
Abstract
Objective:
We aimed to determine whether visual scanning has a detrimental impact on the monitoring of critical signals and the performance of a concurrent laparoscopic training task after participants engaged in Hockey’s strain coping. Strain coping refers to straining cognitive (attentional) resources joined with latent decrements (i.e., stress).
Background:
DeLucia and Betts (2008) reported that monitoring critical signals degraded performance of a laparoscopic peg-reversal task compared with no monitoring. However, performance did not differ between displays in which critical signals were shown on split screens (less visual scanning) and separated displays (more visual scanning). We hypothesized that effects of scanning may occur after prolonged strain coping.
Method:
Using a between-subjects design, we had undergraduates perform a laparoscopic training task that induced strain coping. Then they performed a laparoscopic peg-reversal task while monitoring critical signals with a split-screen or separated display. We administered the NASA–Task Load Index (TLX) and Dundee Stress State Questionnaire (DSSQ) to assess strain coping.
Results:
The TLX and DSSQ profiles indicated that participants engaged in strain coping. Monitoring critical signals resulted in slowed peg-reversal performance compared with no monitoring. Separated displays degraded critical-signal monitoring compared with split-screen displays.
Conclusion:
After novice observers experience strain coping, visual scanning can impair the detection of critical signals.
Application:
Results suggest that the design and arrangement of displays in the operating room must incorporate the attentional limitations of the surgeon. Designs that induce visual scanning may impair monitoring of critical information at least in novices. Presenting displays closely in space may be beneficial.
Keywords
Introduction
In laparoscopy, a camera and instruments are inserted into the patient through small openings. Because it involves smaller incisions and less trauma (Cuschieri, 1995), laparoscopy has benefits for the patient compared with open surgery, such as shorter hospital stays (Cuschieri, 1995) and improved cosmesis (Mattei, 2007). However, surgeons experience perceptual-motor challenges, including disruptions of hand–eye mapping and loss of movement compatibility. The laparoscopic environment may result in loss of task information specificity, in which information critical for the task is not highly accessible because of the camera’s line of sight (DeLucia & Griswold, 2011). Furthermore, the laparoscopic environment is associated with impaired depth perception. For instance, depth compression occurs when the camera’s line of sight is parallel to the grasper’s movement direction (see DeLucia & Griswold, 2011). Depth perception challenges are exacerbated by two-dimensional camera images, requiring surgeons to rely mostly on monocular depth cues (Reinhardt-Rutland, Annett, & Gifford, 1999).
Perceptual-motor challenges in laparoscopy induce high attentional demands (i.e., workload) and stress (Klein et al., 2008; Klein, Riley, Warm, & Matthews, 2005). Hockey’s (1997) theory of compensatory control was developed to explain stress, workload, and performance phenomena. This model is a negative feedback system in which performance goals are compared with performance outcomes. When the outcomes do not meet the goal expectations, people engage in coping strategies. Hockey identified three coping modes: active, passive, and strain coping. The active coping mode refers to small elevations of effort that are sufficient to maintain acceptable primary task performance. This coping mode is not associated with limitations of cognitive (attentional) resources or with other latent decrements (e.g., stress). The passive coping mode refers to a lack of elevation in effort when there is a breakdown in primary task performance. This coping mode is associated with the experience of stress if the performance of the primary task is critical. The strain mode is characterized by a substantial increase in effort to meet task demands. Whereas the strain mode may allow acceptable performance of the primary task, this coping mode is associated with latent decrements, such as stress. Perceptual-motor distortions inherent in laparoscopy induce strain coping in novices (Klein et al., 2008).
Surgeons’ attentional resources are further stressed when multitasking. In addition to manual surgical tasks, surgeons attend to multiple sources of information, such as vital signs, X-rays, anatomical images, and other members of the surgical team (Ibbotson, MacKenzie, Cao, & Lomax, 1999). Consequently, surgeons engage in visual scanning and divide their attention (Levy, Chen, Moffitt, Corber, & McComb, 1998; Peters, 2000). Visual scanning places further demands on the attentional system (i.e., induces workload; Wickens & Carswell, 1995). Moreover, it has been recommended that surgeons use multiple monitors to display the surgical site during surgery (Matern, Faist, Kehl, Giebmeyer, & Buess, 2005; Rogers, Heath, Uy, Suresh, & Kaber, 2012; Shah et al., 2009), which also increases visual scanning. It is important to assess how surgical performance is affected when surgeons perform attentionally demanding secondary tasks that necessitate visual scanning. An understanding of human limitations during multitasking and visual scanning in the laparoscopic environment is necessary to design laparoscopic interfaces effectively.
DeLucia and Betts (2008) assessed novices’ laparoscopic task performance when performing an attentionally demanding concurrent vital sign monitoring task that required more, or less, scanning. Although it is uncommon for surgeons to engage in vital sign monitoring, this task has practical relevance because it requires visual scanning and induces high attentional demands.
