.
Outside of higher education, sentiment analysis has been used by scholars to analyze educator sentiment on social media platforms (Relucio & Palaoag, 2018; Y. Wang & Fikis, 2019). Recently, scholars have used sentiment analysis to understand and assess how educators viewed and discussed the Common Core Standards over Twitter (Y. Wang & Fikis, 2019). The authors focused on which topics were being discussed, who was leading those topics, and the overall sentiment toward the Common Core Standards. The authors found that those who were most negative toward the Common Core Standards were social media leaders; they concluded that this method can be used to inform policy makers on how the public views education policies in real time. As education researchers seek to close research-to-practice and research-to-policy gaps, one concern is how to invite other stakeholders into policy and practice conversations. Sentiment analysis has the potential to increase the types of voices represented in educational decision-making, diversify the perspectives, and further the push toward equity in the field.
Using Reddit as a Data Source
Reddit is a popular social media website, on which users make topic posts in different online forums (referred to as subreddits). As of 2020, Reddit.com has the fifth most traffic of any website in the United States (20th worldwide; Alexa Internet, Inc., 2020), with an average of over 430 million unique users monthly (Reddit Inc., 2020). Reddit’s user base is estimated to encompass 15% of U.S. men and 8% of U.S. women (Pew Research Center, 2019). Its demographic user base skews toward early adults, with 22% of U.S. 18- to 29-year-olds using the website (in comparison with 14% of 30- to 49-year-olds, 6% of 50- to 64-year-olds, and 1% of 65+ year users; Pew Research Center, 2019). Reddit has evolved into a forum where nearly any topic can be discussed and topics related to education are no exception. Given Reddit’s accessibility and widespread use, as well as the ability to draw high-quality data for social science studies (Jamnik & Lane, 2017), scholars are turning to it to conduct research.
Using Reddit as a data collection site might be a way for researchers to access practitioner opinions and attitudes on a large scale. Understanding how stakeholders discuss relevant issues and leverage online communities can inform further work to close these research-to-practice gaps. For example, Neal et al. (2019) found that two thirds of practitioners do not have access to a researcher in their networks. A recent examination of how educators use Reddit suggests that the site is highly trafficked by teachers and that its use could have implications for training preservice educators (Staudt Willet & Carpenter, 2020). The researchers also noted that educators who engaged with Reddit were more likely to share stories and have discussions than to share instructional materials and resources. This usage differs from how teachers use other online communities, such as Teachers Pay Teachers or Etsy, where teachers primarily interact to share resources. To conduct our analysis, we made use of Reddit’s unique composition.
Reddit’s basic structure is made up of four components: subreddits, threads, comments, and votes. A subreddit is a community structured around a theme, in which users post videos, images, links to other websites, and/or text (Duggan & Smith, 2013). For example, in the subreddit /r/aftergifted, users create topic posts about underachieving after being identified as gifted. In each subreddit, members designated as moderators can exercise editorial powers (e.g., modifying posts or deleting them) to ensure that the posts adhere to the theme of the subreddit. Subreddits consist of threads, which are topic posts that can include videos, images, links to other websites, and/or text as well as subsequent comments made by other members (Hogan, 2017). Reddit’s thread structure is a tree format and comments are made directly to other comments rather than to the original topic post. In other words, a graphical display of the structure of a Reddit thread would resemble a tree rather than a chain. Both topic posts and subsequent comments are limited to 40,000 characters. Reddit orders comments by default based on their overall score. A comment’s score is derived from users either “upvoting” or “downvoting” a comment (Staudt Willet & Carpenter, 2020). Upvotes add one vote to a comment’s overall score, and downvotes subtract one. Each account may cast only one vote per comment, although a user with multiple accounts can contribute one vote per account.
Self-Disclosure in Social Media Discourse
Like much of the internet, Reddit users can post anonymously under user-created pseudonyms (Zirikly et al., 2019) or through multiple accounts. Ammari et al. (2019) found that individuals are willing to engage in conversation about sensitive, and potentially stigmatizing, experiences in online communities that allow users to post anonymously. This is facilitated by the option to use “throwaway accounts” that can be created when posting about a particularly sensitive topic or when users are especially concerned about anonymity within a particular subreddit (Ammari et al., 2019). Leavitt (2015) described the use of throwaway accounts on Reddit and used ethnographic trace analysis to explore the contexts in which they are used. Findings indicated a significant relationship between the level of perceived anonymity and the likelihood of a user posting from a throwaway account. However, Leavitt (2015) did not find a significant relationship between the perceived size of the audience and the likelihood of a user posting from a throwaway account. Overall, Leavitt (2015) found that “being identifiable has more impact on using a temporary technical identity than what you say or to how many people you say it” (p. 324). This usage differs from how users may engage on sites with less anonymity, such as Facebook, where users must decide whether disclosing could bring perceived rewards (e.g., affirmation) or risks (e.g., criticism; Walsh et al., 2020).
An aspect of social media that has garnered interest is how individuals self-disclose their identities and experiences in online settings (e.g., Ma et al., 2016; Song et al., 2019). Derlega et al. (1993) defined self-disclosure as an individual’s revelation process when sharing personal information with others. Although this may raise immediate concerns about the veracity behind these self-disclosure statements, L. Wang et al. (2017) found that privacy concerns are negatively associated with honesty in self-disclosure posts. Given Reddit’s relative anonymity, it is plausible that dishonesty is less of a concern in Reddit posts compared with other social media sites. Our goal is to explore reactions to the original posts and not the purported veracity of the original posts; for this reason, we argue that post veracity is irrelevant to our goals.
Interestingly, anonymity does not appear to negatively influence the type of support posters receive from the rest of the community. Using Reddit, De Choudhury and De (2014) studied the difference in online disinhibition and self-disclosure between users who chose to use their main accounts and those who used throwaway accounts in mental health information subreddits. The authors found that anonymity does not hinder the quality of social support redditors receive—in fact they garner more comments on such postings . . . tend to provide greater emotional sustenance and are generally more involving and helpful in their suggestions and feedback. (De Choudhury & De, 2014, p. 9)
Furthermore, Collins and Miller (1994) found that individuals who self-disclose more personal details are more likely to be viewed favorably than individuals who self-disclose fewer personal details.
Additional work elaborates on the difference between self-disclosure, when an individual reveals information with little to no regard for reputation, and self-presentation, when an individual presents information that may or may not be factual to elicit a particular response from the other party (Schlosser, 2020). Although it may be difficult to tease apart the instances of self-disclosure from self-presentation, Ma et al. (2016) found that users tend toward self-disclosure when they are less concerned about their anonymity. Ma et al.’s (2016) findings coincide with Leavitt’s (2015) study on anonymity and self-disclosure. Furthermore, in a 2019 meta-analysis of 14 studies, Clark-Gordon et al. found a positive average correlation of anonymity and self-disclosure. One of the concerns when performing a scraping study is the difficulty of assessing the level of honesty in the posts. However, these previous findings on anonymity indicate that our interest in the average sentiment, or attitude, of gifted education topics will not be significantly affected because of the level of anonymity Reddit provides.
These studies indicate that our interest in the average sentiment of responses on Reddit may provide a baseline for future studies that probe the specifics of these interactions. Although we cannot make causal claims in this exploratory analysis, we hope to provide more groundwork and see which topics exhibit strong sentiment. Our intention for using sentiment analysis in Reddit communities is to establish a baseline for how gifted education is discussed and pave the way for future studies to probe narrower questions related to the public’s conversations about gifted education.
Purpose
Our purpose in conducting this research is to explore how, in terms of sentiment, gifted education is discussed in an online social media website. Social media has become an ever-present part of society and to ignore it within gifted education research is inappropriate. An extensive body of research exists that explores how social media and education interact (e.g., Manca & Ranieri, 2016; Selwyn, 2012), but gifted education is not yet represented in this body of literature. The findings regarding preservice teacher learning in Staudt Willet and Carpenter (2020) demonstrated that individuals are using Reddit for productive means; we hope to explore how individuals communicate about giftedness on Reddit in a similar manner. Our examination of how gifted education is discussed on Reddit will provide scholars with insight into the beliefs of giftedness shared by Reddit users and the topics of interest regarding giftedness and gifted education shared by both educational stakeholders and the public at large.
