
Abstract
Background:
In safety-critical and highly automated environments, more than one person typically monitors the system in order to increase reliability.
Objective:
We investigate whether the anticipated advantage of redundant automation monitoring is lost due to social loafing and whether individual performance feedback can mitigate this effect.
Method:
In two experiments, participants worked on a multitasking paradigm in which one task was the monitoring and cross-checking of an automation. Participants worked either alone or with a team partner on this task. The redundant group was further subdivided. One subgroup was instructed that only team performance would be evaluated, whereas the other subgroup expected to receive individual performance feedback after the experiment.
Results:
Compared to participants working alone, those who worked collectively but did not expect individual feedback performed significantly less cross-checks and found 25% fewer automation failures. Due to this social loafing effect, even the combined team performance did not surpass the performance of participants working alone. However, when participants expected individual performance feedback, their monitoring behavior and failure detection performance was similar to participants working alone and a team advantage became apparent.
Conclusion:
Social loafing in redundant automation monitoring can negate the expected gain, if individual performance feedback is not provided.
Application:
These findings may motivate safety experts to evaluate whether their implementation of human redundancy is vulnerable to social loafing effects.
Keywords
Automation and digital technologies have changed the nature of human work in many ways. Instead of performing tasks manually, people are increasingly in charge of controlling and monitoring machines that actually conduct the task. Unfortunately, there is evidence that human operators do not excel in passively monitoring and controlling automated tasks (Parasuraman, Sheridan, & Wickens, 2000). Keeping a human operator out of the loop of directly controlling a system has often been shown to decrease the operator’s situation awareness and sensitivity to detect and compensate automation failures (Endsley & Kiris, 1995). In part this is due to a lack of transparency regarding the actions of the automation. In addition, it is often observed that humans adapt their behavior when monitoring highly reliable systems. Particularly, if automation monitoring is perceived as a monotonous and boring task, the vigilance level of operators can decrease and in turn raise the probability of missing indications of malfunctions (Hancock, 2017). Another issue is overreliance on automated functions. Especially when dealing with systems that err very rarely, operators may rely too much on the proper functioning of the automation and reduce their monitoring. This phenomenon is referred to as complacency and has repeatedly been shown to arise in multitasking situations where monitoring an automated task is just one of several tasks the operator has to accomplish (see for a review Parasuraman & Manzey, 2010).
Individual limitations of monitoring reliability and related risks of missing automation failures are often counteracted by putting more than one person in charge of the task (Clarke, 2005). This strategy reflects the common assumption that four eyes see more than two (or six more than four, etc.) and has been proposed, for example, as a way to increase the reliability of human performance in so-called high reliability organizations (HROs; Roberts, 1990). The idea underlying such approaches is the technical principle of redundancy, defined as the provision of multiple interchangeable components performing a single function in order to cope with failures and errors. As can be shown by simple probability arithmetic, the inclusion of multiple independent and interchangeable technical components performing the same task can lead to almost perfect overall system reliability even if each individual component is only moderately reliable (Sagan, 2004). For example, assume that the reliability of a single component is 70.0% ([1 – (3/10)] × 100). This reliability increases to 91.0% ([1 – (3/10)²] × 100) for two components and 97.3% ([1 – (3/10)³] × 100) if a third component is added.
When human redundancy is used, similar improvements are implicitly anticipated. But can the redundancy principle be transferred from the engineering domain into domains in which human agents are performing tasks redundantly? In contrast to technical components that are designed to work independently, redundant operators are usually aware of each other. Especially in situations where it would be theoretically sufficient if one person accomplished a task, individuals might adapt their behavior and withhold their effort invested in the task. A particular form of withholding effort that has been discussed in relation to human redundancy is social shirking, which describes the tendency of individuals or groups to shirk from unpleasant duties in the belief that someone else will take care of it (Sagan, 2004). Darley and Latané (1968) found that individuals are less likely to report others’ criminal behavior or to intervene in medical emergencies they observe in public areas if there are other witnesses who could also do this. They argued that in such situations the perceived responsibility is diffused among the observers as is the expected blame for not taking action. They found support for their theory in multiple studies and dubbed this phenomenon unresponsive bystander (Darley & Latané, 1968; Latané & Darley, 1968; Latané & Rodin, 1969). It is, however, unlikely that this form of withholding effort also plays a role in redundant automation monitoring as, when operators redundantly monitor an automated system, they have an explicit task and bear responsibility for potential negative consequences caused by their malperformance.
A potentially more relevant phenomenon in the context of redundant automation monitoring is social loafing (e.g., Skitka, Mosier, Burdick, & Rosenblatt, 2000). Social loafing is defined as a reduction of individual motivation and effort when working on a task collectively (i.e., in groups) rather than alone (Latané, Williams, & Harkins, 1979). It has been observed in a broad variety of tasks including rope-pulling, clapping, shouting, and idea generation (Allport, 1920; Latané et al., 1979; Pessin, 1933; Szymanski & Harkins, 1987). These studies show that, if individuals are assigned the clear responsibility to accomplish a specific task, the fact that they are working together with other group members can negatively affect their performance. Karau and Williams (1993) assume that social loafing occurs because individuals behave hedonistically and try to maximize the expected utility of their actions. According to their collective effort model (CEM), which is based on expectancy-value models of effort (e.g., Vroom, 1964, individuals will exert effort on a collective task only to the degree that they expect their individual efforts to be instrumental in obtaining valued outcomes. The latter is only given if individual effort directly relates to individually achieved performance, which in turn must have an obvious impact on the group’s performance and on related positive outcomes, such as pay, self-evaluation information, and/or feelings of purpose or belonging within the group. Karau and Williams (1993) believe that, if a task performance setting disrupts any of these criteria, social loafing is likely. Whether individuals reduce their effort consciously cannot be clearly said. In an extensive meta-analysis, Karau and Williams (1993) not only identified a large number of variables that moderate the occurrence of social loafing (e.g., evaluation potential, expectation of co-worker performance, task meaningfulness, and culture) but also found that the subjects’ self-reported effort often did not match the reduction found in performance measures. This suggests that participants are either unaware of the fact that they engage in social loafing or are unwilling to report it.
But is this form of withholding effort relevant in the present context? Redundant automation monitoring indeed constitutes a task for which the CEM would predict social loafing effects. Since automation failures are typically rare (Bailey & Scerbo, 2007) and a formal assessment of the quality of individual monitoring behavior is difficult, operators rarely experience or receive the feedback that their individual motivation and effort in performing the task really make a difference. Furthermore, since it is often sufficient that one person detects an automation error, redundant operators might especially feel that their inputs are not essential to a high group performance (i.e., are dispensable). Consequently, redundant automation monitoring might be particularly likely to be affected by social loafing.
If the individual monitoring performance of operators working redundantly is reduced by social loafing, the gain expected from employing the redundancy principle can be compromised. Depending on how strong the individual performance declines, this overall performance gain can be partially or fully offset, or in the worst case may even be reversed into a negative effect. For example, if the individual monitoring reliability of two operators drops from 70% down to 45% as a result of social loafing, their combined reliability would only reach [1 – (5.5/10)²] × 100 = 69.8%, representing no improvement over the single-operator setting. In case of less severe reductions of monitoring reliability due to social loafing, operator dyads do, however, provide advantages, although these might not be as high as expected. For these reasons, it should be tested whether social loafing can occur and how strong social loafing effects are before applying human redundancy. This is difficult, however, as many variables moderate social loafing effects, and as a result of their interplay, individual motivation and performance in collective tasks may be left unchanged or even increase in some cases. For instance, when operators know that their other team member is less reliable or capable, they may actually invest more effort in a meaningful collective task, indicating a sort of social compensation effect (Williams & Karau, 1991). Informing operators that their individual contribution to the group product is assessable was found to be another promising measure to counter social loafing (Karau & Williams, 1993). If operators believe that their individual monitoring performance will be tracked, the perceived contingency between individual performance and group performance is strengthened and more opportunity for self-evaluation is warranted. This makes social loafing less likely (Karau & Williams, 1993).
