
Abstract
Sampling on the dependent variable is unlikely to be an effective way to learn and develop the strategy. Even so, organizations spend millions of dollars on processes such as Appreciative Inquiry that make inferences about how to adapt their strategies, routines, and practices based upon only successful examples. Two techniques that are common to this kind of learning process are searching solely for successful solutions and reframing search problems (e.g., unconditionally positive questions). We build a computational model by formalizing appreciative inquiry and comparing it with other, similar processes to understand their relative effectiveness. We find that the organizations simulated in our computational model almost always improved performance over time, despite learning solely from successful observations. Their relative effectiveness depended on the complexity of the problems, the number of iterations of learning, and how much the learning process preserved variety in potential solutions. These findings suggest that appreciative inquiry may be most effective when people take the cost and complexity of organizational problems into account before engaging in the learning process and adapt the process accordingly. These findings contribute to research on organizational learning by explaining why learners may benefit from structuring the way they communicate as they search, why reframing performance measures may dissolve search problems, and how designed organizational search enables managers to be more deliberate about organizational learning.
Keywords
Organizational search, the process of seeking solutions to existing or anticipated problems (Argote et al., 2021), can take very different forms. Consider a medical device manufacturing company that seeks to develop a strategic capability for introducing innovative products into the market. It could try to develop this capability by selecting a random sample of attempts at product innovation; collecting data regarding the context and outcomes of these attempts; analyzing the data to see which factors have the greatest impact and using the factors that have the greatest impact to create strategies, routines, or practices for introducing innovative products. Alternatively, the company could ask employees to share stories about only the strategies, practices, and routines that have generated their most innovative products; identify themes across these stories; use these themes to create new strategies, routines, or practices; and perhaps repeat this process periodically to make further improvements in their capability for innovation. Although firms sometimes engage in the second approach (Bushe & Kassam, 2005; Cooperrider & Whitney, 2005; Eisenberg, 2011), scholars tend to discourage approaches to search that sample on the dependent variable, pointing out its many shortcomings (e.g., Denrell, 2003; Freeman & Hannan, 1983; Rosenzweig, 2009).
Sampling on the dependent variable occurs when organizations make inferences about what factors lead to desired outcomes using only observations or experiences in which those outcomes were achieved. However, samples in which all of the observations achieve the desired outcome do not accurately represent their underlying populations (e.g., Argote et al., 2021; Denrell, 2003; Rosenzweig, 2009) and as a result, conclusions drawn from such a sample tend to be biased (Freeman & Hannan, 1983) are unlikely to be generalizable (Christmann, 2000), and may hurt rather than help that organization (Denrell, 2003; Rosenzweig, 2009). For example, an organization that makes inferences about how to innovate based solely on cases of successful innovation may be surprised that they are not able to replicate the desired outcomes because they failed to account for factors that would have surfaced with a broader sample (e.g., specific resources, timing, or human error).
Nevertheless, despite the limitations of sampling on success, organizations often use designed processes for seeking solutions to existing or anticipated problems that draw inferences from samples that only include successful cases, encoding their inferences into strategies, routines, and other courses of action. Sometimes they explicitly choose to adopt specific, formal processes for doing this. We refer to these as designed processes to contrast them with the common descriptions of search in organizational learning theory, which describes search processes as relatively automatic, reflexive, problem-driven efforts to find good-enough solutions. Designed search processes are intentionally mapped out from beginning to end with the goal of finding exceptional solutions. One prominent example of this type of search process is Appreciative Inquiry (AI; a method for change management developed in the field of organization development). Appreciative inquiry is a form of organizational search that elevates a system's capacity to learn from successes and apply its strengths and to achieve desired outcomes (Cooperrider & Fry, 2020) and has been used to make strategic changes in organizations such as John Deere, Verizon, British Airways, NASA, and the United Nations (Bushe & Kassam, 2005; Cooperrider & Whitney, 2005). In many well-established and successful organizations, leaders spend millions of discretionary dollars and devote substantial resources to sampling-on-success processes such as AI. 1 Given what we know about sampling on the dependent variable, is this process mass folly, or is there more involved than appears on the surface?
To examine a designed organizational search that samples the dependent variable, we model AI, a well-known organizational change intervention that seeks to learn solely from success (Cooperrider et al., 2005). Our intention is not to advocate for AI over other search processes. Rather, we seek to gain practical insights about what makes a process such as AI effective and to generate theoretical insights by identifying the basic, abstract components of this search process and comparing it with other search processes that also learn solely from success, albeit in different ways.
In their review of the field of organizational search, Posen and colleagues (2018) identified one of the shortcomings of current research as an overly simplistic view of search that treats the search process as a black box, largely examining only antecedents and outcomes. Organizational search is conceptualized as overly routinized and assumes a high degree of automaticity (e.g., Greeve, 2003). These conceptualizations of search do not reflect the choices that organizations can make in selecting a search process and the choices they can make during a search process. Our paper helps address these shortcomings by relaxing assumptions of automaticity and unpacking the so-called black box by comparing three different processes for seeking solutions. In addition, while studies have contrasted learning from success versus learning from failure (e.g., Deichmann & Ende, 2014; Greve & Seidel, 2015; KC et al., 2013; Lapré, & Cravey, 2022; Madsen & Desai, 2010), we are not aware of any studies that have compared different processes for learning from success. By comparing different forms of learning from success, organizations can make better decisions about how and when to apply a designed search that focuses on learning from success. Finally, scholars have suggested studying the process of search as an evolutionary approach, helping us further understand how organizations learn from success (Lee et al., 2020); this study includes such an approach as one of the analyzed processes.
Specifically, the search processes to which we compare AI in this study are those of natural selection and regression analysis of samples using only successful observations. Natural selection is an evolutionary process of success-oriented learning because at the population level, only the fittest survive natural selection, and fitness is a type of success. We modeled natural selection as a model of success-based learning using the genetic algorithm, which is also employed in other computational models of organizational learning (e.g., Bruderer & Singh, 1996; Crowston, 1996). For learning based on regression, we also modeled success-based search as a regression with samples that included only successful observations and, for comprehensiveness, also included a model of regression using random samples as well. Regression, a statistical method of calculating the relationships between independent and dependent variables, used commonly in data analytics and data mining within organizations, provides a useful baseline for comparison. We did not examine every detail of these differing models of learning from success. Rather, our goal is to acquire insights by comparing the general effectiveness of different structured approaches to success-based search.