A secondary purpose of our study is to provide a framework for the replication and extension of our results. Our goal is to create materials for researchers in the field of gifted education to apply this methodological approach quickly and easily to either replicate our study or to explore their own research questions examining social media and gifted education. Furthermore, our work has the potential to create additional interdisciplinary projects such as computer science and linguistics in education research.
Research Questions
Research Question 1
What is the relationship between gifted education topics that have high rates of participation across the subreddits of interest and the sentiment toward those topics?
Hypothesis 1
There is no research in this regard, so our hypothesis is only based on speculation. We hypothesize that the topics that have the greatest rate of participation (as denoted by the number of thread votes and comments) will be those that are negative in sentiment toward gifted education. There is a large enough community on Reddit to form a subreddit dedicated to underachievement, which provides evidence that within the user base of Reddit, the overall sentiment toward gifted education is negative. We considered this hypothesis exploratory and approached it using a descriptive methodology rather than a confirmatory one.
To address this hypothesis, we calculated the average sentiment within each gifted subreddit of interest and within gifted-associated threads within nongifted subreddits. We calculated the correlation between our conditionals (vote average, number of votes, number of responses) within each thread and its associated sentiment. In terms of figures, we plotted the correlations and the distribution of sentiment. In addition, we provided direct examples from the scrape of the thread titles that had the greatest extremes (upper and lower 1% bounds) of sentiment throughout each subreddit.
Research Question 2
To what extent does the average sentiment, or attitude expressed by people discussing gifted education, differ in topic posts that include self-disclosures of giftedness compared with topic posts that do not include these self-disclosures?
Hypothesis 2
Overall, we hypothesize that posts containing self-disclosure will have positive sentiment and that they will have more positive sentiment than posts that do not contain self-disclosure. For example, are self-disclosures more or less likely than non-self-disclosures to elicit responses with positive sentiments? General perceptions of giftedness are charged and rather negative, with Brown and Wishney (2017) noting that “even the term gifted is value-laden, and, in some school districts, is not allowed to be used” (p. 24). However, research on anonymity and self-disclosure indicates that the general response to self-disclosure topic posts is positive (Collins & Miller, 1994).
Previous research indicates that self-disclosures increase when the costs are reduced (Nabity-Grover et al., 2020) and that users are more likely to share information when they feel assured that their anonymity is protected (Ma et al., 2016). Within Reddit, perceived benefits may be increased because of the opportunity to build relationships, participate in communities, and control one’s self-presentation while maintaining anonymity (Cheung et al., 2015; Liu et al., 2016; Nabity-Grover et al., 2020). We addressed this hypothesis in the same way as Hypothesis 1, except for subsetting our data by disclosure status.
Discussion on Self-Disclosure
Nabity-Grover et al. (2020) proposed a series of research questions related to the appropriateness and acceptability of self-disclosures in online environments and we wish to apply their work to gifted education. Our choice to explore self-disclosure in the realm of giftedness is based on speculation, but we hypothesize that there is a positive sentiment to self-disclosure topic posts as the use of social media often fulfills a need to belong (Seidman, 2013). We wish to explore whether this positive sentiment exists in discussions about giftedness despite the reported negative perceptions of giftedness in the literature (Brown & Wishney, 2017). For example, do Reddit users in the gifted forums have a more positive sentiment toward topic posts that contain giftedness self-disclosures compared with topic posts that do not contain self-disclosures? Users may feel a sense of connection in self-disclosure topic posts and their sympathy may be reflected in a higher average positive sentiment in responses. The subreddit (/r/aftergifted) is dedicated to individuals who were identified as gifted but feel disillusioned and are seeking advice and camaraderie, and this is a place where average sentiment may be positive.
Method
Sample
We collected data from three subreddits: /r/gifted, /r/giftedconversation, and /r/aftergifted. These three subreddits are dedicated to the subject of giftedness and gifted education. In our initial examination of subreddits associated with giftedness, we conducted a subreddit search using the terms gifted, giftedness, intelligence, genius, smart, high ability, and high achieving. Because subreddits often contain links to closely related subreddits in a side panel, we analyzed the subreddits listed in /r/gifted for inclusion within our analysis. We observed that not all subreddit results were appropriate for this study; for example, the subreddit “Intelligence” was associated with espionage and spying. In addition, we set a threshold of at least 100 users in a subreddit and excluded those that did not meet this criterion.
We also collected threads dealing with giftedness in the following generalized subreddits: /r/teenagers, /r/parenting, and /r/teachers. These three subreddits represent large communities that are considered stakeholders within education: students (/r/teenagers), parents (/r/parenting), and educators (/r/teachers). Finally, we collected topic posts and responses from threads dealing with giftedness and gifted education from /r/askreddit. As of June 29, 2020, the subreddit /r/askreddit is the third largest in terms of subscribers on the website, behind /r/announcements and /r/funny. The search terms we used to collect topic posts and responses used the same search terms to locate subreddits associated with giftedness (i.e., “gifted,” “giftedness,” “intelligence,” “genius,” “smart,” “high ability,” and “high achieving”). Because of the likelihood that not all threads containing the search words would be appropriate for inclusion (e.g., “gifted” could refer to an action or a trait), two authors examined each set of threads to determine whether or not the thread was appropriate to include in the study. When the two authors did not agree on inclusion, a third author examined the disputed thread and made the final decision on inclusion or exclusion. A description of the subreddits along with the number of subscribers can be found in Table 1.
Description of Subreddits Included in the Analysis.

Subscribers are reported as of June 29, 2020.
To collect the data, we used R 4.02 (R Core Team, 2020) in conjunction with the RedditExtractoR package (Rivera, 2019). The RedditExtractoR package scrapes Reddit through interfacing with the Reddit application programming interface (API). Scraping is the automated process of systematically extracting data from a website (Rivera, 2019). A user can specify a search term(s) and extract results from Reddit as a whole or as a specific subreddit. Furthermore, Reddit’s API allows for a full search of all content on Reddit without time restriction. That said, due to limitations of Reddit’s (2019) API, Rivera recommends limiting a search to fewer search terms with a single-search term being preferable. Furthermore, an in-built limitation to Reddit’s API is limiting returns on threads with greater than 500 comments. Only 500 comments can be extracted from threads that contain more than 500 comments.
Our process of scraping Reddit involved two steps: The first step scraped the URLs for threads on Reddit and the second step scraped the content from those threads using the reddit_urls() function. The second step in scraping Reddit was completed using the reddit_content() function. This command created a data set that contained the comments associated with the thread as well as metadata associated with the comments. The comment metadata includes the author of the comment, the date of the comment, and the comment score. Additional metadata is included about the thread, including thread score and proportion of upvotes. Using the data set extracted from the second step, we then conducted a sentiment analysis.
Sentiment Analysis
Our unit of analysis was words used within topic posts on Reddit. Ultimately, we assigned sentiment values to each word within a topic post and then summed those values to create an aggregate sentiment score. We then derived descriptive statistics to analyze topics, subreddits, and word choice. Our descriptive analysis results have been presented in two formats. The first includes aggregate statistics across subreddits; these results describe the general sentiment across the social media platform. The second format we present includes descriptive statistics by subreddit.
Preprocessing
To preprocess our data, or prepare it for analysis, our first step was to tokenize the data. Tokenization is the process of segmenting a text into individual words (Mullen et al., 2018). After tokenizing the data, we removed extraneous words (e.g., a, an, the), and finally, we standardized tokens (Symeonidis et al., 2018). In this step, all words were changed to lowercase, contractions were reverted to their composite words (e.g., won’t to will not), and numbers were written out in word format (e.g., 10 to ten). Our final step was lemmatization, or the process of standardizing words into their root word form (e.g., being to be or learned to learn; Symeonidis et al., 2018).
Following data preparation, a sentiment score was assigned to each word within a corpus. In our analysis, the corpus signifies the scraped text from Reddit thread titles and comments. Words with positive sentiment were assigned a 1 and words with negative sentiment were assigned a −1. The sentiment score of a thread’s title represents the average sentiment score of the words that compose that thread’s title. Similarly, the sentiment of a reply is the average of the sentiment score of the words that compose the reply.
Descriptive Analysis
Our descriptive analysis reports frequencies, average sentiment, and correlation scores between participation metrics (e.g., number of replies, vote totals, vote average). The following descriptive statistics are reported:
Frequency
We calculated the word frequency of each word within our corpus, the aggregate word frequency across Reddit, and the word frequency for each subreddit of interest. In addition to calculating frequency, we have displayed our results using word clouds.