DeLucia and Betts (2008) required participants to perform a simulated laparoscopic task in three concurrent vital sign monitoring conditions: control, split screen, and separated. In the control condition, participants did not monitor vital signs. The split-screen condition displayed vital signs on the same screen as the simulated surgical field, requiring relatively less visual scanning. In the separated condition, the vital signs and surgical field were shown on separate monitors, requiring relatively more visual scanning. The control group achieved shorter task completion times and lower NASA–Task Load Index (TLX; Hart & Staveland, 1988) scores than the separated and split-screen conditions, but performance did not differ between the latter conditions. However, participants in the split-screen and separated conditions exhibited global workload scores above the midpoint of the TLX scale, indicating that these conditions were substantially demanding and suggesting that participants engaged in the strain mode. We hypothesized that benefits of the split-screen display would occur when the attentional system is strained for an extended time.
Experiment
The goal of the present study was to extend DeLucia and Betts’ (2008) research by comparing control, separated, and split-screen conditions in a simulated laparoscopic environment after participants engaged either a low- or high-strain mode for an extended time. The low-strain condition was induced with a 45-min peg-transfer task with a top camera view of the simulated surgical field. This view has been associated with superior laparoscopic performance (DeLucia & Griswold, 2011). The top camera condition results in depth compression for up-down movements but results in small disruptions of hand–eye mapping, movement compatibility, and task information specificity (DeLucia & Griswold, 2011).
The high-strain mode was induced with a 45-min peg-transfer task with a camera rotated 135°. Previous research of perceptual-motor adaptation indicated that distortions between 90° and 135° resulted in the worst performance (Cunningham, 1989). We expected the 135° camera condition to induce more severe strain coping than the top view.
The 135° camera view also resulted in compression, but it occurred for movements that originated on the front left of the trainer box and traveled along a diagonal path to the back right. In contrast to the top view, the 135° camera view resulted in decreased task information specificity, a severe disruption of the hand–eye mapping, and movement incompatibility.
Task demand (i.e., workload) and latent decrements (task-induced stress) were assessed with the (electronic) TLX and the Dundee Stress State Questionnaire (DSSQ; Matthews et al., 1999, 2002; Matthews, Campbell, & Falconer, 2001), respectively. The TLX is the most widely used workload questionnaire (Wickens & Hollands, 2000) and is reliable, as indicated by a test-retest reliability of .83 (Hart & Staveland, 1988). It assesses workload along six dimensions—mental demands, physical demands, temporal demands, effort, performance, and frustration—and provides a global workload score. We analyzed the scores using the weighted (adjusted) ratings and the global (overall) workload score, consistent with the procedures published by NASA (http://humansystems.arc.nasa.gov/groups/TLX/downloads/TLX.pdf).
The DSSQ is a well-validated measure for assessing transient states that allows the identification of task-induced stress. It consists of 11 scales and has appropriate psychometric properties for a state measure (Matthews et al., 2002), that is, high internal validity and low test-retest reliability (see Zuckerman, 1976).
Method
Participants
Participants were 48 right-handed Texas Tech University undergraduates (24 males, 24 females), with a mean age of 19.73 years, who participated for course credit. All reported normal or corrected visual acuity, normal hearing and motor coordination, and no history of seizures. Participants completed Part 1, in which we induced strain coping, and Part 2, in which we assessed the impacts of monitoring display on performance. We chose undergraduates because we wanted to study the same population as DeLucia and Betts (2008). Undergraduates also allowed a large enough sample size for adequate experimental control, which is difficult to achieve with surgeons. Previous research indicated that nonsurgeons and surgical trainees reflect similar laparoscopic training task performance (Taffinder, Sutton, Fishwick, McManus, & Darzi, 1998).
Part 1
Apparatus
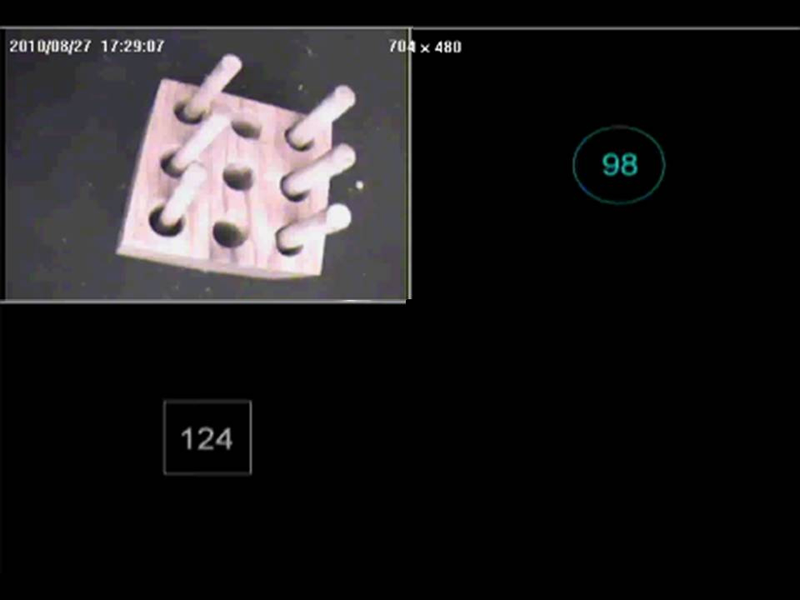
A laparoscopic trainer box (DeLucia, Hoskins, & Griswold, 2004) was located on a 73-cm-high table. A wooden cube (5.1 cm × 5.2 cm × 3.4 cm), with three rows and three columns of equally spaced holes (diameter = 0.9 cm, separation between holes = 0.7 cm) on its top surface was located inside the apparatus. A wooden peg (diameter = 0.6 cm, height = 5.5 cm, weight = 0.98 g) was placed in the middle right hole of the wooden cube. The cube was placed in a slanted position so that all nine holes could be seen with two camera views. One camera provided a top view of the cube. The other camera’s view was 135° to the participant’s right. Camera images were projected onto a 33.02-cm monitor (see Figure 1). The monitor was located 59 cm behind the trainer box, 104.14 cm above the ground, and approximately 124 cm from the participant’s eyes. A direct view of the cube was provided through an opening in the top of the trainer box.