In most highly automated environments (e.g., control room, airplane cockpit) more than one person is available to monitor the system. But despite this, very few studies have addressed the performance consequences of human redundancy for automation monitoring and failure detection. A first set of two studies (Mosier, Skitka, Dunbar, & McDonnell, 2001; Skitka et al., 2000) investigated whether two-person crews detect more automation failures than solo decision makers. Although the studies were not based on the CEM, relating their data and results to the CEM is interesting. The participants of the first study of Skitka et al. (2000) were students who worked on a low-fidelity, computerized flight simulation program that presents participants with a set of tasks simulating the types of monitoring and tracking tasks involved in flying commercial aircrafts (continuous tracking, gauge monitoring, waypoint determination, automation monitoring). In a one-person crew condition, participants worked on all these tasks alone, whereas in a redundancy condition, two crew members performed the automation monitoring task jointly while simultaneously being solely responsible for either the tracking tasks (if they were assigned to the pilot role) or an additional arithmetic task (if they were assigned the copilot role). In the second study, Mosier et al. (2001) then investigated the same research question using one- and two-person crews of professional pilots in an advanced flight simulator. Besides flight-relevant tasks, such as completing checklists and communicating with air traffic control, participants’ tasks also involved the monitoring of automated flying directed by autopilot and flight management system (Mosier et al., 2001). In both studies, the highly reliable automation that participants monitored erred a few times. The authors compared how often these errors were detected within one- versus two-person crews but could not find any performance advantages of two-person crews. They specifically found that the risk of missing events that are not specifically prompted by an automated decisions aid (omission error) is not ameliorated. Nor did having more than one person involved in automation monitoring and verification reduce the likelihood that false automation directives were followed despite the availability of contradicting information (commission error). According to the redundancy principle, even components that are not highly reliable lead to a rapid increase in overall reliability when used in combination. This was obviously not the case in these two studies and thus might be an indication of social loafing within the two-person crews. But without direct measures of participants’ effort, such as the monitoring performance, it remains unclear whether the lack of difference between dyads and solo performers was indeed due to a reduction of individual monitoring effort in collective task settings or whether other factors such as increased task complexity and coordination demand or hierarchy problems influenced automation failure detection. It might be the case that the automation failures were too infrequent to find differences between the groups and/or that the detection of automation errors is too much influenced by chance to serve as a suitable performance measure. Moray and Inagaki (2000) argued that even people who try as hard as possible cannot maintain their attention on multiple tasks simultaneously and can, therefore, miss automation errors without being less motivated. They suggest using more direct and explicit measures of effort, such as sampling behavior, whenever possible.
More direct evidence that human redundancy can lead to social loafing and reduced monitoring effort has been provided by Domeinski, Wagner, Schoebel, and Manzey (2007), who set up their experiment on the basis of the CEM of Karau and Williams (1993). Participants in this study worked on three different tasks concurrently, with one of the tasks involving monitoring and cross-checking an automated process. Three groups were compared: a nonredundant group in which participants worked on all three tasks alone, a redundant group in which participants were told that they had to work on two tasks alone but that a second crew member would perform the automation monitoring task in parallel, and a third, informed-redundant, group in which participants received the same instruction as the members of the redundant group with the additional information that the performance of the other crewmate might be low. The latter group manipulation was done in order to mitigate social loafing by inducing social compensation behavior. Participants in the redundant group, who knew that someone else was also in charge of the automation monitoring task, cross-checked the automation on average 50% less than participants working alone on the task. Interestingly, this effect was not accompanied by increased performance in the other two tasks. This suggests that the participants in the redundant condition tried to reduce their overall effort and workload by decreasing the monitoring of the automation. No comparable reduction occurred in the informed-redundant group, supporting the assumption that social compensation effects might take place when working with a supposedly underperforming crewmate (Domeinski et al., 2007).
Although these results can be taken as first evidence that human redundancy may not necessarily increase the reliability of automation monitoring compared to solo performance, many questions remain unanswered. First, the participants in this study had to work on the three tasks for only 12 minutes. Thus, they might have been overloaded, and it remains unclear whether the decrease of monitoring effort would have persisted as the multitasking became more routine. In addition, the automation in this study was perfectly reliable. It is not clear how the redundancy effect found in the redundant group would have compromised the detection of automation failures. Finally, and most importantly, the mere finding of a decreased automation monitoring effort on the individual level in a redundant work team does not necessarily challenge the concept and benefits of human redundancy. Even if performance decreases on the individual level, the overall crew performance might still be better than the performance of an operator who is alone responsible for automation monitoring.
Experiment 1
The current research was conducted to further explore the possible consequences of human redundancy on human automation monitoring and control. The two experiments presented here directly build on the previous study of Domeinski et al. (2007). Using the same multitasking setting, we investigated the extent to which human redundancy would induce social loafing in participants who have worked long enough to develop some routine in task coordination. In addition, three entirely new aspects were addressed. The first involved possible performance consequences of human redundancy on the detection of automation failures. We assumed that individuals who share the responsibility of automation monitoring and control with another person (redundant work group, R) would not only reduce their individual monitoring effort (Hypothesis 1), as found by Domeinski et al. (2007), but that this reduction would also make redundantly working participants more prone to miss automation failures compared to individuals who are responsible for the task alone (nonredundant work group, NON-R) (Hypothesis 2). Second, we reckoned that the expectation to receive feedback on monitoring performance (redundant work with individual performance feedback group, R-FB) would prevent or at least mitigate possible social loafing effects induced by human redundancy (Hypothesis 3). This was hypothesized based on the model of Karau and Williams (1993) and empirical results showing that social loafing primarily occurs when performance is evaluated on a team level but not if performance feedback is given on the individual level (Harkins & Jackson, 1985; Szymanski, Garczynski, & Harkins, 2000). Third, mean aggregated performances of two participants working collectively on the automation monitoring task were compared with mean performances of solo performers. We predicted that, despite the expected mild (R-FB) or moderate (R) performance decrements in teams on an individual level, the combined team monitoring performance of R teams would still surpass the monitoring performance of solo performers (Hypothesis 4) and that R teams will therefore still detect more automation failures than operators working alone on the monitoring task (Hypothesis 5). Hypotheses 4 and 5 were based on the fact that, provided that possible social loafing effects do not reduce the monitoring performance of individual team members to a severe degree, the net effect of redundancy should remain positive. Since individual feedback was expected to mitigate or completely prevent social loafing occurrence in the R-FB group, the expectation that Hypotheses 4 and 5 are confirmed for this group is higher than for the R condition.
Method
Apparatus and task
The multitasking environment Multi-Task Operator Performance Simulation for Redundancy Research (MTOPS-R; Domeinski et al., 2007) was used to implement three subtasks mimicking basic tasks of operators in a control room of a chemical plant. The user interface is depicted in Figure 1. The first task in the upper left quadrant is a resource ordering task (ROT). The ROT represents a mental arithmetic task. Participants had to ensure the supplies of chemicals to keep the plant processes running. To order supplies, they first had to subtract actual stock (“Reserve”; e.g., 320 tonnes) from a required quantity (“Demand”; e.g., 500 tonnes). Participants had to type the difference into an order field and submit their order by clicking a send button. Each chemical was displayed for 15 seconds. Either after submission of an order or after expiration of the available time, the chemical disappeared and a new chemical (e.g., K0-44BM, T-061MQ) was presented after a delay of 3 seconds. Alternatively, participants could actively request a new chemical by clicking on an arrow (top right). This routine was continued until the experiment ended.
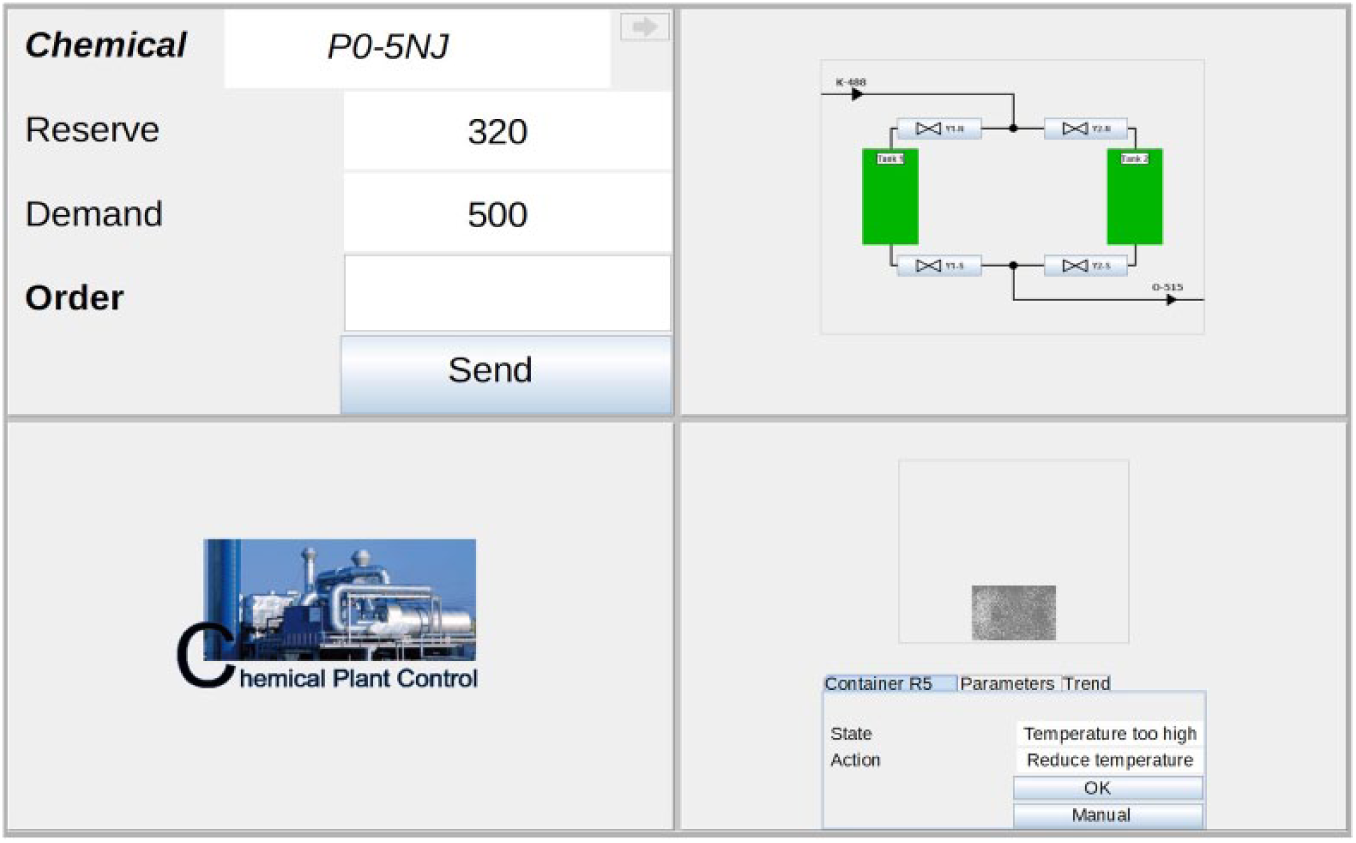
User interface of Multi-Task Operator Performance Simulation for Redundancy Research (MTOPS-R) used in Experiment 1 (upper left: resource ordering task [ROT]; upper right: coolant exchange task [CET]; lower right: monitoring task [MOT]; lower left: static image of a chemical plant).
