
Abstract
This study investigates the production and auditory lexical processing of words involved in a patterned phonological alternation in two dialects of Catalan spoken on the island of Majorca, Spain. One of these dialects, that of Palma, merges /ɔ/ and /o/ as [o] in unstressed position, and it maintains /u/ as an independent category, [u]. In the dialect of Sóller, a small village, speakers merge unstressed /ɔ/, /o/, and /u/ to [u]. First, a production study asks whether the discrete, rule-based descriptions of the vowel alternations provided in the dialectological literature are able to account adequately for these processes: are mergers complete? Results show that mergers are complete with regards to the main acoustic cue to these vowel contrasts, that is, F1. However, minor differences are maintained for F2 and vowel duration. Second, a lexical decision task using cross-modal priming investigates the strength with which words produced in the phonetic form of the neighboring (versus one’s own) dialect activate the listeners’ lexical representations during spoken word recognition: are words within and across dialects accessed efficiently? The study finds that listeners from one of these dialects, Sóller, process their own and the neighboring forms equally efficiently, while listeners from the other one, Palma, process their own forms more efficiently than those of the neighboring dialect. This study has implications for our understanding of the role of lifelong linguistic experience on speech performance.
Keywords
1 Introduction
The present study explores the patterns of stress-induced vowel reduction of two dialects of Catalan spoken on the island of Majorca (Mallorca), Spain. In particular, the study is concerned with the auditory lexical processing of words involved in a process of vowel reduction affecting the three back vowel phonemes of Catalan: /ɔ/, /o/, and /u/. The phonetic structures of this phonological process are also of interest. In Majorcan Catalan, as well as in other dialects of Catalan, a phonological process of vowel reduction is responsible for a decrease in the number of vowel contrasts found in unstressed position with respect to those in stressed position. This process leads to a number of vowel alternations in some lemmas, and—crucially—these alternations differ across dialects, including the two dialects of Majorcan Catalan of concern here. These alternations—how they are produced and processed in words, within and across dialects—are the focus of the present study.
The two dialects of Majorcan Catalan investigated here are that of Palma, the capital city of the Province of the Balearic Islands (population 450,000), and that of Sóller, a relatively isolated small village (population ~14,000). We take the dialect of Palma to represent the general pattern displayed by most Majorcan Catalan dialects, and thus as representative of Majorcan Catalan in general—it is so at least for the phonological process studied here. In one dialect, the phonemes /ɔ/ and /o/ are merged to [o] in unstressed position (Palma), while in the other dialect the two back vowel phonemes are merged to [u] (Sóller). This renders two systematic pronunciation variants for words with unstressed /o/ and /ɔ/, and both variants are found on the island of Majorca. For instance, the word forat ‘hole’ is pronounced [fuˈɾat] in one dialect (Palma) and [fuˈɾat] in the other (Sóller). While the latter form [fuˈɾat] is present, on Majorca, only in the village of Sóller, the form [foˈɾat] can be found throughout the rest of the island—except in Sóller speech, that is.
The present study reports on the results of an acoustic investigation aimed at verifying, quantitatively, the dialectological, phonological descriptions of the reduction patterns affecting the dialects under examination. Then we report on a word recognition experiment for which we used the cross-modal priming paradigm. Participants processed words in both the phonetic variant of their own dialect and in that of the neighboring one. By analyzing the performance of speakers of two neighboring dialects of Catalan that differ in the nature of the target alternations, this study is able to address the following research question: How does language experience—or experience with a particular dialect—modulate speech performance in the context of dialectal variation? The following subsections of this Introduction review the literature on: (i) the acoustic–phonetics of vowel alternations resulting from stress-induced vowel reduction; and (ii) the effects of phonetic variation and dialectal differences on the on-line processing of spoken words.
1.1 Stress-induced vowel reduction and the dialects of Catalan
As elegantly explained in Fourakis (1991, p. 1816) and in Padgett and Tabain (2005, pp. 14–15), the term vowel reduction has two meanings, one for the phonologist and one for the phonetician. Phonetic vowel reduction “refers to the tendency for the obtained formant frequencies of a vowel to fall short of the idealized target values for that vowel—those values that would be obtained if the vowel was produced in isolation—resulting in an overall shrinkage of the vowel space” (Miller, 1981, p. 42, cited in Fourakis, 1991, p. 1816). Phonetic undershoot and assimilation are other terms used to describe this phenomenon (Lindblom, 1963; Padgett & Tabain, 2005). Phonetic vowel reduction is a gradient process that presumably affects all of the vowels in a given vowel inventory (Fourakis, 1991), and it modulates vowel timbre as a function of segmental context, speech tempo and speech register in addition to lexical stress itself.
Phonological unstressed vowel reduction, on the other hand, is a categorical process, a feature of some stress-accented languages, according to which there is a reduction in the number of vowel contrasts implemented in unstressed position with respect to those found in stressed position. In the words of Padgett and Tabain (2005, p. 14), it is “a categorical substitution of sounds, and not gradient undershoot: it does not depend on speech rate or register.” In languages with phonological unstressed vowel reduction, this process typically applies only to some of the vowels of the inventory. Russian, for instance, neutralizes /a/ and /o/ in unstressed vowel position by alternating both vowel phonemes with schwa with respect to how they surface in stressed position (гoд [ˈgot] ‘year’ ~ гoдoвoй [gədɐˈvoj] ‘annual’; право [ˈpɾaf] ‘law’ ~ правовoй [pɾəvɐˈvoj] ‘legal’); the high vowel phonemes, on the other hand, are not involved in any stress-induced alternations (судно [ˈsudnə] ‘ship’ ~ судновoй [sudəˈvoj] ‘adj.’)—examples from Padgett and Tabain (2005).
Catalan is a Romance language spoken along the northeastern shores of the Iberian Peninsula as well as on the Balearic Islands and in the town of Alghero (l’Alguer) on the island of Sardinia, Italy. Catalan, like many other languages, displays a series of categorical vowel alternations conditioned by lexical stress—it is thus a language with phonological unstressed vowel reduction. The alternations lead to a decrease in the number of vowel phonemes that may occur in unstressed syllables relative to those in stressed syllables. The dialects of Catalan differ with regard to how these vowel phonemes surface in unstressed position and which of these vowels neutralize.
Since the work of Milà i Fontanals (1861), dialectologists have divided Catalan into two major regional varieties: eastern and western. The patterns of phonological unstressed vowel reduction were pivotal in Milà i Fontanals’ proposal to classify Catalan into these two major dialectal areas. The isogloss dividing the eastern from the western dialects cuts through Catalonia from north to south. Further to the south, Valencian is a western variety. All of the insular dialects (the Balearic Islands, Sardinia) are eastern varieties of the language. In western Catalan varieties—such as in Valencian, which has seven vowel phonemes, /i e ɛ a ɔ o u/, only instantiated as such (i.e., as contrastive sounds) in stressed position—the number of vowel contrasts is reduced to five sounds, [i e a o u], in unstressed position. In particular, in western Catalan, /e/ and /ɛ/ merge to [e] in unstressed position, and /ɔ/ and /o/ merge to [o]; /i/, /a/ and /u/ retain their quality in unstressed position as [i], [a] and [u], respectively.
In order to illustrate the situation in eastern Catalan, we shall take central Catalan, spoken in the province of Barcelona and in parts of Girona (Gerona) and Tarragona as an example. The central variety of Catalan (upon which the standard variety is based), as most other eastern dialects, has seven vowel phonemes instantiated in stressed position, /i e ɛ a ɔ o u/. In this dialect, /e/, /ɛ/ and /a/ merge to [ə] in unstressed position, and /ɔ/, /o/, and /u/ merge to [u]; /i/ is realized as [i] in both stressed and unstressed positions. 1 The present study is exclusively concerned with the back vowels. Regarding these vowels, the crucial difference between western and eastern dialects of Catalan is that western varieties retain two vowel categories in unstressed position, [o] and [u], while eastern varieties neutralize all three phonemes to one, namely, [u].
Majorcan Catalan, the variety spoken on the island of Majorca and the focus of the present investigation, is classified as an eastern dialect based on a long list of phonological features and processes, including the reduction patterns that affect the mid-front and the low vowels: /e/, /ɛ/ and /a/ merge to [ə] in all varieties of Majorcan Catalan, like they do in central Catalan. 2 However, Majorcan Catalan shares with western varieties of Catalan the fact that it has been described as a dialect that merges the three back vowels into two phonetic categories: /ɔ/ and /o/ are merged to [o] while /u/ remains [u]. In this dialect, [ɔ] alternates with [o] in the /ɔ/-words (plora [ˈplɔɾə] ‘(s/he) cries’ ~ plorar [ploˈɾa] ‘to cry’), while the /o/-words (sopa [ˈsopə] ‘(s/he) eats dinner’ ~ sopar [soˈpa] ‘to eat dinner’) and the /u/-words (dubta [ˈdutːə] ‘(s/he) doubts’ ~ dubtar [duˈtːa] ‘to doubt’) do not alternate. The merger of the three back vowels, in unstressed position, into two categories is a conservative diachronic feature of Majorcan Catalan. The /o/-/u/ merger into [u] is an innovative feature that affected the mainland eastern Catalan dialects as well as the dialects of Minorca (Menorca) and Eivissa (Ibiza), islands neighboring Majorca, but never reached the western dialects—nor Majorcan Catalan. This innovation was completed towards the end of the 15th century (Badia i Margarit, 1981; Veny, 1978).
A most interesting fact, and a crucial point for the present study, is that the dialect spoken in one particular village on Majorca, Sóller, seems to share the vowel reduction pattern of the eastern Catalan dialects spoken on the mainland and on the neighboring islands (Minorca and Eivissa), and thus differs from the rest of the Majorcan dialects. In Sóller Catalan, all three vowel phonemes are reduced to a single phonetic category, [u], in unstressed position. In this dialect, [ɔ] alternates with [u] (plora [ˈplɔɾə] ‘(s/he) cries’ ~ plorar [pluˈɾa] ‘to cry’), [o] alternates with [u] (sopa [ˈsopə] ‘(s/he) eats dinner’ ~ sopar [suˈpa] ‘to eat dinner’), but none of the /u/-words (dubta [ˈdutːə] ‘(s/he) doubts’ ~ dubtar [duˈtːa] ‘to doubt’) alternate.
Sóller is a small village of approximately 14,000 inhabitants (1.75% of the population of Majorca) situated on the northwestern coast of the island. It is geographically isolated from the rest of Majorca by rugged mountains. Migrants leaving Sóller in the 19th century were more likely to settle in France, Catalonia or the Americas than to settle in the capital city of Majorca, Palma, unlike residents of other Majorcan rural areas (Quetgles & Estades, 2009). In 1996, construction was finalized for a tunnel that links the village of Sóller with the main valley plain on the island, and currently the drive from the village to Palma takes about 35 minutes. Before the tunnel was built, travelers had to go through a difficult mountain pass, or take to the seas. Unlike in the past, it is currently common for residents of Sóller to commute daily to Palma for work or school. The historic isolation of Sóller may account for the dialectal differences between this village and the rest of the island. Indeed, the dialect of Sóller has a few other idiosyncratic features that distinguish it from the rest of Majorcan dialects, including an uvularized pronunciation of the alveolar trill [ʁ], as in rata [ˈʁatə] ‘rat’ instead of [ˈratə]. This feature is likely an import brought to the island by émigrés returning to Sóller from France in the late 19th and early 20th centuries (Llompart, 2013). The process that concerns us here (/u/-/o/-/ɔ/ → [u]) is also a phonological innovation rather than a conservative feature.
Any current analyses or descriptions of positional neutralization patterns must consider the phenomenon of incomplete neutralization. Consider, for example, the research on the merger between /t/ and /d/ in word-final position in a number of languages, including Catalan (Charles-Luce, 1993; Charles-Luce & Dinnsen, 1987; Dmitrieva, Jongman, & Sereno, 2010; Fourakis & Iverson, 1984; Kharlamov, 2014; Port & Crawford, 1989; Port & O’Dell, 1985; Roettger, Winter, Grawunder, Kirby, & Grice, 2014; Slowiaczek & Dinnsen, 1985; Warner, Jongman, Sereno, & Kemps, 2004). A number of studies have found that, under some conditions, some “remnants” of /d/ are retained in word-final position; that is, the /t/-/d/ contrast is greatly reduced, in terms of the degree of the phonetic effect, but does not entirely disappear. This has given rise to the term “incomplete neutralization.” This is all the more important when we consider that a study on phonological vowel reduction in Russian also found unanticipated evidence of incomplete neutralization (Padgett & Tabain, 2005). As explained above, Russian is said to merge /a/ and /o/ to schwa in unstressed position, and the findings of Padgett and Tabain indeed support this description with acoustic data. Russian, however, is also said to neutralize /e/ and /i/ by raising /e/ to [i] in unstressed position. Interestingly, the data in Padgett and Tabain (2005) do not entirely corroborate this phonological description. While their acoustic data confirm that /e/ is realized with a raised pronunciation in unstressed position, this vowel does not fully neutralize to /i/ in this prosodic position. In sum, a number of studies have shown that phonological patterns once believed to lead to positional mergers do not, in fact, lead to full neutralization. This could be the case with the Catalan dialects investigated in this study. In fact, any traditional description of a positional neutralization process could hide a pattern of incomplete neutralization detectable only via careful acoustic study.
The main research question addressed in the first part of this study, a speech production experiment, is as follows: is a categorical phonological rule—one that entails full positional neutralization—an adequate description of the phonological processes that affect the two Majorcan Catalan dialects investigated here? In other words, is there evidence for incomplete neutralization in the vowel reduction patterns that affect these two dialects?
1.2 Phonetic variation, dialectal differences, and spoken word recognition
The words of any language may have more than one phonological or phonetic variant, that is, words may exhibit multiple pronunciation variants in a speech community. Variation in the phonetic composition of such words may come from different sources. Lenition processes, for instance, trigger phonetic differences between a full form, often referred to as a citation form, and one or more reduced forms. Several studies have tried to assess the impact of this type of variation on lexical processing. The focus so far has been on a small set of processes including word-final /t/ and /d/ glottalization (Deelman & Connine, 2001; Sumner & Samuel, 2005), /t/ and /d/ tapping (McLennan, Luce, & Charles-Luce, 2003), nasal flapping (Pitt, 2009; Ranbom & Connine, 2007) and schwa elision in American English (Connine, Ranbom, & Patterson, 2008; LoCasto & Connine, 2002) and French (Bürki, Alario, & Frauenfelder, 2011; Bürki, Ernestus, & Frauenfelder, 2010; Bürki & Frauenfelder, 2012). One of the main questions touched upon by this body of literature is whether all word variants, including the reduced or lenited forms, are equally effective at tapping into lexical representations in on-line spoken-word recognition.