Display of wooden cube from the 135° camera view.
Procedure
We randomly assigned 24 participants to the top camera view condition and 24 participants to the 135° camera view condition (each balanced for gender). First, participants completed the pre-DSSQ and watched an instructional video about the peg-transfer task. In this task, participants moved a peg from the middle right hole of the wooden cube to the middle left hole. Because the cube was slanted, the peg-transfer task required not only up-down but also left-right movements that were slightly slanted toward the back of the trainer box. At the beginning of each transfer, the graspers’ jaws were closed around the peg by the experimenter to ensure identical starting positions of the grasper for each transfer. Next, participants practiced the transfer task four times while directly viewing the wooden cube. Then participants performed the transfer task for 45 min in their assigned camera conditions. They were instructed to perform the task as fast as possible without dropping the peg. Finally, participants completed the post-DSSQ and the TLX and had a 10-min break, followed by Part 2.
Part 2
Apparatus
The apparatus was the same as in Part 1 except that six wooden pegs were used. A thick peg (diameter = 0.6 cm, height = 5.5 cm, weight = 0.98 g) was placed into each of the three holes on the right side of the wooden cube, and a thin peg (diameter = 0.4 cm, height = 5.5 cm, weight = 0.47 g) was placed into each of the three holes on the left side of the cube (see Figure 2). The cube was displayed in the top left quadrant of the monitor located behind the trainer box. Critical signals, which represented vital signs (heart and oxygen values, described subsequently), were displayed on two 33.02-cm monitors. The monitors were located 112 cm to the left and right of the trainer box; both were 104.14 cm above the ground and approximately 124 cm from participants.
Example of the split-screen display with the top camera view.
In the control condition, participants exclusively performed the peg-reversal task (described subsequently). In the split-screen condition, participants performed the peg-reversal task while monitoring heart and oxygen values presented on the middle monitor along with the wooden cube. The cube was presented in the top left quadrant of the monitor, and the heart rate and oxygen values were presented in the bottom left and top right quadrants, respectively (see Figure 2). The separated condition was the same as the split-screen condition except that heart and oxygen values were presented on the left and right monitors, respectively, and the cube was shown on the middle monitor (all images were in the same quadrants as the split screen).
The vital sign monitoring task was chosen because it created an attentionally demanding concurrent task that required visual scanning. It was not intended to represent monitoring of vital signs per se; surgeons do not typically monitor vital signs during surgery. However, as noted earlier, surgeons attend to and process information from multiple locations, which induces visual scanning and high attentional demands (Ibbotson et al., 1999; Levy et al., 1998; Peters, 2000; Wickens & Carswell, 1995).
The images of the cube and vital signs subtended the same visual angle in the split-screen and separated display conditions. However, the separated condition imposed greater visual scanning demands because the angle between the participant’s line of sight to the middle monitor and the side monitor was 65°. To change line of gaze from the middle monitor to a side monitor required an eye or head movement of 65°; to change line of gaze from one side monitor to the other side monitor required a movement of 130°. When all three displays were shown in split view on the middle monitor, changing the line of gaze from one image to another required an eye movement of only 5.1° to 6.5°.
Heart and oxygen values were created with PowerPoint slides in Helvetica 66-point font with one number per slide. Each number was centered and drawn in white on black and was presented for 6 s. Heart values were surrounded by a white rectangle; oxygen values were surrounded by a white circle. Critical heart and oxygen values were defined as above 179 and below 70, respectively. One eighth (12.5%) of the heart and oxygen values were critical signals. A 500-ms feedback tone signified out-of-range (critical) values after the critical signal was presented for 6 s.
Procedure
Participants viewed an instructional video about the peg-reversal transfer task, which required participants to use a surgical grasper to reverse the positions of the thick and thin pegs (DeLucia & Betts, 2008). Because the cube was slanted, this task required up-down movements, slanted back-left movements, and slanted forward-right movements. Prior to the start of each reversal, the grasper tip was located in the bottom right hole. First, participants performed four practice reversals with a direct view. This was followed by 12 min of the peg-reversal task with the same camera condition as in Part 1. In each camera position, 4 males and 4 females were assigned to each of the three display conditions: control, split screen, and separated. Participants in the control group exclusively performed the peg-reversal task, whereas participants in the split-screen and separated conditions performed the peg-reversal task while simultaneously monitoring vital signs. They were instructed to orally report critical signals before the feedback tone occurred. The experimenter moved the pegs to their starting positions after each reversal; during these interim periods, participants did not monitor vital signs. After the 12-min experimental phase, participants completed the post-DSSQ and the TLX.
