
Abstract
This study focuses on similarities and differences in the processing of written text by individuals with prelingual deafness from different reading levels that used Hebrew as their first spoken language and Israeli Sign Language as their primary manual communication mode. Data were gathered from three sources, including (a) a sentence comprehension test, (b) a metalinguistic awareness (MLA) test, and (c) a word-processing experiment. Participants were 62 individuals who were prelingually deaf, of whom 36 were high school students (10th and 11th graders) and 26 were undergraduate or graduate university students. Findings imply that neither MLA nor word-processing efficiency distinguishes between skilled and less skilled readers with deafness. Rather, differences in reading comprehension skills seem to reflect variance in the ability to process text at the supralexical (sentence) level. Findings are discussed with regard to their implication for the reading instruction for students who are prelingually deaf.
Nearly half a century ago, Furth (1966) reported that children of deafness between the ages of 11 and 16 manifest mean reading grade level placement equivalent to typically developing hearing children’s grade level range of 2.7 to 3.5. Although findings from some recent studies indicate that early cochlear implantation (Geers, 2003) and intensive instruction of phonics (Trezek & Malmgren, 2005) may bear great potential to prevent such reading deficits, research conducted during the past five decades shows that individuals with prelingual deafness, as a group, continue to manifest alarmingly poor reading comprehension (RC) levels in comparison to typically developing hearing counterparts (Furth, 1966; Gallaudet Research Institute, 2003; Miller, 2000, 2005; Traxler, 2000; Wauters, Van Bon, & Telling, 2006). The aim of the current study was to reexamine the validity of two hypotheses regarding the primary cause of this persistent reading failure. The first of them, the lexical coding deficit hypothesis (e.g., Kelly & Barac-Cikoja, 2007), claims that because of a permanent lack of auditory stimulation individuals with prelingual deafness do not develop sufficient phonemic awareness to sustain the rapid and accurate phonological decoding and subsequent identification of written words (e.g., Perfetti & Sandak, 2000). As a consequence, the integration of their meaning into broader ideas by means of their structural (syntactic) and semantic processing is at risk to fail.
The lexical coding deficit hypothesis intuitively makes sense in view of abundant evidence suggesting that individuals with prelingual deafness have phonological abilities (e.g., phonemic awareness, phonological decoding skills) distinctly below those of their hearing counterparts (Charlier & Leybaert, 2000; Hanson & McGarr, 1989; Miller, 1997, 2006a). It is also reasonable given that more skilled readers with deafness have been found to rely on a phonological memory code for the temporary retention of written words (e.g., Conrad, 1979). Finally, the hypothesis is in accordance with findings suggesting that specific reading disorders in hearing readers coincide with marked deficits in the phonological domain (Shaywitz & Shaywitz, 2005).
The second hypothesis reexamined here, namely, the structural knowledge deficit hypothesis, postulates that readers with deafness fail to comprehend what they read because they lack adequate structural (syntactic) knowledge that sustains the integration of correctly recognized written words into broader ideas at the supralexical (sentence) level (Miller, 2000). Indeed, studies examining the ability of individuals with prelingual deafness to understand messages conveyed in writing, in speech, or by means of manual communication systems that map onto the structural properties of spoken language (e.g., Signing Exact English [SEE]) suggest that the structural knowledge of such individuals remains incomplete even after years of exhaustive schooling and training (Quigley, Power, & Steinkamp, 1977; Webster, 1986). Moreover, some researchers have claimed that because of underspecified structural knowledge, individuals with prelingual deafness may process written text without paying attention to particularities in its syntactic structure (Gormley & Franzen, 1978; Yurkowski & Ewoldt, 1986). Instead, they seem to recreate text meaning by mapping its content words against prior knowledge and experience (top-down processing), a claim that has gained support from studies examining the comprehension of semantically plausible and semantically implausible sentences of readers with prelingual deafness (Miller, 2000, 2005, 2006b, 2010).
The basic assumption in the Miller (2000, 2005, 2006b, 2010) studies is that for the proper understanding of a semantically implausible sentence the application of structural knowledge to a sentence (bottom-up processing) is a prerequisite. This is because a sole top-down processing of its content words leads to its misinterpretation, given that the conveyed message contradicts real-life experience. The proper comprehension of a semantically plausible sentence, in contrast, is assumed to be much less contingent on the processing of its syntactic structure given that its meaning can be elaborated by the mapping of its content words against the reader’s world knowledge. As anticipated by Miller (2000, 2005, 2006b, 2010), readers who are deaf from various grade levels indeed manifested distinctly poorer comprehension for semantically implausible sentences in comparison to semantically plausible ones.
The two above-mentioned explanations of the poor RC for readers who are prelingually deaf are not mutually exclusive; the poor RC levels of such individuals may well result from a weakness at both the lexical and structural levels of text processing. Moreover, other factors, such as substantial dearth in general and domain-specific knowledge, the consequence of inefficient communication with their surroundings, may further contribute to the comprehension breakdown they experience as they work through written materials. Scores on regular RC tests are likely to reflect the combined contribution of all the above-mentioned factors. Therefore, positive associations between the performance of readers with prelingual deafness on such tests and areas hypothesized to foster RC (e.g., phonemic awareness) not only may not reflect causality but also may not allow determining the exact nature of the processing deficit(s) that underlie their poor RC.