The second task is displayed in the upper right quadrant and is a coolant exchange task (CET). Participants had to exchange coolant in a two-vessel cooling system. Valves () had to be opened and closed in a defined sequence to drain used coolant and to refill the vessels with fresh coolant. Participants could tell by the color of the vessel whether it contained no (grey), used (green), or fresh (blue) coolant. The filling and emptying speed differed from exchange to exchange, but it took at least 38 seconds for a complete exchange cycle of both vessels.
The third task is displayed in the lower right quadrant and constitutes a monitoring task (MOT). Here, participants were required to monitor a system that autonomously analyzes and controls chemical processes in different containers. Participants received information about the deduced state (“status”) of the currently displayed container (e.g., “temperature too high,” “reaction running”) and the corresponding action intended to be initiated by the automation based on this deduced state (e.g., “reduce temperature,” “no action”). In total, five different container states and associated actions were possible (see Figure 2). Participants were informed that the automated container status deduction was highly reliable but not perfect, whereas the status-action mapping was always failure free. The task was to monitor the automated processes and to actively allow or prevent each planned action. To verify whether a planned action was adequate, the correctness of the deduced status had to be double-checked by retrieving information from two out of six different parameter displays (temperature, heat distribution, pressure, valve setting, reaction status, filling level). An explanation and overview of the five possible states the automation could deduce and their two associated parameter/raw data settings, which had to be checked for each state, was given as written instructions. A summary of this information was also provided as a hardcopy positioned next to the monitor throughout the experiment (see Figure 2). Before the start of the experiment, participants trained the task and internalized where to find each of the six parameter displays. The “heat distribution” display could be assessed by clicking on the small grey picture at the top of the MOT window. To gain access to all remaining parameter displays, participants had to select the tab “Parameters” or “Trend” first and then click on the specific parameter of interest (the tab “Parameters” subordinated the displays for “temperature,” “pressure,” “valve setting,” and the tab “Trend” uncovered two further parameter displays depicting the “filling level” and “reaction status”). Since each possible status of a given container was defined by two conditions, full automation verification always comprised the inspection of two specific parameters. All parameters/raw data were unambiguous. If participants doubled-checked both corresponding parameters, they could clearly tell whether the deduced status corresponded to the underlying raw data or not. In case participants did double-check none or only one parameter of interest, it was not safe to say whether the automation worked correctly or not for the given container. If participants found the underlying raw data to be in line with the deduced state, a click on an “OK” button permitted the displayed action and completed the work on that container. If an automation failure was identified (e.g., indication of “temperature too high” when temperature was in normal range), participants had to initiate manual control by clicking on the “manual” button. Participants were instructed that initiating manual control would send the container to a different department for control checks and manual treatment. The time period during which a container was displayed varied between 15 to 30 seconds in order to prevent participants from developing highly routinized workflows. This was done in order to make participants continuously decide on which tasks they want to work and not just follow the time scheme imposed by the recurring appearance of the containers. If no cross-checking and/or choice selection was made within the 15 to 30 seconds, the current container disappeared, and the next container appeared after 2 to 5 seconds.
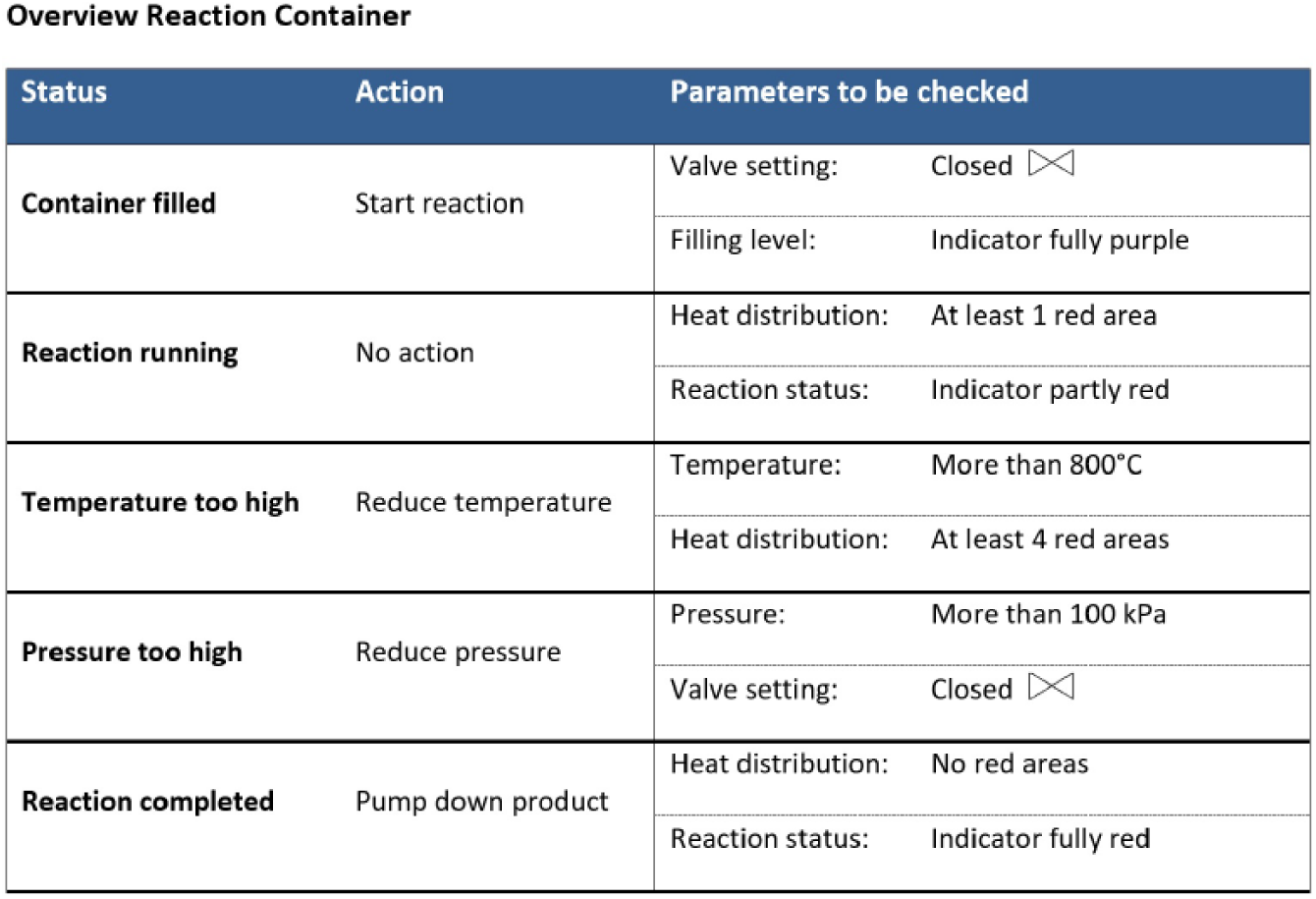
Summary of possible states of the reaction containers and their associated parameter conditions, which was provided as a hardcopy for each workstation.