Deelman and Connine (2001), for example, used a cross-modal semantic priming task to test whether having an unreleased /t/ or /d/ in final position resulted in lower activation for the lexical representation of word forms affected by this process as compared to the fully released variants. The results showed that the auditory renderings of the two variants (released, and unreleased) triggered comparable lexical activation and primed a semantically related target to the same extent. This finding was replicated in Sumner and Samuel (2005) with final-/t/ words. In the latter study, two auditory semantic priming experiments showed that the priming effect was comparably robust with all the final-/t/ prime variants analyzed in the study—including glottalized, unreleased and released variants—demonstrating that the three variants are recognized with the same ease during lexical processing. According to Sumner, Kim, King, and McGowan (2014), the findings to date lead to what they dubbed recognition equivalence. This inference stems from the fact that several immediate processing studies have failed to show evidence of processing costs associated with any of the possible pronunciation variants.
Results from other studies, however, report an advantage for the citation form over the reduced form during lexical processing, at least under some conditions (Bürki et al., 2010; LoCasto & Connine, 2002; Pitt, 2009; Ranbom & Connine, 2007). Ranbom and Connine (2007), for instance, reported a citation-form advantage for nasal flapping in American English. Words like center have two possible pronunciations in American English: they can be pronounced without reducing any of their segments, which the authors call the [nt] variant, or the /nt/ sequence may be reduced to a nasal flap, [ɾ̃]. In a (single-presentation) auditory lexical decision task, response times for words produced with the [nt] variant were shorter than for words with the flapped variant. An experiment using the cross-modal priming paradigm pointed in the same direction: the [nt] variant triggered substantially stronger priming of the written targets than the flapped variant.
An important finding coming from the literature on the auditory lexical processing of phonetic word variants is that one must take into consideration the effects of a speaker’s experience with the phonetic forms of her language variety. In addition to word form (variant)-frequency effects (Bürki et al., 2010; Connine et al., 2008; Ranbom & Connine, 2007), an important effect of experience, and one that is particularly relevant to our study, can be found in the processing of dialectal variation. Divergences in phonological patterns among dialects are an important source of variation in speech, and, as these divergences are instantiated with specific words, they frequently create alternative pronunciations for the same lexical entry.
Substantial processing costs have been observed when recognizing words in an unfamiliar dialect. These costs could be described, in Floccia, Goslin, Girard, and Konopczynski’s (2006, p. 1277) terms, as an attenuated version of the costs associated with processing speech produced with a foreign accent. A generalized advantage for one’s own dialect over an unfamiliar dialect has consistently been found across experimental paradigms (Adank, Evans, Stuart-Smith, & Scott, 2009; Floccia et al., 2006; Impe, Geeraerts, & Speelman, 2008). Floccia et al. (2006), for instance, conducted several lexical decision experiments with words in isolation or as the last word of a carrier sentence produced in either the listeners’ own dialect, a familiar dialect or an unfamiliar dialect. They report longer decision times for the unfamiliar accent, relative to the speakers’ own and the familiar accent, in both the “isolation” and the “sentence” conditions.
Relevant results have been found when cross-dialect word recognition is assessed comparing the listeners’ own dialect to a dialect with which they are expected to be familiar. On the one hand, several studies have shown that speakers that have substantial experience with two dialects are equally efficient at recognizing words in both dialects (Adank et al., 2009; Floccia et al., 2006; Impe et al., 2008). On the other hand, it has been reported that standard varieties show an advantage with respect to regionally-marked varieties in word recognition in noise, not only for speakers of the standard variety but also for speakers of the regional dialect themselves (Clopper & Bradlow, 2008). Clopper, Pierrehumbert, and Tamati (2010) examined the cross-dialectal intelligibility of words with either [ɑ] or [ɔ] by two groups of English-speaking listeners from the United States: (i) a group of Northern American English listeners, familiar with General American (GA), the merging dialect (i.e., [ɑ]-variant), and also with their own regional variety, a non-merging dialect (i.e., [ɔ]-variant); and (ii) a group of GA listeners, not particularly experienced with non-merging dialects. The critical finding was that Northern listeners were more accurate than GA listeners at identifying target words when these were produced in the listeners’ “foreign” dialect—that is, the Northern listeners were accurate when identifying words in the form of their own dialect and in the GA form, while the GA listeners were accurate only when processing their own dialect. In sum, some listeners are able to recognize efficiently words produced in a dialect other than their own provided that they are familiar with the dialect or that the dialect itself enjoys some sort of “standard” status.
A most significant finding for the present research was reported by Sumner and Samuel (2009), who provided further evidence of linguistic experience as a trigger of dialect equivalence in processing tasks by examining final-/r/ words in three varieties of American English. Final-/r/ words are produced with a full –er variant (bak[ə˞]) by GA speakers and without a rhotic sound (bak[ə]) by speakers of the New York City (NYC) dialect. Sumner and Samuel (2009) conducted a form- and a semantic-priming task with three populations having different degrees of exposure to the two target phonetic variants. One group of participants included native New Yorkers who systematically produced the /r/-less variants in their own speech, and who had been raised by native NYC parents. A second group included native New Yorkers who produced the /r/-full variants in their own speech, and who had been brought up by non-NYC-born parents. The last group were speakers of GA who had recently moved to New York and thus lacked the lifelong experience with the NYC dialect that the other two groups had. The two tasks led to comparable results: (i) GA listeners were primed only by the /r/-full word forms, showing a clear advantage of their own dialect over an unfamiliar dialect; and, (ii) on the other hand, the two groups of native New Yorkers were primed by the two /r/ variants.
Although several studies, including Sumner and Samuel (2009), have shown that familiarity with a dialect other than one’s own leads to improved recognition of words in that dialect, this familiarity effect seems to have a limit. Sumner and Samuel found that, when the processing of pronunciation variants was examined via a long-term repetition priming experiment—instead of a short-term form or semantic priming experiment—the familiarity advantage disappeared. The results of this particular experiment showed that only the group of native New Yorkers who produced the /r/-less variant in their own speech and whose parents were native New Yorkers themselves were primed by the NYC, /r/-less variants. The New Yorkers who did not produce the /r/-less variants themselves—those whose parents were not native New Yorkers—did not exhibit long-term priming with the /r/-less primes.
The second experiment in the present study, a lexical decision task with cross-modal priming, is concerned with determining how speakers of the two Catalan dialects spoken on the island of Majorca process words produced in the phonetic form characteristic of their own dialect versus that of their neighboring dialect. One of these phonetic variants is very common on Majorca—the form produced by Palma speakers—while the other is used by a small number of speakers—that of Sóller speakers. Hence, we investigate the role of linguistic experience and dialectal variation on the processing of the phonetic form of Catalan words.
1.3 A note on allomorphy
Most evidence on the effects of phonological variation on auditory lexical access is concerned with cross-dialectal word recognition or with the phonetic variants of single word items, such as reduced or lenited word tokens which occur alongside full, citation forms (see, however, Sumner & Samuel, 2009). There is a different type of phonological pattern that introduces variance across morphologically-related word items rather than within word items, and this pattern is highly predictable. To illustrate, consider once again the effects of a phenomenon known as word-final devoicing, displayed by languages from different language families, including German, Dutch, Russian, Polish, and Catalan (Charles-Luce, 1993; Charles-Luce & Dinnsen, 1987; Dmitrieva et al., 2010; Fourakis & Iverson, 1984; Kharlamov, 2014; Port & Crawford, 1989; Port & O’Dell, 1985; Roettger et al., 2014; Slowiaczek & Dinnsen, 1985; Warner et al., 2004). In these languages, some lemmas show an alternation between a voiced and a voiceless obstruent while others do not, conditioned by position in the word. For example, in German, /t/ and /d/ contrast, as [t] and [d], in intervocalic position (Räder [ˈʁæːdɐ] ‘wheels’, Räte [ˈʁæːtə] ‘councils’), but they do not in word-final position, where only [t] may occur (Rad [ʁaːt] ‘wheel’, Rat [ʁaːt] ‘council’). The /t/-/d/ distinction is thus neutralized in word-final position. If /t/ and /d/ contrast in intervocalic position but they are both merged to [t] in final position, it follows that some morphologically-related words provide evidence of a [t]-[d] alternation (Räder [ˈʁæːdɐ] ‘wheels’ ~ Rad [ʁaːt] ‘wheel’) while in others there is no alternation, as all alveolar stops surface as [t] (Räte [ˈʁæːtə] ‘councils’ ~ Rat [ʁaːt] ‘council’).
An important question—one that we are not able to address here—is whether the presence of phonological alternations such as these entails any processing costs during spoken-word recognition relative to paradigms with no alternation. Consider the following data involving Portuguese verbs. Portuguese has verbs whose stems are affected by a regular vowel alternation conditioned by lexical stress, not unlike the Catalan phenomenon that concerns us here. In Portuguese, [ɔ] alternates with [u] in pairs such as af[ɔ]go ‘I drown’ ~ af[u]gar ‘to drown’. Veríssimo and Clahsen (2009) compared 1st conjugation Portuguese verbs affected by a vowel alternation (e.g., af[ɔ]go ~ af[u]gar) with fully regular verbs (lim[i]to ‘(I) limit’ ~ lim[i]tar ‘to limit’). Their study consisted of a cross-modal priming experiment in which primes were 1st-person-singular-present verbs presented in auditory form (af[ɔ]go, limito) and targets were visually-presented infinitives (afogar, and limitar). While verbs in the fully regular condition led to full priming (i.e., morphologically-related forms triggered as much priming as identical verb forms), verbs in the vowel-alternation condition did not. In other words, Veríssimo and Clahsen (2009) found evidence that, in Portuguese, irregular verbs—those that are affected by a vowel alternation in the stem—are processed differently from fully regular verbs. Regardless of the interpretation of the Portuguese facts, this study suggests that verbs involved in regular alternations trigger a processing cost during spoken-word recognition.
In the present study we investigate the processing of Catalan nouns that are affected by a phonological process that leads to vowel alternations. The pattern of phonological variation we study here, unstressed vowel reduction, is fully predictable and does not depend on context. Our target phonological phenomenon, therefore, differs from those investigated in prior work, such as word-final /t/ and /d/ glottalization (Deelman & Connine, 2001; Sumner & Samuel, 2005), /t/ and /d/ tapping (McLennan et al., 2003), nasal flapping (Pitt, 2009; Ranbom & Connine, 2007), and schwa elision (Connine et al., 2008; LoCasto & Connine, 2002). The latter are not fully predictable—sometimes a word displays them and sometimes it does not—and are affected by the context of the communicative situation, such as register or style, speech rate, among other factors. The present study, on the other hand, explores a pattern of phonological variation that manifests itself only across morphologically related words and does not lead to variation within word items—it manifests itself systematically, but only within a given dialect, and when certain phonological conditions are met. In targeting this type of phenomenon, our study resembles that of Veríssimo and Clahsen (2009), who investigate the processing of stem-changing verbs in Portuguese. Our study, however, is exclusively concerned with the potential effects of experience on word recognition (i.e., intra- versus inter-dialect effects). In order to circumvent possible effects such as those found in Veríssimo and Clahsen (2009), according to which stem-changing verbs are slightly costlier to process than fully regular verbs, our cross-modal priming task uses only identity conditions. In other words, instead of designing prime-target pairs that share a stem but differ in their identity, stem-changing (e.g., af[ɔ]go → af[u]gar) or not (e.g., limito → limitar), our key experimental conditions use only prime-target pairs with the same lexical item (coseta /koz + eta/ → coseta ‘little thing’). We do not present within-dialect mismatching prime-target conditions; all of our mismatching prime-target conditions are interdialectal (coseta /koz + eta/ (c[o]seta; c[u]seta) → coseta ‘little thing’).
Our word recognition study is concerned with assessing any effects of linguistic experience (or accent familiarity) in the processing of patterned, fully predictable phonological variation. Since prior research has documented a processing advantage for one’s own dialect (over other dialects) but has also shown that speakers that have substantial experience with two dialects are equally efficient at recognizing words in both (Adank et al., 2009; Floccia et al., 2006; Impe et al., 2008), we ask whether Majorcan Catalan speakers are able to process the word forms of their own dialect as efficiently as those of a neighboring dialect. Finally, since the phonological phenomenon that we investigate is fully predictable in its application (i.e., there is no within-word variation), and thus listeners’ experience with the phenomenon may differ in critical ways from that of listeners in previous research, there is no a priori reason to assume that prior findings on the effects of within-word phonological variability on spoken-word recognition (e.g., Connine et al., 2008; LoCasto & Connine, 2002; McLennan et al., 2003; Pitt, 2009; Ranbom & Connine, 2007) will apply in the exact same way for the phenomenon that concerns us here. This would need to be established through careful experimental scrutiny.
1.4 The present study
The present study is concerned with a phonological rule of Catalan in two regional dialects. These dialects differ crucially in the nature of the rule at test. We investigate the production of the sounds involved in the alternation as well as the auditory lexical processing of words in which the vowel alternation is manifested in these two dialects. The study, therefore, explores the cross-dialectal production and recognition of words affected by a phonological process.
For the production study, speakers of two different dialects of Majorcan Catalan were asked to read a list of words, some of which are presumably affected by the regular phonological alternation that is the object of the present study. The acoustics of the production data are analyzed in order to verify traditional claims about the categoricity of the phonological alternation(s) and the differences between the two target dialects. For the lexical-processing study, listeners from both dialectal regions were asked to process—in a lexical decision task with cross-modal priming—words produced in the phonetic shape of their own dialect and that of the neighboring dialect.
The two dialects under consideration, Palma and Sóller Catalan, differ in their number of speakers. Palma is a large city while Sóller is a small village; the Palma variant of the phonological rule that we study here also affects all the other dialects of Majorcan Catalan—except for that of Sóller, of course. Thus, an overwhelming majority of the Majorcan Catalan speakers display the “Palma” pattern of reduction; the “Sóller” pattern is found only in Sóller. For this reason, we believe that it is reasonable to hypothesize that a Sóller speaker selected at random is more likely to interact in their daily life with a speaker from outside of Sóller—and thus a speaker of a different variety—than a random Palma speaker is likely to interact with a Sóller speaker. Consequently, and given what previous studies on cross-dialectal spoken-word recognition have shown, we hypothesize that Sóller speakers are able to process the phonetic forms of words of their own dialect as efficiently as those of their neighboring dialect. Palma speakers, on the other hand, are hypothesized to process the phonetic forms of words in their own dialect more efficiently than those typical of Sóller.
Pointing out a caveat, however, is necessary: the stress-induced vowel reduction pattern of Sóller is the same as that of the other eastern Catalan dialects (with the exception of Majorcan Catalan, obviously), including central Catalan, Minorcan and Eivissan. Since central Catalan is the dialect upon which the Catalan standard variety is based, it is possible that Palma speakers process the phonetic forms of words characteristic of Sóller as efficiently as their own word forms. This could be the case if the standard status of central Catalan has had any effect in their long-term lexical representations. Note that exposure to central Catalan happens not only through the media, but also in school.