Using our model to compare three forms of success-driven organizational search, we found that the relative effectiveness of each form of search depended on the complexity of the problems, the number of iterations of learning, and how much the learning process preserved variety in potential solutions. Surprisingly, our findings support the notion that AI may be the most effective form of search when organizations account for the cost and complexity of the problem. Our findings also contribute to research on organizational learning by explaining why reframing performance measures may dissolve search problems, and how designed organizational search enables organizations to be more deliberate about learning. We found that if managers reframe the performance measure that they want to improve to make it broader and more positive, they will often improve the performance of the old performance measure as well as the new performance measure. These findings respond directly to Posen and colleagues’ (2018) call for research that questions assumptions about the automaticity of the search process. Using these findings, we also make five contributions to the theory of organizational search. First, we explain when and why search processes that focus solely on success enable organizations to improve performance despite their members’ bounded rationality. Second, we show how proactively selecting broader and more positive types of performance improves narrower and less positive forms of performance as well. Third, we use the results to demonstrate how conversational structure influences search effectiveness. Fourth, we explain when and why the sacrifice of short-term improvements enables organizations to reap the benefits of learning solely from success. Finally, we illustrate how performance improvements may depend more on iterative learning than on the way people make inferences.
We begin by situating the concepts of designed search, success-based search, and proactive reframing more fully in the literature on organizational search and introduce AI as an appropriate process to model. We then describe how we operationalized AI as a computational model and compare it to the genetic algorithm and regression-based search. We then present the results of our simulation analysis, concluding with an explanation of how our results influence the theory about organizational search and learning.
Theoretical Background
Early organizational learning scholars assumed that actors are boundedly rational and take a largely behavioral approach to organizational search (Cyert & March, 1963). As such, they argued that (1) organizational search occurs when performance falls below aspirations (problemistic search), (2) they search for solutions that are similar to previous solutions before examining dissimilar solutions (local search), and (3) they usually adopt the first solution that solves the problem rather than trying to find optimal solutions (satisficing). As such, organizational search is generally conceptualized as a reactive process that minimizes cognitive effort (Posen et al., 2018). Using assumptions such as these, scholars have developed models that explained either flawed organizational decision-making (e.g., Cohen et al., 1972) or how organizations were able to perform well in spite of these limitations (e.g., Cohen, 1981).
Eventually, scholars introduced more complex assumptions into their models, such as organizational structures and cognition (e.g., Billinger et al., 2014; Gavetti, 2005: Joseph & Gaba, 2020; Nigam et al., 2016), such as simplified mental representations of potential solutions (e.g., Csaszar & Levinthal, 2016), or preferred directions in which actors think they should search (e.g., Winter et al., 2007). Scholars have introduced cognition into accepted search processes and then examined the impact of these changes (e.g., Csaszar & Levinthal, 2016; Winter et al., 2007).
Designed Organizational Search
However, cognition also occurs when organizations deliberately decide on the specific process for organizational search. For example, when managers encounter problems, rather than immediately searching for solutions in an autonomous or reflexive way, they may instead hire consultants who persuade them to use specific, designed search processes (e.g., Bogan & English, 1994; Lilien et al., 2002). People design search processes using scientific research and professional experience to guide their design choices. When organizations adopt designed search processes, they may shop around, selecting from an array of search processes before ever selecting from an array of potential solutions. This approach is still boundedly rational, but it is also more deliberate than most of the other existing models of organizational search.
Some designed organizational processes differ from the predominant/current models of organizational search in the literature by prescribing reframing a goal or a problem (e.g., Ackoff, 1981; Cooperrider et al., 2005; Fritz, 1989). Reframing a goal or a problem introduces cognition and choice into search models that conceptualize organizational search as automatic. Reframing is important because it can change the array of potential solutions. For example, when Roberto Goizueta and his colleagues changed Coca-Cola's frame from “How do we beat Pepsi?” to “What is our share of the stomach?” the array of potential solutions available to Coca-Cola expanded from those involved with producing and selling carbonated sodas to those involved in the production and sale of all nonalcoholic drinks (Charan & Tichy, 1998). The second set of strategic choices included, but was also much larger than, the more constrained conception of Coke's strategy. Goizuetta and his colleagues may not have known what all of the possible solutions were in either frame—they were still boundedly rational—but the array of possible solutions expanded no matter what mental representations they built upon. This distinction is crucial, because the idea of changing the array of possible solutions is highly relevant to strategic management since premeditated approaches to performance improvement involve managerial discretion and strategic choice (Hambrick et al., 2004; Montenari, 1978; Wangrow et al., 2015).
Another feature of designed organizational search processes is that many of them seek to learn solely from successful solutions, and some of them do so intentionally (e.g., Bogan & English, 1994; Cooperrider et al., 2005; Pascale et al., 2010; von Hippel et al., 1999). Learning from success is a growing area of interest for organizational scholars (e.g., Deichmann & Ende, 2014; Gong et al., 2019; KC et al., 2013; Kim et al., 2009). When scholars have studied organizational learning they have often compared learning from success versus learning from failure. Comparing learning from success and failure is important because it helps understand the benefits of learning from success as compared to learning from failure. For example, learning from success versus learning from failure influences the premium a firm is willing to pay for future acquisitions (Gong et al., 2019), and the likelihood and effectiveness of sustained, radical initiative taking (Deichmann & Ende, 2014).
However, when comparing learning from success to learning from failure, scholars have neglected to acknowledge and examine different strategies for learning from success. Learning from success has been examined in a monolithic and sometimes generic form, ignoring the nuance of alternative learning strategies. For example, Kim and colleagues (2009) conceptualized learning from success as a firms’ cumulative history of periods of exceptionally strong performance. This is consistent with those that have studied learning from success at the individual level. Deichmann & Ende (2014) conceptualize learning from success as an individual's prior experience of success. From organizational practice and organizational learning literature, we know there are differing strategies for learning from success.
Many of these benefits and drawbacks were discovered by comparing learning from success against learning from failure or against learning from samples that include both success and failure (e.g., Deichmann & Ende, 2014; Gong et al., 2019; Heckman, 1979; KC et al., 2013; Kim et al., 2009). We know of no research that compares different approaches to learning from success. Some approaches may do a better job of using success’ advantages and avoiding its drawbacks than others. Designed organizational search processes give us an opportunity to compare and contrast different approaches.
Toward a Model of Designed Organizational Search: The Example of AI
An example of a type of designed organizational search that learns solely from success is AI. AI is often used by organizations around the world (Cooperrider et al., 2005), with some organizations even adopting it formally into their structure and routines (e.g., May et al., 2011). Other success-only search processes also exist (e.g., Lilien et al., 2002; Pascale et al., 2010) and could be examined as well. AI is commonly used and relies intentionally on the assumption that much of the world is socially constructed. Social constructionism assumes that some facts—such as the definition of an organizational problem or goal and the solutions that are relevant to that goal—depend as much—if not more—on the agreement of social actors as they do on physical reality (Berger & Luckmann, 1990). Other success-focused search processes also draw on social constructionism but do so less explicitly, so AI provides us with a useful source for building a model that includes problem reframing.
The first step in AI is the reframing of the search problem to be unconditionally positive. For example, if an organization has severe conflicts between management and labor, then a problemistic search will typically assume that the goal of a search may be to reduce severe labor conflicts. In contrast, AI users might reframe this problem as “How do we build ongoing, mutually-beneficial relationships between management and labor?” This new problem statement subsumes the original problem (you cannot have ongoing, mutually beneficial relationships if those relationships are characterized by severe conflict), but it is also broader, more positive, and more ambitious. Once people reframe the problem, the remaining steps include (a) collecting data about times when the new, positive goal was achieved (Discover); (b) inferring ideas from the data that can be used in other places throughout the organization (Dream); (c) coming up with specific experiments to try (Design); (d) implementing those experiments; and (e) learning from the implementation and repeating the process as appropriate (Destiny).