Procedure
Two strangers were introduced to each other and placed next to one another at individual computer workstations separated by a partition. Prior to each experimental session, written instructions explained the specific experimental condition and the different tasks. Participants of the NON-R group were instructed that they would work on all three tasks alone. In the R and R-FB condition, participants were instructed that they alone were responsible for the CET and ROT but that they would perform the MOT collectively with the second participant. Participants of the R group were further informed that both workstations were connected to support the teamwork in the MOT and that only their joint team performance would be evaluated for this task. They were told that if one of them detected an automation failure, this would count as a correct trial for their team. Participants in the R-FB group received the same instruction as participants in the R group but were additionally informed that their individual performance would be tracked and that their own individual performance would be reported back to them at the end of the experiment. This was done to make participants believe that their individual contribution to the group performance was identifiable and to provide more information relevant for the participant’s self-evaluation.
After reading the illustrated written instructions, participants first practiced the three tasks separately to learn the task handling and, in case of the MOT, to internalize where to find the six parameter displays. This was followed by a 6-minute practice phase in which they performed all three tasks concurrently. After clarifying any remaining questions, the data collection started. Each experimental session involved the evaluation of 144 containers in the MOT and took about 48 minutes. At the end of each session, demographic and subjective variables were collected, but feedback on individual task performance was not given. Instead participants were debriefed and informed that this had been part of the group manipulation, but feedback could not be provided by the MTOPS-R program used.
Participants
Forty-seven university students (30 male, 17 female; age: 21–45 years) participated in the experiment and were randomly assigned to the three experimental conditions. Participants had no prior experience with the task and were compensated with EUR 10. In addition, they had the option to participate in a lottery to win one of four additional prizes worth EUR 50 each. One participant of the NON-R group did not comply with the instructions and was excluded from the data analyses. This resulted in group sample sizes of n = 14 (NON-R group), n = 16 (R-group), and n = 16 (R-FB group).
Design
For the present study, a 3 (Group) × 12 (Block) mixed factorial design was used. The first factor, group, represented a between-subjects factor with the three levels defined as nonredundant work (NON-R), redundant work (R), and redundant work with individual performance feedback (R-FB). The second experimental factor, block, represented a within-subjects factor that was included to investigate possible time-on-task effects. Participants were presented a total of 144 containers in the MOT task. For the data analysis, this number was split up into 12 blocks of 12 containers each (this block structure was not transparent for participants). The factor time was investigated because, as an operator’s experience with a system grows, there can be a qualitative shift in how that person interacts with and monitors the system (Bailey & Scerbo, 2007; Lee & Moray, 1992; Muir, 1987). In particular, the perceived reliability of the system over time influences the process and strength of trust in the automated systems, which again impacts system monitoring (e.g., Bailey & Scerbo, 2007). Many researchers suggest examining monitoring behavior in highly reliable systems, with reliability approaching or exceeding 99% over extended periods in order to provide ecologically valid settings that relate to real automation failure frequencies (Bailey & Scerbo, 2007; Molloy & Parasuraman, 1996; Parasuraman, Molloy, & Singh, 1993). To achieve this, the status messages provided by the automation were correct during all blocks except Block 10, in which 4 out of the 12 automatically generated status messages were false, creating potential for missing automation failures and confirming inappropriate actions. System reliability therefore approximated 97% in this study.
Dependent variables
Three sets of dependent variables were considered. The first set comprised different subjective measures. As a manipulation check, participants had to indicate the extent to which they felt solely in charge of the different tasks. Furthermore, they rated their feelings of responsibility and the effort invested in each task. Participants answered by indicating their subjective perception on self-created single-item questions using a 7-point Likert scales format (1–7, not at all–fully, very little–very much).
The second set of variables included individual performance measures for the three tasks and corresponded to the variables used in previous research using the MTOPS-R task (Domeinski et al., 2007). These were derived from log-files in which all actions performed by a participant during the experiment were recorded (mouse-clicks, keyboard inputs, etc.). Performance in the ROT was measured by the total number of correctly sent orders per block. CET performance was assessed by the number of total coolant exchange cycles performed per block. To access the individual performance in the MOT, two different variables were calculated. The first represented the safe automation verification performance, defined by the number of status messages in each block for which the relevant raw data were inspected and the planned automation action was correctly confirmed or rejected. Not inspecting or not fully inspecting the underlying raw data and missing to reject or confirm the automation plan was regarded as unsafe behavior. The second variable represented the automation failure detection performance in the three groups. It was defined as the percentage of the four automation failures detected in Block 10.
Finally, the third set of dependent variables represented estimated performance measures on a team level. These were calculated for the two redundant work groups (R, R-FB) in order to assess whether the aggregated performance of two redundantly working team members would be different from the performance of participants working alone in the NON-R group. To this end, performances within pairs of randomly chosen participants were aggregated. This procedure was chosen because the software version used for the experiment did not log which of the participants had actually worked together. Given a total of 16 participants in each group, this procedure resulted in estimated performance measures for eight artificial dyads in the R and R-FB groups. Automation verification performance on dyad/team level was defined by the number of status messages cross-checked by at least one of the two members of the “team” before deciding whether to confirm or reject a planned automation action. Similarly, automation failure detection performance on a team level was defined as the percentage of automation failures that were detected by at least one participant of the “team.”
Results
Subjective data
Results of the different questionnaire data are given in Table 1. One-way analyses of variance (ANOVA) of the responses to the three items (“I was alone in charge for the . . . MOT/ROT/CET”) confirmed the effectiveness of the experimental manipulation. While the participants of all groups indicated that they felt solely in charge of the ROT and CET, this was not the case for the MOT, F(2, 43) = 29.55, p < .001, ηp2 = .58. Post hoc comparisons (Scheffé) revealed that the mean ratings of the participants of both redundant groups were significantly lower than the ratings of the participants of the NON-R group (both p < .001).
Means (and Standard Deviations) of Subjective Ratings on Seven-Point Likert-Type Scales

Note. MOT = monitoring task; ROT = resource ordering task; CET = coolant exchange task; NON-R = nonredundant work group; R = redundant work group; R-FB = redundant work with individual performance feedback group.
Further differences between the experimental groups emerged with respect to the perceived responsibility for the MOT, F(2, 43) = 8.4, p = .001, ηp2 = .28, and ROT, F(2, 43) = 3.82, p = .030, ηp2 = .15. However, post hoc comparisons of means revealed only the differences between the NON-R and R group as significant for both tasks (ROT: p = .023 [Games-Howell, no variance homogeneity]; MOT: p = .001 [Scheffé]). Concerning the subjective rating of invested effort, no differences between experimental conditions were found for either task.
MOT: Automation verification
The mean numbers of automation cross-checks performed by the participants of the three experimental groups across the 12 blocks are shown in Figure 3 (left). To analyze the impact of the different experimental conditions on automation verification without interference from automation failures in Block 10, only the first nine blocks were included in the statistical analysis. The 3 (Group) × 9 (Block) ANOVA revealed a significant main effect of group, F(2, 43) = 4.40, p = .018, ηp2 = .17. Participants in the NON-R group, on average, cross-checked 10.4 out of the 12 status messages per block (86.7%). In contrast, this number was lower in both redundant conditions (R-FB: M = 9.6 [80.0%]; R: M = 8.5 [70.8%]). However, post hoc Scheffé tests only revealed a statistically significant difference between the NON-R and R group (p = .019). In addition, a significant main effect of block emerged, F(4.78, 205.5) = 13.01, p < .001, ηp2 = .23. Participants of all groups improved their cross-checking performance over time, most likely reflecting a practice effect. No Group × Block interaction was found, F(4.78, 205.5) = 1.23, ns.