The current study is an additional attempt to elucidate the core factor(s) that distinguish between readers with prelingual deafness with markedly different RC levels based on a thorough investigation of their metalinguistic, lexical, and syntactic (structural) processing skills. In line with a lexical coding deficit hypothesis, the present study tested the following research hypotheses:
1. Individuals who are deaf with high RC levels will manifest higher metalinguistic awareness (MLA) than counterparts with lower RC levels.
2. Individuals who are deaf with high RC levels will process written words faster and more accurately than counterparts with lower RC levels.
In line with a structural knowledge deficit hypothesis, the following research hypotheses were tested:
3. There will be no significant difference in the MLA of readers with deafness with high and poor RC levels.
4. There will be no significant difference in the word-processing skills of readers with deafness with high and poor RC levels.
5. There will be notable variance in the ability of readers with deafness with high and poor RC levels to understand semantically implausible sentences.
6. There will be no significant differences between readers who are deaf with high and poor sentence RC levels with regard to the understanding of semantically plausible sentences, which may not necessitate structural (syntactic) processing for proper comprehension.
Method
Participants
The study included 62 individuals with prelingual deafness (diagnosed prior to age 2). Their hearing loss measured at the frequencies of 0.5, 1.0, and 2.0 kHz was 85 dBHL or higher in the better ear (American National Standards Institute, 1989). In all, 36 were high school students (10th and 11th graders) and 26 were undergraduate or graduate university students (average years of schooling = 12.27, SD = 2.59). None of them was diagnosed as learning disabled or repeated a class. Their vision was intact or corrected to normal, and their intelligence was in the range considered normal. Their first spoken and read language was Hebrew, a Semitic language with a unique morpho-phonological and syntactic structure realized predominantly according to a subject–verb–object order (for a detailed description of Hebrew, see Shimron, 2006).
All participants volunteered. They were rewarded with a small gift (high school students) or a small monetary compensation (university students). High school students were selected from deaf classes in central and northern Israel. For all of them, consent for participation was obtained from parents and school authorities. University students responded to an announcement of the experiment published on the campuses of academic institutions in northern and central Israel. Detailed information regarding the participants’ parental hearing status (hearing or deaf), their preferred communication mode (Israeli Sign Language [ISL] or Signed Hebrew; for a detailed description of ISL and Signed Hebrew, see Miller, 2007), and other relevant demographic dimensions is presented in Table 1.
Participants’ Demographic Characteristics With Reference to Their Distribution Into Reading Levels
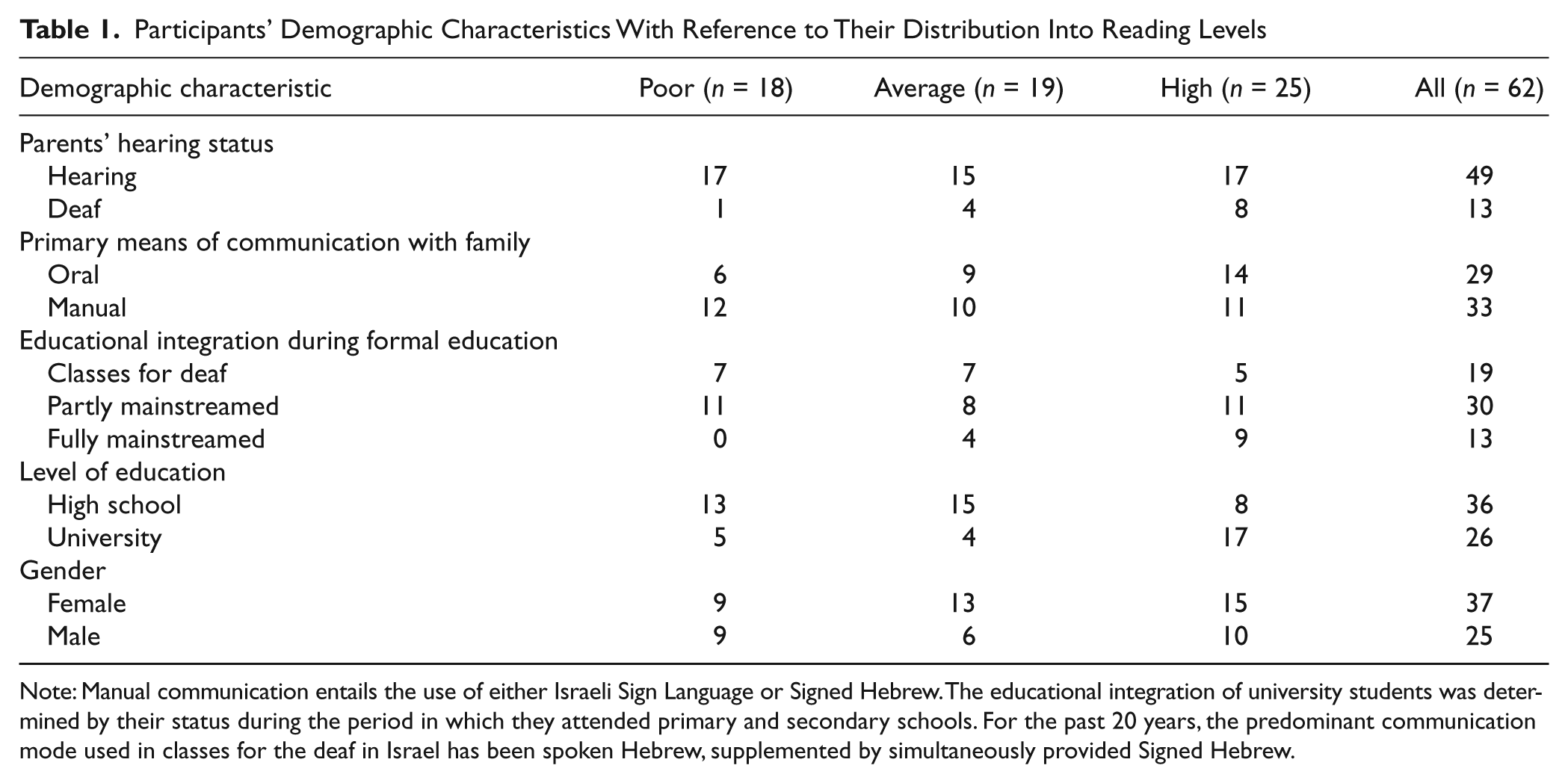
Note: Manual communication entails the use of either Israeli Sign Language or Signed Hebrew. The educational integration of university students was determined by their status during the period in which they attended primary and secondary schools. For the past 20 years, the predominant communication mode used in classes for the deaf in Israel has been spoken Hebrew, supplemented by simultaneously provided Signed Hebrew.