2 Experiment 1: production
For this experiment, two groups of male speakers of Majorcan Catalan, one from Palma and one from Sóller, were recorded while pronouncing a list of words, some of which are hypothesized to manifest the effects of the target phonological alternation. Vowel phonemes are compared across lexical stress conditions (stressed and unstressed positions); that is, the same vowel phonemes, in the same lemmas, occur in different words in the paradigm, some of which trigger a displacement of the stress from the stem to the suffix, thus triggering stress-based variations in the stem. 3
2.1 Method
2.1.1 Speakers
A total of twelve male speakers participated in this experiment. The age of the participants ranged from 19 to 26, and they were bilingual in Spanish and Catalan, since there are no truly monolingual speakers of Catalan on Majorca. Crucially, all of them were Catalan-dominant: Catalan is the language they use the most in their daily lives, and they were born into Catalan-speaking families. 4
The 12 participants were evenly distributed by place of residence, or regional accent, six from Sóller and six from Palma. Recall that, in this study, Palma represents the general Majorcan Catalan pattern. At the time of testing, our 12 male speakers had lived locally throughout their lives. The speakers were recruited in their region of origin and were recorded in a quiet room in their home. Participants did not receive any compensation for their participation in the study.
The experimenter was the first author, a native Majorcan Catalan speaker born and raised in Sóller. He commuted to Palma daily for four years during his undergraduate education. Any accommodation effects of the speakers towards the experimenter are unknown.
2.1.2 Materials and recordings
The materials were 60 target words comprising 30-word pairs consisting of nouns (i.e., lemmas) with a consonant–vowel–consonant–vowel or consonant–vowel–consonant–consonant–vowel structure whose first vowel was a stressed /o/, /ɔ/ or /u/ and their derived diminutive forms (e.g., /o/: copa-copeta ‘cup-small cup’; /ɔ/: cosa-coseta ‘thing-little thing’; /u/: puça-puceta ‘flea-little flea’). Diminutive formation in Catalan triggers systematic stress displacement to the affix (e.g., copa [ˈkopə]–copeta [koˈpətə], ‘cup-small cup’). By using diminutive words, we controlled for lemma, and thus for vowel phoneme, while orthogonally varying the stress configuration of the lexical root. In other words, each target lemma appeared in two different word forms, a base form (copa ‘cup’) and a diminutive form (copeta ‘small cup’). The target words were controlled for vowel, 10 word-pairs (20 target words) per vowel. Ten additional word pairs with the same structure as the target words, but with vowel phonemes other than /o/, /ɔ/ and /u/ (e.g., nina-nineta, ‘girl-little girl’), were used as fillers. The list of target lemmas is given in Table 1.
Materials (target words) used in the production study (Experiment 1). The materials included these 30 morphological bases (the “stressed” set) plus derived words ending in the diminutive suffix -eta (the “unstressed” set).
The 12 speakers carried out a reading task: they read aloud from a randomized list of sentences that was presented to them on a computer screen using PsychoPy2 (Peirce, 2007). Each sentence included only one target word. In each sentence, the target word appeared in sentence-medial position as the direct object of a grammatical structure consisting of a subject, a verb, a direct object and an adjunct. The two forms of each lemma occurred in the same carrier sentence. Thus, for instance, the carrier sentence En Joan menja una___des seu hort ‘John eats a___from his garden’ was shown once with the word poma ‘apple’ and once with the word pometa ‘small apple’ in the blank. Sentences were presented in quasi-random order.
Two iterations of each target word were elicited from each speaker, yielding a total of 1440 vowel tokens: 60 target words × 12 participants × 2 iterations. There were 720 stressed vowel tokens and 720 unstressed vowel tokens. Eighteen tokens (1.25% of dataset) had to be discarded due to production errors, such as misreading a word, or to recording deficiencies, such as loud background noise or coughing.
The recording equipment was a condenser AKG C520 (Vienna, Austria) head-mounted microphone and a Sound Devices USBPre 2 (Reedsburg, Wisconsin) audio interface (pre-amplifier + analog-to-digital converter) connected to a laptop computer running Praat (Boersma, 2001). The speech signal was sampled at 44.1 kHz with 16-bit quantization.
2.1.3 Acoustic analyses
All target tokens were annotated for lemma (spelling of basic word form in standard Catalan orthography), vowel phoneme (/o/, /ɔ/, /u/), stress configuration (stressed, unstressed), speaker dialect (Palma, and Sóller), and individual speaker (12 speakers).
The onset and offset of each vowel token were identified within the carrier sentence by using the information provided by both the waveform and the spectrogram, as generated by Praat; temporal landmarks were manually marked on a time-aligned text file. Target vowels appeared in a range of consonantal contexts; thus, a number of different criteria were used to guide the segmentation of the acoustic data (see, for instance, Nadeu, 2014). Vowel landmarks were always placed at upward zero-crossings. When the consonant preceding target vowel was a voiceless stop, the vowel onset was marked on the first glottal, modal pulse following the release burst that initiated the formant structure of the vowel. In the case in which a voiceless stop followed the target vowel, the vowel onset was placed on the last glottal pulse in which the second formant was readily observable. When the flanking (either preceding or following) consonant was an approximant, vowel onsets were placed by inspecting formant intensity envelopes in the spectrogram and dips in amplitude in the oscillogram. In cases in which trills or taps preceded or followed the target consonants, the vowel onset was placed after the (last) occlusion and the vowel offset was placed before the (first) occlusion. As for neighboring fricatives, we followed the onset or offset of frication noise as observable in the waveform—vowel onsets were marked at the offset of frication noise in cases in which a fricative preceded the vowel and at the onset of frication noise in cases in which a fricative followed the vowel. Finally, in cases in which vowel tokens were adjacent to lateral and nasal consonants, segmentation was accomplished by visually tracking changes in the intensity envelope, more specifically, in the intensity of formant structure as evidenced by spectrogram darkness.
The feature that most readily captures the difference between Catalan [o], [ɔ] and [u] is vowel height (Recasens & Espinosa, 2006, 2009; Simonet, 2011b, 2014). First-formant (F1) frequencies are usually assumed to be adequate acoustic correlates of vowel height. In the present study, however, we explored two additional acoustic parameters: second-formant (F2) frequencies, and vowel duration. Acoustic studies of Catalan vowels show small F2 differences among the back vowels—much smaller than those reflected in F1. While F2 is contrastively used in the Catalan vowel system (to distinguish front from back vowels, for instance), duration is not. Nevertheless, we included duration in our analyses, as vowels may differ along this parameter in Catalan, even if only parasitically (see, for Portuguese, which has a similar vowel system, Escudero, Boersma, Rauber, & Bion, 2009). Exploring three acoustic parameters allowed us to consider incomplete neutralization more thoroughly (see, for instance, Padgett & Tabain, 2005).
We extracted six frequency values for each vowel token, and these were used to obtain two mean (F1, and F2) frequency values per vowel token. First, acoustic data were extracted from three equidistant temporal landmarks, the 1st, 2nd and 3rd quartiles of the acoustic duration of the vowel token. From each of these three temporal locations, both F1 and F2 frequencies were calculated. The mean of the three F1 values from each vowel token was adopted as the representative F1 value of the vowel token; the mean of the three F2 values of the same vowel token was the representative F2 value of the vowel token. In doing this we adopted (but simplified) the procedure in Jacewicz, Fox, and Salmons (2011). Duration values were calculated by subtracting the time of the vowel offset from that of the vowel onset in milliseconds.
In order to obtain F1 and F2 from the spectra, we used the linear predictive coding method (Burg algorithm) as implemented in Praat. The Hz values were then converted to Bark units, a log-based psychoacoustic scale (Traunmüller, 1990; Zwicker, 1961) using Praat’s built-in function hertzToBark(Hz). Duration values were also log-transformed. Hereafter Bark-converted F1 and F2 values are simply referred to as height and fronting, respectively; log-transformed duration (milliseconds) values are referred to as duration.
2.1.4 Statistical analyses
The three selected acoustic parameters were included as predictors in a series of mixed-effects logistic regression models for which the response (i.e., the predicted variable) was vowel phoneme. In other words, we tried to predict the vowel phoneme as a function of the acoustic parameters. This allows us to test the statistical significance of the categorical differences between the relevant vowel phonemes on the three acoustic parameters simultaneously (or in a stepwise manner), and it also allows us to see the significance and relative predictive weight of each parameter. Note, however, that our dependent variable has three levels: /u/, /o/, or /ɔ/. Since, in logistic regression, the response must be binary, we were forced to analyze these data in three different iterations, dividing the dataset into three subsets: /u/ versus /ɔ/, /u/ versus /o/, and /o/ versus /ɔ/.
In order to reduce the number of analyses to perform (and the number of predictors used in each model), we divided the dataset into four subsets, as follows: (i) Palma stressed vowels; (ii) Palma unstressed vowels; (iii) Sóller stressed vowels; and (iv) Sóller unstressed vowels. There is no principled reason to hypothesize that the stressed back vowels of Palma and Sóller are acoustically different, but these are analyzed separately for symmetry. Whether they are different or not is irrelevant for the purposes of the present study. On the other hand, there are principled reasons to hypothesize that the unstressed vowel systems of Palma and Sóller Catalan differ from each other rather substantially. It is thus justified to analyze them separately.
In each of the logistic regression models, the predictors were introduced in a stepwise manner, in the following order: height, fronting, and duration. Previous research had found that the acoustic parameter that most robustly distinguishes /u/, /o/, and /ɔ/ (in stressed position) is height (F1), followed by fronting (F2) (Recasens & Espinosa, 2006, 2009). Duration is, at most, a parasitical parameter, as it is not contrastive in the Catalan vowel system. The first model was always a null model (i.e., no fixed factor, only subject as a random intercept); the second model specified height as a fixed factor, the third model specified height and fronting as fixed factors, and the fourth and last model specified height, fronting and duration as fixed factors—no interactions. The relevance of the predictors was assessed using hierarchical partitioning of variance via nested model comparisons.
2.2 Results
Figure 1 plots the mean height and fronting values as a function of dialect (Palma, and Sóller) and stress configuration (stressed, and unstressed). A cursory examination of the four vowel charts suggests that our data conform to previous descriptions of these dialects, at least regarding height. The vowel charts plotting the stressed vowel tokens, both the Palma and the Sóller ones, suggest that /u/, /o/, and /ɔ/ are all acoustically different from each other in both dialects. The chart plotting the unstressed Palma data suggests that /ɔ/ is raised so that it becomes as high as /o/, but both these vowels differ from /u/. Finally, the chart corresponding to the unstressed Sóller tokens suggest that both /ɔ/ and /o/ are raised as high as /u/. The facts regarding fronting seem to be rather complex—or less reliable—due to large amounts of variance. The statistical analyses reported below examine height, fronting and duration.
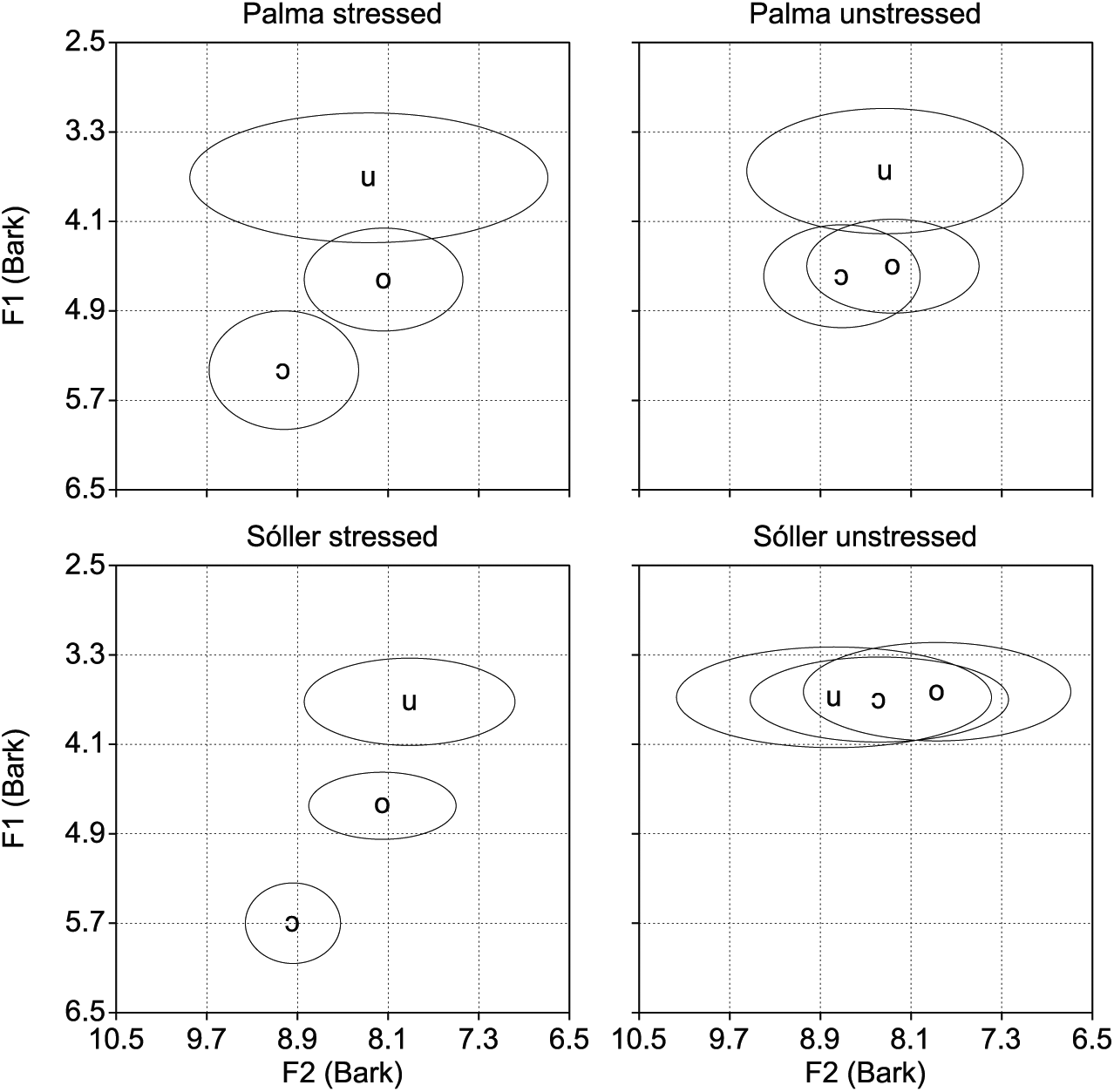
Vowel chart displays of F1 (Bark) and F2 (Bark) group averages (± 1 standard deviation ellipses) as a function of vowel phoneme (/ɔ/, /o/, /u/), further divided by stress configuration (stressed, unstressed) and Majorcan Catalan regional dialect (Palma, Sóller).