Average Sentiment
We calculated average sentiment; this value ranges between −1 and 1, where a value closer to 1 indicates greater positive sentiment. We calculated the average sentiment across Reddit and within each subreddit of interest.
Distribution of Sentiment
We plotted the distribution of sentiment by threads across Reddit. The sentiment of a thread is the average sentiment score of the replies within that thread.
Conditional Descriptives
We calculated conditional descriptives by examining frequency, average sentiment, distribution of sentiment in terms of the number of comments within a topic post, the total vote score attributed to the topic post, and the vote average for the topic post (topic controversy). Votes are either an “up” that corresponds to a +1 or a “down” that corresponds to a −1. For example, three “up” votes and one “down” vote would correspond to a vote average of .5 and a total vote score of 2. Frequency of sentiment was also examined using two approaches. In the first approach, a simple correlation was derived from sentiment and number of comments, total votes, and vote average (respectively).
Self-Disclosure Identification
The second portion of our analysis focused on topic posts that contain self-disclosure. We operationalized self-disclosure using the work of Derlega et al. (1993) and Nabity-Grover et al. (2020). To this end, we employed a four-step process in identifying posts that contained self-disclosures. In the initial step, we identified topic posts that contained the first-person pronoun “I” or “we.” In our next step, we used topic post length to identify probable self-disclosures. We were not interested in the character length of a given topic post, but the number of instances of first-person pronouns. From this, we created a list ordered by frequency of first-person pronoun usage.
Initially, we planned to utilize an algorithmic process to establish inclusion criteria for self-disclosure posts, but we revised this method during the data analysis phase of our study. A description of this method can be found in the Online Technical Appendix. In our revised final step, two members of the research team reviewed each topic post for self-disclosure based on the definition established in previous literature (Derlega et al., 1993; Nabity-Grover et al., 2020). Importantly, self-disclosure affords the participant the opportunity to make an audience aware of the participant’s presence as well as to shape its impressions of the participant (Gibbs et al., 2006). Some examples of self-disclosure are topic posts in which the original poster shares their health status (mental or physical) or an intense emotional state (e.g., guilt, shame, envy), or reveals similar information about their children or other immediate family members. Types of topic posts that we excluded from the analysis were topic posts referring to acquaintances or friends; topic posts in which the authors disclosed generic, nonsensitive information; and topic posts seeking recommendations or providing advertisements. For example, although the statement, “Yes, I’m a fucking genius, say it with me” (/r/teenagers) includes multiple first-person pronouns, we excluded it from analysis because it did not involve the sharing of sensitive information. The authors feel that these types of topic posts do not reflect the personal component of self-disclosure as indicated by Nabity-Grover et al. (2020) and Derlega et al. (1993). For comparison, the authors did choose to include the following statement, as it better aligns with our operationalization of self-disclosure: “This is just me ranting about how horrible life has been recently just to get it off my chest, if you decide to read there’s mention of drugs, cancer, and horrible family situation. . .” (/r/teenagers, edited for clarity). Topic posts had to be identified as containing self-disclosure by both reviewers to be included in the analysis. Table 2 provides more examples from the data about which types of topic posts were included or excluded in the self-disclosure analysis.
Examples of Posts With and Without Self-Disclosure.
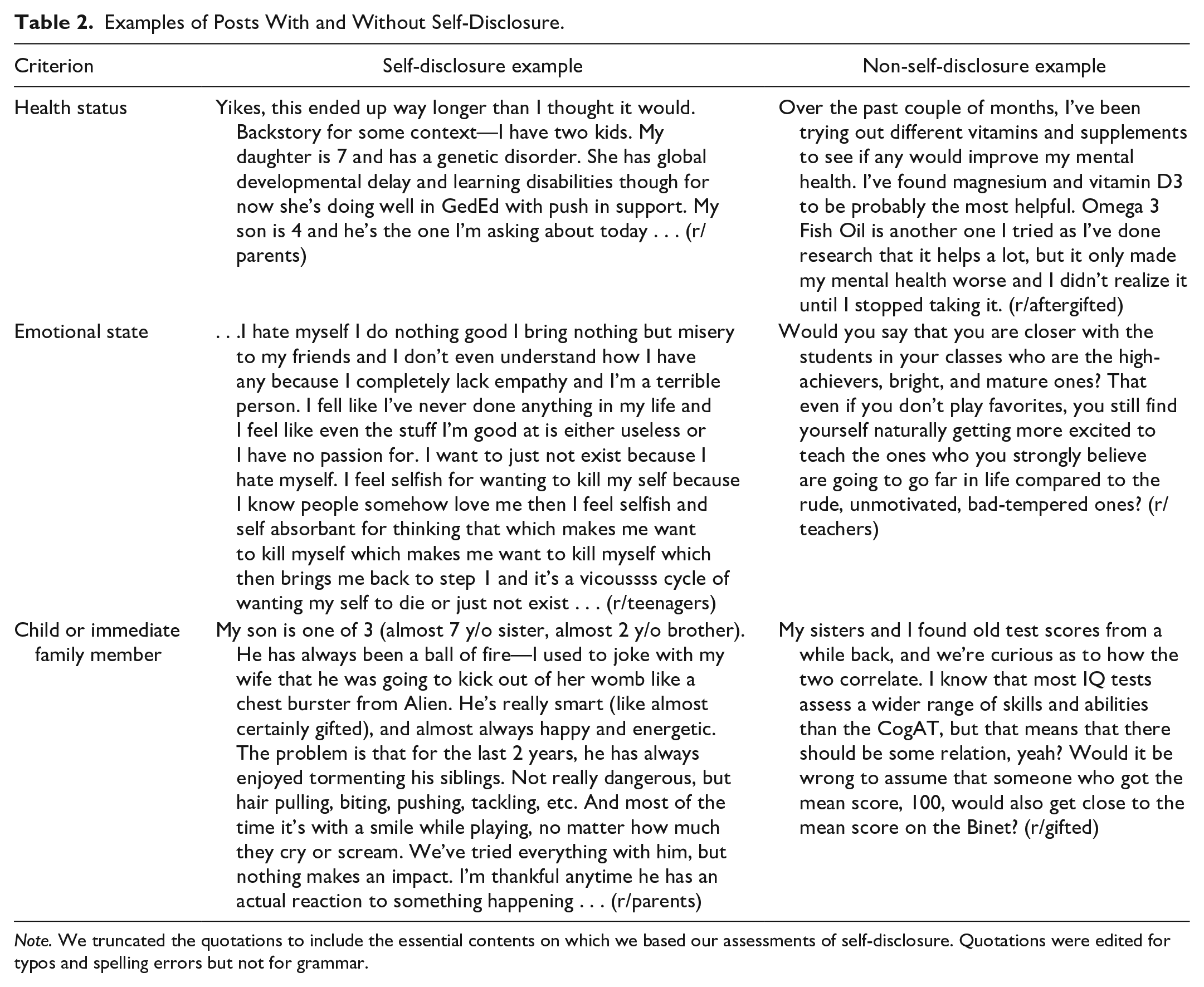
Note. We truncated the quotations to include the essential contents on which we based our assessments of self-disclosure. Quotations were edited for typos and spelling errors but not for grammar.
Results
Sentiment
Descriptive statistics can be seen in Table 3 for our full corpus and Table 4 for disaggregated statistics for the gifted subreddits in our corpus. As previously described, sentiment scores range from −1.00 to 1.00, where −1.00 indicates negative sentiment and 1.00 indicates positive sentiment. Sentiment scores for a topic post or comment are the aggregate of the composite sentiment attributed to the words within that topic post or comment. To provide context, the following topic post in /r/aftergifted was given a sentiment score of −0.27, where the negative value represents the negative connotation found within the thread title itself: “If you have (or had) a high iq [sic] and a learning disability or other mental condition, how was school for you? I have adhd [sic] and I HATED school and disliked the authorities.”
Aggregate Sentiment Across Subreddits.