Results
Part 1
Peg-transfer performance
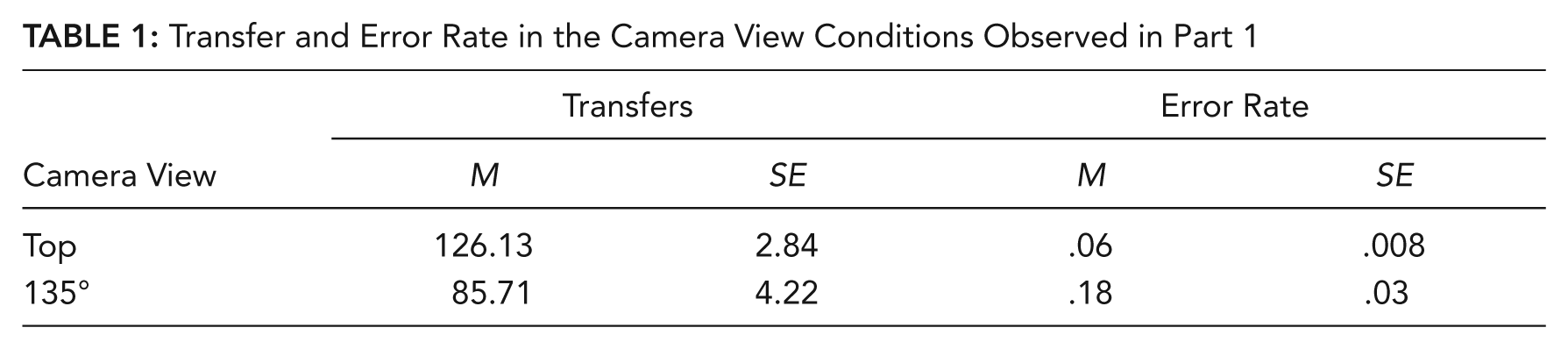
Results are summarized in Table 1. We analyzed the number of completed peg transfers and the error rate (drops/transfers) in the top and 135° camera view conditions. Independent-groups t tests indicated enhanced performance in the top camera view for transfers, t(46) = 7.94, p < .001,
Transfer and Error Rate in the Camera View Conditions Observed in Part 1
TLX
The TLX scores were analyzed with a 2 (camera views) × 6 (weighted NASA-TLX ratings) mixed ANOVA. This and subsequent repeated-measures ANOVAs were analyzed using the Huynh-Feldt correction for violation of the sphericity assumption. There was a main effect for TLX, F(4.62, 212.45) = 7.70, p < .001,
Mean Weighted TLX Ratings in the Camera View Conditions Observed in Part 1
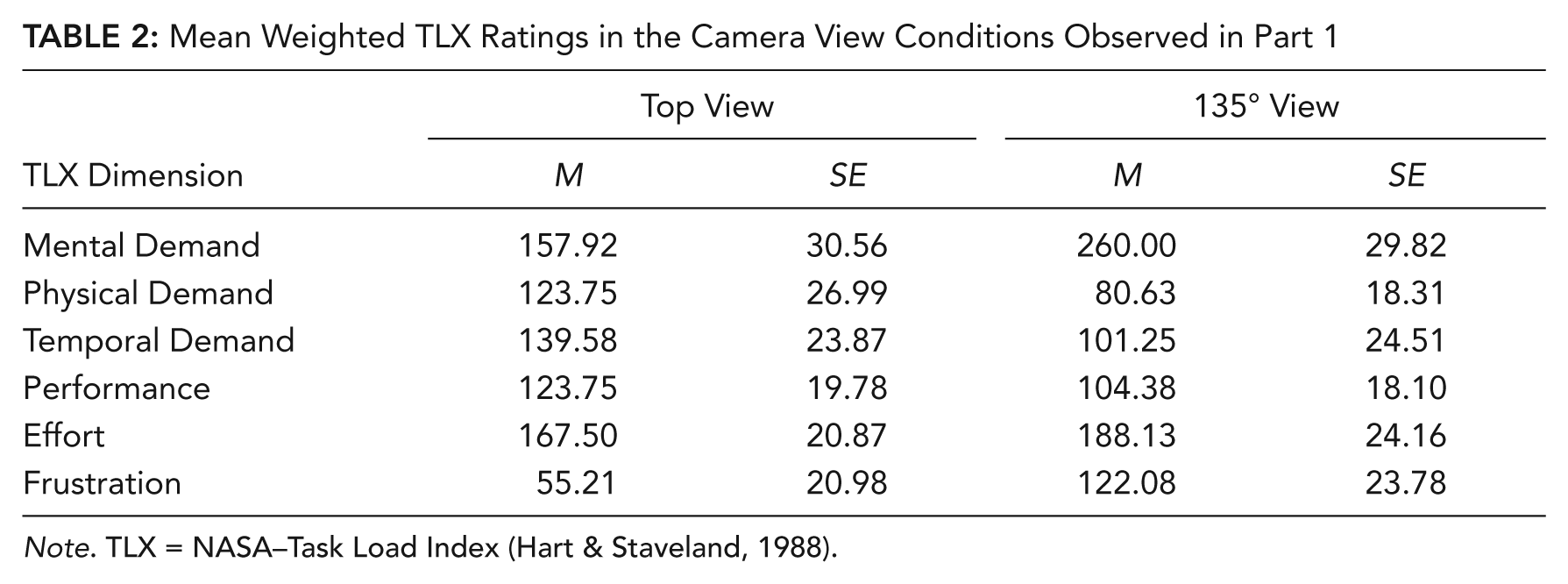
Note. TLX = NASA–Task Load Index (Hart & Staveland, 1988).
