
Abstract
The Lombard effect describes the phenomenon of individuals increasing their vocal intensity when speaking in the presence of background noise. Here, we conducted an investigation of the production of lexical stress during Lombard speech. Participants (N= 27) produced the same sentences in three conditions: one quiet condition and two noise conditions at 70 dB (white noise; multi-talker babble). Manual acoustic analyses (syllable duration, vowel intensity, and vowel fundamental frequency) were completed for repeated productions of two trisyllabic words with opposing patterns of lexical stress (weak–strong; strong–weak) in each of the three conditions. In total, 324 productions were analysed (12 utterances per participant). Results revealed that, rather than increasing vocal intensity equally across syllables, participants alter the degree of stress contrastivity when speaking in noise. This was especially evident in the production of strong–weak lexical stress where there was an increase in contrastivity across syllables in terms of intensity and fundamental frequency. This preliminary study paves the way for further research that is needed to establish these findings using a larger set of multisyllabic stimuli.
1 Introduction
The Lombard effect (Lombard, 1911) is a well-known phenomenon whereby individuals increase their vocal loudness when speaking in noisy environments. Some have proposed that increased vocal loudness in noise serves to facilitate self-monitoring of speech (Amazi & Garber, 1982; Egan, 1971; Garber, Siegel, & Pick, 1976). Others have suggested that Lombard speech enhances intelligibility and, therefore, effective communication (Egan, 1971; Lane & Tranel, 1971). While there have been numerous studies of the Lombard effect on the absolute duration, intensity and fundamental frequency (F0) of continuous speech, there has been little consideration as to whether Lombard speech alters the relative duration, intensity and F0 of strong (i.e., stressed) versus weak (i.e., unstressed) syllables within individual words. Contrastivity across syllables within individual words in English (i.e., lexical stress) is critical for intelligibility. Insight into changes in lexical stress production in noisy environments is invaluable for a comprehensive understanding of speech production mechanisms. The present study was designed to address this gap in the research by examining the three key suprasegmental markers of lexical stress in English during Lombard speech: duration, intensity and F0. 1
The Lombard speech pattern is more intelligible to listeners than speech produced in quiet (Dreher & O’Neill, 1957; Pittman & Wiley, 2001; Summers, Pisoni, Bernacki, Pedlow, & Stokes, 1988). Dreher and O’Neill (1957) found that the accuracy of listeners’ identification of words and sentences produced in 70 dB of white noise was higher than speech produced in quiet, when signal to noise ratio was controlled. This finding was replicated in a study by Pittman and Wiley (2001) where sentences produced in 80 dB of noise were recognised more accurately when presented to listeners in both original and equalised signal to noise ratios, in comparison with those produced in quiet. It is likely that acoustic differences associated with Lombard speech increase accuracy of perception by the listener (Summers et al., 1988); however, this has been debated. Junqua (1993), for example, reported that words produced in noise were less intelligible than words produced in quiet. Conflicting findings have been attributed to the different speech materials that were used in different studies (Pittman & Wiley, 2001).
Of interest, Lombard speech differs from both very high intensity or shouted speech (see Rostolland, 1982a, 1982b for analyses of shouted speech), and very low intensity speech that is produced against a quiet background. Speech at these extremes of vocal intensity is degraded in intelligibility (Pickett, 1956; Pollack & Pickett, 1958). This indicates that Lombard speech has unique acoustic properties that result in it being more intelligible than both quiet and shouted speech (Letowski, Frank, & Caravella, 1993). Vocal intensity has been found to increase in the presence of a range of background noise levels when compared with ‘quiet’, ranging from a low level of 35 dB (Tartter, Gomes, & Litwin, 1993) up to 100 dB (Amazi & Garber, 1982; Brown & Brandt, 1971, 1972; Patel & Schell, 2008; Ringel & Steer, 1963; Summers et al., 1988). Dreher and O’Neill (1957) reported that the initial increase in vocal intensity at 70 dB was the greatest, with each increment of 10 dB of masking noise producing an average vocal increase of 1 dB. In contrast, an increase in 5 dB has also been reported for each 10 dB increase of ambient noise (Webster & Klumpp, 1962). Differences in reported vocal levels may be due to individual differences (Pittman & Wiley, 2001) and other factors such as the speech materials used, the spectrum of ambient noise, the room acoustics and absolute ambient noise level (Webster & Klumpp, 1962). Similarly, fundamental frequency (F0) and duration of vowels, syllables, words and sentences all increase in a variety of noise types (Black, 1946; Letowski et al., 1993; Ringel & Steer, 1963) and background noise levels (Letwoski et al., 1993; Patel & Schell, 2008; Ringel & Steer, 1963; Summers et al., 1988).
1.1 Prosody: relative intensity, fundamental frequency, and duration
Prosody gives language a rhythmic nature where some elements are more strongly emphasised than others. It is a feature of language that serves several important communicative functions, conveying both linguistic and affective information (Peppe, 2009). These functions are achieved by manipulating relative intensity, F0, and speech segment duration (Crystal, 1976; Peppe, 2009; Walker, Joseph, & Goodman, 2009) both within words (i.e., lexical stress) and also across words that are embedded in sentences.