2.2.1 Stressed Palma vowels
The first set of models explored the /u/-/ɔ/ contrast, with /u/ as the reference level. The model with the best fit was one in which both height and fronting were specified as predictors—the results are shown in Table 2. The model with height as the sole fixed predictor, Akaike information criterion (AIC) = 66.84; χ2(1) = 274.63; p < 0.001, was better than the null model, AIC = 339.47, and that with both height and fronting as predictors had an even greater fit, AIC = 51.57; χ2(1) = 17.26; p < 0.001. Including duration in the set of fixed predictors did not result in any significant improvement, AIC = 53.28; χ2(1) = 0.29; p > 0.5. The difference between the null model and the model with height as a fixed predictor, in terms of AIC points, is -272.63. On the other hand, that between the height model and the height + fronting one is merely -15.27. (Large differences are indicative of large reductions in information loss.) The values in Table 2 reveal that, relative to /u/, for every one-unit increase in height, the estimated change in the log-odds of producing /ɔ/ was 10.35, a factor of 31,369. Additionally, holding height at a fixed value, the log odds of producing /ɔ/ changed by -2.09, a factor of 0.123, for every one-unit increase in fronting. In sum, /ɔ/ is characterized by a tendency to be much lower than /u/, and slightly further back. The largest, most robust difference between these two vowel phonemes is accounted for by height, but the effects of fronting are not fully negligible.
Results of three best-fit mixed-effects logistic regression models applied to the stressed vowel tokens of the Palma dialect. Model (i) analyzes the /u/-/ɔ/ contrast, with /u/ as the reference level; model (ii) analyzes the /u/-/o/ contrast, with /u/ as the reference level; and model (iii) analyzes the /ɔ/-/o/ contrast, with /ɔ/ as the reference level.
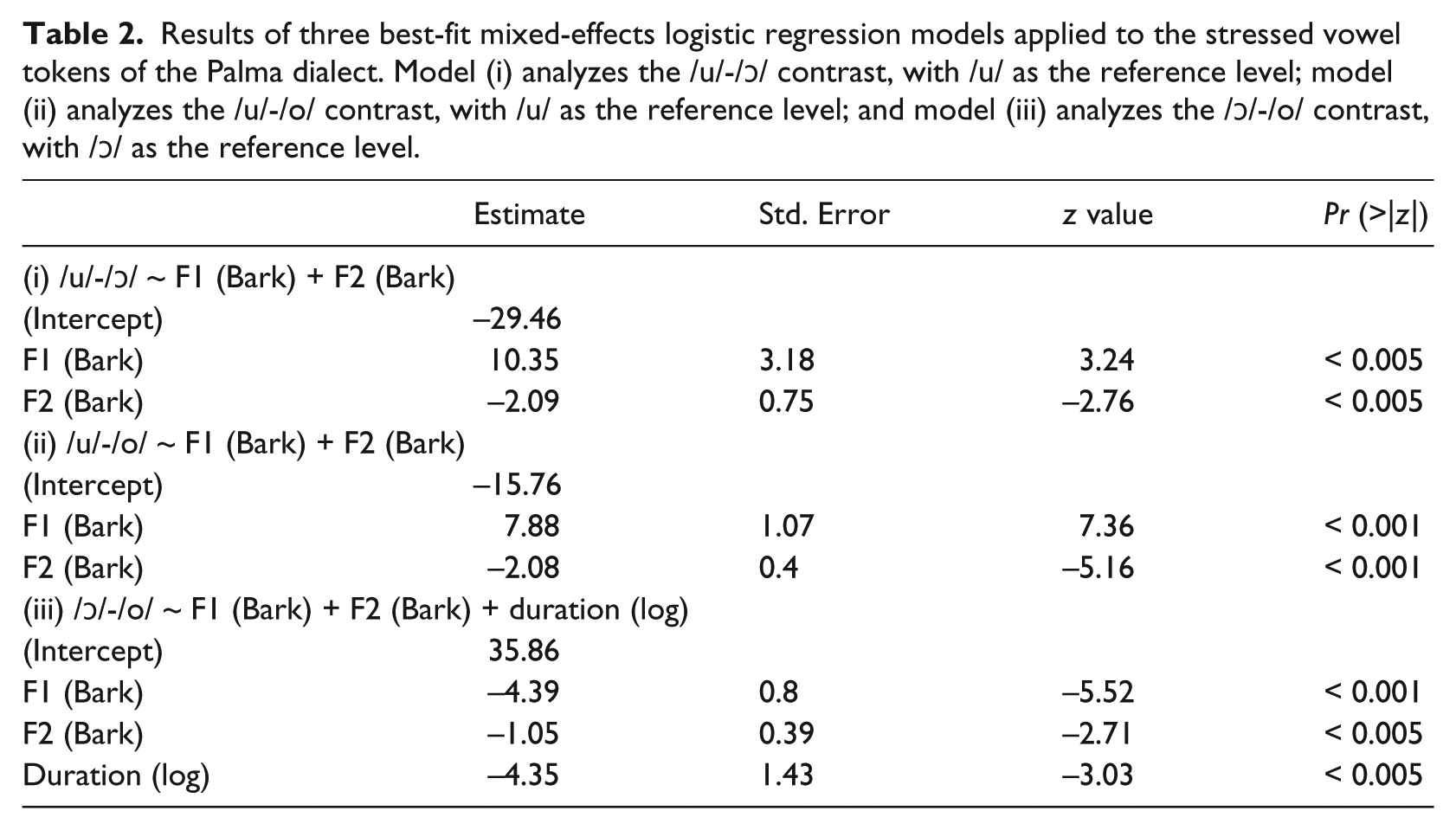
The second analysis focused on the /u/-/o/ contrast, with /u/ as the reference level. Once again, the model with the best fit was the one with both height and fronting as predictors—the results are also shown in Table 2. Duration was not a significant predictor, AIC = 114.51; χ2(1) = 1.25; p > 0.5. Adding height to the regression model, AIC = 165.48; χ2(1) = 175.98; p < 0.001, resulted in a significant improvement over the null model, AIC = 339.47. Fronting was also a significant predictor, AIC = 113.76; χ2(1) = 53.71; p < 0.001. In terms of AIC points, the difference between the null model and the model with height as a fixed predictor is -173.79. On the other hand, that between the height model and the height + fronting one is -51.72. As shown in Table 2, a one-unit increase in height led to a change in the log-odds of producing /o/ (rather than /u/) of 7.88, a factor of 2,643. Holding height constant, a one-unit increase in fronting yielded a change of -2.08, a factor of 0.124, in the log-odds of producing /o/. Thus, while both height and fronting led to significant results, height led to a larger, more robust difference between /u/ and /o/. In other words, /o/ tends to be much lower than /u/, and it has a tendency to be slightly further back.
Thirdly, we examined the binary /ɔ/-/o/ contrast, with /ɔ/ as the reference level. The model with the greatest fit had height, fronting and duration as predictors. Relative to the null model, AIC = 342.26, adding height resulted in a significant improvement in fit, AIC = 162.54; χ2(1) = 181.71; p < 0.001. Adding fronting, AIC = 154.48; χ2(1) = 10.05; p < 0.005, and, then, duration, AIC = 146.25; χ2(1) = 10.23; p < 0.001, yielded relatively modest but significant improvements. The difference between the null model and the model with height as a fixed predictor, in terms of AIC points, is -179.72; that between the height model and the height + fronting one is merely -8.06. Finally, the difference between the height + fronting and the height + fronting + duration models is also only -8.23. According to the estimates of this regression model, a one-unit increase in height led to an increase of 4.44 in the log-odds of producing /ɔ/ rather than /o/, a factor of 84.77. Holding height constant, a one-unit increase in fronting led to an increase of 1.05 in the log-odds of producing /ɔ/, a factor of 2.85. Finally, a one-unit increase in duration, holding both height and fronting constant, yielded an increase of 4.35 in the log-odds of producing /ɔ/ (rather than /o/), a factor of 77.47. In sum, while all three acoustic parameters turn out to be significant, the difference between /ɔ/ and /o/ is accounted for mostly by height, then duration; fronting is a very modest predictor, with /ɔ/ tending to be more fronted than /o/—that is, /ɔ/ is lower, slightly longer, and slightly more fronted than /o/.
2.2.2 Unstressed Palma vowels
The analysis of the unstressed back vowels of Palma began with a comparison of /u/ and /ɔ/, with /u/ as the reference level in the logistic regression models. Adding height yielded a significant result, AIC = 171.19; χ2(1) = 161.79; p < 0.001: a gain in fit over the null model, AIC = 331.17, and a difference of -159.98 in AIC points. In contrast, adding either fronting, AIC = 170.99; χ2(1) = 2.2; p > 0.1, or duration, AIC = 172.9; χ2(1) = 0.009; p > 0.1, failed to affect the fit of the model. As shown in Table 3, a one-unit increase in height led to a change of 4.53 in the log-odds of producing /ɔ/ rather than /u/, a factor of 92.75. The low vowel, /ɔ/, has indeed a higher F1 than the high vowel, /u/. There are no significant differences in either F2 or duration. In sum, unstressed /ɔ/ and /u/, in the dialect of Palma, are acoustically different in terms of vowel height.
Results of three best-fit mixed-effects logistic regression models applied to the unstressed vowel tokens of the Palma dialect. Model (i) analyzes the /u/-/ɔ/ contrast, with /u/ as the reference level; model (ii) analyzes the /u/-/o/ contrast, with /u/ as the reference level; and model (iii) analyzes the /ɔ/-/o/ contrast, with /ɔ/ as the reference level.
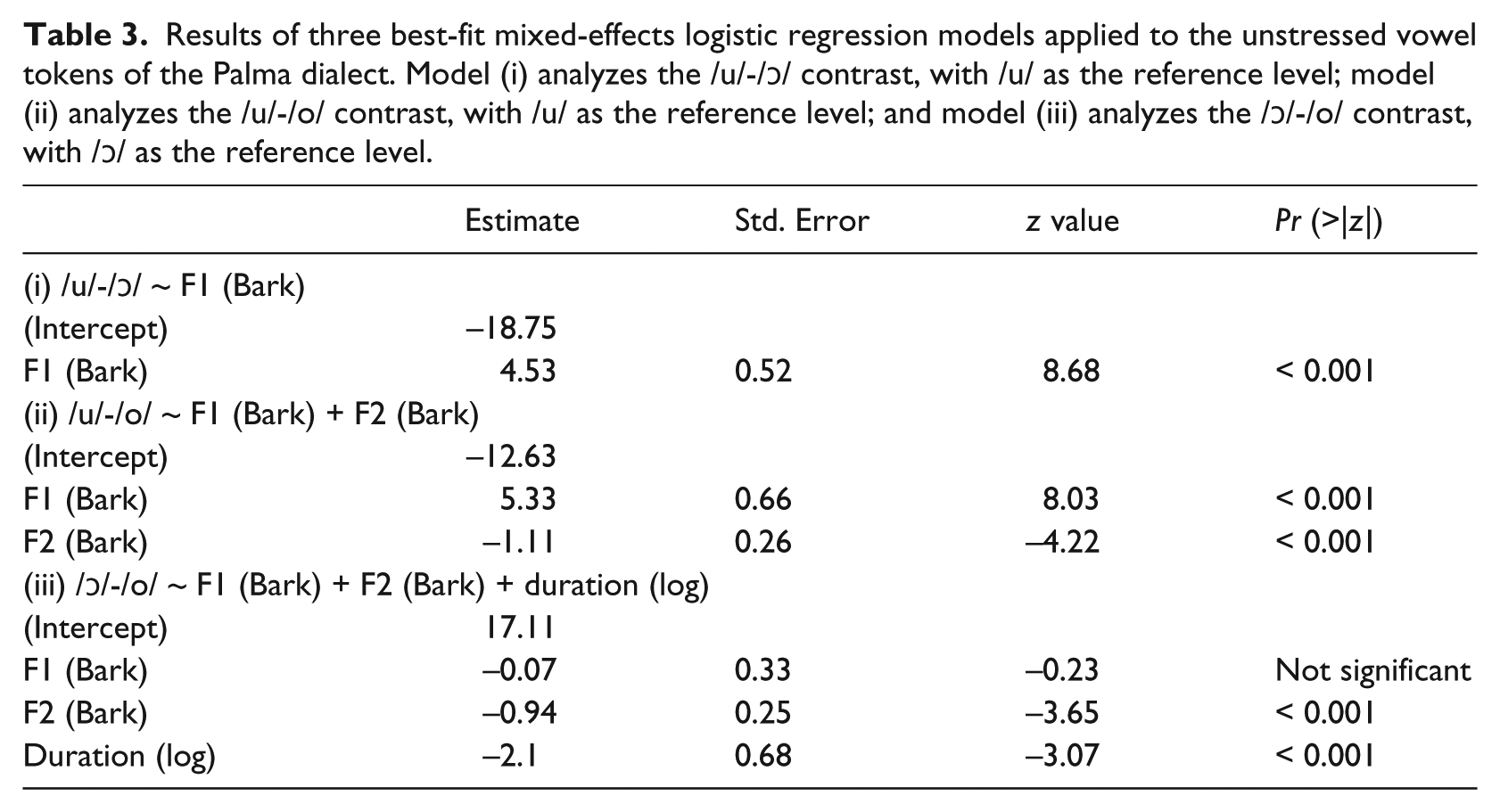
The second comparison focused on the /u/-/o/ contrast, with /u/ as the reference level. The model with the best fit was one in which both height and fronting were used as fixed predictors. Adding duration as a predictor did not lead to any significant change in fit, AIC = 167.73; χ2(1) = 0.07; p > 0.1. A model with height as the sole fixed predictor, AIC = 185.08; χ2(1) = 146.69; p < 0.001, was significantly better than the null model, AIC = 329.77. Adding fronting as a predictor made it slightly better, AIC = 165.8; χ2(1) = 21.27; p < 0.001. The difference between the null model and the model with height as a fixed predictor, in terms of AIC points, is -144.69; that between the height model and the height + fronting one is merely -19.28. A one-unit increase in height led to a change of 5.33 in the log-odds of producing /o/ rather than /u/, a factor of 206.43. Holding height constant, a one-unit increase in fronting led to a decrease of -1.11, a factor of 0.32, in the log-odds of producing /o/ (rather than /u/). Thus, in the dialect of Palma, unstressed /o/ is significantly lower and slightly less fronted than unstressed /u/.