Simple effects (Meyers & Well, 2003) for the interaction between camera view and TLX indicated that participants in the 135° camera view condition experienced greater mental demand, F(1, 46) = 5.72, p = .02, and greater frustration, F(1, 46) = 4.45, p = .04, compared with the top camera view condition.
DSSQ
We analyzed the DSSQ data using change scores, as indexed by the formula (postscore – prescore)/SD of the normative data of the pretest scores (Matthews et al., 2002). Scores were submitted to a 2 (camera views) × 11 (DSSQ scales) mixed ANOVA. There was a main effect for DSSQ scales, F(7.46, 343.24) = 8.13, p < .001,
DSSQ Change Profile in the Camera View Conditions Observed in Part 1
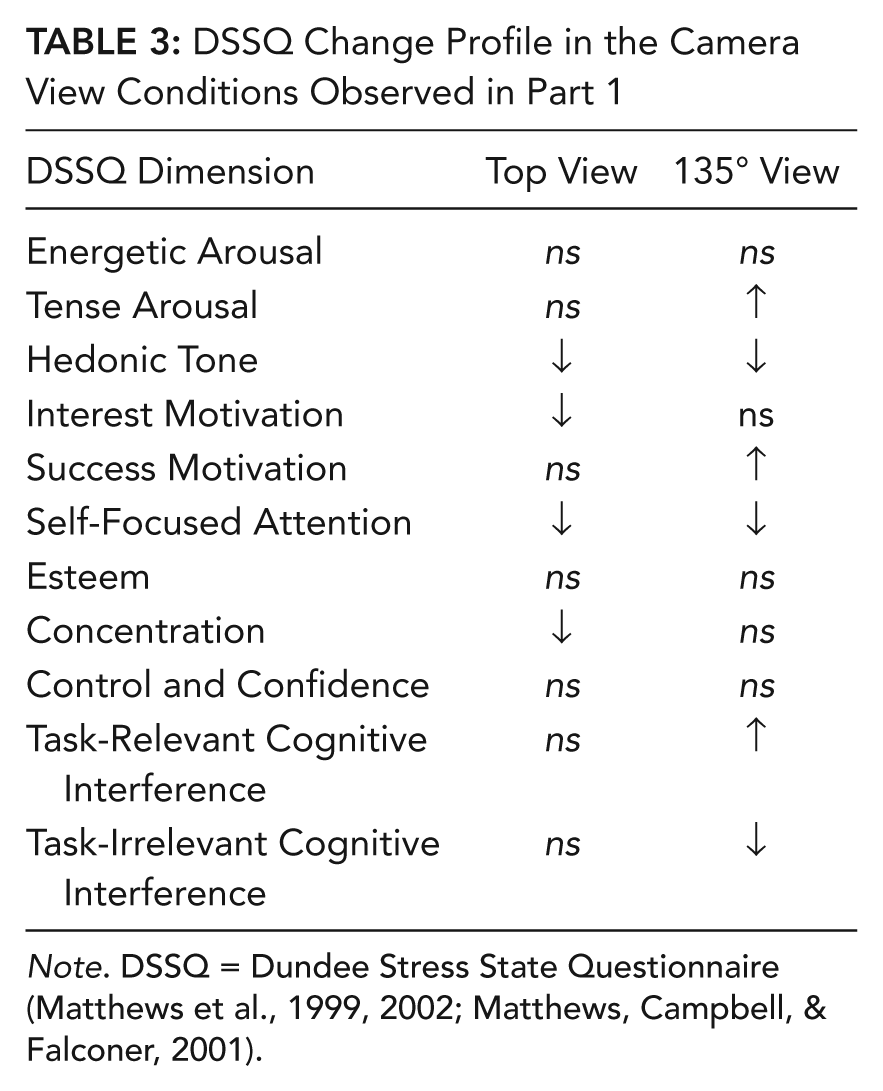
Note. DSSQ = Dundee Stress State Questionnaire (Matthews et al., 1999, 2002; Matthews, Campbell, & Falconer, 2001).