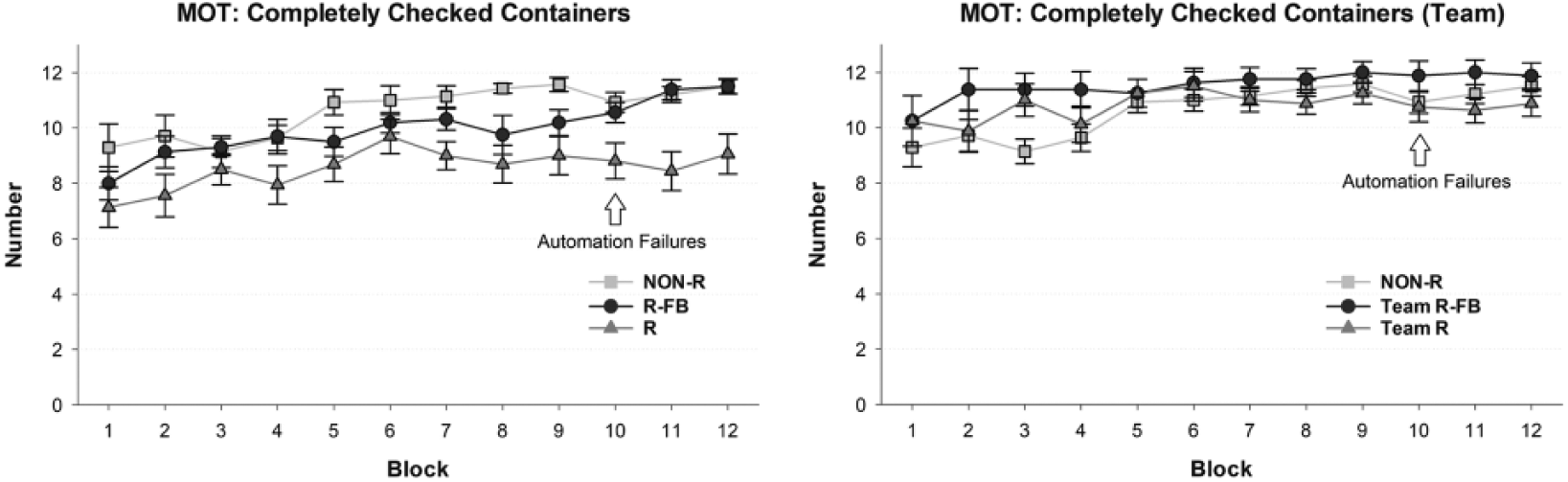
(Left) Mean numbers and standard errors of complete cross-checks in the monitoring task (MOT) on an individual level. (Right) Mean numbers and standard errors of complete cross-checks in the MOT on a “team” level.
MOT: Automation failure detection in Block 10
Participants in the NON-R group, on average, correctly detected 89.9% of all automation failures. This percentage was almost the same in group R-FB (85.9%). In contrast, only 65.6% of automation failures were detected by the participants of the R group. A one-way ANOVA including all experimental groups revealed a significant main effect of group, F(2, 34.56) = 4.58, p = .017, ηp2 = .17 (Brown-Forsythe, no variance homogeneity). Post hoc comparisons found only a significant difference between the NON-R and R group (p = .046, Games-Howell, no variance homogeneity).
To investigate to what extent the detection of automation failures impacted the automation verification performance in the three groups, the number of automation cross-checks performed in Blocks 9, 11, and 12 were analyzed by a separate 3 (Group) × 3 (Block) ANOVA. This analysis revealed a significant main effect of group, F(2, 43) = 9.18, p < .001, ηp2 = .30, and a significant Group × Block interaction, F(3.65, 78.39) = 4.81, p = .002, ηp2 = .18. As is evident from Figure 3 (left), the automation failures in Block 10 only had a visible effect for the R-FB group. Participants in this group increased their number of automation cross-checks considerably in the last two blocks of the experiment. No comparable change of automation cross-checking was observed in the NON-R and R condition.
MOT: Individual vs. “team” automation verification
To check whether “four eyes” still see more than two eyes, the individual automation verification performance of the solo performers in the NON-R group was contrasted to the aggregate performance of pairs of randomly chosen participants in the two redundant groups. The results are shown in Figure 3 (right). Here, the three conditions refer to the mean performances of the 14 participants of the NON-R group, the 8 “teams” formed out of the 16 participants of the R group, and the 8 teams formed out of the 16 participants of the R-FB group. It is evident that the implementation of human redundancy did not lead to a substantial increase of automation cross-checks on a “team” level compared to the solo performers in the NON-R condition and that the occurrence of automation failures in Block 10 had no obvious impact. More precisely, the mean numbers of status messages that were cross-checked during the first nine blocks by at least one of two collectively working individuals in the R condition (M = 10.8 [90.0%]) was very close to the mean number of cross-checks performed by participants who were alone in charge of the task (M = 10.4 [86.7%]). More cross-checks were performed by the R-FB teams (M = 11.4 [95.0%]) than by the NON-R group, but a 3 (Group) × 9 (Block) ANOVA did not yield a significant main effect of group, F(2, 27) =1.61, ns. Only a significant main effect of block emerged, F(8, 216) = 6.73, p < .001, ηp2 = .20, reflecting an increase in cross-checks over time. The Group × Block interaction, F(16, 216) = 1.52, ns, was not significant either. A separate 3 (Group) × 3 (Block) ANOVA including Blocks 9, 11, and 12 did not yield any significant effects—group: F(2, 27) =1.67, ns; block: F(2, 54) = 2.11, ns; Group × Block: F(4, 54) = 0.60, ns.
MOT: Individual vs. “team” automation failure detection in Block 10
On average, the redundant working teams without individual feedback detected 84.4% of the failures, which was slightly lower than the percentage detected by participants of the NON-R group (89.3%). However, an increase in automation failure detection was found for the R-FB teams, which detected all automation failures that occurred during the experiment (100%). Despite this descriptive trend, a one-way ANOVA including the groups NON-R, team R, and team R-FB found no main effect for group, F(2, 27) = 1.30, ns.
ROT and CET
Finally, performance in the two tasks that had to be performed individually in all three experimental conditions was analyzed as a function of condition. As the results in Figure 4 show, performances in both tasks improved considerably over time. Two separate 3 (Group) × 9 (Block) ANOVAs with repeated measures revealed a significant main effect of block for both tasks, ROT: F(3.71, 159.62) = 12.75, p < .001, ηp2 = .23; CET: F(5.75, 247.14) = 20.48, p < .001, ηp2 = .32. No further effects emerged for ROT and CET performance. Two separate 3 (Group) × 3 (Block) ANOVAs were calculated for Blocks 9, 11, and 12. These analyses revealed a significant main effect for block in the ROT, F(2, 86) = 11.27, p < .001, ηp2 = .21, as well as a main effect of group in the CET, F(2, 43) = 4.57, p = .016, ηp2 = .18. Post hoc tests (Scheffé) revealed only the difference between the CET performance of the NON-R group and the R group as significant (p = .016).

(Left) Mean numbers and standard errors of correctly sent orders in the resource ordering task (ROT). (Right) Mean numbers and standard errors of complete exchange cycles in the coolant exchange task (CET).
Discussion
The results of Experiment 1 show that two persons who work redundantly on an automation monitoring task tend to reduce their individual monitoring effort compared to a condition in which only one person is in charge of this task. This negative redundancy effect became particularly evident when comparing safe automation verification performance between the NON-R and R groups. Comparing the number of cross-checks performed by the individual participants in these conditions revealed a significant decrease of automation verification if another team member was also in charge of automation monitoring but no feedback of individual performance was provided. Therefore, more unsafe container handlings (no verification, uncomplete verification, and/or no rejection or confirmation of the automation plan) were performed by participants of the R group. They obviously directed less attention to the automated task. This is in accordance with Hypothesis 1 and directly replicates the findings of Domeinski et al. (2007). Furthermore, it shows that the social loafing effect persists even when participants have to perform the multitask for about an hour, providing an opportunity for routinization of task performance. These objective measures are in line with the reported subjective responsibility for the monitoring tasks. Participants in the R group felt significantly less responsible for MOT than participants in the NON-R group. Nevertheless, no difference in subjective effort was found. This is in line with the CEM and corroborates results by Karau and Williams (1993), who found no effects of social loafing reflected in subjective effort ratings. A possible explanation given by Karau and Williams is that participants are either unaware of the fact that they engage in social loafing or are unwilling to report that they do so.
The results also support Hypothesis 2, which states that the degree of individual performance decline in automation monitoring might increase the risk of missing automation failures. This became evident from the analysis of the detection rate of the four automation failures presented in Block 10. While individual participants of the NON-R group, on average, detected almost 90% of these failures, the detection rate of the participants in the R group was only about 66%. This reduced detection rate might partly explain why the participants of the R group did not change their monitoring behavior in Blocks 11 and 12. Some participants of the R group might not have realized that the automation had become more error prone, while others who detected errors might not have been willing to invest extra effort to ensure automation failure detection after having worked on the multitask for more than half an hour without their individual contribution being identifiable anyway. It is further possible that some participants thought that the other team member was probably taking care of the reliability reduction of the automation by intensifying their automation verification behavior and accepted this as sufficient. If this was the case, it would imply that social loafing even persists in situations where good performance is most obviously needed and a strong contingency between individual effort and individual performance would be achievable.
According to the CEM (Karau & Williams, 1993), individuals will be willing to exert effort on a collective task only to the degree that they expect their individual efforts to be identifiable and instrumental in obtaining valued outcomes. Thus, in order to counteract potential social loafing effects, the R-FB group members were told that both their team’s performance and also their individual performance would be tracked. Individual performance feedback is motivating because it increases the amount of information provided for self-evaluation. It also strengthens feelings of instrumentality by making it possible to relate personal performance to outcomes, such as the number of automation failures detected. In accordance with Hypothesis 3 and in line with a social loafing explanation based on the CEM and other research (e.g., Harkins & Jackson, 1985; Szymanski & Harkins, 1987), this intervention mitigated the redundancy effects found in the R group to a great extent. This was consistently reflected in the subjective responsibility ratings, the objective monitoring effort, and the automation failure detection performance of the individual participants of the R-FB group. No significant difference was found between the NON-R group and the R-FB group for any of these variables. Moreover, in contrast to the R group, the participants of the R-FB group showed a clear response to the occurrence (and detection) of automation failures by increasing their cross-checking afterwards. Overall, this suggests that tracking of individual performance in collective tasks can provide an effective measure to mitigate individual reductions of performance.