The influence of speaking in background noise on the production of linguistic word level stress has previously been examined by comparing the production of compound words versus cognate words in sentences produced in quiet and noise (e.g., ‘The boy’s life was saved by the warmth of the Redcoat / red coat’ 2 ) and noun–verb cognates (e.g., the verb imPACT versus the noun IMpact) (Gammon, Smith, Daniloff, & Kim, 1971). In this previous study, background noise was found to have no significant influence on the production of stress and juncture. However, it is important to note that the dependent variable in this study was perceptual rating of speech rhythm; acoustic analyses of stress production were not conducted. It is possible that objective quantitative measures such as changes in intensity, F0 and duration may reveal subtle but reliable changes in stress contrastivity under Lombard conditions.
At the sentence level, Patel and Schell (2008) created a naturalistic speaking task designed to investigate whether the acoustic parameters of Lombard speech would be enhanced for semantically salient content words compared with function words. The study used a cooperative game to elicit spontaneous sentences from which content words and function words were analysed. As multi-talker noise increased from quiet to 90 dB, speakers enhanced content words that acted as agents, objects and locations via an increase in syllable duration. Additionally, they enhanced content words that acted as agents via an increase in fundamental frequency, when compared with function words (Patel & Schell, 2008). This evidence suggests that acoustic markers of prosody are affected when speaking in background noise, at least when the speaker is attempting to emphasise information-bearing content words over function words that do not carry semantic information. To date, no previous study has examined the effect of Lombard speech on lexical stress contrasts within single words using quantitative acoustic measures.
1.2 Lexical stress
Lexical stress is a word level prosodic feature of some languages and, in English, this opposition of strong and weak syllables is the primary determinant of rhythm (Fear, Cutler, & Butterfield, 1995). Stressed syllables tend to have longer vowel durations, higher peak intensity and higher peak F0 (note that the role of F0 in marking stress contrastivity within words is more controversial relative to the role of markers such as duration and intensity). In English, over 90% of English words contain more than one syllable and, thus, exhibit lexical stress. Appropriate placement of stress within multisyllabic words is critical for intelligibility. This is because lexical stress plays a role in activating entries in the mental lexicon during the comprehension of spoken language (Arciuli & Cupples, 2004; Arciuli & Slowiaczek, 2007; Cooper, Cutler, & Wales, 2002). Grammatical rules dictate word stress to a certain extent (Fry, 1955; Shriberg et al., 2001); bisyllabic nouns are typically first syllable stressed, whereas bisyllabic verbs are typically second syllable stressed (Arciuli & Cupples, 2003; Kelly, 1988; Kelly & Bock, 1988).
Support has been found for utilising a pairwise variability index (PVI) to reflect the degree and direction of contrastive stress across syllables in a word, as it can be calculated for syllable or segment duration, peak intensity and peak F0 (Ballard, Djaja, Arciuli, James, & van Doorn, 2012; Ballard, Robin, McCabe, & McDonald, 2010; Low, Grabe, & Nolan, 2000). Taking syllable duration as an example, the PVI is the difference in duration for any two adjacent syllables, divided by the average duration for those syllables, multiplied by 100. Note that the sign of the difference can be maintained if the goal is to demonstrate direction as well as magnitude of contrastivity (Ballard et al., 2010). Here, we report absolute PVI to reflect magnitude of contrastivity only. Higher PVI values are associated with greater differences in duration between two syllables, that is, higher contrastivity. Values approaching zero indicate equal stress.
Importantly, this normalised PVI measure allows direct comparison across different speakers and speaking conditions. Establishing how lexical stress is produced in various everyday speaking situations (e.g., speaking in background noise) enhances our understanding of how lexical stress is produced and manipulated to maximise speech intelligibility.
1.3 Current study
This study investigated the production of contrastive lexical stress during Lombard speech using objective quantitative measurements of the acoustic speech signal. As far as we are aware, this is the first acoustic study of stress contrastivity in English during Lombard speech. We were not sure what to expect but we predicted that participants may increase contrastivity when speaking in noise evidenced by a larger PVI for syllable duration, vowel intensity, and vowel F0 for a strong–weak stress pattern (SW; i.e., ‘VEgemite’) and a weak–strong stress pattern (WS; i.e., ‘comPUter’).
2 Method
2.1 Participants
Twenty-seven first year undergraduate students from the University of Sydney (25 females and two males; M = 20.33 ± 4.29 years) participated in the study. All spoke Australian English as a first or only language and had no known neurological, speech or language disorders based on self-report. All had passed a pure-tone hearing screen at 25 dB HL for 1, 2, and 4 kHz, as per clinical guidelines (American Speech-Language-Hearing Association, 1997). All participants had given informed consent and the institutional ethics committee approved all study procedures.
