
Abstract
We study behaviour in the E-mini S&P (ES) commodity futures data market to test for violation of the efficient market hypothesis (EMH), and test for market inefficiency. We demonstrate that, on long timescales, a single scaling determines dynamics. ES returns behave in a more general manner than random walks. We find that deviations from the EMH, and the associated heavy-tailed distributions, are more common than expected, and price returns can be fitted with an alpha-stable Lévy distribution. Our results indicate that while the ES futures market operates close to the state predicted by the EMH, the observed transient deviations from this state fail to have a statistical origin consistent with a purely random geometric Brownian motion, and are better described by the fractal market hypothesis.
Introduction
Consideration of market behaviour in terms of a random walk, in due course led to the efficient market hypothesis (EMH) (Samuelson, 1965; Working, 1934). This hypothesis proposes that the random flow of unanticipated information brings about a complete lack of correlation between the temporal fluctuations of price changes.
Market efficiency remains a core concept of economics and forms the foundation for modern portfolio theory, and the methodology of Black and Scholes (1973) to price derivative assets. In an efficient market, the time-series of price returns is a Brownian motion, must be normally distributed and, therefore, asset price distributions are log-normal. Numerous early studies demonstrated market efficiency (Fama, 1970, 1991). However, others question the idea of random behaviour (Bil et al., 2017; Bouchaud & Potters, 2003; Derman & Taleb, 2005; Longin, 2016), due to nonGaussian distributions of different kinds of market data. In short, the EMH does not account for extreme movements and strong market trends. It assumes free and efficient information exchange between competing forces that drive the market to the point of optimal self-organisation. This optimum point, statistically speaking, is associated with steady dynamical balance between buy and sell signals.
In the view of the EMH, bubbles and crashes—persistent, intrinsic deviations of the price from the fundamental value—simply cannot happen. They are unexpected events whose only possible cause would be some unanticipated extrinsic event, such as the revelation of a dramatic incident or piece of information. In practice, deviations from EMH means heavy-tailed distributions are more common than expected, and one is able to earn (or lose) much more than the Gaussian model predicts.
An alternative to the EMH, which here we propose to test for a particular futures market, is what Peters (1991, 1994) has called the fractal market hypothesis (FMH). This hypothesis suggests alternatives to randomness and log-normality. It assumes that market forces include sensitive coupling and feedback mechanisms, which alternatively relax and energise price structure. The FMH recognises the large consensus that bubbles do exist (Abreu & Brunnermeir, 2003; Trichet, 2010), and arise due to interaction between the multiplicity of market forces that initiate and develop highly non-linear price movements. Within the FMH price movement forms a complex system of non-linear phenomena that include components that depend not only on contemporaneous external forces, but also on the history of internal price structure, that is, on market memory. In the EMH, increments of price are statistically independent at any time scale. The FMH implies, rather, that the increments are in some measure statistically dependent, possibly on multiple time scales. This means that the trading ‘froth’, even from small intraday variability, can be related to large scale bubbles.
Within the past several decades, the presence of fractal structure and long-term dependence within markets has exercised the attention of financial economists (Corazza et al., 1997; Mantegna & Stanley, 2000; Peters, 1991, 1994; Qian et al., 2011; Zhou, 2007). Similarly, traders in the pit are interested in detailed knowledge of price level changes of an asset, for instance, the closing price of a stock, or the settlement price of a particular futures contract. The possibility of using fractal analysis methods for estimating stability of complex dynamical systems benefits from the theory of self-organised criticality. This is a fairly new framework, developed initially in statistical physics for modelling catastrophic events in non-linear systems with many coupled degrees of freedom (Bak, 1997), where the fight between order and disorder develops into events punctuated by dramatic, abrupt occurrence of phase transitions. The utility of such ideas, useful in many physical and economic systems (Dorigo et al., 2002; Mantegna & Stanley, 2000; Mitsutake et al., 2004; Vandewalle & Ausloos, 1997; Wanliss & Reynolds, 2003; Wanliss, 2004, 2005; Zhou, 2007), is that stochastic occurrences of events may be quantified by known probabilities.
Here, we put forward the idea that non-linear processes which are statistically stable, but dissimilar, are involved in price movement of a futures market, and that such processes cause multi-scale self-similarity in price structure. We demonstrate application of a fractal approach to explore temporal price dynamics of the E-mini S&P futures market. Studies of the E-mini S&P price dynamics (Kirilenko et al., 2017; Kurov & Lasser, 2004), have considered various equilibrium models that link cost of maintaining continuous market presence with market crashes even in the absence of fundamental shocks and with perfectly offsetting idiosyncratic shocks. Huang and Wang (2009) considered market crashes to emerge endogenously—that is, because of internal fluctuations in dynamics—when a sudden excess of sell orders overwhelm the insufficient risk-bearing capacity of market makers. In this article, we test the FMH hypothesis with the use of detrended fluctuation analysis (DFA), which is capable of detecting statistical self-similarity, whose methodology is discussed in Section II. Section III considers properties of the E-mini S&P commodity futures data that is selected for analysis. Results from the data analysis are discussed in Section IV. Section V gives our conclusions and discusses implications.