However, finding social loafing effects on an individual level in a redundant work team does not necessarily call into question the benefits of human redundancy. It is sufficient for a team to have at least one person who properly cross-checks an action or detects an automation failure. Therefore, the team can outperform a single operator even in the event that each team member’s performance declines, unless team members cross-check exactly the same set of automated processes or miss exactly the same automation failures. Thus, it was hypothesized (Hypotheses 4 and 5) that even in the case of some redundancy effects on the individual level, the average automation monitoring and automation error detection performance of dyads would still be higher than that of solo performers. No significant differences were found between the monitoring performances and automation failure detection rates of the participants of the NON-R group and the two teams, even though the R-FB teams descriptively outperformed the solo operators with a better cross-checking rate and a perfect automation failure detection. At first sight the results seem to contradict these hypotheses and hence suggest that poorer individual performance in redundantly working teams can fully offset any gains expected from redundancy. This would also be in line with the results of Mosier and colleagues (Mosier et al., 2001; Skitka et al., 2000), who did not find a difference in automation monitoring performance of single pilots versus two-pilot crews. However, a look at the data of the NON-R condition shows that the comparison of solo versus “team” performance might have been biased by an obvious ceiling effect in the NON-R group. Participants of the NON-R group cross-checked the automation almost perfectly, making it a priori almost impossible to achieve performance gains through redundancy. One could even argue that a task and situation as in Experiment 1 obviously allows for highly reliable solo operation and, therefore, does not represent a situation where redundancy needs to be employed at all.
One reason for the observed ceiling effect might be that the participants did not monitor the automation in a fully passive manner but were still actively involved in the task due to their obligation to confirm or reject each automation plan. Since they had to direct their attention towards and perform actions on the MOT anyway, it is possible that they integrated the routine of active automation verification into the task. It remains to be investigated whether the findings of this experiment can be confirmed for working scenarios in which participants passively monitor an automation without having to actively confirm each automated decision.
Unfortunately, due to the ceiling effect, Hypotheses 4 and 5 cannot be clearly answered at least for the comparison between participants of the R and NON-R group. Still, even despite this ceiling effect, the finding that participants in the R-FB group invested as much effort on the individual level and monitored the automation as reliably as the NON-R participants can be taken as evidence that human redundancy in this case represents a highly effective measure to increase the reliability of human automation monitoring. Having two people in charge who both perform as well as a single one must lead to a higher overall reliability of team performance compared with a solo performer. In case that both persons’ actions are completely independent, as in technical system, this improvement can be calculated by the well-known formula ([1 – (3/10)2] × 100 – [1 – (3/10)] × 100). Thus, Hypothesis 4 can be regarded as confirmed at least for the R-FB teams. A higher monitoring rate automatically increases the probability of automation failure detection, which is confirmed by the fact that the R-FB teams detected all four automation failures. Therefore, substantial evidence exists that supports Hypothesis 5 for the R-FB team as well. If human redundancy is envisioned to increase overall reliability, it should be implemented along with measures of tracking individual performance in order to avoid negative social loafing effects. However, such measures might not always be feasible and/or legal. In such cases, it is important to assess the extent to which the potential reliability increase of redundantly working teams without individual feedback is outweighed by social loafing effects.
Experiment 2
To clarify whether the missing redundancy gain of the R group in Experiment 1 was just due to the ceiling effect or really a result of the social loafing effect reflected in individual monitoring, a second experiment was conducted, which only contrasted the NON-R and R conditions. To avoid another ceiling effect in the NON-R condition, two changes were made to the MTOPS-R environment. The MOT subtask was modified so that participants were warranted a specific amount of time to check the automation. They only needed to become active if the planned diagnosis and proposed action of the automation was false. If the automation was correct, no active approval was necessary and the automation proceeded with the execution of the planned action automatically after the container disappeared. This made the monitoring task more similar to a typical supervisory control task (Sheridan & Johannsen, 1976) and left the operator more passive in the MOT. As a second countermeasure to avoid ceiling effects, participants’ workload was slightly increased by raising the time demand of each task. This was done to motivate solo performing participants to reduce their workload by skipping the verification of some of the automatically generated container diagnoses.
Method
Apparatus and task
MTOPS-R interface was slightly adapted and is depicted in Figure 5 . Note that the appearance of MTOPS-R was slightly changed, but the functionality was not changed. The OK button was removed from the interface as active human approval of the automation’s decision was not required in this experiment. Additionally, the time available to accomplish each task was slightly reduced. In the MOT, each container was now shown for 10 seconds unless participants clicked on a parameter for verification, which provided them with a number of additional seconds. In the ROT, each resource was now shown for 10 seconds and then disappeared, regardless of whether it had been processed. A new resource appeared after 2 to 5 seconds. In the CET, the filling and emptying of the two vessels was quickened so that the minimum time for an exchange cycle now varied between 14 and 38 seconds.

Revised user interface of Multi-Task Operator Performance Simulation for Redundancy Research (MTOPS-R) for Experiment 2 (upper left: resource ordering task [ROT]; upper right: coolant exchange task [CET]; lower right: monitoring task [MOT]).
Procedure
The procedure was the same as in Experiment 1.
Participants
In total, 36 university students took part in Experiment 2 (13 male, 23 female; age: 20–29 years). Again, participants had no prior experience with the task. They were compensated for their participation with EUR 15 or received a course credit.
Design
A 2 (Group) × 12 (Block) mixed factorial design was used. The first factor group represented a between-subjects factor with the two levels defined as non-redundant (NON-R) and redundant (R). Participants were randomly assigned to one of these two groups.
The second factor, block, represented a within-subjects factor. As in Experiment 1, 12 successive blocks were presented to participants, each consisting of 12 monitoring trials. However, in contrast to the first experiment, the automation worked perfectly reliably throughout all blocks.
Dependent variables
Three sets of dependent variables were considered, similar to Experiment 1: subjective, individual, and team performance measures. Only minor changes were made compared to Experiment 1. First, 4-point Likert-type scales (1–4, a little–very much) were used for the subjective data instead of the 7-point Likert-type scales. The data analysis of Experiment 1 had shown that participants hardly ever used the full range of the 7-point scales. Second, in order to assess the automation monitoring and verification performance on a team level, the combined performance of actual team members was considered, instead of building pairs of randomly chosen participants. This was done to provide more realistic measures for collectively working participants.
Results
Subjective data
Results of the questionnaire data are shown in Table 2. Again, one-way ANOVAs were calculated for each item and each task. A significant main effect of group for the MOT was found for the item “I was alone in charge for the MOT,” which indicated that the manipulation was again successful, F(1, 34) = 16.186, p < .001, ηp2 = .32. No effects were found for any of the other variables.