The third, and final, comparison of this subsection is concerned with the /ɔ/-/o/ contrast, for which the regression models took /ɔ/ as the reference level. This time there was no difference between the null model, AIC = 329.77, and the model with height as the sole fixed predictor, AIC = 329.6; χ2(1) = 2.17; p > 0.1. Thus, in Palma, there is no difference in F1 between unstressed /ɔ/ and /o/. However, adding fronting to the model resulted in a very slight, but significant, increase in fit, AIC = 311; χ2(1) = 19.68; p < 0.001. The same was true when adding duration as a fixed predictor, AIC = 301.27; χ2(1) = 12.64; p < 0.001. In terms of AIC points, the difference between the height model, which is not better than the null one, and the height + fronting model is merely -18.6; that between the height + fronting and the height + fronting + duration is only -9.73. According to the values shown in Table 3, a one-unit increase in fronting led to a change of -0.94 in the log-odds of producing /o/ (rather than /ɔ/), a factor of 0.39. Holding fronting constant, a one-unit increase in duration resulted in a change of -2.1 in the log-odds of producing /o/ (rather than /ɔ/), a factor of 0.122. Thus, while /o/ and /ɔ/ do not differ in F1, they differ in F2 and duration, albeit very modestly. Note that, while both fronting and duration yielded significant results, the changes in the log-odds associated with these two predictors, as well as the changes in the AIC values, are very low—though significant, the predictive power of these parameters is slim. In sum, in Palma, unstressed /o/ is as high as /ɔ/—that is, these vowels are merged in terms of height—but it might be slightly further back and slightly shorter than /ɔ/.
2.2.3 Stressed Sóller vowels
The first comparisons focused on the /u/-/ɔ/ contrast. The model with height as the sole fixed predictor, AIC = 9.66; χ2(1) = 327.66; p < 0.001, was better than the null model, AIC = 335.32, which suggests that /u/ and /ɔ/ differ in terms of F1. When adding fronting, the model failed to converge, and the same occurred when adding duration; this may be due to overfit. In order to provide a statistical analysis of the data we proceeded to run paired, by-subject t-tests on the three continuous variables, with vowel phoneme (/u/, /ɔ/) as the two-level factor. The alpha criterion was adjusted accordingly (0.05/3 = 0.016). An analysis of height yielded significant results, t(5) = -20.42; p < 0.001; mean difference = -1.98. A comparable finding was obtained with fronting as the dependent variable, t(5) = -9.41; p < 0.001; mean difference = -1.03, and also with duration, t(5) = -40.06; p < 0.001; mean difference = -0.38. In sum, /ɔ/ is lower and more fronted than /u/, and it is longer.
The second set of comparisons focused on the /u/-/o/ contrast, with /u/ as the reference level. The model with the best fit was the one with both height and fronting as predictors—the results appear in Table 4. Adding duration did not result in any significant improvements, AIC = 105.7; χ2(1) = 1.24; p > 0.5. Adding height, AIC = 110.09; χ2(1) = 228.62; p < 0.001, resulted in a significant improvement over the null model, AIC = 336.71; fronting was also a significant predictor, AIC = 104.95; χ2(1) = 7.13; p < 0.005. In terms of AIC points, the height model led to a difference of -226.62 units relative to the null one; the difference between the height model and height + fronting one was only -5.14. As shown in Table 4, a one-unit increase in height led to a change in the log-odds of producing /o/ (rather than /u/) of 10.1, a factor of 24,343.01. Holding height constant, a one-unit increase in fronting yielded a slight decrease of -0.91, a factor of 0.4, in the log-odds of producing /o/. While it is true that both height and fronting are significant predictors of vowel phoneme (/u/, /o/), height leads to a larger, more robust difference between /u/ and /o/ than fronting does. In sum, /o/ tends to be much lower than /u/, and it is slightly further back.
Results of two best-fit mixed-effects logistic regression models applied to the stressed vowel tokens of the Sóller dialect. Model (i) analyzes the /u/-/ɔ/ contrast, with /u/ as the reference level; and model (ii) analyzes the /ɔ/-/o/ contrast, with /ɔ/ as the reference level. One model, the one exploring the /u/-/o/ contrast, failed to converge.
The third and final comparison in the subsection focuses on the /ɔ/-/o/ contrast, with /ɔ/ as the reference level in the models. The model with the best fit was one in which height was the sole fixed predictor; that is, adding height as a predictor, AIC = 43.78; χ2(1) = 293.54; p < 0.001, resulted in a significant gain over the null model, AIC = 335.32, a difference of -291.54 in terms of AIC units. On the other hand, adding either fronting, AIC = 44.51; χ2(1) = 1.26; p > 0.1, or duration, AIC = 45.86; χ2(1) = 0.65; p > 0.5, failed to affect the fit of the model. As shown in Table 4, a one-unit increase in height produced a change of 16.11 in log-odds of /ɔ/ (over /o/), a factor of 991937.
In sum, the Sóller stressed back vowels /ɔ/, /o/, and /u/ differ from each other in height. This difference is robust. Additional effects of fronting and duration exist, but these fail to differentiate all three vowels from each other, and, even when found to be significant, the differences are much smaller in size than those of height.
2.2.4 Unstressed Sóller vowels
The unstressed back vowels of Sóller were also examined with a series of mixed-effects logistic regression models, with height, fronting and duration as fixed predictors. The first set of models analyzed the /u/-/ɔ/ contrast, with /u/ as the reference level. Adding height to the null model, AIC = 326.9, did not result in any significant improvement, AIC = 328.8; χ2(1) = 0.09; p > 0.1. Thus, in Sóller, /u/ and /ɔ/ are effectively merged in terms of F1. When fronting was added to the set of predictors, however, there was a very slight, but significant, gain, AIC = 324.46; χ2(1) = 6.31; p < 0.05. Adding duration did not significantly affect the fit of the model, AIC = 323.27; χ2(1) = 3.22; p > 0.05. In terms of AIC points, the height + fronting model represented a difference of -4.34 units relative to the height-only model. As shown in Table 5, a one-unit increase in fronting led to a decrease of -0.26, a factor of 0.77, in the log-odds of producing /ɔ/ (rather than /u/). Any effects of the other two acoustic parameters were negligible. Note that, at any rate, the change in the log-odds triggered by fronting is extremely low, as well as the change in the AIC.
Results of three best-fit mixed-effects logistic regression models applied to the unstressed vowel tokens of the Sóller dialect. Model (i) analyzes the /u/-/ɔ/ contrast, with /u/ as the reference level; model (ii) analyzes the /u/-/o/ contrast, with /u/ as the reference level; and model (iii) analyzes the /ɔ/-/o/ contrast, with /ɔ/ as the reference level.
The second comparison focused on the /u/-/o/ contrast, with /u/ as the reference level. Once again, height was not a significant predictor, AIC = 326.79; χ2(1) = 0.67; p > 0.1—when it was added as a predictor, the fit did not improve over the null model, AIC = 325.47. Adding fronting, on the other hand, did result in a significant, but very modest, increase in fit, AIC = 301.55; χ2(1) = 27.23; p < 0.001. Finally, duration did not prove to be a significant predictor, AIC = 303.51; χ2(1) = 0.04; p > 0.5. The height + fronting model led to a difference of -25.24 AIC units relative to the height-only model. As shown in Table 5, a one-unit increase in fronting yielded a change of -0.57 in the log-odds of producing /o/ (rather than /u/), a factor of 0.56. In sum, in the dialect of Sóller, /u/ and /o/ are merged in terms of height and duration, but they differ very modestly in terms of fronting: /o/ tends to be slightly further back than /u/.
The final comparison was concerned with the /ɔ/-/o/ contrast, with /ɔ/ as the reference level. A model in which height was the sole fixed predictor, AIC = 319.26; χ2(1) = 1.42; p > 0.5, was not significantly better than the null model, AIC = 318.68. Therefore, height cannot be claimed to account for any of the variance; or, in other words, unstressed /ɔ/ and /o/, in the dialect of Sóller, are fully merged in terms of F1. Adding fronting as a predictor increased the fit of the model, albeit minimally, AIC = 311.58; χ2(1) = 9.67; p < 0.01. The same may be said of duration: adding it had a significant, though very modest, effect, AIC = 309.01; χ2(1) = 4.56; p < 0.05. The difference between the height-only model and the height + fronting one is merely -7.68; and that between the height + fronting and the height + fronting + duration models is also only -2.57. The values in Table 5 show that a one-unit increase in fronting led to a change of -0.39 in the log-odds of producing /o/ (as opposed to /ɔ/), a factor of 0.675. Holding fronting constant, a one-unit increase in duration changed the log-odds of producing /o/ (rather than /ɔ/) by -1.04, a factor of 0.353. While the changes in the log-odds triggered by both fronting and duration yielded significant findings, it is fair to say that these effects were exiguous—and the small changes in the AIC confirm this. In sum, /ɔ/ and /o/ were found to be fully merged, in the dialect of Sóller, in terms of height, but /o/ was found to present a slight tendency to be further back and shorter in duration than /ɔ/.
2.3 Interim discussion
The goal of the production experiment was to verify, with acoustic data, whether traditional phonological and dialectological descriptions of the vowel systems of the two Majorcan Catalan dialects under investigation here would stand experimental, quantitative scrutiny. The production study fundamentally confirmed the dialectological descriptions, with some caveats.
First, this experiment found that the variety of Majorcan Catalan spoken in Palma, here representing the more general Majorcan Catalan pattern, has a phonological system with three back vowel phonemes (/ɔ/, /o/, /u/) that are produced as distinct phonetic categories ([ɔ], [o], [u], respectively) only in stressed position. These three back vowels, in this dialect, differ very robustly in F1, and slightly in F2. Duration is also different in /ɔ/ and /o/. The three categories are (almost) reduced to two categories in unstressed position. In unstressed position, /u/ remains different from both /ɔ/ and /o/, and this difference is large in terms of F1, yet slim in terms of F2. The traditional description for this dialect claims that /ɔ/ and /o/ are fully merged in unstressed position. Our analyses indicate that the /ɔ/-/o/ merger is complete, in this dialect, in terms of vowel height (F1). Vowel height is the most robust acoustic correlate of the /ɔ/-/o/ contrast in stressed position, and yet this difference disappears when these two vowels are in unstressed position. Our statistical analyses, on the other hand, suggested that the Palma /ɔ/-/o/ merger is incomplete in terms of two remaining acoustic parameters, namely, F2 and duration. While significant differences remained between these two phonemes with regards to F2 and duration, it is fair to say that these differences are minor—in a regression analysis, the predictive power of these parameters was found to be very small.
Second, it was also found that the three back vowel phonemes (/ɔ/, /o/, /u/) are indeed pronounced in three different acoustic–statistical clouds in the dialect of Sóller. The major correlate differentiating these three vowels is, once again, F1. There were, however, other differences: F2 and duration also served to distinguish /u/ from both /ɔ/ and /o/, but these differences were very small. The latter two vowels are distinct only in terms of F1. The three categories are (almost) reduced to one category in unstressed position. The traditional description for this dialect claims that /ɔ/, /o/, and /u/ are all merged to [u] in unstressed position. Indeed, we detected absolutely no statistical difference between any of these three vowels in terms of F1—the merger, in terms of vowel height, is thus complete. It is fair to say, however, that none of these three vowels were fully merged if we take into account F2 and duration. The high vowel phoneme, /u/, remains distinct from both /ɔ/ and /o/ in terms of F2 (but not duration), and /ɔ/ differs from /o/ in terms of both F2 and duration. An examination of our statistical analyses, however, led us to conclude that the remaining F2 and duration differences in unstressed position are rather minor—they have very low predictive power.
In sum, with respect to the acoustic feature responsible for the largest, most robust differences between the three back vowels of Majorcan Catalan, F1, the Palma unstressed /ɔ/-/o/ merger and the Sóller unstressed /u/-/ɔ/-/o/ merger may be claimed to be complete. Full acoustic neutralization, however, is not obtained due to remaining (very minor) differences in F2 and duration. We now move on to an investigation of the patterns of auditory lexical processing that could be affected by the phonological processes described in this production experiment.
3 Experiment 2: lexical processing
The second step in our study was to investigate the auditory processing of words involved in the phonological alternation that concerns us here. The experimental paradigm used was the cross-modal identity priming paradigm. For this experiment, two groups of Majorcan Catalan speakers, a group from Palma and a group from Sóller, heard auditory stimuli representing words and pseudo-words while performing lexical decisions on Catalan words and pseudo-words shown to them in standard written form on a computer screen. The two groups of participants listened and responded to the same stimuli. Auditory forms of words that had unstressed /o/ or /ɔ/ (e.g., /o/, pometa ‘little apple’; /ɔ/, coseta ‘little thing’) were played with either [o], characteristic of Palma speech (p[o]meta, c[o]seta), or [u], characteristic of Sóller speech (p[u]meta, c[u]seta). A crucial aspect of this study is that it aims to explore whether words with unstressed /o/ and /ɔ/ are as likely to be primed by auditory stimuli with [o] as by auditory stimuli with [u], and whether there is a difference in this respect vis-à-vis the dialect spoken by the participants.
3.1 Method
3.1.1 Participants
A total of 40 participants took part in the experiment. All of them were native speakers of Majorcan Catalan, aged between 18 and 35 years, with no reported hearing, reading or language impairment. Like the speakers who participated in Experiment 1, the listeners in Experiment 2 were Catalan–Spanish bilinguals. These bilinguals were dominant in Catalan as well—they were raised in Catalan-speaking households, they continued to use Catalan much more frequently than Spanish in their adult life, and they maintained tight social networks mostly with other Catalan speakers.
The participants were divided into two groups according to their place of residence. One group consisted of 20 participants who were born, raised, and currently resided in the village of Sóller. The other 20 participants were born and raised in Palma, where they were also residing when the experiment was conducted. None of the participants had lived outside of the island of Majorca, or even outside of their hometown, for any significant period of time. Participants did not receive any compensation for their participation in the study. 5
3.1.2 Materials
The experimental task we used in this study was the cross-modal priming paradigm—primes were auditory stimuli and targets were visual stimuli. The task itself was a lexical decision task, in which participants were asked to indicate as quickly and accurately as possible whether each item in a list of letter strings shown to them on a computer screen (one string per trial) corresponded to an actual Catalan word or not. Auditory stimuli containing words or pseudo-words were played in each trial some milliseconds before the target visual stimuli were shown on a computer screen—the auditory stimuli thus constituted the “primes.” Participants were told not to perform any action on the auditory stimuli and respond solely to the letter strings shown to them.
The auditory stimuli included 80 trisyllabic Catalan words ending in the derivative suffix -eta [ˈətə], a diminutive morpheme (e.g., coseta [koˈzətə] ‘little thing’), and 40 pseudo-words ending also with the sequence [ˈətə] that resembled diminutive words. The stress-bearing suffix -eta displaces the lexical stress from the stem to the first vowel of the suffix (e.g., cosa [ˈkɔzə] ‘thing’, coseta [koˈzətə] ‘little thing’). The target auditory stimuli in the experiment consisted of words whose first syllable contained a mid-back vowel phoneme, /ɔ, o/. Words with /u/ were not tested. The phonetic realization of these two vowel phonemes in unstressed position—but not in stressed position—differs as a function of the two dialects under investigation and thus constitute the focus of this experiment. The high-back vowel phoneme, /u/, was not examined because both dialects implement this vowel phoneme in the same way, [u].