Practitioners and scholars make claims about the effectiveness of AI, but their evidence consists primarily of successful case studies (Fry et al., 2002; Ludema & Barrett, 2007). A review of these case studies compares more successful cases with less successful cases to identify some interesting patterns (e.g., Bushe & Kassam, 2005), but the lack of case studies that report unsuccessful efforts with AI limits our ability to make generalized inferences about its effectiveness as a search process. In contrast, a computational model can simulate AI under multiple conditions, and also compare it with other search processes that learn only from success.
There is no existing computational model of AI. To build such a model, we followed the example of scholars such as Sastry (1997), who build computational models by translating verbal descriptions of processes into formal mathematics and computational commands. The verbal description we used was the Appreciative Inquiry Handbook (Cooperrider et al., 2005), which may be the most accepted description of how to conduct an AI. In other words, we broke down the semantics of the Handbook to create a formal model of AI. However, similar to Sastry's (1997) formalization of organizational change as punctuated equilibrium (Tushman & Romanelli, 1985), verbal texts are seldom precise enough to make a complete formal model. Therefore, similar to Sastry, where the Handbook was insufficient, we used sensitivity tests, logic, and comparisons with descriptions of empirical processes to complete the model.
We began the process of formalization by reading through the Handbook, extracting statements about search, implementation, and feedback, which are categories of activity that scholars identify as necessary for learning (e.g., Cyert & March, 1963; Zollo & Winter, 2002). Examples of statements that fit these categories include “… what are the best stories, practices and wishes that came out of the interviews?” (p. 98) and “Self-selected groups plan the next steps for institutionalization” (p. 176). The first statement describes feedback because identifying the “best” stories implies the assessment of past performance. The second statement describes implementation because it involves introducing new solutions into the organization. We excluded statements that described elements that do not contribute to learning, such as “begin with some kind of energizing activity” (p. 113). Energizing activities may help people to stay alert and engaged while they go through the search process, but they do not search for, implement, or generate feedback on solutions to search problems. Table 1 contains additional examples of statements we did and did not extract.
Text-Coding Categories and Examples*.

*Contains page numbers from the Handbook after each quote.
As we extracted statements, it became clear that reframing the problem—choosing the type of performance one wishes to improve, or “topic choice” as it was called in the Handbook—should be included as its own step in the learning process even though it has not been included in other scholarly models of organizational search (e.g., Cohen, 1981; Cyert & March, 1963; Knudsen & Levinthal, 2007; Rivkin, 2000; Siggelkow & Rivkin, 2006). For example, in problemistic search, performance measures are given because problems are predefined: a solution fails to achieve an aspiration level along an already-existing measure of performance. Thus, in these models, when performance fails, managers simply search for ways to improve performance as currently defined (Cyert & March, 1963). However, if managers change the search topic, or in other words, the type of performance they are trying to improve, that change in the topic also changes what kinds of solutions are relevant for inclusion in the search. These models take topic choice for granted.
Once we extracted statements from the Handbook, we examined them further to break them down into steps that were discrete enough to use in a computational model. Statements about topic choice implied two steps, as shown in Table 2. Step 1 is reframing performance (as suggested in the Handbook by statements about how topics “represent what people want to discover or learn more about,” p. 32). Step 2 is defining the types of solutions for which people are searching (suggested by statements such as “choice of topic defines the scope of the inquiry,” p. 32). Search and feedback broke into interrelated steps in Table 2. A good example of this interrelation comes from statements about activities such as interviewing stakeholders “from many levels and perspectives in the organization” (Cooperrider et al., 2005, p. 88), about “peak” experiences with the topic (p. 89), and about identifying “themes” in these peak experiences (p. 112). The first step of the search process involves activities such as drawing experiences “from many levels and perspectives.” We state this step abstractly in step 3 in Table 2 as “identifying possible solutions from which to learn.” The first step of the feedback process (step 4 in Table 2) is also implied in this description, requiring AI participants to select “peak” experiences when they talk about solutions. Stated abstractly, this involves “evaluating the performance of each solution.” Once the performance of each solution is known, the second step of the search process (step 5 in Table 2) can be completed: “selecting the highest performing solutions.” Participants do this when they focus on only the stories of peak experiences that they hear from each other. Within these peak experiences, participants can perform the second step in the feedback process (step 6 of Table 3) by “identifying information from within the peak experiences from which to learn.” They do this by identifying “themes” that the peak experiences have in common. Finally, we broke statements about implementation into three steps (steps 7, 8, and 9 in Table 2). Examples of such statements include the counsel to use the common themes identified in the feedback process as “design elements” (p. 143) for new solutions or the suggestion that “Individuals and small groups self-organize to implement the Design statements” (p. 176). The steps we derived from statements such as these included (1) removing lower-performing solutions, (2) inferring new solutions, and (3) altering inferences to fit the specific situations.
Translation of Relevant Handbook Descriptions into a Computational Model*.

*Contains page numbers from the Handbook after each quote.
Results of Paired Sample T Tests of a Smooth Solution Landscape (N = 10, K = 1) Versus a Rugged Solution Landscape (N = 20, K = 9), Comparing the Mean Performance of the Same Learning Procedure at the Same Number of Iterations.

Table 2 displays examples of quotations from the Handbook that we used to develop substeps of the learning process (column 1), the substeps as we arranged them in the model (column 2), and the formalization of these steps into the mathematics and computational commands (column 3). Mathematics is a language, so the formalization of these steps is a type of translation. For example, topic choice (row 1) involves identifying the things that people “want to see grow and flourish” (Handbook, p. 32), or in other words, a topic is a dimension of performance (Yi, where Yi = ƒ(x1, x2, …, xN)), a new topic is a different-but-related dimension of performance (Y’i, where Y’i = g(x1, x2, …, xN’)), and if people want more of that performance (“grow and flourish”) then they want Y’i(t+1) > Y’i(t). Similarly, instructions such as “Do as many interviews as possible” implies that there is a population of solutions that people have experienced (row 3) from which they can draw peak experiences and best practices (row 4). The final column in row 3 suggests that we can model solutions as strings (Bi) of zeroes and ones (xi) with the values of the xi in the initial strings being assigned randomly in the. Appreciative Inquiry participants must evaluate the performance of strings (i.e., solutions) if they are to describe a “peak” experience, so row 4 suggests that the computational model should use the formula in row 2 to calculate the performance of the strings in row 3. We provide a more comprehensive explanation of each step shortly.