2.2 Stimuli and apparatus
Stimulus materials consisted of two sentences (drawn from a larger set of sentences used in a separate study). The two sentences were selected as they contained a SW or a WS trisyllabic word; ‘The warm
Two samples of noise were generated for the experiment. The white noise sample was normalised to −6 dB. The multi-talker babble sample was normalised to −2 dB to accommodate the louder peaks in the sample and, therefore, give an overall perceived equivalence in ‘loudness’ across both noise conditions. Noise was presented to participants via Sony Stereo DR7 circumaural headphones using a Dell laptop computer. Both noise samples averaged 70 dB SP at the headphone (as measured by a Digitech QM-1589 sound level meter with A weighting). The samples were long enough that no looping was required throughout the recording sessions. The samples were played via Windows Media Player on a laptop. Background noise level in the sound-treated booth was recorded at 31 dB SPL.
2.3 Procedure
Experiments were conducted in a sound treated room. All conditions were presented while participants were wearing headphones and recordings were made using the headset microphone positioned 5cm from the mouth. Participants were given time to familiarise themselves with the stimuli. They then read each sentence twice under each of the three noise conditions – no noise (i.e., quiet), white noise, and multi-talker babble – using their habitual speaking rate. The quiet condition was always presented first, with order of white noise and babble conditions (counterbalanced across participants). Headphones were worn for all conditions.
2.4 Dependent measures
Acoustic measures were derived using PRAAT (Boersma & Weenink, 2010). Peak vocal intensity was acquired for each sentence in each noise condition. Two trisyllabic words (i.e., ‘vegemite’ and ‘computer’) were then extracted to examine the effects of background noise on the production of lexical stress within sentences. A perceptual rating analysis by two independent raters, blind to study hypotheses, confirmed that participants produced these words with the expected stress pattern.
Three measures were made for each of the first two syllables of the two trisyllabic words: syllable duration (ms), and peak intensity and peak F0 for the vowel nucleus. The boundaries of the first and second syllables were determined for each word using spectrographic landmarks within formant trajectories and F0 and intensity contours (Peterson & Lehiste, 1960). Figure 1 depicts syllable segmentation for one participant. For ‘vegemite’, the first syllable was measured from the onset of the /v/ to the onset of the burst for the affricate /ʤ/ and the second syllable was measured from the onset of the burst of the /ʤ/ to the onset of the nasal /m/. For ‘computer’, the first syllable was measured from the onset of the plosive burst for /k/ to the onset of the plosive burst for /p/ and the second syllable was measured from the onset of the burst of the /p/ to the onset of the plosive burst for the /t/.
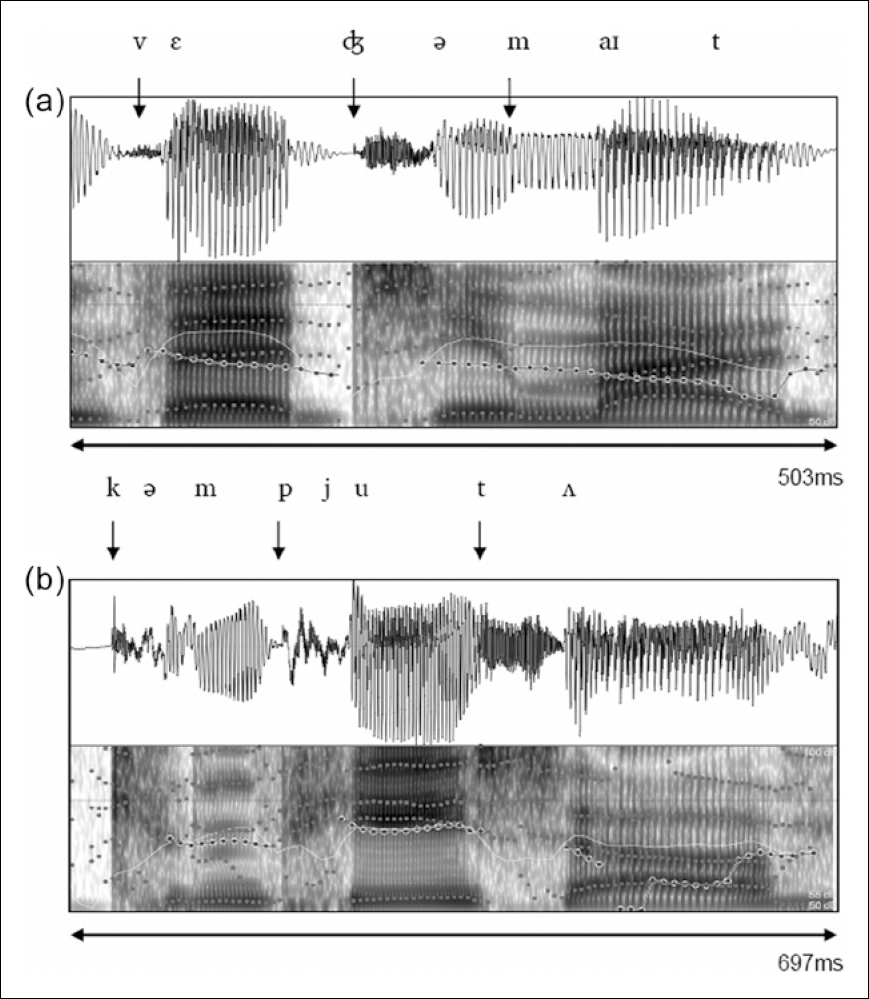
A spectrogram (lower half of each rectangle) and waveform (upper half of each rectangle) taken from PRAAT for the words ‘vegemite’ (a) and ‘computer’ (b). The vertical arrows indicate where the first two syllables of each word were segmented.
