
Abstract
Objective
An experiment used the workload capacity measure C(t) to quantify the processing efficiency of human–automation teams and identify operators’ automation usage strategies in a speeded decision task.
Background
Although response accuracy rates and related measures are often used to measure the influence of an automated decision aid on human performance, aids can also influence response speed. Mean response times (RTs), however, conflate the influence of the human operator and the automated aid on team performance and may mask changes in the operator’s performance strategy under aided conditions. The present study used a measure of parallel processing efficiency, or workload capacity, derived from empirical RT distributions as a novel gauge of human–automation performance and automation dependence in a speeded task.
Method
Participants performed a speeded probabilistic decision task with and without the assistance of an automated aid. RT distributions were used to calculate two variants of a workload capacity measure, COR(t) and CAND(t).
Results
Capacity measures gave evidence that a diagnosis from the automated aid speeded human participants’ responses, and that participants did not moderate their own decision times in anticipation of diagnoses from the aid.
Conclusion and Application
Workload capacity provides a sensitive and informative measure of human–automation performance and operators’ automation dependence in speeded tasks.
Introduction
Automated aids can support cognitive activities in contexts including air and ground transportation (e.g., Parasuraman, Duley, & Smoker, 1998), space teleoperation (e.g., Li, Wickens, Sarter, & Sebok, 2014), and medical diagnosis (e.g., Alberdi, Povyakalo, Strigini, & Ayton, 2004), aiding the human operator at various stages of task performance (Cuevas, Fiore, Caldwell, & Strater, 2007), from gathering and organizing information to making decisions and selecting actions (Parasuraman, Sheridan, & Wickens, 2000). Ideally, they will optimize the operator’s performance while reducing his or her workload.
But automated aids are not always helpful. Operators often fail to use an aid appropriately and therefore benefit less than possible from the aid’s assistance (Parasuraman & Riley, 1997; Wickens & Dixon, 2007). Suboptimal use is typically identified by examining the operator’s response choices, either by measuring accuracy or bias conditionalized on the aid’s behavior or by calculating similarities between the operator’s responses and the aid’s (Wang, Jamieson, & Hollands, 2008, 2009). Automation may influence not only response choices, however, but response times (RTs) as well. Participants in a simulated air-to-ground target acquisition task, for example, showed shorter RTs for detecting automation-cued targets than for detecting uncued targets (Yeh, Wickens, & Seagull, 1999), and participants in a simulated command-and-control task on average made faster enemy engagements when assisted by reliable automation than when unassisted (Rovira, McGarry, & Parasuraman, 2007). The availability of an automated decision aid may even affect operators’ behavior before the aid itself has rendered a diagnostic cue. For instance, participants assisted by a forward collision warning system in a simulated driving task appeared to delay their responses to a lead vehicle’s braking while they awaited alarms from the system (Abe & Richardson, 2006). The assistance of an automated decision aid can thus produce either benefits or costs to RTs.
In analysis of central tendency alone, though, one can overlook important information about automation-aided human performance in RT data. Assuming no trade-offs between speed, accuracy, and workload, an operator in a speeded task should respond at least as fast when assisted by an automated aid as when unassisted; in the worst-case scenario, that using it would slow responses without improving response accuracy or reducing workload, the user’s optimal strategy would be to simply ignore the aid. Thus, holding response accuracy and workload constant, response slowing in aided conditions suggests suboptimal automation use. As discussed later, however, a decrease in mean RT under aided conditions does not by itself give evidence of optimal automation use. A system-level performance gain as measured by mean RT may therefore mask suboptimal automation usage strategy. Here, we propose a measure of automation-aided performance to circumvent this difficulty.
Workload Capacity
In some automation-aided decision tasks, the human operator may receive a cue from the aid before beginning the task himself or herself. In these cases, the aid and operator form a system of serial processing channels. In other tasks, however, the operator and aid work simultaneously, and either may reach a judgment before the other. For example, a human controller and an automated aid may monitor concurrently for the development of air traffic conflicts, and either may be first to detect an emerging conflict. Mean RTs for the human and the aid will vary with factors, including the operator’s skill and workload, and the aid’s detection algorithm, and threshold setting (Thomas, Wickens, & Rantanen, 2003). In cases like this, the operator and the aid constitute parallel, redundant information-processing channels. An automation-aided task of this form is therefore analogous to the redundant-targets task familiar to cognitive psychology (Miller, 1982) and is amenable to the analyses used to study redundant-targets processing. Perhaps the best developed of these is Townsend and colleagues’ systems factorial technology (SFT; Townsend & Nozawa, 1995), which offers theory and methodology for characterizing the relationship between parallel processing channels. Of interest here, SFT provides measures of workload capacity, the efficiency with which information-processing channels operate concurrently versus in isolation (Townsend & Eidels, 2011).