In a few cases, as we translated from the verbal language of the Handbook, the description was not as precise as needed to express mathematically or there were multiple legitimate ways to perform a step. Also, some simplification was required to make the model comprehensible (which is true of any model). For example, one simplification is that the Handbook suggests having multiple, iterative conversations to identify themes in the experiences that people share and to use those themes to make plans. Rather than model every possible conversation, and preserve the essence of the process without creating code for every possible application of the procedure, we coded the outcomes of these conversations (such as the new topic, rather than the process for coming up with a new topic), which accomplishes the same purpose. In cases where the language was not precise, we built parameters into the model that could take on different values, and then conducted sensitivity tests using the different values. For example, the Handbook tells people to look for common themes across success stories, but it was not clear what made a theme “common.” Therefore, we treated commonality as the percentage of stories that contained the same value for a given theme. We simulated the model with multiple permutations of the various parameter values, including but not limited to the percentage of stories that contained the same value for a given theme. We found that if the value was much higher than 60%, then themes occurred too rarely to be useful for learning, and if the value was much lower than 60%, then every element became a theme. Therefore, when we conducted our experiments, we held the common percentage fixed at 60%. We examined each unclear parameter from the Handbook this way. Some parameters only worked at small ranges of values, so we picked a value in that range and used it in all simulations. Other parameters worked at multiple values, so we manipulated that parameter to have multiple values in our experiments. We identify fixed and experimental values in our description of the model.
Steps 1 and 2: Modeling Topic Choice
The model begins with topic choice. As row 1 in Table 2 shows, the first step of topic choice is transforming a problem into an unconditionally positive question. Typically, problems occur when some desired outcome did not turn out as hoped, so people want to improve their performance on this outcome (Cyert & March, 1963). The outcome can be anything that people want to improve, whether financial (e.g., profit, ROI), operational (e.g., productivity, efficiency), a vague-but-desirable outcome (e.g., innovation), or even a subjective outcome (e.g., inclusivity). We model the outcome as a dependent variable, Y. However, in AI, topic choice involves transforming problems (e.g., “How do we fix customer dissatisfaction?”) into unconditionally positive questions (e.g., “How could we inspire our customers to be intrinsically motivated to engage with us in our products’ development and promotion as well as in their consumption?”). Examples might be Coca-Cola ceasing its efforts to win tenths of 1% of share of the cola market from Pepsi (Y) in favor of expanding the market to include all nonalcoholic drinks (Y’) (Charan & Tichy, 1998), or Avon changing its goal of eliminating sexual harassment (Y) to creating high-quality, cross-gender professional relationships (Y’) (Cooperrider & Whitney, 2005).
We capture this transformation by modeling new dependent variables with Y’, recognizing that achieving Y’ typically may also involve achieving Y (e.g., the nonalcoholic drinks market includes colas, and people in high-quality, cross-gender, professional relationships do not engage in sexual harassment). This observation has at least two implications for modeling. First, the independent variables that affect Y are also likely to affect Y’, but because Y’ is a more encompassing goal than Y, there are likely to be more variables that affect Y’ than Y. We model this as follows: Y = ƒ(x1, x2, …, xN), Y’ = g(x1, x2, …, xN, xN+1, xN+2, …, xN’), where N and N’ are the number of variables in each function. (For simplicity, we use only zeroes or ones for the values, consistent with many other computational models; e.g., Gavetti & Levinthal, 2000.) Second, causal relationships in Y’ are likely to be more complex than in Y (see row 2 of Table 2). We capture this complexity using an adapted version of Kaufman’s (1993) NK function to model performance as a landscape. This approach—common in models of organizational search (e.g., Knudsen & Levinthal, 2007; Rivkin, 2000)—treats Y and Y’ as altitudes in the landscape and xis as landscape coordinates. A landscape is rugged when it has many peaks and valleys, which suggest that solutions with similar values in their xis have dramatically different outcomes because of complex interactions between the xis. Landscapes are less rugged when solutions with similar values in their xis have similar levels of performance.
In an NK model, K refers to the number of other independent variables (not x i ) that interact with a given independent variable (x i ) to influence Y. For example, if N equals 5 and K equals 3, then the impact of x1 on Y is also influenced by x2, x3, and x4; the impact of x2 on Y is also influenced by x3, x4, and x5; the impact of x3 is also influenced by x4, x5, and x1; and so on. In this example, if the xis in each solution (Bi) take on the values x1 = 0, x2 = 1, x3 = 1, x4 = 0, x5 = 0, then the impact of x1 on Y would also be influenced by x2, x3, and x4 (i.e., 0|1 1 0). If K = 3, then there are 16 possible permutations of interactions that could define the impact of xi on Y. Thus, once the computational model is told the value of K for a simulation run, it assigns each possible permutation of zeroes and ones a random decimal value as the impact of xi on Y. For example, the permutation (0,0,0,0) may be assigned 0.243, the permutation (0,0,0,1) may be assigned 0.911, and so on. The overall performance of the solution is the average of the assigned values of each of the N x i s. In NK landscapes, the higher K is, the more rugged the landscape will be.
We can use the NK model to describe topic choice by defining Y’ in terms of Y, as follows: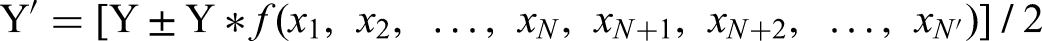
This formula meets our conditions that Y’ should subsume Y (it is partially a function of Y) but should also involve more variables and a more complex relationship between variables. Specifically, x1 through xN represent the same variables in Y and Y’, but xN+1 through xN’ are unique to Y’. The possibility of adding or subtracting the second term in the formula implies that changes in performance for a broader aspiration will affect performance in the less broad aspiration as well, sometimes for better, sometimes for worse. Multiplying Y by f(x1, x2,…,xN’) ensures that the value that is added to or subtracted from Y will not exceed Y. Also, Y and Y* f(x1, x2,…,xN’) both range from 0 to 1, so the lowest value produced by adding these numbers will not fall below zero or exceed two. We divide by 2 so that the value of the equation for Y’ has the same range [0, 1] as the formula for Y. Finally, the decimal score of Y’ will usually be a lower performance score for Y’ (because it involves multiplying decimals and dividing by two). Even though this score will be lower, it may represent a higher total performance in comparison to Y. For example, if Y = 0.600 and Y’ = 0.500, but the size of the cola market is measured in hundreds of millions of dollars and the size of the nonalcoholic drinks market was measured in billions of dollars, then Coca-Cola's performance in the cola market might be 0.600 * $100,000,000 = $60 million, while their performance in the non-alcoholic drinks market might be 0.500 * $1,000,000,000 = $500 million.
Steps 3 Through 6: Search and Feedback
The next four steps model the “Discovery” phase of AI. They involve searching for solutions and getting feedback on the courses selected (Cyert & March, 1963; Zollo & Winter, 2002). Step 3 involves identifying a sample of M solutions within which the organization will search. The computational model generates the initial version of this sample by using strings (B i s) to represent stories/solutions, in which each string is composed of N x i s (i = 1 to N) and each x i is an element of that solution that is present when x i = 1 and absent when if x i = 0. For example, if Y represents customer satisfaction, and B i s represents the solution used to deliver a product to customers, then the x i s might represent elements such as statistical process control, just-in-time delivery, adaptation to local tastes, and so forth. The computational model assigns random values of zero or one to each of the x i s.