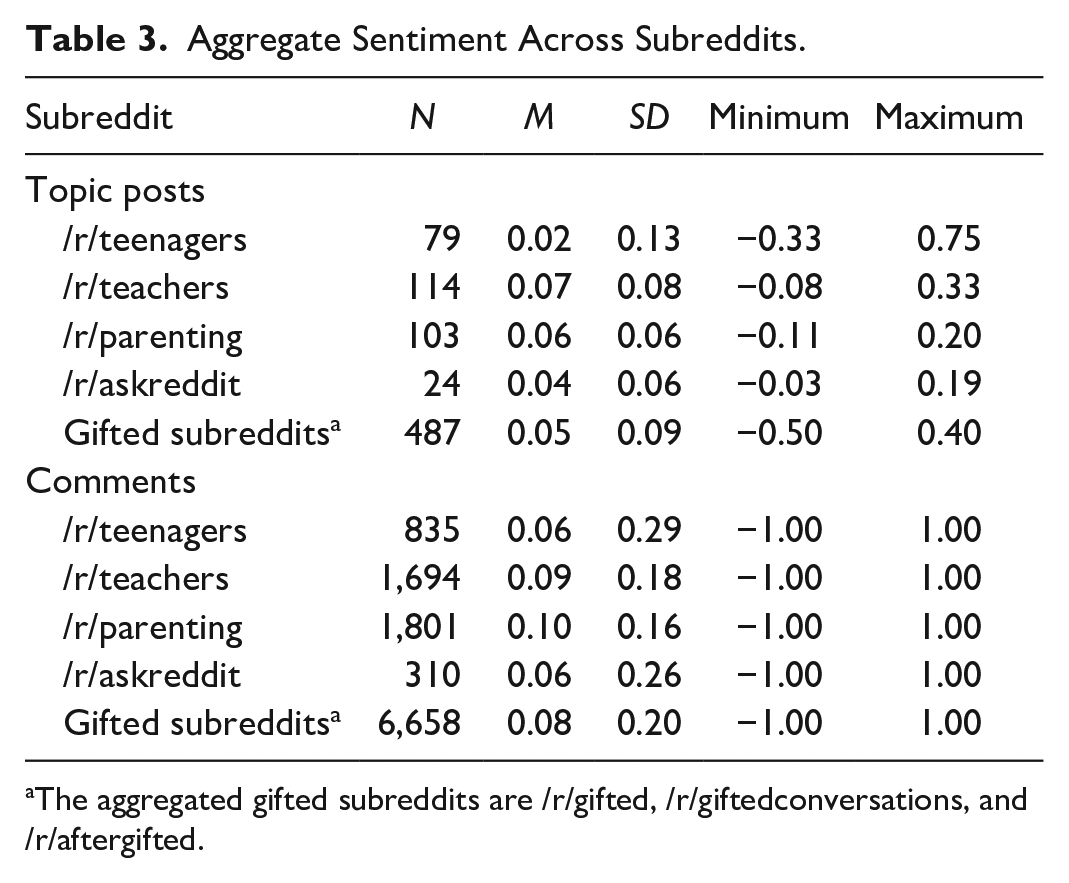
The aggregated gifted subreddits are /r/gifted, /r/giftedconversations, and /r/aftergifted.
Aggregate Sentiment Across Gifted Subreddits.

Distribution of Sentiment
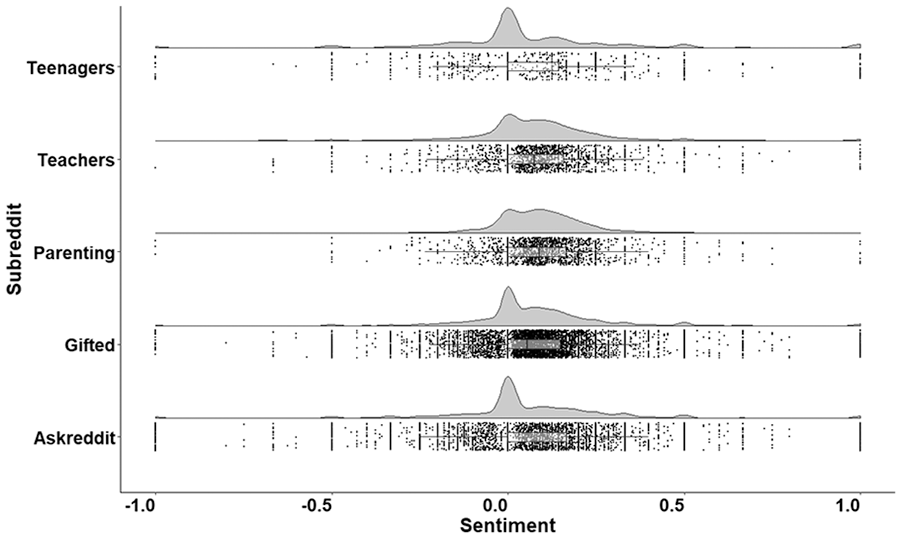
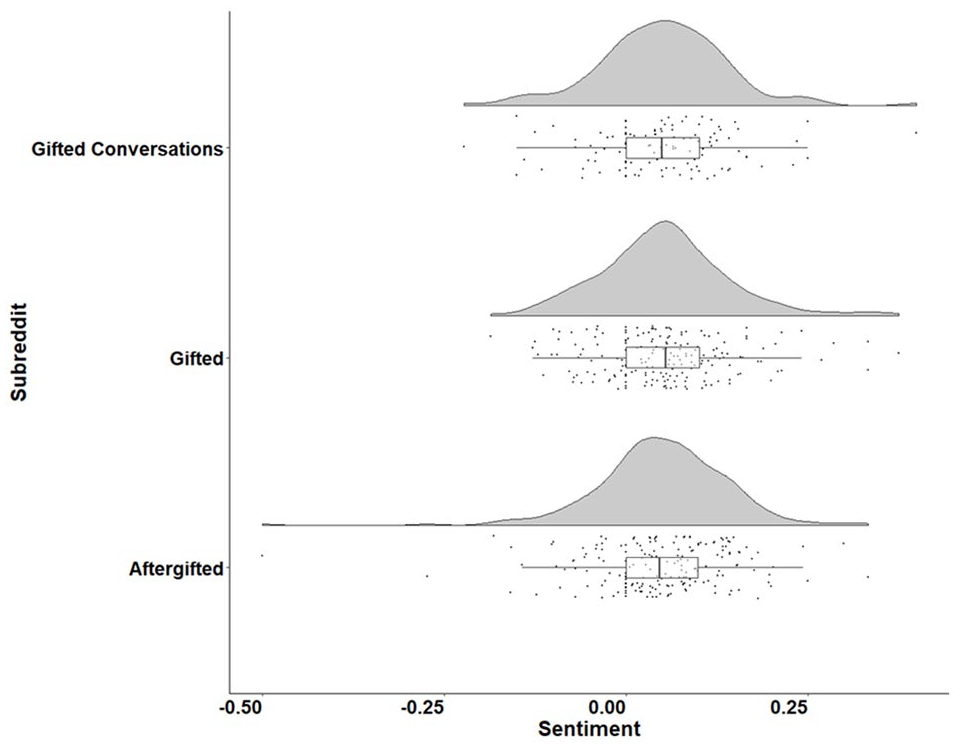
Figure 1 contains the distribution of sentiment scores across topic posts in our corpus. From these distributions, it is clear that while /r/teenagers had the greatest maximum sentiment in topic posts across all subreddits examined, this topic post is likely an outlier and not indicative of the overall distribution. Figure 2 contains the distribution of sentiment across comments in our corpus. The distribution of comments within /r/parenting and /r/teachers showed a positive skew in comparison with the distribution across other subreddits. Interestingly, the greatest density of highly negative comments (i.e., comments with a score of −1) was found in the general subreddit /r/teenagers. Figures 3 and 4 contain the distribution of sentiment across topic posts and comments in gifted subreddits. The distributions were roughly similar across gifted subreddits.

Distribution of Sentiment Across Topic Posts.
Distribution of Sentiment Across Comments.
Distribution of Sentiment Across Topic Posts in Gifted Subreddits.