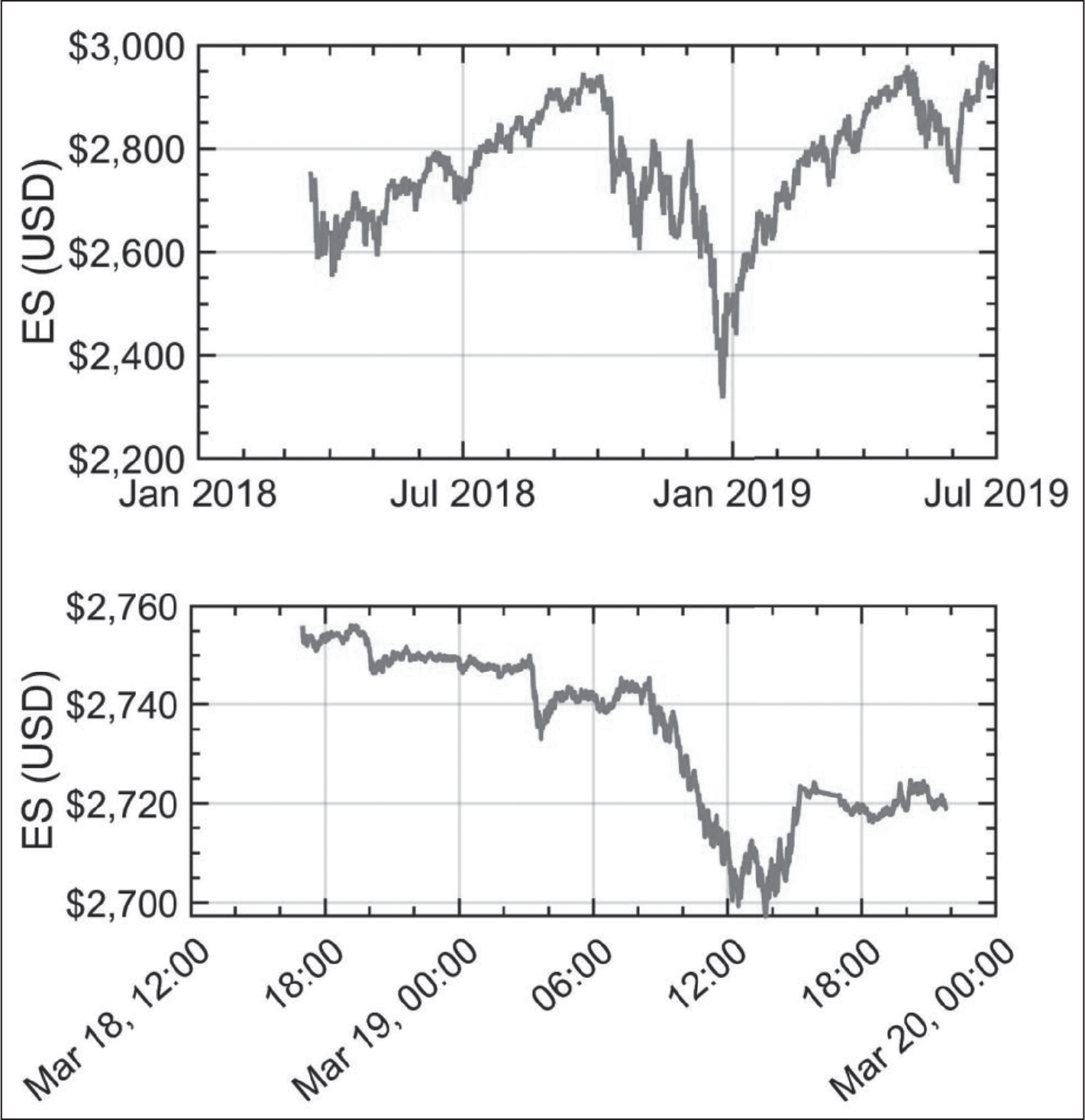
The E-mini S&P, designated by the commodity ticker symbol ES, was introduced by the Chicago Mercantile Exchange (CME) as a stock market index future contract in 1997, and traded on their Globex electronic trading platform. Globex is a fully electronic limit order market; trading is continuous 24 hours a day with the exception of a 15-minute technical maintenance break each day. The notional value of one E-mini contract is $50 multiplied by the current value of the S&P 500 stock index.