The remaining three steps proceed as follows. In step 4, the model evaluates the performance of each B i using the NK function. In step 5, the model identifies the highest-performing M-R of the B i s identified in step 3. In step 6, the model compares each x i across the M-R Bis to see whether more than 60% of each xi have the same value (zero or one). If an xi has the same value in more than 60% of the M-R Bis, the model records the value of that xi, creating a template for making new solutions. In new solutions, some of the xis are held constant and others are not, according to this template. For example, if the higher-performing Bis have five xis each, x1 had a zero in over 60% of the Bis, and x4 had a one in over 60% of the Bis, then the template used for creating new Bis for the organization would be [x1 = 0, x2 = ?, x3 = ?, x4 = 1, x5 = ?].
Steps 7 Through 9: Implementation
The model next begins implementation (Cyert & March, 1963; Zollo & Winter, 2002), which corresponds to the “Dream” and “Design” stages of AI. In the seventh step of Table 2, the model eliminates the R lowest-performing B i s from the simulated organization. The Handbook does not state this step explicitly, but it is implied in the instructions and in the examples of AI projects.
The computational model creates R new solutions (B i s) in the eighth step by replacing the ones that were removed. It does this by introducing values (0 or 1) into the x i s that did not have consistent themes identified in step six. For example, if the template created was [x1 = 0, x2 = ?, x3 = ?, x4 = 1, x5 = ?], then for each new Bi, the model would use a random uniform draw of 0 or 1 to select values for x2, x3, and x5 for each Bi. For example, if the computational model replaces B2, B7, and B10, then it might generate the strings B2 = [0,1,1,1,1], B7 = [0,0,1,1,0], and B10 = [0,0,0,1,1] for implementation in the organization. This is consistent with the instruction from the Handbook to design solutions by grounding future solutions in peak examples from the past. We specify values for R at the beginning of each simulation.
After creating new solutions, the model may make another change in the ninth step. People participating in AI may alter specific elements in new solutions, perhaps because their understanding of specific organizational circumstances suggests poor perceived fit between an element of a solution and those circumstances, or perhaps because they are boundedly rational and make mistakes. Therefore, based on a probability (q) that is set before the model runs, the model makes a random, single-element alteration to one or more of the new solutions. For example, if q = 10%, then with 10% probability, the value of an element (e.g., x4 in string B2) may change (e.g., from one to zero).
Repetition
Finally, the computational model may repeat or not repeat the AI process, consistent with descriptions of the “continuous organizational learning, adjustment, and improvisation” (p. 113) of the Destiny stage of an AI. Some organizations only go through one learning cycle; others engage in a few cycles of learning; and others engage in the process indefinitely. For example, in one health system of which we are aware, the top management team created a “Center of Appreciative Practice” that was responsible for regularly executing many interventions as a way of creating an appreciative learning organization (see Cooperrider et al., 2005). In our computational model, if the learning process occurs more than once, subsequent iterations of the process begin at step 4 instead of step 1.
Assessing Effectiveness
One way to assess the effectiveness of AI as an organizational learning process is to examine how it behaves across performance landscapes of different sizes and complexities. When does it exhibit a general trend of performance improvement over time, and when does it not? Another way is to compare its performance with other learning processes. We used both approaches.
We compared AI to natural selection and statistical regression of successful observations because these learning processes are well-understood and share similarities with AI. We do not describe these two methods in the same level of detail as we did AI because they are already formalized and documented in the scientific literature. We present a comparison of the steps in the processes for AI, natural selection, and statistical regression in Table 4.
Comparison of Computational Models.

For natural selection, we used a model called the genetic algorithm (Holland, 1992), which has been used in organizational learning research (Bruderer & Singh, 1996; March, 1991) and in solving practical problems such as forensic face-matching (Stockdale, 2008), airline booking (George et al., 2012), or creating popular music (BBC News, 1998). As Table 4 suggests, there are differences between AI and the genetic algorithm. First, unlike AI, when organizations learn through natural selection they do not change the topic of the learning process (steps 1 and 2). Second, while AI infers new solutions by looking at building on common themes from high-performing solutions, the genetic algorithm infers by recombining the elements from two higher-performing solutions (similar to how sexual reproduction crosses over the DNA of parents) (steps 5–8). Thus, when organizations in our model learn through natural selection, the model builds a performance landscape for Y (not Y’), identifies solutions (B i s) from which to learn, evaluates the performance of each B i , replaces the R lowest-performing B i s by randomly selecting two (at least probabilistically) higher-performing B i s at a time and randomly recombining their elements (x i s) to make two new B i s, altering some x i s with probability q in the same was as we do with AI, and perhaps repeating the process.
Learning through statistical regression also has similarities with and differences from AI. First, when people learn using statistical regression, they do not usually change the topic. Second, instead of inferring new solutions using themes, they regress the performance of a solution on the elements that make up that solution and retain the values of those elements that have a significant impact on performance. Thus, when organizations in our model learn through regression, the model builds a performance landscape for Y (not Y’); identifies solutions (B i s) from which to learn; evaluates the performance of each B i ; replaces the R lowest-performing B i s by regressing the performance of a solution on the elements that make up that solution (x i s), retaining the values of those elements that have a significant impact on performance, and replacing lower-performing B i s with the new B i s, altering some x i s with probability q, and perhaps repeating the process.
We examine regression that samples only on successful solutions because AI focuses only on successful solutions and our research question focuses on learning from success. We also examined regression with random samples, for the sake of comprehensiveness. Previous research suggests that regression that focuses only on successful solutions should bias results (e.g., Heckman, 1979; Rosenzweig, 2009), making learning based on regression in success-only samples less effective. However, because sampling on the dependent variable does not cause estimation problems if performance is deterministic (Heckman, 1979), we adapted our NK model to be stochastic. We introduced randomness into the model by multiplying each solution (i.e., each point in the landscape) by 1.0 ± u, where u is a number randomly drawn from a pre-specified range (e.g., [0, 0.1] or [0, 0.4]). Even though the error we introduce comes from a random distribution, it introduces error into the learning process because, in each iteration of the learning process, the error term has the potential to (mis)inform all the methods for selection of which solutions to adopt in subsequent iterations. If organizational participants adopt a solution based on errors, then each new iteration of learning is affected by that prior random error. The error is random, but the selection of which path to follow is nonrandom, so the error term can lead to alternate solutions (better or worse) being pursued. In other words, if learners make a 10% positive error while making inferences in one iteration of the model, and then make a 10% negative error in the iteration of learning, learners have not necessarily achieved zero error in their learning process. The first error led participants to adopt a particular solution, and then the next error depends on what path was chosen after the first error was made.