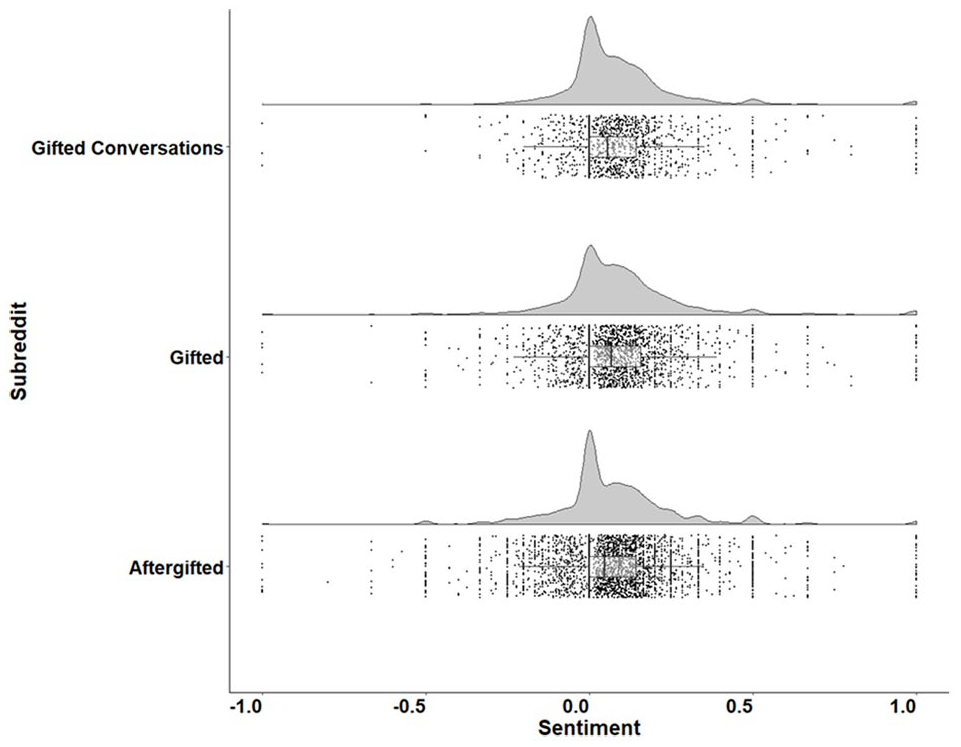
Distribution of Sentiment Across Comments in Gifted Subreddits.
Word Frequencies
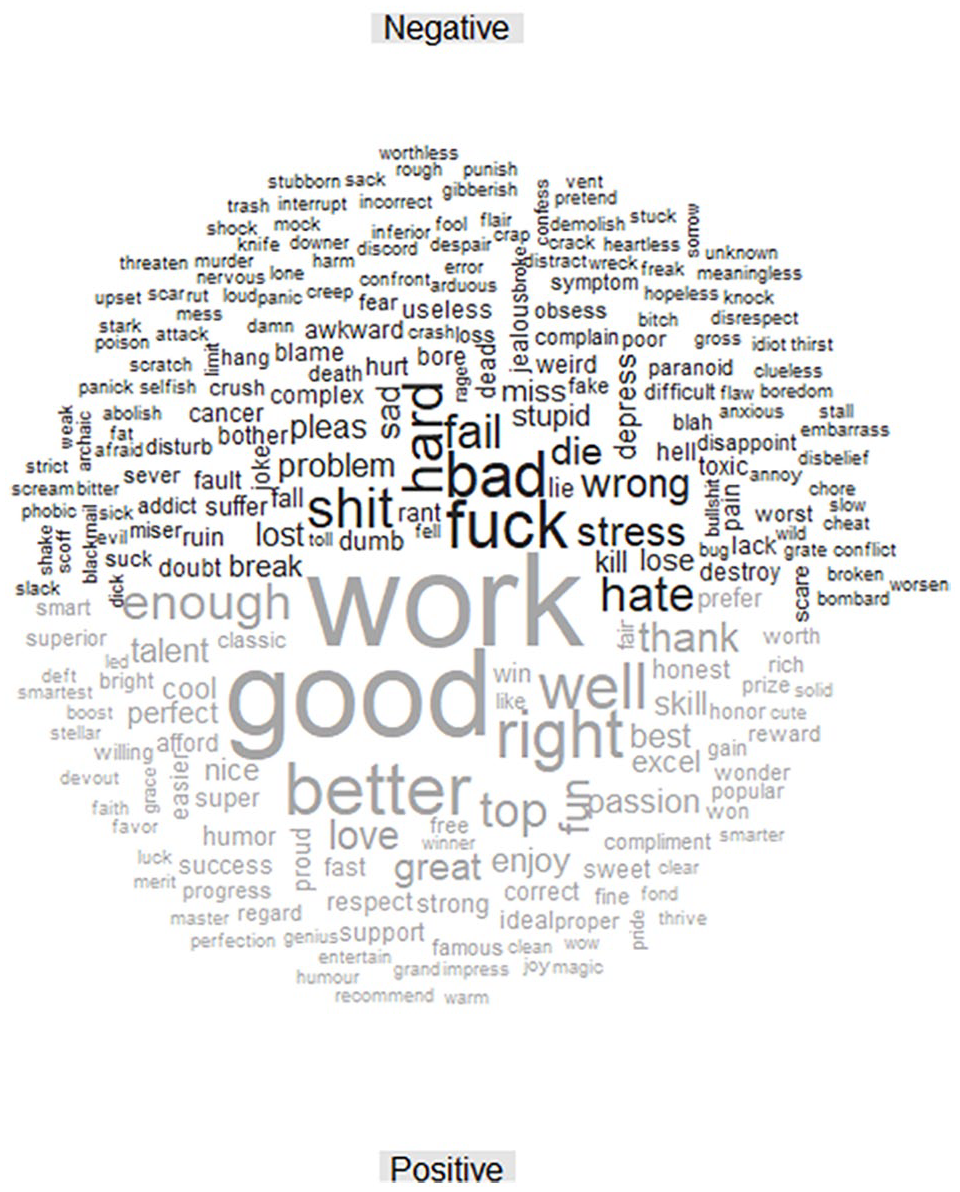
Figures 5 to 9 are comparison clouds that depict the positive and negative words used most frequently across topic posts. The sizes of the words are correlated to their frequency of use. Across all subreddit topic posts, “work” was the most common word, with exception of the gifted subreddits. Negative words across subreddit topic posts were more varied, with “hard” appearing most frequently across all subreddits except /r/parenting and /r/teenagers.
Comparison Cloud of Word Frequencies Used in /r/teenagers Topic Posts.

Comparison Cloud of Word Frequencies Used in /r/parenting Topic Posts.

Comparison Cloud of Word Frequencies Used in /r/teaching Topic Posts.

Comparison Cloud of Word Frequencies Used in /r/askreddit Topic Posts.

Comparison Cloud of Word Frequencies Used in Gifted Subreddits Topic Posts.
Conditional Relationships
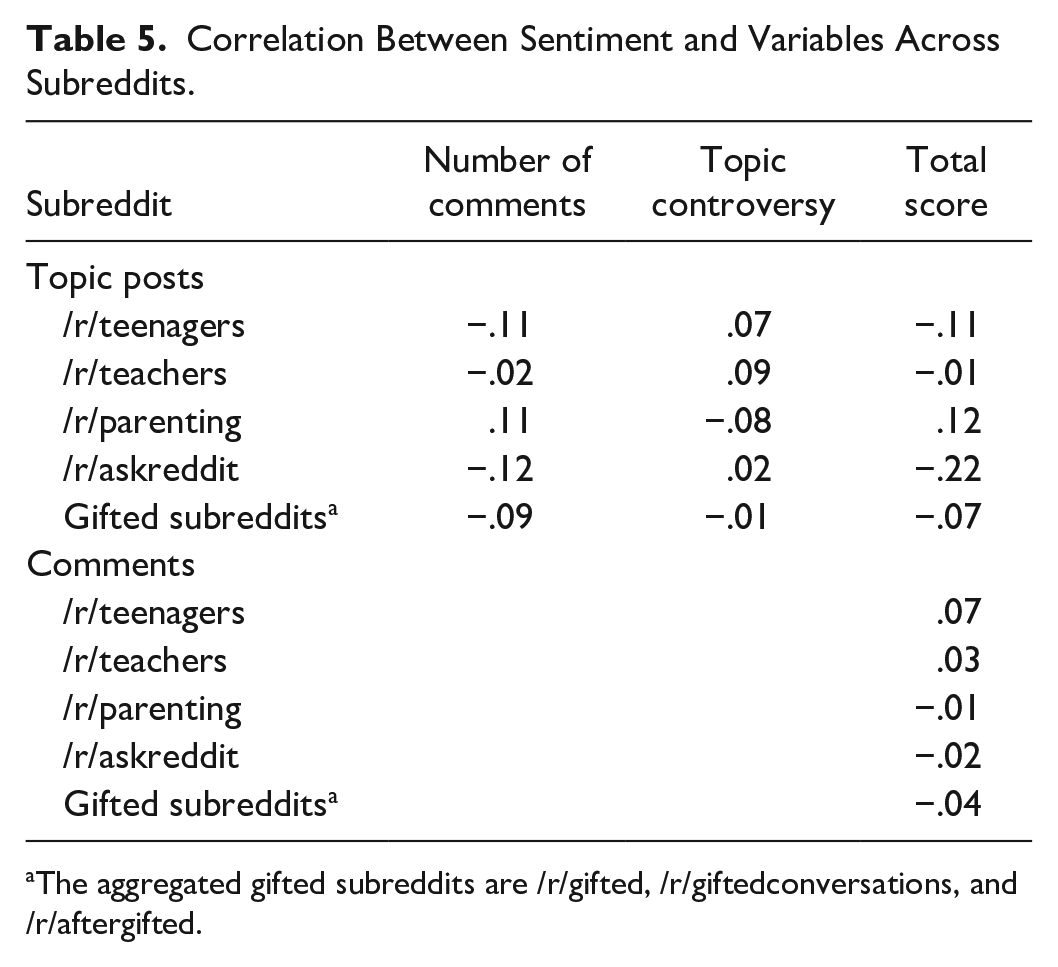
All correlations can be found in Table 5. Of those we examined, there is evidence that a relationship exists between a topic post’s associated sentiment and the user score of the topic thread. Correlations range from −.22 for /r/askreddit to .12 for /r/parenting. In other words, in /r/askreddit a topic post’s overall vote score increases (i.e., receives more upvotes from users) when its overall sentiment is lower. Of the remaining, we found weak to little evidence.