Stimuli and Design
Three tools were used to collect data relevant for testing the different research hypotheses: (a) a sentence comprehension test (SCT) assessing participants’ reliance on structural knowledge with reference to their RC, (b) a picture matching test designed to assess participants’ phonemic and orthographic awareness, and (c) a computerized word-processing experiment designed to assess the efficiency and strategy with which participants process written words.
Sentence comprehension test
The SCT comprised 36 sentences varying in syntactic complexity (length M = 6.97 words, range = 4–12) and built from very basic words ascertained to be within the participants’ active vocabulary. Half of the sentences were semantically plausible (SP) and the remainder semantically implausible (SI). The SP sentences reflected prior knowledge that could be used by the participants to extract sentence meaning through the mere top-down processing of their content words, without the need to process their syntactic structure (e.g., “The tiger attacked the zebra in the zoo”). In contrast, the SI sentences mediated information that contradicts normal real-life experiences (e.g., “The cat bit the dog in the backyard”). For their proper comprehension top-down processing of such sentences’ content words with reference to prior knowledge is insufficient (see Miller, 2000, 2005, 2006b, 2010); that is, processing their syntactic structure is a prerequisite for their proper interpretation.
Comprehension was tested by a short question, with two or three optional answers each. For explanation, four extra sentences were used. The 36 test sentences were presented randomly mixed. Performance time was not limited. Test chance level performance was 45%. Test reliability (Cronbach’s alpha) was .93 for the entire test, .87 for SP sentences, and .87 for SI sentences.
Assessment of MLA
Phonemic awareness (PA) was defined as the ability to refer to the basic phonological components of spoken words (their phonemes) and to intentionally manipulate them if required, both without being contingent on the physical presence of the stimulus. Orthographic awareness (OA), on the other hand, was defined as the ability to refer to the basic orthographic components of written words (their graphemes) and to intentionally manipulate them, both without being contingent on their physical presence. The test used for the assessment of the participants’ PA used 24 drawing sets, each set built on four images depicting familiar objects from the natural environment of Israeli children (for a detailed description of the development of the stimulus materials, see Miller, 1997). Six additional sets (three per phoneme position) served for task explanation and practice. The task was to point out the two images in a stimulus set whose names have the target phonemic feature (pronunciation) in common.
Of the 24 test sets, 12 tested awareness of the initial phonemes of drawing labels; the remainder tested awareness of final phonemes. In each phoneme category (initial or final phoneme), the targeted phonemes in half (6) of the sets were represented at the orthographic level by two different letter graphemes (e.g.,
The remaining six sets in each phoneme category (initial or final phoneme) the targeted phonemes in the drawing labels in a particular test set were identical at both the phonological and orthographic levels (e.g.,
Word-processing experiment
The paradigm used to examine the participants’ word-processing skills required them to decide as quickly as possible whether two Hebrew words presented simultaneously on a computer monitor were the same. To prevent participants from processing the identity of such word dyads on a purely perceptual basis, one of the words was always presented in print  and the other in cursive script
and the other in cursive script  , indicated here in English by a different font. As a result, the two words in identical word pairs ceased to be perceptually identical, obliging participants to determine their identicalness based on the retrieval of conventionalized linguistic knowledge.
, indicated here in English by a different font. As a result, the two words in identical word pairs ceased to be perceptually identical, obliging participants to determine their identicalness based on the retrieval of conventionalized linguistic knowledge.
The paradigm comprised three distinct conditions: (a) a visual similarity condition, assessing the participants’ reliance on visual information in determining the identity of word dyads; (b) a phonological similarity condition, examining whether participants reference the stimulus words’ phonological properties to determine their identity; and (c) a formational (sign) similarity condition, investigating whether participants mediated the processing of the word stimuli by means of their sign language knowledge (e.g., Bonvillian, 1983; Miller, 2007).