The target auditory stimuli consisted of a total of 20 diminutive word forms also used in Experiment 1: 10 of them were morphologically related to disyllabic words with a mid–high back vowel phoneme in the first syllable (/o/, e.g., poma [ˈpomə] ‘apple’) and the other 10 were morphologically related to disyllabic words with a mid–low back vowel in the first syllable (/ɔ/, e.g., cosa [ˈkɔzə] ‘thing’). In other words, although the timbre of the vowel in the first syllable was to be manipulated experimentally (see below), the 20 target auditory stimuli differed in that 10 of these had an “underlying” /ɔ/ (stress-induced alternating pronunciations in both dialects) while the other 10 possessed an “underlying” /o/ (stress-induced alternating pronunciations only in Sóller). 6 Importantly, the /o/-words did not differ from the /ɔ/-words in terms of relative lexical frequency. Relative frequencies were extracted from the Corpus Textual Informatitzat de la Llengua Catalana (Rafel, 1998) by means of the lexical-stimuli search engine NIM (Guasch, Boada, Ferré, & Sánchez-Casas, 2013). A t-test with relative lexical frequency as dependent variable and vowel phoneme (/o/, /ɔ/) as factor failed to reveal any significant differences in relative lexical frequency between the two groups of items (t < 1).
The 20 target lexical items were presented as auditory primes in two different acoustic forms: (i) as they are produced in most varieties of Majorcan Catalan, including Palma (pometa [poˈmətə] ‘little apple’, coseta [koˈzətə] ‘little thing’); and (ii) as they are produced in the regional variety spoken in the town of Sóller (pometa [puˈmətə] ‘little apple’, coseta [kuˈzətə] ‘little thing’). In other words, both the target /ɔ/- and /o/-words were presented with [o] and with [u] in random order. A cross-tabulation of the crucial aspects of the design is shown in Table 6. Listeners thus heard target words presented in auditory forms typical of how they are produced in their own dialectal variety as well as how they are produced in the other variety.
Design of experimental materials (base word forms, phonological forms or “underlying representations”, spelling, and auditory stimuli forms) used in the cross-modal priming task (Experiment 2). All participants heard all auditory stimuli forms, [o]- as well as [u]-forms, before visual targets, represented here by the spelling column. The [o]-forms represent the pattern used in Palma (as well as most Majorcan Catalan varieties), and the [u]-forms represent the pattern used in Sóller.

The auditory stimuli were recorded in a quiet room by a female speaker of Majorcan Catalan from Sóller. The recording equipment consisted of a Sound Devices USBPre 2 interface and a condenser AKG C520 head-mounted microphone. The recordings were sampled at 44.1 kHz with 16-bit quantization. The talker produced both the [u]- and [o]-forms of all of the lexical items. The distinction in vowel timbre between the two types of auditory stimuli was assessed through an independent samples t-test with F1 values in Hz as a function of vowel timbre ([o], [u]) as fixed factor. The analysis revealed a main effect of vowel timbre, t(19) = 19.02, p < 0.001, showing that the F1 values for the [u]-form tokens, mean (M) = 344.6 Hz, range = 328–384 Hz, significantly differed from those of the [o]-forms, M = 467 Hz, range = 420–531 Hz. Notice that the ranges do not overlap.
The visual targets for the experimental pairings, those upon which participants made lexical decisions once having heard the auditory primes, were the words’ spellings in standard Catalan orthography. Visual word forms were shown in capital letters (e.g., POMETA, and COSETA). In standard Catalan orthography, both /ɔ/ and /o/ map to grapheme <o>, irrespective of whether, in pronunciation, these vowel phonemes are merged or not. Phonemic vowel /u/ maps to grapheme <u>; however, when [u] is used as the unstressed version of /ɔ/ or /o/ the spelling does not change. In other words, both poma [ˈpomə] ‘apple’ and cosa [ˈkɔzə] ‘thing’ are spelled with <o> as well as both pometa [poˈmətə]/[puˈmətə] ‘little apple’ and coseta [koˈzətə]/[kuˈzətə] ‘little thing’.
A total of 40 target experimental trials (prime-target pairs) were used. These were divided into two experimental conditions: (i) 20 trials in which participants heard the [o]-form primes and then saw the target words in their standard spelling (e.g., [koˈzətə] → COSETA); and (ii) 20 trials in which they heard the [u]-form primes and then they saw the target words in their standard spelling (e.g., [kuˈzətə] → COSETA). All participants, irrespective of whether they were from Palma or Sóller, were exposed to all 40 target experimental trials. Recall that each condition contains two lists of words, those that have an “underlying” /o/ and those that have an “underlying” /ɔ/.
As controls for the experimental prime-target pairs, we included 20 diminutive word forms to be used as unrelated auditory primes; this provided us with a same-target (different-prime) baseline for potential priming effects in the two experimental conditions. These control auditory stimuli were presented as unrelated auditory primes to the same visual targets used in the two experimental conditions (e.g., tarteta [təɾˈtətə] ‘little pie’ → COSETA ‘little thing’). The unrelated primes differed from the experimental stimuli in that they were all derived from disyllabic words that did not have a back vowel as the vowel phoneme in their first unstressed syllable. The control auditory primes were all formed by adding the diminutive suffix to disyllabic words that had an /a/ as the vowel phoneme in their first syllable—/a/ becomes schwa in unstressed position in all eastern Catalan dialects, including all varieties of Majorcan Catalan. The control items were checked for lexical frequency so that their relative lexical frequency did not differ from that of the items selected for the experimental condition. A t-test with relative lexical frequency as a function of condition (experimental, control) failed to show an effect (t < 1).
In addition to the 40 experimental pairs (trials) and the 20 control pairs (trials), 240 filler pairs were included. Half of the filler pairs (n = 120) contained real-word visual targets and the other half (n = 120) had pseudo-word visual targets. All of the visual stimuli, including the pseudo-words, ended with the diminutive suffix –eta. A list of 40 additional diminutive words and a list of 40 pseudo-words were created to be used as real-word and pseudo-word fillers, respectively. The 40 real-word diminutives used as fillers were derived from disyllabic feminine words that did not contain any of the back vowels (/o, ɔ, u/) or /a/ as the vowel phoneme in the first syllable (e.g., nina ‘girl’, festa ‘party’). The 120 filler pairs that had real-word written targets were organized in the following way: (i) 40 pairs were identity trials, that is, the auditory prime was followed by the orthographic representation of the word played (e.g., [niˈnətə] ‘little girl’ → NINETA ‘little girl’); (ii) 40 pairs had pseudo-word auditory “primes” and real-word visual targets (e.g., [gləˈɾətə] ‘pseudo-word’ → NINETA ‘little girl’); and (iii) the remaining 40 pairs had visual targets preceded by another item from the diminutive word list (e.g., [fesˈtətə] ‘little party’ → NINETA ‘little girl’). Regarding the 120 fillers with pseudo-word visual targets, 40 were identity trials (e.g., [bəɾˈsətə] ‘pseudo-word’ → BERSETA ‘pseudo-word’), 40 had real-word auditory “primes” (e.g., [niˈnətə] ‘little girl’ → BERSETA ‘pseudo-word’), and 40 had visual pseudo-word targets preceded by another item from the pseudo-word list (e.g., [vəˈmətə] ‘pseudo-word’ → BERSETA ‘pseudo-word’).
To summarize the main aspects of the design, the crucial data come from three types of trials: (i) [o]-forms: real auditory primes with [o] as the vowel in the first syllable, both for /ɔ/- and /o/-words (/ɔ/: coseta [koˈzətə] ‘little thing’ → COSETA ‘little thing’; /o/: pometa [poˈmətə] → POMETA ‘little apple’); (ii) [u]-forms: real auditory primes with [u] as the vowel in the first syllable, both for /ɔ/ and /o/-words (/ɔ/: coseta [kuˈzətə] ‘little thing’ → COSETA ‘little thing’; /o/: pometa [puˈmətə] → POMETA ‘little apple’); and (iii) the control condition, with unrelated auditory primes and visual targets identical to conditions (i) and (ii) (tarteta [təɾˈtətə] ‘little pie’ → POMETA ‘little apple’; tarteta [təɾˈtətə] ‘little pie’ → COSETA). The remaining trial types are considered fillers.
3.1.3 Procedure
Participants carried out the task individually in a quiet room. Each trial started with a fixation cross shown for 400 milliseconds (ms) on the center of the screen. Immediately after that, the auditory prime was played, followed by the visual target. The stimulus onset asynchrony was set at 1200 ms, with all auditory stimuli lasting between 800 and 850 ms, which resulted in inter-stimulus intervals of 350 to 400 ms. Participants were asked to make a lexical decision concerning the visual target, as fast and accurately as possible, by pressing one of two labeled buttons on an iHome USB Numeric Keypad (IMAC-A210S) connected to a laptop computer.
Response times (RTs) were measured from the onset of the visual stimulus until the pressing of a key. If participants did not provide an answer within two seconds, a new trial was initiated. The auditory stimuli were presented over closed headphones (AKG K77) connected directly to the laptop. The experiment was administered using PsychoPy2 (Peirce, 2007). The presentation of the stimuli was randomized so that each participant responded to them in a different order. A short practice session consisting of twelve prime-target pairs—six-word and six-pseudo-word targets and primes not included in the study—was completed before the experiment. Including the practice trials, the experiment took approximately 20 minutes.
3.1.4 Data analysis
The dataset contained 2400 responses, 60 responses to crucial trials × 40 participants. Following Ranbom and Connine (2007) and others, RTs faster than 300 ms and slower than 1500 ms were discarded (2.5%). One participant was replaced because of high error rates (above 20%). Furthermore, only correct responses were included in the analysis (92.8% of the data). These data selection criteria resulted in a final dataset of 2226 (2400 – 174) responses to the three target conditions per phoneme, a total of six target conditions per participant.
The factor phoneme or underlying representation has two levels (/o/-words, /ɔ/-words) and the factor phonetic form has three levels ([o]-forms as primes, [u]-forms as primes, and unrelated primes.) This results in a (2) × (3) design. The unrelated condition includes the trials in which the target lexical items were preceded by unrelated primes. We predict no priming in this case; this allows us to compare for each participant (and for each lexical item) this condition with the two other conditions, and to interpret the RTs for each participant. Since we included dialect group as a factor in the analysis, this results in a (2) × (3) × 2 design.
We submitted our response time data to linear mixed-effects regression modeling. We began with a null model—one in which there were no fixed factors, but simply a random effects structure with random intercepts for subject and item. Follow-up analyses considered each of the fixed factors separately (phoneme, phonetic form, and dialect) and compared these with the null model. We subsequently explored more complex models—those formed by two or three fixed predictors and their interactions—until we found the minimal, simpler model that was significantly better (i.e., accounted for significantly more variance) than any simpler models. This was done via nested model comparison. Once we found the “best” model, we maximized the random effects structure to include random intercepts and slopes as appropriate to the design (Barr, Levy, Scheepers, & Tily, 2013). The metric in all cases is logarithmic RTs (i.e., the logarithm of RT in ms) from the onset of the visual cue.
3.2 Results
3.2.1 All trials
Our first linear mixed-effects regression model consisted of a null model—one with no fixed factors and only a basic random effects structure (random intercepts for subject and item). Adding dialect group as a fixed factor did not improve the fit of the model, AIC = 563.8; χ2(1) = 2.37; p > 0.1, and neither did adding phoneme, AIC = 566.1; χ2(1) = 0.19; p > 0.6. On the other hand, a model with phonetic form (of the prime) as a predictor was significantly better than the null model, AIC = 84.1; χ2(2) = 484.2; p < 0.001. The next step was to explore any potential two-way interactions between phonetic form and phoneme, on the one hand, and phonetic form and dialect group, on the other. A model in which both phonetic form and phoneme (and their interaction) were declared as fixed factors was not able to significantly predict any more variance than a model with only phonetic form as a predictor, AIC = 88.1; χ2(3) = 1.97; p > 0.5. On the other hand, a model in which phonetic form and dialectal group (and their interaction) were declared as fixed factors was significantly better than a model with only phonetic form as a predictor, AIC = 72.2; χ2(3) = 17.79; p < 0.001. The final step was to compare this two-factor model to a three-factor one in which phonetic form, dialect group and phoneme (and all their two- and three-way interactions) were declared as fixed predictors. The latter, more complex model was not found to be significantly better than the simpler two-factor model, AIC = 81.2; χ2(6) = 3.01; p > 0.8. We conclude that a statistical exploration of our response time data suggests the existence of significant phonetic form effects and a significant interaction between phonetic form and dialect group. No other significant effects were found.
The next step was to explore the basic model—that with phonetic form, dialect group and their interaction—to better understand the structure of the data. In order to do so, we maximized the random effects structure of this model and refitted it. The random effects structure included random intercepts for both subject and item, random slopes for subject over phonetic form, and random slopes for item over both phonetic form and dialect group. The alpha criterion was set at t > 2 or t < -2. In this model, the control condition (unrelated primes) as responded to by the Palma group was the intercept. For the Palma group (the intercept group), [u]-form primes triggered faster RTs than unrelated primes did, β = -0.158, t = -5.56—a difference of an estimated 106 ms—as did [o]-form primes, β = -0.274, t = -10.4—a difference of an estimated 188 ms. Moreover, while there was no significant difference between the [o]-form primes as responded to by the Sóller versus the Palma group, β = -0.006, t = -0.19, the model detected a significant difference between the two groups in how they responded to the [u]-form primes, β = -0.087, t = -2.25, with Sóller listeners being faster than Palma listeners in this priming condition—an estimated difference of 55 ms. This, arguably, is the cause of the interaction between phonetic form (of the prime) and dialect group reported above. In sum, both [u]- and [o]-form primes triggered faster RTs than unrelated primes, and this was true for both groups of participants. Furthermore, Palma and Sóller listeners were similarly affected by [o]-form primes—that is, they were similarly fast in this condition—but Sóller listeners were faster than Palma listeners when responding after being presented with [u]-form primes.
The analysis reported immediately above allows us to make between-group comparisons for the [u]- and [o]-form conditions. With regards to within-group comparisons, however, we can only establish how both [u]- and [o]-form primes differed from unrelated primes (controls), but not how they differed from each other. In order to look into this question, we extracted two data subsets, one for each dialect group, with only the [u]- and [o]-form primes condition—that is, without the unrelated primes. We ran two linear-mixed effects regression models, one on each data subset, with phonetic form (of the prime) as a fixed predictor and with the maximal random effects structure justified by the design. The model that explored the Palma data showed that, for these participants, [o]-forms triggered faster RTs than [u]-forms, β = -0.116, t = -4.5—an estimated difference of 82 ms. On the other hand, there was no significant effect of phonetic form (of the prime) for the Sóller listeners, β = -0.034, t = -1.7—that is, they responded similarly fast after [u]- and [o]-form auditory primes.