Analytical Strategy
We used a simulation to evaluate the effectiveness of AI in three stages. First, we ran our model through hundreds of thousands of sensitivity tests, using hundreds of different parameters, to understand its general behavior, and to discover which input values would reveal the most if manipulated or held constant in our experiments. We ran multiple permutations of values for all the parameters of our model, such as N, K, N’, K’, the range of error, the number of strings, the rate of replacement of strings, and so on. Then we conducted two experiments, one which focuses on the impact of different forms of inference in the learning process, and the second which examines the impact of choosing different topics/changing the definition of performance. We refer to them as experiments because the manipulations generate results, not because the results are empirical. Our model and data are available upon request.
Experiment 1
In the first experiment, we manipulated two features of our computational model: (1) learning procedures (i.e., AI, the genetic algorithm, regression with random samples, and regression that samples on the dependent variable) and (2) the features of the solution landscape (N and K). We manipulated N and K because our sensitivity tests suggested that the complexity of the solution landscape has one of the most significant effects on the performance of the different learning procedures. K had a more significant impact than N, but N and K are not independent: N serves as an upper limit for K. Therefore, we present the results of the two illustrative combinations of N and K: N = 20, K = 9 (a rugged performance landscape) and N = 10, K = 1 (a smooth landscape).
We hold all other parameters constant in this experiment. We examine the effect of topic choice in our second experiment, not this one. Focusing solely on differences in the inference processes of the different learning procedures enables us to isolate their effects. We held the threshold for commonality constant at 60% in AI, as explained above. We held measurement error constant at 40% because sensitivity tests suggested it was a high value that almost always generated meaningful patterns in learning procedures. Lower values did not alter patterns much. We held the number of strings (B i s) constant at 60, but this number was somewhat arbitrary because it did not appear to affect results much unless the numbers were extreme. We replaced 95% of B i s at each iteration of the simulation because this was consistent with standards from previous research, in which a high number maximizes learning while still preserving the best of what was learned in previous iterations (Manikas et al., 2016). This parameter had a limited impact on outcomes in sensitivity tests.
For each permutation of manipulations in our experiment, we ran the simulation at least 100 times. We also examined results at zero, one, five, and 100 iterations of the learning process. Zero iteration provided a baseline. We examined one, five, and 100 iterations because some organizations only use these learning procedures one time, some use them only long enough to meet predetermined targets, and some treat them as ongoing processes of organizational learning. The output we examine for each simulation is the average performance of all strings in a simulated organization.
Results
Figure 1a and 1b depicts the performance of the four learning processes for all simulations at zero, one, five, and 100 iterations of the model. One observation of interest that is immediately apparent is that as organizations learn over time, average performance improves for all four learning procedures. In fact, in hundreds of thousands of sensitivity tests, decreases in performance over time were exceedingly rare for any learning procedure and only occurred when random error was high (40%). Even when learning was based on regression with success-only samples, performance never worsened, except in those exceptionally rare cases.

(a) Average performance of solutions for each learning procedure at N = 10, K = 1. (b) Average performance of solutions for each learning procedure at N = 20, K = 9.
Performance almost never decreased, but the rate of performance improvement for each learning procedure varied significantly, and the complexity of the solution space (N and K—especially K) also significantly altered the rate of improvement of each learning procedure. For example, if we compare Figure 1a with Figure 1b we see that when N and K are low, AI, regression on successful observations, and regression on random observations who steep performance improvements after a single iteration of learning, and then taper off, while the genetic algorithm improves more slowly but achieves much better performance by the end. In contrast, when N and K are high, performance improvement occurs from one iteration of learning, but the rate of improvement is much less dramatic than when N and K are low. The rate of performance improvement remains small for both types of regression through subsequent iterations, but the learning rate is higher for AI as organizations iterate through the learning process. Dramatic improvement takes longer in the genetic algorithm, but it occurs and exceeds that of AI. Overall average performance is lower for most procedures when the problem space is more complex (see Table 4). This suggests that managers should base their decision about which learning procedure to use on how complex the problem is and how long they intend to engage in the learning process.
When comparing average performance, it is important to remember that performance in our model is an abstract percentage-based scale ranging from no benefit [0.0] to maximum possible benefit [1.0]. The meaning of this scale depends on the type of performance the scale represents. For example, the scale could represent billions of dollars or invaluable social benefit, or it could represent thousands of dollars or minor social benefits. The cost of going through multiple iterations of a learning procedure for a complex problem that will only make thousands of dollars or produce minor social benefits is unlikely to be worth it. However, multiple iterations of a learning process may be worthwhile to get a small improvement when the benefits are measured in millions or billions of dollars, or for important social benefits.
Table 3 displays significance tests for differences between means in the performance of the four learning procedures at one, five, and 100 iterations. Twenty-six out of the 36 of these differences in means are significant at p < .05. One intriguing observation from these tests is that, for simple solutions (N = 10, K = 1), regression analysis using only successful observations often outperforms the other procedures, and the only time it is significantly lower than any learning process is the genetic algorithm at 100 iterations. In complex searches (N = 20, K = 9), neither form of regression performed as well as AI nor the genetic algorithm. This is at least partly because the regression analyses in our model are underspecified for problems with complex interactions between variables. However, in our model-building and sensitivity tests, when we tried to create higher-order interactions in regression analysis, the models became so unwieldy that the interactions were not interpretable, and it was not possible to code meaningful inference processes for implementing solutions. Regression is useful for identifying relatively simple relationships, but not for finding higher-performing solutions to problems that involve complex interactions.
Appreciative Inquiry exhibited significantly better performance improvement than regression when searching for solutions to complex problems at five and 100 iterations of learning, but the genetic algorithm performed best out of all learning procedures at 100 iterations. Thus, it appears that success provides useful information about what combinations of factors (x i s) are likely to exhibit higher performance, but too much reliance on this information may lead organizations to converge too quickly on specific combinations of factors, rather than preserve variety and keep learning. The genetic algorithm—and to a lesser extent, AI—relies on information from success, but preserve variety and learn more over time.
Experiment 2
Next, we examined how topic choice influences model behavior, introducing Y’ to our model in addition to Y. The formula, Y’ = [Y ± Y*f(x1, x2,…,xN’)]/2, implies that if an organization tries to improve Y’ instead of Y, it may still influence Y while seeking to improve Y’. We ran the simulation with a topic choice 100 times for each permutation of the values N’ = 20 and 30; K’ = 3, 9, and 19; N = 10 and 20; and K = 1, 3, and 9, always with N’ > N and K’ > K. We examine these permutations for all four learning procedures using Y, for AI using Y’, and for the impact on Y when AI is applied to Y’ (See Table 5). For this experiment, we held all other parameters at the same levels used in the previous experiment.
Results of Paired Sample T tests of Comparing the Mean Performance of Different Learning Procedures at the Same Number of Iterations.

Results
The patterns of learning were similar across all but the most complex permutations because the simpler permutations were similar to the permutations in our first experiment. Although we found a few significant differences in a few permutations, these differences were uncommon and, among them, few of the patterns of learning were visibly different. Therefore, rather than present learning patterns from different permutations, Figure 2 displays average results. Figure 2 also displays the genetic algorithm and the two regression models as undifferentiated gray lines so that readers have a point of reference for them. In this experiment, the significance of the differences between Y and Y’ is not meaningful because they are different measures of performance. The mathematics of Y’ dictate that Y’ will be less than Y, even though real performance may be higher for Y’ when its decimal score is applied at scale, as explained previously.