Test stimuli were 240 word pairs (80 pairs per experimental condition) presented in unpointed Hebrew, a primarily consonantal shallow orthography (for a detailed description of Hebrew orthography, see Shimron, 2006). All pairs were prepared from basic monosyllabic or bisyllabic Hebrew words with three- to five-letter graphemes. Two speech therapists and two teachers of the deaf rated them to be within the active vocabulary of third graders with hearing impairment. A separate set of word pairs served for explanation and practice. In each experimental condition, half of the word pairs (40) were composed of the same word twice (identical word pairs). The presentation of such pairs required an “identical” response (pressing the “Yes [identical]” key). The other half of the word pairs (40) were composed of two different words (nonidentical word pairs). Their display on the computer monitor called for a “nonidentical” response (pressing the “No [not identical]” key).
Among the 40 nonidentical word pairs, 20 were composed of words that were entirely distinct on all relevant processing dimensions (visual, orthographic, phonological, formational, and semantic or thematic). The remainder were built from two words that resembled each other on one of the processing dimension assessed in this study (visual, phonological, or formational) but differed as much as possible in all other regards. It was anticipated that quantitative (response time) and qualitative (response accuracy) processing differences between the two nonidentical word pair pools would be indicative of the nature of the participants’ word-processing strategy. For a detailed description of the procedure and the criteria underlying the preparation of the stimulus pairs used in each of the three experimental conditions, see Miller (2009).
Procedure
All participants volunteered and were tested individually. High school students were tested in a quiet room on their school grounds. The majority of university students were tested at the author’s research laboratory at the University of Haifa, but some were tested in a quiet room in their homes. All instructions were provided both in spoken and in Signed Hebrew and were complemented with physical demonstrations of the experimental tasks. The PA and OA test was always administered first, followed by the word-processing experiment and, last, the SCT.
Assessment of MLA
The administration of the PA-OA test involved several steps. First, the experimenter presented all the images used on a computer display and asked the participants to name them orally. After presenting all the images, the experimenter redisplayed those that the participants had not labeled correctly the first time, asking them to label them again, so as to ensure that they could now label them properly.
In a second step, the experimenter introduced the participants to the concept of phonemes and phoneme isolation. For this purpose, she asked the participants with deafness to watch her lips and listen carefully; she then pronounced her name and then broke it down into separate phonemes, voicing each of them clearly, one after another. The participants were then asked to try to phonologically segment their own names. After successfully doing so, the experimenter provided them with additional words for further practice. Practice was ended only after she was confident that the participants fully understood that words are composed of a series of discrete sounds.
The order in which the participants received test sets assessing awareness to initial or final phoneme position was rotated. In both instances the instructions they received were basically the same, except for turning their focus of attention to a different phoneme position. The following procedural information refers to testing awareness of initial phonemes but is equally applicable to final phonemes. The experimenter displayed the first of the three practice sets and asked participants to point out the two drawings out of the four with labels that start with the same initial sound. The experimenter corrected erroneous decisions by segmenting aloud the labels of the two chosen images and pointing out the difference in their initial phonemes. The participants were then asked to try once more. The actual testing began only after the participants’ performance on the three examples indicated they understood the task requirements.
At the beginning of the experiment, participants were told to point to the two images only after they were sure that they began with the same initial phoneme. They also were told that they were not limited in time for making their choice, although the experimenter would measure it. The experimenter displayed the first test drawing set and started a stopwatch. Time was stopped the moment the participant pointed to the second image and was recorded on a follow-up sheet. The 6 image sets in which phonemic identicalness in the image labels was reflected also at the graphemic level (identical phonemes equals identical letters) were always administered first, immediately followed by the 6 sets designed to test sheer PA. The 12 image sets testing sensitivity to the initial image label phonemes were presented in succession, paced by the experimenter. Awareness of final phonemes was tested immediately afterward.
Word-processing experiment
Stimulus presentation and reaction time measurements were handled by DMDX software (a computer program that allows reaction time [RT] measurements with exactitude of a millisecond) installed on a laptop computer, which was placed a comfortable distance in front of the participant. Word pairs used for stimulation were displayed at the center of the computer display. The experimenter instructed participants to position their index fingers on the two marked response keys (Yes, No) and initiated the presentation of the first practice word pair. She asked them to press “Yes [identical]” if the words in a pair were the same and “No [not identical]” if they were different. None of the participants exhibited difficulties in understanding the task requirements. After the explanation of the task requirements, the participants received some practice trials in succession for warm-up. The experimenter administered the experiment only after participants’ performance with practice items proved their proper understanding of the task requirements.
The experiment was executed immediately after the practice phase. The experimenter informed participants that they now should work as quickly as possible because their response time was being measured. She further urged them not to stop in case of error but to continue without hesitation. The three stimulus conditions (visual, phonological, formational) were administered consecutively in three separate blocks, with a break of about 3 min between them. The order in which the participants received the blocks was rotated to counteract bias from practice and fatigue. The distribution of identical and nonidentical word pairs within each condition was randomized. The same was true also for the distribution of similar and dissimilar nonidentical pairs. The same word pair distribution pattern was applied in all three blocks.
All 80 word pairs of a particular block were presented in succession. The presentation of each word pair was preceded by a filler mask “####” for 800 ms, so as to empty word memory storage. This filler mask was automatically displayed the moment participants operated one of the response keys. Response times and response accuracy for each pair were automatically recoded by DMDX software for later analysis. The display of “*****” indicated the end of a block.