All ES contracts are cash-settled against the value of the underlying S&P 500 equity index at specified annual expiration dates in March, June, September and December. The contract with the nearest expiration date tends to attract most of the trading activity. This is called the ‘front-month’ contract. In this research report, we analyse ‘front-month’ contracts over the period March 2018 through July 2019. During March 18–20, 2018, the front-month contract was the contract expiring in June 2018. During this time, the S&P 500 index fluctuated slightly above 2,700 points, making each E-mini contract worth about $135,000. Each price increment is called the ‘tick’ size; the minimum tick size of ES is 0.25 index points, or $12.50. Therefore, a price move of one tick signifies a fluctuation of about 2.5 basis points. Figure 1 shows the front month E-mini S&P futures time-series used in this study (upper plot), from 3 March 2018 to 28 June 2019. The lower plot shows a small subset of these data.
Method of Fractal Analysis
To show that asset prices follow fractal processes is to demonstrate something greater than merely the behaviour of a random walk. Random walks are a specific example of fractality. This implies that fractal processes are a mathematical generalisation of random walks. For situations where signals show fractional Brownian motion (fBm), the signal time-series is to have zero-mean, and it may find expression as the stochastic integral (Mandelbrot & Van Ness, 1968):

where the parameter W is defined as a white noise process over (–∞,∞), and Γ is the well-known gamma function. In the above equation, the parameter H ∈ (0,1), known as the scaling exponent, can also be shown to be related to the Hurst exponent (Peters, 1991). In instances where time-series are relatively smooth, the scaling exponent reaches values near 1. By contrast, when the scaling exponent approaches smaller values nearer 0, the time-series tends towards increasing roughness. All fractal signals, in addition to their roughness also feature self-similarity, and usually it is possible to employ the scaling exponent to directly computer the fractal dimension of the set. Any signal that displays fBm has a covariance function given by
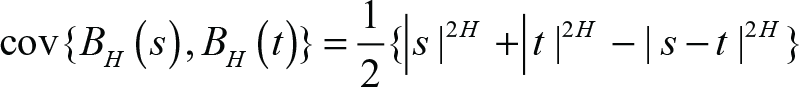
so that the variance
In physical systems, what is usually found is that fBm is a nonstationary process. What we mean by this is that statistical properties vary throughout the signal. Analysis methods which assume stationarity, therefore, cannot be used. It is thus difficult and requires extreme care to accurately detect the presence of memory in the time-series. Numerous studies have investigated fBm. For instance, in fields as diverse as biology (Collins & De Luca, 1994), hydrology (Neuman & Federico, 2003), geophysics (Frisch, 1997), telecommunication networks (Taqqu et al., 1997), space physics (Consolini et al., 2013; Dobias & Wanliss, 2009) and medicine (Khoa et al., 2012).
Data intermittency is found in both upper and lower plots as shown in Figure 1. In addition, there is long-range dependence, and trends that recur over multiple timescales. It is necessary to have an appropriate method to determine the presence of long-range correlations in the time-series. All of the methods have a general methodology. Usually, they will calculate an estimate of how a fluctuation measure, here denoted by F, scales with the size of the time window considered, denoted by n. Well-known techniques to determine scaling include power spectral analysis, the Higuchi (1988) method, Hurst’s rescaled range analysis (Hurst, 1951), DFA (Peng et al., 1995) and structure function analysis (Abramenko et al., 2002). In every method, all essentially calculate varieties of a fluctuation measure, although the measure is different for each technique.
From our development of previous expertise, we find that DFA has qualities that suit it to analysis of the data here considered (see Figure 1). DFA is a modified root mean squared analysis of a random walk. Peng et al. (1995) improved upon ideas in statistical physics to develop the DFA. It was designed specifically to function with non-linear data, and to be able to deal with data nonstationarity. Numerous studies show that it is one of the most robust statistical techniques designed to detect long-range correlations in time-series (Blok, 2000; Cannon et al., 1997; Taqqu et al., 1996). DFA is thus capable of accurately determining data scaling, and is robust to the presence of trends (Hu et al., 2001) and time-series featuring nonstationarity (Chen et al., 2002; Kantelhardt et al., 2002).
To calculate the data scaling, the DFA analysis technique starts by removing the average, symbolised by

The investigator next divides this updated time-series into boxes of equal length, n (see Figure 2). Each box has removed from it the trend, represented by a least-squares fit to the data. Usually, the trend function selected a cubic, quadratic or linear function (Hu et al., 2001; Vjushin et al., 2001). For our purposes, we utilise a quadratic function to remove errors due to linear trends in the time-series. Box n has its abscissa denoted by yn(k). Following this step, the integrated time-series, y(k), is taken and from it trend is removed by subtracting the local trend, yn(k), within each box.