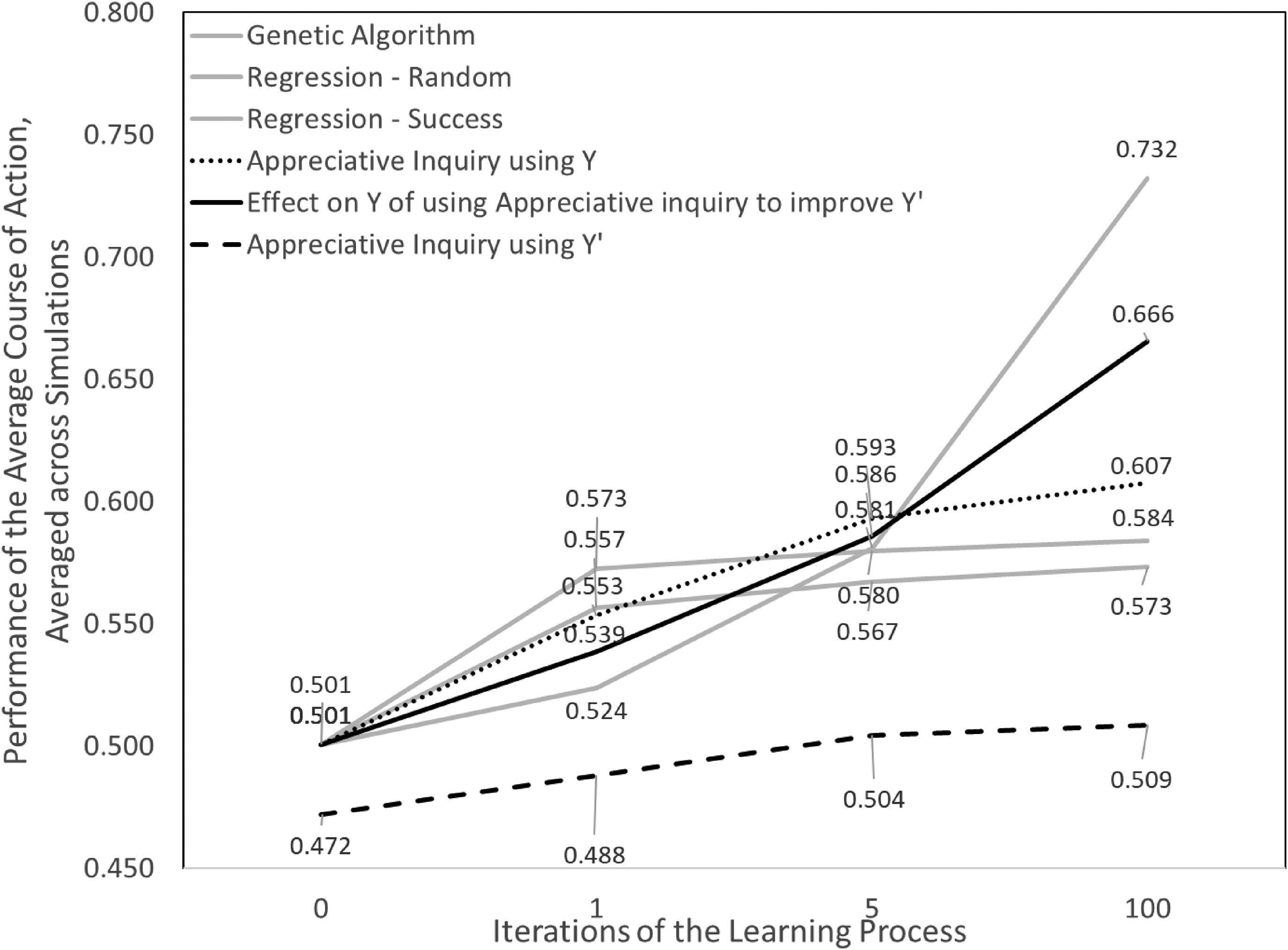
Comparison of average performance of solutions for three approaches to appreciative inquiry.
As with our first experiment, the two new versions of AI also almost always increased performance with more iterations of learning. This was true even when the problem represented by the solution landscape was more complex. This is not surprising for Y’, because it is the same AI procedure applied to a modified search problem. More surprising, however, is that when the model uses AI to improve Y’, Y improves as well. In fact, at one iteration, AI for Y’ led to higher performance in Y than the genetic algorithm; at five iterations, AI for Y’ led to higher performance in Y than the genetic algorithm or either type of regression; and at 100 iterations, AI for Y’ led to higher performance in Y than either type of regression or even than AI for Y. This relatively high performance for Y when trying to improve Y’ at five and 100 iterations occurred because the learning procedure, by focusing on searching the N’K’ landscape, converged less quickly on combinations of x i s that focus on the first high-performing solutions discovered, and continued searching until even higher-performing solutions were found.
Discussion
We built a computational model of AI, the genetic algorithm, and regression (using both success-only and random samples). We did this to examine features of designed organizational search, including problem reframing and learning solely from success. We found that no matter which method was used, performance almost always improved as organizations iterated through each of the learning procedures, even with regression analysis of only successful observations. This was a repeated finding using systematic search processes. We also found that complexity influences the effectiveness of each of these procedures. Regression on success-only samples increased performance most when searching for solutions to relatively simple problems and only engaging in one or a few iterations of learning; AI increased performance most when searching for solutions to relatively complex problems and only engaging in one or a few iterations of learning; and the genetic algorithm increased performance most when engaging in many iterations of learning, no matter how complex the problem involved. When we added topic choice to AI, not only did the potential for performance increase because of the broader aspirations being pursued, but performance in the narrower aspiration also achieved impressive performance.
One of the reasons these results are interesting is because they contrast different approaches to learning from success, rather than comparing success and failure (e.g., Madsen & Desai, 2010; Muehlfeld et al., 2012) or simply cataloging the benefits and drawbacks of learning from success (e.g., Denrell, 2003; Heckman, 1979; Weick, 1984). We explain when and why different approaches to learning from success are more or less effective. These results do not undermine previous research. For example, in a single iteration of learning, inferences made solely from samples with only successful observations are still likely to be biased estimators of causal relationships (Denrell, 2003, 2005; Denrell et al., 2013; Heckman, 1979). However, our results add nuance to these findings. For example, people interested in improving organizational performance may be less interested in identifying accurate causal relationships than they are in finding higher-performing solutions, even if they do not understand the reasons why performance is better. Organizations that iterate through successful solutions, retaining the most successful ones, and ignoring unsuccessful ones, are likely to improve performance over time in spite of problems with the inferences they make from success-only samples in a single iteration of learning. Success-based learning, systematically implemented and repeated, may avoid some of the downsides associated with success-based search. Taking this a step further, even managers’ interest in others’ success may not always be misguided (e.g., Rosenzweig, 2009). For example, there may be ways to iterate systematically through imitative learning that might also increase performance.