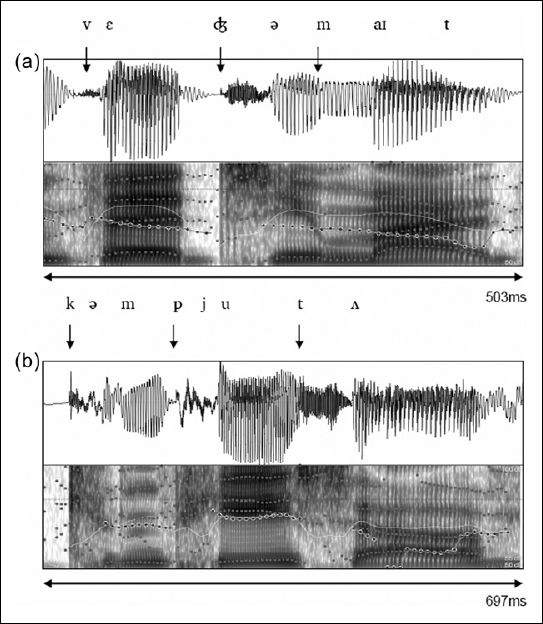
PVIs were then calculated for syllable duration, peak vowel intensity, and peak vowel F0 for each production. PVI represents the degree of contrast between adjacent syllables (Ballard et al., 2010; Low et al., 2000) and is calculated using the formula below.
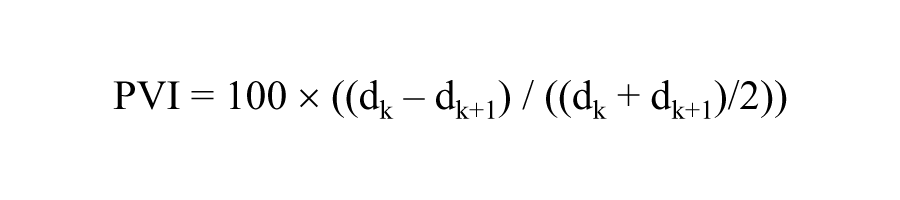
Where d is the duration (or peak intensity or F0) of the kth syllable in a word.
As mentioned, a higher PVI indicates greater contrastivity, that is, a greater difference in duration (or intensity or F0) between the two syllables. A PVI approaching zero represents more equal stress such as in compound words (e.g., base-ball) or the staccato-type speech of syllable-timed languages (e.g., Singapore English; Low et al., 2000). Absolute PVI values were used to examine the magnitude of contrast between syllables across noise conditions, not the direction of contrast.
As the words ‘vegemite’ and ‘computer’ were elicited twice for every participant in each noise condition, the average was taken across both productions for each PVI measure (i.e., duration, intensity and F0) in each noise condition. Outliers, defined as being more than two standard deviations from the group mean for a given stress pattern in a given noise condition, were replaced with the group mean; this represented 3.0% of data.
The general linear model repeated measures statistic was used for three main analyses. First, the effect of noise condition on peak vocal intensity of sentence production was tested to demonstrate the classic Lombard effect. Second, the effect of noise condition on speaking rate (syllables per second) for sentence production was tested (Reinisch, Jess, & McQueen, 2011). Finally, for our target words, planned orthogonal contrasts were run using the general linear model repeated measures statistic with within-subjects contrasts for stress pattern and noise condition, running a separate analysis for each dependent measure (PVI duration, PVI intensity, PVI F0). Interaction effects were explored using simple effects analysis, applying a Helmert contrast to first compare quiet with noise (white and multi-talker noise collapsed) and then white noise with multi-talker noise.
2.5 Reliability
Inter-judge reliability for the measures of syllable duration (ms), vowel peak intensity (dB) and vowel peak F0 (Hz) for the first and second syllables of each word was calculated for a random sample of 10% of the data. The reliability between judges for syllable duration was Pearson’s r = 0.77 (p < .0001; 95% CI: .66–.84) with a mean difference between judges of 4.8 ms. The reliability for peak vocal intensity was r = 0.82 (p < .0001; 95% CI: .74–.88) with a mean difference between judges of 0.78 dB. The reliability for F0 was r = 0.78 (p < .0001; 95% CI: .68–.85) with a mean difference between judges of 3.36 Hz.
3 Results
3.1 Overall vocal intensity and speaking rate for sentences
The main effect of noise condition on peak vocal intensity of sentence production was highly significant, F(2, 26) = 310.95, p < .0001. Tukey–Kramer post-hoc tests revealed that the 4.25 dB increase in intensity from the quiet to the white noise condition and the 5.08 dB increase from quiet to multi-talker noise were significant, q = 27.47 (p < .001) and q = 32.89 (p < .001), respectively. The 0.84 dB increase from white to multi-talker noise was also significant, q = 5.43 (p < .01). All 27 participants showed the Lombard effect for both white noise and multi-talker babble conditions compared with quiet; 85% of participants increased peak vocal intensity in the multi-talker babble condition compared with the white noise condition.