Now, it is possible to derive the characteristic size of the fluctuations, denoted by F(n), for a given box size n. This is computed from the root mean squared deviation between y(k) and its local trend in each box
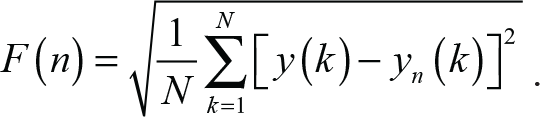
Finally, this calculation is repeated for all the time scales available; these correspond to varying the box size. When a signal is fractal, one finds that relation between F(n) and n follows power-law scaling:

where the scaling exponent is given by the parameter H. If the time-series is indeed an fBm, then the scaling exponent H, comes out to be the well-known Hurst exponent (Mandelbrot & Van Ness, 1968). For the case, when H = 0.5, the signal is identified as white noise. An antipersistent signal finds H < 0.5, and H > 0.5 reveals a persistent time-series, and strong trends.
Data Properties
As mentioned above, the data we use to explore this hypothesis is the E-mini S&P, designated by the commodity ticker symbol ES. It trades on the CME Globex electronic trading platform. CME Globex trading schedule is Sunday (6:00 p.m.) through Friday (5:00 pm) Eastern Time with a trading halt at 4:15 pm to 4:30 pm on each of the trading days. We consider front month data with open-high-low-close prices from 3 March 2018 to 28 June 2019. The top panel in Figure 1 shows the closing prices for the entire interval, and the bottom panel shows the first 10,000 seconds.
Next, we examine the actual distribution of futures price changes or returns. This is an important issue to financial economists. According to classical statistical theory, a system in an equilibrium state will possess Gaussian statistics for measurable physical quantities. On the contrary, systems that cannot reach an equilibrium state might have probability distributions significantly different from normal ones. This is particularly true for non-linear systems that feature inhomogeneous dissipation in time. In an efficient market, it follows that such equilibrium returns are random. In addition, these random returns are postulated to be normally distributed, which means that asset prices follow log–normal distributions.
As a formal test for normally distributed returns, we consider several parameters that characterise a normal distribution. Determining which data to use in financial analysis is not necessarily clear; Hudson and Gregoriou (2015) found that simple and compound returns can yield significantly different results. Accordingly, we calculated statistics for both simple and compounded returns. Figure 2 shows the simple returns.
Returns provide the ability to measure investment performance independently of the scale used. We define simple returns in the usual manner, namely, let X be the ES price, at time t. Then, simple return values on the interval [t, t +1] are given by
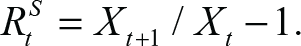
Similarly, compound returns are defined as
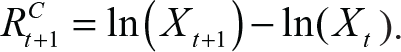

Results from Several Normality Tests Demonstrate that the Returns for ES Futures Fail the Normal Hypothesis (p-Values are Given for Kolmogorov–Smirnov, Lilliefors and Anderson–Darling Tests)
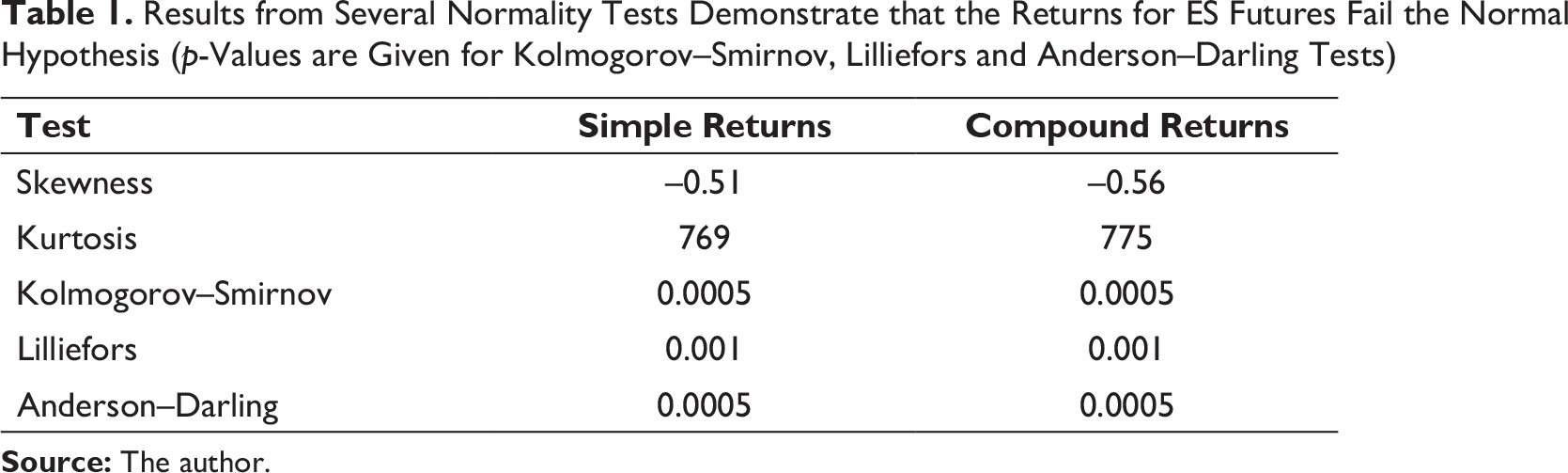
The first normality parameter we consider is skewness. Skewness is a measure of distribution symmetry, and is defined as the normalised third moment of the distribution. A normal distribution has a skewness parameter equalling zero. Skewness is positive (negative) when the data spread out more to the right (left). For our data, the skewness of the simple (compound) returns are, respectively, –0.51(–0.56).