To summarize, Sóller listeners showed comparable priming for the two variants examined, the one they produce ([u]-forms) and the one found in Palma ([o]-forms), while Palma listeners were robustly primed only by the variant they produce ([o]-forms). In fact, relative to the unrelated primes, Palma listeners were also primed by the [u]-form primes. This effect, however, was much smaller than that for [o]-form primes, and much smaller than any of the two effects found for the Sóller listeners. Figure 2 plots the by-subject, by-condition means (and 95% confidence interval) for the two groups of listeners.
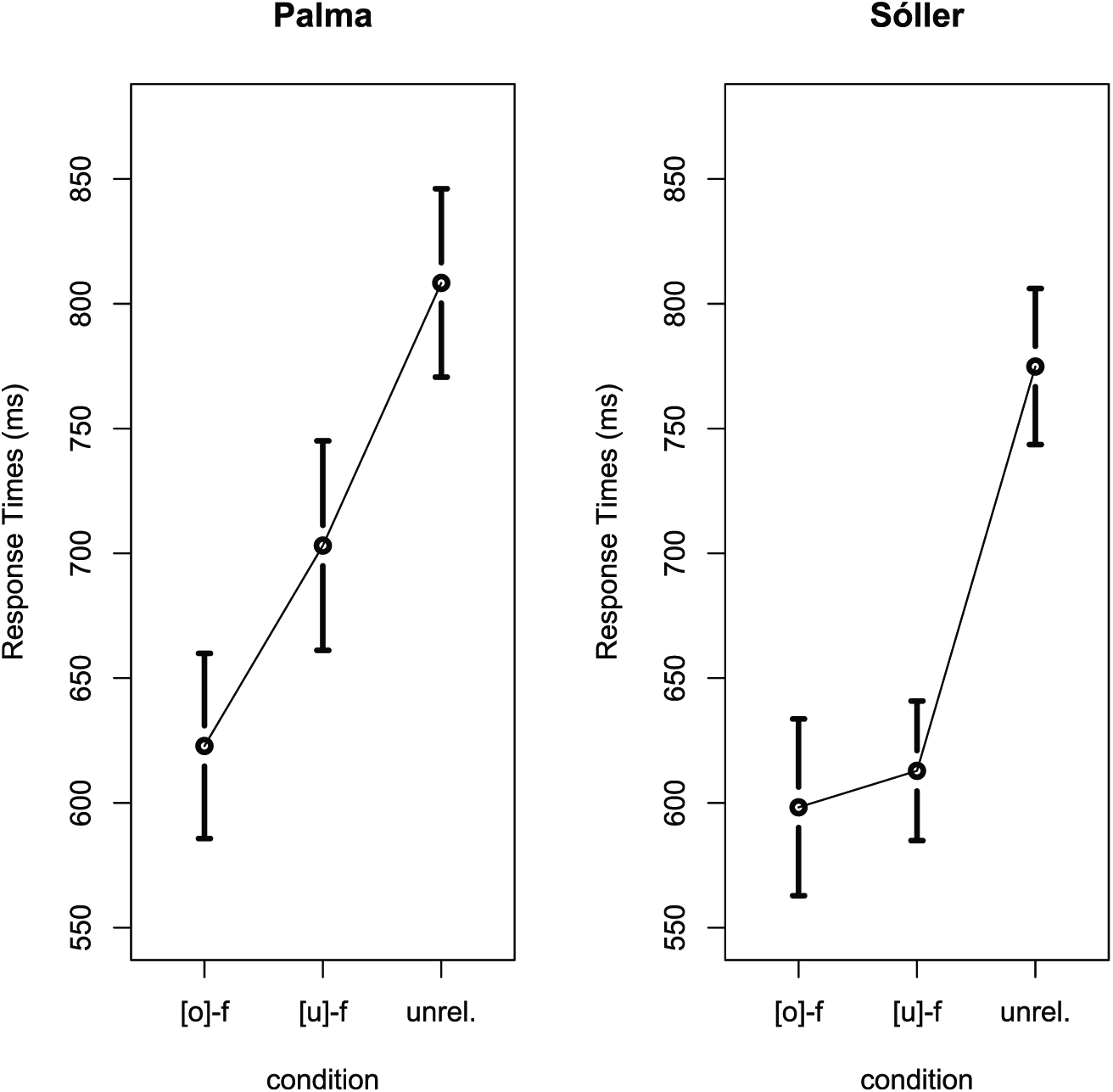
Pooled by-subject means (and 95% confidence intervals) of response times (ms), to visual targets in each of three experimental (or auditory priming) conditions as a function of the (sub)dialect of the listeners (Palma, Sóller). The priming conditions are as follows: (i) primes with [o]-forms ([o]-f), characteristic of Palma; (ii) primes with [u]-forms ([u]-f), characteristic of Sóller; and (iii) unrelated primes, which serve as an anchor to interpret the other two conditions.
In this subsection we have analyzed the response-time patterns as they arise from all the trials, as responded to by all participants. The trials were presented to the listeners in random order within a single block. We have focused on the priming effects within each trial, those found on the response to the visual stimulus and presumably caused by the immediately preceding auditory prime. The fact remains, however, that each visual stimulus was presented three times throughout the experimental block, in random order. Therefore, it is possible that, above and beyond any immediate priming effects, there are medium-term priming effects—those triggered on the second and/or third encounter of each of the visual targets by the first encounter. It is our opinion that any medium-term priming effects should have reduced the significant effects we report in this subsection rather than caused them. In any case—and to be certain of our findings—the following subsection reports on an analysis of only the first encounter of each of the visual targets, in whatever priming condition it was. The dataset is therefore reduced to approximately a third of its original size.
3.2.2 First encounter data
From the original dataset of 2226 trials explored in the preceding section, we selected 723 trials: the 723 trials that represented the first encounter of each participant with the target (visual) lexical items included in the study. We explored these data by means of mixed-effects regression modeling. RTs were log-transformed for analysis.
The primary goal of this analysis is to verify whether first-encounter data are in line with what was found for the entire dataset. It is not our intention to submit this subset of data to a full analysis, as was done above on the entire dataset. Thus, we focus on an analysis of phonetic form (of the prime) and dialect group, as well as their potential interaction, since this is what was found in the preceding section. The random effect structure included random intercepts and slopes for both subject and item.
A regression model with phonetic form as a predictor was significantly better than a null model with no fixed factors, AIC = 51.8; χ2(2) = 157.6; p < 0.001, thus justifying the retention of phonetic form as a fixed factor. A model with both phonetic form (of the prime) and dialect group, in addition to their interaction, was significantly better than one with only phonetic form as a predictor, AIC = 40.1; χ2(3) = 17.6; p < 0.001. These findings corroborate those reported in the preceding section. In particular, the latter model confirms that, for the Palma listeners, both [o]-form, β = -0.29, t = -8.7, and [u]-form, β = -0.11, t = -3.1, primes trigger faster responses than unrelated primes. On average, for these participants, the [o]-form condition is 222 ms faster than the control condition, and the [u]-form one is 87 ms faster than the control. Regarding the Sóller listeners, it was found that their RTs in the [o]-form condition did not differ from those of the Palma listeners (in the same condition), β = -0.008, t = 0.17. Their RTs in the [u]-form condition, on the other hand, were indeed faster—by an estimated 75 ms—than those of the Palma listeners (in the same condition), β = -0.126, t = -2.59. Once again, these findings coincide with those reported in the preceding section.
In order to explore the potential differences between [u]- and [o]-form conditions for the two groups of listeners, we extracted two data subsets, one from each dialect group. These data subsets excluded the control condition (unrelated primes). In the Palma data subset, there was a significant effect of phonetic form, β = -0.180, t = -4.8, with [o]-form primes triggering faster RTs than [u]-form primes—an estimated difference of 131 ms. In the Sóller subset, on the other hand, there was no effect of phonetic form of the prime—both prime types triggered similarly fast responses.
To summarize, the analysis of only the first encounter of each of the visual targets—that is, the first iteration, in whatever condition it appeared—replicated the findings of the main analysis reported above: Sóller listeners showed comparable priming for the two variants examined, the one they produce ([u]-forms) and the one found in Palma ([o]-forms), while Palma listeners were robustly primed only by the variant they produce ([o]-forms). In fact, this crucial difference between dialects seems to be even more robust, with a larger effect size, in the subset analysis than in the main analysis. Judging by both the response time data and the effect sizes, Palma listeners show smaller priming effects faced with [u]-forms in the first-encounter data subset than in the main analysis (the full data set), with response time values in this condition approximating more those of the unrelated condition. For these participants, the differences in average RTs triggered by [u]- and [o]-form primes are much larger in the first-encounter data subset than in the full dataset. Sóller listeners, on the other hand, show almost identical results in both analyses.
3.3 Interim discussion
The results of the cross-modal identity priming experiment showed that participants from the two groups exhibited asymmetrical patterns of response to the two relevant experimental conditions. On the one hand, the participants from Sóller showed comparable priming effects in the two experimental conditions; that is, both the [u]-forms (characteristic of Sóller speech) and the [o]-forms (characteristic of Palma speech) facilitated visual word recognition strongly, and similarly. This suggests that these participants were equally effective at accessing their mental lexical entries for the experimental items when these had been auditorily preceded by any of the two phonetic variants under scrutiny, their own and that of the neighboring dialect. On the other hand, the participants from Palma were more strongly primed by their own phonetic variant (i.e., [o]-forms) than by the one used in the village of Sóller (i.e., [u]-forms). For the Palma speakers, the Sóller variant failed to facilitate the recognition of the written form to the same extent as the general Majorcan Catalan (their own) variant did, even though the former triggered moderate priming effects for these participants. These relatively small priming effects could be attributed to the overall phonological similarity between the two variants beyond the presence of the “anomalous” [u] 7 , to the influence of exposure to standard Central Catalan form, in addition to any exposure to Sóller Catalan these listeners may have had, or to a combination of all these factors. We will return to this issue in the Discussion section.
Taken together, these findings suggest that linguistic experience with the different variants has an impact on the processing of this instance of systematic phonological variation. Listeners who had not been extensively exposed to the variety exhibiting a back-vowel reduction pattern diverging from the general norm of Majorcan Catalan did not display robust facilitatory effects when presented with forms from that variety. Listeners from a regional variety that systematically raises unstressed /o/ and /ɔ/ to [u], on the other hand, were found to show comparable priming effects for forms from their own (regional) variety and forms produced following the (more general) reduction pattern of Majorcan Catalan.
4 Discussion
4.1 Summary of findings
The present study had two main goals: (i) to verify that the traditional phonological descriptions for the two dialects under study stand acoustic scrutiny; and (ii) to explore the effects of dialectal experience on word recognition when different dialects are affected by diverging (morpho)phonological alternation patterns. Our first goal was addressed via a controlled production experiment. In the first place, the study confirmed that Palma Catalan has three back-vowel phonemes (/ɔ/, /o/, /u/) that are produced as distinct phonetic categories ([ɔ], [o], [u], respectively) in stressed position but reduced to two categories in unstressed position; in particular, in this dialect, /ɔ/ and /o/ are merged to [o] and /u/ is produced as [u]. This is what an examination of F1 revealed—and our analysis demonstrated that F1 is the primary acoustic correlate of the /ɔ/-/o/-/u/ contrast. When two secondary acoustic correlates of this back-vowel contrast were included in the regression models (F2 and duration), it was found that, in unstressed position, /ɔ/ and /o/ are distinct—the predictive power, and therefore the effect size, of these acoustic parameters is, however, very modest. Thus, while there is full neutralization in the primary acoustic correlate of this contrast, neutralization is incomplete in two secondary correlates. Secondly, regarding Sóller Catalan, it was found that the three back vowel phonemes (/ɔ/, /o/, /u/), also produced as three distinct categories in stressed position ([ɔ], [o], [u], respectively), merge into a single phonetic category ([u]) in unstressed position. Once again, this is what an examination of the primary acoustic correlate of the /ɔ/-/o/-/u/ reveals, but the facts are more nuanced once one takes into account secondary correlates such as F2 and duration. That is, while unstressed /ɔ/, /o/, and /u/, in Sóller, are fully merged (to [u]) in terms of F1, these three vowel phonemes are all slightly distinct from each other in F2 and/or duration. One must take into consideration, however, that all remaining F2 and/or duration differences are very small.
The word recognition study asked whether regular phonological alternations differing as a function of dialect lead to processing costs during auditory lexical access in within- versus between-dialect listening situations. This question was addressed via a cross-modal lexical decision task, whose results were as follows: firstly, Palma listeners were more robustly primed by the phonetic variants characteristic of their own dialect than by those characteristic of the Sóller dialect. That is, auditory primes in the form of their own dialect led to faster recognition of visual words than auditory primes in the form of the neighboring dialect. Secondly, Sóller listeners were equally primed by the phonetic variants of words characteristic of their own dialect and those of the neighboring dialect. That is, auditory primes in both phonetic forms led to identical rates of recognition speed of the visual targets. In sum, the effects of dialectal familiarity resulted in a revealing asymmetrical priming pattern.
4.2 Interpretation and implications
Our production study asked whether a categorical phonological rule—one that entails full positional neutralizations—serves as an adequate description of the phonological processes that are said to affect the two Majorcan Catalan dialects investigated here. In other words, we were concerned with whether there is evidence for incomplete neutralization in the vowel reduction patterns that affect the two dialects that concern us here.
Does our study provide evidence for incomplete neutralization in the back-vowel merger processes of Majorcan Catalan? Possibly, but the evidence is neither conclusive nor compelling. The only acoustic correlates for which differences remained in unstressed position were secondary, namely, F2 and duration. A study of the primary acoustic correlate of the /ɔ/-/o/-/u/ contrast (F1) fundamentally confirms prior dialectological descriptions for both dialects. Consider the findings regarding duration. The range of durational differences amongst vowel phonemes in unstressed position was in the order of 5 to 7 ms. (As a comparison, note that the average difference between stressed and unstressed vowels in this dataset is 35.7 ms, a difference approximately 6 times larger.) It is therefore possible that such small but statistically significant durational differences are not perceptible, which would make them uninformative in any attempt to distinguish the unstressed vowels under study. Although this is quite plausible, establishing it would require further perceptual testing that we are unable to provide at this juncture. Consider as well the fact that speech rate was not controlled, and this obviously may have affected segmental durations. The three vowel phonemes were instantiated in various words, with the consequence of having unbalanced consonantal contexts in the different conditions. Consonantal contexts, as well as syllable compositions, are known to affect vowel durations (e.g., Katz, 2012). Minor differences in duration, such as the ones found here, could thus be attributed to the effects of the consonants in the context rather than to the phonological contrast between these three phonemes.