Means (and Standard Deviations) of Subjective Ratings Using Four-Point Likert-Type Scales
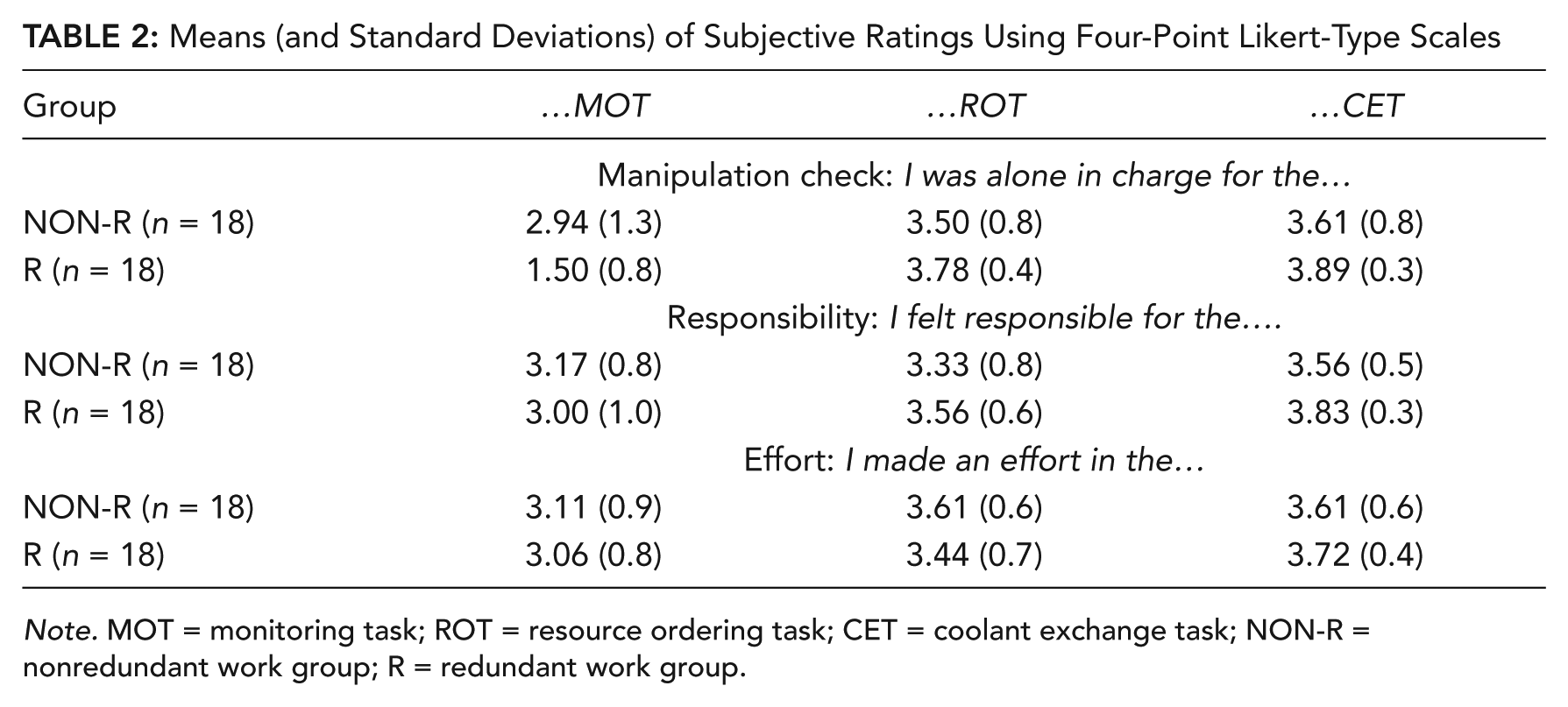
Note. MOT = monitoring task; ROT = resource ordering task; CET = coolant exchange task; NON-R = nonredundant work group; R = redundant work group.
MOT: Automation verification
The mean numbers of completely cross-checked containers for both groups across the 12 blocks are shown in Figure 6 (left). As becomes evident, participants of the NON-R group, on average, only checked 9.1 out of the 12 status messages per block (75.8%). This is considerably less than what was maximally possible. However, the performance of the participants of the R group (M = 6.6 [55.0%]) was again significantly worse than the performance of the NON-R group, F(1, 34) = 5.57, p = .024, ηp2 = .14. In addition, the main effect of block became significant, F(5.72, 194.35) = 2.28, p = .041, ηp2 = .06, indicating a practice effect over time. No interaction effect was found, F(5.72, 194.35) = 1.78, ns.
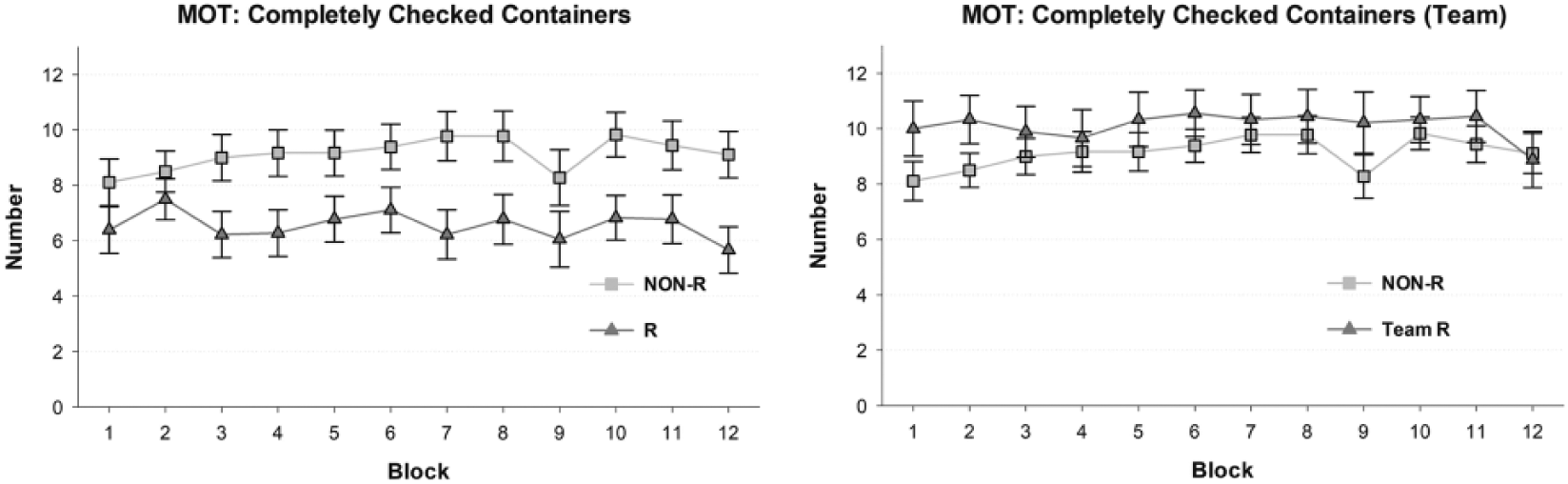
(Left) Mean numbers and standard errors of complete cross-checks in the monitoring task (MOT) on an individual level. (Right) Mean numbers and standard errors of complete cross-checks in the MOT on a team level.
MOT: Individual vs. team automation verification
A comparison of the aggregate performance of teams in the R group to the mean performance of participants in the NON-R group revealed that only a few more cross-checks per block were performed on average by redundantly working teams (M = 10.1 [84.2%] compared to M = 9.1 [75.8%]). This difference (team R vs. NON-R) failed to reach significance, F(1, 25) = 0.94, ns. Also, no main effect emerged for the factor block, F(5.72, 143.00) = 1.94, ns, and no interaction effect was found, F(5.72, 143.00) = 1.25, ns. Figure 6 (right) shows that the R teams only outperformed the NON-R group during the first two blocks. Due to the performance increase in the NON-R group, this benefit was greatly reduced and almost disappeared for all remaining blocks except Block 9.
ROT and CET
Two separate 2 (Group) × 12 (Block) ANOVAs with repeated measures were calculated for the ROT and CET performance. Participants in both groups showed comparable performance in the ROT, F(1, 34) = .79, ns, that decreased slightly over time, resulting in a significant main effect of block, F(6.56, 223.05) = 10.76, p < .001, ηp2 = .24 (Figure 7, left). Also, the two groups did not differ in the CET, F(1, 34) = .76, ns. Here, the interaction of Group × Block became significant, F(7.41, 252.16) = 2.51, p = .014, ηp2 = .07, probably due to a slight increase in completed coolant exchanges over time in the NON-R group compared to a rather stable CET performance in the R group (Figure 7, right).
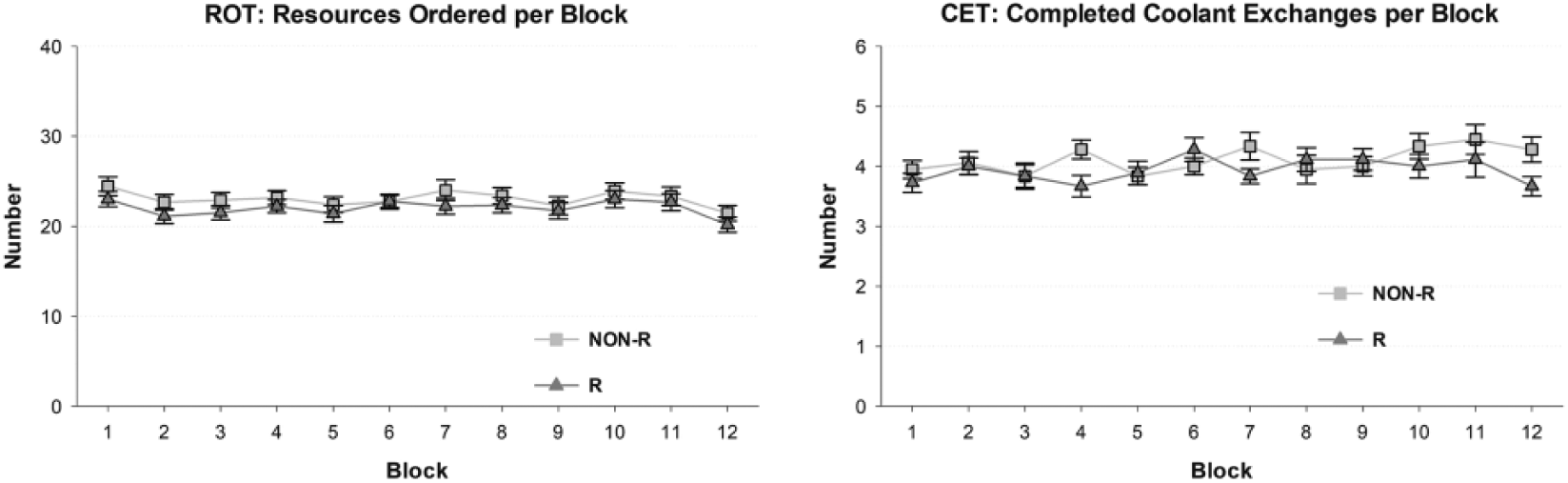
(Left) Mean numbers and standard errors of correctly sent orders in the resource ordering task (ROT). (Right) Mean numbers and standard errors of complete exchange cycles in the coolant exchange task (CET).