In a standard redundant-targets task, the subject is asked each trial to make a speeded target detection. Target signals are presented either in isolation to one of two parallel channels (e.g., visually or aurally) or redundantly to both channels (e.g., visually and aurally). The participant responds with a yes judgment as soon as any target is detected, a demand known as a first-terminating (Colonius & Vorberg, 1994) or OR stopping rule (Townsend & Wenger, 2004). Generally, RTs are shorter for redundant-target trials than for single-target trials, showing a redundancy gain or redundant-targets effect (Ben-David & Algom, 2009; Miller, 1982; Mordkoff & Yantis, 1991; Raab, 1962).
In the simplest model of the redundant-targets effect, the unlimited-capacity independent parallel (UCIP) model (Townsend & Wenger, 2004), the two channels operate with stochastic independence, and each accumulates information at the same rate in the redundant-target condition as it does in the single-target condition. Target redundancy thus has no effect on the speed of the individual channels. However, because processing time for the system as a whole is determined by the first channel to finish each trial, statistical facilitation (Raab, 1962) tends to produce shorter RTs for redundant-target trials. Limited capacity exists when the individual channels operate more slowly under redundant-target conditions than in isolation (Townsend & Wenger, 2004), producing longer RTs and a redundancy gain smaller than expected from the UCIP model. Conversely, supercapacity exists when interaction (Mordkoff & Yantis, 1991) or information pooling (Miller, 1982) between channels produces redundancy gains larger than expected from the UCIP model.
SFT gauges capacity limitations by comparing the observed RT distribution for redundant-target trials to the distribution predicted from the single-target RT distributions, assuming a UCIP model. Following Townsend and Ashby (1978), SFT treats the response hazard function, h(t), as a measure of instantaneous cognitive capacity, where h(t) gives the probability that a response will occur at time t given that it has not yet occurred. Colloquially, a higher capacity or “intensity” of processing at one instant increases the likelihood of a response the next instant. The integrated hazard function, H(t), is then the total amount of capacity that the system has expended up to t. H(t) is related to the cumulative RT density distribution, F(t) = P(RT < t), by the formula (Wenger & Townsend, 2000)
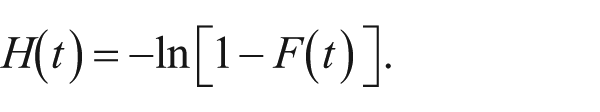
H(t) is useful for the study of parallel processing because the integrated hazard function for channels operating independently, in parallel, and with unlimited capacity are additive (Townsend & Ashby, 1983). Thus, under a UCIP model, the integrated hazard function for responses to a pair of redundant targets is the sum of the integrated hazard functions for responses to each of the single targets,

where HA(t), HB(t), HAB(t) are derived, respectively, from FA(t) and FB(t), the cumulative RT density functions for the two single-target conditions, and FAB(t), the cumulative RT density function for the redundant-targets condition. Under an OR stopping rule, the workload capacity index, COR(t), is therefore defined as the ratio of H(t) for the redundant-targets condition to the summed values of H(t) for the single-target conditions (Townsend & Nozawa, 1995),

A value of COR(t) =1.0 denotes unlimited capacity, matching the predictions of the UCIP model, and COR(t) ≠ 1.0 implies a violation of the model. Values less than 1.0, indicating that HAB(t) is less than the sum of HA(t) and HB(t), denote limited capacity, with COR(t) = 0.5 corresponding to fixed capacity, the point at which redundancy gains disappear. Values greater than 1.0, indicating that HAB(t) exceeds the sum of HA(t) and HB(t), denote supercapacity. COR(t) thus provides theory-driven benchmarks for assessing how efficiently two channels operate in parallel relative to the speed at which they operate in isolation. Data can be collapsed over time into a summary measure (Houpt & Townsend, 2012) or presented as a function of t to reveal the time course of capacity fluctuations. Wenger and Townsend (2000) provide further details on calculating COR(t) from RT data, and Houpt et al. (Houpt, Blaha, McIntire, Havig, & Townsend, 2013) provide R functions for performing the calculations.