Sentence comprehension test
Sentences used for task explanation and practice appeared separately on the first page of the SCT. The experimenter instructed participants to indicate their answers only after they read both the sentences and the questions carefully. She further told participants to ask for help if they encountered an unfamiliar word. She then read the first two practice sentences aloud and indicated their correct answers. Thereafter, she asked participants to read the two remaining practice sentences and to indicate their own answers. Only after the experimenter was confident that the participants understood the test requirements did she tell them to go on solving the actual test sentences, reminding them once more to read both sentences and questions thoroughly before indicating an answer. She further informed them that there was no time limit for completing the test.
Results
The analysis of the data collected was conducted in four steps: (a) the participants were assigned to three distinct reading levels (RLs), (b) the MLA of the three RLs was compared and correlated with their comprehension of SI sentences, (c) the word-processing skills of the three RLs were compared and correlated with their comprehension of SI sentences, and (d) the comprehension of the SP sentences by the three RLs was compared and was correlated with their comprehension of SI sentences.
Creating three distinct RLs
The participants’ understanding of the 18 SI sentences (maximum SI score = 18; chance level performance = 8, 45%) was used to create three RLs. Participants who correctly answered 17 or more of the SI sentences were defined as skilled readers (high; SI score M = 17.60, SD = 0.50). Participants who correctly answered 12 or fewer sentences, which was 2 SDs below the sample mean, were defined as poor readers (low; SI score M = 8.28, SD = 3.20). The remaining participants (average) were defined as having an average RL (SI score M = 14.68, SD = 1.16). The mean SI score for the sample overall was 14.00 (SD = 4.30).
Table 1 provides the number of participants assigned to each RL, including information regarding their demographics. To ascertain that the RC discrepancy between the three RLs was indeed significant, their understanding of SI sentences was compared in a one-way ANOVA. A highly marked RL main effect was revealed, F(2, 59) = 133.56, p < .001, η2 = .82, pointing to notable differences in the RC of the participants assigned to the three RLs. Post hoc analyses (Scheffe test; significance level set to p < .05) confirmed that participants with average RL scored markedly below participants with high RL and that participants with poor RL significantly underscored participants with average RL (all ps < .001).
An additional analysis clarified whether notable differences in years of schooling (level of education) could account for the variance in the RC of the participants assigned to the three RLs, poor RL = 11.57 (SD = 1.76), average RL = 11.32 (SD = 2.41), high RL = 13.80 (SD = 2.59). A one-way ANOVA using level of education as the dependant variable failed to reveal significant differences in the three RLs’ average years of schooling.
Metalinguistic awareness
The test used to assess the participants’ MLA included two distinct experimental conditions, one assessing PA and another in which proper task performance was possible based on the processing of the image labels’ orthographic properties (OA). Table 2 represents the average PA and OA of the three RLs.
Mean Accuracy Scores for Phonemic and Orthographic Awareness

Note: Maximum score for OA and PA = 12; chance-level performance for each test = 2.
The participants’ performance was analyzed in a MANOVA computing type of MLA (PA vs. OA) as a within-subjects factor and RL (poor, average, high) as the between-subjects factor. RL revealed a weak but statistically significant main effect, suggesting that, overall, participants from the three RLs varied in their MLA, F(2, 59) = 3.05, p = .05, η2 = .09. The main effect produced by type of MLA was highly significant, F(1, 59) = 114.26, p < .001, η2 = .66, implying that, overall, correctly matching images based on PA was markedly harder than correctly matching images based on OA. The absence of a statistically significant interaction between the two main effects suggested this to be true for all three RLs.
The origin of the RL main effect was determined in two separate post hoc one-way ANOVAs—one for PA and another for OA. Of interest, none of these analyses revealed a statistically significant RL effect. However, Scheffe tests pointed to a tendency (p = .06) of skilled readers with deafness to have somewhat higher PA than poor readers. Pearson product–moment correlations computing PA, OA, and RC for SI sentences as the study variables failed to reveal statistically significant evidence linking the metalinguistic skills of the participants from the three RLs to their comprehension of SI sentences.
Word-processing skills
The first line of analyses presented focuses on speed of processing (SOP). The performance of the participants from the three RLs, overall and with regard to each of the three stimulus conditions, is provided in Table 3.
Speed of Processing (SOP) Measures (in ms), Overall and for Identical and Nonidentical Stimulus Pairs

In a first step, a MANOVA was run with RL (poor, average, high) as a between-subjects factor and stimulus condition (visual, phonological, formational) and type of response (identical, not identical) as two within-subjects factors. The RL main effect revealed by this analysis was statistically insignificant, suggesting that overall participants from the different RLs processed the identicalness of the stimulus pairs with comparable speed. A series of post hoc one-way ANOVAs was run to check for fine-tuned SOP differences between the RLs in relation to specific stimulus conditions (visual, phonological, formational) or particular response types (identical, not identical). Neither of these analyses revealed evidence that the three RLs were notably different in their ability to process the identicalness of written words.
A MANOVA revealed a marked stimulus condition effect (visual vs. phonological vs. formational), indicating that SOP varied significantly over the different stimulus conditions, F(1, 59) = 24.74, p < .001, η2 = .30 (see Table 3). The absence of a statistically significant interaction between RL and the stimulus condition suggested further that this variance was uniform for all three RLs. A series of post hoc t tests comparing SOP times obtained for each of the three stimulus conditions (paired design) showed that making a same–different decision in the visual condition took significantly more time than in the phonological condition, t(61) = 2.94, p < .01, and in the formational (sign) condition, t(61) = 6.33, p < .001. Moreover, making a same–different decision in the phonological condition took markedly longer than in the formational condition, t(61) = 3.84, p = .001.