The main effect of noise type on speaking rate (syllables per second) for sentence production was not significant, F(2, 26) = 1.67, NS.
3.2 Syllable duration for target words
For the PVI of duration (PVI_dur) the main effect of stress pattern was not significant, F(1, 26) = 3.05, NS. The main effect of noise type was not significant: quiet–noise, F(1, 26) = 0.62, NS; white–multi-talker, F(1, 26) = 0.00, NS. The interaction effect for stress pattern by noise was significant for the quiet–noise comparison only, F(1, 26) = 8.23, p < .01, partial eta2 = .24; white–multi-talker, F(1, 26) = 0.19, NS (see Figure 2). Simple effects analysis revealed that the decrease in PVI_dur values for SW from quiet to noise contributed to the interaction effect rather than an increase in WS contrastivity. For SW: quiet–noise, F(1, 26) = 4.27, p < .05; white–multi-talker, F(1, 26) = 0.11, NS. For WS: quiet–noise, F(1, 26) = 2.95, NS; and white–multi-talker, F(1, 26) = 0.05, NS.
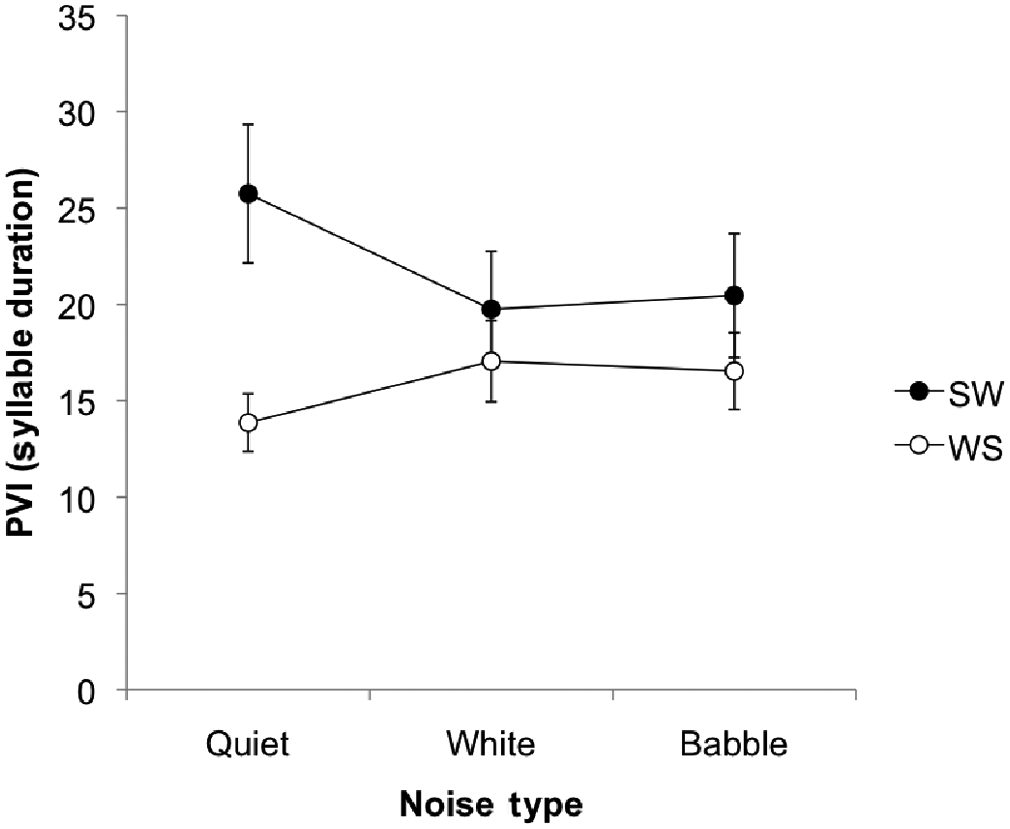
Mean pairwise variability index (PVI) for duration, for both the strong–weak (SW) and weak–strong (WS) words spoken in the three conditions of quiet, white noise and multi-talker babble. Error bars represent standard error of the mean.
3.3 Vowel intensity for target words
For the PVI of intensity (PVI_dB) there was no significant main effect of stress pattern, F(1, 26) = 0.00, NS. Similarly, there was no significant main effect of noise type: quiet–noise, F(1, 26) = 2.77, NS; white–multi-talker, F(1, 26) = 0.43, NS. The interaction effect for stress pattern by noise was significant for the quiet–noise comparison only, F(1, 26) = 4.52, p < .05, partial eta2 = .15; white–multi-talker: F(1, 26) = 1.42, NS (see Figure 3). Simple effects analysis revealed that the increase in PVI_dB values for SW from quiet to noise contributed to the interaction effect rather than any change in WS contrastivity. For SW: quiet–noise, F(1, 26) = 8.00, p < .01; white–multi-talker, F(1, 26) = 0.45, NS. For WS: quiet–noise, F(1, 26) = 0.01, NS; white–multi-talker, F(1, 26) = 1.28, NS.