Another significant insight from our results is the finding that re-framing problems (i.e., topic choice) may increase the performance of an organization relative to both an original goal and a new, broader goal. Of course, our model of topic choice was just one of many ways to model topic choice. Even so, it suggests that it is at least possible that learning how to improve a broader and more complex type of performance will also improve a narrower and less complex type of performance, sometimes even beyond that which would have been achieved by focusing on the narrower type of performance alone.
Organizational Learning
These results have implications for the theory of organizational learning. Identifying procedures and conditions under which learning from success is effective advances theoretical knowledge (see Harris et al., 2013). For example, a common goal of computational models of organizational learning is to examine how organizations can learn effectively despite their members’ bounded rationality. Scholars have shown that cognitive structures such as a moderate obsession (Winter et al., 2007), or social structures such as hierarchy (Cohen, 1981; Knudsen & Levinthal, 2007), help organizations take effective action despite people's cognitive limitations. Our model adds to these insights by suggesting that managers may also help organizational members overcome bounded rationality by structuring their communication. Our model suggests three ways in which people can structure their communication to learn from success. First, they can look for themes in stories of achieving broad, positive goals (AI). Second, they can hypothesize and test variables that might affect performance and require people to implement the results of their tests (regression). Third, they can mix and match ideas from different successful solutions and try these combinations experimentally (genetic algorithm). Each of these is more nuanced and deliberate than simply imitating or repeating past successes (Denrell, 2003; Kim et al., 2009; Muehlfeld et al., 2012). These approaches suggest the beginnings of a typology of communicative patterns for learning from success. People can add these structures of search communication to the cognitive and social structures other scholars have identified. When they use these structures, they should use the ones that are appropriate for the complexity of their problems and the number of times they intend to iterate through the learning cycle. By identifying communicative structures for searching, we answer Posen and colleagues’ (2018) call for research on organizational search that is more deliberate than traditional models, as each of these structures implies deliberate, designed, and social cognition.
Our analysis of the Appreciative Inquiry Handbook also suggested the possibility that learners can reframe or redefine what performance is after encountering problems but before searching for solutions. Typically, models of organizational learning assume that organizational search begins with some kind of stimulus, without reflection on the aspiration (a full critique of this approach can be found in Posen et al., 2018). Many models include cognitive elements, such as forward-thinking (Gavetti & Levinthal, 2000) or goal-oriented search (Winter et al., 2007), but most modelers treat solution landscapes as given and fixed (Nelson, 2006). Our research introduced topic choice, or the reframing of performance, into a model of organizational search and found that it can have a significant impact on learning outcomes. We focused on reframing performance in AI but reframing performance need not be limited to AI. Learners may do better if they use reframing in regression or in evolutionary approaches to learning as well. For example, if an organization intends to search for relatively simple solutions and only intends to iterate through the learning procedure one or a few times, it may be most effective for people to reframe performance and then to conduct regression analyses to find a solution. Of course, we only examined one approach to problem reframing, and future research should examine additional ways, including the possibility that the landscape may change along with the learning process itself.
Implications for Practice
Our model and findings are significant for anyone interested in these applied processes of search. The computational model is helpful to practice because it provides some generalizable results and implications. Our results show that AI, an example of success-based search, is in fact systematically effective as a search process, although its degree of effectiveness depends on factors such as the complexity of the problem and the cost of searching. These findings suggest that we might understand success-based search processes in a new way. Notwithstanding the perceived drawbacks of sampling on success only, organizations can effectively learn through processes such as AI. Once more, our results suggest that AI is more effective at a lower number of learning iterations than natural section (GA). This is interesting considering that evolutionary algorithms set high standards for systematic learning.
Our research highlights the importance of notable features of AI. For example, in AI the topic choice involves transforming problems (e.g., “How do we fix customer dissatisfaction?”) into unconditionally positive questions (e.g., “How might we engage and delight our customers in new and exciting ways?”). We provide preliminary validation for crafting unconditional positive questions, showing that it changes how performance is conceived and also how it may increase the original type of performance under some circumstances, although more research is needed to fully understand when and how this will be the case. Our research also suggests the importance of a systematic approach to AI that includes steps such as defining performance, defining the performance function, identifying an initial population of solutions, evaluating the solutions’ performance, selecting the highest performing solutions, making alterations, and repetiting the cycle (see Table 2). Practitioners should be careful about changing or dropping these steps, if they do so at all, or they may lose the benefits of using designed search processes over automatic, problem-driven satisficing search processes.
Our model helps managers make informed decisions about the systemic method for learning that they should implement. For example, when the problem is complex and it is only possible to iterate a few times, AI is the most effect form of learning. Although overall average performance is lower for most procedures when the problem space is more complex (see Table 4), Appreciate Inquiry demonstrated the highest performance. This suggests that managers should base their decision about which learning procedure to use on how complex the problem is, the cost of the learning procedure relative to the benefit, and how long they intend to engage in the learning process.
Appreciative Inquiry exhibited significantly better performance improvement than regression when searching for solutions to complex problems at five and 100 iterations of learning, but the genetic algorithm performed best out of all learning procedures at 100 iterations. Thus, it appears that success provides useful information about what combinations of factors (x i s) are likely to exhibit higher performance, but too much reliance on this information may lead organizations to converge too quickly on specific combinations of factors, rather than preserve variety and keep learning. The genetic algorithm, AI, and regression on success-only samples all rely on information from success, but the genetic algorithm preserves more variety in this information than AI, and AI preserves more variety than regression as these learning procedures as applied over and over across time. If practitioners wish to preserve the variety of possible solutions to complex problems as a way of maximizing learning over time, then experimenting with partially random recombinations is a more effective way to learn than looking for themes or trying to identify causal relationships.
Moving Forward
There are multiple adaptations scholars could make to our model to examine other, related research questions. For example, are there other ways to structure communication for learning from success that could be built into this model? Future research would also benefit from different research methods. For example, ethnographic observation of learning methods such as these could reveal more nuances in the learning procedures that could be included in models of organizational learning. Experimental research could test the cognitive and behavioral outcomes of using these different learning procedures in groups.
Continued research on the relative effectiveness of different procedures for learning from success is critical because, as Denrell (2003) pointed out, many samples of organizational phenomena no longer have unsuccessful examples in them. This may create bias in learning in some circumstances, but as our research has shown, this bias may be surmountable. In fact, learning from success may reduce defensiveness and increase confidence and trust (Cannon & Edmondson, 2001). If organizations can learn effectively from success, there may be potential for deriving many other benefits as well.
Footnotes
Acknowledgments
The authors would like to thank Yael Goel, Scott Johnson, Peter Madsen, Andrew Manikas, Leslie Perlow, Hart Posen, William Ocasio, and Kyle Oyama for their helpful feedback on this paper, as well as participants in research seminars at Brigham Young University, Northwestern University, Simon Frasier University, Purdue University, Western Ontario University, and the University of Louisville. The code for the computational model used for this research is available from the lead author upon request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.