A MANOVA yielded a marked type of response effect (identical vs. not identical), F(1, 59) = 83.34, p < .001, η2 = .59; that is, it took less time to determine the identity status of two identical words than two different words (see Table 3). The fact that type of response was not found to interact with RL suggested this be true for all three RLs. A MANOVA further yielded a significant interaction between stimulus condition effect and type of response, F(1, 59) = 14.37, p < .001, η2 = .20, suggesting that the effect produced by type of response was not uniform for the different stimulus conditions. As is obvious from Table 3, the SOP difference between response types (identical or not identical) in the visual condition was larger than in the other two conditions. An insignificant triple interaction (Stimulus Condition × Type of Response × RL) further suggested this to be true for all RLs.
To obtain a more detailed picture as to how the stimulus condition interacted with the response type, a response type discrepancy score (SOP for identical – SOP for nonidentical word pairs) was calculated for each condition. A comparison of these scores in a series of post hoc t tests (paired design, one-tailed) revealed that response type discrepancy was more marked in the visual condition than in the phonological condition, t(61) = −3.67, p < .001, and in the formational condition, t(61) = −2.25, p = .01. Moreover, the response type discrepancy was larger in the phonological condition than the formational condition, t(61) = −1.76, p < .05.
A second line of analyses examined the three RLs’ error rates in the three stimulus conditions (maximum = 80 per condition). Overall, the error rates produces by the RLs in the three experimental conditions were very small (2.5% or less). Moreover, a MANOVA computing RL (poor, average, high) as a between-subjects factor and stimulus condition (visual, phonological, formational) as a within-subjects factor failed to statistically distinguish among the three RLs. In addition, there was no significant interaction between the condition main effect and the RL main effect, suggesting that the different study conditions biased the three RLs’ error rates uniformly. In view of the low overall error rate, on one hand, and the absence of marked RL-related error rate differences, on the other hand, it was decided to exclude more detailed analyses of the RLs’ error rates from this report.
A third line of analyses was conducted to elucidate differences in the nature of the word-reading strategy the three RLs relied on in making word-identicalness judgments. For this purpose, the time required for determining the identicalness of two nonidentical words resembling each other on a particular processing dimension (visually, phonologically, or formationally) was subtracted from the time required for determining identicalness of two entirely dissimilar words. The visual word similarity effects (SOP discrepancies in milliseconds, SDs in parentheses) were, overall, 82 (42) and, for the three RLs (poor, average, high), 89 (61), 75(34), and 82 (42), respectively. The phonological word similarity effects were, overall, 25 (50) and, for the three RLs (poor, average, high), 19 (32), 26 (43), and 27 (64), respectively. The formational (sign) word similarity effects were, overall, –5 (47) and, for the three RLs (poor, average, high), −10 (50), −5 (49), and −2 (46), respectively.
A MANOVA computing RL (poor, average, high) as a between-subjects factor and stimulus condition (visual, phonological, formational) as a within-subjects factor was used to analyze the word similarity effect. The RL main effect was statistically insignificant, F(2, 59) = 0.11, suggesting that, overall, participants from the three RLs exhibited similar word similarity effects. The stimulus condition effect was statistically marked, F(1, 59) = 103.90, p < .001, η2 = .64, implying that the size of the word similarity effect was not the same for the three conditions. An insignificant interaction between the RL and the stimulus condition main effects further indicated that this bias was similar for the three RLs. A series of post hoc t tests (paired design, two-tailed) comparing the size of the word similarity effect in the three stimulus conditions revealed that the visual word similarity effect was significantly larger than the phonological word similarity effect, t(61) = 6.24, p < .001, and the formational word similarity effect, t(61) = 10.33, p < .001, respectively. Moreover, this effect was notably larger in the phonological condition than in the formational condition, t(61) = 3.40, p = .001.
An additional series of post hoc t tests (paired design, two-tailed) compared SOP for similar and dissimilar nonidentical word pairs in a straightforward manner, in each of the three stimulus conditions. In the visual condition, deciding that two nonidentical yet visually similar words are different took notably more time than making the same decision for two entirely dissimilar words, t(61) = 14.13, p < .001 (see Table 3). This was also the case in the phonological condition, t(61) = 3.96, p < .001 (see Table 3). There was no evidence that variance in formational similarity biased SOP.
RC for SP sentences
Comprehension scores for SP sentences, overall and for each RL separately (poor, average, high), were 16.29 (SD = 2.83), 13.50 (SD = 3.90), 16.95 (SD = 1.08), and 17.80 (SD = 0.41), respectively (maximum score = 18, chance level performance = 8, 45%). The participants’ comprehension of SP sentences was examined by means of a one-way ANOVA with RL computed as the between-subjects factor. A significant RL main effect, F(2, 59) = 21.37, p < .001, η2 = .42, pointed to marked differences in the abilities of the three RLs to understand SP sentences. Scheffe post hoc analyses indicated that—in comparison to participants with average or high RLs—participants with a poor RL manifested markedly impoverished RC scores for SP sentences. Participants from the average and highest RLs were statistically indistinguishable in this regard.