More recent work has extended workload capacity analysis to tasks employing an exhaustive or AND stopping rule (Townsend & Wenger, 2004). Under this rule, both channels must complete processing before a response can be made, and system-level RT is therefore determined by the second channel to finish. Workload capacity is calculated using the integrated reverse hazard function, K(t) = ln[F(t)], which gives the cumulative probability that the system has just completed processing at time t, given that processing completes at or before t (Chechille, 2011). CAND(t) is defined as

where KA(t) and KB(t) are the reverse hazard functions for the two single-target conditions, and KAB(t) is the reverse hazard functions for the redundant-targets condition. Houpt et al. (2013) provide R functions for calculating CAND(t) from RT data.
Note that COR(t) and CAND(t) are both empirical measures for characterizing the behavior of parallel channel systems: A system is capacity limited if channels operate more slowly together than in isolation and is supercapacity if they operate more quickly together than in isolation. These descriptions presuppose no particular form of processing resources or resource constraints (Logan, 2002), nor do they presuppose that either or both channels are neural or biological. Conceptualizing the human–automation team as a parallel redundant channel system thus suggests that we can use workload capacity as a measure of human–automation system performance. The first-terminating RT, as needed to calculate COR(t), is simply the RT of the first agent—human or aid—to respond on a given trial. The exhaustive RT, as needed to calculate CAND(t), is the RT of the second agent to respond.
The performance benchmarks of C(t) may in fact be diagnostic of automation usage strategies. Consider COR(t). Assuming the aid’s processing rate is unaffected by the human operator, any deviation of COR(t) from the benchmark of unlimited capacity will indicate a change in the operator’s response speed prior to the onset of a cue from the aid. A value of COR(t) less than 1.0 for the human–automation team will imply a tendency for operators to delay their own responses in anticipation of a cue from the aid (e.g., Abe & Richardson, 2006), making slower responses in the time before the aid has issued a cue than in the corresponding time window of an unassisted trial. In contrast, a value greater than 1.0 will imply a tendency for operators to speed up their responses in anticipation of a cue from the aid, effectively racing the aid to a response. A value of 1.0 will indicate no change in the observers’ response speed preceding a cue from the aid as compared to the same time window of an unassisted trial.
Conversely, a deviation of CAND(t) from the benchmark value of 1.0 will indicate a change in the operator’s behavior following a cue from the aid. A value of greater than 1.0 will indicate a tendency for operators to respond faster after a cue than they do during the corresponding time window of an unassisted trial, acting on the aid’s judgments to speed their own decisions. A value less than 1.0 will imply a tendency for the operators to render judgments more slowly following a cue from the aid than during the corresponding time window of an unassisted trial. Such an effect might result if low trust causes operators to confirm the aid’s diagnoses before acting on them or if disagreements between the aid and the operators cause the operators to reinspect the raw data or take time to carefully reconsider their own judgments. Finally, a value equal to 1.0 will indicate no effect of the aid’s judgments on the operator’s RTs.
Pursuing these ideas, we use C(t) here to measure the efficiency of human–automation team performance and explore users’ automation usage strategies. Participants performed a speeded decision task, with and without the assistance of an automated aid that issued cues with varying decision times. To gauge the effects of the aid’s speed on user behavior, mean cue onset time for the aid varied between groups of participants. Empirical RT distributions for the participants and simulated cue onset time distributions for the aid were used to calculate capacity measures.
Method
Participants
Participants were 40 adults (mean age = 22.28 years, SD = 7.55, range = 17–49; 31 females, nine males) recruited from the community of Flinders University, Adelaide. Participants were screened for normal or corrected-to-normal visual acuity and normal color vision. Participants were remunerated with course credit.
Apparatus
Displays were presented on a Samsung SA750 23-in. LED monitor with 1,920 × 1,080 resolution. The experiment was controlled by a PC running E-Prime Version 2.0 (Psychology Software Tools, Inc., Pittsburgh, PA).
Procedure
Participants performed a multi-element probabilistic decision task modeled after those used by Sorkin and colleagues (e.g., Sorkin, Mabry, Weldon, & Elvers, 1991). Instructions asked participants to imagine that they were monitoring operations at a power plant and were required to judge whether the system was in a safe or dangerous state. Each trial, the participant saw a 500-ms blank screen followed by a set of four three-digit numbers, labeled Reading 1: through Reading 4:, presented in black 18-pt Courier New font in a column in the center of the display (Figure 1). On system-safe trials, the readings were sampled independently from a pseudorandom Gaussian distribution of M = 485 and SD = 20. On system-dangerous trials, readings were sampled independently from a pseudorandom Gaussian distribution of M = 515 and SD = 20. Because values were probabilistic, no single reading was perfectly diagnostic of the system state (d′ = 1.5 for an ideal observer). Collectively, however, the four values allowed judgments at accuracy well above chance (d′ = 3.0 for an ideal observer; Sorkin et al., 1991). The need to integrate information across multiple information readings ensured that the experimental task was cognitively demanding and was intended to give participants incentive to attend to and use the automated aid when it was available. True system state was determined pseudorandomly each trial, with a 0.50 probability of being safe.