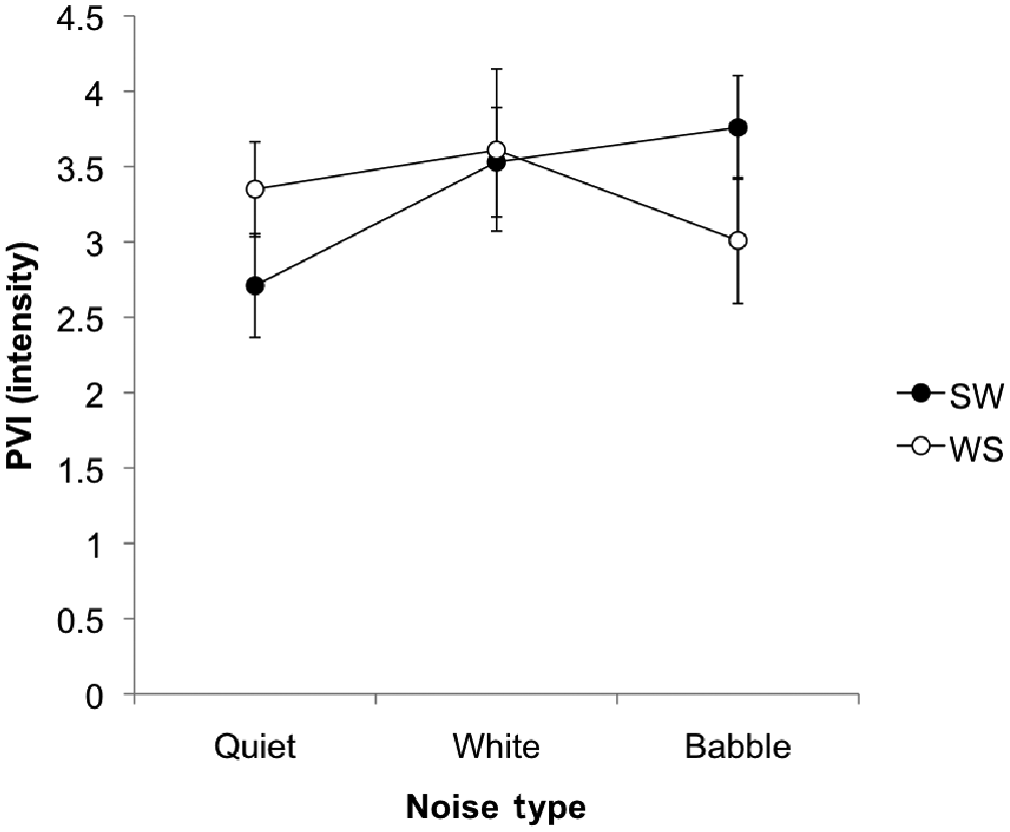
Mean pairwise variability index (PVI) for intensity, for both the strong–weak (SW) and weak–strong (WS) words spoken in the three conditions of quiet, white noise and multi-talker babble. Error bars represent standard error of the mean.
3.4 Vowel F0 for target words
For the PVI of F0 (PVI_ F0) the main effect of stress pattern was not significant, F(1, 26) = 3.45, NS. Noise type was also not significant: quiet–noise, F(1, 26) = 0.48, NS; white–multi-talker, F(1, 26) = 3.56, NS. The interaction effect for stress pattern by noise was significant for the quiet–noise comparison only, F(1, 26) = 4.68, p < .05, partial eta2 = .15; white–multi-talker, F(1,26) = 0.95, NS (see Figure 4). No comparisons in the simple effects analysis, applying the Helmert contrast, were significant. For SW: quiet–noise, F(1, 26) = 1.95, NS; white–multi-talker, F(1, 26) = 0.98, NS. For WS: quiet–noise, F(1, 26) = 2.23, NS; white–multi-talker, F(1, 26) = 2.69, NS. The significant interaction effect was likely due to the difference in WS contrastiveness between quiet and the multi-talker noise condition.