Correlating participants’ performance in the three studied domains
Several Pearson product–moment correlations were executed correlating MLA with RC for SP sentences, for each RL separately. For all three RLs, the association between PA and RC in this sentence category was statistically significant, r = .44, p < .05 (n = 18); r = .40, p < .05 (n = 19); r = .52, p < .01 (n = 25), for poor, average, and high RL, respectively. No statistical evidence was found that correlated RC for SP sentences with OA for any of the RLs.
A series of correlation analyses focused on the relationship between the efficiency of the participants’ word-processing skills (speed and accuracy) and their ability to comprehend SP and SI sentences, taking into consideration their RLs. Neither of these analyses revealed statistical evidence of a significant association between these domains. This was true whether the analyses considered word-processing efficiency overall, in relation to identical or nonidentical responses, or in relation to different types of nonidentical responses.
Discussion
This study aimed to clarify to what extent RC failure in students with prelingual deafness reflects a processing deficit at the lexical (word) level, at the structural (syntactic) level, or both. In line with the first of these possibilities, two specific hypotheses were tested. The first predicted that individuals with deafness who had high RC levels would manifest higher MLA than counterparts with lower RC levels. Findings regarding the participants’ comprehension of SP and SI sentences seem to contradict a claim (Perfetti & Sandak, 2000) that differences in prelingually deaf individuals’ RC are causally linked to variance in their metalinguistic skills (also see McQuarrie & Parrila, 2009; Miller, 1997). In fact, despite rather impressive differences in their RC, analyses failed to reveal statistically significant evidence that distinguished the participants from the three RLs with regard to their MLA (see Table 2), although some evidence was yielded that, overall, higher RC was paralleled by somewhat increased sensitivity to the metalinguistic properties of image labels.
It may, of course, be argued that the test used to assess MLA was not sensitive enough to detect fine-tuned differences in this domain among the three RLs. Assessing their word-processing skills in a more straightforward manner (by asking them to judge the identicalness of written words) may, however, reveal marked differences among the groups, differences that may also explain variance in their RC. To test for this possibility, a second hypothesis forecasting that individuals with deafness who had high RC levels would process written words faster and more accurately than counterparts with lower RC levels was tested.
Analysis of performance under three distinct stimulus conditions failed to reveal notable qualitative (accuracy) or quantitative (speed) differences in the three RLs’ word-processing skills (see Table 3). In view of such uniform performance, the adequacy of a lexical coding deficit hypothesis (e.g., Kelly & Barac-Cikoja, 2007) for explaining RC differences in readers with prelingual deafness seems untenable. A similar conclusion is warranted given that performance in the word experiment was not significantly correlated with RC for SP or SI sentences for any of the three RLs. This is in agreement with evidence showing that the word-processing skills of the readers with prelingual deafness are not notably different from those of regularly developing hearing readers (Miller, 2002, 2005, 2006a, 2006b, 2009; Wauters et al., 2006).
Evidence suggests that, at all RLs, participants performed a thorough analysis of the written words’ visual properties, with some attention given also to their phonological dimension, but not to the paralleling signs of the stimulus words. Such enhanced visual analysis of the stimuli may imply that their reading strategy was primarily orthographic in nature, a possibility that should be further clarified in future research. The finding that OA was significantly enhanced relative to PA, at all RLs, supports this conclusion.
Integrating findings obtained from the participant groups’ MLA, their word-processing skills, and the way these two domains related to comprehension of SI sentences (RC), it does not seem reasonable to attribute the generally observed reading weakness of individuals with prelingual deafness, as well as variance in their reading skills, to a processing deficit at the lexical level (e.g., Kelly & Barac-Cikoja, 2007; Perfetti & Sandak, 2000). Given that this is true, explanations assigning such RC failure to a processing and/or knowledge deficit at the structural (syntactic) level must be taken under serious consideration.
Several hypotheses were tested to corroborate the validity of a structural knowledge deficit hypothesis. The first two of them postulated that there would be no significant differences in the MLA (Hypothesis 3) or the word-processing skills (Hypothesis 4) of deaf readers with high and poor RC levels. Analyses of the MLA and word-processing skills of the participants assigned to the three RLs substantiated both of these hypotheses. It therefore seems defensible to assume that differences in RC found between the three RLs do not reflect processing deficits carried over from the lexical level to higher order processes responsible for the structural integration of the meaning of single words into broader ideas.
To substantiate whether a structural knowledge deficit hypothesis is tenable, two specific hypotheses were tested. The rationale behind the first (Hypothesis 5) was that although in some instances structural (syntactic) processing may not be a prerequisite for generating proper sentence comprehension (e.g., SP sentences), for the comprehension of SI sentences it is. It was therefore predicted that there would be notable variance in the ability of readers with deafness who had high, average, and poor RC levels to understand SI sentences. Findings obtained from comparing the RC of the three RLs confirmed that variance in the ability to use structural knowledge may indeed distinguish between skilled and less skilled readers who were deaf.
To further substantiate the validity of a structural knowledge deficit hypothesis, it was predicted (Hypothesis 6) that readers with deafness from high and poor RLs would be comparable in understanding of SP sentences that may not require the application of structural (syntactic) knowledge. Evidence indeed suggested that the comprehension of such sentences by deaf participants with an average RL approached the ceiling (17 out of 18 correct answers) and was statistically indistinguishable from that of the high RL group. Their understanding of SI sentences, in contrast, was found to be markedly below that of participants with a high RL. Taking these findings together, ascribing the deficient RC of such readers to a primary failure in processing the structural level of written sentences makes sense.