A sample of the stimulus display including a cue from the automated aid.
Instructions informed the participants that on average, the readings would be less than 500 if the system was in a safe state and greater than 500 if the system was in a dangerous state. But the instructions further specified that the individual readings were imperfect and that the participant should attend to all four readings to reach accurate judgments. Participants were instructed to click the left mouse button to indicate a safe state and the right button to indicate a dangerous state. They were asked to be as accurate as possible in their judgments without taking any longer than necessary to make each response. The stimulus display remained visible each trial until a response occurred. The trial ended with a 500-ms feedback screen, with the symbol + appearing to indicate a correct response and an x to indicate an error.
On alternating blocks of trials, participants were assisted by an automated aid. The aid provided diagnostic cues as text messages, presenting the word SAFE in green font or UNSAFE in red font. Cues appeared in all caps above the readings. A SAFE message appeared offset 192 pixels (10% of the display width) to the left of the screen center, and an UNSAFE message appeared offset 192 pixels to the right of the display center, creating a high level of spatial stimulus-response compatibility (Fitts & Seeger, 1953; Simon, 1969) between the cues and corresponding mouse clicks. Cues appeared with a variable delay across trials. In the slow aid conditions, onset times for the cues were sampled pseudorandomly from an exponential distribution with a mean of 1,200 ms. In the fast aid conditions, onset times were sampled pseudorandomly from an exponential distribution with a mean of 600 ms. Mean onset time for the slow aid condition was chosen on the basis of pilot experimentation to roughly match the RTs of unaided human participants.
The choice of the exponential distribution for onset times was intended to avoid distortions in subjects’ behavior that might have resulted from alternative distributions. Because the exponential distribution is memoryless, the probability that the cue would appear at any moment, given that it had not yet appeared, was constant. The distribution of cue onset times therefore gave subjects no motivation to strategically vary their behavior over time in response to a changing instantaneous probability that the cue would appear (e.g., to further delay a slow response as the likelihood of message onset increased). Cues from the aid were correct with a probability of 0.90, a value chosen to approximate the accuracy rate for unaided human participants in pilot experimentation. Conditionalized on the true system state, the accuracy of the aid’s response each trial was determined independently of the readings displayed to the user.
Each participant performed a block of 30 unaided practice trials and a block of 30 aided practice trials, followed by four blocks of 50 experimental trials each. Experimental blocks alternated between aided and unaided conditions, with order counterbalanced across participants. A message at the start of each block informed the participant whether the upcoming trials would be aided or unaided. Participants were allowed to rest between blocks.
Analyses
Mean RTs and error rates were calculated from the human participants’ responses. RTs for incorrect responses were excluded from all analyses, as were data from all trials with human RTs less than 250 ms or greater than 5,000 ms.
To allow calculation of workload capacity measures, a cue onset time for the automated aid was sampled every trial. On aided trials, this value determined the time at which the diagnostic cue appeared to the participant, as explained earlier. On unaided trials, cue onset times provided single-channel data for the aid, as needed to calculate workload capacity but had no influence on the trial itself. For statistical analysis, raw capacity scores were transformed to the statistic CZ (Houpt & Townsend, 2012). CZ provides a summary measure of capacity, aggregated over time, allowing comparisons of mean values across experimental conditions. Values follow a standard normal distribution, meaning that a value of 0 indicates unlimited capacity, a negative value indicates limited capacity, and a positive value indicates supercapacity. COR(t), CAND(t), CZOR, and CZANDvalues were calculated using the sft package for R (Houpt et al., 2013).
Statistical analyses employed default Bayesian tests (Rouder & Morey, 2012; Rouder, Morey, Speckman, & Province, 2012) in place of conventional null-hypothesis significance tests. In this approach, Bayes factors, likelihood ratios that indicate the degree to which the observed data favor one statistical model over another, serve as the measure of evidence. Bayes factors here are reported with the model including a statistical effect of interest in the numerator and the model lacking the effect in the denominator. Values greater than 1.0 therefore give evidence of the effect, whereas values less than 1.0 give evidence against it. Following Rouder and Morey (2012), these values are labeled as B10. Terms used to discuss Bayes factors (anecdotal, substantial, strong, very strong, decisive) are taken from Wetzels et al. (2011). The effect size measure reported is generalized eta squared (Olejnik & Algina, 2003).