Second, we consider kurtosis, which is a measure of peak steepness of the probability distribution. The normal distribution has kurtosis equal to 3, but heavy-tailed distributions have higher kurtosis. The kurtosis of the simple (compound) returns is, respectively, 769 (775).
Third, we apply the one-sided Kolmogorov–Smirnov test (Marsaglia et al., 2003). We use this non-parametric method to test the null hypothesis that the population cumulative distribution function (cdf) of the data is equal to the normal distribution cdf. The null hypothesis is rejected in favour of the alternative hypothesis, at the default 5 per cent significance level and the p-value is close to zero.
Fourth, we apply the Lilliefors normality test (Conover, 1980; Lilliefors, 1969), which strongly rejects the normality hypothesis, with p ~ 0.
A final test for normality is the Anderson–Darling test (Malevergne & Sornette, 2006) which provides a measure to test the null hypothesis that the data is from a population with a normal distribution. Again, we find, with strong confidence, that the null hypothesis is rejected (p ~ 0). The results of all tests for normality reject the hypothesis that the returns come from a normal distribution, as summarised in Table 1.
Distribution Function
An important question considered in the study of complex systems is what causes the appearance of power law distributions. Suggestions have considered such distributions to be the consequence, and the signature, of self-organising mechanisms at the origin of a hierarchy of scales (Harras & Sornette, 2011; Sornette, 2004, 2009). Given the return distribution functions are significantly different from normal, demonstrated above, the question is what distribution best represents these data. An example of a distribution function P(x) that exhibits the requisite heavy power law probability tail for large x, possibly up to some limiting cut-off, is as follows:
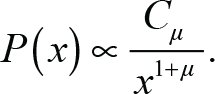
Here, the µ-exponent is a metric characterising the nature of the tail. When µ < 2, the tail is termed a ‘heavy tail’ and has a theoretically undefined variance. Accurate fitting the tails of this kind of an empirical distribution with a power law is notoriously difficult (Bielinskyi et al., 2019; Rachev et al., 2005; Weron, 2001).