Correlation Between Sentiment and Variables Across Subreddits.
The aggregated gifted subreddits are /r/gifted, /r/giftedconversations, and /r/aftergifted.
Self-Disclosure
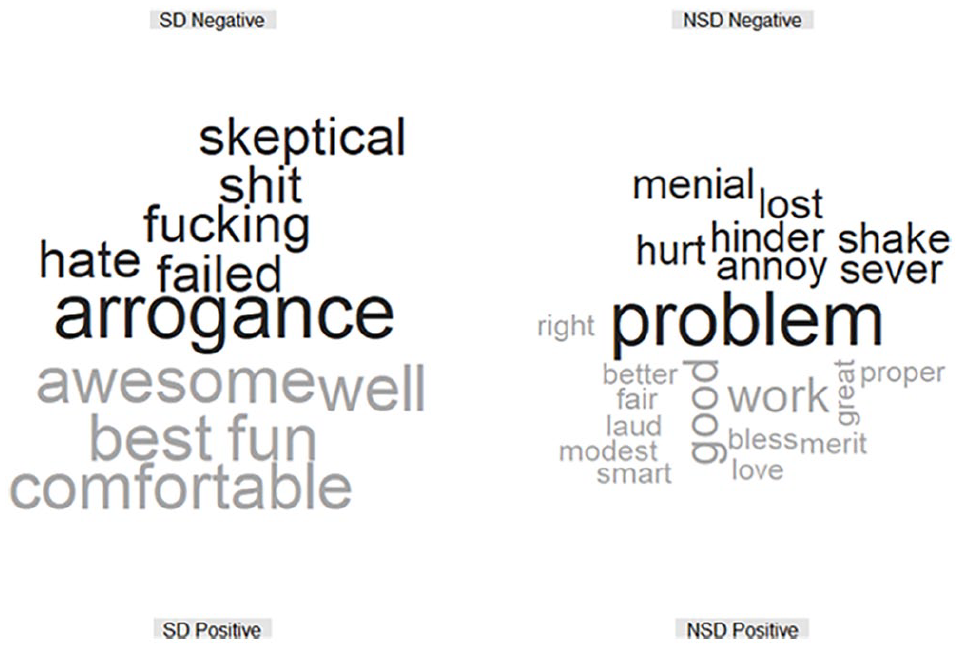
Comparison word clouds for topic posts by self-disclosure status can be seen in Figures 10 through 14. The distribution of sentiment across the self-disclosure subsamples can be found in Figure 15. Except for /r/parenting, the self-disclosure topic posts have a much tighter distribution of sentiment than the nondisclosure topic posts. The self-disclosure topic posts are longer on average, so there is more room for moderation. For example, topic posts in gifted subreddits averaged 1,830.94 characters across topic posts containing self-disclosure, whereas topic posts that did not contain self-disclosure averaged 349.32. The nondisclosure topic posts are more likely to contain brief statements like, “Hey there, is there any notable differences between the two [exceptionally and profoundly gifted]? If there is, can they be altered?” (from /r/gifted).
Comparison Cloud for /r/askreddit Comparing Topic Posts That Contain Self-Disclosure (SD) and Those That Do Not (NSD).
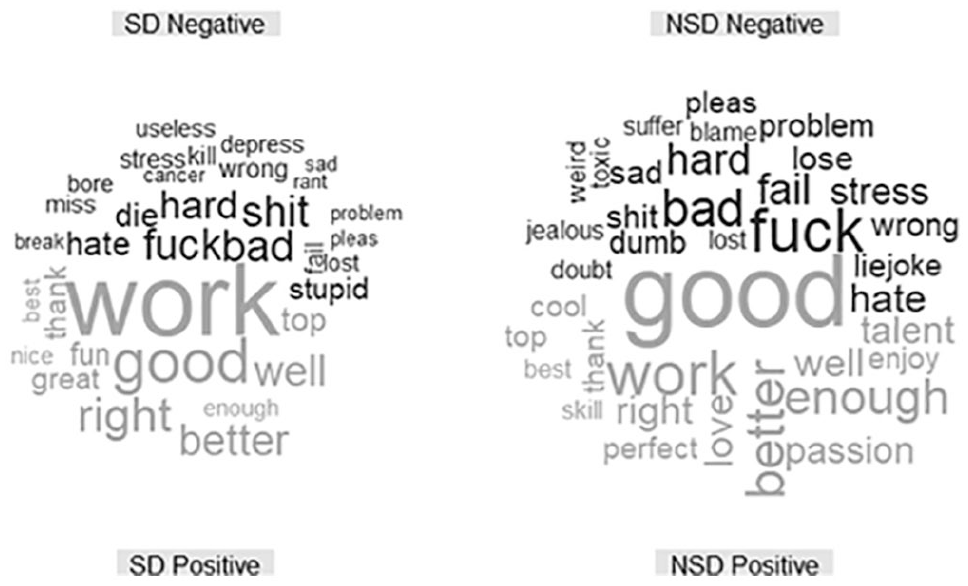
Comparison Cloud for /r/teenagers Comparing Topic Posts That Contain Self-Disclosure (SD) and Those That Do Not (NSD).
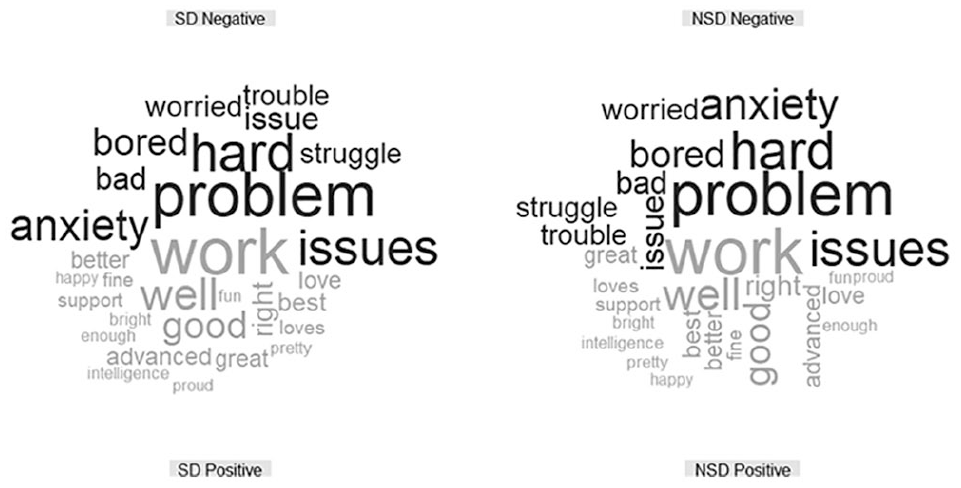
Comparison Cloud for /r/teachers Comparing Topic Posts That Contain Self-Disclosure (SD) and Those That Do Not (NSD).