Part 2
Peg-reversal performance
Completed peg reversals and error rate (drops/completed reversals) were analyzed with separate 2 (camera views) × 3 (display conditions) between-groups ANOVAs. Analyses of peg reversals indicated a main effect for camera, F(1, 42) = 367.39, p < .001,
The error-rate analysis revealed a main effect of camera views, F(1, 42) = 14.71, p < .001,
TLX
The TLX data were analyzed with a 2 (camera view) × 3 (display conditions) × 6 (weighted TLX scales) mixed ANOVA. There was a main effect for TLX scales, F(5.00, 210.00) = 17.04, p < .001,
Mean Weighted TLX Ratings in the Camera View Conditions Observed in Part 2
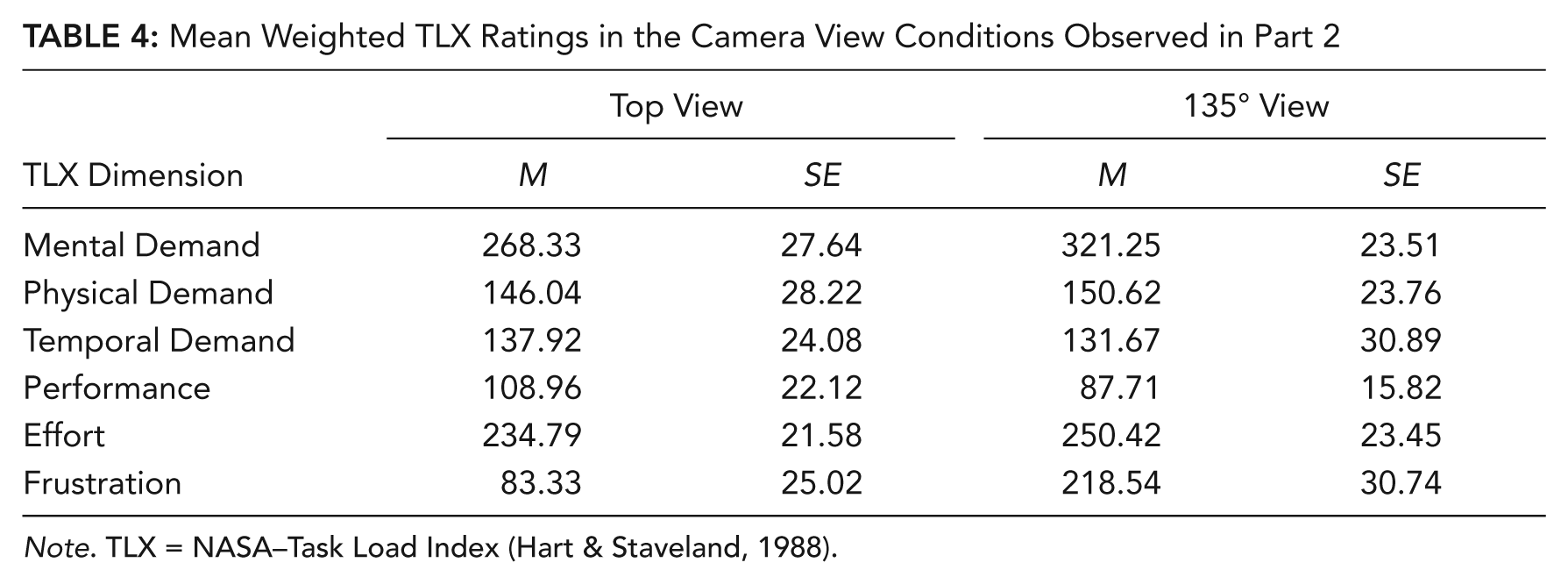
Note. TLX = NASA–Task Load Index (Hart & Staveland, 1988).
Analyses of the simple main effects for the interaction between display and TLX indicated differences among the three display conditions for temporal demand, F(2, 45) = 11.15, p < .001, and effort, F(2, 45) = 3.99, p = .026. Tukey HSD tests (α = .05) indicated that temporal demand was significantly higher in the separated condition than in the split-screen and control conditions. The split-screen condition also resulted in higher effort than the control condition. Refer to Table 5.