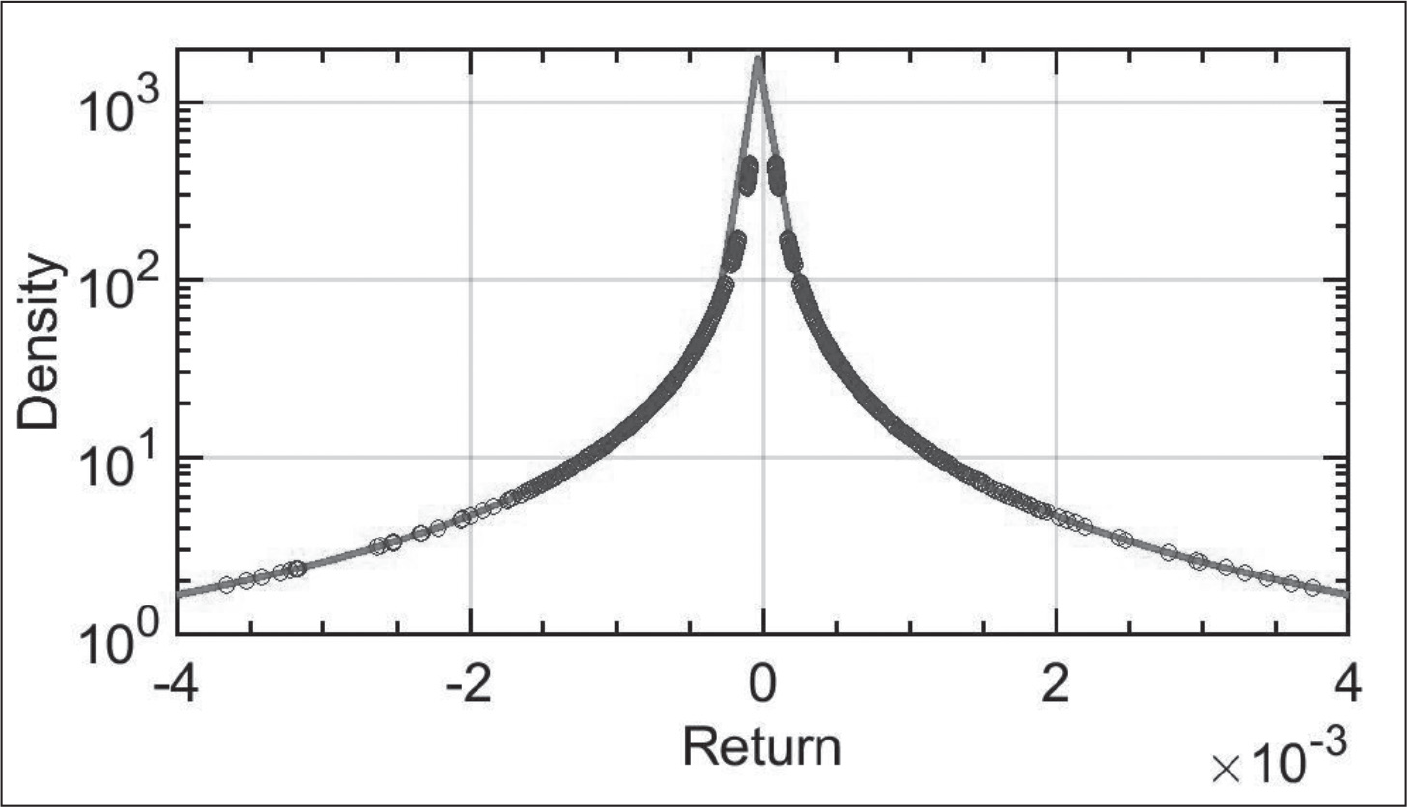
Having determined that the ES returns are significantly different from normal, we will compute the empirical ES futures return distribution, and fit it to a stable form, using the method outlined by Koutrouvelis (1980, 1981). We select the stable function for several reasons. First, because the kurtosis in our data is reminiscent of Lévy-stable distributions. Second, heavy-tailed Lévy-type behaviour is common in many physical systems (Wanliss, 2005; Wanliss & Reynolds, 2003), and is finding increasing relevance in economics (Basegmez & Cekici, 2017; Caginalp & Caginalp, 2018; Champagnat et al., 2013). Finally, stable distributions are a very general, broad and rich class of distributions allowing for heavy-tails and skewness. The most common stable distribution is the Gaussian normal curve. Rejecting the assumption of normal distribution of returns supports the hypothesis that a stable distribution is suitable for these data.
A distribution is stable if its shape remains unchanged under sums of the same type. Also, all non-degenerate stable distributions are continuous distributions with infinitely differentiable density. For example, if one took a Gaussian normal distribution, and added a second Gaussian normal distribution to it, the result would remain a Gaussian normal distribution. Every possible stable distribution is a special case of the Lévy alpha-stable distribution, defined by the Fourier transform of its characteristic function (Nolan, 2016),
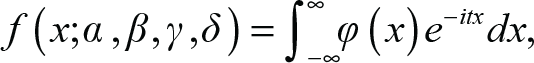
and φ(t) is given by

and
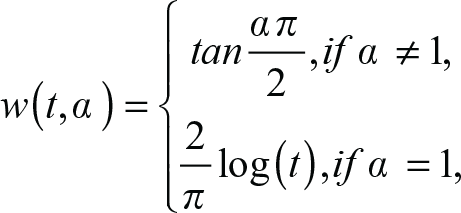
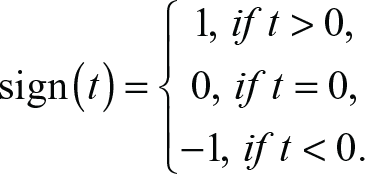
The alpha-stable Lévy distribution function is a function of four variables, α, β, γ and δ. Generally speaking, the α and β statistics are parameters that determine the shape of the distributions. The γ and δ statistics are location parameters.
The first shape parameter, α, is known as the characteristic exponent, or index of stability. It ranges over (0, 2). When α decreases, the central peak gets higher, the regions flanking the peak flatten and the tails at large values get heavier. When α = 2, we recover the Gaussian normal distribution.