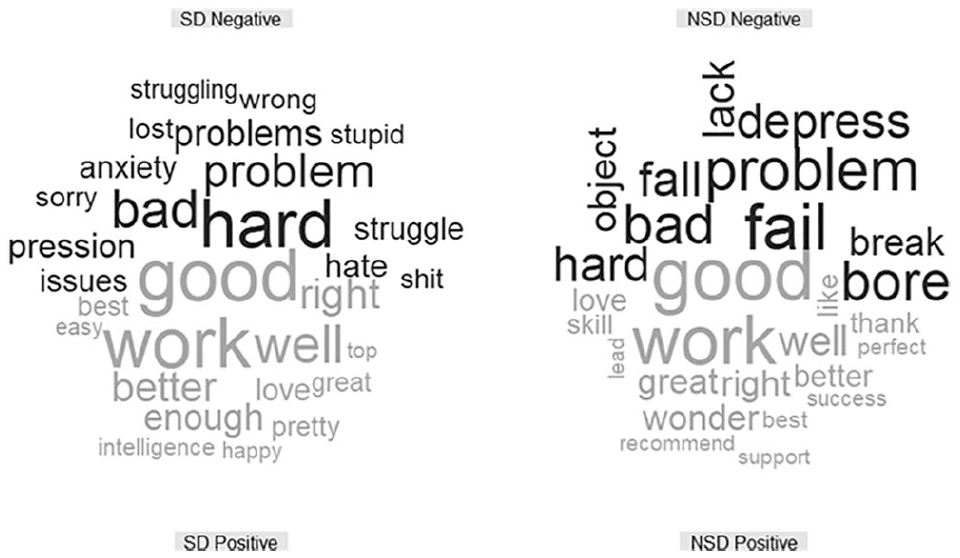
Comparison Cloud for Gifted Subreddits Comparing Topic Posts That Contain Self-Disclosure (SD) and Those That Do Not (NSD).

Comparison Cloud for /r/parenting Comparing Topic Posts That Contain Self-Disclosure (SD) and Those That Do Not (NSD)

Comparison of the Distribution of Sentiment in Topic Posts Across Subreddits by Whether the Topic Post Contained Self-Disclosure
Table 6 contains the descriptive statistics associated with topic posts disaggregated by self-disclosure status. Across subreddits and topic post types, the means vary between 0.01 and 0.08. This suggests an overall neutral tone across the subreddit topic posts regardless of self-disclosure status. Aligning with Figure 15, topic posts without self-disclosure have greater standard deviations across Reddit.
Aggregate Sentiment Across Subreddits by Self-Disclosure.

The aggregated gifted subreddits are /r/gifted, /r/giftedconversations, and /r/aftergifted.
Finally, Table 7 contains the correlations between sentiment and the number of comments, topic controversy (average vote score), and the total sentiment score. Of the correlations calculated, the two most extreme are the correlation between posts with self-disclosure and the number of comments in the subreddit /r/askreddit (−.33) and the correlation between posts without self-disclosure and the topic controversy in the subreddit /r/parenting (−.32). Given the magnitude of the correlations, it is less likely that they occurred due to statistical chance. For the subreddit /r/askreddit, this correlation means that for topic posts containing self-disclosure, the more negative the sentiment is, the more comments it receives. However, as can be seen in Figure 15, sentiment in this subreddit ranges from neutral to positive. It is possible that a more appropriate interpretation is that the more positive the sentiment, the fewer comments a post receives. For /r/parenting, higher (more positive) sentiment was correlated with lower average vote scores. Like the findings regarding /r/askreddit, Figure 15 indicates that /r/parenting contained fewer extreme posts in terms of sentiment than did the other subreddits. Regardless, both findings likely warrant additional study.
Correlation Between Sentiment and Variables Across Subreddits by Self-Disclosure.
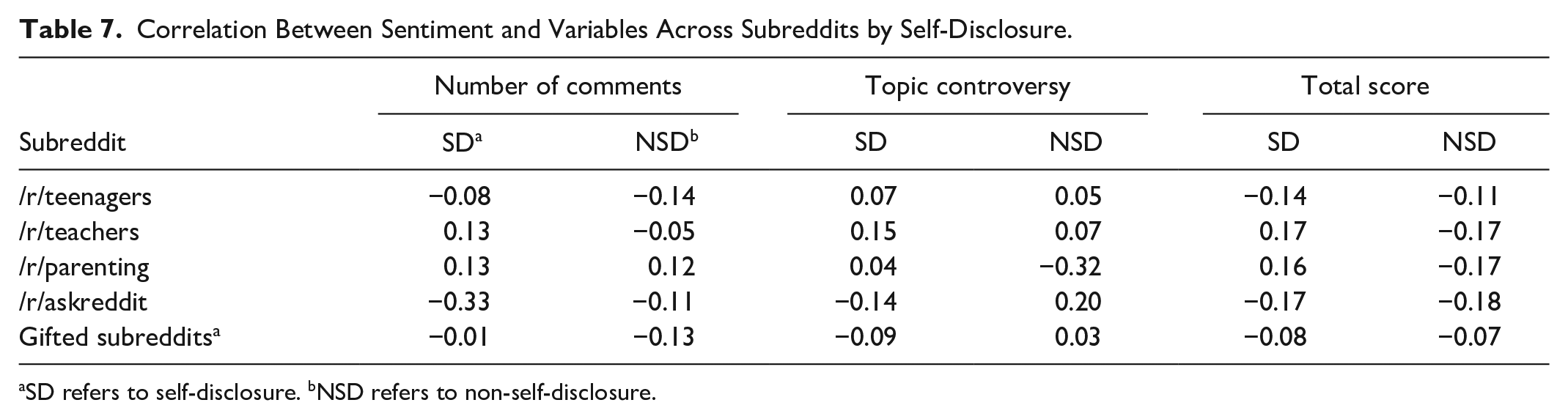
SD refers to self-disclosure. bNSD refers to non-self-disclosure.
Discussion
Overall Findings
Discussions of giftedness on Reddit vary widely. After examining our findings, we conclude that giftedness is discussed in positive, negative, and neutral ways. Furthermore, in the subreddits examined, there was no clear direction of sentiment. The varied nature of discussions of giftedness on Reddit runs contrary to the writings of Brown and Wishney (2017), who described giftedness as a “value-laden” word so emotionally charged that it is barred from some school districts. Our examination of online discussions related to giftedness did not reveal the overall negativity that Brown and Wishney (2017) might have hypothesized. It is quite possible that how scholars and practitioners believe giftedness is viewed is not how the public views giftedness. The negativity toward the notion of giftedness observed by Brown and Wishney (2017) could be from a vocal minority rather than reflective of the overall prevailing feelings of the public.
Along that line of potential misconceptions, what surprised us most in the current study were the findings associated with the subreddit /r/aftergifted. It was our expectation that a subreddit focusing on underachievement after gifted identification would be negative. On the contrary, the distribution of sentiment within this subreddit was like those of the other subreddits we examined. As can be seen in Figure 4, /r/aftergifted did have a greater frequency of comments that were negative, indicating a higher number of interactions containing negative sentiment. Furthermore, as can be seen in Figure 3, the topic post with the most negative sentiment overall was found in /r/aftergifted. That said, the overall distribution of sentiment was like those of the other two gifted-associated subreddits. This points to the likelihood that while the overall behavior across gifted subreddits in terms of sentiment is similar, /r/aftergifted is more likely than the other two subreddits to have outliers that skew toward negative sentiment.
How People Discuss Giftedness on Reddit
A central goal in the current study was to examine how Reddit users engage in discussions of giftedness and gifted education to gain insight into the sentiment expressed by both educational stakeholders and the public at large. Although the conclusions we are able to draw from this study are limited, our findings do indicate some modest differences across stakeholder groups. For example, the subreddit /r/teenagers contained a much larger cluster of highly negative comments when compared with both the /r/teachers and /r/parenting subreddits, which each contained very few highly negative posts. This indicates that students may express more negative sentiment in online discussions of giftedness than teachers and parents. However, the overall tone in which giftedness is discussed across subreddits is neutral. Interestingly, our findings also reveal a relative commonality of language used in discussions of giftedness across subreddits. Figures 5 through 9 demonstrate extensive overlap in the language used to discuss giftedness. For words containing negative sentiment, words with socioemotional context (e.g., depression and anxiety) were common across all subreddits in discussion of giftedness. A possible explanation is that individuals discussing giftedness made use of the social network of like-minded or sympathetic individuals to gain support (Ammari et al., 2014, 2019). In other words, it is possible that social media platforms like Reddit allow for individuals to disclose what might otherwise be sensitive or possibly detrimental information (Lapidot-Lefler & Barak, 2012).