Results
Figure 2 presents mean RTs. Data were analyzed in a 2 × 2 mixed design with automation condition (aided vs. unaided) as a within-subject factor and speed of the aid (slow vs. fast) as a between-subject factor. Data gave strong evidence for a main effect of automation condition, F(1, 38) = 9.57, η2G = .007, B10 = 10.73, indicating that assistance from the aid reduced human participants’ RTs. Data showed no substantial evidence either for or against a main effect of the aid’s speed, F(1, 38) = 0.33, η2G = .008, B10 = 0.72, or an interaction, F(1, 38) = 0.95, η2G < .001, B10 = 0.44, producing only anecdotal trends in favor of the null.

Mean response times for the human subjects as a function of the aid conditions and speed of the aid. Error bars represent within-subject 95% confidence intervals (Loftus & Masson, 1994) based on the error term for the main effect of the aid condition and the interaction of aid condition by aid speed.
Workload capacity scores provide insight into these effects. Figure 3 presents values of COR(t) (top panel) and CAND(t) (bottom panel), plotted separately for slow and fast aids. To reiterate, COR(t) measures the processing efficiency of the human–automation team as determined by the RT of the first agent to respond each trial. CAND(t) measures the processing efficiency of the team as determined by the RT of the second agent to respond. Values shown in Figure 3 are means and 95% confidence intervals (CIs) based on 1,000 bootstrap samples from the aggregated data of the 20 participants within each group. COR(t) values hewed close to the benchmark of 1.0, denoting UCIP processing. CAND(t) values held slightly above 1.0, in the range of modest supercapacity, trending slightly upward through the course of a trial. Raw C(t) values thus imply that the presence of an aid had little effect on the speed with which participants rendered responses prior to onset of a cue, as reflected by COR(t), but facilitated responses following onset of a cue from the aid, as reflected by CAND(t). Data were similar for participants assisted by fast and slow aids.

Group aggregate values of COR(t) (top panel) and CAND(t) (bottom panel). Error bars represented 95% bootstrap confidence intervals.
Analysis of capacity values aggregated over time affirmed these conclusions. Figure 4 presents mean values of CZOR and CZAND. Mean CZOR scores did not differ between participants aided by fast versus slow aids, t(38) = 0.41, η2G = .004, B10 = 0.33. Collapsed across levels of aid speed, mean CZOR scores fell near the benchmark value of 0.0, indicating unlimited capacity, M = 0.32, t(39) = 1.73, 95% CI [–0.05, 0.70], though data gave only anecdotal support for the null hypothesis, B10 = 0.67 by one-sample test. Results thus failed to decisively affirm the hypothesis of UCIP processing but clearly gave no evidence that participants modified their response speed in anticipation of a cue from the aid.

Mean normalized capacity scores under the OR and AND stopping rules for the slow and fast aid conditions. Error bars represent between-subject 95% confidence intervals.
In contrast, CZAND values gave clear evidence of automation dependence. Mean scores again were similar across participants aided by the fast versus slow aids, t(38) = −0.63, η2G = .01, B10 = 0.36. Collapsed across levels of aid speed, mean values of CZAND reliably exceeded 0.0, giving very strong evidence of supercapacity, t(39) = 3.63, M = 0.82, 95% CI [0.36, 1.28], B10 = 36.27 by one-sample test. In other words, the RTs for trials in which the participant responded after onset of a cue were shorter than expected based on the participants’ unaided RTs.
Mean response accuracy was 0.88, 95% CI [0.87, 0.90], for aided blocks and 0.86, 95% CI [0.84, 0.88], F(1, 28) = 10.09, η2G = .03, B10 = 13.38, for unaided blocks, confirming that the RT advantage for aided conditions was not the result of a speed–accuracy trade-off. Accuracy rates showed no evidence for a main effect of the aid’s speed, F(1, 38) = 0.91, η2G = .02, B10 = 0.65, or an interaction, F(1, 38) < 0.01, η2G < .001, B10 = 0.31.