The second shape parameter β is the skewness parameter. It ranges over [–1, 1]. This variable determines the thickness, or heaviness, of the tails. When α = 1, β = 0, the Cauchy distribution is obtained, and when α = 0.5, the Lévy distribution is obtained. When β < 0, the distribution skews towards the right tail, when β > 0, the distribution skews towards the left tail. For the case β = 0, the distribution is symmetric, and when β = ± 1, the distribution is completely skewed towards that tail, that is, there is no tail on the other side. An interesting feature of the Gaussian normal distribution (α = 2) is that β has no effect on this distribution.
The meaning of the final two parameters is very simple. The scale is determined by γ; increasing or decreasing the scale will magnify or shrink the distribution. The final variable is the location parameter, δ, which serves to shift the centre of the distribution left or right.
Given the size of the empirical returns for ES, with a mean very close to zero, as seen in Figure 2, it is to be expected that there should be negligible difference between statistical results whether one looks at simple or compound returns. Since the compound return equation yields very small values, the difference between simple and compound returns, at least for the data we examine, is essentially the same, as is shown below, with a Taylor series expansion:
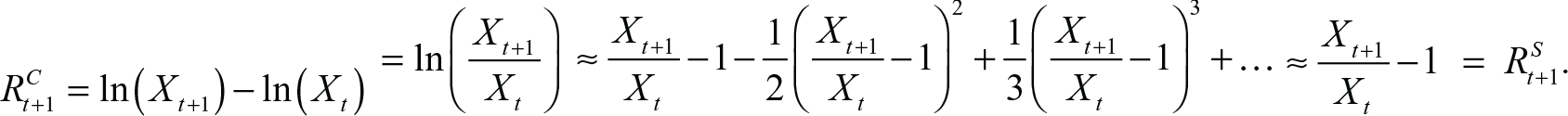
We model the ES returns by calculating the empirical PDF, and using maximum likelihood to estimate the parameters α, β, γ and δ in the alpha-stable distribution. Results for the fit to the empirical PDF of the ES-series are summarised in Figure 3, with parameters given in Table 2. Most of the stable distribution parameters are identical whether from simple or compound returns, except for β, which is slightly, but not significantly, different.
Stable Distribution Function Fitted Parameters

DFA
Serlitis et al. (2008) and Uritskaya (2005) demonstrated use of DFA to stock market prices. Here, we perform similar analysis to ES data. Figure 4 shows the DFA of ES prices. The best-fit slope, H, the Hurst exponent, is estimated using non-linear least-squares for a power law. The result for the slope is
In this article, we have considered whether the E-mini S&P futures market returns follow a random walk, or some other behaviour in its price dynamics. Large, but rare events punctuating periods of relative quiescence are remarkable emergent properties found not only in physical sciences, but also in economics. These events are usually quantified by heavy-tailed distributions of event sizes, in which often unexpected events come to dominate system development. Theoretical considerations suggest that dynamic fluctuations of selling pressure can generate a market crash even in the absence of a fundamental shock (Kirilenko et al., 2017). Huang and Wang (2009) expanded on the theoretical framework of Grossman and Miller (1988), in which an equilibrium model links the cost of maintaining continuous market presence with market crashes even in the absence of fundamental shocks and with perfectly offsetting idiosyncratic shocks. In their model, market crashes emerge endogenously when a sudden excess of sell orders overwhelms the insufficient risk-bearing capacity of market makers.