Mean Weighted TLX Ratings in the Display Conditions Observed in Part 2
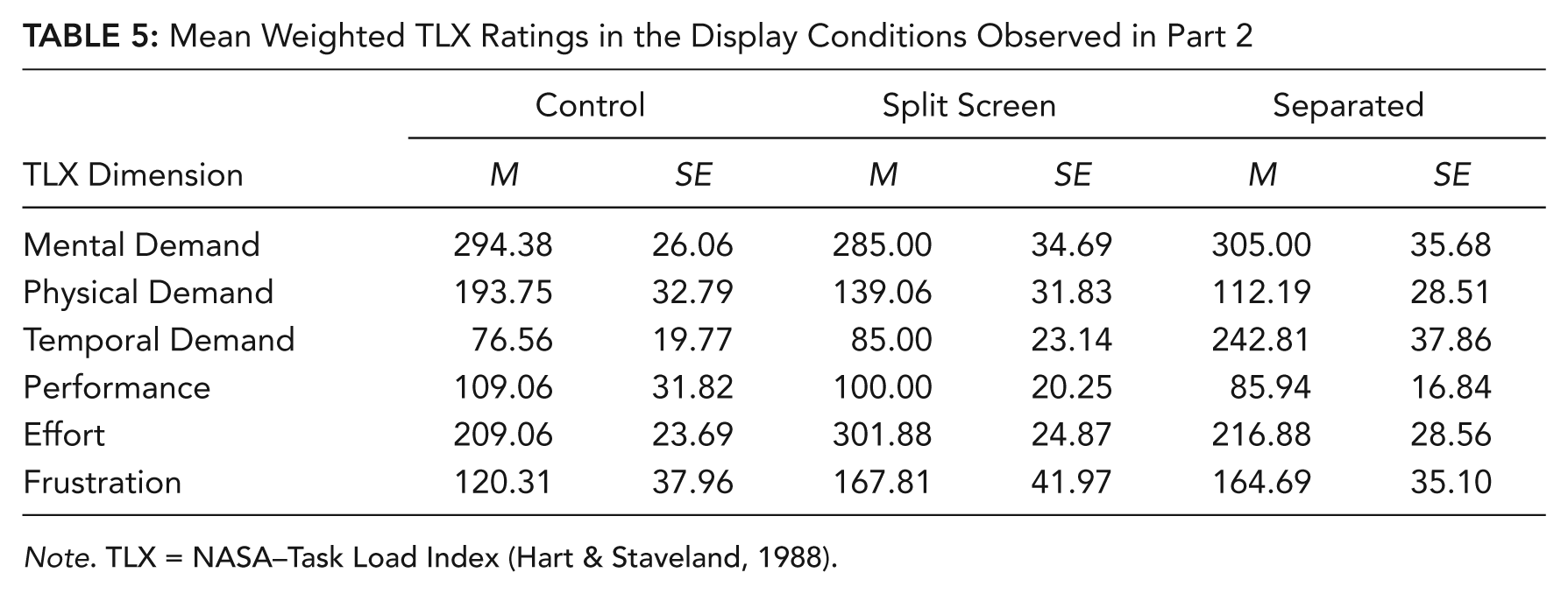
Note. TLX = NASA–Task Load Index (Hart & Staveland, 1988).
DSSQ
We analyzed the DSSQ data using change scores using a 2 (camera-view) × 3 (display conditions) × 11 (DSSQ scales) mixed ANOVA. There were main effects of DSSQ scales, F(7.47, 313.92) = 18.03, p < .0001,
Significant DSSQ Changes as Indexed by 95% Confidence Intervals in the Camera View Conditions Observed in Part 2

Note. DSSQ = Dundee Stress State Questionnaire (Matthews et al., 1999, 2002; Matthews, Campbell, & Falconer, 2001).
Monitoring display
We analyzed the monitoring display using percentage of missed critical signals with a 2 (camera views) × 2 (display conditions) between-groups ANOVA. A main effect of display condition, F(1, 28) = 17.95, p < .001,
Discussion
Part 1
Peg-transfer performance
Consistent with our predictions, the 135° camera condition resulted in worse peg-transfer performance than did the top condition. Because the peg-transfer task required mostly up-down movements and slanted backward-left movements, depth compression was observed in the top camera view but not the 135° view. However, compared with the 135° condition, the top camera view had less severe disruption of hand–eye mapping and maintained movement compatibility and task information specificity. The implication is that combined benefits of mild disruption of hand–eye mapping, movement compatibility, and task specificity outweighed the cost of depth compression.
Strain coping mode
The peg-transfer task was demanding in both camera view conditions, as evidenced by global workload scores close to the scale’s midpoint. However, contrary to our prediction that the 135° condition would result in greater workload, the global workload score did not differ between the two camera conditions. Mental demand and effort were the major contributors to workload in both conditions, with higher mental demand and frustration in the 135° view than the top view.
The DSSQ profiles in both camera conditions were qualitatively different, but both were consistent with strain coping. The DSSQ profile in the top camera condition indicated a decline in self-focused attention, consistent with being focused on the task. However, the DSSQ profiles showed latent decrements indicated by declines in hedonic tone (pleasantness), interest motivation, and concentration. Similarly, the DSSQ profile in the 135° camera condition was consistent with being task focused, as indicated by an increase in success motivation and by a decline in self-focused attention and task-irrelevant cognitive interference (worrying about things not pertaining to the task). However, the DSSQ profile in the 135° condition also was consistent with the experience of latent decrements, indicated by a decline in hedonic tone and an increase in tense arousal (nervousness) and task-relevant cognitive interference (worrying about the task).
Part 2
Peg-reversal performance
Consistent with Part 1 and prior research (Cunningham, 1989; DeLucia & Griswold, 2011), participants in the top camera condition completed more peg reversals and achieved a lower error rate than did participants in the 135° condition. Combined benefits of mild disruption of hand–eye mapping, movement compatibility, and task specificity outweighed the cost of depth compression. Furthermore, participants in the split-screen and separated monitoring conditions completed fewer peg reversals than did participants in the control condition, consistent with DeLucia and Betts (2008). The secondary monitoring task did not affect accuracy (error rate) of the peg-reversal task.
Strain coping
In Part 2, participants in both camera views experienced high task demand, as indexed by global workload scores above the scale’s midpoint. In contrast to Part 1, the global workload score was lower in the top camera view than in the 135° view. In both camera views, effort and mental demand were major contributors to workload, and frustration was a substantial contributor to workload in the 135° condition (see Table 4). The global workload score did not differ across the three display conditions. However, as seen in Table 5, mental demand and effort were major contributors to workload in all three display conditions. Temporal demand (time pressure) was significantly higher in the separated than in the split-screen and control conditions.