The enhanced RC of participants from the average RL for SP sentences suggests that although their use of structural knowledge to interpret sentence meaning may be deficient, they approached reading in a strategic manner. It also indicates that their ability to recruit prior knowledge to semantically top-down process what they read was highly developed. This finding is compatible with evidence suggesting that the effective use of a semantic top-down text processing strategy may, at least partly, compensate for a failure to elaborate sentence meaning bottom-up based on the application of structural knowledge (Gormley & Franzen, 1978; Miller, 2000, 2005, 2006b, 2010; Yurkowski & Ewoldt, 1986). Regrettably, for the participants who were deaf and who had a poor RL, the picture portrayed by the analyses of SP sentences is far more pessimistic. Their poor RC for such sentences suggests that, in many instances, they tend to approach reading in a nonstrategic manner. As a consequence, they probably experience reading as a mere technical process that ends with the identification of written words without producing any understanding of the broader message conveyed by them.
The comprehension of SI sentences by about 40% of the participants reflected reliance on structural knowledge to determine final meaning is encouraging as it suggests that prelingual deafness per se does not prevent the internalization of such knowledge, nor does it prevent its application during reading. A question of particular interest is, of course, whether there are particular background conditions fostering the development of proper reading strategies in children who are prelingually deaf. It is tempting to associate such enhanced development with the presence of an intact spoken language model (hearing parents) and with an environment stressing oral communication. However, a close look at the distribution of participants with these demographic characteristics in the three RLs (see Table 1) suggests that neither of them proves clearly indicative of the development of adequate reading skills; that is, having a hearing parent or being raised orally may not be sufficient to promote development of structural knowledge that reliably sustains the processing of written text.
It may, of course, be argued that the degree of educational integration (class for the deaf, partly mainstreamed or fully mainstreamed) during formal education creates conditions that vary in how much they foster the development of structural knowledge. For example, in the tested sample, none of the fully mainstreamed participants exhibited a poor RL (see Table 1), which may be interpreted as reflecting the contribution of mainstreaming to the development of reading. However, it is more likely that such absence primarily reflects the fact the only better readers are considered for full mainstreaming. The same selective principle is also likely to explain why university students were primarily assigned to the high RL group.
Of particular interest is the finding that participants who had parents with deafness were proportionally overrepresented in the high RL group (see Table 1). This may suggest that growing up in a deaf family exposes the deaf child to experiences that somehow facilitate the acquisition of reading. It is, of course, tempting to assign this gain to the fact that such children communicate manually. However, examining the way manual communication interacts with the participants’ RL (see Table 1), it becomes obvious that its contribution when used by hearing parents may be rather limited. From among the 12 manually communicating participants assigned to a poor RL, 11 (92%) were children with deafness with hearing parents. Moreover, from among 20 deaf students with hearing parents who communicated with their family in a manual mode, only 3 (15%) manifested a high RL. This is in sheer contrast to 8 of the 13 participants (62%) who came from deaf families.
It appears that manual communication has high potential for enhancing reading skills in children who are deaf if it is acquired as a native language from a competent sign language model, such as a parent with deafness. Manual communication used by hearing parents seems to be rather impotent in this regard, an impotence that is likely to reflect low competence, on one hand, and the use of some signed form of spoken language rather than a fully fledged sign language, on the other hand. How exactly sign language used by deaf parents contributes to the development of reading skills in their deaf children is not clear from this study, and further research is needed to elucidate the critical factors in this regard. However, given that such experience seems to benefit RC in such individuals, the involvement of teachers with deafness, particularly in the early education of such individuals, seems to bear great potential.
In summary, findings from this study corroborate a theory that associates prelingual readers’ reading failure with a processing deficit at the supralexical level. Although the poor RC of some of these readers seems to result primarily from a lack of sufficient structural knowledge or from a failure to effectively apply such knowledge during reading, others manifest a more substantial problem as they seem to approach written text in a nonstrategic manner, skipping both its structural (syntactic) and its semantic processing. As a result, reading for them is likely to remain a mere technical and meaningless activity. The fact that a substantial number of individuals tested in this study manifested this reader profile shortly before leaving formal education must be considered alarming.
Although the majority of participants tested in this study manifested RC profiles that are likely to lead to imperfect understanding of what they read, a notable portion of them demonstrate mastery of reading to a level that turns it into a tool for learning. Regrettably, findings fail to disclose the exact nature of the critical experience that underlies the development of such mastery. However, they clearly indicate that educational philosophy (oralism vs. manualism) on its own is insufficient to provoke such development. Rather, as implied by the impressively high rate of native signing individuals assigned to a high RL, what may give such readers a lead is an exposure to a competent signing environment from early childhood (also see Chamberlain & Mayberry, 2008). It is for future research to unveil the critical features of those unique experiences that bear the potential to facilitate the acquisition and application of knowledge guaranteeing literacy among the individuals with prelingual deafness.
Finally, the participants examined in this study read unpointed Hebrew, a primarily consonantal writing system that by default is phonologically underspecified and essentially deviates at the morpho-phonological and syntactic levels from some Latin and Anglo-Saxon languages. A similar deviation is likely to exist with regard to ISL and Signed Hebrew. Such disparity, of course, has to be taken into consideration in generalizing the reported findings to deaf readers from countries with languages and orthographies that are essentially different from Hebrew.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research and/or authorship of this article.