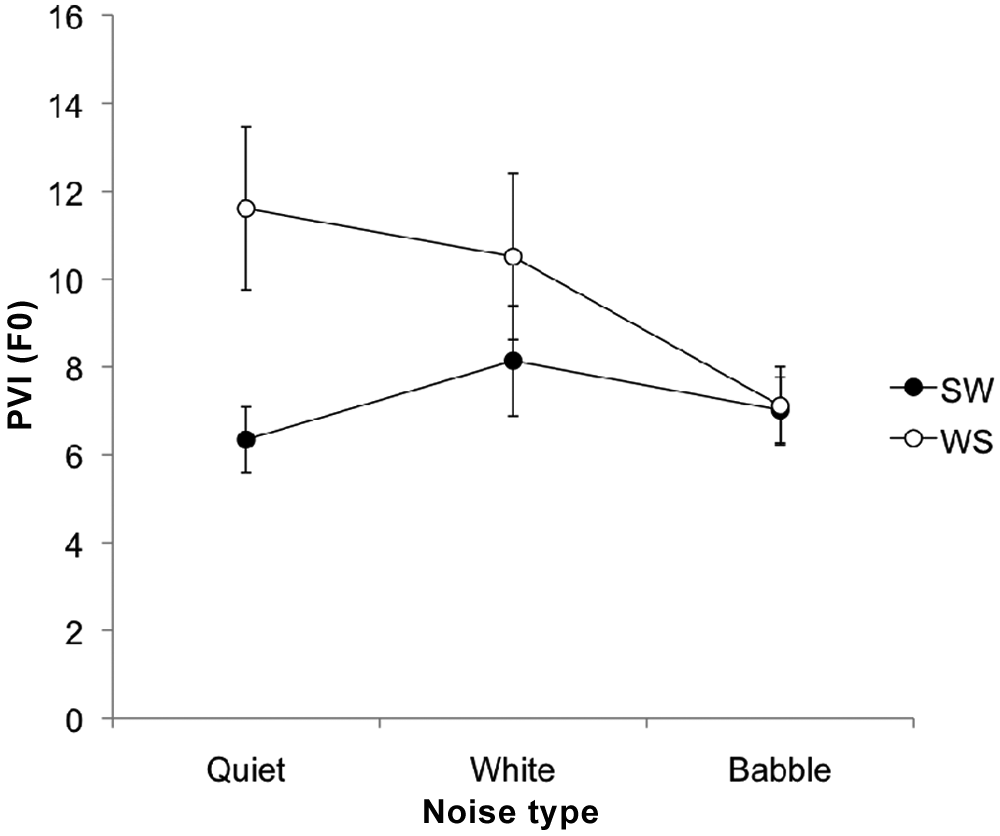
Mean pairwise variability index (PVI) for fundamental frequency (F0) for both the strong–weak (SW) and weak–strong (WS) words spoken in the three conditions of quiet, white noise, and multi-talker babble. Error bars represent standard error of the mean.
4 Discussion
Speaking in noise is known to increase overall vocal intensity, the Lombard effect, yet few studies have addressed the possibility of fine-grained changes in the production of prosody during Lombard speech. To our knowledge, no previous study has undertaken acoustic analyses of the relative duration, intensity and fundamental frequency of strong versus weak syllables within single words. The current study addressed this gap in the research by examining the effects of competing background noise on the degree of contrastivity in productions of lexical stress. Specifically, we examined changes in relative duration, intensity and F0 across adjacent syllables of target words using the PVI. As this was an exploratory study, we were not sure what to expect; however, we predicted that participants might increase lexical stress contrastivity in multisyllabic words when speaking in noise, reflected by an increase in the pairwise variability for syllable duration, vowel intensity and vowel F0 in both SW (i.e., ‘VEgemite’) and WS (i.e., ‘comPUter’) words.
4.1 Vocal intensity and speaking rate for sentences
A clear Lombard effect was elicited in this study. Participants increased their overall vocal intensity when speaking in both white noise and multi-talker babble – relative to speaking in quiet. In contrast to some previous studies (Letowski et al., 1993; Pittman & Wiley, 2001), there was a small but significant increase in vocal intensity in the multi-talker babble condition compared with the white noise condition. This increase in intensity may have been due to the multi-talker noise being more ‘speech like’ than white noise, with participants possibly increasing their vocal level to maintain intelligibility and/or better monitor their own speech signal. Alternatively, the multi-talker babble contained a range of intensities. While both signals had an average intensity of 70 dB SPL, participants may have increased their long-term average intensity more in the babble condition to accommodate the wider dynamic range.
Importantly, there was no effect of noise condition on speaking rate for the sentences produced in this study. Reinisch et al. (2011) have reported that speaking rate influences the perception of duration as a cue to lexical stress.
4.2 Duration, intensity, and fundamental frequency measurements for target words
In English, the acoustic parameters of duration, intensity and possibly F0 can be manipulated to mark lexical stress – the difference between strong and weak syllables within words. It is not known what happens to these parameters when speaking in background noise. The findings of our preliminary study suggest that speakers modulate these parameters when speaking in background noise. Participants reduced the degree of contrastivity for syllable duration in SW words in noise compared with quiet. Contrastivity for syllable duration in WS words, however, was not affected by noise. All raw PVI values for SW words were positive and those for WS all negative, indicating that duration continued to be a reliable marker of lexical stress (Fry, 1955; Sluijter & van Heuven, 1996); however, the contrastivity changes for SW but not WS words was unexpected.
Unlike the reduction in contrastivity seen for duration, the peak intensity contrast over SW words increased from quiet to noise conditions. While Lombard speech is marked by a global increase in vocal intensity, our results revealed that speakers performed finer-grained manipulations of intensity in SW words to increase the contrastivity of adjacent syllables against background noise. Similarly to the duration measure noise did not significantly affect the relative intensity of syllables in WS productions. As for duration, however, the raw PVI values differentiated well the SW from the WS words across all conditions.
Fundamental frequency showed an interesting pattern whereby contrastiveness increased from quiet to noise for the SW tokens but decreased in the WS condition, bringing the degree of absolute variability to similar levels across the two word types.