Discussion
Analysis of workload capacity gave insights into participants’ automation usage strategies that were opaque to the analysis of mean RTs. COR(t) scores hewed close to the level of unlimited capacity for both groups of participants, indicating that participants maintained their normal response speed even when anticipating a cue from the aid, regardless of the aid’s speed. CAND(t) scores exceeded the level of unlimited capacity, however, indicating that participants relied on cues as they arrived to speed their own responses. Notably, evidence of automation dependence appeared more robust in CAND(t) than in mean RTs, with the Bayes factor favoring supercapacity processing in CZAND (B10 = 36.27) reaching a value over 3 times larger than the Bayes factor indicating a difference in mean RTs for aided versus unaided trials (B10 = 10.73). This advantage for the workload capacity measure is likely to have resulted from either of two factors. First, the capacity indices exploit information from across the RT distribution and may thereby achieve higher sensitivity than measures of central tendency alone (Townsend, 1990). Second, CAND(t) isolates the effect of the aid on trials for which the human user responds after the aid, whereas mean RT for aided trials conflates data for trials on which the human responds before the aid and those on which the aid responds first.
Data confirm that workload capacity is a sensitive and informative gauge of automation dependence as it manifests in users’ RTs. COR(t) can be calculated for any task in which an operator and an aid work in parallel to make speeded decisions. Calculation of CAND(t) imposes the additional constraint that both the human and the automation provide an RT for each trial. As in the current experiments, RT distributions for the aid may be generated by simulation when necessary. The need for RTs from both the operator and the aid, however, implies that CAND(t) cannot be calculated for tasks in which the aid executes a response by default, without consent from the human operator. Importantly, analysis of workload capacity does not require that either the aid or the operator perform a task with perfect accuracy. Capacity estimates are robust against error rates of 25% or higher in a two-choice task (Townsend & Wenger, 2004).
Analysis of workload capacity is applicable with automated aids working at any of the four processing stages identified by Parasuraman et al. (2000)—information acquisition, information analysis, decision selection, and action implementation—with the caveat noted earlier that CAND(t) requires an RT each trial from both the aid and the human operator. In the current experiment, the aid can be considered to have operated at the level of either information analysis or decision selection (since analysis outcomes and responses were related one-to-one). Other automation-aided tasks to which the analysis of C(t) is applicable might include detection of auto collisions (Kramer, Cassavaugh, Horrey, Becic, & Mayhugh, 2007), detection of air traffic conflicts (Metzger & Parasuraman, 2005; Rovira & Parasuraman, 2010), and the detection of air-to-ground targets (Yeh et al., 1999). Topics of interest might include the influence of cue threshold (Rice & McCarley, 2011; Thomas et al., 2003), aid reliability (Metzger & Parasuraman, 2005; Wickens & Dixon, 2007), and cue format (Yeh et al., 1999) on the operators’ automation usage strategies. Analysis of capacity can also be extended to include process modeling (Eidels, Donkin, Brown, & Heathcote, 2010) or to incorporate more detailed analysis of capacity timelines (Burns, Houpt, Townsend, & Endres, 2013). It may also be used to characterize individual differences in performance (e.g., Yu, Chang, & Yang, 2014).
Workload capacity, of course, measures automation dependence only as it manifests in the operator’s RTs. It takes no account of the operator’s response accuracy (though see Townsend & Altieri, 2012), nor does it gauge the operator’s mental workload or subjective trust in the automation (Lee & See, 2004; Madhavan & Wiegmann, 2007). A comprehensive understanding of human–automation interaction in any given context will thus require diverse measures of system performance and operator state. Workload capacity, though, provides a novel and revealing measure by which human–automation systems may be characterized in a multidimensional analytic space.
Key Points
We analyzed workload capacity, a response time–based measure of parallel channel processing efficiency (Townsend & Nozawa, 1995), to explore the performance of human–automation teams in a probabilistic decision task.
Together, the workload capacity measures COR(t) and CAND(t) gave clear evidence that participants did not modulate their own decision speed in anticipation of a decision cue from the automated aid but that cues from the aid speeded human decisions.
Workload capacity provides a more sensitive and informative measure of automation usage in speeded tasks.
Footnotes
Acknowledgements
We thank Megan Bartlett and Steph Morey for assistance with data collection.
Yusuke Yamani is an assistant professor in the Department of Psychology at Old Dominion University. He earned his PhD in psychology at the University of Illinois at Urbana-Champaign in 2013.
Jason S. McCarley is a professor in the School of Psychology at Flinders University, Adelaide, South Australia. He received his PhD in experimental psychology from the University of Louisville in 1998.