Furthermore, we noted a lack of language used to describe equity as can be seen in Figures 5 and 9. A possible explanation for this lack of equity is that when faced with being anonymous, individuals do not discuss equity. A more likely explanation for the lack of equity is that those individuals from marginalized populations are not using Reddit to discuss gifted education issues.
Research Question 1
In general, we found that the rate of participation in a topic post or comment was independent of its sentiment. We hypothesized that negative sentiment would lead to greater rates of participation, but this hypothesis was not supported. That said, a small amount of caution might be appropriate for this result. Our result excludes topic posts that contain memes, videos, or other media content. For example, the topic post with the greatest rate of participation across gifted subreddits was found in /r/aftergifted under the thread title of “aaaaaaaaaaaaa.” The image from this post can be found in Figure 16. The sentiment from this topic post could not be extracted due to it being media content. However, the corresponding sentiment from the comments within this topic post was used in the analysis.

Topic Post From /r/aftergifted With the Greatest Participation in Terms of Rate of Comments Across Gifted Subreddits.
The only subreddit that yielded evidence of a relationship between rate of participation and overall sentiment was /r/askreddit and to a lesser extent /r/parenting. However, given the number of correlations we examined, it is difficult for us to attribute this to a real phenomenon rather than pure statistical chance. It is possible that there is some mechanism that could explain the negative correlation found in /r/askreddit and the positive correlation in /r/parenting, but there is nothing within the literary basis that we can draw upon to offer an explanation.
These results do not align with prior research analyzing twitter data using sentiment analysis. Y. Wang and Fikis (2019) found that high participation was related to negative sentiment. However, there are notable differences between our study and the Wang and Fikis study. For one, our study examined Reddit where users are anonymous and Wang and Fikis analyzed Twitter where users are not anonymous. Furthermore, Wang and Fikis focused on highly engaged users rather than individual tweets or threads. Finally, the subject matter and related social context are different. Wang and Fikis conducted their study regarding common core standards at a time in which the topic was highly relevant across much of the United States. It is quite possible that the timeliness and immediate relevance to the public affects how people discuss such issues online.
Research Question 2
We found that the characteristics of sentiment did not differ between topic posts that contained self-disclosure and those that did not. We had hypothesized that topic posts that contained self-disclosure would have positive sentiment based on our interpretation of current literature on self-disclosure, anonymity, and relationship development (Collins & Miller, 1994; Derlega et al., 2008; Ma et al., 2016; Nabity-Grover et al., 2020). According to our findings, however, there is little evidence to support the idea that topic posts containing self-disclosure are positive in terms of sentiment. Where we do find potential differences is in the distribution of sentiment across subreddits; however, we are cautious in our interpretation. On one hand, a possible explanation is that topic posts without self-disclosure are more extreme. For example, users may be paying more attention to how they are curating their identities when self-disclosing, compared with users who are not creating topic posts with self-disclosure. Figure 15 provides some evidence supporting this. On the other hand, topic posts that contained self-disclosure were substantially longer than those that did not (1,830.94 vs. 349.32 characters). We find it more likely that the increased length of topic posts containing self-disclosure allows for more nuanced discussions and wider variation of sentiment across the topic post. For example, a self-disclosure post may contain shifts in tone as the poster relates information from different points in time or on related but different subjects. This is in contrast to much shorter topic posts that do not contain self-disclosure, where a single statement with strong sentiment in one direction is more likely to have an influence on the aggregate of the topic post’s sentiment score. One interesting finding is the possible relationship between topic controversy and sentiment within the subreddit /r/parenting. As the sentiment of a topic post increased in terms of positivity, its overall controversy also increased. In other words, topic posts that contained self-disclosure and used positive language to discuss giftedness were more likely to receive “down” votes. This seems in contrast with Collins and Miller’s (1994) foundational work that found that self-disclosure led to positive reactions. Perhaps, the context (a subreddit dedicated to parents), the manner (using positive language to discuss giftedness), and the location (a social media platform) can influence how self-disclosures are perceived.
An important point to consider in interpreting this result is that a sentiment analysis provides no subjective judgment of content of what is being discussed (Yue et al., 2019). Instead, it examines the language used to discuss the topic. An individual using language that is highly negative in sentiment when discussing an issue like underachievement would have a different sentiment score than an individual who used language that was more neutral in tone.
Sentiment Analysis
One of the goals of our research was to showcase sentiment analysis as a methodological approach and to assess the efficacy of conducting a sentiment analysis. In our reflection on conducting a sentiment analysis, we noted the number of choices that a researcher must make that are independent from statistical choices. In our study, for example, we needed to select the dictionary used to assign sentiment values and multiple preprocessing steps. Given the number of researcher-made choices, it is possible that another team examining the data might come to a different conclusion (Makel & Plucker, 2017). Considering this, we tried to mitigate the influence of researcher-made choice using techniques like an aggregate dictionary. There are additional techniques that we did not employ that could also influence results, such as valence shifters wherein the sentiment of the statement can change due to a modifier (e.g., “I am happy” vs. “I am extremely happy”; Singh et al., 2020). Overall, we found sentiment analysis to be a powerful and effective methodological technique and would caution researchers who choose to use this technique to fully immerse themselves in the surrounding literature to fully understand how researcher choice can influence outcomes.
Limitations
One limitation to conducting a sentiment analysis is the lexicon. No lexicon is all-encompassing, so there is the possibility that substantive and non-neutral words are not included with any given lexicon (Ding et al., 2008). Furthermore, there is always the possibility of misspecification of a word within a lexicon; for example, a word could be assigned an inappropriate sentiment. Lexicons commonly use crowdsourcing as validation (Hu & Liu, 2004). These methods are useful and allow for large-scale validations of a lexicon, but they are not immune to human error. To mitigate this limitation, we used three lexicons in our analysis: AFINN, BING, and NRC (Silge & Robinson, 2016) as parts of an aggregate lexicon.
A second limitation is linked within our chosen unit of analysis. In all levels of granularity, there are advantages and disadvantages. Using words as a unit of analysis leads to the possibility of inappropriate sentiment, as meaning within a language is often more than the sum of its composite parts.
In our initial registration of this research, we speculated that a third limitation would relate to the nature of algorithmic processes. Scholars have noted the limitations of using algorithms to conduct searches or process data (Magnini et al., 2003; Mahindrakar & Hanumanthappa, 2013). In an algorithmic process, there is the possibility of an exception to the ruleset governing the algorithm. In conducting this research, we found that this limitation was untenable. It is likely that much further research needs to be conducted on the feasibility of using algorithmic processes to identify complex communication categories.
Future Research
Sentiment analysis has enabled researchers to explore educational questions, such as student learning and performance (Altrabsheh et al., 2013) and how to improve electronic learning experiences (Mite-Baidal et al., 2018). Moreover, Dolianiti et al. (2018) found that sentiment analysis has been informative for researching instructional evaluation, designing policy, and improving feedback. We believe that these types of insights are relevant to gifted and talented research and our study aims to demonstrate the utility of the technique for the field. We also hope that our study can act as a launch pad for future work related to the use of sentiment analysis for enhancing instruction, informing policy, and incorporating general attitudes into intervention and practice. We suggest that sentiment analysis can and should be extended to research on giftedness and talent and that Reddit contains promise as a site for educational data mining.
One area that we were unable to explore in this study is sentence-level sentiment analysis. We see the value in a future, sentence-level sentiment analysis study, but at this time we are concerned about the lack of a solid framework for conducting sentence-level sentiment analysis. We do not believe that using such a method is appropriate when a well-defined metric for addressing it, or a well-defined process for examining it, does not yet exist and we look forward to future work in this area when such a framework or metric is available. We also hope to see future work that explores whether a shorter topic post length might have more of an influence on aggregate sentiment.
Supplemental Material
sj-docx-1-gcq-10.1177_00169862221076403 – Supplemental material for Gifted Education on Reddit: A Social Media Sentiment Analysis
Supplemental material, sj-docx-1-gcq-10.1177_00169862221076403 for Gifted Education on Reddit: A Social Media Sentiment Analysis by Jaret Hodges, Mary Simonsen and Jessica Ottwein in Gifted Child Quarterly
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Open Science Statement
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.