One possible reason for the discrepancy between the production of SW and WS words in the current study relates to typicality effects. It is well known that in English, nouns tend to have stress on the initial syllable (Kelly, 1988). As such ‘vegemite’ is an example of a typically stressed noun while ‘computer’ may be considered to be an example of an atypically stressed noun. In the emerging body of research into infants’ perception and production of stress it has been found that first syllable stressed trisyllabic words assisted infants to segment the speech signal (Houston, Santelmann, & Jusczyk, 2004). Research with adults, too, shows sensitivity to these typical patterns of lexical stress (Arciuli & Cupples, 2003, 2004; Arciuli & Slowiaczek, 2007). Thus, for all words in English, and especially English nouns, a SW pattern could be considered the preferred or typical pattern. It may be that typically stressed words are preferentially manipulated acoustically when speaking in noise, perhaps to improve intelligibility through supporting segmentation of the speech signal.
Our finding that the production of lexical stress changes when speaking in background noise is novel. A previous study (Gammon et al., 1971) that utilised perceptual measures reported no effects of background noise on the production of these prosodic parameters. Another study that utilised acoustic methodology found that syllable duration for linguistically salient words was manipulated in sentence level stress when speaking in background noise (Patel & Schell, 2008). That study did not examine lexical stress contrasts within words. It is plausible that due to the complex interaction of acoustic variables within sentence and word level prosody, different acoustic parameters are manipulated across different levels of language. These results support the use of acoustic analysis to reveal the complex manipulations of duration, intensity and F0 that occur in speech.
4.3 Limitations
Although we elicited multiple productions (12 per participant), the stimuli consisted of one SW word and one WS word; hence, the results reported here may be item specific. Then again, the effects we reported were obtained across a substantial number of participants. Over 300 productions were examined in this study, which is comparable to other recent studies that have utilised manual acoustic analyses (Ballard et al., 2012). Future studies seeking to examine a larger set of multisyllabic stimuli may need to include a smaller number of participants than we tested due to the time required to undertake these kinds of manual acoustic analyses. Future studies should also incorporate a more even balance of males and females and a wider age-range in order to increase generalisability. Importantly, the results of our preliminary study indicate that this is a worthwhile endeavour in order to learn more about stress contrastivity during Lombard speech.
A second issue concerns aspects of our method, namely, the use of headphones to create noisy conditions and the nature of the task that was used to elicit the stimuli. While the use of headphones is the most commonly used paradigm in Lombard speech research, a recent study has shown that modifications are greater during Lombard speech produced while wearing headphones versus listening to loudspeakers (Garnier, Henrich, & Dubois, 2010). It would be interesting to investigate the production of lexical stress in noisy conditions using loudspeakers.
As has been discussed in the literature, the task performed when speaking in noise can influence the degree to which participants attempt to maximise intelligibility (Amazi & Garber, 1982). In this study, participants read sentences. A reading task may have less of a premium on intelligibility than a task with a greater communicative purpose. The recent study by Garnier and colleagues examined the effect of communicative interaction during Lombard speech, something which would be worthwhile pursuing in the study of lexical stress production during Lombard speech (especially given the importance of lexical stress for intelligibility in languages such as English).
Finally, it is known that the position of a word within a sentence influences the way that duration, intensity, and F0 are used to indicate stress (Patel & Campellone, 2009). In this study, the position of the word and the position of the nuclear accent were not controlled, which could have resulted in sentence level stress production influencing the word level stress examined here. However, any additional effects of sentential stress were present across all noise conditions. In addition, the overlay of nuclear accent on the WS token, but not the SW token, might have resulted in opposite effects to those reported here (i.e., increased stress contrastivity on the accented word) (Fletcher, 2010). The lack of such a finding suggests that nuclear accent had little impact here. We reiterate that our aim is to present these initial findings in order to pave the way for future research in this area.
4.4 Future directions
Future research exploring the production of lexical stress within loud or shouted speech versus Lombard speech may also be warranted. This would assist in establishing whether our results are unique to Lombard speech or are a feature of loud speech more generally. A previous study has reported that loud speech is different from Lombard speech (Pickett, 1956); however, it did not examine relative contrastivity between the production of strong versus weak syllables in single words. Furthermore, experimentally testing the effects of lexical stress manipulations on perceived intelligibility in noise, across grammatical classes and in different speaking contexts would provide valuable insight into these word level changes in Lombard speech. The current study provides the results of acoustic analyses but does not provide any evidence of increased intelligibility.
5 Conclusion
Lombard speech has unique properties, which make it more intelligible than speech produced in quiet. Our study was designed to ascertain whether speakers of English make fine-grained manipulations of stress contrastivity during Lombard speech, in order to provide initial evidence to be followed up in subsequent studies. Our analyses revealed that participants alter the degree of contrastivity in their production of lexical stress when speaking in noise. In particular, participants increased contrastivity in their SW productions in terms of intensity. We hope these findings will lead to subsequent studies that will mine a larger corpus of multisyllabic productions, ideally, with the assistance of automated acoustic analyses (which we are currently working on).
Footnotes
Conflict of interest
None declared.
Funding
Ballard was funded in part by an Australian Research Council Future Fellowship.