As in Part 1, DSSQ profiles in both camera conditions were qualitatively different, but both were consistent with strain coping. The top camera view indicated decreases in self-focused attention and task-irrelevant cognitive interference, consistent with task focus. However, participants also experienced latent decrements at this camera condition, as indicated by an increase in tense arousal and by declines of hedonic tone. Similarly, the DSSQ profile in the 135° camera condition was consistent with task focus, indicated by increases in energetic arousal (alertness) and success motivation and by declines in self-focused attention and task-irrelevant cognitive interference. However, the DSSQ profile observed in the 135° camera condition also revealed latent decrements, indicated by increases in tense arousal and task-related cognitive interference and declines in hedonic tone and control confidence.
Whereas the DSSQ profile in Part 1 and Part 2 were consistent with strain coping, there were some differences between the DSSQ profiles observed in Parts 1 and 2 (see Tables 3 and 6). These differences might be attributable to differences in the timing of testing (first vs. second part), the length of the task (45 min vs. 12 min), or slight differences in the task (peg-transfer vs. peg-reversal task).
Monitoring display
After participants engaged in strain coping, monitoring performance was superior in the split-screen than in the separated condition.
Practical Implications and Future Directions
The results have practical implications for the laparoscopic environment. First, the combined benefits of mild disruption of hand–eye mapping, movement compatibility, and task specificity outweighed the cost of depth compression, indicated by superior peg-transfer performance in the top camera condition in Parts 1 and 2 of the study. Thus, observers can benefit from multiple information sources, and degradations in depth perception can be compensated by reducing other distortions (e.g., incompatibility) or providing other effective information (e.g., task information specificity). These results are consistent with previous comparisons of 2-D and 3-D displays that suggested that when many monocular depth cues are available in the surgical environment, binocular information may not lead to an advantage compared with 2-D displays (Hanna & Cuschieri, 2001; Hanna, Shimi, & Cuschieri, 1998; Hofmeister, Frank, Cuschieri, & Wade, 2001). The practical implication is that before displays are designed for the operating room, it is important to determine how surgeons use multiple information sources and which combination of sources is most effective for the surgical task (DeLucia & Griswold, 2011).
Second, current results replicate those of DeLucia and Betts (2008), indicating that concurrent monitoring can degrade performance of a primary laparoscopic task. The implication is that surgeons should keep monitoring tasks to a minimum while performing manual surgical tasks. Doing so is particularly important in surgeries that induce strain coping. Results suggest further that medical displays that portray fluctuating information should be located closely in space to minimize effects of visual scanning on monitoring performance. However, before any recommendations can be implemented, it is important to determine whether the current results generalize from undergraduates to the real-life surgical environment, which poses additional manual and cognitive demands than those in the present study and poses challenges including equipment failures, operating room delays, conversations, and anesthesia and ergonomic issues. Furthermore, although the present study indicated that monitoring was less effective when displays were separated by 130° than by 5.1° to 6.5°, it is important to determine the visual angle within which critical information can be presented without resulting in performance degradation in laparoscopy. Future research also should assess whether the size of this angle is a function of surgical skill.
Third, the current results replicated DeLucia and Betts’ (2008) finding that split-view displays did not result in worse laparoscopic performance compared with separated displays. As noted by DeLucia and Betts, the practical implication is that split-view displays may be useful in decluttering the operating room. By presenting multiple displays on a single monitor, fewer monitors can be used.
Finally, the present study assessed only the impact of a monitoring task that required visual scanning on a manual peg-reversal task. However, the surgical environment is more complex. Surgeons divide their attention and engage in multitasking that involves the processing of both auditory and visual signals. These include pagers, cell phones, and auditory alarms as well as X-rays, ultrasound, and fluorescent targeting aids. In the future, researchers should examine how surgical performance is affected by concurrent auditory monitoring tasks and the use of targeting aids during strain coping.
Key Points
The laparoscopic environment induces strain coping.
The combined benefits of mild disruption of hand–eye mapping, movement compatibility, and task information specificity outweigh the cost of depth compression in the laparoscopic environment.
Monitoring vital signs resulted in the completion of fewer peg reversals after information-processing resources were strained.
At least in novices, extensive visual scanning resulted in the detection of fewer critical signals after information-processing resources were strained.
Footnotes
Acknowledgements
We thank Ryan L. Stacy for assistance with data entry.
Martina I. Klein is an assistant professor of psychology at Texas Tech University. She completed her PhD at the University of Cincinnati.
Patricia R. DeLucia is a professor of psychology and coordinator of the Human Factors Psychology Program at Texas Tech University and an adjunct professor in the School of Nursing at Texas Tech University Health Sciences Center. She is a fellow of the American Psychological Association and the Human Factors and Ergonomics Society. She completed her PhD at Columbia University.
Ryan Olmstead is a graduate student in George Mason University’s Human Factors and Applied Cognition Program. He received his BA in psychology from Texas Tech University in 2010.