Now consider the findings regarding F2. It has been found that the assimilatory effects of contextual consonants are maximally reflected in F2 rather than in F1. Cole, Linebaugh, Munson, and McMurray (2010), for instance, found that, after partialling out the effects of speaker and vowel phoneme from a corpus of English vowel tokens produced in various consonantal contexts, much of the remaining variance in F2 (63%), but not F1 (18%), could be explained by the immediate phonetic (consonantal) context of the vowels. It is certainly possible, therefore, that the F2 differences found in our analyses are in fact a reflection of their contextual differences rather than the effects of a phonological pattern. Padgett and Tabain (2005) and Herrick (2003) discuss the existence of perceptual biases underrating the F2 dimension relative to the F1 dimension. This led these authors to weigh F2 less heavily than F1 in some of their statistical analyses. This also raises the question of whether listeners may even be able to perceive (or not) the F2 effects found in our data, a fact reminiscent of the “near-merger” phenomenon discussed in Labov (1994) (see also, for example, Labov, Yaeger, & Steiner, 1972; Labov, Karen, & Miller, 1991). Once again, we are unable to verify whether any of the F2 differences detected in our acoustic study are perceptible. We do know, however, that their size is small.
In sum, for the most part, the acoustic study confirmed the impressionistic dialectological descriptions and verified that the patterns of variance for these two dialects may be appropriately described with recourse to discrete, categorical alternations and positional neutralizations, at least concerning what the analysis of the primary acoustic correlate of the /ɔ/-/o/-/u/ contrast (F1) revealed. However, we cannot deny that some evidence of incomplete neutralization (Charles-Luce, 1993; Charles-Luce & Dinnsen, 1987; Fourakis & Iverson, 1984; Port & Crawford, 1989; Port & O’Dell, 1985; Slowiaczek & Dinnsen, 1985) was found for two secondary acoustic correlates, that is, F2 and duration.
We now turn to a discussion of the spoken-word recognition experiment. Perhaps the most interesting finding of the present study was that the Sóller listeners were able to process the word forms characteristic of a neighboring dialect ([koˈzətə], [poˈmətə]) as efficiently as those characteristic of their own dialect ([kuˈzətə], [puˈmətə]). Indeed, both types of phonetic forms led to similarly faster visual word recognition rates relative to an unrelated condition. This suggests that both phonetic forms had been able to activate (or allow access to) the relevant lexical entries, which accelerated the recognition of the subsequent visual items. The Palma listeners, on the other hand, processed the forms characteristic of their own dialect ([koˈzətə], [poˈmətə]) more efficiently than those characteristic of the Sóller dialect ([kuˈzətə], [puˈmətə]). To be sure, both types of phonetic forms led to significant priming effects for these listeners relative to a condition in which visual targets were preceded by unrelated auditory primes. The results indicated, however, that the word forms in their own dialect led to significantly faster rates of recognition of the visual targets, when compared to a control condition, than the word forms in the Sóller variant. These findings point towards the existence of experience effects with the surface forms of derived words. Throughout this discussion, we talk about “efficient” spoken-word recognition patterns. This is a “filtered” interpretation of the facts, and the facts are that some auditory word forms are able to induce faster recognition rates of subsequent visual targets than other words forms. We surmise that this is due to the fact that some auditory forms may have triggered a higher activation of the corresponding entries in the lexicon than other word forms. This would suggest that some phonetic forms are more “efficient” than others—for some groups of speakers, at least—at accessing (or contacting, or checking, or activating) lexical entries.
The differential treatment of one’s own versus “foreign” phonetic forms revealed by the Palma listeners is not unexpected. Indeed, numerous studies have captured a processing preference for words presented in the phonetic characteristics of one’s own dialect (Adank et al., 2009; Clopper & Bradlow, 2008; Clopper et al., 2010; Floccia et al., 2006; Impe et al., 2008; Sumner & Samuel, 2009). Recall that the variety of Sóller is spoken by only 1.75% of the population of Majorca. The variety of Palma, at least with respect to the phonological phenomenon investigated here, is used not only in Palma but also in all other Majorcan municipalities. It is reasonable to assume that while Sóller speakers interact with speakers of other Majorcan Catalan varieties quite frequently, speakers from Palma are not as likely to encounter Sóller speakers in their daily lives. It appears, therefore, that phonetic forms with which a listener has had a lifelong experience efficiently tap into lexical representations during word recognition. Forms with which a listener has relatively less experience may tap into lexical representations less effectively, or not at all. Frequency of exposure with word forms manifesting particular phonological phenomena, therefore, seems to be a good predictor of recognition speed, efficiency, and effectiveness (e.g., Sumner & Samuel, 2009).
The fact that the Sóller listeners processed the forms characteristic of a neighboring dialect as efficiently as those characteristic of their own dialect is reminiscent of the results of some studies discussed above (Adank et al., 2009; Clopper & Bradlow, 2008; Clopper et al., 2010; Impe et al., 2008; Sumner & Samuel, 2009). Several studies have found that speakers of regional dialects can process words in the form of a standard or less regionally-marked dialect as efficiently as in the form of their own dialect (Clopper et al., 2010; Floccia et al., 2006; Sumner & Samuel, 2009). 8 Floccia et al. (2006), for instance, found that listeners from the Franche-Comté region of northeastern France process with similar efficiency word forms characteristic of their own regional dialect and of that of Paris, the standard variety of hexagonal French (i.e., the French of France, more generally) and the variety used in the national media. These listeners’ word-recognition abilities, however, were slightly handicapped when word forms typical of southern French varieties, such as those of Aix-en-Provence and Toulouse, were used as stimuli. Unfamiliar dialects, therefore, led to processing costs while familiar (even if “foreign”) varieties did not. It seems that this is also the case for the Sóller listeners investigated in the present study: the latter processed with similar efficiency the word forms of their own regional dialect and those of the neighboring dialect. Note thus that the relative status of the two dialects under study appears to be asymmetrical. It would appear, following the findings in the studies that have addressed this, that “foreign-though-familiar” dialects tend to include the standard, prestigious, regionally-unmarked varieties. In terms of the behavior of the back-vowel phonemes, the Palma dialect is representative of all of the dialects spoken on the island of Majorca. The Sóller dialect stands in the minority. This asymmetry might be the source of the word recognition patterns reported in the present study. Perhaps the pattern of Palma occupies, on Majorca, the position that Parisian French occupies in the Franche-Comté region of France, that of a standard, familiar dialect (Floccia et al., 2006). It is not obvious to us that the variety of Palma has indeed the rank of a standard or prestigious variety on Majorca. What seems obvious, however, is that Sóller speakers are clearly outnumbered, on the island, by speakers of dialects with a radically different back-vowel reduction process, and thus must be relatively familiar with the process. Our finding, therefore, may be due to the probability of encountering a particular pattern on the island rather than to prestige.
It is interesting, nonetheless, that the vowel-reduction pattern displayed by Sóller Catalan coincides with that of central Catalan, the variety upon which the standard Catalan dialect is based, while that of Palma differs from it. We have not directly tested how our Majorcan listeners process the word forms of central Catalan. But let us assume, for a moment (and for the sake of the argument), that Palma residents process words in central Catalan in the same way they process words in Sóller Catalan. If this were the case, it would appear that the Palma dialect is, in effect, the one considered “foreign-though-familiar” (or perhaps even “standard”) by the Sóller listeners while the Palma listeners are hindered by the alternation characteristic of Sóller and central Catalan. The findings in this study would indirectly suggest that any effects of central Catalan on Majorcan Catalan speakers are not robust, or that they do not lead to the representation of “standard” (or “foreign-though-familiar”) lexical forms for Palma listeners. From our results, one could hypothesize that central Catalan does not have a strong effect on the lexicon—or the word-processing abilities—of Majorcan Catalan listeners. In other words, returning to the Franche-Comté listeners studied in Floccia et al. (2006) as a parallel, we would suggest that it is rather questionable that central Catalan occupies, for Majorcan Catalan listeners, the position or status that Parisian French occupies for the Franche-Comté listeners. Even though central Catalan is the standard Catalan variety and is found in the media (though most media consumed on the island is in Spanish), it would not seem particularly familiar for Palma listeners—if, again, they do react to it as they react to the Sóller variety, with which, for the phenomenon under study, it coincides in form.
On a related note, the moderate priming effects of [u]-forms for Palma listeners could also be explained by, or at least in conjunction with, overall similarity between the two types of experimental primes ([o]-forms, [u]-forms). The mismatch in the first unstressed vowel caused by the Sóller reduction pattern does not create lexical competitors for Palma listeners and thus the shared onset consonant and whole coda could have been enough to lead to priming effects, despite the regionally-marked vowel mismatch (Norris, McQueen, & Cutler, 2002; Slowiaczek, Nusbaum, & Pisoni, 1987; Slowiaczek, Soltano, Wieting, & Bishop, 2003). It could therefore be the case that the marginal facilitatory effect of Sóller forms, which coincide with central Catalan forms in the present study, is found even when access to these forms is not facilitated by dialectal familiarity for Palma listeners. However, we once again acknowledge the fact that the role of exposure to central Catalan cannot be fully ruled out with the present experimental design. In sum, there seem to be two factors that could potentially favor priming effects in this condition, regardless of the amount of experience with Sóller forms: (i) experience with central Catalan; and (ii) overall phonological similarity beyond the vowel in question. Nonetheless, priming is relatively small, especially when compared to the very strong effects triggered by their own regional variant. This finding, on the one hand, casts even more doubt on the role of central Catalan as a supra-standard variety for Majorcan Catalan listeners, and, on the other hand, reinforces our main interpretation of the results, that is, that there is a dialectal asymmetry in word recognition strongly modulated by linguistic experience that cannot be made up for even when additional factors are supposed to bridge the gap between the two form types (Palma [o]-forms and Sóller/central Catalan [u]-forms) tested in the present study. 9
Whether Palma (or Sóller) listeners process central Catalan word forms as efficiently as they process those of their own variety is still an open question, but a particularly important one. Note the following findings pertaining to English: General American (GA) English forms are efficiently processed by speakers of regional varieties of American English (Clopper et al., 2010), and Southern British English (SBE) word forms are also processed efficiently by speakers of Scottish English varieties (Adank et al., 2009). But, how are, for instance, Southern British English word forms processed in North America? Sumner and Kataoka (2013) address precisely this question. In their study, GA listeners were asked to participate in a lexical decision task with semantic priming in which they were exposed to primes uttered in the phonetic forms of three dialects: GA (rhotic), New York City (NYC, non-rhotic) and SBE (non-rhotic). The GA listeners processed GA and SBE word forms equally efficiently, and more efficiently than NYC words, which triggered a processing cost. The finding, therefore, was as follows: for GA listeners, processing non-rhotic word forms is not particularly problematic as long as they have been uttered by an SBE speaker and not a New Yorker. Sumner and Kataoka (2013) speculate that this could be due to the special social status of SBE in North America: perhaps the saliency of this accent in this particular location creates a sense of social novelty, one that ends up adding social weight to these word forms, and one that is not shared with the NYC accent. This would result in the development of robust representations for word forms with which listeners are not particularly familiar, provided that they have a high social visibility. There could be two roads to representation, Sumner and Kataoka (2013) explain, one that goes through frequency (or familiarity) and one that goes through socially-weighted novelty. Could word forms uttered by a central Catalan speaker thus be efficiently processed by Palma Catalan listeners even after what we have found regarding Sóller word forms? Answering this question must be left for future research.
What our data do allow us to conclude, we believe, is that Palma speakers have a more restrictive phonological representation for words involving /o/ and /ɔ/ in unstressed position than Sóller listeners do—at least if the words they are asked to process have been uttered by a speaker of Majorcan Catalan, a Sóller speaker. For listeners from Palma, the representation of /o/- and /ɔ/-words in which these phonemes appear in unstressed position does not seem to include the possibility that these vowel phonemes can surface as [u], even though such forms may trigger moderate—though much weaker—priming effects. For Sóller listeners, the representation of these same words includes [u], their own dialectal form, and [o], the form characteristic of the dialects that surround their own. The multiplicity of phonetic forms linked to a single lexical representation displayed by the Sóller listeners in our study does not need to be different in nature from that which has been revealed by prior studies on the processing of reduced or lenited speech (Bürki et al., 2010, 2011; Bürki & Frauenfelder, 2012; Connine et al., 2008; Deelman & Connine, 2001; LoCasto & Connine, 2002; McLennan et al., 2003; Pitt, 2009; Ranbom & Connine, 2007; Sumner & Samuel, 2005).
In studies on the processing of words manifesting phonetic variation such as Deelman and Connine (2001) and Sumner and Samuel (2005), listeners are typically found to be able to process words in their various phonological forms with equal efficiency, provided they are familiar with these phonological forms. Thus, auditory renderings of English words with released or unreleased /t/ or /d/ triggered comparable lexical activation and primed a semantically related target to the same extent in a group of English-speaking listeners (Deelman & Connine, 2001). English /t/- and /d/-final words may be variably released or unreleased—even if one of these phonological variants is more common in everyday communication, both may be encountered. The typical results of studies such as these lead to the inference that listeners are able to store, in their lexicon, various phonological forms linked to the same lexical entry. Development of these multiple-form-to-single-item links could be caused by at least two mechanisms, as Sumner and Kataoka (2013) propose: (i) exposure to large quantities of tokens for each of the two (or more) phonological forms of a given lexical item; and (ii) social saliency linked to one (or more) of these phonological forms, even if exposure is more limited. The phonological phenomenon we study here leads to allomorphy, and is thus fully predictable. In that, it differs from the patterns investigated in most of the previous studies, for unreduced vowels—such as [ɔ], for instance—are never viable pronunciations in unstressed position in any dialect of Majorcan Catalan. It appears, however, that complete predictability due to (morpho)phonological alternations, and thus dialectally-consistent exposure to the word forms involved in such alternations, does not lead to an improvement in word-processing if a speaker is not sufficiently familiar with a particular word-form (or a particular version of the phonological rule), even if the form exists in a neighboring dialect.
Footnotes
Acknowledgements
We wish to express our gratitude to the editorial team of Language & Speech, especially to Associate Editor Jeffrey Steele and to Editor Joan Sereno. We are also grateful to the two anonymous Language & Speech reviewers who read all the many versions of the manuscript leading to this article. Portions of this research were presented at the Berkeley Linguistics Society, the Arizona Linguistics Circle, and the International Congress of Phonetic Sciences in Glasgow, Scotland. We thank the members of those audiences who kindly gave us feedback. Any remaining shortcomings are, of course, our own. A Human Subjects Protection Program Review Board approved the procedures in this study.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.