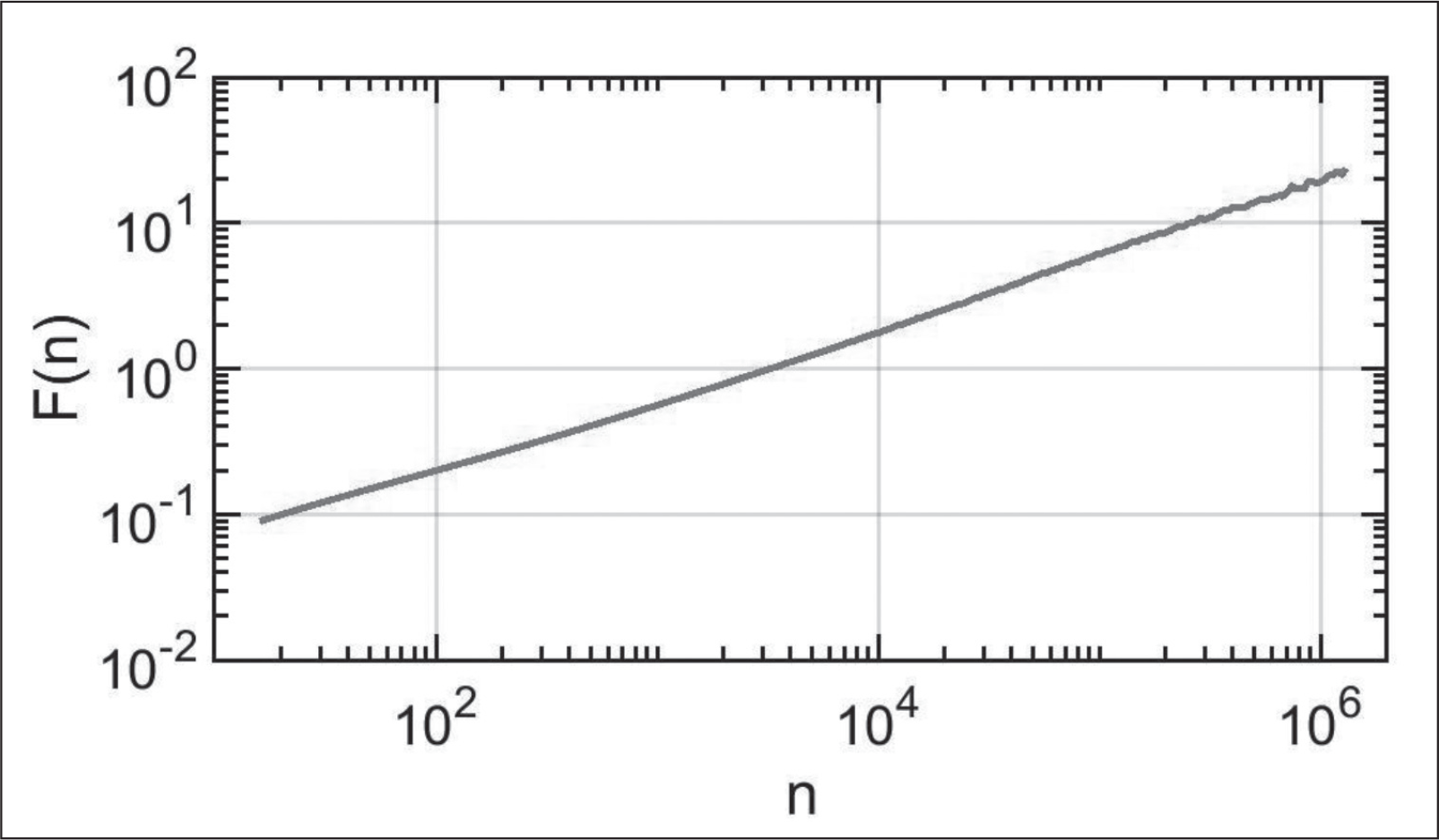
We have found that the ES returns data violate the normality requirement of the EMH, and that returns are fractal. Several tests confirmed the violation of normality. We fitted the ES return distribution to the Lévy alpha-stable process. This process generalises the special case of the normal distribution, and shows how the ES returns have heavy tails, supporting the FMH. Estimates of the four Lévy alpha-stable parameters are consistent with the conjecture that the stochastic process generating the returns is fractal.
We used DFA to determine the Hurst exponent, measuring long-range dependence in ES futures data. This method, from statistical physics, has the advantage that it is better able to deal with nonstationarities than typical methods in financial economics, such as variance analysis. The detrended fluctuation functions were approximately linear over about five decades in log–log space (see Figure 4). Thus, on a long timescale, ES appears monofractal. This suggests that on a scale of approximately 1 year a single scaling controls the dynamics over a wide range of scales. However, it is possible that the scaling exponent varies as a function of time. Since ‘local’ changes in scaling exponents can be observed through DFA, it could be important to consider shorter intervals to get a full view of the non-linear characterisation of ES futures. An improved understanding of the dynamics of these kinds of data are an important part of understanding economic intermittency observed in business cycles and financial markets (Chian, 2007).
The fractal scaling exponent we find is essentially that of a random walk. However, our findings imply that, on the roughly annual scale we have examined, ES financial returns behave in a more general manner than random walks. Random walks are, of course, but a special case of general fractal processes. Technically, this means that deviations from the EMH, and the associated heavy-tailed distributions, are more common than expected. One is thus able to earn (or lose) much more than the Gaussian model predicts. In addition, the analysis reveals that crisis prevention on the basis of the EMH, would be a theoretically flawed methodology with disadvantages compared to the FMH. Our results indicate that the ES futures market operates close to the state predicted by the EMF, but that the observed transient deviations from this state fail to have a statistical origin, consistent with a purely random geometric Brownian motion, and are better described by the FMH. Our results help to improve understanding of dynamical instabilities of ES futures markets and suggest future directions for analysis of multiscale trends within this market.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.