Discussion
The modifications implemented for Experiment 2 successfully avoided a ceiling effect in automation monitoring of solo performing participants. Whether the increased time demands and/or the slight change in how the human-automation interaction was set up reduced the cross-checking behavior of the NON-R group cannot be clearly determined. However, the experimental set-up of Experiment 2 created a situation in which employing human redundancy could in theory increase the overall reliability of automation monitoring. As in Experiment 1, individuals working collectively with a team partner on the automation monitoring task reduced their automation cross-checking behavior compared to participants working alone (Hypothesis 1), without increasing their performance in the concurrent tasks. Even more importantly, the combined team performance was again not significantly different from solo working participants (Hypothesis 4). This again contradicts the expectation that human redundancy might be effective even if individuals in a team reduce their efforts to some extent, while offering further evidence that the social loafing effect found between the R teams and NON-R participants in the first experiment was not just due to the ceiling effect in the NON-R group.
Conclusions and Limitations
Human operators often need to monitor autonomously running processes. In some work domains such as in HROs, automation monitoring is performed by more than one person to increase the reliability of monitoring in order to detect failures and prevent potential harm. This idea is primarily based on the prediction that even unreliable components, if independent and placed in parallel, lead to a rapid increase of overall system reliability when combined to redundant systems. However, since humans working in teams are aware of each other, independence is not guaranteed. This has led to the concern that humans working redundantly may reduce their individual performance in the knowledge that someone else is conducting the same task (Sagan, 2004). Both experiments presented here raise serious concerns by showing that when two individuals redundantly monitor an automation process without individual performance feedback, each of them cross-checks the automation less than a single operator in sole charge of the task. As a consequence, they are also more prone to miss automation failures (Experiment 1).
The results of both experiments further suggest that social loafing effects in redundantly working dyads can reach a level that completely annuls the expected advantages of human redundancy. This casts doubts on whether human redundancy is an effective design element to compensate for effects known to negatively affect performance in human automation monitoring, such as declining vigilance or complacency effects. It seems that four eyes do not necessarily see more than two if people who work in dyads tend to turn a blind eye on shared responsibility tasks. Furthermore, these findings provide a possible explanation for results of previous studies that compared automation failure detection performance of redundantly working dyads to that of solo performers and could not find an advantage of team performance (Mosier et al., 2001; Skitka et al., 2000).
The CEM of Karau and Williams (1993) predicts that by making individual contributions in a collective task identifiable, it is possible to mitigate effects of social loafing. Support for this prediction has already been reported in other settings (e.g., Harkins & Jackson, 1985; Szymanski & Harkins, 1987). The results of the first experiment suggest that this also holds true for automation monitoring tasks. Participants of the R-FB group cross-checked the automation as much as the NON-R participants (R-FB: 80.0%; NON-R: 86.7%). Even though the R-FB team did not significantly surpass the generally high-performing NON-R group in terms of cross-checking, an improvement is observable (team R-FB: 95.0%), which is the expected consequence if (to some degree) independent actions of two operators working as reliable as a single one are combined. The obtained improvement is almost certainly what would be expected under the ideal condition of completely independent operators ([1 – (2/10)²] × 100 = 96%). This suggests that, besides social loafing effects, no other dependencies (e.g., shared preferences to perform cross-checks predominantly on the same containers or container states) diminished the achievable overall reliability. The general efficacy of individual feedback is further supported by the finding that a perfect automation failure detection rate was reached by the R-FB teams. Informing individuals that their individual performance will be tracked and reported back to them therefore seems to represent an intervention that can mitigate the effects of social loafing also in automation monitoring and can make human redundancy effective again.
Consequently, if a system engineer encounters the problem that the automation monitoring reliability of a single operator in a given work context (such as HROs) is not sufficiently high, various approaches could be considered. It might be possible to reduce the workload of the operator so as to allow more time for automation monitoring, to make the cross-checking less laborious, and/or to change the monitoring task in a way that makes cross-checking more likely. A possibility to achieve the latter could be a change in the way a human operator interacts with the automation. In Experiment 1, participants had to attend to the monitoring task frequently in order to actively permit or hinder each action the automation wanted to initiate. Here, the monitoring reliability of operators working alone was higher than that observed in Experiment 2, where operators only needed to become active if they suspected that the action intended by the automation was not suitable. In cases in which it is neither possible nor desired to reduce the task demands or to change the type of human–automation interaction, human redundancy can still be considered, as long as it is possible to track individual performance. In combination with feedback on individual performance, which could be provided to operators either continuously or at the end of a shift, human redundancy does promote safety. In practice, tracking operators’ eye movements or at least detecting whether eyes frequently focus on certain displays could be one way to provide this information. If no individualized performance tracking and feedback is possible, redundancy should be implemented with caution, because the collective work setting can reduce each individual’s motivation. Human redundancy then may not achieve the anticipated gain in overall reliability.
Beside the identifiability of individual contributions, Karau and Williams (1993) found many other variables that moderate social loafing. Some of them should be investigated in the context of redundant automation monitoring. One example is the expectation of coworker’s performance. If an operator believes that his or her co-worker’s performance is generally high, it is more likely that social loafing will be enhanced, whereas if the performance is expected to be low, then social loafing will be reduced. A study comparing groups with different expectations of coworker’s performance (no information, low performance, high performance) could not only further test the assumptions of the CEM but may also be indicative of whether operators should receive information on their coworker’s performance or not.
Future research should also try to use working scenarios that are more realistic. Certainly, there are limitations to the external validity of the current research—that is, the extent to which the findings apply to trained operators in real-life situations. However, the fact that the lack of a redundancy effect has also been reported in research with certified pilots in a more realistic simulation of a flight task (Mosier et al., 2001) and in anecdotal reports from the field (Armitage, 2008; Bertovic, 2015) suggests that social loafing in automation monitoring is not limited to the laboratory. A second potential limitation of this work is that participants worked only for about an hour on the automation monitoring task. The effects of redundant automation monitoring lasting for several hours daily over many days or weeks, as in realistic work situations, should also be investigated. A third limitation is that the studies presented here investigated the effects of human redundancy only in situations in which the monitoring task represented one out of three tasks. Complacency effects found for multitasking vanished when only a single task was presented (Parasuraman et al., 1993), and this possibility should be investigated for social loafing effects, too. Furthermore, it would be interesting to compare settings in which participants are sitting side-by-side without visual contact and situations in which they can see each other as in usual control room settings. Moreover, the experiments presented here used dyads of members who did not know each other. While such working contexts exist (e.g., pilots flying a plane together often do not know each other and jointly monitor the autopilot), it would also be important to investigate real teams with members who do know each other, since this is the case in many working contexts. The prediction of social loafing in such contexts is expected to be much more complex. Thus, the current research only represents an early step toward investigating effects of human redundancy in a human–machine context and will hopefully stimulate more research in this area.
Key Points
A person monitoring an automated process collectively with a partner monitors the automation less frequently and misses more automation errors.
If no individual performance feedback is given, the joint performance of two team members does not surpass the automation monitoring performance of an operator working alone.
When a person who works redundantly receives individual performance feedback, social loafing effects are greatly reduced. This could make human redundancy effective.
Footnotes
Acknowledgements
The author thanks D. H. Manzey for his support and detailed feedback, S. Jahn and K. Boehme for collecting the data in the course of their master’s theses, M. Schoebel for providing feedback on an early draft, and three anonymous reviewers for their helpful comments.
Each experiment presented here has been published in the form of a proceedings paper (Cymek, Jahn, & Manzey, 2016; Manzey, Boehme, & Schoebel, 2013). Past publications did not contain all analyses and all data presented here. Important conclusions drawn here are based on consideration involving both experiments together.
Dietlind Helene Cymek is a PhD candidate in the Department of Work, Engineering, and Organizational Psychology at the Institute of Psychology and Ergonomics, Technische Universität Berlin, Germany. She received a BSc in business psychology at the Leuphana University of Lüneburg, Germany, in 2009 and an MSc in human factors at Technische Universität Berlin, Germany, in 2013.